
Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing





Abstract
1. Introduction
1.1. Would MLLM Be Leading the Future of Object Detection?
1.2. Study Contribution
- Provides a detailed review of MLLMs and VLMs in transportation object detection, highlighting benefits and limitations.
- Introduces a structured taxonomy for end-to-end object detection methods in transportation using MLLMs.
- Proposes future directions and applications for MLLMs in transportation object detection.
- Conducts real-world empirical tests on MLLMs for three transportation problems: road safety attribute extraction, safety-critical event detection, and visual reasoning of thermal images.
- Highlights the potential of MLLMs to enhance intelligent transportation systems, contributing to safer, more efficient AVs and traffic management.
- Identifies key challenges and limitations in MLLMs, such as order compositional understanding, fine-detail recognition, object hallucination, and computational limitations.
2. Existing Object Detection Technologies
Limitations of Existing Object Detection Technologies
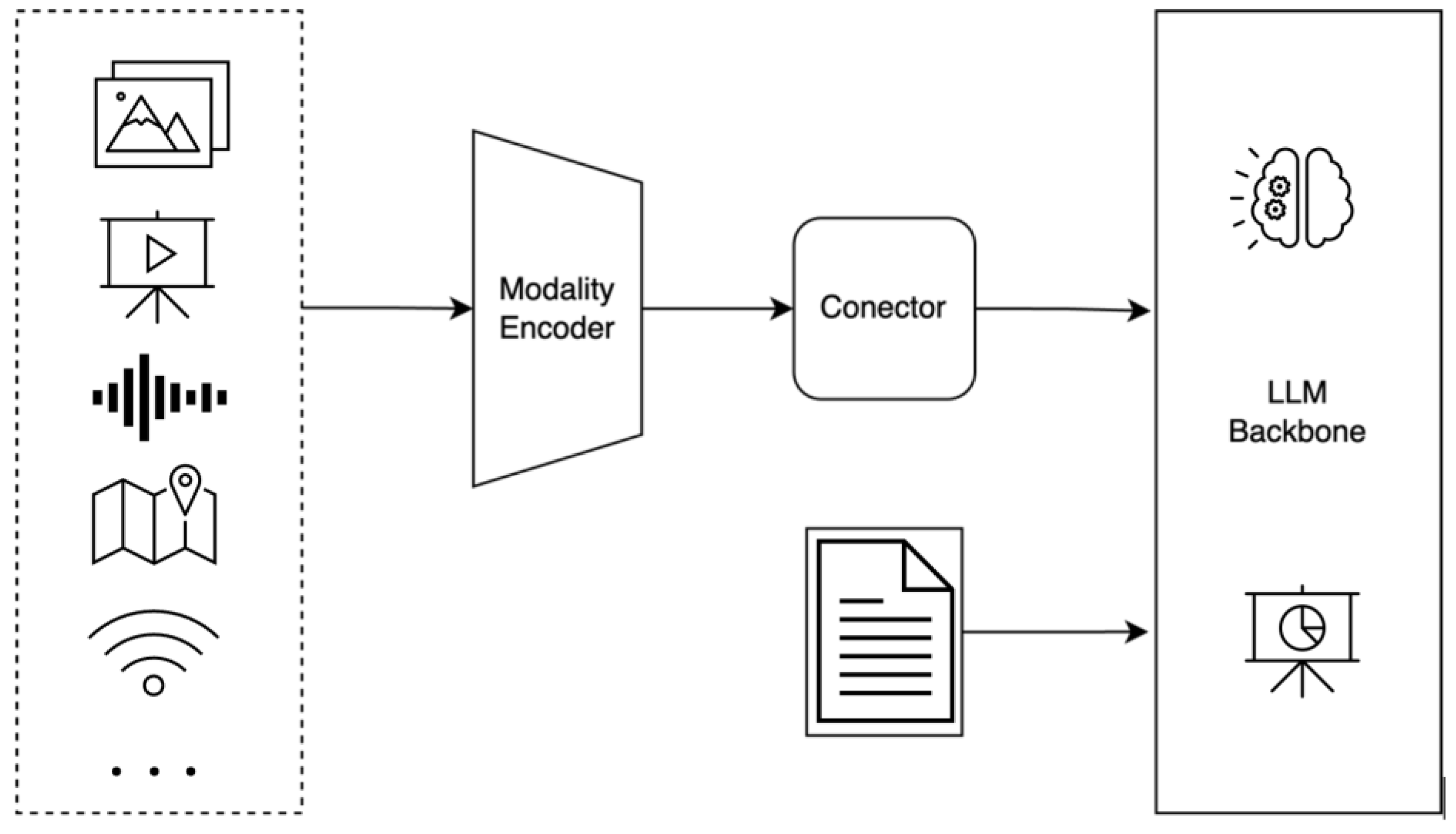
3. Object Detection Using MLLMs
3.1. Focused State-of-the-Art
3.1.1. Relevance to Transportation
3.1.2. Models and Architectures
3.1.3. Dataset Description
3.1.4. Performance Metrics
3.1.5. Model Complexity
3.1.6. Prompt Engineering
3.1.7. Limitations of MLLMs from Previous Studies
- Knapik et al.: the main limitation lies in the reliance on far-infrared imaging, which may not perform well in diverse weather or lighting conditions. Additionally, the model’s ability to generalize to different types of drivers or vehicles is not fully explored, as it is limited to specific driver conditions (e.g., yawning).
- Tami et al.: while the framework effectively detects traffic safety-critical events, its reliance on multimodal data inputs may result in computational inefficiencies, making real-time deployment in complex urban settings a challenge [6].
- Liao et al.: the complexity of using GPT-4 and vision transformers for object detection creates significant computational demand, limiting its scalability for real-world autonomous driving applications. Furthermore, fine-tuning the model for diverse driving conditions and weather scenarios remains an unresolved challenge.
- de Curtò et al.: the study’s focus on UAV scene understanding presents limitations when applied to crowded or fast-changing environments. The zero-shot learning approach may also struggle with novel or highly complex scenes that it has not been pre-trained on.
- Zang et al.: the general focus on human-AI interaction object detection is broad, leading to limitations in transportation-specific contexts. The model’s ability to provide contextually relevant outputs in real-time may falter when faced with highly dynamic or ambiguous scenes.
- Chi et al.: the limitations are noted in real-world applicability due to safety concerns in dynamic environments.
- Zhou et al.: the challenges in scaling the tool for larger datasets, especially when dealing with high-dimensional sensor data.
- Mu et al.: the high computational demand of the Pix2Planning model, which may limit real-time deployment.
3.2. Not Focused State-of-the-Art
3.3. Future Work from Previous Studies
4. Future Directions and Potential Applications
4.1. Case Study 1: Road Safety Attributes Extraction
4.2. Case Study 2: Safety-Critical Event Detection
4.3. Case Study 3: Visual Reasoning of Thermal Images
5. Challenges and Limitations
5.1. Order Compositional Understanding
5.2. Fine-Detail Recognition: Perceptual Limitation
5.3. Cross-Modal Alignment
5.4. Object Hallucination
5.5. Object Counting Accuracy
5.6. Computational Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Campbell, A.; Both, A.; Sun, C. Detecting and mapping traffic signs from Google Street View images using deep learning and GIS. Comput. Environ. Urban. Syst. 2019, 77, 101350. [Google Scholar] [CrossRef]
- Jain, N.K.; Saini, R.K.; Mittal, P. A Review on Traffic Monitoring System Techniques. In Soft Computing: Theories and Applications; Ray, K., Sharma, T.K., Rawat, S., Saini, R.K., Bandyopadhyay, A., Eds.; Springer: Singapore, 2019; Volume 742, pp. 569–577. [Google Scholar] [CrossRef]
- Zitar, R.A.; Alhadhrami, E.; Abualigah, L.; Barbaresco, F.; Seghrouchni, A.E. Optimum sensors allocation for drones multi-target tracking under complex environment using improved prairie dog optimization. Neural Comput. Appl. 2024, 36, 10501–10525. [Google Scholar] [CrossRef]
- Sivaraman, S.; Trivedi, M.M. Looking at Vehicles on the Road: A Survey of Vision-Based Vehicle Detection, Tracking, and Behavior Analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Huang, D.; Yan, C.; Li, Q.; Peng, X. From Large Language Models to Large Multimodal Models: A Literature Review. Appl. Sci. 2024, 14, 5068. [Google Scholar] [CrossRef]
- Tami, M.A.; Ashqar, H.I.; Elhenawy, M.; Glaser, S.; Rakotonirainy, A. Using Multimodal Large Language Models (MLLMs) for Automated Detection of Traffic Safety-Critical Events. Vehicles 2024, 6, 1571–1590. [Google Scholar] [CrossRef]
- Jaradat, S.; Alhadidi, T.I.; Ashqar, H.I.; Hossain, A.; Elhenawy, M. Exploring Traffic Crash Narratives in Jordan Using Text Mining Analytics. arXiv 2024, arXiv:2406.09438. [Google Scholar]
- Elhenawy, M.; Abutahoun, A.; Alhadidi, T.I.; Jaber, A.; Ashqar, H.I.; Jaradat, S.; Abdelhay, A.; Glaser, S.; Rakotonirainy, A. Visual Reasoning and Multi-Agent Approach in Multimodal Large Language Models (MLLMs): Solving TSP and mTSP Combinatorial Challenges. Mach. Learn. Knowl. Extr. 2024, 6, 1894–1920. [Google Scholar] [CrossRef]
- Belhaouari, S.B.; Kraidia, I. Efficient self-attention with smart pruning for sustainable large language models. Sci. Rep. 2025, 15, 10171. [Google Scholar] [CrossRef]
- Luo, S.; Chen, W.; Tian, W.; Liu, R.; Hou, L.; Zhang, X.; Shen, H.; Wu, R.; Geng, S.; Zhou, Y.; et al. Delving Into Multi-Modal Multi-Task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives. IEEE Trans. Intell. Veh. 2024, 1–25. [Google Scholar] [CrossRef]
- Zhang, D.; Zheng, H.; Yue, W.; Wang, X. Advancing ITS Applications with LLMs: A Survey on Traffic Management, Transportation Safety, and Autonomous Driving. In Proceedings of the Rough Sets: International Joint Conference, IJCRS 2024, Halifax, NS, Canada, 17–20 May 2024; pp. 295–309. [Google Scholar] [CrossRef]
- Veres, M.; Moussa, M. Deep Learning for Intelligent Transportation Systems: A Survey of Emerging Trends. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3152–3168. [Google Scholar] [CrossRef]
- Naveed, Q.N.; Alqahtani, H.; Khan, R.U.; Almakdi, S.; Alshehri, M.; Rasheed, M.A.A. An Intelligent Traffic Surveillance System Using Integrated Wireless Sensor Network and Improved Phase Timing Optimization. Sensors 2022, 22, 3333. [Google Scholar] [CrossRef] [PubMed]
- Yoon, S.; Cho, J. Deep Multimodal Detection in Reduced Visibility Using Thermal Depth Estimation for Autonomous Driving. Sensors 2022, 22, 5084. [Google Scholar] [CrossRef]
- Wang, Y.; Mao, Q.; Zhu, H.; Deng, J.; Zhang, Y.; Ji, J.; Li, H.; Zhang, Y. Multi-Modal 3D Object Detection in Autonomous Driving: A Survey. Int. J. Comput. Vis. 2023, 131, 2122–2152. [Google Scholar] [CrossRef]
- Guo, J.; Song, B.; Chen, S.; Yu, F.R.; Du, X.; Guizani, M. Context-Aware Object Detection for Vehicular Networks Based on Edge-Cloud Cooperation. IEEE Internet Things J. 2020, 7, 5783–5791. [Google Scholar] [CrossRef]
- Lee, W.-Y.; Jovanov, L.; Philips, W. Cross-Modality Attention and Multimodal Fusion Transformer for Pedestrian Detection. In Proceedings of the Computer Vision—ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; pp. 608–623. [Google Scholar] [CrossRef]
- Chen, Y.; Ye, J.; Wan, X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electr. Veh. J. 2023, 14, 352. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, W.; Lin, H.; Liu, Y.; Qu, X. Applying masked language model for transport mode choice behavior prediction. Transp. Res. Part A Policy Pract. 2024, 184, 104074. [Google Scholar] [CrossRef]
- Wang, X.; Chen, G.; Qian, G.; Gao, P.; Wei, X.-Y.; Wang, Y.; Tian, Y.; Gao, W. Large-scale Multi-modal Pre-trained Models: A Comprehensive Survey. Mach. Intell. Res. 2023, 20, 447–482. [Google Scholar] [CrossRef]
- Zhou, S.; Deng, C.; Piao, Z.; Zhao, B. Few-shot traffic sign recognition with clustering inductive bias and random neural network. Pattern Recognit. 2020, 100, 107160. [Google Scholar] [CrossRef]
- Bansal, A.; Sikka, K.; Sharma, G.; Chellappa, R.; Divakaran, A. Zero-Shot Object Detection. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 397–414. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, L.; He, T. A Closer Look at Few-Shot Object Detection. In Pattern Recognition and Computer Vision; Springer: Singapore, 2024; pp. 430–447. [Google Scholar] [CrossRef]
- Liu, Y.; Meng, S.; Wang, H.; Liu, J. Deep learning based object detection from multi-modal sensors: An overview. Multimed. Tools Appl. 2023, 83, 19841–19870. [Google Scholar] [CrossRef]
- Hu, Z.; Lam, W.H.K.; Wong, S.C.; Chow, A.H.F.; Ma, W. Turning traffic surveillance cameras into intelligent sensors for traffic density estimation. Complex. Intell. Syst. 2023, 9, 7171–7195. [Google Scholar] [CrossRef]
- Radwan, A.; Amarneh, M.; Alawneh, H.; Ashqar, H.I.; AlSobeh, A.; Magableh, A.A.A.R. Predictive Analytics in Mental Health Leveraging LLM Embeddings and Machine Learning Models for Social Media Analysis. Int. J. Web Serv. Res. (IJWSR) 2024, 21, 1–22. [Google Scholar] [CrossRef]
- Fan, Z.; Loo, B.P.Y. Street life and pedestrian activities in smart cities: Opportunities and challenges for computational urban science. Comput. Urban. Sci. 2021, 1, 26. [Google Scholar] [CrossRef]
- Masri, S.; Ashqar, H.I.; Elhenawy, M. Leveraging Large Language Models (LLMs) for Traffic Management at Urban Intersections: The Case of Mixed Traffic Scenarios. arXiv 2024, arXiv:2408.00948. [Google Scholar]
- Elhenawy, M.; Ashqar, H.I.; Masoud, M.; Almannaa, M.H.; Rakotonirainy, A.; Rakha, H.A. Deep transfer learning for vulnerable road users detection using smartphone sensors data. Remote Sens. 2020, 12, 3508. [Google Scholar] [CrossRef]
- Li, H.; Yin, Z.; Fan, C.; Wang, X. YOLO-MFE: Towards More Accurate Object Detection Using Multiscale Feature Extraction. In Proceedings of the Sixth International Conference on Intelligent Computing, Communication, and Devices (ICCD 2023), Hong Kong, China, 3–5 March 2023. [Google Scholar] [CrossRef]
- Channakeshnava Gowda, S.V.; Lokesh, D.S.; Peddinni Sai, K.; Praveen Kumar, S.; Pushpanathan, G. Object Detection Using Open CV and Deep Learning. Int. J. Sci. Res. Eng. Manag. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Nabati, R.; Qi, H. RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles. arXiv 2019, arXiv:1905.00526. [Google Scholar] [CrossRef]
- García-Aguilar, I.; García-González, J.; Luque-Baena, R.M.; López-Rubio, E. Object detection in traffic videos: An optimized approach using super-resolution and maximal clique algorithm. Neural Comput. Appl. 2023, 35, 18999–19013. [Google Scholar] [CrossRef]
- Moreau, H.; Vassilev, A.; Chen, L. The devil is in the details: An efficient convolutional neural network for transport mode detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 12202–12212. [Google Scholar] [CrossRef]
- Wei, J.; He, J.; Zhou, Y.; Chen, K.; Tang, Z.; Xiong, Z. Enhanced object detection with deep convolutional neural networks for advanced driving assistance. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1572–1583. [Google Scholar] [CrossRef]
- Nafaa, S.; Ashour, K.; Mohamed, R.; Essam, H.; Emad, D.; Elhenawy, M.; Ashqar, H.I.; Hassan, A.A.; Alhadidi, T.I. Advancing Roadway Sign Detection with YOLO Models and Transfer Learning. In Proceedings of the 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), Mount Pleasant, MI, USA, 13–14 April 2024; IEEE: New York, NY, USA, 2024; pp. 1–4. [Google Scholar]
- Nafaa, S.; Ashour, K.; Mohamed, R.; Essam, H.; Emad, D.; Elhenawy, M.; Ashqar, H.I.; Hassan, A.A.; Alhadidi, T.I. Automated Pavement Cracks Detection and Classification Using Deep Learning. In Proceedings of the 2024 IEEE 3rd International Conference on Computing and Machine Intelligence (ICMI), Mount Pleasant, MI, USA, 13–14 April 2024; IEEE: New York, NY, USA, 2024; pp. 1–5. [Google Scholar]
- Lu, K.; Zhao, F.; Xu, X.; Zhang, Y. An object detection algorithm combining self-attention and YOLOv4 in traffic scene. PLoS ONE 2023, 18, e0285654. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, J.; Ma, Y.; Ren, P. Lightweight object detection algorithm based on YOLOv5 for unmanned surface vehicles. Front. Mar. Sci. 2023, 9, 1058401. [Google Scholar] [CrossRef]
- Ding, Q.; Liu, H.; Luo, H.; Chen, X. Road detection network based on anti-disturbance and variable-scale spatial context detector. IEEE Access 2021, 9, 114640–114648. [Google Scholar] [CrossRef]
- Li, G.; Xie, H.; Yan, W.; Chang, Y.; Qu, X. Detection of road objects with small appearance in images for autonomous driving in various traffic situations using a deep learning based approach. IEEE Access 2020, 8, 211164–211172. [Google Scholar] [CrossRef]
- Tao, Y.; Zhang, X.; Zhou, F. Autonomous Railway Traffic Object Detection Using Feature-Enhanced Single-Shot Detector. IEEE Access 2020, 8, 145182–145193. [Google Scholar] [CrossRef]
- Chen, Y.; Duan, Z.; Yan, H. R-YOLOv5: A Lightweight Rotation Detector for Remote Sensing. In Proceedings of the International Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2022), Zhuhai, China, 25–27 February 2022. [Google Scholar] [CrossRef]
- Gaidash, V.; Grakovski, A. ‘Mass Centre’ Vectorization Algorithm for Vehicle’s Counting Portable Video System. Transp. Telecommun. J. 2016, 17, 289–297. [Google Scholar] [CrossRef]
- Knapik, M.; Cyganek, B.; Balon, T. Multimodal Driver Condition Monitoring System Operating in the Far-Infrared Spectrum. Electronics 2024, 13, 3502. [Google Scholar] [CrossRef]
- Liao, H.; Shen, H.; Li, Z.; Wang, C.; Li, G.; Bie, Y.; Xu, C. GPT-4 enhanced multimodal grounding for autonomous driving: Leveraging cross-modal attention with large language models. Commun. Transp. Res. 2024, 4, 100116. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I.; Calafate, C.T. Semantic Scene Understanding with Large Language Models on Unmanned Aerial Vehicles. Drones 2023, 7, 114. [Google Scholar] [CrossRef]
- Zang, Y.; Li, W.; Han, J.; Zhou, K.; Loy, C.C. Contextual Object Detection with Multimodal Large Language Models. Int. J. Comput. Vis. 2024, 133, 825–843. [Google Scholar] [CrossRef]
- Chi, F.; Wang, Y.; Nasiopoulos, P.; Leung, V.C.M. Multi-Modal GPT-4 Aided Action Planning and Reasoning for Self-driving Vehicles. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 7325–7329. [Google Scholar] [CrossRef]
- Zhou, Y.; Cai, L.; Cheng, X.; Zhang, Q.; Xue, X.; Ding, W.; Pu, J. OpenAnnotate2: Multi-Modal Auto-Annotating for Autonomous Driving. IEEE Trans. Intell. Veh. 2024, 1–13. [Google Scholar] [CrossRef]
- Mu, X.; Qin, T.; Zhang, S.; Xu, C.; Yang, M. Pix2Planning: End-to-End Planning by Vision-language Model for Autonomous Driving on Carla Simulator. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: New York, NY, USA, 2024; pp. 2383–2390. [Google Scholar] [CrossRef]
- Sammoudi, M.; Habaybeh, A.; Ashqar, H.I.; Elhenawy, M. Question-Answering (QA) Model for a Personalized Learning Assistant for Arabic Language. arXiv 2024, arXiv:2406.08519. [Google Scholar]
- Tami, M.; Ashqar, H.I.; Elhenawy, M. Automated Question Generation for Science Tests in Arabic Language Using NLP Techniques. arXiv 2024, arXiv:2406.08520. [Google Scholar]
- Rouzegar, H.; Makrehchi, M. Generative AI for Enhancing Active Learning in Education: A Comparative Study of GPT-3.5 and GPT-4 in Crafting Customized Test Questions. arXiv 2024, arXiv:2406.13903. [Google Scholar]
- Xi, S.; Liu, Z.; Wang, Z.; Zhang, Q.; Ding, H.; Kang, C.C.; Chen, Z. Autonomous Driving Roadway Feature Interpretation Using Integrated Semantic Analysis and Domain Adaptation. IEEE Access 2024, 12, 98254–98269. [Google Scholar] [CrossRef]
- Ou, K.; Dong, C.; Liu, X.; Zhai, Y.; Li, Y.; Huang, W.; Qiu, W.; Wang, Y.; Wang, C. Drone-TOOD: A Lightweight Task-Aligned Object Detection Algorithm for Vehicle Detection in UAV Images. IEEE Access 2024, 12, 41999–42016. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Gurbuz, A.C.; Ball, J.E. Emerging Trends in Autonomous Vehicle Perception: Multimodal Fusion for 3D Object Detection. World Electr. Veh. J. 2024, 15, 20. [Google Scholar] [CrossRef]
- Murozi, A.-F.M.; Ishak, S.Z.; Nusa, F.N.M.; Hoong, A.P.W.; Sulistyono, S. The application of international road assessment programme (irap) as a road infrastructure risk assessment tool. In Proceedings of the 2022 IEEE 13th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, 23 July 2022; IEEE: New York, NY, USA, 2022; pp. 237–242. [Google Scholar]
- World Health Organization. Global Status Report on Road Safety 2015; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Angelo, A.A.; Sasai, K.; Kaito, K. Assessing critical road sections: A decision matrix approach considering safety and pavement condition. Sustainability 2023, 15, 7244. [Google Scholar] [CrossRef]
- Alhadidi, T.I.; Jaber, A.; Jaradat, S.; Ashqar, H.I.; Elhenawy, M. Object Detection Using Oriented Window Learning Vision Transformer: Roadway Assets Recognition. arXiv 2024, arXiv:2406.10712. Available online: https://api.semanticscholar.org/CorpusID:270560797 (accessed on 1 January 2025).
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Wang, Z. Receive, reason, and react: Drive as you say, with large language models in autonomous vehicles. IEEE Intell. Transp. Syst. Mag. 2024, 16, 81–94. [Google Scholar] [CrossRef]
- Sha, H.; Mu, Y.; Jiang, Y.; Chen, L.; Xu, C.; Luo, P.; Li, S.E.; Tomizuka, M.; Zhan, W.; Ding, M. Languagempc: Large language models as decision makers for autonomous driving. arXiv 2023, arXiv:2310.03026. [Google Scholar]
- Xu, Z.; Zhang, Y.; Xie, E.; Zhao, Z.; Guo, Y.; Wong, K.-Y.K.; Li, Z.; Zhao, H. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. arXiv 2023, arXiv:2310.01412. [Google Scholar] [CrossRef]
- Yu, X.; Marinov, M. A study on recent developments and issues with obstacle detection systems for automated vehicles. Sustainability 2020, 12, 3281. [Google Scholar] [CrossRef]
- He, Y.; Deng, B.; Wang, H.; Cheng, L.; Zhou, K.; Cai, S.; Ciampa, F. Infrared machine vision and infrared thermography with deep learning: A review. Infrared Phys. Technol. 2021, 116, 103754. [Google Scholar] [CrossRef]
- Nidamanuri, J.; Nibhanupudi, C.; Assfalg, R.; Venkataraman, H. A progressive review: Emerging technologies for ADAS driven solutions. IEEE Trans. Intell. Veh. 2021, 7, 326–341. [Google Scholar] [CrossRef]
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal object detection in difficult weather conditions using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Leira, F.S.; Helgesen, H.H.; Johansen, T.A.; Fossen, T.I. Object detection, recognition, and tracking from UAVs using a thermal camera. J. Field Robot. 2021, 38, 242–267. [Google Scholar] [CrossRef]
- Krišto, M.; Ivašić-Kos, M. Thermal imaging dataset for person detection. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; IEEE: New York, NY, USA, 2019; pp. 1126–1131. [Google Scholar]
- Yuksekgonul, M.; Bianchi, F.; Kalluri, P.; Jurafsky, D.; Zou, J. When and why vision-language models behave like bags-of-words, and what to do about it? In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liu, H.; Xue, W.; Chen, Y.; Chen, D.; Zhao, X.; Wang, K.; Hou, L.; Li, R.; Peng, W. A survey on hallucination in large vision-language models. arXiv 2024, arXiv:2402.00253. [Google Scholar]
- Zhang, J.; Hu, J.; Khayatkhoei, M.; Ilievski, F.; Sun, M. Exploring perceptual limitation of multimodal large language models. arXiv 2024, arXiv:2402.07384. [Google Scholar]
- Yang, S.; Zhai, B.; You, Q.; Yuan, J.; Yang, H.; Xu, C. Law of Vision Representation in MLLMs. arXiv 2024, arXiv:2408.16357. [Google Scholar]
- Li, Y.; Du, Y.; Zhou, K.; Wang, J.; Zhao, W.X.; Wen, J.-R. Evaluating object hallucination in large vision-language models. arXiv 2023, arXiv:2305.10355. [Google Scholar]
- Jaradat, S.; Nayak, R.; Paz, A.; Ashqar, H.I.; Elhenawy, M. Multitask Learning for Crash Analysis: A Fine-Tuned LLM Framework Using Twitter Data. Smart Cities 2024, 7, 2422–2465. [Google Scholar] [CrossRef]
- Masri, S.; Raddad, Y.; Khandaqji, F.; Ashqar, H.I.; Elhenawy, M. Transformer Models in Education: Summarizing Science Textbooks with AraBART, MT5, AraT5, and mBART. arXiv 2024, arXiv:2406.07692. [Google Scholar]
- Bai, G.; Chai, Z.; Ling, C.; Wang, S.; Lu, J.; Zhang, N.; Shi, T.; Yu, Z.; Zhu, M.; Zhang, Y.; et al. Beyond efficiency: A systematic survey of resource-efficient large language models. arXiv 2024, arXiv:2401.00625. [Google Scholar]
- Kwon, W.; Li, Z.; Zhuang, S.; Sheng, Y.; Zheng, L.; Yu, C.H.; Gonzalez, J.; Zhang, H.; Stoica, I. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, Koblenz, Germany, 23–26 October 2023; pp. 611–626. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Title | Taxonomy | Transportation Relevance |
|---|---|---|---|
| [45] | Multimodal Driver Condition Monitoring System Operating in the Far-Infrared Spectrum | Driver fatigue detection via thermal images | High relevance for transportation safety |
| [6] | Using Multimodal LLMs for Automated Detection of Traffic Safety-Critical Events | Safety-critical traffic events detection | High relevance for road safety and potential hazards |
| [46] | GPT-4 Enhanced Multimodal Grounding for Autonomous Driving: Leveraging Cross-Modal Attention with Large Language Models | Object detection for autonomous driving | High relevance for autonomous driving systems |
| [47] | Semantic Scene Understanding with Large Language Models on Unmanned Aerial Vehicles | Scene understanding for Unmanned Aerial Vehicles | Indirect relevance but a potential application in aerial traffic monitoring |
| [48] | Contextual Object Detection with Multimodal Large Language Models | General object detection in human-AI interaction scenarios | Indirect relevance but a potential for object detection in varied contexts |
| [49] | Multi-Modal GPT-4 Aided Action Planning and Reasoning for Self-driving Vehicles | Explainable decision-making from monocular cameras | High relevance for planning and reasoning in self-driving vehicles |
| [50] | OpenAnnotate2: Multi-Modal Auto-Annotating for Autonomous Driving | Integrates various modalities to improve annotation accuracy for large datasets | High relevance for auto-annotating data in autonomous driving systems |
| [51] | Pix2Planning: End-to-End Planning by Vision-language Model for Autonomous Driving on Carla Simulator | End-to-end vision-language modeling for autonomous driving | High relevance for translation visual inputs into language-based trajectory planning |
| Study | Dataset | Data Type | MLLM/LLM Used | Size | Performance |
|---|---|---|---|---|---|
| [45] | Thermal image dataset | Images | ChatGPT3.5-turbo + YOLOv8 | Large | mAP = 0.94 |
| [6] | DRAMA dataset | Images, text | Gemini Pro-Vision 1.5 MLLM | Medium | Accuracy = 79% |
| [46] | Talk2Car | Images, text | GPT-4, Vision Transformer | Large | mAP = 0.75 |
| [47] | Custom UAV dataset | Images, video | GPT-3, CLIP, YOLOv7 | Medium | - |
| [48] | COCO, CODE Benchmark | Images, text | GPT-3, BLIP-2 | Large | AP = 43.4 |
| [49] | CARLA | Images, text, and sensor data | GPT-4, Graph-of-Thought (GoT) | Large | - |
| [50] | SemanticKITTI | Images and multimodal sensor data | GPT-4, Langchain | Large | - |
| [51] | CARLA | Images, BEV representations, and text | Autoregressive transformer | Large | DS = 92.39 RC = 99.60 |
| |||||
| Your role is systematically inspecting an image for various road features. --- Road Inspection Checklist 1. Number of Lanes—Count the number of lanes in the direction closest to the camera. Provide the number without additional comment. 2. School Zone Warning—Inspect for school zone warning signs and select the appropriate option: 1. School zone flashing beacons 2. School zone static signs or road markings 3. No school zone warning 4. Not applicable (no school at the location) 3. School Zone Crossing Supervisor—Observe for the presence of a school zone crossing supervisor and select one: 1. Supervisor present at school start and finish times 2. Supervisor not present 3. Not applicable (no school at the location) 4. Roads that Cars Can Read - Inspect the following and provide ‘yes’, ‘no’, or an applicable comment: - Clear and consistent road signage visible and unobstructed. - Well-defined road markings, maintained with high contrast for visibility. 5. Roadworks—Examine the area for roadworks and choose one: 1. No roadworks 2. Minor roadworks in progress 3. Major roadworks in progress 6. Pedestrian Fencing—Check for pedestrian fencing (guard rails) and select one: 1. Not present 2. Present 7. Vehicle Parking—Inspect the area for vehicle parking and select one: 1. None 2. Each roadside has at least one parked vehicle 3. At least one vehicle is parked on one side of the road 8. Speed Management/Traffic Calming —Identify any present speed management features such as curb buildouts, speed humps, raised tables, etc. 9. Median Type - Examine the image and identify any present median type: - Options include centreline, wide centreline, central hatching, continuous central turning lane, various physical median widths, safety barriers, etc. 10. Carriageway—Inspect the image and select one: 1. Divided carriageway 2. Undivided carriageway 11. Quality of curve—Inspect the image to identify any present road curvature then select one: 1. Poor 2. Not applicable 3. Adequate |
 Map data: © 2024 Google. Number of Lanes: there are four lanes in the direction closest to the camera. School Zone Warning: no school zone warning School Zone Crossing Supervisor: not applicable (no school at the location) Roads that Cars Can Read: yes, clear and consistent road signage is visible and unobstructed. Yes, well-defined road markings, maintained with high contrast for visibility. Roadworks: no roadworks Pedestrian Fencing: present, as there is a barrier between the pedestrian walkway and the road. Vehicle Parking: none Speed Management/Traffic Calming: No visible speed management features such as curb buildouts, speed humps, raised tables, etc. Median Type: safety barriers are present between the opposite lanes of traffic. Carriageway: divided carriageway Quality of Curve: not applicable, as no significant road curvature is visible in the image provided. |
| Q/A Stage | Gemini Pro Vision 1.0 with Two-Frame Input | Llava-7B 1.5 with Two-Frame Input | Gemini Pro Vision 1.0 with Video as Input |
|---|---|---|---|
| Risk | 55% | 46% | 75% |
| Scene | 90% | 76% | 100% |
| What | 83% | 71% | 66% |
| Which | 87% | 59% | 66% |
| Where | 61% | 49% | 66% |
| Recommended Action | 55% | 51% | 75% |
| Overall | 71.8% | 58.6% | 74.67% |
| MLLM Model | GPT4 Vision Preview | Gemini 1.0 Pro Vision | ||
|---|---|---|---|---|
| Evaluation Metrics per Category | TPR | FPR | TPR | FPR |
| Category ID 1: person | 0.57 | 0 | 0.39 | 0 |
| Category ID 2: bike | 0.31 | 0.01 | 0.41 | 0.02 |
| Category ID 3: car | 0.86 | 0.09 | 0.90 | 0.08 |
| Category ID 4: motorcycle | 0.08 | 0 | 0.24 | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ashqar, H.I.; Jaber, A.; Alhadidi, T.I.; Elhenawy, M. Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing. Computation 2025, 13, 133. https://doi.org/10.3390/computation13060133
Ashqar HI, Jaber A, Alhadidi TI, Elhenawy M. Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing. Computation. 2025; 13(6):133. https://doi.org/10.3390/computation13060133
Chicago/Turabian StyleAshqar, Huthaifa I., Ahmed Jaber, Taqwa I. Alhadidi, and Mohammed Elhenawy. 2025. "Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing" Computation 13, no. 6: 133. https://doi.org/10.3390/computation13060133
APA StyleAshqar, H. I., Jaber, A., Alhadidi, T. I., & Elhenawy, M. (2025). Advancing Object Detection in Transportation with Multimodal Large Language Models (MLLMs): A Comprehensive Review and Empirical Testing. Computation, 13(6), 133. https://doi.org/10.3390/computation13060133