4.1. Base Code
The present work focuses on the
Exciting-Plus code, hereafter “EP” for brevity [
8]. EP was developed from an early version of the ELK/
exciting code, that was branched at the time when independent evolution of
exciting and ELK had just begun. EP was developed with emphasis on post-ground-state calculations such as for the density response function [
63] and RPA [
8] and GW [
64] calculations. Ground state KS calculations are done in EP with
k-point task distribution and LAPACK [
65] diagonalization support. EP also implemented a convenient
mpi-grid task parallelization in several independent variable dimensions, e.g.,
k-points,
i-
j index pairs of KS states, and
q points in the calculation of the KS density response function.
EP was constructed conscientiously in terms of coding practices. However, its design did not focus on high performance for multi-atom unit cells. Our context makes that important. Our goal is to retain the features and capabilities of EP while making it fast enough for routine all-electron DFT calculations to be feasible for large, complicated systems such as the magnetic molecules, spin-crossover molecules, and aggregates discussed at the outset.
4.2. Separation of Concerns and the SIRIUS Package
LAPW/APW+ codes evidently share their central formalism. Because their basis sets start from plane waves, those codes also share significant procedural elements with PW-PP-PAW codes. Shared tasks include unit cell setup, atomic configurations, definition and generation of reciprocal lattice vectors , combinations with Bloch vectors , definition of basis functions on regular grids as Fourier expansion coefficients, construction of the plane wave contributions to the KS Hamiltonian matrix, generation of the charge density, effective potential, and magnetization on a regular grid, iteration-to-iteration mixing schemes for density and potential, and diagonalization of the secular equation. Compared to PW-PP-PAW codes, LAPW/APW+ codes additionally have spatially decomposed basis sets as outlined above.
These extensive commonalities constitute an opportunity for performance enhancement via separation of concerns. Computer scientists can bring their skills to bear on the shared algorithmic core of LAPW/APW+ methodology while computational materials physicists can focus on implementation of analysis, post-processing, better exchange-correlation functionals, etc.
With achievement of the benefits of this separation in mind, an optimized package, SIRIUS [
66], was created by some of us. It has explicit, focused, highly refined implementation of LAPW/APW+
commonalities (and PW-PP-PAW to the extent of the broader commonality) as the goal. That is, abstracting and encapsulating objects common to LAPW and APW+
as the design objective for SIRIUS. By concept, it had both task parallelization and data parallelization. It has been optimized for multiple MPI levels as well as OpenMP parallelization and for GPU utilization.
SIRIUS can be used two ways, as a library or as a simple LAPW/APW+
code. Elsewhere, we will report on its use in the latter way [
67]. In that case the compromise involved is to accept the functionality limits of SIRIUS in return for being able to handle very large systems by both task and data parallelism. Here we report on exploitation of SIRIUS purely as a DFT library by construction of an EP-SIRIUS interface using the SIRIUS API. The expected gain is speed-up while retaining the familiar user-interface and post-processing functionalities of EP.
Figure 1 illustrates the scheme. The intrinsic limitation of separation of concerns is that the resulting package has limitations that, in essence, are the union of the limitations of the host code and of the library. We discuss that briefly at the end.
4.3. SIRIUS Characteristics and Features
SIRIUS is written in C++ in combination with the CUDA [
68] back-end to provide (1) low-level support (e.g., pointer arithmetic, type casting) as well as high-level abstractions (e.g., classes and template meta-programming); (2) easy interoperability between C++ and widely used Fortran90; (3) full support from the standard template library (STL) [
69]; and (4) easy integration with the CUDA nvcc compiler [
70]. The SIRIUS code provides dedicated API functions to interface to
exciting and to QuantumEspresso [
29,
71,
72].
Virtually all KS electronic structure calculations rely at minimum on two basic functionalities: distributed complex matrix-matrix multiplication (e.g., pzgemm in LAPACK) and a distributed generalized eigenvalue solver (e.g., pzhegvx also in LAPACK). SIRIUS handles these two major tasks with data distribution and multiple task distribution levels.
The eigenvalue solver deserves particular attention. Development of
exciting led to significant code facilities to scale the calculation to larger numbers of distributed tasks than originally envisioned by making the code switchable from LAPACK to ScaLAPACK. This can be verified by comparing the task distribution and data distribution of the base ground state subroutine in recent versions of
exciting (version Nitrogen for example) and ELK (version 5.2.14 or earlier for example). ELK development appears to have emphasized physics features and functionalities rather than adding ScaLAPACK support. The EP situation is similar. It has only LAPACK support and does not have data distribution of large arrays.
Table 1 summarizes the diagonalization methods available in these codes.
Eigenvalue solver performance depends strongly upon the algorithm type. Widely used linear algebra libraries (e.g., LAPACK, ScaLAPACK) implement robust full diagonalization. They can handle system size up to about . Unfortunately for LAPW/APW+ calculations on systems as large as 100+ atoms, the eigensystem often is several times larger. A Davidson-type iterative diagonalization algorithm is appropriate in that case because it typically suffices to solve for the lowest 10–20 percent of all occupied eigenvalues and associated eigenvectors up through and somewhat above the Fermi energy.
Davidson-type diagonalization algorithms are available in some APW+
and PW-PP-PAW codes, e.g., WIEN2k [
73] and PWscf [
74] respectively. They are not offered in standard linear algebra libraries however. At least in part that is because such algorithms repeatedly apply the Hamiltonian to a sub-space of the system. Therefore the algorithm depends upon details of the Hamiltonian matrix, hence upon the specific basis-set formalism. By virtue of focus on tasks central to LAPW/APW+
and PW-PP calculations, the SIRIUS package can provide an efficient implementation of Davidson-type diagonalization [
75] for LAPW/APW+
and PW-PP-PAW codes.
4.4. Interfacing Exciting-Plus with SIRIUS
Despite its many attractive features, especially for important post-ground state calculations, EP has some significant limitations in regard to ground state calculations on large systems such as magnetic and spin-crossover molecules. Those limits include: (1) provision of only the LAPACK eigensolver; and (2) -point-only MPI parallelization. This second limit renders the code completely serial for single -point calculations, e.g., on an isolated molecule in a big cell.
We frame the task therefore as straight-forward interfacing to SIRIUS as an unaltered library with comparatively minimal modification of EP. This black-box approach is pure separation of concerns, since it is the simplest route an experienced EP user could take to try to gain advantage from SIRIUS without investing effort in learning its inner workings. A benefit is that the user interface to EP+SIRIUS is essentially unaltered EP, yet the combined system provides (a) ScaLAPACK support, (b) Davidson iterative eigensolver, (c) band MPI parallelization for one -point, and (d) thread-level OMP parallelization per k-point per band. It also exposes some oddities introduced by the black-box strategy.
Interface implementation benefits from the FORTRAN API functionalities provided by SIRIUS. Listing 1 displays the FORTRAN API function calls for parsing the atomic configuration, the APW and basis from EP, and passing them to SIRIUS.
| Listing 1: Setting up atomic configuration.
|
call sirius_set_atom_type_coniguration(sctx, string(trim(label)),& & spn(ist,is), spl(ist,is),spk(ist,is), spocc(ist,is),& & logical(spcore(ist,is),kind=c_bool)) enddo
|
The code segment in Listing 1 loops over the number of states of a single atom type atom (spnst: species’ number of states). For each state, the API call provides to SIRIUS the quantum numbers n, l and k for each state (spn, spl and spk), the occupation of that state (spocc), and whether that state is treated as a core state (spcore).
The first of the two double loops in the code chunk shown in Listing 2 goes over the APWs of one atom type and the ℓ-channels of each APW. For each ℓ-channel, the API call passes the following information to SIRIUS: principle quantum numbers n (apwpqn), value of ℓ (l), value of the initial linearization energy (apwe0), the order of energy derivative of that APW (apwdm), and whether the linearization energy is allowed to be adjusted automatically (autoenu). The second loop is over the total number of local orbitals (nlorb) of one atom type and the orders (lorbord) of each local orbital (i.e., number of or terms in that local orbital). The API call passes the following information to SIRIUS: quantum numbers n and l (lopqn and lorbl), initial linearization energy (lorbe0), order of energy derivative (lorbdm), and whether the linearization energy is allowed to be adjusted automatically (autoenu).
| Listing 2: Fortran API for basis description.
|
! parsing APW descriptions from host code to SIRIUS do l = 0, lmaxapw do io = 1, apword(l, is) autoenu = .false. if (use_sirius_autoenu.and.apwve(io,l,is)) autoenu = .true. call sirius_add_atom_type_aw_descriptor(sctx, string(trim(label)),& &apwpqn(l,is), l, apwe0(io, l, is), apwdm(io, l, is),& &logical(autoenu,kind=c_bool)) enddo enddo ! parsing LO/lo description from host code to SIRIUS do ilo = 1, nlorb(is) do io = 1, lorbord(ilo, is) autoenu = .false. if (use_sirius_autoenu.and.lorbve(io, ilo, is)) autoenu = .true. call sirius_add_atom_type_lo_descriptor(sctx, string(trim(label)),& &ilo, lopqn(ilo,is), lorbl(ilo, is),lorbe0(io, ilo, is),& &lorbdm(io, ilo, is), logical(autoenu,kind=c_bool)) enddo enddo
|
General input parameters such as the plane-wave cutoff,
ℓ cutoff for the APWs and for density and potential expansion,
-points, lattice vectors and atom positions, etc., all are set as usual in the EP input file. Then they are passed to SIRIUS via its built-in
import and
set parameter functionalities. Other important parameters such as the fast Fourier transform grid, radial function grid inside each MT sphere, and number of first variational states [
37] often are not set in EP input files but defaulted. For EP+SIRIUS, however, those also must be passed to SIRIUS in the initialization step to ensure that the Hamiltonian matrix and eigenvectors are precisely the same in EP and SIRIUS. Other information such as specification of core states, linearization energy values and MT radii defined in the so-called species files of EP is passed to SIRIUS at the beginning of the calculation to overwrite the corresponding SIRIUS default values. Consider Listing 3 therefore.
| Listing 3: Fortran API for setting inputs for SIRIUS.
|
call sirius_set_parameters( sctx,& &use_symmetry=bool(.true.),& &valence_rel=string(’zora’),& &core_rel=string(’none’),& &auto_rmt=0,& &fft_grid_size=ngrid(1),& &num_mag_dims=ndmag,& &num_fv_states=nstfv,& &pw_cutoff=gmaxvr,& &gk_cutoff=gkmax,& &lmax_apw=lmaxapw,& &lmax_rho=lmaxvr,& &lmax_pot=lmaxvr )
|
The code chunk shown in Listing 3 is an example of basic inputs that are added to EP in the initialization step, in the piece of code named init0.f90. Most of the meanings are explicit in the name. zora means zero-order relativistic approximation. ngrid is the FFT grid set up in EP and passed to SIRIUS. Plane wave cutoff and cutoff values are gmaxvr and gkmax in EP. The lmaxapw and lmaxvr are the angular momentum cutoff for APW and for charge density (and potential) inside the MT.
The inserted code shown in Listing 4 supplies SIRIUS with additional parameters for the Davidson method if it is used. After ensuring that the setup of input quantities is identical between the host code (EP) and SIRIUS, the ground state calculation is done solely by SIRIUS. The results, eigenvalues and eigenvectors, are passed back to EP for further calculation.
| Listing 4: Eigen-solver selection and Davidson solver parameter setup.
|
if (sirius_davidson_eigen_solver) then call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“type” : “davidson” }}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“energy_tolerance” : 1e-13}}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“residual_tolerance” : 1e-6}}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“num_steps” : 32}}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“subspace_size” : 8 }}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“converge_by_energy” : 1 }}’)) call sirius_import_parameters(sctx, string(’{“iterative_solver” : {“num_singular’’ : 20 }}’)) else ! otherwise use full eigen solver from LAPACK call sirius_set_parameters(sctx, iter_solver_type=string(’exact’)) endif
|
Next we display, in Listing 5, a code segment with the typical API calls from EP to retrieve the resulting eigenvalues and eigenvectors. It is inserted in the ground state subroutine, the piece of code named gndstate.f90.
| Listing 5: Fortran API for retrieving eigenvalues and eigenvectors from SIRIUS.
|
! get local fraction of eigen-vectors do ikloc=1,nkptloc ik=mpi_grid_map(nkpt,dim_k,loc=ikloc) call sirius_get_fv_eigen_vectors(ks_handler, ik, evecfvloc(1, 1, 1, ikloc), nmatmax, nstfv) call sirius_get_sv_eigen_vectors(ks_handler, ik, evecsvloc(1, 1, ikloc), nstsv) enddo !ikloc ! get all eigen-values and band occupancies do ik = 1, nkpt if (ndmag.eq.0.or.ndmag.eq.3) then call sirius_get_band_energies(ks_handler, ik, 0, evalsv(1, ik)) call sirius_get_band_occupancies(ks_handler, ik, 0, occsv(1, ik)) else call sirius_get_band_energies(ks_handler, ik, 0, evalsv(1, ik)) call sirius_get_band_energies(ks_handler, ik, 1, evalsv(nstfv+1, ik)) call sirius_get_band_occupancies(ks_handler, ik, 0, occsv(1, ik)) call sirius_get_band_occupancies(ks_handler, ik, 1, occsv(nstfv+1, ik)) endif enddo
|
Care is needed in dealing with the MPI task schedules when interfacing to SIRIUS as a library because typically the host code will have an MPI implementation that differs from that in SIRIUS. For EP as the host, the task is simplified because EP has only k-point parallelization in the ground-state calculation. In the initialization step, we set the SIRIUS MPI communicator to be derived from the global MPI communicator (MPI_COMM_WORLD) of the host code so that all MPI ranks will be used by SIRIUS. Then the user needs to specify how SIRIUS will carry out the k-point distribution, how to plan further band parallelization within a k-point, and thread-level parallelization. The schedules of k-point parallelization and band parallelization are required additional inputs. Thread-level parallelization also has additional inputs which are specified in the run job script.
If band parallelization is used in SIRIUS, the eigenvalues and eigenvectors associated with a single k-point are distributed in multiple MPI tasks. It therefore is necessary to combine the band subset results before transmitting the eigenvalues and eigenvectors back to EP. Thus, after SIRIUS finishes the ground state calculation but before calling the API to return the eigenvalues and eigenvectors to EP, SIRIUS will do mpi_reduce in the MPI band dimension and prepare full eigenvalues and eigenvectors labeled by k-points and by the global band index at each k-point.
The last piece of the interface provides the additional inputs for the SIRIUS Davidson diagonalization algorithm. These are adjustable numerical parameters passed directly to SIRIUS by EP.
As anticipated, the MPI parallelization in the band degree of freedom is one major gain from interfacing EP to SIRIUS. We noted above that EP runs entirely in non-parallel mode for a single k-point calculation (often a “Gamma-point calculation” or “Balderschi-point calculation”), such as is typical for isolated molecule calculations. Hence the SIRIUS-enhanced-EP has the same scaling as SIRIUS alone in the case of single k-point calculations. This is an example of the antithesis of the union of limitations that is inherent in separation of concerns. Here, separation of concerns actually avoids a limitation of the host code.
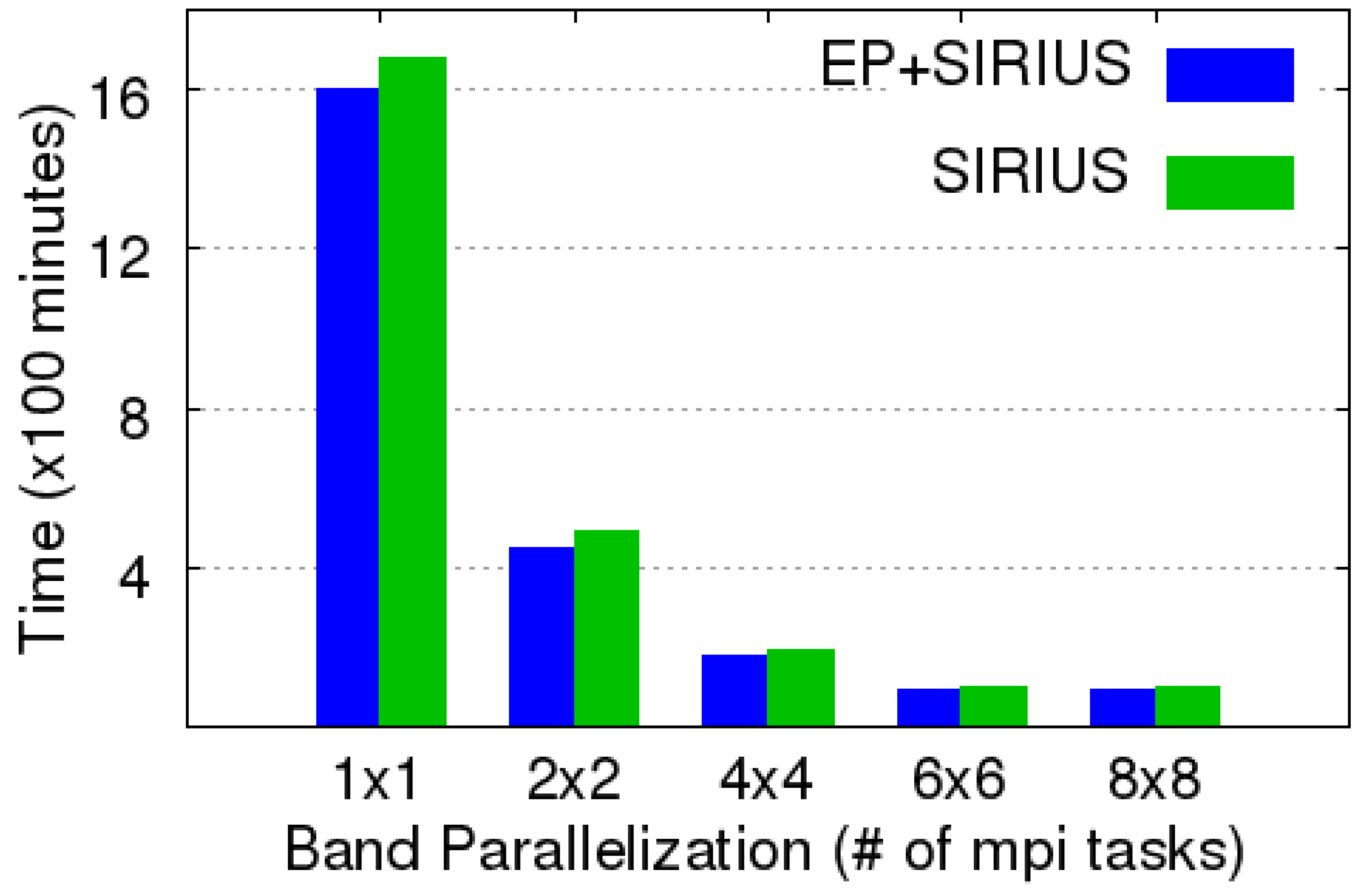
To illustrate,
Figure 2 displays the benchmark of band-parallelization on the DTN molecule (brief details about the molecule are below). It is placed in a
Å cubic unit cell, with plane-wave cutoff
(inverse Bohr radius) and angular momentum cutoff
. All jobs were set to 16 multi-threads in one task in accord with the hardware configuration. The recorded time is for the first 100 SCF iterations using the Davidson diagonalization eigensolver. Note that the figure also shows that employment of EP as a front-end to SIRIUS does not introduce any significant overhead. The timings for EP+SIRIUS are almost identical to those for SIRIUS alone. Timings compared to PW-PP-PAW codes are in the next section.






{kind=link}
{kind=link}
{kind=link}
{kind=link}