Calibration of C-Logit-Based SUE Route Choice Model Using Mobile Phone Data


Abstract
1. Introduction
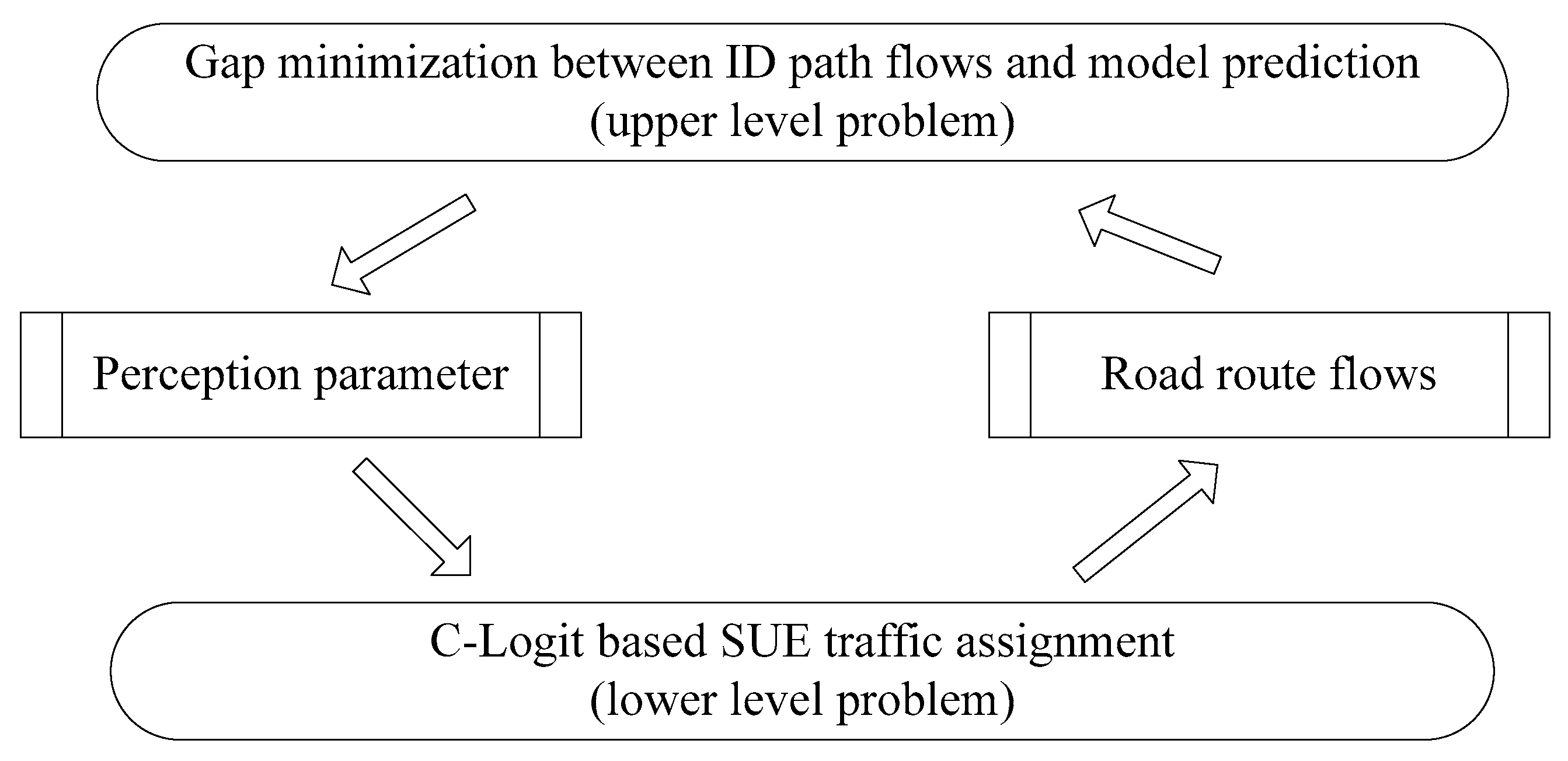
2. Methodology
2.1. Model of Upper Level
Minimization of Flow-Ratio Gap Square
2.2. Model of Lower Level
3. Solution Algorithms
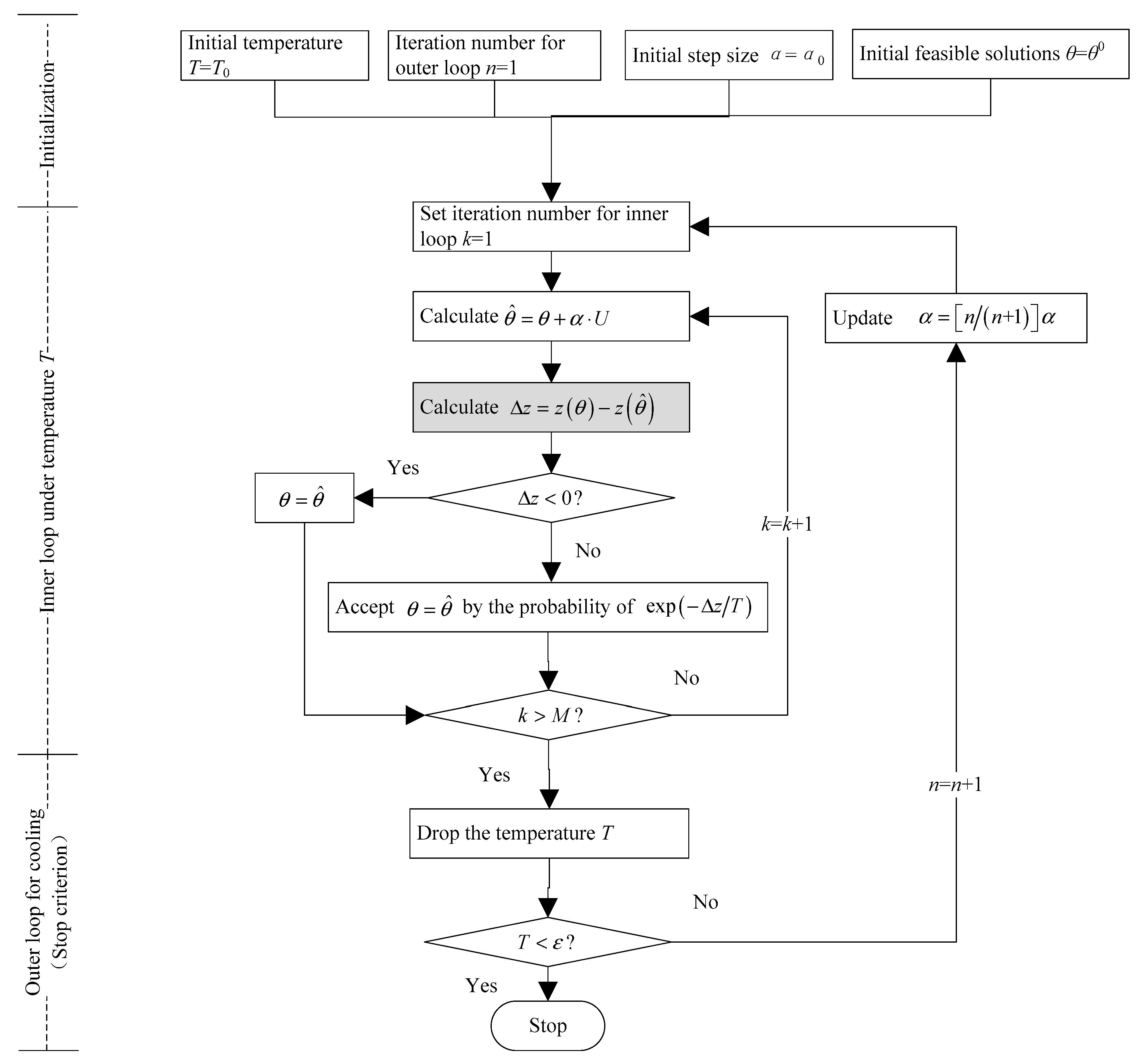
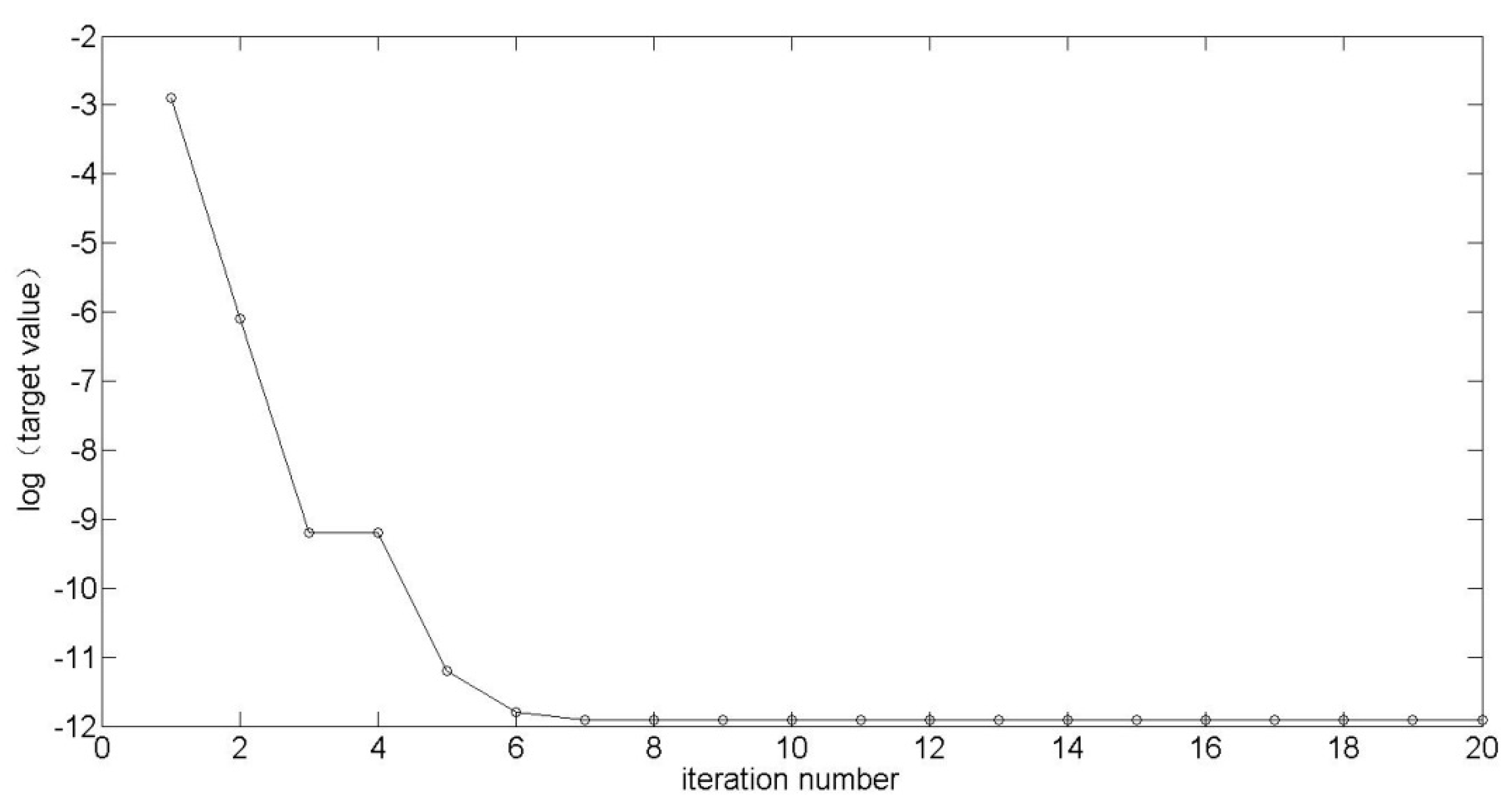
3.1. Adopted SA Algorithm
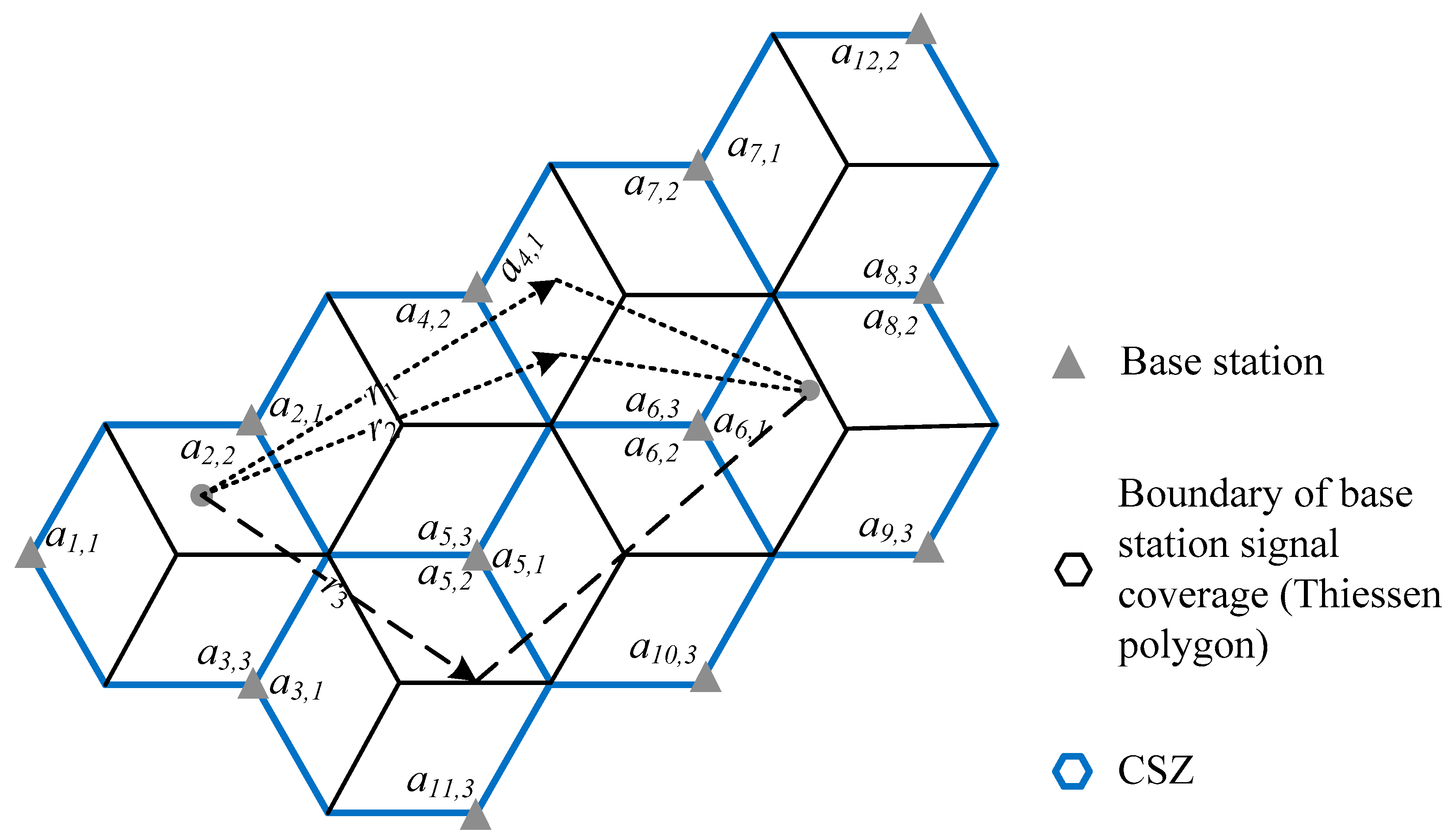
3.2. Objective Function Calculation Inside SA Algorithm
4. Case Study
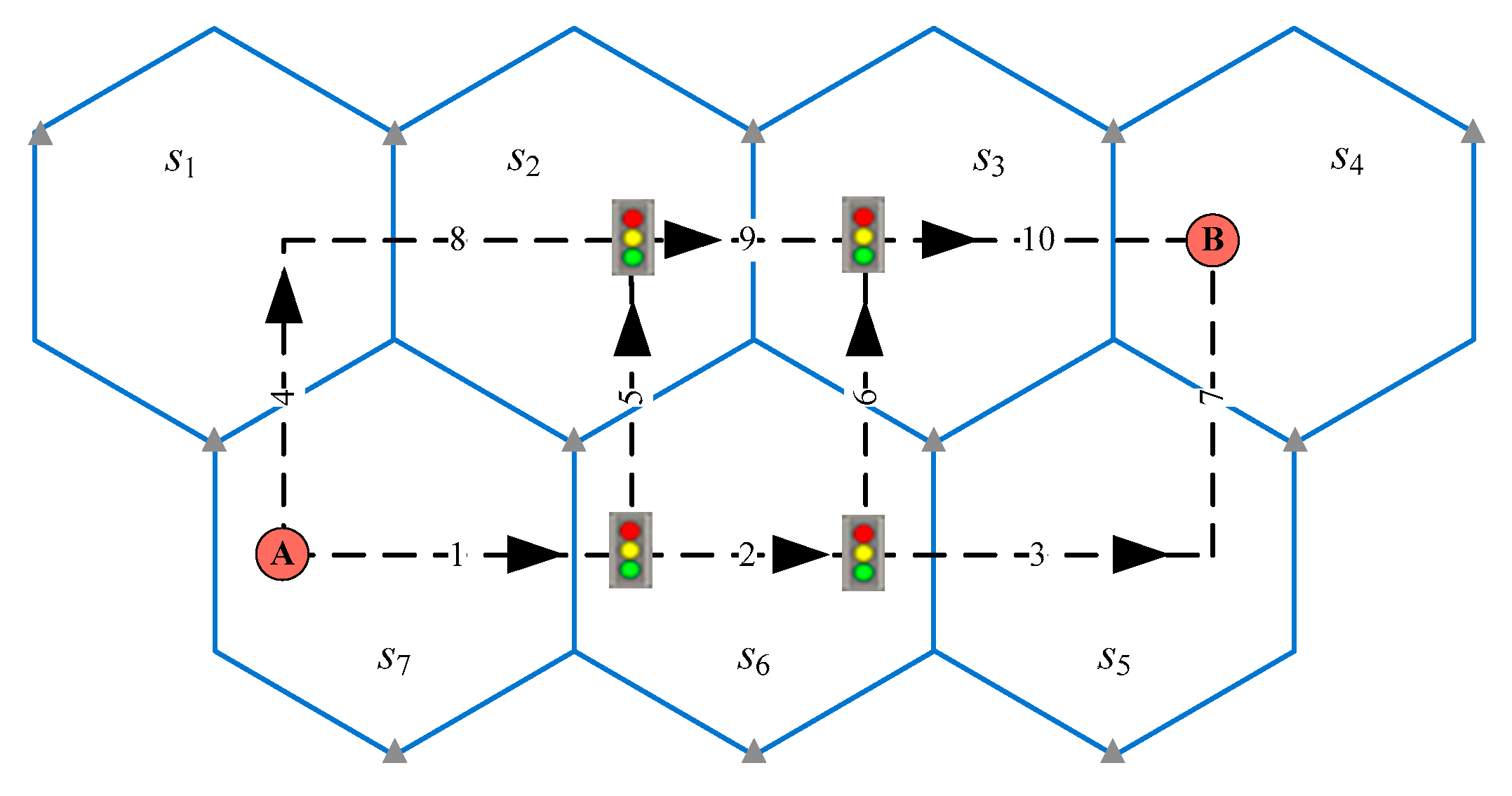
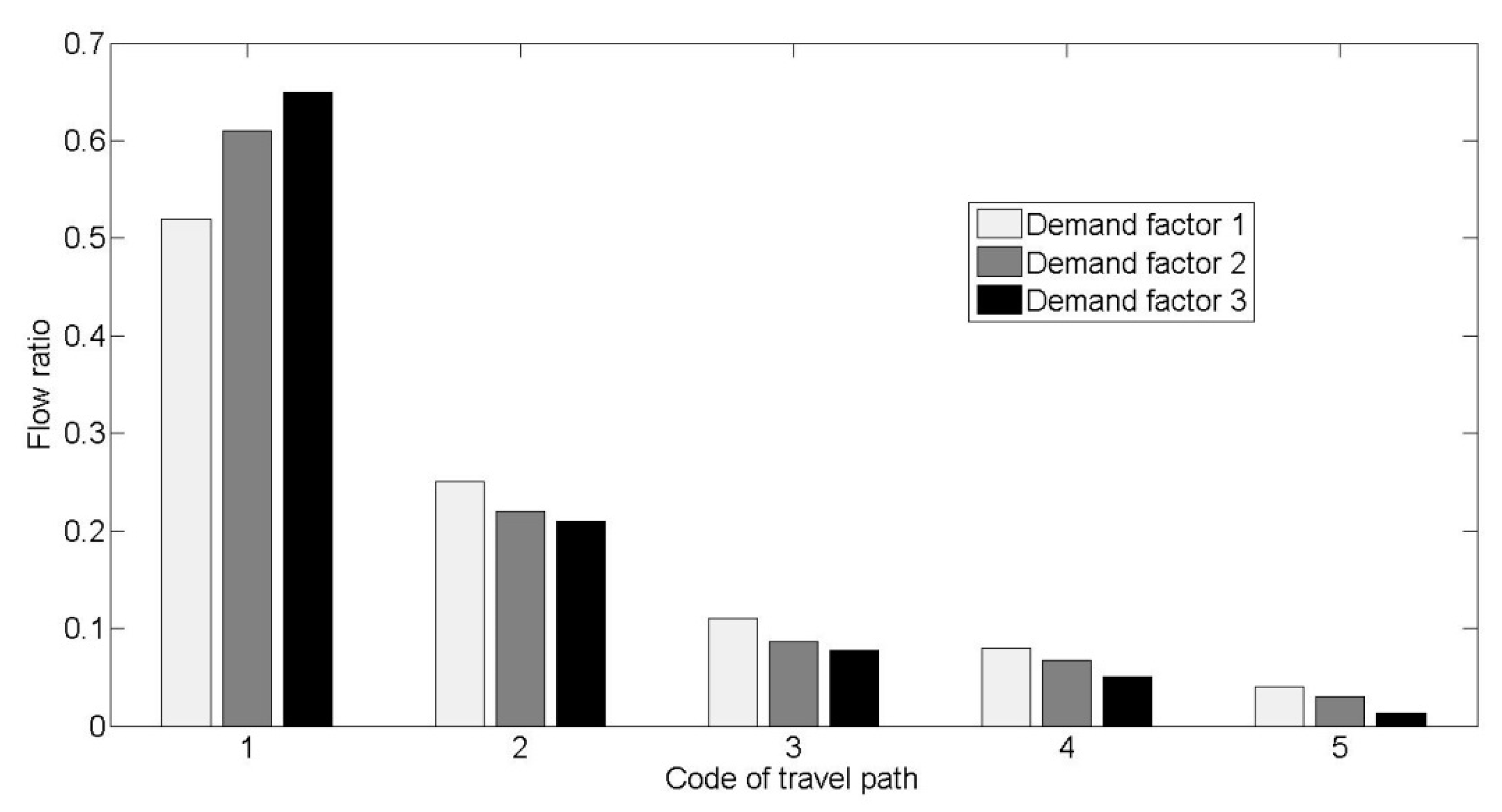
4.1. Small-Sized Network
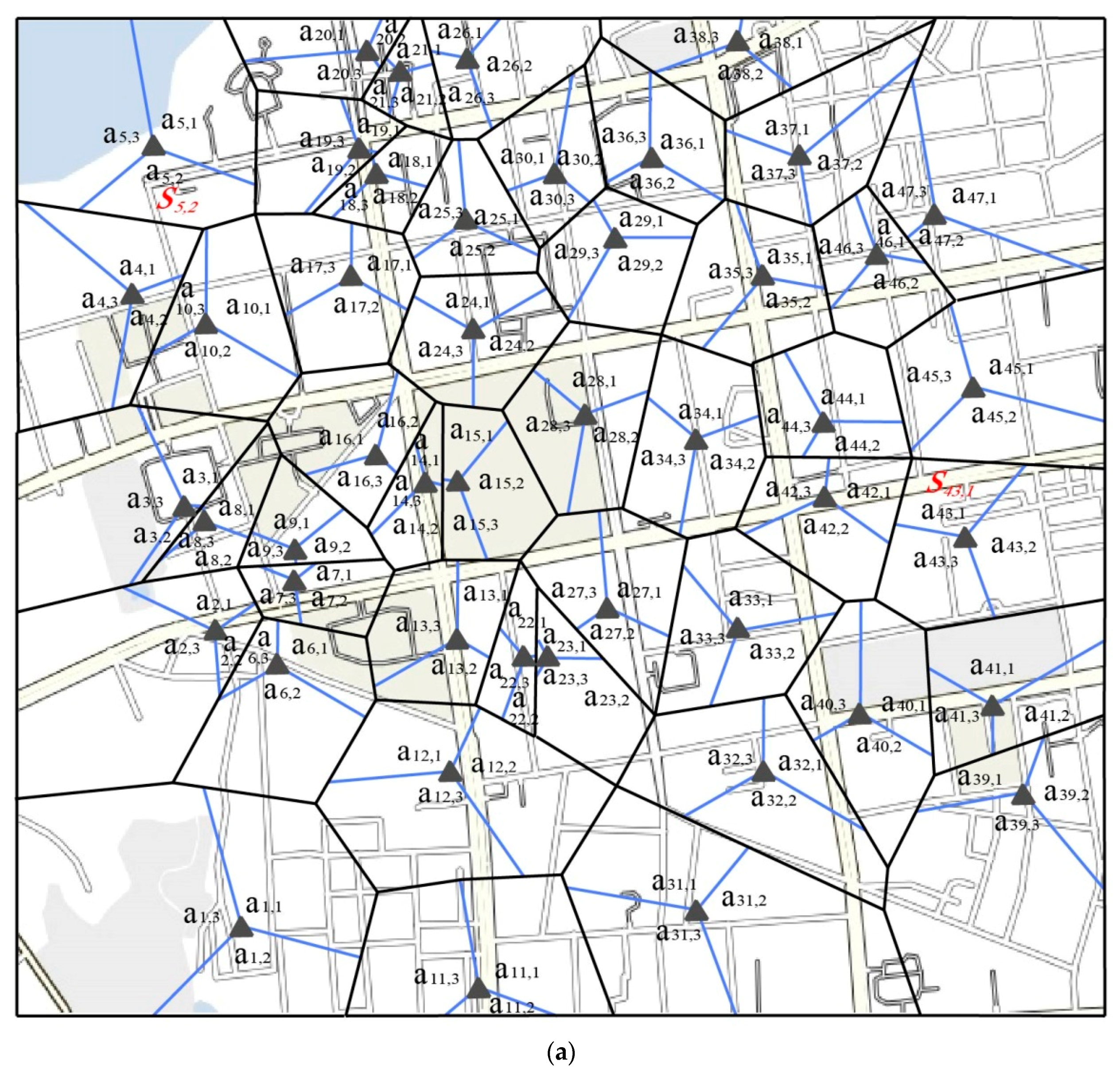
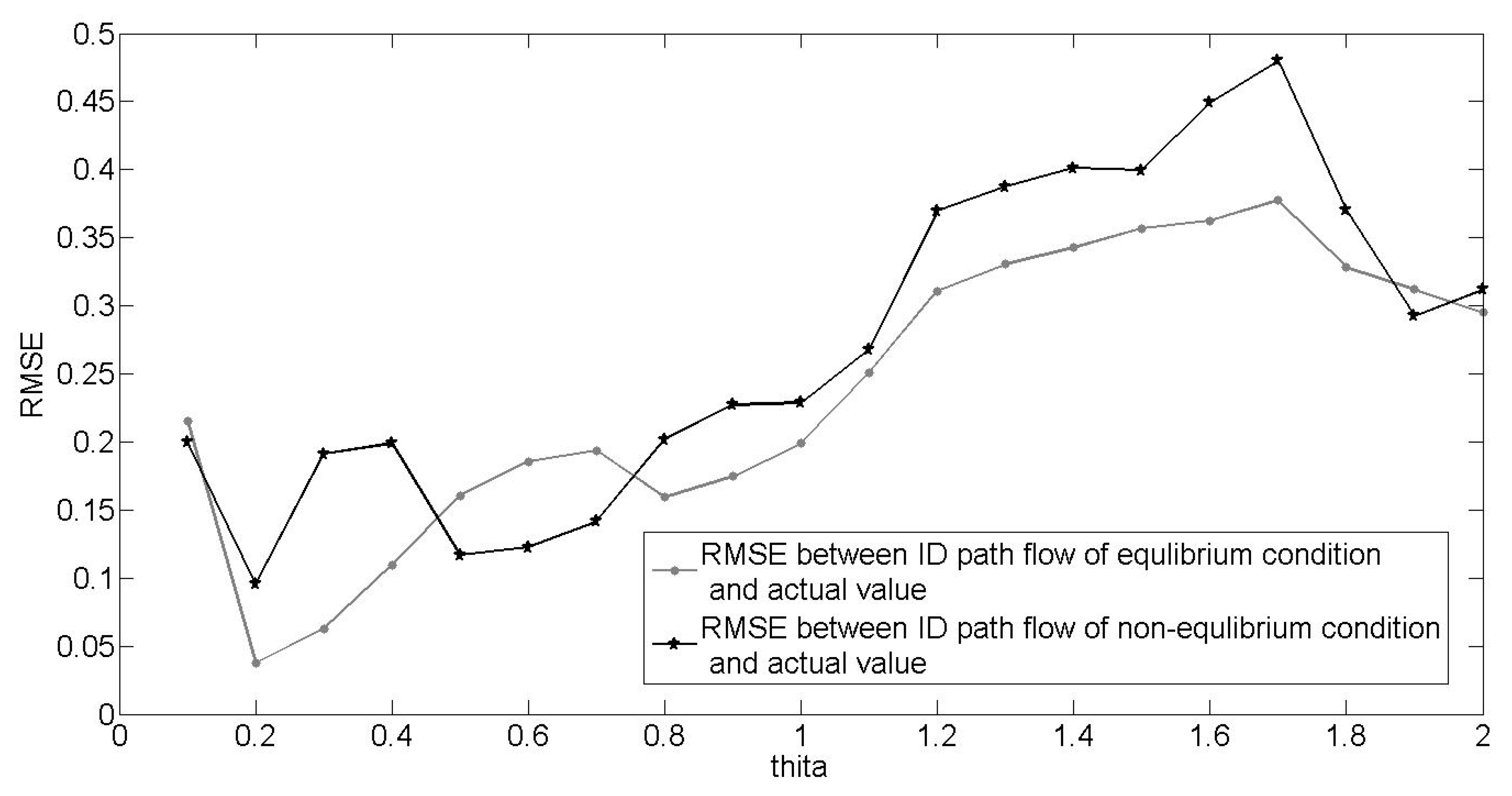
4.2. Case Study for Urban Street Network
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Cascetta, E.; Nuzzolo, A.; Russo, F.; Vitetta, A. A modified logit route choice model overcoming path overlapping problems: Specification and some calibration results for interurban networks. In Proceedings of the 13th International Symposium on Transportation and Traffic Theory, Oxford, NY, USA, 24–26 June 1996; pp. 697–711. [Google Scholar]
- Bekhor, S.; Prashker, J. Stochastic user equilibrium formulation for generalized nested logit model. Transp. Res. Record J. Transp. Res. Board 2001, 1752, 84–90. [Google Scholar] [CrossRef]
- Ben-Akiva, M.; Bierlaire, M. Discrete choice methods and their applications to short term travel decisions. In Handbook of Transportation Science; Springer: New York, NY, USA, 1999; pp. 5–33. [Google Scholar]
- Xu, X.; Chen, A.; Zhou, Z.; Bekhor, S. Path-based algorithms to solve c-logit stochastic user equilibrium assignment problem. Transp. Res. Record J. Transp. Res. Board 2012, 2279, 21–30. [Google Scholar] [CrossRef]
- Zhang, X.; Rey, D.; Waller, S.T. Method of parameter calibration for error term in stochastic user equilibrium traffic assignment model. World Acad. Sci. Eng. Technol. Int. J. Math. Comput. Phys. Electr. Comput. Eng. 2014, 8, 1397–1403. [Google Scholar]
- Quddus, M.A.; Ochieng, W.Y.; Noland, R.B. Current map-matching algorithms for transport applications: State-of-the art and future research directions. Transp. Res. Part C Emerg. Technol. 2007, 15, 312–328. [Google Scholar] [CrossRef]
- Schuessler, N.; Axhausen, K.W. Processing Raw Data from Global Positioning Systems Without Additional Information. Transp. Res. Record J. Transp. Res. Board 2009, 2105, 28–36. [Google Scholar] [CrossRef]
- Bierlaire, M.; Chen, J.; Newman, J. Modeling Route Choice Behavior from Smartphone GPS data. In Proceedings of the 12th International Conference on Travel Behaviour Research, Jaipur, Rajasthan, India, 13–16 December 2009. [Google Scholar]
- Ozdemir, E.; Topcu, A.E.; Ozdemir, M.K. A hybrid HMM model for travel path inference with sparse GPS samples. Transportation 2018, 45, 233–246. [Google Scholar] [CrossRef]
- Iqbal, M.S.; Choudhury, C.F.; Wang, P.; González, M.C. Development of origin–destination matrices using mobile phone call data. Transp. Res. Part C Emerg. Technol. 2014, 40, 63–74. [Google Scholar] [CrossRef]
- Wu, C.; Thai, J.; Yadlowsky, S.; Pozdnoukhov, A.; Bayen, A. Cellpath: Fusion of cellular and traffic sensor data for route flow estimation via convex optimization. Transp. Res. Part C Emerg. Technol. 2015, 59, 111–128. [Google Scholar] [CrossRef]
- Yadlowsky, S.; Thai, J.; Wu, C.; Pozdnukhov, A.; Bayen, A. Link density inference from cellular infrastructure. In Proceedings of the Transportation Research Board (TRB) 94th Annual Meeting, Washington, DC, USA, 11–15 January 2014. [Google Scholar]
- Jiang, S.; Ferreira, J.; González, M.C. Activity-based human mobility patterns inferred from mobile phone data: A case study of Singapore. IEEE Trans. Big Data 2017, 3, 208–219. [Google Scholar] [CrossRef]
- Chiou, Y.C.; Hsieh, C.W. A virtual trip line matching model for cellular vehicle probe positioning and tracking. J. East. Asia Soc. Transp. Stud. 2015, 11, 1959–1969. [Google Scholar]
- Leontiadis, I.; Lima, A.; Kwak, H.; Stanojevic, R.; Wetherall, D.; Papagiannaki, K. From cells to streets: Estimating mobile paths with cellular-side data. In Proceedings of the 10th ACM International on Conference on Emerging Networking Experiments and Technologies, Sydney, Australia, 2–5 December 2014; ACM: New York, NY, USA, 2014; pp. 121–132. [Google Scholar]
- Farahani, R.Z.; Miandoabchi, E.; Szeto, W.Y.; Rashidi, H. A review of urban transportation network design problems. Eur. J. Oper. Res. 2013, 229, 281–302. [Google Scholar] [CrossRef]
- Jayakrishnan, R.; Tsai, W.K.; Prashker, J.N.; Rajadhyaksha, S. A Faster path-based algorithm for traffic assignment. Transp. Res. Record J. Transp. Res. Board 1994, 1443, 75–83. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Travel Route | ID Path |
|---|---|---|
| 1 | A-1-2-3-7-B | |
| 2 | A-1-2-6-10-B | |
| 3 | A-1-5-9-10-B | |
| 4 | A-4-8-9-10-B |
| Iteration Interval | Solution at 0.382 | Objective Value at 0.382 | Solution at 0.618 | Objective Value at 0.618 |
|---|---|---|---|---|
| [0.0263,0.0288] | 0.0273 | 6.7451 × 10−6 | 0.0278 | 6.8870 × 10−6 |
| [0.0263,0.0278] | 0.0269 | 6.9731 × 10−6 | 0.0273 | 6.7451 × 10−6 |
| [0.0269,0.0278] | -- | -- | -- | -- |
| # of Travel Route | Demand | Total Cost |
|---|---|---|
| 1 | 242.6 | 6.0817 |
| 2 | 228.3 | 8.1091 |
| 3 | 215 | 10.1046 |
| 4 | 209.1 | 11.0389 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Huang, Z.; Zheng, P.; Xu, W. Calibration of C-Logit-Based SUE Route Choice Model Using Mobile Phone Data. Information 2018, 9, 115. https://doi.org/10.3390/info9050115
Huang Z, Huang Z, Zheng P, Xu W. Calibration of C-Logit-Based SUE Route Choice Model Using Mobile Phone Data. Information. 2018; 9(5):115. https://doi.org/10.3390/info9050115
Chicago/Turabian StyleHuang, Zhengfeng, Zhaodong Huang, Pengjun Zheng, and Wenjun Xu. 2018. "Calibration of C-Logit-Based SUE Route Choice Model Using Mobile Phone Data" Information 9, no. 5: 115. https://doi.org/10.3390/info9050115
APA StyleHuang, Z., Huang, Z., Zheng, P., & Xu, W. (2018). Calibration of C-Logit-Based SUE Route Choice Model Using Mobile Phone Data. Information, 9(5), 115. https://doi.org/10.3390/info9050115