Artificial Intelligence and the Limitations of Information

Abstract
1. Introduction
- Broad fitness: that associated with multiple interactions (of the same or different types) and the consequent need to manage and prioritize resources between the different types—this is the type of fitness linked to specialization, for example;
- Adaptiveness: that associated with environment change and the consequent need to adapt—this is the type of fitness that has led organizations to undertake digital transformation activities [11].
- Analyze the integration challenges of different AI approaches—the requirements for delivering reliable outcomes from a range of disparate components reflecting the conventions of different information ecosystems;
- Understand the best way to manage ecosystems boundaries—initially, how AI and people can work together but increasingly how AI can support effective interaction across other ecosystem boundaries;
- Provide assurance about the impact and risks as AI becomes more prevalent and the issues discussed above become more important to organizational success.
- How is fitness for AGI determined?
- How will AGI handle the integration of components, the need to accommodate different ecosystem conventions and be sufficiently adaptive?
- How will AGI process and relate abstractions and will it be able to avoid the difficulties that humans have with the relationship between abstractions and information quality?
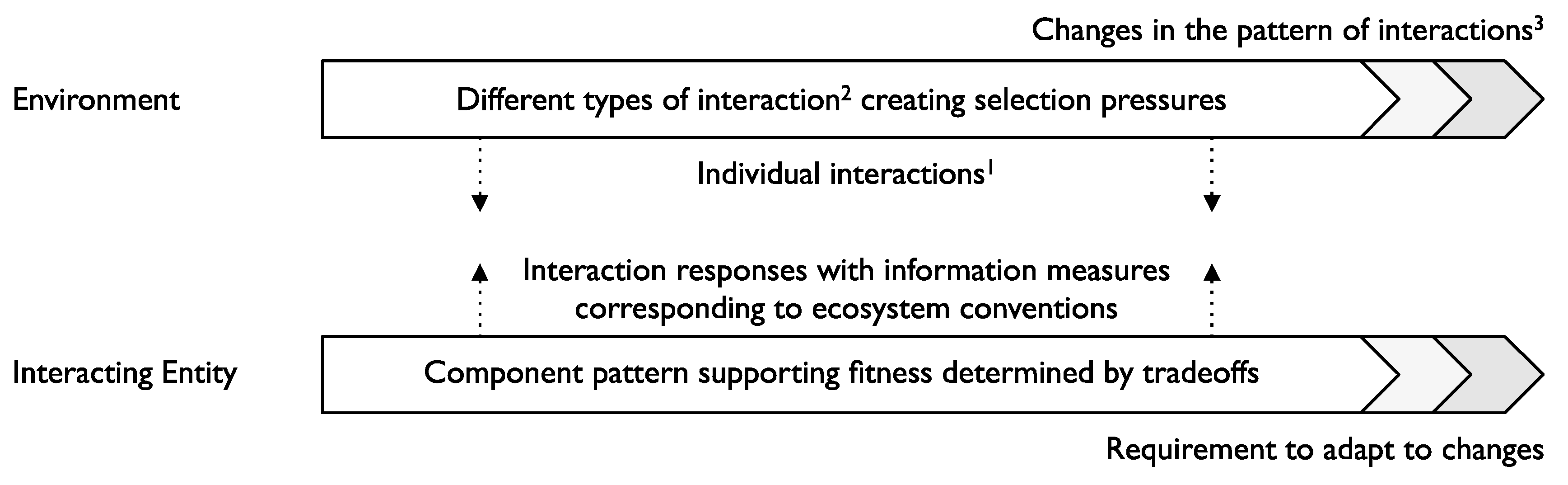
2. Selection and Fitness
- broad fitness: the ability to achieve favorable outcomes over multiple interactions, potentially of different types;
- adaptiveness: the ability to achieve favorable outcomes when the nature of interactions available in the environment changes.
2.1. AI and Machine Learning
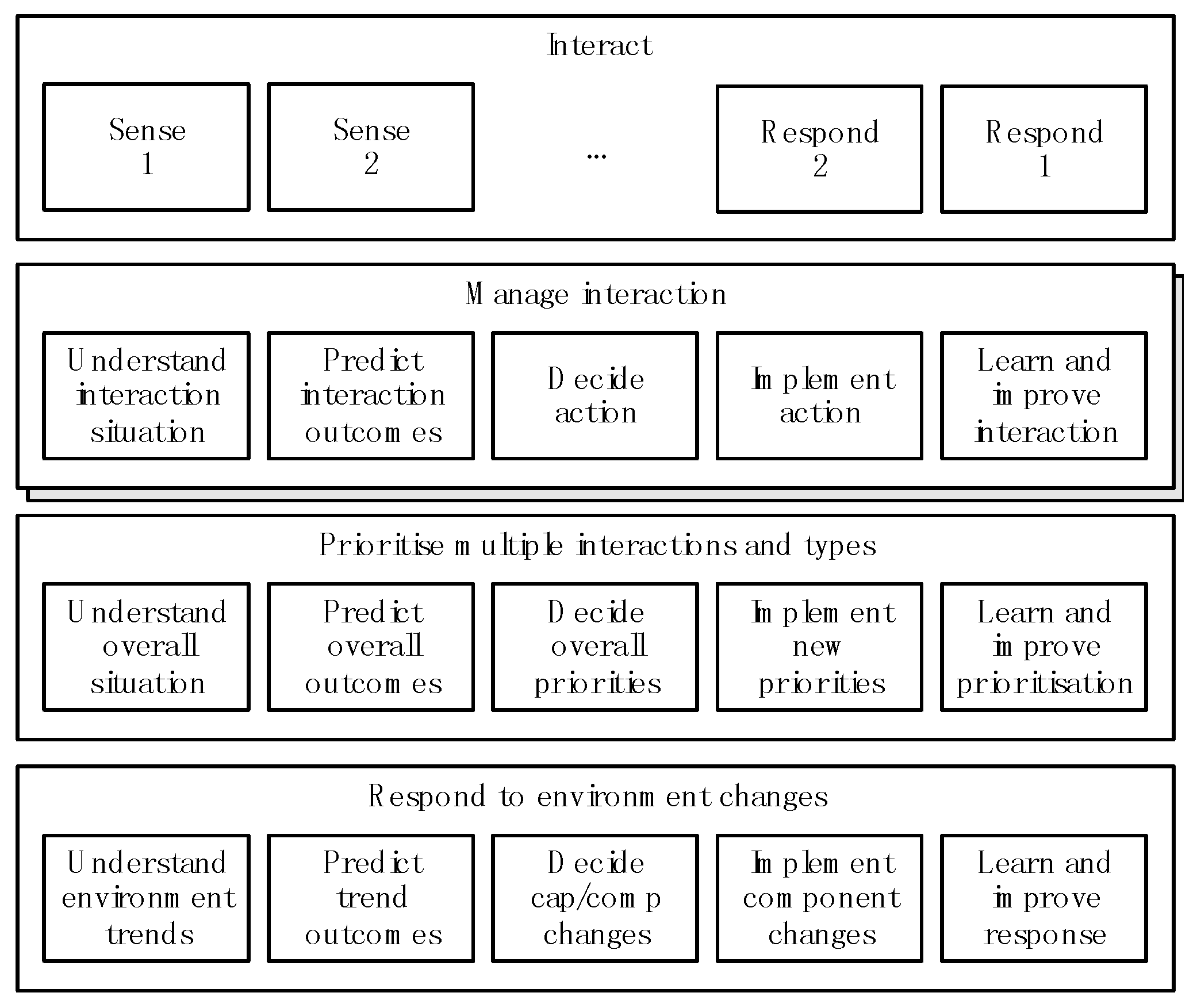
2.2. Capability Requirements
- manage each interaction and to decide how to respond (if at all)—each type of interaction may require different specific capabilities;
- prioritize the response to different interactions of the same or different types;
- respond to environment change—this is a priority for businesses as the world becomes increasingly digital and the implementation of AI and machine learning takes hold [11].
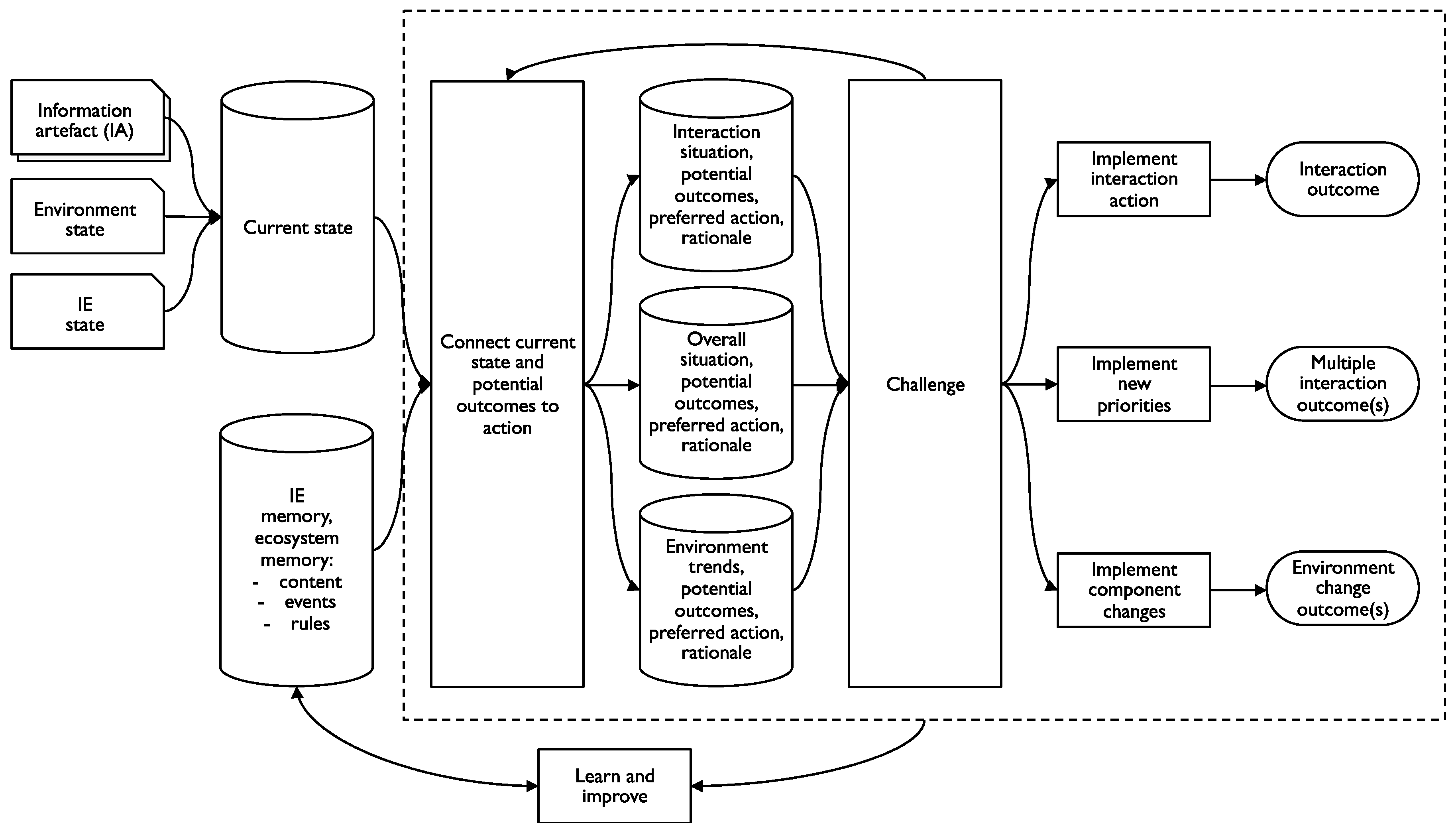
- understand the situation—identifying what is relevant (distinguishing signal from noise), interpreting the relevant information in the environment by connecting it to information in memory, and distilling it to an appropriate level for analysis and decision-making;
- link the situation to potential outcomes and understand their relative favorability;
- decide how to respond;
- implement the change—in information terms this means converting the decision into instructional information;
- learn and improve.
3. The Limitations of Information and Applications of AI to Business
- what properties to measure in the environment and to what quality?
- how to overcome the complexities involved in interpretation, inference, and instruction—how to develop shortcuts in the provision of the required quality?
- how to overcome contention at different levels—between different information measures, between the needs of the present and the needs of the future, between the needs of different interaction types, between different ecosystems (especially at ecosystem boundaries) and how to keep the IE aligned with fitness even as the requirements of the environment change?
- how to challenge the level of quality achieved—how the ecosystem can apply selection pressures of its own to ensure quality?
3.1. The Combinatorial Problem
- The use of symbols separates information from source slices and their properties;
- Ecosystem conventions separate symbols from particular slice representations (so words can be written or spoken, for example);
- Evolving ecosystem conventions separate processing (and the making of connections) from particular IEs (so computers can automate some human activities, for example);
- Communication separates content from a physical location (so content can be duplicated at distance).
- Developments in data warehouses, business intelligence, data engineering, data lakes and data hubs enable the collation and manipulation of data from many different sources;
- Digital technologies enable information to be available at widely different times and places and on many different devices.
3.2. Selection Tradeoffs, Viewpoints and Rules
- with the same evidence, different political parties reach very different conclusions about the right course of action in any case;
- in legal cases, the prosecution and defense represent different viewpoints;
- even in science, there are divisive debates about the merit of particular hypotheses (this is represented, for example, in Kuhn’s philosophy of science [34]).
3.2.1. Measurement
3.2.2. Information Processing Limitations and Rules
“What makes relevant inferences possible […] is the existence in the world of dependable regularities. Some, like the laws of physics, are quite general. Others, like the bell-food regularity in Pavlov’s lab, are quite transient and local. […] No regularities, no inference. No inference, no action.”
- Content inference—using only the rules associated with a particular modelling tool (for example, formal logic or mathematics);
- Causation—in which inference is based on one or more causation processes;
- Similarity—in which inference is based on the similarity between sets of slices and the assumption that the similarity will extend.
3.2.3. Contention
3.2.4. Challenge and Assurance
3.3. Component Pattern
- Channel-aligned: in this case, interaction components extend to encompass wider information processing. For example, Pinker [47] gives many examples in which the processing of the human brain is influenced (and constrained) by language and, indeed, some believe that language processing underpins all of human thought (for example in [48] the author says “I believe that language is also the medium by which we formulate our conceptual thinking. I regard thinking as silent language.”).
- Function-aligned: in this case, components (like interaction components) are built out from particular functions. For example, many organizational capabilities (such as finance and HR) are supported by software products that have developed from a functional base and also provide interaction (e.g., through web sites) and analytics.
- Multi-function: in this case, different components providing different functions are integrated together. For example, in [19], the authors make the case that many specialized inference mechanisms have evolved in people; they say: “inference, and cognition more generally, are achieved by a coalition of relatively autonomous modules that have evolved […] to solve problems and exploit opportunities”. Another example is an extension of the previous case in which organizations have specific components to support finance, HR, manufacturing, retailing and other organizational functions.
- Providing high quality, coherent descriptive, predictive, and prescriptive information from disparate components each learning in different ways from different subsets of data at different times;
- Tackling the discrimination problem especially where components need to be integrated;
- Ensuring that content information processing does not suffer from the same limitations as for humans;
- Ensuring that the underlying data is of the required quality for each component.
4. The Limitations of Information and AGI
- How is fitness for AGI determined?
- How will AGI handle the integration of components, the need to accommodate different ecosystem conventions and be sufficiently adaptive?
- How will AGI process and relate abstractions and will it be able to avoid the difficulties that humans have with the relationship between abstractions and information quality?
5. Conclusions
- Fitness: AI can make a significant improvement to all levels of fitness but to turn this into benefits the implementation of AI for organizations should be based on a detailed understanding of the three levels of fitness, the relationship of the levels and how each AI opportunity can improve them. In turn, this requires an understanding of measures of information such as friction, pace, and quality.
- Integration: Organizations will need to analyze the integration challenges of different AI approaches. As AI becomes more pervasive, integration will provide challenges in the following four areas:
- ○
- Providing high quality, coherent descriptive, predictive, and prescriptive information from disparate components each learning from different subsets of data at different times using different techniques;
- ○
- Tackling the discrimination problem especially where components need to be integrated;
- ○
- Ensuring that content processing does not suffer from the same limitations that it has for humans;
- ○
- Ensuring that the underlying data is of the required quality for each component.
- Ecosystem boundaries: One initial driver of AI (the Turing Test) was aimed at the human/computer ecosystem boundary. This is still important but a related question in business is understanding how AI and people can work together and how AI can support other ecosystem boundaries.
- Assurance: As AI becomes more prevalent and the issues discussed above become more important, organizations will need to understand and manage the potential impacts and risks. This requires an organizational assurance function that will analyze and, where necessary, forecast the impact of AI on business results.
- How is fitness for AGI determined?
- How will AGI handle the integration of components, the need to accommodate different ecosystem conventions and be sufficiently adaptive?
- How will AGI process and relate abstractions and will it be able to avoid the difficulties that humans have with the relationship between abstractions and information quality?
Funding
Conflicts of Interest
References
- Bostrom, N. Superintelligence: Paths, Dangers, Strategies; Oxford University Press: New York, NY, USA, 2014. [Google Scholar]
- Tegmark, M. Life 3.0: Being Human in the Age of Artificial Intelligence; Knopf Publishing Group: New York, NY, USA, 2017. [Google Scholar]
- Bringsjord, S.; Govindarajulu, N.S. Artificial Intelligence. The Stanford Encyclopedia of Philosophy. Zalta, E.N., Ed.; 2018. Forthcoming. Available online: https://plato.stanford.edu/archives/fall2018/entries/artificial-intelligence/ (accessed on 19 December 2018).
- Kahneman, D. Thinking, Fast and Slow; Macmillan: London, UK, 2011. [Google Scholar]
- Walton, P. A Model for Information. Information 2014, 5, 479–507. [Google Scholar] [CrossRef]
- Walton, P. Measures of information. Information 2015, 6, 23–48. [Google Scholar] [CrossRef]
- Walton, P. Information and Meaning. Information 2016, 7, 41. [Google Scholar] [CrossRef]
- Walton, P. Information and Inference. Information 2017, 8, 61. [Google Scholar] [CrossRef]
- Ford, N.; Parsons, R.; Kua, K. Building Evolutionary Architectures: Support Constant Change; O’Reilly Media: Sevvan, CA, USA, 2017. [Google Scholar]
- Darwin, C. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life; John Murray: London, UK, 1859. [Google Scholar]
- Westerman, G.; Bonnet, D.; McAfee, A. Leading Digital: Turning Technology into Business Transformation; Harvard Business Review Press: Cambridge, MA, USA, 2014. [Google Scholar]
- The TOGAF Standard. Available online: https://publications.opengroup.org/standards/togaf (accessed on 19 December 2018).
- Avgeriou, P.; Uwe, Z. Architectural patterns revisited: A pattern language. In Proceedings of the 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Bavaria, Germany, 6–10 July 2005. [Google Scholar]
- Burgin, M. Principles of General Ecology. Proceedings 2017, 1, 148. [Google Scholar] [CrossRef]
- Burgin, M.; Zhong, Y. Information Ecology in the Context of General Ecology. Information 2018, 9, 57. [Google Scholar] [CrossRef]
- Floridi, L. The Philosophy of Information; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- DeBrusk, C. The Risk of Machine-Learning Bias (And How to Prevent It). MITSloan Management Review. 2018. Available online: https://sloanreview.mit.edu/article/the-risk-of-machine-learning-bias-and-how-to-prevent-it/ (accessed on 19 December 2018).
- Miller, A. Want Less-Biased Decision? Use Algorithms. Harvard Business Review. 2018. Available online: https://hbr.org/2018/07/want-less-biased-decisions-use-algorithms (accessed on 19 December 2018).
- Mercier, H.; Sperber, D. The Enigma of Reason; Harvard University Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Quine, W.V.O. “Two Dogmas of Empiricism”, Reprinted in from a Logical Point of View, 2nd ed.; Harvard University Press: Cambridge, MA, USA, 1951; pp. 20–46. [Google Scholar]
- Gates, B.; Myhrvold, N.; Rinearson, P. The Road Ahead; Viking Penguin: New York, NY, USA, 1995. [Google Scholar]
- Norris, P. Digital Divide: Civic Engagement, Information Poverty and the Internet Worldwide; Cambridge University Press: New York, NY, USA, 2001. [Google Scholar]
- Government Digital Inclusion Strategy. 2014. Available online: https://www.gov.uk/government/publications/government-digital-inclusion-strategy/government-digital-inclusion-strategy (accessed on 19 December 2018).
- Prensky, M. Digital Natives, Digital Immigrants Part 1. On The Horizon 2001, 9, 1–6. [Google Scholar] [CrossRef]
- Manyika, J.; Bughin, J. The Promise and Challenge of the Age of Artificial Intelligence. McKinsey Global Institute Executive Briefing. 2018. Available online: https://www.mckinsey.com/featured-insights/artificial-intelligence/the-promise-and-challenge-of-the-age-of-artificial-intelligence?cid=eml-app (accessed on 19 December 2018).
- Logan, R.K. (Ed.) Special Issue AI and the Singularity: A Fallacy or an Opportunity. Information. 2018. Available online: https://www.mdpi.com/journal/information/special_issues/AI%26Singularity (accessed on 19 December 2018).
- Domingos, P. The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World; Penguin: London, UK, 2015. [Google Scholar]
- Logan, R.K.; Tandoc, M. Thinking in Patterns and the Pattern of Human Thought as Contrasted with AI Data Processing. Information 2018, 9, 83. [Google Scholar] [CrossRef]
- De Saussure, F. Course in General Linguistics; Bally, C., Sechehaye, A., Eds.; Duckworth: London, UK, 1983. [Google Scholar]
- Walton, P. Digital information and value. Information 2015, 6, 733–749. [Google Scholar] [CrossRef]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: New York, NY, USA, 2011. [Google Scholar]
- Moore, G.E. Cramming more components onto integrated circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Kuhn, T.S. The Structure of Scientific Revolutions, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1970. [Google Scholar]
- Duffy, B. The Perils of Perception: Why We’re Wrong About Nearly Everything; Atlantic Books: London, UK, 2018. [Google Scholar]
- Wittgenstein, L. Remarks on the Foundations of Mathematics, Revised Edition; von Wright, G.H., Rhees, R., Anscombe, G.E.M., Eds.; Basil Blackwell: Oxford, UK, 1978. [Google Scholar]
- Wittgenstein, L.; Bosanquet, R.G. Wittgenstein’s Lectures on the Foundations of Mathematics; Diamond, C., Ed.; Cornell University Press: Ithaca, NY, USA, 1976. [Google Scholar]
- Brown, J.S.; Duguid, P. The Social Life of Information; Harvard Business Press: Boston, MA, USA, 2000. [Google Scholar]
- Sommerville, I. Software Engineering; Addison-Wesley: Harlow, UK, 2010. [Google Scholar]
- Plato. Plato’s the Republic; Books, Inc.: New York, NY, USA, 1943. [Google Scholar]
- Porter, M.E. Competitive Strategy: Techniques for Analyzing Industries and Competitors; Free Press: New York, NY, USA, 1980. [Google Scholar]
- Goldacre, B. Bad Science; Harper Perennial: London, UK, 2009. [Google Scholar]
- Turing, A. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- James Wilson, H.; Daugherty, P.R. Collaborative Intelligence: Humans and AI are Joining Forces. Harvard Business Review. 2018. Available online: https://hbr.org/2018/07/collaborative-intelligence-humans-and-ai-are-joining-forces (accessed on 19 December 2018).
- Foy, K. Artificial Intelligence System Uses Transparent, Human-Like Reasoning to Solve Problems. MIT News. 2018. Available online: http://news.mit.edu/2018/mit-lincoln-laboratory-ai-system-solves-problems-through-human-reasoning-0911 (accessed on 19 December 2018).
- Bostrom, N. The Ethics of Artificial Intelligence (PDF); Cambridge University Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Pinker, S. The Stuff of Thought; Viking: New York, NY, USA, 2007. [Google Scholar]
- Logan, R.K. Can Computers Become Conscious, an Essential Condition for the Singularity? Information 2017, 8, 161. [Google Scholar] [CrossRef]
- Correia, R.C.M.; Spadon, G.; De Andrade Gomes, P.H.; Eler, D.M.; Garcia, R.E.; Olivete Junior, C. Hadoop Cluster Deployment: A Methodological Approach. Information 2018, 9, 131. [Google Scholar] [CrossRef]
- Macknik, S.L.; Martinez-Conde, S. Sleights of Mind; Picador: Surrey, UK, 2011. [Google Scholar]
- Sutcliffe, B.; Allgrove, A.-M. How Do We Build an Ethical Framework for the Fourth Industrial Revolution. Available online: https://www.weforum.org/agenda/2018/11/ethical-framework-fourth-industrial-revolution/ (accessed on 19 December 2018).
- Wang, P.; Liu, K.; Dougherty, Q. Conceptions of Artificial Intelligence and Singularity. Information 2018, 9, 79. [Google Scholar] [CrossRef]
- Wang, P. Rigid Flexibility: The Logic of Intelligence; Springer: Dordrecht, The Netherlands, 2006. [Google Scholar]
- Wang, P. Non-Axiomatic Logic: A Model of Intelligent Reasoning; World Scientific: Singapore, 2013. [Google Scholar]
- Capgemini Digital Transformation Institute. Understanding Digital Mastery Today. 2018. Available online: https://www.capgemini.com/wp-content/uploads/2018/07/Digital-Mastery-DTI-report_20180704_web.pdf (accessed on 19 December 2018).
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: New York, NY, USA, 2012. [Google Scholar]
- Chomsky, N. Language and Problems of Knowledge: The Managua Lectures; MIT Press: Cambridge, MA, USA; London, UK, 1988. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Ecosystem | Hypothesis | Challenge |
|---|---|---|
| English criminal law (prosecution) | The defendant is guilty | The defense (plus, potentially, the appeals process) |
| Science | A prediction made by a hypothesis is true | Experiments to refute or confirm the prediction |
| Mathematics | A theorem is proved | Peer review |
| Computer systems | The system will perform as required | Tests that the system meets its requirements |
| IE | Interaction Component | Interpretation, Inference, and Instruction Component |
|---|---|---|
| People | Senses (eyes,…) | Different brain mechanisms (see [19]) |
| Organizations | Sales people, customer research, web sites, … | Different organizational functions and their supporting computer systems (for example, qualifying sales opportunities, deciding the chances of winning and deciding how to price the product or service) |
| Computer system architectures | Virtual assistants (e.g., Alexa, Siri), apps, enterprise applications, security intrusion detection, … | Algorithms, machine learning tools |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walton, P. Artificial Intelligence and the Limitations of Information. Information 2018, 9, 332. https://doi.org/10.3390/info9120332
Walton P. Artificial Intelligence and the Limitations of Information. Information. 2018; 9(12):332. https://doi.org/10.3390/info9120332
Chicago/Turabian StyleWalton, Paul. 2018. "Artificial Intelligence and the Limitations of Information" Information 9, no. 12: 332. https://doi.org/10.3390/info9120332
APA StyleWalton, P. (2018). Artificial Intelligence and the Limitations of Information. Information, 9(12), 332. https://doi.org/10.3390/info9120332