

Novel Techniques with Memory Extension of Three-Step Derivative-Free Iterative Scheme for Nonlinear Systems

Abstract
1. Introduction
2. With Memory Method and Its Convergence Analysis
- Scheme 1.
- Scheme 2.this divided difference operator is also known as Kurchatov’s divided difference.
- Scheme 3.
- Scheme 4.
- Scheme 5.
- Scheme 6.By substituting the parameter in method (2) with schemes 1 through 6, we obtain six new three-step iterative methods with memory, which are described in detail as follows:
- The sequence , produced using the method in (14), converges to α with a convergence rate of .
- The sequence , generated by the procedure described in (15), converges to α with a convergence rate of .
- The sequence , formed through the technique outlined in (16), converges to α with a convergence order of .
- The sequence , produced by the approach specified in (17), converges to α with a convergence order of .
3. Computational Efficiency
- The evaluation of G requires computing m scalar functions
- Calculating the divided difference involves evaluating and independently and requires scalar functions.
- Each divided difference calculation includes quotients, m products for vector–scalar multiplication, and products for matrix–scalar multiplication.
- Computing the inverse of a linear operator involves solving a linear system, which entails products and quotients during LU decomposition, as well as products and m quotients for solving two triangular systems.
Efficiency Comparison
- versus :Here, the inequality is valid for . This indicates that for .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, which implies that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :In this case, we have for , which means for .
- versus :In this case, we have for , which means for .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, which implies that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :In this case, we have for , which means for .
- versus :Here, the inequality is valid for , which indicates that for .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, which implies that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :The inequality is valid for . This demonstrates that when .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, implying that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :The inequality holds true for . This implies that when .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, which implies that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :In this case, the inequality is valid when . This indicates that for , .
- versus :The inequality holds true when , indicating that for .
- versus :When , the inequality is valid, which implies that for .
- versus :For , the inequality holds, indicating that the efficiency index exceeds .
- versus :For , the inequality is satisfied, which implies that the efficiency index is greater than .
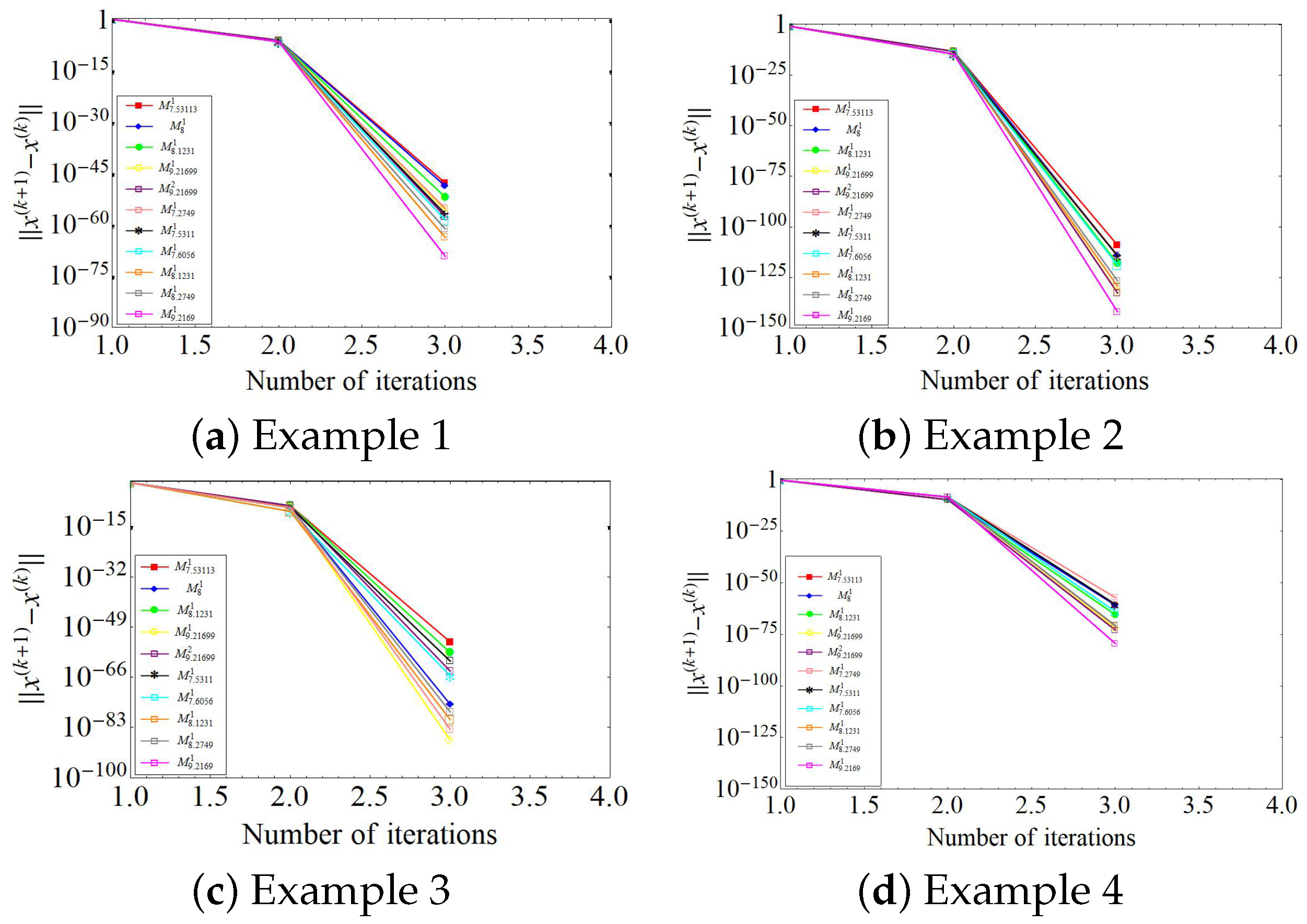
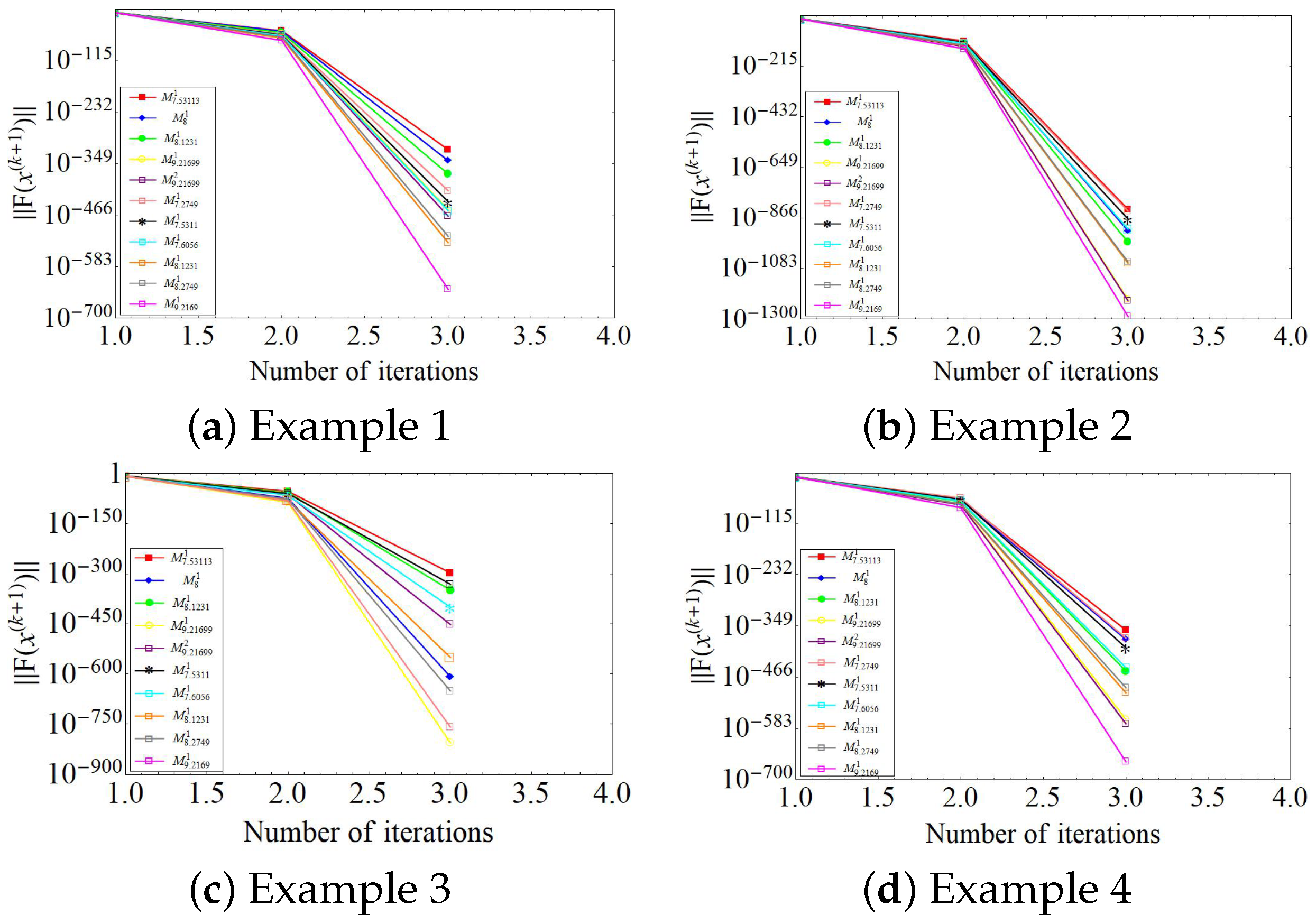
4. Numerical Results and Discussion
Evaluation Metrics
- The computed approximation ().
- The function value ().
- Distance between consecutive iterations, ().
- Iteration count required to satisfy the stopping criteria.
- The approximated computational order of convergence (ACOC):
- The total CPU time taken for the entire computation process.
- Specific Case:
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Steffensen, J. Remarks on iteration. Scand. Actuar. J. 1993, 1, 64–72. [Google Scholar] [CrossRef]
- Cordero, A.; Garrido, N.; Torregrosa, J.R.; Triguero, P.N. Design of iterative methods with memory for solving nonlinear systems. Math. Methods Appl. Sci. 2023, 46, 12361–12377. [Google Scholar] [CrossRef]
- Chicharro, F.I.; Cordero, A.; Garrido, N.; Torregrosa, J.R. On the improvement of the order of convergence of iterative methods for solving nonlinear systems by means of memory. Appl. Math. Lett. 2020, 104, 106277. [Google Scholar] [CrossRef]
- Cordero, A.; Garrido, N.; Torregrosa, J.R.; Triguero, P.N. Improving the order of a fifth-order family of vectorial fixed point schemes by introducing memory. Fixed Point Theory J. 2023, 24, 155–172. [Google Scholar] [CrossRef]
- Behel, R.; Cordero, A.; Torregrosa, J.R.; Bhalla, S. A new high-order jacobian-free iterative method with memory for solving nonlinear system. Mathematics 2021, 9, 2122. [Google Scholar] [CrossRef]
- Petkovic, M.S.; Sharma, J.R. On some efficient derivative-free iterative methods with memory for solving systems of nonlinear equations. Numer. Algorithms 2016, 71, 457–474. [Google Scholar] [CrossRef]
- Argyros, I.K. The Theory and Applications of Iteration Methods, 2nd ed.; Engineering Series; CRC Press—Taylor and Francis Corp.: Boca Raton, FL, USA, 2022. [Google Scholar]
- Sharma, J.R.; Arora, H. A novel derivative free algorithm with seventh order convergence for solving systems of nonlinear equations. Numer. Algorithms 2014, 67, 917–933. [Google Scholar] [CrossRef]
- Ortega, J.M.; Rheinboldt, W.C. Iterative Solution of Nonlinear Equations in Several Variables; SIAM: Philadelphia, PA, USA, 2000. [Google Scholar]
- Kurchatov, V.A. On a method of linear interpolation for the solution of functional equations. Dokl. Akad. Nauk. SSSR 1971, 198, 524–526. [Google Scholar]
- Shakhno, S.M. On a Kurchatov’s method of linear interpolation for solving nonlinear equations. PAAM-Proc. Appl. Math. Mech. 2004, 4, 650–651. [Google Scholar] [CrossRef]
- Shakhno, S.M. On the difference method with quadratic convergence for solving nonlinear operator equations. Mat. Stud. 2006, 26, 105–110. [Google Scholar]
- Ezquerro, J.A.; Grau, A.; Grau-Sanchez, M.; Hernandez, M. On the efficiency of two variants of Kurchatov’s method for solving nonlinear systems. Numer. Algorithms 2013, 64, 685–698. [Google Scholar] [CrossRef]
- Argyros, I.K. Advances in the Efficiency of Computational Methods and Applications; World Scientific Publishing Company: Singapore, 2000. [Google Scholar]
- Grau-Sánchez, M.; Grau, Á.; Noguera, M. Ostrowski type methods for solving systems of nonlinear equations. Appl. Math. Comput. 2011, 218, 2377–2385. [Google Scholar] [CrossRef]
- Grau-Sánchez, M.; Noguera, M. A technique to choose the most efficient method between secant method and some variants. Appl. Math. Comput. 2012, 218, 6415–6426. [Google Scholar] [CrossRef]
- Grau-Sánchez, M.; Grau, Á.; Noguera, M. Frozen divided difference scheme for solving systems of nonlinear equations. J. Comput. Appl. Math. 2011, 235, 1739–1743. [Google Scholar] [CrossRef]
- Grau-Sánchez, M.; Noguera, M.; Amat, S. On the approximation of derivatives using divided difference operators preserving the local convergence order of iterative methods. J. Comput. Appl. Math. 2013, 237, 363–372. [Google Scholar] [CrossRef]
- Wolfram, S. The Mathematica Book; Wolfram Research, Inc.: Champaign, IL, USA, 2003. [Google Scholar]
- Sharma, J.R.; Arora, H. An efficient derivative free iterative method for solving systems of nonlinear equations. Appl. Anal. Discret. Math. 2013, 141, 390–403. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Method | Iteration | ACOC | CPU | ||
|---|---|---|---|---|---|
| 4 | 6.4713 | 0.12497 | |||
| 4 | 6.9013 | 0.12497 | |||
| 3 | 7.4977 | 0.10935 | |||
| 3 | 8.1214 | 0.09372 | |||
| 3 | 8.4288 | 0.09376 | |||
| 3 | 7.2829 | 0.07820 | |||
| 3 | 7.5839 | 0.09369 | |||
| 3 | 7.6127 | 0.09372 | |||
| 3 | 8.1148 | 0.09372 | |||
| 3 | 8.2785 | 0.09371 | |||
| 3 | 9.0000 | 0.07810 |
| Method | Iteration | ACOC | CPU | ||
|---|---|---|---|---|---|
| 3 | 7.7019 | 1.62081 | |||
| 3 | 8.1189 | 1.44667 | |||
| 3 | 8.4372 | 1.70871 | |||
| 3 | 9.5661 | 1.55475 | |||
| 3 | 9.6019 | 1.58814 | |||
| 3 | 7.2153 | 1.35980 | |||
| 3 | 7.2502 | 1.23408 | |||
| 3 | 7.5866 | 1.32781 | |||
| 3 | 8.3395 | 1.32781 | |||
| 3 | 8.1448 | 1.32781 | |||
| 3 | 9.2559 | 1.32781 |
| Method | Iteration | ACOC | CPU | ||
|---|---|---|---|---|---|
| 3 | 5.9409 | 96.67874 | |||
| 3 | 7.8965 | 95.12069 | |||
| 3 | 6.4033 | 105.39603 | |||
| 3 | 9.3335 | 102.83968 | |||
| 3 | 7.2114 | 83.71736 | |||
| 3 | 6.2215 | 80.48735 | |||
| 3 | 5.7464 | 96.65305 | |||
| 3 | 7.2814 | 87.39948 | |||
| 3 | 8.2819 | 93.83893 | |||
| 3 | 8.9837 | 93.94005 |
| Method | Iteration | ACOC | CPU | ||
|---|---|---|---|---|---|
| 3 | 5.3853 | 0.07810 | |||
| 3 | 5.3905 | 0.07810 | |||
| 3 | 5.8755 | 0.07806 | |||
| 3 | 6.5931 | 0.10935 | |||
| 3 | 6.6658 | 0.10934 | |||
| 3 | 5.9520 | 0.07807 | |||
| 3 | 6.3465 | 0.07814 | |||
| 3 | 6.7772 | 0.07814 | |||
| 3 | 7.6376 | 0.07807 | |||
| 3 | 7.6028 | 0.06245 | |||
| 3 | 8.6682 | 0.10934 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, N.; Jaiswal, J.P.; Argyros, I.K. Novel Techniques with Memory Extension of Three-Step Derivative-Free Iterative Scheme for Nonlinear Systems. Computation 2025, 13, 55. https://doi.org/10.3390/computation13020055
Kumar N, Jaiswal JP, Argyros IK. Novel Techniques with Memory Extension of Three-Step Derivative-Free Iterative Scheme for Nonlinear Systems. Computation. 2025; 13(2):55. https://doi.org/10.3390/computation13020055
Chicago/Turabian StyleKumar, Nishant, Jai P. Jaiswal, and Ioannis K. Argyros. 2025. "Novel Techniques with Memory Extension of Three-Step Derivative-Free Iterative Scheme for Nonlinear Systems" Computation 13, no. 2: 55. https://doi.org/10.3390/computation13020055
APA StyleKumar, N., Jaiswal, J. P., & Argyros, I. K. (2025). Novel Techniques with Memory Extension of Three-Step Derivative-Free Iterative Scheme for Nonlinear Systems. Computation, 13(2), 55. https://doi.org/10.3390/computation13020055