1. Introduction
Object recognition is one of the most popular practical applications of computer vision. Solving the problem of visual detection opens opportunities for optimizing many processes. In manufacturing, systems often identify and sort objects without human intervention [
1]. The existence of autonomous vehicles is impossible without automatic object localization, which allows for the detection of obstacles and route planning. Object recognition systems help monitor important events or suspicious activities in the security sector, significantly enhancing monitoring efficiency. In healthcare, such systems assist in diagnostics. Optimizing the model development process for recognition will significantly save resources [
2].
Synthetic data for training object detection models has attracted growing interest due to its scalability and flexibility. However, existing methods often suffer from adaptability, precision, or generalizability limitations.
Traditional simulation tools [
3,
4] offer scalable data generation but require complex scene setups and are limited to generic object categories. Copy-paste techniques [
5,
6,
7] are simpler and produce pure consistency with background and appearance in terms of positioning, interaction with other objects, and lightning. GAN-based methods [
8,
9,
10] provide realism but often require complicated training; hence, it is difficult to adapt them to new objects. Recent diffusion models [
11,
12,
13,
14,
15] achieve high visual quality but still struggle with precise spatial control and object-specific generation, limiting their effectiveness for domain-specific tasks.
In contrast, the proposed method introduces a framework that leverages the strengths of current generative models—particularly diffusion models—while addressing their limitations in spatial control and fidelity. Our architecture integrates a 3D representation to preserve object-specific geometric features, allowing for consistent and accurate placement within complex scenes. After relevant views are sampled, context is generated using generative vision models.
By avoiding heavy retraining or architecture-specific modifications, our method remains compatible with new generative model versions as they become available, making it significantly more adaptable and resource-efficient than prior work.
The proposed solution holds practical value for developing object recognition models, as it provides a flexible and scalable way to obtain training data applicable in various fields—from industry to medicine and life safety. These changes will enhance production capacities, reduce energy resource consumption and material costs, and improve product quality [
16].
On the other hand, it presents new challenges for society, such as improving workplace safety and adapting the workforce to new working conditions. It is also important to consider new technologies’ social and environmental aspects, such as their impact on employee health and well-being, environmental preservation, ethical issues related to artificial intelligence, and other concerns that require a balanced approach and careful investigation [
17].
The relevance of this research is determined by the need to develop strategies to implement technological innovations effectively. These strategies must consider economic, social, and environmental aspects to ensure sustainable development and an improved quality of life.
This research aims to investigate existing image generation methods and propose a holistic approach for building recognition models based on synthetic training data. The contributions of this work include:
Comprehensive analysis of current synthetic data generation methods for automated dataset creation.
Introduces a diffusion-based pipeline that supports robust object localization with minimal real data, enhancing efficiency and reducing computational cost.
This work validates the algorithm’s effectiveness on real-world data.
2. Related Works
Object recognition generally involves two main stages: object detection—locating all objects within a predefined set—and classification—assigning each detected object its correct label. Traditional approaches such as SIFT [
18] and HOG [
19] rely on handcrafted features; SIFT detects scale and rotation invariant key points, while HOG computes gradient histograms over subregions. These methods, however, require significant manual effort and often fall short when dealing with complex object variations. Early classification techniques like SVM [
20] and Adaboost [
21] built on these features but were limited by their simplistic representations. The advent of Convolutional Neural Networks [
22] (CNNs) transformed object recognition by automatically learning hierarchical features. Starting from AlexNet [
23] and evolving through architectures such as VGG [
24] and ResNet [
25], CNNs have dramatically improved both accuracy and efficiency. Modern object detection frameworks now fall into two categories: two-stage detectors (e.g., Faster R-CNN [
26]) that first propose candidate regions before detailed classification and single-stage detectors (e.g., YOLO [
27], SSD [
28]) that perform localization and classification simultaneously, offering a practical balance between speed and precision. However, due to the empirical nature of these methods, high-quality training data are essential to achieve robust performance.
2.1. Synthetic Data Generation for Object Detection
Simulation-based approaches such as Unity Perception [
4] offer scalable pipelines for generating large amounts of synthetic data through traditional 3D rendering. These methods leverage 3D scene setups to produce realistic visualizations; however, they require complex scene design and calibration, and they are typically limited to broad, general-purpose datasets featuring everyday objects like vehicles or pedestrians. As demonstrated in [
3], the performance gains from synthetic datasets often scale non-linearly—especially when the generated samples lack the necessary realism or exhibit insufficient spatial variability.
Copy-paste techniques provide an alternative augmentation strategy by compositing object instances from one scene into another. Methods like those presented in [
5,
6] have shown measurable improvements in low-data regimes. Despite their simplicity and efficiency, these techniques do not synchronize background and object appearance. This difference leads to unrealistic object placements and reduced generalization, particularly when dealing with occlusions or non-standard viewpoints.
GAN-based approaches—including [
8,
9,
10]—aim to generate synthetic training images via adversarial training. Although these models show promise in producing detailed images, they often struggle to maintain spatial consistency and preserve object fidelity in complex or industrial scenes. Their training processes are computationally intensive and require significant re-adaptation when extending to new object categories or domains.
Recent diffusion-based methods, such as DiffusionEngine [
11], ODGEN [
12], Gen2Det [
13], and InstaGen [
29], represent a noteworthy advancement in text-to-image synthesis by achieving high image quality. However, these models typically lack the precise spatial control to dictate object placement, scale, or orientation. Even advanced systems like GEODIFFUSION [
14] and The Big Data Myth [
15] rely on coarse structural guidance or necessitate domain-specific fine-tuning with real data, which limits their scalability in practical applications.
For product placement scenarios, approaches like [
30,
31] have explored reference-based inpainting. While these methods can insert products under generated masks, they are generally confined to advertising applications and do not support arbitrary, user-defined spatial control. In contrast, techniques such as [
32,
33]’s framework offer more straightforward yet effective strategies for maintaining object identity during image generation.
Overall, each synthetic data generation method category presents its advantages and limitations regarding scalability, realism, and spatial control. Our work addresses these challenges by proposing a novel, model-agnostic framework that integrates 3D reconstruction with controlled image generation. This framework ensures high visual fidelity, maintains precise spatial representation, and is well-suited for generating synthetic data for unique or custom object detection tasks.
2.2. Methods of 3D Object Reconstruction
One of Computer Vision’s most popular research directions is 3D object reconstruction. Modern 3D reconstruction methods allow for highly precise digitalization of objects and environments. This ensures their wide application in various fields, such as game development and industry. We will examine the main approaches to 3D reconstruction.Structure from Motion (SfM) [
34] is a widely used method for reconstructing 3D geometry from 2D images taken from multiple angles. Instead of generating a complete 3D model, SfM creates a point cloud. Its simplicity and low computational requirements make it accessible, even with a basic camera or smartphone. However, the quality of the point cloud is highly dependent on the consistency and quality of the input images; poor image quality or inconsistent lighting can lead to errors in keypoint matching and, consequently, a lower-quality reconstruction.
Figure 1 shows the basic idea of Structure from Motion (SfM) and other 3D reconstruction methods is to use multiple images taken from different angles.
NeRF (Neural Radiance Fields) [
35] is a modern 3D reconstruction method that implicitly trains a compact neural network to encode scene geometry from multiple 2D images. The model predicts pixel values using a ray-based sampling process by specifying a camera position. NeRF excels at reconstructing complex, reflective, or refractive surfaces from limited input data, making it ideal for applications in virtual reality and digital art. However, its high computational demands and slow rendering prevent real-time visualization and require significant GPU resources.
The 3D Gaussian Splatting method [
36] is a recent 3D reconstruction technique that offers high-quality, real-time rendering through a compact scene representation. Unlike NeRF, which relies on large neural networks and extensive training, Gaussian Splatting uses a set of 3D Gaussians—allowing for similar visual fidelity without heavy computational requirements or a GPU for visualization. The process starts with a Structure-from-Motion (SfM) reconstruction, which generates an initial point cloud that forms the basis for placing the 3D Gaussians. These Gaussians are then iteratively optimized using a differentiable rendering process similar to NeRF, where gradient backpropagation minimizes the difference between the predicted and original images. Each Gaussian is defined by its position, radii along three axes, color parameters, and transparency value [
36]. Overall, the Gaussian Splatting method delivers exceptional detail and performance, making it an attractive option for computer vision tasks in complex real-world scenarios, including virtual and augmented reality applications.
3. Method
The method for generating synthetic data begins with the stage of 3D reconstruction of the object, which allows for the creation of a detailed three-dimensional model of the object. The previously mentioned SfM reconstruction method is used for this step. This approach produces a digital model that can generate various perspectives of the object. As a result, the obtained three-dimensional models can represent the object from different viewpoints, enabling it to learn to recognize the object from any angle, simulating various scenarios of its appearance in the real world.
3.1. 3D Reconstruction
A comparative analysis was conducted between Structure from Motion (SfM) and Gaussian Splatting. The objective was to determine the method that most effectively generates a 3D model of a selected object using a fixed set of input images.
The 3D reconstruction process employed in this study utilizes COLMAP’s incremental Structure-from-Motion (SfM) pipeline, followed by dense reconstruction and mesh generation. Sparse reconstruction produces point clouds of 10,000 to 100,000 points, depending on the object’s complexity and image quality. In this experiment, 50 images with a resolution of 1024 × 1024 were used, resulting in nearly 20,000 points produced after the first stage.
The official implementation of Gaussian Splating was used. No additional filtering was applied. Reconstruction was done on the same image set as in SfM.
Table 1 summarizes four representative reconstruction views. Gaussian Splatting successfully reproduced the object from training-set viewpoints 1 and 2. However, it introduced significant artifacts when rendering unseen angles, such as the sole or rear of the sneaker, as shown in views 3 and 4.
In contrast, SfM delivered less realistic images but maintained consistent reconstruction across all viewpoints. Given this consistency and acceptable quality, SfM is preferred for future reconstruction tasks where stability across views is critical.
3.2. Rendering View Sampling
Each training sample requires a camera view, but not all views are equally valid or meaningful. Objects appear more frequently from certain angles—such as front or top-down views—while others, like views from underneath or extreme side angles, are less plausible or useful. A semi-automated method for view sampling was introduced. Algorithm 1 demonstrates constrained view sampling on the unit sphere. The user sets sampling constraints in spherical coordinates. This allows for reproducible and flexible sampling of plausible viewpoints while maintaining a uniform distribution within the desired range.
| Algorithm 1: Constrained View Sampling on the Unit Sphere |
Input:
1. Number of views to sample: N
2. Azimuth angle range: θ ∈ [θ_min, θ_max]
3. Elevation angle range: φ ∈ [φ_min, φ_max] (measured from the positive z-axis)
Output:
1. List of 3D unit vectors (x, y, z) representing sampled view directions
Procedure:
For each of the N views, do:
Sample azimuth angle θ uniformly from [θ_min, θ_max]
Sample a uniform random number u ∈ [0, 1], then compute:
φ = arccos(cos(φ_min) − u * (cos(φ_min) − cos(φ_max)))
Convert spherical coordinates (θ, φ) to Cartesian coordinates on the unit sphere:
x = sin(φ) * cos(θ)
y = sin(φ) * sin(θ)
z = cos(φ)
Store the vector (x, y, z) as a sampled camera direction |
3.3. Prompt Generation
A structured prompt generation method that uses a LLM (Large Language Model) was developed to enable the creation of contextually rich and precise scene descriptions. In our case, we applied OpenAI’s GPT-4o model. The guide prompt begins with a clear objective statement that specifies the central target object and the overall narrative goal, followed by guidelines outlining the scene context—such as location, time of day, and weather. This approach ensures that the resulting description is comprehensive. Finally, style constraints and example prompts are provided to guide the LLM toward producing coherent and context-rich narratives. The LLM is not forced to generate a target object-centric prompt because it will cause bias in target object locations. In contrast, all remaining objects are described in detail, and additional object categories may appear in the foreground to more closely emulate real-world scenarios.
3.4. Object Locations Sampling
In object detection tasks, the precise location of the target object within training samples is critical because many detection models are not translation invariant. To address this issue, we estimate the spatial distribution of the target object through a multi-step process. First, 1000 training samples were generated using our text-to-image Flux.1-dev model, guided by the prompt generation procedure.
Figure 2 demonstrates the resulting spatial distribution of the generated samples.
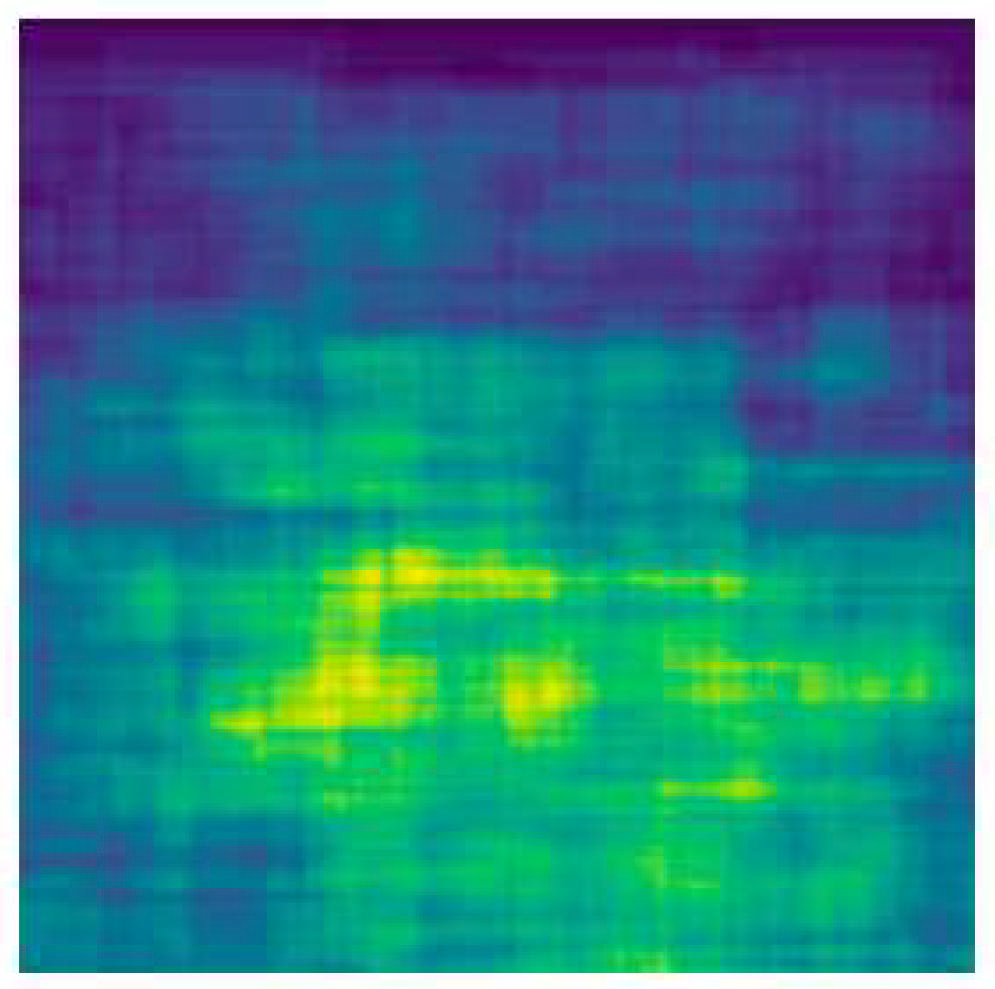
Next, a text-based object detector OWL-ViT [
37] was applied to these samples to provide rough localization of the target object. Images were then filtered based on a model confidence score to filter out generations without target objects. In instances where multiple objects were detected, all detected instances were kept and incorporated into the statistical analysis.
Figure 3 presents a heatmap showing the distribution of shoe bounding boxes across the image frame.
3.5. Proposed Generation Method
The environment is generated after the object’s visualization is obtained, and the position is sampled from the estimated spatial distribution. This is done using a two-step generation process that uses FLUX.1 fill [
38]; a diffusion model was used as the base model.
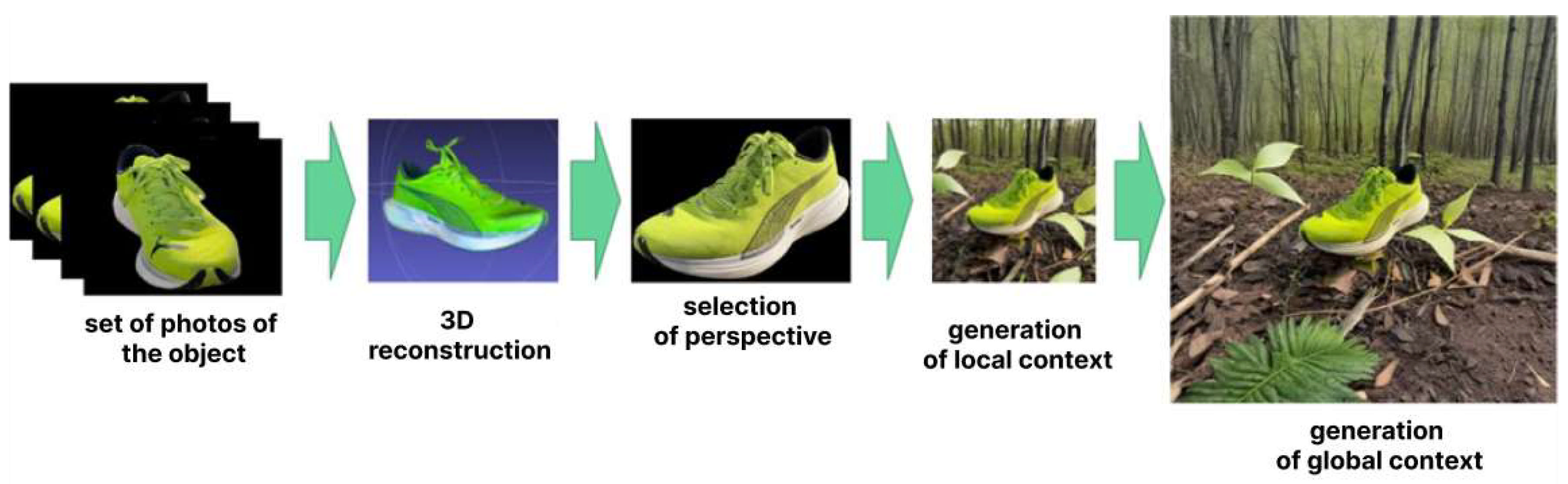
In the first step, a local context around the object is generated. The target object may rarely appear in the training data of the generative model, so it requires considerable “attention” for accurate generation. The generation quality is primarily limited by the object’s size in latent space. Therefore, in the first generation step, the target object occupies almost the entire image. This approach allows for the precise and accurate generation of the local context because of the object size in the model latent space.
Next, we place the generated image in a sampled location on the global context image with a sampled scale from the estimated spatial distribution. At this stage, the global context is generated. Here, the object is positioned in a larger environment corresponding to its natural surroundings. The generation of this step is performed using outpainting via FLUX.1 fill [
38].
Figure 4 demonstrates a visualization of the proposed generation method. This method allows for gradually expanding the image around the target object and its local context, adding new context and details that match the style and texture of the selected environment.
The combination of these technologies—3D reconstruction and generative outpainting—creates high-quality synthetic data that feature details and a variety of perspectives. Including a wide range of contexts significantly improves the quality of model training, making them more adaptive and capable of achieving high accuracy in real-world conditions.
4. Experiments
4.1. Implementation Details
All components were implemented using Python 3.10 and the PyTorch 2.5.1 library, which are widely adopted as the current industry standard for deep learning and computer vision tasks. Considering the significant computational resources required for image generation using diffusion models, this research was conducted using an NVIDIA A40 graphics card. This GPU provides substantial computational power, enabling work with high resolutions of 1024 × 1024 pixels and supporting significant volumes of concurrent calculations necessary for complex image generation. Using a powerful graphics card significantly accelerates the generation process, reducing the execution time of each iteration and enhancing overall productivity.
Additionally, to flexibly manage computational resources and optimize development costs, the platform vast.ai [
39] was selected. This platform allows for renting the necessary graphics cards under flexible conditions, enabling adaptation to the workload and minimizing expenses on cloud computing. By utilizing vast.ai [
25], we could quickly scale computational power for testing and refining the model without compromising the quality or performance.
The Diffusers library is used for the generation process, which is a powerful tool for creating generative image models. This library offers ready-made modules for working with diffusion models, allowing specialists to adapt the model to the project’s specific needs without the necessity of building all components from scratch.
4.2. Synthetic Data Generation Methods for Comparison
We considered various approaches to generating synthetic data. Methods that require training an additional generative model were dismissed due to their resource intensity in time and computation. Training additional models such as GANs is unstable due to the need to balance the generator and discriminator depending on the complexity of the target data.
We utilized the classical copy-paste approach from [
6] as a baseline. This method is highly efficient and does not require GPU acceleration, which enables rapid dataset generation at a minimal cost. In addition, the Gen2Det [
13] framework was used for comparison. The original Gen2Det implementation employs an inpainting model that generates objects under a mask based solely on text descriptions, thereby lacking high-precision control over object placement. To align it more closely with our approach, we extended Gen2Det with the Paint-by-Example [
40] method, which leverages a reference image of the target object for inpainting. We also evaluated another setup that uses the FLUX.1 fill model combined with an IP adapter [
41] for enhanced visual control. Importantly, none of these methods require pretraining, and each is designed to preserve the identity of the target object. Moreover, precise bounding box extraction is a critical component of our pipeline, as all these approaches provide explicit control over the region in which the target object is generated, resulting in highly accurate labels.
Figure 5 shows comparison of synthetic training data generation method.
4.3. Results of Training the Detector on Synthetic Data
A comparative analysis of the training results of the models on datasets generated using the proposed method versus conventional approaches was conducted. The primary objective of the experiment was to assess the impact of the proposed methodology on the quality of the models in terms of various accuracy and adaptability metrics, as well as to investigate the dependence of these metrics on the volume of data used.
The test dataset was collected manually. Example images from the test set are shown in
Figure 6. We had access to the target object, allowing us to capture it in various locations. In total, 200 photos of the sneakers were gathered in different environments. These data are sufficient for a quality assessment of the models’ accuracy within a realistic time investment.
Table 2 demonstrates a synthetic data generation method comparison.
Three metrics were chosen to evaluate the performance of the models. Precision describes the percentage of the detected objects that are target objects. Recall indicates how many of the available objects were found. The F1 score is the harmonic mean of the precision and recall, providing a single number that reflects the model’s quality. The threshold value for IoU was selected manually and fixed at 0.8. This choice of metrics allows for a standardized and detailed assessment of the recognition model’s performance. All metrics are in percent from 0 to 100. These metrics are measured on our custom test set.
The effectiveness of the proposed method was tested and confirmed through an experiment. In this experiment, the model was trained on four datasets. A standard YOLO v5 [
42] model architecture and identical training parameters for both datasets were used. This allowed for more objective results, which are presented in
Table 2. The analysis of the results showed that the dataset generated using the proposed method achieves higher scores across all metrics (
Table 2).
The reason for such performance is the nature of testing data. Often, an object appears under various lightning, as shown in
Figure 6. The copy-paste approach does not change the lightning of the object; hence, it tends to fail when the object is under lightning, which significantly differs from the initial photo set used to generate training data.
The Gen2Det-based approaches face significant challenges in preserving the identity of the target object, particularly in the variant utilizing Paint-by-Example, as illustrated in
Figure 5. This limitation negatively impacts performance, as the object detector converges less effectively when trained on noisy or inconsistent data.
This supports the hypothesis that the proposed methodology’s additional context and coherence enhance the model’s overall quality and ability to operate in real-world conditions.
4.4. Data Volume Influence
For a deeper analysis, we conducted an experiment to determine the relationship between accuracy and other metrics and the amount of data used. This experiment involved training models on different data volumes: 10%, 25%, 50%, 75%, and 100% of the initial amount for both dataset generation methods (
Table 3). Moreover, 100% corresponds to 3000 samples. The results showed that even with 50% of the data, the model trained on the dataset generated by the new method achieved similar or better metrics than the model trained on the full volume of data created using the traditional method. This indicates the effectiveness of the proposed method. While the traditional method demonstrated results close to this level with the full dataset, our findings confirm that the proposed method allows for competitive performance, even with reduced datasets on selected test sets. The reason is that the proposed generation method more effectively covered selected real-world test cases.
Because of the lower sim to the real gap between training and testing data, the proposed approach enables better detector convergence and reduces the need for training data on the proposed test set; other works also investigate the impact of the quality of training data [
43,
44]. This intuition applies in synthetic data because the data generation process aims to create samples that are as close as possible to real-world inputs. Hence, better similarity increases metrics and reduces the need for large datasets, which works because the increase in size adds samples that improve the overall coverage of real situations.
4.5. Generation Speed and Memory Usage
Memory usage and generation time are highly dependent on generative model selection. In our implementation, 48 GB of VRAM is required.
To estimate the spatial distribution of the target object, we generated 1000 samples using a diffusion model at 768 × 768 resolution with 20 sampling steps per image. This process took approximately 6 s per sample on an NVIDIA A40 GPU. Subsequently, we applied the OWL-ViT model to detect bounding boxes, which required about 0.5 s per image.
In the final synthetic image generation stage, the rasterization of object masks and scene elements took approximately 100–150 milliseconds per image. The inpainting process, performed using a guided diffusion model at 1024 × 1024 resolution with 30 sampling steps, required around 15 s per image on the NVIDIA A40. This inpainting stage is the most computationally intensive part of the pipeline and scales approximately linearly with the number of sampling steps.
5. Conclusions
This study presented a novel pipeline for generating high-fidelity synthetic datasets to train object recognition models, particularly when real data are limited or unavailable. The proposed method combines Structure from Motion (SfM) for robust 3D reconstruction with a two-stage diffusion-based generative model that includes local and global context generation. This hybrid approach ensures high visual realism, spatial control, and object identity preservation—key aspects for effectively training object detection models.
The experimental evaluation demonstrated that models trained on data generated by our method outperformed those trained using traditional techniques such as copy-paste and Gen2Det-based inpainting. Specifically, the proposed method achieved the highest F1 score of 91.8, surpassing both copy-paste (87.0) and the best Gen2Det variant (78.0). Additionally, the method showed strong performance even when trained on only 50% of the data, indicating its efficiency and potential for reducing labeling and data collection costs.
One of the limitations of the current pipeline lies in its reliance on large GPU memory for the inpainting stage, which may restrict its accessibility for some users. Also, further two-stage generation can be replaced with only one stage when the latent space resolution of generative models increases and will be able to preserve all object details while spending less time on generation.
As a next step, we plan to develop an approach that enables the generation of high-quality 3D object models from only a few input images [
45,
46,
47,
48,
49,
50,
51,
52]. This direction builds on recent advances in mesh and texture reconstruction, such as the Hunyuan3D framework recently released by Tencent. Incorporating such techniques will significantly simplify and accelerate the data generation process while preserving the geometric and visual consistency of the target object across all synthetic samples [
53,
54,
55,
56,
57]. This improvement is expected to further enhance the efficiency of training datasets, especially for applications where obtaining high-quality image collections for reconstruction is impractical.
Author Contributions
Conceptualization, S.L. and B.S.; methodology, S.L. and B.S.; software, B.S.; validation, S.L. and B.S.; formal analysis, N.S. and O.D.; investigation, B.S. and S.L.; resources, B.S. and V.V.; data curation, B.S.; writing—original draft preparation, S.L. and Y.M.; writing—review and editing, N.S. and Y.M.; visualization, Y.M. and B.S.; supervision, N.S. and S.L.; project administration, O.D. and Y.M.; funding acquisition, V.V. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded by the European Union’s Horizon Europe research and innovation program under grant agreement No. 101138678, project ZEBAI (Innovative Methodologies for the Design of Zero-Emission and Cost-Effective Buildings Enhanced by Artificial Intelligence).
Data Availability Statement
Acknowledgments
Some of the authors (S.L. and O.D.) would also like to thank the British Academy for the award of a Researcher at Risk Fellowship Aware, Reference: RaR\102705.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ye, Y.; Ma, X.; Zhou, X.; Bao, G.; Wan, W.; Cai, S. Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots. Sensors 2023, 23, 9482. [Google Scholar] [CrossRef] [PubMed]
- Yahia, Y.; Lopes, J.C.; Lopes, R.P. Computer Vision Algorithms for 3D Object Recognition and Orientation: A Bibliometric Study. Electronics 2023, 12, 4218. [Google Scholar] [CrossRef]
- Nowruzi, F.E.; Kapoor, P.; Kolhatkar, D.; Al Hassanat, F.; Laganière, R.; Rebut, J. How much real data do we actually need: Analyzing object detection performance using synthetic and real data. arXiv 2019, arXiv:1907.07061. [Google Scholar]
- Borkman, S.; Crespi, A.; Dhakad, S.; Ganguly, S.; Hogins, J.; Jhang, Y.-C.; Kamalzadeh, M.; Li, B.; Leal, S.; Parisi, P.; et al. Unity Perception: Generate Synthetic Data for Computer Vision. arXiv 2021, arXiv:2107.04259. [Google Scholar]
- Borrego, J.; Dehban, A.; Figueiredo, R.; Moreno, P.; Bernardino, A.; Santos-Victor, J. Applying domain randomization to synthetic data for object category detection. arXiv 2018, arXiv:1807.09834. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar] [CrossRef]
- Lin, S.; Wang, K.; Zeng, X.; Zhao, R. Explore the Power of Synthetic Data on Few-shot Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 638–647. [Google Scholar] [CrossRef]
- Mustikovela, S.K.; De Mello, S.; Prakash, A.; Iqbal, U.; Liu, S.; Nguyen-Phuoc, T.; Rother, C.; Kautz, J. Self-Supervised Object Detection via Generative Image Synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 8610–8620. [Google Scholar]
- Liu, L.; Muelly, M.; Deng, J.; Pfister, T.; Li, L.-J. Generative Modeling for Small-Data Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6073–6081. [Google Scholar]
- Hu, J.; Xiao, F.; Jin, Q.; Zhao, G.; Lou, P. Synthetic Data Generation Based on RDB-CycleGAN for Industrial Object Detection. Mathematics 2023, 11, 4588. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, J.; Ren, Y.; Li, M.; Qin, J.; Xiao, X.; Liu, W.; Wang, R.; Zheng, M.; Ma, A.J. DiffusionEngine: Diffusion Model is Scalable Data Engine for Object Detection. arXiv 2023, arXiv:2309.03893. [Google Scholar]
- Zhu, J.; Li, S.; Liu, Y.; Huang, P.; Shan, J.; Ma, H.; Yuan, J. ODGEN: Domain-specific Object Detection Data Generation with Diffusion Models. arXiv 2024, arXiv:2405.15199. [Google Scholar]
- Suri, S.; Xiao, F.; Sinha, A.; Culatana, S.C.; Krishnamoorthi, R.; Zhu, C. Gen2Det: Generate to Detect. arXiv 2023, arXiv:2312.04566. [Google Scholar]
- Chen, K.; Xie, E.; Chen, Z.; Wang, Y.; Hong, L.; Li, Z.; Yeung, D.-Y. GeoDiffusion: Text-Prompted Geometric Control for Object Detection Data Generation. arXiv 2023, arXiv:2306.04607. [Google Scholar]
- Voetman, R.; Aghaei, M.; Dijkstra, K. The Big Data Myth: Using Diffusion Models for Dataset Generation to Train Deep Detection Models. arXiv 2023, arXiv:2306.09762. [Google Scholar]
- Yemets, K.; Izonin, I.; Dronyuk, I. Time Series Forecasting Model Based on the Adapted Transformer Neural Network and FFT-Based Features Extraction. Sensors 2025, 25, 652. [Google Scholar] [CrossRef] [PubMed]
- Clark, J.; Johnson, G.; Duran, O.; Argyriou, V. Fabric Composition Classification Using Hyper-Spectral Imaging. In Proceedings of the 2023 19th International Conference on Distributed Computing in Smart Systems and the Internet of Things (DCOSS-IoT), Pafos, Cyprus, 19–21 June 2023; pp. 347–353. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Feng, C.; Zhong, Y.; Jie, Z.; Xie, W.; Ma, L. InstaGen: Enhancing Object Detection by Training on Synthetic Dataset. arXiv 2024, arXiv:2402.05937. [Google Scholar]
- Alam, M.M.; Sokhandan, N.; Goodman, E. Automated Virtual Product Placement and Assessment in Images using Diffusion Models. arXiv 2024, arXiv:2405.01130. [Google Scholar]
- Chen, X.; Feng, W.; Du, Z.; Wang, W.; Chen, Y.; Wang, H.; Liu, L.; Li, Y.; Zhao, J.; Li, Y.; et al. CTR-Driven Advertising Image Generation with Multimodal Large Language Models. arXiv 2025, arXiv:2502.06823. [Google Scholar]
- Chen, H.; Zhou, M.; Jiang, J.; Chen, J.; Lu, Y.; Xiao, B.; Ge, T.; Zheng, B. PAID: A Framework of Product-Centric Advertising Image Design. arXiv 2025, arXiv:2501.14316. [Google Scholar]
- Malhi, I.; Dutta, P.; Talius, E.; Ma, S.; Driscoll, B.; Holden, K.; Pruthi, G.; Narayanaswamy, A. Preserving Product Fidelity in Large Scale Image Recontextualization with Diffusion Models. arXiv 2025, arXiv:2503.08729. [Google Scholar]
- Tomasi, C.; Kanade, T. Shape and motion from image streams under orthography: A factorization method. Int. J. Comput. Vis. 1992, 9, 137–154. [Google Scholar] [CrossRef]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2020; pp. 405–421. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. arXiv 2023, arXiv:2308.04079. [Google Scholar] [CrossRef]
- Minderer, M.; Gritsenko, A.; Stone, A.; Neumann, M.; Weissenborn, D.; Dosovitskiy, A.; Mahendran, A.; Arnab, A.; Dehghani, M.; Shen, Z.; et al. Simple Open-Vocabulary Object Detection with Vision Transformers. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2022; pp. 75–91. [Google Scholar]
- Black Forest Labs. Flux: Text-to-Image AI Model; Black Forest Labs: Freiburg im Breisgau, Germany, 2024; Available online: https://en.wikipedia.org/wiki/Flux_(text-to-image_model) (accessed on 18 April 2025).
- Loges Siva Understanding and Exploring 3D Gaussian Splatting: A Comprehensive Overview. Available online: https://vast.ai/ (accessed on 18 April 2025).
- Yang, B.; Gu, S.; Zhang, B.; Zhang, T.; Chen, X.; Sun, X.; Chen, D.; Wen, F. Paint by Example: Exemplar-Based Image Editing with Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18377–18386. [Google Scholar]
- Ye, H.; Zhang, J.; Liu, S.; Han, X.; Yang, W. IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models. arXiv 2023, arXiv:2308.06721. [Google Scholar]
- Jocher, G.; Ultralytics. YOLOv5: PyTorch Implementation of Object Detection Models. GitHub Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 18 April 2025).
- Vodrahalli, K.; Li, K.; Malik, J. Are All Training Examples Created Equal? An Empirical Study. arXiv 2018, arXiv:1811.12569. [Google Scholar]
- Mishra, S.; Arunkumar, A. A Proposal to Study “Is High Quality Data All We Need?”. arXiv 2022, arXiv:2203.06404. [Google Scholar]
- Shakhovska, N.; Shymanskyi, V.; Prymachenko, M. FractalNet-LSTM Model for Time Series Forecasting. Comput. Mater. Contin. CMC 2025, 82, 4469–4484. [Google Scholar] [CrossRef]
- Yemets, K.; Izonin, I.; Dronyuk, I. Enhancing the FFT-LSTM Time-Series Forecasting Model via a Novel FFT-Based Feature Extraction–Extension Scheme. Big Data Cogn. Comput. BDCC 2025, 9, 35. [Google Scholar] [CrossRef]
- Liaskovska, S.; Tyskyi, S.; Martyn, Y.; Augousti, A.T.; Kulyk, V. Systematic Generation and Evaluation of Synthetic Production Data for Industry 5.0 Optimization. Technologies 2025, 13, 84. [Google Scholar] [CrossRef]
- Mochurad, L.; Davidekova, M.; Mitoulis, S.-A. Parallel Rapidly Exploring Random Tree Method for Unmanned Aerial Vehicles Autopilot Development Using Graphics Processing Unit Processing. IAES Int. J. Artif. Intell. IJ-AI 2025, 14, 712. [Google Scholar] [CrossRef]
- Nykoniuk, M.; Basystiuk, O.; Shakhovska, N.; Melnykova, N. Multimodal Data Fusion for Depression Detection Approach. Computation 2025, 13, 9. [Google Scholar] [CrossRef]
- Kachouane, M.; Sahki, S.; Lakrouf, M.; Ouadah, N. HOG Based Fast Human Detection. In Proceedings of the 2012 24th International Conference on Microelectronics (ICM), Algiers, Algeria, 16–20 December 2012; pp. 1–4. [Google Scholar]
- Tang, Y. Deep Learning Using Linear Support Vector Machines. arXiv 2015, arXiv:1306.0239. [Google Scholar]
- Beja-Battais, P. Overview of AdaBoost: Reconciling Its Views to Better Understand Its Dynamics. arXiv 2023, arXiv:2310.18323. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Ali, M.L.; Zhang, Z. The YOLO Framework: A Comprehensive Review of Evolution, Applications, and Benchmarks in Object Detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Liu, W.; Liu, J.; Luo, B. Can Synthetic Data Improve Object Detection Results for Remote Sensing Images? arXiv 2020, arXiv:2006.05015. [Google Scholar]
- Wang, T.; Lin, Y. CycleGAN with Better Cycles. arXiv 2024, arXiv:2408.15374. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv 2022, arXiv:2112.10752. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







