1. Introduction
The purpose of biometrics is the identification of an individual using biological or physical measurement that can be related to a unique person. For example, the use of fingerprints had been employed by criminologists since the 19th century, but it was not until the second part of the 20th century that technology allowed the automation of the identification using this characteristic [
1].
Other than criminology, the first commercial application of biometrics was the regulated access to buildings, where only a few persons were allowed to enter for security reasons; thus the correct identification of such persons is an essential concern. The most common elements used for this purpose are fingerprints. More recently, other measurements, such as faces and iris recognition have been applied in smartphones [
2] and airports [
3].
Any measurements of individuals that can allow a proper and unique identification can likely be considered for biometrics. The two main categories considered in the literature, and the most representative measures are [
4]: physiological (fingerprints, iris, face) and behavioral (voice, signature recognition, keystroke dynamics, footsteps). Each biometrics has its challenges and possibilities, and recent research that analyzes and provides robustness to existing systems can be found in the literature [
5,
6].
The case of using footsteps patterns to recognize an individual has a short history, from the first proposals [
7] to validation using a proper dataset [
8] about thirty-five years ago. The footsteps can be measured and analyzed using several approaches, combining sensors and classification systems [
9].
Similar to other biometrics, increasing attention from several research groups arose in recent years [
10,
11], and similar to other measures, some concerns on practicality and privacy have been reported [
12]. For these reasons, several sensing of the phenomenon like vision, sound, pressure, and accelerometry has been explored [
13]. The benefits of an application that is based on footsteps recognition can be used in medicine (monitoring and assessment of Parkinson’s disease), physiotherapy (evaluation of recovery from injuries), security, and smarthomes [
9,
14].
Using sound measures of footsteps to determine a person’s identity is a challenging possibility, given the continuous presence of noise and background sounds present in any real-life application. But the use of sole sounds can represent an advantage given the simplicity and low cost of a sound sensor.
3. Results
The challenges of a classification process of footsteps in the presence of noise are remarkable in the case of a distant microphone.
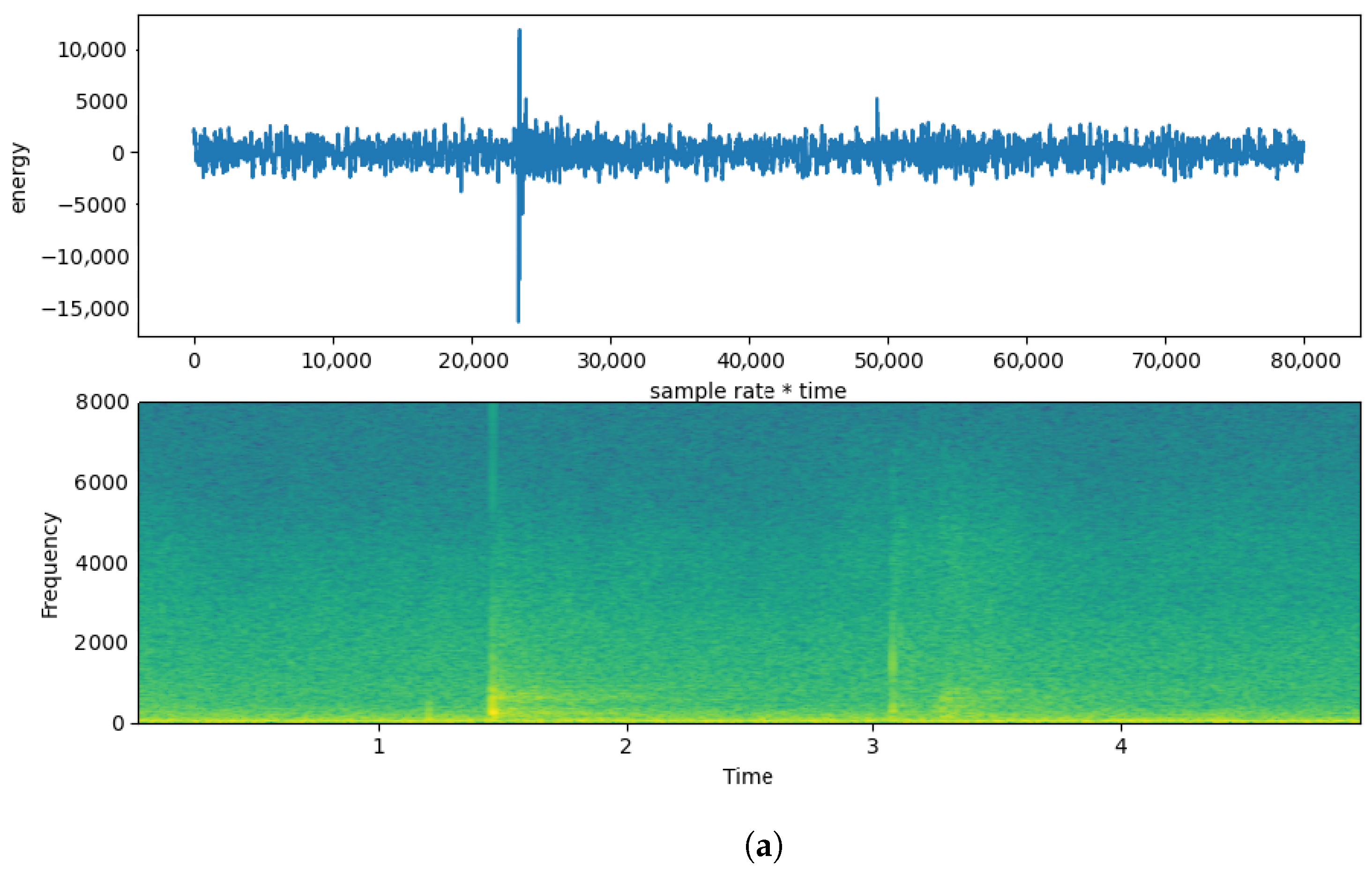
Figure 2 illustrates the case of White noise with SNR 0. In
Figure 2b it is evident how the noise affects the entire spectrum and makes almost unrecognizable the impulses of the footsteps shown in
Figure 2a. For traditional algorithms, such degradation may represent a very difficult task, in terms of recovering the original signal. But with the application of deep learning denoising, the impulses became visible again after the denoising, as shown in
Figure 2c.
As expected, for the case of a non-stationary, natural noise, such as Babble, the denoising process is not as effective as White noise case, even with the application of deep learning algorithm. Given this observation, it is expected that the classification process with signals degraded with this kind of noise becomes less effective in terms of Accuracy, Precision, Recall, and F1-score (
Figure 3).
The availability of data became an important issue for the application of deep learning-based denoising. To keep a proper comparison, the SVM classifier was trained using only the test set of the deep neural network training process. This means that most of the data collected during the recording sessions were used for training and validation of the deep learning denoising process, and only the test set was available for the training of the classifier. The large data requirements are a limitation to consider if a two-stage denoising and classification proposal considers deep learning for both processes.
The detailed results for Babble, White, and Office of our experiments are organized according to the type of noise and level, in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15. In each table, the classification metrics are reported for the noisy signal and the results of the four denoising algorithms. The first results correspond to Babble SNR-10, in
Table 1.
This natural noise, at such high SNR level, affects the performance of the classifier considerably, with an accuracy as low as 0.60 in this binary case. Most of the denoising algorithms did not obtain improvements in any of the classification measures, with the only exception of Wiener filtering.
Table 1.
Babble Noise SNR 10. * is the best result for each particular measure.
Table 1.
Babble Noise SNR 10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.60 | 0.65 | 0.59 | 0.62 |
| MMSE [24] | 0.56 | 0.50 | 0.57 | 0.53 |
| Spectral subtraction [25] | 0.67 | 0.58 | 0.71 | 0.64 |
| Wiener [27] | 0.77 * | 0.77 * | 0.77 * | 0.77 * |
| Deep learning [28] | 0.43 | 0.40 | 0.42 | 0.41 |
A similar situation of poor denoising performance is observed in
Table 2. None of the algorithms could enhancing the signal to achieve acceptable accuracy. In fact, proper classification results were obtained from SNR 0 or lower levels, as shown in
Table 3,
Table 4 and
Table 5. For such SNR levels, the application of denoising algorithms may represent a favorable procedure that increases accuracy, precision, and F1-score for SNR 0 and SNR 5. The SNR 10 of Babble seems to impact very slightly the performance of the SVM classifier, and the unfiltered version of the signal is the best option for the biometric identification of the volunteers.
Table 2.
Babble Noise SNR −5. * is the best result for each particular measure.
Table 2.
Babble Noise SNR −5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.75 | 0.77 | 0.74 | 0.75 |
| MMSE [24] | 0.65 | 0.58 | 0.68 | 0.63 |
| Spectral subtraction [25] | 0.77 * | 0.81 | 0.75 | 0.78 * |
| Wiener [27] | 0.75 | 0.85 * | 0.71 | 0.77 |
| Deep learning [28] | 0.73 | 0.55 | 0.85 * | 0.67 |
Table 3.
Babble Noise SNR 0. * is the best result for each particular measure.
Table 3.
Babble Noise SNR 0. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.92 | 0.88 | 0.96 | 0.92 |
| MMSE [24] | 0.79 | 0.77 | 0.80 | 0.78 |
| Spectral subtraction [25] | 0.92 | 0.92 * | 0.92 | 0.92 |
| Wiener [27] | 0.94 * | 0.88 | 1.00 * | 0.94 * |
| Deep learning [28] | 0.78 | 0.55 | 1.00 * | 0.71 |
Table 4.
Babble Noise SNR 5. * is the best result for each particular measure.
Table 4.
Babble Noise SNR 5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.96 | 0.92 | 1.00 * | 0.96 |
| MMSE [24] | 0.90 | 0.85 | 0.96 | 0.90 |
| Spectral subtraction [25] | 0.98 * | 0.96 * | 1.00 * | 0.98 * |
| Wiener [27] | 0.94 | 0.92 | 0.96 | 0.94 |
| Deep learning [28] | 0.88 | 0.75 | 1.00 * | 0.86 |
Table 5.
Babble Noise SNR 10. * is the best result for each particular measure.
Table 5.
Babble Noise SNR 10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.96 * | 0.92 * | 1.00 * | 0.96 * |
| MMSE [24] | 0.92 | 0.85 | 1.00 * | 0.92 |
| Spectral subtraction [25] | 0.94 | 0.92 * | 0.96 | 0.94 |
| Wiener [27] | 0.96 * | 0.92 * | 1.00 * | 0.96 * |
| Deep learning [28] | 0.95 | 0.90 | 1.00 * | 0.95 |
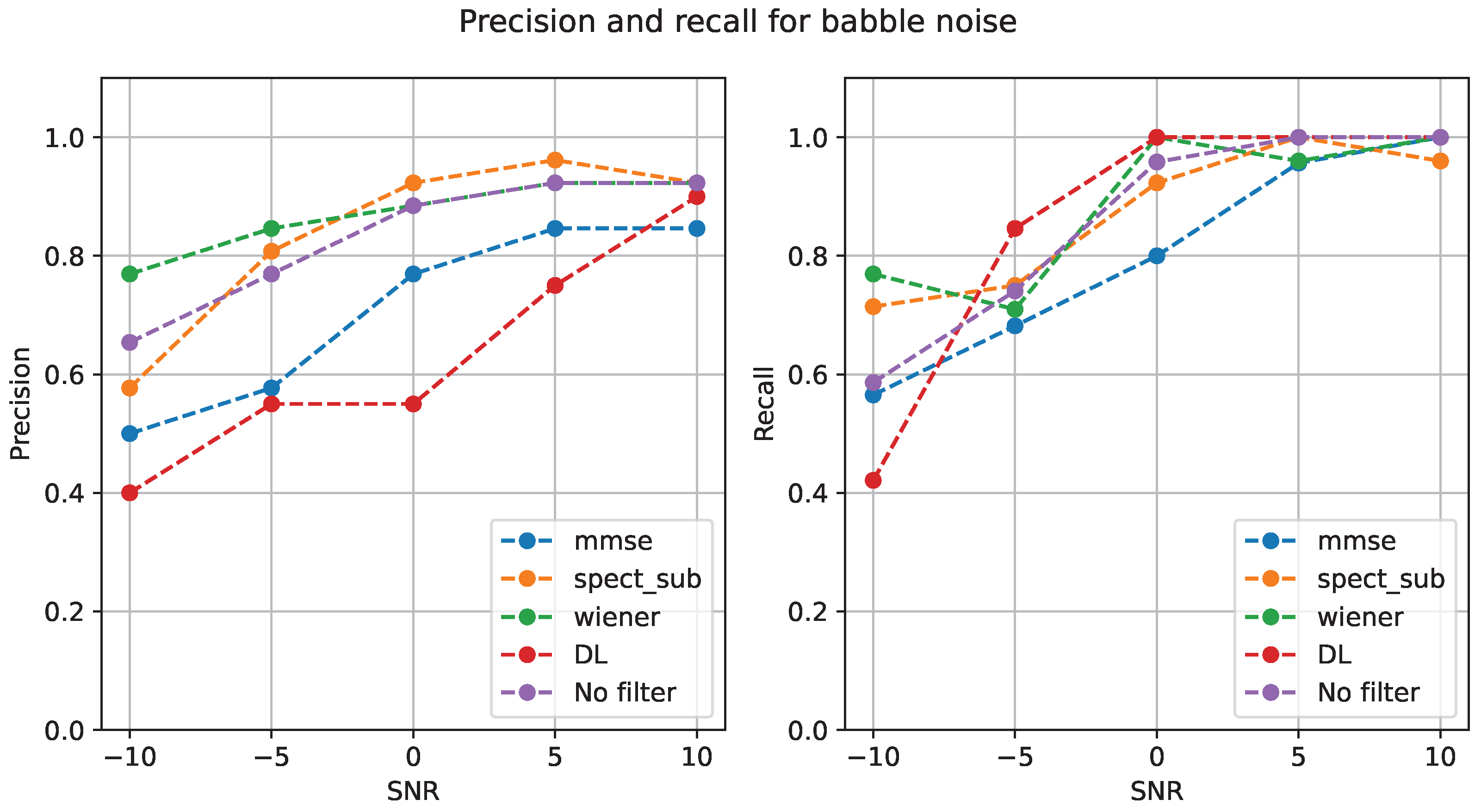
The trend lines of Precision and Recall measures for the case of Babble are presented in
Figure 4. It can be observed that some denoising algorithms, such as deep learning and MMSE did not represent any advantage for the process, because the no-filter version of the signal performs better, particularly in terms of Precision. The Recall measure presents fewer differences among the algorithms, with some advantages at the higher level of noise but no significant improvements at SNR 5 or SNR 10.
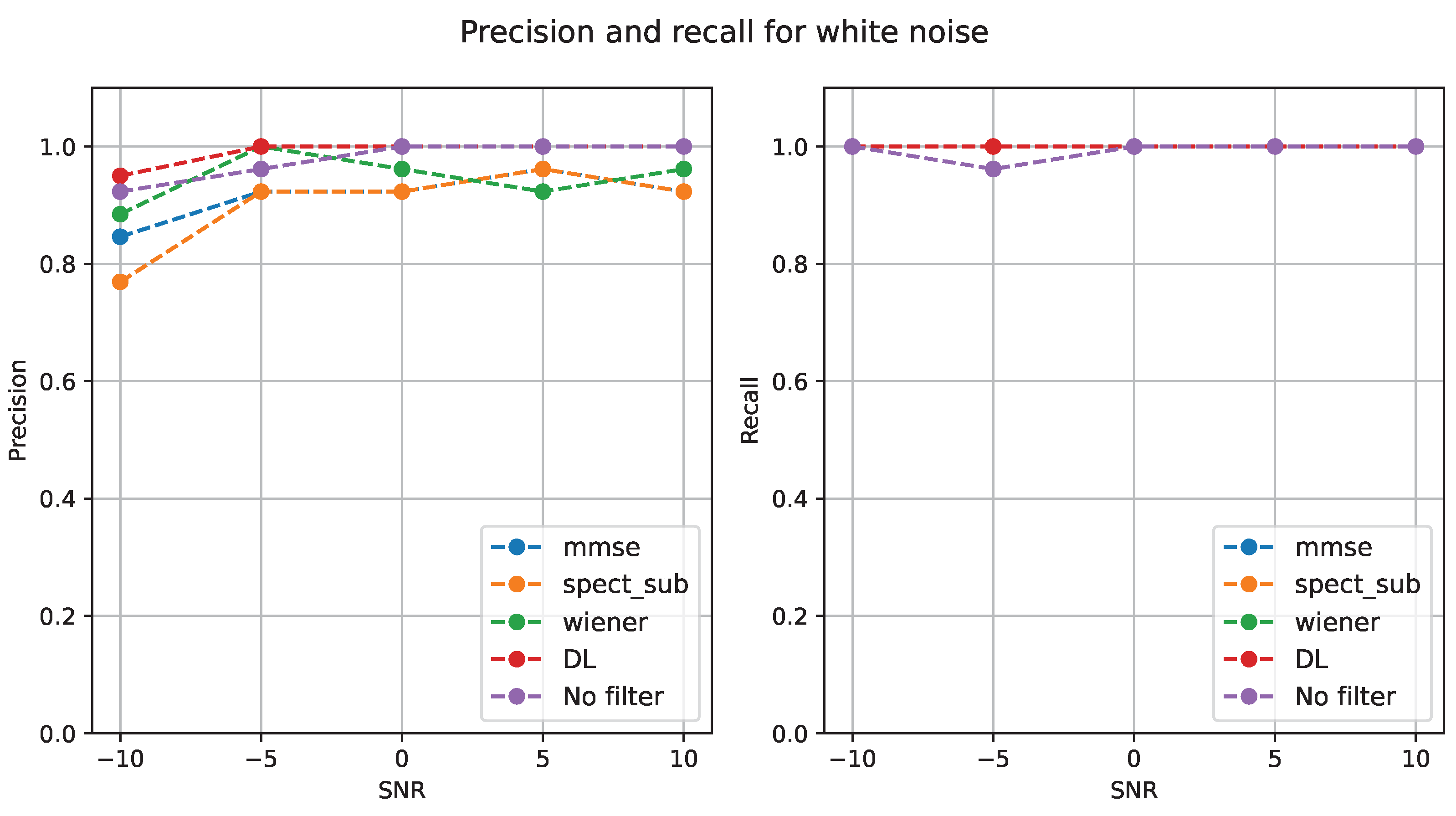
A very different group of results are presented for the case of White noise, as shown in
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. For these results, it seems that the noise does not significantly affect the biometric identification, even for the higher SNR levels. But in every case, deep learning as a denoising algorithm improves the performance of the classification task.
Table 6.
White Noise SNR −10. * is the best result for each particular measure.
Table 6.
White Noise SNR −10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.96 | 0.92 | 1.00 * | 0.96 |
| MMSE [24] | 0.92 | 0.85 | 1.00 * | 0.92 |
| Spectral subtraction [25] | 0.88 | 0.77 | 1.00 | 0.87 |
| Wiener [27] | 0.94 | 0.88 | 1.00 * | 0.94 |
| Deep learning [28] | 0.98 * | 0.95 * | 1.00 * | 0.97 * |
Table 7.
White Noise SNR −5. * is the best result for each particular measure.
Table 7.
White Noise SNR −5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.96 | 0.92 | 1.00 * | 0.96 |
| MMSE [24] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Spectral subtraction [25] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Wiener [27] | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
| Deep learning [28] | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
A relevant observation is that White noise at SNR 0, SNR 5 and SNR 10 does not require filtering, given the perfect performance of the classifier. But, unlike the other denoising algorithms, deep learning application does not affect the performance.
The drop in recognition accuracy with the application of MMSE, Spectral subtraction and Wiener filtering can be explained by the indiscriminate filtering of footsteps information alongside the noise or some introduced distortions, that were not present with deep learning.
Table 8.
White Noise SNR 0. * is the best result for each particular measure.
Table 8.
White Noise SNR 0. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
| MMSE [24] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Spectral subtraction [25] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Wiener [27] | 0.98 | 0.96 | 1.00 * | 0.98 |
| Deep learning [28] | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
Table 9.
White Noise SNR 5. * is the best result for each particular measure.
Table 9.
White Noise SNR 5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
| MMSE [24] | 0.98 | 0.96 | 1.00 * | 0.98 |
| Spectral subtraction [25] | 0.98 | 0.96 | 1.00 * | 0.98 |
| Wiener [27] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Deep learning [28] | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
Table 10.
White Noise SNR 10. * is the best result for each particular measure.
Table 10.
White Noise SNR 10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
| MMSE [24] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Spectral subtraction [25] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Wiener [27] | 0.98 | 0.96 | 1.00 * | 0.98 |
| Deep learning [28] | 1.00 * | 1.00 * | 1.00 * | 1.00 * |
The trend lines of Precision and Recall shown in
Figure 5 illustrate the benefit of the deep learning denoising, but the non-need for denoising in SNR 0 or lower levels.
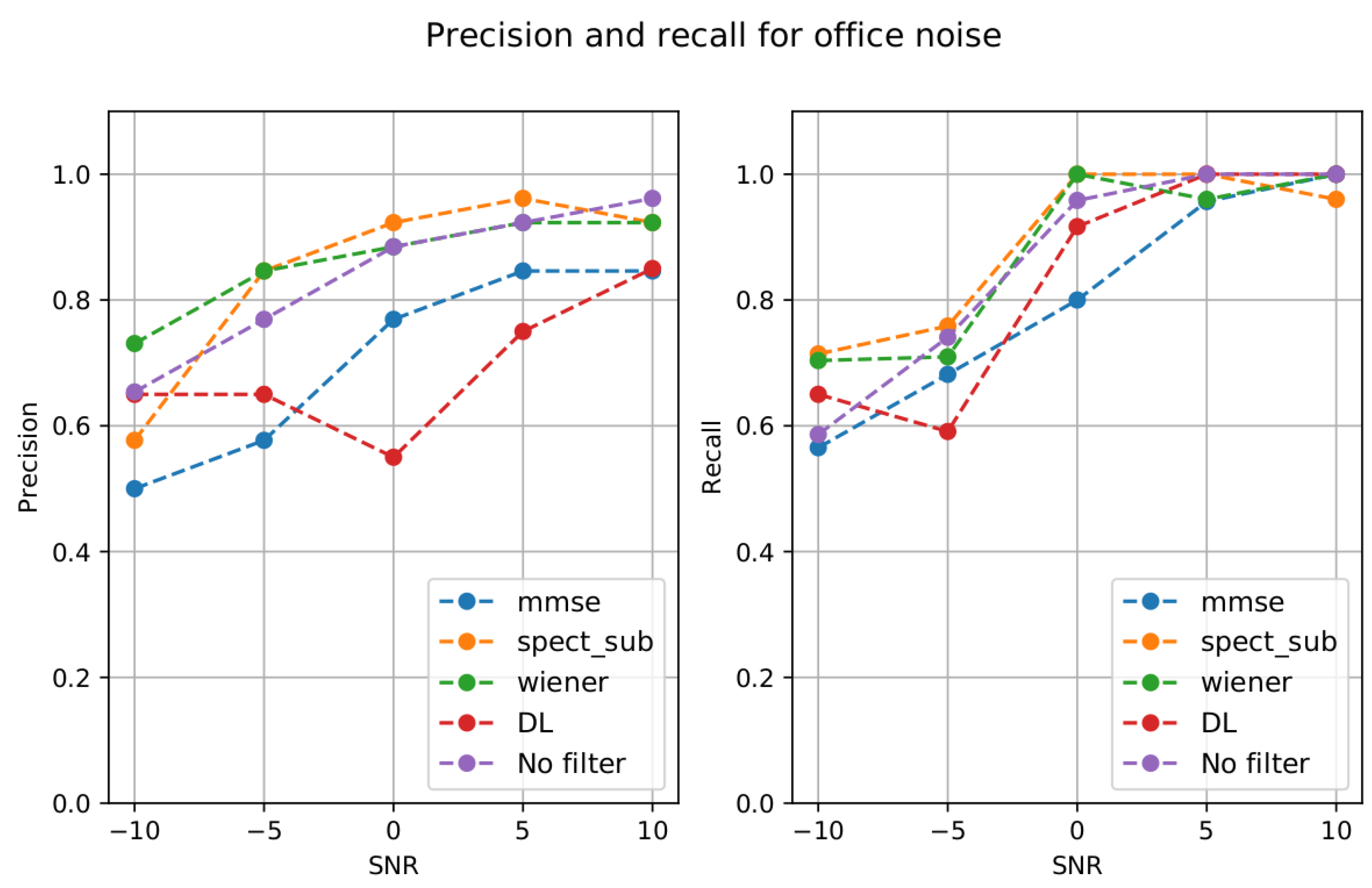
The previous results differ from the last case analyzed: the natural Office noise. The measures for the classification task are shown from
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15. The noise effect on the person’s identification is evident from accuracy as low as 60% or 75% for the case of SNR −10 and SNR −5. Denoising algorithms of Spectral subtraction and Wiener seems to benefit the process, but were incapable of achieving high enough results to consider them for a real-life application of a biometric system.
Table 11.
Office Noise SNR −10. * is the best result for each particular measure.
Table 11.
Office Noise SNR −10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.60 | 0.65 | 0.59 | 0.62 |
| MMSE [24] | 0.56 | 0.50 | 0.57 | 0.53 |
| Spectral subtraction [25] | 0.67 | 0.58 | 0.71 | 0.64 |
| Wiener [27] | 0.71 * | 0.73 * | 0.70 * | 0.72 * |
| Deep learning [28] | 0.65 | 0.65 | 0.65 | 0.65 |
Table 12.
Office Noise SNR −5. * is the best result for each particular measure.
Table 12.
Office Noise SNR −5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.75 | 0.77 | 0.74 | 0.75 |
| MMSE [24] | 0.65 | 0.58 | 0.68 | 0.63 |
| Spectral subtraction [25] | 0.79 * | 0.85 * | 0.76 * | 0.80 * |
| Wiener [27] | 0.75 | 0.85 * | 0.71 | 0.77 |
| Deep learning [28] | 0.60 | 0.65 | 0.59 | 0.62 |
Benefits of denoising algorithms began to appear at SNR 0 and SNR 5. Here, the classification task reaches results as high as 0.98 in accuracy, improving the metrics of the unfiltered, noisy signals.
Table 13.
Office Noise SNR 0. * is the best result for each particular measure.
Table 13.
Office Noise SNR 0. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.92 | 0.88 | 0.96 | 0.92 |
| MMSE [24] | 0.79 | 0.77 | 0.80 | 0.78 |
| Spectral subtraction [25] | 0.96 * | 0.92 * | 1.00 * | 0.98 * |
| Wiener [27] | 0.94 | 0.88 | 1.00 * | 0.94 |
| Deep learning [28] | 0.75 | 0.55 | 0.92 | 0.69 |
Table 14.
Office Noise SNR 5. * is the best result for each particular measure.
Table 14.
Office Noise SNR 5. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.96 | 0.92 | 1.00 * | 0.96 |
| MMSE [24] | 0.90 | 0.85 | 0.96 | 0.90 |
| Spectral subtraction [25] | 0.98 * | 0.96 * | 1.00 * | 0.98 * |
| Wiener [27] | 0.94 | 0.92 | 0.96 | 0.94 |
| Deep learning [28] | 0.88 | 0.75 | 1.00 * | 0.86 |
Table 15.
Office Noise SNR 10. * is the best result for each particular measure.
Table 15.
Office Noise SNR 10. * is the best result for each particular measure.
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|
| No filter | 0.98 * | 0.96 * | 1.00 * | 0.98 * |
| MMSE [24] | 0.92 | 0.85 | 1.00 * | 0.92 |
| Spectral subtraction [25] | 0.94 | 0.92 | 0.96 | 0.94 |
| Wiener [27] | 0.96 | 0.92 | 1.00 * | 0.96 |
| Deep learning [28] | 0.93 | 0.85 | 1.00 * | 0.92 |
The mixed benefits of the different denoising algorithms are summarized in
Figure 6. The deep learning was unable to successfully filter the Office noise in terms of the biometric identification. However, such results should be interpreted in the context of the amount of data available for the first stage of neural network training and the second stage of classification.
4. Discussion
The results presented in the
Section 3 show how the different denoising algorithms differ in their capacity to enhance the sound signal for proper biometric identification of individuals. The main differences arose in the higher levels of noise (SNR −10 and SNR −5) for the two natural noises: Babble and Office.
The case of White noise seems to affect the biometric identification in a less considerable way across all SNR levels. This can be explained by the stationary nature of white noise, compared to natural noises like Babble and Office.
Given that each of the audio segments of the dataset has a length of five seconds, the sound of the footsteps may occur at any point in the audio. This means that the impulsive nature of Office sound and the non-stationary nature of Babble can affect the audio in very different ways, thus producing training and testing sets that can be very difficult to identify for the algorithms.
For a similar reason, the corresponding algorithms may encounter a significant challenge in denoising signals degraded by natural noises, which explains the lower Accuracy, Precision, Recall, and F1-score presented for those cases.
The comparison of the denoising algorithms in terms of their advantages and disadvantages is presented in
Table 16.
Table 16.
Denoising algorithm comparison.
Table 16.
Denoising algorithm comparison.
| Algorithm | Advantages | Disadvantages |
|---|
| MMSE [24] | competitive results in the lower levels of noise (SNR 10) | The algorithm did not achieve good results in four of the five SNR levels for all kinds of noise |
| Spectral subtraction [25] | Easy of implementation. Achieved very good results for natural noises. | In the presence of White noise, the algorithm degrades the signals and significantly lower the accuracy and precision. |
| Wiener [27] | Obtains the best accuracy results of Babble noise, and competitive results for White noise. | A tendency to lower the accuracy for low levels of noise (SNR 10) was observed. |
| Deep learning [28] | Obtained the best performance in all SNR levels of White Noise. | Large training time. It may require much larger datasets to enhance natural noises. |
The results presented in this paper can be comparable to recent works in the literature. For example, in [
29], an accuracy of 0.95 was achieved in a person’s identification, a similar value to our experiments at the lower levels of noise. The same metric can be compared to other works, like [
30] (accuracy of 0.975) and more recently in [
10] (accuracy of 0.98 using Convolutional Neural Networks).
Other than accuracy, the results are difficult to compare to other recent works on biometrics of footstep sounds given the dissimilarities between the datasets, and the focus on noisy environments of our study. The best algorithms for the classification of the state-of-the-art works may be tested in a similar way to our proposal, with several types of noise at several SNR levels, in order to bring the biometric identification closer to real-life environments.
5. Conclusions
In this investigation, a comparative analysis of the benefits of denoising algorithms for footstep sounds as biometrics was presented. The novelty of the study for the state-of-the-art work is its focus on considering noise as an unavoidable part of the real-life implementations of footstep sounds as biometrics.
Given the number of possibilities that a person’s identification can mean in terms of experimentation, for this study we focused on the simple case of binary classification using segments of five seconds of distant recording and decided on the SVM algorithm to identify the volunteers from the sound of their footsteps.
For the testing of the denoising algorithms, we chose three noise types and five noise levels. Such a large number of possibilities allow for the comparison of diverse scenarios and provide a baseline for the use of distant sound recognition of footsteps as a biometric under noisy conditions. The accuracy of the different conditions contemplated in the experiments presented a range of 0.60 to 1.0, where the lower values were obtained with the Office noise at SNR −10, and the higher with White Noise at SNR 10. After applying the denoising algorithms, the accuracy range is 0.71 to 1.0, but the filtering method should be properly chosen for each case.
For the real-life application of a biometric system using distant footstep sounds, the results allow us to foresee the possibility of adequate recognition performance when non-stationary noise levels are not too high and provide a basis for establishing when denoising filters are recommendable or not.
For example, when stationary White Gaussian noise is present, the deep learning denoising provides the best results, but none of the algorithms tested in the work seems to benefit the process for low levels of natural noise. Certainly, deep learning denoising has several other possibilities than those presented in this work. For example, taking advantage of transfer learning, or training networks to simultaneously denoise several types of noise can be considered in the future.
Another possibility is the application of two stages of deep learning for denoising and classification. This is a promising opportunity for the development of future systems, and is scalable in other cases, such as multiple class identification, or identification of a single person within a group. For any of those possibilities, the large amount of data required should be considered: and will probably need very controlled conditions during recording sessions to homogenize the recordings.
Future work may also include the comparison of feature selection for classification and the selection and weighting methods of the DCT coefficient that are part of the features employed in this research. The feature selection methods should also be analyzed in terms of their robustness for noisy environments using this research as a comparison baseline in order to evaluate possible performance improvement.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






