
Deep Reinforcement Learning for Efficient Digital Pap Smear Analysis




Abstract
:1. Introduction
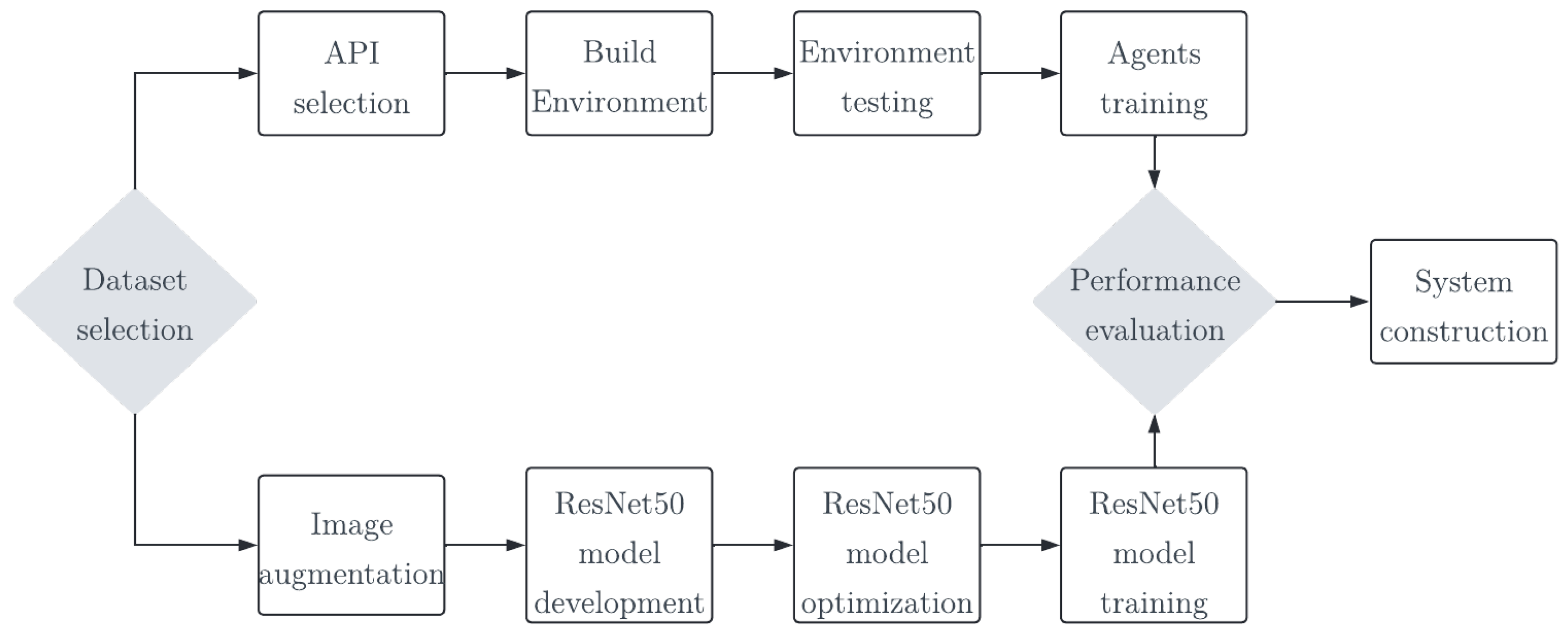
2. Methods and Materials
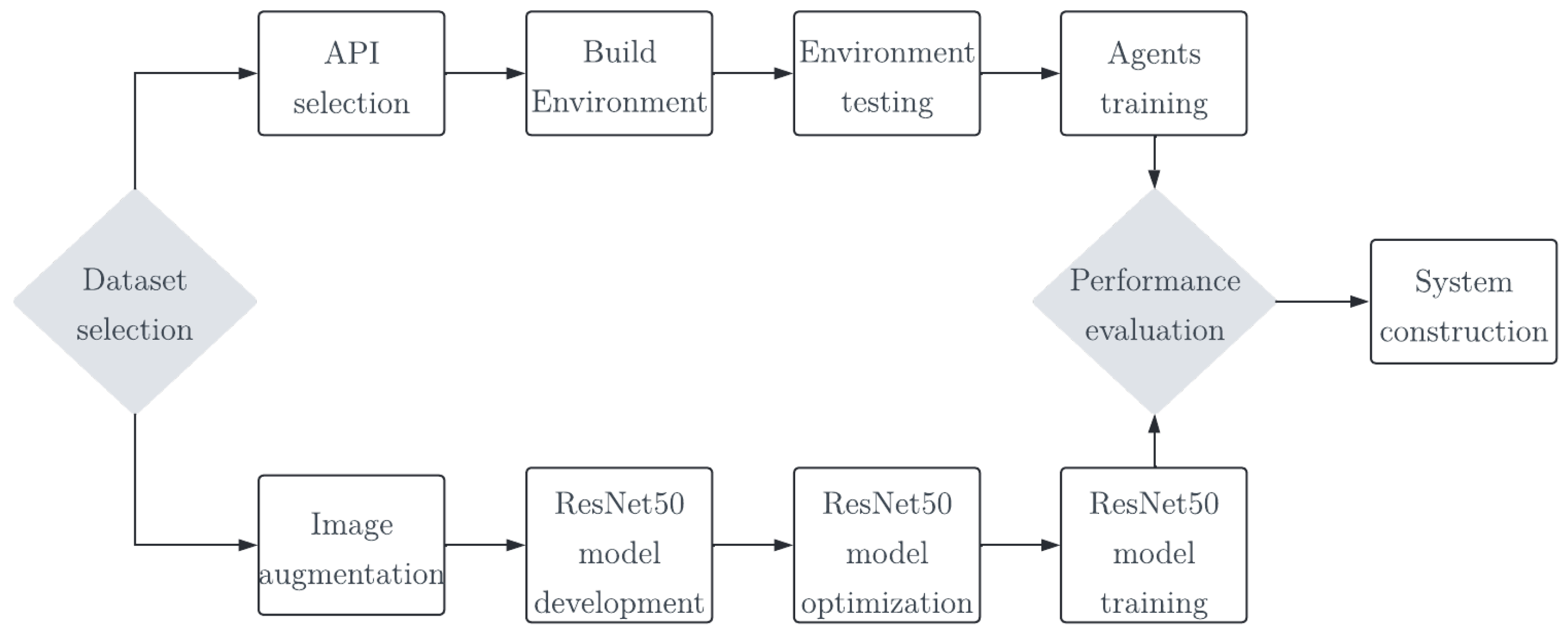
2.1. Proposed Approach
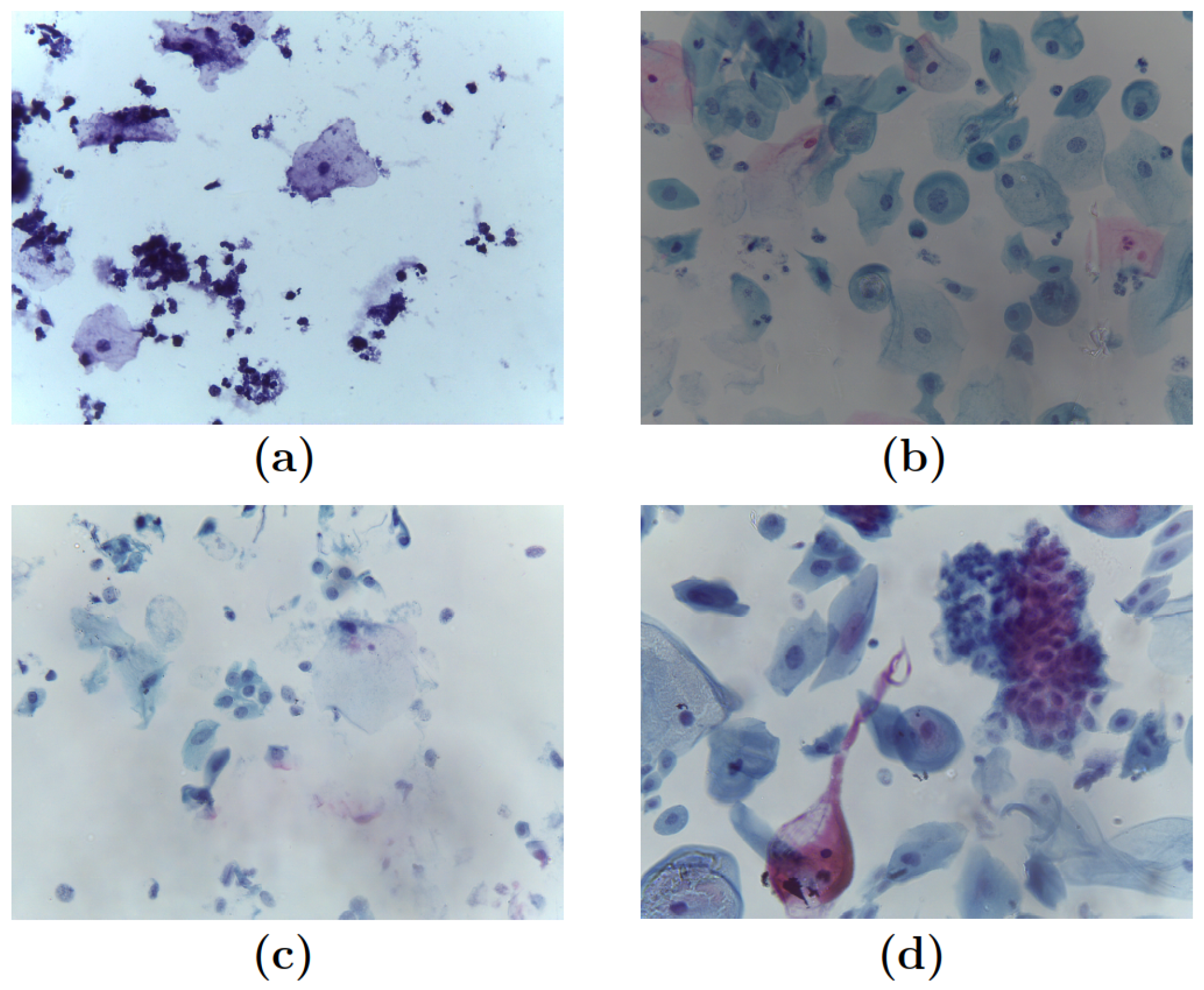
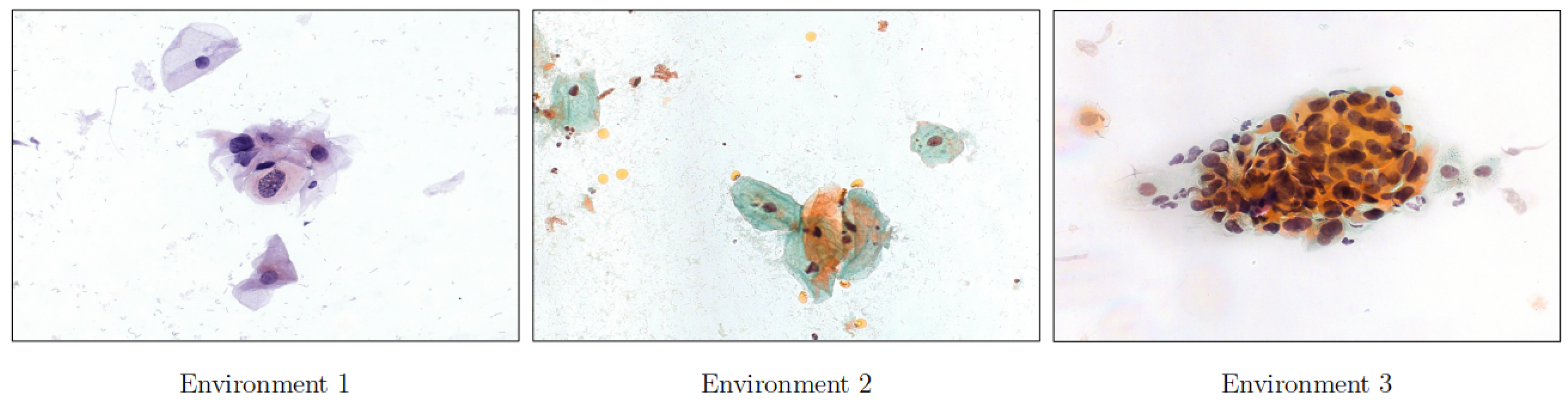
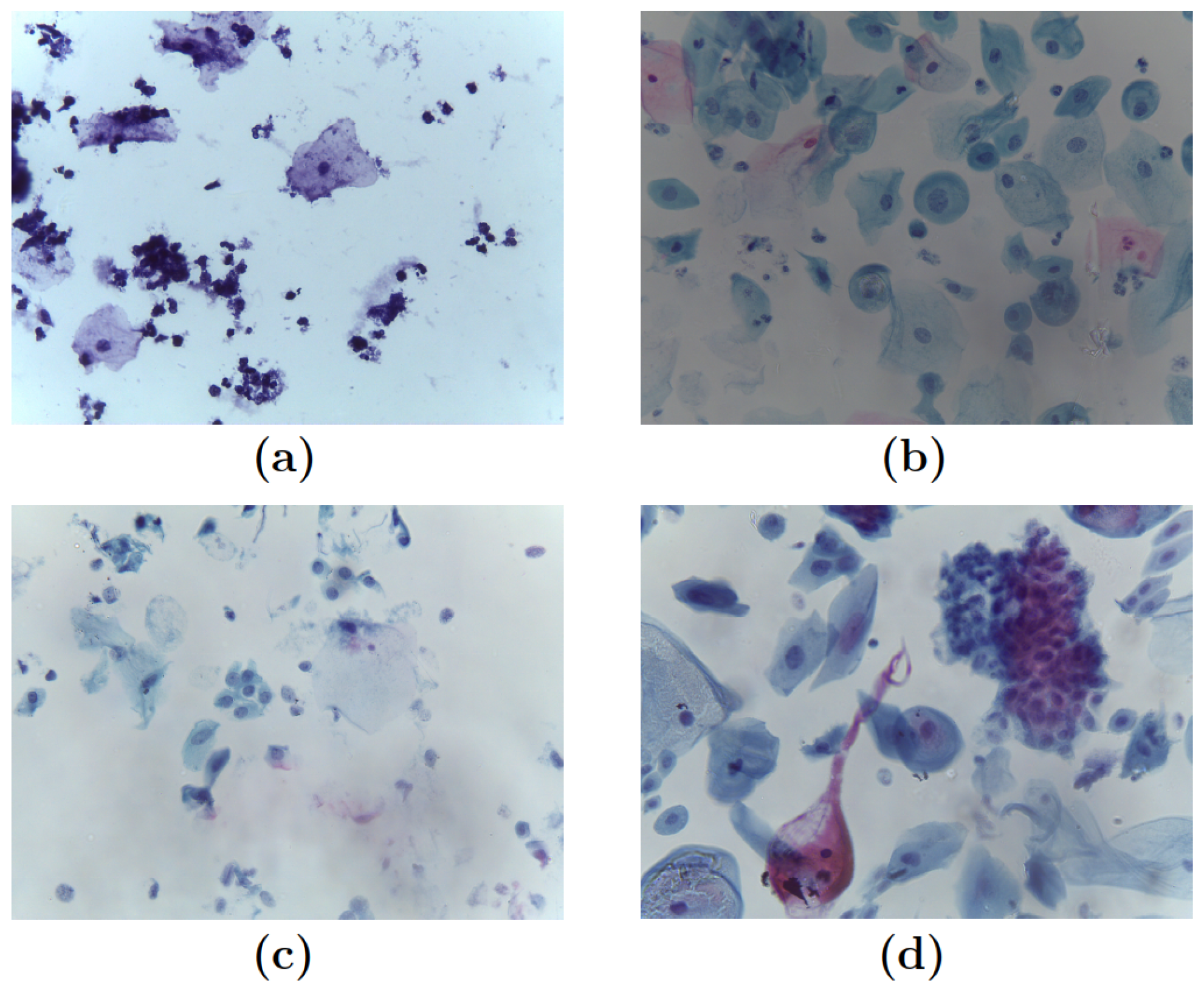
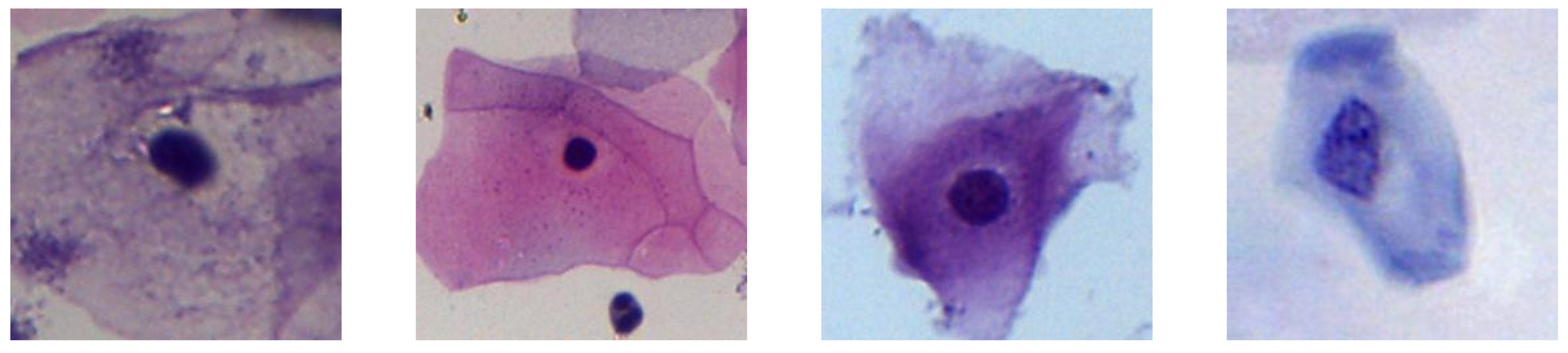
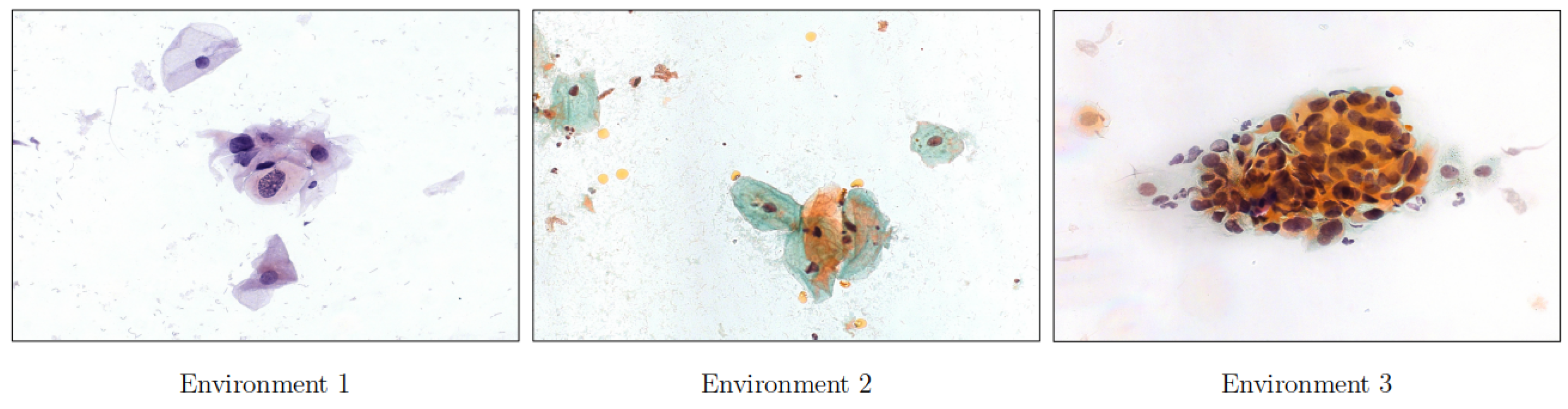
2.2. Data Acquisition
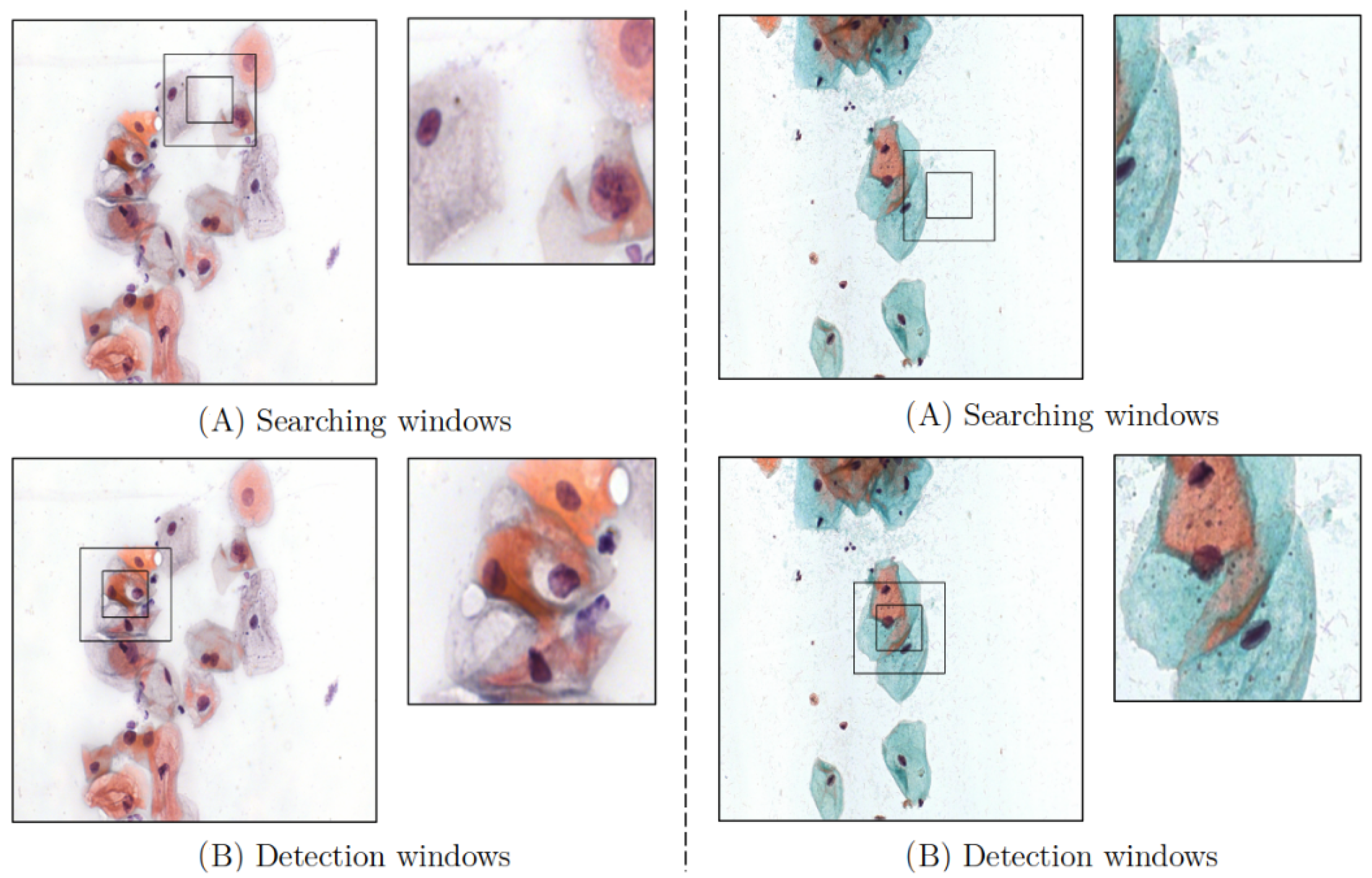
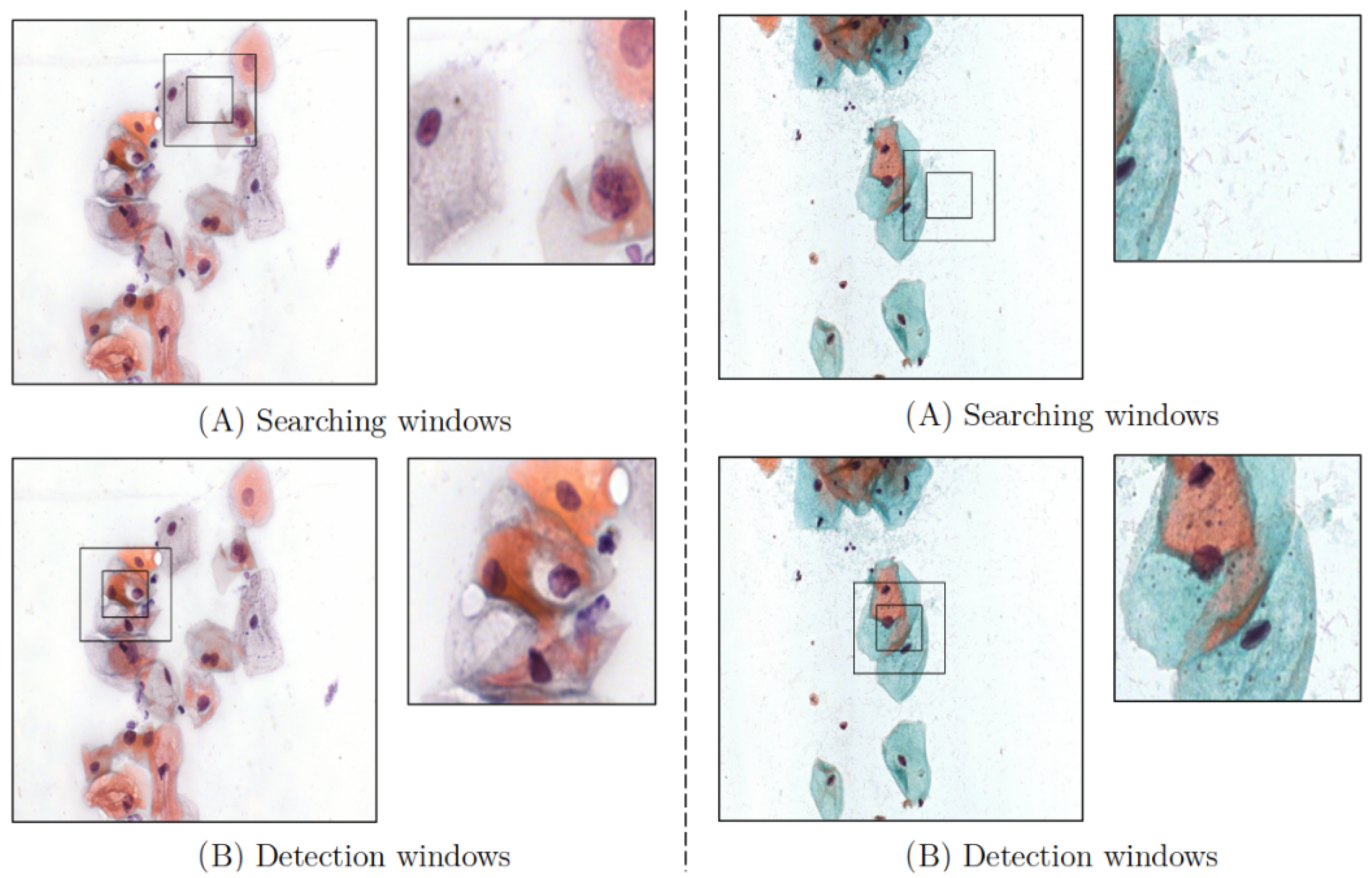
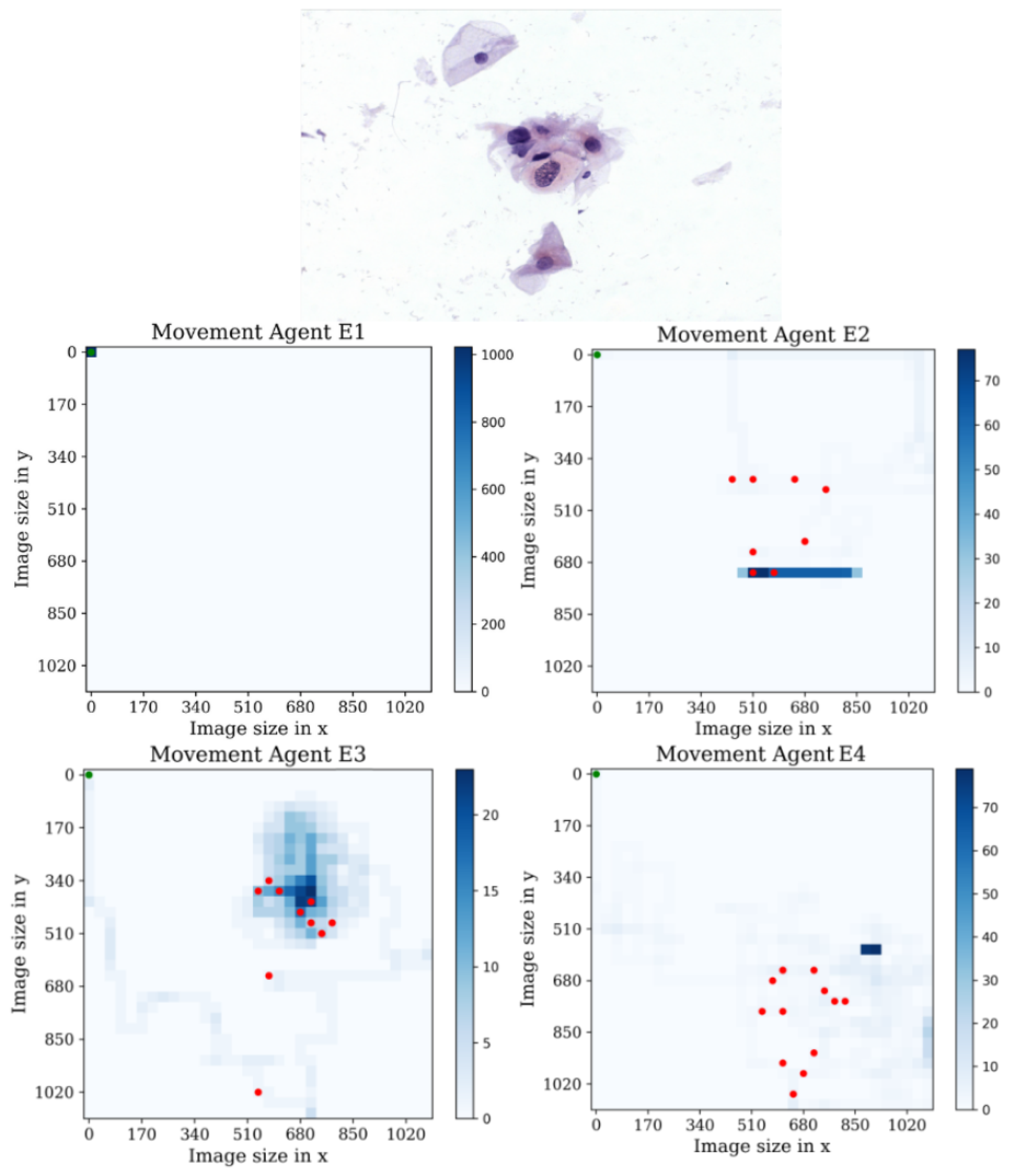
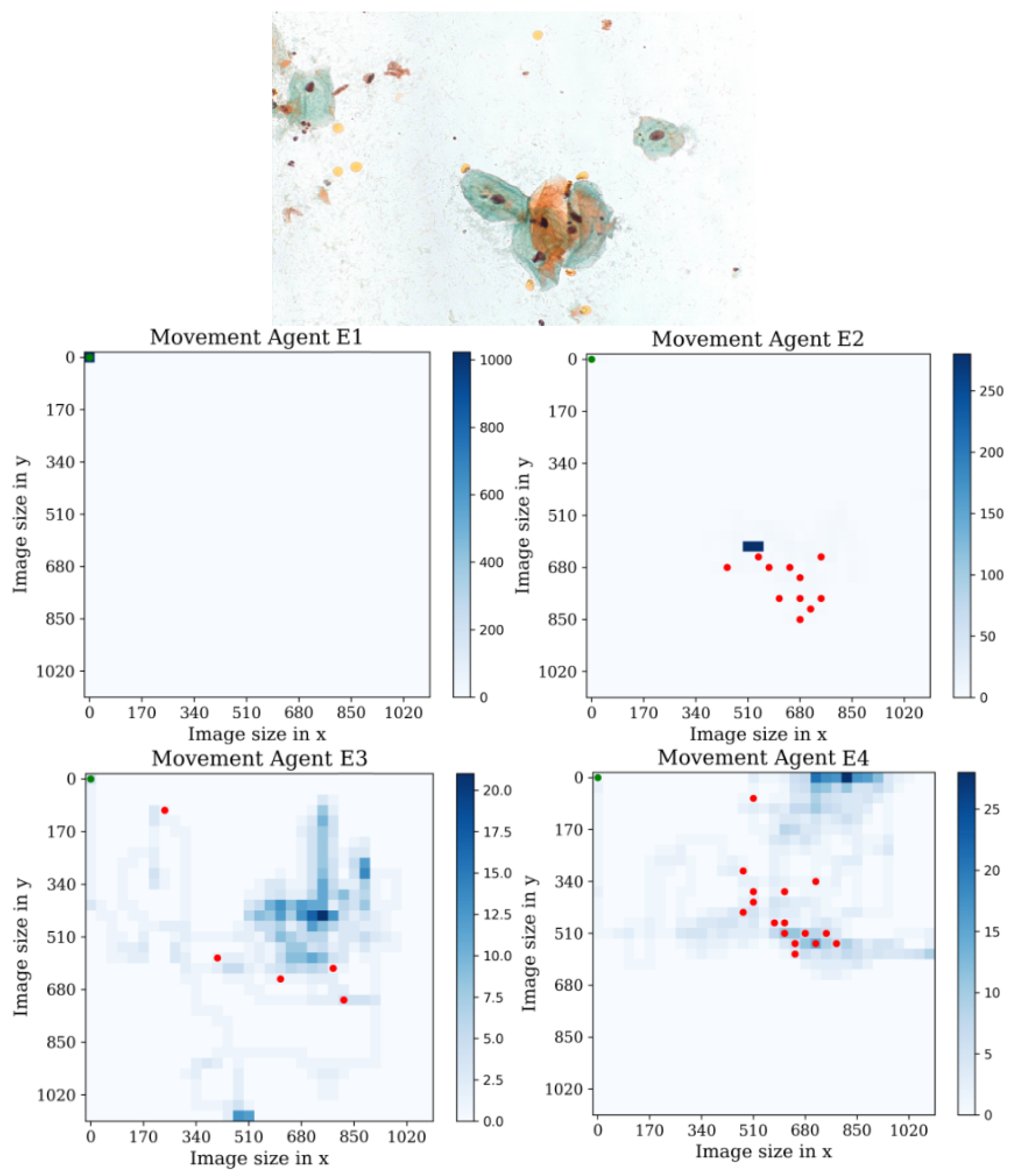
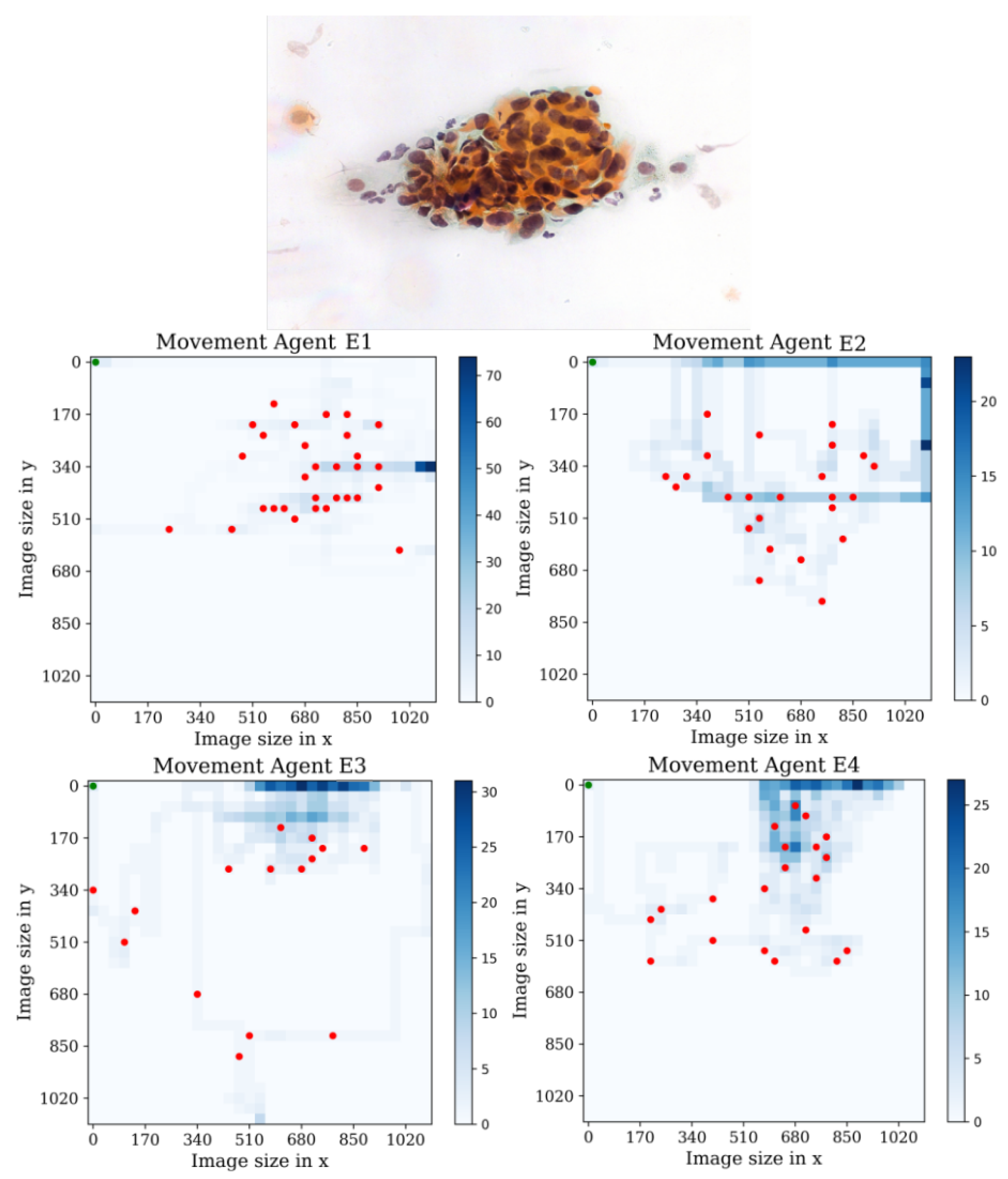
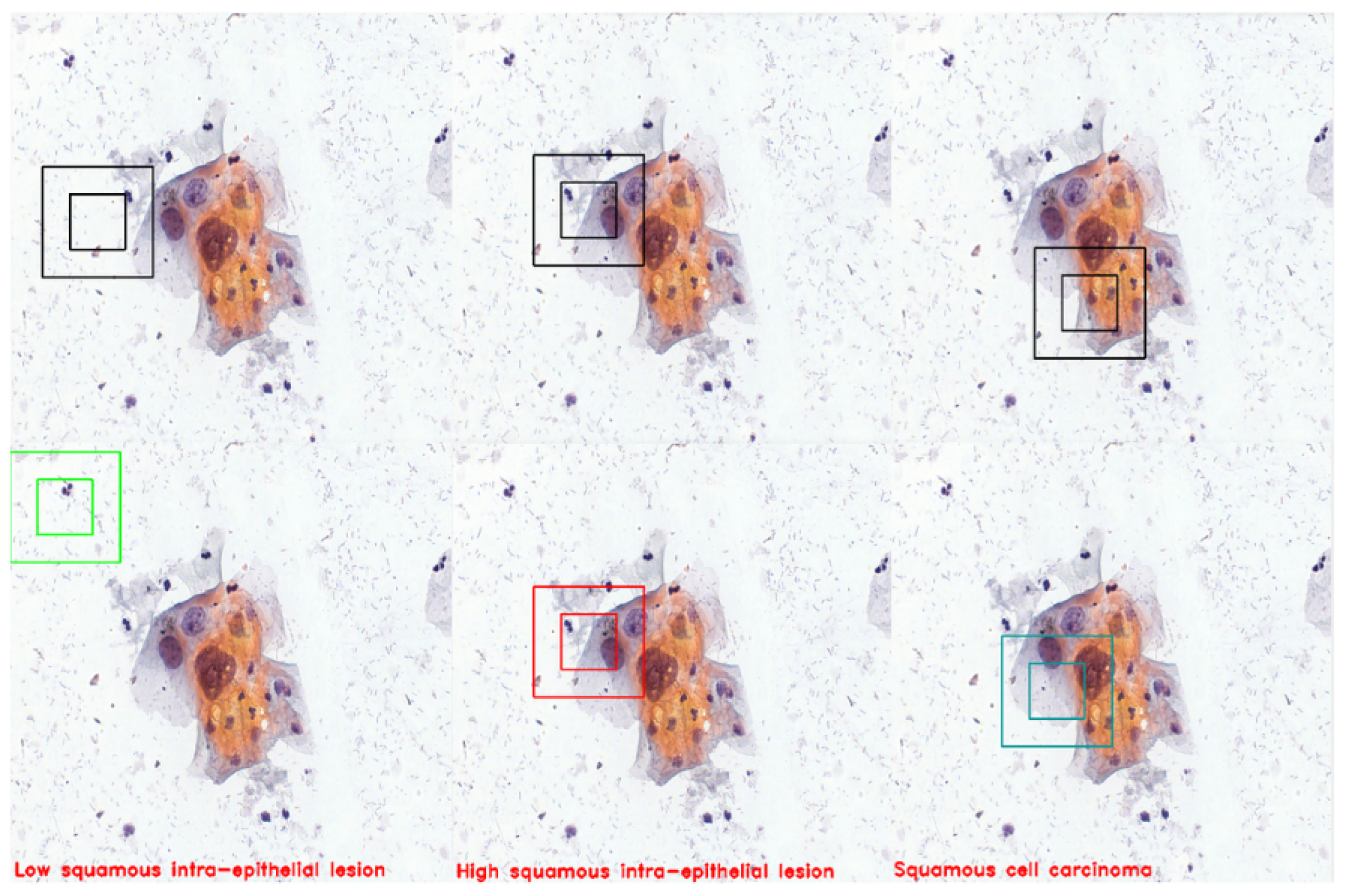
3. Agent Design
4. Environment Design
4.1. Reward Signal
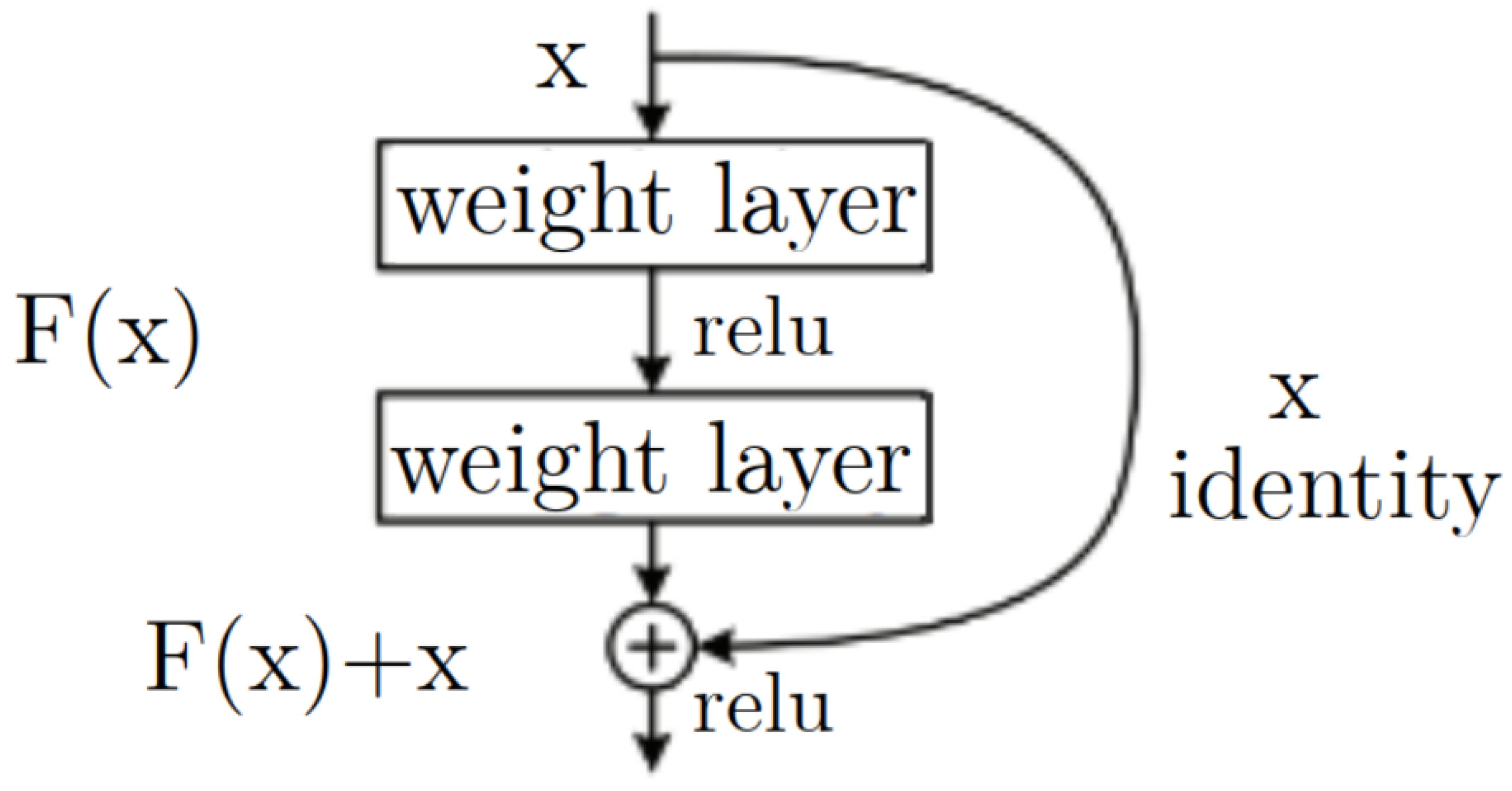
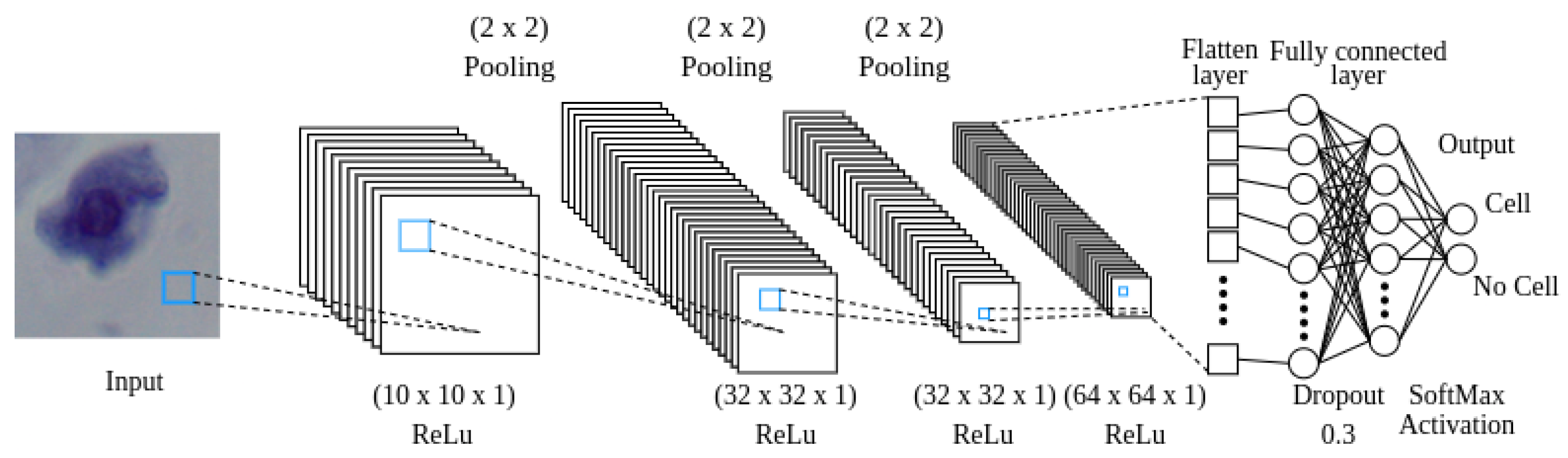
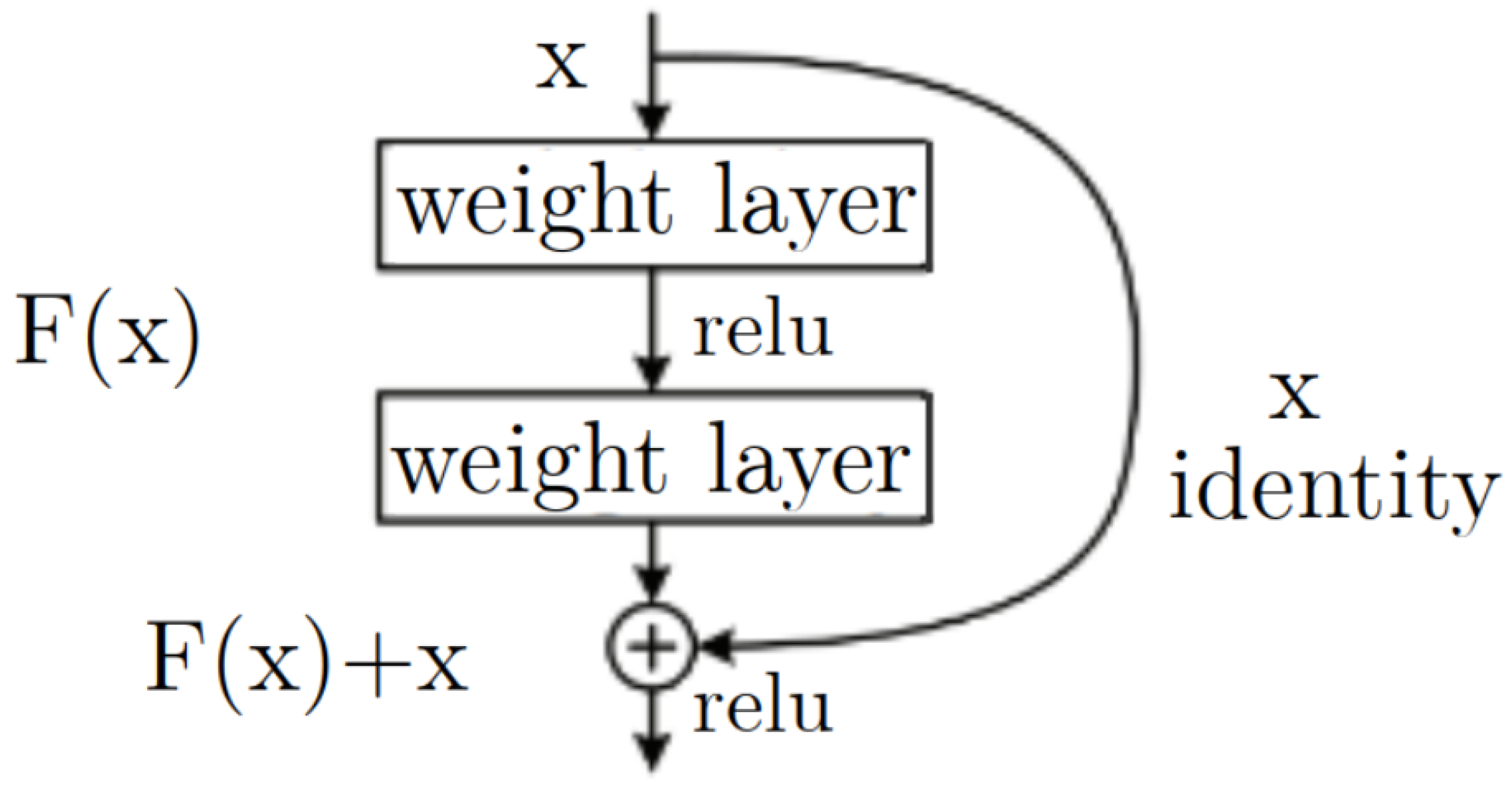
4.2. Cell Recognition Model
4.3. Pseudocode
| Algorithm 1 Environment feature extraction |
| Initialize agent and its weights; |
| while train do Reset the environment and gather initial observation S; |
| while episode not completed do |
| for time step do |
| Let agent choose action A based on state S; |
| Update environment according to action A; |
| Get new image (State ) from environment; |
| Calculate reward R; |
| Calculate advantage ; |
| Check if episode completed; |
| ; |
| end for |
| Update weights with PPO; |
| end while |
| end while |
4.4. Cell Classifier Model
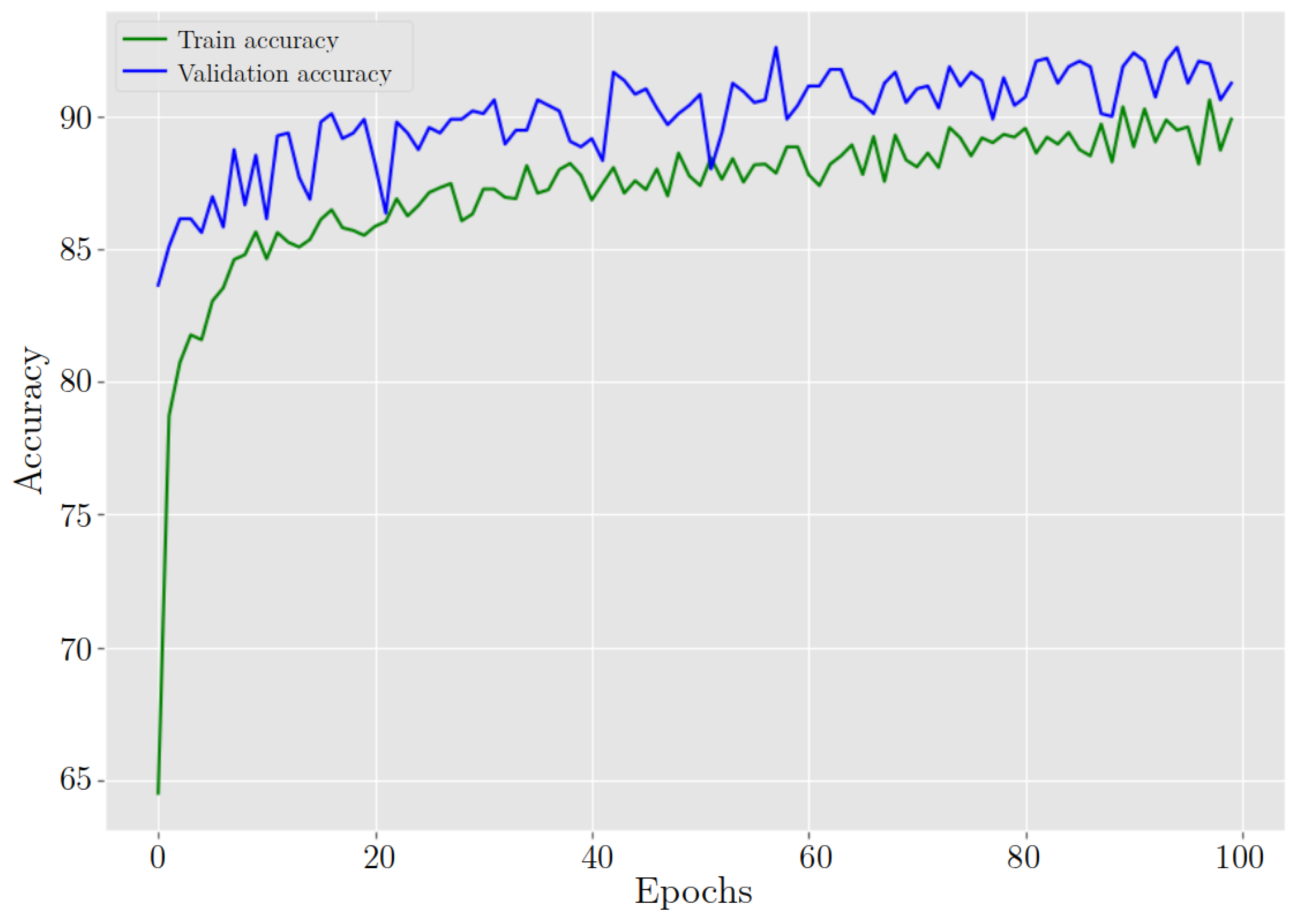
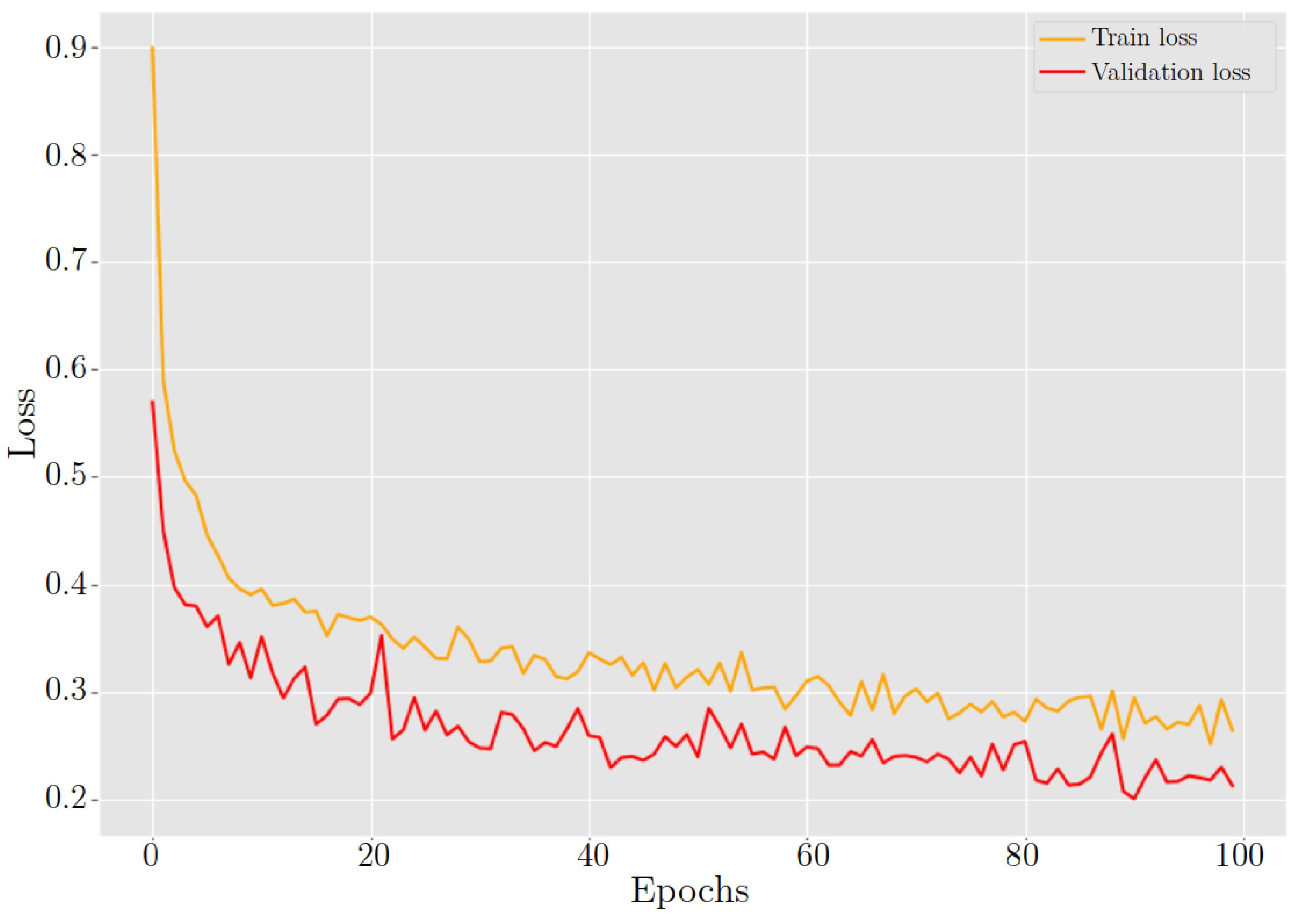
4.5. Training Process
| Algorithm 2 PPO Clip |
| Initialize ; |
| for iteration do |
| for time step do |
| Sample time step with policy ; |
| Calculate advantage ; |
| end for |
| for epoch do |
| Optimize with respect to ; |
| Update ; |
| end for |
| end for |
4.6. Experiments
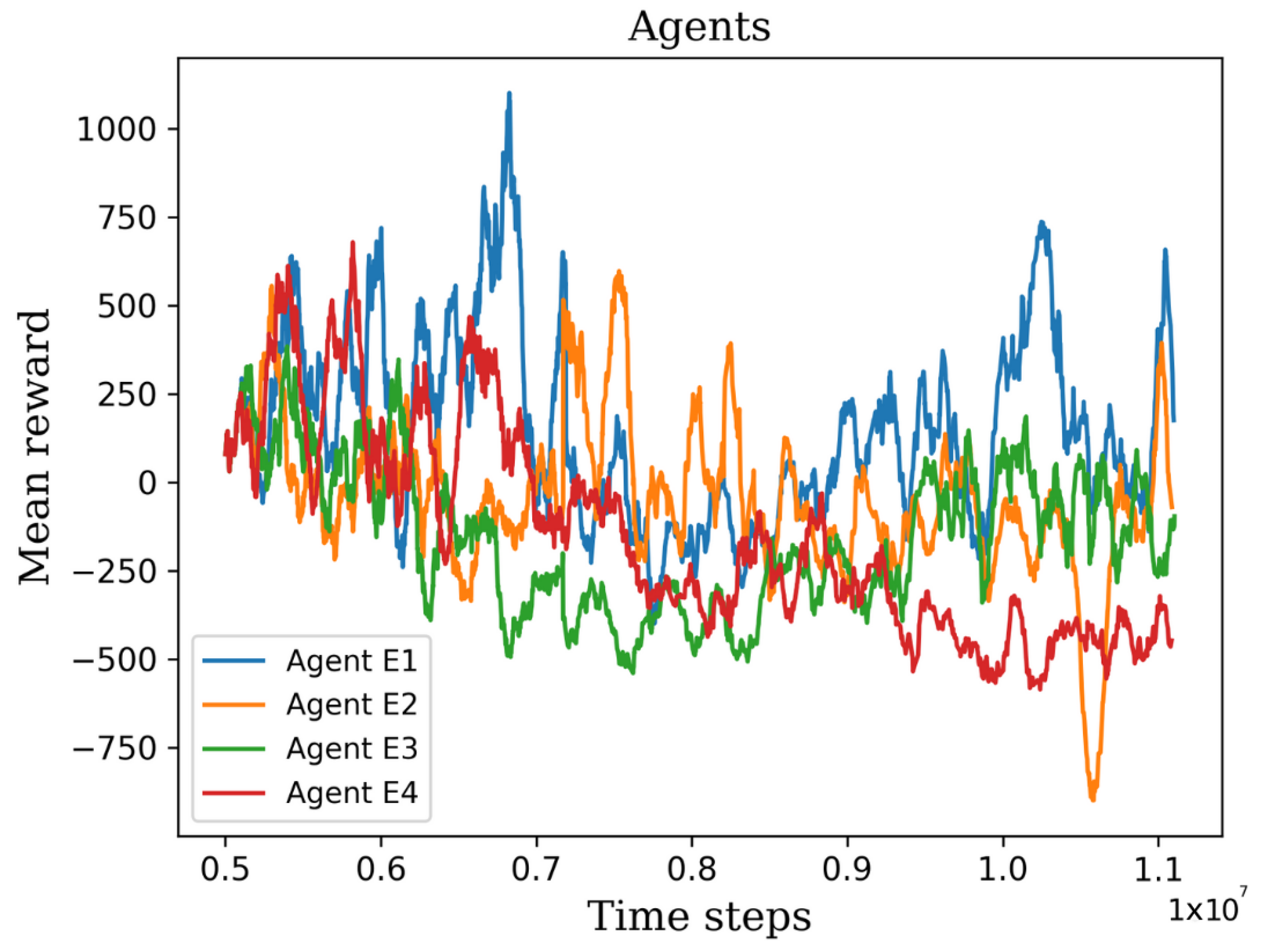
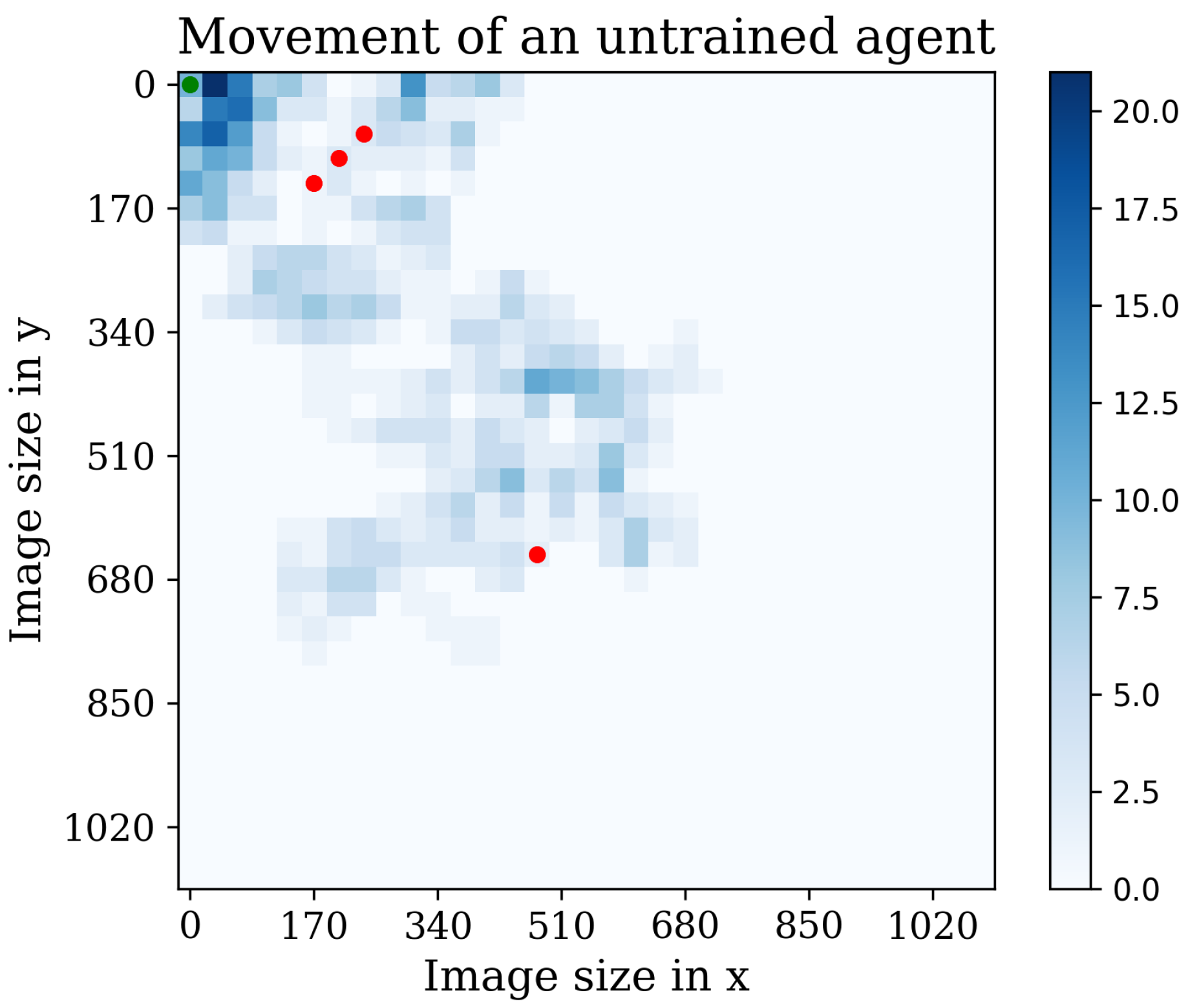
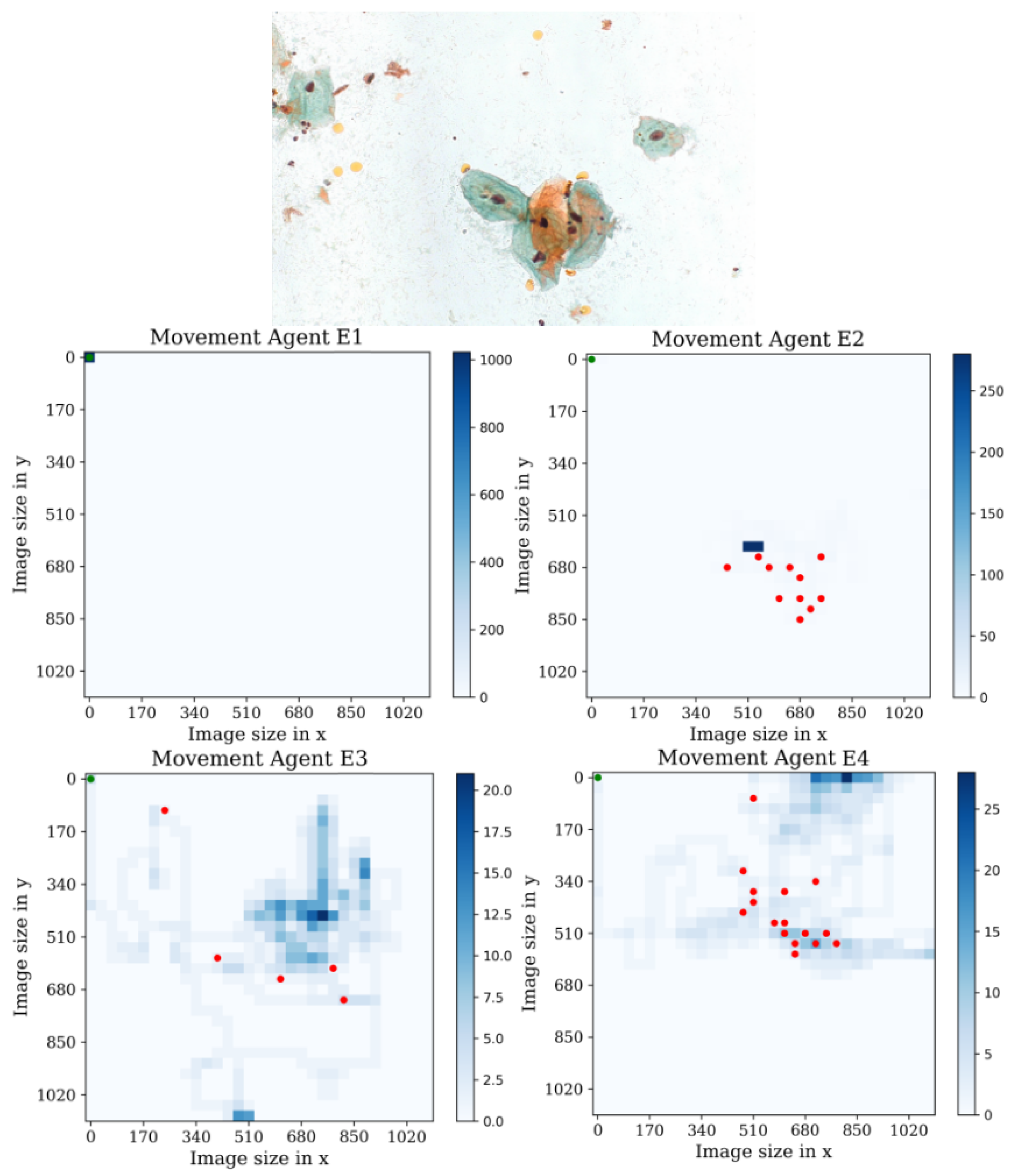
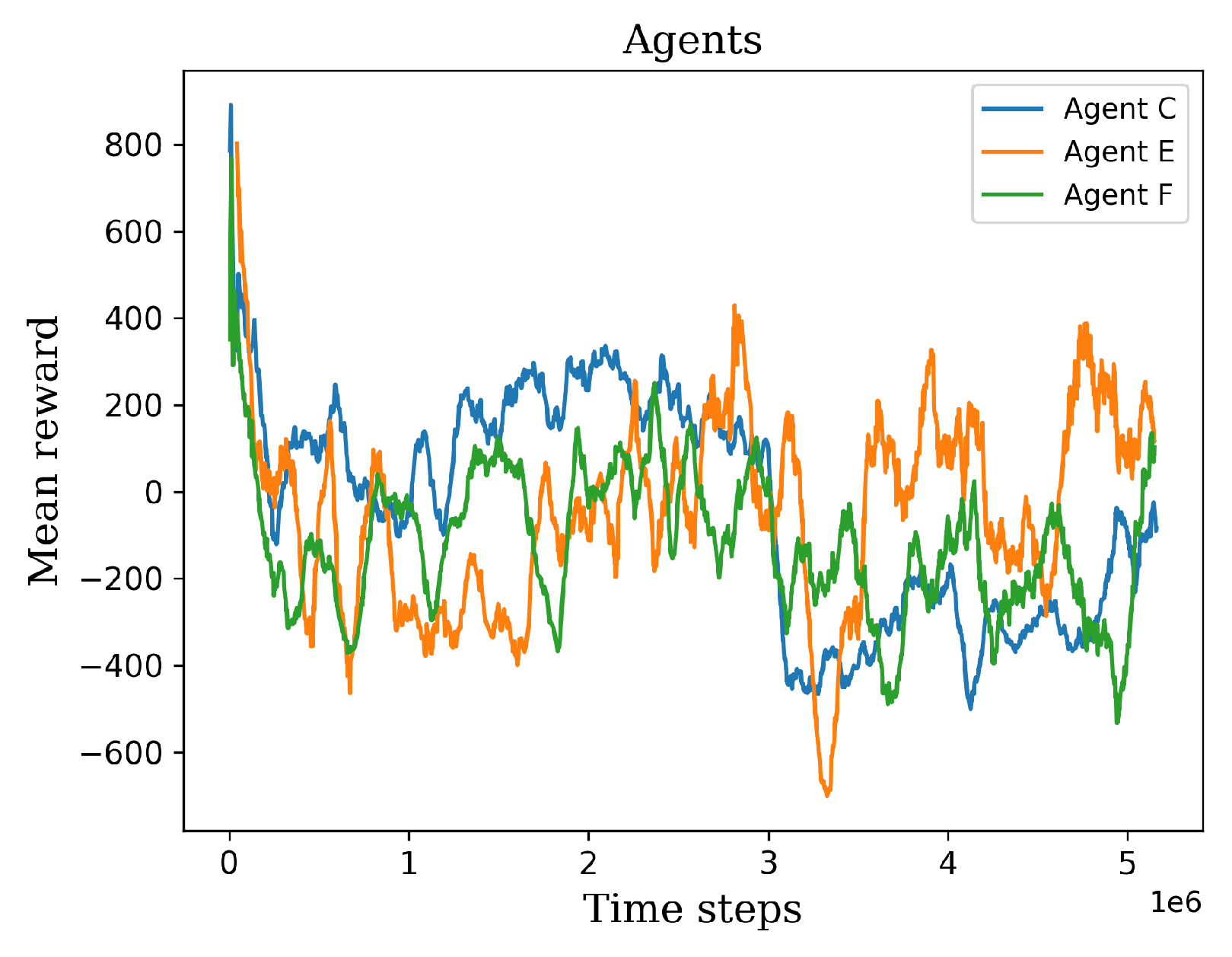
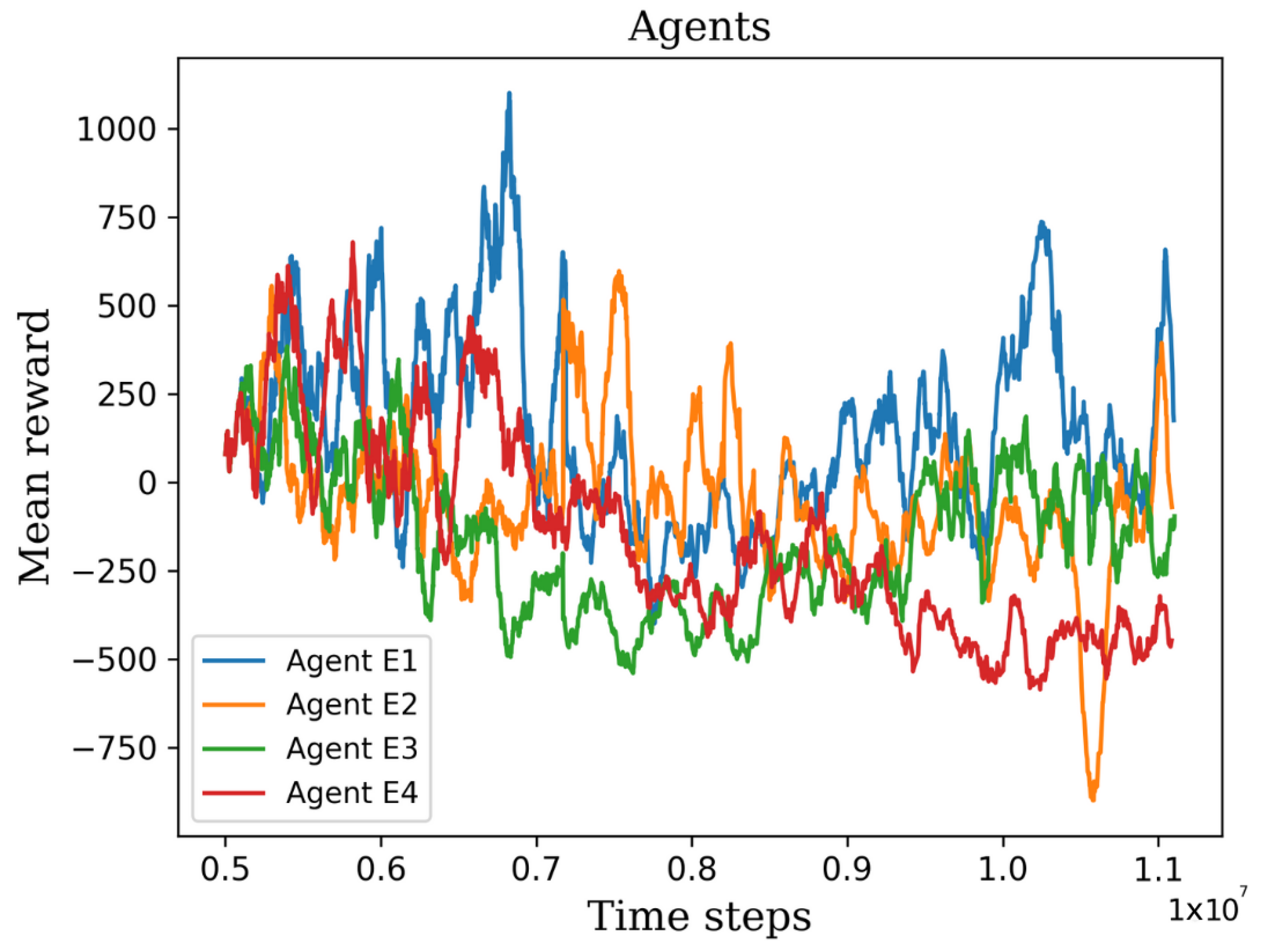
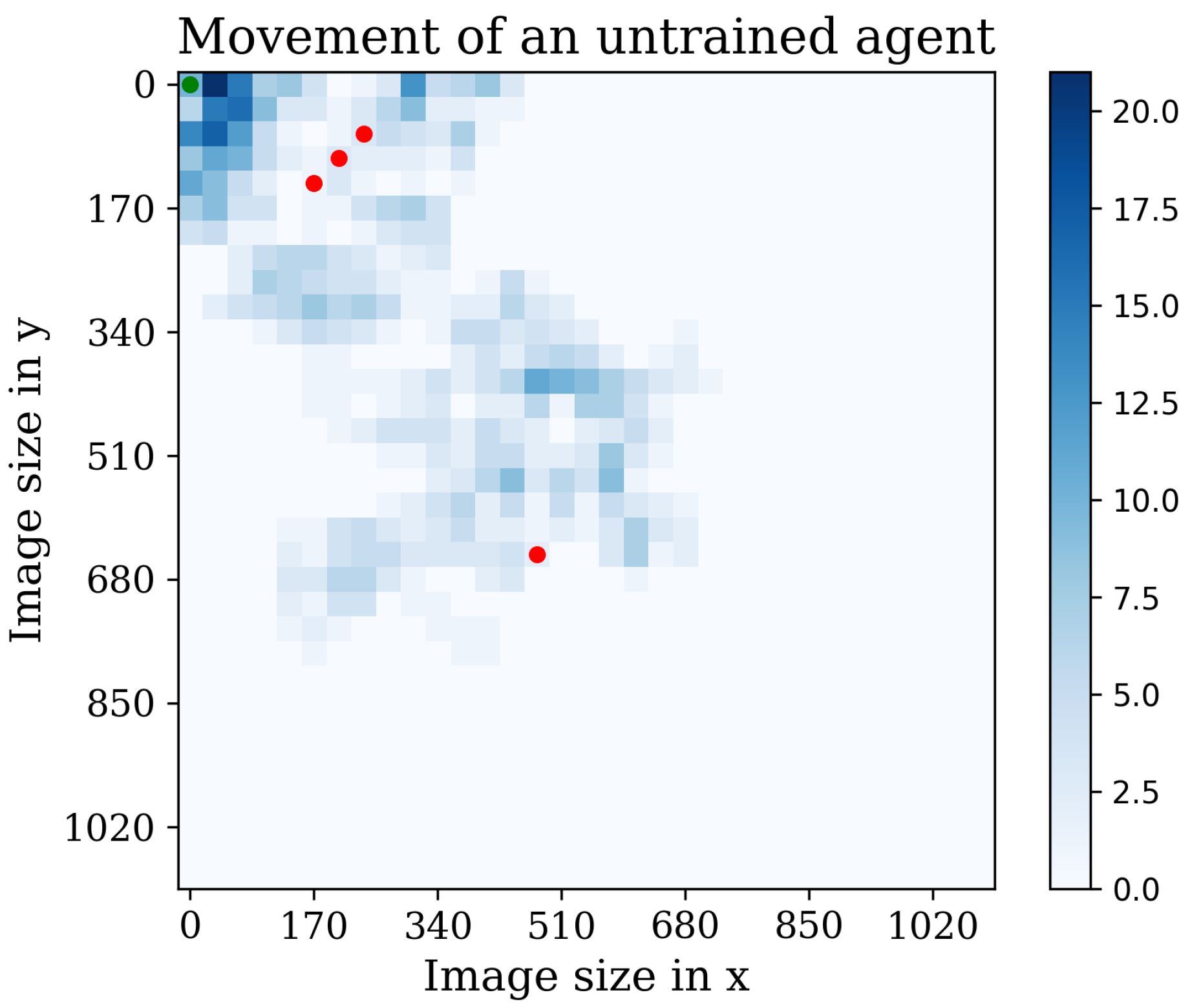
5. Results and Discussion
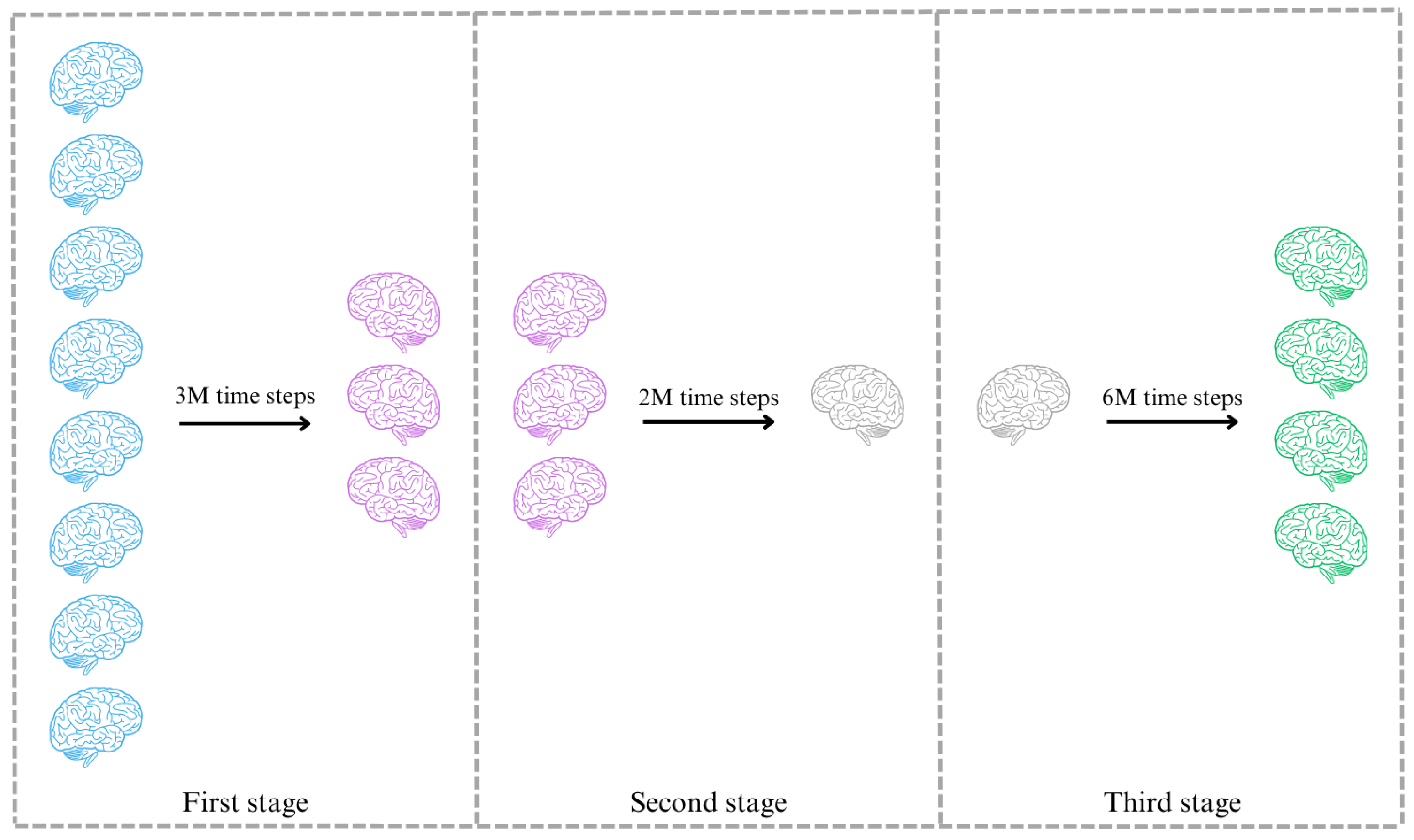
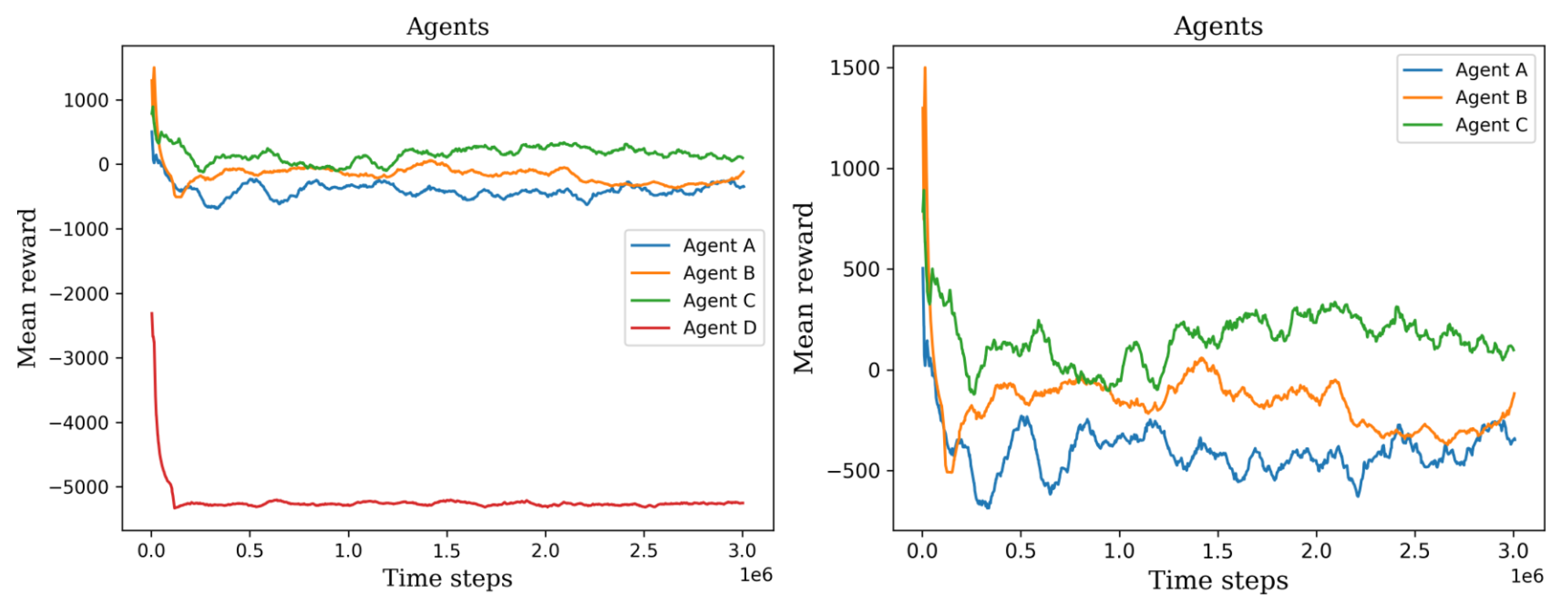
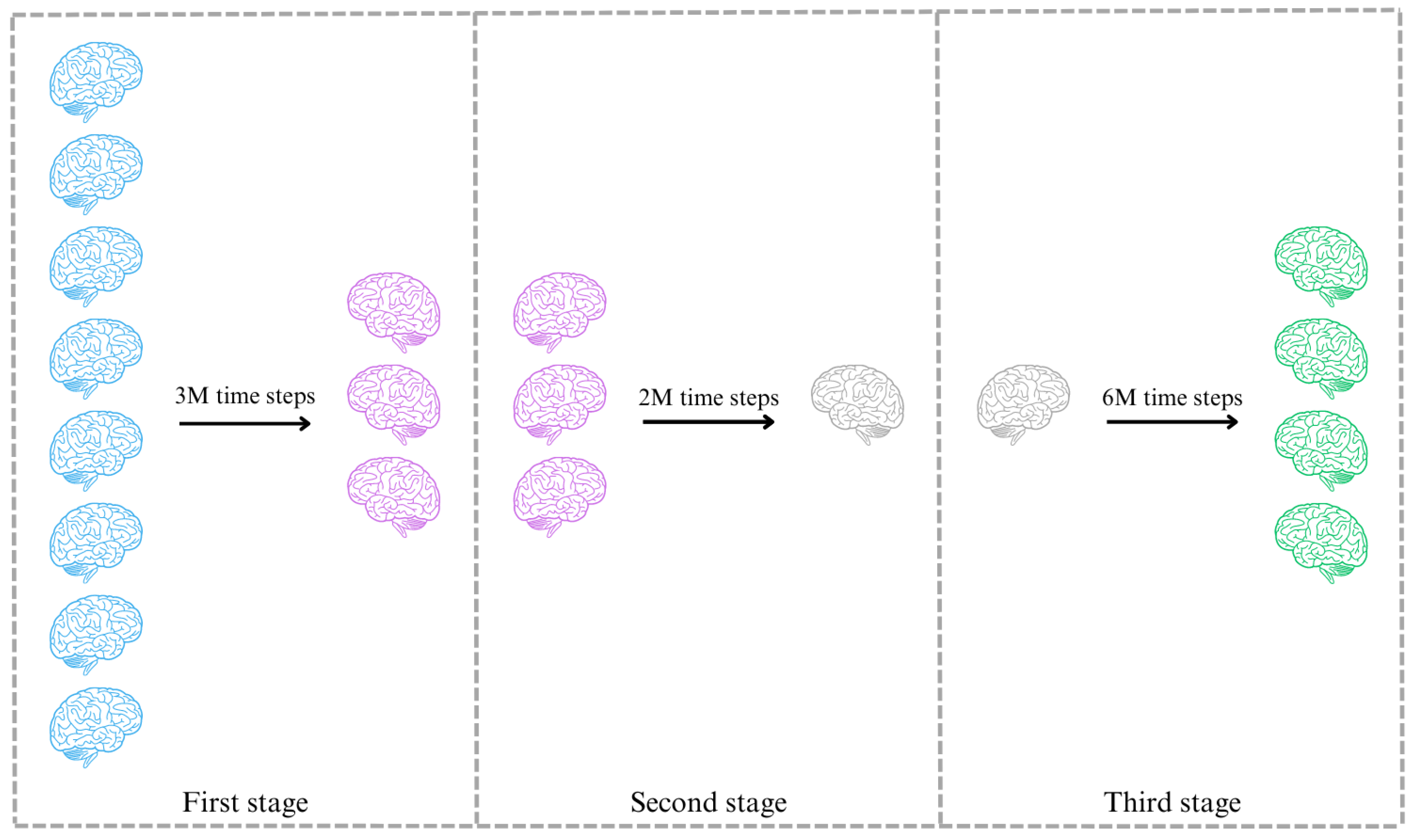
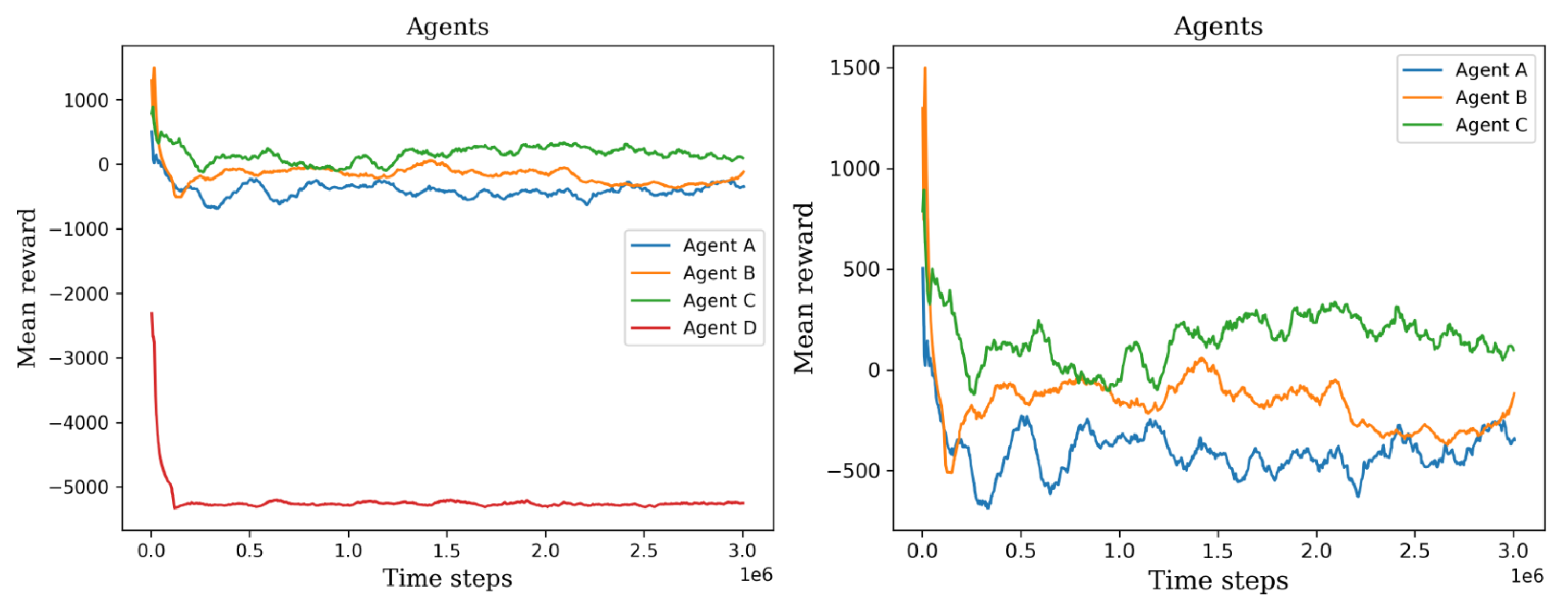
5.1. First Stage
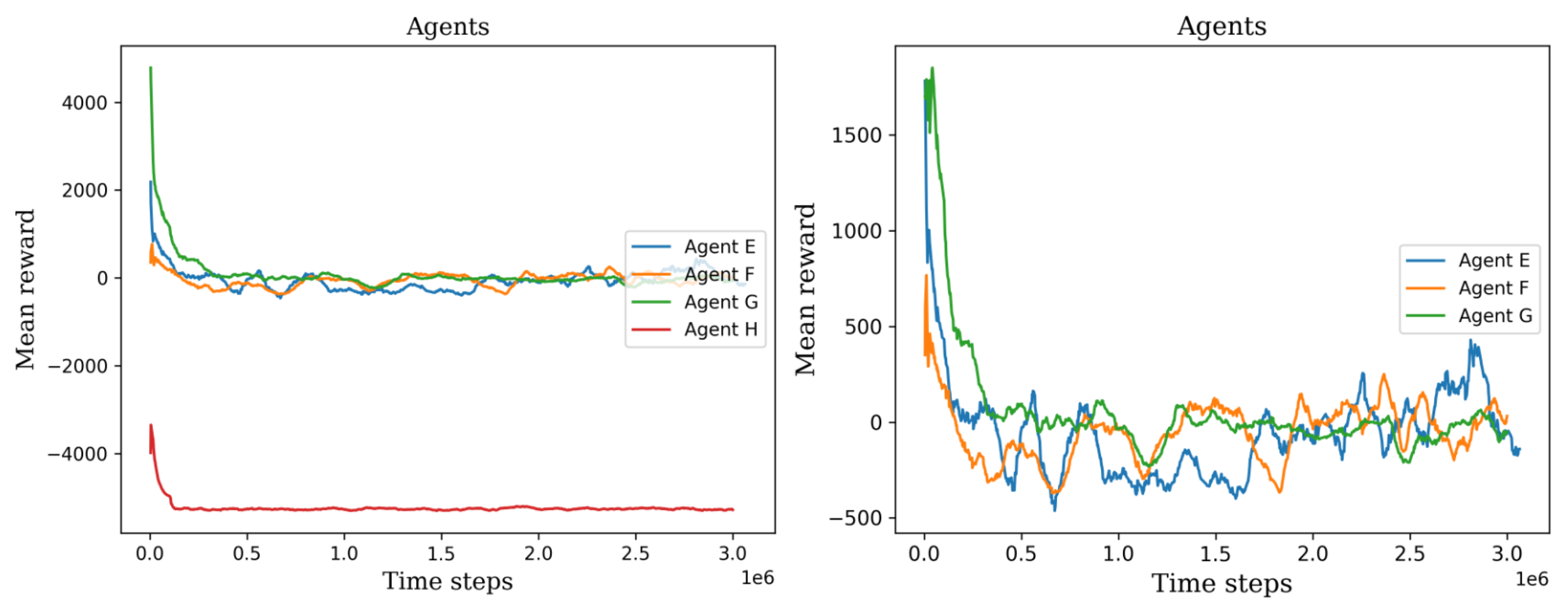
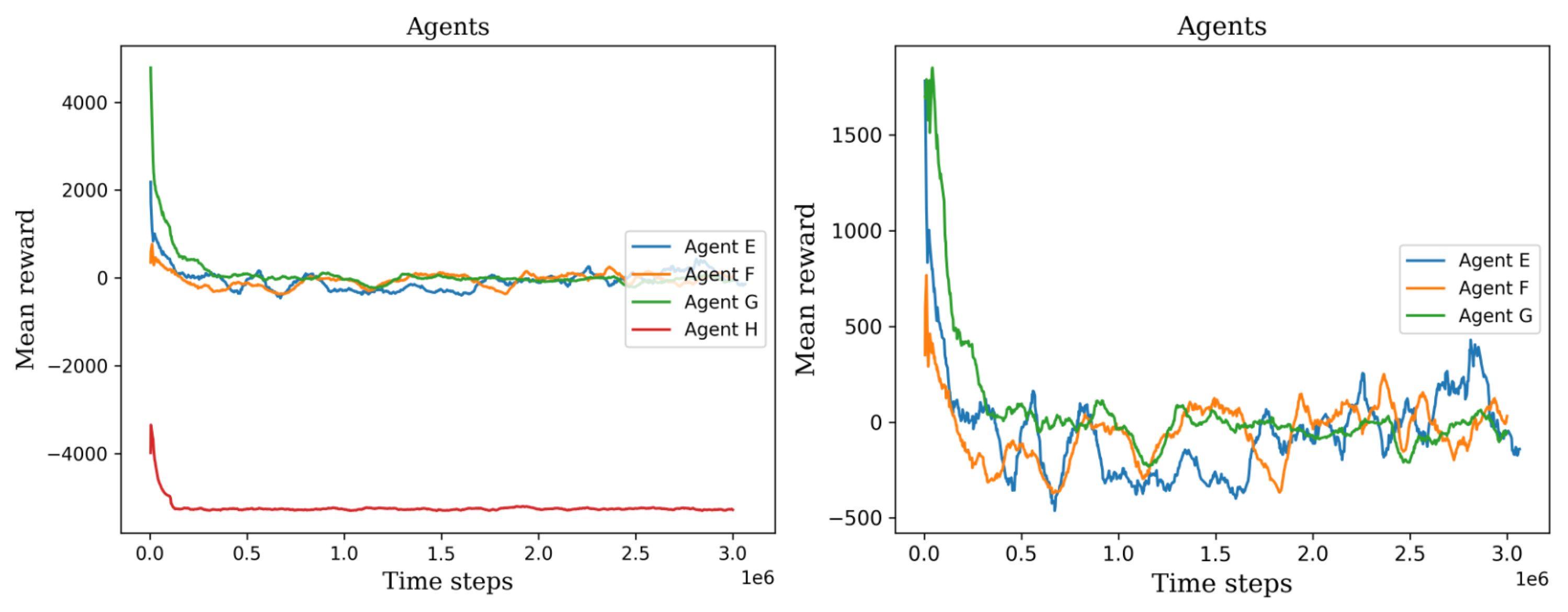
5.2. Second Stage
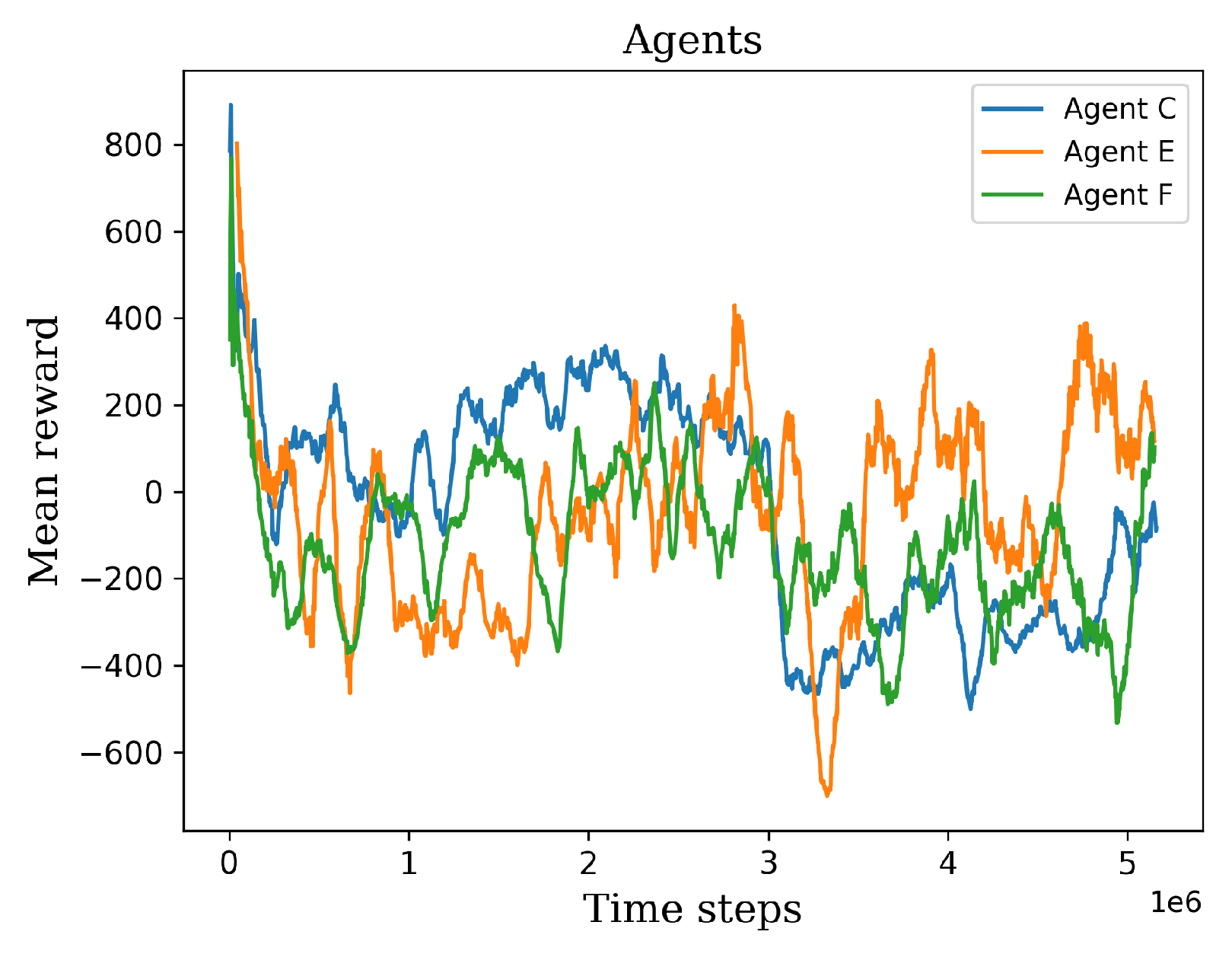
5.3. Third Stage
Behavior Testing
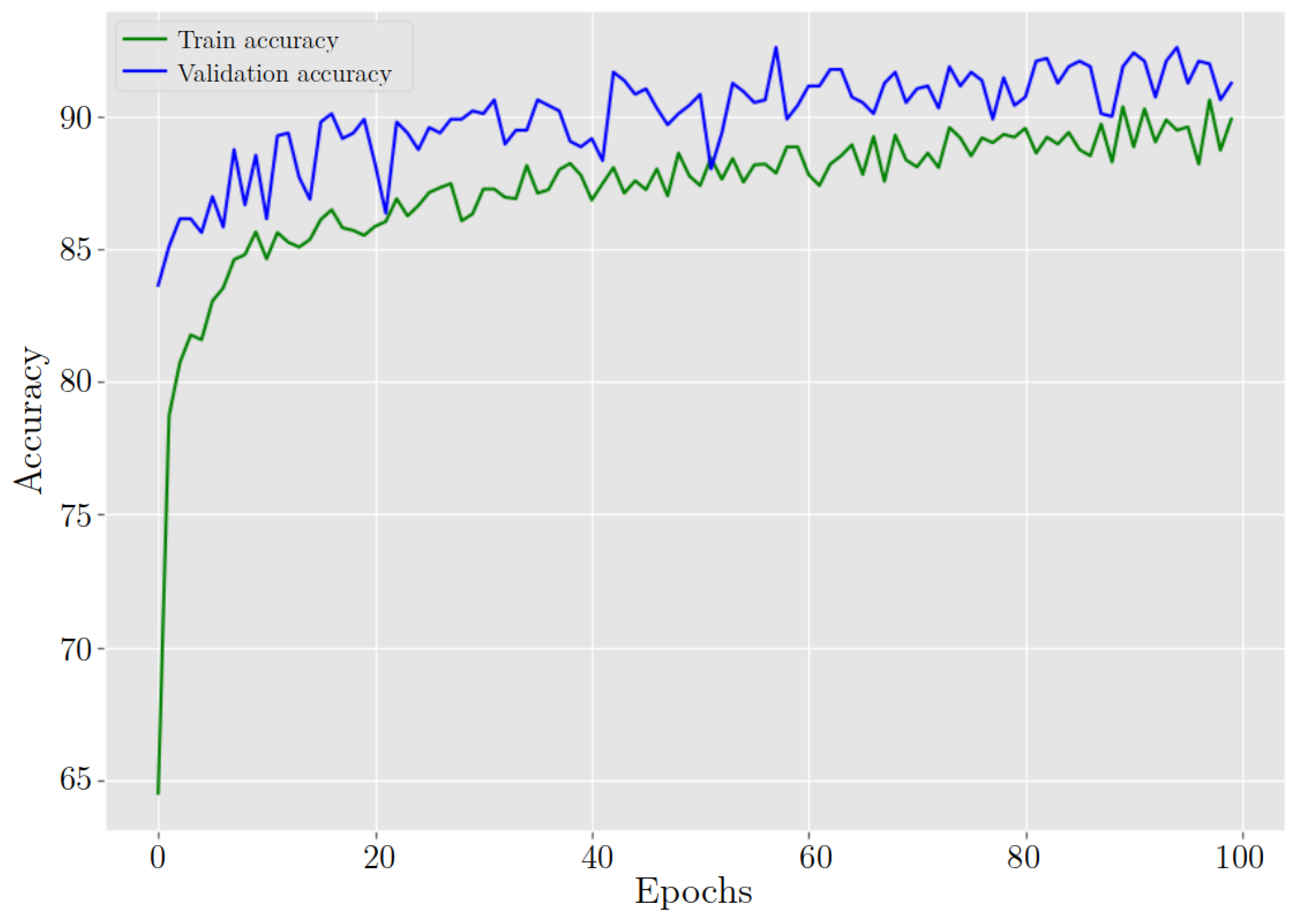
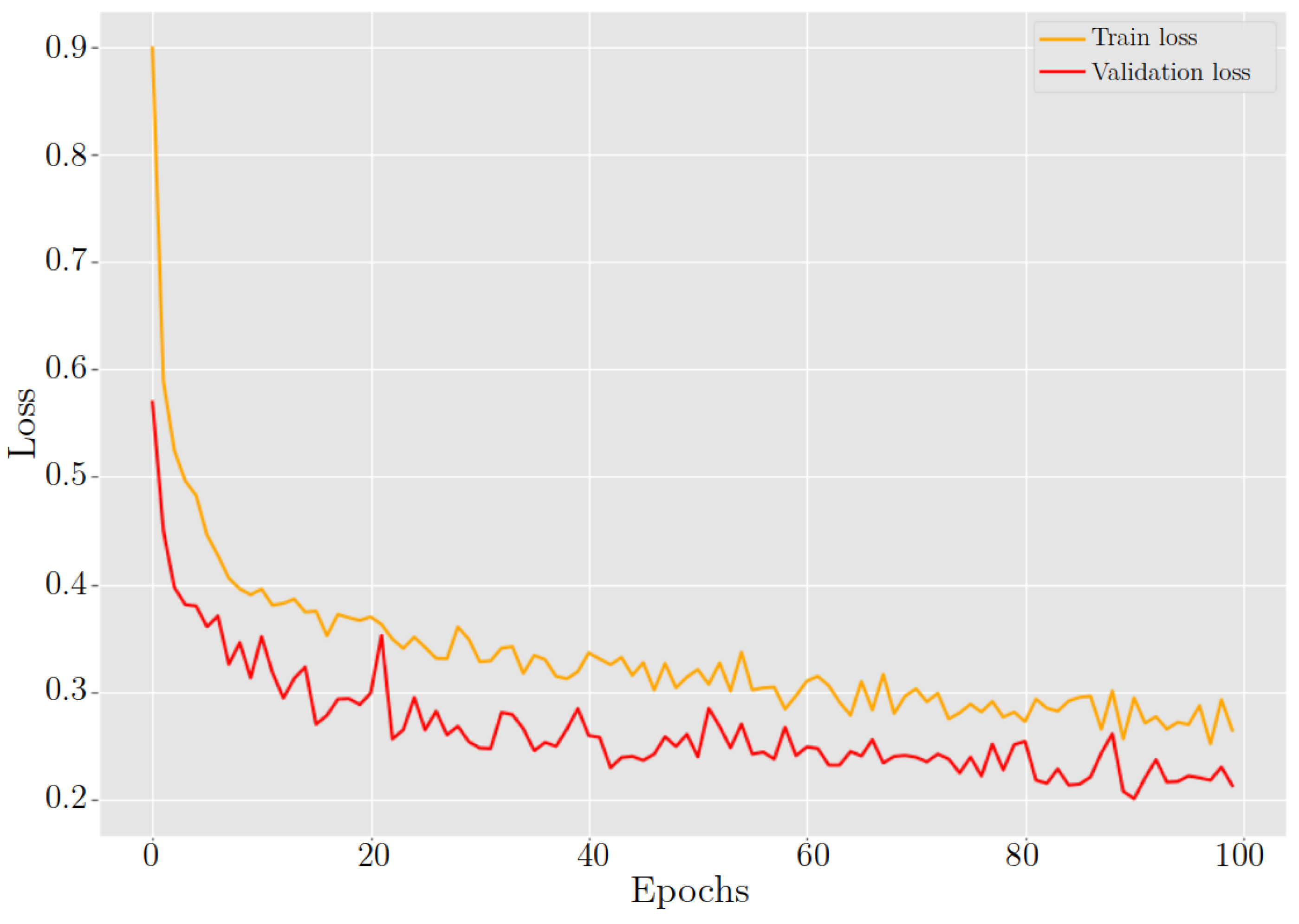
5.4. Cell Classifier Model
Comparison with Other Studies
5.5. Final System
5.5.1. Hyperspectral and Multispectral Systems Discussion
5.5.2. Faced Limitations
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cohen, P.A.; Jhingran, A.; Oaknin, A.; Denny, L. Cervical cancer. Lancet 2019, 393, 169–182. [Google Scholar] [CrossRef] [PubMed]
- Hasenleithner, S.O.; Speicher, M.R. How to detect cancer early using cell-free DNA. Cancer Cell 2022, 40, 1464–1466. [Google Scholar] [CrossRef] [PubMed]
- Nuche-Berenguer, B.; Sakellariou, D. Socioeconomic determinants of cancer screening utilisation in Latin America: A systematic review. PLoS ONE 2019, 14, e0225667. [Google Scholar] [CrossRef] [PubMed]
- Davies-Oliveira, J.; Smith, M.; Grover, S.; Canfell, K.; Crosbie, E. Eliminating Cervical Cancer: Progress and Challenges for High-income Countries. Clin. Oncol. 2021, 33, 550–559. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. 2021. Available online: www.who.int/publications/m/item/cervical-cancer-ecu-country-profile-2021 (accessed on 17 October 2023).
- Liebermann, E.J.; VanDevanter, N.; Hammer, M.J.; Fu, M.R. Social and Cultural Barriers to Women’s Participation in Pap Smear Screening Programs in Low- and Middle-Income Latin American and Caribbean Countries: An Integrative Review. J. Transcult. Nurs. 2018, 29, 591–602. [Google Scholar] [CrossRef] [PubMed]
- Strasser-Weippl, K.; Chavarri-Guerra, Y.; Villarreal-Garza, C.; Bychkovsky, B.L.; Debiasi, M.; Liedke, P.E.R.; de Celis, E.S.P.; Dizon, D.; Cazap, E.; de Lima Lopes, G.; et al. Progress and remaining challenges for cancer control in Latin America and the Caribbean. Lancet Oncol. 2015, 16, 1405–1438. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, UK, 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hussain, E.; Mahanta, L.B.; Borah, H.; Das, C.R. Liquid based-cytology Pap smear dataset for automated multi-class diagnosis of pre-cancerous and cervical cancer lesions. Data Brief 2020, 30, 105589. [Google Scholar] [CrossRef] [PubMed]
- Chang, O.G.; Toapanta, B.O. Automatic High-Resolution Ananlysis of Pap Test Cells. Bachelor’s Thesis, Universidad de Investigación de Tecnología Experimental Yachay, San Miguel de Urcuquí, Ecuador, 2021. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Plappert, M.; Houthooft, R.; Dhariwal, P.; Sidor, S.; Chen, R.Y.; Asfour, T.; Abbeel, P.; Andrychowicz, M. Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research. In Proceedings of the Conference on Robot Learning, Zurich, Switzerland, 29–31 October 2018. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- He, F.; Liu, T.; Tao, D. Why resnet works? residuals generalize. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5349–5362. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Gautier, P.; Aydore, S. DropCluster: A structured dropout for convolutional networks. arXiv 2020, arXiv:2002.02997. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Wong, L.; Ccopa, A.; Diaz, E.; Valcarcel, S.; Mauricio, D.; Villoslada, V. Deep Learning and Transfer Learning Methods to Effectively Diagnose Cervical Cancer from Liquid-Based Cytology Pap Smear Images. Int. J. Online Biomed. Eng. (iJOE) 2023, 19, 7–93. [Google Scholar] [CrossRef]
- Zhao, S.; He, Y.; Qin, J.; Wang, Z. A Semi-supervised Deep Learning Method for Cervical Cell Classification. Anal. Cell. Pathol. 2022, 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zhu, H.; Luo, J.; Liao, J.; He, S. High-accuracy Rapid Identification and Classification of Mixed Bacteria Using Hyperspectral Transmission Microscopic Imaging and Machine Learning. Prog. Electromagn. Res. 2023, 178, 49–62. [Google Scholar] [CrossRef]
- Shen, F.; Deng, H.; Yu, L.; Cai, F. Open-source mobile multispectral imaging system and its applications in biological sample sensing. Spectrochim. Acta Part Mol. Biomol. Spectrosc. 2022, 280, 121504. [Google Scholar] [CrossRef] [PubMed]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Moreno-Vera, F. Performing Deep Recurrent Double Q-Learning for Atari Games. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019. [Google Scholar] [CrossRef]
- Gao, R.; Lu, H.; Al-Azzawi, A.; Li, Y.; Zhao, C. DRL-FVRestore: An Adaptive Selection and Restoration Method for Finger Vein Images Based on Deep Reinforcement. Appl. Sci. 2023, 13, 699. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actions Number | Action |
|---|---|
| 1 | Right |
| 2 | Left |
| 3 | Up |
| 4 | Down |
| Agents | Description |
|---|---|
| A, E | Using the reward signal without changes. |
| B, F | No penalty for detecting the same cell multiple times |
| C, G | No penalty while searching for a cell |
| D, H | High penalty while searching for a cell, |
| Hyperparameters | Values | Description |
|---|---|---|
| learning_rate | Progress remaining, which ranges from 1 to 0. | |
| n_steps | 512; 1024 | Steps per parameters update. |
| batch_size | 128 | Images processed by the network at once |
| n_epochs | 10 | Updates for the policy using the same trajectory |
| gamma | Discount factor | |
| gae_lambda | Bias vs. variance trade-off | |
| clip_range | Range of clipping | |
| vf_coef | Value function coefficient | |
| ent_coef | Entropy coefficient | |
| max_grad_norm | Clips gradient if it becomes too large |
| Categories | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| NILM | 1.00 | 0.97 | 0.98 | 200 |
| LSIL | 0.94 | 0.92 | 0.93 | 200 |
| HSIL | 0.78 | 0.92 | 0.84 | 200 |
| SCC | 0.91 | 0.86 | 0.85 | 200 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macancela, C.; Morocho-Cayamcela, M.E.; Chang, O. Deep Reinforcement Learning for Efficient Digital Pap Smear Analysis. Computation 2023, 11, 252. https://doi.org/10.3390/computation11120252
Macancela C, Morocho-Cayamcela ME, Chang O. Deep Reinforcement Learning for Efficient Digital Pap Smear Analysis. Computation. 2023; 11(12):252. https://doi.org/10.3390/computation11120252
Chicago/Turabian StyleMacancela, Carlos, Manuel Eugenio Morocho-Cayamcela, and Oscar Chang. 2023. "Deep Reinforcement Learning for Efficient Digital Pap Smear Analysis" Computation 11, no. 12: 252. https://doi.org/10.3390/computation11120252
APA StyleMacancela, C., Morocho-Cayamcela, M. E., & Chang, O. (2023). Deep Reinforcement Learning for Efficient Digital Pap Smear Analysis. Computation, 11(12), 252. https://doi.org/10.3390/computation11120252