Hybrid Visualization Approach to Show Documents Similarity and Content in a Single View


{kind=link}
{kind=link}
{kind=link}
{kind=link}
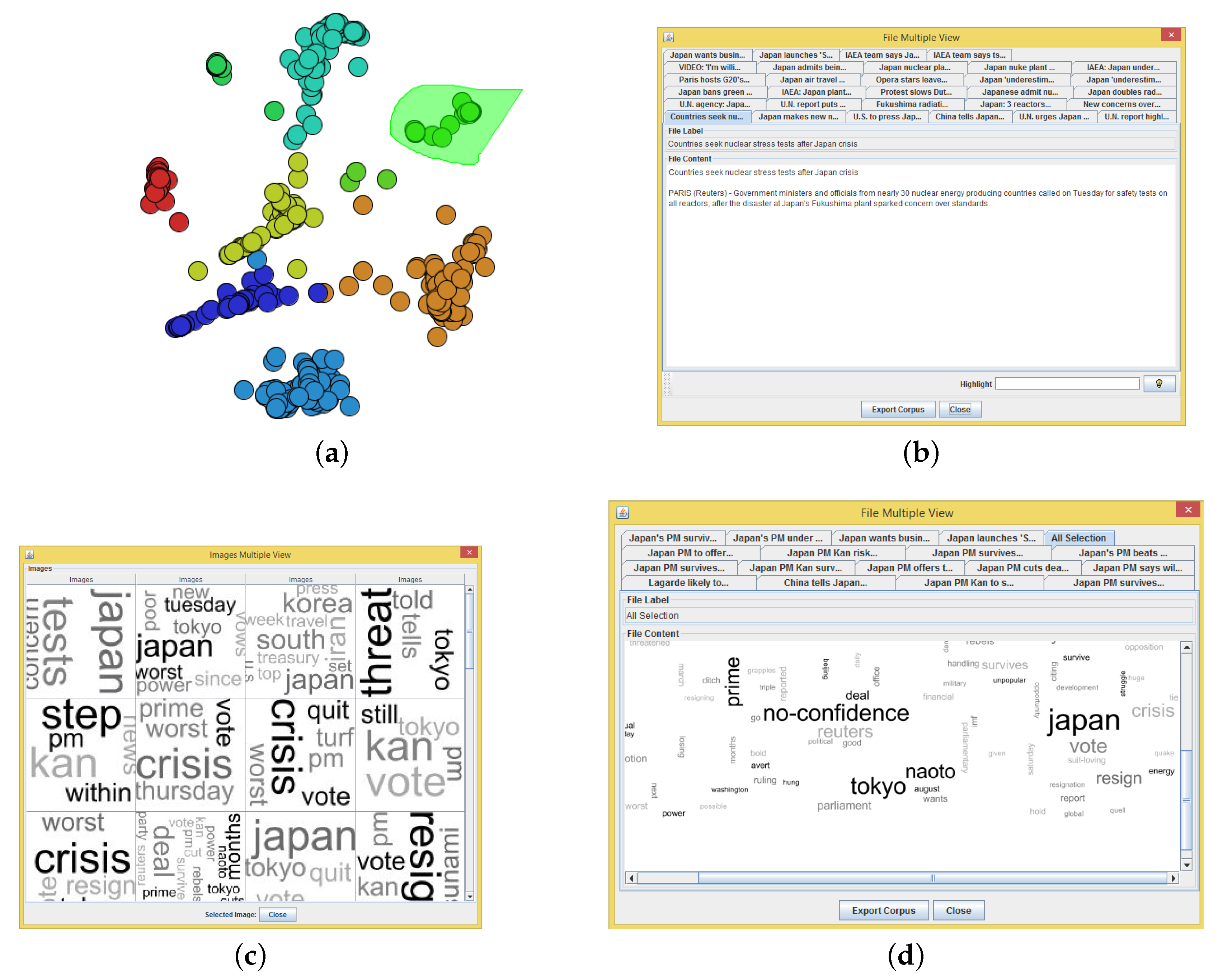{kind=link}
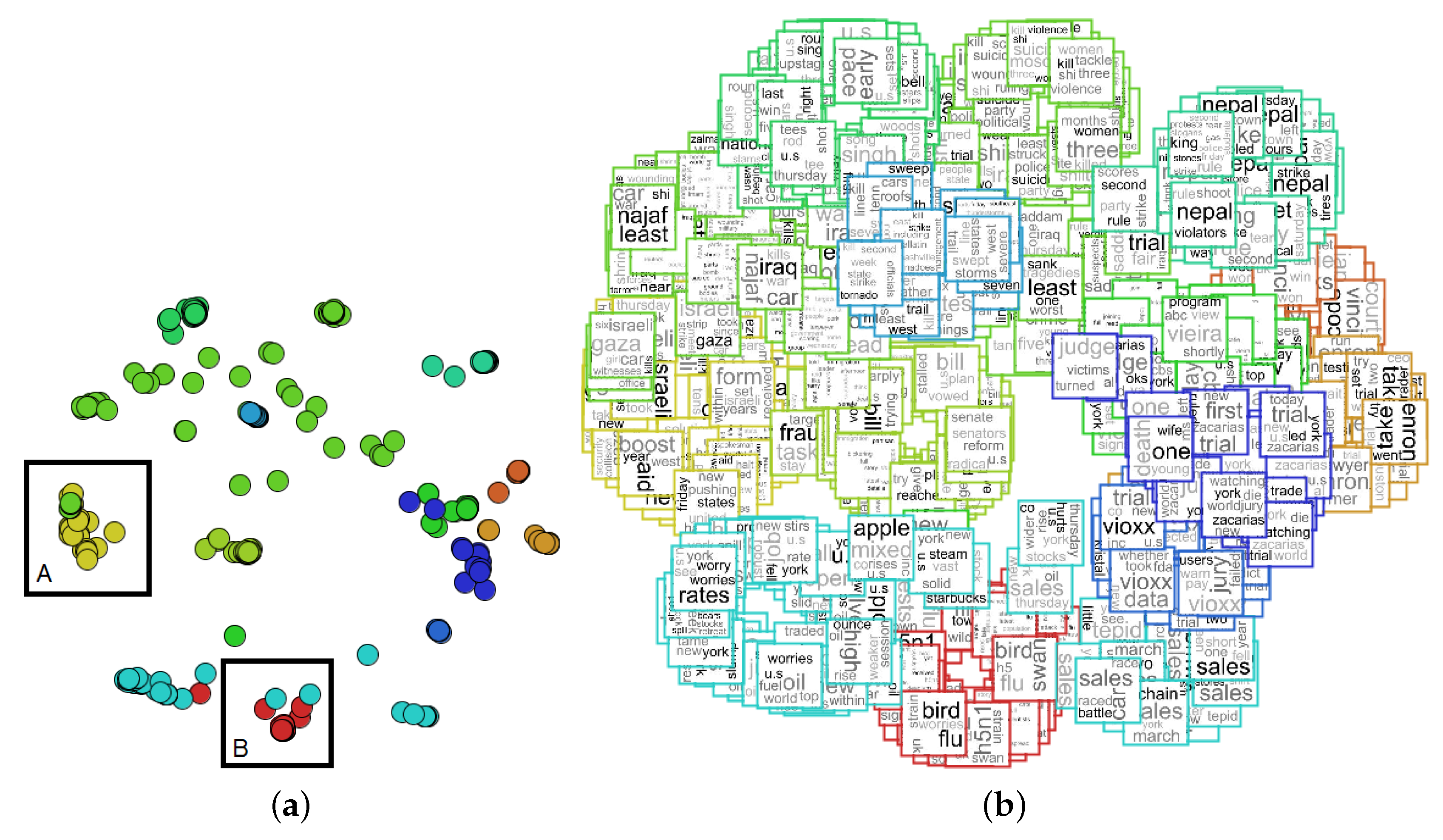{kind=link}
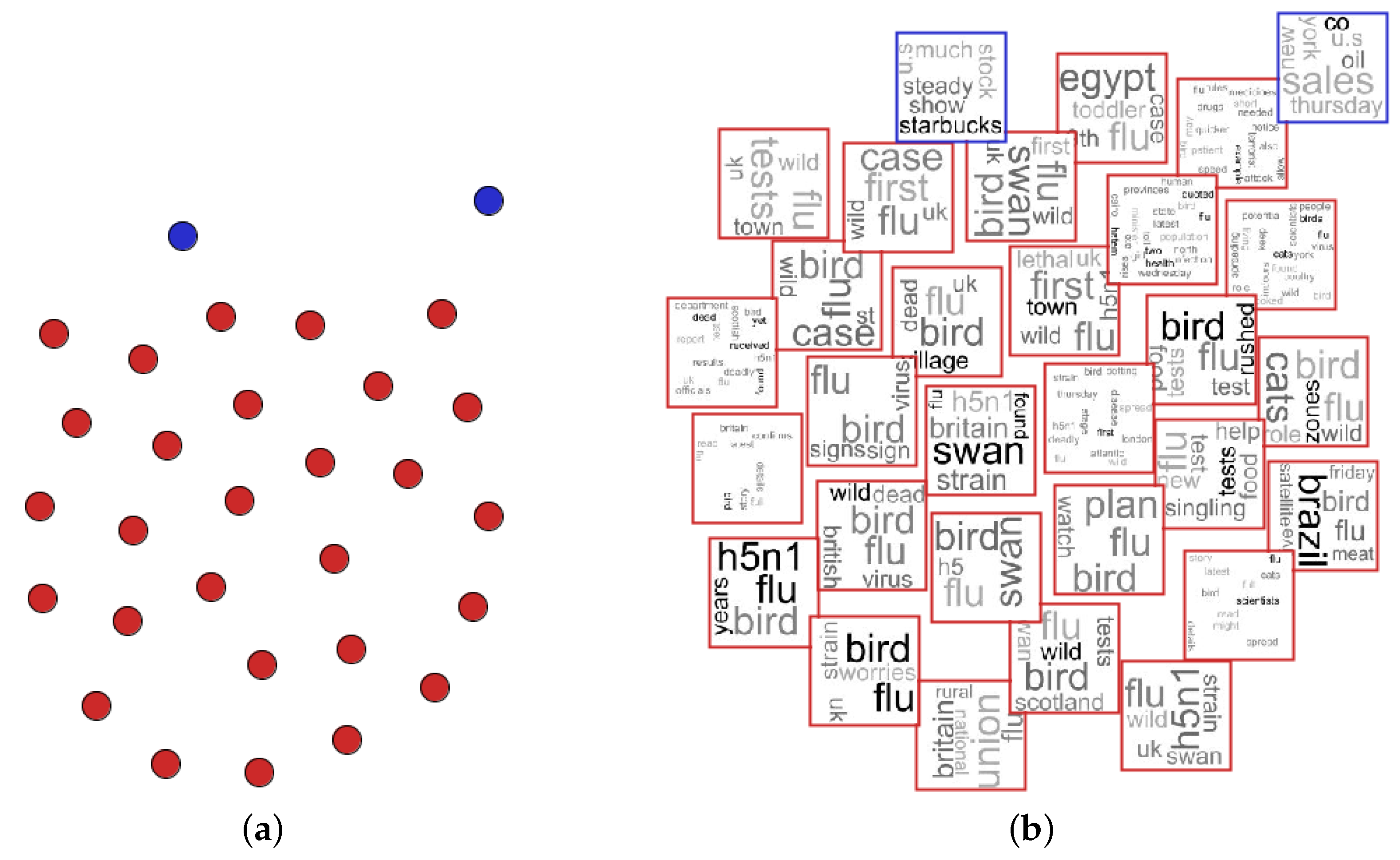{kind=link}
{kind=link}
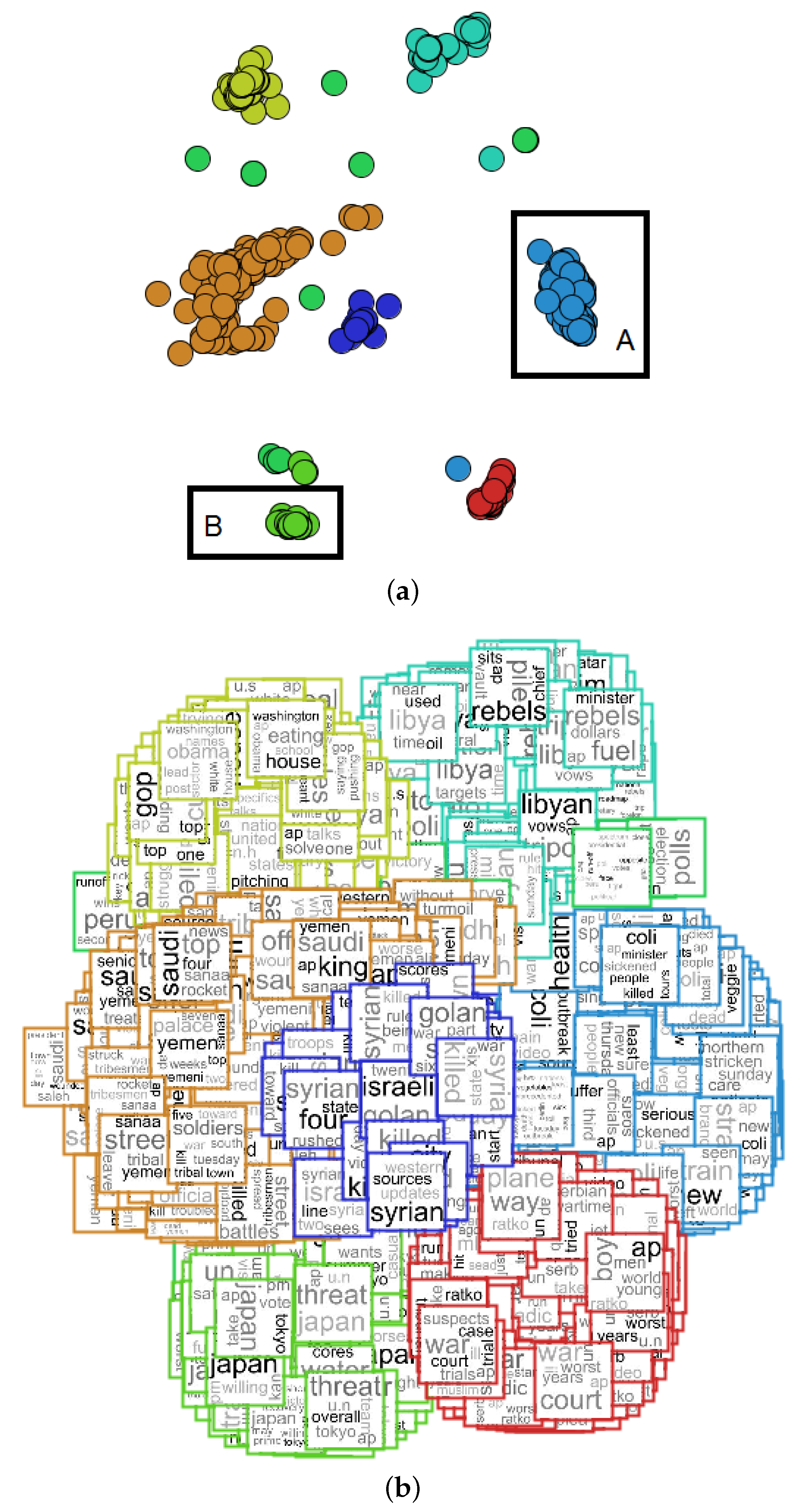{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
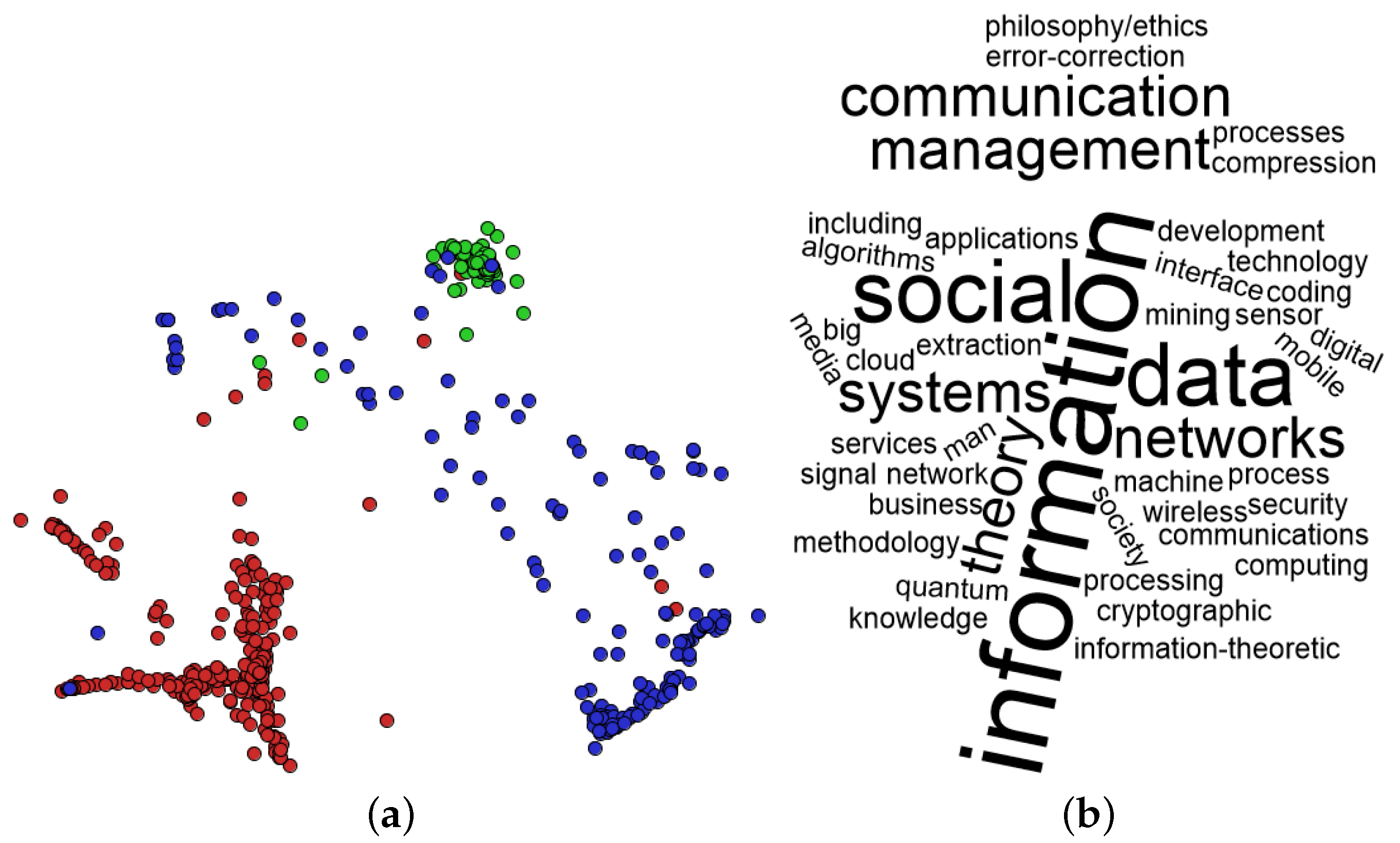
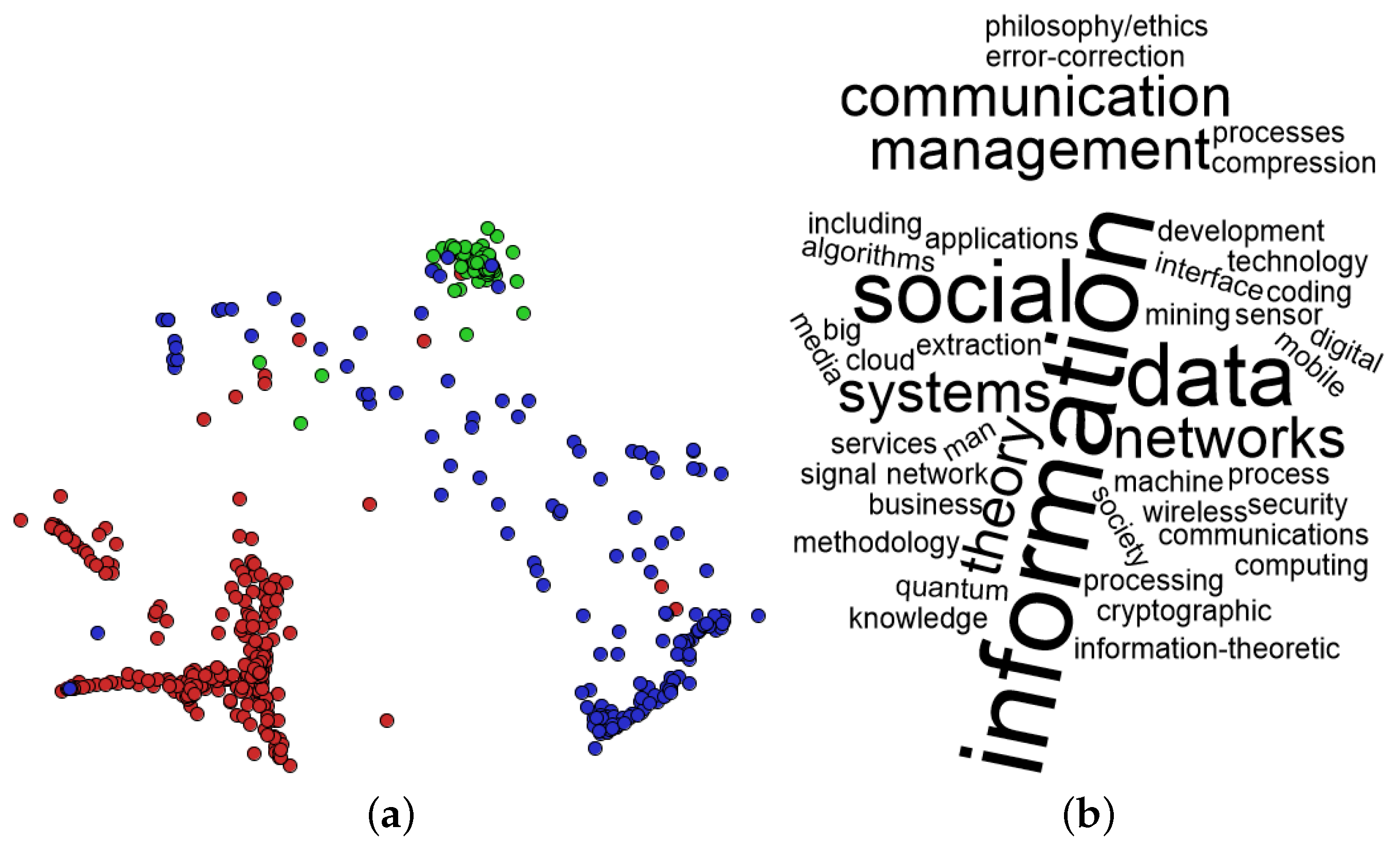
2. Background
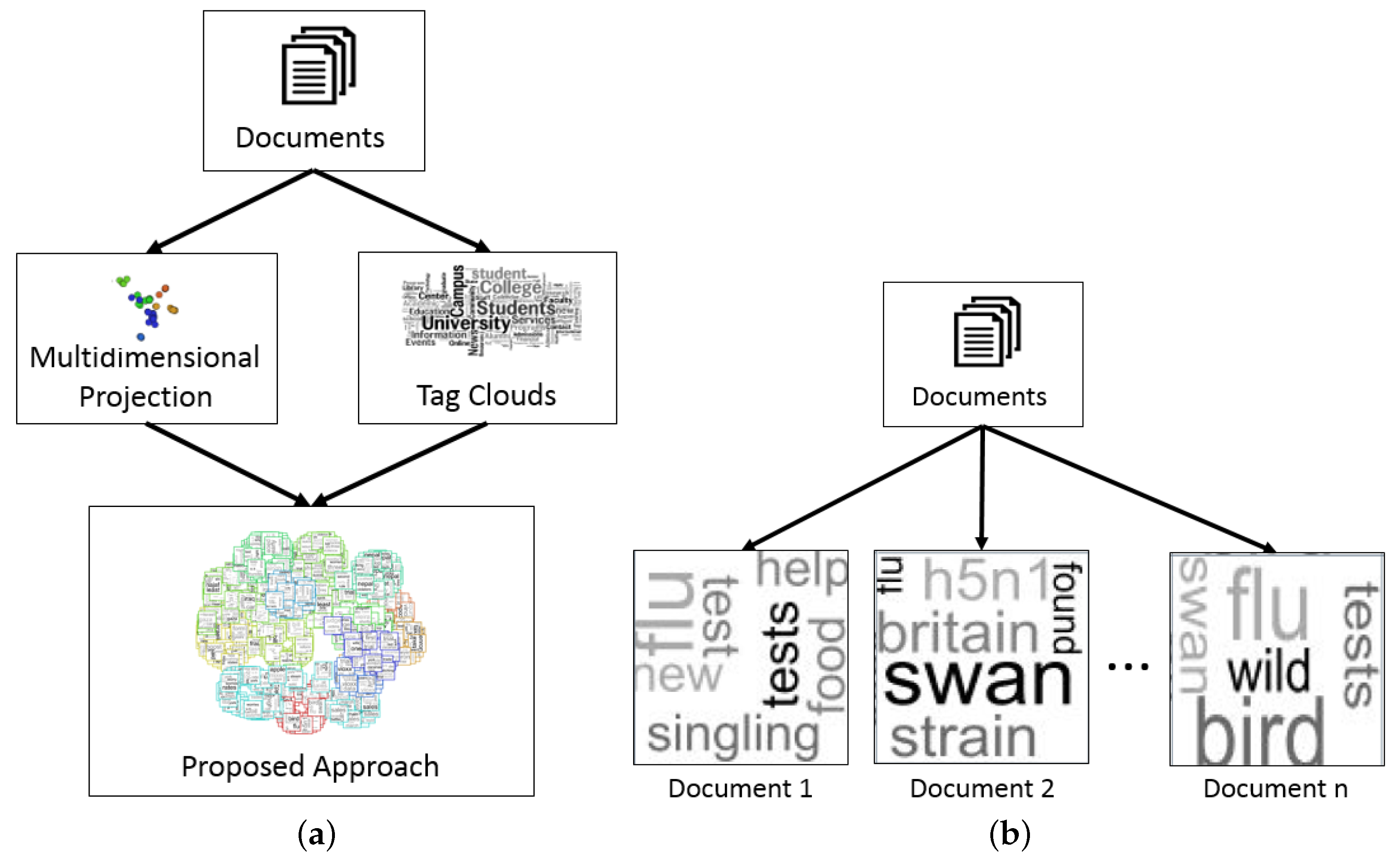
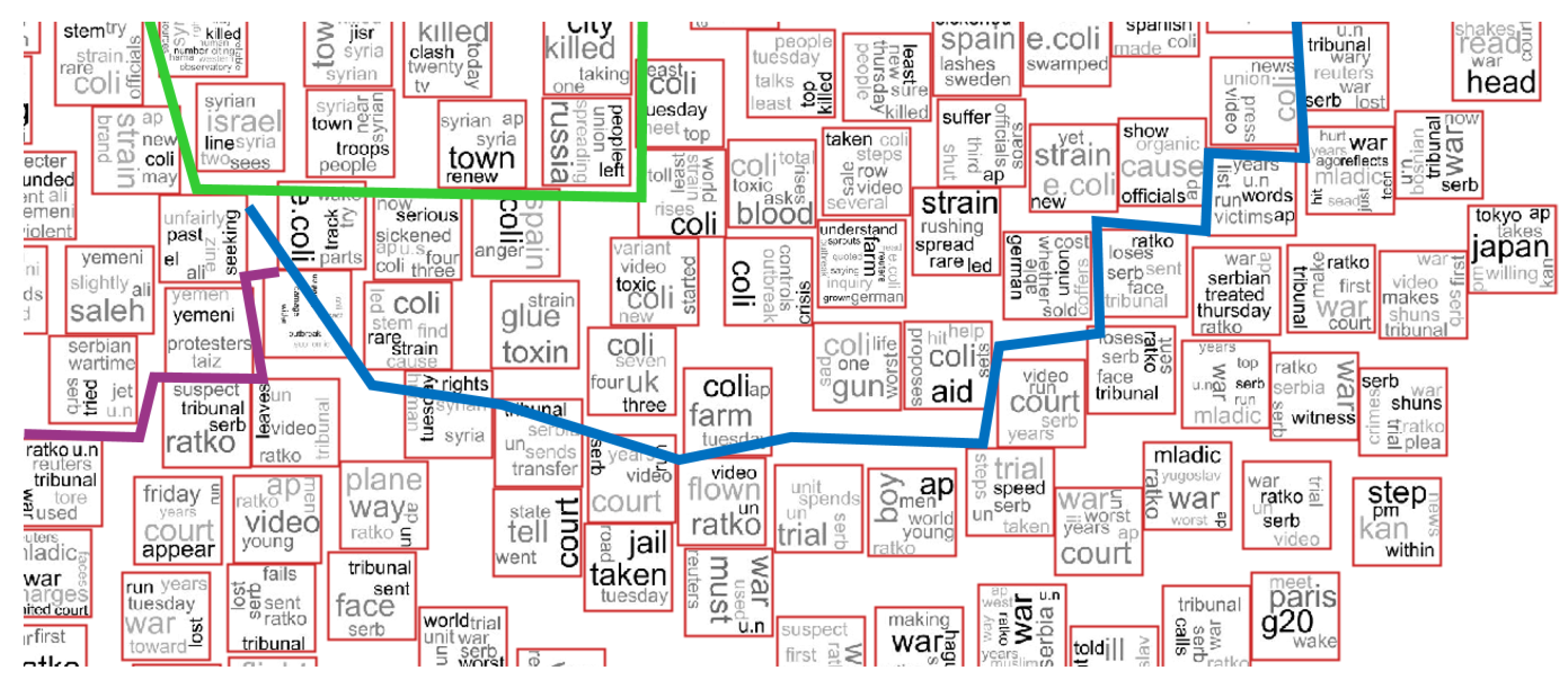
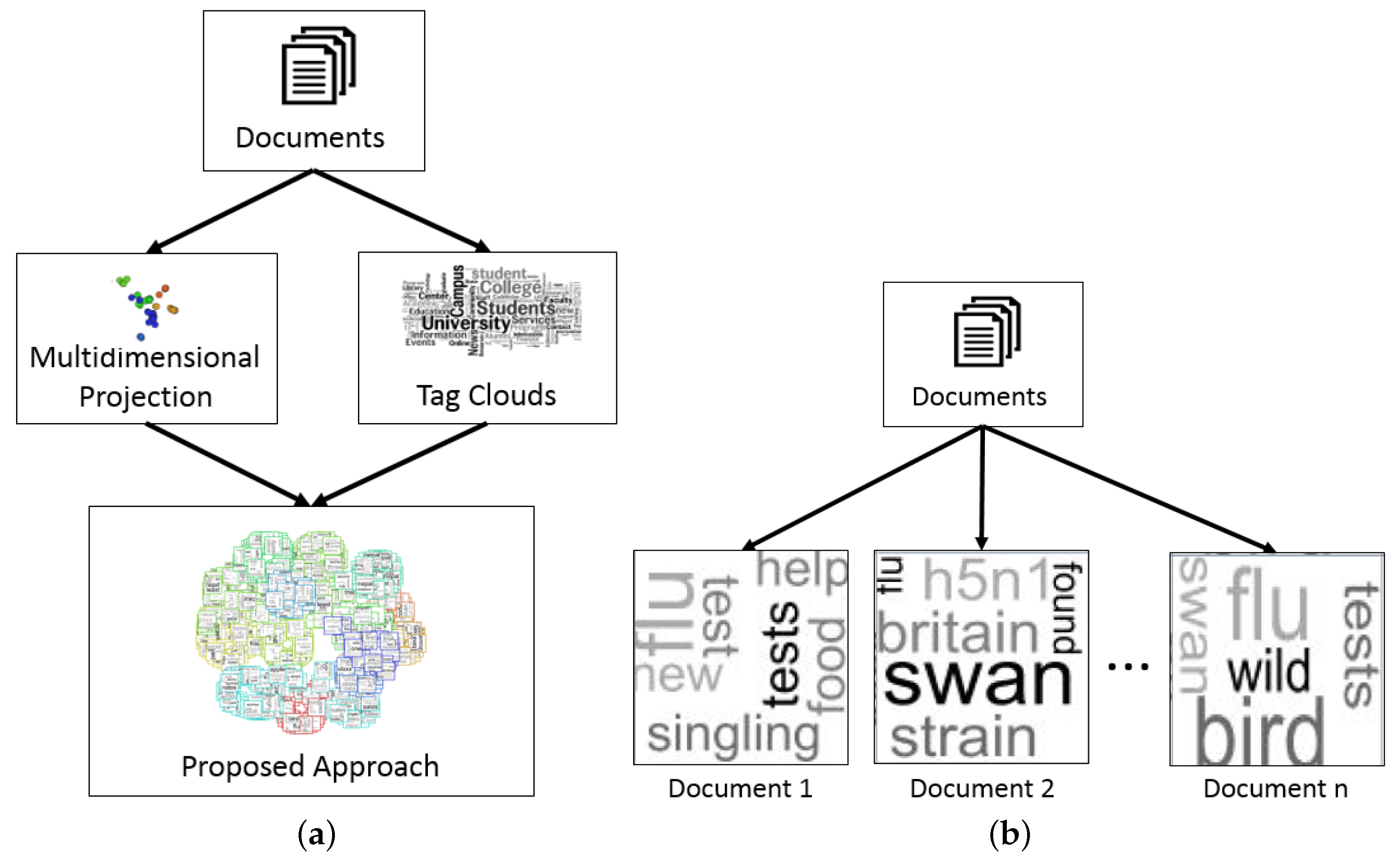
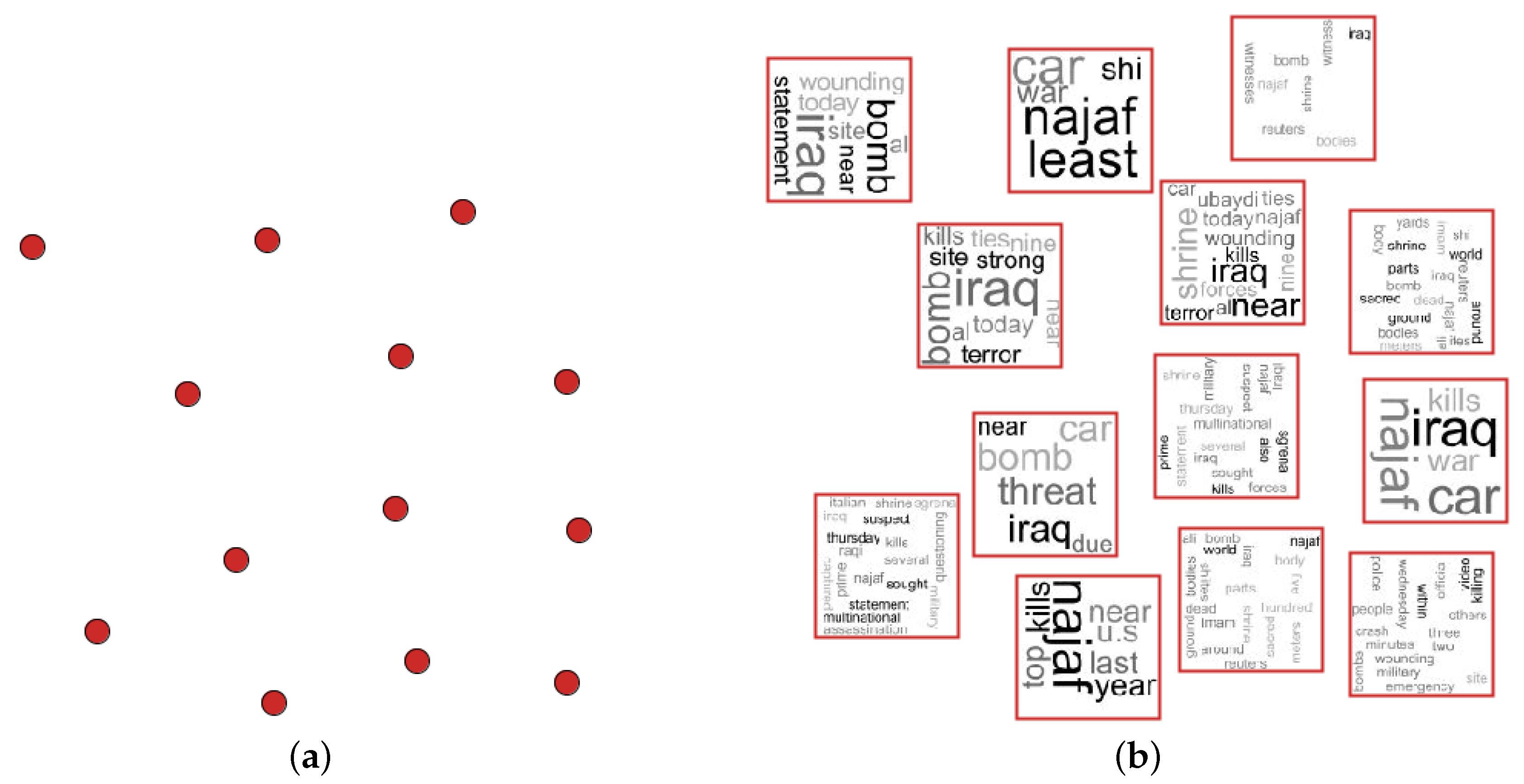
3. Proposed Approach
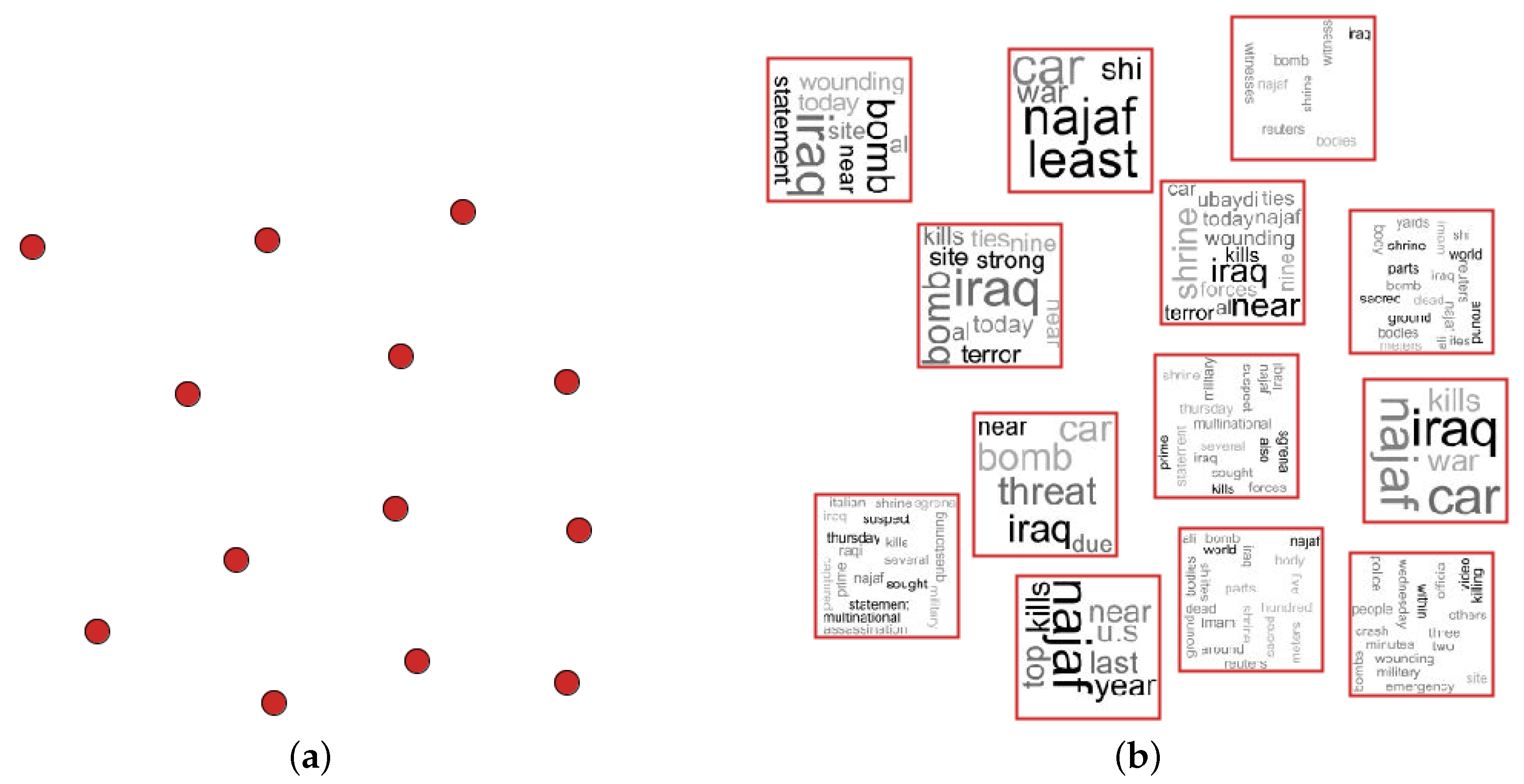
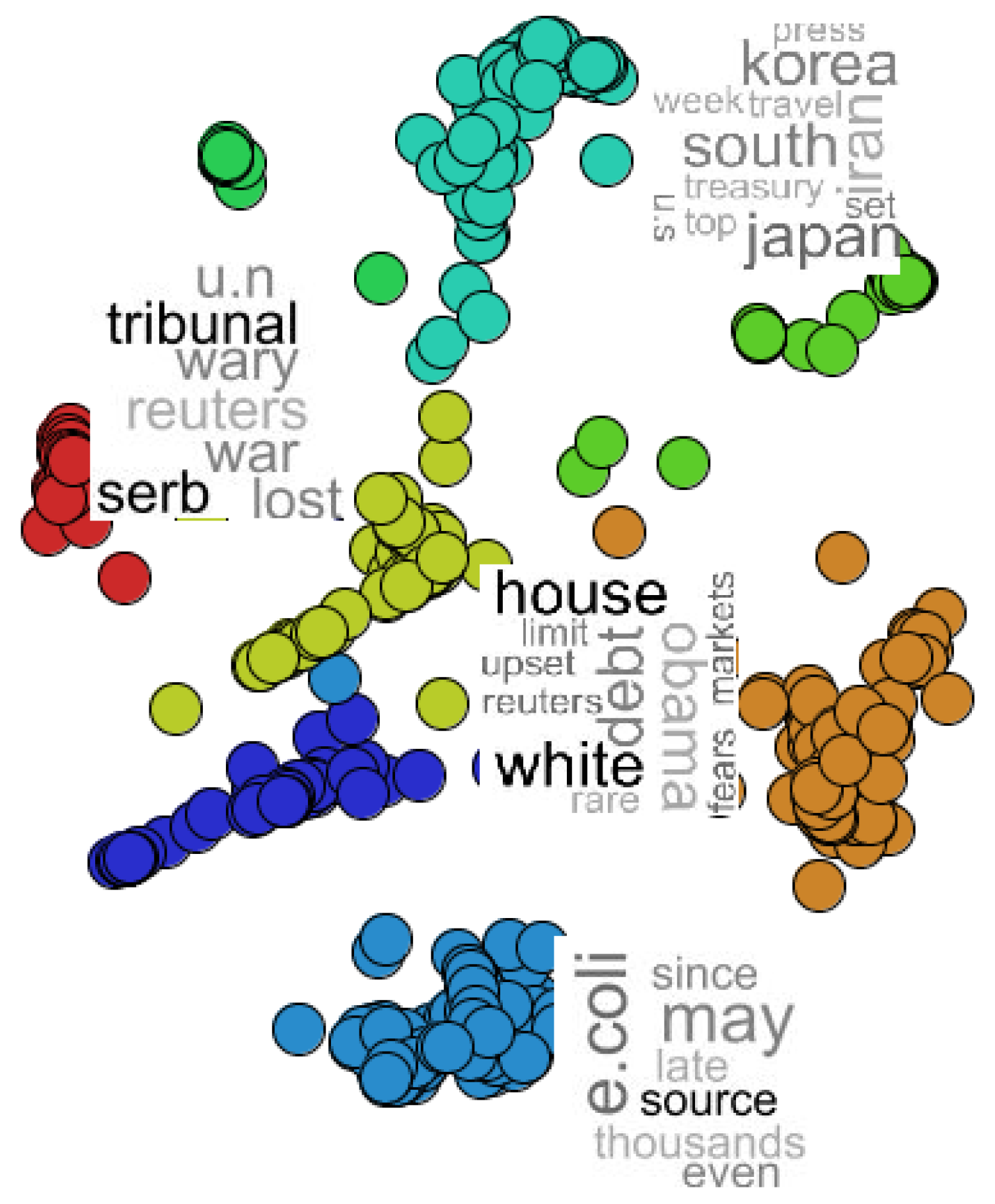
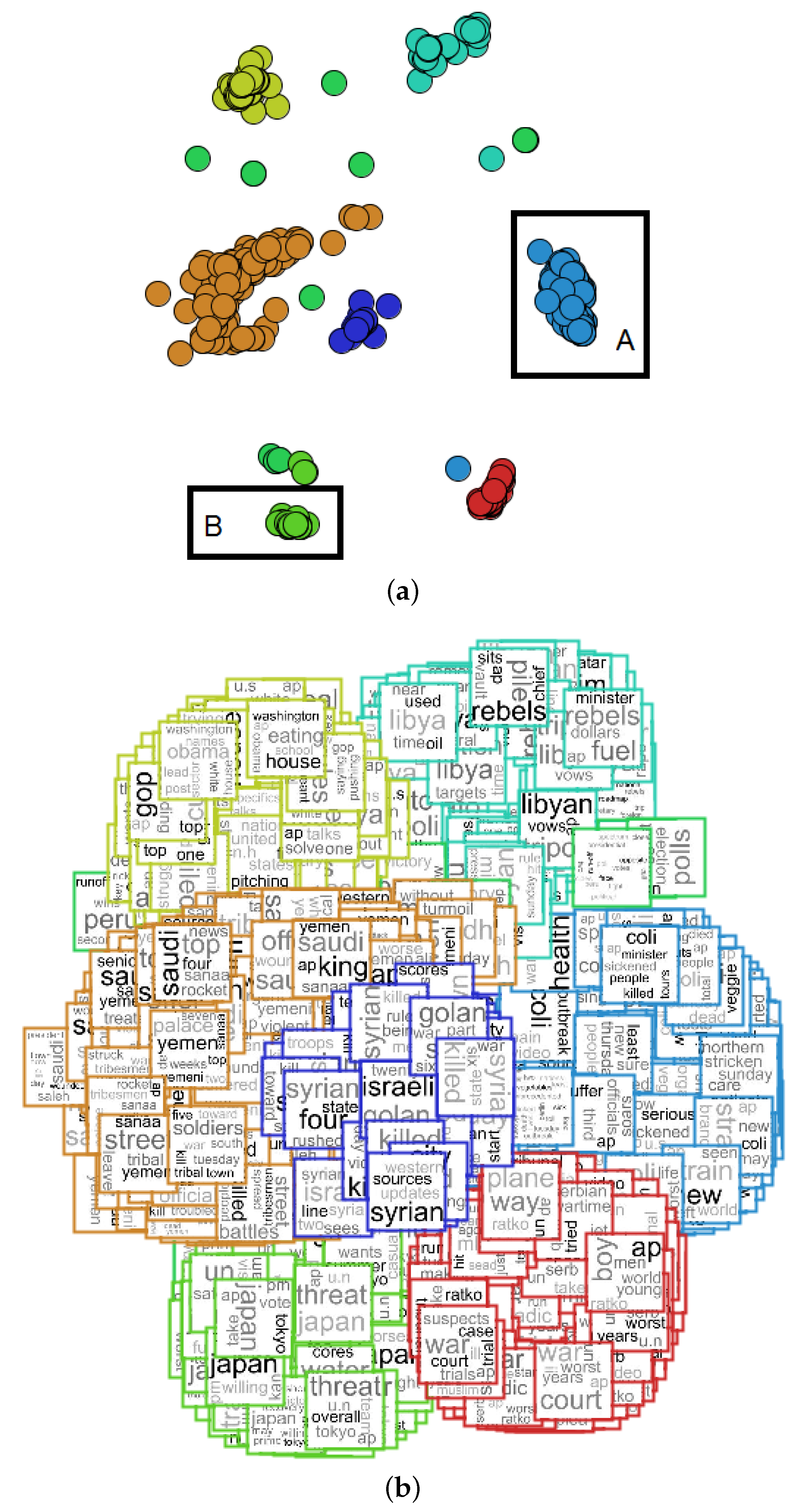
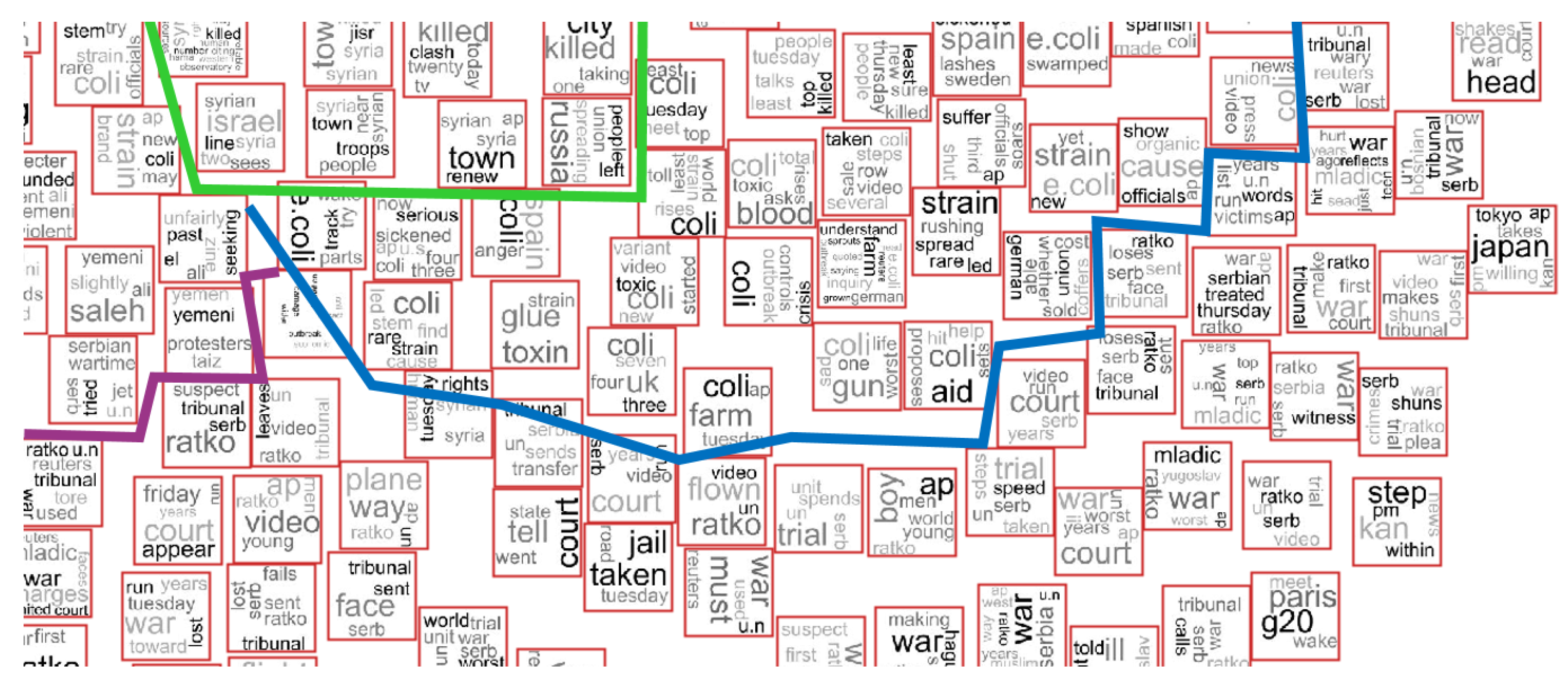
4. Applications
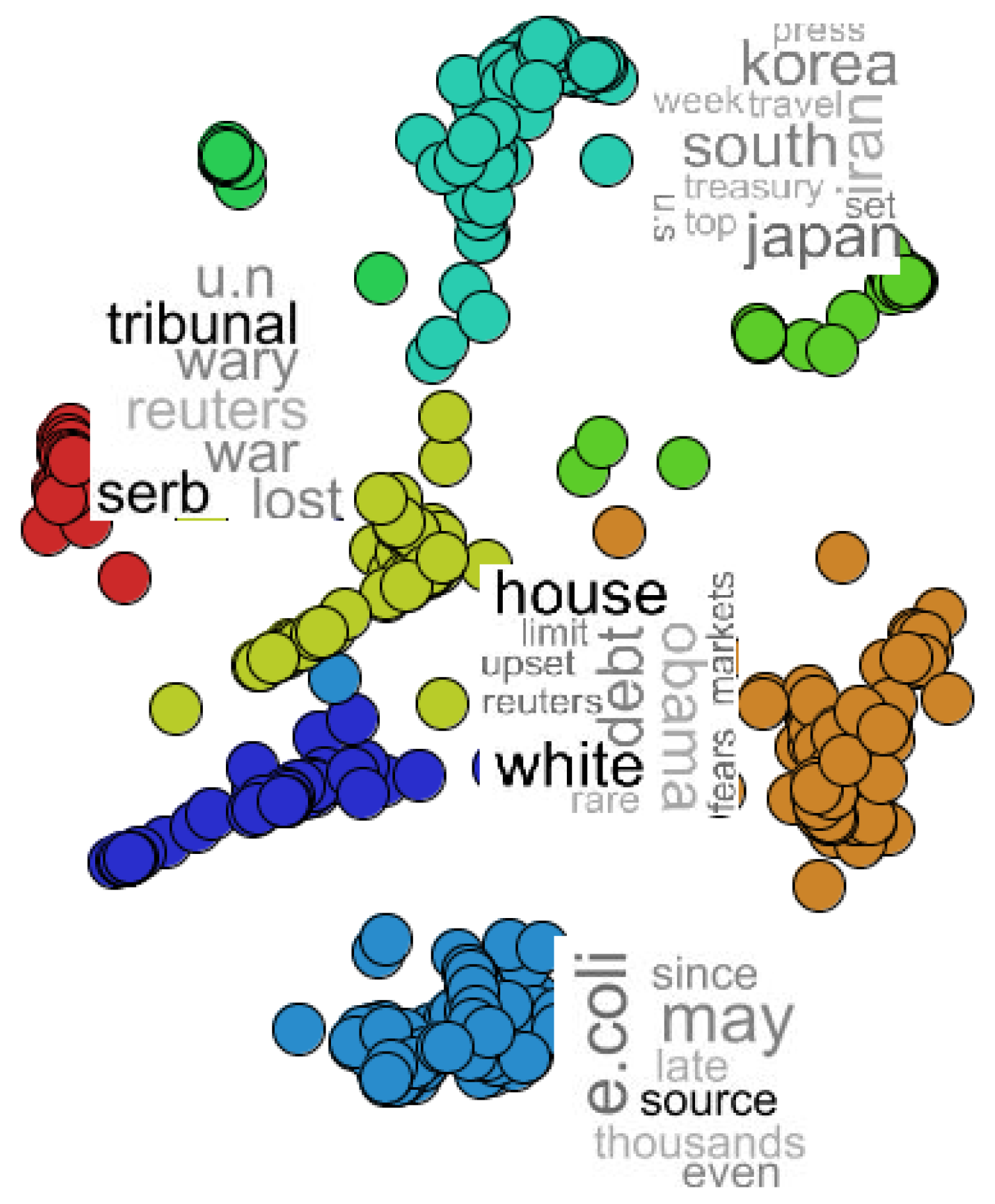
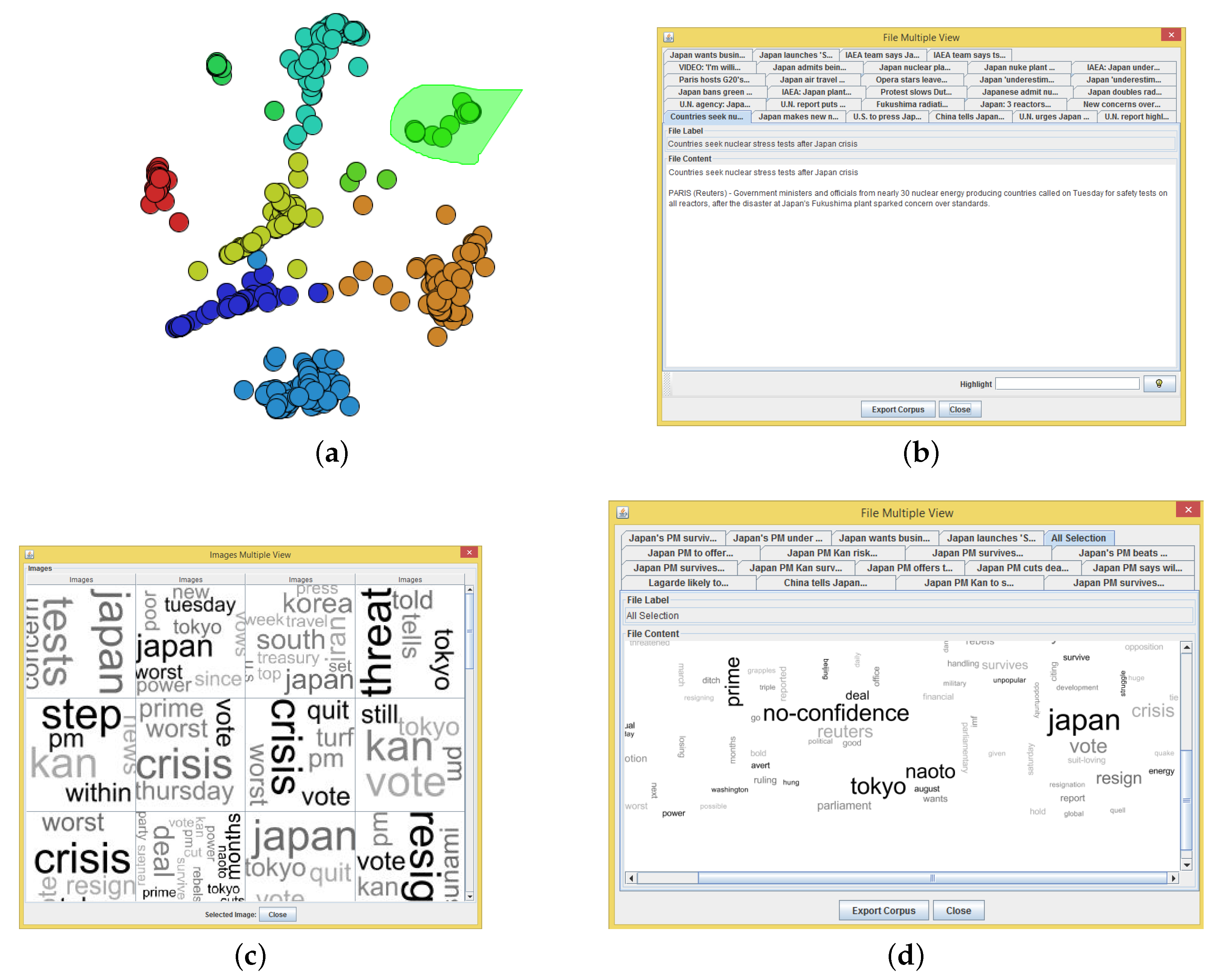
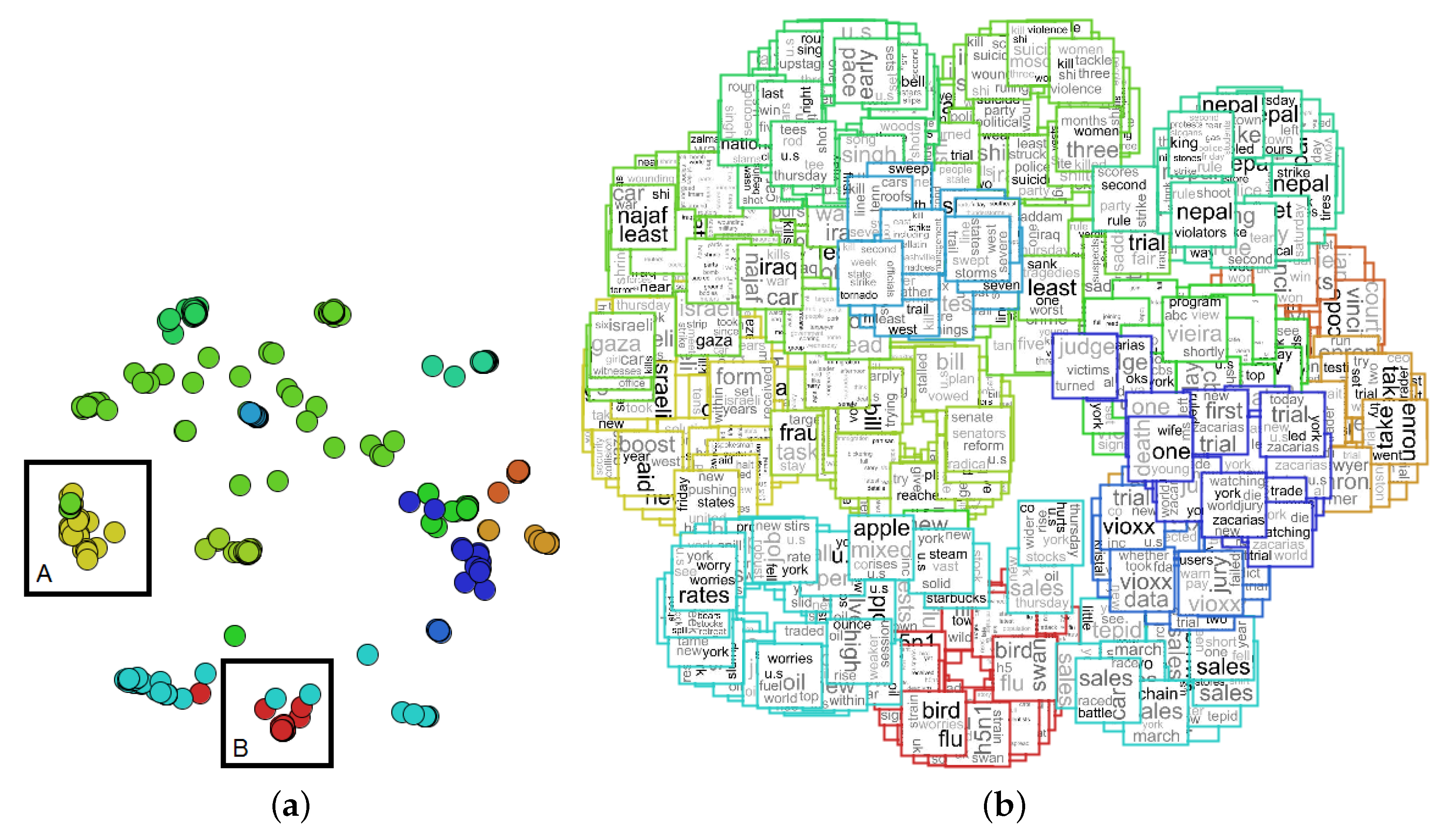
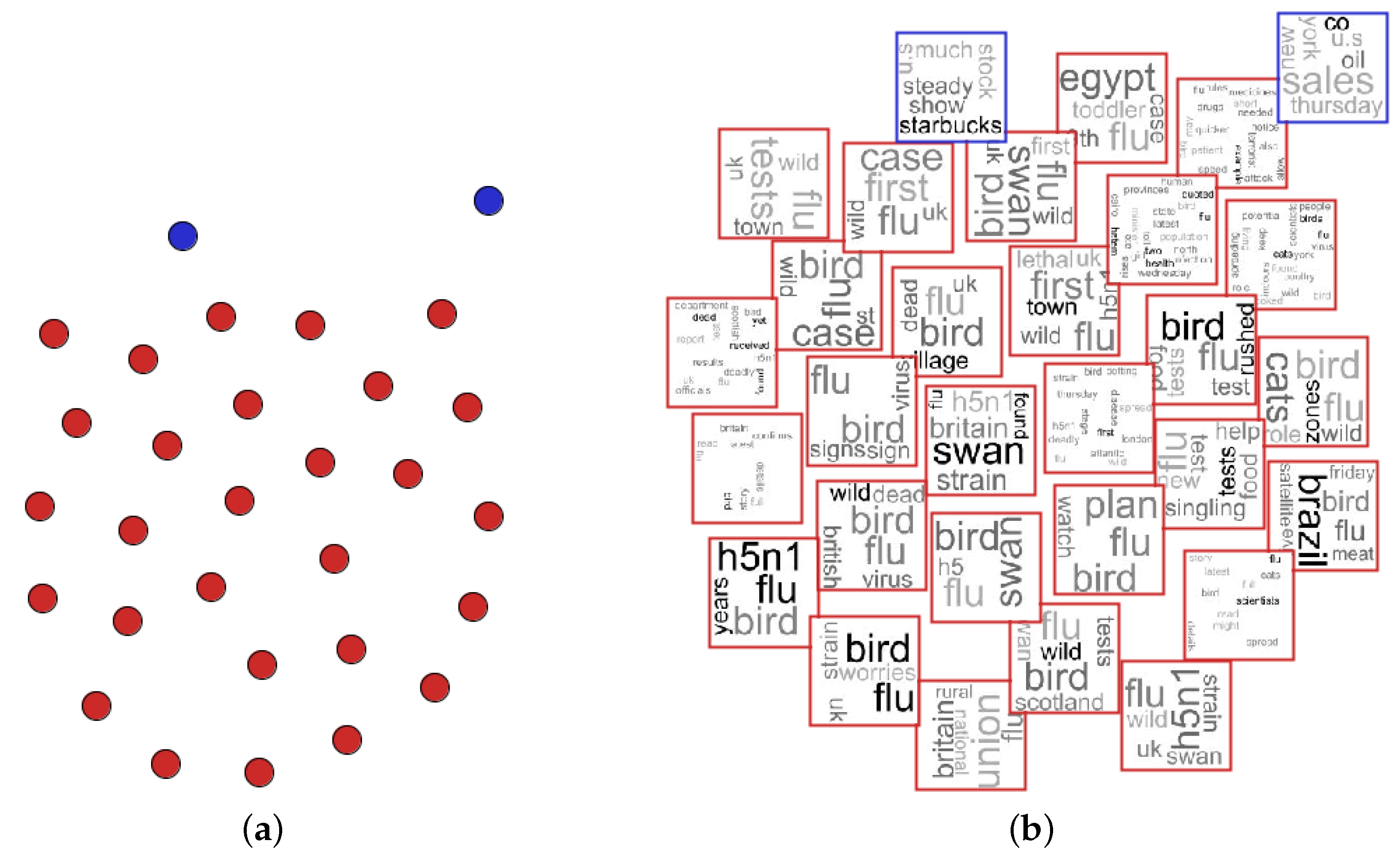
- NEWS-8: 495 news articles from Reuters, AP, BBC and CNN, divided into eight classes;
- NEWS-13: RSS news from BBC, CNN, Reuters and Associated Press, collected during two days in April 2006. We only used 381 documents, which are divided into 13 classes of news.
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tejada, E.; Minghim, R.; Nonato, L.G. On Improved Projection Techniques to Support Visual Exploration of Multidimensional Data Sets. Inf. Visual. 2003, 2, 218–231. [Google Scholar] [CrossRef]
- Eler, D.M.; Almeida, A.; Teixeira, J.; Pola, I.; Pola, F.; Dias, M.; Olivete, C. Feature Space Unidimensional Projections for Scatterplots. Colloq. Exactarum 2017, 9, 58–68. [Google Scholar] [CrossRef]
- Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information 2018, 9, 100. [Google Scholar] [CrossRef]
- Silva, L.F.; Eler, D.M. Visual Approach to Boundary Detection of Clusters Projected in 2D Space. In Proceedings of the 14th International Conference on Information Technology: New Generations (ITNG 2017), Las Vegas, NV, USA, 10–12 April 2017; Advances in Intelligent Systems and Computing. Springer International Publishing: Cham, Switzerland, 2017; pp. 849–854. [Google Scholar]
- Card, S.; Mackinlay, J.; Shneiderman, B. Readings in Information Visualization: Using Vision to Think; Interactive Technologies Series; Morgan Kaufmann Publishers: Burlington, MA, USA, 1999. [Google Scholar]
- Ware, C. Information Visualization: Perception for Design; Interactive Technologies; Elsevier Science: New York, NY, USA, 2012. [Google Scholar]
- De Oliveira, M.; Levkowitz, H. From visual data exploration to visual data mining: A survey. IEEE Trans. Visual. Comput. Graph. 2003, 9, 378–394. [Google Scholar] [CrossRef]
- Paulovich, F.V.; Nonato, L.G.; Minghim, R.; Levkowitz, H. Least square projection: A fast high-precision multidimensional projection technique and its application to document mapping. IEEE Trans. Visual. Comput. Graph. 2008, 14, 564–575. [Google Scholar] [CrossRef] [PubMed]
- Paulovich, F.V.; Oliveira, M.C.F.; Minghim, R. The projection explorer: A flexible tool for projection-based multidimensional visualization. In Proceedings of the SIBGRAPI 2007 XX Brazilian Symposium on Computer Graphics and Image Processing, Minas Gerais, Brazil, 7–10 October 2007; pp. 27–36. [Google Scholar]
- Burch, M.; Lohmann, S.; Beck, F.; Rodriguez, N.; Di Silvestro, L.; Weiskopf, D. RadCloud: Visualizing Multiple Texts with Merged Word Clouds. In Proceedings of the 2014 18th International Conference on Information Visualisation (IV), Paris, France, 16–18 July 2014; pp. 108–113. [Google Scholar]
- Lohmann, S.; Heimerl, F.; Bopp, F.; Burch, M.; Ertl, T. Concentri Cloud: Word Cloud Visualization for Multiple Text Documents. In Proceedings of the 2015 19th International Conference on Information Visualisation, Barcelona, Spain, 21–24 July 2015; pp. 114–120. [Google Scholar]
- Chen, Y.X.; Santamaría, R.; Butz, A.; Therón, R. TagClusters: Semantic Aggregation of Collaborative Tags beyond TagClouds. In Proceedings of the 10th International Symposium on Smart Graphics, Salamanca, Spain, 28–30 May 2009; Butz, A., Fisher, B., Christie, M., Krüger, A., Olivier, P., Therón, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 56–67. [Google Scholar]
- Paulovich, F.V.; Toledo, F.M.B.; Telles, G.P.; Minghim, R.; Nonato, L.G. Semantic Wordification of Document Collections. Comput. Graph. Forum 2012, 31, 1145–1153. [Google Scholar] [CrossRef]
- Eler, D.M.; Teixeira, J.B.M.; Macanha, P.A.; Garcia, R.E. Simplified Stress and Simplified Silhouette Coefficient to a Faster Quality Evaluation of Multidimensional Projection Techniques and Feature Spaces. In Proceedings of the International Conference on Information Visualization, Barcelona, Spain, 21–24 July 2015; IEEE Computer Society: New York, NY, USA, 2015; pp. 133–139. [Google Scholar]
- Eler, D.M.; Garcia, R.E. Using Otsu’s Threshold Selection Method for Eliminating Terms in Vector Space Model Computation. In Proceedings of the International Conference on Information Visualization, London, UK, 16–18 July 2013; IEEE Computer Society: New York, NY, USA, 2013; pp. 220–226. [Google Scholar]
- G-Nieto, E.; Roman, F.S.; Pagliosa, P.; Casaca, W.; Helou, E.S. Similarity Preserving Snippet-Based Visualization of Web Search Results. IEEE Trans. Visual. Comput. Graph. 2014, 20, 457–470. [Google Scholar] [CrossRef] [PubMed]
- Gansner, E.R.; Hu, Y. Efficient, Proximity-Preserving Node Overlap Removal. J. Graph. Algorithms Appl. 2010, 14, 53–74. [Google Scholar] [CrossRef]
- Dwyer, T.; Marriott, K.; Stuckey, P.J. Fast Node Overlap Removal. In Proceedings of the 13th International Conference on Graph Drawing, Limerick, Ireland, 12–14 July 2005; pp. 153–164. [Google Scholar]
- Strobelt, M.; Spicker, M.; Stoffel, A.; Keim, D.; Deussen, O. Rolled-out Wordles: A Heuristic Method for Overlap Removal of 2D Data Representatives. Comput. Graph. Forum 2012, 31, 1135–1144. [Google Scholar] [CrossRef]




© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andreotti, A.L.D.; Silva, L.F.; Eler, D.M. Hybrid Visualization Approach to Show Documents Similarity and Content in a Single View. Information 2018, 9, 129. https://doi.org/10.3390/info9060129
Andreotti ALD, Silva LF, Eler DM. Hybrid Visualization Approach to Show Documents Similarity and Content in a Single View. Information. 2018; 9(6):129. https://doi.org/10.3390/info9060129
Chicago/Turabian StyleAndreotti, Andre Luiz Dias, Lenon Fachiano Silva, and Danilo Medeiros Eler. 2018. "Hybrid Visualization Approach to Show Documents Similarity and Content in a Single View" Information 9, no. 6: 129. https://doi.org/10.3390/info9060129
APA StyleAndreotti, A. L. D., Silva, L. F., & Eler, D. M. (2018). Hybrid Visualization Approach to Show Documents Similarity and Content in a Single View. Information, 9(6), 129. https://doi.org/10.3390/info9060129