1. Introduction
Classification algorithms assign labels to objects (instances or examples) based on a predefined set of labels. Several classification models have been proposed in the literature [
1]. However, there is no algorithm that achieves good performance for all domain problems. Therefore, the idea of combining different algorithms in one classification structure has emerged. These structures, called ensemble systems, are composed of a set of classification algorithms (base classifiers), organized in a parallel way (all classifiers are applied to the same task), and a combination method with the aim of increasing the classification accuracy of a classification system. In other words, instead of using only one classification algorithm, an ensemble uses a set of classifiers whose outputs are combined to provide a final output, which is expected to be more precise than those generated individually by the classification algorithms [
2]. A good review of ensemble of classifiers can be found in [
3,
4,
5].
An important issue in the design of ensemble systems is the parameter setting. More specifically, the selection of the base classifiers, features and the combination method plays an important role in the design of effective ensemble systems. Although feature selection may not be a parameter of the ensemble system structure, feature selection may have a strong effect in the performance of these systems and, therefore, it will be considered as a pre-processing parameter. The parameter setting of an ensemble system can be modeled as an optimization problem, in which the parameter set that provides the best ensemble system must be found. When considering the ensemble parameter selection as an optimization problem, it is possible to apply search strategies to solve these problems, applying exhaustive or metaheuristic approaches. Among the metaheuristic search algorithms, the most popular techniques are the population-based ones (genetic algorithm, particle swarm intelligence, ant colony optimization, et.c) since they have been successfully applied in traditional classification algorithms as well as ensemble systems [
6].
The idea of efficiently combining metaheuristics has emerged lately, in a field called hybridization of metaheuristics or hybrid metaheuristics. The main motivation for hybridization is to combine the advantages of each algorithm to form a hybrid algorithm, trying to minimize any substantial disadvantage of the combined algorithms. Some hybridization techniques have been proposed in the literature (e.g., [
7,
8,
9,
10,
11]). These hybrid metaheuristics have been successfully applied to traditional optimization problems. In [
7], for instance, the mono-objective MAMH (Multiagent Architecture for Metaheuristic Hybridization) architecture is proposed. The idea is to present a PSO-based multiagent system, using a multiagent framework with some swarm intelligence elements. According to the authors, MAMH can be considered as a simple hybrid architecture, taking advantage of the full potential of several metaheuristics and using theses advantages to better perform a given optimization problem. Another promising hybrid architecture is mono-objective MAGMA (Multiagent Metaheuristic Architecture), which was originally proposed by Milano et al. [
12]. This architecture has also been efficiently applied to traditional optimization problems [
12].
To the best of the authors knowledge, there is no study using hybrid architecture in the optimization of ensemble systems. Therefore, we aimed to adapt two promising hybrid architectures, MAMH and MAGMA, to be applied in the automatic design of classifier ensembles (or ensemble systems), which is a well-known optimization problem of the Pattern Recognition field. Specifically, the use of MAMH and MAGMA architectures to define two important parameters of classifier ensembles (the individual classifiers and features) was investigated. In this investigation, two important aspects of an ensemble system were considered, accuracy and diversity, using them as objective function in both mono- and multi-objective versions of the analyzed architectures. For accuracy, the error rate was used as objective function, while, for diversity, two diversity measures were used as objective functions, good and bad diversity [
13].
To investigate the potential of the hybrid architectures as an ensemble generator method, an empirical investigation was conducted in which the hybrid metaheuristics were evaluated using 26 classification datasets, in both mono- and multi-objective contexts. A comparative analysis was also performed, comparing the performance of the hybrid architectures to some traditional metaheuristics as well as to traditional and recent ensemble generation techniques.
In [
14], our first attempt to use one hybrid architecture (MAMH) for the automatic design of ensemble systems (features and base classifiers), when optimizing the classification error and good and bad diversity, is presented. However, in [
14], we only analyzed these three objectives separately, in the mono-objective context. In this paper, we extend the work done in [
14], using one more hybrid architecture and performing a comparative analysis with traditional population and trajectory-based metaheuristics. In addition, an empirical analysis with all different combinations of error rate, good diversity and bad diversity as optimization objectives is presented. In doing this investigation, we aimed at defining the set of objectives that generates the most accurate ensembles. In addition, our aim was to analyze whether the diversity measures can have an important role in the design of effective and robust classifier ensembles. Hence, we can describe the main contributions of this papers as follows:
Propose the multi-objective MAMH: In [
7], only the mono-objective version is proposed. In this paper, we extend the work in [
7] by presenting its multi-objective version.
Propose the multi-objective MAGMA: In [
12], the mono-objective MAGMA is proposed. In this paper, we extend the work in [
12] by presenting its multi-objective version.
We adapt these two metaheuristics to the automatic design of ensemble of classifiers.
We compare the results delivered by both hybrid metaheuristics when accuracy, good diversity and bad diversity were used as objectives to generate robust classifier ensembles.
This paper is divided into six sections and is organized as follows.
Section 2 describes the research related to the subject of this paper, while the proposed hybrid architectures are described in
Section 3.
Section 4 presents the methodology employed in the experimental work of this paper, while an analysis of the results provided by the empirical analysis is shown in
Section 5. Finally,
Section 6 presents the final remarks of this paper.
2. State-of-the-Art: Optimization Techniques for Classifier Ensembles
The definition of the best technique for a particular classification application is a challenging problem and has been addressed by several authors [
15,
16,
17,
18,
19,
20,
21]. This problem has been treated as a meta-learning problem [
17,
22], automatic selection of machine learning (auto-ML) [
16,
18,
20] or an optimization problem [
15,
19,
21]. In [
18], for instance, the authors used an auto-ML technique to define the best classification algorithm, along with the best set of parameters, for a specific classification problem. Usually, these classification algorithms can be either single classifiers or ensemble systems. In this study, the main focus was ensemble systems, more specifically the selection of features, which is not fully exploited in auto-ML techniques, as well as members of an ensemble. Therefore, it was treated as an optimization problem.
Despite the high number of studies, finding an optimal parameter set that maximizes classification accuracy of an ensemble system is still an open problem. The search space for all parameters of an ensemble system (classifier type, size, classifier parameters, combination method and feature selection) is very large. For simplicity, we considered two important parameters: members and feature selection.
When using optimization techniques in the design of ensemble systems, there are several studies involving the use of these techniques in the definition of the best feature set [
23,
24,
25,
26] and the members of an ensemble [
27,
28,
29]. In the selection of the feature set, different optimization techniques have been applied, most of them population-based techniques, individually. Examples of these techniques are bee colony optimization [
24], particle swarm optimization (PSO) [
30] and genetic algorithms [
26]. On the contrary, some studies have combined different optimization techniques, for example, in [
23], bee colony optimization is combined with particle swarm optimization for feature selection and genetic algorithms for the configuration of some ensemble parameters. Additionally, in [
25], different metaheuristics are applied to the selection of feature set in ensembles.
In the selection of ensemble members, in [
29], the authors proposed the use of genetic algorithms to select the set of weak classifiers and their associated weights. The genetic algorithm applied a new penalized fitness function that aimed to limit the number of weak classifiers and control the effects of outliers. According to the authors, the proposed method proved to be more resistant to outliers and resulted in achieving simpler predictive models than AdaBoost and GentleBoost.
As can be observed, the majority of studies of optimization techniques for the automatic design of ensemble system apply only mono-objective techniques. Nevertheless, some effort has been done to employ multi-objective techniques in the context of ensembles [
31,
32,
33,
34]. In [
32], for instance, the authors proposed the use of an optimization technique to design ensemble systems, taking into account the accuracy and diversity. However, different from this paper, it does not address diversity as an optimization objective. Another study that uses an optimization technique, simulated annealing, to calculate competence and diversity of ensemble components is [
31]. However, once again, it uses diversity measures as a guide to select members or features in ensemble systems, not in the multi-objective context. In [
33], the authors proposed a framework to obtain ensembles of classifiers from a Multi-objective Evolutionary Algorithm (MOEA), applying two objectives, the Correct Classification Rate or Accuracy (CCR) and the Minimum Sensitivity (MS) of all classes. However, different from this paper, the MOE algorithm was applied to select the classifiers of an ensemble individually, not considering the combination of these classifiers as a whole.
In either the mono- or multi-objective context, to the best of the authors knowledge, there is no study using hybrid metaheuristics in the optimization of ensemble systems. In [
15], for instance, an exploratory study with several optimization techniques in the design of ensemble systems is presented. In the presented study, the authors investigated several techniques in both mono- and multi-objective versions. As a result of this study, the authors stated that the choice of the optimization technique is an objective-dependent selection and no single technique is the best selection for all cases (mono- and multi-objective as well as datasets). The results obtained in [
15] are the main motivation for the investigation performed here.
4. Experimental Methodology
Aiming to investigate the effects of applying hybrid metaheuristics in the automatic design of classifier ensembles, we conducted an empirical analysis. In this investigation, the performance of MAMH and MAGMA in the selection of important parameters of classifier ensembles was assessed. In addition, both mono- and multi-objectives versions of these hybrid architectures were assessed in which all possible combinations of the used optimization objectives (accuracy, bad diversity and good diversity) were considered.
The feature selection procedure is defined as follows. Let
X be the original dataset, containing
s attributes. Then,
N subsets are selected,
where
N is the number of individual classifiers of a classifier ensemble. Hence, each
subset has a cardinality
. Additionally, the member selection procedure chooses the presence or absence of a classifier in a classifier ensemble. Once selected, the classifier type was then defined. Hence, given the initial size of a classifier ensemble,
N,
N′ classifiers were selected to be part of this where
. It is important to highlight that the selection of both parameters is not made in an independent way, once each possible solution always contains information of both parameters (see
Section 4.2).
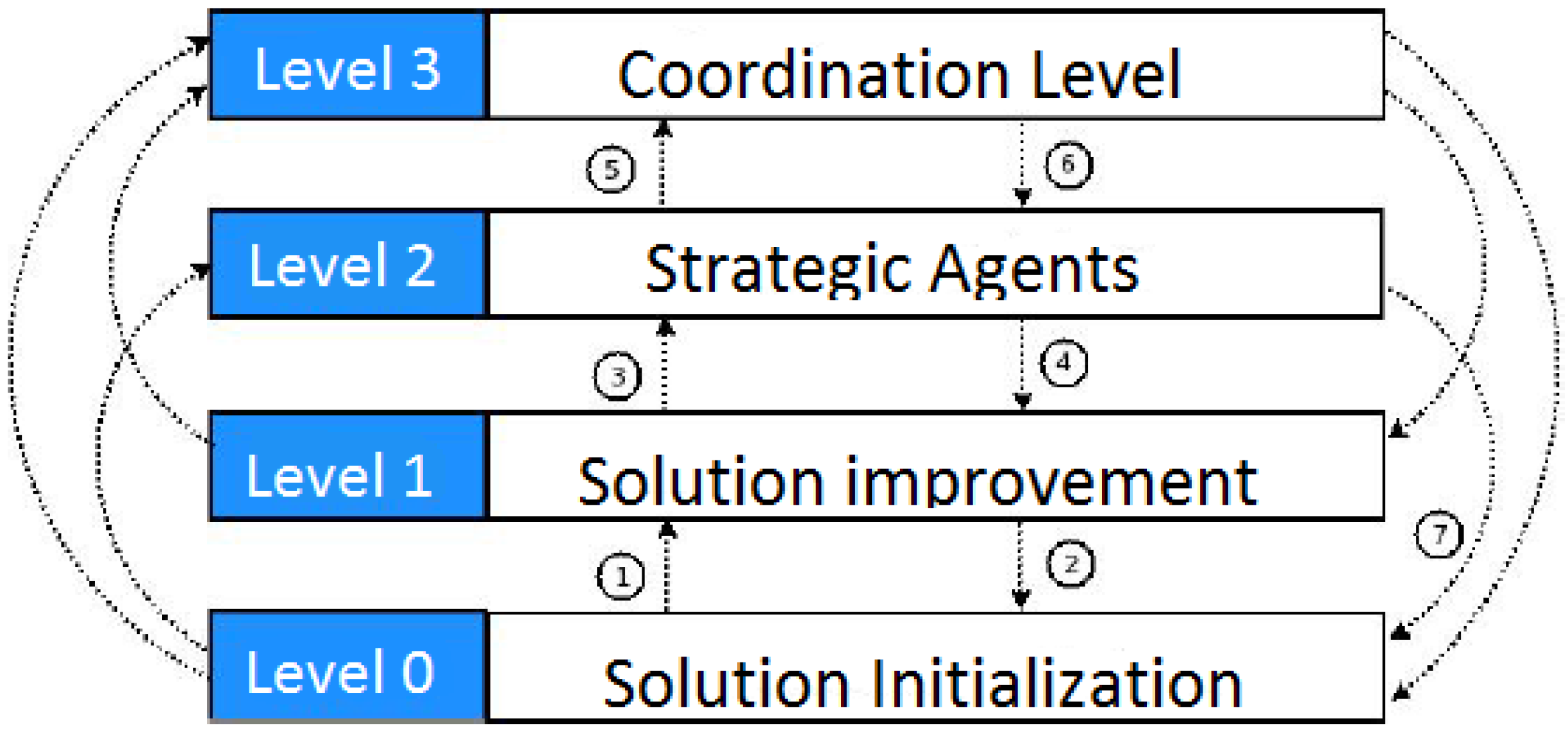
The main steps of the used methodology are presented in Algorithm 3. As can be observed in Algorithm 3, this is a general algorithm that can be applied to both mono- and multi-objective versions. For instance, ND represents the set of Non-Dominated solutions. In the mono-objective versions, this set is composed by only one solution.
| Algorithm 3 General methodology. |
| Require:, |
| 1: |
| 2: while not StopCondition do |
| 3: |
| 4: |
| 5: |
| 6: if () and () then |
| 7: |
| 8: end if |
| 9: end while |
| 10: return |
In the selection of the classification algorithms, three possible algorithms are used, k-NN (k nearest neighbour), Decision Tree and Naive Bayesian. These algorithms are used since they are simple and efficient algorithms and have been widely used in ensemble systems. All classification algorithms were combined using the Majority Voting method. In addition, all classifiers of the same type use the same parameter setting, since these classifiers are built based on different training datasets. For k-NN, for simplicity reasons, we decided to use its simplest version, using only one neighbour. In relation to the feature selection process, there is no restriction about the number of classifiers in which an attribute may be assigned. In other words, an attribute can be assigned to all classifiers or to none of them.
Once the components are selected, the ensemble systems are created and a standard stacking procedure is used to define the learning process for the individual classifiers and for the combination methods. The use of a stacking procedure is due to the fact that it allows all individual classifiers to be trained using the same instance datasets. In this sense, the feature selection plays an important role in the performance of a stacking-based ensemble system.
To compare the accuracy of the obtained ensemble system, a statistical test was applied, the Friedman test with a post-hoc test [
40]. The used test is the bi-caudal analysis, in which the null hypothesis is based on the idea that the samples come from the same population. In this test, the confidence level is 95% (
). The post-hoc Nemenyi test was used for the pairwise comparisons. These non-parametric tests were chosen because they are suitable to compare the performance of different learning algorithms when applied to multiple datasets (for a thorough discussion of these statistical tests, see [
40]).
4.2. The Used Traditional Optimization Techniques
To perform a comparative analysis, the performance of the hybrid architectures was compared to four traditional metaheuristics. Therefore, six different optimization techniques were used in this empirical analysis. In the next two subsections, the use of these techniques in the selection of features and members of ensembles is described.
Before describing the optimization techniques, the description of a solution must be done. In all metaheuristic algorithms (Traditional and hybrid), the solutions are represented by a vector of values that indicates the composition of a classifier ensemble (the individual classifiers and attributes). The parameter N represents the maximum size of an ensemble (number of individual classifiers). In this sense, when N is set to 15, all possible solutions must consist of classifier ensembles that contain from 2 to 15 individual classifiers. The size of the solution vector is defined by the number of attributes of the selected dataset s times the maximum number of individual classifiers N plus 1, . For example, suppose that and the number of attributes of a problem . Then, a vector with elements is created to represent a possible solution. In this vector, the first six elements represent the configuration of the first individual classifier, in which the first element indicates the type of classification algorithm. For this element, we use the following representation: 0 represents the absence of this classifier in the classifier ensemble; 1 represents a k-NN classifier; and 2 and 3 represent Decision Tree and Naive Bayesian, respectively. The other five elements indicate the attributes used by this classifier. In these cases, 0 indicates absence and 1 indicates presence of the corresponding attribute. Based on the same representation, the following six elements represent the configuration of the second classifier and so on until the last classifier.
4.2.1. Trajectory-Based Algorithms
Trajectory-based Algorithms (NbA), or neighbourhood-based Algorithms, use only one solution s in the searching procedure. Additionally, they apply a local search process to move to a better solution in the neighbourhood of s, in an iterative way. In this study, we applied only one trajectory-based algorithm, GRASP. This algorithm is one of the main components used in the hybrid architectures described in the previous section.
GRASP (Greedy Randomized Adaptive Search Procedure) has two distinct phases (constructive and refinement). In the first phase, a set of solutions is built and the best solution is selected. In the second phase, a local search is applied to this selected solution [
43,
44].
The first (constructive) phase consists of an interactive process starting from a solution in which all the classification algorithms are randomly selected. For the selected classification algorithms, all features are active. We selected a strategy to remove attributes instead of adding them due to the processing time for evaluating the cost function of a partial solution. The strategy assumes that classification algorithms using more attributes tend to yield better solutions. Then, for each individual classifier, a set of attributes is selected, determining the final configuration of the ensemble. This selection consists of a constructive and randomized method, as described in [
43,
44]. Nevertheless, the features are removed rather than added.
The solution obtained by the constructive process is refined by local search. In this paper, the mono-objective local search has as input a cost function f, an initial solution s and a neighbourhood structure for a solution s that generates a set of neighbour solutions (m is set to 30). Initially, m identical solutions to s are generated and m positions are chosen randomly and uniformly from the solution vector s. Each position represents a modification on the position of the ith neighbour . Additionally, Each modification generates a neighbour of the s. Finally, the best neighbour is selected as .
Algorithm 4 describes the step of the multi-objective local search. The multi-objective local search is similar to its mono-objective version. The main difference is that a set of functions is used instead of just one. In the multi-objective context, the performance evaluation of the solutions is made by a dominance relationship procedure. In addition, the best solution is replaced by a set of non-dominated solutions that will be returned at the end of the local search. The set of non-dominated solutions starts with the initial solution s and, at each step, a solution of is randomly and uniformly selected. The neighbours of are generated and those who dominate will update the set of non-dominated solutions. The initial solution s becomes and the process repeats itself until a solution is selected in which none of its neighbours dominates it.
| Algorithm 4 Multi-objective local search algorithm |
| Require: |
| 1: {set of non-dominated solutions} |
| 2: and dominates s in |
| 3: while do |
| 4: for all do |
| 5: |
| 6: end for |
| 7: choice where |
| 8: |
| 9: and dominates s in |
| 10: end while |
| 11: return |
Finally, a path-relinking procedure is applied to the solution returned by the local search [
45]. If a better solution is found, then it becomes the best solution found by the algorithm. In the multi-objective context, path-relinking is also applied to each solution returned by the local search. In other words, for each solution of the
set, a path-relinking procedure is performed. Each solution returned by path-relinking can update the set of non-dominated solutions.
4.2.2. Population-Based Algorithms
In this class of algorithms, a population of solutions is used, instead of just one. In this study, three population-based methods were analyzed: Genetic algorithm (GA), Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO).
Genetic algorithm (GA): It is a bio-inspired metaheuristic algorithm [
46], which has been widely applied in the optimization classification structures. The functioning of a GA uses the concept of some biological mechanisms as hereditary and evolution. In addition, each solution of a problem is described as a chromosome. In each iteration of a GA, a population of chromosomes has to be selected and evaluated.
We use a standard genetic algorithm in this paper, performing selection, genetic operator (crossover and mutation) and evaluation in an iterative way. For the multi-objective context, the NSGA-II algorithm, originally proposed in [
47], was used. Hence, the following parameters were used for both versions: two-point crossover operator (
); uniform mutation operator (
); a random and uniform selection of both newly created and parent solutions; and 30 chromosomes for the GA population.
Ant Colony Optimization (ACO): As a bio-inspired algorithm, ACO can also be considered as a population-based (ants) method, used in several optimization applications. However, these problems have to be reduced to the idea of defining good paths in graph structures. In this study, a set of attributes and classifiers represent a path to be followed by the ants. Each ant builds a solution by selecting the attributes subsets and/or individual classifiers that will compose a possible solution. The pheromone is then updated using the quality of the its solution as basis [
48].
In this study, we applied a pheromone equation that considers only the attributes of a classifier ensemble. Conversely, for simplicity, a random selection was made to choose the individual classifiers. The attribute selection is defined by Equation (
1).
where
consists of the attribute subset that has not yet been selected by ant
k;
is the pheromone for the
ith attribute of
jth classifier;
represents a pre-defined heuristic that assigns the importance of the
ith attribute for the classifier ensemble; and
and
represent the importance of pheromone and heuristic information, respectively. In this paper,
indicates the cost of a solution when only the
ith attribute is selected by the corresponding individual classifier.
Based on the selection probability of each attribute, a solution is built in an iterative process. This iterative process begins with a solution containing the whole attribute set and an attribute is selected in each iteration to be changed (from presence to absence or vice versa), according to Equation (
1).
In the selection of an attribute, the current cost of the current solution is compared to the cost of a solution when the status of one attribute changes. If the cost of this newer solution is lower than the current one, then a new iteration starts. Otherwise, this process is interrupted the solution containing with the attribute set selected until then.
The multi-objective ACO version is very similar to the mono-objective one, since both use only one colony. However, for the multi-objective version, all different objectives share the same pheromone matrix. Hence, one objective is chosen at each iteration and the pheromone matrix is updated based on this selected objective.
Particle Swarm Optimization (PSO): it is based on a population of particles moving in a search space, in an iterative way, of a problem to solve a problem of optimization [
49]. At each iteration, all particles have a three-part movement operation: (1) follow its own path; (2) return to the local best (the best position so far); and (3) go to the global best (the best position found by all other particles so far).
An implementational methodology similar to the one in [
50] to manage mono-objective discrete problems is applied in this paper. The main difference of this algorithm to a standard PSO algorithm lies in the speed operator, consisting of three main components. The first one describes a particle following its own path (local search). The second and third components represent the cases in which a particle selects local and global best (path-relinking), respectively. For all three components, a selection probability has to be defined, and one component is chosen using these probabilities.
The multi-objective PSO implementation is similar to the mono-objective version. Nevertheless, there exist two main differences: (1) the local search is replaced by a local multi-objective search, illustrated in Algorithm 4; and (2) the path-relinking operator is adapted to be applied in the multi-objective context. In addition, the multi-objective algorithm assumes that all optimization objective are normalized and that all objectives have to be maximized.
5. Experimental Results
In this section, we present the results of the empirical analysis, which divided into four parts. In the first part, we analyze the performance of both hybrid architectures, using all seven combinations of objective sets. Therefore, we investigate which objective set achieves the most accurate ensembles. Then, in the second part, we analyze the best hybrid architecture, i.e., the one that provides the most accurate ensembles. In the last two parts, a comparative analysis is conducted, in which a comparison with traditional optimization techniques is done in the third part and with traditional and recent ensemble generation techniques in the last part.
5.1. The Best Objective Set
This section presents the results of the hybrid metaheuristics in each set of objectives. The objective of this analysis was to evaluate which set of objectives provide the best performance, in terms of the accuracy. For simplicity, the obtained results are summarized in
Table 2, which displays the number of best results obtained by each objective set. These data were obtained as follows: the error rates of all seven objective sets of the same hybrid architecture were evaluated and the objective set that provided the lowest error rate was considered as the best result. This process was performed on all 26 datasets.
In
Table 2, the MAGMA algorithm presents a clear preference for the optimization of the classification error (E) while the MAMH algorithm presents preference for the E and EG objective.
To evaluate the obtained results from a statistical point of view, the Friedman test was applied, taking into account the performance of the different objective sets. The result of the Friedman test indicates a statistical difference in performance, for both hybrid architectures (
p-value= 1.8613e-22 for MAMH and
p-value= 2.5636e-25 for MAGMA). Therefore, this statistical investigation continued by applying the post-hoc Nemenyi test between each of pair of objective sets.
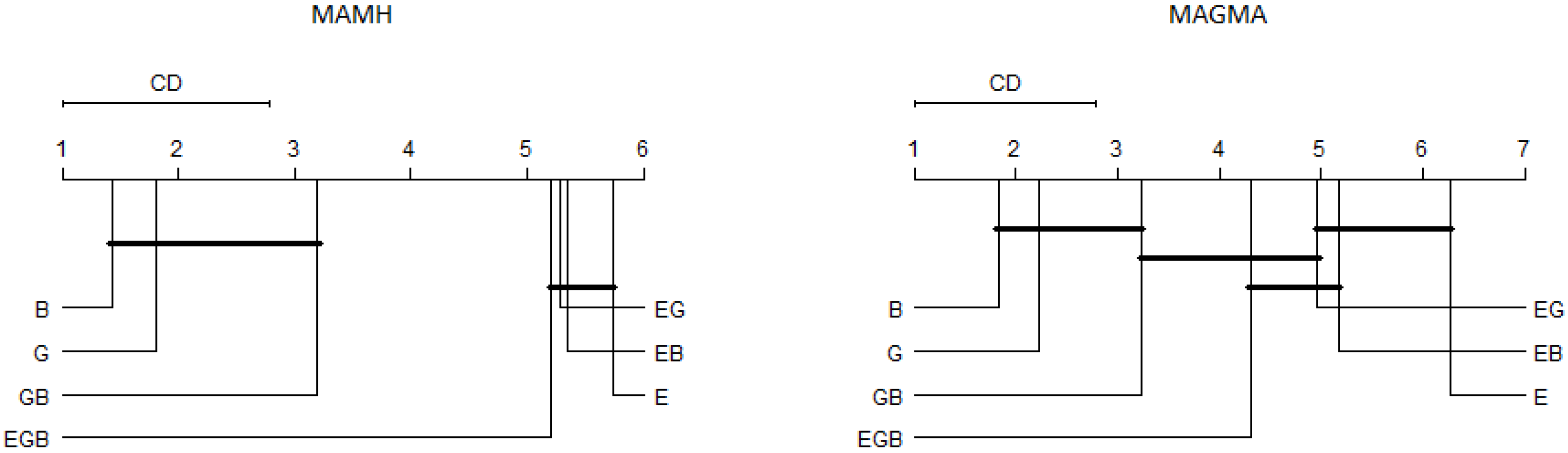
Figure 2 presents the results of the critical difference (CD) diagram of The post-hoc Nemenyi test. As we used the error rate as input, the highest values represent the lowest error rates.
In
Figure 2, E, EG and EB objectives have provided similar performance, for both MAMH and MAGMA, from a statistical point of view. For MAMH, EGB objective set was similar to E, EB and EG. These results show that the use of the error rate and one diversity measure had a positive effect in the performance of the hybrid architecture. Based on this statistical analysis, we can conclude that there is no best objective set, for both hybrid architectures and any objective set can be selected without strongly deteriorating the performance of the obtained ensembles.
We analyzed the objective sets based solely in the error rate of the obtained ensembles. However, this analysis is not sufficient to evaluate the performance in the multi-objective context. Thus, we then analyzed the performance of the multi-objective cases. As mentioned previously, we first considered the result of the Dominance Ranking to determine a difference between both objective sets. If a statistical difference was not detected at this level, we then applied the Hyper-volume and Binary-
measures. Therefore, a statistical significant difference was detected if a difference was detected at Dominance Ranking or a simultaneous difference in hyper-volume and Binary-
[
52].
Table 3 and
Table 4 present the results of the multi-objective context for MAMH and MAGMA, respectively.These tables compare EG to EB and EGB. In addition, the cases highlighted in bold or shaded cells mean that there is a significant statistical difference between the two analyzed objective sets. In this sense, the shaded cells are in favor of EG and the cases highlighted in bold are in favor of the EB or EGB, depending on the comparison.
As shown in
Table 3 and
Table 4, we detected a few statistical differences. When considering the MAMH algorithm in the comparison of the EG × EB, for instance, there are only four significant differences, being only one in favor of the EG. In the comparison of EG × EGB, there are also four significant differences, being all of them in favor of the EGB. For the MAGMA algorithm, in the comparison of EG × EB, there are six significant differences, being two in favor of EG. In the comparison of EG × EGB, there are seven significant differences, being all of them in favor of EG.
Thus, based on the obtained results, it is clear that the optimizing the EG generates slightly worse results than optimizing EB and EGB, in the MAMH algorithm. However, for MAGMA, it is not clear which objective set, EG, EB or EGB, has the best results, but EG provided slightly better results than EB.
In summary, there is no consensus about the best set of objectives, for both hybrid architectures, since MAGMA obtained the best results with Error (E) and MAMH obtained the best results with Error (E) and Error along with Good diversity (EG). However, these differences were not detected by the statistical test. As the Error objective (E) appeared in both architectures, we used this objective in the comparison analysis with existing ensemble methods. However, before starting this comparative analysis, we compared both MAGMA and MAMH, which is presented in the next subsection.
5.4. Comparison with Existing Ensemble Generation Techniques
In the final part of the analysis, a comparative analysis with existing ensemble generation techniques was conducted. First, we compared the results of the hybrid metaheuristic with some traditional ensemble generation techniques: random selection, bagging and boosting (more details about these methods can be found [
53]). The random selection generates a heterogeneous committee by randomly choosing individual classifiers. In addition, it has a feature selection step, in which a random selection of around 70% of the feature set is selected, for each individual classifier. Bagging and Boosting are designed using a decision tree as base classifiers (
k-NN and Naive Bayesian were analyzed but DT provided the best overall result). One hundred iterations were used in both methods since it provided the overall best performance. The results of this analysis are presented in
Table 7.
In this table, we can observe that the hybrid architectures provided more accurate ensembles than traditional ensemble generation techniques, for all datasets. We then applied the Friedman test, obtaining a
p-value
. In other words, the statistical test detected a significant difference in performance of all ensemble generation techniques. The
p-vales of the post-hoc Nemenyi test, comparing each pair of techniques are presented in
Table 8. In this table, the shaded cells indicate a significant difference in favor of the hybrid architecture.
The Nemenyi test showed that the superiority of the hybrid architectures was statistically significant. The results obtained are promising, showing that the hybrid architectures proposed in this paper are able to provide accurate ensembles, better than well-established ensemble generation techniques.
Once the comparison with traditional ensemble techniques was conducted, a comparison with recent and promising ensemble techniques was conducted. We selected four ensemble generation techniques: Random Forest (it has largely been used in the ensemble community), XGBoost (a more powerful version of Boosting, proposed in [
54]) and P2-SA and P2-WTA [
33] (two versions of a multi-objective algorithm for selecting members for an ensemble system).
The Random Forest implementation was exported from WEKA package and we used 100–1000 random trees, depending on the dataset. The XGBoost implementation was the one indicated by the authors in [
54] and we used 100–500 gbtrees. However, for P2-SA and P2-WTA, we used the original results, provided in [
33]. Thus, this comparative analysis used a different group of datasets, since they are the ones used in [
33] and are publicly available. All datasets were also extracted from UCI repository [
42].
Table 9 presents the error rates of all six ensemble methods. Once again, the bold numbers represents the ensemble method with the lowest error rate for a dataset.
As can be seen in
Table 9, the lowest error rate was almost always obtained by a hybrid metaheuristic, with both architectures having five bold numbers. The only exception was the Vehicle dataset, in which the lowest error rate was obtained by XGBoost. We then applied the Friedman test, obtaining a
p-value = 0.002, when comparing MAMH, MAGMA, Random Forest and XGBoost. In other words, the statistical test detected a significant difference in performance of these four ensemble generation techniques. It is important to highlight that P2-SA and P2-WTA were not included in the statistical test since we only had access to the mean accuracy and standard deviation of these techniques, not allowing the application of the statistical test. The Nemenyi test was then applied and it showed that MAGMA and MAMH were statistically superior to Random Forest and XGBoost.
Our final analysis was related to the time processing for all four implemented ensemble techniques. Once again, the time processing, measured in seconds, was not provided in [
33] and we could not include P2-SA and P2-WTA processing time values in this comparison.
Table 10 presents the processing time of all four ensemble methods.
In fact, the hybrid metaheuristics need more processing time than Random Forest and XGBoost. We believe that the use of ensemble accuracy as an objective in MAMH and MAGMA is a complex function, leading to higher processing time than the other two ensemble methods. The use of less complex objectives as well as the use of techniques to optimize the search process will cause a decrease in the processing time and this is the subject of an on-going research.
In summary, the results in
Table 7 and
Table 9 show that the use of hybrid metaheuristics provided more accurate ensembles than traditional and recent ensemble techniques. However, in
Table 10, we can observe that these techniques need more processing time.
Author Contributions
Conceptualization, A.A.F.N., A.M.P.C. and J.C.X.-J.; methodology, A.A.F.N., A.M.P.C. and J.C.X.-J.; software, A.A.F.N., A.M.P.C. and J.C.X.-J.; validation, A.A.F.N., A.M.P.C. and J.C.X.-J.; formal analysis, A.A.F.N., A.M.P.C. and J.C.X.-J.; investigation, A.A.F.N., A.M.P.C. and J.C.X.-J.; resources, A.A.F.N., A.M.P.C. and J.C.X.-J.; data curation, A.A.F.N., A.M.P.C. and J.C.X.-J.; writing—original draft preparation, A.A.F.N., A.M.P.C. and J.C.X.-J.; writing—review and editing, A.A.F.N., A.M.P.C. and J.C.X.-J.; visualization, A.A.F.N., A.M.P.C. and J.C.X.-J.; supervision, A.A.F.N., A.M.P.C. and J.C.X.-J.; project administration, A.A.F.N., A.M.P.C. and J.C.X.-J.; funding acquisition, A.A.F.N., A.M.P.C. and J.C.X.-J.
Funding
This work was financially supported by CNPq (Brazilian Research Councils).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997. [Google Scholar]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Brown, G.; Wyatt, J.; Harris, R.; Yao, X. Diversity creation methods: A survey and categorisation. Inf. Fusion 2005, 6, 5–20. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, L.; Suganthan, P.N. Ensemble Classification and Regression—Recent Developments, Applications and Future Directions. IEEE Comput. Intell. Mag. 2016, 11, 41–53. [Google Scholar] [CrossRef]
- Woźniak, M.; Graña, M.; Corchado, E. A survey of multiple classifier systems as hybrid systems. Inf. Fusion 2014, 16, 3–17. [Google Scholar] [CrossRef]
- Boussaïd, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Souza, G.; Goldbarg, E.; Goldbarg, M.; Canuto, A. A multiagent approach for metaheuristics hybridization applied to the traveling salesman problem. In Proceedings of the 2012 Brazilian Symposium on Neural Networks, Curitiba, Paraná, Brazil, 20–25 October 2012; pp. 208–213. [Google Scholar]
- Tiejun, Z.; Yihong, T.; Lining, X. A multi-agent approach for solving traveling salesman problem. Wuhan Univ. J. Nat. Sci. 2006, 11, 1104–1108. [Google Scholar] [CrossRef]
- Xie, X.-F.; Liu, J. Multiagent optimization system for solving the traveling salesman problem (tsp). IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 489–502. [Google Scholar]
- Fernandes, F.; Souza, S.; Silva, M.; Borges, H.; Ribeiro, F. A multiagent architecture for solving combinatorial optimization problems through metaheuristics. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 3071–3076. [Google Scholar]
- Malek, R. An agent-based hyper-heuristic approach to combinatorial optimization problems. In Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems (ICIS), Xiamen, China, 29–31 October 2010; pp. 428–434. [Google Scholar]
- Milano, M.; Role, A. MAGMA: A multiagent architecture for metaheuristics. IEEE Trans. Syst. Man Cybern. Part B 2004, 34, 925–941. [Google Scholar] [CrossRef]
- Brown, G.; Kuncheva, L. “Good” and “bad” diversity in majority vote ensembles. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 124–133. [Google Scholar]
- Feitosa Neto, A.A.; Canuto, A.M.P.; Xavier-Júnior, J.C. A multi-agent metaheuristic hybridization to the automatic design of ensemble systems. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN 2017), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Feitosa Neto, A.; Canuto, A.M.P. An exploratory study of mono- and multi-objective metaheuristics to ensemble of classifiers. Appl. Intell. 2018, 48, 416–431. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. Adv. Neural Inf. Process. Syst. 2015, 28, 2962–2970. [Google Scholar]
- Kordík, P.; Černý, J.; Frýda, T. Discovering Predictive Ensembles for Transfer Learning and Meta-Learning. Mach. Learn. 2018, 107, 177–207. [Google Scholar] [CrossRef]
- Kotthoff, L.; Thornton, C.; Hoos, H.; Hutter, F.; Leyton-Brown, K. Auto-WEKA 2.0: Automatic model selection and hyperparameter optimization in WEKA. J. Mach. Learn. Res. 2017, 18, 826–830. [Google Scholar]
- Albukhanajer, W.A.; Jin, Y.; Briffa, J.A. Classifier ensembles for image identification using multi-objective Pareto features. Neurocomputing 2017, 238, 316–327. [Google Scholar] [CrossRef]
- Wistuba, M.; Schilling, N.; Schmidt-Thieme, L. Automatic Frankensteining: Creating Complex Ensembles Autonomously. In Proceedings of the 2017 SIAM International Conference on Data Mining, Houston, TX, USA, 27–29 April 2017; pp. 741–749. [Google Scholar]
- Zhang, L.; Srisukkham, W.; Neoh, S.C.; Lim, C.P.; Pandit, D. Classifier ensemble reduction using a modified firefly algorithm: An empirical evaluation. Expert Syst. Appl. 2018, 93, 395–422. [Google Scholar] [CrossRef]
- Nascimento, D.S.C.; Canuto, A.M.P.; Coelho, A.L.V. An Empirical Analysis of Meta-Learning for the Automatic Choice of Architecture and Components in Ensemble Systems. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 1–6. [Google Scholar]
- Khan, S.A.; Nazir, M.; Riaz, N. Optimized features selection for gender classication using optimization algorithms. Turk. J. Electr. Eng. Comput. Sci. 2013, 21, 1479–1494. [Google Scholar] [CrossRef]
- Palanisamy, S.; Kanmani, S. Classifier Ensemble Design using Artificial Bee Colony based Feature Selection. IJCSI Int. J. Comput. Sci. 2012, 9, 522–529. [Google Scholar]
- Wang, L.; Ni, H.; Yang, R.; Pappu, V.; Fenn, M.B.; Pardalos, P.M. Feature selection based on meta-heuristics for biomedicine. Opt. Methods Softw. 2014, 29, 703–719. [Google Scholar] [CrossRef]
- Zhang, T.; Dai, Q.; Ma, Z. Extreme learning machines’ ensemble selection with GRASP. Appl. Intell. 2015, 43, 439–459. [Google Scholar] [CrossRef]
- Liu, Z.; Dai, Q.; Liu, N. Ensemble selection by GRASP. Appl. Intell. 2014, 41, 128–144. [Google Scholar] [CrossRef]
- Acosta-Mendoza, N.; Morales-Reyes, A.; Escalante, H.; Gago-Alonso, A. Learning to Assemble Classifiers via Genetic Programming. Int. J. Pattern Recognit. Artif. Intell. 2014, 28, 1460005. [Google Scholar] [CrossRef]
- Oh, D.-Y.; Brian Gray, J. GA-Ensemble: A genetic algorithm for robust ensembles. Comput. Stat. 2013, 28, 2333–2347. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, Y. A novel ensemble of classifiers for microarray data classification. Appl. Soft Comput. 2008, 8, 1664–1669. [Google Scholar] [CrossRef]
- Lysiak, R.; Kurzynski, M.; Woloszynski, T. Optimal selection of ensemble classifiers using measures of competence and diversity of base classifiers. Neurocomputing 2014, 126, 29–35. [Google Scholar] [CrossRef]
- Mao, L.C.S.; Jiao, L.; Xiong, S.G. Greedy optimization classifiers ensemble based on diversity. Pattern Recognit. 2011, 44, 1245–1261. [Google Scholar] [CrossRef]
- Fernández, J.C.; Cruz-Ramírez, M.; Hervás-Martínez, C. Sensitivity Versus Accuracy in Ensemble Models of Artificial Neural Networks from Multi-objective Evolutionary Algorithms. Neural Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Qasem, S.N.; Shamsuddin, S.M.; Hashim, S.Z.; Darus, M.; Al-Shammari, E. Memetic multiobjective particle swarm optimization-based radial basis function network for classificationproblems. Inf. Sci. 2013, 239, 165–190. [Google Scholar] [CrossRef]
- Salman, I.; Ucan, O.; Bayat, O.; Shaker, K. Impact of Metaheuristic Iteration on Artificial Neural Network Structure in Medical Data. Processes 2018, 6, 57. [Google Scholar] [CrossRef]
- Bertolazzi, P.; Felici, G.; Festa, P.; Fiscon, G.; Weitschek, E. Integer programming models for feature selection: New extensions and a randomized solution algorithm. Eur. J. Oper. Res. 2016, 250, 389–399. [Google Scholar] [CrossRef]
- Festa, P.; Resende, M.G.C. GRASP: Basic components and enhancements. Telecommun. Syst. 2011, 46, 253–271. [Google Scholar] [CrossRef]
- Fiscon, G.; Weitschek, E.; Cella, E.; Presti, A.L.; Giovanetti, M.; Babakir-Mina, M.; Ciotti, M.; Ciccozzi, M.; Pierangeli, A.; Bertolazzi, P.; et al. MISSEL: A method to identify a large number of small species-specific genomic subsequences and its application to viruses classification. BioData Min. 2016, 9, 38. [Google Scholar] [CrossRef] [PubMed]
- Blum, C.; Puchinger, J.; Raidl, G.R.; Roli, A. Hybrid metaheuristics in combinatorial optimization: A survey. Appl. Soft Comput. 2011, 11, 4135–4151. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple datasets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Dheeru, D.; Taniskidou, E.K.; UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 23 October 2018).
- Monti, S.; Tamayo, P.; Mesirov, J.; Golub, T. Consensus clustering—A resampling-based method for class discovery and visualization of gene expression microarray data. Mach. Learn. 2003, 52, 91–118. [Google Scholar] [CrossRef]
- Feo, T.A.; Resende, M.G.C. Greedy randomized adaptive search procedures. J. Glob. Opt. 1995, 6, 109–133. [Google Scholar] [CrossRef]
- Gendreau, M.; Potvin, J. Handbook of Metaheuristics, 2nd ed.; Springer: Berlin, Germany, 2010. [Google Scholar]
- Glover, F. Tabu Search and Adaptive Memory Programming—Advances, Applications and Challenges. In Interfaces in Computer Sciences and Operations Research; Kluwer Academic Publishers: Norwell, MA, USA, 1996; pp. 1–75. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley: Berkeley, CA, USA, 1989. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Dorigo, M. Optimization, Learning and Natural Algorithms. Ph.D. Thesis, Dipartimento di Elettronica, Politecnico di Milano, Italy, 1992. [Google Scholar]
- Lee, K.Y.; El-Sharkawi, M.A. Modern Heuristic Optimization Techniques—Theory and Applications to Power Systems; Wiley-Interscience: Hoboken, NJ, USA, 2008. [Google Scholar]
- Goldbarg, E.F.G.; Goldbarg, M.C.; de Souza, G.R. Particle Swarm Optimization Algorithm for the Traveling Salesman Problem; Springer: Berlin, Germany, 2006; pp. 99–110. [Google Scholar]
- López-Ibáñez, M.; Dubois-Lacoste, J.; Cáceres, L.P.; Stützle, T.; Birattari, M. The irace package: Iterated Racing for Automatic Algorithm Configuration. Oper. Res. Perspect. 2016, 3, 43–58. [Google Scholar] [CrossRef]
- Knowles, J.D.; Thiele, L.; Zitzler, E. A tutorial on the performance assessment of stochastic multiobjective optimizers. In Computer Engineering and Networks Laboratory (TIK); ETH Zurich: Zürich, Switzerland, 2006. [Google Scholar]
- Witten, I.H.; Frank, E. Data Mining—Pratical Learning Tools and Techniques, 2nd ed.; Morgan Kaufmann: Burlington, MA, USA, 2005. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. arXiv, 2016; arXiv:160302754C. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}