
Face Detection & Recognition from Images & Videos Based on CNN & Raspberry Pi

 , , , and
, , , and
Abstract
:1. Introduction
2. Literature Review
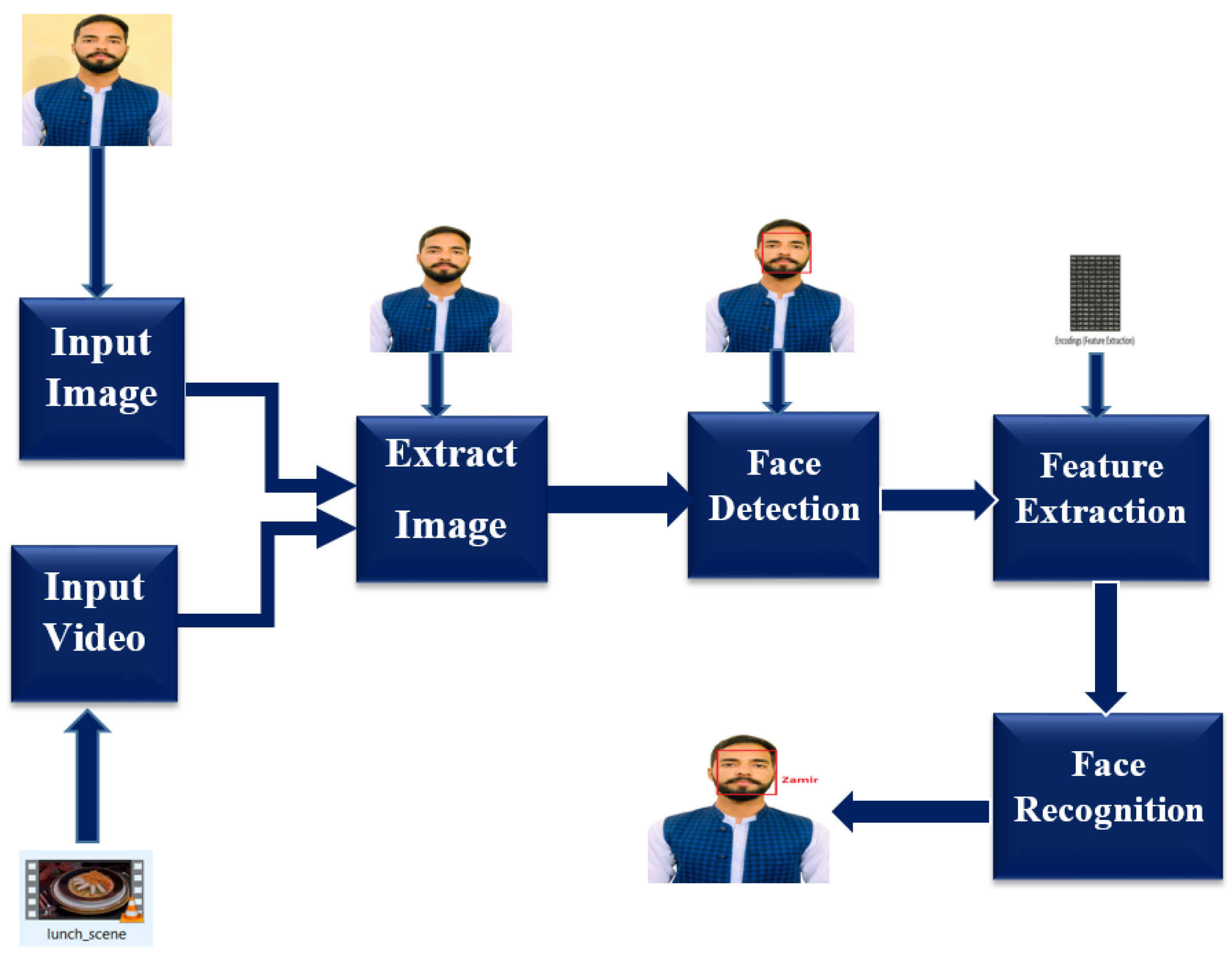
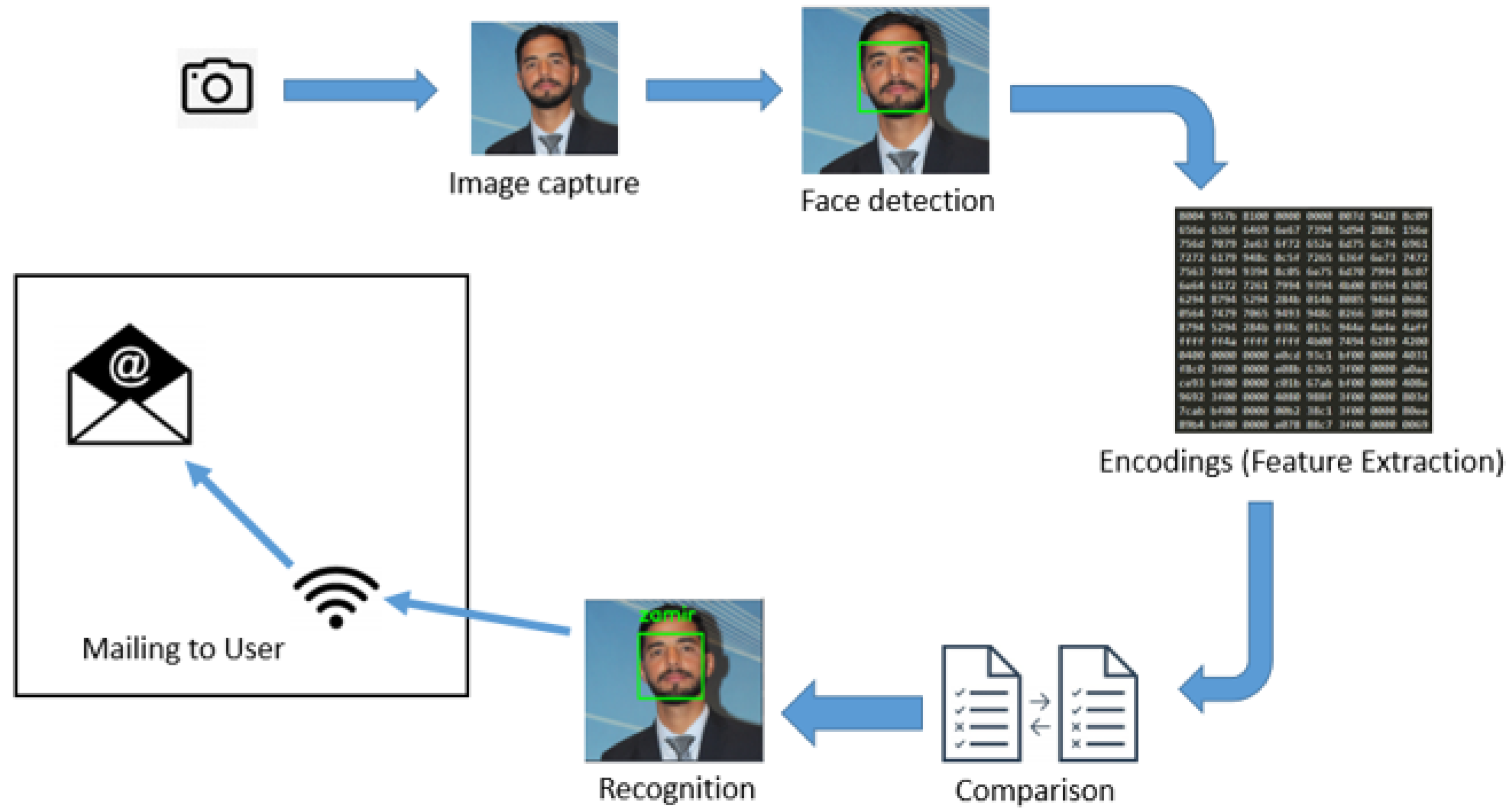
3. Proposed Methodology
3.1. Open CV
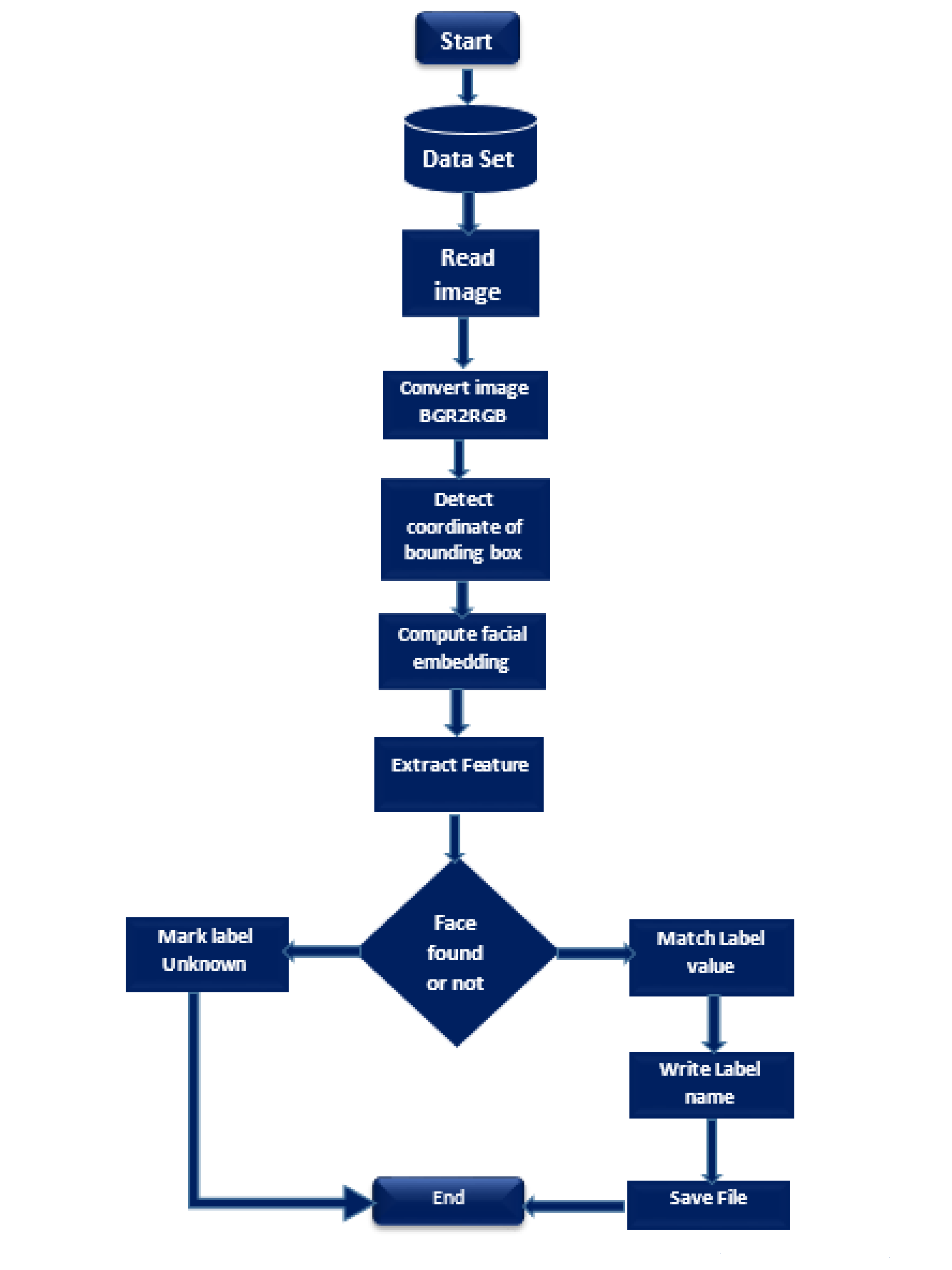
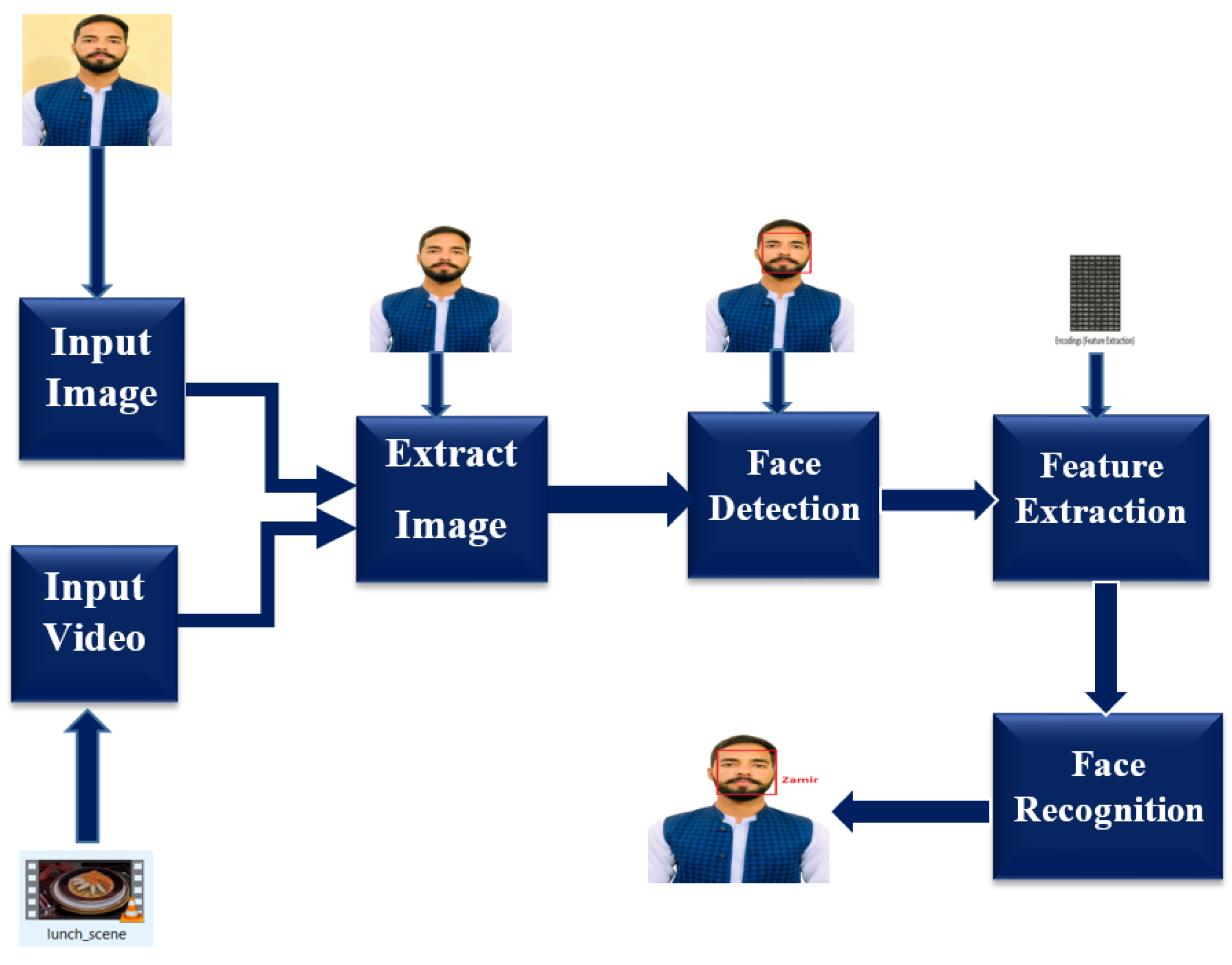
3.2. Image Processing Module
- First read the image.
- Load known encoding.
- Convert image into RGB color.
- Detect the coordinate of the bounding box of face from the image to extract the face from the whole image.
- Then, it computes the facial embedding or features of each image that we detect on training time.
- Extract the face from the image.
- Try to match the input face to the training dataset.
- Then, it takes the decision that either the face is known or not.
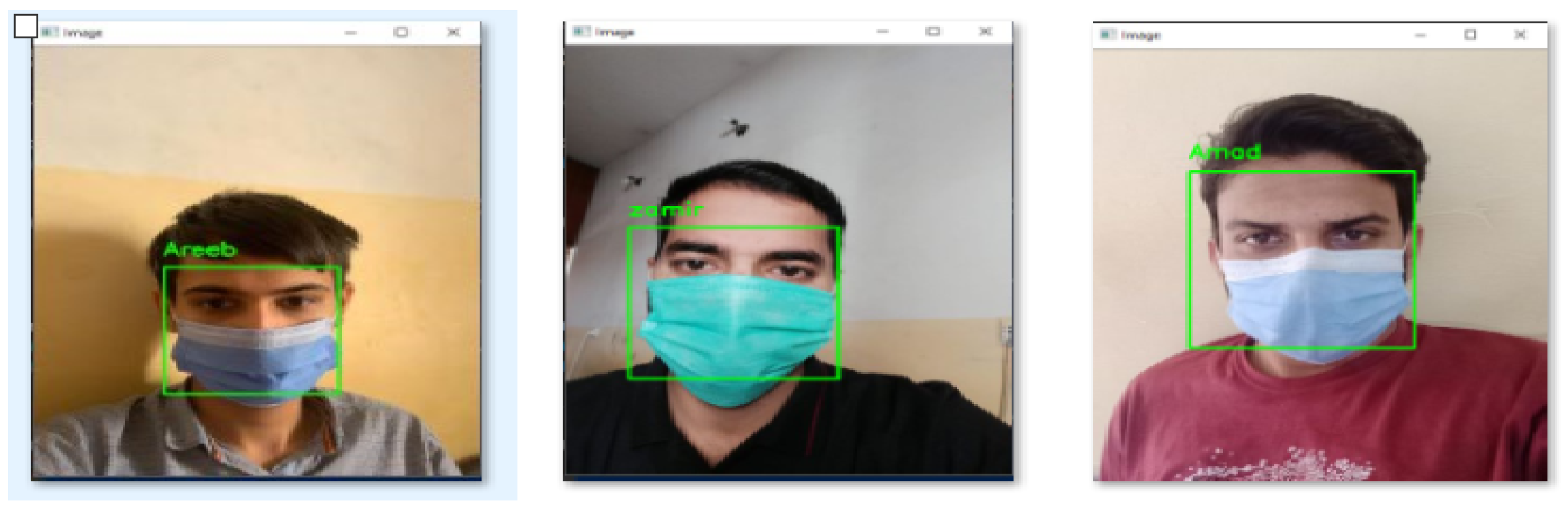
- If the face is known, it marks the label with the image folder name, or else it is marked as unknown.
- The flow chart summarizes the steps of how our code recognizes a face from an image.
3.3. Hardware
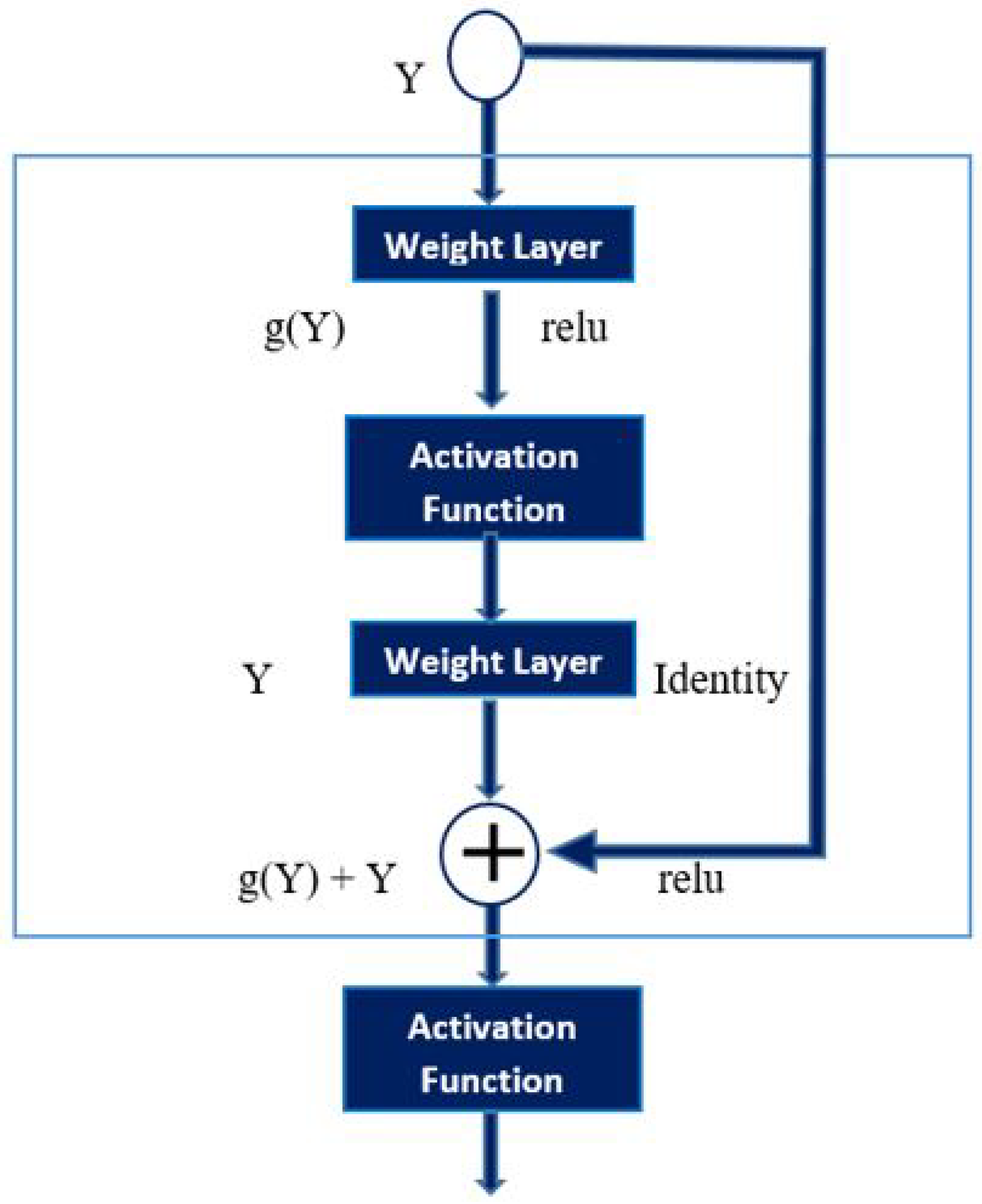
3.4. Face Recognition Based On CNN
- height of feature map;
- width of feature map;
- number of channels in the feature map;
- f size of filter;
- s stride length.
4. Datasets and Results
4.1. Evaluation Metrics
- [I]
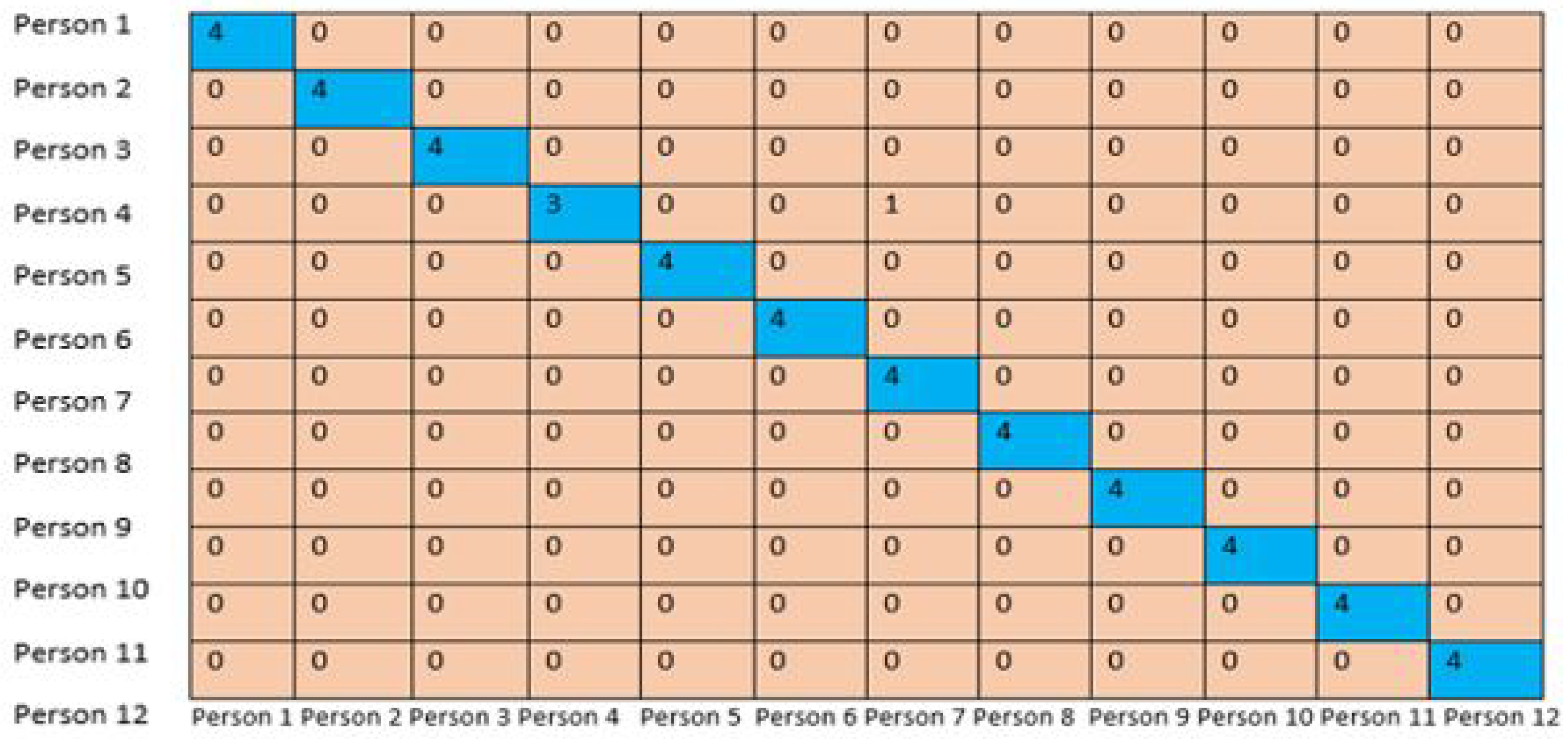
- Confusion Matrix: Both Precision and recall can be intercepted from the confusion matrix [51]. The confusion matrix is used to represent how well a model made its predictions. In Table 2, is the true positive mean if we give the known image to test a model, it leaves the correct result mark label unknown. is true negative, which means that if we give an unknown image to test a model, it gives the correct result mark label unknown. is false positive, which means that if we give an unknown image (negative) to test a model, it gives the wrong correct result mark label known (positive). is false negative, it means that if we give the known image (positive) to test a model, it gives the correct result mark label unknown (negative).
- [II]
- Accuracy (ACC): Accuracy is the measurement of how accurately the model recognizes a face. Accuracy is the ratio of sum of true positive and true negative over the total number of images.
- [III]
- Recall: In recall, instead of looking for false positives, it looks at the number of false negatives. Recall is used whenever a false negative is predicted.
- [IV]
- Precision: Precision is the ratio of true positive to the total of the true positive and false positives. Precision measures how much positive junk got thrown in the matrix. The smaller the number of false positives, the greater the model precision and vice versa.
- [V]
- F-measure/F1-Score: F1-score is one of the important evaluation criteria in deep learning. It is also known as the harmonic mean of precision and recall. It combines precision and recall into a single number.
4.2. Training of Proposed Research Model
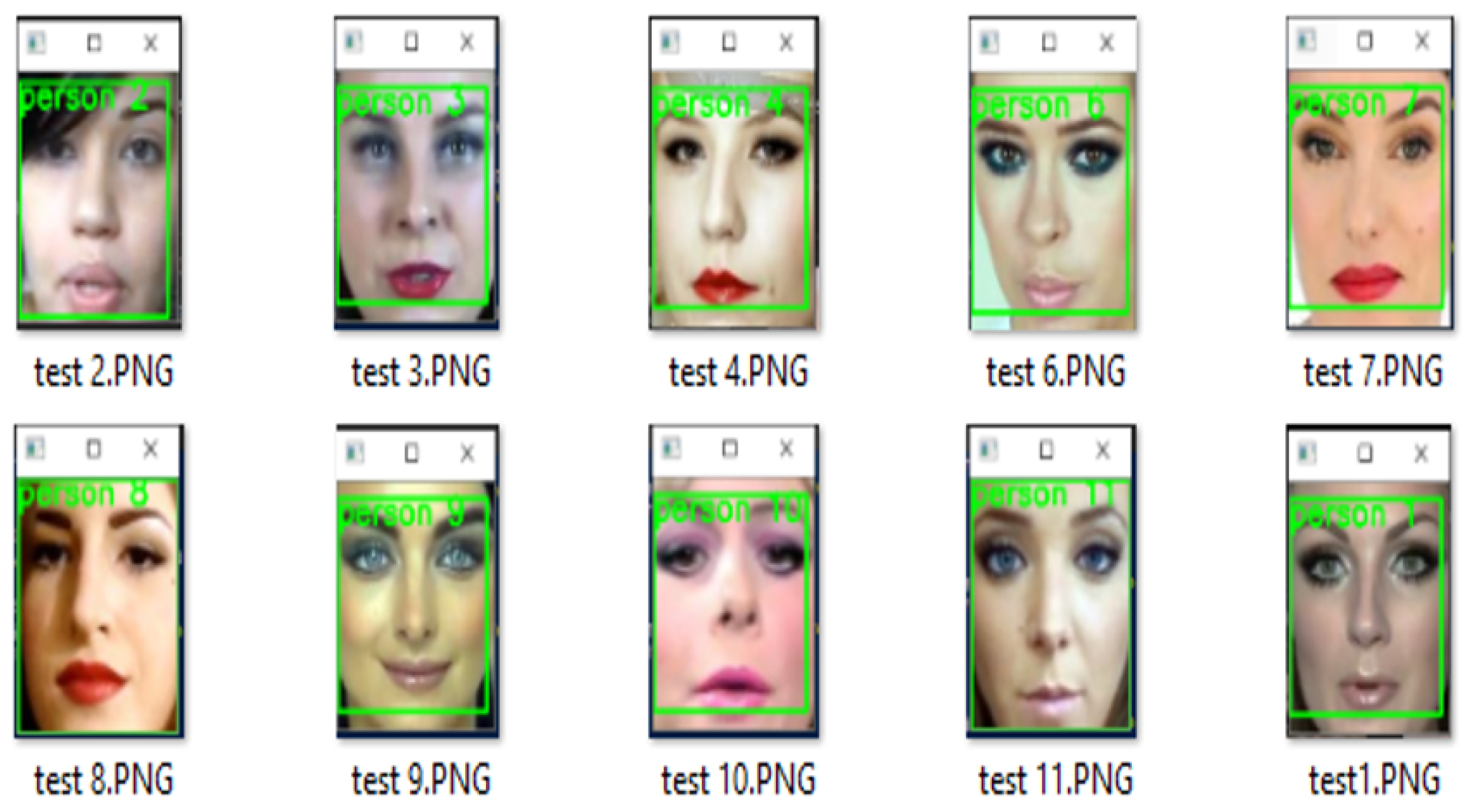
4.3. Testing of the Proposed Research Model
4.3.1. Testing of the Proposed Research Model Using Video Files
4.3.2. Testing of the Proposed Research Model Using Live Videos
4.4. Comparison of Proposed Research with HoG While Using Hard-Disk-Drive (HDD) and Sold-State-Drive (SSD)
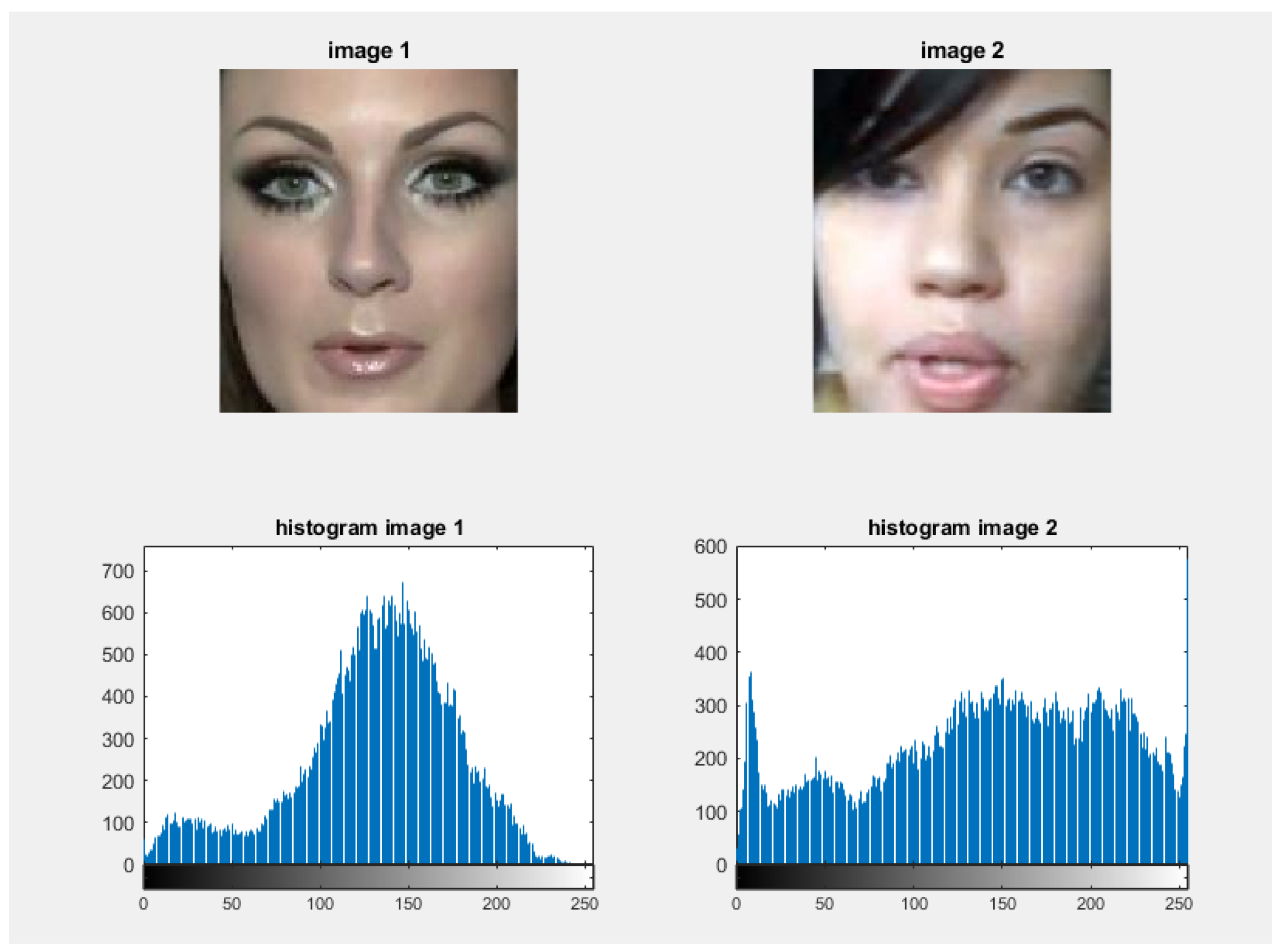
4.5. Experimental Results on Standard Image Benchmarks
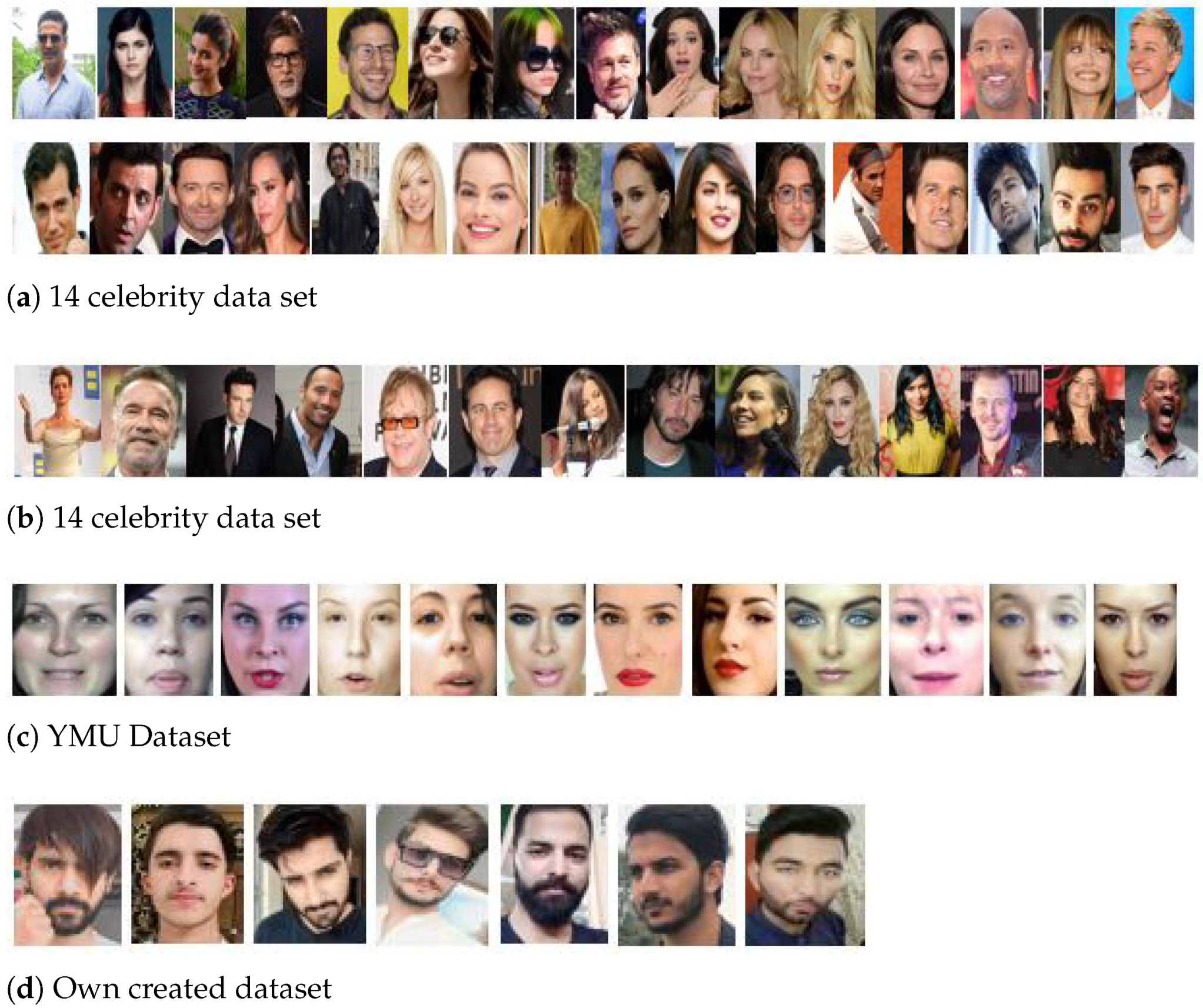
4.5.1. Results for VMU Image Dataset
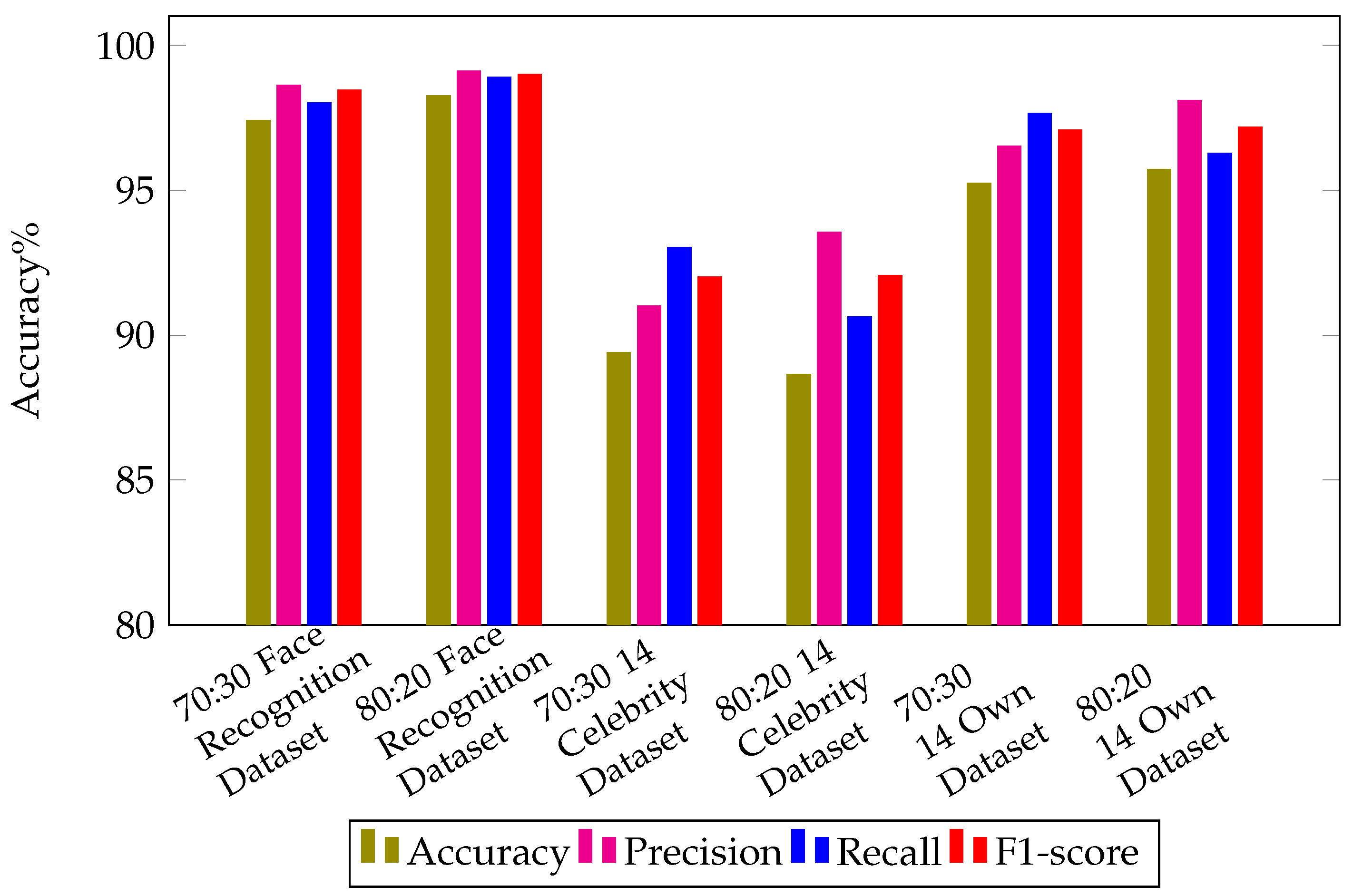
4.5.2. Results for Face Recognition Dataset
4.5.3. Results for 14 Celebrity Dataset
4.5.4. Results for Own Created Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Latif, A.; Rasheed, A.; Sajid, U.; Ahmed, J.; Ali, N.; Ratyal, N.I.; Zafar, B.; Dar, S.H.; Sajid, M.; Khalil, T. Content-based image retrieval and feature extraction: A comprehensive review. Math. Probl. Eng. 2019, 9658350. [Google Scholar] [CrossRef]
- Saqlain, M.; Rubab, S.; Khan, M.M.; Ali, N.; Ali, S. Hybrid Approach for Shelf Monitoring and Planogram Compliance (Hyb-SMPC) in Retails Using Deep Learning and Computer Vision. Math. Probl. Eng. 2022, 4916818. [Google Scholar] [CrossRef]
- Shabbir, A.; Rasheed, A.; Shehraz, H.; Saleem, A.; Zafar, B.; Sajid, M.; Ali, N.; Dar, S.H.; Shehryar, T. Detection of glaucoma using retinal fundus images: A comprehensive review. Math. Biosci. Eng. 2021, 18, 2033–2076. [Google Scholar] [CrossRef]
- Sajid, M.; Ali, N.; Ratyal, N.I.; Dar, S.H.; Zafar, B. Facial asymmetry-based Feature extraction for different applications: A review complemented by new advances. Artif. Intell. Rev. 2021, 54, 4379–4419. [Google Scholar] [CrossRef]
- Rasheed, A.; Zafar, B.; Rasheed, A.; Ali, N.; Sajid, M.; Dar, S.H.; Habib, U.; Shehryar, T.; Mahmood, M.T. Fabric defect detection using computer vision techniques: A comprehensive review. Math. Probl. Eng. 2020, 8189403. [Google Scholar] [CrossRef]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Zou, Q.; Xiong, K.; Fang, Q.; Jiang, B. Deep imitation reinforcement learning for self-driving by vision. CAAI Trans. Intell. Technol. 2021, 6, 493–503. [Google Scholar] [CrossRef]
- Ali, N.; Bajwa, K.B.; Sablatnig, R.; Chatzichristofis, S.A.; Iqbal, Z.; Rashid, M.; Habib, H.A. A novel image retrieval based on visual words integration of SIFT and SURF. PLoS ONE 2016, 11, e0157428. [Google Scholar] [CrossRef]
- Bellini, P.; Nesi, P.; Pantaleo, G. IoT-Enabled Smart Cities: A Review of Concepts, Frameworks and Key Technologies. Appl. Sci. 2022, 12, 1607. [Google Scholar] [CrossRef]
- Qazi, S.; Khawaja, B.A.; Farooq, Q.U. IoT-Equipped and AI-Enabled Next Generation Smart Agriculture: A Critical Review, Current Challenges and Future Trends. IEEE Access 2022, 10, 21219–21235. [Google Scholar] [CrossRef]
- Afzal, K.; Tariq, R.; Aadil, F.; Iqbal, Z.; Ali, N.; Sajid, M. An optimized and efficient routing protocol application for IoV. Math. Probl. Eng. 2021, 9977252. [Google Scholar] [CrossRef]
- Malik, U.M.; Javed, M.A.; Zeadally, S.; ul Islam, S. Energy efficient fog computing for 6G enabled massive IoT: Recent trends and future opportunities. IEEE Internet Things J. 2021, 9, 14572–14594. [Google Scholar] [CrossRef]
- Fatima, S.; Aslam, N.A.; Tariq, I.; Ali, N. Home security and automation based on internet of things: A comprehensive review. In Proceedings of the IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 899, p. 012011. [Google Scholar]
- Saponara, S.; Giordano, S.; Mariani, R. Recent Trends on IoT Systems for Traffic Monitoring and for Autonomous and Connected Vehicles; MDPI: Basel, Switzerland, 2021; Volume 21, p. 1648. [Google Scholar]
- Zobaed, S.; Hassan, M.; Islam, M.U.; Haque, M.E. Deep learning in iot-based healthcare applications. In Deep Learning for Internet of Things Infrastructure; CRC Press: Boca Raton, FL, USA, 2021; pp. 183–200. [Google Scholar]
- Kumar, A.; Salau, A.O.; Gupta, S.; Paliwal, K. Recent trends in IoT and its requisition with IoT built engineering: A review. Adv. Signal Process. Commun. 2019, 15–25. [Google Scholar] [CrossRef]
- Ahmad, R.; Alsmadi, I. Machine learning approaches to IoT security: A systematic literature review. Internet Things 2021, 14, 100365. [Google Scholar] [CrossRef]
- Harbi, Y.; Aliouat, Z.; Refoufi, A.; Harous, S. Recent Security Trends in Internet of Things: A Comprehensive Survey. IEEE Access 2021, 9, 113292–113314. [Google Scholar] [CrossRef]
- Jabbar, W.A.; Wei, C.W.; Azmi, N.A.A.M.; Haironnazli, N.A. An IoT Raspberry Pi-based parking management system for smart campus. Internet Things 2021, 14, 100387. [Google Scholar] [CrossRef]
- Majumder, A.J.; Izaguirre, J.A. A smart IoT security system for smart-home using motion detection and facial recognition. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 1065–1071. [Google Scholar]
- Chao, W.L. Face Recognition. Available online: http://disp.ee.ntu.edu.tw/~pujols/Face%20Recognition-survey.pdf (accessed on 5 April 2022).
- Sajid, M.; Ali, N.; Dar, S.H.; Iqbal Ratyal, N.; Butt, A.R.; Zafar, B.; Shafique, T.; Baig, M.J.A.; Riaz, I.; Baig, S. Data augmentation-assisted makeup-invariant face recognition. Math. Probl. Eng. 2018, 2850632. [Google Scholar] [CrossRef]
- Patel, V. Face Recognition Dataset. Available online: https://www.kaggle.com/datasets/vasukipatel/face-recognition-dataset (accessed on 5 March 2022).
- Danup, N. 14 Celebrity Faces Dataset. Available online: https://www.kaggle.com/datasets/danupnelson/14-celebrity-faces-dataset (accessed on 7 March 2022).
- Sajid, M.; Ali, N.; Dar, S.H.; Zafar, B.; Iqbal, M.K. Short search space and synthesized-reference re-ranking for face image retrieval. Appl. Soft Comput. 2021, 99, 106871. [Google Scholar] [CrossRef]
- Ratyal, N.; Taj, I.A.; Sajid, M.; Mahmood, A.; Razzaq, S.; Dar, S.H.; Ali, N.; Usman, M.; Baig, M.J.A.; Mussadiq, U. Deeply learned pose invariant image analysis with applications in 3D face recognition. Math. Probl. Eng. 2019, 3547416. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Guo, L. Research on face recognition based on deep learning. In Proceedings of the 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture (AIAM), Manchester, UK, 23–25 October 2021; pp. 540–546. [Google Scholar]
- Ge, H.; Zhu, Z.; Dai, Y.; Wang, B.; Wu, X. Facial expression recognition based on deep learning. Comput. Methods Programs Biomed. 2022, 215, 106621. [Google Scholar] [CrossRef] [PubMed]
- Kaya, Y.; Kobayashi, K. A basic study on human face recognition. In Frontiers of Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 1972; pp. 265–289. [Google Scholar]
- Kanade, T. Computer Recognition of Human Faces; Birkhäuser: Basel, Germany, 1977; Volume 47. [Google Scholar]
- Turk, M.A.; Pentland, A.P. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991; pp. 586–587. [Google Scholar]
- Anggo, M.; Arapu, L. Face recognition using fisherface method. J. Physics Conf. Ser. 2018, 1028, 012119. [Google Scholar] [CrossRef]
- Liu, C. The development trend of evaluating face-recognition technology. In Proceedings of the 2014 International Conference on Mechatronics and Control (ICMC), Jinzhou, China, 3–5 July 2014; pp. 1540–1544. [Google Scholar]
- Li-Hong, Z.; Fei, L.; Yong-Jun, W. Face recognition based on LBP and genetic algorithm. In Proceedings of the 2016 Chinese Control and Decision Conference (CCDC), Yinchuan, China, 28–30 May 2016; pp. 1582–1587. [Google Scholar]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- Shamrat, F.J.M.; Al Jubair, M.; Billah, M.M.; Chakraborty, S.; Alauddin, M.; Ranjan, R. A Deep Learning Approach for Face Detection using Max Pooling. In Proceedings of the 2021 5th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 3–5 June 2021; pp. 760–764. [Google Scholar]
- Ding, R.; Su, G.; Bai, G.; Xu, W.; Su, N.; Wu, X. A FPGA-based accelerator of convolutional neural network for face feature extraction. In Proceedings of the 2019 IEEE International Conference on Electron Devices and Solid-State Circuits (EDSSC), Xi’an, China, 12–14 June 2019; pp. 1–3. [Google Scholar]
- Tufail, A.B.; Ma, Y.K.; Kaabar, M.K.; Martínez, F.; Junejo, A.; Ullah, I.; Khan, R. Deep learning in cancer diagnosis and prognosis prediction: A minireview on challenges, recent trends, and future directions. Comput. Math. Methods Med. 2021, 9025470. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, M.; Shahzad, A.; Zafar, B.; Shabbir, A.; Ali, N. Remote Sensing Image Classification: A Comprehensive Review and Applications. Math. Probl. Eng. 2022, 5880959. [Google Scholar] [CrossRef]
- Tufail, A.B.; Ullah, I.; Khan, W.U.; Asif, M.; Ahmad, I.; Ma, Y.K.; Khan, R.; Kalimullah; Ali, S. Diagnosis of diabetic retinopathy through retinal fundus images and 3D convolutional neural networks with limited number of samples. Wirel. Commun. Mob. Comput. 2021, 6013448. [Google Scholar] [CrossRef]
- Ray, A.K.; Bagwari, A. IoT based Smart home: Security Aspects and security architecture. In Proceedings of the 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT), Gwalior, India, 10–12 April 2020; pp. 218–222. [Google Scholar]
- Khan, I.; Wu, Q.; Ullah, I.; Rahman, S.U.; Ullah, H.; Zhang, K. Designed circularly polarized two-port microstrip MIMO antenna for WLAN applications. Appl. Sci. 2022, 12, 1068. [Google Scholar] [CrossRef]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Huang, Y.; Wang, Y.; Tai, Y.; Liu, X.; Shen, P.; Li, S.; Li, J.; Huang, F. Curricularface: Adaptive curriculum learning loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5901–5910. [Google Scholar]
- Yousafzai, B.K.; Khan, S.A.; Rahman, T.; Khan, I.; Ullah, I.; Ur Rehman, A.; Baz, M.; Hamam, H.; Cheikhrouhou, O. Student-performulator: Student academic performance using hybrid deep neural network. Sustainability 2021, 13, 9775. [Google Scholar] [CrossRef]
- Wang, J.; Li, Z. Research on face recognition based on CNN. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Banda Aceh, Indonesia, 26–27 September 2018; Volume 170, p. 032110. [Google Scholar]
- Aydin, I.; Othman, N.A. A new IoT combined face detection of people by using computer vision for security application. In Proceedings of the 2017 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 16–17 September 2017; pp. 1–6. [Google Scholar]
- yzimm. Parameters and Flops in Convolutional Neural Network CNN. Available online: https://chowdera.com/2021/04/20210420120752555v.html (accessed on 7 June 2022).
- Sajid, M.; Ali, N.; Ratyal, N.I.; Usman, M.; Butt, F.M.; Riaz, I.; Musaddiq, U.; Aziz Baig, M.J.; Baig, S.; Ahmad Salaria, U. Deep learning in age-invariant face recognition: A comparative study. Comput. J. 2022, 65, 940–972. [Google Scholar] [CrossRef]
- Shabbir, A.; Ali, N.; Ahmed, J.; Zafar, B.; Rasheed, A.; Sajid, M.; Ahmed, A.; Dar, S.H. Satellite and scene image classification based on transfer learning and fine tuning of ResNet50. Math. Probl. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Wang, F.; Chen, L.; Li, C.; Huang, S.; Chen, Y.; Qian, C.; Loy, C.C. The devil of face recognition is in the noise. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 765–780. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. Shot classification of field sports videos using AlexNet Convolutional Neural Network. Appl. Sci. 2019, 9, 483. [Google Scholar] [CrossRef] [Green Version]
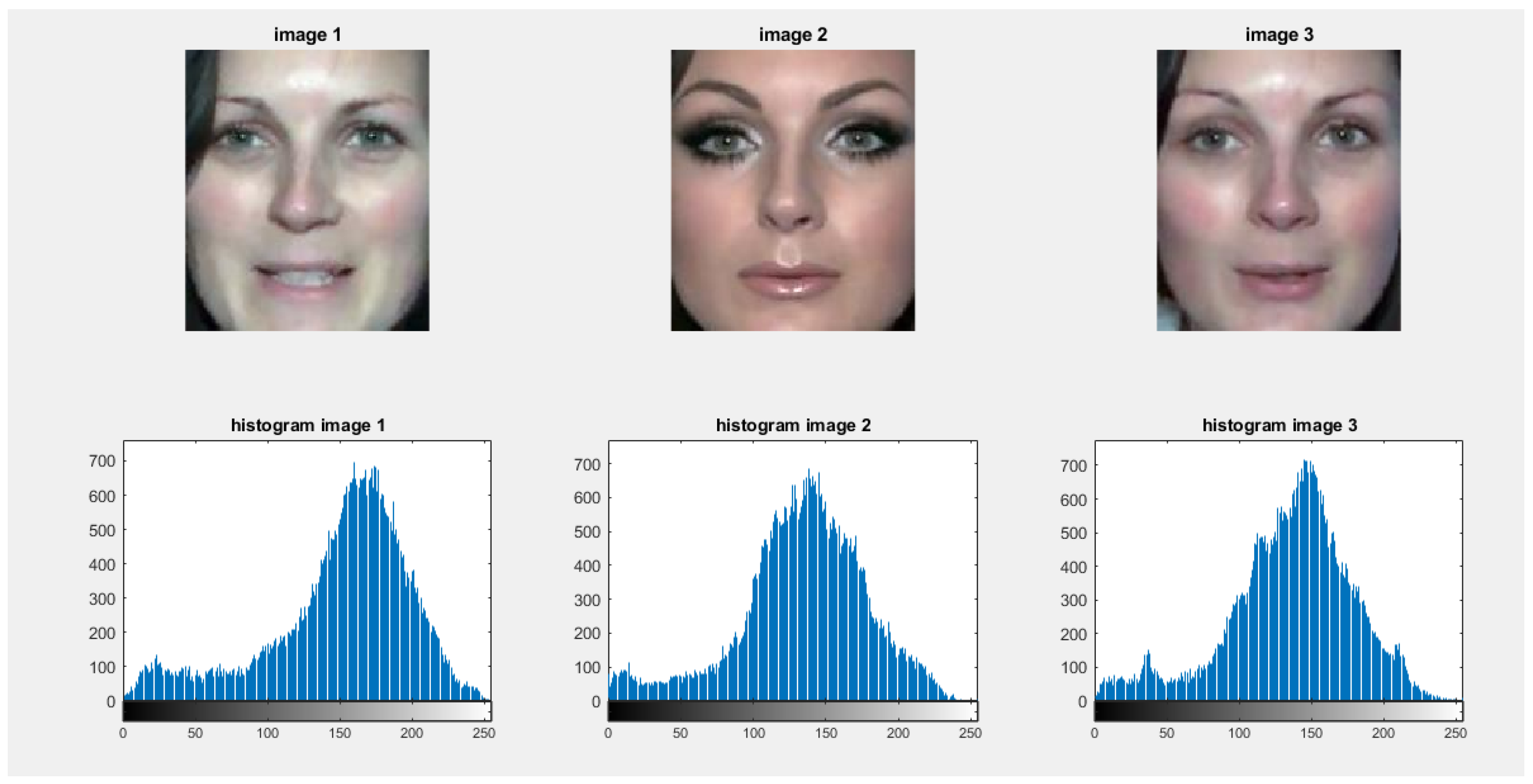
- Guo, G.; Wen, L.; Yan, S. Face authentication with makeup changes. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 814–825. [Google Scholar]
- Tripathi, R.K.; Jalal, A.S. Make-Up Invariant Face Recognition under Uncontrolled Environment. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 459–463. [Google Scholar]
- Wang, S.; Fu, Y. Face behind makeup. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Deng, J.; Guo, J.; An, X.; Zhu, Z.; Zafeiriou, S. Masked face recognition challenge: The insightface track report. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1437–1444. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Dataset | Total Images | No. of Classes | Ratio | No. of Training Images | No. of Test Images |
|---|---|---|---|---|---|
| VMU Dataset [23] | 156 | 12 | 70:30 80:20 | 110 125 | 46 31 |
| Face Recognition Dataset [24] | 2562 | 31 | 70:30 80:20 | 1794 2049 | 768 512 |
| 14 Celebrity Face Dataset [25] | 220 | 14 | 70:30 80:20 | 154 176 | 66 44 |
| Own created dataset | 700 | 7 | 70:30 80:20 | 490 560 | 210 140 |
| Predicted Case | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual Case | Positive | ||
| Negative | |||
| Train System | Input Image | Accuracy | |
|---|---|---|---|
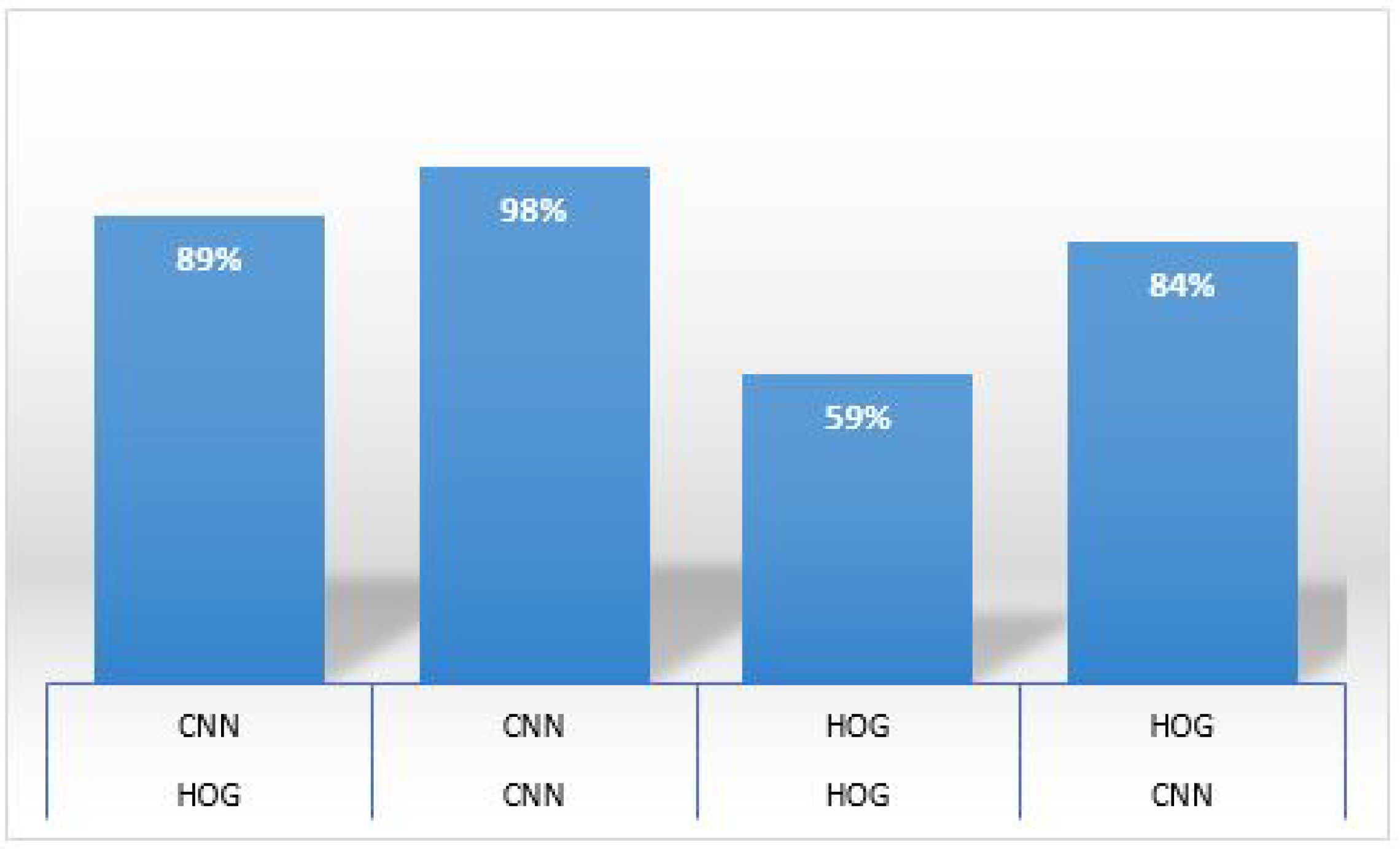
| Small Dataset | HOG | HOG | 80% |
| HOG | CNN | 90% | |
| CNN | HOG | 94% | |
| CNN | CNN | 98% | |
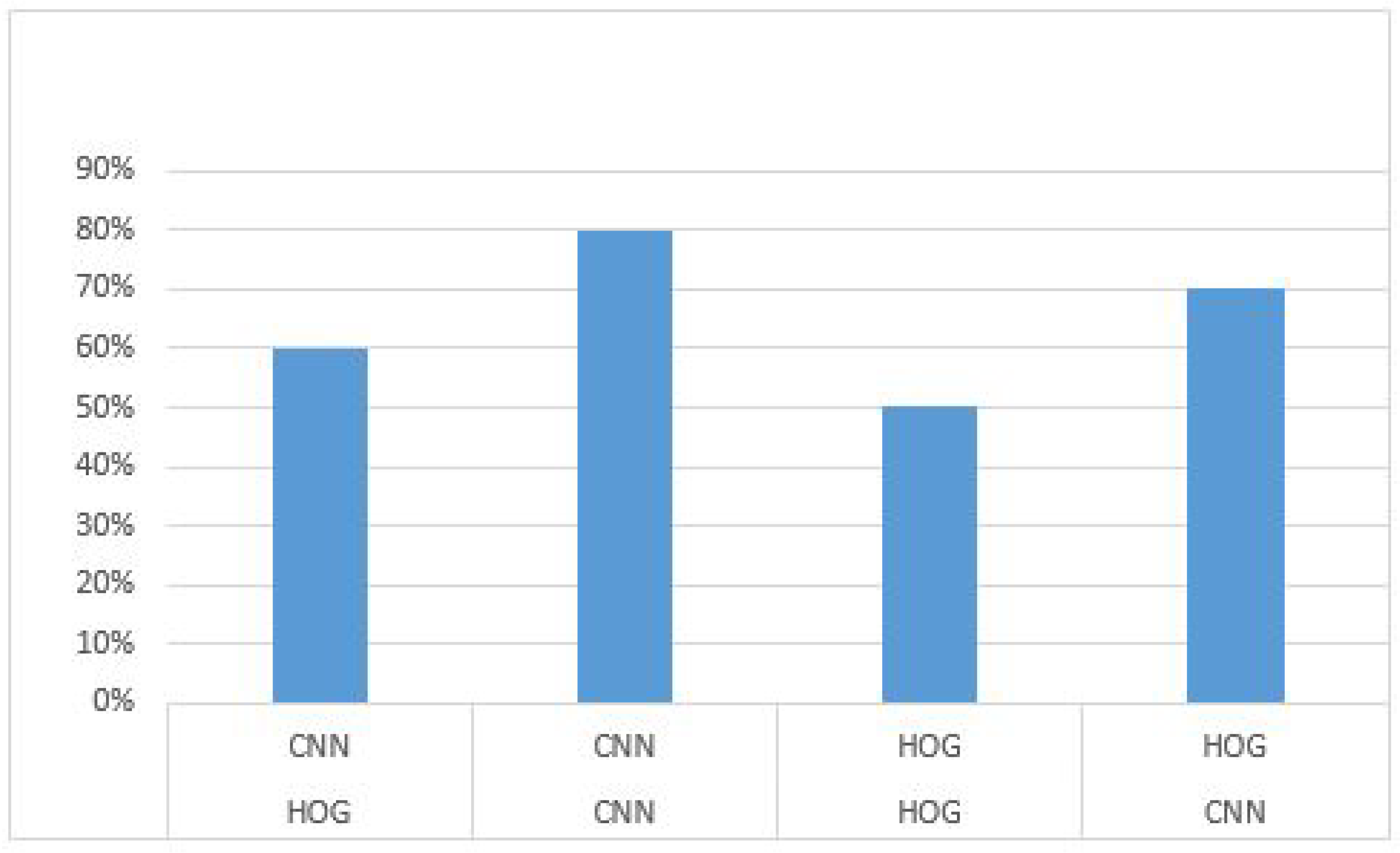
| Large Dataset | HOG | HOG | 90% |
| HOG | CNN | 93% | |
| CNN | HOG | 95% | |
| CNN | CNN | 98.3% |
| Algorithm | Time Taken on 1 Image | Time Taken on 50 Images | Memory Consumption | |
|---|---|---|---|---|
| Using HDD | HOG | 0.25 min | 12.5 min | 20% during training |
| CNN | 1.5 min | 75 min | 40% during training | |
| Using SSD | HOG | 0.06 s | 3 min | 15% during training |
| CNN | 0.5 min | 30 min | 25% during training | |
| Without SSD | HOG | 0.5 min | 30 min | 25% during training |
| CNN | 2 min | 120 min | 30% during training |
| Algorithm | Accuracy of Face Recognition |
|---|---|
| Guo et al. [55] | 82.2% |
| Tripathi et al. [56] | 87.35% |
| Sajid et al. [23] | 88.48% |
| Sajid et al. [23] | 92.99% |
| Wang and Fu et al. [57] | 93.75% |
| Proposed Research (CNN) | 98% |
| Dataset | Training to Test Ratio | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| Face Recognition Dataset | 70:30 | 97.39% | 98.61% | 98% | 98.45% |
| Face Recognition Dataset | 80:20 | 98.24% | 99.10% | 98.88% | 98.98% |
| 14 Celebrity Dataset | 70:30 | 89.39% | 91.00% | 93.02% | 92.00% |
| 14 Celebrity Dataset | 80:20 | 88.63% | 93.54% | 90.62% | 92.05% |
| Own Created Dataset | 70:30 | 95.23% | 96.51% | 97.64% | 97.07% |
| Own Created Dataset | 80:20 | 95.71% | 98.09% | 96.26% | 97.16% |
| Algorithm | Accuracy of Face Recognition |
|---|---|
| HOG | 90% |
| CNN | 98.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zamir, M.; Ali, N.; Naseem, A.; Ahmed Frasteen, A.; Zafar, B.; Assam, M.; Othman, M.; Attia, E.-A. Face Detection & Recognition from Images & Videos Based on CNN & Raspberry Pi. Computation 2022, 10, 148. https://doi.org/10.3390/computation10090148
Zamir M, Ali N, Naseem A, Ahmed Frasteen A, Zafar B, Assam M, Othman M, Attia E-A. Face Detection & Recognition from Images & Videos Based on CNN & Raspberry Pi. Computation. 2022; 10(9):148. https://doi.org/10.3390/computation10090148
Chicago/Turabian StyleZamir, Muhammad, Nouman Ali, Amad Naseem, Areeb Ahmed Frasteen, Bushra Zafar, Muhammad Assam, Mahmoud Othman, and El-Awady Attia. 2022. "Face Detection & Recognition from Images & Videos Based on CNN & Raspberry Pi" Computation 10, no. 9: 148. https://doi.org/10.3390/computation10090148
APA StyleZamir, M., Ali, N., Naseem, A., Ahmed Frasteen, A., Zafar, B., Assam, M., Othman, M., & Attia, E.-A. (2022). Face Detection & Recognition from Images & Videos Based on CNN & Raspberry Pi. Computation, 10(9), 148. https://doi.org/10.3390/computation10090148