
Short-Term Predictions of Global Horizontal Irradiance Using Recurrent Neural Networks, Support Vector Regression, Gradient Boosting Random Forest and Advanced Stacking Ensemble Approaches



Abstract
1. Introduction
1.1. Overview
1.2. Literature Review
1.3. Research Highlights and Contributions
2. Models
2.1. Recurrent Neural Networks
2.2. Support Vector Regression
2.3. Random Forests
- = the set of data points selected prior to the tree construction;
- = the cell containing x;
- = the number of points that fall into .
2.4. Gradient Boosting Model
2.5. Stacking Ensemble
2.6. Double Nested Stacking
Base Models and Meta Model
2.7. Bayesian Optimisation
2.8. Variable Selection
2.9. Metrics for Evaluating Forecasts
3. Empirical Results
3.1. Software and Packages
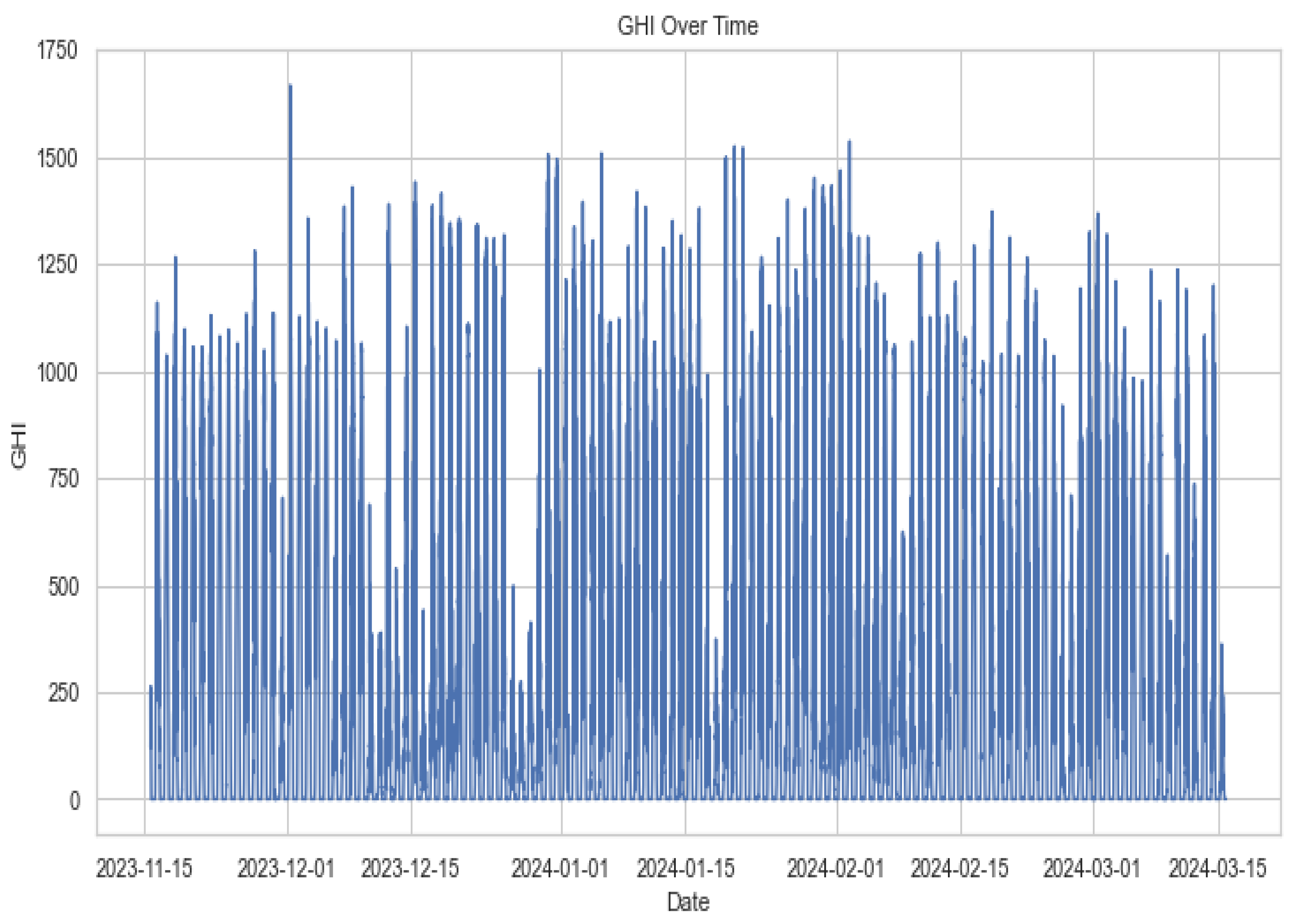
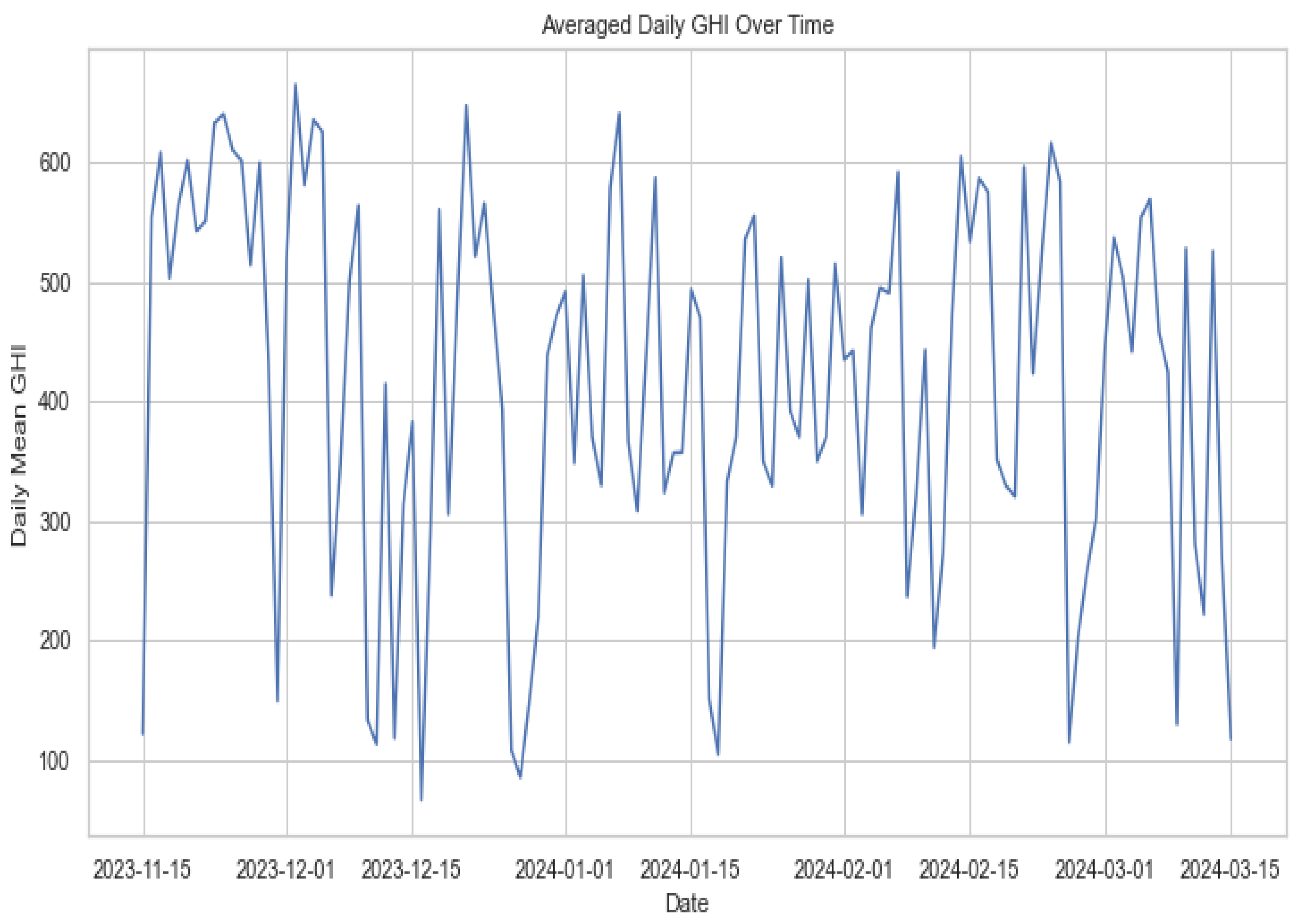
3.2. Exploratory Data Analysis
3.3. Visualisations
3.4. Variable Selection
3.5. Machine Learning Models
3.6. Selected Parameters
3.7. Model Comparison
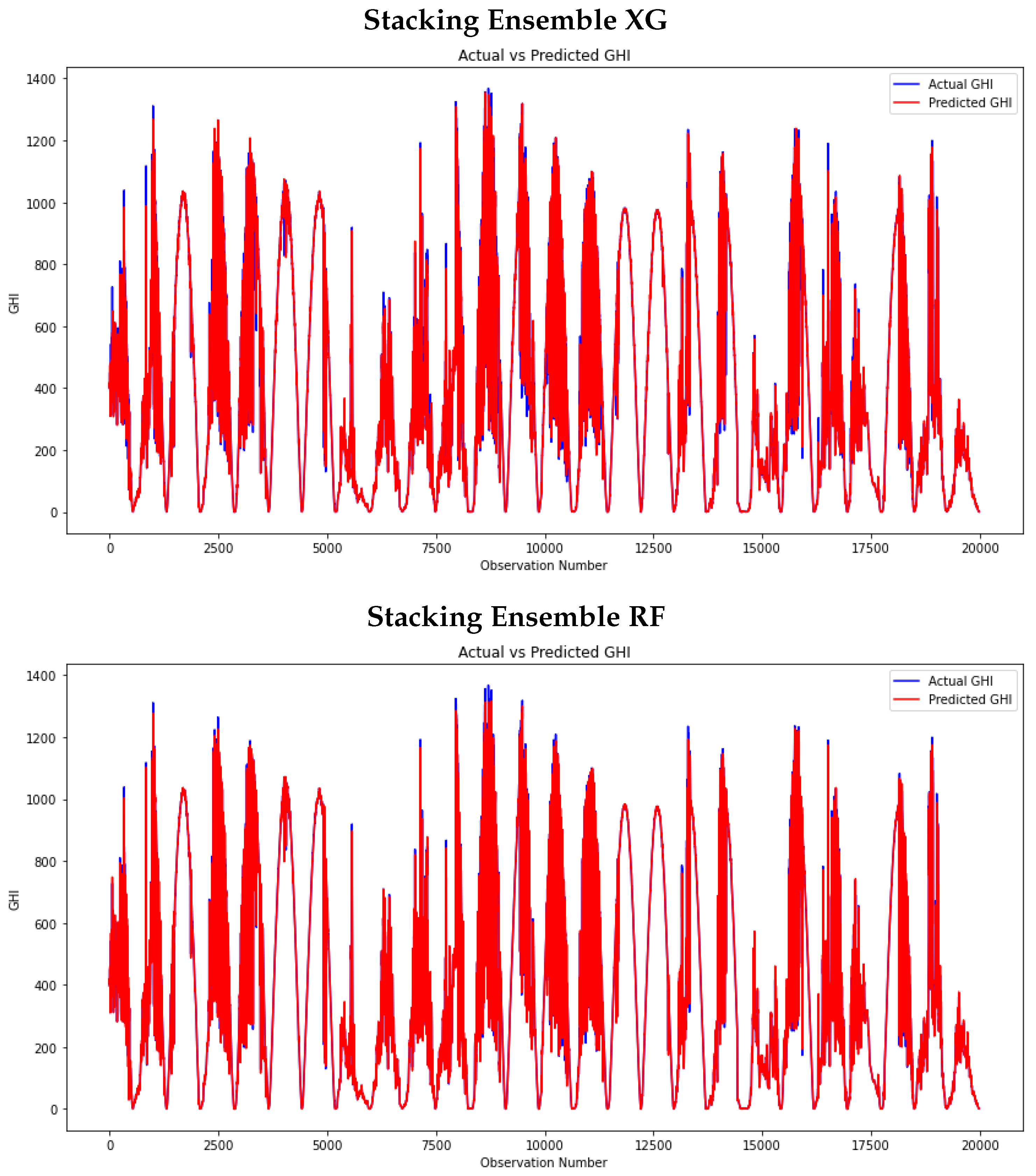
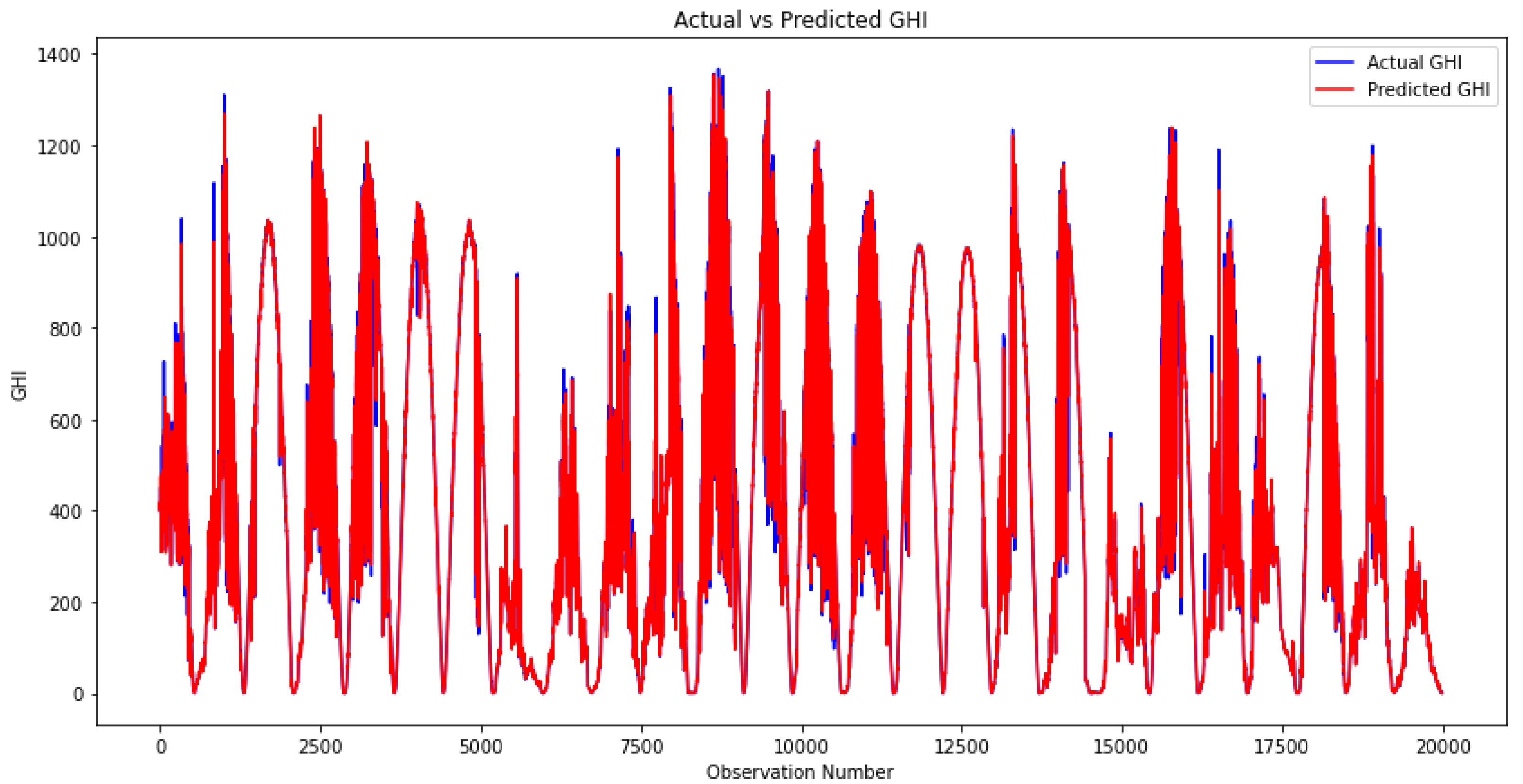
3.8. Stacking Ensemble Models
3.9. Model Comparison
3.10. Meta-Model Order Impact
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GHI | Global Horizontal Irradiance |
| RNN | Recurrent Neural Network |
| SAURAN | Southern African Universities Radiometric Network |
| GB | Gradient Boosting |
| RF | Random Forest |
| SE | Stacking Ensemble |
| DNS | Double Nested Stacking |
| SVR | Support Vector Regression |
| LSTM | Long Short-Term Memory |
| ANN | Artificial Neural Network |
| GPR | Gaussian Process Regression |
| nRMSE | Normalized Root Mean Square Error |
| DMAE | Dynamic Mean Absolute Error |
| DNN | Deep Neural Network-based |
| DHI | Diffuse Horizontal Irradiation |
| BMI | Beam Normal irradiation |
| SP | Smart Persistence |
| FFN | Feed Forward Network |
| ARIMA | Auto Regressive Integrated Moving Average |
| AdaBoost | Adaptive Boosting |
| MLP | Multi-Layer Perceptron |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| XGBOOST | Extreme Gradient Boosting |
| LGBM | Light Gradient Boosting Machine |
| GBDT | Gradient Boosting Decision Tree |
| SVM | Support Vector Machine |
| RMAE | Relative Mean Absolute Error |
| RRMSE | Relative Root Mean Squared Error |
| ACF | Autocorrelation Function |
| PACF | Partial Autocorrelation Function |
| EDA | Exploratory Data Analysis |
| SE XG | Stacking Ensemble XGBOOST |
| SE RF | Stacking Ensemble Random Forest |
| DNS XG | Double Nested Stacking XGBOOST |
| DNS RF | Double Nested Stacking Random Forest |
| DNS XG RF | Double Nested Stacking XGBOOST Random Forest |
| DNS RF XG | Double Nested Stacking Random Forest XGBOOST |
References
- Demirbas, A. Recent advances in biomass conversion technologies. Energy Educ. Sci. Technol. 2000, 6, 19–41. [Google Scholar]
- Armaroli, N.; Balzani, V. The legacy of fossil fuels. Chem. Asian J. 2011, 6, 768–784. [Google Scholar] [CrossRef] [PubMed]
- Gbémou, S.; Eynard, J.; Thil, S.; Guillot, E.; Grieu, S. A comparative study of machine learning-based methods for global horizontal irradiance forecasting. Energies 2021, 14, 3192. [Google Scholar] [CrossRef]
- Rajaprasad, S.V.S.; Mukkamala, R. A hybrid deep learning framework for modeling the short term global horizontal irradiance prediction of a solar power plant in India. Polityka-Energetyczna-Energy Policy J. 2023, 26, 101–116. [Google Scholar] [CrossRef]
- Yamani, A.Z.; Alyami, S.N. Investigating Hourly Global Horizontal Irradiance Forecasting Using Long Short-Term Memory. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Brisbane, Australia, 8–10 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Benali, L.; Notton, G. A Fouilloy, Cyril Voyant, and Rabah Dizene. Solar radiation forecasting using artificial neural network and random forest methods: Application to normal beam, horizontal diffuse and global components. Renew. Energy 2019, 132, 871–884. [Google Scholar] [CrossRef]
- Krishnan, N.; Kumar, K.R.; Anirudh R., S. Solar Radiation Forecasting using Gradient Boosting based Ensemble Learning Model for Various Climatic Zones. Sustain. Energy Grids Netw. 2024, 38, 101312. [Google Scholar] [CrossRef]
- Nziyumva, E.; Nsengimna, M.; Niyogisubizo, J.; Murwanashyaka, E.; Nisingizwe, E.; Kwitonda, A. A Novel Two Layer Stacking Ensemble for Improving Solar Irradiance Forecasting. Int. J. Eng. Res. Technol. (IJERT) 2023, 10, 364–373. Available online: https://www.ijert.org/a-novel-two-layer-stacking-ensemble-for-improving-solar-irradiance-forecasting (accessed on 25 August 2024).
- Guo, X.; Gao, Y.; Zheng, D.; Ning, Y.; Zhao, Q. Study on short-term photovoltaic power prediction model based on the Stacking Ensemble learning. Energy Rep. 2020, 6, 1424–1431. [Google Scholar] [CrossRef]
- Zhou, B.; Chen, X.; Li, G.; Gu, P.; Huang, J.; Yang, B. Xgboost—sfs and Double Nested Stacking Ensemble model for photovoltaic power forecasting under variable weather conditions. Sustainability 2023, 15, 13146. [Google Scholar] [CrossRef]
- Mandic, D.P.; Chambers, J. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2001. [Google Scholar] [CrossRef]
- Garcia-Pedrero, A.; Gomez-Gil, P. Time series forecasting using recurrent neural networks and wavelet reconstructed signals. In Proceedings of the 2010 20th International Conference on Electronics Communications and Computers (CONIELECOMP), Cholula, Puebla, Mexico, 22–24 February 2010; pp. 169–173. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; ISBN 978-0-471-03003-4. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1996, 9, 156–161. Available online: https://proceedings.neurips.cc/paper_files/paper/1996/file/d38901788c533e8286cb6400b40b386d-Paper.pdf (accessed on 27 May 2024).
- Aghelpour, P.; Mohammadi, B.; Biazar, S.M. Long-term monthly average temperature forecasting in some climate types of Iran, using the models SARIMA, SVR, and SVR-FA. Theor. Appl. Climatol. 2019, 138, 1471–1480. [Google Scholar] [CrossRef]
- Breiman, L.; Ihaka, R. Nonlinear Discriminant Analysis via Scaling and ACE; Department of Statistics, University of California Davis One Shields Avenue: Davis, CA, USA, 1984; Available online: https://www.stat.berkeley.edu/~breiman/nldiscanace.pdf (accessed on 14 June 2024).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lahouar, A.; Slama, J.B.H. Random forests model for one day ahead load forecasting. In Proceedings of the IREC2015 the Sixth International Renewable Energy Congress, Sousse, Tunisia, 24–26 March 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. Available online: https://www.jstor.org/stable/2699986 (accessed on 3 August 2024). [CrossRef]
- Nemalili, R.C.; Jhamba, L.; Kirui, J.K.; Sigauke, C. Nowcasting Hourly-Averaged Tilt Angles of Acceptance for Solar Collector Applications Using Machine Learning Models. Energies 2023, 16, 927. [Google Scholar] [CrossRef]
- Alcántara, A.; Galván, I.M.; Aler, R. Deep neural networks for the quantile estimation of regional renewable energy production. Appl. Intell. 2023, 53, 8318–8353. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super Learner. Stat. Appl. Genet. Mol. Biol. 2007, 6. [Google Scholar] [CrossRef]
- Khandelwal, Y. Ensemble stacking for machine learning and deep learning. Anal. Vidhya 2021, 9. Available online: https://www.analyticsvidhya.com/blog/2021/08/ensemble-stacking-for-machine-learning-and-deep-learning/ (accessed on 24 May 2024).
- Divina, F.; Gilson, A.; Goméz-Vela, F.; Torres, M.G.; Torres, J.F. Stacking Ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef]
- Joy, T.T.; Rana, S.; Gupta, S.; Venkatesh, S. Hyperparameter tuning for big data using Bayesian optimisation. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2574–2579. [Google Scholar] [CrossRef]
- Gardner, J.R.; Kusner, M.J.; Xu, Z.E.; Weinberger, K.Q.; Cunningham, J.P. Bayesian optimization with inequality constraints. ICML 2014, 2014, 937–945. Available online: https://proceedings.mlr.press/v32/gardner14.pdf (accessed on 13 July 2024).
- Fox, E.W.; Hill, R.A.; Leibowitz, S.G.; Olsen, A.R.; Thornbrugh, D.J.; Weber, M.H. Assessing the accuracy and stability of variable selection methods for random forest modeling in ecology. Environ. Monit. Assess. 2017, 189, 316. [Google Scholar] [CrossRef] [PubMed]
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Range |
|---|---|
| GHI | 0.0064–1666.7258 |
| diff1 | −973.2486–961.2202 |
| diff2 | −1031.5691–1052.9602 |
| diff15 | −1219.3918–1191.9289 |
| diff30 | −1281.9041–1239.3146 |
| diff60 | −1270.3455–1442.9946 |
| Temp (°C) | 14.07–41.14 |
| RH (%) | 15.0–100.0 |
| WS (m/s) | 0.0–10.5 |
| WVec_Mag (m/s) | 0.0–10.21 |
| WD (°) | 0.0–360.0 |
| WD_StdDev (°) | 0.0–77.37 |
| WS_Max (m/s) | 0.0–17.84 |
| BP (hPa) | 934.1265–953.3445 |
| Calc_Azimuth (°) | −180.0–180.0 |
| Calc_Tilt (°) | 0.04–153.1 |
| Min | Q1 | Median | Mean | Q3 | Max | Std | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| 0.006 | 103.463 | 314.610 | 415.996 | 692.425 | 1666.725 | 359.767 | 0.653 | −0.811 |
| MAE | RMAE | RMSE | RRMSE | |
|---|---|---|---|---|
| RNN | 22.1037 | 0.4290 | 25.6224 | 0.4973 |
| SVR | 26.4253 | 0.0668 | 81.9700 | 0.2073 |
| RF | 28.9002 | 0.0730 | 79.6583 | 0.2014 |
| GB | 29.6836 | 0.0750 | 78.0158 | 0.1973 |
| MAE | RMAE | RMSE | RRMSE | |
|---|---|---|---|---|
| SE XG | 7.2808 | 0.0184 | 19.9125 | 0.0504 |
| SE RF | 11.7188 | 0.0296 | 30.6534 | 0.0775 |
| DNS XG | 5.0633 | 0.0128 | 16.0328 | 0.0406 |
| DNS RF | 2.9217 | 0.0074 | 7.5926 | 0.0192 |
| DNS XG RF | 4.5771 | 0.0116 | 11.8832 | 0.0301 |
| DNS RF XG | 1.5369 | 0.0038 | 2.9341 | 0.0074 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mugware, F.W.; Ravele, T.; Sigauke, C. Short-Term Predictions of Global Horizontal Irradiance Using Recurrent Neural Networks, Support Vector Regression, Gradient Boosting Random Forest and Advanced Stacking Ensemble Approaches. Computation 2025, 13, 72. https://doi.org/10.3390/computation13030072
Mugware FW, Ravele T, Sigauke C. Short-Term Predictions of Global Horizontal Irradiance Using Recurrent Neural Networks, Support Vector Regression, Gradient Boosting Random Forest and Advanced Stacking Ensemble Approaches. Computation. 2025; 13(3):72. https://doi.org/10.3390/computation13030072
Chicago/Turabian StyleMugware, Fhulufhelo Walter, Thakhani Ravele, and Caston Sigauke. 2025. "Short-Term Predictions of Global Horizontal Irradiance Using Recurrent Neural Networks, Support Vector Regression, Gradient Boosting Random Forest and Advanced Stacking Ensemble Approaches" Computation 13, no. 3: 72. https://doi.org/10.3390/computation13030072
APA StyleMugware, F. W., Ravele, T., & Sigauke, C. (2025). Short-Term Predictions of Global Horizontal Irradiance Using Recurrent Neural Networks, Support Vector Regression, Gradient Boosting Random Forest and Advanced Stacking Ensemble Approaches. Computation, 13(3), 72. https://doi.org/10.3390/computation13030072