
Parallel Simulation Using Reactive Streams: Graph-Based Approach for Dynamic Modeling and Optimization
 , , , ,
, , , ,  and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Section 2 explains the basic modeling concepts and entities that we will use in this paper.
- Section 3 extends basic modeling to be represented in the form of a transition graph and shows how a simulation can be performed on this graph.
- Section 4 shows how the transition graph can be implemented with reactive streams and how simulations can be executed.
2. Substates
2.1. Substates as a Decomposition of the State
2.2. Representation of the Dependence of Y on X as a Set of Substates:
2.3. Reflection as a Record of Changes in the Values of Variables
2.4. Model as an Imitation of Changes in the Variables V
2.5. Simulation of the Model as a Calculation of a Subset of from the Subset and the Parameters
3. Graph Modeling
3.1. The Transition Graph and the Simulation Graph
3.2. Construction of a Consistent Transition Graph
- For each graph , each substate (i.e., located on one of all possible paths ) must have a unique key regarding the .
- For each graph , the values of some variable should only belong to the set of substates such that there exists in at least one path , including all of these substates.
- I.
- The set of keys must be linearly ordered.
- II.
- Each transition function(where ) for each transition(where ) in some graph must generate the resulting substate such that its key will always satisfy the conditionsorwhere
- III.
- For each variable , its values must belong to no more than one root node :where(i.e., the set of all values in all substates form the domain of the variable ).
- IV.
- If, for some node and some variable the condition is true, then either the node must be a root, or there must be a transition functionwith one or more arguments for which the condition is true and in the graph there exists a chainthat includes all . Moreover, for the last argument in the chain, there should not be another functionfor which the condition is true.
3.3. Computability of the Simulation Graph and the Initial Set of Substates
3.4. Representation of the Dependence of Y on X in the Form of a Simulation Graph and a Graph Model
3.5. Simulation of the Graph Model as a Calculation of a Subset of the Values on the Subset and the Parameters G
- Push pattern:This pattern can help synchronize the simulation with some external processes (for example, to synchronize with real-time). The essence of the pattern is that some function cannot be calculated until all its arguments are defined; thus, we can locally pause the simulation, leaving some of the root nodes uninitialized. We can then continue it by defining these nodes.
- Pool pattern:This pattern can be used to implement an asynchronous simulation reaction to some external events—for example, to respond to user input. As in the previous case, some remain uninitialized. However, the simulation does not stop there. Their values are constructed as needed to calculate the next . Using this approach, it is figuratively possible to imagine that undefined is computed by some set of unknown transition functions, possibly also combined into a transition graph. In other words, there is some “shadow” or “unknown” part of the graph and, as a result of its calculation, the is initialized (see Figure 5).
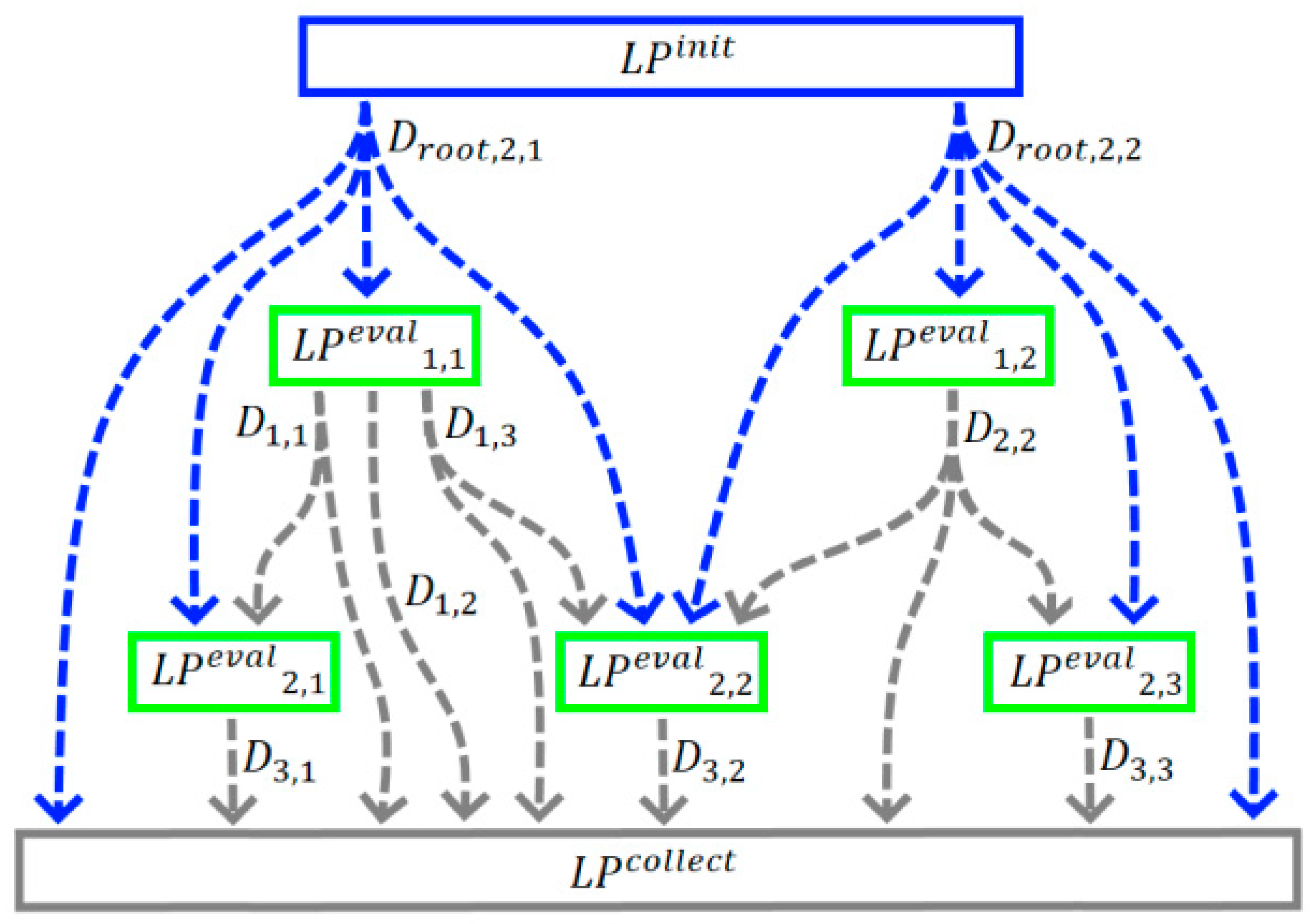
4. Logical Processors
4.1. Reactive Streams and Graph Model
- To represent each substate with the message .
- To replace all for which with equivalent processors :and all (for which ) with processors equivalent to the inverse functions :
- To successively replace all functions and all arguments that are already replaced by the channels , which are equivalent to :
- And to successively replace all , with the result having already been replaced by channel , by , which is equivalent to the inverse functions , consider the following:
4.2. Graph Optimization
- Folding of cyclic sequences in the graph :Consider a chain with an arbitrary length of the same functions , as in Figure 8a. This can be transformed into a chain of logical processors of equal length, as in Figure 8b. We can fold this chain into a single by adding a message-return loop as in Figure 8c. Thus, more than one message will go through one , so that if has more than one argument, it can lead to collisions. To resolve collisions and also to implement breakage of the loop, we need to determine the loop-iteration number of messages . The simple way to do this is to add an iteration counter for each loop in . Another approach is to use history-sensitive values [21]. As a more complex example, we consider the graph in Figure 9a, which can be converted and collapsed into a compact graph as in Figure 9b.
- Folding of graph :
4.3. Simulation of the Graph Model Using the Computational Graph
- Calculate the set of substatesFor this, we initialize the calculation by sending messages using the processors . Using the processors , we collect all the calculated messages, .
- Find all substates for each key , and then collect the values from the found substates (Formula (6)).
5. Practice
5.1. Description of the Modeled Object and the Construction of Model
5.2. Building and Simulating a Graphical Model
5.3. Constructing and Calculating Graph Using the Graphical Model
6. Discussion
- Modularity and Reusability: By encapsulating transition rules as independent functional blocks, the approach supports reuse and flexibility. This modular structure is similar in spirit to block-diagram environments like Simulink [30,31,32] and has parallels in dataflow programming models discussed by Kuraj and Solar-Lezama [21].
7. Future Work
- Effective optimization of computational graph and simulation on it:Section 4.2 and Section 4.3 dealt with this topic. However, due to its complexity and vastness, it did not fit into this article. In general, this is a very important issue from a practical point of view. Solving it will significantly reduce the number of resources required to perform simulations. Another interesting question is the automation of the optimization of graph . Say that, initially, we have non-optimal , for example, obtained by the method described in Section 4.1. We want to automatically make C compact and computationally easy without loss of accuracy and consistency.The ML technique can be used to resolve the optimization task. For example, reinforcement rearming agents can be trained to explore various graph configurations (i.e., different ways to fold or collapse the computational graph) and learn which configurations yield the best performance in terms of latency, throughput, or resource consumption [35,36,37,38,39]. Also, techniques like neural architecture search (NAS) can be adapted to optimize the layout and parameters of the computational graph. This includes automatically deciding how to fold cyclic sequences, balancing load among logical processors, and minimizing redundant computations [38,39,40].
- Accurate simulation of continuous-valued models:Many properties of modeled objects can be represented in continuous quantities, for example, values from the set ℝ. However, the simulation (the calculation of which is based on message forwarding) is inherently discrete. An open question remains as to how accurately continuous quantities can be calculated. The question is how to increase the accuracy of calculating such quantities without increasing the requirements for computer resources.
- Fault-tolerance of reactive streams:We did not touch on fault tolerance of simulation in this work, but in most real/practical applications, fault tolerance is very important. This question was partially explored in [23], but we also suggest this for future work.
- Manual and automatic graph construction :From a practical viewpoint, it is interesting to be able to use some IDE to manually construct a computational graph and to do this in such a way that the corresponding graph will be consistent and optimal. For example, this might be performed similarly to the Simulink package [30,41], SwiftVis tool [25,42], or XFRP language (Version 2.9.644) [24,43]. It is also interesting to find ways to automate the construction of . For example, the model can initially be defined as a certain set of rules by which graph can be automatically and even dynamically constructed. Specialized programming languages are also an interesting area to explore. For example, the EdgeC [33] language can be considered a tool to describe computational graphs.Also, the ML technique can be applied wildly here. For example, graph learning techniques from graph neural networks (GNNs) can be applied to learn the structure of the optimal computational graph from historical data. The learned model can then suggest or automatically construct a more efficient graph based on current simulation requirements. Adaptive scheduling ML algorithms can dynamically adjust the scheduling of tasks across logical processors, optimizing the execution order and balancing the load [44,45]. This is particularly useful in interactive or real-time simulations where conditions may change frequently.
- Testing with complex models and comparing with other parallelizing approaches:This work provides a small, simple example of parallel simulation to show how the described approach can be implemented in practice. However, the questions of checking this approach with large and complex models and comparing its effectiveness with other parallelizing approaches remain open.
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jeerson, D.R.; Sowizral, H.A. Fast Concurrent Simulation Using the Time Warp Mechanism; Part I: Local Control; Rand Corp: Santa Monica, CA, USA, 1982. [Google Scholar]
- Richard, R.; Fujimoto, M. Parallel and Distributed Simulation Systems; Wiley: New York, NY, USA, 2000. [Google Scholar]
- Radhakrishnan, R.; Martin, D.E.; Chetlur, M.; Rao, D.M.; Wilsey, P.A. An Object-Oriented, Time Warp Simulation Kernel. In Proceeding of the International Symposium on Computing in Object-Oriented Parallel Environments (ISCOPE’98), Santa Fe, NM, USA, 8–11 December 1998; Caromel, D., Oldehoeft, R.R., Tholburn, M., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; Volume 1505, pp. 13–23. [Google Scholar]
- Jefferson, D.; Beckman, B.; Wieland, F.; Blume, L.; Diloreto, M. Time warp operating system. In Proceedings of the eleventh ACM Symposium on Operating systems principles, Austin, TX, USA, 8–11 November 1987; Volume 21, pp. 77–93. [Google Scholar]
- Aach, J.; Church, G.M. Aligning gene expression time series with time warping algorithms. Bioinformatics 2001, 17, 495–508. [Google Scholar] [CrossRef] [PubMed]
- Nicol, D.M.; Fujimoto, R.M. Parallel simulation today. Ann. Oper. Res. 1994, 53, 249. [Google Scholar] [CrossRef]
- Falcone, A.; Garro, A. Reactive HLA-based distributed simulation systems with rxhla. In Proceedings of the 2018 IEEE/ACM 22nd International Symposium on Distributed Simulation and Real Time Applications (DS-RT), Madrid, Spain, 15–17 October 2018; pp. 1–8. [Google Scholar]
- Debski, A.; Szczepanik, B.; Malawski, M.; Spahr, S. In Search for a scalable & reactive architecture of a cloud application: CQRS and event sourcing case study. IEEE Software 2016, 99. [Google Scholar] [CrossRef]
- Bujas, J.; Dworak, D.; Turek, W.; Byrski, A. High-performance computing framework with desynchronized information propagation for large-scale simulations. J. Comp. Sci. 2019, 32, 70–86. [Google Scholar] [CrossRef]
- Reactive Stream Initiative. Available online: https://www.reactive-streams.org (accessed on 15 April 2025).
- Davis, A.L. Reactive Streams in Java: Concurrency with RxJava, Reactor, and Akka Streams; Apress: New York, NY, USA, 2018. [Google Scholar]
- Curasma, H.P.; Estrella, J.C. Reactive Software Architectures in IoT: A Literature Review. In Proceedings of the 2023 International Conference on Research in Adaptive and Convergent Systems (RACS ‘23), Association for Computing Machinery, New York, NY, USA, 6–10 August 2023; Article 25. pp. 1–8. [Google Scholar] [CrossRef]
- The Implementation of Reactive Streams in AKKA. Available online: https://doc.akka.io/docs/akka/current/stream/stream-introduction.html (accessed on 15 April 2025).
- Oeyen, B.; De Koster, J.; De Meuter, W. A Graph-Based Formal Semantics of Reactive Programming from First Principles. In Proceedings of the 24th ACM International Workshop on Formal Techniques for Java-like Programs (FTfJP ‘22), Association for Computing Machinery, New York, NY, USA, 7 June 2022; pp. 18–25. [Google Scholar] [CrossRef]
- Posa, R. Scala Reactive Programming: Build Scalable, Functional Reactive Microservices with Akka, Play, and Lagom; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Baxter, C. Mastering Akka; Packt Publishing: Birmingham, UK, 2016. [Google Scholar]
- Nolte, D.D. The tangled tale of phase space. Phys. Today 2010, 63, 33–38. [Google Scholar] [CrossRef]
- Myshkis, A.D. Classification of applied mathematical models-the main analytical methods of their investigation. Elem. Theory Math. Models 2007, 9, 9. [Google Scholar]
- Briand, L.C.; Wust, J. Modeling development effort in object-oriented systems using design properties. IEEE Trans. Softw. Eng. 2001, 27, 963–986. [Google Scholar] [CrossRef]
- Briand, L.C.; Daly, J.W.; Wust, J.K. A unified framework for coupling measurement in object-oriented systems. IEEE Trans. Softw. Eng. 1999, 25, 91–121. [Google Scholar] [CrossRef]
- Shibanai, K.; Watanabe, T. Distributed functional reactive programming on actor-based runtime. In Proceedings of the 8th ACM SIGPLAN International Workshop on Programming Based on Actors, Agents, and Decentralized Control, Boston, MA, USA, 5 November 2018; pp. 13–22. [Google Scholar]
- Lohstroh, M.; Romeo, I.I.; Goens, A.; Derler, P.; Castrillon, J.; Lee, E.A.; Sangiovanni-Vincentelli, A. Reactors: A deterministic model for composable reactive systems. In Cyber Physical Systems. Model-Based Design; Springer: Cham, Switzerland, 2019; pp. 59–85. [Google Scholar]
- Mogk, R.; Baumgärtner, L.; Salvaneschi, G.; Freisleben, B.; Mezini, M. Fault-tolerant distributed reactive programming. In Proceedings of the 32nd European Conference on Object-Oriented Programming (ECOOP 2018), Amsterdam, The Netherlands, 19–21 July 2018. [Google Scholar]
- About the Graphs in AKKA Streams. Available online: https://doc.akka.io/docs/akka/2.5/stream/stream-graphs.html (accessed on 15 April 2025).
- Kurima-Blough, Z.; Lewis, M.C.; Lacher, L. Modern parallelization for a dataflow programming environment. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA), The Steering Committee of the World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), Las Vegas, NV, USA, 17–20 July 2017; pp. 101–107. [Google Scholar]
- Kirushanth, S.; Kabaso, B. Designing a cloud-native weigh-in-motion. In Proceedings of the 2019 Open Innovations (OI), Cape Town, South Africa, 2–4 October 2019. [Google Scholar]
- Prymushko, A.; Puchko, I.; Yaroshynskyi, M.; Sinko, D.; Kravtsov, H.; Artemchuk, V. Efficient State Synchronization in Distributed Electrical Grid Systems Using Conflict-Free Replicated Data Types. IoT 2025, 6, 6. [Google Scholar] [CrossRef]
- Oeyen, B.; De Koster, J.; De Meuter, W. Reactive Programming without Functions. arXiv 2024, arXiv:2403.02296. [Google Scholar] [CrossRef]
- Babaei, M.; Bagherzadeh, M.; Dingel, J. Efficient reordering and replay of execution traces of distributed reactive systems in the context of model-driven development. In Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, Virtual Event, 16–23 October 2020. [Google Scholar]
- Simulink. Available online: https://www.mathworks.com/help/simulink/index.html?s_tid=CRUX_lftnav (accessed on 15 April 2025).
- Karris, S.T. Introduction to Simulink with Engineering Applications; Orchard Publications: London, UK, 2006. [Google Scholar]
- Dessaint, L.-A.; Al-Haddad, K.; Le-Huy, H.; Sybille, G.; Brunelle, P. A power system simulation tool based on Simulink. IEEE Trans. Ind. Electron. 1999, 46, 1252–1254. [Google Scholar] [CrossRef]
- Kuraj, I.; Solar-Lezama, A. Aspect-oriented language for reactive distributed applications at the edge. In Proceedings of the Third ACM International Workshop on Edge Systems, Analytics and Networking 2020, (EdgeSys ‘20), Association for Computing Machinery, New York, NY, USA, 27 April 2020; pp. 67–72. [Google Scholar] [CrossRef]
- Babbie, E.R. The Practice of Social Research; Wadsworth Publishing: Belmont, CA, USA, 2009; ISBN 0-495-59841-0. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Nakata, T.; Chen, S.; Saiki, S.; Nakamura, M. Enhancing Personalized Service Development with Virtual Agents and Upcycling Techniques. Int. J. Netw. Distrib. Comput. 2025, 13, 5. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, L.; Chen, J.; Chen, W.-A.; Yang, Z.; Lo, L.J.; Wen, J.; O’Neil, Z. Large language models for building energy applications: Opportunities and challenges. Build. Simul. 2025, 18, 225–234. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. International Conference on Learning Representations (ICLR). arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Nie, M.; Chen, D.; Chen, H.; Wang, D. AutoMTNAS: Automated meta-reinforcement learning on graph tokenization for graph neural architecture search. Knowl.-Based Syst. 2025, 310, 113023. [Google Scholar] [CrossRef]
- Kuş, Z.; Aydin, M.; Kiraz, B.; Kiraz, A. Neural Architecture Search for biomedical image classification: A comparative study across data modalities. Artif. Intell. Med. 2025, 160, 103064. [Google Scholar] [CrossRef]
- Chaturvedi, D.K. Modeling and Simulation of Systems Using MATLAB and Simulink; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Lewis, M.C.; Lacher, L.L. Swiftvis2: Plotting with spark using scala. In Proceedings of the International Conference on Data Science (ICDATA’18), Las Vegas, NV, USA, 30 July–2 August 2018; Volume 1. [Google Scholar]
- Yoshitaka, S.; Watanabe, T. Towards a statically scheduled parallel execution of an FRP language for embedded systems. In Proceedings of the 6th ACM SIGPLAN International Workshop on Reactive and Event-Based Languages and Systems, Athens, Greece, 21 October 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Bassen, J.; Balaji, B.; Schaarschmidt, M.; Thille, C.; Painter, J.; Zimmaro, D.; Games, A.; Fast, E.; Mitchell, J.C. Reinforcement learning for the adaptive scheduling of educational activities. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ‘20, Honolulu, HI, USA, 25–30 April 2020; pp. 1–12. [Google Scholar] [CrossRef]
- Long, L.N.B.; You, S.-S.; Cuong, T.N.; Kim, H.-S. Optimizing quay crane scheduling using deep reinforcement learning with hybrid metaheuristic algorithm. Eng. Appl. Artif. Intell. 2025, 143, 110021. [Google Scholar] [CrossRef]
- Pietarinen, A.; Senden, Y.; Sharpless, S.; Shepperson, A.; Vehkavaara, T. The Commens Dictionary of Piece’s Terms, “Object,” 2009-03-19. Available online: https://web.archive.org/web/20090214004523/http:/www.helsinki.fi/science/commens/terms/object.html (accessed on 15 April 2025).
- Sismondo, S. Models, Simulations, and Their Objects. Sci. Context 1999, 12, 247–260. [Google Scholar] [CrossRef]
- Achinstein, P. Theoretical models. Br. J. Philos. Sci. 1965, 16, 102–120. [Google Scholar] [CrossRef]
- Banks, J.; Carson, J.; Nelson, B.; Nicol, D. Discrete-Event System Simulation; Prentice Hall: Hoboken, NJ, USA, 2001; ISBN 0-13-088702-1. [Google Scholar]
- Brézillon, P.; Gonzalez, A.J. (Eds.) Context in Computing: A Cross-Disciplinary Approach for Modeling the Real World; Springer: New York, NY, USA, 2014. [Google Scholar]
- Varga, A. Discrete event simulation system. In Proceedings of the European Simulation Multiconference (ESM2001), Prague, Czech Republic, 6–9 June 2001; Volume 17. [Google Scholar]
- Choi, B.K.; Kang, D. Modeling and Simulation of Discrete Event Systems; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Goldsman, D.; Goldsman, P. Discrete-event simulation. In Modeling and Simulation in the Systems Engineering Life Cycle: Core Concepts and Accompanying Lectures; Springer London: London, UK, 2015; pp. 103–109. [Google Scholar]
- Robinson, S. Conceptual modeling for simulation. In Winter Simulations Conference (WSC); IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Robinson, S. A tutorial on conceptual modeling for simulation. In Winter Simulation Conference (WSC); IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Abdelmegid, M.A.; Gonzales, V.A.; Naraghi, A.M.; O’Sullivan, M.; Walker, C.G.; Poshdar, M. Towards a conceptual modeling framework for construction simulation. In Winter Simulation Conference (WSC); IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Curtright, T.L.; Zachos, C.K.; Fairlie, D.B. Quantum mechanics in phase space. Asia Pac. Phys. Newsl. 2012, 1, 37–46. [Google Scholar] [CrossRef]
- Wu, B.; He, X.; Liu, J. Nonadiabatic field on quantum phase space: A century after Ehrenfest. J. Phys. Chem. Lett. 2024, 15, 644–658. [Google Scholar] [CrossRef] [PubMed]
- Hastings, N.B. Workshop Calculus: Guided Exploration with Review; Springer Science & Business Media: Berlin, Germany, 1998. [Google Scholar]
- Keller, R.M. Formal verification of parallel programs. Commun. ACM 1976, 19, 371–384. [Google Scholar] [CrossRef]
- Erwig, M.; Kollmansberge, S. Functional pearls: Probabilistic functional programming in Haskell. J. Funct. Program. 2006, 16, 21–34. [Google Scholar] [CrossRef]
- Saini, A.; Thiry, L. Functional programming for business process modeling. IFAC-PapersOnLine 2017, 50, 10526–10531. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sirotkin, O.; Prymushko, A.; Puchko, I.; Kravtsov, H.; Yaroshynskyi, M.; Artemchuk, V. Parallel Simulation Using Reactive Streams: Graph-Based Approach for Dynamic Modeling and Optimization. Computation 2025, 13, 103. https://doi.org/10.3390/computation13050103
Sirotkin O, Prymushko A, Puchko I, Kravtsov H, Yaroshynskyi M, Artemchuk V. Parallel Simulation Using Reactive Streams: Graph-Based Approach for Dynamic Modeling and Optimization. Computation. 2025; 13(5):103. https://doi.org/10.3390/computation13050103
Chicago/Turabian StyleSirotkin, Oleksii, Arsentii Prymushko, Ivan Puchko, Hryhoriy Kravtsov, Mykola Yaroshynskyi, and Volodymyr Artemchuk. 2025. "Parallel Simulation Using Reactive Streams: Graph-Based Approach for Dynamic Modeling and Optimization" Computation 13, no. 5: 103. https://doi.org/10.3390/computation13050103
APA StyleSirotkin, O., Prymushko, A., Puchko, I., Kravtsov, H., Yaroshynskyi, M., & Artemchuk, V. (2025). Parallel Simulation Using Reactive Streams: Graph-Based Approach for Dynamic Modeling and Optimization. Computation, 13(5), 103. https://doi.org/10.3390/computation13050103