1. Introduction
Numerical techniques to find approximated solutions instead of exact ones were found to be helpful in various fields of science, engineering, physics, and many other disciplines where mathematical models were used to describe real-world phenomena. Over the past 60 years, as noted by Thomée V. [
1], the research and development of computational methods have successfully addressed numerous engineering problems, including heat transfer and fluid flow. As a result, the field of Computational Fluid Dynamics (CFD) became an essential part of the modern industrial design process [
2].
Numerical algorithms involve iterative processes, where an initial guess is refined through successive calculations to approach the true solution. The process continues until a predefined convergence criterion is met. Still, the processing efficiency and solution accuracy are strongly related to the hardware capacity and software optimization. For instance, the electronic connections between processor and memory units may limit the data throughput. Therefore, it is important to evaluate the Random Access Memory (RAM) and Video Random Access Memory (VRAM) implementations in terms of operational speeds [GHz] [
3]. The RAM device may be defined as the main computer memory used to store and process data, being placed at the computer’s motherboard. Conversely, GPUs possess a distinct and non-removable type of memory known as VRAM, which is directly integrated into the graphics card. In GPU processing platforms such as CUDA
®, RAM is often referred to as host machine memory, while VRAM is termed device memory [
4].
Over the past few decades, many commercial CFD packages have been developed. However, most are designed to perform computations based on CPU processors. With the advent of high-performance computing, parallelized numerical methods have become increasingly important. When parallel computing is employed, calculations are distributed among multiple processors or cores to efficiently solve large-scale problems. In such conditions, the computational cost is often decreased compared to sequential computation via CPUs.
A subject of industrial interest is yield stress fluids, which do not deform until the yield stress is exceeded. In the case of flow into a narrow eccentric annulus, this type of phenomenon can be decomposed into multiple long-thin flows. The nonlinearity in the governing equations requires substantial calculations, so the Lagrangian algorithm is often applied. Medina Lino et al. (2023) [
5] proposed implementing a non-Newtonian Hele–Shaw flow to model the displacement of Herschel–Bulkley fluids in narrow eccentric annuli. They utilized the CUDA
® Fortran language to accelerate calculations compared to CPU processing. The calculations run in an NVIDIA GeForce
® RTX
™ 2080 Ti were up to 40 times faster than the simulations run in an Intel
® Core
™ I7 3770 processor.
Continuing in the field of fluid flow modeling, Xia et al. (2020) [
6] developed a CUDA-C language GPU-accelerated package for simulation of flow in nanoporous source rocks with many-body dissipative particle dynamics. The authors demonstrated through a flow simulation in realistic shale pores that the CPU counterpart requires 840 Power9 cores to rival the performance delivered by the developed package with only four Nvidia V100 GPUs. More recently, Viola et al. (2022) [
7] applied CUDA to perform GPU-accelerated simulations of the Fluid–structure–electrophysiology Interaction (FSEI) in the left heart. The resulting GPU-accelerated code can solve a single heartbeat within a few hours (ranging from three to ten hours depending on the grid resolution), running on a premises computing facility consisting of a few GPU cards. These cards can be easily installed in a medical laboratory or hospital, thereby paving the way for a systematic Computational Fluid Dynamics (CFD)-aided diagnostic approach.
Simulations in the field of computational biomedicine have also been accelerated with the aid of GPU processing. The desire to create a three-dimensional virtual human as a digital twin of one’s physiology has led to the development of simulations using the CUDA
® computing platform as a means of reducing processing time. For example, the HemeLB solver, which is based on the lattice Boltzmann method, is widely utilized for simulating blood flow using real patient images. Zacharoudiou et al. (2023) [
8] utilized the method’s strong scaling capability to adapt their algorithm for execution on a GPU architecture using CUDA-C language. Indeed, such scalability extends to a higher level of parallelism for GPU codes compared to CPU codes. When comparing computations using an equivalent number of GPU and CPU threads, computations using the GPU were still up to 85 times faster. The authors compared different settings of supercomputers.
Applying the GPU for calculations may also facilitate the achievement of more detailed and realistic simulations. In 2021, O’Connor and Rogers [
9] adapted and implemented the open-source DualSPHysics code to run on a GPU. This adaptation was aimed at achieving more reliable simulations of coupled interactions between free-surface flows and flexible structures, addressing concerns that frequent use of reduced models may lead to erroneous assumptions. The execution time needed to perform the calculations using an NVIDIA
™ Tesla
® V100 GPU and an Intel
® Xeon
™ E5 2690 were compared. The GPU outperformed the CPU for all numbers of particles investigated. However, the speed-up was proportional to the number of particles. Thus, when dealing with a small number of particles, the speed-up on the GPU was relatively low. As the number of particles increased, so did the speed-up, reaching up to 50 times faster on the GPU.
In addition to fluid flow, some authors also use numerical models computed through GPUs to investigate heat transfer. For example, Satake et al. (2012) [
10] performed optimizations of a GPU-accelerated heat conduction equation by a programming of CUDA Fortran from an analysis of a Parallel Thread Execution (PTX) file. Before implementing the proposed code corrections, CUDA-C exhibited a speed 1.5 times faster than by CUDA Fortran. Later, Klimeš and Štětina (2015) [
11] employed the Finite Difference Method (FDM) to perform three-dimensional simulations with solidification modeling. The results demonstrated that the GPU implementation outperformed CPU-based simulations by 33–68 times when utilizing a single Nvidia Tesla C2075 GPU to execute kernels. This considerable speed-up was enough to enable the application of their method in real-time scenarios. Szénási (2017) [
12] solved the Inverse Heat Conduction Problem (IHCP) using NVLink capable power architecture between the host and devices. This implementation (running on four GPUs) was about 120 times faster than a traditional CPU implementation using 20 cores.
Continuing the literature review in GPU-based computational methods in heat transfer, Semenenko et al. (2020) [
13] simulated conductive stationary heat transfer on a two-dimensional domain to compare the performance of CPU and GPU architectures. Their study was performed through several simulations using various hardware configurations, including four different GPUs: AMD Radeon
™ RX VEGA
® 56, NVIDIA GeForce
® GTX
™ 1060, NVIDIA GeForce
® GTX
™ 860 m, and NVIDIA Tesla
™ M40
®. It also utilized five Intel
® Core
™ i7 CPU processors: 3630 QM, 4720 HQ, 6700 K, 7700, and 7820 HQ. Different numbers of mesh elements were simulated. The results indicated that with an increase in the number of elements in the mesh, GPU calculations were faster compared to those on the CPU. Across all configurations considered, the GPU was, on average, 9 to 11 times faster than the CPU.
Convective and radiative heat transfers can also be studied using parallel computing. For instance, Taghavi et al. (2021) [
14] performed simulations of convective heat transfer in nanofluids inside a sinusoidal wavy channel. The authors solved the tridiagonal matrices obtained through the Spline Alternating Direction Implicit (SADI) technique using the Parallel Thomas Algorithm (PTA) on the GPU and the classic Thomas algorithm on the CPU, respectively. Implementing this high-order method on the GPU significantly reduced the computing time. The simulations could be performed up to 18.32 times faster on a GeForce
® GTX
™ 970 than on an Intel
® Core
™ i7 5930K processor. Additionally, the Monte Carlo, Runge–Kutta, and ray tracing methods were combined to simulate radiative heat transfer in a graded-index (GRIN) medium. Despite providing high precision, such sequential computations often require a significant amount of computational time.
Shao et al. (2021) [
15] developed two- and three-dimensional models optimized for graded-index (GRIN) media using parallel computing on GPUs to enhance processing. Computational times were compared between GPU implementations using an NVIDIA GeForce
® GTX
™ 1080 Ti and CPU implementations using the Intel
® Core
™ i7 8750H and the Xeon
™ Gold 5120 processors. In the two-dimensional model, the GPU demonstrated a speed-up of over 43 times and 5 times compared to the equivalent CPU implementation using a single core and six CPU cores, respectively. In the three-dimensional case, the GPU was 35 times and 2 times faster than the CPU, considering a single core and 14 CPU cores sequentially.
As discussed in the previous literature review, crucial contributions have made possible the acceleration of computational processing times through the application of GPU parallelization in several fields of engineering research. The CPU-based processing has been investigated for over fifty years, while GPU processing methods are still in early development, having been a research focus for nearly fifteen years. Hence, there is ample opportunity to explore new parallelized methods and specific studies for better addressing the GPU capabilities. For instance, in previous work, Azevedo et al. (2022) [
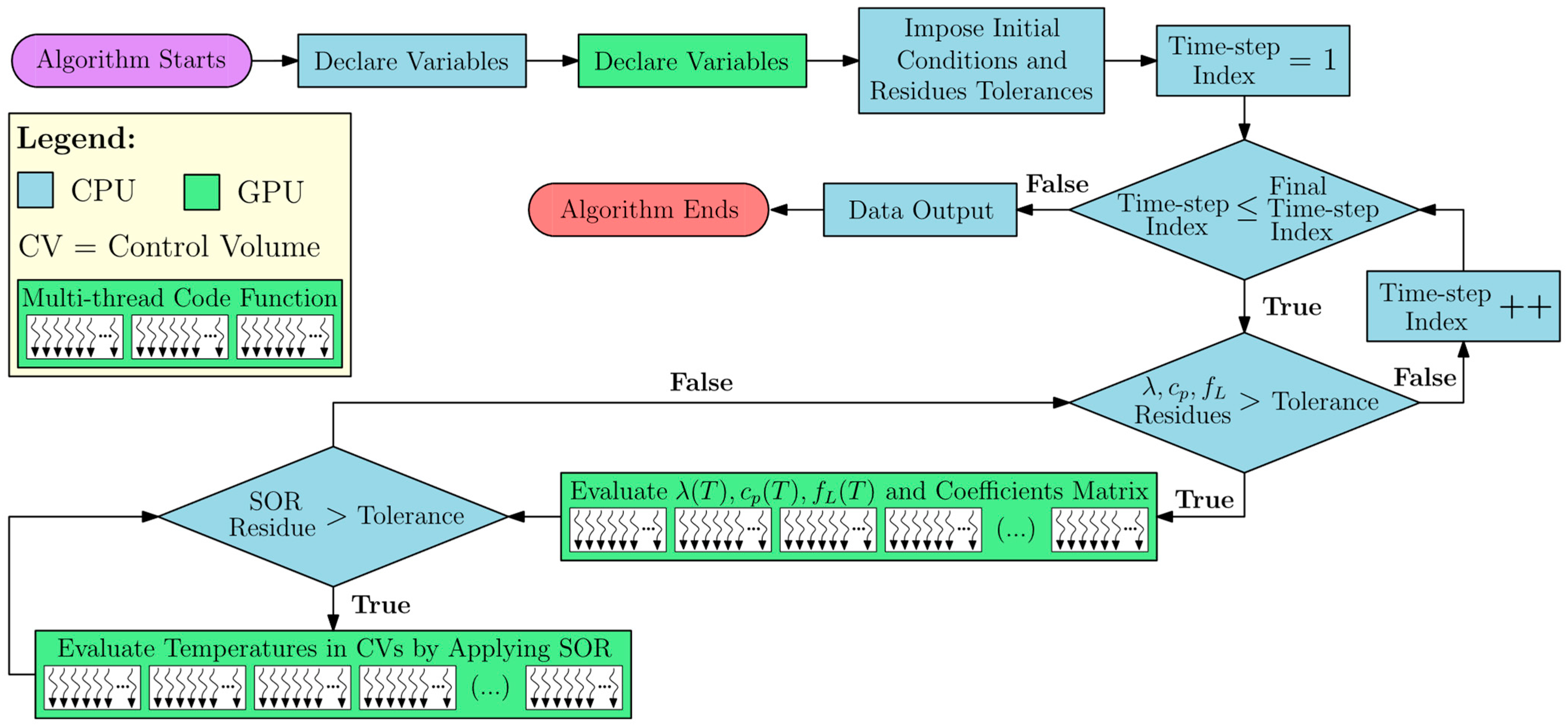
16] compared nonlinear and constant thermal properties approaches applied for estimating the temperature in LASER Beam Welding (LBW) simulations. The authors conducted a detailed study on the temperature gradient, its influence on thermocouple positioning, and a methodology to evaluate thermal properties convergence. However, the results were not extensively compared in terms of processing performance, energy, optimization and accuracy to well-established commercial code solutions. Therefore, in the present research, the advantages and drawbacks of an implementation of LASER Beam Welding (LBW) simulation using CUDA were investigated. The developed numerical solution utilizes CPU and GPU runtime code functions, along with multithreaded GPU parallelization, as illustrated in
Figure 1.
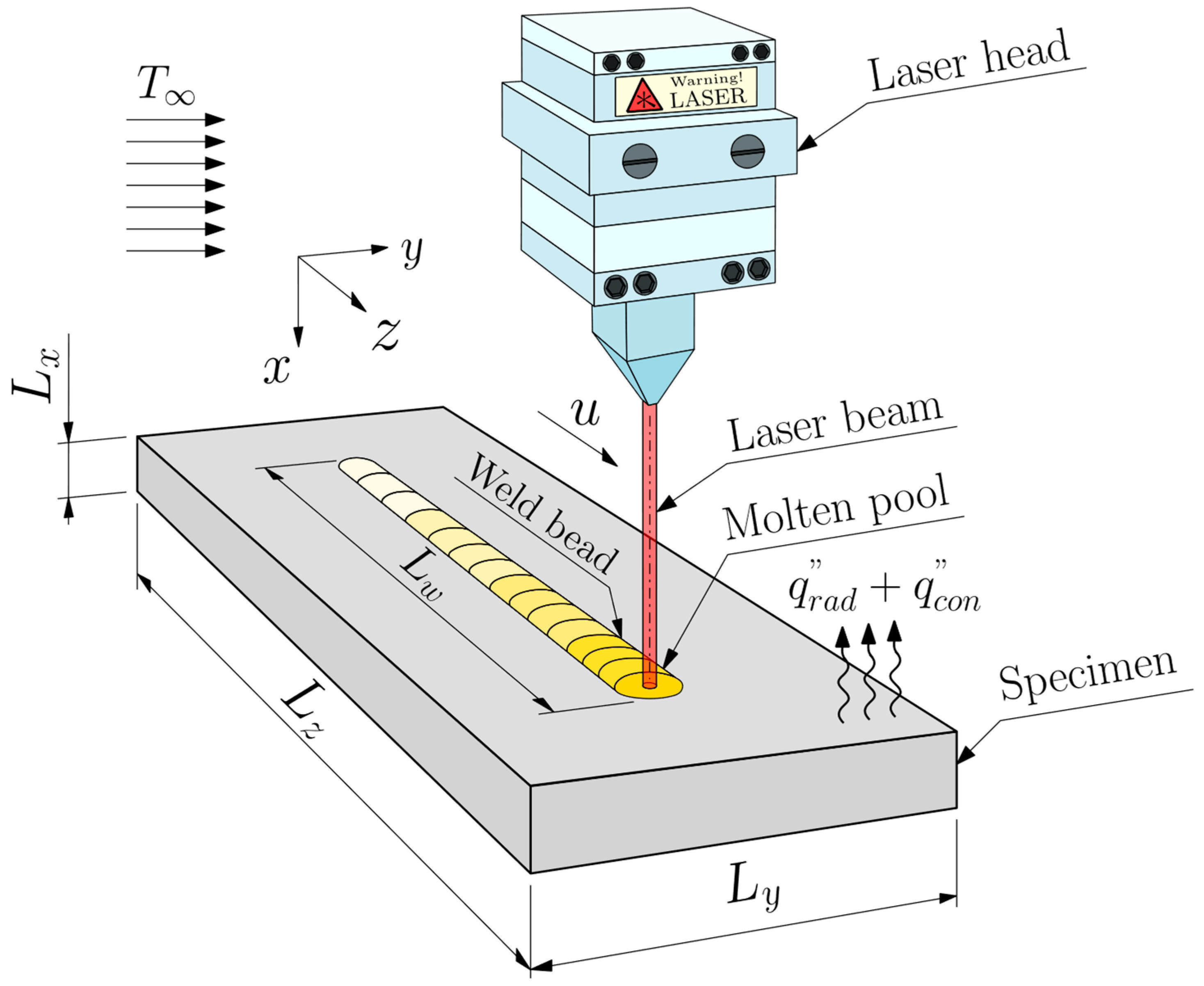
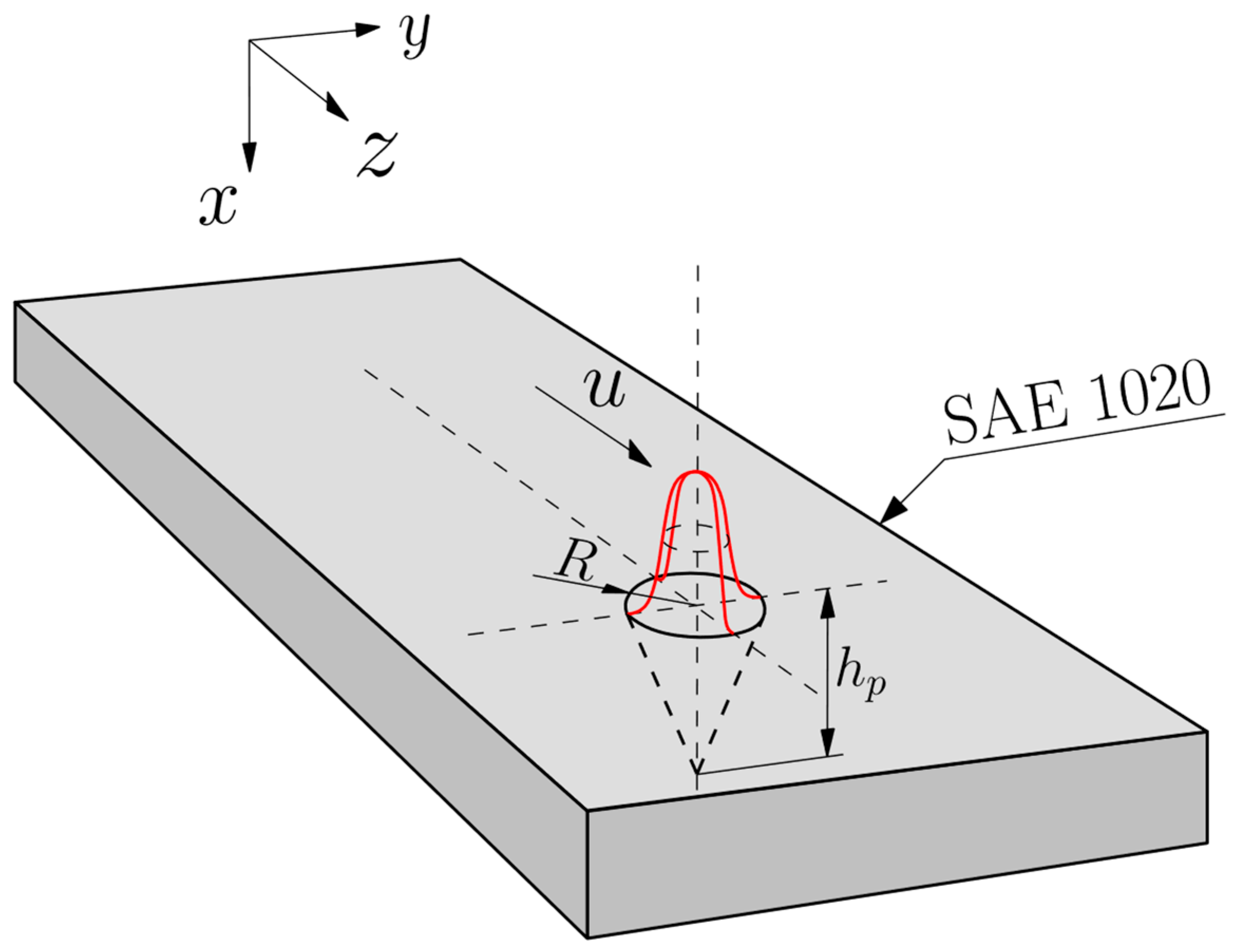
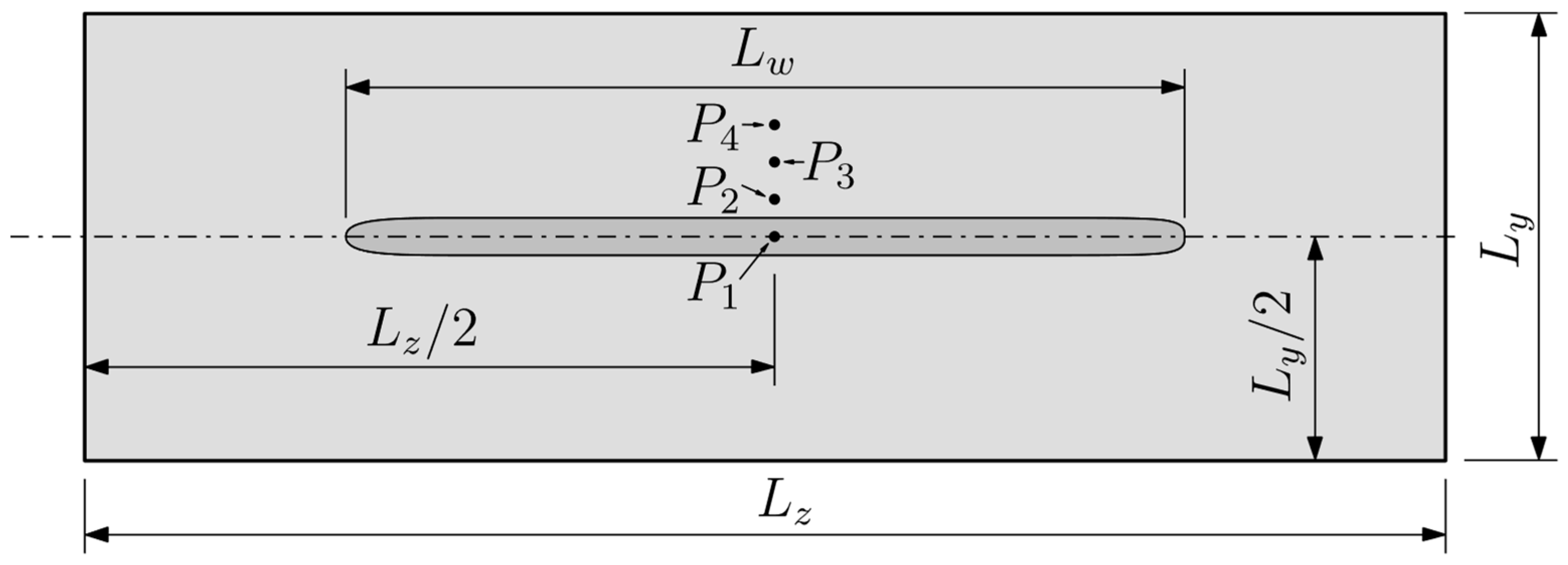
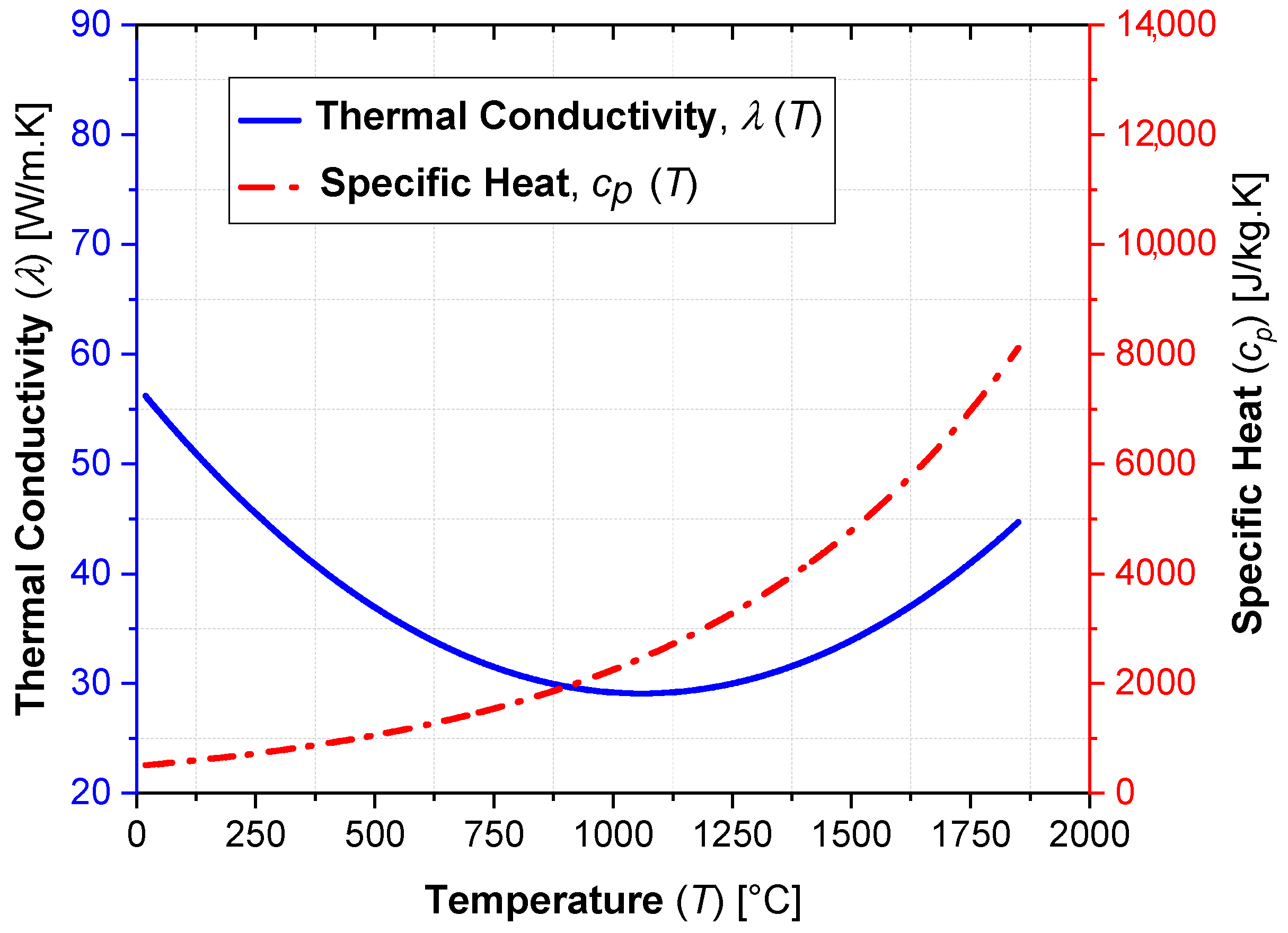
The investigation was conducted through the application of the heat conduction Partial Differential Equation (PDE) with a transient total enthalpy term to model the LBW process. The latter is needed to account for the phase change (melting) according to the Volumetric Thermal Capacitor (VTC) approach [
17]. The equations were discretized in space and time over a three-dimensional domain by applying the Finite Volume Method (FVM). The heat losses through convection at the boundaries of the domain were accounted for using Newton’s law of cooling and the losses through radiation were calculated by applying the Stefan–Boltzmann law. A Gaussian conical profile models the welding heat source. The effects of implementing constant and temperature-dependent thermophysical properties for the specimen’s material were evaluated. The GPUs simulations were performed in an in-house code written in CUDA-C language and run in an Nvidia
™ Geforce
® RTX
™ 3090 and a Geforce
® RTX
™ 4090, both with 24 GB of video memory. A parallelized form of the Successive Over-Relaxation (SOR) solver was used to find the solution of the linear system of equations. The CUDA
® code, as well as the three other top-rated CPU-based commercial codes, were executed on a desktop PC equipped with an Intel
® Core
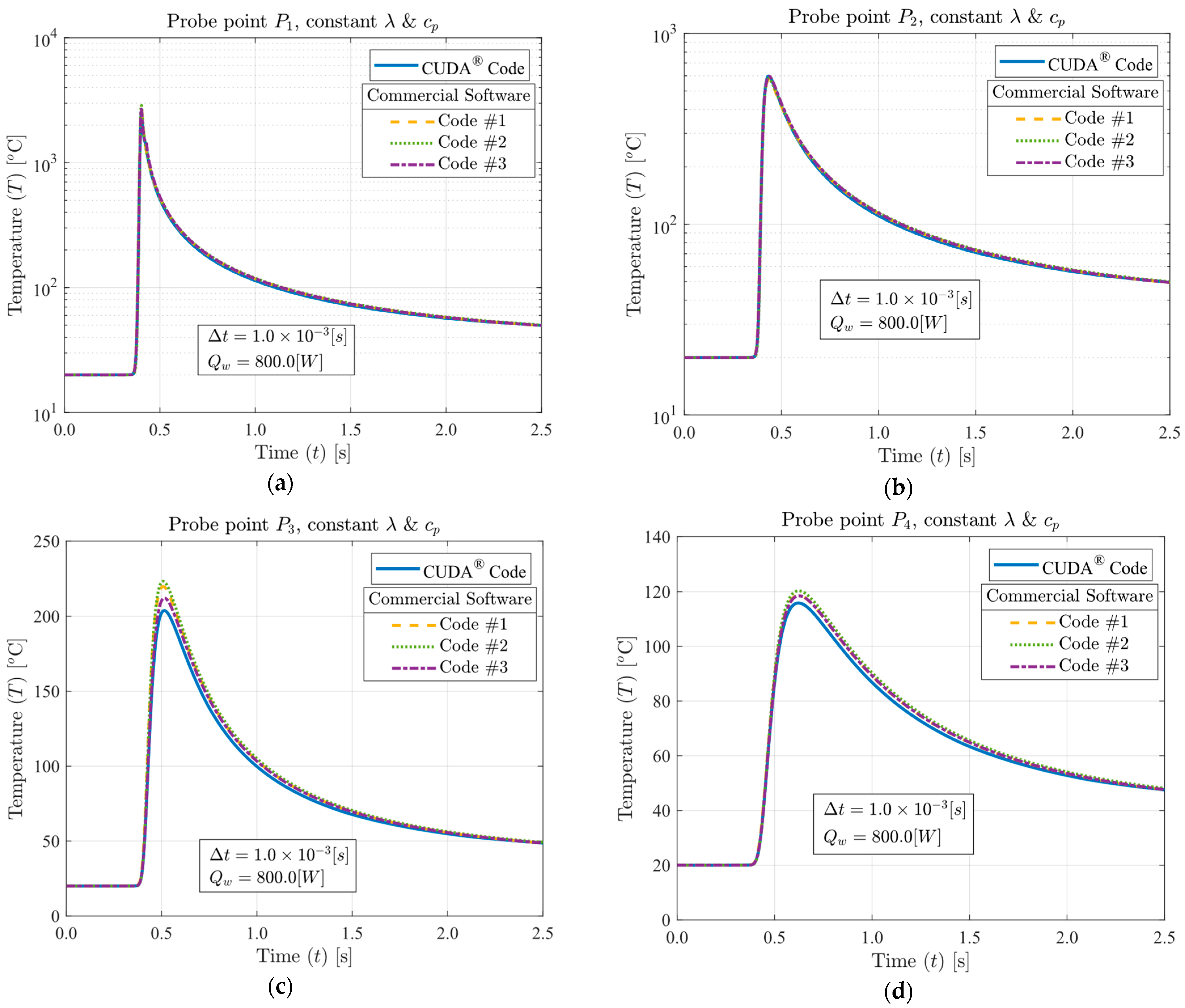
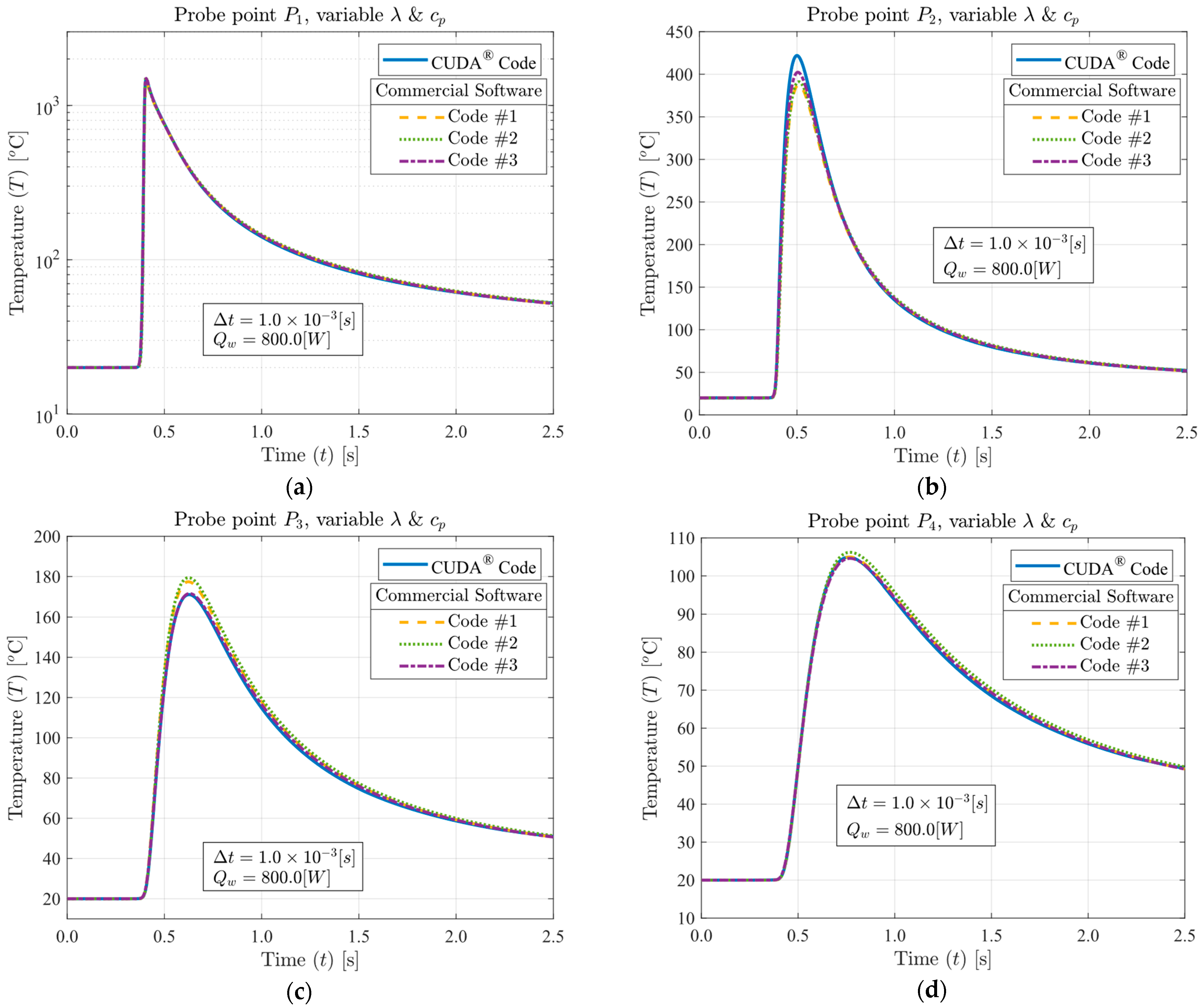
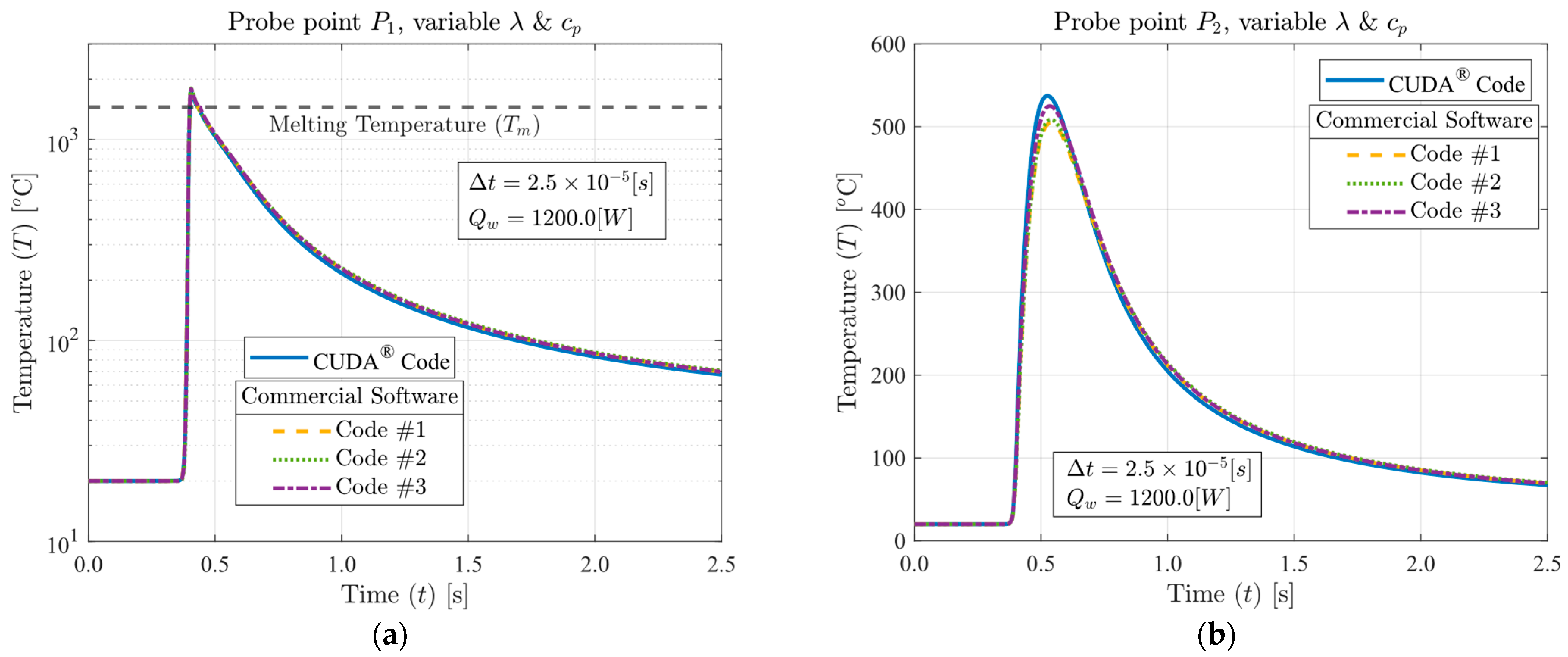
™ i9 12900KF processor. The temperature profiles simulated using equivalent solutions produced by GPU and CPU were compared, as well as the computational performance in terms of processing time, energy consumption, cost efficiency, and memory usage. The enhanced performance demonstrated in the research results highlights the significant potential for GPUs to replace CPUs in CFD applications.
4. Conclusions
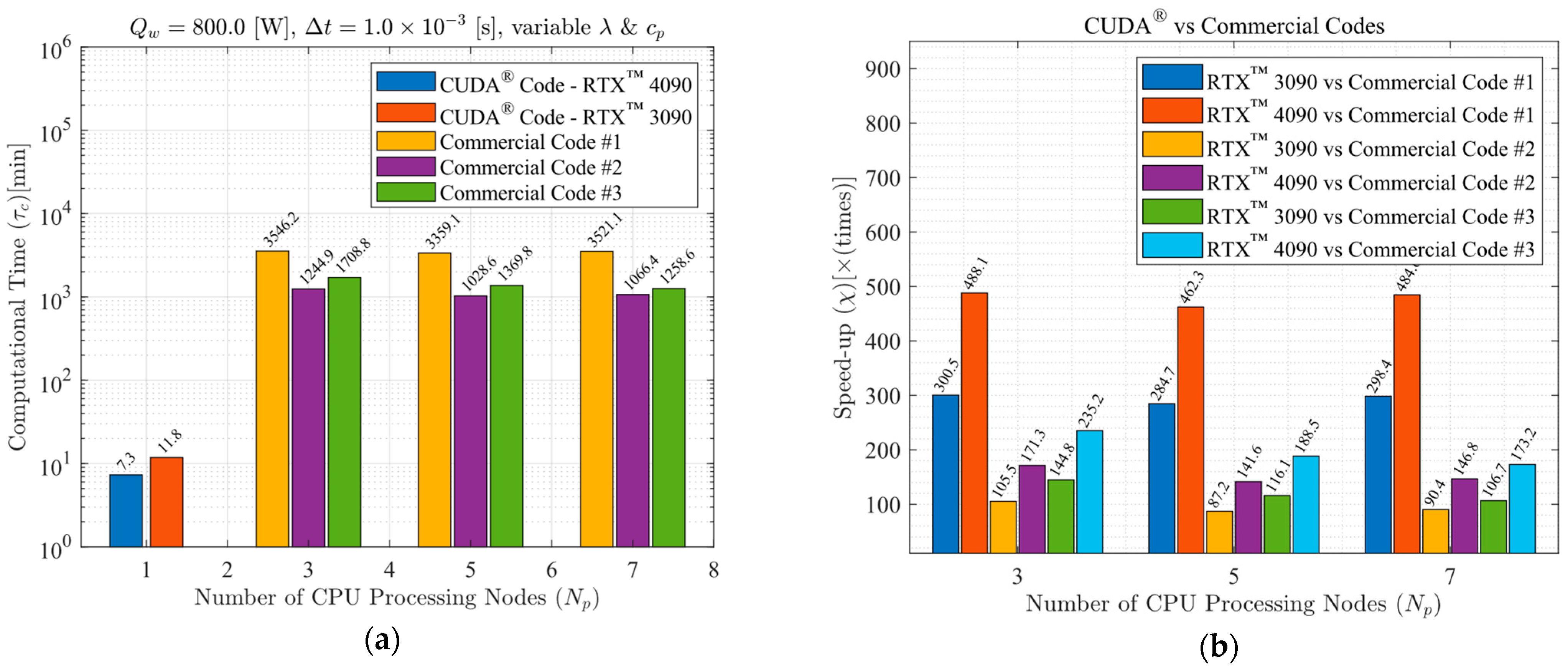
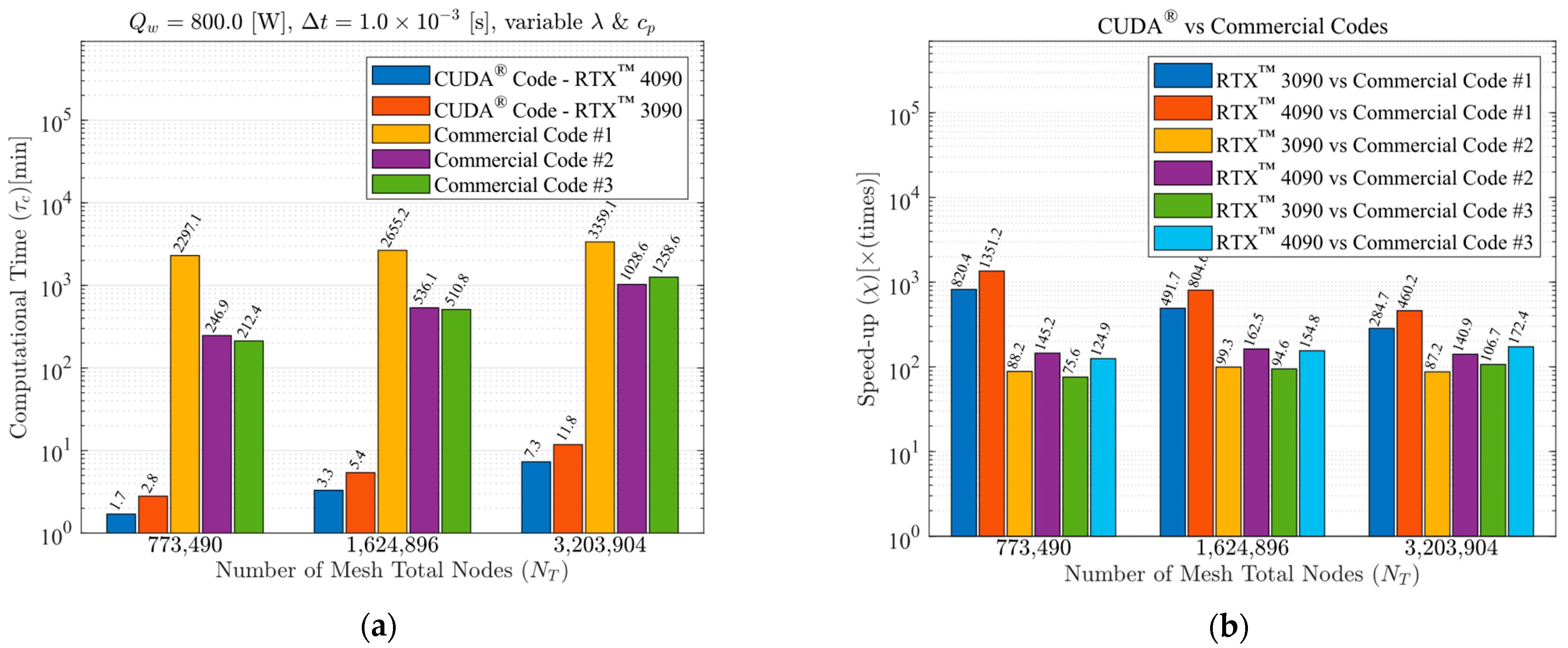
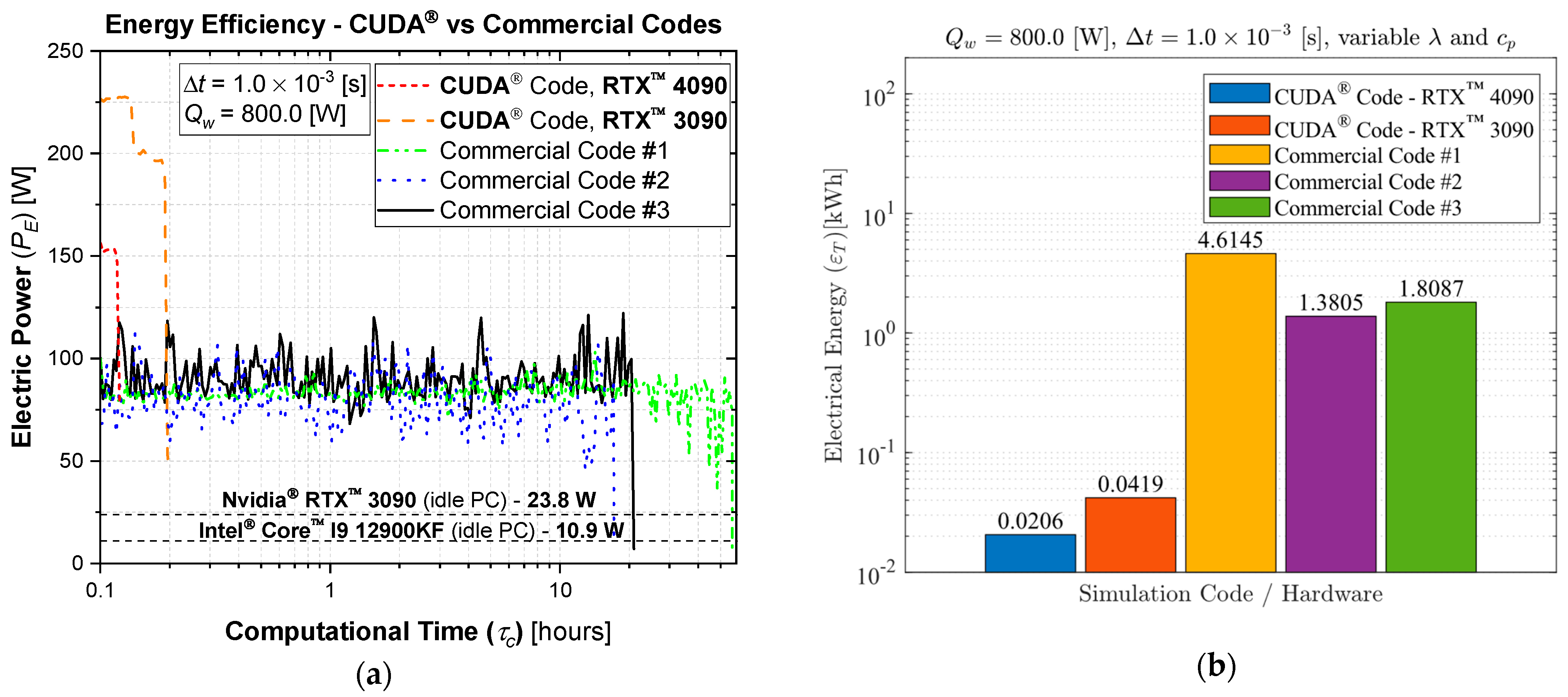
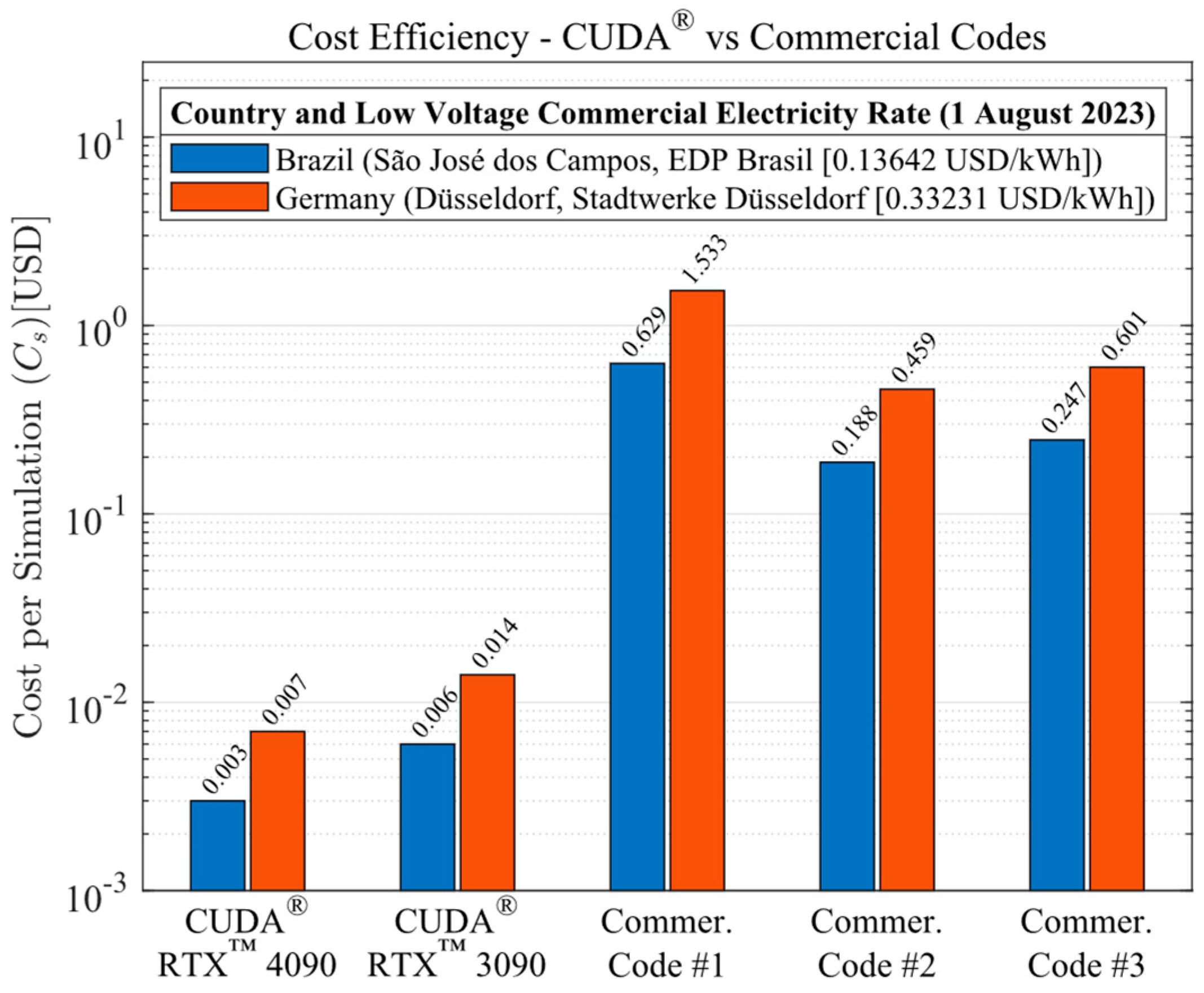
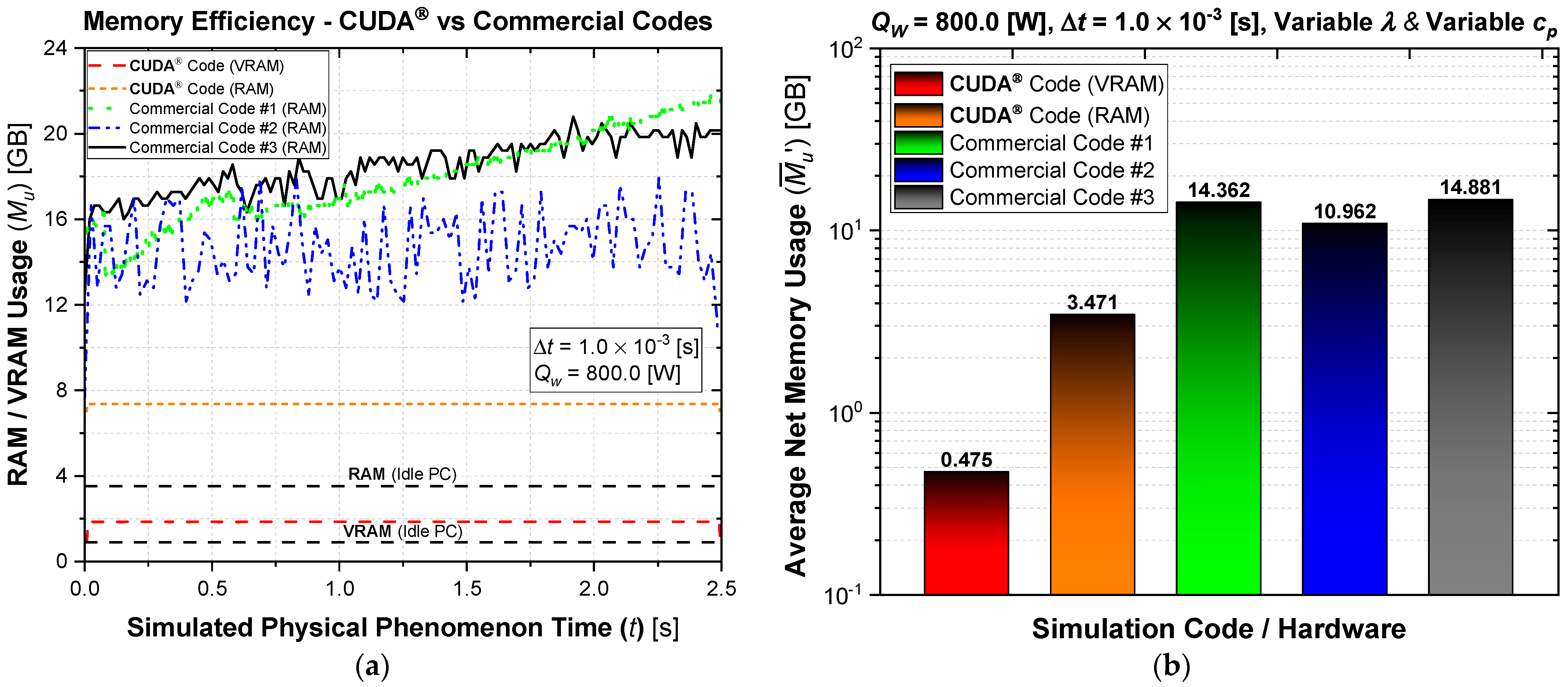
A computational performance analysis of a GPU LASER beam welding implementation using CUDA® was conducted. The applied methodology involved calculating temperature-dependent thermal properties, the temperature-dependent liquid mass fraction function, the coefficients matrix, and the final temperatures of each control volume through multi-thread parallelization. These code functions were executed on the GPU to achieve high-scale parallelism. The CPU was then utilized to coordinate the sequence of execution of all code functions and handle memory management. The results of this implementation were compared to output data from three top-rated commercial codes, assessing accuracy, processing performance, energy consumption, cost efficiency, and code optimization. The GPU solutions demonstrated vast potential in reducing CFD costs and time. The performance investigation yielded speed-ups ranging from 75.6 to 1351.2 times faster than the commercial solutions. This study also demonstrated that each commercial code has an optimum number of CPU parallel processing nodes (Np) that may vary with the type of physics simulated, mesh, number of chip physical cores, and other parameters (for the cases in the present study, Np = 5, 5, and 7, for commercial codes #1, #2, and #3, respectively). The double precision capability of modern graphics cards was evidenced through their calculations, resulting in an accuracy similar to that of the CPU solutions. Some of the cutting-edge GPU chips have similar or higher Thermal Design Power (TDP) than high-performance CPUs, but end up consuming far less electricity due to the ability to execute higher parallel processing scaling and thus finishing tasks much faster. As a matter of fact, the investigation revealed that the proposed GPU solutions required an average of 83.24 times less electrical energy in comparison to the commercial codes. In terms of budget, this higher energy efficiency of the GPU solutions resulted in an average cost per simulation 80.57 times lower than the average cost required by the commercial codes (regardless of the country). The in-house code also demonstrated optimized RAM and VRAM usage, averaging 3.86 times less RAM utilization in comparison to the commercial CFD solutions. Lastly, the primary drawbacks of implementing CFD simulations using CUDA® are the heightened coding complexity and the necessity of a CUDA-compatible graphics card. Future work will involve code enhancements through adopting an unstructured multigrid approach.







 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}