1. Introduction
Artificial intelligence and machine learning techniques are now widely used in the analysis of many real-world complex systems coming from manufacturing, business, information technology, and engineering, to name a few among many others [
1,
2,
3]. They are important techniques that aim at capturing key data patterns [
4,
5]. From the theoretical perspective, it is a fundamental problem to understand how the response variables of a complex system change when the input conditions and values of independent variables/factors change [
6,
7]. If a research study is observational, answering this question is difficult and, in fact, almost impossible due to lack of cause-and-effect relationships between the response variables and the factors that are used for describing the responses [
8]. The observational study can tell if there are some associations between response variables and predictor variables. If yes, one can only be able to conclude that predictor variables are useful and are able to contribute the explanations of data variation of the response variables. Therefore, data obtained from the real-world observational study is not able to provide us with the causal inference for the regression model that is used for describing the response variables [
8]. Because of this, to be able to better understand the nature of complex systems, a computer simulation of complex systems becomes an important approach. This is due to its capability of justifying the cause-and-effect relationships between the response variables and input configuration parameters values. Most of the real-word information applications are complex systems [
9,
10,
11]. For example, robots are complex systems that involve complicated software and hardware systems, as well as interactive information processing [
12]. Intelligent robots are expected to be able to improve their ability by self-learning from past experiences. The entire process of improvement of an intelligent robot is exactly the application of machine learning techniques, such as feature extraction, feature selection, and neural networks [
13,
14]. To carry out some tasks (e.g., exploration of unknown space), it is more efficient and reliable to employ swarm of simple robots instead of employing one complex robot, as a swarm of robots can accomplish the task faster and more effectively even if some robots break [
14,
15]. The small and simple robots cost less to be produced, and the maintenance cost is much lower than the cost of a complex robot. Another example is the risk appetite of investors in stock markets. When stock prices go up or down, investors must decide either to buy more or to sell more or to do nothing and wait until next time. The investing behavior can be complex, and knowing how investment decisions are related to the risk appetite could be important for a better understanding of the dynamics of financial markets.
All of these factors motivated us to conduct a simulation study of cognitive agents learning to cross a cellular automaton-based highway, developed by Lawniczak, Di Stefano, Ernst, and Yu [
16,
17,
18,
19,
20,
21,
22] and its modeling problem of the data coming from the simulation. Within this modeling and simulation study, the cognitive agents are abstractions of simple robots, which are generated at a crossing point of the highway. The sole goal of the agents is to learn to cross the road successfully through vehicle traffic. The agents can share and update their knowledge about their previous performance in carrying the task of crossing the unidirectional single lane road. Through the learning process, they can make more sensible decisions to cross or to wait, so that the successful crossing rates or successful waiting rates are improved. This is very much like the situation when an autonomous vehicle is waiting at the edge of a country highway and it is trying to make a left turn. A country highway is often bi-directional and has only a single lane in each direction. When crossing to make a left turn, to avoid being hit by an incoming vehicle, the autonomous vehicle must decide, sequentially at each given time step, according to the traffic conditions, on either continuing to wait or making a left turn. This simulation study and its analysis can help us better understand the effects of various experimental conditions on the experimental outcomes such as successful crossing. Because of the similarity between the decision-making of cognitive agents in our simulation and an autonomous vehicle decision-making in an actual situation, the research outcomes eventually may contribute to better understanding of how to improve the performance of autonomous vehicles’ decision-making process. Also, for the financial market example mentioned earlier, this study may help to provide a guide for understanding the effect of different levels of risk appetite on the investment decision-making.
When simulating the experiment of cognitive agents learning to cross a highway, the agents’ crossing behavior will depend on the set-ups of the configuration parameters’ values in the simulation, such as a value of car creation probability, or the values of agents’ fear and desire to cross the highway. The different combinations of the parameters’ values can lead to the different outcomes (e.g., success or failure) of the agents’ crossing or waiting decisions. Thus, it is important to investigate the cause-and-effect relationships among these factors and the decision types, and to study how much the main factors can contribute to the regression model that is used to capture such relationships. Due to this expectation of our study, we firstly applied canonical correlation analysis (CCA) to investigate the correlation between the combined configuration parameters’ values and the combined decisions, which are all linear combinations of either configuration parameters’ values or decision types. From the computational point of view, CCA maps the original data to canonical variate space, in which the potential association between the canonical variates can be discovered. On the one hand, it helps to reduce the data dimension, which is particularly important when the number of output response variables or the number of predictors is large. On the other hand, it justifies the use of statistical modeling techniques in the further analysis. From the methodological perspective, CCA is related to principal component analysis (PCA) and factor analysis (FA). The major difference is that CCA is applied to both, i.e., response variables and predictors, while PCA or FA is applied only to one set of variables, either response variables or predictor variables. However, it is not applied to both at the same time. The similarity among them is that they intend to transform the original data to the feature subspace, with the potential of having dimension reduction, so that the interpretation of data becomes easier. Since we tried to investigate the association between two set of variables, CCA became a better choice in this regard.
The objective of CCA is to maximize the canonical correlation between two variable sets, and then to produce a set of canonical variates that may be used to replace original variables when capturing correlations [
23]. A more thorough study of the use of CCA allows us to reduce the dimension of the data frame while preserving the main effects of the relationships. It also allows us to find out which configuration of parameters’ values may influence the cognitive agents’ decisions the most. CCA is widely used in various areas. For example, in the field of economics, by constructing a CCA model for the Zimbabwe stock exchange, the impact of macroeconomic variables on stock returns could be verified [
24]; in the field of biology, this method was promising in investigating the multivariate correlation between impulsivity and psychopathy [
25]; in machine learning, the CCA method was applied to map the representation of biological images from the extracted features from extreme machine learning to a new feature space, which was used to reconstruct the biological images [
26]. In brain–computer interfaces (BCIs), canonical correlation analysis was used to study the visual evoked potential for steady-state targets [
27]. In this work, CCA is applied in a novel way to a simulation study to validate the cause-and-effect relationship between multivariate dependent variables and multiple independent variables.
Our simulation model is a complicated fully discrete algorithmic mathematical model involving many elements, e.g., a cellular automaton (CA)-based highway, vehicular traffic, cognitive agents, decision-making formulas, and knowledge base, and it involves many different experimental set-ups of the parameters’ values. Thus, the output data from the simulation are extremely large, and it is difficult to fit the data to some standard statistical models that often require certain assumptions. Because of this, we use the regression tree modeling approach to explore how the configuration parameters’ values influence the agents' decision-making abilities in different traffic density, which is considered as one of the key factors affecting the decision outcomes. In statistics, a decision tree is a modern method in decision analysis for explorations of the data grouping. It can also be used to predict the values of the underlying response variable [
28], which is often referred to as the regression tree approach. It is widely used in many different fields. In Reference [
29], a methodological review of the classification and regression tree (CART) analysis was conducted to help researchers to familiarize with this method. In Reference [
30], a logistic regression tree-based method was applied to American older adults to identify fall risk factors and interaction effects of those risk factors. In Reference [
31], the regression tree method was used to predict the school absenteeism severity from various demographic and academic variables such as youth age and grade level, and to find the main factors that lead to the absence. In Reference [
32], a coastal ecosystem was simulated to study the growth behavior of bivalve species, and the regression tree analysis was conducted to investigate the leading factors associated with the water conditions that promote the quality and growth rate of species the most. In Reference [
33], a simulation model of a rat in an elevated plus-maze was constructed to measure the anxiety-like behavior. After the computational simulation, the dominant parameters were investigated to improve the model performance through the regression tree method. As an algorithm-based method, regression tree can be useful to explore the complex data characteristics. Also, this method does not require any model assumptions. Since we focus on predictive modeling to better understand the effects of the factors that we designed for our simulation models, this is a typical type ANOVA model. However, from our investigation (not presented in this paper), validation of the model assumption becomes a big concern when the ANOVA linear model is considered. This is because our response variable is the accumulated effect from a given stochastic process, and it is unlikely to follow some specific distribution [
34]. This means that the assumption about our response variable as a random variable with an identical distribution is unrealistic. Because of this, it is more suitable to model our response variable using a distribution-free method. The decision-tree type of regression approach becomes a natural choice for this problem. These factors motivated us to apply the regression tree method in a novel way to our designed computer simulation experiment of cognitive agents learning to cross a CA-based highway.
The main contribution of this work is the proposed method that combines CCA and regression trees for analyzing data from a designed computer simulation experiment for a better understanding of the nature of a complex system. It provides a systematic solution on investigating the effect of input parameters’ values on its response variables, especially the effect coming from the knowledge base transfer on the decision outcomes. To the best of our knowledge, this is the first type of work that uses a CCA and regression tree approach in modeling computer simulation data. The proposed methodologies are also suitable for other designed experiments with a similar research objective.
This paper is organized as follows: in
Section 2, we introduce the simulation model including the associated variables. We discuss the simulation process and describe the data used in this work. In
Section 3, we discuss the methodologies, including canonical correlation analysis and regression tree methods, which are used for obtaining the results presented in this paper. In
Section 4, the justification of statistically significant correlation between the designed configuration parameters’ values and agents’ decisions is reported, and the regression tree results obtained for all four types of considered decisions are analyzed. Finally, in
Section 5, we conclude our findings and provide summary remarks and outline potential future work.
2. Simulation Model Description
The model of autonomous agents’ learning to cross cellular automaton (CA)-based highway is a fully discrete algorithmic model, and it was developed by Lawniczak, Di Stefano, Ernst, and Yu [
16,
17,
18,
19,
20,
21,
22]. It simulates the epitome of an actual vehicle driving and crossing environment and decision-making process through four main components: highway, vehicles, agents, and their decisions. In this paper, we provide a brief introduction to the model and its simulation process. The diagram of the abstraction of the highway, vehicles, and agents crossing the CA-based highway implemented in the model is displayed in
Figure 1. For more information about the model description and previous statistical analysis of it simulation data, the reader is referred to References [
16,
17,
18,
19,
20,
21,
22,
35,
36,
37,
38,
39,
40,
41]. The highway and the vehicular traffic are modeled by the Nagel–Schreckenberg highway traffic model [
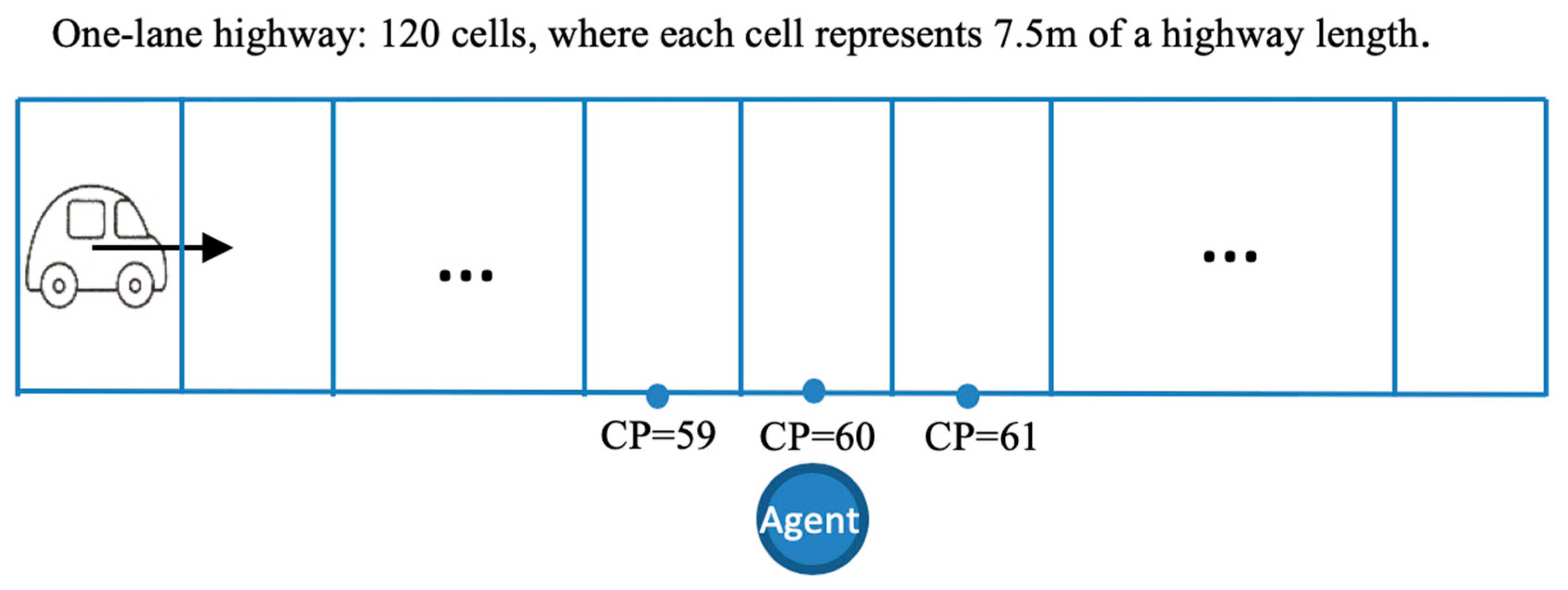
42], which is a CA-based model consisting of a collection of cells, with each cell representing a segment of a highway of 7.5 m in length [
42]. In our study, we consider a unidirectional one-lane highway composed of 120 cells. The vehicles move along the highway and the agents move across the highway. Thus, the state of each cell (i.e., empty or occupied) depends on whether a vehicle or an agent is present in a cell, and it is updated at each time step as the simulation progresses. Each car is randomly generated with speed 0 at the first cell of the highway at each time step. Once cars run on the highway, they follow the rules of the Nagel–Schreckenberg traffic model [
42]. Notice that each car tries to reach its maximum speed set at software initialization, but to prevent a collision with another car, it adjusts its speed as required. However, it does not decelerate to avoid hitting an agent crossing the highway. There are two configuration parameters associated with the vehicle in the model, car creation probability and random deceleration. Car creation probability (CCP) is the probability that a vehicle is generated at the beginning of the highway, which simulates the density of traffic flow. Random deceleration (RD) controls the moving behaviors of the cars. It is a dummy variable that takes a value of either 0 or 1. If vehicles do not decelerate randomly as in the Nagel–Schreckenberg traffic model, then RD = 0; if the vehicles randomly and independently decelerate with the probability 0.5, as in the Nagel–Schreckenberg traffic model, then RD = 1.
The agents are an abstraction of autonomous robots. They aim at successfully crossing the highway without being hit by incoming cars. In the presented study, at each time step, an agent is generated at the selected crossing point (CP) on the same side of the highway. The CP at which agents are generated and placed in the queue, if there are other agents already waiting to cross the highway, is located at cell 60 (i.e., 450 m from the first cell), far away from the beginning of the highway, to allow emergence of the car traffic profiles typical for the considered CCP values. The agents have limited field of vision and they can perceive only fuzzy proximity values (e.g., close, medium, far) and fuzzy speed values (e.g., slow, medium fast, fast, very fast) of incoming cars. Two attributes are randomly and independently assigned to each agent: fear and desire. The values with which agents can experience fear and desire are set at the initialization of the software. Thus, the fear and desire can be interpreted as factors with various levels. Hence, the fear is the latent variable which measures an agent’s propensity to risk aversion in crossing the highway. The desire is the latent variable that measures an agent’s propensity to risk-taking in crossing the highway. The values of both fear and desire enter agents’ decision-making formulas, and they determine the value of the threshold with which an agent makes its decision to cross or not to cross the highway. If the decision-making formula tells an agent not to cross at its current location at a given time, depending on the initial set-up of the simulation software, the agent may move randomly with equal probability to one of the adjacent cells of its current CP location, or it may remain at its current CP. The agents’ ability to change their crossing points is governed by the horizontal movement (HM) factor. If HM = 0, then agents cannot change their CP set at the initialization at cell 60. If HM = 1, then each agent can change its crossing point by moving up to five cells away from CP = 60 in each direction. Thus, if HM = 1, then many more agents may simultaneously attempt to cross the highway, and agents may potentially attempt to cross from 11 crossing points.
An agent attempting to cross the highway is called an
active agent, and it must make a decision that leads to one of the following decision outcomes: (1) correct crossing decision (CCD), an agent made a crossing decision and crossed successfully; (2) incorrect crossing decision (ICD), an agent made a crossing decision but it was hit by an incoming car; (3) correct waiting decision (CWD), an agent made a waiting decision, but if it decided to cross the highway, it would have been hit by an incoming car; (4) incorrect waiting decision (IWD), an agent made a waiting decision, but if it decided to cross the highway, it would have crossed successfully. The assessment of each active agent’s decision, i.e., if the decision was CCD, ICD, CWD, or IWD, is recorded as a count into the knowledge-based (KB) table of all the agents waiting at the crossing point of the active agent. Notice that, if HM = 1, then a KB table is associated with each crossing point and the values of its entries are used by active agents in the calculation of decision-making formula values when they are deciding what to do. Each knowledge-based table is organized as a matrix with the extra row entry reserved for out-of-range field-of-vision results. The columns of the KB table store information about qualitative descriptions of incoming cars velocities (i.e.,
slow, medium speed, fast, very fast) and the rows of the KB table store information about qualitative descriptions of the incoming cars proximities (i.e.,
close, medium far, far, and out of range). For details, see References [
20,
21,
22]. In the presented simulation results, a car is perceived as
close if it is 0–5 cells away,
medium far if it is 6–10 cells away,
far if it is 11–15 cells away, and
out of range if it is 16 or more cells away, regardless of the velocity value of the car, and this is encoded in the extra entry of the KB table. A car is perceived as
slow if its perceived velocity is 0–3 cells per time step,
medium speed if its perceived velocity is 4–5 cells per time step,
fast if its perceived velocity is 6–7 cells per time step, and
very fast if its perceive velocity is 8–11 cells per time step. A car’s maximum speed can be 11 cells per time step.
At each time step, the KB table values provide cumulative information about the assessment of active agents’ decision type, from the beginning of each simulation run. The KB tables are updated at each simulation time step and, as time progresses, they accumulate more and more information about the active agents’ performance in their decision-making process. Thus, as time progresses, the active agents make their crossing and waiting decisions based on more information/knowledge about their performance in similar traffic conditions observed in the past. The decision-making formula they use is based on the
observational social learning mechanism: “
If this situation worked well for somebody else, it will probably work for me and, thus, I will imitate that somebody else. If this situation did not work well for somebody else, it will probably not work for me; thus, I will not imitate that somebody else.” [
43]. Thus, using this
observational social learning mechanism encoded into the agents decision-making formula and with the accumulation of information about their performance as time progresses, the agents learn how to cross the highway within each simulation run.
In the presented simulation model, in the first scenario (i.e., KBT = 0), each simulation run starts with the KB table initialized as tabula rasa, i.e., a “blank slate”, represented by “(0, 0, 0, 0)” at each table entry for the assumption that the active agents can cross for all possible (proximity, velocity) combinations. At the start of each simulation, active agents cross the highway regardless of the observed (proximity, velocity) combinations until the first successful crossing of an active agent or five (selected for the presented simulation results) consecutive unsuccessful crossings of the active agents, whichever comes first. This initial condition is introduced to more quickly populate the KB table entries. After the initialization of the simulation, for each observed (proximity, velocity) pair of an incoming car, each active agent consults the KB table to get information about agents’ performance in the past, to decide if it is safe or not to cross. Its decision is based on the implemented intelligence/decision-making formula, which for the observed (proximity, velocity) pair combines the success ratio of crossing the highway for this (proximity, velocity) pair with the active agent’s fear and/or desire parameters’ values, which determine that agent decision threshold value. Notice that, in the first scenario (i.e., KBT = 0), the active agents do not have any exiting knowledge/information about their performance when they start learning to cross the highway, and this knowledge/information is built only during each simulation run. Thus, it is interesting to investigate the active agents’ learning performance in crossing the highway if they have access to the information about agents’ performance in some other traffic environment, i.e., with some different CCP value. In the simulation model, this is incorporated through KB transfer. Thus, in the second scenario (i.e., KBT = 1), the KB table of the initial crossing point, CP = 60, is transferred at the end of a simulation run with a lower CCP value to the agents at the beginning of a simulation run with an immediately higher value of CCP. When KBT = 0, the KB tables are never transferred from agents in a traffic environment with a lower CCP value to the agents in an environment with an immediately higher CCP value or any other value. We considered the following CCP values in the presented simulations: 0.1, 0.3, 0.5, 0.7, and 0.9. When KBT = 1, each simulation in the traffic environment with CCP = 0.1 starts with the KB table tabula rasa, and the KB table built in this simulation run is transferred next to the agents at the beginning of the simulation run in the traffic environment with CCP = 0.3. This process of transferring the KB tables continues until the simulation starts in the traffic environment with CCP = 0.9, where the simulation with CCP = 0.9 starts with the KB table accumulated over the other four less dense traffic environments, i.e., with CCP = 0.1, 0.3, 0.5, and 0.7. This process of transferring KB tables is carried out for each simulation repeat when KBT = 1.
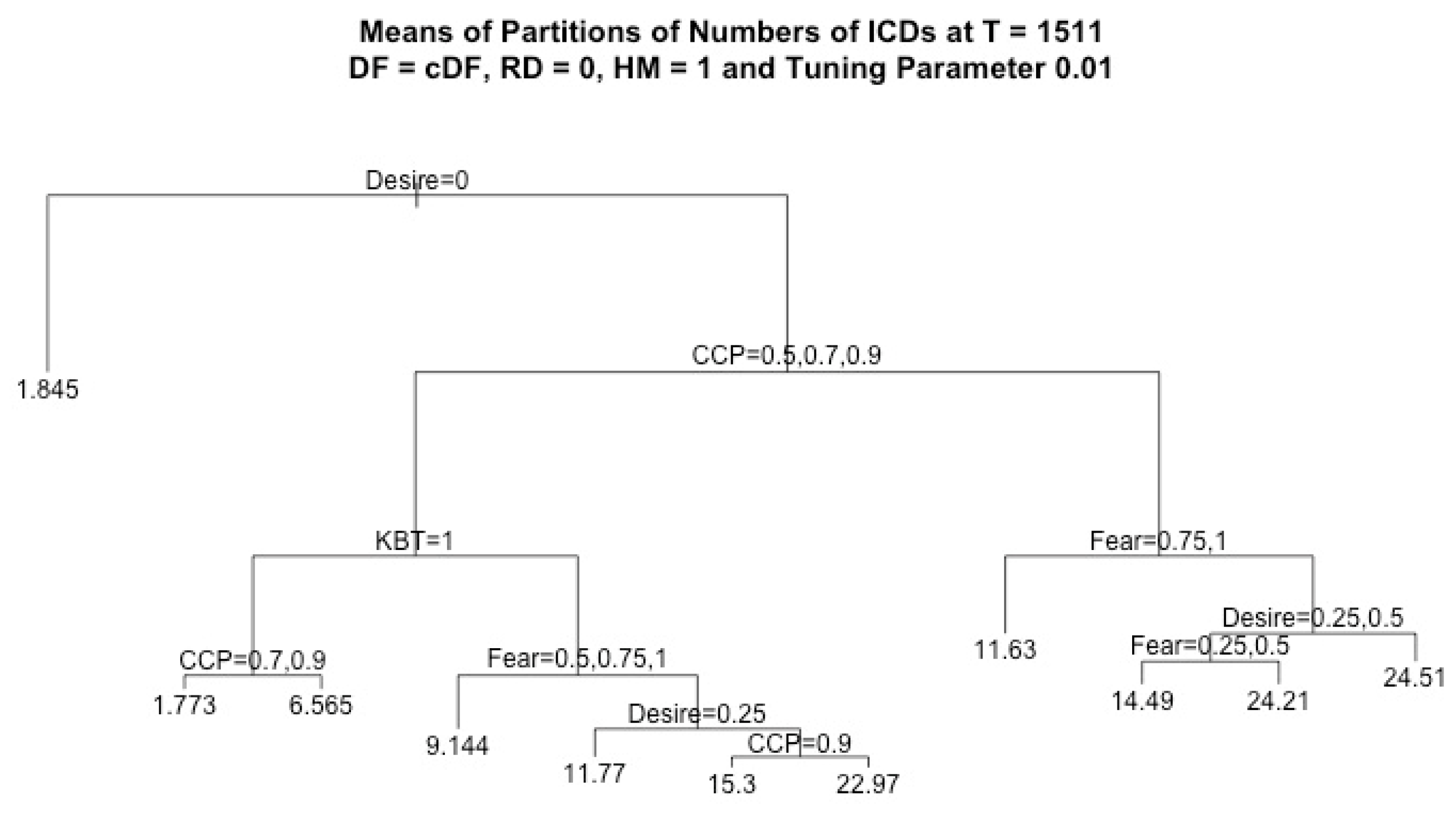
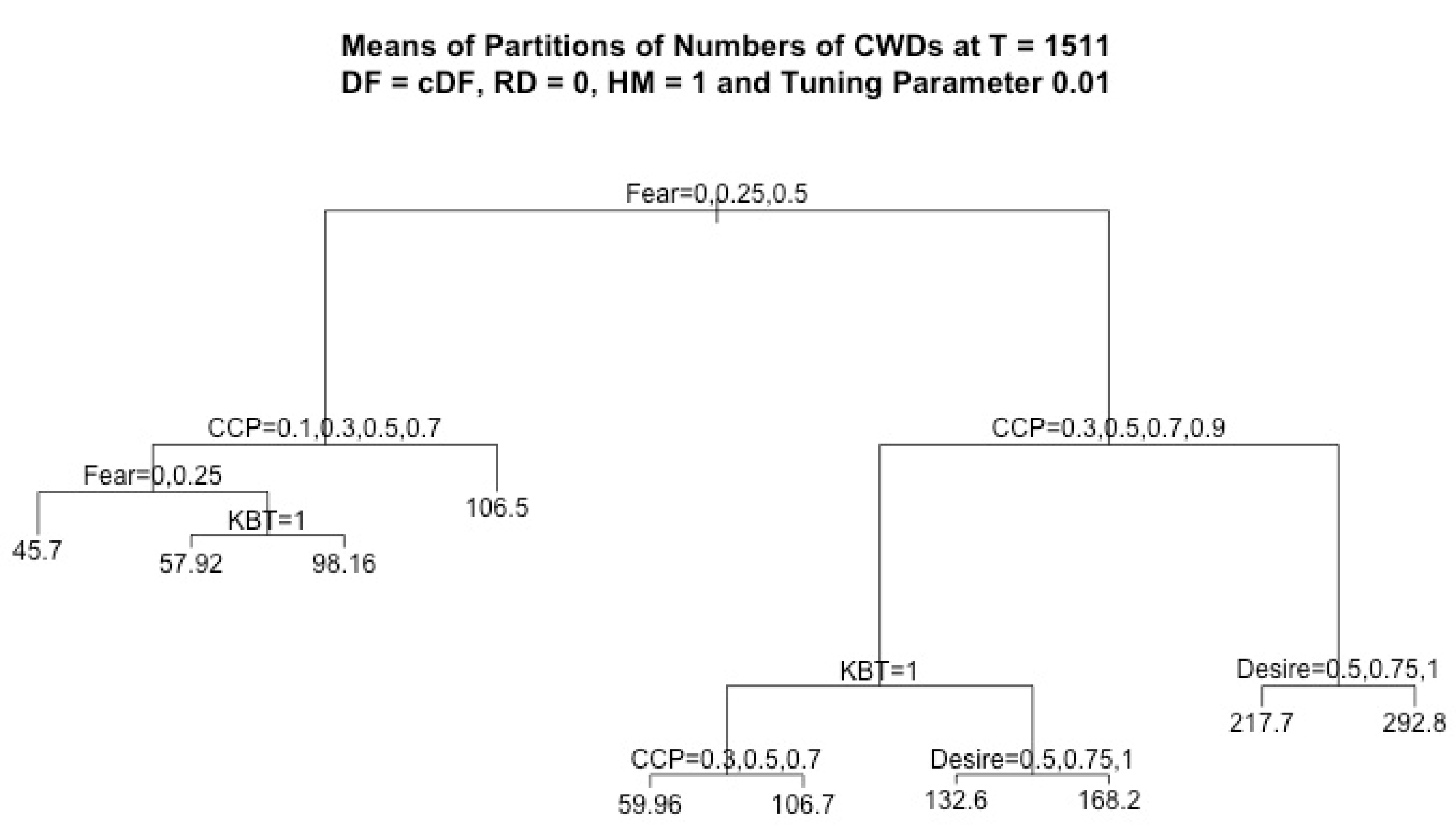
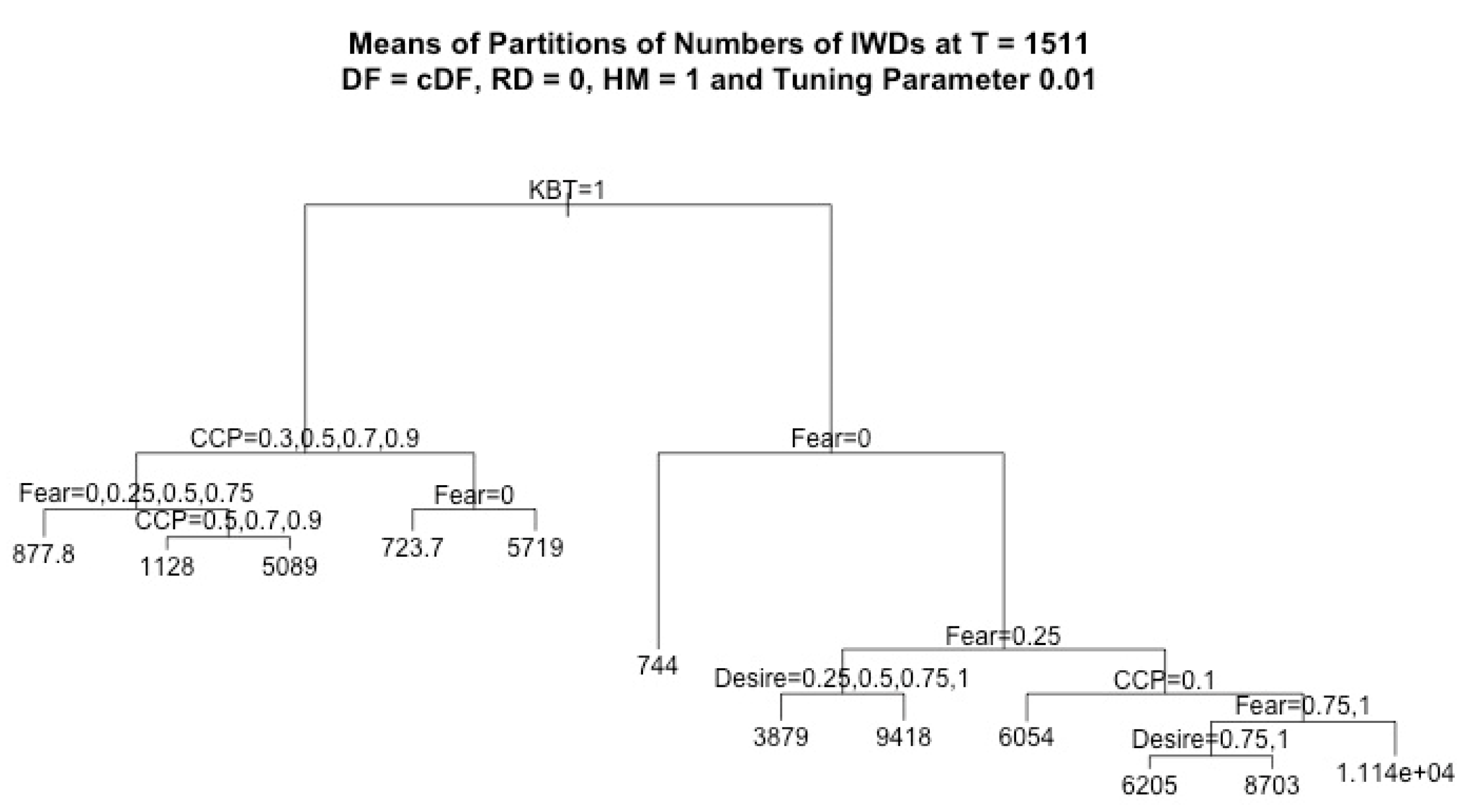
Given the above description of the model, the agents’ learning performance in crossing the highway is affected by the above-discussed model parameters, which are car creation probability (CCP), random deceleration (RD), agents’ fear and desire, horizontal movement (HM), and KB transfer (KBT). Therefore, we focus on studying the effects of these factors and their levels on the agents’ learning performance when they use a crossing-based decision formula (cDF) [
20,
21,
22], which is described below.
After the initialization phase, at each time step t, each active agent, while deciding whether to cross or to wait, carries out several tasks: (1) it determines if there is a car in its horizon of vision; if yes, then it determines the fuzzy (i, j) values of the (proximity, velocity) pair for the current closest incoming car; (2) from the KB table associated with its CP, the active agent gets information about the number of CCDs and the number of ICDs for the observed (i, j) values of the (proximity, velocity) pair, or for the observed out-of-range vision situation, the entry of which is denoted by the (0,0) pair of indexes in the KB table; (3) for the observed (i, j) values of the (proximity, velocity) pair, the active agent calculates the value of the decision formula cDF, i.e., the value
, corresponding to the (i, j) entry of the KB table (including the extra row entry). The expression
(t) is calculated as follows:
where v(Desire) and v(Fear) are the values of the active agent’s fear and desire factors (parameters), and
is the crossing-based success ratio (cSR) corresponding to the (i, j) entry of the KB table. The
is calculated as follows:
The terms
and
are, respectively, the numbers of CCDs and the numbers of ICDs recorded in the (i, j) entry of the KB table at up to time t − 1. The term
is the number of all CCDs made by active agents up to time t − 1, i.e., it is the sum of numbers of CCDs made up to time t − 1 over all the entries of the KB table. The number
is equivalent to the total number of successful agents up to time t − 1.
After the initialization period, an active agent decides to cross or to wait based on an outcome of its calculation of the crossing-based decision formula value. If , then the active agent decides to cross. If , then the active agent decides to wait and, if HM = 1, it may move randomly, with probability 1/3, by one cell to one of the neighboring cells of its CP, or it may stay at its CP with probability 1/3. Thus, we assume that each option is equally likely to occur.
The decision formula cDF takes under consideration only the numbers of CCDs and the numbers ICDs, i.e., numbers of successful agents and hit agents. Notice that each CCD corresponds to a successful agent and each ICD corresponds to a hit agent. Since cDF ignores the numbers of CWDs and IWDs, this decision formula was modified in References [
20,
21,
22], and a new decision-making formula, called the crossing-and-waiting-based decision formula (cwDF), was introduced. Even though we do not provide an analysis of simulation results for cwDF in this paper, for the completeness of the simulation model description and the reader’s sake, we introduce the cwDF formula below. For the analysis of some simulation results when cwDF is used and for a comparison of these results with those when cDF is employed instead, the reader is referred to References [
20,
21,
22]. Similarly, as with cDF, the decision formula cwDF is defined based on the information about the assessment of agents’ decisions contained in the KB table. Recall that the KB table at each time t stores information about the assessments of crossing and waiting decisions made by agents up to time step t − 1. The decision formula cwDF is obtained from cDF formula by replacing the term
by the term
in the cDF formula, i.e., by replacing the term in Equation (2) by the term
in Equation (1). The term
called the crossing-and-waiting-based success ratio (cwSR), is defined for each (i, j) entry of the KB table at time t as follows:
where
,
,
, and
are, respectively, the numbers of CCDs, ICDs, CWDs, and IWDs made by active agents, up to time t − 1, and recorded in the KB table entry (i, j). The terms
and
are, respectively, the sum of all the numbers of CDs and the sum of all the numbers of WDs, regardless of their assessments, which were made for all the observed (proximity, velocity) pairs (i, j) up to time t − 1 (inclusive), i.e., they are given by the following formulas:
Thus, at each time step
, for each observed (proximity, velocity) pair (i, j), i.e., for each entry
of the KB table, the decision formula cwDF can be written as follows:
where the terms
and
, respectively, are the values of an active agent’s desire and fear parameters.
The main simulation loop of the model of cognitive agents learning to cross a CA-based highway consists of the following steps [
16,
17,
18,
19,
20,
21,
22]:
Randomly generate a car at the beginning of the highway with a selected CCP value;
Generate an agent with its attributes of fear and desire at the crossing point, CP = 60;
Update the car speeds according the Nagel–Schreckenberg model;
Move active agents from their CPs queue into the highway, if the decision algorithm indicates this should occur. If, for some active agent, the decision algorithm indicates that the agent should wait, then if HM = 1, decide randomly if the agent stays at its current CP or moves to a neighboring one;
Update locations of the cars on the highway, checking if any agent is killed and update the KB table entries, i.e., update the assessment of the decisions (i.e., CCD, ICD, CWD, and IWD) in the KB tables;
Advance the current time step by one;
Repeat steps 1–6 until the final simulation time step.
After the simulation is completed, the results are written to output files using an output function.
For each set-up of the simulation model parameters’ values, each simulation run is of a duration of 1511 time steps and it is repeated 30 times. We selected 30 repeats based on our previous work [
20,
21,
22,
35,
36,
37,
38,
39,
40,
41], which showed that the natural variation of simulations was captured sufficiently well by this number of repeats. For the presented study, we selected the data at the simulation end as our object of study. It contained cumulative information about the agents’ performance during each simulation period. Note that, in this paper, we only consider data for the case of HM = 1 and RD = 0, that is, agents can move randomly to the neighboring crossing points, but the cars cannot randomly decelerate. The results of the other cases will be presented elsewhere. The variables considered in this work are summarized in
Table 1.
In the remainder of the text, when CCD, ICD, CWD, and IWD are written in italic and bold font, it means that they are the names of the above-introduced response variables. Notice that KBT is a categorical variable which we converted into a binary real valued variable, by assigning values of 0 and 1, denoting no transfer of the KB simulation scenario and transfer of the KB simulation scenario, respectively.
3. Methods
The agents’ decision-making and learning performance, measured by the assessment of their crossing and waiting decisions, depends on many factors (i.e., CCP, HM, RD, fear, desire, KBT) which are considered with various levels. Thus, it is important to identify if there is a significant correlation between the considered factors and the assessments of decisions (i.e., response variables, CCD, ICD, CWD, and IWD, which are the numbers, respectively, of CCDs, ICDs, CWDs, and IWDs made by agents during each simulation). To explore and quantify this relationship, canonical correlation analysis (CCA) was applied. After verifying that the relationship between two sets of variables was significant, the regression tree method was applied to provide a graphical description of the estimated mean values of the response variables and their dependence on the parameter values. The regression trees transparently display all possible dependencies on the parameter values, allowing an easy trace for each different condition. This method also accounted for interactions among different factors with different levels, where we could conduct a quantitative and qualitative analysis for each type of decision. Since KBT and CCP were two important factors in our model, we focus on the study of the effects of KBT on the agents’ decision-making abilities in traffic environments with different densities of cars, determined by different CCP values.
3.1. Canonical Correlation Analysis
The generalized algorithm of canonical correlation analysis (CCA), applied in this work, is described in Reference [
44]. In this work, we considered two multivariate variables
and
, where
X = (X
1, X
2, X
3, X
4) stands for the multivariate factor or the multivariate explanatory variable (CCP, fear, desire, KBT), i.e., where X
1 = CCP, X
2 = fear, X
3 = desire, and X
4 = KBT, and
Y = (Y
1, Y
2, Y
3, Y
4) stands for the multivariate response variable (
CCD, ICD,
CWD, IWD), i.e., where Y
1 =
CCD, Y
2 =
ICD, Y
3 =
CWD, and Y
4 =
IWD. Notice that CCP, fear, and desire are real values and, even though KBT is a categorical variable, through the assignment of values 0 and 1, we converted it into a binary real valued variable, where 0 corresponds to the simulation scenario which is considered as a reference, i.e., KBT is off, and 1 corresponds to the simulation scenario with KBT being on. Thus, the value 0 can be interpreted as a base, and the value 1 can be interpreted as an effect coming from KBT.
We looked for a linear combination of the original variables
and
, called canonical variates
U and
V, where
U corresponds to variable
, and
corresponds to variable
. That is, we constructed two linear equations as follows:
In the matrix notation, they are given by
where
where
,
, and
and
are the coefficients vectors of each canonical variate. We aimed to search for the optimal
and
such that the correlations, denoted by
were successively maximized. Finding the canonical correlation requires the following assumptions [
44]: (1) the relationship between the canonical variates and each set of variables must be linear; (2) the distributions of the variables must be multivariate normally distributed. Since our data were generated with a sufficiently large sample size, the results from the CCA were robust.
We now briefly discuss how the canonical variates were obtained, and how the canonical correlation was computed. Let the mean vectors of the variables
and
be
and
, and let their variance–covariance matrices be
and
, respectively. Then, the variance–covariance matrix between
and
is defined by
=
. Note that
, , and
. The first pair of canonical variates (
), via the pair of combination vectors (
), maximizes the following correlation between
and
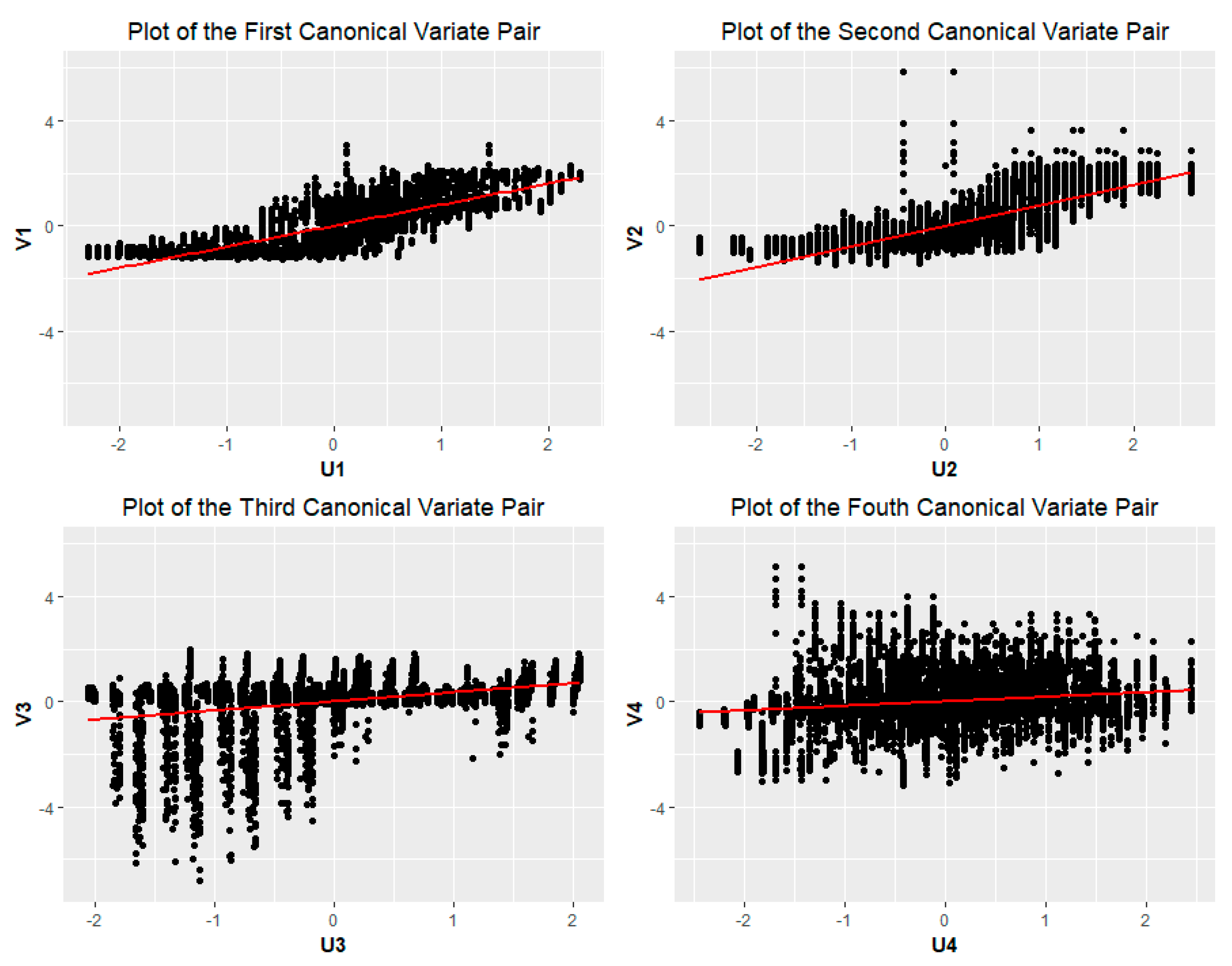
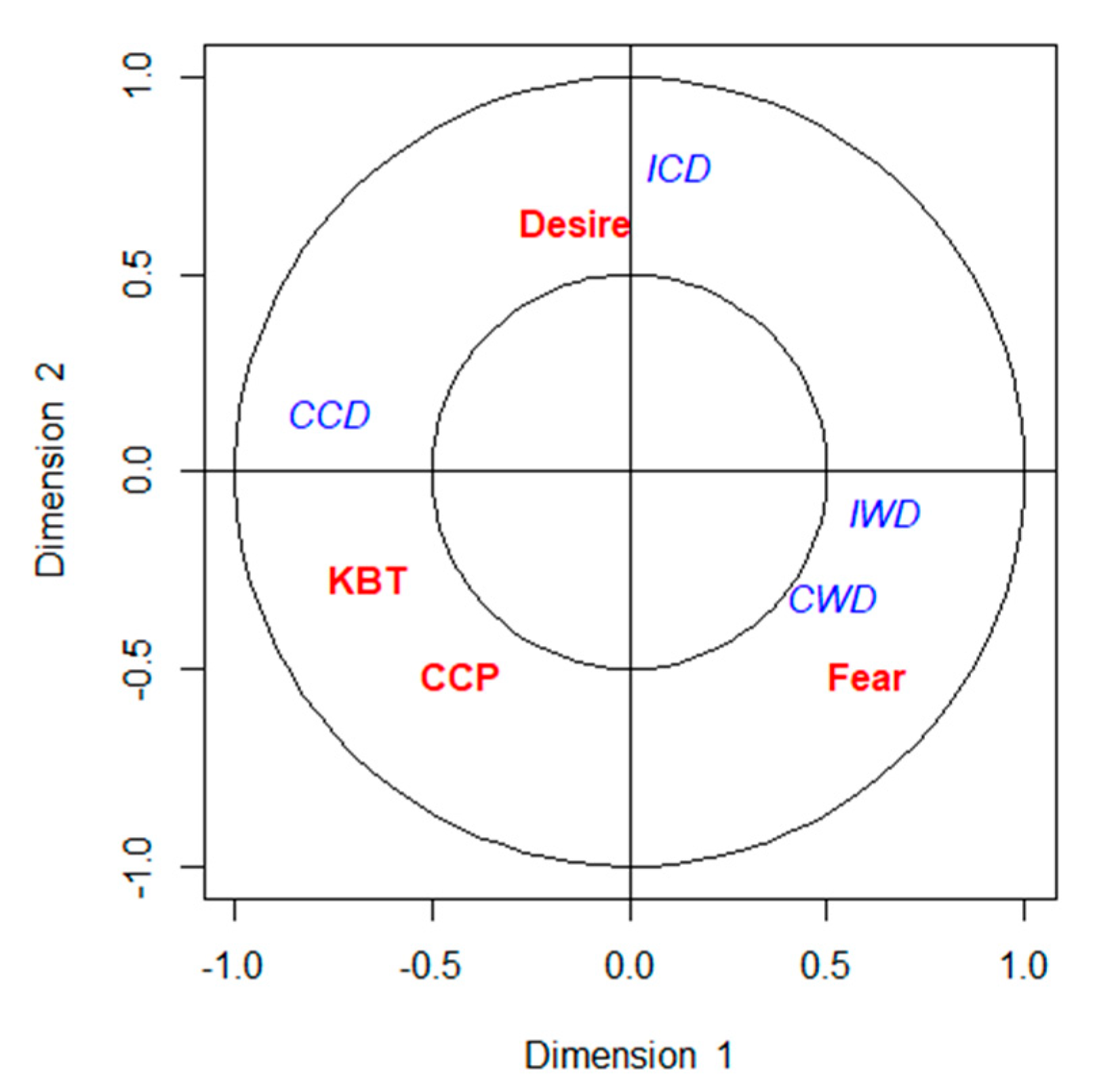
The remaining canonical variates () maximize the above expression and are uncorrelated with (), for all k < l. The maximization problem of the above correlations leads to the eigenvalue decomposition of the matrices and . This implies that the k-th pair of the canonical variates is given by and , where is the k-th eigenvector of and is the k-th eigenvector of . Finally, the k-th canonical correlation is given by .
3.2. Regression Tree
A regression tree is an effective method for predictive modeling and can be useful for exploring data characteristics. It is widely used in many fields of application [
30,
31,
32]. Unlike the classical linear regression, this method does not require an assumption of linearity in the data, such that potential nonlinear relationships among configuration parameters do not affect the performance of the regression tree. In fact, from the statistical point of view, constructing a regression tree can be seen as a type of variable selection, where the leading parameters can be identified through the algorithm. The potential interaction between variables is handled automatically by a monotonic transformation of the variables [
33]. In regression tree modeling, we firstly split the data into two regions by one variable, compute the mean value of the response variables in each region, and then split the data further by the other variables. We select the variable and the split-point that achieve the best fit. A key advantage of the recursive binary tree is its interpretability. In the final result of partitioning, the variable space partition is fully described by a single tree.
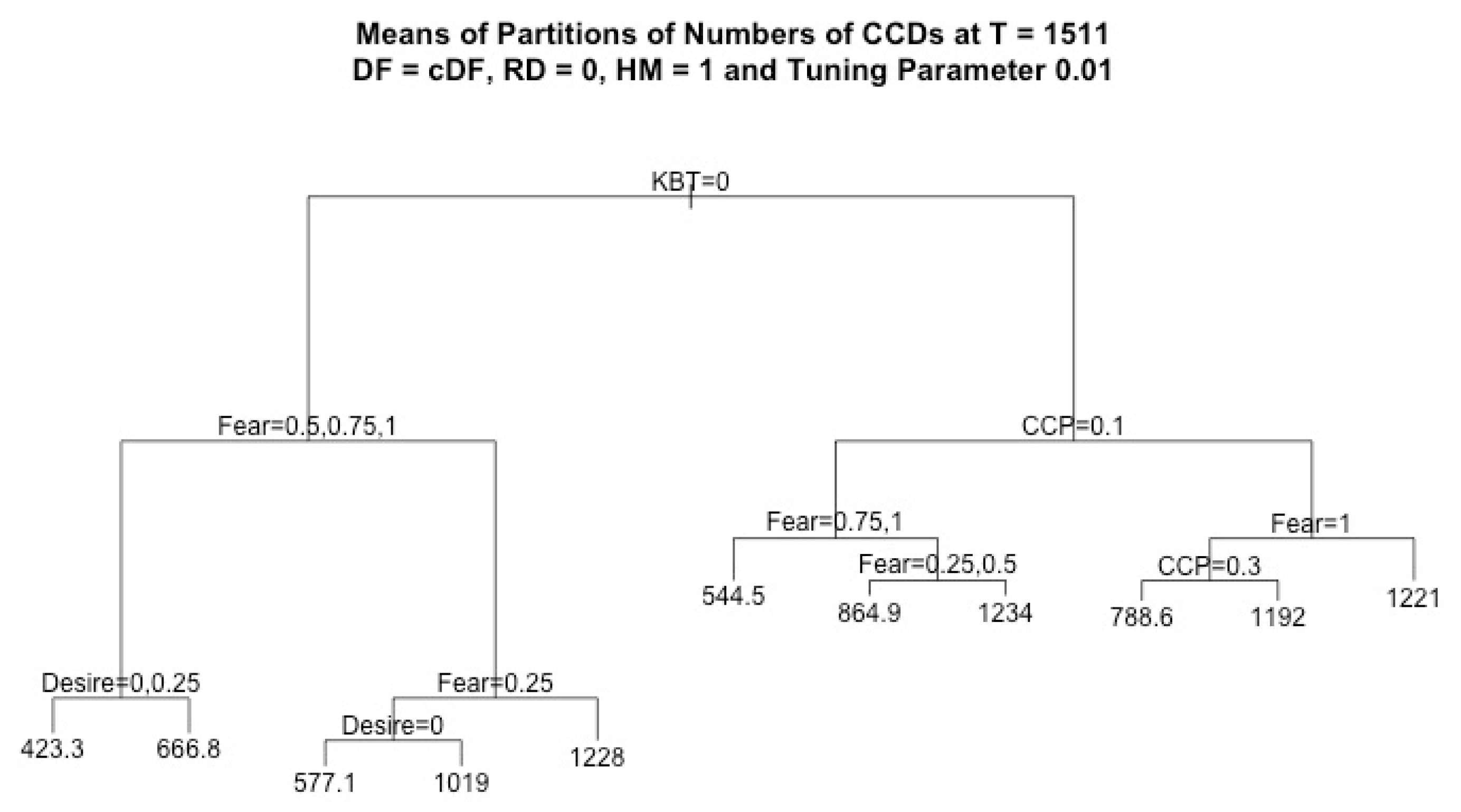
In this work, we assumed that RD = 0 and HM = 1, and we considered four response variables, CCD, ICD, CWD, and IWD, which denote the cumulative number of CCDs, ICDs, CWDs, and IWDs, respectively, recorded for each run at the final simulation time T = 1511. For each regression tree of the k-th response variable, where k = 1, …, 4, we considered four factors (CCP, fear, desire, KBT) and we denoted the observation pairs by () for each observation i = 1, …, N, where N = 7500. The vectors consist of the data values of independent variables, i.e., the factors in each observation i, and stands for the outcome of the k-th response variable in each observation i. Since the independent variables were the same for all response variables, for simplicity, we denote the observation pair for each regression tree of each response variable by () in the discussion of the regression algorithm below.
The idea of the regression tree approach is to separate the data of a response variable into two parts, denoted by
, which is a pair of half-planes, and to calculate the mean value of data in each part, denoted by
, respectively, and to find the optimal values
by using the minimization of the residual sum of squares. Notice that the four factors, i.e., CCP, fear, desire, and KBT, are our splitting variables, and the values of the splitting variables at each node are the split points. For example, if CCP is the splitting variable, then the value that CCP takes is the value of a split point. The detailed algorithm of the construction of a regression tree is described below [
28].
Starting with all the data, denote the splitting variable by
and the split point by
, and define the pair of half planes by
where
represents the data values corresponding to the splitting variable
j, and
is a part of the data values satisfying either the condition
or
. Below, we again use (
) to indicate the observation pairs for either
. Compute the residual sum of squares of data of all possible partitions, and select
and
by the criterion of the minimum residual sum of squares, that is, by solving
For
and
, the solution of the inner minimization is
which is just the average of
in each partition.
Having found the best split from process 1, we split into two resulting partitions and by the selected splitting variable and split point .
Repeat the splitting process of each of the new parts and .
When the splitting process is repeated for all the partitions, the regression tree stops growing, if the decrease in residual sum of squares is less than a small threshold value [
32]. However, if we only follow the steps above, then the tree grows with a large number of nodes. Although the tree can perfectly fit the given data through a complicated and long decision tree, it will be inaccurate in prediction, because it may over fit the data. On the other hand, if we only consider a small tree, it might lose some vital information on the structure. Thus, the adaptive tree size is an important factor to be considered in controlling the tree complexity. A common strategy in controlling a regression tree size is called “tree pruning”, and it is explained in Reference [
32]. In this strategy, the “tuning parameter”, which is a threshold used to determine the tree size, is employed, and, if the cost of adding another parameter to the decision tree from the current node exceeds the value of the tuning parameter, then the tree will not continue to grow. We generated the regression trees following this strategy using different values of “tuning parameter” and we cross-validated them for all the branches. After conducting k-fold cross-validation of the regression trees, the value of the tuning parameter was selected as 0.01. The depths of trees were controlled from 4 to 6.
By using regression tree analysis, we can not only focus on the analysis of the effects of the main factors but also capture all significant structural information. In addition, given the same value of the tuning parameter, it is easy to compare how factors affect different decisions. In each plot of a regression tree, each node stands for a decision based on its variable, where the left branch corresponds to true, and the right branch corresponds to false.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}