
Improvement and Assessment of a Blind Image Deblurring Algorithm Based on Independent Component Analysis


Abstract
:1. Introduction
2. Theoretical Developments and Methods
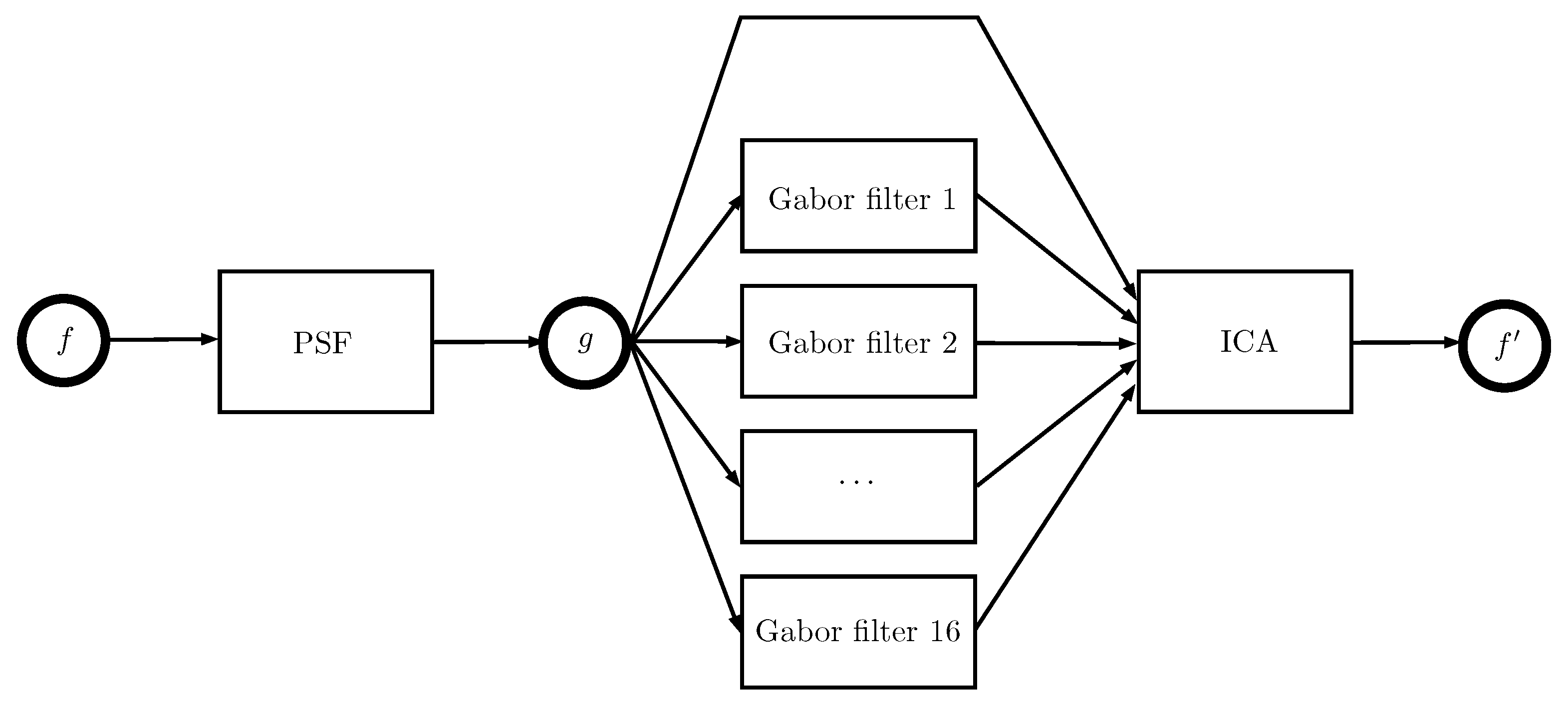
2.1. Bi-Dimensional Gabor Filters
2.2. A Blurred Image Model Based on Taylor Series Expansion
2.3. Blind Deblurring by Independent Component Analysis
- Column-centering consists of making the columns of the data matrix X zero-mean. Let us decompose the matrix X into its columns as follows:where each column-array has dimension . The empirical mean value of the set of columns is calculated asand the centered columns of the data matrix are defined asLet us denote by the matrix whose columns are .
- Row-shrinking is based on empirical covariance estimation and on thresholding the eigenvalues of the estimated empirical covariance matrix [31]. The empirical covariance matrix associated to the columns of the centered data matrix is defined by:and has dimensions . The eigenvalue decomposition of the covariance matrix reads , where E is an orthogonal matrix of eigenvectors and D is a diagonal matrix of eigenvalues, namely , assumed to be ordered by decreasing values. Rank deficiency and numerical approximation errors might occur, which might make a number of eigenvalues in D be zero or even negative. Notice that, in particular, rank deficiency makes the matrix D be singular, which unavoidably harms the process of ‘whitening’, as explained in the next point. In order to mitigate such unwanted effect, it is customary to set a threshold (in this study, a value was chosen as threshold) and to retain those ℓ eigenpairs corresponding to the ℓ eigenvalues above the threshold. The corresponding eigenmatrix pair is denoted by , where is of size and is of size . Since, most likely, , thresholding has the effect of shrinking the centered data matrix.
- Column-whitening is a linear transformation applied to each column of the data matrix to obtain a quasi-whitened data matrix whose columns exhibit a unit covariance. Such linear transformation is described byNotice that the whitened data matrix has size and, in general, its covariance matrix is perfectly unitary only if row-shrinking did not take place, namely, only if . If, however, some of the eigenvalues of the empirical covariance matrix are zero or negative, whitening is not possible since the (non-shrunken) matrix is either not calculable or complex-valued.
2.4. An ICA Learning Algorithm Based on Exponentiated Gradient on the Unit Hypersphere
3. Experimental Results
3.1. Experiments on Deblurring Artificially Blurred Images
- An isotropic point-spread function with variance 1, denoted as Gaussian-(1,1): The clean image, the blurred image and the point-spread function are shown in Figure 4. In this case, the PSF has size .
- An isotropic point-spread function with variance 2, denoted as Gaussian-(2,2): The clean image, the blurred image and the point-spread function are shown in Figure 5. In this case, the PSF has size .
3.2. Limitations of the Restoration Method on Artificially Blurred Images
3.3. Experiments on Deblurring Naturally Blurred Images
3.4. First Comprehensive Set of Experiments
- In general, the discussed deblurring method performed poorly on human faces, unless the level of blur was moderate.
- When a picture originated from a phone camera, the distance between the subject and the camera should range between 10 and 30 cm to achieve a good result (over 40 cm of distance, deblurring was not achieved successfully).
- Distance and defocusing level should be inversely proportional to one another: the farther the subject, the lower the defocusing level should be.
- In general, the level of defocusing should range between 1% and 40% to achieve a B or A result; however, there are exceptions. In fact, an excellent result was obtained on a 100% defocused large-sized text.
- Although most images were of size 240 pixels × 240 pixels, comparable results were obtained on images whose size ranged between 200 × 200 and 300 × 300 pixels.
- The file format (image encoding algorithm) did not seem to influence the final result.
- In general, objects in the foreground resulted to be more focused than objects in the background; according to our estimations, good results were achieved up to 7 cm of staggering with a maximum initial defocusing of 30%.
3.5. Second Comprehensive Set of Experiments
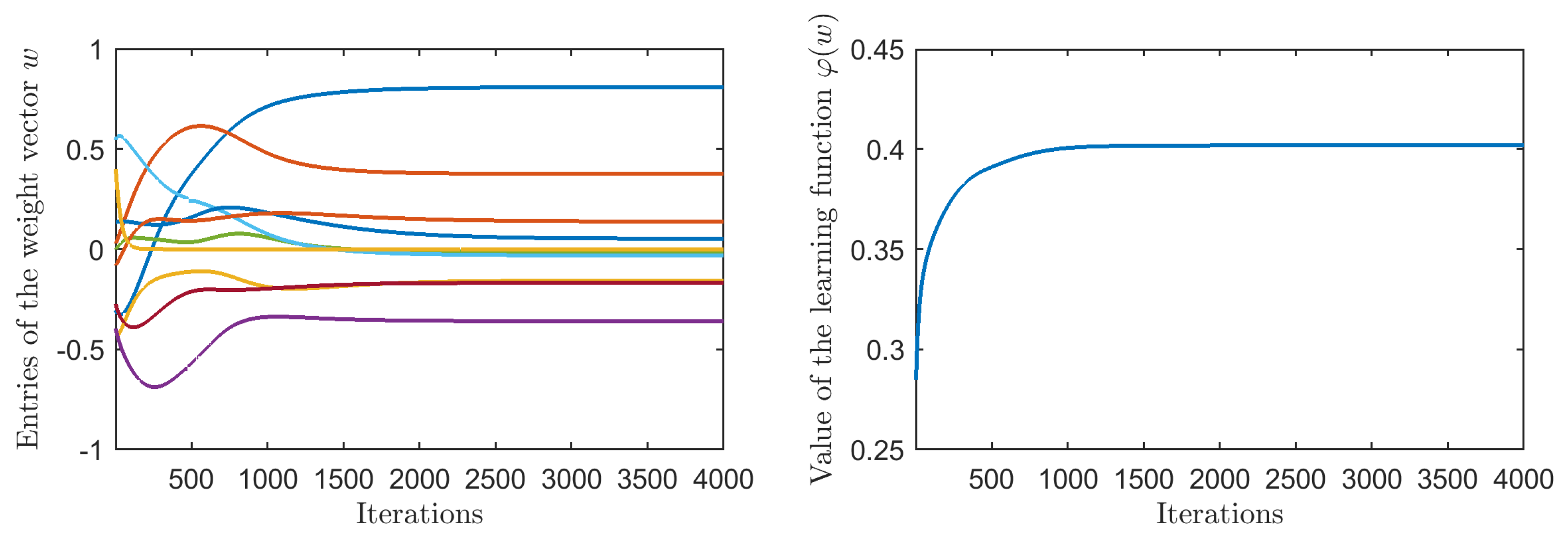
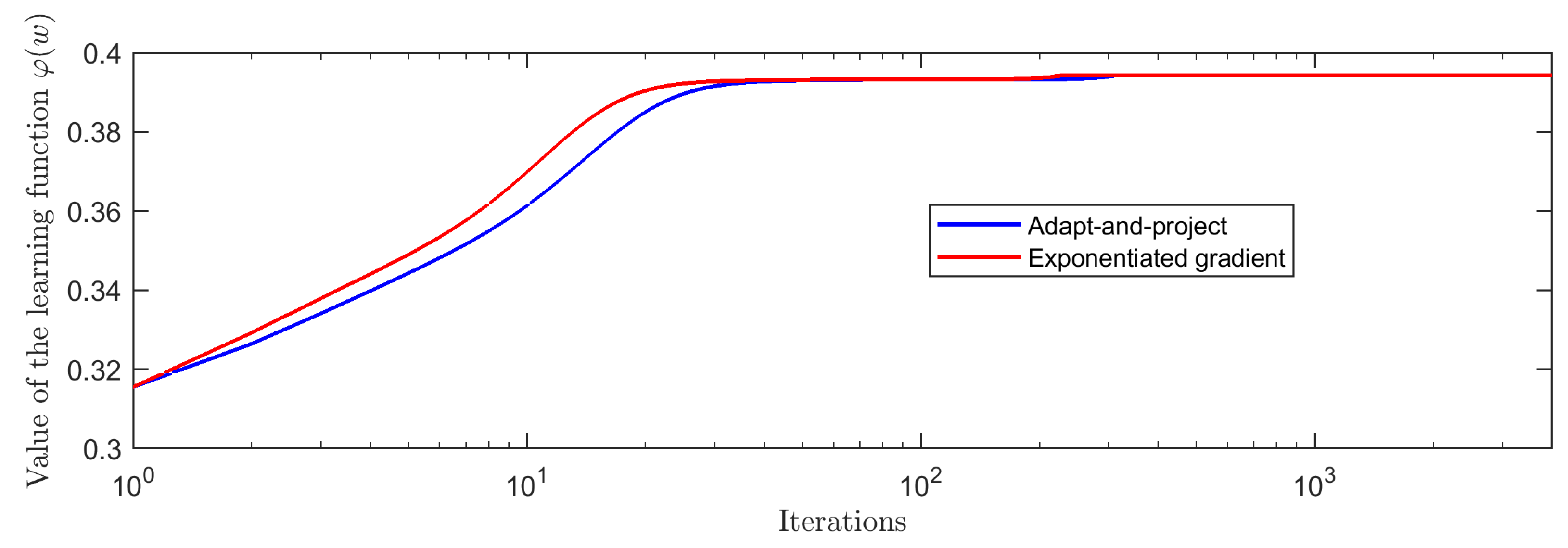
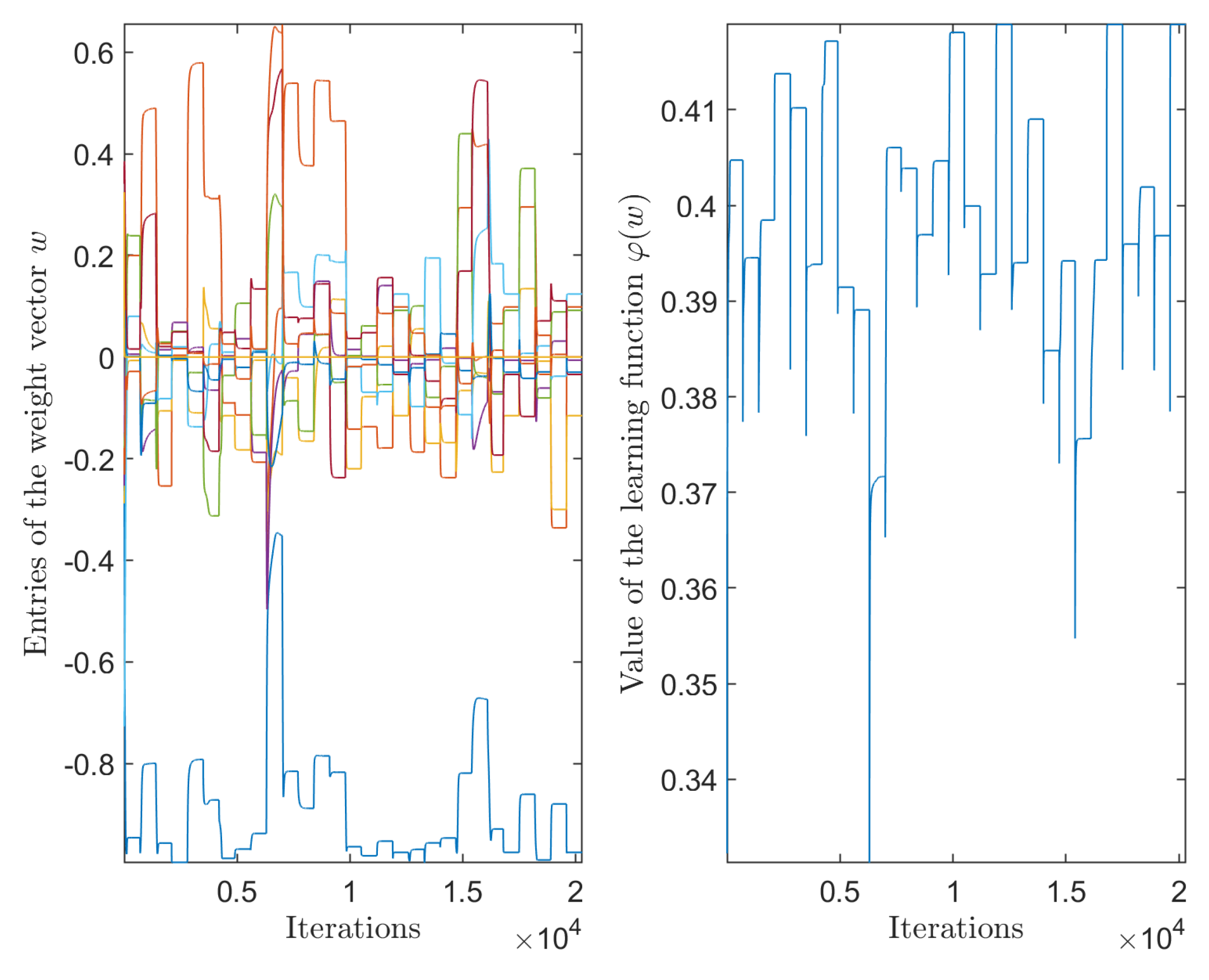
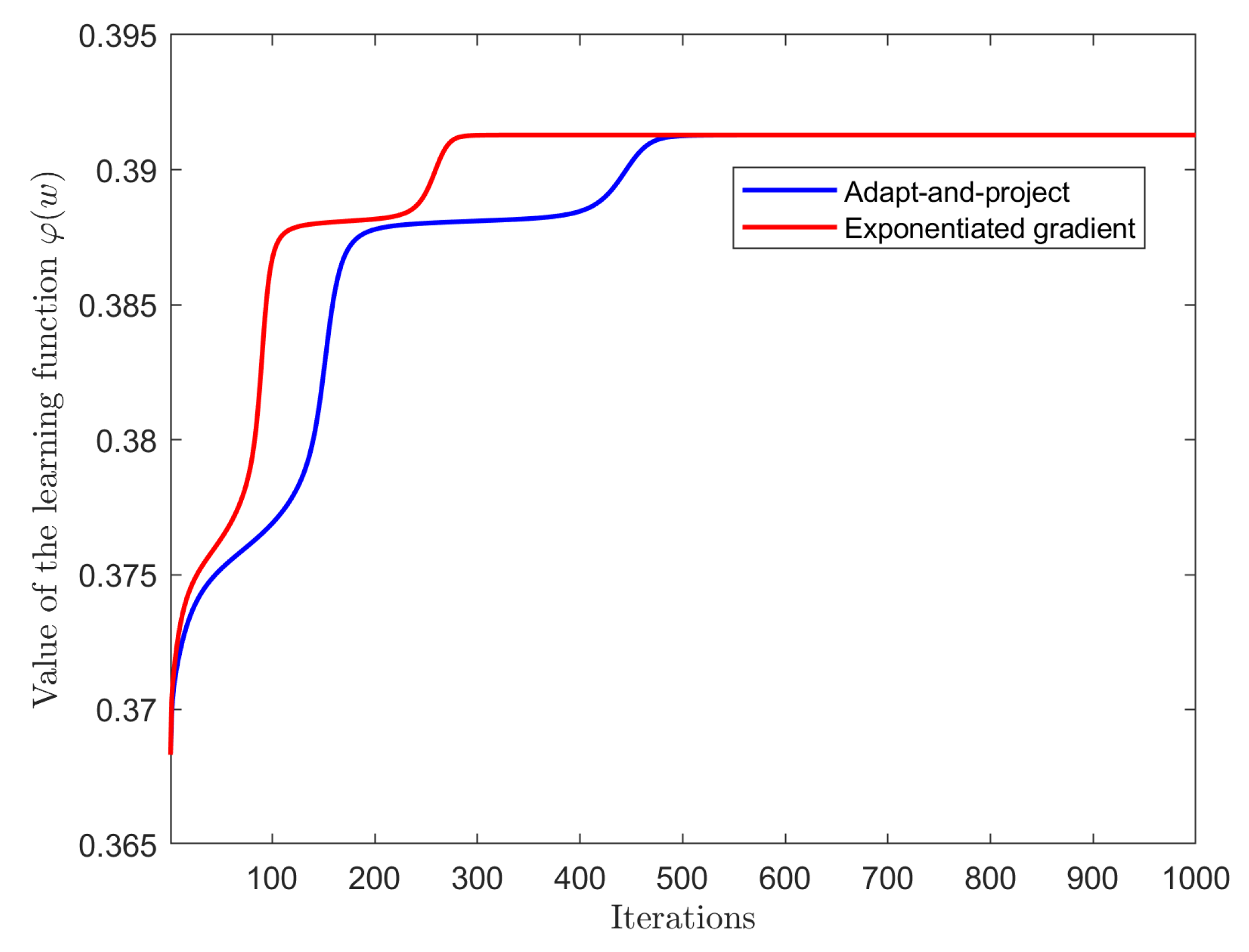
3.6. Experiments on Choosing a Suitable Learning Step Size
4. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lai, W.; Huang, J.; Hu, Z.; Ahuja, N.; Yang, M. A Comparative Study for Single Image Blind Deblurring. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1701–1709. [Google Scholar] [CrossRef]
- Bahat, Y.; Efrat, N.; Irani, M. Non-uniform Blind Deblurring by Reblurring. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3306–3314. [Google Scholar] [CrossRef]
- Zhang, H.; Wipf, D.; Zhang, Y. Multi-image Blind Deblurring Using a Coupled Adaptive Sparse Prior. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1051–1058. [Google Scholar] [CrossRef]
- Srinivasan, P.P.; Ng, R.; Ramamoorthi, R. Light Field Blind Motion Deblurring. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2354–2362. [Google Scholar] [CrossRef] [Green Version]
- Fiori, S. Fast fixed-point neural blind-deconvolution algorithm. IEEE Trans. Neural Netw. 2004, 15, 455–459. [Google Scholar] [CrossRef]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Understanding Blind Deconvolution Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2354–2367. [Google Scholar] [CrossRef]
- Vorontsov, S.V.; Jefferies, S.M. A new approach to blind deconvolution of astronomical images. Inverse Probl. 2017, 33, 055004. [Google Scholar] [CrossRef]
- Brylka, R.; Schwanecke, U.; Bierwirth, B. Camera Based Barcode Localization and Decoding in Real-World Applications. In Proceedings of the 2020 International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Lou, Y.; Esser, E.; Zhao, H.; Xin, J. Partially Blind Deblurring of Barcode from Out-of-Focus Blur. SIAM J. Imaging Sci. 2014, 7, 740–760. [Google Scholar] [CrossRef] [Green Version]
- Umeyama, S. Blind deconvolution of blurred images by use of ICA. Electron. Commun. Jpn. (Part III Fundam. Electron. Sci.) 2001, 84, 1–9. [Google Scholar] [CrossRef]
- Umeyama, S. Blind deconvolution of images using Gabor filters and independent component analysis. In Proceedings of the 4th International Symposium on Independent Component Analysis and Blind Signal Separation, Nara, Japan, 1–4 April 2003; pp. 319–324. [Google Scholar]
- Lei, S.; Zhang, B.; Wang, Y.; Dong, B.; Li, X.; Xiao, F. Object Recognition Using Non-Negative Matrix Factorization with Sparseness Constraint and Neural Network. Information 2019, 10, 37. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Wang, X.; Zhang, T. Crime Scene Shoeprint Retrieval Using Hybrid Features and Neighboring Images. Information 2019, 10, 45. [Google Scholar] [CrossRef] [Green Version]
- Aladjem, M.; Israeli-Ran, I.; Bortman, M. Sequential Independent Component Analysis Density Estimation. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5084–5097. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Tian, X.; Chen, S. Monitoring Nonlinear and Non-Gaussian Processes Using Gaussian Mixture Model-Based Weighted Kernel Independent Component Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 122–135. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Navarro, F.; Carbonero-Ruz, M.; Becerra Alonso, D.; Torres-Jiménez, M. Global Sensitivity Estimates for Neural Network Classifiers. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2592–2604. [Google Scholar] [CrossRef]
- Howard, P.; Apley, D.W.; Runger, G. Distinct Variation Pattern Discovery Using Alternating Nonlinear Principal Component Analysis. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 156–166. [Google Scholar] [CrossRef] [PubMed]
- Matsuda, Y.; Yamaguchi, K. A Unifying Objective Function of Independent Component Analysis for Ordering Sources by Non-Gaussianity. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5630–5642. [Google Scholar] [CrossRef] [PubMed]
- Safont, G.; Salazar, A.; Vergara, L.; Gómez, E.; Villanueva, V. Probabilistic Distance for Mixtures of Independent Component Analyzers. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 1161–1173. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Dong, J.; Xie, T.; Diallo, D.; Benbouzid, M. A Self-Learning Fault Diagnosis Strategy Based on Multi-Model Fusion. Information 2019, 10, 116. [Google Scholar] [CrossRef] [Green Version]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–20 June 2018; pp. 8183–8192. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8877–8886. [Google Scholar]
- Spivak, M. Calculus On Manifolds—A Modern Approach To Classical Theorems Of Advanced Calculus; CRC Press—Taylor & Francis Group: Boca Raton, FL, USA, 1971. [Google Scholar]
- Lautersztajn-S, N.; Samuelsson, A. On application of differential geometry to computational mechanics. Comput. Methods Appl. Mech. Eng. 1997, 150, 25–38. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Wei, G.W. DG-GL: Differential geometry-based geometric learning of molecular datasets. Int. J. Numer. Methods Biomed. Eng. 2019, 35, e3179. [Google Scholar] [CrossRef]
- Mathis, W.; Blanke, P.; Gutschke, M.; Wolter, F. Nonlinear Electric Circuit Analysis from a Differential Geometric Point of View. In Proceedings of the VXV International Symposium on Theoretical Engineering, Lübeck, Germany, 22–24 June 2009; pp. 1–4. [Google Scholar]
- Li, K.B.; Su, W.S.; Chen, L. Performance analysis of differential geometric guidance law against high-speed target with arbitrarily maneuvering acceleration. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2019, 233, 3547–3563. [Google Scholar] [CrossRef]
- Grigorescu, S.E.; Petkov, N.; Kruizinga, P. Comparison of texture features based on Gabor filters. IEEE Trans. Image Process. 2002, 11, 1160–1167. [Google Scholar] [CrossRef] [Green Version]
- Zhong, L.; Cho, S.; Metaxas, D.; Paris, S.; Wang, J. Handling Noise in Single Image Deblurring Using Directional Filters. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 612–619. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.; Gavish, M.; Johnstone, I. Optimal shrinkage of eigenvalues in the spiked covariance model. Ann. Stat. 2018, 46, 1742–1778. [Google Scholar] [CrossRef]
- Fiori, S. On vector averaging over the unit hypersphere. Digit. Signal Process. 2009, 19, 715–725. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, J. Scale Adaptive Blind Deblurring. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSF | Original/Blurred | Original/Deblurred (AAP) | Original/Deblurred (EG) |
|---|---|---|---|
| Gau-(1,1) | 0.9658 | 0.9682 | 0.9684 |
| Gau-(2,2) | 0.8836 | 0.9484 | 0.9509 |
| Image | Subject | Blur Type | Result |
|---|---|---|---|
| 01_IM | Male face | 10% defocusing | D |
| 02_IM | Male face | 30% defocusing | D |
| 03_IM | Books on background | 10% defocusing, 40 cm away | D |
| 04_IM | Books on background | 20% defocusing, 20 cm away | A |
| 05_IM | Books on background | 30% defocusing, 20 cm away | C |
| 06_IM | Books on background | 37.5% defocusing | B |
| 07_IM | Books on background | 37.5% defocusing, 300 × 300 pixels | C |
| 08_IM | Books on background | 37.5% defocusing, 200 × 200 pixels | C |
| 09_IM | Books on background | 50% defocusing, 20 cm away | D |
| 10_IM | Books staggered of 10 cm | 10% defocusing, 40 cm away | D |
| 11_IM | Books staggered of 10 cm | 40% defocusing, 10 cm away | C |
| 12_IM | Books staggered of 10 cm | 10% defocusing, 10 cm away | B |
| 13_IM | Books staggered of 7 cm | 10% defocusing, 10 cm away | A |
| 14_IM | Books staggered of 7 cm | 25% defocusing, 10 cm away | A |
| 15_IM | Books staggered of 7 cm | 30% defocusing, 10 cm away | C |
| 16_IM | Books staggered of 5 cm | 30% defocusing, 10 cm away | C |
| 17_IM | Lined-up books | 30% defocusing, 20 cm away | C |
| 18_IM | Lined-up books | 30% defocusing, 10 cm away | D |
| 19_IM | Lined-up books | 20% defocusing, 10 cm away | D |
| 20_IM | Giant letter | 100% defocusing | A |
| 21_IM | White tag | 100% defocusing | D |
| 22_IM | White tag | 60% defocusing | A |
| 23_IM | White tag | 70% defocusing | B |
| 24_IM | White tag | 80% defocusing | D |
| 25_IM | Orange tag | 60% defocusing | B |
| 26_IM | Yellow tag | 60% defocusing | B |
| 27_IM | Black tag | 60% defocusing | D |
| 28_IM | Green-white tag | 60% defocusing | D |
| 29_IM | Blue tag | 60% defocusing | D |
| 30_IM | White-green tag | 60% defocusing | A |
| 31_IM | Canary yellow tag | 60% defocusing | A |
| 32_IM | Red-white tag | 60% defocusing | D |
| 33_IM | Car with passenger | 20% defocusing | A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiori, S. Improvement and Assessment of a Blind Image Deblurring Algorithm Based on Independent Component Analysis. Computation 2021, 9, 76. https://doi.org/10.3390/computation9070076
Fiori S. Improvement and Assessment of a Blind Image Deblurring Algorithm Based on Independent Component Analysis. Computation. 2021; 9(7):76. https://doi.org/10.3390/computation9070076
Chicago/Turabian StyleFiori, Simone. 2021. "Improvement and Assessment of a Blind Image Deblurring Algorithm Based on Independent Component Analysis" Computation 9, no. 7: 76. https://doi.org/10.3390/computation9070076
APA StyleFiori, S. (2021). Improvement and Assessment of a Blind Image Deblurring Algorithm Based on Independent Component Analysis. Computation, 9(7), 76. https://doi.org/10.3390/computation9070076