Reducing the Deterioration of Sentiment Analysis Results Due to the Time Impact †

Abstract
:1. Introduction
- a section about the third method of “weighting scheme with linear computational complexity”;
- a section about the “metrics of the classifier’s performance evaluation”;
- extended information about collection gathering and preprocessing;
- added information about five sentiment lexicons based on the training collection;
- as well as some figures and tables, which can help to understand the data.
2. Reduced Quality of Sentiment Classification Due to Changes in Emotional Vocabulary
2.1. Short Text Collections
2.2. Metrics of Classifier’s Performance Evaluation
2.3. The Problem of Reduced Quality in Sentiment Classification Due to Changes in Emotional Vocabulary
3. Ways to Reduce the Deterioration of Classification Results for Text Collections Staggered over Time
3.1. Weighting Scheme with Linear Computational Complexity
3.2. Using External Lexicons of Emotional Words and Expressions
- The total number of terms (w, p) in the text of the tweet;
- The sum of all polarity values of words in the lexicon: ;
- The maximum polarity value: .
3.3. Using Distributed Word Representations as Features
3.3.1. The Space of Distributed Word Representations
3.3.2. Using the Skip-Gram Model to Reduce Dependence on the Training Collection
- size 300: every word is represented as a vector of this length;
- windows 5: how many words of context the training algorithm should take into account;
- negative 10: the number of negative examples for negative sampling;
- samples 1 × 10−4: sub-sampling (the usage of sub-sampling improves performance); the recommended parameter for sub-sampling is from 1 × 10−3–1 × 10−5;
- threads 10: the number of threads to use;
- min-counts 3: limits the size of the lexicon to significant words. Words that appear in the text less than this specified number of times were ignored; the default value was five;
- iter 15: the amount of training iterations.
4. Conclusions
- Updating the lexicon increases the dimension of the feature space. Thus, with every lexicon update, the system requires more resources, and the text vector becomes more sparse.
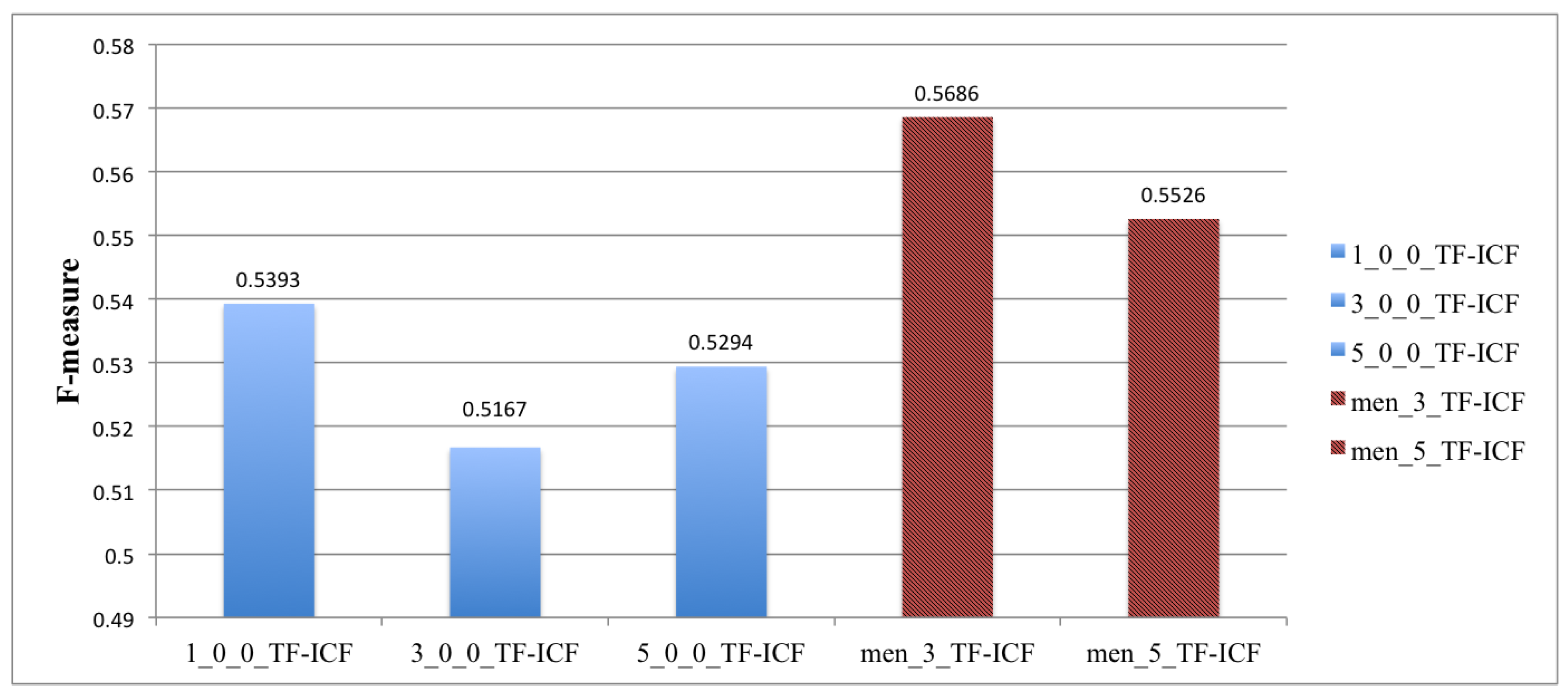
- The quality of classification with TF-ICF is significantly lower than with the bag-of-words method.
Funding
Conflicts of Interest
References
- Pang, B.; Lee, L. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar]
- Turney, P. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL-02), Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 417–424. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase level sentiment analysis. In Proceedings of the Human Languages Technologies Conference/Conference on Emperical Methods in Natural Language Processing (HLT/EMNLP 2005), Vancouver, BC, Canada, 5–8 October 2005. [Google Scholar]
- Rubtsova, Y.V. Research and Development of Domain Independent Sentiment Classifier. Trudy SPIIRAN 2014, 36, 59–77. [Google Scholar] [CrossRef]
- Agarwal, A.; Xie, B.; Vovsha, I.; Rambow, O.; Passonneau, R. Sentiment analysis of twit-ter data. In Proceedings of the Workshop on Languages in Social Media, Portland, OR, USA, 23 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 30–38. [Google Scholar]
- Kouloumpis, E.; Wilson, T.; Moore, J. Twitter sentiment analysis: The good the bad and the omg! In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; Volume 11, pp. 538–541. [Google Scholar]
- Pak, A.; Paroubek, P. Twitter as a Corpus for Sentiment Analysis and Opinion Mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 1320–1326. [Google Scholar]
- Lek, H.H.; Poo, D.C.C. Aspect-based Twitter sentiment classification. In Proceedings of the 2013 IEEE 25th International Conference on Tools with Artificial Intelligence, Herndon, VA, USA, 4–6 November 2013; pp. 366–373. [Google Scholar]
- Loukachevitch, N.; Rubtsova, Y. Entity-Oriented Sentiment Analysis of Tweets: Results and Problems. In Proceedings of the International Conference on Text, Speech, and Dialogue, Pilsen, Czech Republic, 14–17 September 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 551–559. [Google Scholar]
- Rubtsova, Y. Reducing the Degradation of Sentiment Analysis for Text Collections Spread over a Period of Time. In Proceedings of the International Conference on Knowledge Engineering and the Semantic Web, Szczecin, Poland, 8–10 November 2017; Springer: Cham, Switzerland, 2017; pp. 3–13. [Google Scholar]
- Read, J. Using emoticons to reduce dependency in machine learning techniques for sen-timent classification. In Proceedings of the 43rd Meeting of the Association for Computational Linguistics (ACL-05), Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005. [Google Scholar]
- Rubtsova, Y.V. A Method for development and analysis of short text corpus for the review classiification task. In Proceedings of the XV All-Russian Scientific Conference “Digital libraries: Advanced Methods and Technologies, Digital Collections” (RCDL2013), Yaroslavl, Russia, 14–17 October 2013; pp. 269–275. [Google Scholar]
- Loukachevitch, N.; Rubtsova, Y. Entity-Oriented Sentiment Analysis of Tweets: Results and Problems. In Proceedings of the XVII International Conference on Data Analytics and Management in Data Intensive Domains, Obninsk, Russia, 13–16 October 2015; pp. 499–507. [Google Scholar]
- Loukachevitch, N.; Rubtsova, Y. SentiRuEval-2016: Overcoming Time Gap and Data Sparsity in Tweet Sentiment Analysis. In Computational Linguistics and Intellectual Technologies, Proceedings of the International Conference on “Dialogue 2016”, Moscow, Russia, 1–4 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 375–384. [Google Scholar]
- Manning, C.D.; Schutze, H. Foundations of Statistical Natural Language Processing; The MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Fan, R.-E.; Chang, K.-W.; Hsieh, C.-J.; Wang, X.-R.; Lin, C.-J. LIBLINEAR: A Library for Large Linear Classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Reed, J.W.; Jiao, Y.; Potok, T.E.; Klump, B.A.; Elmore, M.T.; Hurson, A.R. TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams. In Proceedings of the 2006 5th International Conference on Machine Learning and Applications, Orlando, FL, USA, 14–16 December 2006; pp. 258–263. [Google Scholar]
- Mohammad, S.M.; Kiritchenko, S.; Zhu, X. NRC-Canada: Build-ing the state-of-the-art in sentiment analysis of tweets. In Proceedings of the Second Joint Conference on Lexical and Computational Semantics (SEMSTAR’13), Atlanta, GA, USA, 13–14 June 2013. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Klekovkina, M.V.; Kotelnikov, E.V. The automatic sentiment text classification method based on emotional vocabulary. In Proceedings of the 14th All-Russian Scientific Conference “Digital libraries: Advanced Methods and Technologies, Digital Collections”, Pereslavl-Zalessky, Russia, 15–18 October 2012; pp. 118–123. [Google Scholar]
- Loukachevitch, N.V.; Chetverkin, I.I. Extraction and use of evaluation words in the problem of classifying reviews into three classes. Comput. Methods Programm. 2011, 12, 73–81. [Google Scholar]
- Mansour, R.; Refaei, N.; Gamon, M.; Abdul-Hamid, A.; Sami, K. Revisiting the Old Kitchen Sink: Do We Need Sentiment Domain Adaptation? In Proceedings of the International Conference Recent Advances in Natural Language Processing (RANLP-2013), Hissar, Bulgaria, 7–13 September 2013; pp. 420–427. [Google Scholar]
- Loukachevitch, N.V.; Levchik, A.V. Creating a General Russian Sentiment Lexicon. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portoroz, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Paris, France, 2016. [Google Scholar]
- Alexeeva, S.; Koltsov, S.; Koltsova, O. Linis-crowd.org: A lexical resource for Russian sentiment analysis of social media. In Proceedings of the Internet and Modern Society (IMS-2015), Moscow, Russia, 23–25 June 2015; pp. 25–32. [Google Scholar]
- Titov, I.; McDonald, R. Modeling Online Reviews with Multi-grain Topic Models. In Proceedings of the 17th International Conference on World Wide Web (WWW’08), Beijing, China, 21–25 April 2008; pp. 111–120. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems; NIPS: La Jolla, CA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving Distributional Similarity with Lessons Learned from Word Em-bedding. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Positive Messages | Negative Messages | Neutral Messages | |
|---|---|---|---|
| I_collection | 114,911 | 111,922 | 107,990 |
| II_collection | 5000 | 5000 | 4293 |
| III_collection | 10,000 | 10,000 | 9595 |
| BOW | Men_3_TF-IDF | Men_5_TF-IDF | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F | Acc | P | R | F | Acc | P | R | F |
| I_collection | |||||||||||
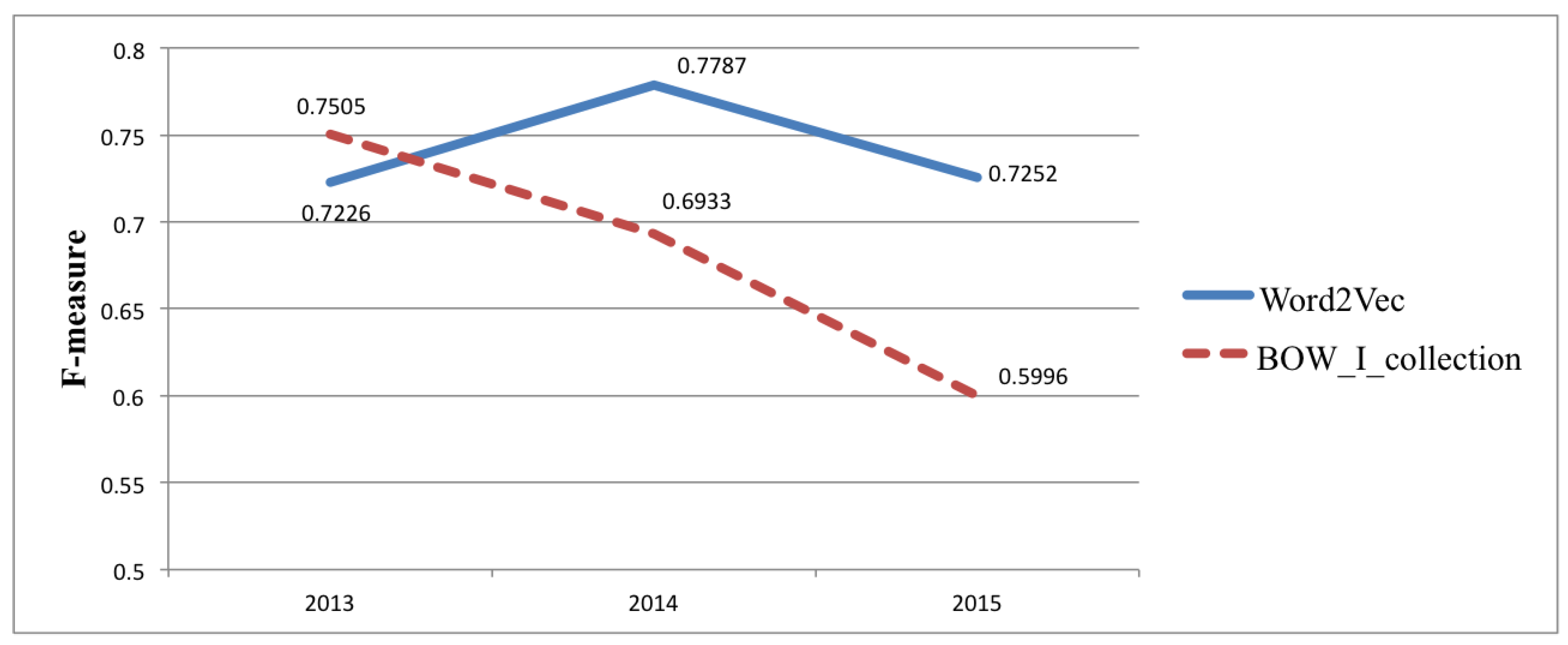
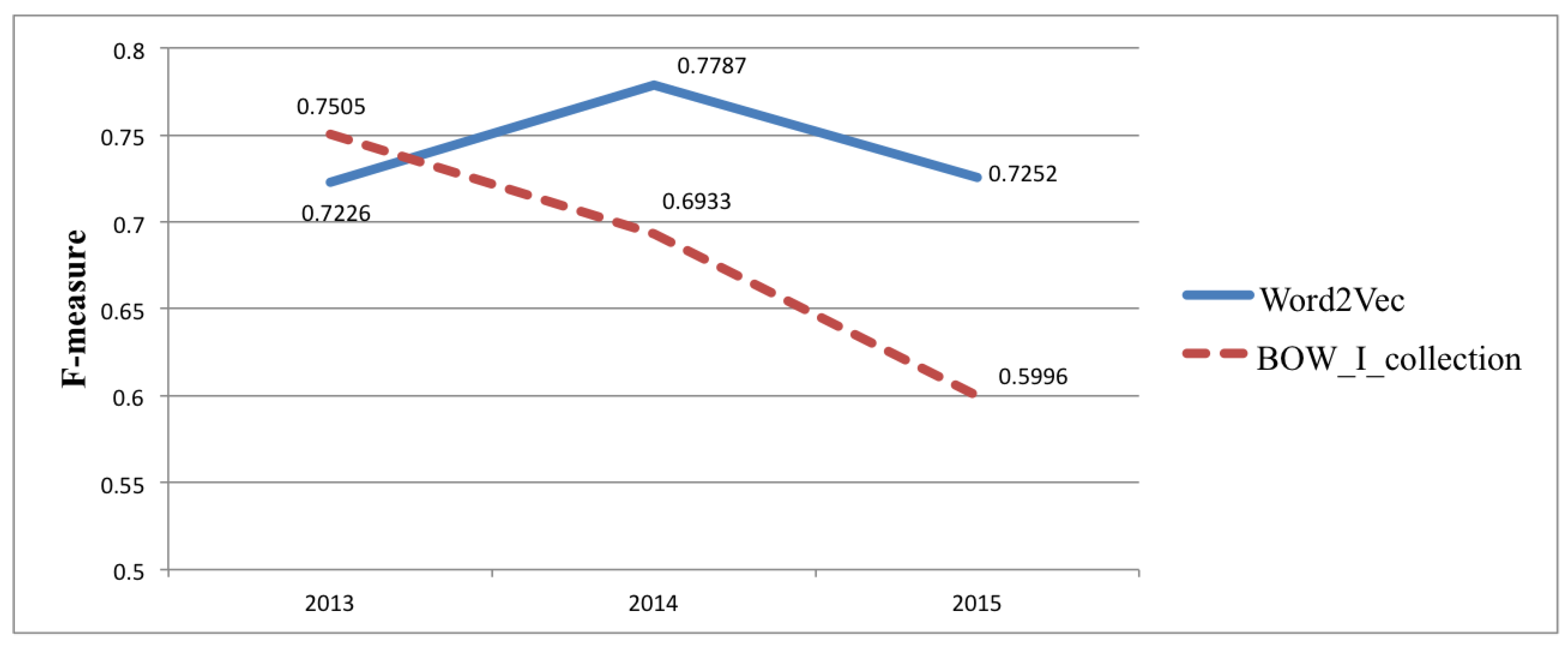
| 0.7459 | 0.7595 | 0.7471 | 0.7505 | 0.6457 | 0.6591 | 0.6471 | 0.6506 | 0.6189 | 0.6542 | 0.6184 | 0.6223 |
| II_collection | |||||||||||
| 0.6964 | 0.6984 | 0.7062 | 0.6933 | 0.5086 | 0.5829 | 0.5040 | 0.5026 | 0.5745 | 0.5823 | 0.5795 | 0.5808 |
| III_collection | |||||||||||
| 0.6118 | 0.6317 | 0.6156 | 0.5996 | 0.4651 | 0.5218 | 0.4638 | 0.4549 | 0.5343 | 0.5337 | 0.5360 | 0.5344 |
| Men_3_TF-ICF | Men_5_TF-ICF | |||
|---|---|---|---|---|
| F-Measure | Accuracy | F-Measure | Accuracy | |
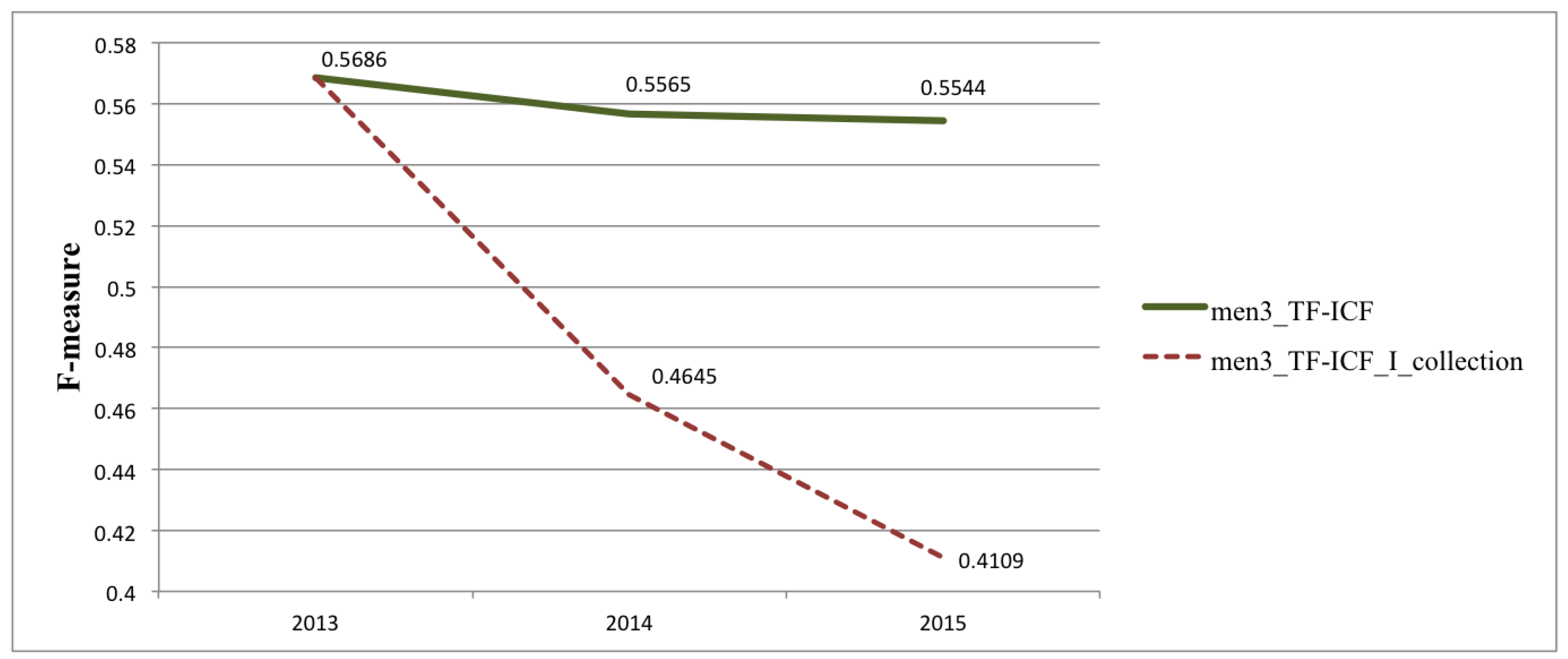
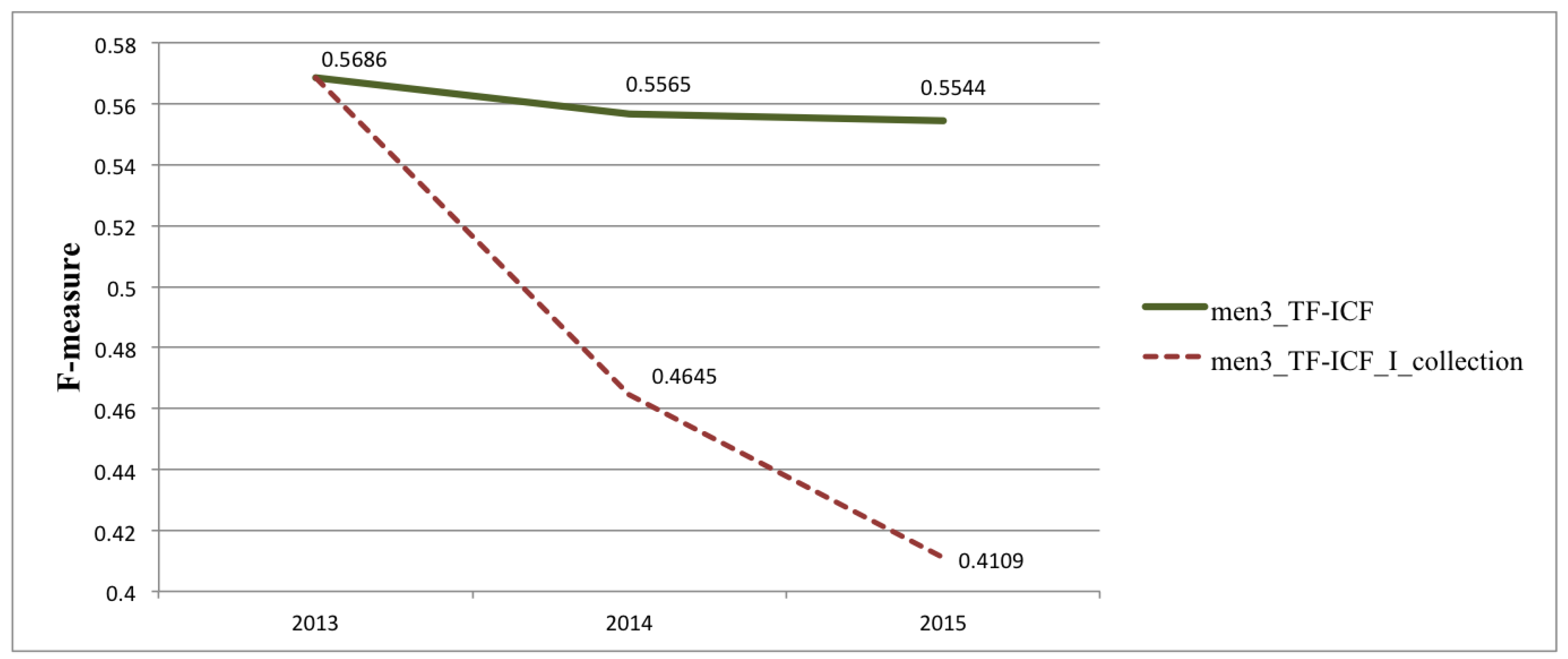
| I_collection | 0.5686 | 0.5648 | 0.5526 | 0.5541 |
| II_collection | 0.4645 | 0.4833 | 0.4564 | 0.4971 |
| III_collection | 0.4109 | 0.4278 | 0.4143 | 0.4516 |
| BOW | Men_3_TF-ICF | |||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F | Acc | P | R | F | |
| I + II cross-validation | 0.7205 | 0.7339 | 0.7215 | 0.7250 | 0.5539 | 0.5806 | 0.5550 | 0.5565 |
| III_collection | 0.6848 | 0.6889 | 0.6862 | 0.6872 | 0.5348 | 0.5571 | 0.5361 | 0.5334 |
| RuSentiLex | Linis-Crowd | |||||||
|---|---|---|---|---|---|---|---|---|
| Acc | P | R | F | Acc | P | R | F | |
| 2013 | 0.7273 | 0.74 | 0.7284 | 0.7318 | 0.7272 | 0.7398 | 0.7283 | 0.7316 |
| 2014 | 0.7245 | 0.7387 | 0.7259 | 0.7295 | 0.7244 | 0.7386 | 0.7258 | 0.7294 |
| 2015 | 0.6724 | 0.6802 | 0.6733 | 0.6759 | 0.6725 | 0.6803 | 0.6733 | 0.6760 |
| Acc. | Precision | Recall | F-Measure | |
|---|---|---|---|---|
| I_collection | 0.7206 | 0.7250 | 0.7221 | 0.7226 |
| II_collection | 0.7756 | 0.7763 | 0.7836 | 0.7787 |
| III_collection | 0.7289 | 0.7250 | 0.7317 | 0.7252 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rubtsova, Y. Reducing the Deterioration of Sentiment Analysis Results Due to the Time Impact. Information 2018, 9, 184. https://doi.org/10.3390/info9080184
Rubtsova Y. Reducing the Deterioration of Sentiment Analysis Results Due to the Time Impact. Information. 2018; 9(8):184. https://doi.org/10.3390/info9080184
Chicago/Turabian StyleRubtsova, Yuliya. 2018. "Reducing the Deterioration of Sentiment Analysis Results Due to the Time Impact" Information 9, no. 8: 184. https://doi.org/10.3390/info9080184
APA StyleRubtsova, Y. (2018). Reducing the Deterioration of Sentiment Analysis Results Due to the Time Impact. Information, 9(8), 184. https://doi.org/10.3390/info9080184