1. Introduction
Simulations are becoming an increasingly prominent alternative to often expensive and time consuming laboratory experiments. Therefore, engineers are interested in introducing more and more physical effects to explore complex phenomena with the help of computers. These multiphysics simulations, thus, feature a combination of different algorithms to describe the physical phenomena, like multiphase fluid flow [
1], particle motion [
2,
3], or free surfaces [
4]. Typical applications can be found in environmental science [
5], additive manufacturing [
6], and petroleum engineering [
7]. Due to their computational cost, it is often necessary to utilize thread-based and distributed memory parallelization techniques to obtain results in reasonable time and to make use of the immense capabilities provided by today’s supercomputers. This is commonly achieved by a spatial domain partitioning where the computational domain is subdivided into smaller pieces which are then distributed among the available processes, see e.g., [
8]. As the majority of the parallel numerical codes consist of computation and synchronization, the desired properties of such a distribution are that the overall workload (originating from the computations) is spread evenly among the processes and that the amount of communication (due to synchronization) is minimized. If the first property is violated, the simulation suffers from load imbalances and the processes must wait at the synchronization points for the slowest process, i.e., the one with the largest workload, until the simulation can proceed. As a result, the runtime of the whole simulation increases and the hardware resources at hand are utilized less efficiently due to the idle times. Acquiring and maintaining a distribution with balanced workloads is, thus, crucial to achieve efficient parallel simulations.
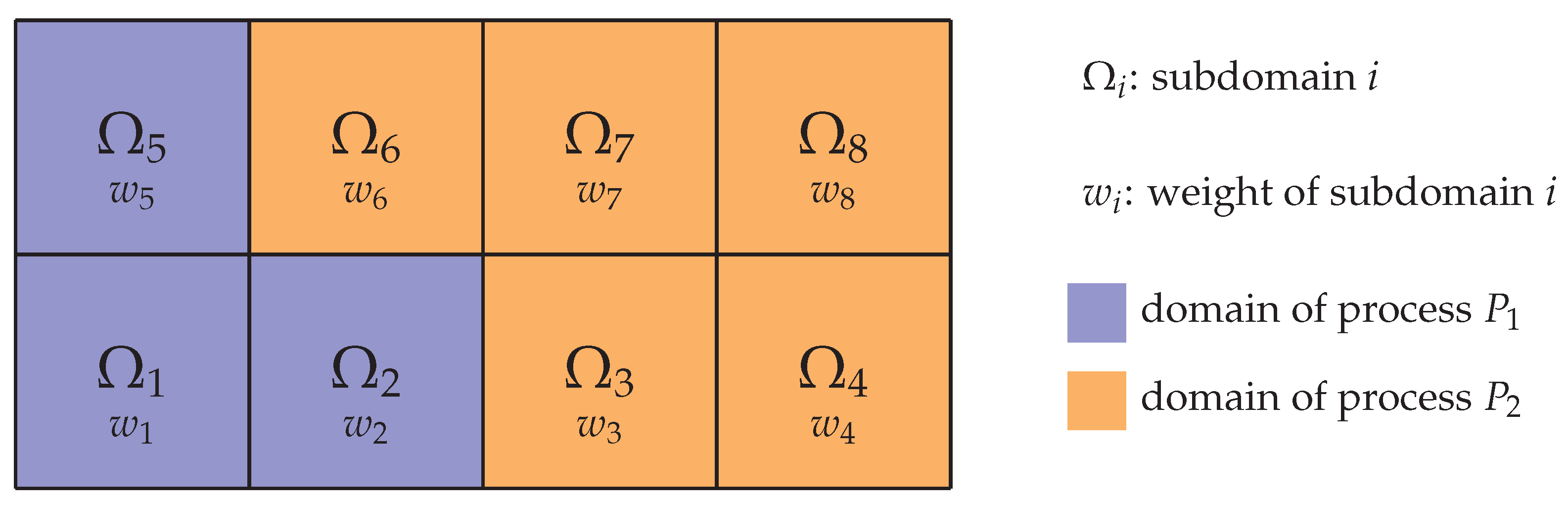
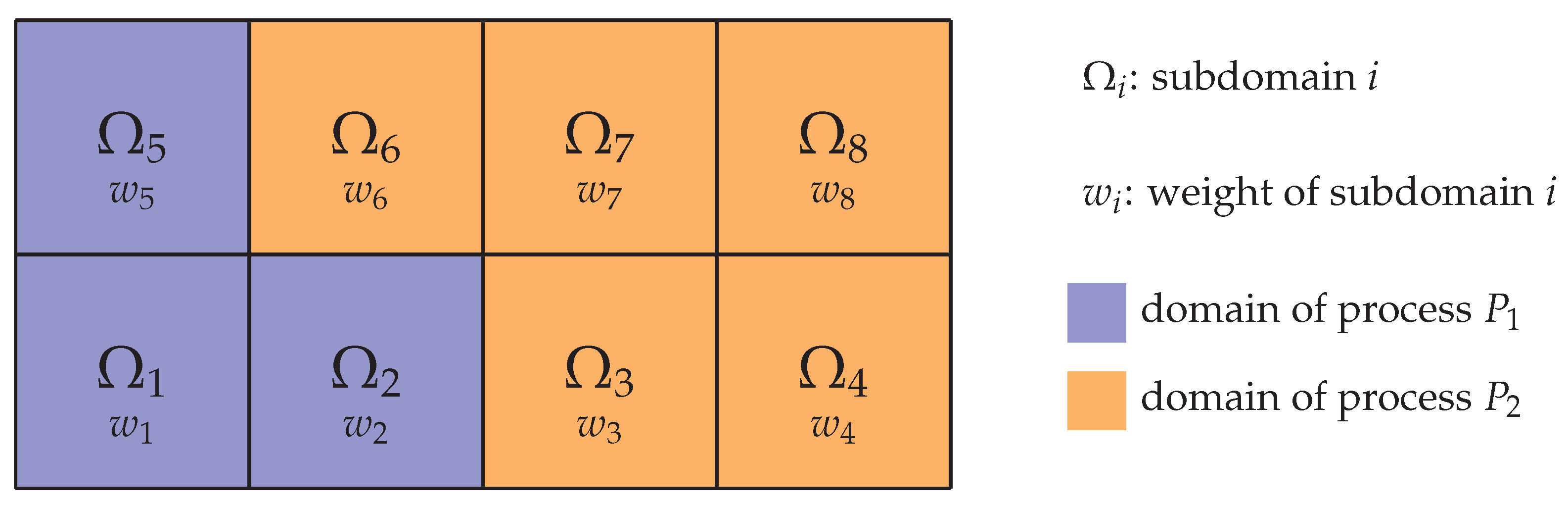
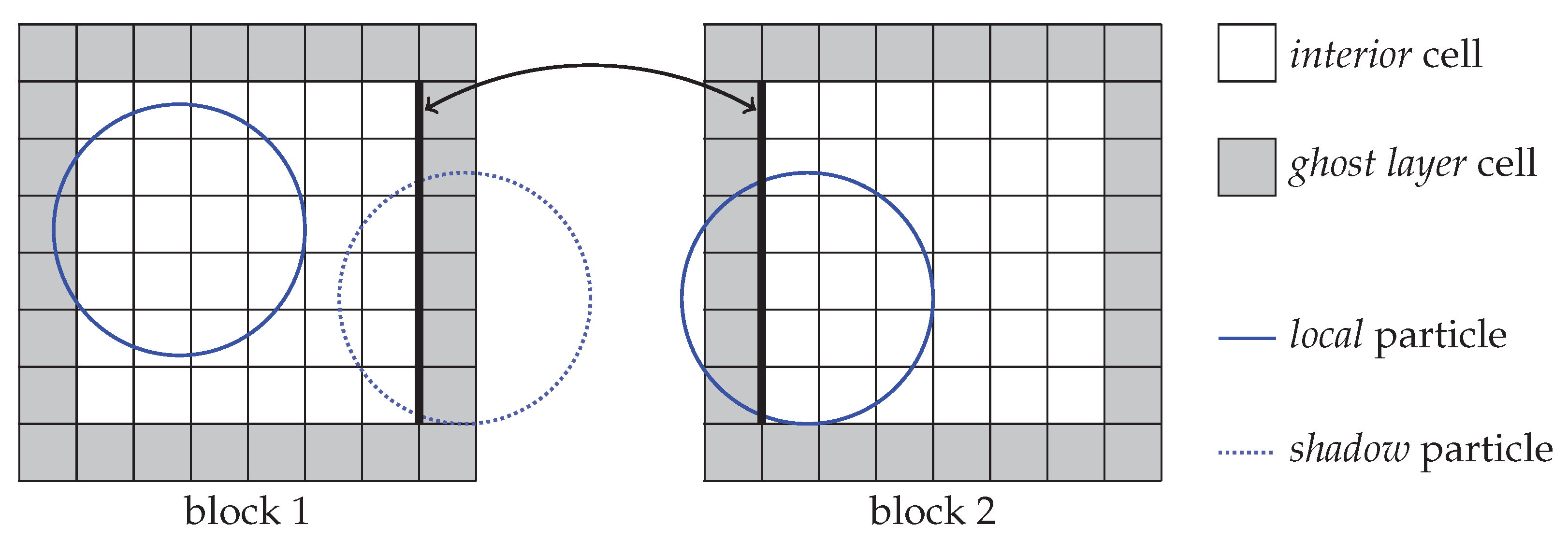
Conceptually, the task of load balancing can be split into two steps: At first, referred to as
load estimation, each subdomain is assigned a weight that quantifies the workload present on that subdomain. Based on these weights, a
load distribution routine is executed in a second step to reassign the subdomains to the processes. An illustration is given in
Figure 1. Depending on the characteristics of the underlying algorithms and the targeted degree of parallelism, various load balancing strategies have been developed, as reviewed in [
9]. Meshless methods, like the discrete element method (DEM) [
10] or the discrete dipole approximation (DDA) [
11], typically use the number of particles [
12,
13] or collisions [
14] per subdomain as weight function. Consequently, this weight may vary significantly in space and time, requiring dynamic load balancing techniques. This can be achieved, e.g., by changing the geometric position of the subdomains [
12,
13] or further subdivision [
14]. Contrary to that, in grid-based algorithms like finite volume or lattice Boltzmann methods, the weight of a subdomain is typically given as the number of grid cells [
15,
16,
17,
18]. As a special case, if the grid remains unchanged during the simulation and a constant number of cells per subdomain is chosen, a distribution of one subdomain per process is an obvious choice and, thus, encountered in many such programs. However, when adaptive mesh refinement (AMR) is applied to improve the accuracy and efficiency of these simulations [
19,
20], the workload is altered significantly and load balancing becomes an essential component. Apart from these techniques, load distribution routines have attracted a lot of attention throughout the years and various methods have been proposed, since they are also used for classical graph partitioning problems [
9,
21,
22].
It becomes apparent, however, that the applied techniques differ substantially for meshless and grid-based methods where in the first case the subdomains are modified solely for load balancing whereas this is not desired for the grid-based methods as it could affect the accuracy of the simulation. Determining a suitable load balancing approach for multiphysics simulations that incorporate both types of algorithms, thus, poses a challenge. Commonly, in cases where one of the algorithms is the workload-wise dominant one, the specific approaches of this algorithm are used, e.g., the grid-based fluid solver in particulate flow simulations [
5,
23], which comes at the cost of load imbalances. Alternatively, a different domain partitioning for each part can be used [
12], which, however, requires expensive communication and complicated mapping mechanisms between the subdomains for distributed memory simulations. In this paper, we will therefore present a different strategy for dynamic load balancing of these simulations. We will use particulate flows as an illustrating example, which features a coupling between a fluid solver and a particle simulation. Our primary design objective is to enable massively parallel simulations on supercomputers for large physical systems. This restriction already excludes all algorithms that require global knowledge about process local quantities, e.g., the position of all particles, as they will inevitably not scale to several thousand or more processes. Additionally, we require that all parts of our simulation use the same domain partitioning to avoid the previously mentioned difficulties and bottlenecks. Furthermore, the simulation result should be unaffected by the applied strategy. A variant that complies with these specifications is a static partitioning of the computational domain into blocks of constant size [
8], as shown in
Figure 1. Load balancing is achieved by dynamically distributing these blocks among the available processes with the goal to have a similar workload on each process by specifically assigning several blocks to each process. We develop a genuine load estimation approach to quantify the workload per block by taking into account all aspects of the coupled simulation and evaluate different load distribution routines in detail.
Ultimately, this results in an efficient simulation approach for large-scale particulate flow problems. It can be used for predictive studies and model development by exploring vast parameter spaces that would not be accessible with laboratory experiments. Such problems can be found in a wide range of applications, e.g., sediment transport in riverbeds [
24,
25], flow of proppant-laden fracturing fluid in petroleum engineering [
7,
26], swarms of microswimmers in biological flows [
27], and fluidized bed reactors in chemical engineering [
28,
29].
The remainder of this paper is structured as follows: At first, we briefly describe the numerical methods we apply for geometrically fully resolved particulate flow simulations in
Section 2, consisting of the lattice Boltzmann method, a hard contact particle solver and the fluid–particle coupling mechanism. Next, in
Section 3, we present and calibrate our load estimation strategy that predicts the block’s weight based on locally available quantities. This estimator is then applied in
Section 4, where additionally the performance of several load distribution approaches is investigated and compared. We summarize our findings in
Section 5.
3. Development and Calibration of a Workload Estimator
3.1. Description
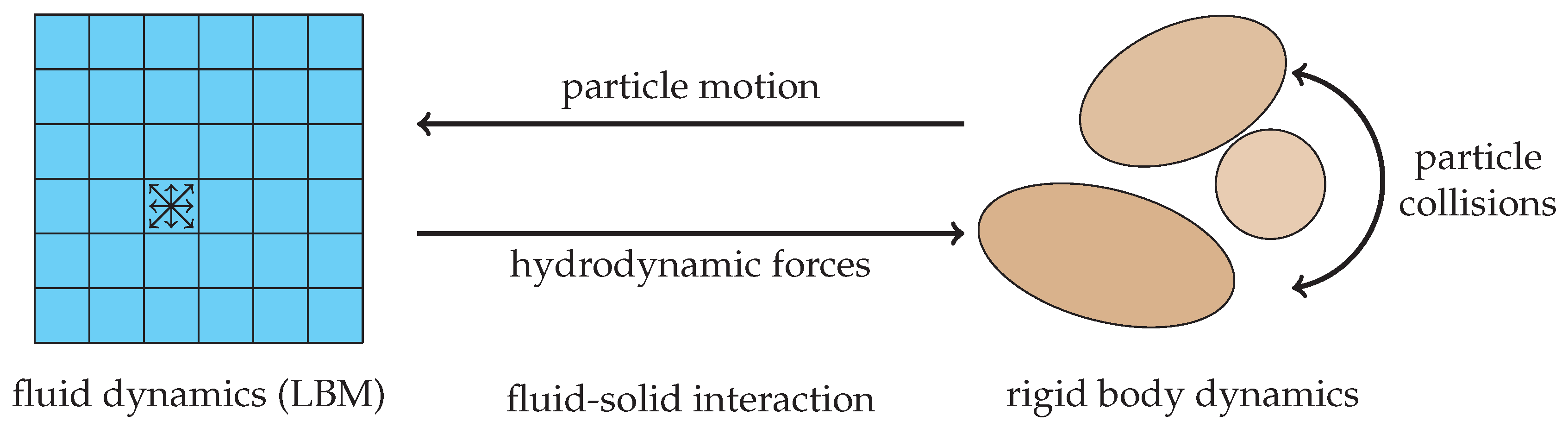
The algorithm outlined in Algorithm 1 is a typical representative for a simulation procedure to solve multiphysics problems. One time step consists of contributions from the individual physical components, here fluid flow,
Section 2.1, and rigid body dynamics,
Section 2.2, as well as coupling algorithms for their interaction. Depending on the physical setup at hand, each of these parts generates a different workload within a block, used for the partitioning of the simulation domain, see
Section 2.4. Taking particulate flows as an example, blocks with dense particle packings result in longer compute times, i.e., larger workloads, for the rigid body simulation in comparison to blocks without any particles. Additionally, in many physical problems, the location of these areas, and consequently the workload per block, changes over time. Since the simulation gets synchronized via communications in each time step, unbalanced workload distributions result in waiting times for the processes that own blocks with smaller workloads. These idle times reduce the overall efficiency of the simulation and result in a longer time to solution than ideally achievable. For successful load balancing, it is, thus, important to first estimate the workload per block. This is resembled by a scalar quantity and we denote it as
weight of the block, see
Figure 1. Once the weights of all blocks are known, a load distribution algorithm can then be used to reassign the blocks to the processes to establish a balanced state.
In this section, we present our approach to develop a load estimator for particulate flow simulations with Algorithm 1. The goal is to find a function that is able to predict the workload of a block, depending on local quantities that describe the state of this block. The workload is here given as the runtime of a single time step in this simulation, excluding communication routines. For that reason, simulations of a characteristic setup have to be carried out. During these simulations, the block local quantities and the corresponding runtimes of the different parts of the algorithm are continuously evaluated and stored. Based on this data, function fitting is applied to finally obtain a estimator function that can be used in all subsequent simulations to predict the workload for a block.
The simulation setup hast to be chosen such that different cases which can be encountered in a real application also occur in the simulation. This means that blocks with no particles and dilute as well as densely packed particles should be included in the setup and, thus, in the data. Only then, the function that is to be fitted to these measurements can later on predict these cases accurately enough. Specifically, we execute several simulations to obtain separate time measurements of the major parts of Algorithm 1 and vary some of the important parameters to increase the amount of data and the reliability. The block local quantities that are available in our fluid–particle simulation are given in
Table 1 and their definition can be obtained from
Figure 3 and
Figure 4. For function fitting, we first have to determine the form of the functions that map these quantities to the measured runtime. For each part, this is achieved by analyzing the structure of the individual algorithm. In a calibration step, those functions are then fitted to the timing measurements of the separate parts based on the block local quantities to determine the functions’ coefficients. Finally, those functions are combined to obtain a complete estimator for the workload per block.
We note that this procedure must be carried out only once as a preprocessing step for all upcoming simulations. Once the load estimator is found, it is simply applied, i.e., the fitted function is evaluated, in the simulations whenever load balancing is carried out. This procedure also only involves simulations of small systems which keeps the computational effort small.
3.2. Workload Contributions
In the following, we establish the form of the functions we use to fit the measured times based on the local quantities from
Table 1. The contributions are mainly gathered from the structure of the respective implementation, which are briefly outlined for each part.
3.2.1. LBM Module
The simulation of the fluid flow is carried out by the LBM, which consists of the collision (line 4 of Algorithm 1) and the stream (line 7) step. These are only carried out for cells marked as
fluid and the pseudocode is given in Algorithms 2 and 3, respectively. The resulting workload heavily depends on the applied collision operator and the actual implementation [
41,
42] but it will generally be mainly determined by the number of cells
C and the number of fluid cells
F. Thus, a function that represents the workload generated by the two LBM steps is given by
| Algorithm 2: Pseudocode for LBM (collision). |
![Computation 07 00009 i002]() |
| Algorithm 3: Pseudocode for LBM (stream). |
![Computation 07 00009 i003]() |
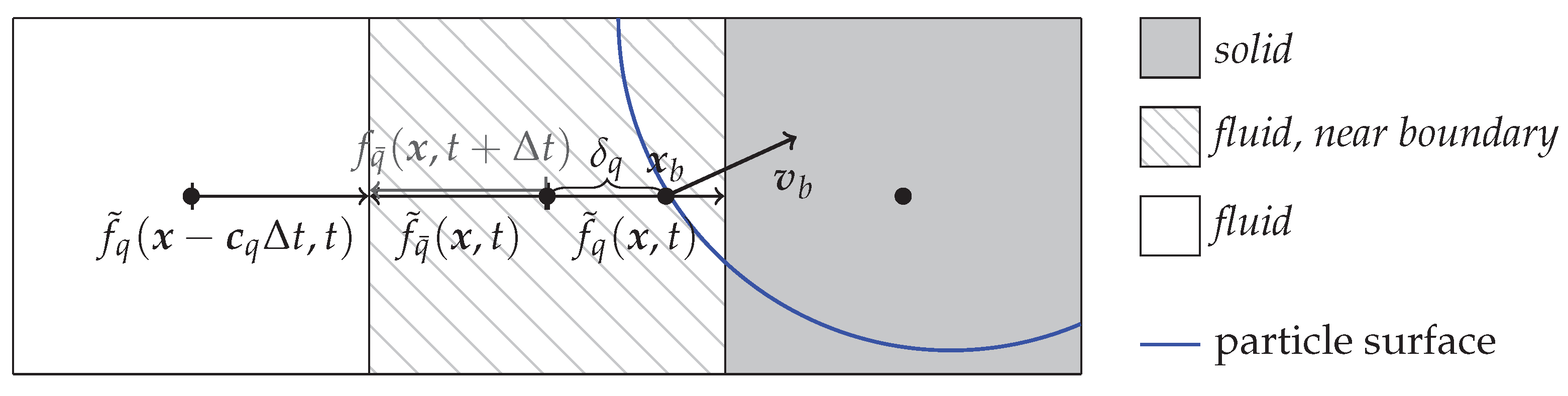
3.2.2. Boundary-Handling Module
The boundary-handling procedure for LBM, line 6 of Algorithm 1, applies the chosen condition for each near boundary cell. More specifically, it does so for each fluid-boundary link of the near boundary cell As can be seen in the pseudocode of Algorithm 4, the resulting workload will, thus, be related to the number of these links. However, evaluating this number for each block is computationally more costly than simply counting the number of near boundary cells and the workload per link depends on the specific boundary condition, which we do not distinguish here. We therefore simply use a function of the form
where we additionally included
C to represent the outer loop.
| Algorithm 4: Pseudocode for boundary-handling. |
![Computation 07 00009 i004]() |
3.2.3. Particle-Mapping Module
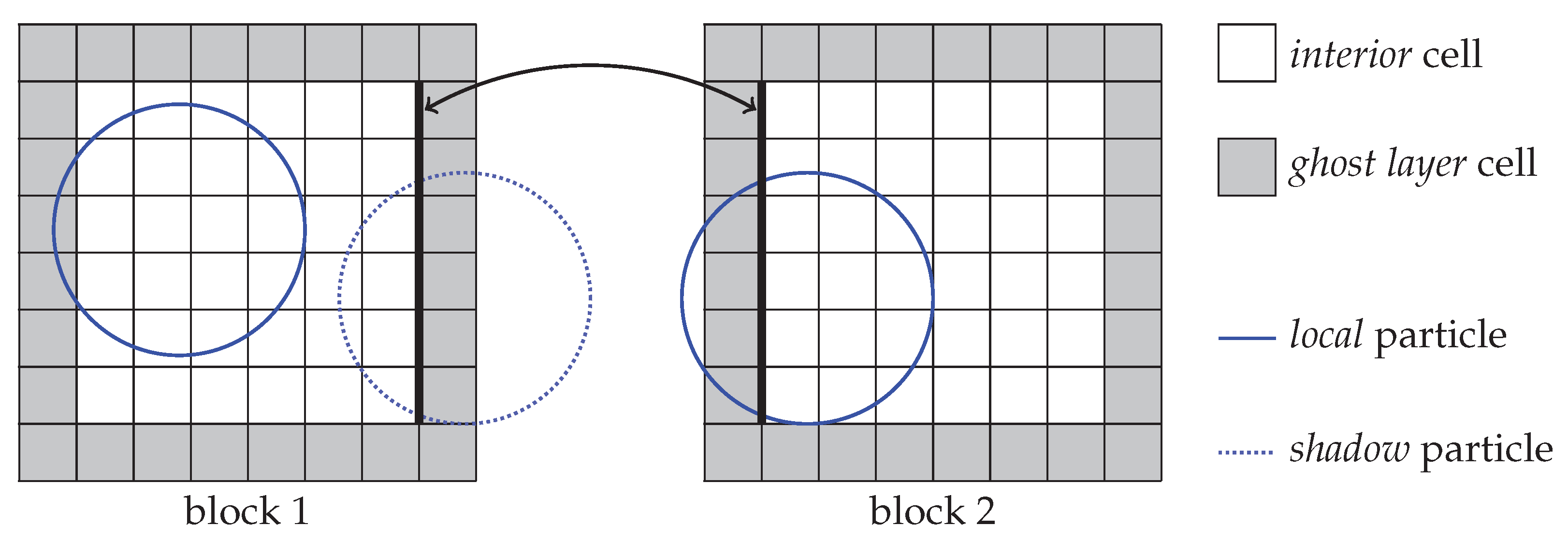
Mapping the particles into the domain by marking the contained cells as boundary cells is an important part of the applied fluid–particle coupling algorithm, see line 2 of Algorithm 1. The pseudocode is outlined in Algorithm 5. The resulting workload, thus, depends on the number of particles, local and shadow, as well as the extent of their axis-aligned bounding box. Since the size of this box depends on the diameter of the particle, this information is not readily available. Instead, we can analyze the result of the mapping by including the number of non-fluid cells as a kind of block local solid volume fraction. Since shadow particles are only partially present on the block they will generate a smaller workload than local particle and we should, thus, distinguish workload contributions originating from local and shadow particles in our function. We therefore propose the following function:
| Algorithm 5: Pseudocode for particle-mapping (Coup1). |
![Computation 07 00009 i005]() |
3.2.4. PDF Reconstruction Module
The second part of the coupling algorithm, line 3 in Algorithm 1, reconstructs the PDF values in cells that have changed from being solid to being fluid due to the motion of the corresponding particle, see Algorithm 6. The generated workload, thus, depends on the position, orientation and velocity of the individual particles and is therefore difficult to predict in general. Assuming that chances for these cell state changes are higher if there are more particles around and the solid volume fraction is larger, we estimate its workload by:
| Algorithm 6: Pseudocode for PDF reconstruction (Coup2). |
![Computation 07 00009 i006]() |
3.2.5. Rigid Body Simulation Module
The rigid body simulation part, line 9 of Algorithm 1, consists of several components which for simplicity will all be included in a single function. Algorithm 7 outlines these different sub steps [
35]. The first part, contact detection, is typically of squared complexity since all particles have to be checked against all other particles to find possible contacts. Our implementation makes use of hash grids for optimizing this routine to obtain linear complexity. This, however, is only activated if a reasonable number of particles is present on a block since otherwise the computational overhead renders it less efficient. In a second step, the contact resolution treats each contact according to the applied collision model in order to resolve the overlaps between particles. Determining the needed information for these two steps is simple for spherical particles but can become complex and costly for other shapes. The last step uses a time integrator scheme to update the local particles’ position and velocity. In the simulation algorithm, the whole rigid body algorithm is embedded into a loop over
S number of sub cycles, see line 8 of Algorithm 1. Combining these steps, we use the following function to estimate the workload:
| Algorithm 7: Pseudocode for rigid body simulation. |
![Computation 07 00009 i007]() |
3.2.6. Total Workload Estimator
Since, in the general case, only a single weight per block has to be provided, the aforementioned contributions must be combined in order to obtain a estimator function for the total workload per block. A natural and simple choice is to add up all individual functions, Equations (
10)–(
14), effectively combing the coefficients of the block quantities:
3.3. Simulation Setup
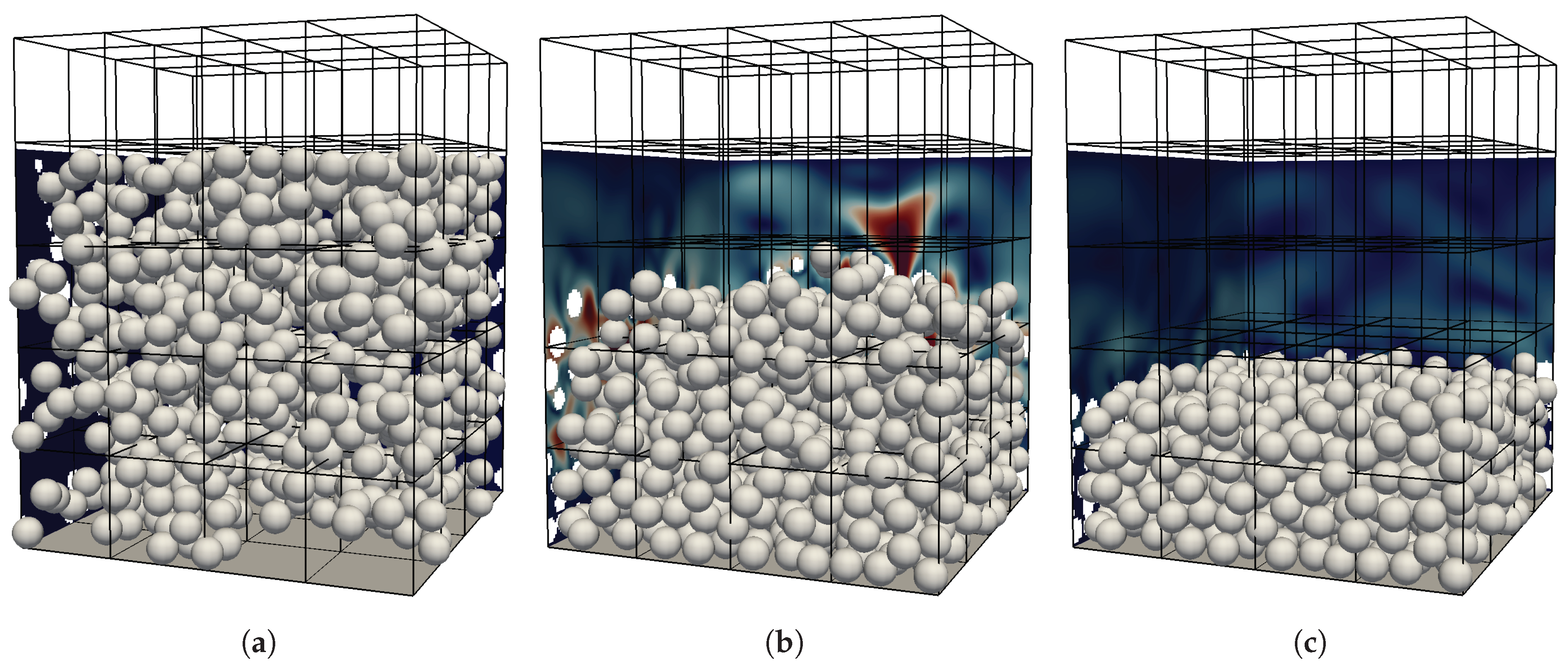
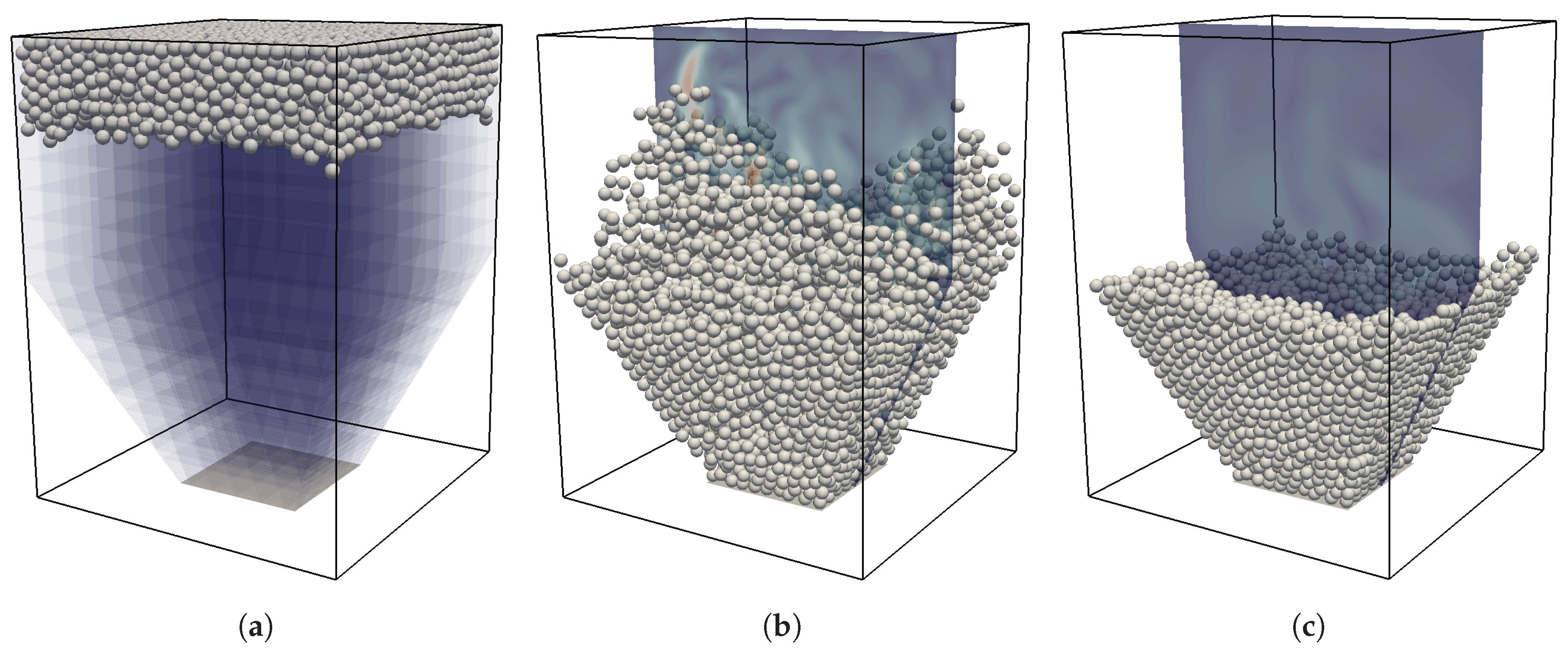
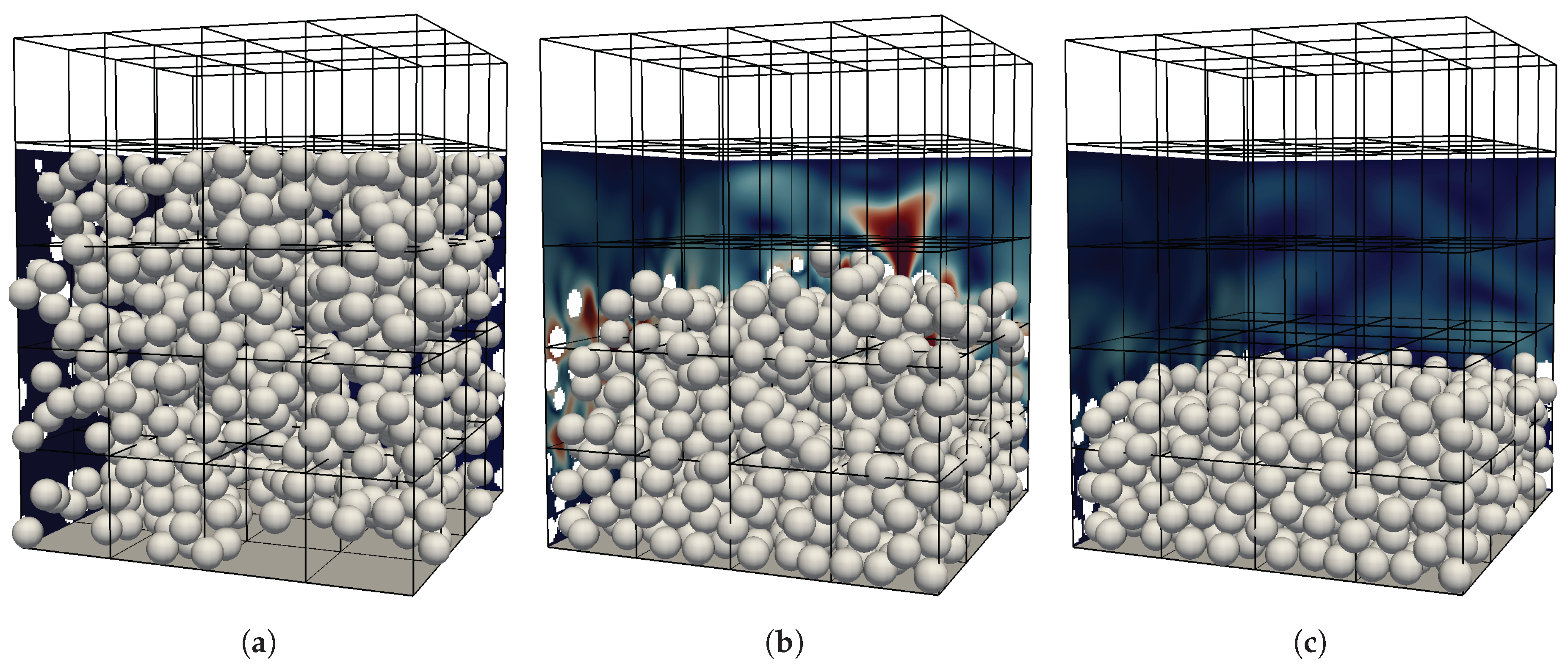
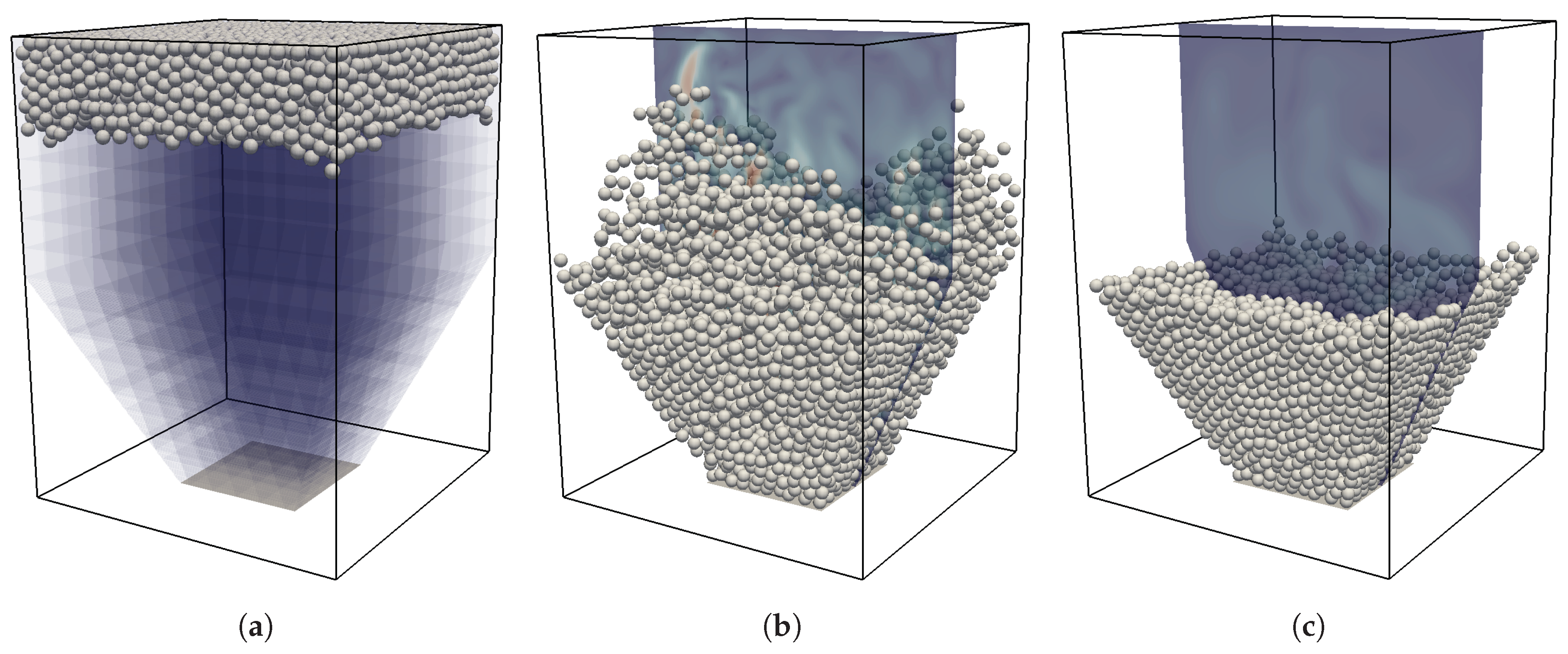
After having identified and defined the workload functions for the different modules of the algorithm, we now carry out multiple simulations of a characteristic setup to obtain timing information that are then used to fit the functions and determine the coefficients. To obtain a generally applicable estimator, the setup should be designed such that it contains various cases that are also encountered in typical applications involving particulate flows. Those are e.g., bounding walls, densely packed areas with many inter-particle collisions as well as dilute regions with only few or even no particles. Additionally, due to complex bounding geometries, some parts of the computational domain could be completely excluded from the simulation as neither fluid nor particles can enter these regions. We therefore chose a horizontally periodic setup with an initially random distribution of particles. Those particles are then set into a settling motion and then pack at the bottom plane until all particles have settled. Visualizations of the initial, intermediate and final state of the simulations with spherical particles can be seen in
Figure 5.
The characteristic parameters of this setup are the Galileo number, , with a characteristic settling velocity , the diameter D and kinematic viscosity . The particles have a density ratio of and are subjected to acceleration g in the vertical direction, resulting in buoyancy forces. The domain size is with , and . Here, is the block size and we introduce a constant offset of the top wall . The global solid volume fraction of the domain is . The simulation is run for unitless time steps, where one time step is . As the definition of the domain size already suggests, we subdivide the whole domain into blocks of size .
As a result, we obtain five vertical layers of blocks with different characteristics throughout the simulation. The bottom layer experiences a continuous increase in the number of particles until it is densely packed. The second layer features the interface between the particle packing and the bulk fluid region at the end of the simulation. Blocks of the third layer are traversed by all upper particles during the settling phase and end up without any particles or boundaries. Similarly, the fourth layer ends up with no particles but, due to the offset in the top wall, with a constant number of boundary and near-boundary cells. The blocks of the topmost row contain neither fluid cells nor particles throughout the complete simulation since they are completely overlapped by the top wall.
Those simulations are carried out for different typical block sizes
and diameters
to obtain a large enough variance in the samples. Each simulation is executed in parallel on 80 processes of the SuperMUC Haswell cluster at the LRZ such that each process is assigned one block. This allows to obtain separate measurements for each block with 2000 samples each. In total, this results in around
data points that will be used for the function fitting. In the first 50 time steps, no measurements are taken to exclude possible warm-up effects of the hardware. Furthermore, we make use of thread pinning provided by the LIKWID tool [
43,
44] to obtain reliable measurements. Each sample consists of the current values for the block-local quantities from
Table 1, where
is kept in all simulations, and additionally timing measurements of the five algorithm parts from
Section 3.2, i.e.,
and
.
3.4. Results of the Calibration
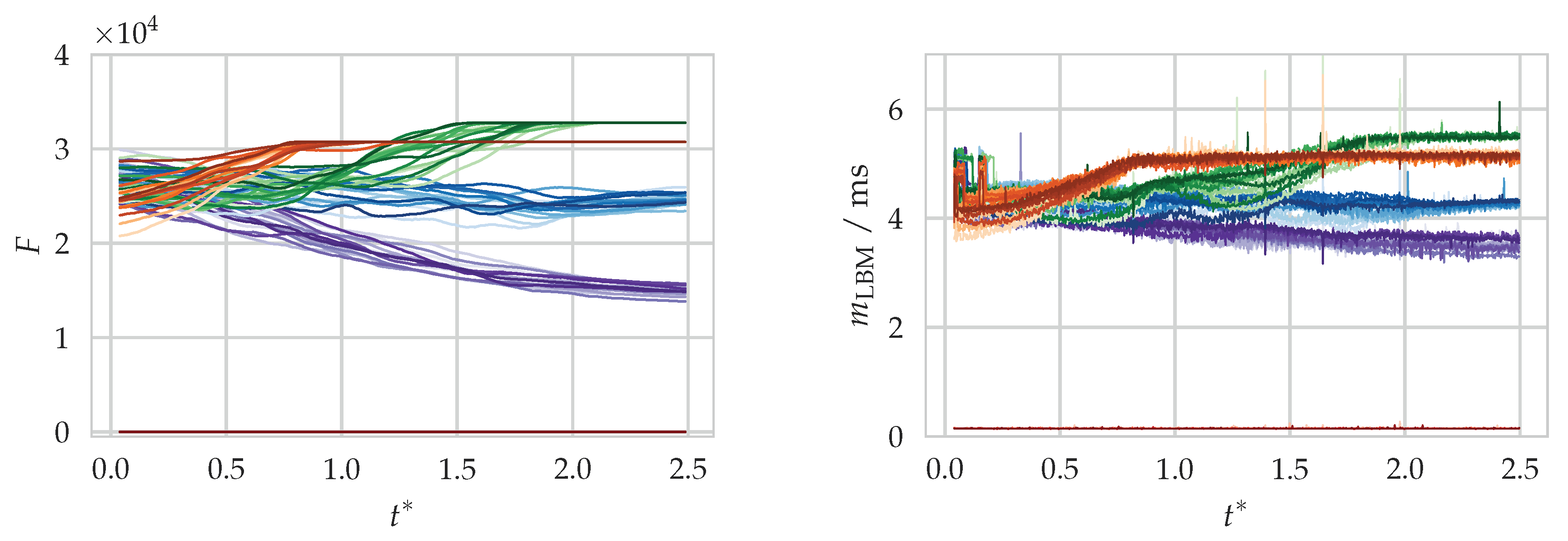
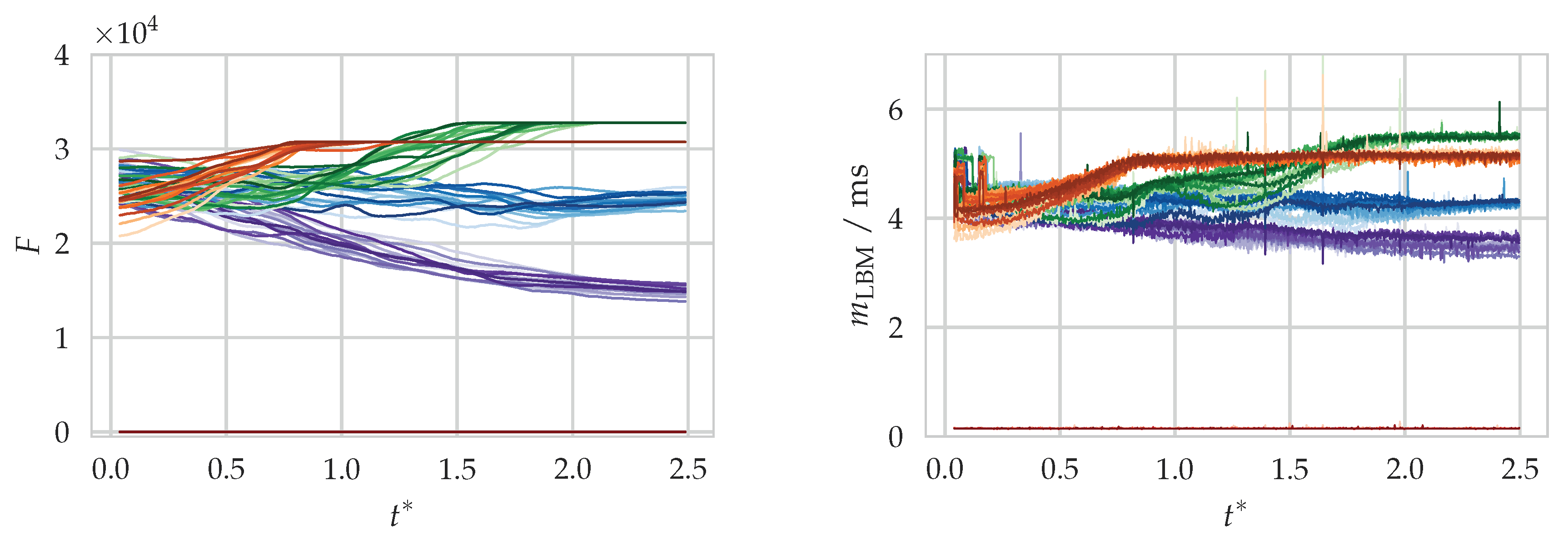
An example of the quantity evaluation and time measurement for the LBM module of the aforementioned simulation setup is shown in
Figure 6. From the temporal evolution of
F, the curves can be matched to a block of one of the five rows. Clearly, a correlation between
F and
can be seen which is in agreement with the assumption made in Equation (
10).
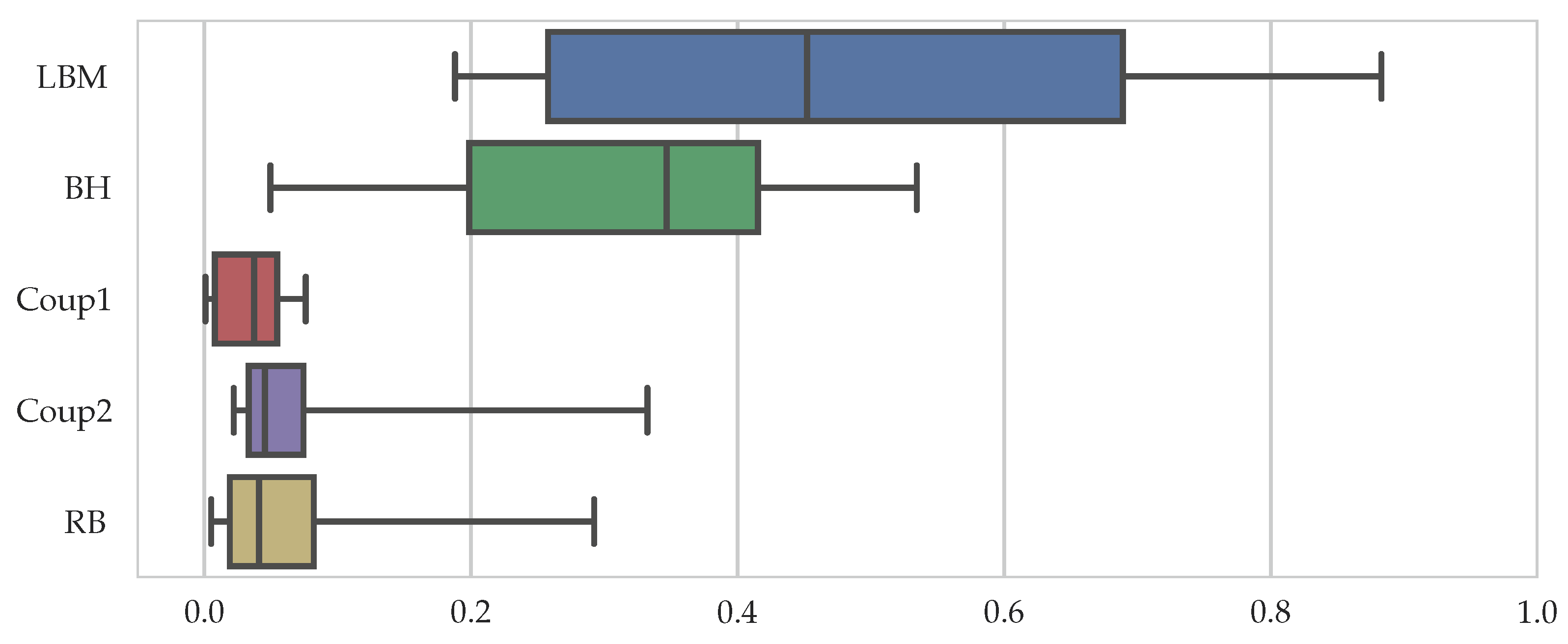
Before we evaluate the result of the calibration process of the workload estimator, we want to obtain insight into the proportion of the different parts of the total runtime, given by
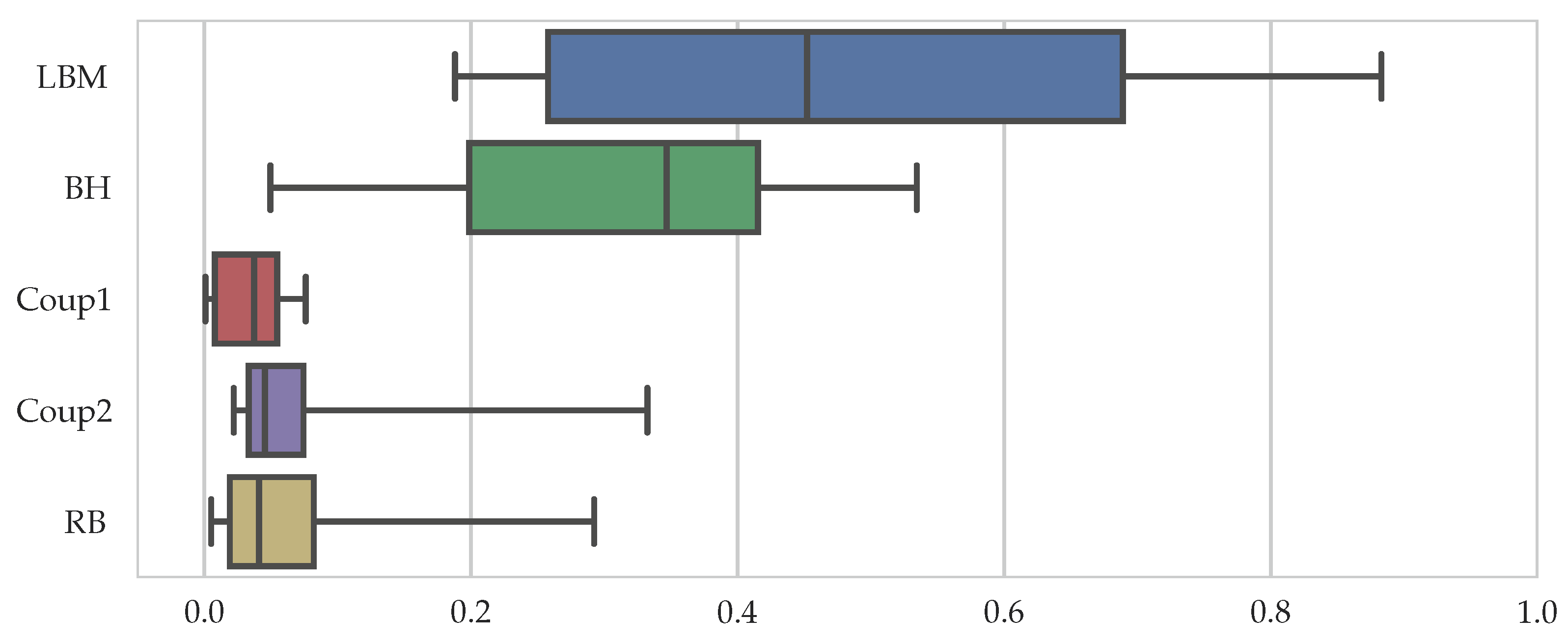
These proportions are different for each sample and are, thus, visualized in a compact format as a box-and-whiskers plot in
Figure 7, showing the median, the upper, and lower quartile values as a box, as well as whiskers that extend to the 5th and 95th percentiles. It can be seen that the LBM and the BH part make up most of the workload with an average of 45% and 35%, respectively. This is followed by the rigid body simulation and the coupling parts with median values below 5%. The relatively large spread in the whiskers is introduced by the empty blocks of the fifth block row in the setup where total runtimes are very low and the different parts, except for Coup1, contribute similarly to it. We can conclude that for spherical particles with the chosen coupling algorithm, it is most important to accurately predict the workload from the lattice Boltzmann and the boundary-handling routines.
With all samples available, we make use of the curve fitting functionality provided by the Python library SciPy in a post-processing step to obtain the coefficients from Equations (
10)–(
14). The outcome is presented in
Table 2.
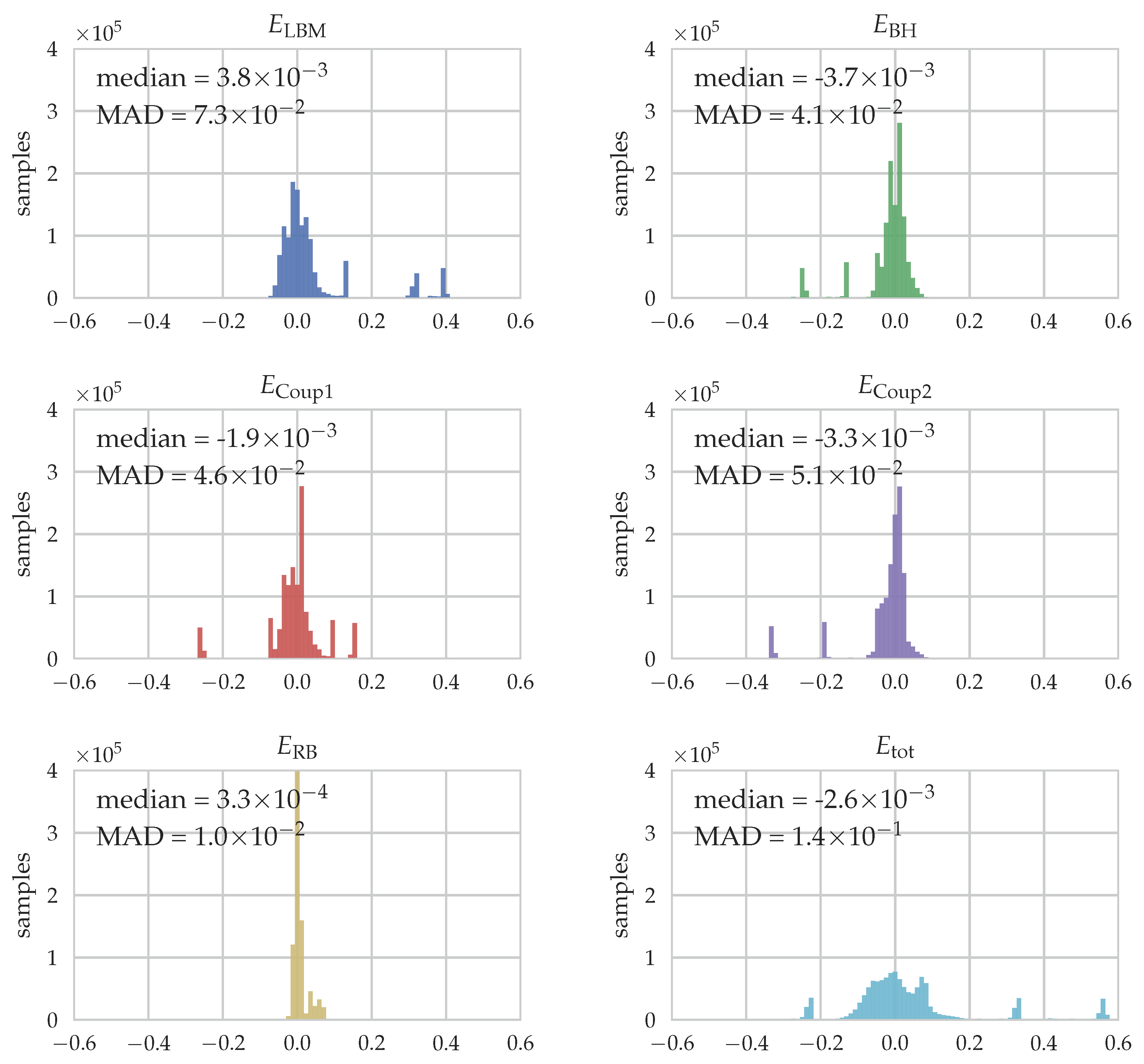
To quantify the quality of the fit for each part, various measures can potentially be evaluated. One of them is the relative error of predicted workload by the five different fits for each individual sample, calculated as
. It is visualized as histograms for the different parts and the total workload in
Figure 8. Additionally, the median and the median absolute deviation (MAD), which is a robust measure of the statistical dispersion, are stated. Note that we calculate the relative error with respect to the total runtime instead of
to avoid the division by almost zero for the small runtimes of Coup1 and RB, see
Figure 7.
For the LBM part, we obtain good predictions of the workload with a median close to zero. Outliers can be seen at some distinct error values which originate from the empty blocks where the prediction is generally worse. A similar conclusion can be drawn for the BH part, where again the median is close to zero and some outliers can be found, this time on the negative side, i.e., due to underpredictions of the workload. These samples can again be attributed to those with empty blocks but also the ones of the third row which eventually end up with no boundary cells like the empty blocks. The Coup1 part shows an acceptable median value but a relatively large MAD value due to the outliers at around
. These are again the empty blocks where the assumption we have formulated when establishing our fit function in Equation (
12), i.e., the mapping should be related to the number of boundary cells as a measure of the solid volume fraction, breaks down as no particles are present. Similarly, for Coup2 the median is close to zero but the MAD value is relatively large. As discussed when setting up the equation for the fit, Equation (
13), predicting the workload for this part is especially difficult as it can not be directly related to any of the available quantities. This is then also the source of deviations from the predictions. At last, the RB part is well-predicted in average and also the variance is small. Considering the relative error for the total runtime, shown in the last histogram, the obtained estimator from Equation (
15) is able to predict the observed runtimes with good accuracy. Outliers originating from the empty blocks of different block sizes where the fits do not work as good can be seen. We also find that over
of all samples are predicted with a relative error of less than
.
3.5. Discussion
In this section, we have constructed a specific workload estimator for coupled fluid–particle simulations with the methods from
Section 2. Here, the derivation of the specific form of the fit functions, Equations (
10)–(
14), was purely driven by the algorithms themselves. These functions can, thus, only be valid assumptions for the here applied algorithms. As they calibration process of the coefficients relies on data from actual runtime measurements, the obtained coefficients for these functions also depend on the hardware on which the corresponding measurements were obtained. However, it can be expected that they still remain good predictors if the hardware design is similar to the used one. In case of larger differences, like e.g., using a GPU instead of a CPU to run the simulation [
45,
46], this might no longer be the case and the measurements and fits should be redone. A possible improvement to overcome this drawback would be to also add hardware details, like cache sizes, clock frequency, etc., to the estimator and try to come up with a performance model for hardware-aware predictions. Since this is a topic of active research, even for simple, stencil-based algorithms like LBM [
42,
47], this is not further pursued here.
Generally, the here reported values for the coefficients from
Table 2 should not be blindly reused in other programs even if the same algorithms and hardware are used, as also the actual implementation of the algorithms can have a large influence on the runtimes. Nevertheless, by following the procedure presented in this section as a general recipe, workload estimators for many different applications, including pure CFD or complicated multiphysics setups, can be obtained. They are then tailored and calibrated for the specific algorithms, hardware and implementation, and can be used in upcoming simulations of that kind to predict, and in a next step also distribute, the workload.
Besides the form of the fit functions, the simulation setup to generate the measurements has to be selected with care. As reported in
Section 3.4, in our case the predictions of the empty blocks were generally worse than for other, regular blocks as some assumptions broke down. We still included them in the calibration procedure in order to obtain a general workload estimator and to avoid any special treatment of these empty blocks in our load estimation step. However, if empty blocks do not appear in the simulations in which this workload estimator will then be applied, we suggest to remove them from the test scenario as well. This improves the quality of the fits notably and a more accurate estimator can be obtained.
Future work will aim at further improvements of the load estimator. By including information available from performance models for the different algorithms, the workload estimator can be made more general and flexible. Tools like Kerncraft [
48] automatically analyze the performance of a given implementation for the hardware at hand, which would render the estimator independent of these factors. Furthermore, a workload estimate based on the current runtimes is a natural alternative to the proposed predictor as it is able to use actual data from the currently running simulation. Such an estimator can not be used in an a-priori fashion which renders it less useful for adaptive grid refinement where new blocks are created and have to be distributed immediately to avoid huge imbalances. However, a combination of both strategies would result in a kind of predictor-corrector approach which could be a superior strategy.
5. Conclusions
In this work, we present and evaluate different techniques to improve the performance of particulate flow simulations that exhibit spatially and temporally varying workloads during their parallel execution.
To this end, first a workload estimator is designed and calibrated that predicts the workload for each block of the domain using locally available information. It is based on analyzing the involved algorithms and setting up suitable functions that describe the generated load. The coefficients of the functions are determined by fitting them to timing measurements obtained from simulations of a small but representative setup. Choosing such a setup is a crucial step as all relevant phenomena and properties that can lead to varying workloads must be included to obtain a generally applicable estimator. Since timing measurements are influenced by various factors, like the hardware used or the actual implementation details, major changes in these might require a reevaluation of the fitted coefficients. Even though the article focuses on particulate flow simulations, the presented approach can be readily used for other multiphysics simulations.
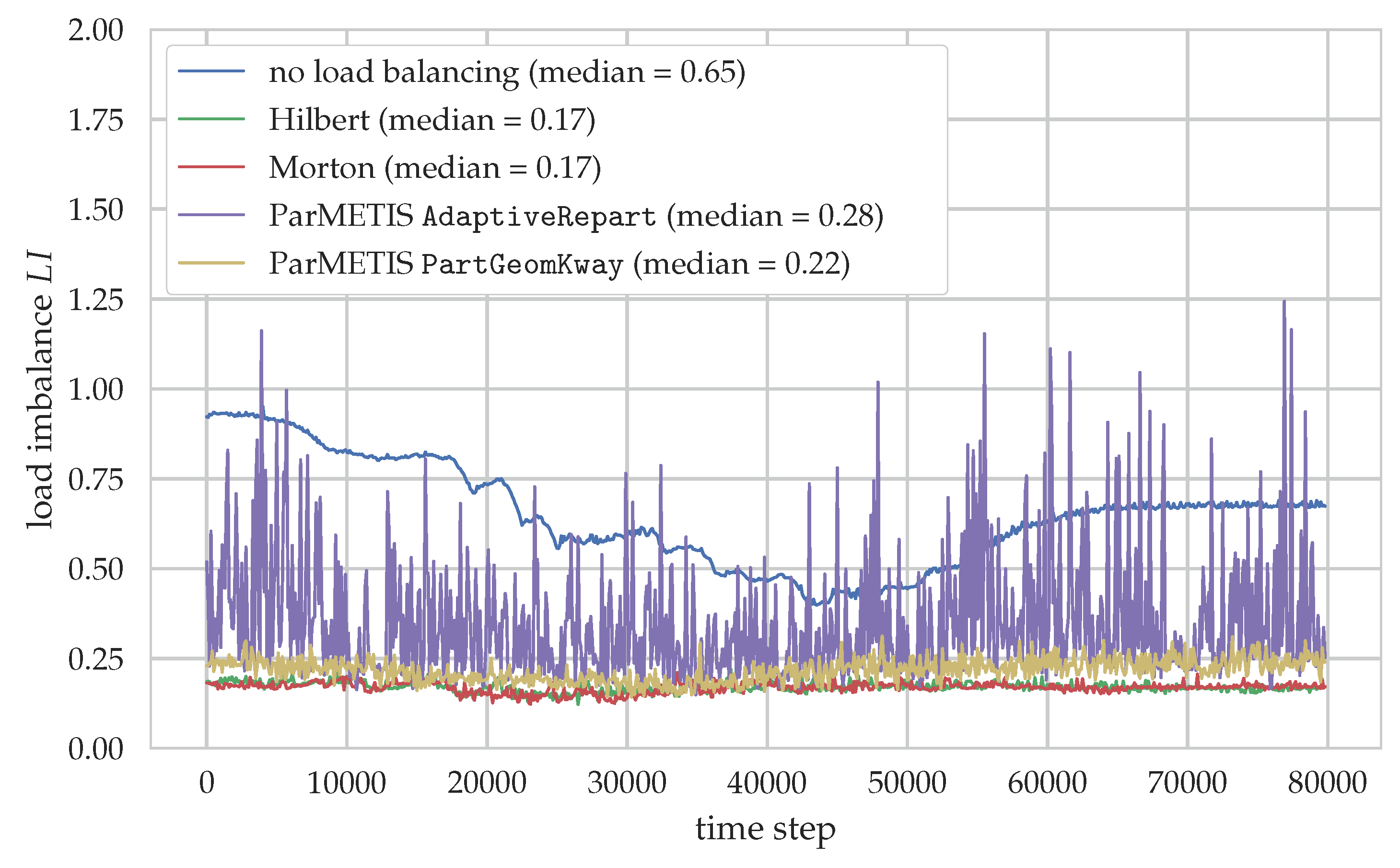
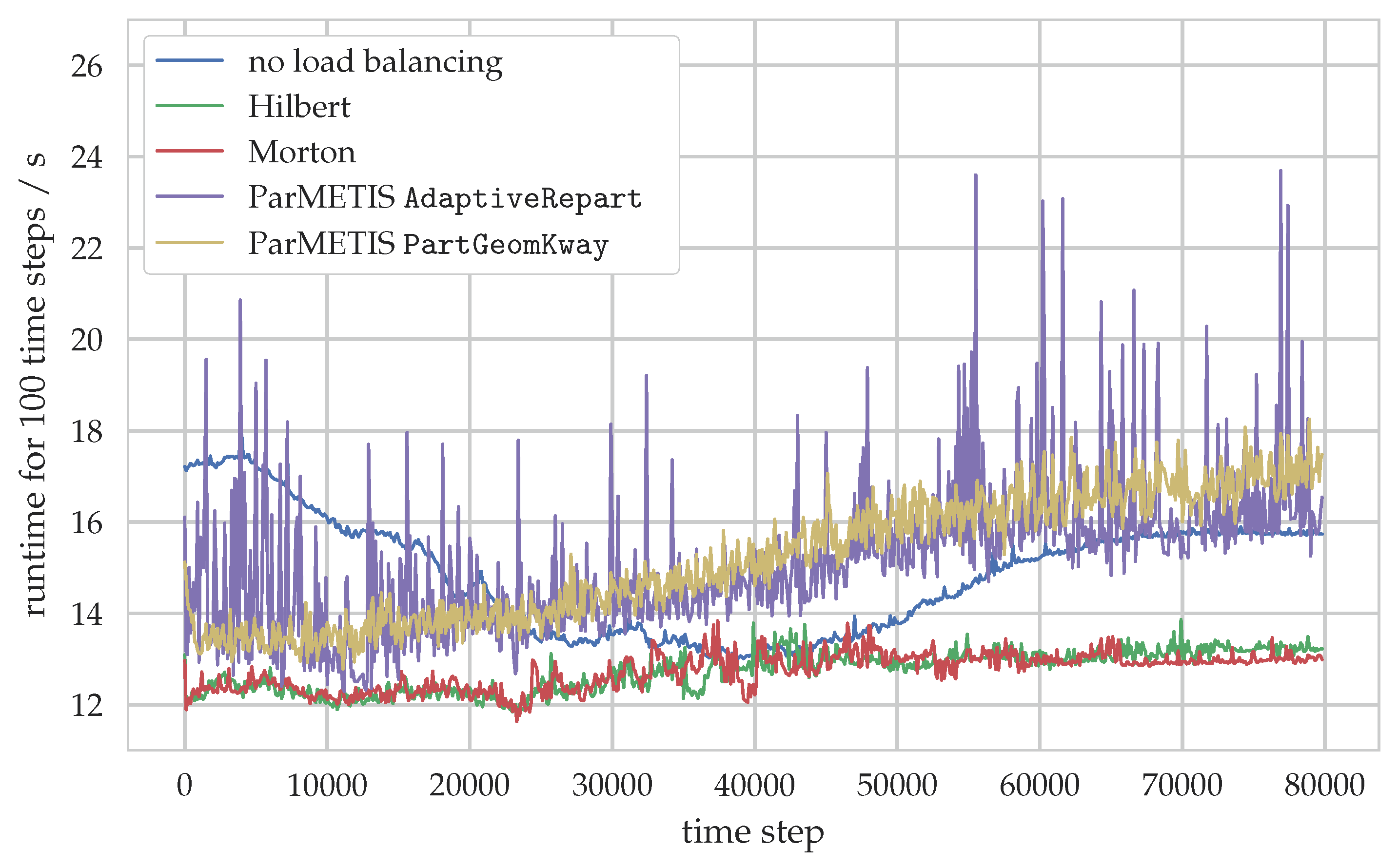
In a second step, this workload estimator is applied in a more complex simulation scenario in conjunction with a load distribution technique to reduce load imbalances between the processes. We compare and evaluate load distribution via space-filling curves and with the help of the graph partitioning tool ParMETIS to the case without any load balancing. For the case of space-filling curves, a significant reduction of the time to solution by 14% can be observed, demonstrating how these techniques can be used to utilize hardware resources more efficiently by minimizing load imbalances. On the other hand, the ParMETIS-based distributions are unable to improve the runtime for this specific scenario. This can be attributed to the relatively large computational overhead produced by the load balancing step but also generally to the different focus of these graph partitioning tools that would require a finer granularity.
All in all, this study shows that load balancing is an effective tool for parallel multiphysics simulations where workloads change in time and space. It is typically used in combination with adaptive mesh refinement, where it becomes a necessity due to the strongly varying work loads when the grid is updated. Thus, naturally, we aim to apply the here presented load balancing approach with AMR to enable efficient simulations of various engineering applications. But, as we have shown, it can also be advantageous to apply it with uniform grids to reduce the time to solution of the simulation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}