1. Introduction
The COVID-19 pandemic, with its associated transmission risk and infection concerns, as well as the resulting travel restrictions and movement controls, has led to a surge in online grocery ordering and delivery services. Consequently, pick-cart jobs have become overloaded, as online grocery purchasing necessitates the grocer to retrieve items from their inventory, pack them, and deliver them to the buyer. The implementation of an unmanned pick-cart robot would be extremely useful in such situations. One of the most vital aspects when designing an autonomous robot is identifying the target’s position and orientation before calculating the gripper’s path to reach the object [
1,
2,
3]. The use of a monocular vision positioning system with artificial markers can assure the system’s performance. Quick response (QR) codes are printed on the grocery packaging, and they can be used as artificial markers. Thus, this eliminates the need to design markers and place them manually on each item. This study is crucial, as the proposed iterative-based pose estimation model provides a new approach to determining the three-dimensional (3D) position of a single tilted QR code from an image captured at a single location using a monocular camera.
Generally, imaging sensing systems use multiple cameras for localization, as can be seen for the widely used positioning systems used in landmark-based localization and navigation (L&N) systems [
4,
5,
6,
7] and augmented reality technologies [
8]. In augmented reality systems, the two-dimensional (2D) image is used to provide orientation information [
8,
9,
10,
11,
12]. In a more complex environment, Ref. [
13] proposed a method to identify the complete 3D curvature of a flexible marker using five cameras. The system did capture the 3D information needed, but the camera calibration process was too complex. On the other hand, Ref. [
1] reformed the 3D structure of the object using a mono-imaging device on a robot arm using the silhouette method. However, the 3D structure reformation process involves multiple angular movements and consumes more computation time. Furthermore, the augmented reality concepts can be exploited to support object-grasping robots [
2,
3,
11]. For example, Ref. [
2] built a grasping system using artificial markers and a stereo vision system. This simplifies the target detection process and ensures the system’s robustness. However, stereo camera positioning systems involve costly baseline calibration processes [
3].
Stereo vision systems can be simplified to mono-imaging systems with artificial landmarks. A previous study [
2] used customized markers, called VITags, in their automated picking warehouse, in which the VITag technology is not available to the public, and its functionalities are limited. In addition, Ref. [
14] measured the distance of a circle marker from the camera using a mono-imaging system. However, the circular marker could not provide the marker’s orientation. The existing 2D barcode technologies can be used as artificial landmarks that provide location and orientation information [
6,
7,
15,
16]. For example, Ref. [
15] developed a fully automated robotic library system with the aid of a stereo camera system. The system uses QR code landmarks and book labels to ease the positioning process. QR codes are now widely applied due to their high producibility at low cost. Moreover, they can be designed with various sizes, and are detectable even when partially damaged [
17]. However, QR codes in most L&N system serve as fixed references and provide only 2D positions. A previous study [
18] utilized a QR code’s corner point information to identify the distortion level, but the distance of the QR code from the camera was still unknown. Object-grasping automation tasks require position and orientation information in the 3D space. Thus, the current system has limitations in 3D positioning using the information obtained from the QR codes, specifically for monocular vision systems. There is very limited research performed on 3D positioning using a monocular camera and QR code. To the best of our knowledge, Ref. [
19] is the only scholar who has implemented a monocular vision-based 3D positioning system with two parallel QR code landmarks. Although the system functions well, the use of two QR codes placed side-by-side as artificial landmarks on existing grocery product packaging is challenging.
The use of more lightweight positioning systems is essential for developing automated pick-cart robots. The current vision positioning systems require two or more optical sensors or multiple landmarks. Some automation systems perform positioning with a single camera but need to capture a few photos from distinct optical points. The process is complicated, from identifying the camera distortion parameters, performing image rectification and matching, followed by positioning. This paper proposes a method for positioning using a mono-imaging system’s image captured from one optical point. It simplifies the intricate camera calibration process and uses a pre-processing analysis for multiple images. However, the use of the computation method to yield the target’s location information, such as the position, depth, size, and orientation from a single image using one QR code marker, remains an open issue to be solved. Therefore, developing a new approach to reduce the complexity and heavy computation costs of the mono-imaging-based positioning system using numerical computation is the main focus of this paper.
The remainder of this paper is structured as follows.
Section 2 presents the QR code’s geometric primitives.
Section 3 describes the mathematical model that defines the position of the QR code. Then,
Section 4 explains the distance model that is used to formulate the updating rules for the positioning model.
Section 5 shows the conditioning rules using the QR marker’s side length to update the guess value in the numerical method to obtain the position information. Additionally, a detailed numerical computation of the object point from the image point is provided.
Section 6 describes the calculation required to obtain the orientation of the marker. In addition,
Section 7 compares the proposed system with the previous work. Next,
Section 8 describes the parameters and conditions for the simulation while
Section 9 presents the results and discussion. Finally,
Section 10 concludes this paper with significant and possible future research directions.
3. The Positioning Model of the QR Code
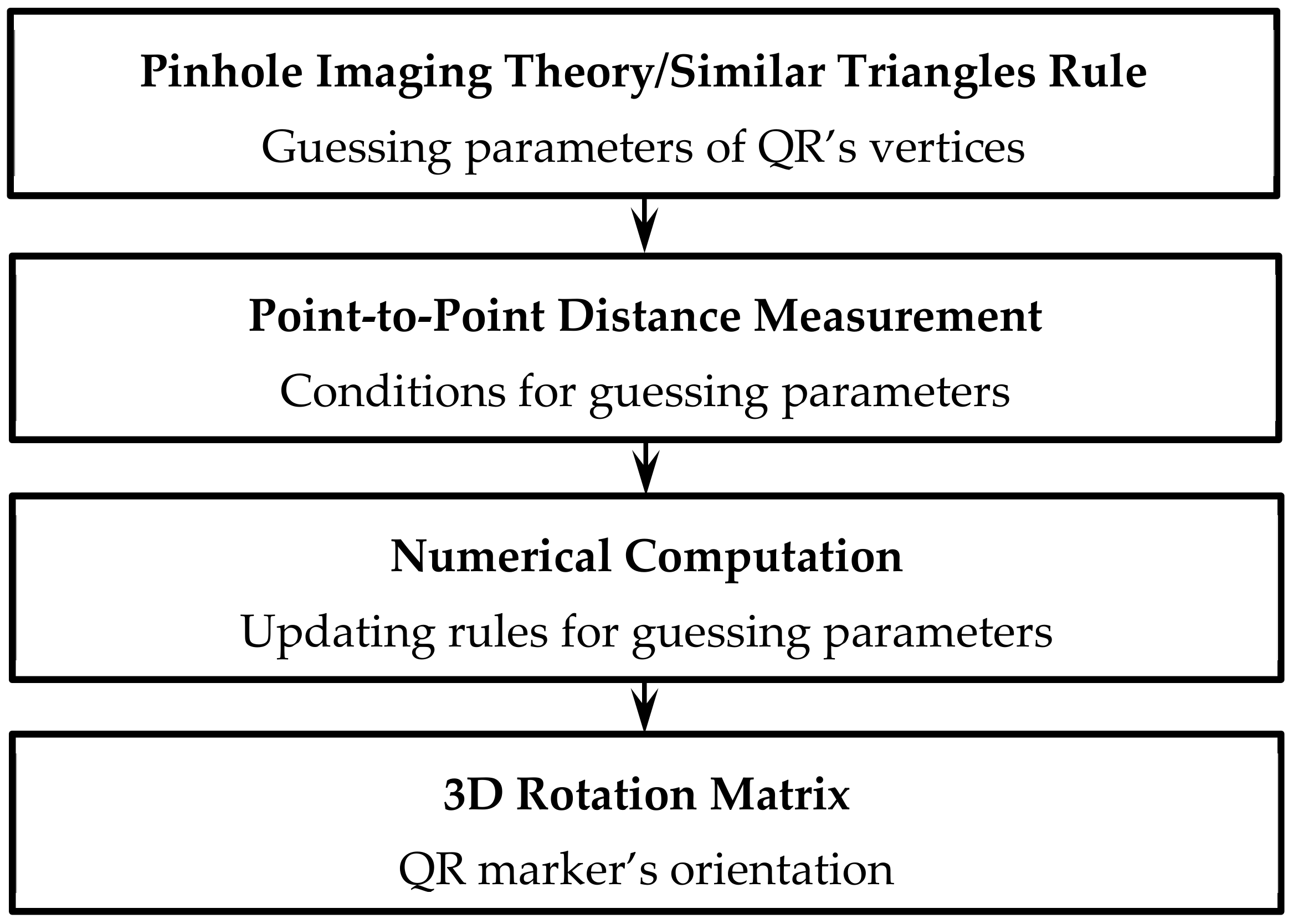
Figure 2 shows the main workflow used to develop the mathematical model for the proposed positioning system:
The system extracts the QR code’s 2D image coordinates and maps them to their corresponding 3D geometrical characteristics;
The estimated distance between two corner points scales the estimated conditions of the z coordinates. Note that the QR code’s z coordinates are the guessing parameters for the numerical computation;
The z coordinate values for the next iteration are computed using the updating rules derived based on the difference between the calculated and actual QR code length;
The result converges when the absolute convergence error fulfils the requirement;
The orientation information is calculated using the inverse rotation matrix.
Decoding the information stored in the QR code is not the main aim of this research.
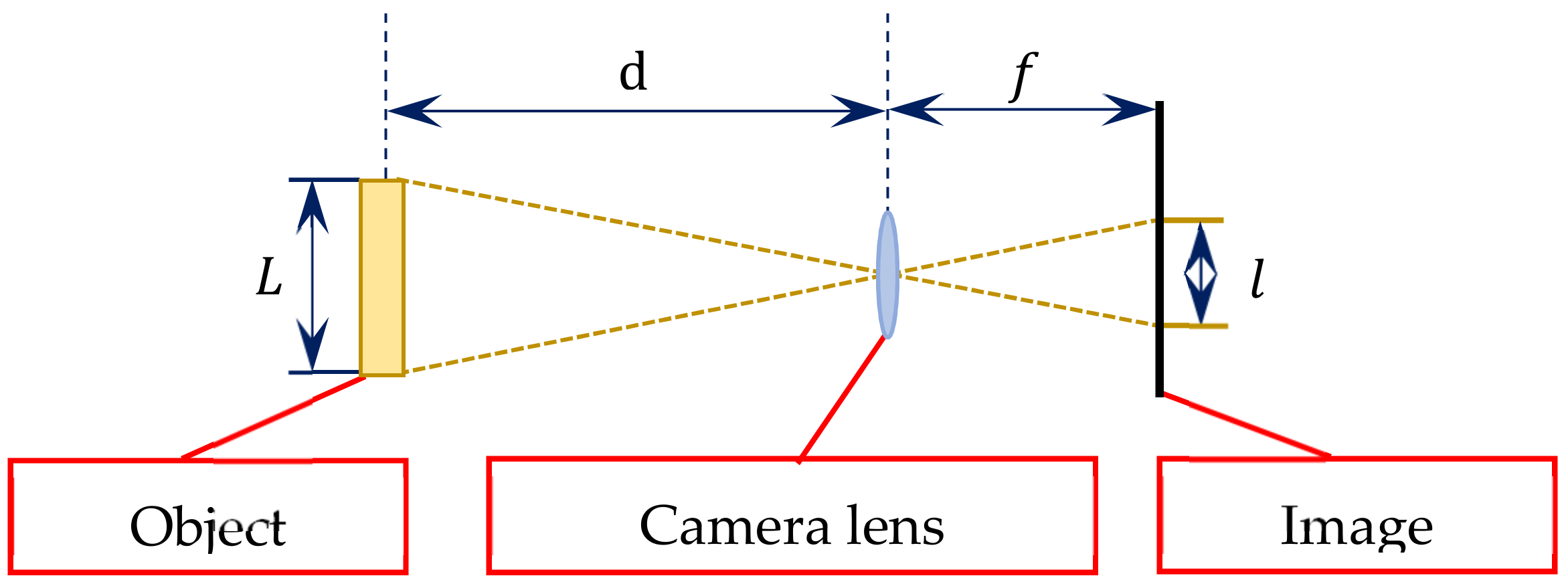
The pinhole imaging theory and similar triangles rule are adopted to determine the object’s location from an image [
12,
14,
23]. This relates the object to the corresponding 2D image, as illustrated in
Figure 3, where
denotes the actual side length of the object,
is the side length of the object in the captured image, d represents the working distance between the object and the camera lens, and
is the focal length or the distance between the lens and the camera sensor.
Referring to pinhole imaging theory, the ratio of the focal length to the object distance can be defined as:
Thus, the actual side length of the object is:
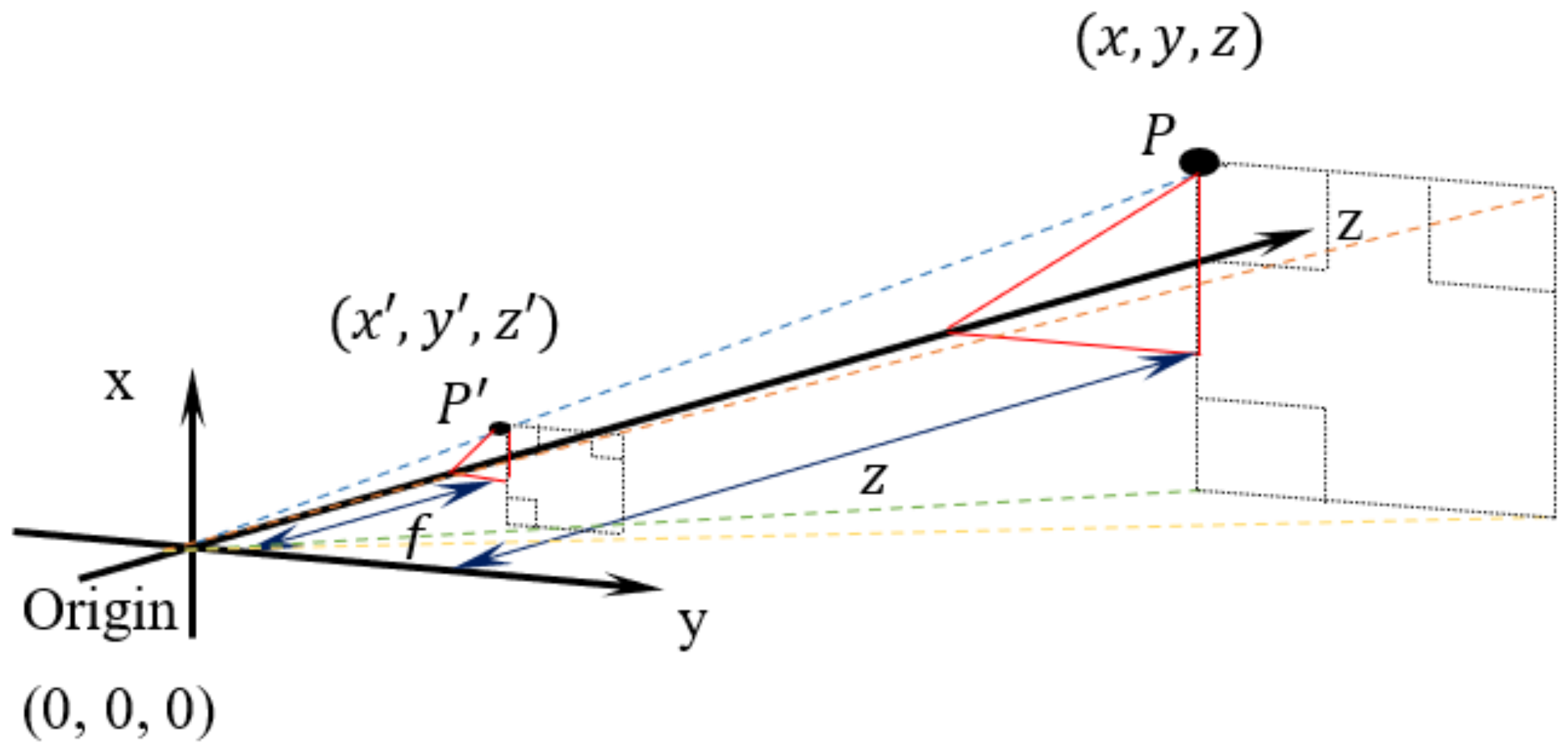
Figure 4 illustrates the forward perspective projection in a 3D environment. The camera lens is referred to as a zero-reference coordinate frame, while the focus point is reflected towards the positive z direction. Referring to the figure,
is the object point that corresponds to the image points
.
Figure 4 shows the camera’s focal length,
f, which is also the
coordinate of the image point
. Thus, the image point can also be defined as
). Then, using the pinhole imaging theory and similar triangles rule in Equation (2), the relationship between the real-world point and image point is:
The x-coordinate of object point
is:
The y-coordinate of object point
is:
Substituting the QR code’s vertices,
to
, as the object point
, the QR code’s x-coordinate and y-coordinate can be defined in a general form as:
where
and
represent the QR code image points’ x- and y-coordinates, respectively, and
,
, and
respectively represent the x-, y- and z-coordinates of the QR code’s vertices in a real-world environment, concerning the zero-reference frame.
Referring to Equation (6), the 2D image points’ coordinates and the real-world z-coordinates can be used to compute the x- and y-coordinates of the QR code. The 2D image coordinate information can be extracted from the captured image, while the z-coordinate is an unknown parameter. Thus, the z-coordinate is set as the guessing parameter in the numerical computation. In addition, proper updating rules are required to update the guessed z-coordinate value after each iteration in the numerical computation.
5. QR’s Points Positioning Using Numerical Method
This paper proposes a lightweight numerical method to overcome the complexity of the QR corner point computation.
5.1. Guessed Z-Value Conditions
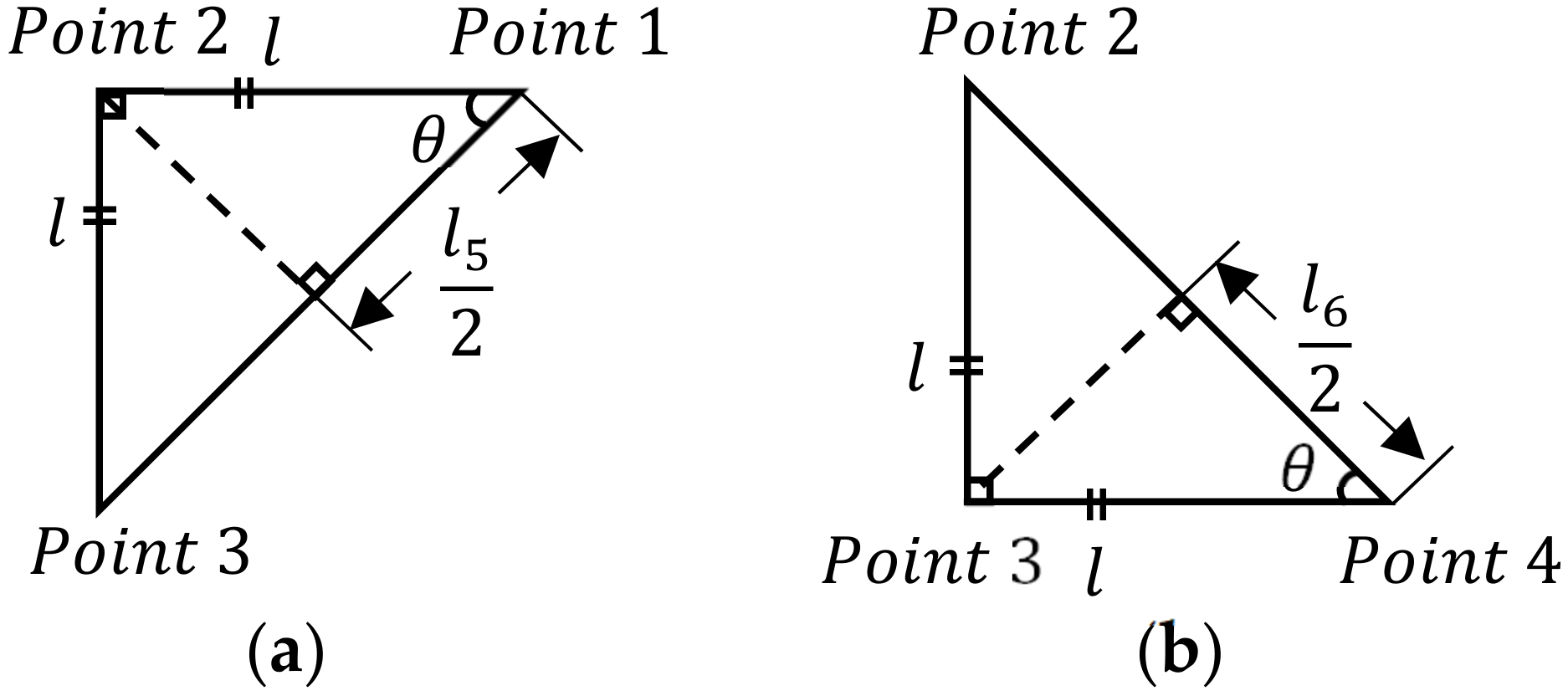
The estimation condition for the z-coordinate can be identified using the QR’s side length or diagonal length calculated from Equation (7). Then, the condition error, , as defined in Equations (10) and (11), is used to formulate the updating rules of the z-coordinate for the next iteration.
The conditions when using the horizontal or vertical side length, , are:
If , either or or both and are too big;
If , either or or both and are too small;
If , then and is the right guess.
The condition error related to the horizontal and vertical side length is:
The conditions when using diagonal length, , are:
If , either or or both and are too big;
If , either or or both and are too small;
If ; and hits the right guess.
The condition error related to the diagonal length is:
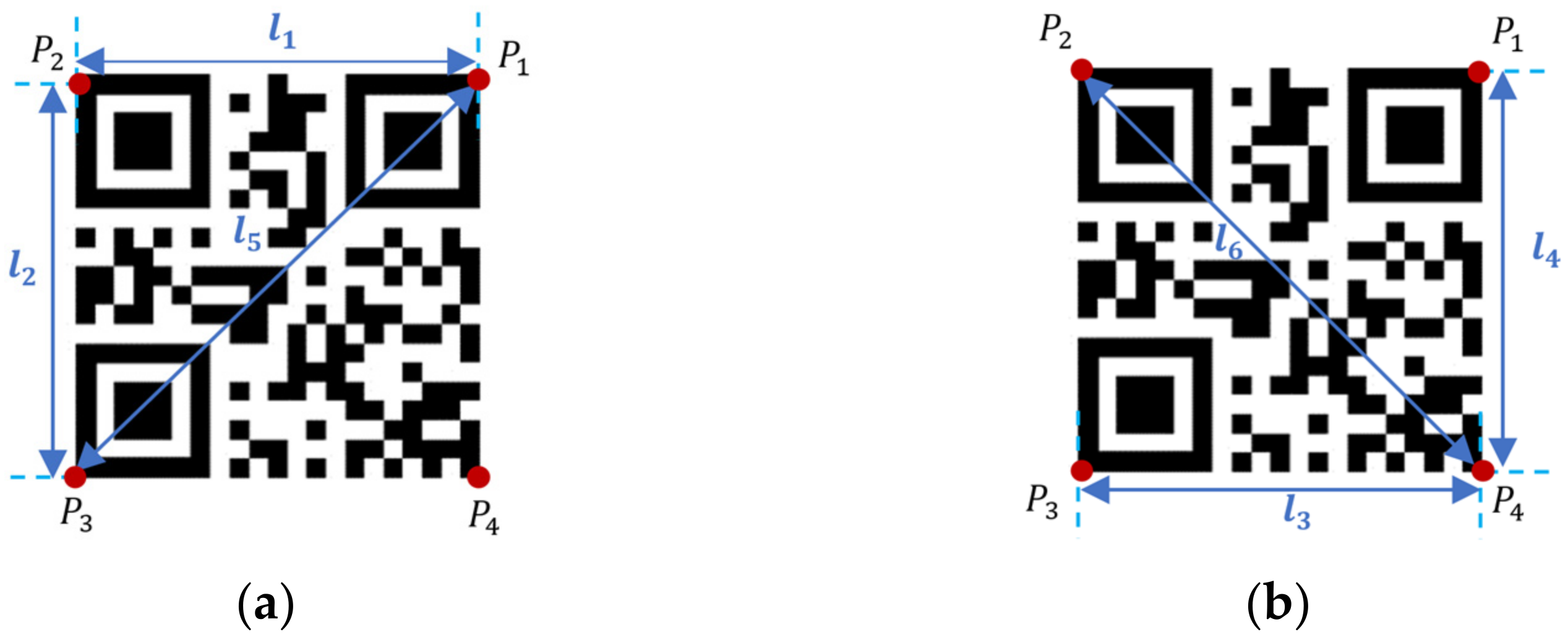
Referring to
Figure 1 and
Table 1, three corresponding lengths,
, and
, are used to justify the conditions when updating the value of
. Similarly, one can justify the value of
, and
in the same way. Thus, the updating rule for each value of
corresponds with three condition errors is tabulated in
Table 2.
5.2. Updating Rules
The updating rules for the subsequent guessed value,
with
as the updating coefficient and n as the number of iterations, are defined as:
The z-coordinate value for the corner points can be updated using the old value plus the average error, as per Equation (12), based on the corresponding condition error listed in
Table 2 at each iteration until the numerical computation converges to a stable value within the acceptable convergence error range. The sum of the absolute convergence error,
, is defined as the absolute sum of the current
minus the previous
as per Equation (13). The desired sum of the absolute convergence error,
is set as the acceptable error, where convergence is achieved when
.
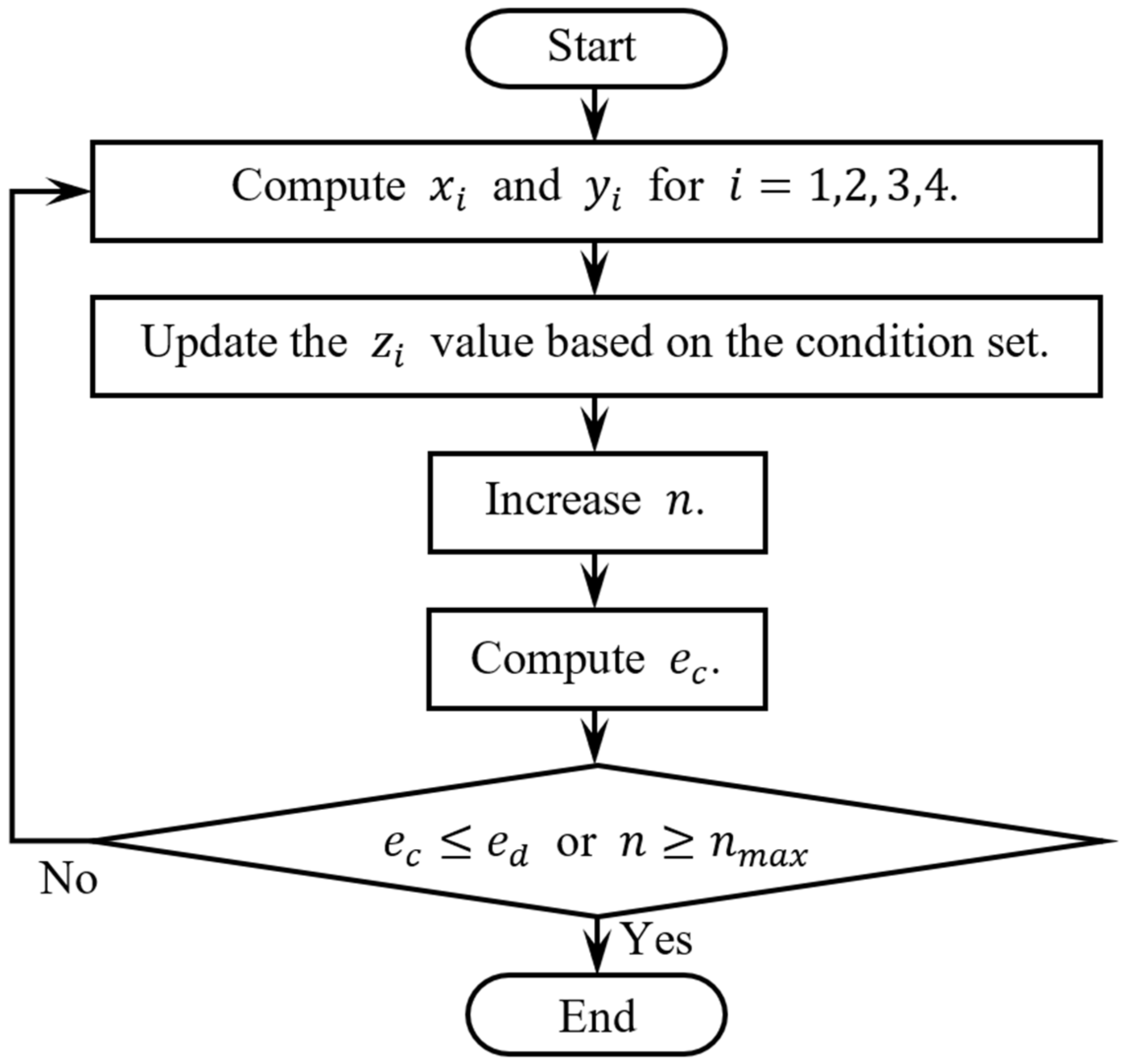
5.3. Numerical Computation
The flow of the numerical computation is shown in
Figure 6. During the numerical computation, the values of
and
for
i = 1, 2, 3, 4 are computed using Equation (6), based on the assumed
given
, and image point coordinates. An initial guess value of
is used at the beginning of the computation and the
is then updated at each iteration using Equation (12) with reference to
Table 2. Next, substituting the previous and updated
values into Equation (13) will yield the sum of the absolute convergence error,
, which is used for comparison with the desired sum of the absolute convergence error,
. In the meantime, to avoid an infinite looping state, the maximum number of iterations,
, is set. The computation will exit the loop when
or
is achieved.
6. Orientation Calculation of 2D QR Code Marker
The orientation of the QR code marker can be obtained from a 3D rotation matrix using the three basic counterclockwise rotation vectors about the x-, y-, and z-axes [
26], as shown below.
The 3D rotation matrix for the
system, which rotates angle
about the x-axis, followed by angle
about the y-axis and then angle
about the z-axis, is shown in Equation (17):
where
and
denote
and
respectively. The local coordinate system parallel to the gripper coordinate using the QR marker point
, shown in
Figure 1, as the base point of the rotation is defined as
. Thus, at
, the QR vertices with reference to the origin
are,
On the other hand, the result from the numerical computation provides the coordinates of QR code’s corner points with reference to the coordinate system based on the camera mounted on the gripper. For this situation, Equation (19) is used to transform the coordinates computed with the local rotation-based point coordinate system
Referring to Equations (17) and (18),
also can also be yielded as a result of the rotation of point
as:
From
and
in Equations (19)–(21), the value of angle
that rotates about the z-axis can be obtained.
The value of
is then substituted into
from Equation (20) to get the value of
, the angle of rotation about the y-axis.
Lastly, the value of angle
that rotates about the x-axis can be obtained after substituting
and
into
and
from Equations (20).
7. Comments on the Proposed Method and Comparison with Previous Work
A previous study [
19] proposed a 3D positioning model using a monocular camera and two QR codes. The two QR code landmarks are placed side-by-side to improve the detection accuracy. The previous study [
19] used six positioning points, while this paper only uses four points. This paper uses only one QR code marker for the real-life application, as only one QR code will be printed on most grocery packaging. As the system proposed by [
19] requires two QR codes for positioning purposes, so it is not practical to identify the position of the grocery goods using the single QR code on the grocery packaging. On the other hand, although the QR code on the grocery packaging come in various sizes, the QR code’s size and information can be registered and updated easily through the current proposed system. Additionally, this paper uses a 50 mm QR code, which is smaller than the 120 mm QR codes used by [
19].
The proposed method has advantages over the other monocular-based positioning systems (to the best of our knowledge):
The numerical computation solves the underdetermined positioning system with simple arithmetic operations, using a lightweight positioning method with four positioning points;
It works with basic geometry principles and trigonometry relations, and results in a minor error of floating points;
It can perform position and orientation estimations with the known camera’s focal length and QR code’s size, meaning the camera calibration process can be diminished;
It can extract the depth information between the QR code landmark and the monocular camera using one QR code image captured at a fixed optical point; rectification and matching of the images are unnecessary.
On the other hand, the previous study [
19] uses an efficient perspective-in-point (EPnP) algorithm for camera pose calculation. The system is able to calculate the 3D position at all locations. However, the proposed numerical computation method in this paper might provide diverged results, which can mean the positional information is not computed at a certain location. Additionally, the translation parameters such as the z working distance and x translation used in [
19] are higher than the parameters set in this paper, which is due to the size of the QR code landmark used in [
19] being 1.4 time larger than the one used in this paper.
8. Positioning Model Simulation Using MATLAB
MATLAB is the numerical computing platform used to simulate the proposed positioning model. The simulation was configured in MATLAB version R2017b and performed on a Windows 10 desktop with an Intel CPU Core i7-3517U with 1.90 GHz and 8 GB RAM. The authors fully implemented the MATALB code and no library was used.
Figure 7 shows the main workflow of the simulation model. First, the theoretical image coordinates of the QR code’s vertices are estimated based on the rotation matrix and the QR code’s world coordinates. Then, the proposed positioning model computes the 3D position information using Equation (6). The initial value of 450 mm is set for the guessing parameters, z-coordinate of the QR code’s corner points. Then, it will update for the next iteration based on the updating rules as per Equation (12). Furthermore, the convergence error,
, scales the estimating conditions of the guessing parameters. The simulation is looped until the maximum number of loops,
, is reached or when the absolute convergence error is within the tolerance range.
Simulations are conducted to study the maximum value of the rotation angle achievable with different rotation combination sets based on the parameters listed in
Table 3. The QR code’s size and the camera’s focal length are the only given parameters for the positioning model. The length of the QR code is set as 50 mm and the camera’s focal length is set as 2.8 mm. In addition, the value of the rotation angle about the cardinal axes and notations for the 12 rotation combination sets are listed in
Table 4.
The simulation is repeated for each rotation combination set, and the maximum angle of rotation at each coordinate point is determined. For each simulation, is 30 loops and the value of 1 is set. Additionally, the error of the calculation for the rotation angle is not more than 2 and the error of distance () is within 5 mm. Using the initial assumption value, , the simulation is conducted for the range:
X-axis translation from −100 mm to +100 mm, with a 10 mm step size;
Y-axis translation from −100 mm to +100 mm, with a 10 mm step size;
Z-axis translation from +100 mm to +500 mm, with a 100 mm step size;
Angle of rotation () from 0 to 25, with a 1° increment;
Updating coefficient from 0.8 to 2.0, with an increment of 0.1.
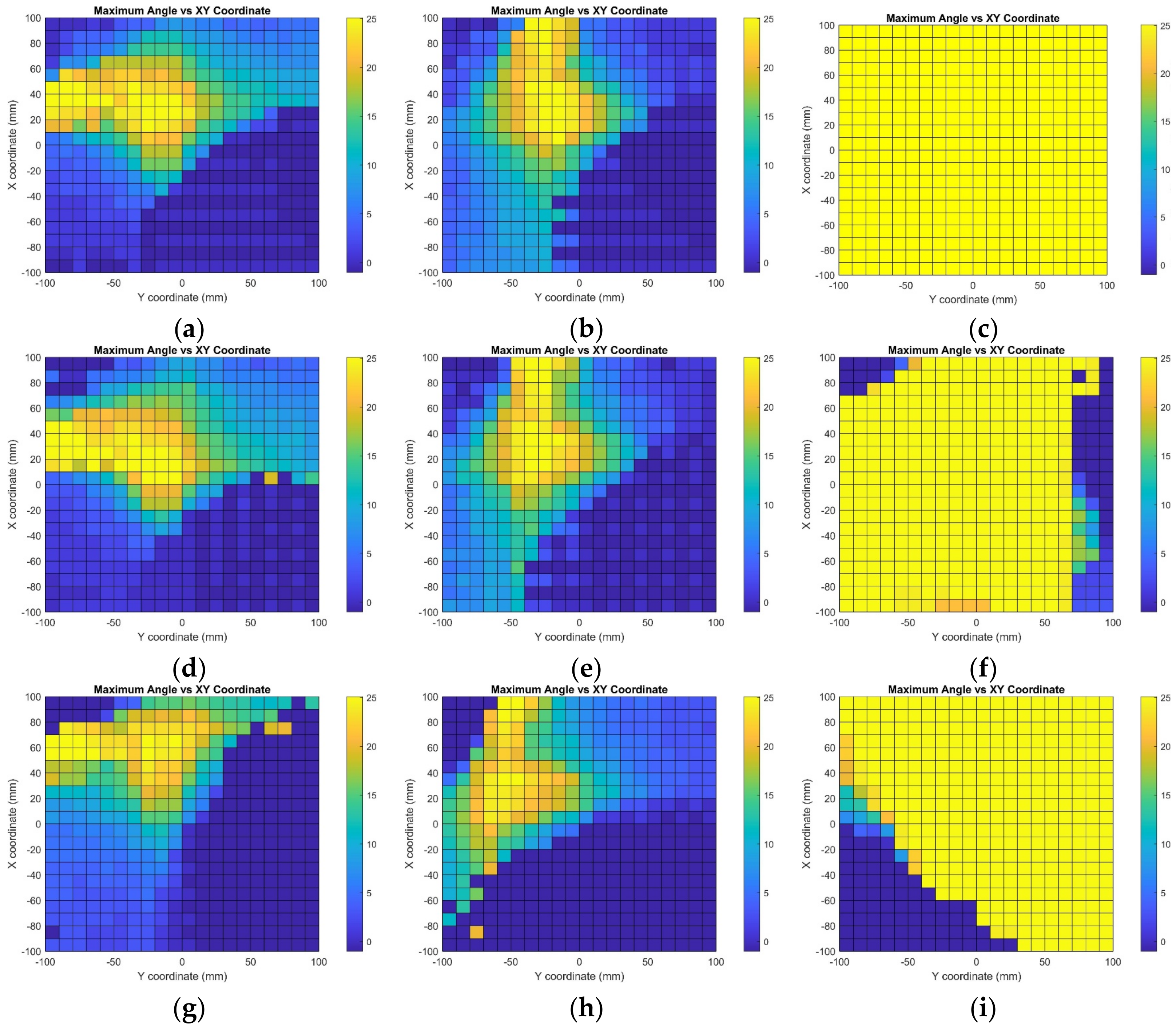
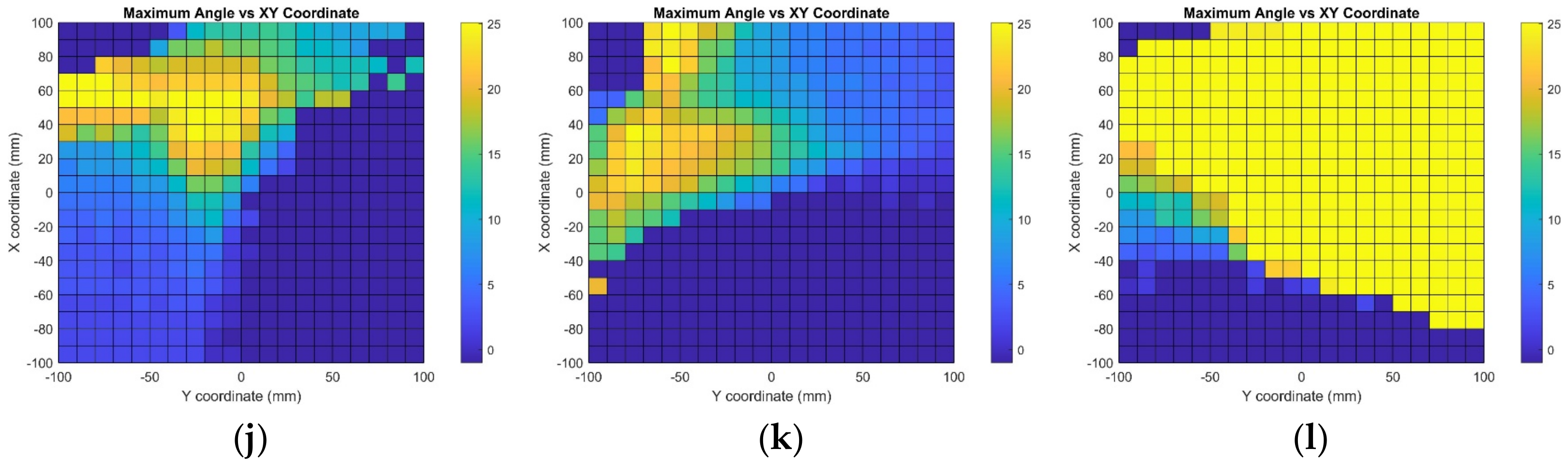
9. Results and Discussions
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 illustrate the simulation results for the positioning model at the working distance from 500 mm to 100 mm. The coordinate of the center of rotation,
of the QR marker, is used as the reference point to plot the results. At the given location
with the working distance z, the maximum rotation angle for the respective combination sets is tabulated graphically on the coordinate plane. The coordinate plane’s horizontal axis represents the y-axis translation. On the vertical axis is the translation in the x-axis direction. Moreover, the working distance is the translation in the z-axis direction of
away from the camera origin. The color gradient indicates the solvable value of the angle of rotation, with yellow representing the maximum value of 25° and dark blue representing the diverged result.
The simulation results for the maximum angle of rotation achievable at each coordinate at a working distance of 500 mm are as shown in
Figure 8.
The simulation results for the maximum angle of rotation achievable at each coordinate at a working distance of 400 mm are as shown in
Figure 9.
The simulation results for the maximum angle of rotation achievable at each coordinate at a working distance of 300 mm are as shown in
Figure 10.
The simulation results for the maximum angle of rotation achievable at each coordinate at a working distance of 200 mm are as shown in
Figure 11.
The simulation results for the maximum angle of rotation achievable at each coordinate at a working distance of 100 mm are as shown in
Figure 12.
9.1. Result Validation
This section compares the calculated values of the rotation angle and 3D coordinates with the simulated value to validate the results. A point selected from each rotation combination at five working distances from 500 mm to 100 mm is used for comparison. The simulation results show that the positioning model achieves satisfactory accuracy, and this is verified by the monocular single QR code image positioning and orientation results using the numerical system. The average error achieved is not more than two degrees and there is less than 5 mm difference for the simulated values, as shown in
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9.
9.2. Convergence Area of the Simulation Results
Table 10 shows the percentages of the area that converged for the five working distances ranging from 500 mm to 100 mm, calculated from the 2D graph. It shows that the area of convergence increases with reduced working distance z in most rotation combination sets. However, the area decreases with further translation for rotation combinations X—0—0, X—0—5, 0—Y—0, and 0—Y—5. Overall, the simulation shows 77.28% of the converged results.
9.3. Discussions and Comments
Overall, the area of the converged results and the maximum angle of rotation that is achievable increase when the QR marker’s distance moves nearer to the camera. This is because when the QR marker is further away, the changes in rotation angle are barely noticeable as the amount of rotation is analogous to the working distance. The countable rotation angle is inversely proportional to the working distance. In other words, when the working distance is nearer, the distortion caused by the orientation of the QR marker is more noticeable. Additionally, for the rotation combination sets that involve two or more axes, the tilting and distortion of the QR marker are much more complicated, which leads to certain areas showing diverged results.
For combination sets at the maximum working distance of 500 mm away from the camera, which involve rotation around only one single axis or the z-axis together with either the x- or y-axis, more than 75% of the area of the simulated coordinate plane shows converged results. Additionally, among the combination sets for rotation around the x-axis, the combination with the 0° y-axis and 5° z-axis rotation shows the best result for 94.33% of the converged area. The rotation around the y-axis with a 5° x-axis and 5° z-axis rotated combination shows that only about 53% of the area can yield an angle of rotation and distance within the error tolerance range. Furthermore, the simulation results of different combinations of rotation around the z-axis show that the z-axis rotation has a minor effect on the computation, as 77% of the area of the field of view converged. The positional information can be calculated accurately at all points for rotation around the z-axis and without rotation from other axes. Nevertheless, the computation convergence area shrank to around 53% with the combination sets that included both x- and y-axis rotation. The feasibility of the proposed monocular-vision-based positioning system using a QR code as the landmark via numerical method computation has been verified and is ready for real-world verification.
9.4. Comparison between the Proposed Method with Previous Work
A point-to-point comparison is made with the information extract from the graphical data presented in [
19]. The data are extracted from the graphs with
0.2 mm tolerance. The absolute error levels of computed x-, y-, and z-axis locations with 25° z-axis rotation and 60 mm translation in the x-axis are compared and listed in
Table 11. The proposed positioning method achieved greater accuracy with less than 3 mm error. Although the error rate of the proposed model was lower compared to [
19], the convergence rate for the proposed method was not 100%. However, the method used by [
19] can perform positioning at highly translated locations with satisfactory performance.
10. Conclusions and Future Works
The proposed lightweight numerical-based positioning model successfully simplifies the extraction of positional information from one single 2D image. The proposed model applies the pinhole imaging theory and similar triangles rule to find the geometric relationship between the QR code and the captured image. Then, a positioning model is developed using the numerical method to estimate the QR code’s depth information and to perform computations toward convergence using the updating rule. The four corner points of the QR code are the positioning points for the model. The 3D coordinates can be identified using the 2D image coordinates and the guessing parameters from the underdetermined system. In addition, the QR code’s orientation in the 3D environment is calculated using an inversed rotation matrix. Next, data verification for 12 rotation combination sets around the three cardinal axes is performed using the MATLAB computing platform. The maximum rotation angle at various coordinates at five working distances from 100 mm to 500 mm is determined. A comparison between the calculated and simulated results is accomplished for the 3D position and orientation information with error levels of less than two degree and 5 mm within 30 iterations. Overall, 77.28% of the simulation results converged. The feasibility of the proposed monocular vision-based positioning system using a QR code as the landmark via a numerical method of computation has been verified via computations and is ready for real-world verification.
Our future research work will involve experimental verification for the positioning system. The hardware specifications will be synchronized with the application requirements. Then, an experimental prototype will be built using a high-speed computation processor, pinhole-type cameras, and QR codes available on the market. Experiments will be carried out using the same parameters and variables as for the simulated model to compare the similarities. A difference between the simulated and experimental results of not more than 15% is tolerable to proceed with real-life applications. Research and comparisons are required to ensure the hardware chosen is sufficient to accommodate the system’s requirements. At the same time, the communication between the camera and robot control system will be established for the processor to obtain the images and provide the position and orientation information to the robot control system. Lastly, the experimentally verified system will be implemented in a robot grasping automation system to perform real-time pick and place operations.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}