1. Introduction
Multi-criteria group decision-making (MCGDM) problems are wide-spread in real-life decision-making situations, especially with the increasing complexity of the socio-economic environment [
1,
2]. In reality, decision-making information is usually uncertain or fuzzy, due to the complexity of things and in recognition of the limitations of decision makers. In order to thoroughly describe fuzzy information, Herrera and Martinez [
3] proposed the 2-tuple linguistic model, composed of a linguistic term and a real number, to represent assessment information in a way that can effectively avoid information loss. Consequently, 2-tuple linguistic MCGDM problems have captured the attention of many researchers in recent years [
4,
5,
6]. 2-tuple linguistic information can describe the fuzziness of decision-making information, while it seems imperfect and inaccurate to deal with information in terms of randomness. In fact, randomness and fuzziness are the most important and fundamental of all kinds of uncertainty [
7,
8]. For instance, for a linguistic decision-making problem, decision maker A may think that 75% fulfillment of a task is “good”, while decision maker B may hold that less than 80% fulfillment of the same task cannot be considered to be “good” with the same linguistic term scale. So in such a way, when considering the degree of certainty of an element belonging to a qualitative concept in a specific universe, it is more feasible to allow a stochastic disturbance of the membership degree encircling a determined central value than to allow a fixed number [
9,
10]. Fortunately, the cloud model can easily overcome this weakness and make decision-making processes more realistic. The cloud model, which is a quantitative and qualitative uncertainty conversion model proposed by Professor Deyi Li based on traditional fuzzy set theory and probability statistics [
11], has distinct advantages in terms of dealing with vague and random decision-making information. It not only easily characterizes the concept of uncertainty in the natural language, but also reflects the intrinsic connection between randomness and fuzziness. Therefore, the cloud model can be used to depict the randomness of 2-tuple linguistic information. To the best of the authors’ knowledge, however, research on converting 2-tuple linguistic variables into clouds has not been reported in the existing literature.
One aim of this paper is to propose a 2-tuple hybrid ordered weighted geometric (THOWG) operator which synthetically considers the importance of both individual and the ordered position to overcome the defect of the existing operators. Another aim of this paper is to develop a new cloud generation method to transform 2-tuple linguistic variables into clouds. The novelty of this paper is as follows:
(i) We develop a new THOWG operator. Traditional 2-tuple linguistic operators either ignore the importance of the individual or neglect the importance of ordered position. To overcome the limitations of existing 2-linguistic power aggregation operators, we develop a new THOWG operator. The THOWG operator combines the advantages of TWG operators and TOWG operators. In this way, it can synthetically consider the importance of both individuals and the ordered position. Moreover, both the TWG operator and the TOWG operator are proved to be special cases of the THOWG operator.
(ii) We present a new cloud generation method to transform 2-tuple linguistic variables into clouds. In real life, fuzziness and randomness are used to describe the uncertainty of natural languages. In addition, randomness and fuzziness are tightly related and inseparable. However, the 2-tuple linguistic variable finds it hard to deal with information in terms of randomness, which will lead to the loss of decision information. To deal with this limitation, we present a new cloud generating method to transform 2-tuple linguistic variables into clouds. This method integrates the significant advantages of the cloud model, so that it can deal with the randomness of natural languages, which will significantly improve the decision quality.
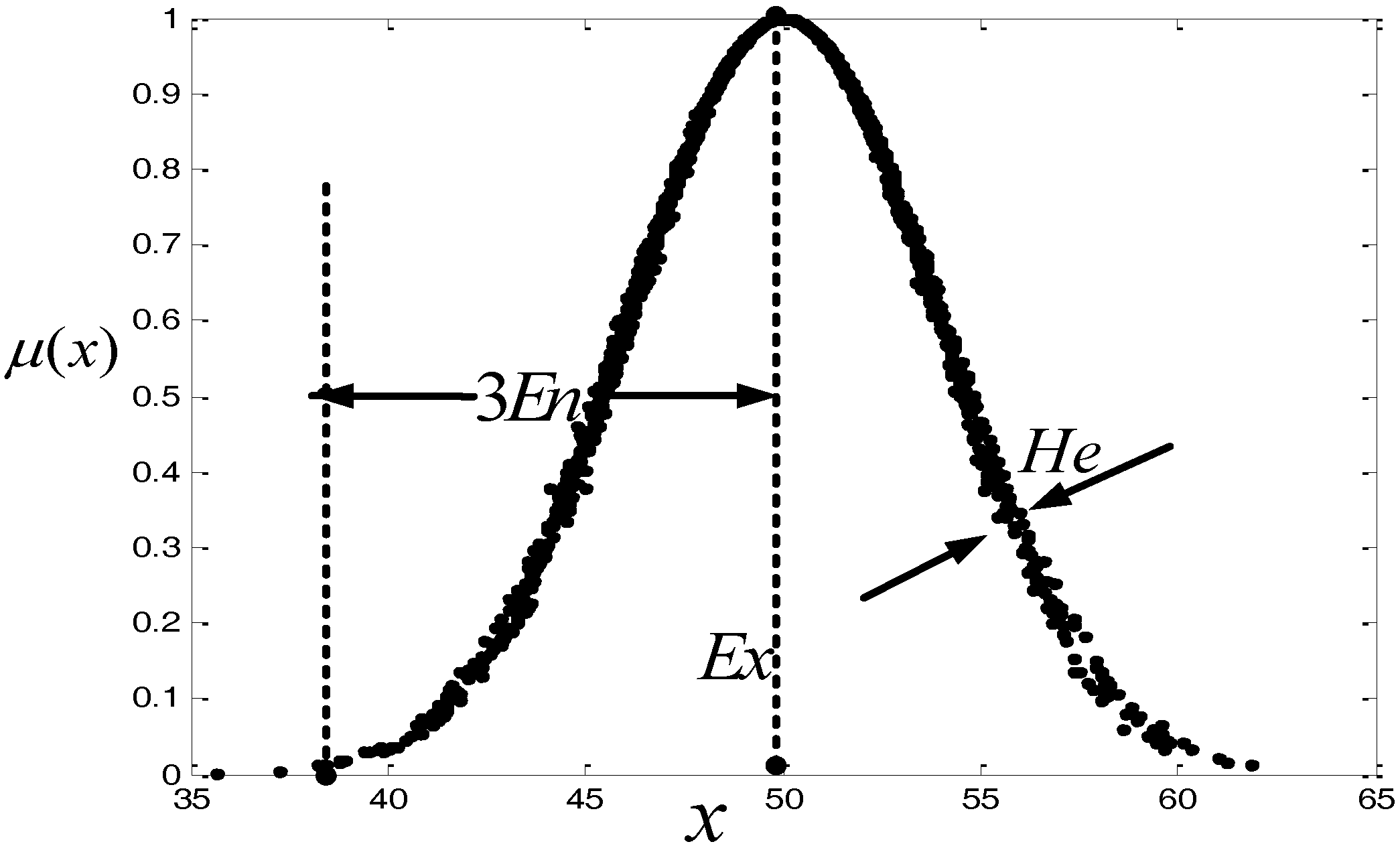
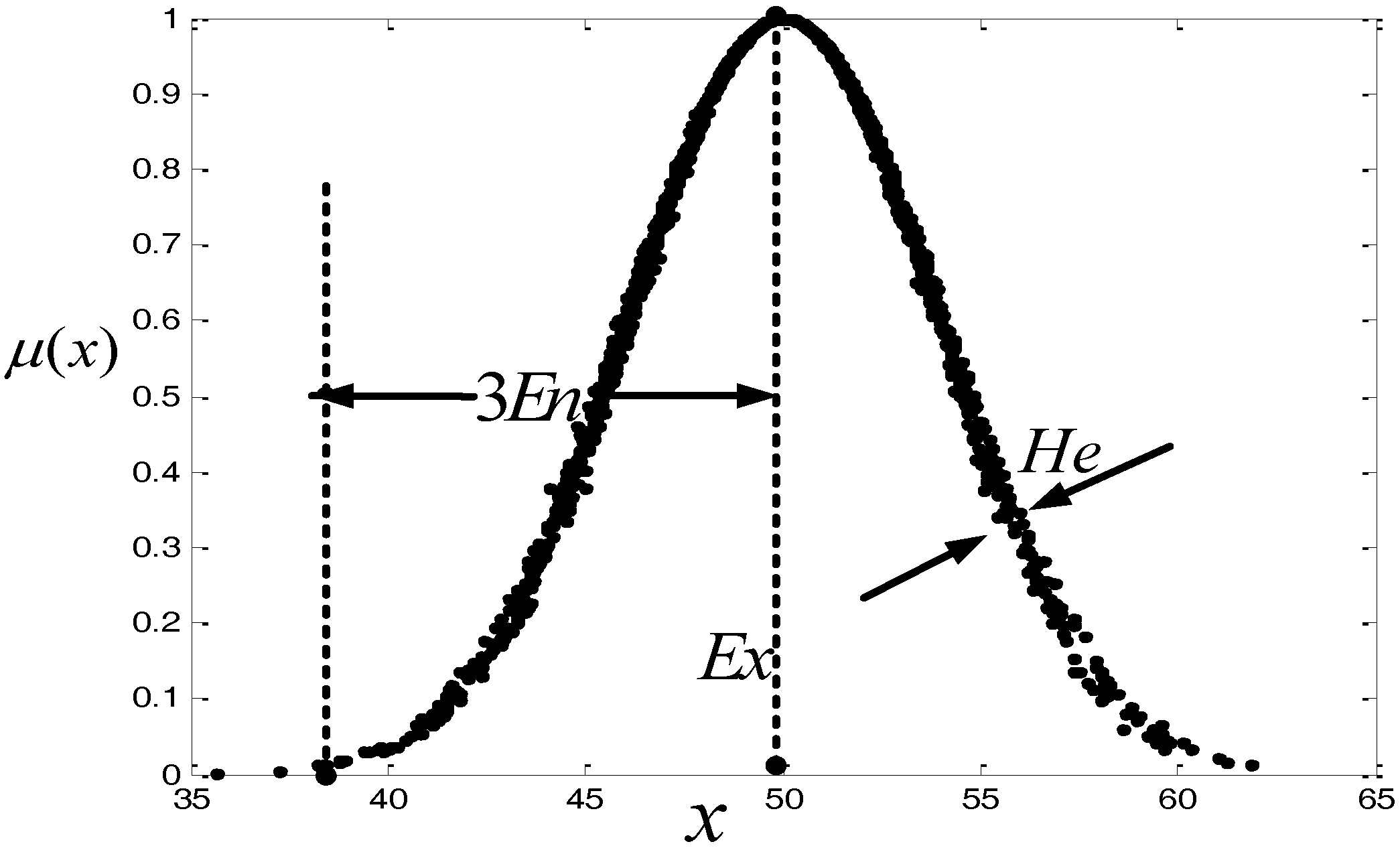
(iii) We address some new cloud algorithms: cloud distance, cloud possibility degree and cloud support degree. Based on the “3En rules” of cloud models, a cloud distance is defined. We further put forward a cloud possibility degree according to this cloud distance, which can be used to compare clouds, and define a cloud support degree which is a similarity index. That is, the greater the similarity is, the closer the two clouds are, and consequently the more they support each other. The support degree can be used to determine the weights of aggregation operators.
To verify the application of the developed approach, a case study of social effect evaluation for BPPs in China is illustrated, and a comparative analysis of the existing approach and the proposed one is carried out to prove the effectiveness of the new developed approach.
The rest of this paper is organized as follows.
Section 2 reviews some recent studies regarding 2-tuple linguistic MCGDM problems and aggregating operators, as well as cloud models.
Section 3 introduces the fundamental conceptions of 2-tuple linguistic variables and cloud models.
Section 4 develops a new averaging operator, and discusses its properties.
Section 5 introduces a method for converting a 2-tuple linguistic into a corresponding normal cloud and defines some new algorithms of the cloud model.
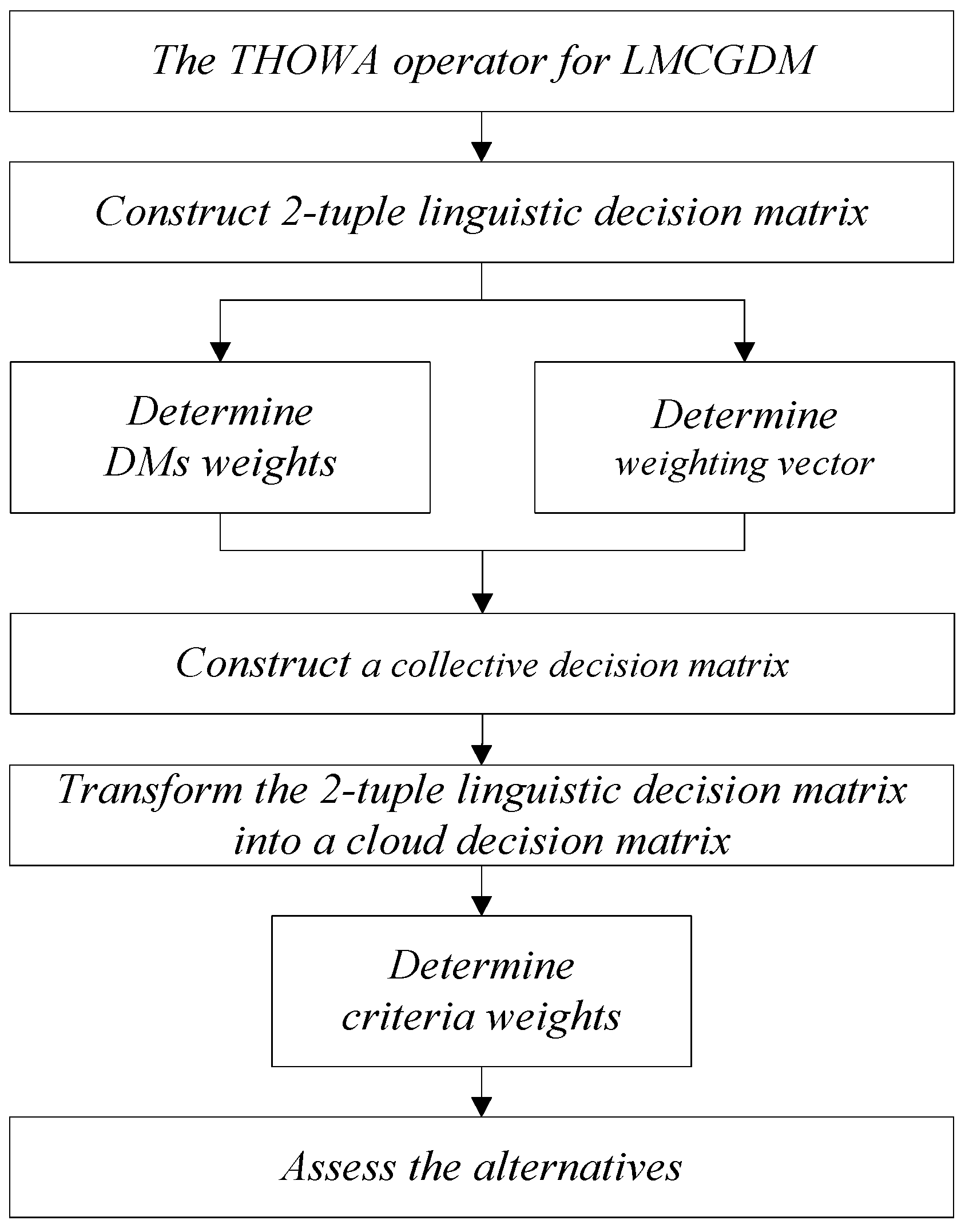
Section 6 proposes a 2-tuple linguistic MCGDM approach based on the cloud model.
Section 7 presents a case study to verify the application of the proposed method and
Section 8 draws conclusions.
2. Literature Review
The decision information in some practical MAGDM situations may be unquantifiable due to its nature, or cannot be precisely assessed in a quantitative form, but may be assessed in a qualitative one. Thus, it may take the form of linguistic variables [
12], such as “poor”, “fair”, and “very good”. To utilize linguistic variables, a pre-defined linguistic assessment set is needed. Unfortunately, the traditional linguistic assessment set is discrete. So in many cases, the decision information provided by DMs may not match any of the original linguistic phrases in the linguistic assessment sets, resulting in loss of information. To overcome these limitations, Herrera and Martinez [
3] introduced the 2-tuple linguistic representation model of which the significant advantage is to be continuous in its domain. Therefore, it can express any counting of information in the universe of the discourse. Recently, the 2-tuple linguistic model has been widely studied. Dong, et al. [
13] developed two different models based on linguistic 2-tuples to address term sets that are not uniformly and symmetrically distributed. Truck [
14] stressed a comparison between the 2-tuple semantic model and the 2-tuple symbolic model, and then proved that links can be made between them. Zhu et al. [
15] utilized two 2-tuples in a 2-dimension linguistic lattice implication algebra to represent a 2-dimension linguistic label for more precise computing and aggregating 2-dimension linguistic information. Xu et al. [
16] proposed a four-way procedure to estimate missing preference values when dealing with acceptable incomplete 2-tuple fuzzy linguistic preference relations in group decision-making. Gong et al. [
17] established an optimization model of group consensus of 2-tuple linguistic preferential relations. In addition, the 2-tuple linguistic variable has been applied to many practical MCGDM problems such as supplier selection [
18,
19], material selection [
20], site selection [
21], emergency response capacity evaluation [
22] and in-flight service quality evaluation [
23].
In light of the fact that information aggregation always plays an important role in decision-making processes, many 2-tuple aggregation operators have been proposed to aggregate information. The ordered weighted averaging (OWA) operator is one of the most common aggregation methods [
24,
25,
26,
27]. It provides a parameterized family of aggregation operators that include as special cases the maximum, the minimum and the average [
28]. Motivated by the idea of the OWA operator, Xu and Wang [
29] developed the 2-tuple linguistic power ordered weighted averaging (2TLPOWA) operator, which can take all the decision arguments and their relationships into account. Jiang and Fan [
30] proposed the 2-tuple ordered weighted geometric (TOWG) operator on the basis of the 2-tuple OWA operator. Li et al. [
28] developed the 2-tuple linguistic induced generalized ordered weighted averaging distance (2LIGOWAD) operator. Zeng et al. [
31] developed the 2-tuple linguistic generalized ordered weighted averaging distance (2LGOWAD) operator, which is an extension of the OWA operator that utilizes generalized means, distance measures and uncertain information represented as 2-tuple linguistic variables. Wang and Hao [
32] introduced the quantifier-guided OWA aggregation operator and anchoring value-based OWA aggregation operator for 2-tuples. However, it needs to point out that these above operators only take into account the importance degrees of relative position and fail to consider the individual importance. On the other hand, some operators just consider individual significance, but neglect the importance of ordered position. For instance, Liu et al. [
33] developed a dependent interval 2-tuple weighted averaging (DITWA) operator and a dependent interval 2-tuple weighted geometric (DITWG) operator.
Randomness and fuzziness are the most important and fundamental of all kinds of uncertainties [
8]. Here, fuzziness mainly refers to uncertainty regarding the range of extension of concept, and randomness implies that any concept is related to the external world in various ways [
10]. However, it is necesssary to point out that the 2-tuple linguistic variable can describe the fuzziness of decision making information, whereas it seems imperfect and inaccurate in dealing with information in terms of randomness. Cloud models, proposed by Professor Deyi Li, has distinct advantages in terms of dealing with vague and random decision-making information. The cloud model depicts the fuzziness and randomness of a qualitative concept with three numerical characteristics perfectly, in such a way that objective and interchangeable transformation between qualitative concepts and quantitative values becomes possible [
11]. Therefore, the cloud model makes it possible to improve the accuracy of decisions. With the rapid development of the cloud model theory, successful applications were carried out in various fields, such as intelligent control [
34], network security [
35], and algorithm improvement [
36]. In particular, since Wang and Feng [
37] introduced the conversion between linguistic variables and clouds, the cloud model has also been applied to the field of decision-making [
9,
38,
39,
40].
From what has been discussed above, it is necessary to develop a new 2-tuple linguistic variable aggregation operator which considers the importance degrees of relative position and individual importance simultaneously. In addition, regarding the significant advantages of 2-tuple linguistic variable and cloud model, it is meaningful to combine them together to deal with MCGDM problems. On the basis of the aforementioned improvements, the decision results will be more reasonable than before.
4. A New 2-Tuple Aggregation Operator
The use of the fuzzy linguistic approach provides a direct way to manage the uncertainty and model the linguistic assessments by means of linguistic variables. In order to effectively avoid the loss and distortion of information in linguistic information processing processes, Herrera and Martinez [
3] proposed a 2-tuple linguistic model, composed of a linguistic term and a real number, to represent the assessment information.
Definition 5 [
30]
. Let be a set of 2-tuple and be the weighting vector of 2-tuple and , the 2-tuple weighted geometric (TWG) operator is Definition 6 [
30]
. Let be a set of 2-tuple, a 2-tuple ordered weighted geometric operator of dimension n is a mapping that has an associated vector such that and . Furthermore,Where is a permutation of such that for all . It is obvious that the two operators have their own defect by Definitions 5 and 6. That is to say, the fundamental aspect of the TWG operator just considers individual significance, but the importance of ordered position is neglected. On the contrary, the TOWG operator only takes the importance degrees of relative position into account and ignores the individual importance.
Therefore, in this section, we propose a new 2-tuple aggregation operator by combining with the advantages of two kinds of operators.
Definition 7. Let be a set of 2-tuple, A 2-tuple hybrid ordered weighted geometric operator of dimension n is a mapping that has an associated vector such that an d . Furthermore,where is a permutation of , such that for all , in which is the weighting vector of 2-tuple and . is the balance factor. The advantage of taking the expression is that it ranks 2-tuple variables by taking the difference and balance into account. Proposition 1. If , then THOWG operator can degenerate into TOWG operator.
Proof. If , then .
Thus, . ☐
Proposition 2. If and , then THOWG operator can degenerate into TWG operator.
Proof. If , then THOWG operator can degenerate into TOWG operator by Proposition 1.
Moreover, . That is to say, the corresponding weight of is .
Thus . ☐
Proposition 3. If for all then
Proposition 4. Let and be two set of 2-tuple, if for all and the rest of the conditions are not changed, then .
Proof. According to Equation (6), ,
If , then so , .
Therefore, .
Thus, . ☐
Remark 1. Definition 7 shows that the new 2-tuple aggregation operator not only considers individual significance, but also considers the importance of ordered position.




{kind=link}
{kind=link}