1. Introduction
The human face plays an important role in daily life. Pursuing beauty, especially facial beauty, is the nature of human beings. As the demand for aesthetic surgery has increased widely over the past few years, an understanding of beauty is becoming increasingly important for medical settings. The physical beauty of faces affects many social outcomes, such as mate choices and hiring decisions [
1,
2]. Thus, the cosmetic industry has produced various products that target to enhance different parts of the human body, including hair, skin, eye, eyebrow, and lips. Not surprisingly, research topics based on the face features have a long track record in psychology, and many other scientific fields [
3]. During recent decades, computer vision systems have played a major role in obtaining an image from a camera to process and analyse it in a manner similar to natural human vision system [
4]. Computer vision algorithms have recently attracted increasing attention and been considered one of hottest topics due to its significant role in healthcare, industrial and commercial applications [
4,
5,
6,
7,
8,
9]. Facial image processing and analysis are essential techniques that help extract information from images of human faces. The extracted information such as locations of facial features such as eyes, nose, eyebrows, mouth, and lips, can play a major role in several fields, such as medical purposes, security purposes, cosmetic industry, social media applications, and recognition [
5]. Several techniques have been developed to localise these parts and extract them for analysis [
10]. The landmarks used in computational face analysis often resemble the anatomical soft tissue landmarks that are used by physicians [
11]. Recently, advanced technologies such as artificial intelligence and machine/deep learning algorithms have helped the beauty industry in several ways, from providing statistical bases for attractiveness and helping people alert their looks to developing products which would tackle specific needs of customers [
12,
13]. Furthermore, cloud computing facilities and data centre services have gained a lot of attention due to their significant role for customers’ access to such products by building web-based and mobile applications [
14].
In the literature, there have been many facial attribute analysis methods presented to recognise whether a specific facial attribute is present in a given image. The main aim of developing facial attribute analysis methods was to build a bridge between feature representations required by real-world computer vision tasks and human-understandable visual descriptions [
15,
16]. Deep learning-based facial attribute analysis methods can generally be grouped into two categories: holistic methods which exploit the relationships among attributes to get more discriminative cues [
17,
18,
19] and part-based methods that emphasise facial details for detecting localisation features [
20,
21]. Unlike the existing facial attribute analysis methods, which focus on recognising whether a specific facial attribute is present in a given face image or not, our proposed method suggests that all concerned attributes are present but in more than one label.
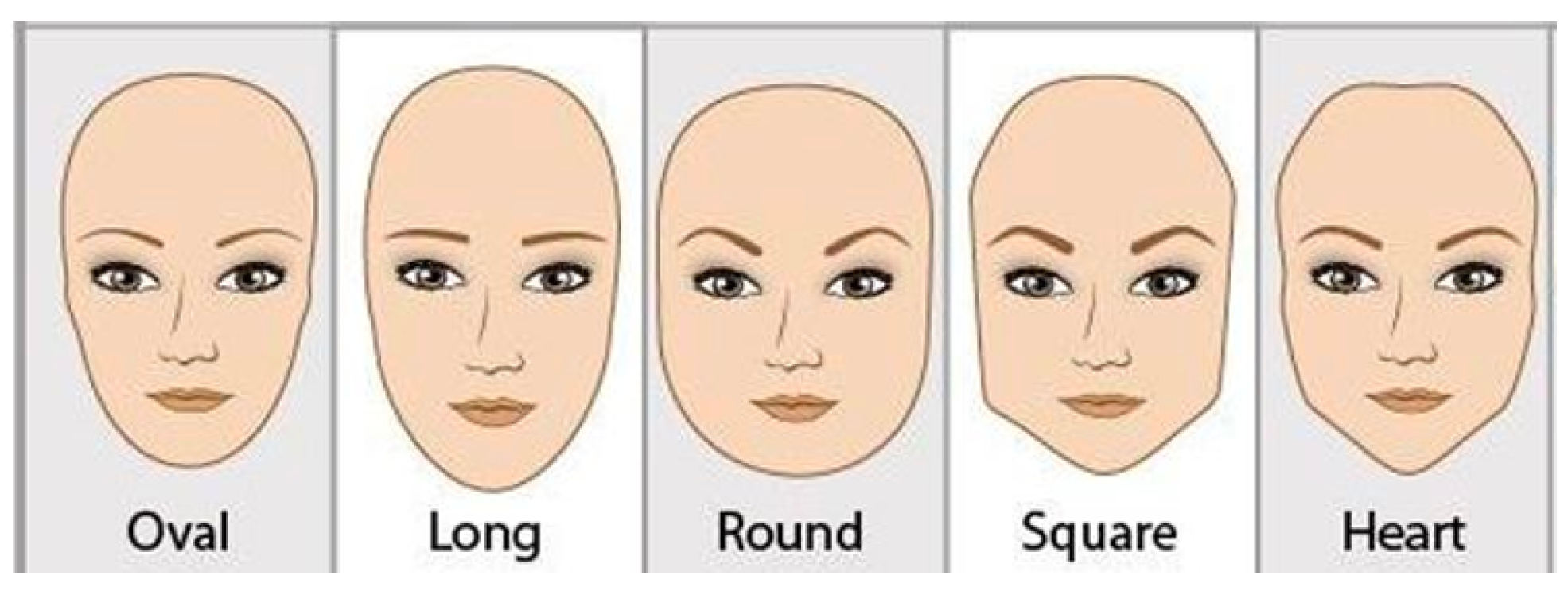
Furthermore, many automated face shape classification systems were presented in the literature. Many of these published face classification methods consider extracting the face features manually then passing them to three classifiers for classification, including linear discriminant analysis (LDA), artificial neural networks (ANN), and support vector machines (SVM) [
22,
23], k-nearest neighbours [
24], and probabilistic neural networks [
25]. Furthermore, Bansode et al. [
26] proposed a face shape identification method based on three criteria which are region similarity, correlation coefficient and fractal dimensions. Recently, Pasupa et al. [
27] presented a hybrid approach combining VGG convolutional neural network (CNN) with SVM for face shape classification. Moreover, Emmanuel [
28] adopted pretrained Inception CNN for classifying face shape using features extracted automatically by CNN. The work presented by researchers showed progress in face shape interpretation; however, existing face classification systems require more effort to achieve better performance. The aforementioned methods perform well only on images taken from subjects looking straight towards the camera and their body in a controlled position and acquired under a clear light setting.
Recently, many approaches were developed for building fashion recommender systems [
29,
30]. Conducting a deep search in the literature seeking the existing recommendation systems leads to find out two hairstyle recommendation systems [
27,
31]. The system developed by Liang and Wang [
31] considers many attributes such as age, gender, skin colour, occupation and customer rating for recommending hairstyle. However, the recommended haircut style might not fit the beauty experts’ recommendations based on face shape attributes. Furthermore, the hairstyle recommender system presented by [
27] is not general and focuses only on women. To the best of our knowledge, our proposed eyelashes and hairstyle recommendation system is the first study conducted to automatically make a recommendation of a suitable eyelash type based on computer vision techniques.
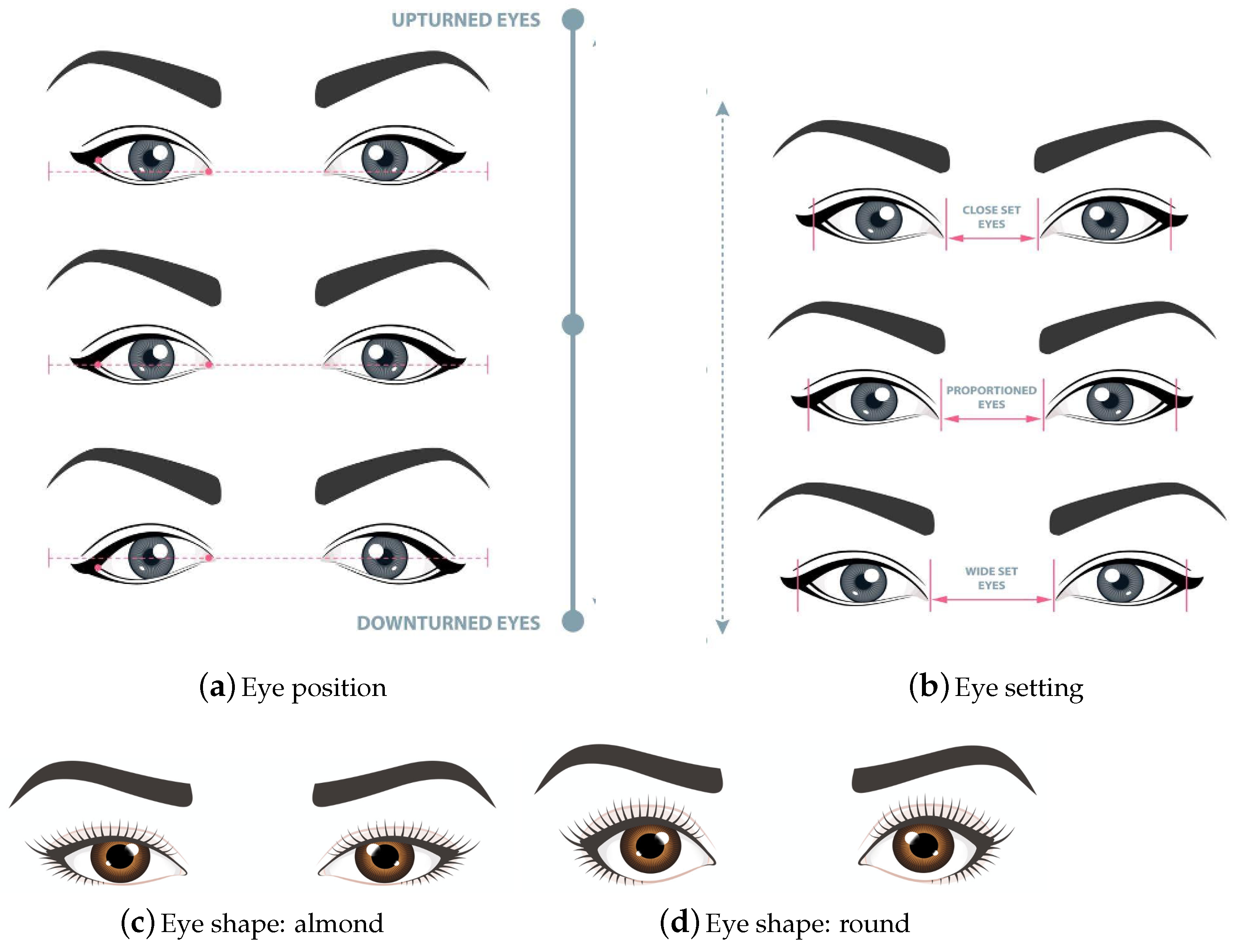
Facial attributes such as eye features, including shape, size, position, setting, face shape, and contour determine what makeup technique, eyelashes extension and haircut styles should be applied. Therefore, it is important for beautician to know clients’ face and eye features before stepping into the makeup-wearing, haircut style and eyelashes extension applying. The face and eye features are essential for beauty expert because different types of face shape and eye features are critical information to decide what kind of eye shadows, eyeliners, eyelashes extension, haircut style and colour of cosmetics are best suited to a particular individual. Thus, automation of facial attribute analysis tasks based on developing computer-based models for cosmetic purposes would help to easing people’s life and reducing time and effort spent by beauty experts. Furthermore, virtual consultation and recommendation systems based on facial and eye attributes [
27,
31,
32,
33,
34,
35,
36] have secured a foothold in the market and individuals are opening up to the likelihood of substituting a visit to a physical facility with an online option or use a specific-task software. Use of the innovation of virtual recommendation systems has numerous advantages; including accessibility, enhanced privacy and communication, cost saving, and comfort. Hence, our work’s motivation is to automate the identification of eye attributes and face shape and subsequently produce a recommendation to the user for the appropriate eyelashes and suitable hairstyle.
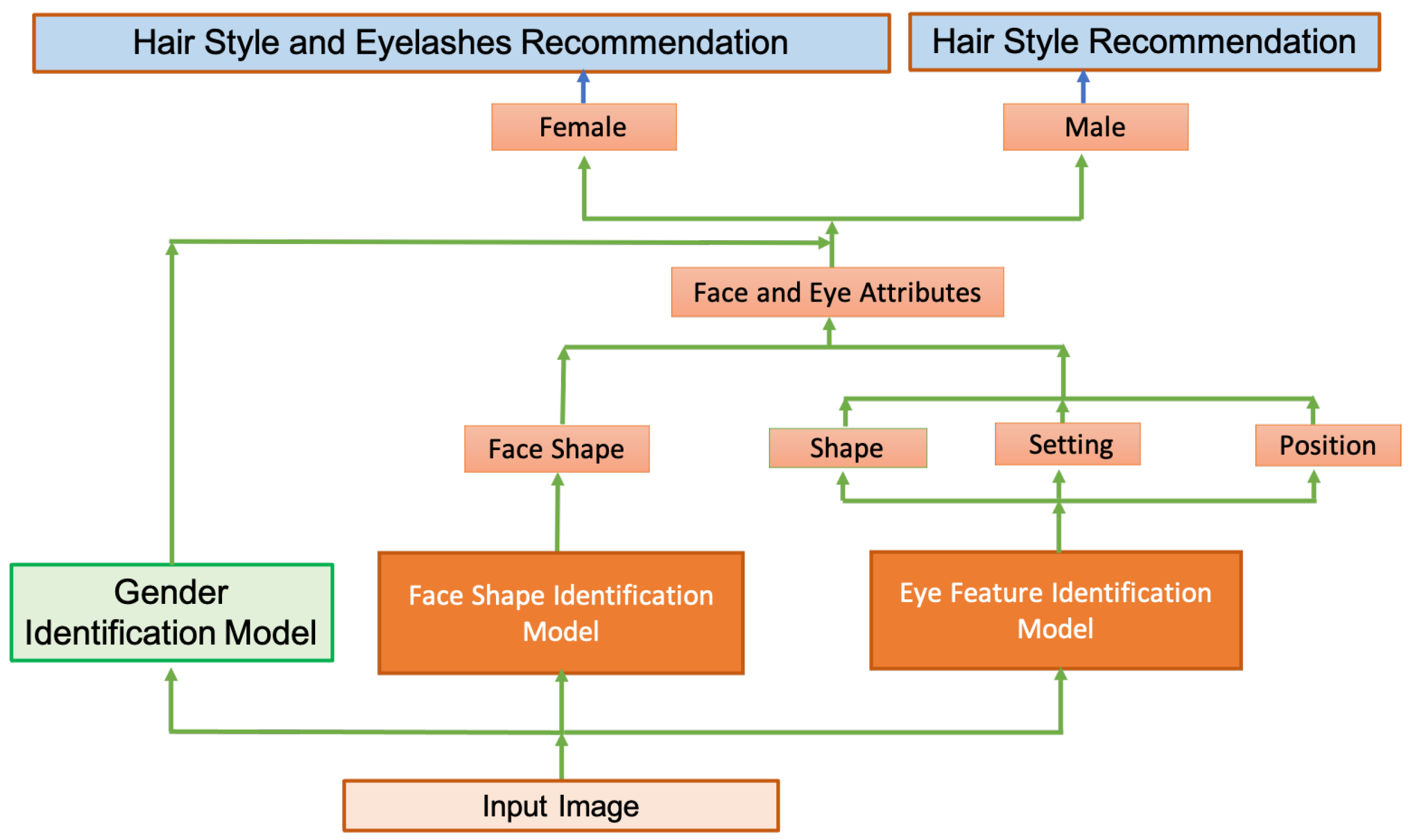
This research work includes the development of system with friendly graphical user interface that can analyse eye and face attributes from an input image. Based on the detected eye and face features, the system suggests a suitable recommendation of eyelashes and hairstyles for both men and women. The proposed framework integrates three main models: face shape classification model, gender prediction model for predicting the gender of user, and eye attribute identification model to make a decision on the input image. Machine and deep learning approaches with various facial image analysis strategies including facial landmark detection, facial alignment, and geometry measurements schemes are designed to establish and realise the developed system. The main contributions and advantages of this work are summarised as follows:
We introduce a new framework merging two types of virtual recommendation, including hairstyle and eyelashes. The overall framework is novel and promising.
The proposed method is able to extract many complex facial features, including eye attributes and face shape, accomplishing the extraction of features and detection simultaneously.
The developed system could help the worker in beauty centres and reduce their workload by automating their manual work and can produce subjective results, particularly with a large dataset.
Our user-friendly interface system has been evaluated on a dataset provided with a diversity of lighting, age, and ethnicity.
The labelling of a publicly available dataset with three eye attributes, five face shape classes, and gender has been conducted by a beauty expert to run our experiments.
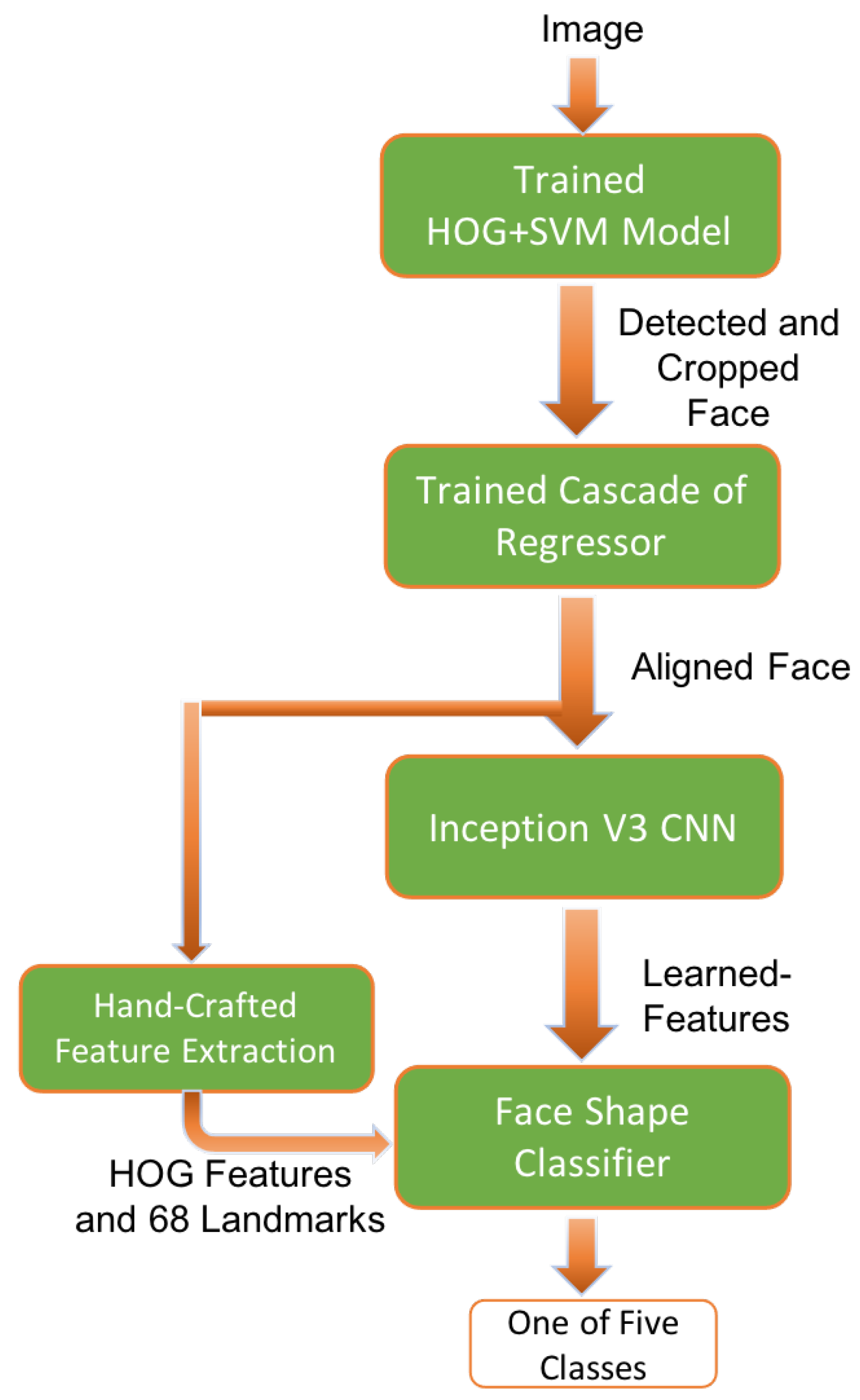
In the face shape classification method, we developed a method based on merging the handcrafted features with deep learning features.
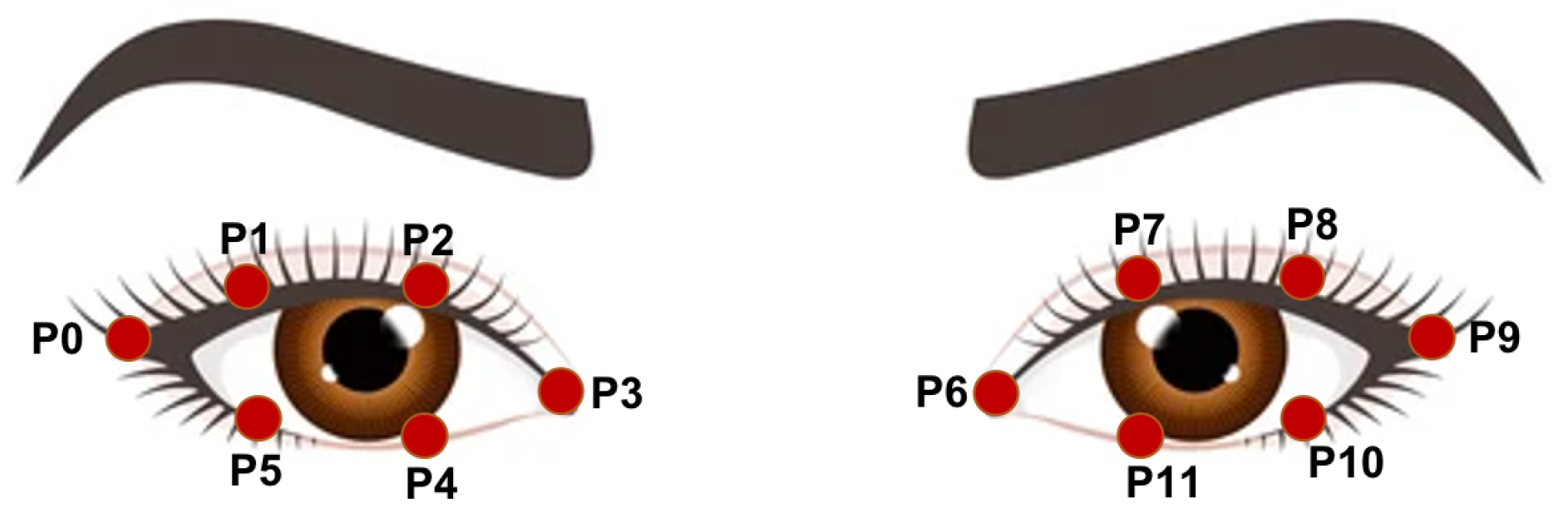
We presented a new geometrical measurement method to determine the eye features, including eye shape, position, and setting, based on the coordinates of twelve detected eye landmarks.
The remainder of this paper is presented as follows: in
Section 2, the materials and proposed framework are described and explained; results of the proposed system are revealed and discussed in
Section 3, and finally, the work has been concluded in
Section 4.
3. Results and Discussions
A new approach based on merging three models in one framework has been proposed for the simultaneous detection of the face shape, eye attributes, and gender from webcam images. The designed framework achieves the detection by extracting hand-crafted features, learning features automatically, and exploiting the face geometry measurements. To evaluate the performance of the proposed system, different measurements, including accuracy (Acc.), sensitivity (Sn.), specificity (Sp.), Matthews Correlation Coefficient (MCC), Precision (Pr), and
score, have been calculated. These metrics are defined as follows:
where
,
=
,
: True Positive,
: True Negative,
: False Positive,
: False Negative
Table 1 depicts the confusion matrix of face shape classes, reporting an identification accuracy of 85.6% on 500 test images (100 image per each class). To compare our face shape classification model with the existing face shape classification methods,
Table 2 presents a comparison in terms of classification accuracy. It can be noticed that our developed face shape classification system [
44] outperforms the other methods in the literature.
Initially, images belong to one subject were excluded from data because of failure detecting the eye landmarks of this subject in the eye attributes identification system due to extreme eye closing and obstacle. Thus, the number of subjects that will be considered for evaluation is 275. For the gender identification, the gender detection model has achieved prediction performance of
,
,
,
, and
in terms of accuracy, sensitivity, specificity, precision, and
score measures; respectively, on 275 subjects. Likewise, the gender detection model achieved
,
,
,
, and
; respectively, using the same metrics in terms of 748 image per camera.
Table 3 presents the confusion matrix obtained from gender identification system. The first part of
Table 3 shows the gender prediction in terms of the number of subjects, whereas the second part explores the prediction in terms of images per camera. In terms of comparison with the existing methods, authors in [
48] achieved an accuracy of
on the Adience dataset [
48]. On the same dataset, Duan et al. [
52] reported accuracy of
using convolutional neural network (CNN) and extreme learning machine (ELM) method. On Pascal VOC [
53] dataset, De et al. [
54] obtained accuracy of
based on a deep learning approach.
There are five webcams used to photograph each subject. In the following experiments, we name the webcams with five letters (A–E) including, Cam A, Cam B, Cam C, Cam D, and Cam E. Symbols X and Y (used in Cam X vs. Cam Y) refer to any individual webcam from the five cameras. Our developed system has provided flavour results on eye attributes identification.
Table 4,
Table A1 and
Table A2 in
Appendix A report eye setting attributes detection performance using various evaluation metrics and state the obtained results from the proposed system by comparing the eye setting attribute prediction performance in one camera with ground truth using confusion matrices, and compare the prediction performance in each camera with another camera using confusion matrices, respectively. Likewise,
Table 5,
Table A3 and
Table A4 report eye position classes detection performance using various evaluation metrics and state the obtained results from the proposed system by comparing the eye position classes prediction performance in one camera with ground truth using confusion matrices, and comparing the prediction performance in each camera with another camera using confusion matrices, respectively. In the same way,
Table 6,
Table A5 and
Table A6 present eye shape labels prediction performance.
From the reported results of eye attributes, it can be noticed that the model achieves the highest performance on eye shape detection, reporting accuracy of 0.7535, sensitivity of 0.7168, specificity of 0.7861, precision of 0.7464, F1 score of 0.7311 and MCC of 0.5043 while the lowest results were obtained from eye position class identification giving 0.6869, 0.7075, 0.8378, 0.6917, 0.6958, and 0.5370 using the same evaluation metrics, respectively. Likewise, the model reveals the results of 0.7021, 0.6845, 0.8479, 0.7207, 0.6926, and 0.5501 on eye setting detection in terms of the same aforementioned metrics. Although the system shows many misclassified prediction of eye attributes, it could be considered to be tolerated prediction cases (skew is small). By “tolerated prediction”, we mean that most misclassified cases are resulted from predicting the class into average labels, which is clear in all the reported confusion matrices. For example, in
Table A3, the major predictions of images in Cam E were misclassified as straight rather than upturned label giving: downturned label: 149, straight: 64, upturned: 0. This proves that the predicted measurements of attributes are closer to the ground truth value. This also can be clearly noticed in the reported confusion matrix of the eye setting shown in
Table A1.
To study the correlation of prediction among different webcams, all the evaluation metrics mentioned earlier, as well as confusion matrices, have been utilised to depict the variance and closeness of prediction. For instance,
Table 4 presents the correlation between cameras (such as Cam A vs. Cam B and so on) in terms of evaluation metrics. Whilst,
Table A2 reports the confusion matrices explaining the correlation of prediction among different webcams, which shows good prediction agreement among images captured from different cameras’ positions. Matthews Correlation Coefficient (MCC) is a correlation measurement that returns a value between +1 and −1, where −1 value refers to a total disagreement between two assessments and +1 represents the perfect detection (agreement). The range of obtained MCC value (between two webcams) was (0.3250–0.9145), which indicates of strong correlation of prediction among various webcam positions.
In comparison with the existing methods considering eye attributes detection, Borza et al. [
55] and Aldibaja [
56] presented eye shape estimation method. Yet, they have not reported the accuracy of the shape detection and instead reported eye region segmentation performance. To the best of our knowledge, our proposed method for eye attributes detection seeking the suitable eyelashes recommendation is the first work carried out automatically based on computer vision approaches. Thus, we could not find more related works in the literature to conduct further comparison with the results obtained from our framework. To further investigate our model’s performance, we validated the developed framework on external data represented by sample images of celebrities, as shown in
Table 7. Thus, we have demonstrated that the system generalises well on another data and performs well under variant conditions such as camera position, obstacle (wearing glasses), light condition, gender and age. Yet, on the other hand, it should be considered that the proposed framework brings up some limitations, including: (1) the developed system has not been evaluated on diverse ethnic and racial groups, (2) the presented research work has not considered eye situation characteristics analysis such as mono-lid, hooded, crease, deep-set, and prominent. However, these limitations are due to a lack of labelled data captured from variant races and ethnicities. These challenges can be overcome when larger annotated data becomes available. Moreover, the threshold parameter values used for converting scalar value into a nominal label of eye attribute are selected empirically. For future studies, studying the possibility of using automatic parameter tuning strategies (heuristic mechanisms) for determining and setting optimum threshold values could be investigated.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







