Abstract
The Working Set concept, originally introduced by P. Denning for memory management, defines a dynamic subset of system elements actively in use. Designed to reduce page faults and prevent thrashing, it has proven effective in optimizing memory performance. This study explores the interdisciplinary potential of the Working Set by applying it to two distinct domains: virtual memory systems and epidemiological modeling. We demonstrate that focusing on the active subset of a system enables optimization in both contexts—minimizing page faults and containing epidemics via dynamic isolation. The effectiveness of this approach is validated through memory access simulations and agent-based epidemic modeling. The advantages of using the Working Set as a general framework for describing the behavior of dynamic systems are discussed, along with its applicability across a wide range of scientific and engineering problems.
1. Introduction
The concept of the Working Set (WS) describes a set of resources or elements that are actively used by a system over a defined time interval. This model was originally introduced by Peter Denning in 1967 to describe program behavior in virtual memory and to guide page replacement decisions [1,2]. The Working Set of a process at time is defined as the set of pages referenced during the most recent time window and is denoted as . Pages that are frequently accessed during this interval are retained in memory, while infrequently used pages can be evicted. The strategy keeps active pages in RAM to prevent thrashing, when the system spends more time paging than running programs. This approach significantly reduces page faults and increases system throughput by matching memory allocation to actual program demands [3,4,5]. Most existing research in this area is based on clustering techniques [6,7]. In [8], proposed page replacement policy monitors the current working-set size and controls the deferring level of dirty pages, preventing excessive preservation that could lead to increased page faults, thus optimizing performance while minimizing write traffic to phase change memory. In [9], the authors modified the ballooning mechanism to enable memory allocation at huge page granularity. Next, they developed and implemented a huge page working set estimation mechanism capable of precisely assessing a virtual machine’s memory requirements in huge page-based environments. Integrating these two mechanisms, they employed a dynamic programming algorithm to attain dynamic memory balancing. Also, in [10,11] discussed Working Set Size estimation to predict memory demand in virtual machines, which helps optimize memory management. The working set strategy solves the problem of page faults by preventing actively used pages from being freed, even if the code is suboptimal. In [12], the authors presented a lightweight online WSS estimation technique to dynamically tune cache capacity, achieving over an order-of-magnitude higher accuracy in tracking active data and cutting query latency by 79%. These demonstrate that Denning’s working set notion remains highly relevant for optimizing performance in diverse computing environments. Indeed, the core idea focusing resources on the “active” subset of interest is not limited to computing, as we explore next in the context of epidemic control.
Notably, the idea of a dynamic Working Set has strong interdisciplinary implications. In particular, in epidemiological modeling, the concept can be adapted to define the “Working Set” of a population as the group of individuals actively participating in transmission chains of an infectious disease at a given time. Just as keeping frequently used memory pages in RAM reduces the need to access the slower disk, a similar principle can be applied to controlling the spread of infectious diseases. By identifying and isolating highly contagious individuals, those who interact with many others, the overall transmission of the disease can be significantly reduced. These individuals act like central hubs in a network, and limiting their interactions can effectively break the chain of infection, much like how reducing disk access improves system performance. This study presents a unified view of the Working Set as an optimization tool for dynamic systems, exploring both its traditional application in computer memory and its novel adaptation in public health modeling. Accurately modeling infectious disease dynamics is essential for guiding public health interventions. Traditional compartmental models, such as SIR and SEIR, divide populations into distinct health states and use differential equations to describe transitions [13,14,15,16]. Each successive model extends the previous one by adding new aspects to more accurately capture disease dynamics. The seminal SIR model by Kermack and McKendrick [17] segments the population into Susceptible (), Infected (), and Recovered () groups and describes their interactions with a simple system of Ordinary Differential Equations (ODEs) [18,19]. However, the classical SIR model assumes that individuals become infectious immediately upon exposure, whereas most diseases have an incubation period before infectivity. To address this, an Exposed compartment () can be added to form an SEIR model that accounts for latency [20,21]. While the SIR model is mathematically simpler and sometimes convenient for analysis, it lacks biological realism in many scenarios [22]. In practice, data from outbreaks often fit better to SEIR-like models despite the added complexity [23,24,25]. An extended SEIR-V model further includes a Vaccinated () compartment to capture the impact of vaccination [26,27], and it is often combined with agent-based approaches to reflect individual heterogeneity in behavior and contact networks [28,29]. Still, the compartmental models have limitations, especially regarding dynamic interventions like isolation or quarantine. Because they assume homogeneous mixing and continuous interaction between all susceptible and infected individuals [30,31,32,33]. Incorporating isolation into these models typically requires adding special compartments or time-dependent parameters, which can complicate analysis.
In this work, we adapt the Working Set concept from computer science for epidemiological modeling. In the adapted WS model, agents actively transmitting the disease are removed from the working set (i.e., isolated), thereby reducing opportunities for further spread. In effect, the WS algorithm helps identify potential super-spreaders [34], infected agents who would otherwise transmit infection to an unusually large number of susceptibles. Notably, real-world outbreak data suggest that a small minority of infected people can be responsible for the majority of transmissions. For example, approximately 19% of COVID-19 cases were estimated to cause 80% of local transmissions in one analysis, underscoring the importance of identifying and isolating such high-transmission agents [35]. Unlike classical SIR and SEIR models, our adaptive WS model explicitly accounts for dynamic isolation and variable transmission rates that depend on the current active contact set size. Numerous studies have shown that timely isolation and quarantine are critical for controlling epidemics [36,37,38]. These measures prevent disease spread, protect vulnerable groups, allow time for case detection and treatment, reduce burdens on health systems, facilitate contact tracing, and have proven historical effectiveness. Despite the social and economic costs of strict isolation policies, their public health benefits are significant, making isolation and quarantine integral components of epidemic response strategies.
This paper is structured in the following manner: Section 1 is Introduction, Section 2 describes the methodology, including the adaptive formulation of the Working Set model and parameter settings. Section 3 presents the results of numerical simulations in both virtual memory and epidemic modeling domains. Section 4 discusses the interdisciplinary insights and addresses the limitations of the approach. Finally, Section 5 concludes the study and outlines directions for future research.
2. Methods
In this section, we detail the respective methodologies for both applications of the Working Set, in virtual memory page management and in epidemiological simulation. We then present joint results from computational experiments, comparing different replacement strategies as FIFO (First-In, First-Out), LRU (Least Recently Used), WS and modeling disease progression under various isolation policies. The discussion synthesizes insights gained from both domains, highlighting the Working Set’s capacity to serve as a general-purpose framework for analyzing and improving dynamic system behavior.
2.1. Working Set in Virtual Memory Systems
In the context of computer architecture, the Working Set model is used to manage physical memory by identifying the subset of memory pages most frequently accessed during a recent time interval. This approach is crucial in systems with limited memory resources, where excessive page faults can significantly degrade performance. To evaluate the effectiveness of the Working Set strategy, we implemented a simulation of three-page replacement algorithms as FIFO, LRU and WS. The input for the simulation consisted of memory access traces representing realistic process workloads. For each algorithm, we recorded the number of page faults generated for varying numbers of allocated memory frames. The FIFO algorithm replaces the oldest page in memory, regardless of how often it is accessed. The LRU algorithm replaces the page that has not been used for the longest time. In contrast, the Working Set strategy retains all pages that were accessed within a defined time window , dynamically adapting the set of loaded pages to current workload demands. The Working Set is recalculated after every access, and pages outside the window are eligible for replacement. The performance of each algorithm was assessed based on the number of page faults and memory usage. The WS algorithm consistently outperformed FIFO and LRU in high-frequency access scenarios, demonstrating the benefits of context-aware memory management.
2.2. Adaptive Working Set in Epidemiological Modeling
We adapted the Working Set principle for use in agent-based epidemiological modeling. Here, the Working Set represents the group of agents actively involved in transmission at any point in time. The original concepts of the WS model are reinterpreted in epidemiological terms as follows: Population: the complete set of agents in the system, analogous to all memory pages in a computer. This is the total population . Working set: the subset of the population consisting of agents that are not currently isolated and thus potentially interacting and transmitting infection. In other words, the WS includes all active, non-quarantined agents. Isolation: the process of removing agents from the working set, akin to unloading pages from RAM in the computing analogy. Isolated agents are temporarily not involved in disease transmission. They have no contacts that could spread infection while isolated. Super-spreader: an infected agent who transmits infection to an unusually large number of susceptible agents. Such an agent causes significantly more secondary cases than an average infected individual, often due to high contact frequency or other factors, e.g., a person with many social connections or present at a crowded event.
2.3. Model States and Equations
To capture the epidemic dynamics, the adaptive WS model introduces additional states beyond the standard compartments, reflecting isolation status. The states can be defined as follows: Susceptible (): Agents who are healthy and can contract the infection upon contact with an infectious person. Infected (): Agents who are currently infected and capable of transmitting the disease. Recovered (): Agents who have recovered or otherwise been removed and are no longer infectious. Isolated (): Agents who have been physically isolated from the population to prevent further spread. This can include infected agents in isolation, and in some cases, susceptible agents put in preventive quarantine. We also account for isolated recovered agents, who represent those who were infected and recovered while in isolation. They remain isolated until cleared. The adative WS model is described by a system of ordinary differential equations (ODEs):
where —isolated susceptible; —isolated infected; —isolated recovered (transferred from after recovery); —dynamic infection rate; —current working set size (sum of agents in states and ) at time t; —isolation rate for ; —isolation rate for ; —isolation escape velocity for ; —isolation escape velocity for ; —rate of recovery. This system accounts for all key processes: infection, recovery, isolation and release. The total population in the model is defined as follows: The size of the working set is determined by the formula:
The key innovation is the use of a time window to identify the current Working Set of infectious agents—those who have recently had contact with others. Agents within this set are prioritized for testing and isolation, enabling more efficient containment of outbreaks. The simulation environment was developed using an agent-based framework in Python 3.12. At each time step, agents interact based on probabilistic contact rules. If an agent becomes infected and is part of the Working Set, they are evaluated for isolation depending on isolation efficiency parameters and time delay. The model supports different isolation strategies: no isolation, static isolation, and adaptive isolation.
3. Modeling and Results
3.1. Simulation Results for Virtual Memory Page Management
To evaluate the efficiency of the Working Set algorithm compared to FIFO and LRU, we conducted simulations on a 10-node FPGA-based system using randomized memory access patterns. Each node executed 100,000 memory operations, with 80% being local accesses and 20% remote. Performance was assessed through average page fault time, page fault frequency, and total execution time. The superior performance of WS likely stems from its ability to maintain a set of actively used pages, adapting even to random access patterns. LRU and FIFO, while effective in workloads with locality, offer little advantage here, and the lack of pattern consideration makes them the least efficient. We varied the cache size to 1%, 5%, 10%, and 20% of total memory using the Working Set algorithm, sourcing memory from both free reserves and data memory (overflow). As the cache size increased from 1% to 10%, the page fault frequency dropped from 39% to 33%, and the total execution time decreased from 14.8 s to 12.8 s, as shown in Figure 1a. Beyond 10%, at 20%, the frequency stabilized at 32%, and execution time plateaued at 12.7 s, indicating diminishing returns. Average page fault time remained steady at around 6 µs across all sizes. With data memory caching, fault frequency decreased from 38% at 1% to 30% at 10%, with execution time improving from 14.5 s to 13.5 s. However, at 20%, execution time rose to 14 s despite a frequency of 29%, as reduced data memory led to more frequent evictions and reloads, as shown in Figure 1b.
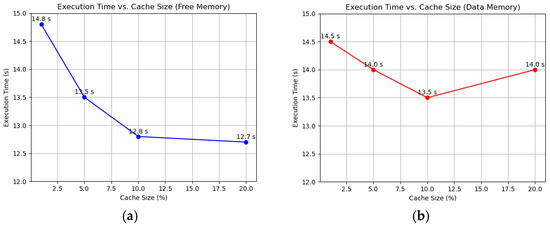
Figure 1.
Impact of cache size on performance using the WS algorithm: (a) Free memory caching, showing reduced page fault frequency and execution time; (b) Data memory caching, highlighting contention at higher cache sizes.
These experiments reaffirm the efficacy of RAM page caching, with the Working Set algorithm proving optimal for random workloads. The choice of algorithm significantly impacts performance, with WS reducing execution time by up to 14% compared to no caching (15 s). Table 1 shows the results indicate that the WS algorithm outperformed the alternatives. WS reduced the average page fault time to 6 µs and the fault frequency to 35%, yielding a total execution time of 13 s. LRU and FIFO showed similar performance, with average fault times of 7 µs and frequencies around 38%, resulting in execution times of 14.5 s. Random Replacement performed the worst, with a fault time of 8 µs, a frequency of 40%, and an execution time of 15 s.

Table 1.
Performance Metrics for Caching Algorithms.
The evaluation of page replacement strategies revealed clear differences in performance across the tested algorithms. For each memory size configuration, we measured the total number of page faults generated by FIFO, LRU, and Working Set algorithms. The FIFO algorithm showed high page fault rates, particularly in scenarios with smaller memory allocation. Due to its static replacement policy, FIFO often evicts pages that were still in active use, leading to inefficient memory utilization. The LRU algorithm performed better than FIFO in most cases, thanks to its recency-based replacement strategy. However, its performance declined under high-frequency access patterns due to limitations in tracking long-term temporal locality. The Working Set algorithm consistently achieved the lowest page fault rates. Its dynamic nature allowed it to adapt to the current workload by retaining only the pages accessed within the most recent time window. This effectively minimized unnecessary page replacements and reduced thrashing.
Figure 2 presents the number of page faults across all three algorithms as a function of allocated memory frames. The Working Set approach not only minimized faults but also demonstrated stability across varying memory capacities, proving its robustness for real-time systems.
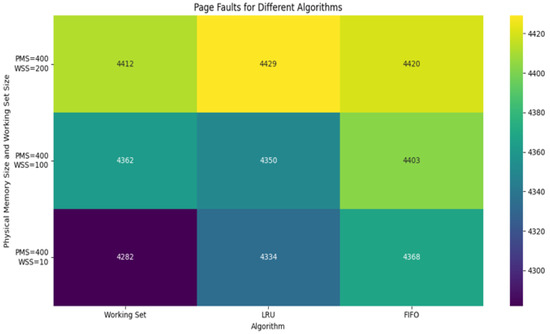
Figure 2.
Comparing simulation results of page faults with different algorithms.
Figure 2 indicates a comparison result of page faults simulation in different algorithms, such as Working Set, LRU and FIFO. Experiments were performed with different parameters, such as Virtual Memory Size, Physical Memory Size, Working Set Size, Access Sequence Length and Locality Factor. The Working Set algorithm tries to keep only actively used pages in memory. If the working set size is smaller than the physical memory size, the number of page faults will be low; if working set size increases, then page faults also increase accordingly. The LRU algorithm unloads the page that has not been used for the longest time. It performs well, especially when there is locality in the order of accesses.
3.2. Results from Epidemiological Modeling with Working Set
A Working Set, in the context of an epidemic, is a dynamic set of agents who are participating in social interactions at a given time and are not isolated. The size and composition of this working set evolve and depend on two main factors: (1) Isolation policy: When an infected agent from is identified, its contacts from in the last days are relegated to the state . This shortens the WS and reduces the likelihood of new infections. At the end of the isolation period, agents from are tested: susceptible agents return to , recovered agents to . An alternative scenario is high-coverage isolation, in which a large fraction of the population is isolated. (2) Time window (): Analogous to the WS model in computing, we introduce a time window to define the “relevance” of contacts in the epidemiological context. Only contacts that occurred within the past time units are considered when determining whom to isolate after a case is detected. In practice, might represent the look-back period for contact tracing. Agents who had contact with an infected individual within that window are candidates for isolation. Importantly, this scheme can capture super-spreading events: if a detected case was a super-spreader who had many contacts in the last days, all those contacts would be quarantined. Identifying and isolating such super-spreaders is particularly crucial because it can significantly slow the disease spread. In the WS model, the parameter effectively sets how far back in time we consider interactions as part of the current working set. A shorter means only the most recent contacts remain in the working set, whereas a longer includes a broader history of interactions.
To evaluate the adaptive WS model, we conducted numerical simulations under several scenarios reflecting different isolation strategies. We consider three scenarios for the isolation parameters. 1. Basic scenario: No isolation (, ); 2. Moderate isolation: Low isolation parameters (, ); 3. High-coverage isolation: High isolation parameters (, ). Because the SIR and SEIR models do not include isolation mechanisms, we only simulate those models under the Basic (no isolation) scenario for comparison purposes. Table 2 shows the values of parameters and descriptions used for numerical simulations. These parameters were generated from an extensive literature review [39,40,41,42,43] of COVID-19 and epidemic modeling. In contrast to agent-based models [44,45,46,47], which are tailored to specific countries or regions, our model is designed for a generalized small-city population. This abstraction enables flexible adaptation and does not require detailed prior knowledge of regional parameters.
Table 2.
Model Parameters and Descriptions.
We implemented an agent-based simulation of the model to observe the infection spread and the impact of different isolation strategies in a virtual population. Agent-based modeling is a powerful method for capturing the behaviors and interactions of agents in a population. By modeling spread of an infection, we are able to trace a typical epidemiological dynamic that progresses through several key stages. Figure 3 illustrates the dynamics of the epidemic spread process considering five types of agents.

Figure 3.
Stages of epidemic spread in the adaptive WS model for 100 days, considering five types of agents with a total population of 10,000 agents: Blue dots represent susceptible agents, orange dots represent infected agents, red dots indicate super-spreaders (highly infectious agents), black dots represent isolated agents, and gray dots represent recovered agents. (a) Initial stage: a very small infected fraction and no isolation yet; (b) Early growth: more infections and first isolations and super-spreaders emerging (around day 10). Local clusters form around super-spreaders; (c) First recoveries (gray) appear after isolation, susceptible count declines by day 36; (d) Peak stage (day 59): susceptible—0.2%, infected—12%, super-spreaders—51%, isolated—26%, recovered—10.8%. Intensive isolation—38%, is applied to curb the peak; (e) Late stage (day 65): infections decline—5% infected, many super-spreaders—41%, among remaining infected, isolation still significant—21%, recovered—32%; (f) Final stage: infection disappears and nearly the entire population transitions to the recovered state by day 100. Super-spreaders contribute disproportionately to early epidemic growth, but effective isolation eventually contains it.
Figure 3a shows an early outbreak. At the start, the population is almost entirely susceptible (blue). Only 0.3% of agents are infected (orange), and no one is isolated yet. Ten days into the epidemic, as shown in Figure 3b, the infection has grown. About 2.4% of the population is infected, and the first isolated agents (black, ~0.08%) and super-spreaders (red, ~0.18%) appear. These early super-spreaders rapidly infect their neighbors, creating the first clusters of infection (indicated conceptually by red “hotspots”). Localized outbreak foci emerge around each super-spreader, demonstrating how a few highly infectious agents can jump-start an epidemic in a susceptible community. Figure 3c shows the moment when the first recovered agents (gray squares) appear following their isolation periods by day 36. By this stage, the susceptible count has started to decline substantially as many agents have either been infected or isolated. Figure 3d shows the peak of the epidemic. At the height of the outbreak, susceptibility in the population is almost exhausted: only ~0.2% of agents remain susceptible. About 12% of agents are actively infected, and a large proportion (~51%) are categorized as super-spreaders (red)—indicating that many of the infected agents have high contact rates. Meanwhile, ~26% of agents are isolated, and ~10.8% have recovered. This snapshot corresponds to day 59 of the simulation, when the epidemic peak occurs. Around this time, more stringent isolation protocols are often introduced in response to the surge in cases. In our model, implementing aggressive isolation at this point proves pivotal: by isolating a greater fraction of the population (up to ~38% in this scenario), further propagation of the virus is significantly impeded. After the peak, the epidemic starts to wane, largely due to the depletion of susceptibles and the high isolation rate. By the stage shown in Figure 3e, the proportion of infected agents has fallen to around 5% by day 65. However, a considerable fraction of those who are still infected are super-spreaders (~41% of the population is red at this point), and about 21% remain in isolation. The recovered fraction has grown to roughly 32%. The high percentage of super-spreaders among the remaining infected suggests that ongoing transmission is driven by a small core of highly connected agents, but with many others isolated, their ability to cause new infections is limited. Finally, Figure 3f represents the end of the outbreak: the infection has virtually disappeared, and nearly all agents have recovered or returned to a susceptible state. In this simulation, the epidemic is effectively over by day 100. These results highlight the pivotal role of super-spreaders in accelerating epidemic propagation and, conversely, the paramount importance of prompt isolation of such agents and their contacts in controlling the epidemic. The dynamic patterns demonstrate that early intervention to isolate high-transmission agents can break the chain of rapid spread.
Figure 4a shows infection curves for the WS model under three isolation scenarios: no isolation, moderate isolation, and high-coverage isolation. Without isolation, as noted, the peak is about 3050 infected on day 26. With a moderate isolation policy, the epidemic peak is dramatically lower and delayed. In the simulation, the peak dropped to roughly 755 infected and shifted to around day 59. Under a high-coverage isolation strategy, the outbreak is effectively crushed—the number of infections starts around 100 and then continually declines, never forming a large peak at all. In the high-coverage isolation scenario, the infection curve is significantly flattened, reducing the peak number of infected individuals by nearly 95% compared to the baseline. This outcome confirms the crucial role of dynamic isolation in suppressing outbreaks, especially in the presence of super-spreaders. These results demonstrate that increasing the isolation rate flattens the curve: it reduces the height of the infection peak and pushes it to later times. In our experiments, the high-coverage isolation with the highest isolation parameters was the most effective, reducing the peak infection count by roughly a factor of 3–4 relative to the moderate scenario and by an even greater factor compared to no isolation. This delay and reduction of the peak provide critical extra time for healthcare response and can prevent hospitals from being overwhelmed. Figure 4b shows the histogram that illustrates the number of secondary infections attributed to each super-spreader agent, based on a Poisson distribution with A small subset of agents accounts for a disproportionately large number of infections, highlighting the importance of early identification and isolation of such agents.
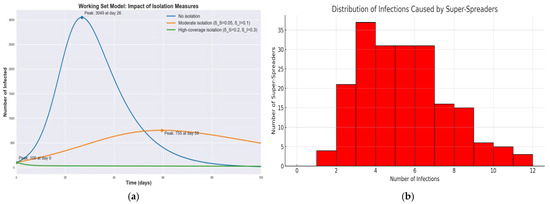
Figure 4.
Comparative dynamics of epidemic progression in SIR, SEIR and WS models: effects of incubation and isolation on infection peaks and epidemic size. (a) Infection curves under three WS scenarios; (b) Distribution of Infections per Super-Spreader.
Figure 5 explores the sensitivity of the WS model outcomes to various parameters via heatmaps.
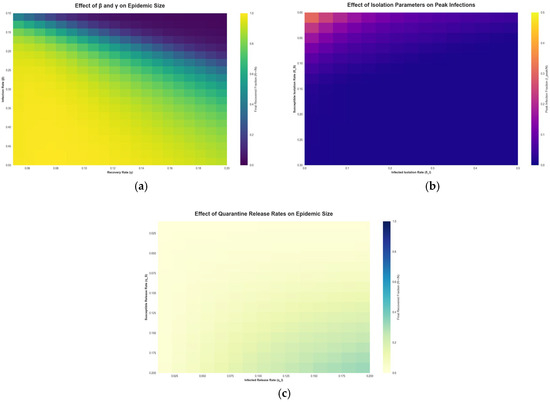
Figure 5.
Epidemic Sensitivity Heatmaps of the Working Set Model.
Figure 5a shows the final outbreak size as a function of the infection rate and the recovery rate . The heatmap shows that as increases (moving right on the plot) or decreases (moving down), the epidemic infects a larger portion of the population. Conversely, higher recovery rates or lower transmission rates confine the epidemic to a smaller size (lighter regions). This aligns with classic model expectations, faster recovery or lower transmissibility leads to fewer people ultimately infected. The WS model framework reproduces these dependencies and allows us to quantify how intervention success might vary with different pathogen characteristics. Figure 5b shows the impact of the isolation rate for infected agents on the peak number of infections. The heatmap illustrates that increasing the isolation rate of infectious agents markedly reduces the peak prevalence of infection. In other words, the more aggressively and quickly infected cases are isolated, the lower the highest burden on the population at any given time. However, this panel also implicitly reflects the diminishing returns and trade-offs of extremely high isolation levels. Implementing very strong isolation for a large portion of the population can indeed nearly eliminate transmission, but at the cost of significant social disruption. In practice, strong isolation and quarantine policies have been shown to reduce strain on health systems by preventing surges of cases [48,49,50], but they may also entail substantial economic and societal costs [51]. Our model’s sensitivity analysis aligns with these real-world observations: while perfect isolation of all infectious agents is the optimal way to suppress an epidemic, it may not be fully feasible to achieve. Thus, public health policies must balance the isolation rate with the resources available and the indirect effects on society. Figure 5c shows the effect of the isolation release rate on epidemic outcomes. This heatmap examines how quickly releasing people from quarantine influences the epidemic. A fast release means agents spend less time in isolation; if someone were infectious, they could re-enter the working set sooner and potentially spark new transmissions. Therefore, as Figure 5c suggests, very high release rates can lead to larger epidemics. On the other hand, a slow release keeps potentially infectious agents out of circulation for longer, aiding in control but requiring more isolation resources. In summary, this trade-off implies that while prolonged isolation is epidemiologically beneficial, it must be weighed against practical constraints like quarantine capacity and agents’ willingness to remain isolated.
Thus, comparing the SIR, SEIR, and WS models, we can say that WS is flexible due to isolation, which makes it more realistic for modeling control measures. To evaluate the efficiency of the adapted WS model, we compare it with the classical SIR and SEIR models, as shown in Table 3.
Table 3.
Comparison results of models.
The proposed WS model has several advantages, such as accounting for contact heterogeneity and the ability to quantify the impact of isolation, contact tracing, and other strategies. Also, similar to memory management in computer science, the model allows us to explore the effectiveness of epidemic control. These analyses demonstrate how an adapted WS model can be useful in investigating epidemic dynamics, providing valuable insights for infectious disease management.
4. Discussion
The presented results underscore the versatility and efficiency of the Working Set concept as a unifying framework for optimizing dynamic systems across disciplines. Despite their differing domains, virtual memory management and epidemiological modeling, both applications rely on the central idea of dynamically identifying and prioritizing a subset of active elements critical to system performance. In virtual memory systems, the Working Set algorithm effectively reduces page faults by adapting to the locality of reference exhibited by running programs. Unlike static strategies such as FIFO or LRU, which lack contextual awareness, the Working Set dynamically maintains a memory footprint aligned with the program’s current operational needs. This minimizes unnecessary memory operations and improves system throughput. Similarly, in epidemiological simulations, the Working Set enables adaptive containment strategies. By identifying individuals who are currently most active in transmission, whether due to recent contacts or elevated infectivity, the model can isolate them promptly, thus suppressing epidemic growth. This approach is particularly advantageous in scenarios involving super-spreaders, whose early identification and isolation can significantly alter the course of an outbreak. The interdisciplinary application of the Working Set also suggests broader implications. Both use cases illustrate how the Working Set functions as a cognitive filter, separating signal from noise within complex systems. Whether managing memory pages or human interactions, the model helps allocate limited resources, such as memory or healthcare interventions, to where they are most needed.
Furthermore, this approach offers potential benefits in other domains that involve dynamic participation or resource usage. Nevertheless, the Working Set approach is not without limitations. In memory systems, selecting an optimal time window remains nontrivial and workload-dependent. In epidemiological modeling, accurate identification of current contacts requires sufficient data, and privacy or infrastructure constraints may hinder implementation. Future work could address these challenges by incorporating adaptive time windows or leveraging real-time data sources.
5. Conclusions
This study has demonstrated the effectiveness and flexibility of the Working Set concept as a powerful strategy for optimizing the behavior of dynamic systems. Originally formulated for managing virtual memory, the Working Set has proven to be equally applicable in modeling and controlling the spread of infectious diseases. The results of our simulations confirm that the Working Set strategy outperforms traditional fixed or heuristic approaches in terms of efficiency and adaptability. In virtual memory systems, the Working Set minimizes page faults and mitigates thrashing by maintaining a dynamic memory footprint aligned with recent access patterns. In epidemiological simulations, the same principle enables efficient isolation policies that target agents actively involved in transmission, thus reducing infection peaks and epidemic duration. The interdisciplinary application of the WS model reveals its conceptual elegance as a general-purpose optimization strategy. Both domain, computing and epidemiology benefit from the model’s ability to filter signal from noise, allocating limited resources to the most critical elements at any given time. This shared principle suggests that the WS model could extend to other fields involving dynamic resource management, such as network traffic optimization, supply chain logistics, or ecological conservation, where identifying and prioritizing active subsets of a system is crucial for efficiency. For instance, in network traffic management, the WS model could prioritize bandwidth allocation to active users, while in conservation, it could focus monitoring efforts on actively threatened species or habitats. Despite its strengths, the WS model is not without challenges. In virtual memory systems, selecting an optimal time window for defining the working set remains workload-dependent, and suboptimal choices can lead to inefficiencies. In epidemiological applications, accurate identification of the working set relies on timely and reliable contact tracing data, which may be constrained by privacy concerns, logistical barriers, or incomplete reporting.
In conclusion, the Working Set model transcends its origins in memory management to offer an adaptable framework for managing complex, evolving systems. Its successful application to virtual memory and epidemiological modeling underscores its potential as a universal strategy for resource optimization. By continuing to refine and extend the WS model, researchers can unlock its full potential to address pressing challenges in science, engineering, and public health, fostering more resilient and efficient systems in an increasingly dynamic world.
Author Contributions
The authors confirm contribution to the paper as follows: Conceptualization, A.M. and G.B.; methodology, A.M. and A.T.; software, A.M.; validation, Z.T., A.M. and G.B.; formal analysis, A.T.; investigation, Z.T.; resources, A.T.; data curation, A.M.; writing—original draft preparation, A.M. and G.B.; writing—review and editing, A.M. and A.T.; visualization, Z.T.; supervision, A.M.; project administration, G.B.; funding acquisition, A.M. and G.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science Committee of the Ministry of Science and Higher Education of the Republic of Kazakhstan, grant number AP19174930—“Research and development of model for programs reorganization and data in segment-page systems based on two-level dictionary and geometric interpretation”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data can certainly be provided upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Denning, P.J. The working set model for program behavior. In Proceedings of the ACM Symposium on Operating System Principles—SOSP ’67, Gatlinburg, TN, USA, 1–4 October 1967; ACM Press: New York, NY, USA, 1967; pp. 15.1–15.12. [Google Scholar] [CrossRef]
- Denning, P.J. Working Set Analytics. ACM Comput. Surv. 2021, 53, 1–36. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Wu, C.-F.; Chang, Y.-H.; Kuo, T.-W. Exploring Synchronous Page Fault Handling. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 3791–3802. [Google Scholar] [CrossRef]
- Doron-Arad, I.; Naor, J.S. Non-Linear Paging. LIPIcs ICALP 2024, 297, 57.1–57.19. [Google Scholar] [CrossRef]
- Wood, C.; Fernandez, E.B.; Lang, T. Minimization of Demand Paging for the LRU Stack Model of Program Behavior. Inf. Process. Lett. 1983, 16, 99–104. [Google Scholar] [CrossRef]
- Arasteh, B.; Ghanbarzadeh, R.; Gharehchopogh, F.S.; Hosseinalipour, A. Generating the Structural Graph-based Model from a Program Source-code Using Chaotic Forrest Optimization Algorithm. Expert Syst. 2023, 40, e13228. [Google Scholar] [CrossRef]
- Arasteh, B.; Abdi, M.; Bouyer, A. Program Source Code Comprehension by Module Clustering Using Combination of Discretized Gray Wolf and Genetic Algorithms. Adv. Eng. Softw. 2022, 173, 103252. [Google Scholar] [CrossRef]
- Park, Y.; Bahn, H. A Working-Set Sensitive Page Replacement Policy for PCM-Based Swap Systems. JSTS J. Semicond. Technol. Sci. 2017, 17, 7–14. [Google Scholar] [CrossRef]
- Sha, S.; Hu, J.-Y.; Luo, Y.-W.; Wang, X.-L.; Wang, Z. Huge Page Friendly Virtualized Memory Management. J. Comput. Sci. Technol. 2020, 35, 433–452. [Google Scholar] [CrossRef]
- Hu, J.; Bai, X.; Sha, S.; Luo, Y.; Wang, X.; Wang, Z. Working Set Size Estimation with Hugepages in Virtualization. In Proceedings of the 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, Australia, 13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 501–508. [Google Scholar]
- Nitu, V.; Kocharyan, A.; Yaya, H.; Tchana, A.; Hagimont, D.; Astsatryan, H. Working Set Size Estimation Techniques in Virtualized Environments: One Size Does Not Fit All. In Proceedings of the Abstracts of the 2018 ACM International Conference on Measurement and Modeling of Computer Systems, Irvine, CA, USA, 12 June 2018; ACM: New York, NY, USA, 2018; pp. 62–63. [Google Scholar]
- Verbart, A.; Stolpe, M. A Working-Set Approach for Sizing Optimization of Frame-Structures Subjected to Time-Dependent Constraints. Struct. Multidisc. Optim. 2018, 58, 1367–1382. [Google Scholar] [CrossRef]
- Billah, M.A.; Miah, M.M.; Khan, M.N. Reproductive Number of Coronavirus: A Systematic Review and Meta-Analysis Based on Global Level Evidence. PLoS ONE 2020, 15, e0242128. [Google Scholar] [CrossRef]
- Pastor-Satorras, R.; Castellano, C.; Van Mieghem, P.; Vespignani, A. Epidemic Processes in Complex Networks. Rev. Mod. Phys. 2015, 87, 925–979. [Google Scholar] [CrossRef]
- Hethcote, H.W. The Mathematics of Infectious Diseases. SIAM Rev. 2000, 42, 599–653. [Google Scholar] [CrossRef]
- Siegenfeld, A.F.; Kollepara, P.K.; Bar-Yam, Y. Modeling Complex Systems: A Case Study of Compartmental Models in Epidemiology. Complexity 2022, 2022, 3007864. [Google Scholar] [CrossRef]
- Kermak, W.O.; McKendrick, A.G. A Contribution to the Mathematical Theory of Epidemics. Proc. R. Soc. Lond. A 1927, 115, 700–721. [Google Scholar] [CrossRef]
- Sun, R. Global Stability of the Endemic Equilibrium of Multigroup SIR Models with Nonlinear Incidence. Comput. Math. Appl. 2010, 60, 2286–2291. [Google Scholar] [CrossRef]
- Turkyilmazoglu, M. A Highly Accurate Peak Time Formula of Epidemic Outbreak from the SIR Model. Chin. J. Phys. 2023, 84, 39–50. [Google Scholar] [CrossRef]
- KhudaBukhsh, W.R.; Rempała, G.A. How to Correctly Fit an SIR Model to Data from an SEIR Model? Math. Biosci. 2024, 375, 109265. [Google Scholar] [CrossRef]
- Korobeinikov, A. Global Properties of SIR and SEIR Epidemic Models with Multiple Parallel Infectious Stages. Bull. Math. Biol. 2009, 71, 75–83. [Google Scholar] [CrossRef]
- Džiugys, A.; Bieliūnas, M.; Skarbalius, G.; Misiulis, E.; Navakas, R. Simplified Model of COVID-19 Epidemic Prognosis under Quarantine and Estimation of Quarantine Effectiveness. Chaos Solitons Fractals 2020, 140, 110162. [Google Scholar] [CrossRef]
- Gumel, A.B.; Iboi, E.A.; Ngonghala, C.N.; Elbasha, E.H. A Primer on Using Mathematics to Understand COVID-19 Dynamics: Modeling, Analysis and Simulations. Infect. Dis. Model. 2021, 6, 148–168. [Google Scholar] [CrossRef]
- Yan, P.; Chowell, G. Beyond the Initial Phase: Compartment Models for Disease Transmission. In Quantitative Methods for Investigating Infectious Disease Outbreaks; Springer International Publishing: Cham, Switzerland, 2019; Volume 70, pp. 135–182. ISBN 9783030219222. [Google Scholar]
- Marques, J.A.L.; Gois, F.N.B.; Xavier-Neto, J.; Fong, S.J. Epidemiology Compartmental Models—SIR, SEIR, and SEIR with Intervention. In Predictive Models for Decision Support in the COVID-19 Crisis; Springer International Publishing: Cham, Switzerland, 2021; pp. 15–39. ISBN 9783030619121. [Google Scholar]
- Meng, X.; Cai, Z.; Si, S.; Duan, D. Analysis of Epidemic Vaccination Strategies on Heterogeneous Networks: Based on SEIRV Model and Evolutionary Game. Appl. Math. Comput. 2021, 403, 126172. [Google Scholar] [CrossRef] [PubMed]
- Safarishahrbijari, A.; Lawrence, T.; Lomotey, R.; Liu, J.; Waldner, C.; Osgood, N. Particle Filtering in a SEIRV Simulation Model of H1N1 Influenza. In Proceedings of the 2015 Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015; pp. 1240–1251. [Google Scholar]
- Bissett, K.R.; Cadena, J.; Khan, M.; Kuhlman, C.J. Agent-Based Computational Epidemiological Modeling. J. Indian Inst. Sci. 2021, 101, 303–327. [Google Scholar] [CrossRef] [PubMed]
- Salem, F.A.; Moreno, U.F. A Multi-Agent-Based Simulation Model for the Spreading of Diseases Through Social Interactions During Pandemics. J. Control Autom. Electr. Syst. 2022, 33, 1161–1176. [Google Scholar] [CrossRef]
- Tolles, J.; Luong, T. Modeling Epidemics With Compartmental Models. JAMA 2020, 323, 2515. [Google Scholar] [CrossRef]
- Roberts, M.; Andreasen, V.; Lloyd, A.; Pellis, L. Nine Challenges for Deterministic Epidemic Models. Epidemics 2015, 10, 49–53. [Google Scholar] [CrossRef]
- Givan, O.; Schwartz, N.; Cygelberg, A.; Stone, L. Predicting Epidemic Thresholds on Complex Networks: Limitations of Mean-Field Approaches. J. Theor. Biol. 2011, 288, 21–28. [Google Scholar] [CrossRef]
- Dhar, A. What One Can Learn from the SIR Model. Iascs 2020, 3, 213–215. [Google Scholar] [CrossRef]
- Lloyd-Smith, J.O.; Schreiber, S.J.; Kopp, P.E.; Getz, W.M. Superspreading and the Effect of Individual Variation on Disease Emergence. Nature 2005, 438, 355–359. [Google Scholar] [CrossRef]
- Adam, D.C.; Wu, P.; Wong, J.Y.; Lau, E.H.Y.; Tsang, T.K.; Cauchemez, S.; Leung, G.M.; Cowling, B.J. Clustering and Superspreading Potential of SARS-CoV-2 Infections in Hong Kong. Nat. Med. 2020, 26, 1714–1719. [Google Scholar] [CrossRef]
- Poonia, R.C.; Saudagar, A.K.J.; Altameem, A.; Alkhathami, M.; Khan, M.B.; Hasanat, M.H.A. An Enhanced SEIR Model for Prediction of COVID-19 with Vaccination Effect. Life 2022, 12, 647. [Google Scholar] [CrossRef]
- Ramalingam, R.; Gnanaprakasam, A.J.; Boulaaras, S. Stability and Control Analysis of COVID-19 Spread in India Using SEIR Model. Sci. Rep. 2025, 15, 9095. [Google Scholar] [CrossRef]
- James, A.; Plank, M.J.; Hendy, S.; Binny, R.; Lustig, A.; Steyn, N.; Nesdale, A.; Verrall, A. Successful Contact Tracing Systems for COVID-19 Rely on Effective Quarantine and Isolation. PLoS ONE 2021, 16, e0252499. [Google Scholar] [CrossRef] [PubMed]
- Kabanikhin, S.I.; Krivorotko, O.I. Mathematical Modeling of the Wuhan COVID-2019 Epidemic and Inverse Problems. Comput. Math. Math. Phys. 2020, 60, 1889–1899. [Google Scholar] [CrossRef]
- Lieberthal, B.; Gardner, A.M. Connectivity, Reproduction Number, and Mobility Interact to Determine Communities’ Epidemiological Superspreader Potential in a Metapopulation Network. PLOS Comput. Biol. 2021, 17, e1008674. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Zhang, Y.; Xu, Y.; Xia, C.; Tanimoto, J. An Epidemic Spread Model with Nonlinear Recovery Rates on Meta-Population Networks. Nonlinear Dyn. 2025, 113, 3943–3957. [Google Scholar] [CrossRef]
- Horii, M.; Gould, A.; Yun, Z.; Ray, J.; Safta, C.; Zohdi, T. Calibration Verification for Stochastic Agent-Based Disease Spread Models. PLoS ONE 2024, 19, e0315429. [Google Scholar] [CrossRef]
- Taghizadeh, E.; Mohammad-Djafari, A. SEIR Modeling, Simulation, Parameter Estimation, and Their Application for COVID-19 Epidemic Prediction. Phys. Sci. Forum 2022, 5, 18. [Google Scholar] [CrossRef]
- Chen, K.; Jiang, X.; Li, Y.; Zhou, R. A Stochastic Agent-Based Model to Evaluate COVID-19 Transmission Influenced by Human Mobility. Nonlinear Dyn. 2023, 111, 12639–12655. [Google Scholar] [CrossRef]
- Fan, Q.; Li, Q.; Chen, Y.; Tang, J. Modeling COVID-19 Spread Using Multi-Agent Simulation with Small-World Network Approach. BMC Public Health 2024, 24, 672. [Google Scholar] [CrossRef]
- Wood, A.D.; Berry, K. COVID-19 Transmission in a Resource Dependent Community with Heterogeneous Populations: An Agent-Based Modeling Approach. Econ. Hum. Biol. 2024, 52, 101314. [Google Scholar] [CrossRef]
- Gallagher, K.; Bouros, I.; Fan, N.; Hayman, E.; Heirene, L.; Lamirande, P.; Lemenuel-Diot, A.; Lambert, B.; Gavaghan, D.; Creswell, R. Epidemiological Agent-Based Modelling Software (Epiabm). J. Open Res. Softw. 2024, 12, 3. [Google Scholar] [CrossRef]
- Nitzsche, C.; Simm, S. Agent-Based Modeling to Estimate the Impact of Lockdown Scenarios and Events on a Pandemic Exemplified on SARS-CoV-2. Sci. Rep. 2024, 14, 13391. [Google Scholar] [CrossRef]
- Schluter, P.J.; Généreux, M.; Landaverde, E.; Chan, E.Y.Y.; Hung, K.K.C.; Law, R.; Mok, C.P.Y.; Murray, V.; O’Sullivan, T.; Qadar, Z.; et al. An Eight Country Cross-Sectional Study of the Psychosocial Effects of COVID-19 Induced Quarantine and/or Isolation during the Pandemic. Sci. Rep. 2022, 12, 13175. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Wu, L.; Ouyang, H.; Zhan, J.; Wang, J.; Liu, W.; Jia, Y. Behavioral Intentions and Perceived Stress under Isolated Environment. Brain Behav. 2024, 14, e3347. [Google Scholar] [CrossRef]
- Yamaka, W.; Lomwanawong, S.; Magel, D.; Maneejuk, P. Analysis of the Lockdown Effects on the Economy, Environment, and COVID-19 Spread: Lesson Learnt from a Global Pandemic in 2020. Int. J. Environ. Res. Public Health 2022, 19, 12868. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).