Addressing Examination Timetabling Problem Using a Partial Exams Approach in Constructive and Improvement


Abstract
1. Introduction
2. Examination Timetabling Problem
2.1. Definition
2.2. Toronto Dataset
2.2.1. Problem Description
- Hard constraint: One student can attend only one exam at a time (it is known as a clashing constraint).
- Soft constraint: Conflicting examinations are spread as far as possible. This constraint measures the quality of the timetable.
2.2.2. Problem Formulation
- N is the number of exams.
- M is the total number of students.
- is an examination, .
- T is the available time slots.
- is the conflict matrix. where each element in the matrix is the number of students taking examination i and j, and where . Each element is n if examination i and examination j are taken by n students , otherwise is zero.
- is the time slot associated with examination k, and .
2.3. ITC2007 Exam Dataset
2.3.1. Problem Description
- Number of examinations: Every instance has a specific number of examinations. Each individual examination has a definite duration with a set of students who enrolled for the examination.
- Number of time slots: Every instance has a specific number of time slots or periods. There are some time slots that have penalties. Besides, penalties are associated with two examinations in a row, two examinations in a day, examination spreading and later period.
- Number of rooms: Every instance has some predefined rooms where examinations have to be placed. This collection of rooms is assigned to every time slot of an instance. Also, some rooms are associated with penalties.
- Room capacity: Different room has a different capacity. It is observed that ITC2007 exam dataset does not allow splitting of an examination into several rooms, albeit multiple examinations can be assigned in a single room.
- Time slot length: All of the time slots of an instance have either different or same time slot duration. The penalty is involved when the different duration of examinations share the same room and period.
- Period hard constraint-AFTER: For any pair of examinations (, ), this constraint means must be assigned after . Some of the instances have more complex constraints where the same examinations are associated with AFTER constraint more than one time. For instance, AFTER ; AFTER . This increases the complexity for the dataset ( see and ).
- Period hard constraint-EXCLUSION: For any pair of examinations (, ), this constraint means must not be assigned with .
- Period hard constraint-EXAM-COINCIDENCE: For any pair of examinations (, ), this constraint means and must be placed in the same time slot.
- Room hard constraint- EXCLUSIVE: This constraint indicates an examination must be assigned in an allocated room. Any other examinations must not be assigned in this particular room. Only three instances (, , and ) have this constraint.
- Front load expression: It is expected that examinations with a large number of students should be assigned at the beginning of the examination schedule. Every instance defines the number of larger examinations. Another parameter is the number of last periods to be considered for penalty. If any larger examination falls in that period, an associated penalty is included.
- . One student can sit only one exam at a time.
- . The capacity of the exam will not exceed the capacity of the room.
- . The examination duration will not violate the duration of the period.
- . There are three types of examination ordering that must be respected.
- -
- Precedences: exam i will be scheduled before exam j.
- -
- Exclusions: exam i and exam j must not be placed at the same period.
- -
- Coincidences: exam i and exam j must be scheduled in the same period.
- . Room exclusiveness must be kept. For instance, an exam i must take place only in room number 206.
- . Two Exams in a Row: There is a restriction for a student to sit successive exams on the same day.
- . Two Exams in a Day: There is a restriction for a student to sit two exams in a day.
- . Spreading of Exams: The exams are spread as evenly as possible over the periods so that the preferences of students such as avoiding closeness of exams are preserved.
- . Mixed Duration: Scheduling exams of different duration should be avoided in the same room and period.
- . Scheduling of Larger Exams: There is a restriction to assign larger exams at the late of the timetables.
- . Room Penalty: Some rooms are restricted, and an associated penalty is imposed if assigned.
- . Period Penalty: Some periods are restricted, and an associated penalty is imposed if assigned.
2.3.2. Problem Formulation
- E: Set of Examinations.
- : Size of examination .
- : Duration of Examination .
- : A boolean value that is 1 iff examination i is subject to front load penalties, 0 otherwise.
- D: Set of durations used .
- : A boolean value that is 1 iff examination i has the duration type .
- : A boolean value that is 1 iff duration type d is used for period p and room r, 0 otherwise.
- S: Set of students.
- : A boolean value that is 1 iff student s takes examination i, 0 otherwise.
- R: Set of rooms.
- : Size of room .
- : A weight that indicates a specific penalty for using the room r.
- P: Set of periods.
- : Duration of period .
- : A boolean value that is 1 iff period p is subject to FRONTLOAD penalties, 0 otherwise.
- : A weight that indicates a specific penalty for using the period p.
- : A Boolean value that is 1 iff period p and q are in the same day, 0 otherwise.
- when examination i is in period p, 0 otherwise.
- when examination i is in room r, 0 otherwise.
- when examination i is in room r and period p, 0 otherwise.
- : Weight for two in a row.
- : Weight for two in a day.
- : Weight for period spread.
- : Weight for no mixed duration.
- : Weight for the front load penalty.
- : Two in a row penalty for student s.
- : Two in a row penalty for the entire set of students.
- : Two in a day penalty for student s.
- : Two in a day penalty for the entire set of students.
- : Period spread penalty for student s.
- : Period spread penalty for the entire set of students.
- : No mixed duration penalty.
- : Front load penalty.
- : Soft period penalty.
- : Soft room penalty.
- : Pair of examinations set where in each pair , the examination must be assigned after the examination .
- : Pair of examinations sets where in each pair , the examination and must be assigned at the same period.
- : Pair of examinations set where in each pair , the examination and must not be assigned at the same period.
- : A set of examinations where each examination is allocated to a room r and no other examinations are allocated in this room.
3. Background
3.1. Graph Heuristic Orderings
- Largest degree (LD): In this ordering, the number of conflicts is counted for each examination by checking its conflict with all other examinations. Examinations are then arranged in decreasing order such that exams with the largest number of conflicts are scheduled first.
- Largest weighted degree (LWD): This ordering is similar to LD. The difference is that in the ordering process the number of students associated with the conflict is considered.
- Largest enrolment (LE): The examinations are ordered based on the number of registered students for each exam.
- Saturation degree (SD): Examination ordering is based on the availability of the remaining time slots where unscheduled examinations with the lowest number of available time slots are given priority to be scheduled first. The ordering is dynamic as it is updated after scheduling each exam.
3.2. Great Deluge Algorithm
| Algorithm 1. GD algorithm. |
 |
4. Proposed Method: PGH-mGD
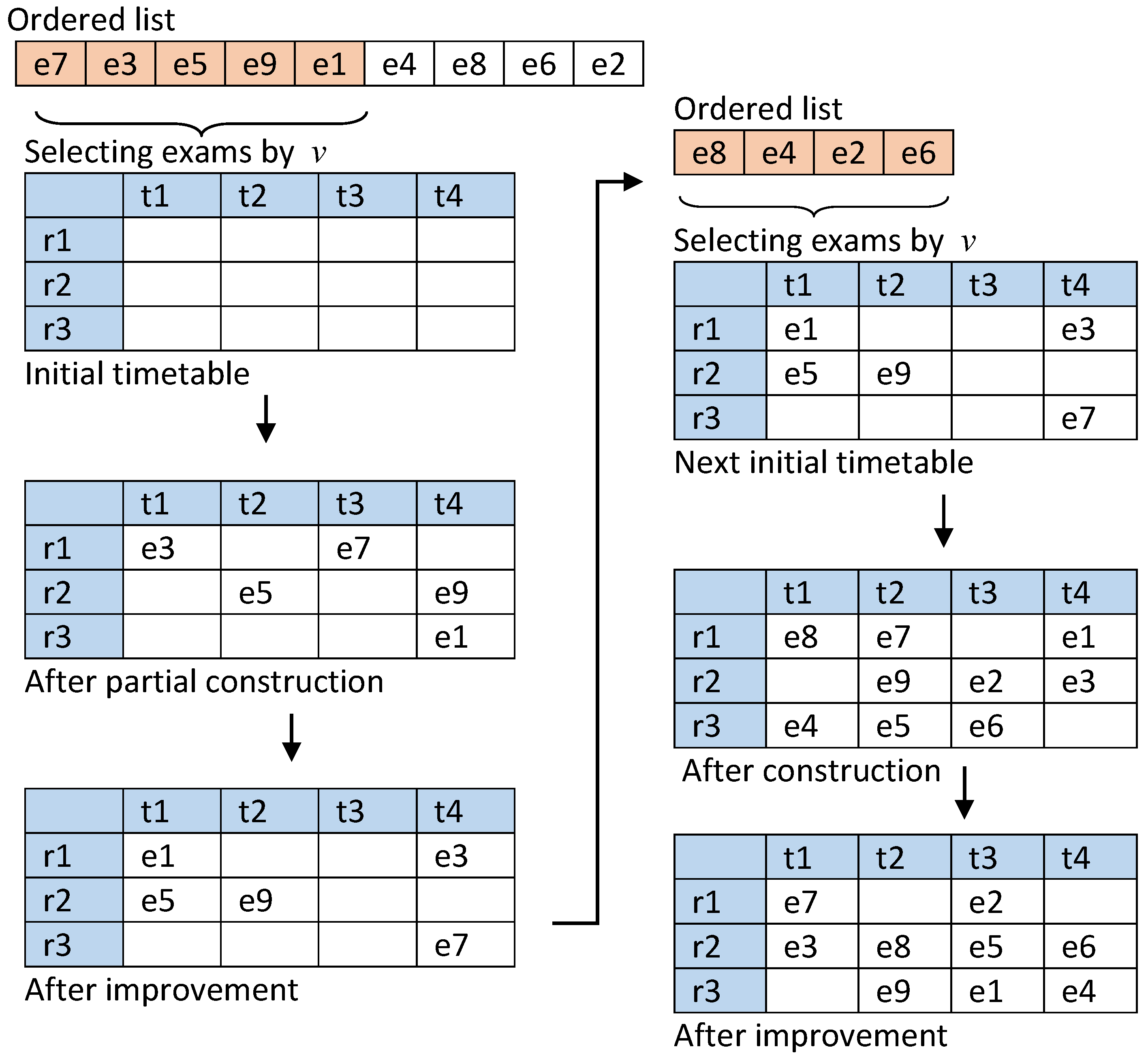
4.1. Definition and an Illustrative Example
4.2. PGH-mGD Algorithm
| Algorithm 2. PGH-mGD approach. |
 |
| Algorithm 3. Scheduling partial exams. |
 |
4.3. Scheduling Procedure of Partial Exams
4.4. Exam Resolution Manager Procedure
| Algorithm 4.ExamResolutionManager procedure. |
 |
4.5. Improvement Using Modified GD
| Algorithm 5. Modified GD for improvement of partial scheduled exams. |
 |
5. TGH-mGD Algorithm
| Algorithm 6. TGH-mGD approach. |
 |
6. Experimental Setup
6.1. Toronto Dataset
- : Move—an examination is randomly selected and moved to a random time slot.
- : Swap—Two examinations are randomly selected, and their time slots are swapped.
- : Swap time slot—Two time slots are randomly selected, and all examinations between the two time slots are swapped.
6.2. ITC2007 Exam Dataset
- : An examination is randomly selected and is moved to a random time slot and room.
- : Two examinations are randomly selected, and their time slots and rooms are swapped.
- : After selecting an examination, it is moved to a different room within the same time slot.
- : Two examinations are selected randomly and moved to different time slots and rooms.
7. Experimental Result
7.1. Experimental Results with Toronto Dataset
7.2. Experimental Results with ITC2007 Exam Dataset
7.3. Comparison with the State-of-the-Art Approaches
7.3.1. Toronto Dataset
7.3.2. ITC2007 Exam Dataset
8. Discussion and Analysis
9. Conclusions and Future Work
- The partial construction phase could be extended and improved by introducing adapting ordering strategies or fuzzy logic that may select the appropriate heuristics (i.e., LD, LE, LWD) for exam ordering.
- The partial improvement phase can also be improved by incorporating other meta-heuristic approaches, such as SA, tabu search and genetic algorithms, or hybridising of meta-heuristics.
- This paper has studied the impact of different exam assignment value v on the penalty cost. However, it would be worthwhile to study the effect of dynamic or adaptive exam assignment value on the penalty cost.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PGH-mGD | Partial graph heuristic orderings with a modified great deluge |
| TGH-mGD | Traditional graph heuristic orderings with a modified great deluge |
| ITC2007 | 2nd International Timetable Competition |
| LD | Largest degree |
| LWD | Largest weighted degree |
| LE | Largest enrolment |
| SD | Saturation degree |
| GD | Great deluge |
| SD-LD | Saturation degree - Largest degree |
| SD-LWD | Saturation degree -Largest weighted Degree |
| SD-LE | Saturation degree- Largest enrolment |
References
- Wren, A. Scheduling, timetabling and rostering—A special relationship. In Practice and Theory of Automated Timetabling; Springer: Berlin/Heidelberg, Germany, 1996; pp. 46–75. [Google Scholar]
- Johnson, D. Timetabling university examinations. J. Oper. Res. Soc. 1990, 41, 39–47. [Google Scholar] [CrossRef]
- Burke, E.K.; Newall, J.P. Solving examination timetabling problems through adaption of heuristic orderings. Ann. Oper. Res. 2004, 129, 107–134. [Google Scholar] [CrossRef]
- Burke, E.K.; Petrovic, S.; Qu, R. Case-based heuristic selection for timetabling problems. J. Sched. 2006, 9, 115–132. [Google Scholar] [CrossRef]
- Carter, M.W.; Laporte, G.; Lee, S.Y. Examination timetabling: Algorithmic strategies and applications. J. Oper. Res. Soc. 1996, 47, 373–383. [Google Scholar] [CrossRef]
- Kahar, M.N.M.; Kendall, G. The examination timetabling problem at Universiti Malaysia Pahang: Comparison of a constructive heuristic with an existing software solution. Eur. J. Oper. Res. 2010, 207, 557–565. [Google Scholar] [CrossRef]
- Asmuni, H.; Burke, E.K.; Garibaldi, J.M.; McCollum, B.; Parkes, A.J. An investigation of fuzzy multiple heuristic orderings in the construction of university examination timetables. Comput. Oper. Res. 2009, 36, 981–1001. [Google Scholar] [CrossRef][Green Version]
- Pillay, N.; Banzhaf, W. A study of heuristic combinations for hyper-heuristic systems for the uncapacitated examination timetabling problem. Eur. J. Oper. Res. 2009, 197, 482–491. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Qu, R.; Kendall, G. A graph coloring constructive hyper-heuristic for examination timetabling problems. Appl. Intell. 2012, 37, 1–11. [Google Scholar] [CrossRef]
- Dueck, G. New optimization heuristics: The great deluge algorithm and the record-to-record travel. J. Comput. Phys. 1993, 104, 86–92. [Google Scholar] [CrossRef]
- Burke, E.K.; Newall, J.P. Enhancing timetable solutions with local search methods. In Practice and Theory of Automated Timetabling IV; Springer: Berlin/Heidelberg, Germany, 2003; pp. 195–206. [Google Scholar]
- Burke, E.K.; Bykov, Y. Solving exam timetabling problems with the flex-deluge algorithm. In Proceedings of the 6th International Conference on the Practice and Theory of Automated Timetabling (PTATA 2006), Brno, Czech Republic, 30 August–1 September 2006; pp. 370–372. [Google Scholar]
- Landa-Silva, D.; Obit, J.H. Great deluge with non-linear decay rate for solving course timetabling problems. In Proceedings of the 4th International IEEE Conference on Intelligent Systems, Varna, Bulgaria, 6–8 September 2008; Volume 1, pp. 11–18. [Google Scholar] [CrossRef]
- Müller, T. ITC2007 solver description: A hybrid approach. Ann. Oper. Res. 2009, 172, 429–446. [Google Scholar] [CrossRef][Green Version]
- McCollum, B.; McMullan, P.; Parkes, A.J.; Burke, E.K.; Abdullah, S. An extended great deluge approach to the examination timetabling problem. In Proceedings of the 4th multidisciplinary international scheduling: Theory and applications 2009 (MISTA 2009), Dublin, Ireland, 10–12 August 2009; pp. 424–434. [Google Scholar]
- Kahar, M.N.M.; Kendall, G. A great deluge algorithm for a real-world examination timetabling problem. J. Oper. Res. Soc. 2013, 66, 16–133. [Google Scholar] [CrossRef]
- Abdullah, S.; Shaker, K.; McCollum, B.; McMullan, P. Construction of course timetables based on great deluge and tabu search. In Proceedings of the MIC 2009: VIII Metaheuristic International Conference, Hamburg, Germany, 13–16 July 2009; pp. 13–16. [Google Scholar]
- Turabieh, H.; Abdullah, S. An integrated hybrid approach to the examination timetabling problem. Omega Int. J. Manag. Sci. 2011, 39, 598–607. [Google Scholar] [CrossRef]
- Fong, C.W.; Asmuni, H.; McCollum, B.; McMullan, P.; Omatu, S. A new hybrid imperialist swarm-based optimization algorithm for university timetabling problems. Inf. Sci. 2014, 283, 1–21. [Google Scholar] [CrossRef]
- Abuhamdah, A. Modified Great Deluge for Medical Clustering Problems. Int. J. Emerg. Sci. 2012, 2, 345–360. [Google Scholar]
- Kifah, S.; Abdullah, S. An adaptive non-linear great deluge algorithm for the patient-admission problem. Inf. Sci. 2015, 295, 573–585. [Google Scholar] [CrossRef]
- Jaddi, N.S.; Abdullah, S. Nonlinear great deluge algorithm for rough set attribute reduction. J. Inf. Sci. Eng. 2013, 29, 49–62. [Google Scholar]
- Burke, E.K.; Bykov, Y. The Late Acceptance Hill-Climbing Heuristic; Technical Report CSM-192, Computing Science and Mathematics; University of Stirling: Stirling, UK, 2012. [Google Scholar]
- Burke, E.K.; Bykov, Y. An Adaptive Flex-Deluge Approach to University Exam Timetabling. INFORMS J. Comput. 2016, 28, 781–794. [Google Scholar] [CrossRef]
- Battistutta, M.; Schaerf, A.; Urli, T. Feature-based tuning of single-stage simulated annealing for examination timetabling. Ann. Oper. Res. 2017, 252, 239–254. [Google Scholar] [CrossRef]
- June, T.L.; Obit, J.H.; Leau, Y.B.; Bolongkikit, J. Implementation of Constraint Programming and Simulated Annealing for Examination Timetabling Problem. In Computational Science and Technology; Springer: Berlin/Heidelberg, Germany, 2019; pp. 175–184. [Google Scholar]
- Alinia Ahandani, M.; Vakil Baghmisheh, M.T.; Badamchi Zadeh, M.A.; Ghaemi, S. Hybrid particle swarm optimization transplanted into a hyper-heuristic structure for solving examination timetabling problem. Swarm Evol. Comput. 2012, 7, 21–34. [Google Scholar] [CrossRef]
- Abayomi-Alli, O.; Abayomi-Alli, A.; Misra, S.; Damasevicius, R.; Maskeliunas, R. Automatic examination timetable scheduling using particle swarm optimization and local search algorithm. In Data, Engineering and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 119–130. [Google Scholar]
- Bolaji, A.L.; Khader, A.T.; Al-Betar, M.A.; Awadallah, M.A. A hybrid nature-inspired artificial bee colony algorithm for uncapacitated examination timetabling problems. J. Intell. Syst. 2015, 24, 37–54. [Google Scholar] [CrossRef]
- Tilahun, S.L. Prey-predator algorithm for discrete problems: A case for examination timetabling problem. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 950–960. [Google Scholar] [CrossRef]
- Lei, Y.; Gong, M.; Jiao, L.; Shi, J.; Zhou, Y. An adaptive coevolutionary memetic algorithm for examination timetabling problems. Int. J. Bio-Inspired Comput. 2017, 10, 248–257. [Google Scholar] [CrossRef]
- Leite, N.; Fernandes, C.M.; Melicio, F.; Rosa, A.C. A cellular memetic algorithm for the examination timetabling problem. Comput. Oper. Res. 2018, 94, 118–138. [Google Scholar] [CrossRef]
- Demeester, P.; Bilgin, B.; De Causmaecker, P.; Vanden Berghe, G. A hyperheuristic approach to examination timetabling problems: Benchmarks and a new problem from practice. J. Sched. 2012, 15, 83–103. [Google Scholar] [CrossRef]
- Anwar, K.; Khader, A.T.; Al-Betar, M.A.; Awadallah, M.A. Harmony Search-based Hyper-heuristic for examination timetabling. In Proceedings of the 9th IEEE International Colloquium on Signal Processing and its Applications (CSPA), Kuala Lumpur, Malaysia, 8–10 March 2013; pp. 176–181. [Google Scholar] [CrossRef]
- Pillay, N.; Özcan, E. Automated generation of constructive ordering heuristics for educational timetabling. Ann. Oper. Res. 2019, 275, 181–208. [Google Scholar] [CrossRef]
- Gogos, C.; Alefragis, P.; Housos, E. An improved multi-staged algorithmic process for the solution of the examination timetabling problem. Ann. Oper. Res. 2012, 194, 203–221. [Google Scholar] [CrossRef]
- Burke, E.K.; Pham, N.; Qu, R.; Yellen, J. Linear combinations of heuristics for examination timetabling. Ann. Oper. Res. 2012, 194, 89–109. [Google Scholar] [CrossRef]
- Ei Shwe, S. Reinforcement learning with EGD based hyper heuristic system for exam timetabling problem. In Proceedings of the 2011 IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS), Beijing, China, 15–17 September 2011; pp. 462–466. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. Automatic Design of a Hyper-Heuristic Framework With Gene Expression Programming for Combinatorial Optimization Problems. IEEE Trans. Evol. Comput. 2015, 19, 309–325. [Google Scholar] [CrossRef]
- Qu, R.; Burke, E.; McCollum, B.; Merlot, L.; Lee, S. A survey of search methodologies and automated system development for examination timetabling. J. Sched. 2009, 12, 55–89. [Google Scholar] [CrossRef]
- Abdul Rahman, S.; Bargiela, A.; Burke, E.K.; Özcan, E.; McCollum, B.; McMullan, P. Adaptive linear combination of heuristic orderings in constructing examination timetables. Eur. J. Oper. Res. 2014, 232, 287–297. [Google Scholar] [CrossRef]
- Soghier, A.; Qu, R. Adaptive selection of heuristics for assigning time slots and rooms in exam timetables. Appl. Intell. 2013, 39, 438–450. [Google Scholar] [CrossRef]
- Eng, K.; Muhammed, A.; Mohamed, M.A.; Hasan, S. A hybrid heuristic of Variable Neighbourhood Descent and Great Deluge algorithm for efficient task scheduling in Grid computing. Eur. J. Oper. Res. 2020, 284, 75–86. [Google Scholar] [CrossRef]
- Obit, J.H.; Landa-Silva, D. Computational study of non-linear great deluge for university course timetabling. In Intelligent Systems: From Theory to Practice; Springer: Berlin/Heidelberg, Germany, 2010; pp. 309–328. [Google Scholar]
- Bagayoko, M.; Dao, T.M.; Ateme-Nguema, B.H. Optimization of forest vehicle routing using the metaheuristics: Reactive tabu search and extended great deluge. In Proceedings of the 2013 International Conference on Industrial Engineering and Systems Management (IESM), Rabat, Morocco, 28–30 October 2013; pp. 1–7. [Google Scholar]
- Guha, R.; Ghosh, M.; Kapri, S.; Shaw, S.; Mutsuddi, S.; Bhateja, V.; Sarkar, R. Deluge based Genetic Algorithm for feature selection. Evolut. Intell. 2019. [Google Scholar] [CrossRef]
- Mafarja, M.; Abdullah, S. Fuzzy modified great deluge algorithm for attribute reduction. In Recent Advances on Soft Computing and Data Mining; Springer: Berlin/Heidelberg, Germany, 2014; pp. 195–203. [Google Scholar]
- Nahas, N.; Nourelfath, M. Iterated great deluge for the dynamic facility layout problem. In Metaheuristics for Production Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 57–92. [Google Scholar]
- Benchmark Data Sets in Exam Timetabling. Available online: http://www.asap.cs.nott.ac.uk/resources/data.shtml (accessed on 30 November 2019).
- Examination Timetabling Track. Available online: http://www.cs.qub.ac.uk/itc2007/examtrack/ (accessed on 30 November 2019).
- McCollum, B.; McMullan, P.; Parkes, A.J.; Burke, E.K.; Qu, R. A new model for automated examination timetabling. Ann. Oper. Res. 2012, 194, 291–315. [Google Scholar] [CrossRef]
- McCollum, B.; McMullan, P.; Burke, E.K.; Parkes, A.J.; Qu, R. The Second International Timetabling Competition: Examination Timetabling Track; Technical Report QUB/IEEE/Tech/ITC2007/Exam/v4. 0/17; Queen’s University: Belfast, UK, 2007. [Google Scholar]
- Burke, E.K.; Kingston, J.; De Werra, D. Applications to Timetabling. In Handbook of Graph Theory; Rosen, K.H., Ed.; CRC Press: Boca Raton, FL, USA, 2004; pp. 445–474. [Google Scholar]
- Abdullah, S.; Turabieh, H.; McCollum, B.; McMullan, P. A hybrid metaheuristic approach to the university course timetabling problem. J. Heuristics 2012, 18, 1–23. [Google Scholar] [CrossRef]
- Qu, R.; Pham, N.; Bai, R.B.; Kendall, G. Hybridising heuristics within an estimation distribution algorithm for examination timetabling. Appl. Intell. 2015, 42, 679–693. [Google Scholar] [CrossRef]
- Turabieh, H.; Abdullah, S. A Hybrid Fish Swarm Optimisation Algorithm for Solving Examination Timetabling Problems. In Learning and Intelligent Optimization; Lecture Notes in Computer Science; Book Section 42; Coello, C.C., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6683, pp. 539–551. [Google Scholar] [CrossRef]
- Burke, E.K.; Eckersley, A.J.; McCollum, B.; Petrovic, S.; Qu, R. Hybrid variable neighbourhood approaches to university exam timetabling. Eur. J. Oper. Res. 2010, 206, 46–53. [Google Scholar] [CrossRef]
- Alzaqebah, M.; Abdullah, S. Hybrid bee colony optimization for examination timetabling problems. Comput. Oper. Res. 2015, 54, 142–154. [Google Scholar] [CrossRef]
- Gogos, C.; Alefragis, P.; Housos, P. Amulti-staged algorithmic process for the solution of the examination timetabling problem. In Proceedings of the 7th International Conference on the Practice and Theory of Automated Timetabling (PATAT 2008), Montreal, QC, Canada, 18–22 August 2008; pp. 19–22. [Google Scholar]
- Atsuta, M.; Nonobe, K.; Ibaraki, T. ITC-2007 Track2: An Approach Using General CSP Solver. In Proceedings of the Practice and Theory of Automated Timetabling (PATAT 2008), Montreal, QC, Canada, 19–22 August 2008. [Google Scholar]
- De Smet, G. ITC2007—Examination track. In Proceedings of the 7th International Conference on the Practice and Theory of Automated Timetabling (PATAT 2008), Montreal, QC, Canada, 18–22 August 2008. [Google Scholar]
- Pillay, N.; Banzhaf, W. A Developmental Approach to the Uncapacitated Examination Timetabling Problem. In Parallel Problem Solving from Nature—PPSN X. PPSN 2008; Rudolph, G., Jansen, T., Beume, N., Lucas, S., Poloni, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5199. [Google Scholar]
- Hamilton-Bryce, R.; McMullan, P.; McCollum, B. Directed selection using reinforcement learning for the examination timetabling problem. In Proceedings of the PATAT’14 Proceedings of the 10th International Conference on the Practice and Theory of Automated Timetabling, York, UK, 26–29 August 2014. [Google Scholar]


{kind=link}
| Instances | No. of Time Slots | No. of Exams | No. of Students | Conflict Density |
|---|---|---|---|---|
| car-s-91 | 35 | 682 | 16,925 | 0.13 |
| car-f-92 | 32 | 543 | 18,419 | 0.14 |
| ear-f-83 | 24 | 190 | 1125 | 0.27 |
| hec-s-92 | 18 | 81 | 2823 | 0.42 |
| kfu-s-93 | 20 | 461 | 5349 | 0.06 |
| lse-f-91 | 18 | 381 | 2726 | 0.06 |
| pur-s-93 | 42 | 2419 | 30,029 | 0.03 |
| rye-s-93 | 23 | 486 | 11,483 | 0.07 |
| sta-f-83 | 13 | 139 | 611 | 0.14 |
| tre-s-92 | 23 | 261 | 4360 | 0.18 |
| uta-s-92 | 35 | 622 | 21,267 | 0.13 |
| ute-s-92 | 10 | 184 | 2750 | 0.08 |
| yor-f-83 | 21 | 181 | 941 | 0.29 |
| Instances | Number of Students | Number of Exams | Number of Time slots | Number of Rooms | Period Hard Constraint | Room Hard Constraint | Conflict Density |
|---|---|---|---|---|---|---|---|
| Exam_1 | 7833 | 607 | 54 | 7 | 12 | 0 | 5.05% |
| Exam_2 | 12,484 | 870 | 40 | 49 | 12 | 2 | 1.17% |
| Exam_3 | 16,365 | 934 | 36 | 48 | 170 | 15 | 2.62% |
| Exam_4 | 4421 | 273 | 21 | 1 | 40 | 0 | 15.0% |
| Exam_5 | 8719 | 1018 | 42 | 3 | 27 | 0 | 0.87% |
| Exam_6 | 7909 | 242 | 16 | 8 | 23 | 0 | 6.16% |
| Exam_7 | 13,795 | 1096 | 80 | 15 | 28 | 0 | 1.93% |
| Exam_8 | 7718 | 598 | 80 | 8 | 20 | 1 | 4.55% |
| Instances | Weight for Two in a Day | Weight for Two in a Row | Weight for Period Spread | Weight for No Mixed Duration | Weight for the Front Load Penalty | Weight for period Penalty | Weight for Room Penalty |
|---|---|---|---|---|---|---|---|
| Exam_1 | 5 | 7 | 5 | 10 | 100 | 30 | 5 |
| Exam_2 | 5 | 15 | 1 | 25 | 250 | 30 | 5 |
| Exam_3 | 10 | 15 | 4 | 20 | 200 | 20 | 10 |
| Exam_4 | 5 | 9 | 2 | 10 | 50 | 10 | 5 |
| Exam_5 | 15 | 40 | 5 | 0 | 250 | 30 | 10 |
| Exam_6 | 5 | 20 | 20 | 25 | 25 | 30 | 15 |
| Exam_7 | 5 | 25 | 10 | 15 | 250 | 30 | 10 |
| Exam_8 | 0 | 150 | 15 | 25 | 250 | 30 | 5 |
| Instances | 600 s | 1800 s | 3600 s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| car-s-91 | 5.98 | 6.19 | 5.69 | 5.83 | 5.78 | 5.99 | 5.60 | 5.69 | 5.58 | 5.70 | 4.58 | 4.72 |
| car-f-92 | 4.95 | 5.11 | 4.66 | 4.78 | 4.80 | 4.95 | 4.57 | 4.69 | 4.58 | 4.66 | 3.82 | 3.93 |
| ear-f-83 | 38.67 | 40.46 | 37.00 | 38.69 | 37.23 | 39.24 | 36.35 | 37.33 | 33.68 | 34.76 | 33.23 | 34.49 |
| hec-s-92 | 11.92 | 12.19 | 11.25 | 11.91 | 11.44 | 11.92 | 11.18 | 11.75 | 10.53 | 11.02 | 10.32 | 11.09 |
| kfu-s-93 | 15.65 | 16.80 | 14.61 | 15.43 | 15.37 | 16.09 | 14.44 | 14.91 | 14.79 | 15.10 | 13.34 | 13.97 |
| lse-f-91 | 12.75 | 13.61 | 11.78 | 12.34 | 12.40 | 12.99 | 11.05 | 11.47 | 10.85 | 11.12 | 10.24 | 10.62 |
| rye-s-93 | 11.90 | 12.24 | 11.44 | 11.89 | 11.71 | 11.88 | 11.25 | 11.71 | 11.39 | 11.54 | 9.79 | 10.29 |
| sta-f-83 | 158.21 | 158.48 | 157.66 | 158.28 | 157.86 | 158.14 | 157.50 | 158.19 | 157.39 | 157.72 | 157.14 | 157.64 |
| tre-s-92 | 9.42 | 9.80 | 8.58 | 8.88 | 9.21 | 9.49 | 8.20 | 8.44 | 8.24 | 8.50 | 7.74 | 8.03 |
| uta-s-92 | 4.12 | 4.17 | 3.70 | 3.82 | 3.93 | 4.04 | 3.61 | 3.68 | 3.22 | 3.29 | 3.13 | 3.22 |
| ute-s-92 | 28.49 | 29.47 | 27.38 | 28.61 | 28.04 | 28.82 | 27.08 | 27.83 | 26.96 | 27.79 | 25.28 | 26.04 |
| yor-f-83 | 40.44 | 41.35 | 39.00 | 40.43 | 39.52 | 40.22 | 38.34 | 39.39 | 35.51 | 36.71 | 35.68 | 36.79 |
| Instances | 600 s | 1800 s | 3600 s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| car-s-91 | 5.98 | 6.19 | 5.63 | 5.82 | 5.78 | 5.99 | 5.57 | 5.67 | 5.58 | 5.70 | 4.60 | 4.68 |
| car-f-92 | 4.95 | 5.11 | 4.68 | 4.85 | 4.80 | 4.95 | 4.63 | 4.71 | 4.58 | 4.66 | 3.89 | 4.04 |
| ear-f-83 | 38.67 | 40.46 | 36.82 | 38.89 | 37.23 | 39.24 | 35.93 | 37.83 | 33.68 | 34.76 | 33.30 | 34.43 |
| hec-s-92 | 11.92 | 12.19 | 11.31 | 12.05 | 11.44 | 11.92 | 11.23 | 11.78 | 10.53 | 11.02 | 10.49 | 11.09 |
| kfu-s-93 | 15.65 | 16.80 | 14.71 | 15.57 | 15.37 | 16.09 | 14.60 | 15.27 | 14.79 | 15.10 | 13.55 | 14.34 |
| lse-f-91 | 12.75 | 13.61 | 12.06 | 12.67 | 12.40 | 12.99 | 11.46 | 12.10 | 10.85 | 11.12 | 10.25 | 10.76 |
| rye-s-93 | 11.90 | 12.24 | 11.40 | 11.86 | 11.71 | 11.88 | 11.38 | 11.71 | 11.39 | 11.54 | 10.68 | 11.20 |
| sta-f-83 | 158.21 | 158.48 | 157.71 | 158.34 | 157.86 | 158.14 | 157.70 | 158.12 | 157.39 | 157.72 | 157.03 | 157.41 |
| tre-s-92 | 9.42 | 9.80 | 8.79 | 9.06 | 9.21 | 9.49 | 8.56 | 8.85 | 8.24 | 8.50 | 7.94 | 8.15 |
| uta-s-92 | 4.12 | 4.17 | 3.77 | 3.88 | 3.93 | 4.04 | 3.61 | 3.74 | 3.22 | 3.29 | 3.17 | 3.26 |
| ute-s-92 | 28.49 | 29.47 | 27.97 | 28.85 | 28.04 | 28.82 | 27.56 | 28.53 | 26.96 | 27.79 | 25.47 | 25.95 |
| yor-f-83 | 40.44 | 41.35 | 39.18 | 40.78 | 39.52 | 40.22 | 39.11 | 40.06 | 35.51 | 36.71 | 35.68 | 36.91 |
| Instances | 600 s | 1800 s | 3600 s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| car-s-91 | 5.98 | 6.19 | 5.82 | 6.05 | 5.78 | 5.99 | 4.63 | 4.80 | 5.58 | 5.70 | 4.09 | 4.41 |
| car-f-92 | 4.95 | 5.11 | 4.81 | 5.00 | 4.80 | 4.95 | 5.56 | 5.72 | 4.58 | 4.66 | 4.63 | 4.74 |
| ear-f-83 | 38.67 | 40.46 | 36.91 | 39.11 | 37.23 | 39.24 | 36.28 | 38.13 | 33.68 | 34.76 | 33.43 | 34.68 |
| hec-s-92 | 11.92 | 12.19 | 11.70 | 12.13 | 11.44 | 11.92 | 11.41 | 11.92 | 10.53 | 11.02 | 10.59 | 11.17 |
| kfu-s-93 | 15.65 | 16.80 | 15.12 | 15.86 | 15.37 | 16.09 | 14.78 | 15.38 | 14.79 | 15.10 | 13.51 | 14.46 |
| lse-f-91 | 12.75 | 13.61 | 12.44 | 13.10 | 12.40 | 12.99 | 11.75 | 12.45 | 10.85 | 11.12 | 10.50 | 10.99 |
| rye-s-93 | 11.90 | 12.24 | 11.62 | 12.08 | 11.71 | 11.88 | 11.47 | 11.86 | 11.39 | 11.54 | 11.24 | 11.55 |
| sta-f-83 | 158.21 | 158.48 | 157.86 | 158.40 | 157.86 | 158.14 | 157.43 | 158.05 | 157.39 | 157.72 | 157.15 | 157.54 |
| tre-s-92 | 9.42 | 9.80 | 9.00 | 9.20 | 9.21 | 9.49 | 8.77 | 8.99 | 8.24 | 8.50 | 8.03 | 8.22 |
| uta-s-92 | 4.12 | 4.17 | 3.85 | 4.02 | 3.93 | 4.04 | 3.77 | 3.88 | 3.22 | 3.29 | 3.26 | 3.36 |
| ute-s-92 | 28.49 | 29.47 | 28.26 | 29.00 | 28.04 | 28.82 | 27.68 | 28.40 | 26.96 | 27.79 | 25.52 | 26.57 |
| yor-f-83 | 40.44 | 41.35 | 39.34 | 41.00 | 39.52 | 40.22 | 38.99 | 40.19 | 35.51 | 36.71 | 35.46 | 36.75 |
| Instances | 600 s | 1800 s | 3600 s | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| car-s-91 | 5.98 | 6.19 | 4.82 | 5.02 | 5.78 | 5.99 | 4.70 | 4.85 | 5.58 | 5.70 | 4.83 | 5.06 |
| car-f-92 | 4.95 | 5.11 | 5.92 | 6.15 | 4.80 | 4.95 | 5.68 | 5.91 | 4.58 | 4.66 | 3.96 | 4.11 |
| ear-f-83 | 38.67 | 40.46 | 37.16 | 39.55 | 37.23 | 39.24 | 36.73 | 38.09 | 33.68 | 34.76 | 32.48 | 33.46 |
| hec-s-92 | 11.92 | 12.19 | 11.55 | 12.19 | 11.44 | 11.92 | 11.33 | 11.85 | 10.53 | 11.02 | 10.52 | 10.99 |
| kfu-s-93 | 15.65 | 16.80 | 15.35 | 16.14 | 15.37 | 16.09 | 14.76 | 15.47 | 14.79 | 15.10 | 13.51 | 14.43 |
| lse-f-91 | 12.75 | 13.61 | 12.66 | 13.43 | 12.40 | 12.99 | 12.44 | 12.91 | 10.85 | 11.12 | 10.37 | 11.15 |
| rye-s-93 | 11.90 | 12.24 | 11.59 | 12.16 | 11.71 | 11.88 | 11.57 | 11.82 | 11.39 | 11.54 | 10.53 | 11.09 |
| sta-f-83 | 158.21 | 158.48 | 157.87 | 158.31 | 157.86 | 158.14 | 157.64 | 158.05 | 157.39 | 157.72 | 157.20 | 157.63 |
| tre-s-92 | 9.42 | 9.80 | 9.05 | 9.33 | 9.21 | 9.49 | 8.68 | 8.98 | 8.24 | 8.50 | 8.04 | 8.25 |
| uta-s-92 | 4.12 | 4.17 | 3.94 | 4.06 | 3.93 | 4.04 | 3.79 | 3.92 | 3.22 | 3.29 | 3.26 | 3.36 |
| ute-s-92 | 28.49 | 29.47 | 27.94 | 28.97 | 28.04 | 28.82 | 27.69 | 28.48 | 26.96 | 27.79 | 25.48 | 26.12 |
| yor-f-83 | 40.44 | 41.35 | 39.42 | 40.78 | 39.52 | 40.22 | 38.81 | 40.00 | 35.51 | 36.71 | 35.48 | 36.68 |
| Instances (A) | TGH-mGD | PGH-mGD | %Impro- vement = (I) | t-Test | |||||
|---|---|---|---|---|---|---|---|---|---|
| Initial Solution with Graph Heuristics (B) | Modified GD Algorithm | Best (E) | Avg (F) | Graph Heuristic Orderings (G) | v(%) (H) | ||||
| Best (C) | Avg (D) | p-Value (J) | |||||||
| car-s-91 | 8.33 (LD) | 5.58 | 5.70 | 4.58 | 4.72 | SD-LD | 10% | 17.92 | 1.41 × |
| car-f-92 | 7.00 (LD) | 4.58 | 4.66 | 3.82 | 3.93 | SD-LD | 10% | 16.59 | 1 × |
| ear-f-83 | 52.35 (SD-LE) | 33.68 | 34.76 | 32.48 | 33.46 | SD-LD | 75% | 3.56 | 0.00047 |
| hec-s-92 | 16.21 (SD-LWD) | 10.53 | 11.02 | 10.32 | 10.99 | SD-LD | 10% | 1.99 | 0.046692 |
| kfu-s-93 | 23.68 (LD) | 14.79 | 15.10 | 13.34 | 13.97 | SD-LD | 10% | 9.80 | 1.84 × |
| lse-f-91 | 18.83 (LE) | 10.85 | 11.12 | 10.24 | 10.62 | SD-LD | 10% | 5.62 | 1.45 × |
| rye-s-93 | 18.28 (SD-LD) | 11.39 | 11.54 | 9.79 | 10.29 | SD-LD | 10% | 14.05 | 4.16 × |
| sta-f-83 | 166.43 (SD-LE) | 157.39 | 157.72 | 157.03 | 157.41 | SD-LWD | 25% | 0.23 | 0.018815 |
| tre-s-92 | 12.07 (SD-LE) | 8.24 | 8.50 | 7.74 | 8.03 | SD-LD | 10% | 6.07 | 9.53 × |
| uta-s-92 | 5.53 (LE) | 3.22 | 3.29 | 3.13 | 3.22 | SD-LWD | 10% | 2.80 | 1.32 × |
| ute-s-92 | 38.03 (SD-LD) | 26.96 | 27.79 | 25.28 | 26.08 | SD-LWD | 10% | 6.23 | 3.95 × |
| yor-f-83 | 49.8 (LD) | 35.51 | 36.71 | 35.46 | 36.68 | SD-LWD | 50% | 0.14 | 0.043694 |
| Instances | 600 s | 3600 s | ||||||
|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| Exam_1 | 12,096 | 12,599.26 | 7837 | 8687.40 | 9791 | 10,727.64 | 5328 | 5676.74 |
| Exam_2 | 2114 | 3160.99 | 1448 | 2171.43 | 996 | 1170.77 | 407 | 653.49 |
| Exam_3 | 34,333 | 41,308.88 | 19,119 | 22,332.93 | 23,052 | 27,456.67 | 11,692 | 13,461.00 |
| Exam_4 | 33,910 | 34,693.51 | 19,988 | 26,017.32 | 33,621 | 34,323.08 | 16,204 | 19,005.79 |
| Exam_5 | 10,118 | 11,006.88 | 8714 | 9711.07 | 7415 | 7877.17 | 4786 | 4993.68 |
| Exam_6 | 28,150 | 30,506.54 | 26,350 | 26,754.63 | 29,960 | 30,941.25 | 25,880 | 26,085.05 |
| Exam_ 7 | 16,572 | 18,459.67 | 11,081 | 11,904.77 | 9399 | 9757.41 | 6181 | 6834.67 |
| Exam _8 | 15,366 | 17,662.61 | 11,863 | 19,124.70 | 11,845 | 12,847.23 | 8238 | 9708.57 |
| Instances | 600 s | 3600 s | ||||||
|---|---|---|---|---|---|---|---|---|
| TGH-mGD | PGH-mGD | TGH-mGD | PGH-mGD | |||||
| Best | Avg | Best | Avg | Best | Avg | Best | Avg | |
| Exam_1 | 12,096 | 12,599.26 | 8322 | 9124.77 | 9791 | 10,727.64 | 5794 | 6039.93 |
| Exam_2 | 2114 | 3160.99 | 1356 | 2623.73 | 996 | 1170.77 | 476 | 529.33 |
| Exam_3 | 34,333 | 41,308.88 | 21,027 | 25,542.00 | 23,052 | 27,456.67 | 11,709 | 13,806.63 |
| Exam_4 | 33,910 | 34,693.51 | 22,298 | 28,292.99 | 33,621 | 34,323.08 | 16,591 | 19,897.41 |
| Exam_5 | 10,118 | 11,006.88 | 8557 | 10,233.27 | 7415 | 7877.17 | 4300 | 4941.47 |
| Exam_6 | 28,150 | 30,506.54 | 26,510 | 29,284.95 | 29,960 | 30,941.25 | 26,245 | 26,839.18 |
| Exam _7 | 16,572 | 18,459.67 | 11,276 | 12,289.63 | 9399 | 9757.41 | 5507 | 6119.60 |
| Exam _8 | 15,366 | 17,662.61 | 12,414 | 22,078.43 | 11,845 | 12,847.23 | 9626 | 10,461.21 |
| Instances (A) | TGH-mGD | PGH-mGD | %Impro- vement = (I) | t-Test | |||||
|---|---|---|---|---|---|---|---|---|---|
| Initial Solution with Graph Heuristics (B) | Modified GD Algorithm | Best (E) | Avg (F) | Graph Heuristic Orderings (G) | v(%) (H) | ||||
| Best (C) | Avg (D) | p-Value (J) | |||||||
| Exam_1 | 25,989 (SD-LE) | 9791 | 10,727.64 | 5328 | 5676.74 | SD-LWD | 5% | 45.58 | 5.82 × |
| Exam_2 | 30,960 (SD-LE) | 996 | 1170.77 | 407 | 653.49 | SD-LD | 5% | 59.14 | 1.49 × |
| Exam_3 | 85,356 (SD-LD) | 23,052 | 27,456.67 | 11,692 | 13,461.00 | SD-LE | 5% | 49.27 | 4.94 × |
| Exam_4 | 41,702 (SD-LD) | 33,621 | 34,323.08 | 16,204 | 19,005.79 | SD-LD | 5% | 51.80 | 7.66 × |
| Exam_5 | 132,953 (LD) | 7415 | 7877.17 | 4300 | 4941.47 | SD-LE | 10% | 42.00 | 4.24 × |
| Exam_6 | 44,160 (SD-LE) | 29,960 | 30,941.25 | 25,880 | 26,085.05 | SD-LWD | 5% | 13.61 | 1.95 × |
| Exam_7 | 53,405 (SD-LE) | 9399 | 9757.41 | 5507 | 6119.60 | SD-LWD | 10% | 41.41 | 1.8 × |
| Exam_8 | 92,767 (SD-LE) | 11,845 | 12,847.23 | 8238 | 9708.57 | SD-LD | 5% | 30.45 | 1.7 × |
| Instances | Carter et al. [5] | Alinia Ahandani et al. [27] | Abdul Rahman et al. [41] | Qu et al. [55] | Turabieh and Abdullah [56] | Burke et al. [57] | Nelishia Pillay and Özcan [35] | Pillay and Banzhaf [8] | Sabar et al. [9] | Our Approach |
|---|---|---|---|---|---|---|---|---|---|---|
| car-s-91 | 7.1 (10) | 5.22 (9) | 5.12 (6) | 4.95 (4) | 4.8 (3) | 4.6 (2) | 5.16 (8) | 4.97 (5) | 5.14 (7) | 4.58 (1) |
| car-f-92 | 6.2 (10) | 4.67 (8) | 4.41 (7) | 4.09 (3) | 4.1 (4) | 3.9 (2) | 4.32 (6) | 4.28 (5) | 4.7 (9) | 3.82 (1) |
| ear-f-83 | 36.4 (7) | 35.74 (5) | 36.91 (9) | 34.97 (4) | 34.92 (3) | 32.8 (2) | 36.52 (8) | 35.86 (6) | 37.86 (10) | 32.48 (1) |
| hec-s-92 | 10.8 (5) | 10.74 (4) | 11.31 (7) | 11.11 (6) | 10.73 (3) | 10 (1) | 11.87 (9) | 11.85 (8) | 11.9 (10) | 10.32 (2) |
| kfu-s-93 | 14 (3) | 14.47 (5) | 14.75 (8) | 14.09 (4) | 13 (1) | 13 (1) | 14.67 (7) | 14.62 (6) | 15.3 (9) | 13.34 (2) |
| lse-f-91 | 10.5 (4) | 10.76 (6) | 11.41 (9) | 10.71 (5) | 10.01 (2) | 10 (1) | 10.81 (7) | 11.14 (8) | 12.33 (10) | 10.24 (3) |
| rye-s-93 | 7.3 (1) | 9.95 (7) | 9.61 (4) | 9.2 (2) | 9.65 (5) | – (9) | 9.48 (3) | 9.65 (5) | 10.71 (8) | 9.79 (6) |
| sta-f-83 | 161.5 (9) | 157.1 (3) | 157.52 (4) | 157.64 (5) | 158.26 (6) | 156.9 (1) | 157.64 (5) | 158.33 (7) | 160.12 (8) | 157.03 (2) |
| tre-s-92 | 9.6 (9) | 8.47 (6) | 8.76 (8) | 8.27 (4) | 7.88 (2) | 7.9 (3) | 8.48 (7) | 8.48 (7) | 8.32 (5) | 7.72 (1) |
| uta-s-92 | 3.5 (6) | 3.52 (7) | 3.54 (8) | 3.33 (3) | 3.2 (2) | 3.2 (2) | 3.35 (4) | 3.4 (5) | 3.88 (9) | 3.13 (1) |
| ute-s-92 | 25.8 (3) | 25.86 (4) | 26.25 (7) | 26.18 (6) | 26.11 (5) | 24.8 (1) | 27.16 (8) | 28.88 (9) | 32.67 (10) | 25.28 (2) |
| yor-f-83 | 41.7 (10) | 38.72 (5) | 39.67 (6) | 37.88 (4) | 36.22 (3) | 34.9 (1) | 41.31 (9) | 40.74 (8) | 40.53 (7) | 35.46 (2) |
| Avg. Rank | 6.41 (6) | 5.75 (5) | 6.91 (9) | 4.17 (4) | 3.25 (3) | 2.17 (2) | 6.75 (8) | 6.58 (7) | 8.50 (10) | 2.00 (1) |
| Instances | Müller [14] | Gogos et al. [59] | Atsuta et al. [60] | De Smet [61] | Pillay [62] | Leite et al. [32] | Abdul Rahman et al. [41] | Hamilton -Bryce et al. [63] | Alzaqebah and Abdullah [58] | Our Approach |
|---|---|---|---|---|---|---|---|---|---|---|
| Exam_1 | 4370 (1) | 5905 (6) | 8006 (9) | 6670 (8) | 12,035 (10) | 6207 (7) | 5231 (3) | 5517 (5) | 5154 (2) | 5328 (4) |
| Exam_2 | 400 (1) | 1008 (8) | 3470 (10) | 623 (7) | 3074 (9) | 535 (5) | 433 (4) | 538 (6) | 420 (3) | 407 (2) |
| Exam_3 | 10,049 (2) | 13,862 (7) | 18,622 (9) | - (10) | 15,917 (8) | 13,022 (6) | 9265 (1) | 10,325 (4) | 10,182 (3) | 11,692 (5) |
| Exam_4 | 18,141 (6) | 18,674 (7) | 22,559 (8) | - (10) | 23,582 (9) | 14,302 (1) | 17,787 (5) | 16,589 (4) | 15,716 (2) | 16,204 (3) |
| Exam_5 | 2988 (1) | 4139 (7) | 4714 (9) | 3847 (6) | 6860 (10) | 3829 (5) | 3083 (2) | 3632 (4) | 3350 (3) | 4300 (8) |
| Exam_6 | 26,950 (6) | 27,640 (7) | 29,155 (9) | 27,815 (8) | 32,250 (10) | 26,710 (5) | 26,060 (2) | 26,275 (4) | 26,160 (3) | 25,880 (1) |
| Exam_7 | 4213 (1) | 6683 (7) | 10,473 (8) | 5420 (4) | 17,666 (10) | 5508 (6) | 10,712 (9) | 4592 (3) | 4271 (2) | 5507 (5) |
| Exam_8 | 7861 (1) | 10,521 (6) | 14,317 (8) | - (10) | 16,184 (9) | 8716 (5) | 12,713 (7) | 8328 (4) | 7922 (2) | 8238 (3) |
| Avg Rank | 2.38 (1) | 6.88 (7) | 8.75 (9) | 7.88 (8) | 9.38 (10) | 5.0 (6) | 4.13 (4) | 4.25 (5) | 2.50 (2) | 3.88 (3) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mandal, A.K.; Kahar, M.N.M.; Kendall, G. Addressing Examination Timetabling Problem Using a Partial Exams Approach in Constructive and Improvement. Computation 2020, 8, 46. https://doi.org/10.3390/computation8020046
Mandal AK, Kahar MNM, Kendall G. Addressing Examination Timetabling Problem Using a Partial Exams Approach in Constructive and Improvement. Computation. 2020; 8(2):46. https://doi.org/10.3390/computation8020046
Chicago/Turabian StyleMandal, Ashis Kumar, M. N. M. Kahar, and Graham Kendall. 2020. "Addressing Examination Timetabling Problem Using a Partial Exams Approach in Constructive and Improvement" Computation 8, no. 2: 46. https://doi.org/10.3390/computation8020046
APA StyleMandal, A. K., Kahar, M. N. M., & Kendall, G. (2020). Addressing Examination Timetabling Problem Using a Partial Exams Approach in Constructive and Improvement. Computation, 8(2), 46. https://doi.org/10.3390/computation8020046