Causal Modeling of Twitter Activity during COVID-19



Abstract
1. Introduction
2. Going Beyond Correlations
3. Methods
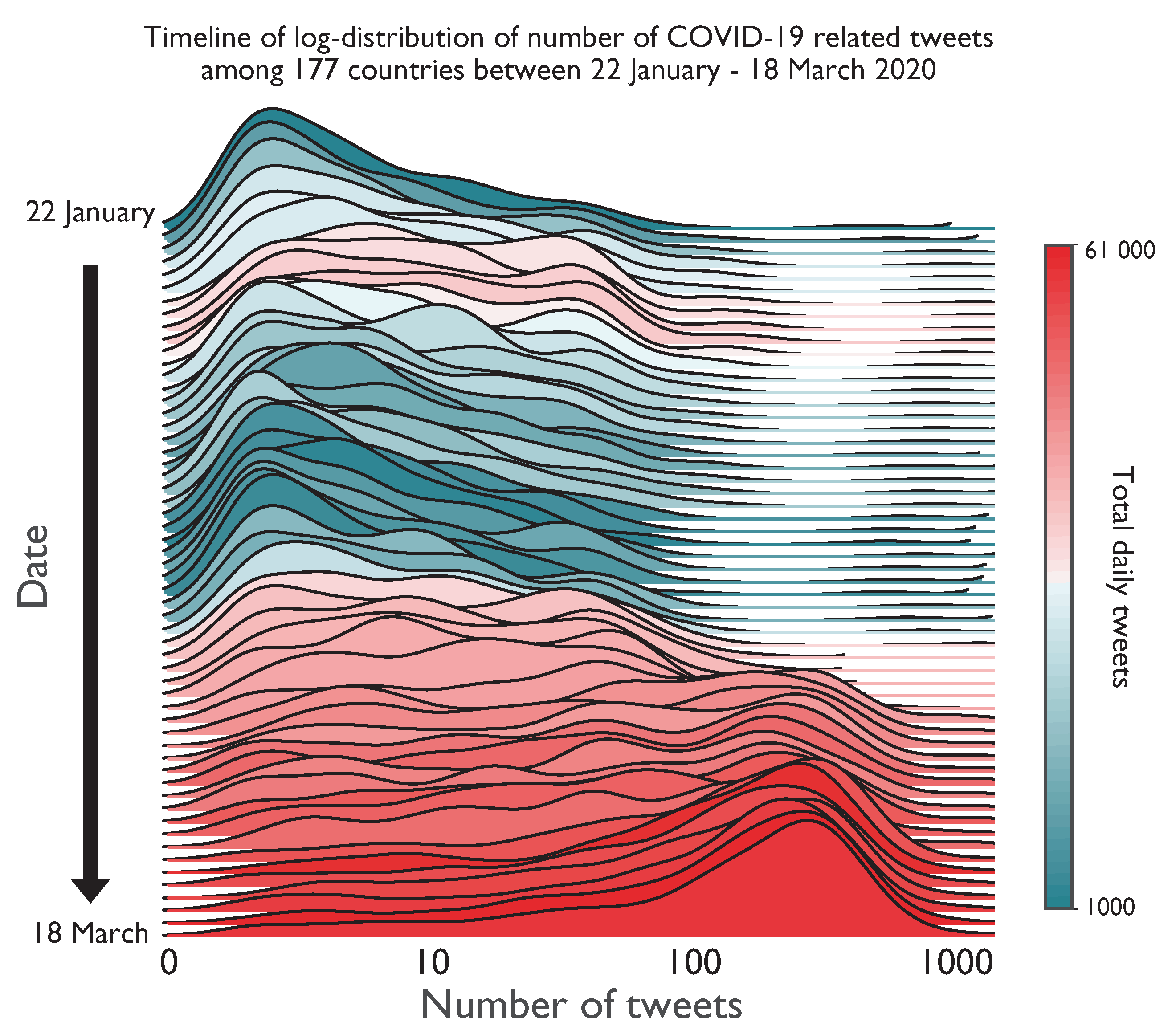
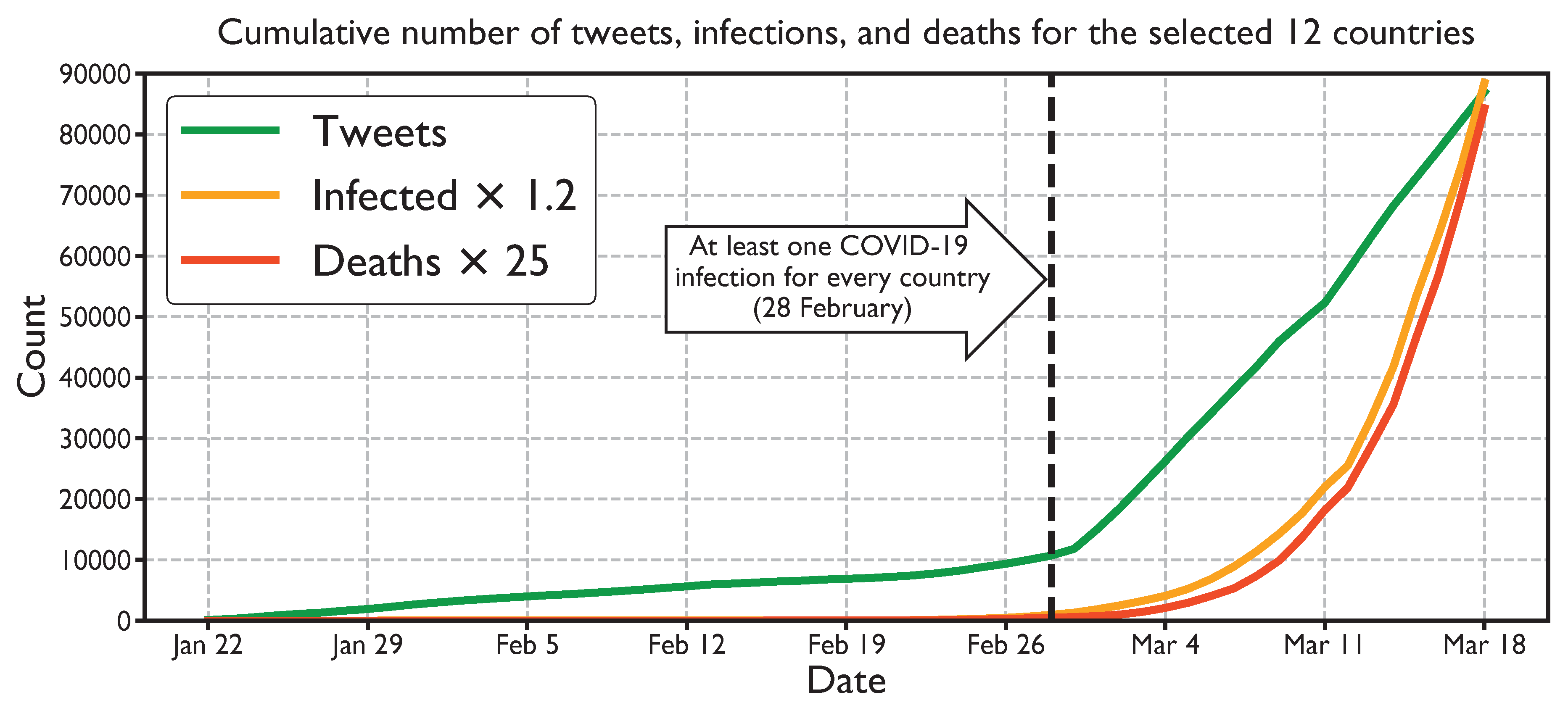
3.1. Data
3.2. Feature Selection
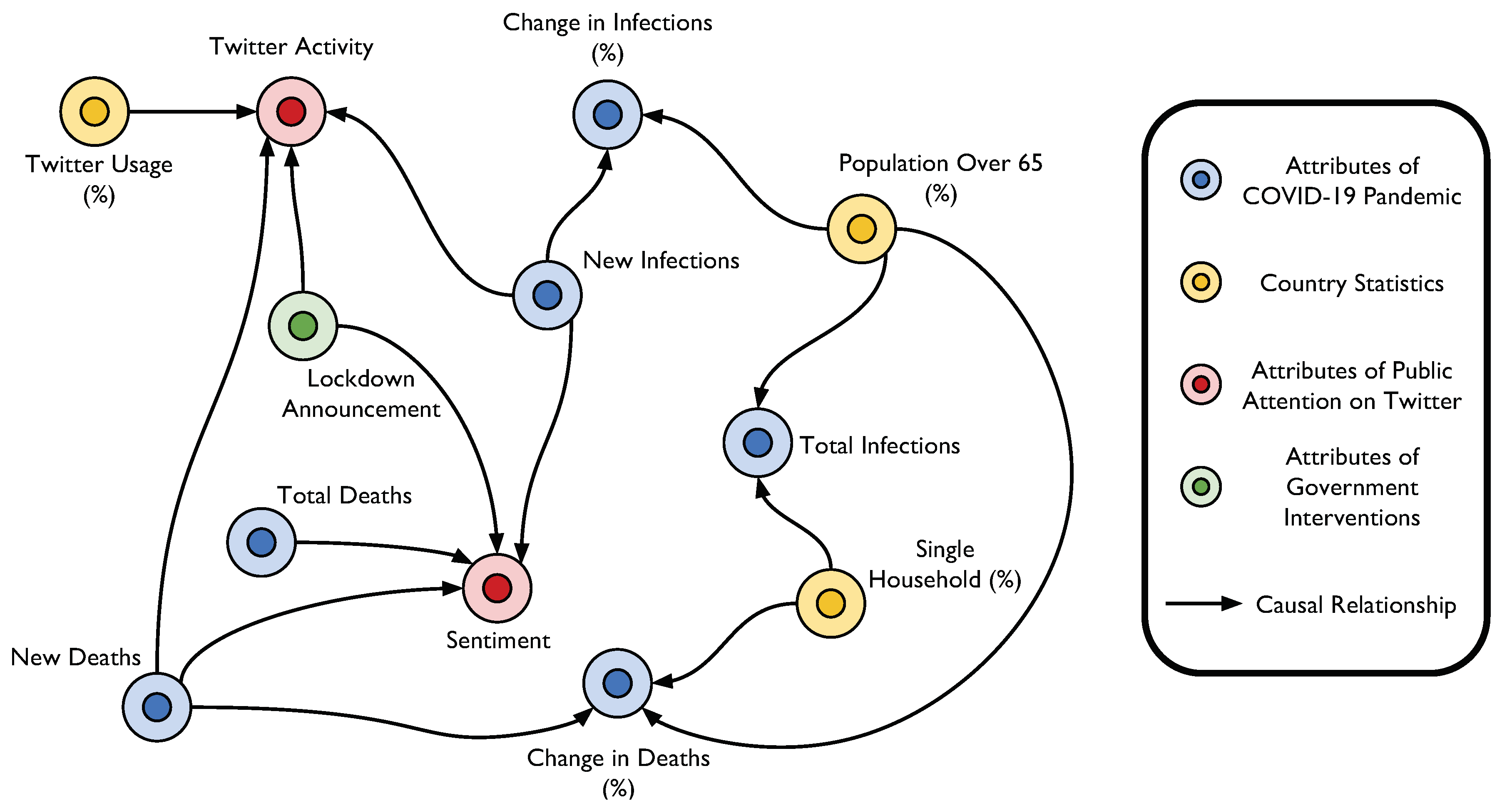
3.3. Structure Learning and Causal Inference
3.4. Evaluation
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AUROC | Area Under the Receiver Operating Characteristic curve |
| COVID-19 | Coronavirus Disease 2019 |
| BN | Bayesian Network |
| DAG | Directed Acyclic Graph |
| LOCO | Leave-One-Country-Out |
| NOTEARS | Non-combinatorial Optimization via Trace Exponential and Augmented lagRangian for |
| Structure learning |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| From | To |
|---|---|
| Population Over 65 (%) | |
| Any node | Twitter Usage (%) |
| Single Household (%) | |
| Twitter Activity | Any node |
| Sentiment | |
| Total Infections | |
| New Infections | |
| Twitter Usage (%) | Change in Infections (%) |
| Lockdown Announcement | Total Deaths |
| New Deaths | |
| Change in Deaths (%) | |
| Population Over 65 (%) | Twitter Activity |
| Single Household (%) | Sentiment |
| Twitter Usage (%) | Sentiment |
References
- Cucinotta, D.; Vanelli, M. WHO Declares COVID-19 a Pandemic. Acta Bio-Medica Atenei Parm. 2020, 91, 157–160. [Google Scholar] [CrossRef]
- Dong, E.; Du, H.; Gardner, L. An Interactive Web-based Dashboard to Track COVID-19 in Real Time. Lancet Infect. Dis. 2020. [Google Scholar] [CrossRef]
- Van Bavel, J.J.; Baicker, K.; Boggio, P.S.; Capraro, V.; Cichocka, A.; Cikara, M.; Crockett, M.J.; Crum, A.J.; Douglas, K.M.; Druckman, J.N.; et al. Using Social and Behavioural Science to Support COVID-19 Pandemic Response. Nat. Hum. Behav. 2020, 1–12. [Google Scholar] [CrossRef]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The Use of Twitter to Track Levels of Disease Activity and Public Concern in the US during the Influenza A H1N1 Pandemic. PLoS ONE 2011, 6. [Google Scholar] [CrossRef]
- Ji, X.; Chun, S.A.; Geller, J. Monitoring Public Health Concerns Using Twitter Sentiment Classifications. In Proceedings of the IEEE International Conference on Healthcare Informatics, Philadelphia, PA, USA, 9–11 September 2013; pp. 335–344. [Google Scholar] [CrossRef]
- Ji, X.; Chun, S.A.; Wei, Z.; Geller, J. Twitter Sentiment Classification for Measuring Public Health Concerns. Soc. Netw. Anal. Min. 2015, 5, 13. [Google Scholar] [CrossRef]
- Weeg, C.; Schwartz, H.A.; Hill, S.; Merchant, R.M.; Arango, C.; Ungar, L. Using Twitter to Measure Public Discussion of Diseases: A Case Study. JMIR Public Health Surveill. 2015, 1, e6. [Google Scholar] [CrossRef]
- Mollema, L.; Harmsen, I.A.; Broekhuizen, E.; Clijnk, R.; De Melker, H.; Paulussen, T.; Kok, G.; Ruiter, R.; Das, E. Disease Detection or Public Opinion Reflection? Content Analysis of Tweets, Other Social Media, and Online Newspapers during the Measles Outbreak in the Netherlands in 2013. J. Med. Internet Res. (JMIR) 2015, 17, e128. [Google Scholar] [CrossRef]
- Jordan, S.E.; Hovet, S.E.; Fung, I.C.H.; Liang, H.; Fu, K.W.; Tse, Z.T.H. Using Twitter for Public Health Surveillance from Monitoring and Prediction to Public Response. Data 2019, 4, 6. [Google Scholar] [CrossRef]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter Pandemic: The Critical Role of Twitter in the Dissemination of Medical Information and Misinformation during the COVID-19 Pandemic. Can. J. Emerg. Med. 2020, 1–7. [Google Scholar] [CrossRef]
- Chen, E.; Lerman, K.; Ferrara, E. Covid-19: The First Public Coronavirus Twitter Dataset. arXiv 2020, arXiv:2003.07372. [Google Scholar]
- Gao, Z.; Yada, S.; Wakamiya, S.; Aramaki, E. NAIST COVID: Multilingual COVID-19 Twitter and Weibo Dataset. arXiv 2020, arXiv:2004.08145. [Google Scholar]
- Lamsal, R. Corona Virus (COVID-19) Tweets Dataset. IEEEDataPort 2020. [Google Scholar] [CrossRef]
- Aguilar-Gallegos, N.; Romero-García, L.E.; Martínez-González, E.G.; García-Sánchez, E.I.; Aguilar-Ávila, J. Dataset on Dynamics of Coronavirus on Twitter. Data Brief 2020, 30, 105684. [Google Scholar] [CrossRef] [PubMed]
- Thelwall, M.; Thelwall, S. Retweeting for COVID-19: Consensus Building, Information Sharing, Dissent, and Lockdown Life. arXiv 2020, arXiv:2004.02793. [Google Scholar]
- Sha, H.; Hasan, M.A.; Mohler, G.; Brantingham, P.J. Dynamic Topic Modeling of the COVID-19 Twitter Narrative Among US Governors and Cabinet Executives. arXiv 2020, arXiv:2004.11692. [Google Scholar]
- Wong, C.M.L.; Jensen, O. The Paradox of Trust: Perceived Risk and Public Compliance During the COVID-19 Pandemic in Singapore. J. Risk Res. 2020, 1–10. [Google Scholar] [CrossRef]
- Turiel, J.; Aste, T. Wisdom of the Crowds in Forecasting COVID-19 Spreading Severity. arXiv 2020, arXiv:2004.04125. [Google Scholar]
- Gharavi, E.; Nazemi, N.; Dadgostari, F. Early Outbreak Detection for Proactive Crisis Management Using Twitter Data: COVID-19 a Case Study in the US. arXiv 2020, arXiv:2005.00475. [Google Scholar]
- Chary, M.; Overbeek, D.; Papadimoulis, A.; Sheroff, A.; Burns, M. Geospatial Correlation Between COVID-19 Health Misinformation on Social Media and Poisoning with Household Cleaners. medRxiv 2020. [Google Scholar] [CrossRef]
- Kayes, A.; Islam, M.S.; Watters, P.A.; Ng, A.; Kayesh, H. Automated Measurement of Attitudes Towards Social Distancing Using Social Media: A COVID-19 Case Study. Preprints 2020. [Google Scholar] [CrossRef]
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate Psychological Responses and Associated Factors During the Initial Stage of the 2019 Coronavirus Disease (COVID-19) Epidemic Among the General Population in China. Int. J. Environ. Res. Public Health 2020, 17, 1729. [Google Scholar] [CrossRef] [PubMed]
- Cullen, W.; Gulati, G.; Kelly, B. Mental Health in the COVID-19 Pandemic. QJM An Int. J. Med. 2020, 113, 311–312. [Google Scholar] [CrossRef] [PubMed]
- Brooks, S.K.; Webster, R.K.; Smith, L.E.; Woodland, L.; Wessely, S.; Greenberg, N.; Rubin, G.J. The Psychological Impact of Quarantine and How to Reduce It: Rapid Review of the Evidence. Lancet 2020, 395, 912–920. [Google Scholar] [CrossRef] [PubMed]
- Dubey, A.D.; Tripathi, S. Analysing the Sentiments towards Work-From-Home Experience during COVID-19 Pandemic. J. Innov. Manag. 2020, 8. [Google Scholar] [CrossRef]
- Duong, V.; Pham, P.; Yang, T.; Wang, Y.; Luo, J. The Ivory Tower Lost: How College Students Respond Differently than the General Public to the COVID-19 Pandemic. arXiv 2020, arXiv:2004.09968. [Google Scholar]
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An “Infodemic”: Leveraging High-Volume Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak. medRxiv 2020. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Preprints 2020. [Google Scholar] [CrossRef]
- Batooli, Z.; Sayyah, M. Measuring Social Media Attention of Scientific Research on Novel Coronavirus Disease 2019 (COVID-19): An Investigation on Article-level Metrics Data of Dimensions. Prepr. Res. Sq. 2020. [Google Scholar] [CrossRef]
- Kwon, J.; Grady, C.; Feliciano, J.T.; Fodeh, S.J. Defining Facets of Social Distancing during the COVID-19 Pandemic: Twitter Analysis. medRxiv 2020. [Google Scholar] [CrossRef]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 Social Media Infodemic. arXiv 2020, arXiv:2003.05004. [Google Scholar]
- Park, H.W.; Park, S.; Chong, M. Conversations and Medical News Frames on Twitter: Infodemiological Study on COVID-19 in South Korea. J. Med. Internet Res. (JMIR) 2020, 22, e18897. [Google Scholar] [CrossRef] [PubMed]
- Thelwall, M.; Thelwall, S. Covid-19 tweeting in English: Gender differences. arXiv 2020, arXiv:2003.11090. [Google Scholar] [CrossRef]
- Alshaabi, T.; Minot, J.; Arnold, M.; Adams, J.L.; Dewhurst, D.R.; Reagan, A.J.; Muhamad, R.; Danforth, C.M.; Dodds, P.S. How the World’s Collective Attention is Being Paid to a Pandemic: COVID-19 Related 1-gram Time Series for 24 Languages on Twitter. arXiv 2020, arXiv:2003.12614. [Google Scholar]
- Lopez, C.E.; Vasu, M.; Gallemore, C. Understanding the Perception of COVID-19 Policies by Mining a Multilanguage Twitter Dataset. arXiv 2020, arXiv:2003.10359. [Google Scholar]
- Dewhurst, D.R.; Alshaabi, T.; Arnold, M.V.; Minot, J.R.; Danforth, C.M.; Dodds, P.S. Divergent Modes of Online Collective Attention to the COVID-19 Pandemic are Associated with Future Caseload Variance. arXiv 2020, arXiv:2004.03516. [Google Scholar]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study. J. Med. Internet Res. (JMIR) 2020, 22, e19016. [Google Scholar] [CrossRef]
- Wicke, P.; Bolognesi, M.M. Framing COVID-19: How We Conceptualize and Discuss the Pandemic on Twitter. arXiv 2020, arXiv:2004.06986. [Google Scholar]
- Jarynowski, A.; Wójta-Kempa, M.; Belik, V. Trends in Perception of COVID-19 in Polish Internet. medRxiv 2020. [Google Scholar] [CrossRef]
- Ordun, C.; Purushotham, S.; Raff, E. Exploratory Analysis of Covid-19 Tweets Using Topic Modeling, UMAP, and DiGraphs. arXiv 2020, arXiv:2005.03082. [Google Scholar]
- Yang, K.C.; Torres-Lugo, C.; Menczer, F. Prevalence of Low-Credibility Information on Twitter During the COVID-19 Outbreak. arXiv 2020, arXiv:2004.14484. [Google Scholar]
- Ahmed, W.; Vidal-Alaball, J.; Downing, J.; Seguí, F.L. COVID-19 and the 5G Conspiracy Theory: Social Network Analysis of Twitter Data. J. Med. Internet Res. (JMIR) 2020, 22, e19458. [Google Scholar] [CrossRef] [PubMed]
- Ferrara, E. #COVID-19 on Twitter: Bots, Conspiracies, and Social Media Activism. arXiv 2020, arXiv:2004.09531. [Google Scholar]
- Bridgman, A.; Merkley, E.; Loewen, P.J.; Owen, T.; Ruths, D.; Teichmann, L.; Zhilin, O. The Causes and Consequences of COVID-19 Misperceptions: Understanding the Role of News and Social Media. OSF Prepr. 2020. [Google Scholar] [CrossRef]
- Ahmed, W.; Vidal-Alaball, J.; Downing, J.; Seguí, F.L. Dangerous Messages or Satire? Analysing the Conspiracy Theory Linking 5G to COVID-19 through Social Network Analysis. J. Med. Internet Res. (JMIR) 2020. [Google Scholar] [CrossRef]
- Gallotti, R.; Valle, F.; Castaldo, N.; Sacco, P.; De Domenico, M. Assessing the Risks of “Infodemics” in Response to COVID-19 Epidemics. medRxiv 2020. [Google Scholar] [CrossRef]
- Golder, S.; Klein, A.; Magge, A.; O’Connor, K.; Cai, H.; Weissenbacher, D. Extending A Chronological and Geographical Analysis of Personal Reports of COVID-19 on Twitter to England, UK. medRxiv 2020. [Google Scholar] [CrossRef]
- Sarker, A.; Lakamana, S.; Hogg-Bremer, W.; Xie, A.; Al-Garadi, M.A.; Yang, Y.C. Self-reported COVID-19 Symptoms on Twitter: An Analysis and a Research Resource. J. Am. Med. Informat. Assoc. 2020. [Google Scholar] [CrossRef]
- Li, I.; Li, Y.; Li, T.; Alvarez-Napagao, S.; Garcia, D. What Are We Depressed about When We Talk about COVID19: Mental Health Analysis on Tweets Using Natural Language Processing. arXiv 2020, arXiv:2004.10899. [Google Scholar]
- Xu, P.; Dredze, M.; Broniatowski, D.A. The Twitter Social Mobility Index: Measuring Social Distancing Practices from Geolocated Tweets. arXiv 2020, arXiv:2004.02397. [Google Scholar]
- Lyu, H.; Chen, L.; Wang, Y.; Luo, J. Sense and Sensibility: Characterizing Social Media Users Regarding the Use of Controversial Terms for COVID-19. IEEE Trans. Big Data 2020. [Google Scholar] [CrossRef]
- Schild, L.; Ling, C.; Blackburn, J.; Stringhini, G.; Zhang, Y.; Zannettou, S. “Go Eat A Bat, Chang!”: An Early Look on the Emergence of Sinophobic Behavior on Web Communities in the Face of COVID-19. arXiv 2020, arXiv:2004.04046. [Google Scholar]
- Rovetta, A.; Bhagavathula, A.S. COVID-19-Related Web Search Behaviors and Infodemic Attitudes in Italy: Infodemiological Study. JMIR Public Health Surveill. 2020, 6, e19374. [Google Scholar] [CrossRef] [PubMed]
- Shahsavari, S.; Holur, P.; Tangherlini, T.R.; Roychowdhury, V. Conspiracy in the Time of Corona: Automatic detection of Covid-19 Conspiracy Theories in Social Media and the News. arXiv 2020, arXiv:2004.13783. [Google Scholar]
- Li, J.; Xu, Q.; Cuomo, R.; Purushothaman, V.; Mackey, T. Data Mining and Content Analysis of the Chinese Social Media Platform Weibo during the Early COVID-19 Outbreak: Retrospective Observational Infoveillance Study. JMIR Public Health Surveill. 2020, 6, e18700. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The Impact of COVID-19 Epidemic Declaration on Psychological Consequences: A Study on Active Weibo Users. Int. J. Environ. Res. Public Health 2020, 17, 2032. [Google Scholar] [CrossRef] [PubMed]
- Velásquez, N.; Leahy, R.; Restrepo, N.J.; Lupu, Y.; Sear, R.; Gabriel, N.; Jha, O.; Johnson, N. Hate Multiverse Spreads Malicious COVID-19 Content Online Beyond Individual Platform Control. arXiv 2020, arXiv:2004.00673. [Google Scholar]
- Zhao, Y.; Xu, H. Chinese Public Attention to COVID-19 Epidemic: Based on Social Media. medRxiv 2020. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Q.; Wang, X.; Zhang, J.; Wang, T.; Gao, T.L.; Duan, W.; Tsoi, K.K.f.; Wang, F.Y. Characterizing the Propagation of Situational Information in Social Media during COVID-19 Epidemic: A Case Study on Weibo. IEEE Trans. Comput. Soc. Syst. 2020, 7, 556–562. [Google Scholar] [CrossRef]
- Lampos, V.; Moura, S.; Yom-Tov, E.; Cox, I.J.; McKendry, R.; Edelstein, M. Tracking COVID-19 Using Online Search. arXiv 2020, arXiv:2003.08086. [Google Scholar]
- Boberg, S.; Quandt, T.; Schatto-Eckrodt, T.; Frischlich, L. Pandemic Populism: Facebook Pages of Alternative News Media and the Corona Crisis–A Computational Content Analysis. arXiv 2020, arXiv:2004.02566. [Google Scholar]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, H. Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach. arXiv 2020, arXiv:2004.11695. [Google Scholar] [CrossRef]
- Liu, D.; Clemente, L.; Poirier, C.; Ding, X.; Chinazzi, M.; Davis, J.T.; Vespignani, A.; Santillana, M. A Machine Learning Methodology for Real-time Forecasting of the 2019-2020 COVID-19 Outbreak Using Internet Searches, News Alerts, and Estimates from Mechanistic Models. arXiv 2020, arXiv:2004.04019. [Google Scholar]
- Hou, Z.; Du, F.; Jiang, H.; Zhou, X.; Lin, L. Assessment of Public Attention, Risk Perception, Emotional and Behavioural Responses to the COVID-19 Outbreak: Social Media Surveillance in China. medRxiv Prepr. 2020. [Google Scholar] [CrossRef]
- Stokes, D.C.; Andy, A.; Guntuku, S.C.; Ungar, L.H.; Merchant, R.M. Public Priorities and Concerns Regarding COVID-19 in an Online Discussion Forum: Longitudinal Topic Modeling. J. Gen. Intern. Med. 2020. [Google Scholar] [CrossRef] [PubMed]
- Shen, C.; Chen, A.; Luo, C.; Liao, W.; Zhang, J.; Feng, B. Reports of Own and Others’ Symptoms and Diagnosis on Social Media Predict COVID-19 Case Counts in Mainland China. arXiv 2020, arXiv:2004.06169. [Google Scholar]
- Chen, Q.; Min, C.; Zhang, W.; Wang, G.; Ma, X.; Evans, R. Unpacking the Black Box: How to Promote Citizen Engagement through Government Social Media during the COVID-19 Crisis. Comput. Hum. Behav. 2020, 106380. [Google Scholar] [CrossRef]
- Lucas, B.; Elliot, B.; Landman, T. Online Information Search During COVID-19. arXiv 2020, arXiv:2004.07183. [Google Scholar]
- Pekoz, E.A.; Smith, A.; Tucker, A.; Zheng, Z. COVID-19 Symptom Web Search Surges Precede Local Hospitalization Surges. SSRN Prepr. 2020. [Google Scholar] [CrossRef]
- Ellis, B.; Wong, W.H. Learning Causal Bayesian Network Structures from Experimental Data. J. Am. Stat. Assoc. 2008, 103, 778–789. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Rubin, D.B. Causal Inference Using Potential Outcomes: Design, Modeling, Decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Pearl, J. An Introduction to Causal Inference. Int. J. Biostat. 2010, 6. [Google Scholar] [CrossRef]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Twitter. Available online: https://twitter.com/ (accessed on 12 May 2020).
- Dowd, J.B.; Andriano, L.; Brazel, D.M.; Rotondi, V.; Block, P.; Ding, X.; Liu, Y.; Mills, M.C. Demographic Science Aids in Understanding the Spread and Fatality Rates of COVID-19. Proc. Natl. Acad. Sci. USA 2020, 117, 9696–9698. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.R.; Cao, Q.D.; Hong, Z.S.; Tan, Y.Y.; Chen, S.D.; Jin, H.J.; Tan, K.S.; Wang, D.Y.; Yan, Y. The Origin, Transmission and Clinical Therapies on Coronavirus Disease 2019 (COVID-19) Outbreak-An Update on the Status. Mil. Med. Res. 2020, 7, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yu, Y.; Xu, J.; Shu, H.; Liu, H.; Wu, Y.; Zhang, L.; Yu, Z.; Fang, M.; Yu, T.; et al. Clinical Course and Outcomes of Critically Ill Patients with SARS-CoV-2 Pneumonia in Wuhan, China: A Single-centered, Retrospective, Observational Study. Lancet Respir. Med. 2020, 8, 475–481. [Google Scholar] [CrossRef]
- Wang, W.; Tang, J.; Wei, F. Updated Understanding of the Outbreak of 2019 Novel Coronavirus (2019-nCoV) in Wuhan, China. J. Med. Virol. 2020, 92, 441–447. [Google Scholar] [CrossRef] [PubMed]
- WHO. Report of the WHO-China Joint Mission on Coronavirus Disease 2019 (COVID-19); World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Li, C.; Ji, F.; Wang, L.; Hao, J.; Dai, M.; Liu, Y.; Pan, X.; Fu, J.; Li, L.; Yang, G.; et al. Asymptomatic and Human-to-Human Transmission of SARS-CoV-2 in a 2-Family Cluster, Xuzhou, China. Emerg. Infect. Dis. 2020, 26, 1626–1628. [Google Scholar] [CrossRef] [PubMed]
- World Bank Open Data—Population Ages 65 and Above. Available online: https://data.worldbank.org/ (accessed on 12 May 2020).
- Distribution of Households by Household Type from 2003 Onwards—EU-SILC Survey. Available online: https://appsso.eurostat.ec.europa.eu/nui/show.do?dataset=ilc_lvph02&lang=en (accessed on 12 May 2020).
- Social Media Stats-February 2020. Available online: https://gs.statcounter.com/ (accessed on 12 May 2020).
- National Responses to the COVID-19 Pandemic—Lockdown Data. Available online: https://en.wikipedia.org/wiki/National_responses_to_the_COVID-19_pandemic (accessed on 12 May 2020).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, A Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Zheng, X.; Aragam, B.; Ravikumar, P.; Xing, E.P. DAGs with NO TEARS: Continuous Optimization for Structure Learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 9492–9503. [Google Scholar] [CrossRef]
- Chickering, D.M. Learning Bayesian Networks is NP-complete. In Learning from Data; Springer: Berlin/Heidelberg, Germany, 1996; pp. 121–130. [Google Scholar] [CrossRef]
- Chickering, D.M.; Heckerman, D.; Meek, C. Large-sample Learning of Bayesian Networks is NP-hard. J. Mach. Learn. Res. 2004, 5, 1287–1330. [Google Scholar]
- Wise, T.; Zbozinek, T.D.; Michelini, G.; Hagan, C.C.; Mobbs, D. Changes in Risk Perception and Self-reported Protective Behaviour during the First Week of the COVID-19 Pandemic in the United States. R. Soc. Open Sci. 2020, 7, 200742. [Google Scholar] [CrossRef]
- Zhong, B.L.; Luo, W.; Li, H.M.; Zhang, Q.Q.; Liu, X.G.; Li, W.T.; Li, Y. Knowledge, Attitudes, and Practices Towards COVID-19 Among Chinese Residents during the Rapid Rise Period of the COVID-19 Outbreak: A Quick Online Cross-sectional Survey. Int. J. Biol. Sci. 2020, 16, 1745. [Google Scholar] [CrossRef]
- Merchant, R.M.; Lurie, N. Social Media and Emergency Preparedness in Response to Novel Coronavirus. J. Am. Med. Assoc. (JAMA) 2020, 323. [Google Scholar] [CrossRef] [PubMed]



| Cross Validation Test Country | AUROC |
|---|---|
| Austria | 0.798 |
| Belgium | 0.728 |
| Denmark | 0.831 |
| France | 0.776 |
| Germany | 0.992 |
| Italy | 0.976 |
| Netherlands | 0.746 |
| Norway | 0.907 |
| Spain | 0.766 |
| Sweden | 0.998 |
| Switzerland | 0.789 |
| United Kingdom | 0.684 |
| Average | 0.833 |
| Query | Variable and State | |
|---|---|---|
| Single-person household (%) = H | Total Infections = H | 0.178 |
| 65+ (%) = L | ||
| Single-person household (%) = L | Total Infections = H | 0.241 |
| 65+ (%) = H | ||
| New Infections = H | Twitter Activity = H | 0.496 |
| New Deaths = H | ||
| New Infections = L | Twitter Activity = H | 0.184 |
| New Deaths = L | ||
| New Infections = H | ||
| New Deaths = H | Twitter Activity = H | 0.800 |
| Twitter Usage = H | ||
| Lockdown Announcement = Yes | ||
| New Infections = L | ||
| New Deaths = L | Twitter Activity = H | 0.120 |
| Twitter Usage = L | ||
| Lockdown Announcement = No | ||
| New Deaths = H | Sentiment = Neg | 0.624 |
| New Deaths = L | Sentiment = Neg | 0.277 |
| Total Deaths = H | Sentiment = Neg | 0.344 |
| Total Deaths = L | Sentiment = Neg | 0.290 |
| Lockdown Announcement = Yes | Sentiment = Neg | 0.501 |
| Lockdown Announcement = No | Sentiment = Neg | 0.286 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gencoglu, O.; Gruber, M. Causal Modeling of Twitter Activity during COVID-19. Computation 2020, 8, 85. https://doi.org/10.3390/computation8040085
Gencoglu O, Gruber M. Causal Modeling of Twitter Activity during COVID-19. Computation. 2020; 8(4):85. https://doi.org/10.3390/computation8040085
Chicago/Turabian StyleGencoglu, Oguzhan, and Mathias Gruber. 2020. "Causal Modeling of Twitter Activity during COVID-19" Computation 8, no. 4: 85. https://doi.org/10.3390/computation8040085
APA StyleGencoglu, O., & Gruber, M. (2020). Causal Modeling of Twitter Activity during COVID-19. Computation, 8(4), 85. https://doi.org/10.3390/computation8040085