
Should We Gain Confidence from the Similarity of Results between Methods?


Abstract
:1. Introduction
2. Methodology
2.1. Frame
2.2. Reliability and Similarity of Computational Results
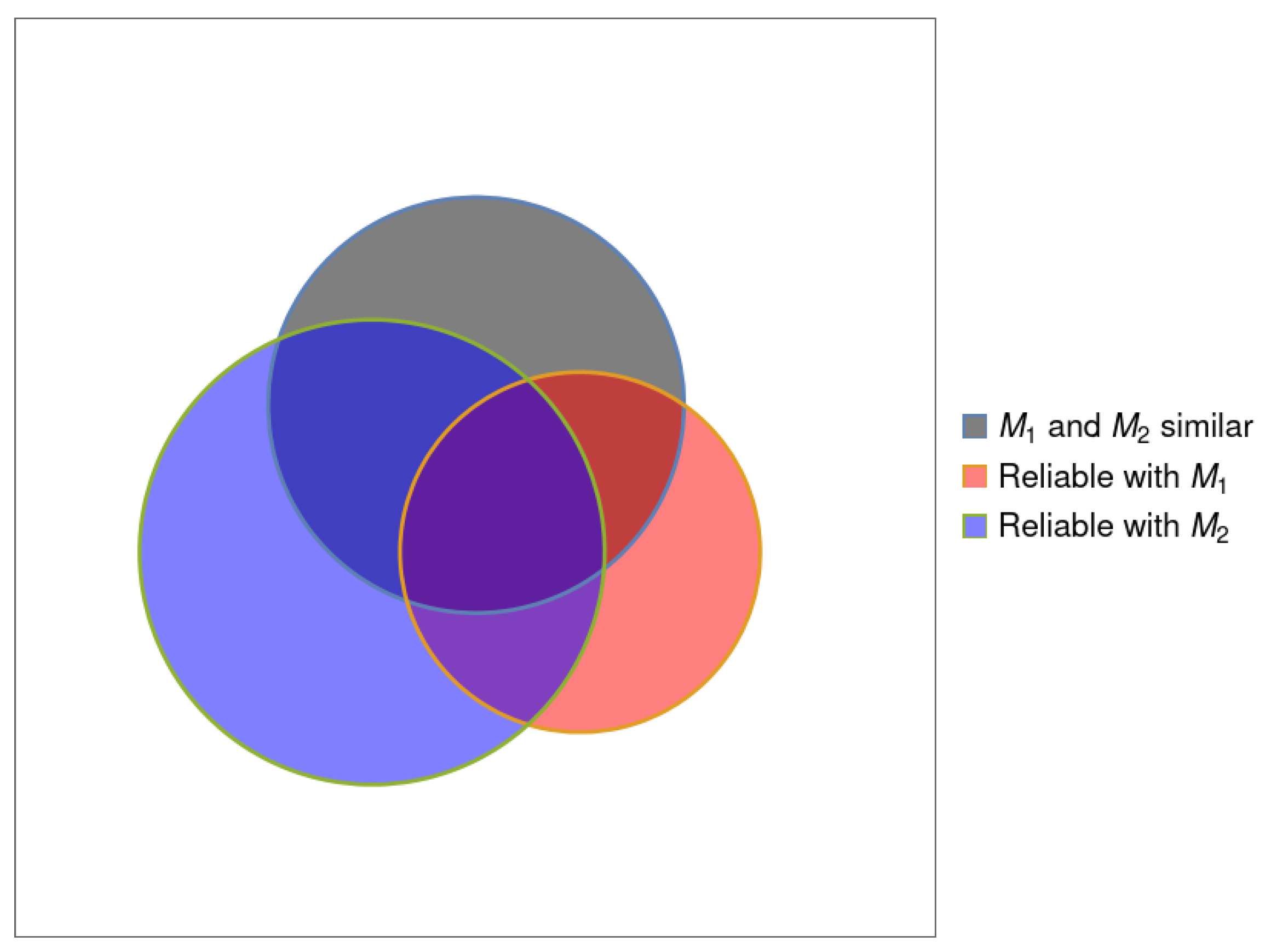
- N, the number of systems in the data set (corresponding to the white square in Figure 1).
- , or for brevity, the number of systems that yield similar results (within ) using methods . (corresponding to the gray disk in Figure 1).
- , the number of systems for which method M is reliable (corresponding to the red or blue disk in Figure 1).
- , the number of systems for which method M is reliable and similar to the other methods (corresponding to the overlap region of the three disks in Figure 1).
2.3. Probabilities
- The probability to obtain a reliable result with method M,
- The probability to obtain similar results for the set of considered methods,For a finite sample, the smallest value of for which is called the Hausdorff distance [4].
- The (conditional) probability to obtain reliable results with method M, given that this method is similar to the other methods in the set,
- The (conditional) probability that a result with method M is similar to that of the other methods, given that it is reliable,
2.4. Statistical Measures
- The reliability probability is equivalent to the ECDF of the absolute errors, noted in our previous work.
- The qth percentile of the absolute errors is the value of , such as .
3. Applications
3.1. Guidelines
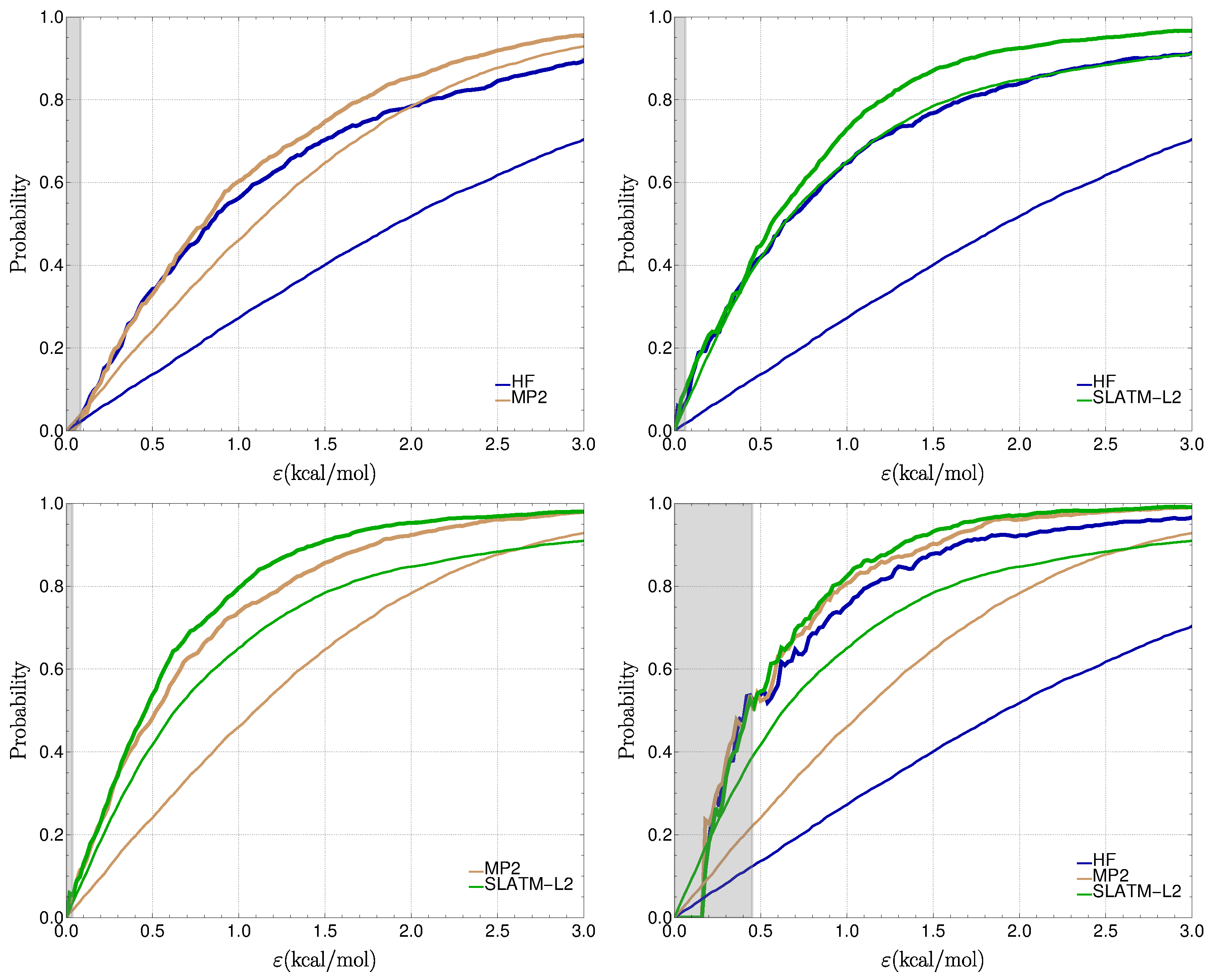
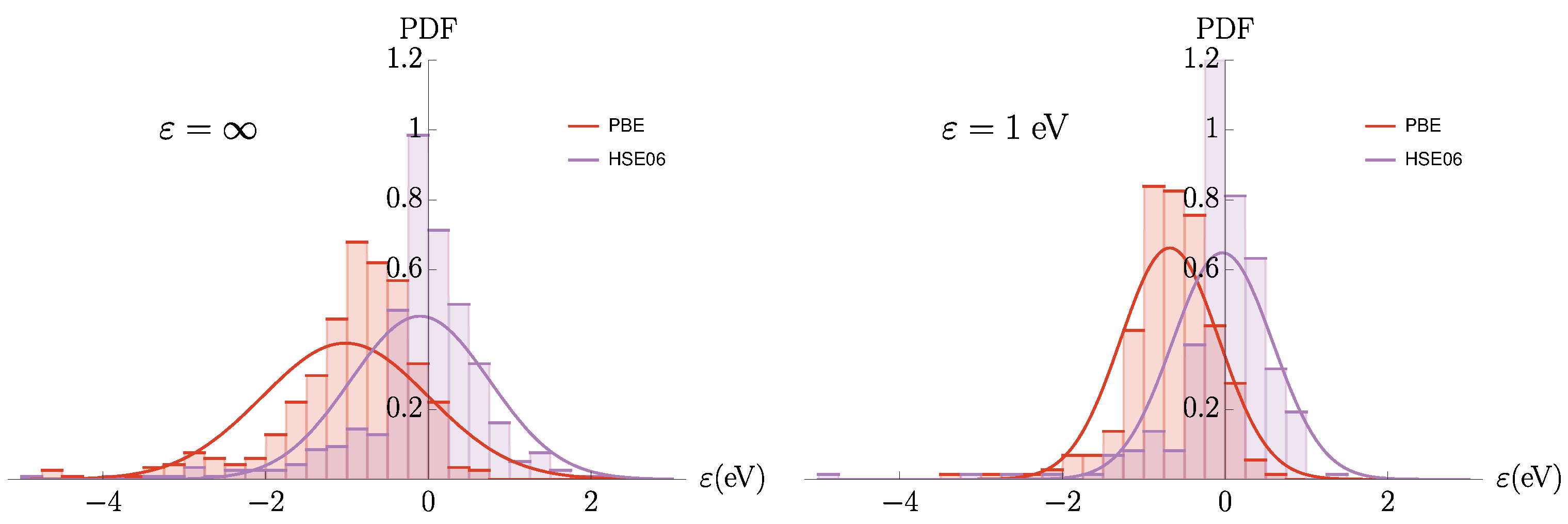
3.2. The BOR2019 Dataset
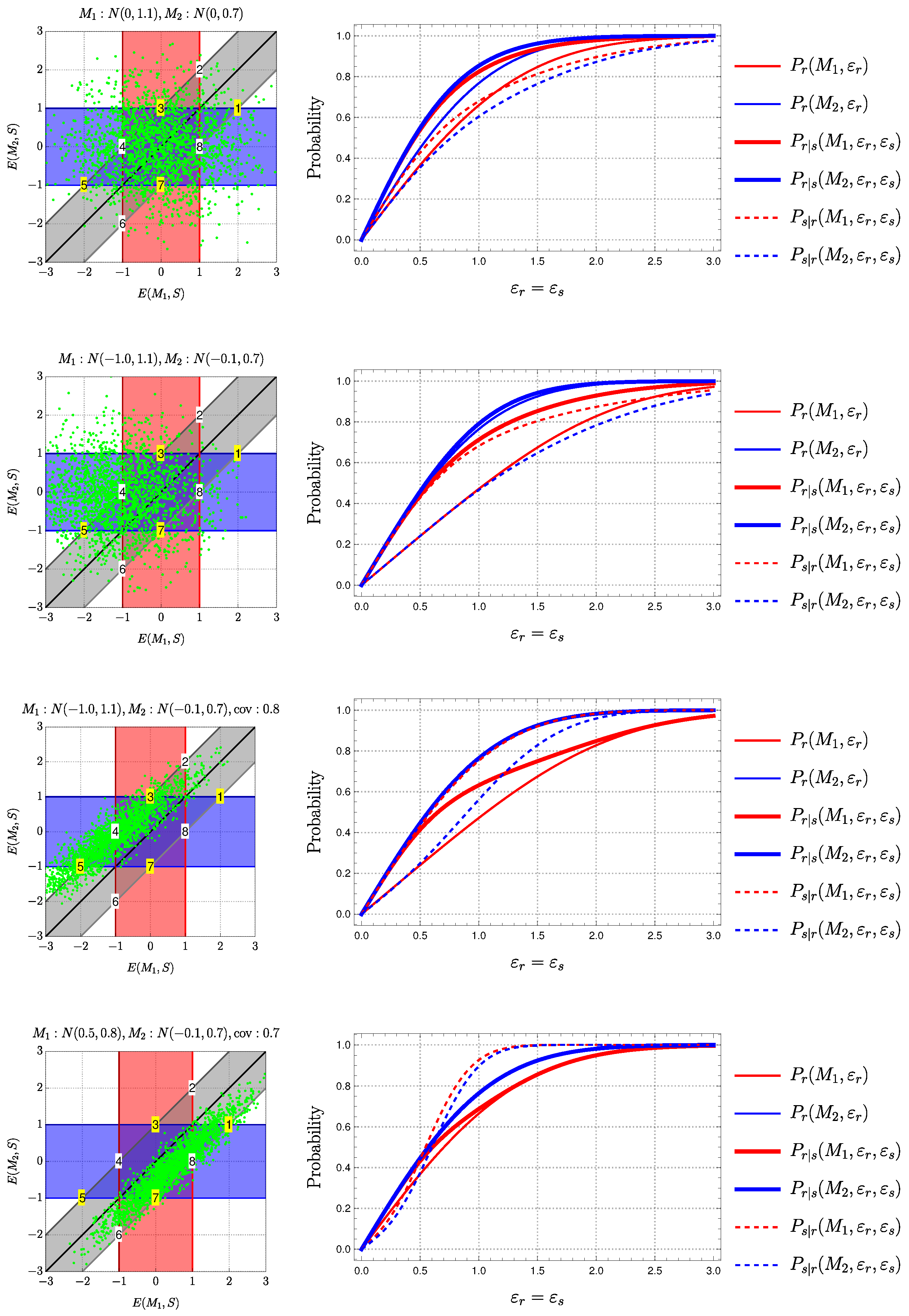
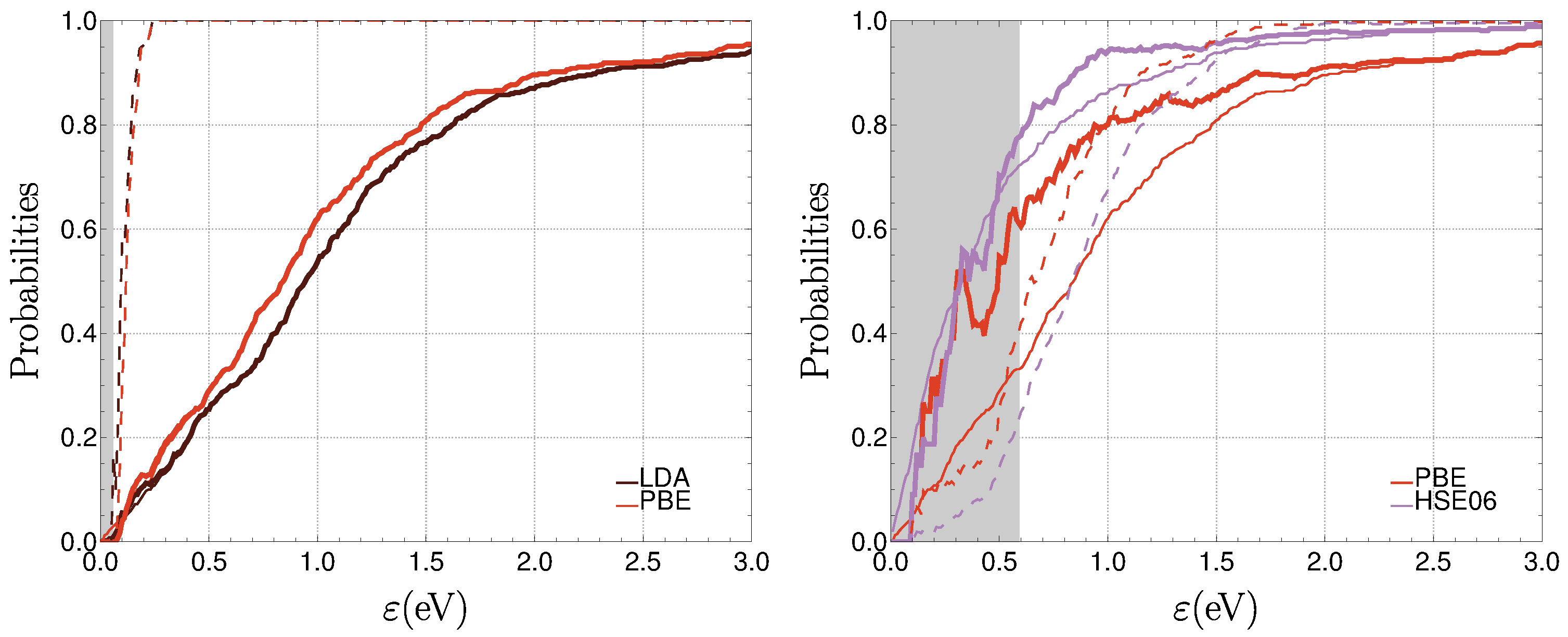
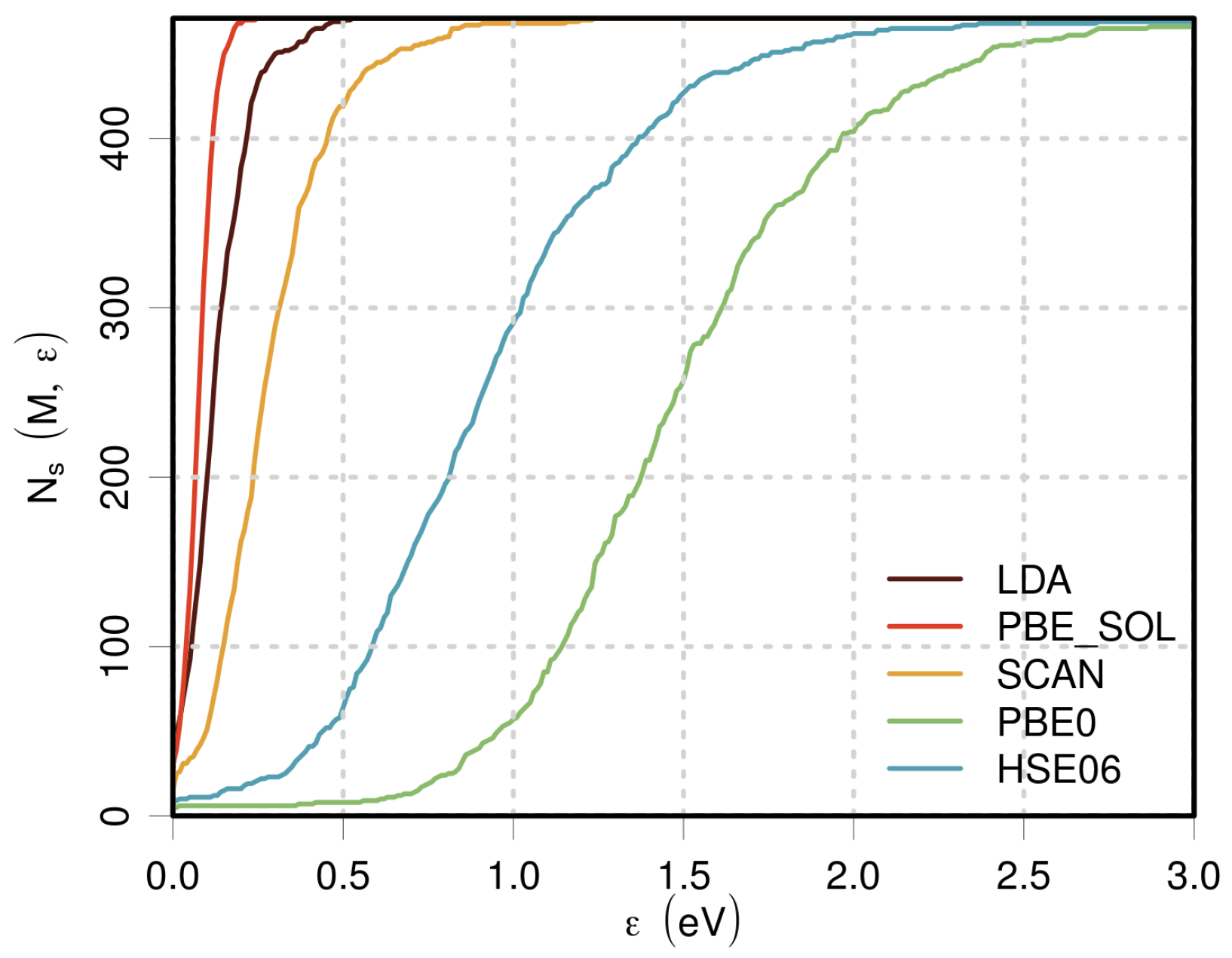
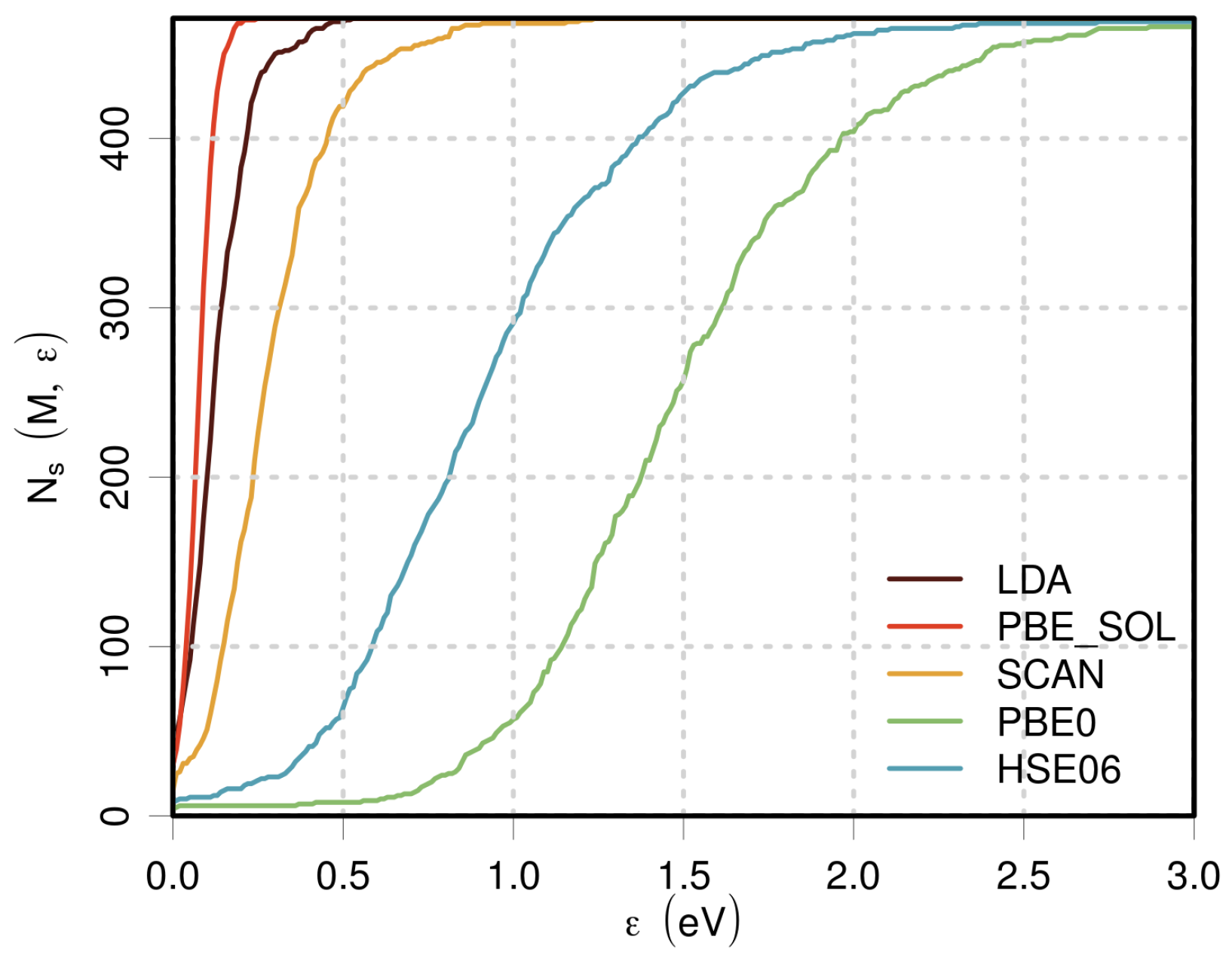
3.2.1. Performance of Individual Methods
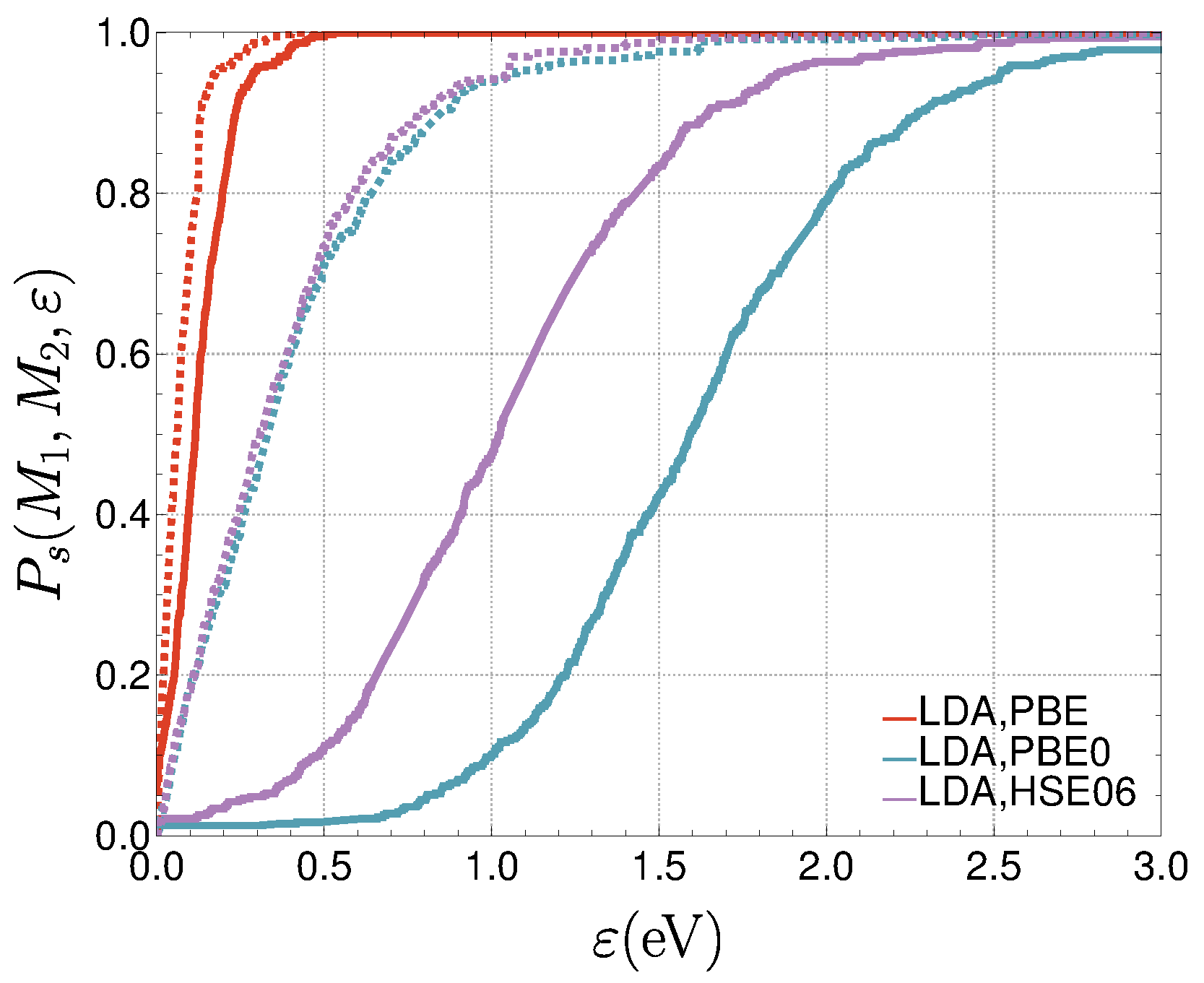
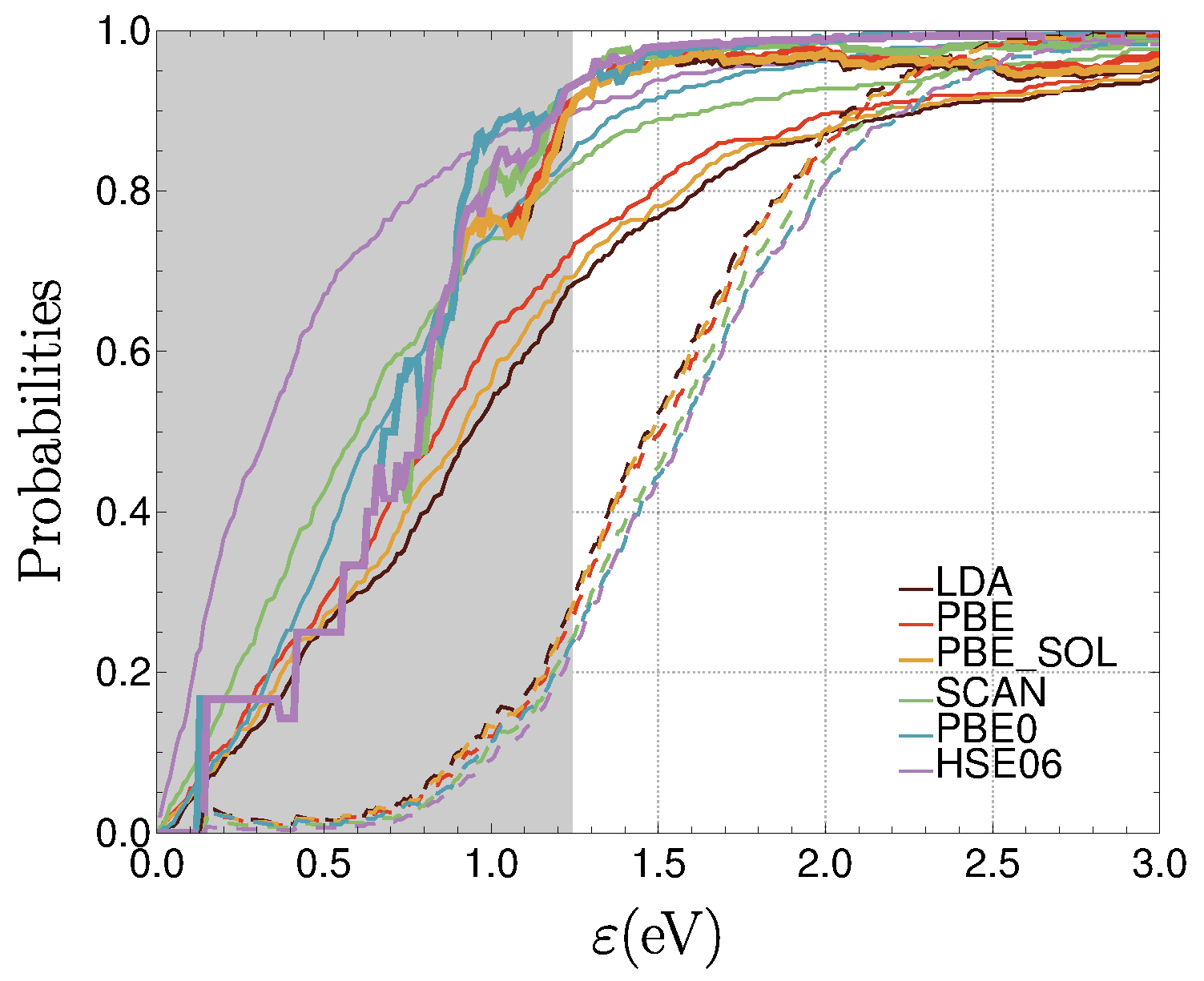
3.2.2. Similarity and Reliability
3.2.3. Impact of Similarity on Reliability
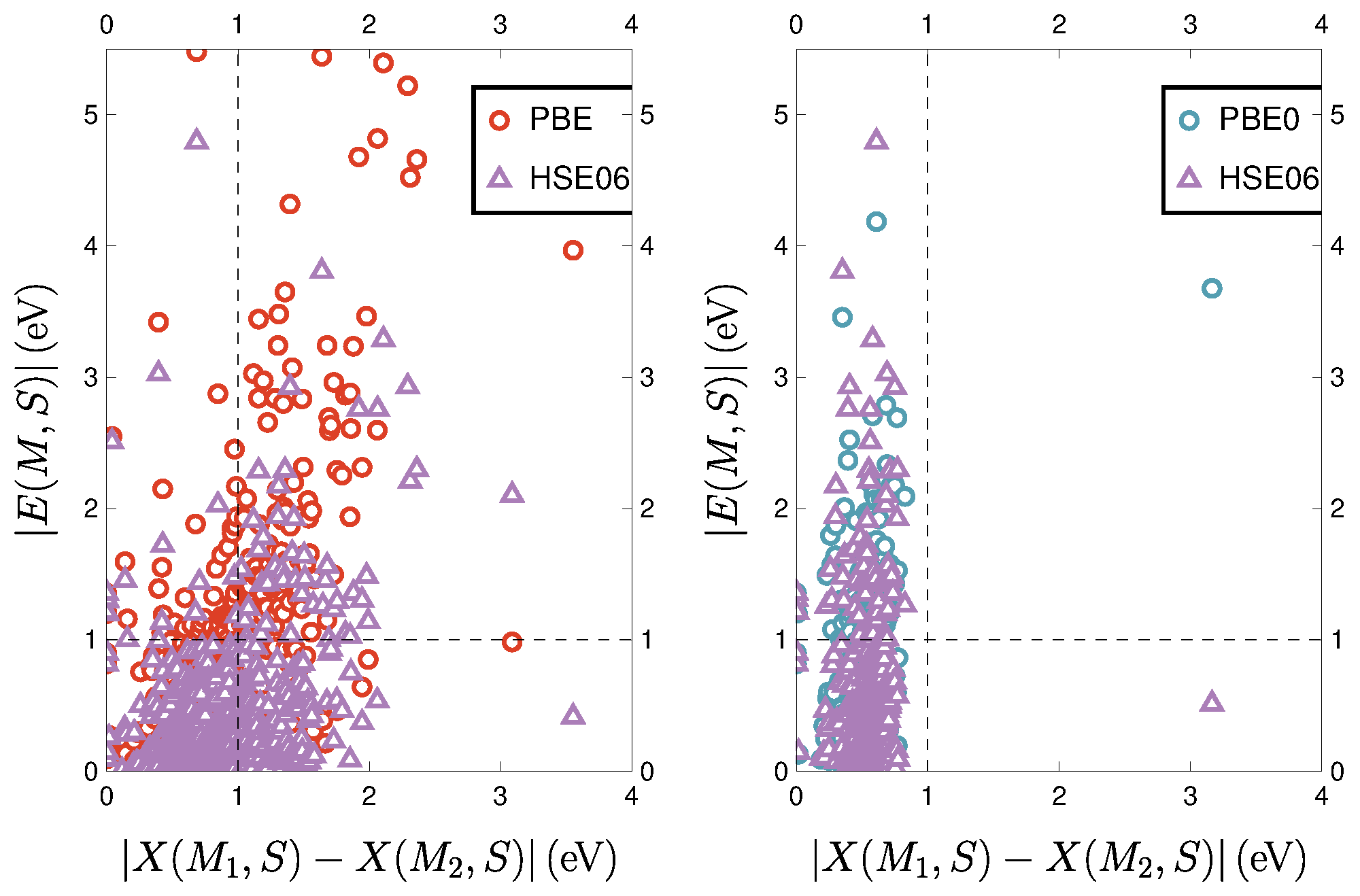
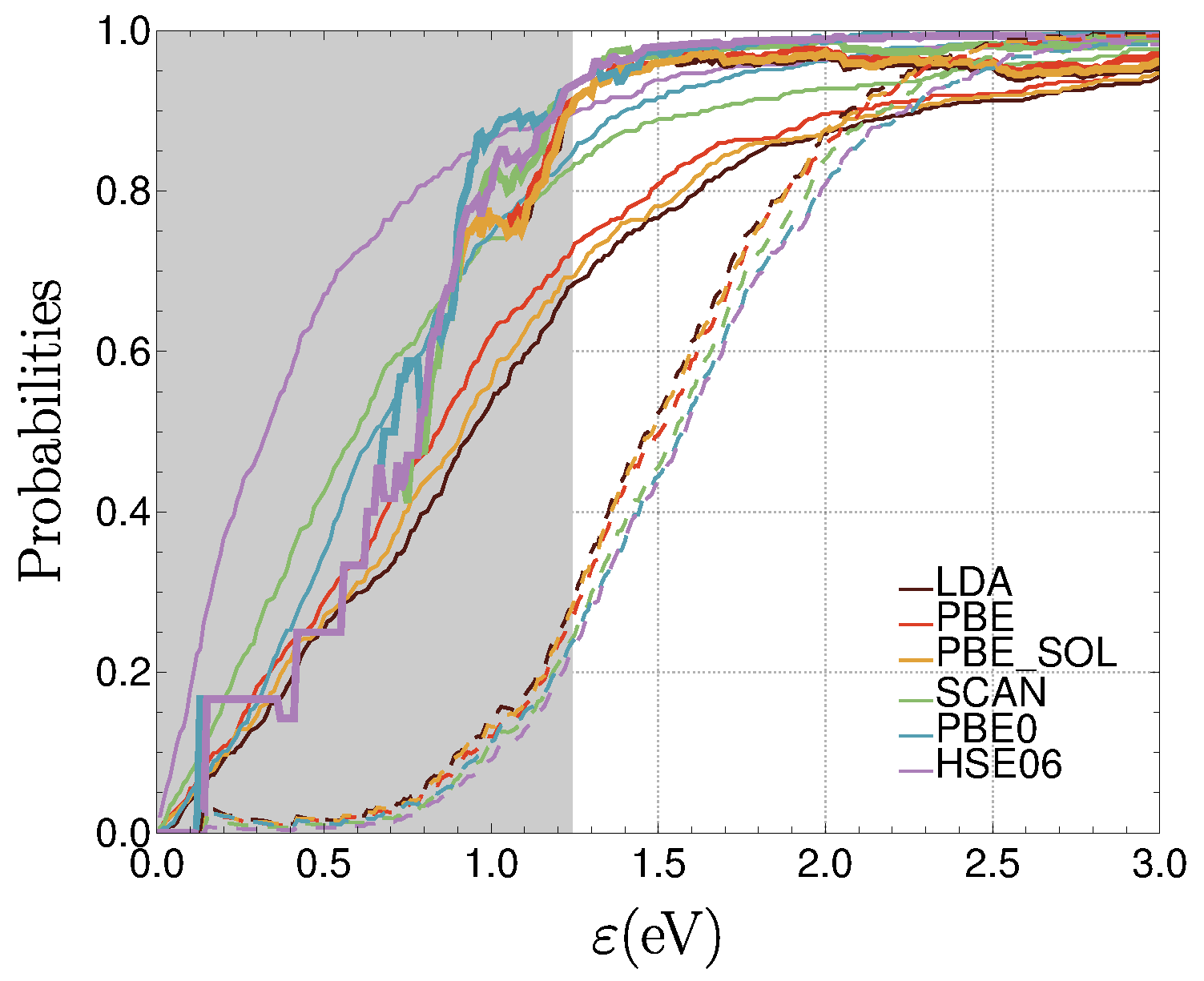
3.2.4. Eliminating Strange Results?
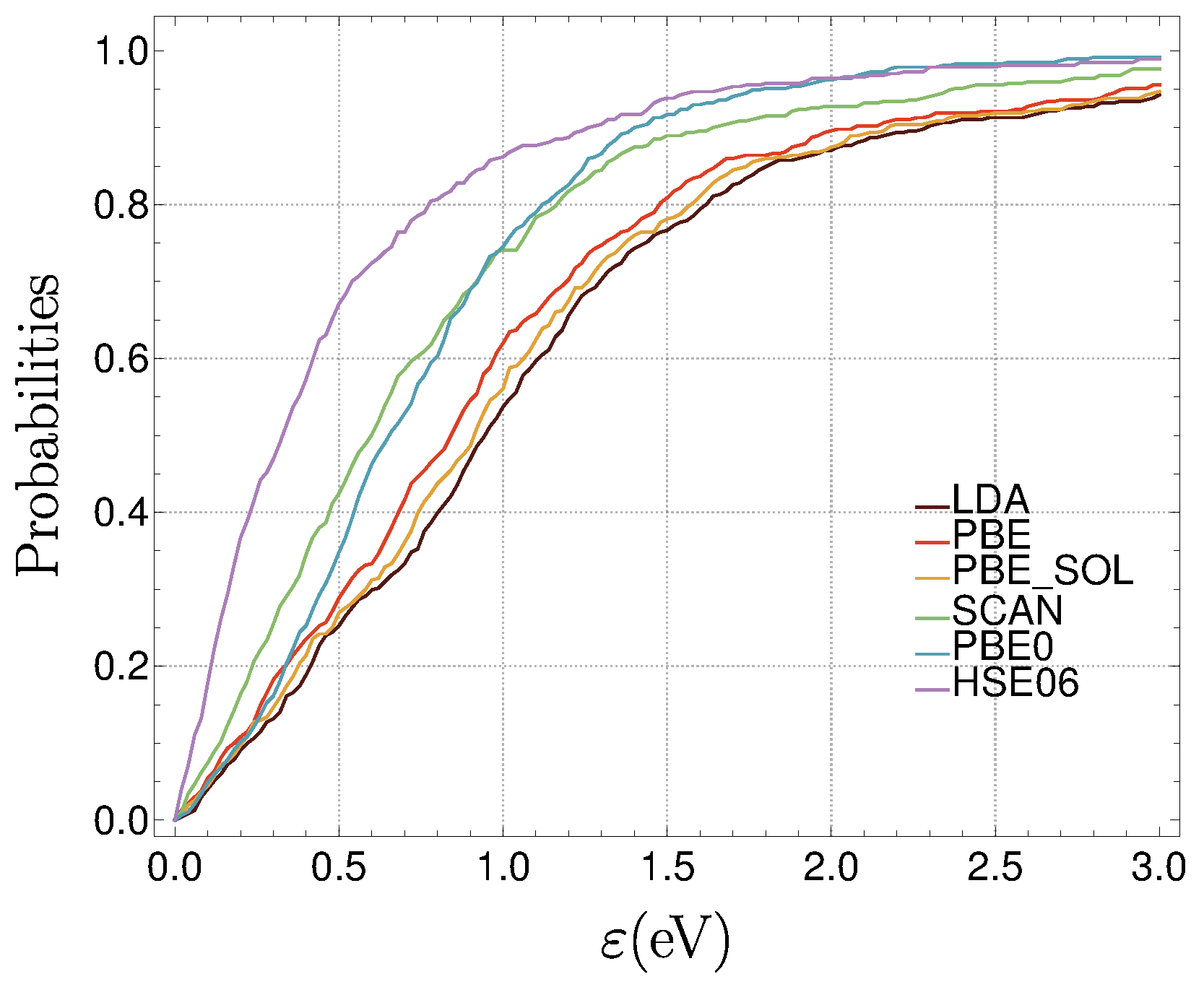
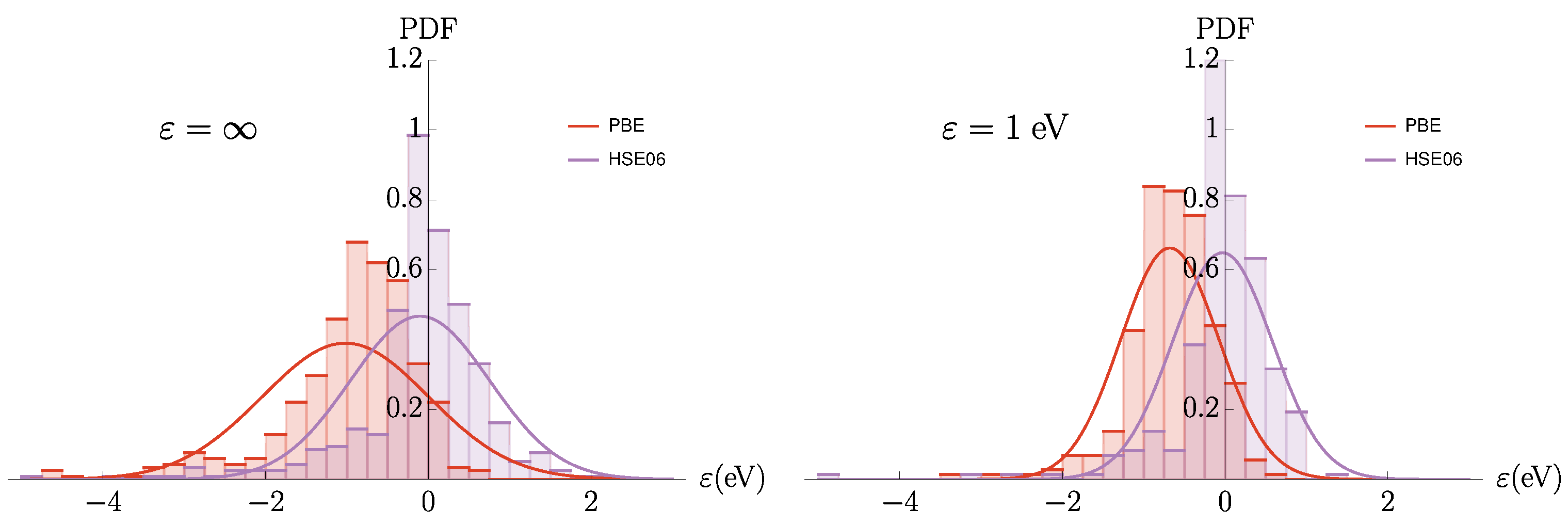
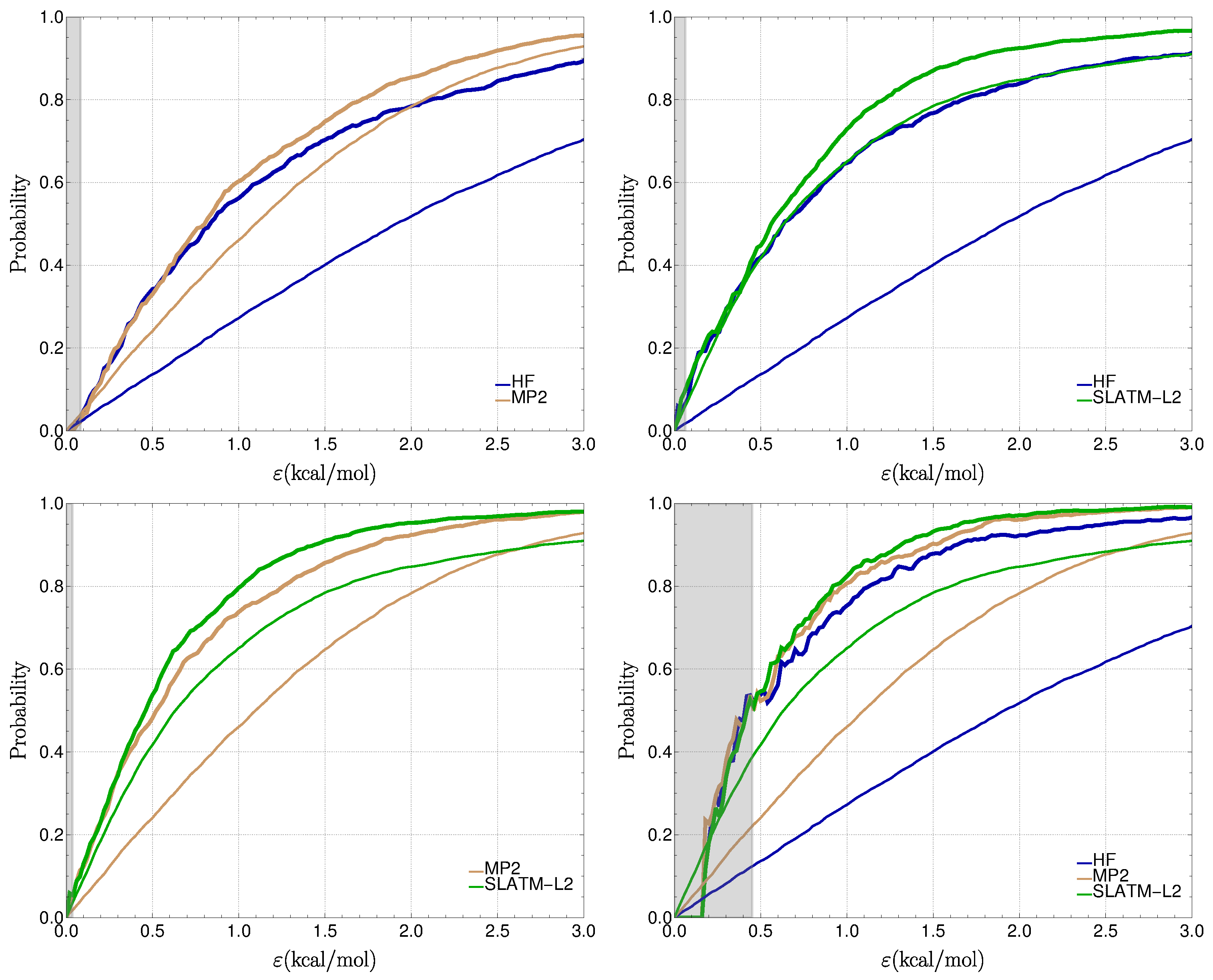
3.3. The ZAS2019 Dataset
4. Conclusions
- methods that always give close results, for which similarity is irrelevant; and
- methods for which an improvement can be achieved, especially by eliminating certain systems that behave strangely with one or the other methods—similarity is mainly effective for eliminating large errors.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pernot, P.; Savin, A. Probabilistic performance estimators for computational chemistry methods: Systematic Improvement Probability and Ranking Probability Matrix. I. Theory. J. Chem. Phys. 2020, 152, 164108. [Google Scholar] [CrossRef] [PubMed]
- Pernot, P.; Savin, A. Probabilistic performance estimators for computational chemistry methods: Systematic Improvement Probability and Ranking Probability Matrix. II. Applications. J. Chem. Phys. 2020, 152, 164109. [Google Scholar] [CrossRef] [PubMed]
- Pernot, P.; Savin, A. Probabilistic performance estimators for computational chemistry methods: The empirical cumulative distribution function of absolute errors. J. Chem. Phys. 2018, 148, 241707, Erratun in J. Chem. Phys. 2019, 150, 219906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hausdorff, F. Set Theory; Chelsea: London, UK, 1978. [Google Scholar]
- Pernot, P.; Savin, A. Using the Gini coefficient to characterize the shape of computational chemistry error distributions. Theor. Chem. Acc. 2021, 140, 24. [Google Scholar] [CrossRef]
- Dirac, P.A.M. Note on Exchange Phenomena in the Thomas Atom. Math. Proc. Camb. Philos. Soc. 1930, 26, 376–385. [Google Scholar] [CrossRef] [Green Version]
- Vosko, S.H.; Wilk, L.; Nusair, M. Accurate spin-dependent electron liquid correlation energies for local spin density calculations: A critical analysis. Can. J. Phys. 1981, 58, 1200–1211. [Google Scholar] [CrossRef] [Green Version]
- Perdew, J.P.; Burke, K.; Ernzerhof, M. Generalized Gradient Approximation Made Simple. Phys. Rev. Lett. 1996, 77, 3865–3868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perdew, J.P.; Ruzsinszky, A.; Csonka, G.I.; Vydrov, O.A.; Scuseria, G.E.; Constantin, L.A.; Zhou, X.; Burke, K. Restoring the Density-Gradient Expansion for Exchange in Solids and Surfaces. Phys. Rev. Lett. 2008, 100, 136406, Erratun in Phys. Rev. Lett. 2009, 102, 039902. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Kitchaev, D.A.; Yang, J.; Chen, T.; Dacek, S.T.; Sarmiento-Perez, R.A.; Marques, M.A.L.; Peng, H.; Ceder, G.; Perdew, J.P.; et al. Efficient first-principles prediction of solid stability: Towards chemical accuracy. Npj Comput. Mater. 2018, 4, 9. [Google Scholar] [CrossRef]
- Perdew, J.P.; Ernzerhof, M.; Burke, K. Rationale for mixing exact exchange with density functional approximations. J. Chem. Phys. 1996, 105, 9982–9985. [Google Scholar] [CrossRef]
- Adamo, C.; Barone, V. Toward reliable density functional methods without adjustable parameters: The PBE0 model. J. Chem. Phys. 1999, 110, 6158–6170. [Google Scholar] [CrossRef]
- Heyd, J.; Scuseria, G.E.; Ernzerhof, M. Hybrid functionals based on a screened Coulomb potential. J. Chem. Phys. 2003, 118, 8207–8215, Erratun in J. Chem. Phys. 2006, 124, 219906. [Google Scholar] [CrossRef] [Green Version]
- Krukau, A.V.; Vydrov, O.A.; Izmaylov, A.F.; Scuseria, G.E. Influence of the exchange screening parameter on the performance of screened hybrid functionals. J. Chem. Phys. 2006, 125, 224106. [Google Scholar] [CrossRef] [PubMed]
- Borlido, P.; Aull, T.; Huran, A.W.; Tran, F.; Marques, M.A.L.; Botti, S. Large-scale benchmark of exchange-correlation functionals for the determination of electronic band gaps of solids. J. Chem. Theor. Comput. 2019, 15, 5069–5079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Montavon, G.; Rupp, M.; Gobre, V.; Vazquez-Mayagoitia, A.; Hansen, K.; Tkatchenko, A.; Müller, K.R.; Anatole von Lilienfeld, O. Machine learning of molecular electronic properties in chemical compound space. New J. Phys. 2013, 15, 095003. [Google Scholar] [CrossRef]
- Zaspel, P.; Huang, B.; Harbrecht, H.; von Lilienfeld, O.A. Boosting Quantum Machine Learning Models with a Multilevel Combination Technique: Pople Diagrams Revisited. J. Chem. Theory Comput. 2019, 15, 1546–1559. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pernot, P.; Huang, B.; Savin, A. Impact of non-normal error distributions on the benchmarking and ranking of Quantum Machine Learning models. Mach. Learn. Sci. Technol. 2020, 1, 035011. [Google Scholar] [CrossRef]
- Savin, A.; Pernot, P. Acknowledging User Requirements for Accuracy in Computational Chemistry Benchmarks. Z. Anorg. Allg. Chem. 2020, 646, 1042–1045. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LDA | PBE | PBEsol | SCAN | PBE0 | HSE06 | |
|---|---|---|---|---|---|---|
| LDA | 3.1 | 3.1 | 3.1 | 3.1 | 2.1 | 3.1 |
| PBE | 2.9 | 2.9 | 2.9 | 2.9 | 2.1 | 2.9 |
| PBEsol | 3.0 | 3.0 | 3.0 | 3.0 | 2.2 | 3.0 |
| SCAN | 2.4 | 2.4 | 2.4 | 2.4 | 2.1 | 2.4 |
| PBE0 | 1.4 | 1.4 | 1.4 | 1.5 | 1.8 | 1.8 |
| HSE06 | 1.1 | 1.3 | 1.1 | 1.7 | 1.7 | 1.7 |
| LDA | PBE | PBEsol | SCAN | PBE0 | HSE06 | |
|---|---|---|---|---|---|---|
| LDA | 1 | 0.99 | 1.00 | 0.95 | 0.76 | 0.81 |
| PBE | - | 1 | 1.00 | 0.97 | 0.78 | 0.83 |
| PBEsol | - | - | 1 | 0.96 | 0.77 | 0.82 |
| SCAN | - | - | - | 1 | 0.83 | 0.87 |
| PBE0 | - | - | - | - | 1 | 0.98 |
| HSE06 | - | - | - | - | - | 1 |
| LDA | PBE | PBEsol | SCAN | PBE0 | |
|---|---|---|---|---|---|
| PBE | 0.1(0.1) | - | - | - | - |
| PBEsol | 0.1(0.1) | 0.1(0.0) | - | - | - |
| SCAN | 0.4(0.3) | 0.3(0.2) | 0.4(0.2) | - | - |
| PBE0 | 1.6(0.6) | 1.5(0.5) | 1.6(0.5) | 1.2(0.4) | - |
| HSE06 | 1.1(0.5) | 0.9(0.5) | 1.0(0.5) | 0.6(0.3) | 0.6(0.2) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pernot, P.; Savin, A. Should We Gain Confidence from the Similarity of Results between Methods? Computation 2022, 10, 27. https://doi.org/10.3390/computation10020027
Pernot P, Savin A. Should We Gain Confidence from the Similarity of Results between Methods? Computation. 2022; 10(2):27. https://doi.org/10.3390/computation10020027
Chicago/Turabian StylePernot, Pascal, and Andreas Savin. 2022. "Should We Gain Confidence from the Similarity of Results between Methods?" Computation 10, no. 2: 27. https://doi.org/10.3390/computation10020027
APA StylePernot, P., & Savin, A. (2022). Should We Gain Confidence from the Similarity of Results between Methods? Computation, 10(2), 27. https://doi.org/10.3390/computation10020027