
An Image-Based Water Turbidity Classification Scheme Using a Convolutional Neural Network


Abstract
1. Introduction
2. Materials and Methods
2.1. Sample Generation
2.2. Image Collection
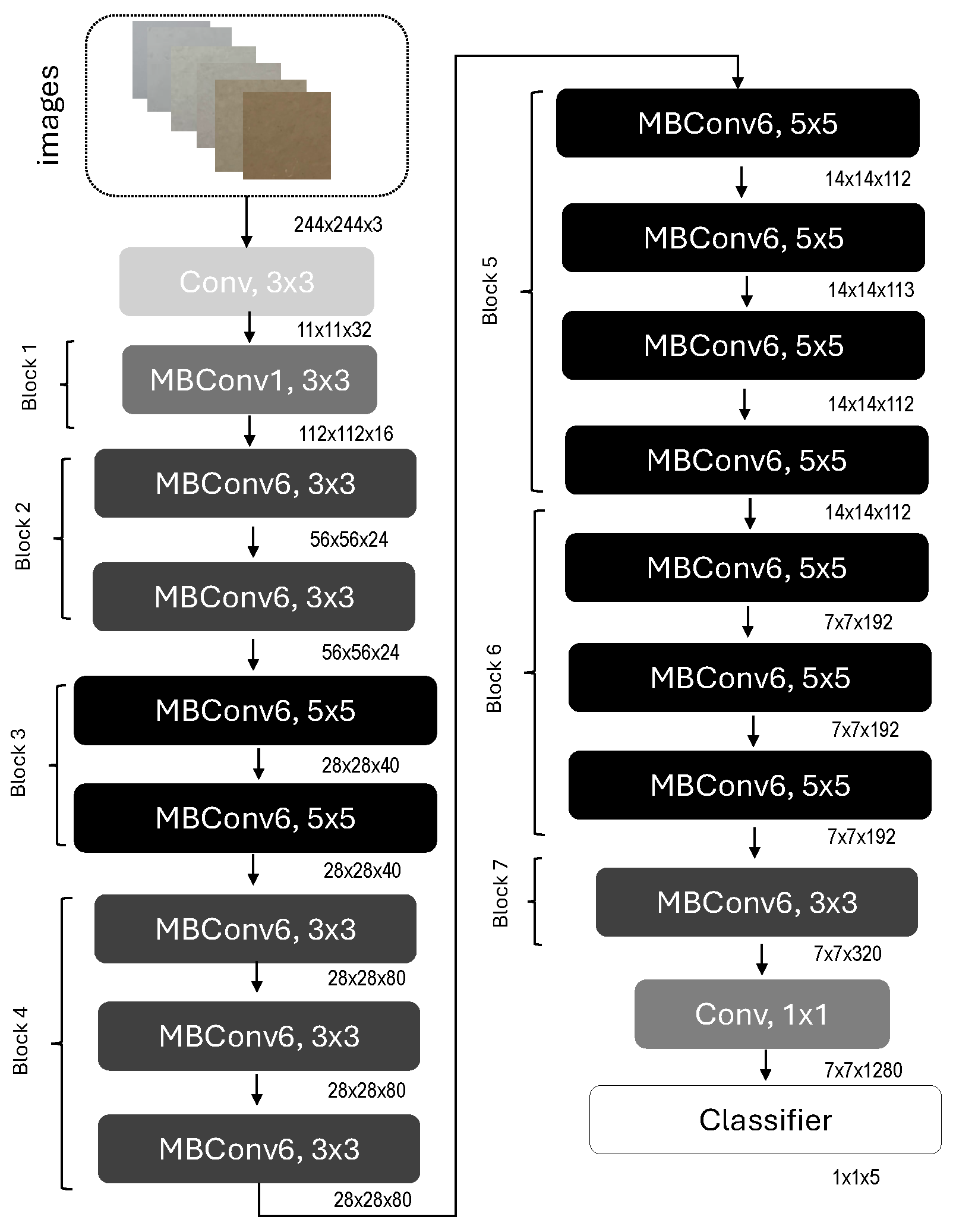
2.3. CNN Model Development
2.4. CNN Performance Evaluation
3. Results
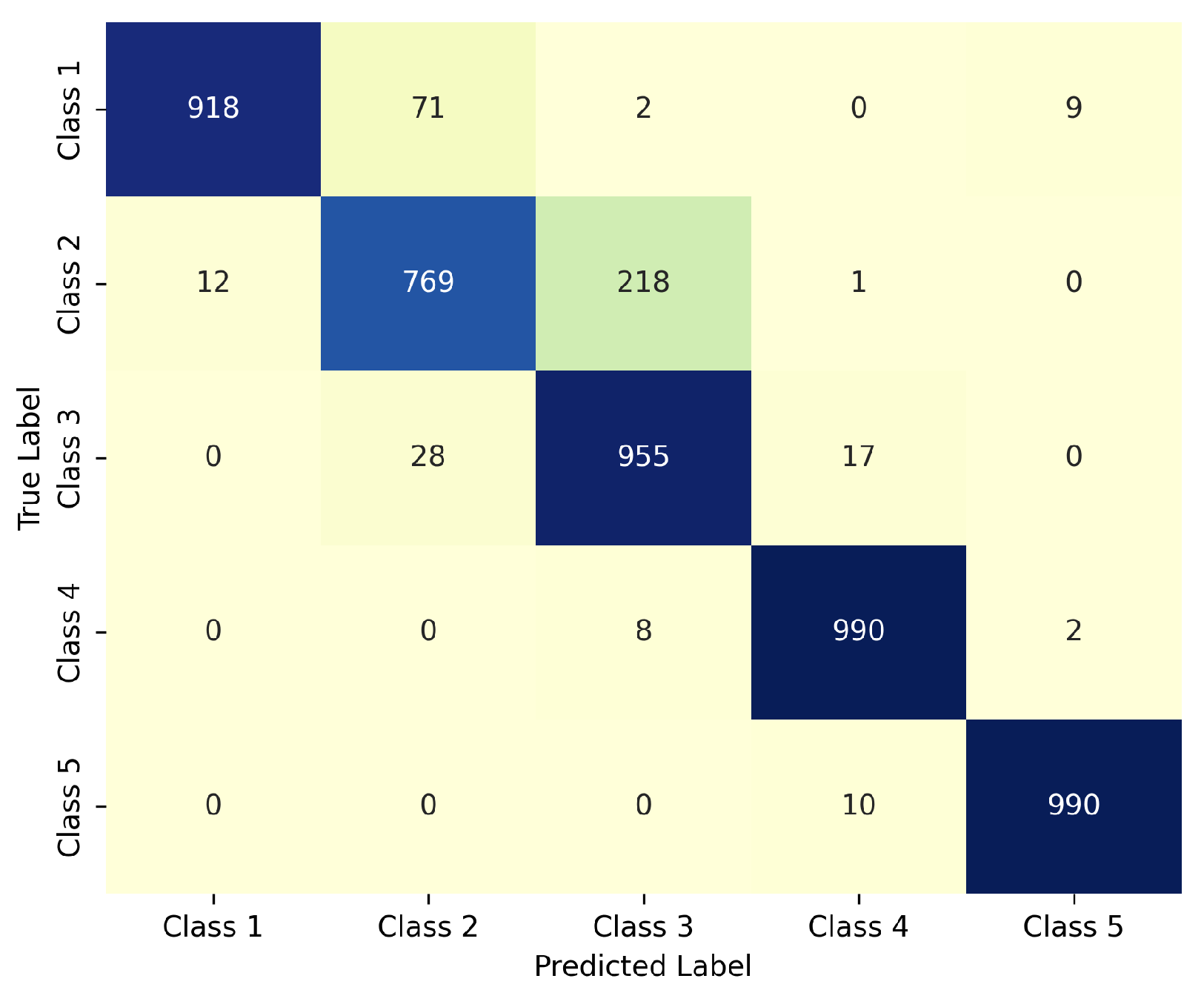
4. Discussion
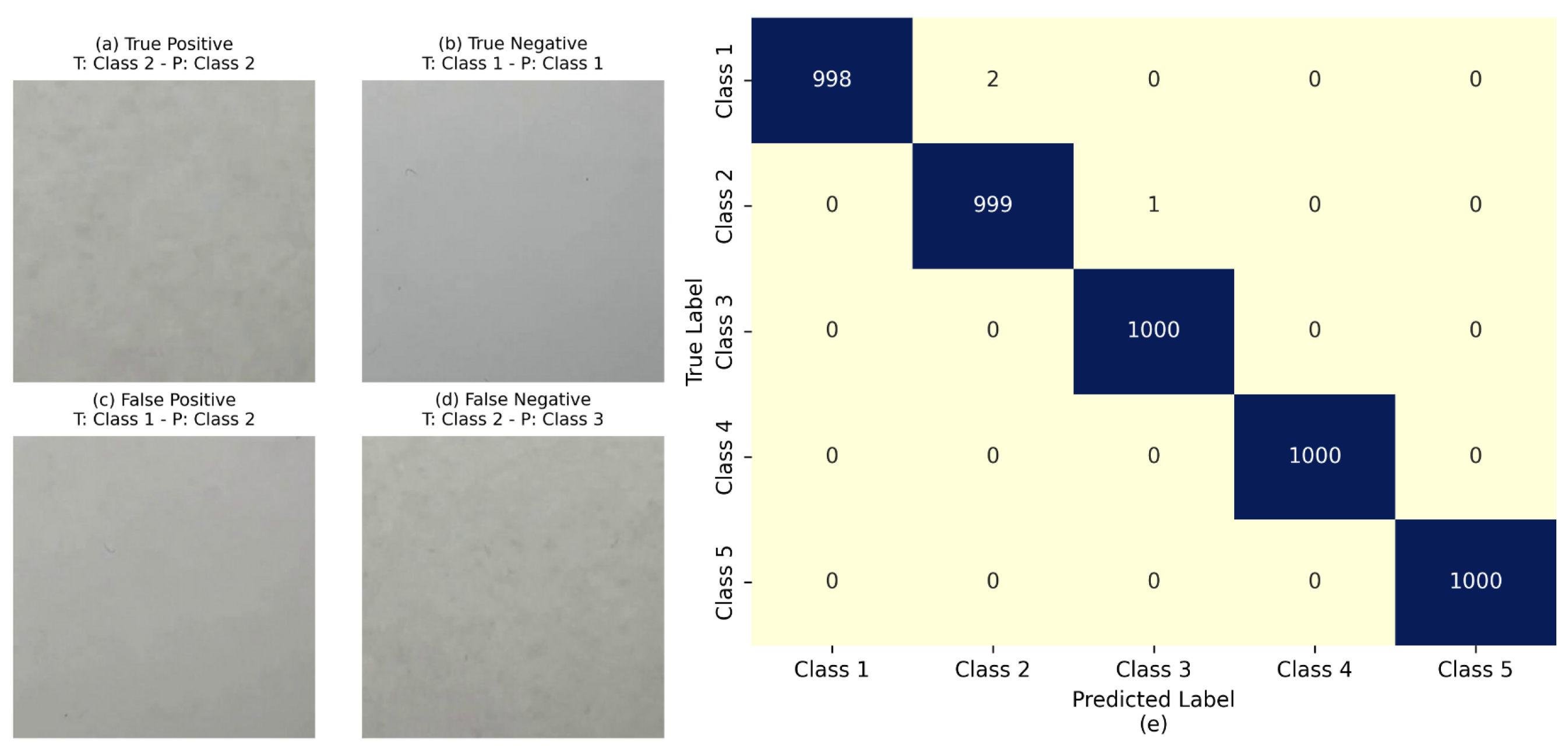
4.1. Representative Classification Examples
4.2. Comparison with Similar Studies
4.3. Model Limitations
5. Conclusions
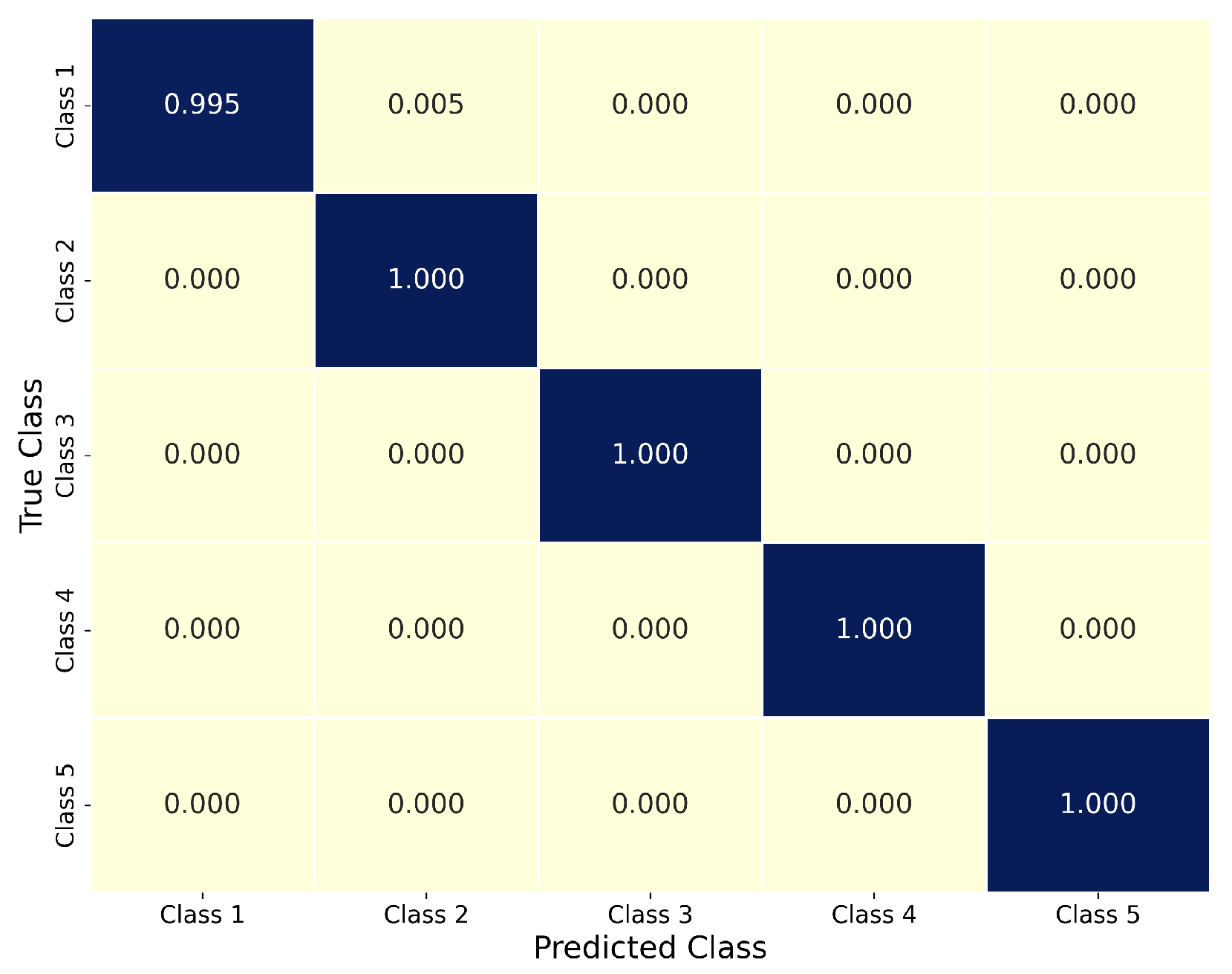
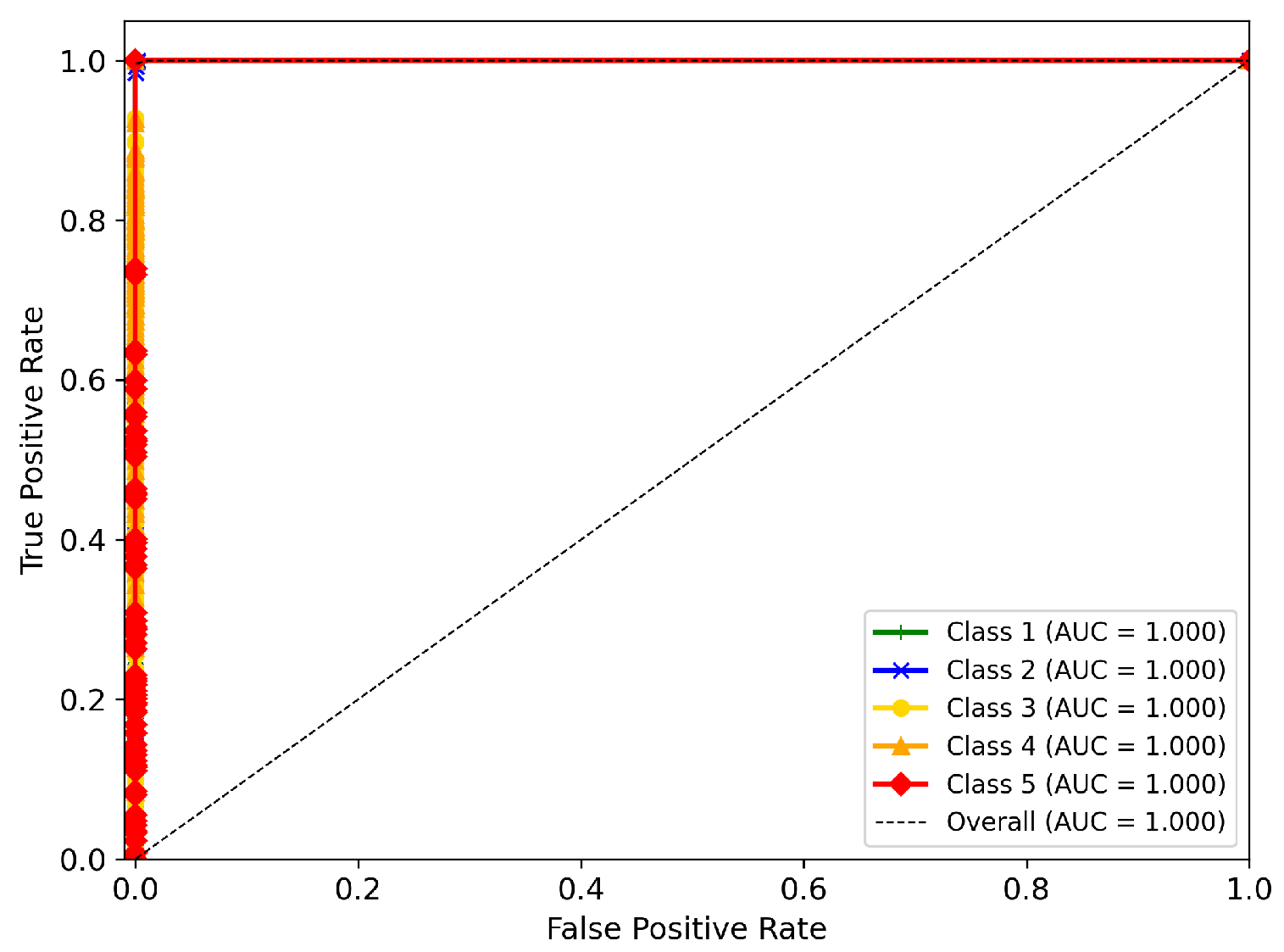
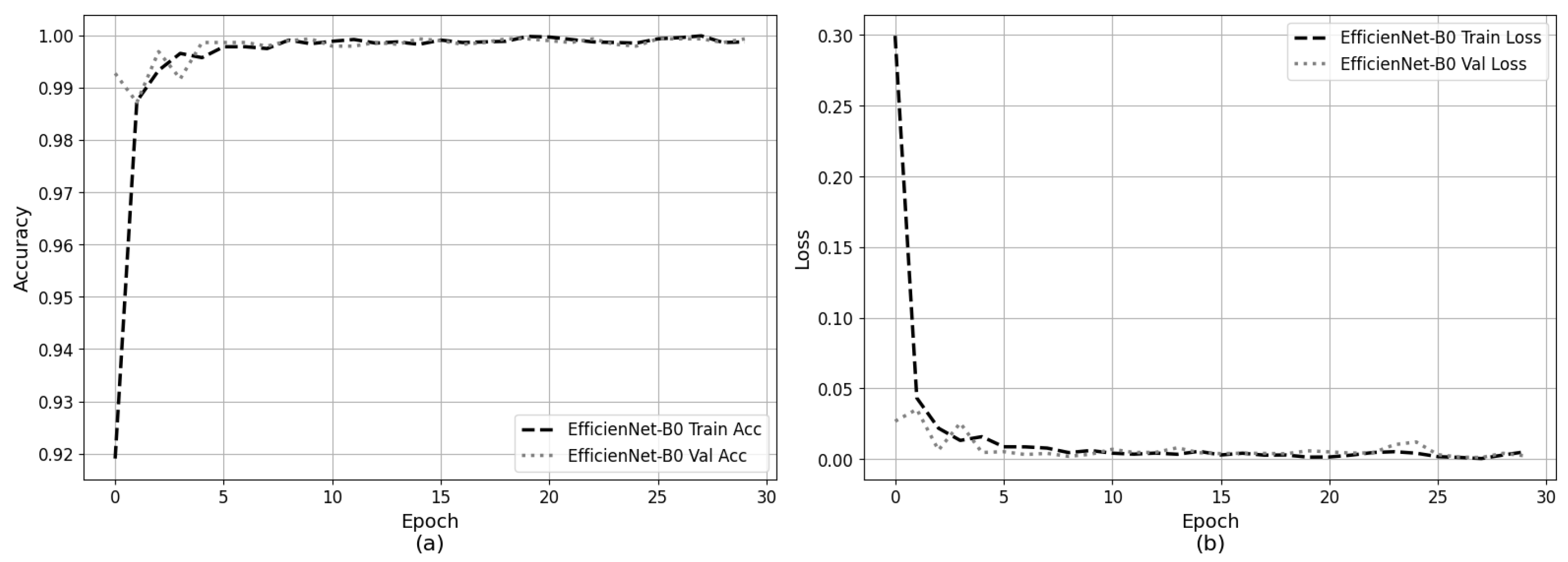
- The proposed CNN model achieved outstanding accuracy (99.93%) in classifying five turbidity levels, showing high precision, recall, and F1-score across multiple runs with low variability.
- Most classification errors occurred between Class 1 and Class 2, which correspond to low turbidity levels with subtle visual differences. This suggests the need for enhanced resolution or additional spectral information for borderline cases.
- Representative classification examples and confusion matrices confirm the robustness of the model and highlight its limitations, particularly for adjacent classes with overlapping features.
- Compared to previous studies, the proposed model outperformed other CNN-based approaches, benefiting from the use of TL and a standardized image acquisition protocol.
- Although trained exclusively with laboratory-prepared samples, the model establishes a reproducible framework that can be extended to real-world water conditions with appropriate validation (see Appendix A).
- Future work will include expanding the dataset with real water samples, increasing the number of samples in low-turbidity classes, and incorporating real water conditions to improve model generalizability and support claims of broader applicability.
- Additionally, we plan to evaluate the effect of different camera types and image resolutions on model performance, in order to assess their influence on classification accuracy and error propagation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| TSS | Total Suspended Solids |
| NTU | Nephelometric Turbidity Units |
| YOLO | You Only Look Once |
| FNU | Formazin Nephelometric Unit |
| ML | Machine Learning |
| TL | Transfer Learning |
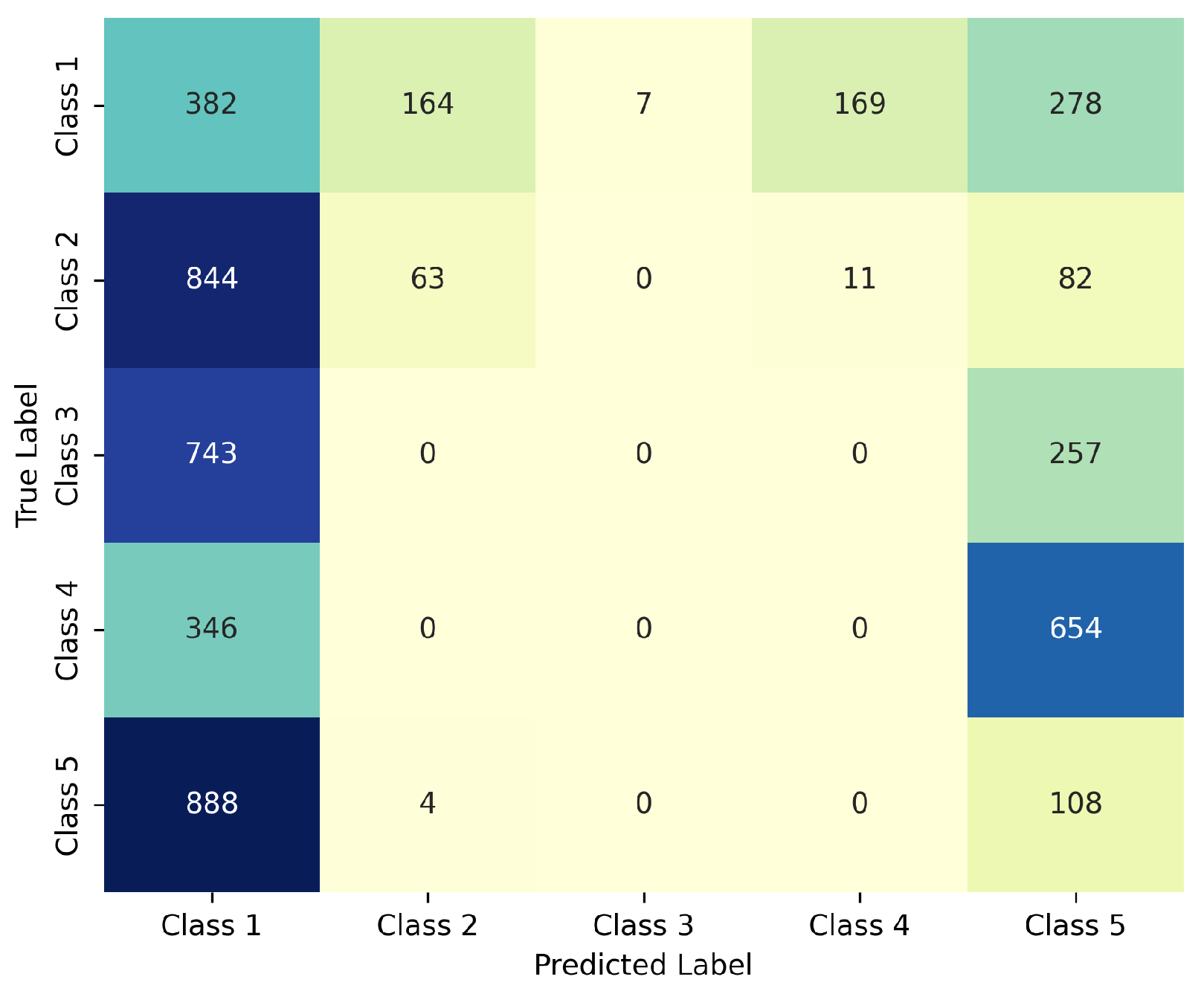
Appendix A. Exploratory Validation of the CNN Model and Using Red Clay-Based Turbidity

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Precision | Recall | F1-Score | Images Evaluated |
|---|---|---|---|---|
| Class 1 | 0.57 | 0.80 | 0.67 | 5 |
| Class 2 | 1.00 | 0.67 | 0.80 | 6 |
| Class 3 | 0.50 | 0.67 | 0.57 | 3 |
| Class 4 | 0.00 | 0.00 | 0.00 | 5 |
| Class 5 | 0.71 | 1.00 | 0.83 | 5 |
| Accuracy | 0.62 (24 total samples) | |||
Appendix B. Exploratory Validation of MLP Using Red Clay-Based Turbidity
| Class | Precision | Recall | F1-Score | Images Evaluated |
|---|---|---|---|---|
| Class 1 | 0.0000 | 0.0000 | 0.0000 | 5 |
| Class 2 | 0.0000 | 0.0000 | 0.0000 | 6 |
| Class 3 | 0.6000 | 1.0000 | 0.7500 | 3 |
| Class 4 | 0.3571 | 1.0000 | 0.5263 | 5 |
| Class 5 | 1.0000 | 1.0000 | 1.0000 | 5 |
| Accuracy | 0.5417 (24 total samples) | |||
Appendix C. Exploratory Validation of Random Forest Classifier Using Red Clay-Based Turbidity
| Class | Precision | Recall | F1-Score | Images Evaluated |
|---|---|---|---|---|
| Class 1 | 0.0000 | 0.0000 | 0.0000 | 5 |
| Class 2 | 0.0000 | 0.0000 | 0.0000 | 6 |
| Class 3 | 0.0000 | 0.0000 | 0.0000 | 3 |
| Class 4 | 0.0000 | 0.0000 | 0.0000 | 5 |
| Class 5 | 0.2174 | 1.0000 | 0.3571 | 5 |
| Accuracy | 0.2083 (24 total samples) | |||
References
- National Water Commission (CONAGUA). Laboratories of the National Water Commission. 2025. Available online: https://laboratorios.conagua.gob.mx:8446/LABORATORIOS/Pages/Laboratorios.aspx (accessed on 8 April 2025).
- Miljojkovic, D.; Trepsic, I.; Milovancevic, M. Assessment of physical and chemical indicators on water turbidity. Phys. A Stat. Mech. Its Appl. 2019, 527, 121171. [Google Scholar] [CrossRef]
- West, A.O.; Scott, J.T. Black disk visibility, turbidity, and total suspended solids in rivers: A comparative evaluation. Limnol. Oceanogr. Methods 2016, 14, 658–667. [Google Scholar] [CrossRef]
- Farrell, C.; Hassard, F.; Jefferson, B.; Leziart, T.; Nocker, A.; Jarvis, P. Turbidity composition and the relationship with microbial attachment and UV inactivation efficacy. Sci. Total Environ. 2018, 624, 638–647. [Google Scholar] [CrossRef] [PubMed]
- Dunlop, J.; McGregor, G.; Horrigan, N. Potential impacts of salinity and turbidity in riverine ecosystems. In National Action Plan for Salinity and Water Quality, State of Queensland; Department of Natural Resources and Mines: Brisbane, QLD, Australia, 2005. [Google Scholar]
- Lloyd, D.S. Turbidity as a water quality standard for salmonid habitats in Alaska. N. Am. J. Fish. Manag. 1987, 7, 34–45. [Google Scholar] [CrossRef]
- Huey, G.M.; Meyer, M.L. Turbidity as an indicator of water quality in diverse watersheds of the upper Pecos River basin. Water 2010, 2, 273–284. [Google Scholar] [CrossRef]
- Packman, J.J.; Comings, K.J.; Booth, D.B. Using turbidity to determine total suspended solids in urbanizing streams in the Puget Lowlands. In Confronting Uncertainty: Managing Change in Water Resources and the Environment, Canadian Water Resources Association Annual Meeting, Vancouver, BC, Canada, 27–29 October 1999; Canadian Water Resources Association: Vancouver, BC, Canada, 1999; pp. 158–165. Available online: http://hdl.handle.net/1773/16333 (accessed on 30 April 2025).
- Gippel, C.J. Potential of turbidity monitoring for measuring the transport of suspended solids in streams. Hydrol. Process. 1995, 9, 83–97. [Google Scholar] [CrossRef]
- Grayson, R.B.; Finlayson, B.L.; Gippel, C.J.; Hart, B.T. The potential of field turbidity measurements for the computation of total phosphorus and suspended solids loads. J. Environ. Manag. 1996, 47, 257–267. [Google Scholar] [CrossRef]
- Omar, A.F.B.; MatJafri, M.Z.B. Turbidimeter design and analysis: A review on optical fiber sensors for the measurement of water turbidity. Sensors 2009, 9, 8311–8335. [Google Scholar] [CrossRef] [PubMed]
- Secretaría de Economía. NMX-AA-038-SCFI-2001: Water Analysis—Determination of Turbidity in Natural, Wastewater, and Treated Wastewater—Test Method; Cancels NMX-AA-038-1981. CDU: 543.31/.38; Secretaría de Economía: Mexico City, Mexico, 2001.
- Fu, G.; Jin, Y.; Sun, S.; Yuan, Z.; Butler, D. The role of deep learning in urban water management: A critical review. Water Res. 2022, 223, 118973. [Google Scholar] [CrossRef] [PubMed]
- Benisi Ghadim, H.; Salarijazi, M.; Ahmadianfar, I.; Heydari, M.; Zhang, T. Developing a sediment rating curve model using the curve slope. Pol. J. Environ. Stud. 2020, 29, 1151–1159. [Google Scholar] [CrossRef] [PubMed]
- Lewis, D.J.; Tate, K.W.; Dahlgren, R.A.; Newell, J. Turbidity and total suspended solid concentration dynamics in streamflow from California oak woodland watersheds. In Proceedings of the Fifth Symposium on Oak Woodlands: Oaks in California’s Challenging Landscape, San Diego, CA, USA, 22–25 October 2001; Gen. Tech. Rep. PSW-GTR-184. Standiford, R.B., Ed.; Pacific Southwest Research Station, Forest Service, U.S. Department of Agriculture: Albany, CA, USA, 2002; pp. 107–118. [Google Scholar]
- Nikoonahad, A.; Ebrahimi, A.A.; Nikoonahad, E.; Ghelmani, S.V.; Mohammadi, A. Evaluation the correlation between turbidity and total suspended solids with other chemical parameters in Yazd wastewater treatment effluent plant. J. Environ. Health Sustain. Dev. 2016, 1, 78–86. [Google Scholar]
- Anderson, P.; Davie, R.D. Use of Transparency Tubes for Rapid Assessment of Total Suspended Solids and Turbidity in Streams. Lake Reserv. Manag. 2004, 20, 110–120. [Google Scholar] [CrossRef]
- Villa, A.; Fölster, J.; Kyllmar, K. Determining suspended solids and total phosphorus from turbidity: Comparison of high-frequency sampling with conventional monitoring methods. Environ. Monit. Assess. 2019, 191, 605. [Google Scholar] [CrossRef] [PubMed]
- Hannouche, A.; Chebbo, G.; Joannis, C.; Ruban, G.; Tassin, B. Relationship between turbidity and total suspended solids concentration within a combined sewer system. Water Sci. Technol. 2011, 64, 2445–2452. [Google Scholar] [CrossRef] [PubMed]
- Rudy, I.M.; Wilson, M.J. Turbidivision: A computer vision application for estimating turbidity from underwater images. PeerJ 2024, 12, e18254. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Betancur, D.; Moreno, I.; Guerrero-Mendez, C.; Saucedo-Anaya, T.; González, E.; Bautista-Capetillo, C.; González-Trinidad, J. Convolutional neural network for measurement of suspended solids and turbidity. Appl. Sci. 2022, 12, 6079. [Google Scholar] [CrossRef]
- Mullins, D.; Coburn, D.; Hannon, L.; Jones, E.; Clifford, E.; Glavin, M. A novel image processing-based system for turbidity measurement in domestic and industrial wastewater. Water Sci. Technol. 2018, 77, 1469–1482. [Google Scholar] [CrossRef] [PubMed]
- Guapacho, J.J.; Guativa, J.A.V.; Baquero, J.E.M. Analysis of artificial vision techniques for implementation of virtual instrumentation system to measure water turbidity. J. Eng. Sci. Technol. Rev. 2021, 14, 161–168. [Google Scholar] [CrossRef]
- Parra, L.; Ahmad, A.; Sendra, S.; Lloret, J.; Lorenz, P. Combination of machine learning and RGB sensors to quantify and classify water turbidity. Chemosensors 2024, 12, 34. [Google Scholar] [CrossRef]
- Cao, P.; Zhao, W.; Liu, S.; Shi, L.; Gao, H. Using a digital camera combined with fitting algorithm and T-S fuzzy neural network to determine the turbidity in water. IEEE Access 2019, 7, 83589–83599. [Google Scholar] [CrossRef]
- Feizi, H.; Sattari, M.T.; Mosaferi, M.; Apaydin, H.A.L.İ.T. An image-based deep learning model for water turbidity estimation in laboratory conditions. Int. J. Environ. Sci. Technol. 2023, 20, 149–160. [Google Scholar] [CrossRef]
- Magrì, S.; Ottaviani, E.; Prampolini, E.; Besio, G.; Fabiano, B.; Federici, B. Application of machine learning techniques to derive sea water turbidity from Sentinel-2 imagery. Remote Sens. Appl. Soc. Environ. 2023, 30, 100951. [Google Scholar] [CrossRef]
- Huang, J.; Qian, R.; Gao, J.; Bing, H.; Huang, Q.; Qi, L.; Song, S.; Huang, J. A novel framework to predict water turbidity using Bayesian modeling. Water Res. 2021, 202, 117406. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yao, X.; Wu, Q.; Huang, Y.; Zhou, Z.; Yang, J.; Liu, X. Turbidity prediction of lake-type raw water using random forest model based on meteorological data: A case study of Tai lake, China. J. Environ. Manag. 2021, 290, 112657. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Zhang, H. Study on turbidity prediction method of reservoirs based on long short term memory neural network. Ecol. Model. 2020, 432, 109210. [Google Scholar] [CrossRef]
- Risfendra, R.; Ananda, G.F.; Setyawan, H. Deep learning-based waste classification with transfer learning using EfficientNet-B0 model. J. Resti (Rekayasa Sist. Dan Teknol. Inf.) 2024, 8, 535–541. [Google Scholar] [CrossRef]
- Luviano Soto, I.; Sánchez, Y.C.; Raya, A. Water quality polluted by total suspended solids classified within an artificial neural network approach. Water Qual. Res. J. 2025, 60, 214–228. [Google Scholar] [CrossRef]
- SEMARNAT (Secretariat of Environment and Natural Resources). Water Quality Indicators. Government of Mexico. 2020. Available online: https://apps1.semarnat.gob.mx:8443/dgeia/compendio_2020/dgeiawf.semarnat.gob.mx_8080/approot/dgeia_mce/html/RECUADROS_INT_GLOS/D3_AGUA/D3_AGUA04/D3_R_AGUA05_01.htm (accessed on 25 March 2025).
- Perry, C.; Taylor, K. Environmental Sedimentology; John Wiley & Sons, Blackwell Publishing: Malden, MA, USA, 2009. [Google Scholar]
- Nayak, D.R.; Padhy, N.; Mallick, P.K.; Zymbler, M.; Kumar, S. Brain tumor classification using dense efficient-net. Axioms 2022, 11, 34. [Google Scholar] [CrossRef]
- Shahriar Maswood, M.M.; Hussain, T.; Khan, M.B.; Islam, M.T.; Alharbi, A.G. CNN based detection of the severity of diabetic retinopathy from the fundus photography using EfficientNet-B5. In Proceedings of the 2020 11th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Virtual, 4–7 November 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- UÇan, M.; Kaya, B.; Kaya, M. Multi-class gastrointestinal images classification using EfficientNet-B0 CNN model. In Proceedings of the 2022 International Conference on Data Analytics for Business and Industry (ICDABI), Sakhir, Bahrain, 25–26 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of remote sensing images using EfficientNet-B3 CNN model with attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, X.W.; Sun, Z.; Zheng, Y.L.; Su, S.C.; Chen, F.J. Identification of oil tea (Camellia oleifera C.Abel) cultivars using EfficientNet-B4 CNN model with attention mechanism. Forests 2022, 13, 1. [Google Scholar] [CrossRef]
- Ab Wahab, M.N.; Nazir, A.; Zhen Ren, A.T.; Mohd Noor, M.H.; Akbar, M.F.; Mohamed, A.S.A. EfficientNet-Lite and hybrid CNN-KNN implementation for facial expression recognition on Raspberry Pi. IEEE Access 2021, 9, 134065–134080. [Google Scholar] [CrossRef]
- Luviano-Soto, I.; Concha-Sánchez, Y.; Raya, A.; Flores-Fernández, G.C. Comparative Study of Convolutional Neural Networks for Evaluating Suspended Solids Pollution Levels in Water; Internal Report; 2025. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research, 97. pp. 6105–6114. Available online: https://proceedings.mlr.press/v97/tan19a.html (accessed on 12 March 2025).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar] [CrossRef]
- Seliya, N.; Khoshgoftaar, T.M.; Van Hulse, J. A study on the relationships of classifier performance metrics. In Proceedings of the 2009 21st IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Newark, NJ, USA, 2–4 November 2009; pp. 59–66. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Romano, F. Learning Python: Learn to Code like a Professional with Python—An Open Source, Versatile, and Powerful Programming Language; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Nazemi Ashani, Z.; Zainuddin, M.F.; Che Ilias, I.S.; Ng, K.Y. A combined computer vision and convolution neural network approach to classify turbid water samples in accordance with national water quality standards. Arab. J. Sci. Eng. 2024, 49, 3503–3516. [Google Scholar] [CrossRef]
- Jantarakasem, C.; Sioné, L.; Templeton, M.R. Estimating drinking water turbidity using images collected by a smartphone camera. AQUA Water Infrastruct. Ecosyst. Soc. 2024, 73, 1277–1284. [Google Scholar] [CrossRef]
- Nie, Y.; Chen, Y.; Guo, J.; Li, S.; Xiao, Y.; Gong, W.; Lan, R. An improved CNN model in image classification application on water turbidity. Sci. Rep. 2025, 15, 11264. [Google Scholar] [CrossRef] [PubMed]
- Trejo-Zúñiga, I.; Moreno, M.; Santana-Cruz, R.F.; Meléndez-Vázquez, F. Deep-learning-driven turbidity level classification. Big Data Cogn. Comput. 2024, 8, 89. [Google Scholar] [CrossRef]
- Kumar, L.; Afzal, M.S.; Ahmad, A. Prediction of water turbidity in a marine environment using machine learning: A case study of Hong Kong. Reg. Stud. Mar. Sci. 2022, 52, 102260. [Google Scholar] [CrossRef]
- Durga Devi, P.; Mamatha, G. Machine learning approach to predict the turbidity of Saki Lake, Telangana, India, using remote sensing data. Meas. Sens. 2024, 29, 101139. [Google Scholar] [CrossRef]


| Class | Turbidity (NTU) | Error (%) | TSS Range (mg/L) | Number of Samples |
|---|---|---|---|---|
| Excellent quality (Class 1) | 0.0–7.0 | ±10.07 | 0–25 | 5 |
| Good quality (Class 2) | 10.0–25.0 | ±5.13 | 30–80 | 8 |
| Acceptable quality (Class 3) | 30.0–55.0 | ±3.10 | 90–150 | 8 |
| Contaminated (Class 4) | 60.0–120.0 | ±2.39 | 175–400 | 8 |
| Highly contaminated (Class 5) | 140.0–180.0 | ±3.95 | 500–800 | 4 |
| Class 1 | Class 2 | Class 3 | Class 4 | Class 5 |
|---|---|---|---|---|
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  | |
 |  |  | ||
 |  |  | ||
 |  |  |
| Layer | Output Channels | Kernel Size | Stride | Repeat | Additional Information |
|---|---|---|---|---|---|
| Conv2d | 32 | 3 × 3 | 2 | 1 | BatchNorm, SiLU activation |
| MBConv | 16 | 3 × 3 | 1 | 1 | SE module, BatchNorm, SiLU |
| MBConv | 24 | 3 × 3 | 2 | 2 | SE module, BatchNorm, SiLU |
| MBConv | 40 | 5 × 5 | 2 | 2 | SE module, BatchNorm, SiLU |
| MBConv | 80 | 3 × 3 | 2 | 3 | SE module, BatchNorm, SiLU |
| MBConv | 112 | 5 × 5 | 1 | 3 | SE module, BatchNorm, SiLU |
| MBConv | 192 | 5 × 5 | 2 | 4 | SE module, BatchNorm, SiLU |
| MBConv | 320 | 3 × 3 | 1 | 1 | SE module, BatchNorm, SiLU |
| Conv2d | 1280 | 1 × 1 | 1 | 1 | BatchNorm, SiLU activation |
| Fully Connected | 5 | - | - | 1 | Dropout 0.2, Softmax |
| Hyperparameter | Setting |
|---|---|
| Algorithm optimizer | Adam |
| Learning rate | 0.0001 |
| Bachsize | 50 |
| Epoch | 30 |
| Metric | Validation Value | Standard Deviation | Standard Error |
|---|---|---|---|
| Accuracy | 0.9993 | 0.00137 | 0.00043 |
| Precision | 0.9993 | 0.00132 | 0.00041 |
| Recall | 0.9993 | 0.00137 | 0.00043 |
| F1-score | 0.9993 | 0.00136 | 0.00042 |
| Loss | 0.0020 | 0.0036 | 0.00115 |
| Method | Accuracy | Year | Reference |
|---|---|---|---|
| EfficientNet-B0 CNN model with TL approach | 99.93% | 2025 | This work |
| Designed shallow CNN model with data augmentation | 94.34–98.42% | 2024 | [48] |
| Designed CNN model with sintetic samples of formazine and kaolin clays | 90.9–98.7% | 2024 | [49] |
| Customized 4 CNN models: 8 layers, 8 layers with dropout, 10 layers, and 10 layers with dropout, trained with synthetic samples of turbidity caused by calcium carbonate (CaCO3) | 84.0–88.0% | 2025 | [50] |
| Shallow desainged CNN with laboratory and real samples | 97 (laboratory samples)–85% (real samples) | 2024 | [51] |
| Designed a 5 layers CNN model with 3 fully-conected layers | 87.5–97.5% | 2023 | [26] |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN (EfficientNet-B0 + TL) | 99.85% | 99.85% | 99.85% | 99.86% |
| Random Forest | 99.62% | 99.58% | 99.56% | 99.57% |
| MLP | 94.58% | 95.08% | 93% | 94% |
| Class | Precision | Recall | F1-Score | Images Evaluated |
|---|---|---|---|---|
| Class 1 | 0.9882 | 0.9190 | 0.9523 | 1000 |
| Class 2 | 0.8821 | 0.7560 | 0.8142 | 1000 |
| Class 3 | 0.8003 | 0.9540 | 0.8704 | 1000 |
| Class 4 | 0.9725 | 0.9900 | 0.9812 | 1000 |
| Class 5 | 0.9880 | 0.9910 | 0.9895 | 1000 |
| Accuracy | 0.9220 (5000 total samples) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soto, I.L.; Concha-Sánchez, Y.; Raya, A. An Image-Based Water Turbidity Classification Scheme Using a Convolutional Neural Network. Computation 2025, 13, 178. https://doi.org/10.3390/computation13080178
Soto IL, Concha-Sánchez Y, Raya A. An Image-Based Water Turbidity Classification Scheme Using a Convolutional Neural Network. Computation. 2025; 13(8):178. https://doi.org/10.3390/computation13080178
Chicago/Turabian StyleSoto, Itzel Luviano, Yajaira Concha-Sánchez, and Alfredo Raya. 2025. "An Image-Based Water Turbidity Classification Scheme Using a Convolutional Neural Network" Computation 13, no. 8: 178. https://doi.org/10.3390/computation13080178
APA StyleSoto, I. L., Concha-Sánchez, Y., & Raya, A. (2025). An Image-Based Water Turbidity Classification Scheme Using a Convolutional Neural Network. Computation, 13(8), 178. https://doi.org/10.3390/computation13080178