Abstract
Information is transmitted between multiple insecure routing hops in text, image, video, and audio. Thus, this multi-hop digital data transfer makes secure transmission with confidentiality and integrity imperative. This protection of the transmitted data can be achieved via hashing algorithms. Furthermore, data integrity must be ensured, which is feasible using hashing algorithms. The advanced cryptographic Secure Hashing Algorithm 3 (SHA-3) is not sensitive to a cryptanalysis attack and is widely preferred due to its long-term security in various applications. However, due to the ever-increasing size of the data to be transmitted, an effective improvement is required to fulfill real-time computations with multiple types of optimization. The use of FPGAs is the ideal mechanism to improve algorithm performance and other metrics, such as throughput (Gbps), frequency (MHz), efficiency (Mbps/slices), reduction of area (slices), and power consumption. Providing upgraded computer architectures for SHA-3 is an active area of research, with continuous performance improvements. In this article, we have focused on enhancing the hardware performance metrics of throughput and efficiency by reducing the area cost of the SHA-3 for all output size lengths (224, 256, 384, and 512 bits). Our approach introduces a novel architectural design based on pipelining, which is combined with a simplified format for the round constant (RC) generator in the Iota () step only consisting of 7 bits rather than the standard 64 bits. By reducing hardware resource utilization in the area and minimizing the amount of computation required at the Iota () step, our design achieves the highest levels of throughput and efficiency. Through extensive experimentation, we have demonstrated the remarkable performance of our approach. Our results showcase an impressive throughput rate of 22.94 Gbps and an efficiency rate of 19.95 Mbps/slices. Our work contributes to advancing computer architectures tailored for SHA-3, therefore unlocking new possibilities for secure and high-performance data transmission.
1. Introduction
The transmission of sensitive data in a highly dependable, highly secure, and highly reliable way has become urgent in the last few years. Cryptography is an important technique used to store information, protect it, and secure it against unauthorized access while it is being transmitted. These three goals may all be accomplished using cryptography. For example, the healthcare sector, the military, the government, industry, educational institutions, and private businesses collect a vast amount of personally identifiable digital information stored in a network environment. Therefore, cryptographic algorithms have seen an increased amount of application in recent years due to their ability to ensure a high level of security for various digital media formats, such as photos, text, video, and audio [1,2,3].
A binding domain of cryptography consists of hashing. Hashing is computing a fixed-length string using a standard algorithm, regardless of the input size. The output string will be the same length for the same hashing algorithm, no matter the input size. Each output string is unique for a specific input, and vice versa; even one byte altered results in a very different output. This property makes hashing a cornerstone in our ICT infrastructure, and algorithms have become essential in every aspect of our lives [4,5,6]. Hashing is used in every authentication scheme, from our local operating system to cloud banking or web email services. Hashing is also used in integrity verification, from the local file system like Zettabyte File System (ZFS) [7], which stores a hash for every block, to the operating system that keeps hashes for every critical file. Windows, Linux, FreeBSD, and other popular file systems keep a database with hashes for core components, up to the intrusion detection systems that inspect every file and compute its hash compared to a golden reference. Hashing is also used in data transmission to guarantee integrity, from the IP protocol up to the secure web browsing of the HTTPS/TLS protocol. Hashing is also used in indexing databases, allowing queries to execute faster, which is essential in our modern era with the humongous amounts of data created and processed. Everyone interacts with multiple hashing techniques, even if they do not know it. For this reason, it is a lucrative target for malicious individuals to exploit. They are utilizing, implementing, and accelerating new, more robust, and secure hashing algorithms [8].
Today, old standards of hash functions are vulnerable to attacks. Up today, many successful attacks have been recorded against the SHA-1 [9] and the SHA-2 hashing algorithms [10,11,12]. Thus, the National Institute of Standards and Technology (NIST) decided to investigate new, more secure hashing algorithms and adopted the SHA-3 (Keccak), which offers a higher level of security [13,14,15]. These new hash functions use larger hash values and more complex algorithms, making it much more difficult for attackers to find collisions or other vulnerabilities. Hash functions are widely used in the Hashed Message Authentication Code (HMAC) [16], network security [17], in the Digital Signatures [18], in Secure Electronic Transactions (SET) [19], and in Public Key Infrastructure (PKI) [20].
The new SHA-3 emerged during a competition organized by NIST in 2011 for the new Secure Hash Algorithm (SHA). Open competitions have been used as methods of selection for cryptographic standards worldwide. Therefore, in 2012, NIST announced that the Keccak hash function would represent SHA-3. The new hashing algorithm, SHA-3, provides high efficiency and throughput in hardware, both in Graphics Processing Unit (GPU) and in Field-Programmable Gate Array (FPGA) [21]. The FPGA-based embedded processing systems provide significant computing resources as security requirements grow [22]. FPGAs are also well-known for their high-performance capabilities and low energy consumption, making them ideal for embedded applications where space and power are limited [23,24]. With the growing need for secure systems, FPGAs have become attractive for implementing security features such as encryption, authentication, and intrusion detection. Therefore, the cryptography community concentrates on the SHA-3 (Keccak algorithm), which provides high performance in hardware and flexibility [25,26].
The following is a summary of the contributions given in this article:
- We propose a new method optimization technique based on pipelining for the algorithm SHA-3. This method places the additional register after step Theta () in the function f. The newly presented optimization technique can operate as the policy for the hardware optimization technique of the SHA-3. Our design performs significant advancements in performance metrics and reduces the area cost of FPGA devices.
- We suggest a novel format for the RC generator that is more straightforward to increase performance (throughput and efficiency) while simultaneously decreasing the amount of hardware resources available in the area. The new, more straightforward structure RC generator only consists of 7-bits rather than the previous 64-bits, which helps minimize the amount of computation required at the Iota () step, where the number of necessary XORs is decreased to 7.
- We confirmed the accuracy of the whole design with reliable examples provided by NIST. At the same time, we performed extensive evaluation and analysis to compare the proposed architecture’s area (slices), throughput (Gbps), frequency (MHz), and efficiency (Mbps/slices) to other similar methods in the published literature.
The rest of the article is organized as follows: In the following Section 2, we briefly introduce the SHA-3 overview. In Section 3, we present the related works in the literature. Section 4 defines our new proposed hardware optimization techniques of the SHA-3 algorithm on FPGA. In Section 5, we show the experimental outcomes of our study. In Section 6, we discuss the effects of our optimization technique and the comparisons with other relevant studies. Finally, Section 7 summarizes our article’s conclusions and future work.
2. The SHA-3 Overview
In 2012, after a contest conducted by the NIST, the Keccak hash function was the next SHA-3 standard. However, unlike the SHA-1 and SHA-2 standards, SHA-3 primarily depends on the sponge functions (absorb/squeeze), as presented in Figure 1.
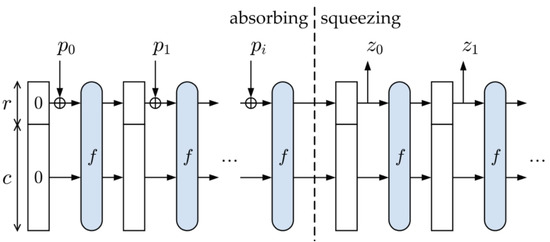
Figure 1.
Sponge function of the SHA-3.
The sponge procedure is a state matrix of bits, where c bits is the capacity and r bits are the bit rate. In the beginning, this state matrix is initialized from zero values. Keccak hash function manages the state b as a three-dimensional matrix . An input message is padded to form its total size, a multiple of r bits. Then the padded message is split into blocks of equal size Pi. At the absorbing step, r bits with each block and permutation function f. The f function is the central processing part and includes 24 rounds with procedures. The five distinct steps of the function f are Theta (), Rho (), Pi (), Chi () and Iota () on a 1600-bit state matrix A [27].
The process’s Theta () step includes a parity computation, rotated by one position, then bitwise XOR. The Rho () step rotates by an offset that depends on the word assignment, and the Pi () step is a permutation. The Chi () step operates bitwise XOR, NOT, and AND gates to modify the process. Lastly, the Iota () step involves adding a constant value to the sequence at each round. The steps Theta (), Rho (), Pi (), Chi () and Iota () are detailed in Equations (1)–(4).
Step Theta ():
The state array A is also used to calculate a serviceable array B in the following two steps. Interestingly, the array describes a bit stream with w bits.
Steps Rho () and Pi ():
Step Chi ():
Step Iota ():
The round constants are produced by the RC generator that is used in Iota () step. The function is present in Table 1, and it is made up of 24 different value permutations that may assign 64-bit data to the SHA-3 function [15].

Table 1.
The generator in Iota () step.
According to Table 2, the NIST has determined four different variants of the SHA-3 hashing algorithm based on the message M and the output length size d.
Table 2.
The four forms of the SHA-3.
3. Related Work
The community of cryptography has done substantial research on optimizing models and techniques for the SHA-3 in FPGA devices [28]. Each of these models aims to improve the throughput of the FPGA while simultaneously decreasing the amount of area and the amount of power it needs [29,30,31,32]. Despite this, there is still an urgent need to increase performance measures related to throughput and area reduction. In this part, we will discuss other research studies comparable to ours.
The paper’s authors [33], suggested a pipelining technique for the SHA-3 512 bits. The proposed design was implemented in the FPGA Virtex-5. The proposed architecture needs 2.326 slices (area), achieves the highest frequency rate of 306 MHz, and demonstrates a throughput rate of 5.56 Gbps and a rate of efficiency of 2.40 Mbps/slices. In [34], the authors proposed a two-staged pipelined technique for the SHA-3 256. The proposed design was implemented in FPGA Virtex-5. They achieved a maximum frequency of 317.11 MHz, throughput of 12.68 Gbps, area (slices) of 4.793, and efficiency of 2.71 Mbps/slices.
The authors [35] suggested a pipelining design for the SHA-3 512. The proposed method was implemented in the FPGA Virtex-5. The proposed architecture achieves the highest frequency rate of 273 MHz, needs 1.163 slices (area), demonstrates a throughput rate of 7.80 Gbps, and an efficiency rate of 6.06 Mbps/slices. In [36], the writers proposed a two-stage pipelined design for the SHA-3 512 on three FPGA devices. The proposed architecture was implemented in FPGA boards, Virtex-4, Virtex-5, and Virtex-6. The outcomes demonstrate that the suggested method for the SHA-3 512 performs more promising effects with Virtex-6. They reached a maximum frequency rate of 391 MHz, throughput rate of 18.76 Gbps, area (slices) of 2.296, and efficiency of 8.17 Mbps/slices.
In a study by [37], the authors proposed a two-staged pipelined technique for the SHA-3 256. The VHDL programing language is used and implemented in the Virtex-5, Virtex-6, and Virtex-7 FPGA boards. Outcomes indicate that the suggested design achieves better results with Virtex-7. They gained a throughput rate of 20.8 Gbps, the highest frequency rate of 434 MHz, an area rate of 1618 slices, and an efficiency of 12.90 Mbps/slices. The authors [38] suggested a pipelining design for the SHA-3 256 and SHA-3 512. The proposed method was implemented in the Virtex-5 and Virtex-6 FPGA boards. The proposed method for SHA-3 256 needs 1.456 slices (area) and demonstrates a throughput rate of 14.942 Gbps and an efficiency rate of 10.26 Mbps/slices with Virtex-6, and for SHA-3 512 needs 1.263 slices (area) and demonstrates a throughput rate of 8.114 Gbps and an efficiency rate of 6.42 Mbps/slices with Virtex-6.
In [39] they proposed an architecture that supports all output size lengths (224, 256, 384, and 512 bits) of the SHA2 and SHA-3 cryptographic hash functions. The proposed design was implemented and verified on a Stratix IV FPGA, utilizing the NIOS II processor. The proposed architecture for the SHA-3 needs 5.363 slices (area) and achieves the highest frequency rate of 110 MHz. The authors of [40] presented a design for the SHA-3 512 algorithm. This design was implemented in the Virtex-5 FPGA boards. In Virtex-5, the proposed architecture required 1.680 slices and a frequency of 387 MHz. The proposed architecture achieves a throughput of 8.06 Gbps and 4.91 Mbps/slices efficiency.
Table 3 summarizes the techniques thought with the two-staged pipelined method for the SHA-3 algorithm. Most of the study has focused on the register’s placement after the Pi step () and used the classic RC generator with 64 bits. This work aims to compare the performance metrics efficiency (Mbps/slices) and throughput (Gbps) when we insert the register after step Pi () or step Theta () in the hash permutation f function with the new format of the RC generator with 7-bits for all output lengths 224, 256, 384 and 512 bits. Our extensive experiments reveal that the outcomes obtained are directly affected by the critical path of the f function, which decreases significantly when the register is inserted after step Theta () with the new simplified structure RC generator. The proposed optimization technique surpasses previous investigations in performance measures and can be applied as a strategy for FPGA boards.
Table 3.
Summary of the approaches in the publications of pipelined technique for the SHA-3 algorithm.
4. Proposed Pipelining Optimization Technique of the SHA-3
The main goal of our work is to attain a higher rate of throughput (Gbps) and efficiency (Mbps/slices) in our system without further hardware resources. This objective is achieved by introducing the register after the Theta () step and with the new simplified format of the proposed RC generator.
In Figure 2, we present the system design of the proposed pipelining optimization technique. The first unit is the padding unit, which pads the input message to ensure that it is of the appropriate length. Next, the mapping unit maps the input message into a state array that is compatible with the Keccak round. The Keccak round is the core of the design and performs the bulk of the processing. It is responsible for executing the sponge function, which converts the input message into a hash value. The truncating unit is then responsible for truncating the hash value to the desired output length. The control unit is an essential system component as it manages and coordinates data flow throughout the architecture. The input message to our system is 64 bits, and the selected output length can be varied according to the requirements. The possible values for the select output length are presented in Table 4.
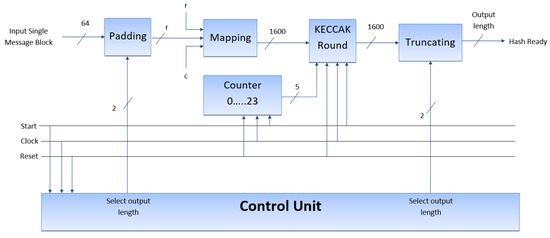
Figure 2.
The proposed approach of the SHA-3.
Table 4.
Select output length.
The padding scheme ensures that the input message has a fixed size and is processable by the algorithm. In the case of SHA-3, the padding scheme involves appending the input message with a certain number of bits such that the total message size is a multiple of a fixed number of bits denoted by r (576, 832, 1088, or 1152). To achieve this, the input message of 64-bits is first appended with a “1”-bit, followed by as many “0”-bits as necessary to bring the total message size to -bits, and then appended with a “1”-bit. This ensures that the final message size is a multiple of r-bits [41].
The padding scheme used in SHA-3 consists of a 4-to-1 multiplexer. The output length of the algorithm determines which padding scheme is used. For example, if the output length is set to 224 bits, then the padding scheme for bits is used. The padding scheme is shown in Figure 3.
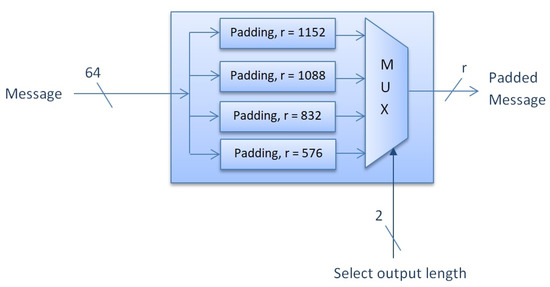
Figure 3.
Padding scheme of the SHA-3.
Once the message has been padded, it is passed to the mapping scheme, which is XORed with the initial r-bits. This ensures that the padded message is different from the initial message. The result is then appended with the initial c-bits, where c is a constant value that depends on the value of r. This completes the padding scheme and prepares the message for processing by the hashing algorithm.
A data transformation that includes truncating the digits of a state depending on the desired output length is shown in Equation (5). The specific digits chosen depend on the output length selected (576, 832, 1088, or 1152). This process is achieved using a truncating unit consisting of a 4-to-1 multiplexer.
In addition, the Iota () step includes modifying a few bits of the state array A, as shown in Equation (6).
The RC is calculated as shown in Equation (7), which can be found in the SHA-3 specifications [15] and all other values of are set to zero. It can be seen from Equation (7) that only 7 of the 64 bits may have the value 1.
In accordance with the specifications of the SHA-3, Table 5 details the precise placements of the 7 bits when the value of m = 6. Therefore, the only bit locations with the value “1” are 0, 1, 3, 7, 15, 31, and 63; all other bit places have the value “0”.
Table 5.
The places for each of the 7-bits where have the value 1.
Table 6 shows an example of the simplified format that was used for RC[6] of Table 7. As a result, the gate in state array A can have 7 particular bits set.
Table 6.
Example of the new format of the RC[6] in Iota () step.
Table 7.
The new format of the in Iota () step.
The pipelined architecture is a popular design approach for achieving low power consumption, high security, and increased performance [42]. In our system, we aim to optimize the two-stage pipelined architecture to achieve higher frequency (MHz), efficiency (Mbps/slices), and throughput (Gbps) for all output lengths. We designed two strategies for optimizing a two-stage pipelined architecture to achieve that goal. Improving performance is directly related to reducing the crucial path of the f operation. The f operation consists of a total of 24 rounds and five special operations: Theta (), Rho (), Pi (), Chi () and Iota (). Therefore, the registry pipeline must be appropriately positioned to decrease the crucial path to the f procedure.
The first proposed pipelined architectural design of the Keccak is shown in Figure 4. In this architecture, the first pipeline is placed between the Pi () and Chi () steps, while the second is at the end of the round. The second proposed pipelined architectural design of the Keccak round is presented in Figure 5. In this design, the first pipeline is placed between the Theta () and Rho () steps, while the second is at the end of the round. In both proposed pipelined architectures (Figure 4 and Figure 5), the control signs of the two registers are the reset and the clock. The component counter provides the control signal of the round constant.
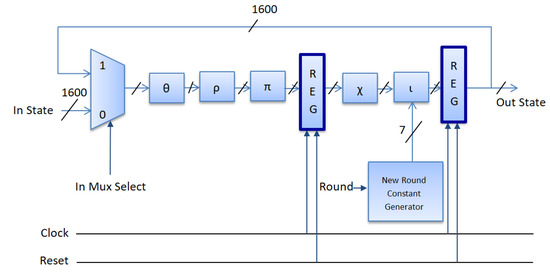
Figure 4.
First proposed pipelined (dark blue) optimization technique where the first pipeline is placed after step Pi ().
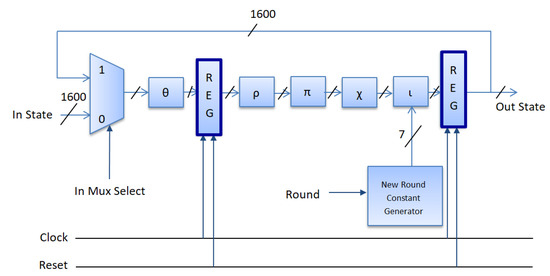
Figure 5.
Second proposed pipelined (dark blue) optimization technique where the first pipeline is placed after step Theta ().
5. Experimental Results
We use the Virtex-5, Virtex-6, and Virtex-7 FPGA boards to compare the suggested strategy to other existing studies fairly. The methods were implemented in the Virtex-5/Virtex-6 using Xilinx ISE, and the designs in the Virtex-7 using Xilinx Vivado.
5.1. Validating the Modified Construction
The modified construction is based on the SHA-3 specifications [15], especially Equation (7). According to Equation (7), only 7 of the 64 bits in the RC format can have the value 1; by strictly adhering to the SHA-3 specification and relying on the established security properties of SHA-3, the modified construction benefits from the security guarantees provided by SHA-3. Simulation examples provided by NIST [43], a reputable source for cryptographic standards, are employed to validate the modified construction’s implementation further and ensure its correct functioning. This validation process ensures that the modified construction behaves as intended and consistently produces the expected results when tested against valid examples. Therefore, the combination of adhering to the SHA-3 specification and validating the modified construction through simulation using NIST-provided examples collectively contributes to confidence in the system’s security.
5.2. Efficiency and Throughput Performance Measures
Standard evaluation measures, such as efficiency and throughput, are used to conduct the metrics of SHA-3 when implemented on FPGA [28,44]. The term “throughput” refers to the number of bits that are processed in a certain amount of time and may be expressed in either Gbps or Mbps. The throughput is determined with Equation (8).
In Equation (8), a message block’s bits are the bitrate size r (576, 832, 1088, 1152), frequency is the maximum clock periodicity, and cycles of the clock for each message block characterize the number of resumptions needed for the five unique processes: Theta (), Rho (), Pi (), Chi () and Iota () to generate the hash value. The efficiency is determined with Equation (9).
5.3. Results of Our Two Architectures
To enhance the performance of the algorithm SHA-3, it is crucial to identify the most computationally costly steps in the algorithm and focus on optimizing those steps. In traditional construction, the computation of parity bits across the columns of the state array requires accessing the entire array, resulting in significant data movement and computational overhead. This increases resource utilization and hinders the algorithm’s overall throughput and efficiency. We introduce a register immediately after the Theta () step to address this challenge because this step is the most computation-costly in the permutation function, consuming over 50% of the total computation time. This register is a temporary storage element that retains the computed parity bits, eliminating the need to access the entire state array repeatedly. By storing the parity bits in the register, subsequent steps within the algorithm can directly access these data without requiring extensive data movement or recomputation. Therefore, introducing the register significantly reduces the computation load and resource requirements in subsequent steps, improving throughput and efficiency. Second, it streamlines the data flow within the algorithm, enabling faster and more efficient processing. Last, it minimizes the overall area cost of the SHA-3 implementation by optimizing resource utilization.
On the other hand, inserting a pipeline after the Pi () step may also improve the throughput of the algorithm, but to a lesser extent. The Pi () step is mainly responsible for rearranging the order of the bits in the state array, and its computation is less intensive than that of the Theta () step. Therefore, inserting a pipeline after the Theta () step has a more significant improvement in the throughput of the SHA-3 algorithm than inserting a pipeline after the Pi () step.
Table 8 displays the results of our two pipelined optimization techniques with Virtex-5, Virtex-6, and Virtex-7 FPGA boards. The proposed design with the first pipelined optimization technique requires 1102 slices operating at 374 MHz, while the second pipelined design requires 998 slices operating at 402 MHz in Virtex-5. On the FPGA board Virtex-6, the proposed design with the first pipelined architecture requires 1146 slices operating at 392 MHz, while the second pipelined optimization technique requires 1042 slices operating at 422 MHz. Finally, on the FPGA board Virtex-7, the proposed design with the first pipelined optimization technique requires 1288 slices operating at 446 MHz, while the second pipelined design requires 1150 slices operating at 478 MHz.
Table 8.
Metrics on the performance of our two pipelined optimization techniques for SHA-3 when implemented on the Virtex-5, Virtex-6, and Virtex-7 FPGA.
The power consumption of our proposed designs is evaluated using the Xilinx XPower Analysis tool [45]. Table 9 displays the power consumption results of our two pipelined optimization techniques with Virtex-5, Virtex-6, and Virtex-7 FPGA boards. In the first proposed pipelined optimization technique, the power consumption on Virtex-5, Virtex-6, and Virtex-7 FPGAs, was 267 mW, 222 mW, and 179 mW, respectively. In the second proposed pipelined optimization technique, the power consumption on Virtex-5, Virtex-6, and Virtex-7 FPGAs was 242 mW, 198 mW, and 157 mW, respectively. Across all FPGA models, the second proposed pipelined optimization technique (after step Theta ()) exhibits lower power consumption than the first proposed technique (after step Pi ()). Among the Virtex FPGA models, Virtex-7 consistently demonstrates the lowest power consumption for both optimization techniques. Virtex-6 generally exhibits lower power consumption than Virtex-5 in both cases. Therefore, the second proposed pipelined optimization technique, with the first pipeline placed after step Theta (), is more power-efficient across the evaluated FPGA models.
Table 9.
The power consumption of our two pipelined optimization techniques for SHA-3 when implemented on the Virtex-5, Virtex-6, and Virtex-7 FPGA.
6. Result in Discussion
The main target of our work is to attain a higher rate of throughput (Gbps) and efficiency (Mbps/slices) in our system. The experimental procedure showed that the obtained results are directly affected by the critical path of the function f, which is significantly reduced when the register is inserted after step Theta () than when the register is inserted after step Pi (). Table 10 and Table 11 present the comparison with other similar architectures for all output lengths (224, 256, 384, and 512 bits) of the measures of throughput (Gbps), frequency (MHz) and efficiency (Mbps/slices) for the SHA-3 (Keccak) algorithm. Most authors experiment only with output lengths of 256 or 512 bits. All results are reported for single-block messages.
Table 10.
Results and comparisons of throughput for the SHA-3 algorithm for each of the output lengths (224, 256, 384, and 512 bits).
Table 11.
Results and comparisons of the SHA-3’s efficiency for each output length (224, 256, 384, and 512 bits).
The researchers in the works [33,34,35,36,38,40] with the Virtex-5 FPGA board show a high area in comparison to our implementations, and the frequency which they achieved is lower than our practical applications. Furthermore, in the works of [36,37] with the Virtex-6 FPGA board, there is a lower frequency than we accomplished, showing significant growth in the area. Yet, in the work of [37] with the Virtex-7 FPGA board, the investigators display a more extensive area and frequency than we achieved with our optimization techniques. Finally, in the work of [39] with the Stratix IV FPGA board, the investigators depict a more extensive area and poor frequency than we achieved with our optimization techniques.
With our method in the new simplified format of the RC generator for the output length of 256-bits with Virtex-7 FPGA, our architecture achieves better throughput, over 10%, efficiency over 14%, frequency over 11%, and reduction in the area over 14%, compared to the immediately better implementation of [37]. Finally, for the output length of 512-bits with Virtex-6 FPGA, our architecture achieves higher throughput, over 10%, efficiency of over 11%, frequency of over 10%, and reduction in the area of over 22% compared to the immediately better implementation of [36].
7. Conclusions and Future Work
In today’s digital age, information is transmitted in various forms, such as image, text, video, and audio; therefore, transmissions must be carried out with safety, confidentiality, and integrity to avoid unauthorized access. Cryptography algorithms are widely used to provide high security in digital media. Aggressions against SHA-1 and SHA-2 directed NIST to embrace a new and more secure algorithm, SHA-3. The SHA-3 (Keccak) algorithm offers a high level of security and shows strong resistance to cryptanalysis attacks. Additionally, it provides us with a suitable combination of acceleration, performance and safety.
In this article, we concentrate our study on the optimal performance of the throughput and efficiency measures of the SHA-3 for all output lengths (224, 256, 384, and 512 bits) on the Virtex-5, Virtex-6, and Virtex-7 FPGA boards. We compare the innovative method we propose to similar designs and show that our suggested method has the highest performance in the standard evaluation criteria throughput (Gbps) and efficiency (Mbps/slices). We achieved a throughput rate of 22.94 Gbps and an efficiency rate of 19.95 Mbps/slices with Virtex-7. The suggested architecture works correctly with single-block messages.
In future work, we will analyze the architectural technique of more in-depth pipelines to reduce the crucial path and enhance throughput and efficiency performance metrics per round. Also, we intend to propose more practical experiments implementing FPGA and entire systems-on-chip.
Author Contributions
Methodology, A.S.; formal analysis, A.S.; conceptualization, A.S.; software, A.S.; investigation, A.S.; resources, A.S.; project administration, A.S.; visualization, A.S.; validation, A.S.; writing—original draft preparation, A.S.; writing—review and editing, A.S.; supervision, M.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ALM | Adaptive Logic Module |
| CAD | Computer-aided design |
| CPU | Central Processing Unit |
| DDR4 | Double Data Rate 4 |
| DSE | Design Space Explorer |
| FPGA | Field-Programmable Gate Array |
| GB | Gigabytes |
| Gbps | Gigabits per second |
| GHz | Gigahertz |
| GPU | Graphics Processing Unit |
| HDL | Hardware Description Language |
| HMAC | Hashed Message Authentication Code |
| Mbps | Megabits per second |
| MHz | Megahertz |
| NIST | National Institute of Standards and Technology |
| PKI | Public Key Infrastructure |
| PLL | Phase Locked Loop |
| RC | Round Constant |
| SDRAM | Synchronous Dynamic Random-Access Memory |
| SET | Secure Electronic Transactions |
| SHA | Secure Hash Algorithm |
| VHDL | Very High Speed Integrated Circuit HDL |
References
- Abusukhon, A.; Mohammad, Z.; Al-Thaher, A. An authenticated, secure, and mutable multiple-session-keys protocol based on elliptic curve cryptography and text-to-image encryption algorithm. Concurr. Comput. Pract. Exp. 2022, 34, e6649. [Google Scholar] [CrossRef]
- Sideris, A.; Sanida, T.; Tsiktsiris, D.; Dasygenis, M. Image Hashing Based on SHA-3 Implemented on FPGA. In Recent Advances in Manufacturing Modelling and Optimization: Select Proceedings of RAM 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 521–530. [Google Scholar] [CrossRef]
- Bhatia, T.; Verma, A.K.; Sharma, G. Towards a secure incremental proxy re-encryption for e-healthcare data sharing in mobile cloud computing. Concurr. Comput. Pract. Exp. 2020, 32, e5520. [Google Scholar] [CrossRef]
- Chi, X.; Yan, C.; Wang, H.; Rafique, W.; Qi, L. Amplified locality-sensitive hashing-based recommender systems with privacy protection. Concurr. Comput. Pract. Exp. 2022, 34, e5681. [Google Scholar] [CrossRef]
- Hu, H.; Dobbie, G.; Salcic, Z.; Liu, M.; Zhang, J.; Lyu, L.; Zhang, X. Differentially private locality sensitive hashing based federated recommender system. Concurr. Comput. Pract. Exp. 2021, 35, e6233. [Google Scholar] [CrossRef]
- Sideris, A.; Sanida, T.; Tsiktsiris, D.; Dasygenis, M. Acceleration of Image Processing with SHA-3 (Keccak) Algorithm using FPGA. J. Eng. Res. Sci. 2022, 1, 20–28. [Google Scholar] [CrossRef]
- Bang, J.; Kim, C.; Byun, E.K.; Sung, H.; Lee, J.; Eom, H. Accelerating I/O performance of ZFS-based Lustre file system in HPC environment. J. Supercomput. 2022, 79, 7665–7691. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, J.; Xiao, R.; Du, X.; Gong, P.; Lin, X. Toward more efficient locality-sensitive hashing via constructing novel hash function cluster. Concurr. Comput. Pract. Exp. 2021, 33, e6355. [Google Scholar] [CrossRef]
- Stevens, M.; Bursztein, E.; Karpman, P.; Albertini, A.; Markov, Y. The first collision for full SHA-1. In Proceedings of the Annual International Cryptology: 37th Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 570–596. [Google Scholar] [CrossRef]
- Sideris, A.; Sanida, T.; Dasygenis, M. Hardware acceleration of SHA-256 algorithm using NIOS-II processor. In Proceedings of the 2019 8th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Nikolić, I.; Biryukov, A. Collisions for step-reduced SHA-256. In Proceedings of the International Workshop on Fast Software Encryption, Lausanne, Switzerland, 10–13 February 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–15. [Google Scholar] [CrossRef]
- Sanadhya, S.K.; Sarkar, P. New collision attacks against up to 24-step SHA-2. In Proceedings of the International Conference on Cryptology in India, Kharagpur, India, 14–17 December 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 91–103. [Google Scholar] [CrossRef]
- Sideris, A.; Sanida, T.; Dasygenis, M. High throughput implementation of the keccak hash function using the nios-ii processor. Technologies 2020, 8, 15. [Google Scholar] [CrossRef]
- Guo, J.; Liao, G.; Liu, G.; Liu, M.; Qiao, K.; Song, L. Practical collision attacks against round-reduced SHA-3. J. Cryptol. 2020, 33, 228–270. [Google Scholar] [CrossRef]
- Dworkin, M.J. SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [Google Scholar] [CrossRef]
- Jiang, S.; Zhu, X.; Wang, L. An efficient anonymous batch authentication scheme based on HMAC for VANETs. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2193–2204. [Google Scholar] [CrossRef]
- Schwenk, J. Attacks on SSL and TLS. In Guide to Internet Cryptography: Security Protocols and Real-World Attack Implications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 267–328. [Google Scholar] [CrossRef]
- Yin, H.L.; Fu, Y.; Li, C.L.; Weng, C.X.; Li, B.H.; Gu, J.; Lu, Y.S.; Huang, S.; Chen, Z.B. Experimental quantum secure network with digital signatures and encryption. Natl. Sci. Rev. 2023, 10, nwac228. [Google Scholar] [CrossRef]
- Olanrewaju, R.F.; Khan, B.U.I.; Mattoo, M.M.U.I.; Anwar, F.; Nordin, A.N.B.; Mir, R.N. Securing electronic transactions via payment gateways–a systematic review. Int. J. Internet Technol. Secur. Trans. 2017, 7, 245–269. [Google Scholar] [CrossRef]
- Spies, T. Public key infrastructure. In Computer and Information Security Handbook; Elsevier: Amsterdam, The Netherlands, 2017; pp. 691–711. [Google Scholar] [CrossRef]
- Goz, D.; Ieronymakis, G.; Papaefstathiou, V.; Dimou, N.; Bertocco, S.; Simula, F.; Ragagnin, A.; Tornatore, L.; Coretti, I.; Taffoni, G. Performance and energy footprint assessment of FPGAs and GPUs on HPC systems using astrophysics application. Computation 2020, 8, 34. [Google Scholar] [CrossRef]
- Ruiz-Rosero, J.; Ramirez-Gonzalez, G.; Khanna, R. Field programmable gate array applications—A scientometric review. Computation 2019, 7, 63. [Google Scholar] [CrossRef]
- Siddiqui, F.; Amiri, S.; Minhas, U.I.; Deng, T.; Woods, R.; Rafferty, K.; Crookes, D. FPGA-Based Processor Acceleration for Image Processing Applications. J. Imaging 2019, 5, 16. [Google Scholar] [CrossRef]
- Kalaitzis, K.; Sotiriadis, E.; Papaefstathiou, I.; Dollas, A. Evaluation of external memory access performance on a High-End FPGA hybrid computer. Computation 2016, 4, 41. [Google Scholar] [CrossRef]
- Sideris, A.; Sanida, T.; Chatzisavvas, A.; Dossis, M.; Dasygenis, M. High Throughput of Image Processing with Keccak Algorithm using Microprocessor on FPGA. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Nguyen, T.; MacLean, C.; Siracusa, M.; Doerfler, D.; Wright, N.J.; Williams, S. FPGA-based HPC accelerators: An evaluation on performance and energy efficiency. Concurr. Comput. Pract. Exp. 2022, 34, e6570. [Google Scholar] [CrossRef]
- Lefevre, C.; Mennink, B. Tight Preimage Resistance of the Sponge Construction. In Proceedings of the Advances in Cryptology–CRYPTO 2022: 42nd Annual International Cryptology Conference, CRYPTO 2022, Santa Barbara, CA, USA, 15–18 August 2022; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2022; pp. 185–204. [Google Scholar] [CrossRef]
- Al-Odat, Z.A.; Ali, M.; Abbas, A.; Khan, S.U. Secure hash algorithms and the corresponding fpga optimization techniques. ACM Comput. Surv. (CSUR) 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Ma, K.M.; Le, D.H.; Pham, C.K.; Hoang, T.T. Design of an SoC Based on 32-Bit RISC-V Processor with Low-Latency Lightweight Cryptographic Cores in FPGA. Future Internet 2023, 15, 186. [Google Scholar] [CrossRef]
- El Moumni, S.; Fettach, M.; Tragha, A. High throughput implementation of SHA3 hash algorithm on field programmable gate array (FPGA). Microelectron. J. 2019, 93, 104615. [Google Scholar] [CrossRef]
- Wong, M.M.; Haj-Yahya, J.; Sau, S.; Chattopadhyay, A. A new high throughput and area efficient SHA-3 implementation. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Kundi, D.-e.-S.; Aziz, A. A low-power SHA-3 designs using embedded digital signal processing slice on FPGA. Comput. Electr. Eng. 2016, 55, 138–152. [Google Scholar] [CrossRef]
- Provelengios, G.; Kitsos, P.; Sklavos, N.; Koulamas, C. FPGA-based design approaches of keccak hash function. In Proceedings of the 2012 15th Euromicro Conference on Digital System Design, Cesme, Turkey, 5–8 September 2012; pp. 648–653. [Google Scholar] [CrossRef]
- Mestiri, H.; Kahri, F.; Bedoui, M.; Bouallegue, B.; Machhout, M. High throughput pipelined hardware implementation of the KECCAK hash function. In Proceedings of the 2016 International Symposium on Signal, Image, Video and Communications (ISIVC), Tunis, Tunisia, 21–23 November 2016; pp. 282–286. [Google Scholar] [CrossRef]
- Sundal, M.; Chaves, R. Efficient FPGA implementation of the SHA-3 hash function. In Proceedings of the 2017 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Bochum, Germany, 3–5 July 2017; pp. 86–91. [Google Scholar] [CrossRef]
- Ioannou, L.; Michail, H.E.; Voyiatzis, A.G. High performance pipelined FPGA implementation of the SHA-3 hash algorithm. In Proceedings of the 2015 4th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 14–18 June 2015; pp. 68–71. [Google Scholar] [CrossRef]
- Athanasiou, G.S.; Makkas, G.P.; Theodoridis, G. High throughput pipelined FPGA implementation of the new SHA-3 cryptographic hash algorithm. In Proceedings of the 2014 6th International Symposium on Communications, Control and Signal Processing (ISCCSP), Athens, Greece, 21–23 May 2014; pp. 538–541. [Google Scholar] [CrossRef]
- Gaj, K.; Homsirikamol, E.; Rogawski, M.; Shahid, R.; Sharif, M.U. Comprehensive Evaluation of High-Speed and Medium-Speed Implementations of Five SHA-3 Finalists Using Xilinx and Altera FPGAs. 2012. Available online: https://eprint.iacr.org/2012/368 (accessed on 30 May 2023).
- Nannipieri, P.; Bertolucci, M.; Baldanzi, L.; Crocetti, L.; Di Matteo, S.; Falaschi, F.; Fanucci, L.; Saponara, S. SHA2 and SHA-3 accelerator design in a 7 nm technology within the European Processor Initiative. Microprocess. Microsyst. 2021, 87, 103444. [Google Scholar] [CrossRef]
- Mestiri, H.; Barraj, I. High-Speed Hardware Architecture Based on Error Detection for KECCAK. Micromachines 2023, 14, 1129. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, B.; Byrne, A.; Lu, L.; Hamilton, M.; Hanley, N.; O’Neill, M.; Marnane, W.P. FPGA implementations of the round two SHA-3 candidates. In Proceedings of the 2010 International Conference on Field Programmable Logic and Applications, Milan, Italy, 31 August–2 September 2010; pp. 400–407. [Google Scholar] [CrossRef]
- Katayama, K.; Matsumura, H.; Kameyama, H.; Sazawa, S.; Watanabe, Y. An FPGA-accelerated high-throughput data optimization system for high-speed transfer via wide area network. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 11–13 December 2017; pp. 211–214. [Google Scholar] [CrossRef]
- Computer Security Division, Information Technology Laboratory (I.T.L.) Example Values—Cryptographic Standards and Guidelines: CSRC. Available online: https://nist.gov/itl/csd (accessed on 2 May 2023).
- Michail, H.; Kakarountas, A.; Milidonis, A.; Goutis, C. A top-down design methodology for ultrahigh-performance hashing cores. IEEE Trans. Dependable Secur. Comput. 2008, 6, 255–268. [Google Scholar] [CrossRef]
- AMD Inc Xilinx Power Estimator v2018.2. User Guide. Available online: https://docs.xilinx.com/v/u/2018.2-English/ug440-xilinx-power-estimator (accessed on 7 May 2023).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).