1. Introduction
Neural networks (NNs) have found a growing range of applicability in several domains, such as marketing, cybersecurity for fraud detection, image recognition and classification, geology for seismic facies classification, stock prediction in financial institutions, industrial automation, and healthcare, just to name a few. Feedforward neural networks (FNNs) can be highlighted as one of the most widely recognized and commonly employed methods in neural networks. FNNs, known as multi-layer perceptrons (MLPs), follow the architectural model of input, hidden, and output layers of interconnected nodes/neurons. Each node connects to other nodes in the successive layer to form a pathway known as a feedforward pathway in the direction from the input to the output layer. Within the feedforward neural network (FNN) context, the activation function injects non-linearity into the neural network’s output by processing the input data. FNNs with activation function
, an output node, and a hidden layer consisting of
m neurons can be written as:
where, for
denote the connection weights,
represent the threshold values,
is the inner product of the vectors
and
u, and
are the coefficients. Feedforward neural networks (FNNs) are powerful tools for making approximations due to their adaptable architecture with considerable invisible layers and non-linear activation functions. They are effective since they can theoretically discover, learn, and approximate to an arbitrary level of exactness any continuous function on a compact set due to their versatile approximation property. Extensive research has been performed using FNNs in distinct topics such as density results [
1,
2], the complexity of approximation of NNs [
3,
4] and quantitative estimation for the approximation order [
5,
6,
7].
Cardaliaguet and Euvrard [
8] initiated the exploration of approximating feedforward neural network operators (FNNOs) to the identity operator. Then, Anastassiou [
5] has successfully determined the rate of convergence of the Cardaliaguet–Euvrard and “squashing” neural network operators by utilizing the modulus of continuity. Further, Costarelli and Spigler [
9] explored the pointwise and uniform convergence by certain NN operators induced by sigmoidal functions. Their research demonstrated an enhanced rate of convergence for the
-class of functions through the consideration of logistic and hyperbolic tangent sigmoidal functions. In Yu’s work [
10], the author comprehensively examined pointwise and uniform approximation for distinct neural network operators, activated by sigmoidal functions on a compact set. The study indicated that significant enhancements in the order of convergence can be achieved through the assortment of these operators.
In their study, Costarelli and Spigler [
4] introduced a set of multivariate NN operators of Kantorovich type employing specific density functions. They examined the convergence results in both the uniform and
norms. Furthermore, in their paper [
4], the same authors advocated for the use of NN Kantorovich-type operators to explore the approximation of functions within
spaces. In their comprehensive research, Yu and Zhou [
11] examined the direct and converse outcomes for specific NN operators induced by a smooth ramp function, resulting in a significant enhancement in the convergence rate for smooth functions via the combination of these operators. Costarelli et al. [
12] conducted a careful analysis of the pointwise and uniform convergence by linear and the corresponding non-linear NN operators, showing valuable insights. They also provided a detailed discussion on the approximation by their Kantorovich version for
, where
. Additionally, Costarelli and Vinti [
13,
14] delivered compelling findings on the quantitative results for the Kantorovich variant of NN operators, utilizing the modulus of continuity and Peetre’s
-functional. Uyan et al. [
15] introduced a family of neural network interpolation operators utilizing the first derivative of generalized logistic-type functions as a density function. The research demonstrates their interpolation properties for continuous functions on finite intervals and examines parameter efficiency for function approximation in
spaces for
.
In [
16], the researchers analyzed the asymptotic expansion and Voronovskaja-type result for the NN operators and received a more promising rate of convergence by considering a combination of these operators. Coroianu et al. [
17] researched quantitative results for the classical as well as Kantorovich-type NN operators. Kadak [
18] delved into the development of fractional neural network interpolation operators activated by a sigmoidal function in the multivariate scenario. Additionally, Qian and Yu [
19] established NN interpolation operators induced by specific sigmoidal functions, and subsequently derived both the direct and converse results for these operators.
In their paper [
20], Costarelli and Vinti investigated pointwise and uniform approximation and derived results for
spaces, where
, using max-product NN Kantorovich operators. Additionally, in another paper [
21], the authors put forward and examined the approximation properties of the max-product NN and quasi-interpolation operators. Wang et al. [
22] have demonstrated the direct and converse results for distinctive multivariate NN interpolation operators applied to continuous functions. Their work also encompasses the investigation of the Kantorovich variant of these operators to analyze the approximation of functions within the
space, where
. Qian and Yu [
23] studied the direct and converse theorems for NN interpolation operators induced by smooth ramp functions and achieved an improved order of approximation by means of a combination of these operators. Qian and Yu [
19] presented a single-layer NN interpolation operator based on a linear combination of general sigmoidal functions and discussed the direct and converse results. In a subsequent section of the paper, the authors expound upon the approximation properties of a linear combination and the Kantorovich variant of the NN operators. Wang et al. [
24] introduced NN interpolation operators by incorporating Lagrange polynomials of degree
and presented direct and converse findings in both univariate and multivariate scenarios. Bajpeyi and Kumar [
25] proposed exponential-type NN operators and studied some direct approximation theorem.
Bajpeyi [
26] proposed a Voronovskaja-type theorem and the pointwise quantitative estimates for the exponential-type NN operators and obtained a better rate of convergence by evaluating a combination of these operators.
Mahmudov and Kara [
27] presented and examined the order of convergence of the Riemann–Liouville fractional integral type Szász–Mirakyan-Kantorovich operators in the univariate and bivariate cases. Recently, Kadak [
28] introduced a family of multivariate neural network operators (NNOs) involving a Riemann–Liouville fractional integral operator of order
and examined their pointwise and uniform approximation properties.
A measurable function
is said to be a sigmoidal function, provided that
Costarelli [
1] pioneered the study of interpolation by NN operators. For a bounded and measurable function
, he defined the following NN interpolation operators:
where
with
, and the density function
is given by
, with the ramp function
being
Li [
29] introduced a generalization of the above ramp function by means of a parameter
as follows:
where
, and
. The associated density function is given by
It is clear that, in the case
, and
, the functions
and
turn into
and
, respectively.
Li [
29] proposed the following NN interpolation operators:
and proved that
, together with a convergence estimate by utilizing a second-order modulus of continuity.
Yu [
11] introduced a smooth ramp sigmoidal function
, with the help of the function
as defined above, in the following manner:
The corresponding density function is given by
and
We present a lemma listing the properties of the density function
.
Lemma 1. [11] The function verifies the following useful properties: - (1)
is nonenegative and smooth;
- (2)
is even;
- (3)
is non-decreasing when and non-increasing when ;
- (4)
;
- (5)
.
Let
be a bounded and measurable function. Yu [
11] introduced a new neural network interpolation operator based on
as
where
and
are the uniformly spaced nodes defined by
with
It is clear that
and hence, from (
4), it follows that
Yu [
11] showed that the operators
interpolate
at the nodes
. They obtained the following estimates for
and its derivative.
Lemma 2. [11] Let Then, for we haveand, for there follows Theorem 1. [11] For any interpolates at the nodes that is, Theorem 2. [11] We assume that It holds that The paper is organized as follows: Some auxiliary definitions and results are given in
Section 1. The high order of approximation by using the smoothness of
as well as the related fractional approximation result have been discussed in
Section 2. In
Section 3, we research the quantitative approximation of complex valued continuous functions on
by the NN operators activated by smooth ramp functions. Finally, we discuss a few examples of functions for which our results are applicable by using NN operators activated by smooth ramp functions.
2. Main Results
We present the following high-order approximation result, by using the smoothness of
Theorem 3. Let Then, we have
(3) We assume further that for some, is fixed, it holdsa high speed pointwise convergence and Proof. Let
Then, we can write from the Taylor formula
Thus, we can write what follows:
Let us obtain it:
We also obtain
We distinguish the following cases:
(i) We assume that
then
(ii) Moreover, in case of
then, we have
Consequently, we have found that
Therefore, it holds that
Noting that
for some
we obtain
Next, we observe
Therefore, we derive
Using (
12) and (
13), we derive (
8)–(
10). It is clear that taking
we immediately obtain the relation (
11). □
We present a related Voronovskaya-type asymptotic expansion for the error of approximation.
Theorem 4. Let Then, we havewhere If the sum above disappears.
From the asymptotic expansion given by the relation (14), it follows thatwhere When or then Proof. Let
then, we can write the following from the Taylor formula:
For any fixed
there exists
such that
Now, we can write what follows:
Here, we also divide
as follows:
So that
Hence, it holds that
We distinguish the following cases:
(2) Moreover, in the case of
then, we have
Thus, in both cases, we have proved that
Clearly, we find
From the above estimates, we find
So, for
we obtain
as
That is,
which proves the theorem. □
Let us give some of the limitations and lemmas we need for the validation of the following theorems. Let be the space of functions with being absolutely continuous functions.
Definition 1. [30] Let ( is the ceiling of the number), and We call left Caputo fractional derivative the functionwhere Γ
is the gamma function. We set Lemma 3. [30] Let , and Then, Definition 2. [30] Let The right Caputo fractional derivative of order is given by We set Lemma 4. [30] Let , and Then, As in [
30], for all
we assume that
In the following, we present the related fractional estimates result.
Theorem 5. Let Then, we have
Proof. For any fixed
there exists
such that
We have that
From (
18), for all
we obtain
From ([
31]), we can write from the right Caputo fractional Taylor formula
Also from ([
32], p. 54), from the left Caputo fractional Taylor formula, we obtain
for all
Hence, it holds that
where
for all
Similarly, for
we have that
where
Now, by adding (
21) and (
22), we can write what follows:
Now, we can estimate
and
We have that
We have proved that
Furthermore, we observe that
That is, we have proved
Thus, from the above estimates we obtain
Now, finally, by using (
24) and (
25), we find (
19), which implies (
20).
In the following, we prove that the right-hand side of (
20) is finite.
We have
Hence,
Thus, for
, we have
Similarly, by simple calculations, it follows that
This implies
>Thus,
Now, for
, we can write what follows:
Hence, it holds that
Thus, we finally have
and, similarly, we obtain
This completes the proof. □
Corollary 1. We assume all the conditions of Theorem 5; also, let us assume that Then, we haveWe notice in the previous expression, the high-speed of pointwise convergence at Next, we present a result of the fractional Voronovskaya-type asymptotic expansion.
Theorem 6. Let then, we havewhere If the sum above disappears.
From the asymptotic expansion given by the relation (30), it follows thatas When or thenas Of great interest is the case .
Proof. From the left Caputo fractional Taylor formula ([
32], p. 54), we obtain
for all
Furthermore, from [
31], using the right Caputo fractional Taylor formula, we obtain
for all
Hence,
is fixed such that
for some
Hence, it holds that
for all
Furthermore, it holds that
for all
Hence, we obtain
We also see that, for any
by (
27) and (
28), we have
with
That is, we find
We easily see that
Similarly, we reach
Therefore, it holds that
Thus,
and
Thus, finally letting
we derive
as
so that
proving the claim. □
3. Complex Multivariate Neural Network Approximation
Let with real and imaginary parts Clearly, is continuous if and are continuous. Let . Then and hence both are bounded which implies that is bounded.
Let us define
We observe that
and, hence,
Clearly, if
is bounded, then
,
are also bounded functions.
In order to establish the interpolation property, let us assume that is bounded and measurable. Then, , are bounded and measurable in .
From Theorem 1 and (
31), for
, we have
for every
Hence, it follows that, for every
, the operators
interpolate the function
at the nodes
for every
In the following result, we present the uniform error estimate for the operators (
31) in terms of modulus of smoothness by using (
33) and Theorem 2.
Theorem 7. We assume that . Then, there holds the inequality In view of (
32) and (
33), using Theorem 3, we easily derive the following convergence estimates in the pointwise and uniform approximation of smooth complex functions by the operators (
31).
Theorem 8. Let and . Then,



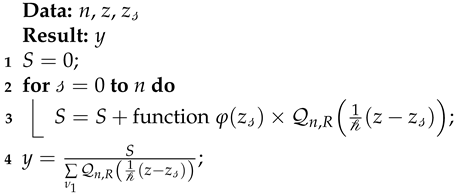

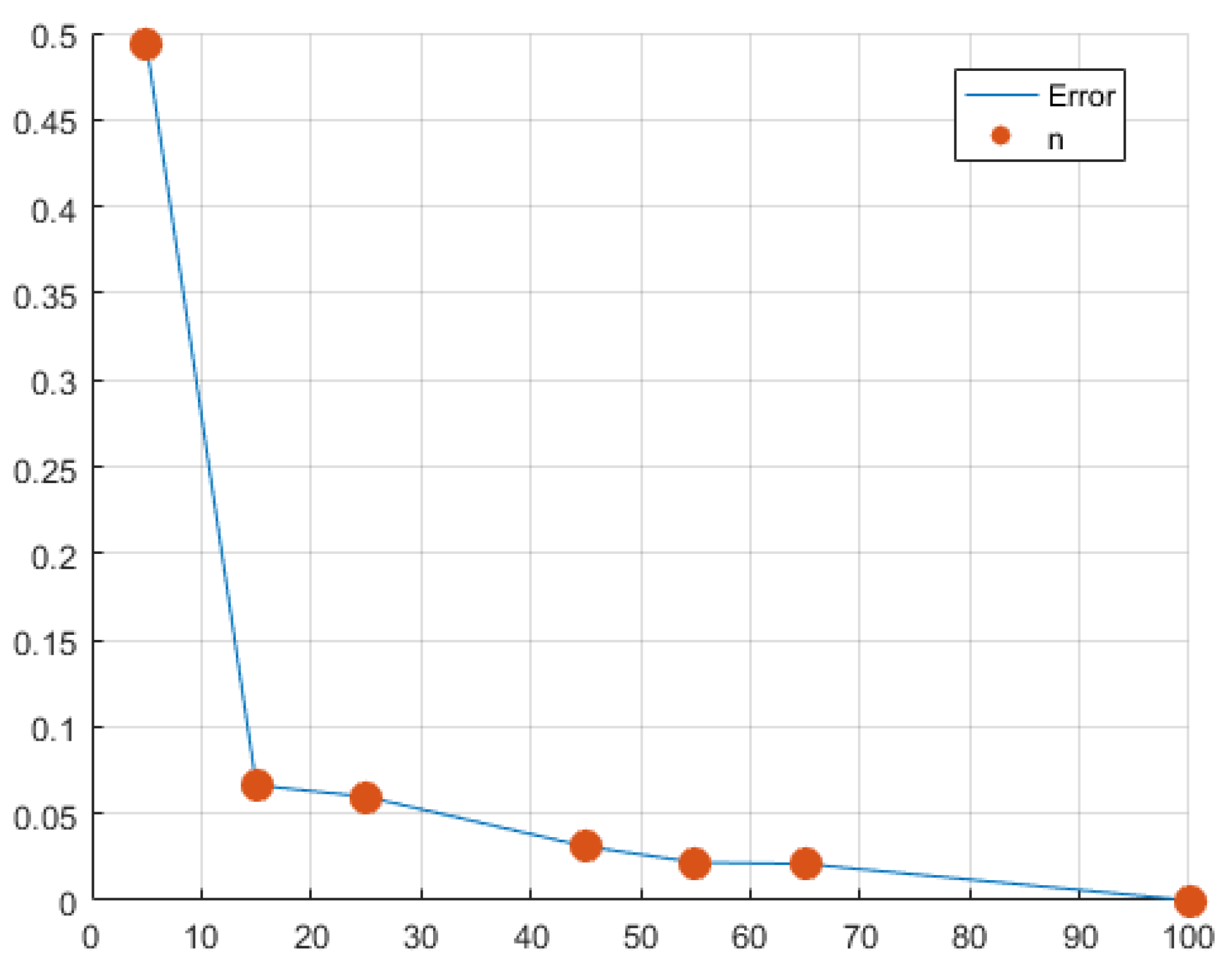

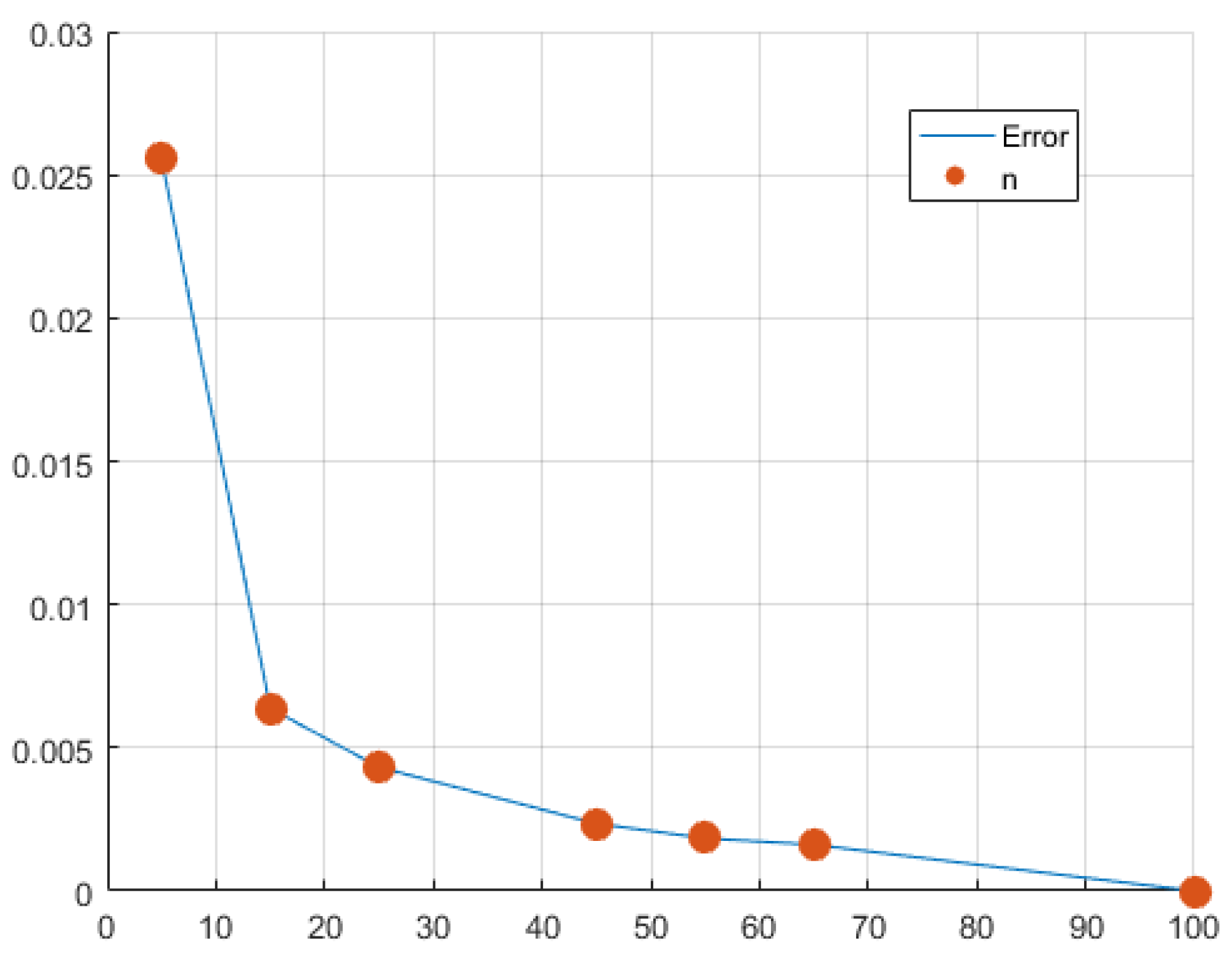

{kind=link}
{kind=link}
{kind=link}
{kind=link}