
Deep Learning for Fake News Detection in a Pairwise Textual Input Schema




Abstract
1. Introduction
- While the problem of fake news detection has been tackled in the past in a number of ways, most reported approaches rely on a limited set of existing, widely accepted and validated real/fake news data. The present work builds the pathway towards developing a new Twitter data set with real/fake news regarding a particular incident, namely the Hong Kong protests of the summer of 2019. The process of exploiting the provided fake tweets by Twitter itself, as well as the process of collecting and validating real tweet news pertaining to the particular event, are described in detail and generate a best practice setting for developing fake/real news data sets with significant derived findings.
- Another novelty of the proposed work is the form of the input to the learning schema. More specifically, tweet vectors are used, in a pairwise setting. One of the vectors in every pair is real and the other may be real or fake. The correct classification of the latter relies on the similarity/diversity it presents when compared to the former.
- The high performance of fake news detection in the literature relies to a large extent on the exploitation of exclusively account-based features, or to the exploitation of exclusively linguistic features. Unlike related work, the present work places high emphasis on the use of multimodal input that varies from word embeddings derived automatically from unstructured text to string-based and morphological features (number of syllables, number of long sentences, etc.), and from higher-level linguistic features (like the Flesh-Kincaid level, the adverbs-adjectives rate, etc.) to network account-related features.
- The proposed deep learning architecture is designed in an innovative way, that is used for the first time for fake news detection. The deep learning network exploits all aforementioned input types in various combinations. Input is fused into the network at various layers, with high flexibility, in order to achieve optimal classification accuracy.
- The input tweet may constitute the news text or the news header (defined in detail in Section 4). Previous works have used news articles headers and text as the two inputs for pairwise settings. However, this is the first time that tweets are categorized to headers and text based on their linguistic structure. This distinction in twitter data for fake news detection is made for the first time herein, accompanied by an extensive experimental setup that aims to compare the classification performance depending on the input type.
- Our work provides a detailed comparison of the proposed model with commonly used classification models according to related work. Additionally, experiments with these models are conducted, in order to assess and compare directly their performance with that of the proposed pairwise schema, by using the same input.
- Finally, an extensive review of the recent literature in fake news detection with machine learning is provided in the proposed work. Previous works with various types of data (news articles, tweets, etc.), different categories of features (network account, linguistic, etc.), and the most efficient network architectures and classification models are described thoroughly.
2. Related Work
3. Data
4. Methodology
4.1. Feature Set
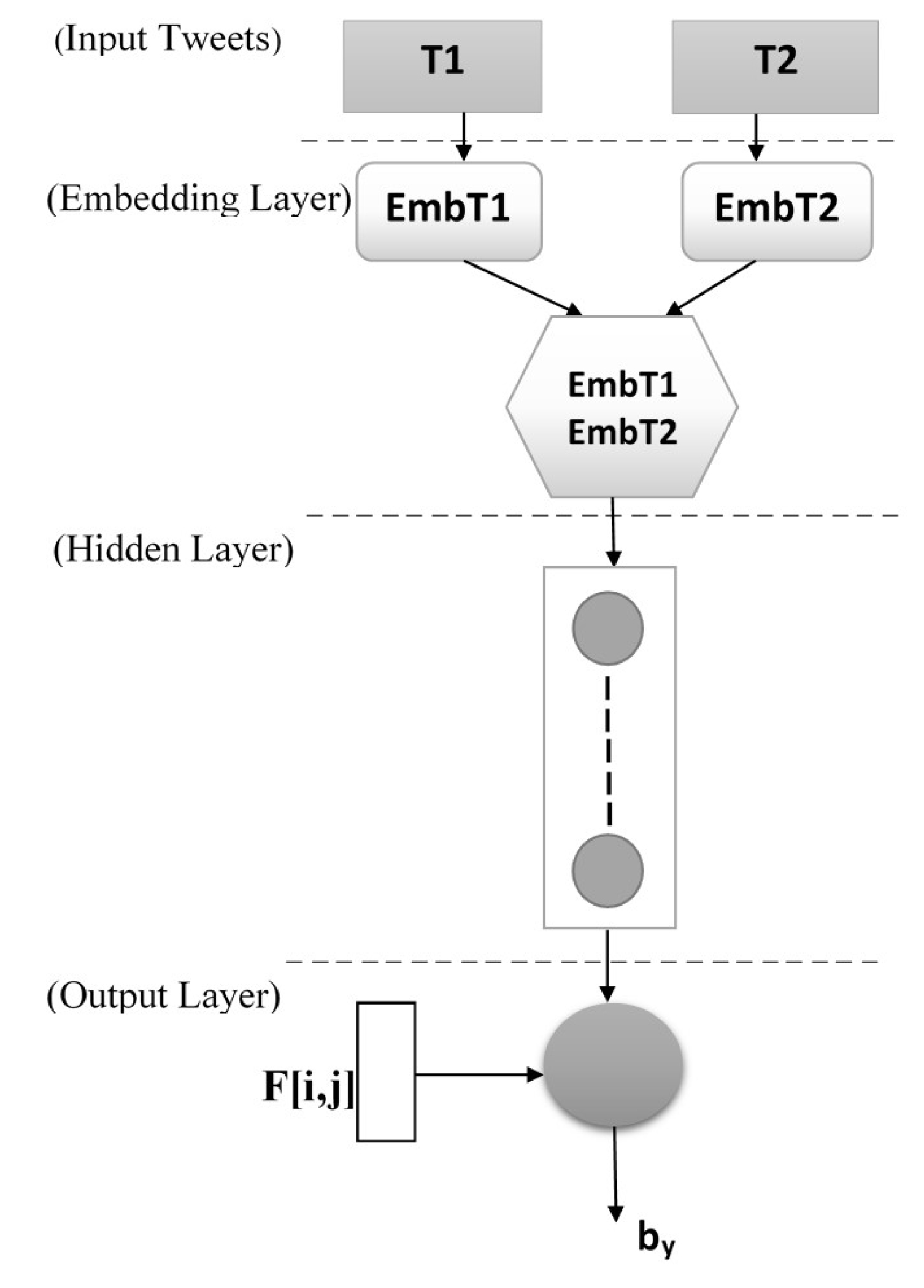
4.2. Embedding Layer
4.3. Network Architecture
5. Experiments
- Size of layers: Dense 1 and 2 with 128 hidden units, Dense 3 with 1 hidden unit (last layer).
- Output layer: Activation Sigmoid.
- Activation function of dense layers: 1 and 2 Relu, 3 Sigmoid.
- Dropout of dense layers: 0.4.
6. Results
6.1. Accuracy Performance
6.2. Comparison to Related Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| KNN | k-Nearest Neighbor |
| LIWC | Linguistic Inquiry and Word Count |
| LSTM | Long Short-Term Memory |
| NLP | Natural Language Processing |
| RNN | Recurrent Neural Networks |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency–Inverse Document Frequency |
References
- Nikiforos, M.N.; Vergis, S.; Stylidou, A.; Augoustis, N.; Kermanidis, K.L.; Maragoudakis, M. Fake News Detection Regarding the Hong Kong Events from Tweets. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Berlin/Heidelberg, Germany, 2020; pp. 177–186. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Victor, U. Robust Semi-Supervised Learning for Fake News Detection. Ph.D Thesis, Prairie View A&M University, Prairie View, TX, USA, 2020. [Google Scholar]
- Merryton, A.R.; Augasta, G. A Survey on Recent Advances in Machine Learning Techniques for Fake News Detection. Test Eng. Manag. 2020, 83, 11572–11582. [Google Scholar]
- Agarwal, A.; Dixit, A. Fake News Detection: An Ensemble Learning Approach. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 1178–1183. [Google Scholar]
- Wang, Y.; Yang, W.; Ma, F.; Xu, J.; Zhong, B.; Deng, Q.; Gao, J. Weak supervision for fake news detection via reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 516–523. [Google Scholar]
- Dong, X.; Victor, U.; Chowdhury, S.; Qian, L. Deep Two-path Semi-supervised Learning for Fake News Detection. arXiv 2019, arXiv:1906.05659. [Google Scholar]
- Vishwakarma, D.K.; Jain, C. Recent State-of-the-art of Fake News Detection: A Review. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–6. [Google Scholar]
- Gill, H.; Rojas, H. Chatting in a mobile chamber: Effects of instant messenger use on tolerance toward political misinformation among South Koreans. Asian J. Commun. 2020, 30, 470–493. [Google Scholar] [CrossRef]
- Koirala, A. COVID-19 Fake News Classification with Deep Learning. Preprint 2020. [Google Scholar] [CrossRef]
- Mahyoob, M.; Al-Garaady, J.; Alrahaili, M. Linguistic-Based Detection of Fake News in Social Media. Forthcom. Int. J. Engl. Linguist. 2020, 11, 99–109. [Google Scholar] [CrossRef]
- Alam, S.; Ravshanbekov, A. Sieving Fake News From Genuine: A Synopsis. arXiv 2019, arXiv:1911.08516. [Google Scholar]
- Han, W.; Mehta, V. Fake News Detection in Social Networks Using Machine Learning and Deep Learning: Performance Evaluation. In Proceedings of the 2019 IEEE International Conference on Industrial Internet (ICII), Orlando, FL, USA, 11–12 November 2019; pp. 375–380. [Google Scholar]
- Agrawal, T.; Gupta, R.; Narayanan, S. Multimodal detection of fake social media use through a fusion of classification and pairwise ranking systems. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1045–1049. [Google Scholar]
- Abdullah, A.; Awan, M.; Shehzad, M.; Ashraf, M. Fake News Classification Bimodal using Convolutional Neural Network and Long Short-Term Memory. Int. J. Emerg. Technol. Learn. 2020, 11, 209–212. [Google Scholar]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake news detection using deep learning models: A novel approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Bahad, P.; Saxena, P.; Kamal, R. Fake News Detection using Bi-directional LSTM-Recurrent Neural Network. Procedia Comput. Sci. 2019, 165, 74–82. [Google Scholar] [CrossRef]
- Zervopoulos, A.; Alvanou, A.G.; Bezas, K.; Papamichail, A.; Maragoudakis, M.; Kermanidis, K. Hong Kong Protests: Using Natural Language Processing for Fake News Detection on Twitter. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Berlin/Heidelberg, Germany, 2020; pp. 408–419. [Google Scholar]
- Sansonetti, G.; Gasparetti, F.; D’Aniello, G.; Micarelli, A. Unreliable Users Detection in Social Media: Deep Learning Techniques for Automatic Detection. IEEE Access 2020, 8, 213154–213167. [Google Scholar] [CrossRef]
- Jeronimo, C.L.M.; Marinho, L.B.; Campelo, C.E.; Veloso, A.; da Costa Melo, A.S. Fake News Classification Based on Subjective Language. In Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services, Munich, Germany, 2–4 December 2019; pp. 15–24. [Google Scholar]
- Alves, J.L.; Weitzel, L.; Quaresma, P.; Cardoso, C.E.; Cunha, L. Brazilian Presidential Elections in the Era of Misinformation: A Machine Learning Approach to Analyse Fake News. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 72–84. [Google Scholar]
- Perera, K. The Misinformation Era: Review on Deep Learning Approach to Fake News Detection. Preprint 2020. [Google Scholar] [CrossRef]
- Anshika, C.; Anuja, A. Linguistic feature based learning model for fake news detection and classification. Expert Syst. Appl. 2021, 169, 114–171. [Google Scholar]
- De Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M.F. Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information 2021, 12, 38. [Google Scholar] [CrossRef]
- Ranjan, S.S.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106–983. [Google Scholar]
- Wang, W.Y. “liar, liar pants on fire”: A new benchmark dataset for fake news detection. arXiv 2017, arXiv:1705.00648. [Google Scholar]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Lee, D.; Liu, H. Fakenewsnet: A data repository with news content, social context, and spatiotemporal information for studying fake news on social media. Big Data 2020, 8, 171–188. [Google Scholar] [CrossRef]
- Ruchansky, N.; Seo, S.; Liu, Y. Csi: A hybrid deep model for fake news detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 797–806. [Google Scholar]
- Köppel, M.; Segner, A.; Wagener, M.; Pensel, L.; Karwath, A.; Kramer, S. Pairwise learning to rank by neural networks revisited: Reconstruction, theoretical analysis and practical performance. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 237–252. [Google Scholar]
- Mouratidis, D.; Kermanidis, K.L.; Sosoni, V. Innovative Deep Neural Network Fusion for Pairwise Translation Evaluation. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Berlin/Heidelberg, Germany, 2020; pp. 76–87. [Google Scholar]
- Augenstein, I.; Ruder, S.; Søgaard, A. Multi-task learning of pairwise sequence classification tasks over disparate label spaces. arXiv 2018, arXiv:1802.09913. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Keras, K. Deep Learning Library for Theano and Tensorflow. Available online: https://keras.io/ (accessed on 31 January 2021).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Izonin, I.; Trostianchyn, A.; Duriagina, Z.; Tkachenko, R.; Tepla, T.; Lotoshynska, N. The combined use of the wiener polynomial and SVM for material classification task in medical implants production. Int. J. Intell. Syst. Appl. 2018, 10, 40–47. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | |
|---|---|
| Real Header | 1.027 |
| Fake Header | 127 |
| Real Text | 1.065 |
| Fake text | 144 |
| Linguistic Features | Network Account Features |
|---|---|
| Num words | User id |
| Num syllables | Follower count |
| Avg syllables | Following count |
| Avg Words in Sentence | Account creation date |
| Flesh-Kincaid | Tweet time |
| Num big Words | Like count |
| Num long sentences | Retweet count |
| Num short sentences | Num URLs |
| Num sentences | |
| Rate adverbs adjectives |
| Parameter | Value |
|---|---|
| Optimizer | Adam [35] |
| Learning Rate | 0.005 |
| Loss function | Binary cross entropy |
| Experiment 1 | Experiment 2 | |
|---|---|---|
| Tweet | Real Fake | Real Fake |
| Prior_to_SMOTE_2.363 tweets segments | ||
| Precision | 97% 100% | 99% 100% |
| Recall | 95% 74% | 97% 93% |
| Total Accuracy | 95% | 94% |
| Average F1 score | 99% | 98% |
| SMOTE_3.766 tweets segments | ||
| Precision | 100% 100% | 100% 100% |
| Recall | 100% 96% | 96% 96% |
| Total Accuracy | 98% | 97% |
| Average F1 score | 100% | 99% |
| Tweet Precision | Recall F1 score | |
|---|---|---|
| Deep Learning Model | Fake 100% | 96% 98% |
| with SMOTE | Real 100% | 100% 100% |
| Average 100% | 98% 99% | |
| Random Forest [18] | Fake 97.5% | 84.3% 90.3% |
| Real 89.7% | 98.4% 93.8% | |
| Average 93.6% | 91.3% 92.1% | |
| SVM [18] | Fake 96% | 84% 89.6% |
| Real 89.4% | 97.5% 93.3% | |
| Average 92.7% | 90.8% 91.4% | |
| Naive Bayes [1] | Fake 100% | 98.1% - |
| Real 99.7% | 100% - | |
| Average 99.8% | 99% - | |
| Random Forest [1] | Fake 100% | 94.4% - |
| Real 99.2% | 100% - | |
| Average 99.6% | 97.2% - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mouratidis, D.; Nikiforos, M.N.; Kermanidis, K.L. Deep Learning for Fake News Detection in a Pairwise Textual Input Schema. Computation 2021, 9, 20. https://doi.org/10.3390/computation9020020
Mouratidis D, Nikiforos MN, Kermanidis KL. Deep Learning for Fake News Detection in a Pairwise Textual Input Schema. Computation. 2021; 9(2):20. https://doi.org/10.3390/computation9020020
Chicago/Turabian StyleMouratidis, Despoina, Maria Nefeli Nikiforos, and Katia Lida Kermanidis. 2021. "Deep Learning for Fake News Detection in a Pairwise Textual Input Schema" Computation 9, no. 2: 20. https://doi.org/10.3390/computation9020020
APA StyleMouratidis, D., Nikiforos, M. N., & Kermanidis, K. L. (2021). Deep Learning for Fake News Detection in a Pairwise Textual Input Schema. Computation, 9(2), 20. https://doi.org/10.3390/computation9020020