
An Approach to the Match between Experts and Users in a Fuzzy Linguistic Environment

Abstract
:1. Introduction
2. Related Works
2.1. Tacit Knowledge-Sharing
2.2. Fuzzy Linguistic Method
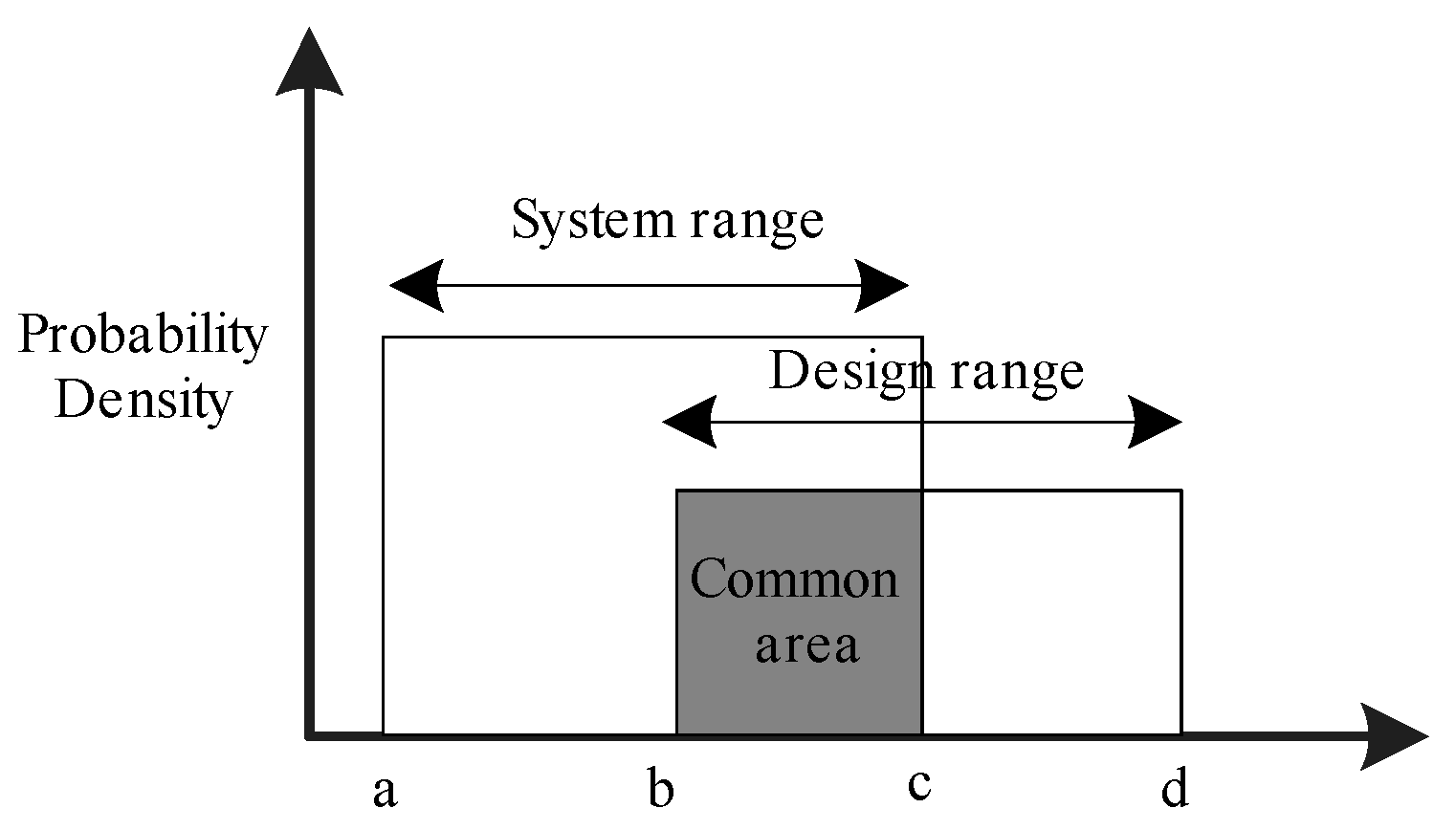
2.3. Axiomatic Design
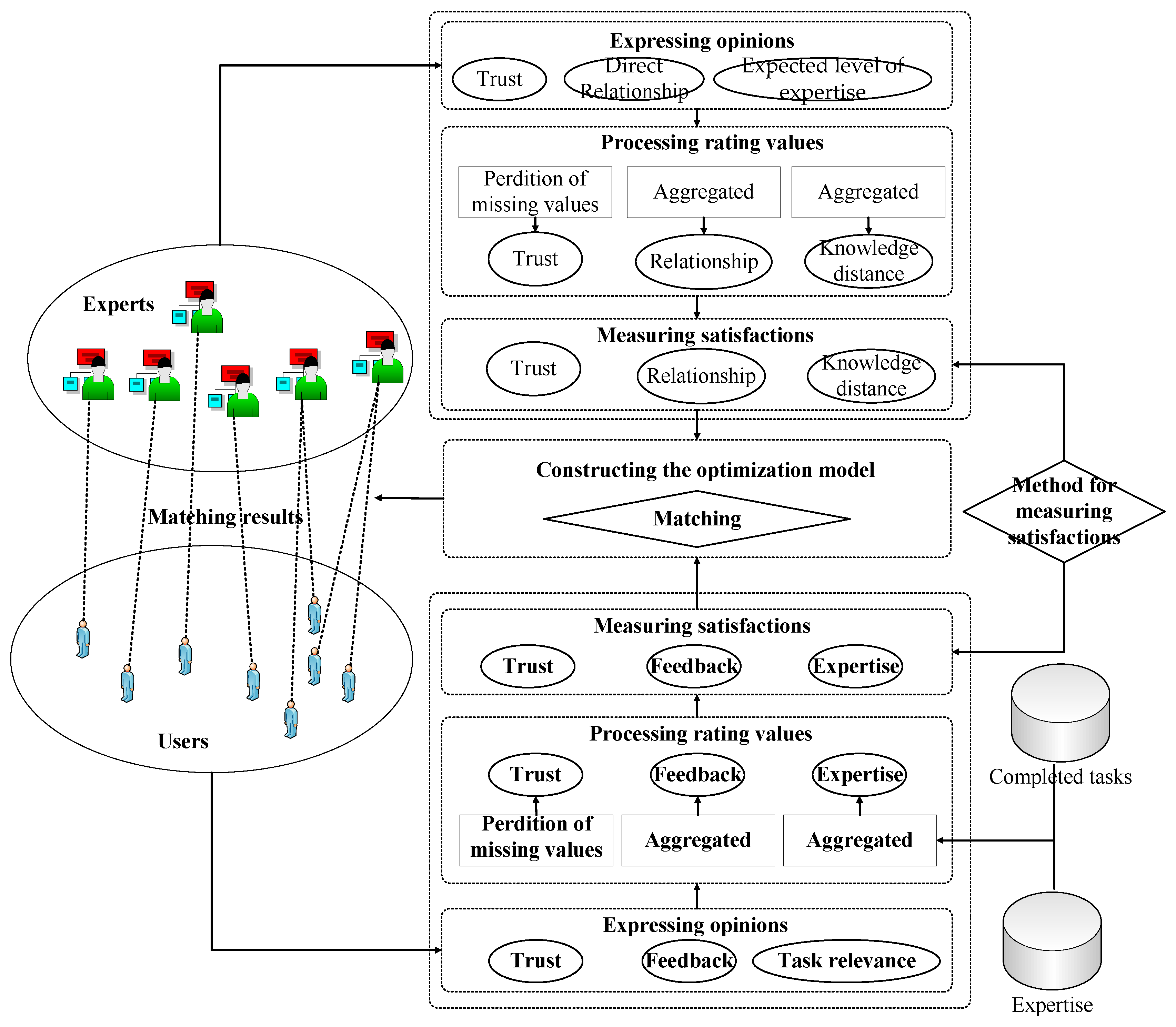
3. Approach to the Match between Experts and Users
3.1. Establishing Criteria for the Match
3.1.1. Expertise
3.1.2. Trust
3.1.3. Relationship
3.1.4. Feedback
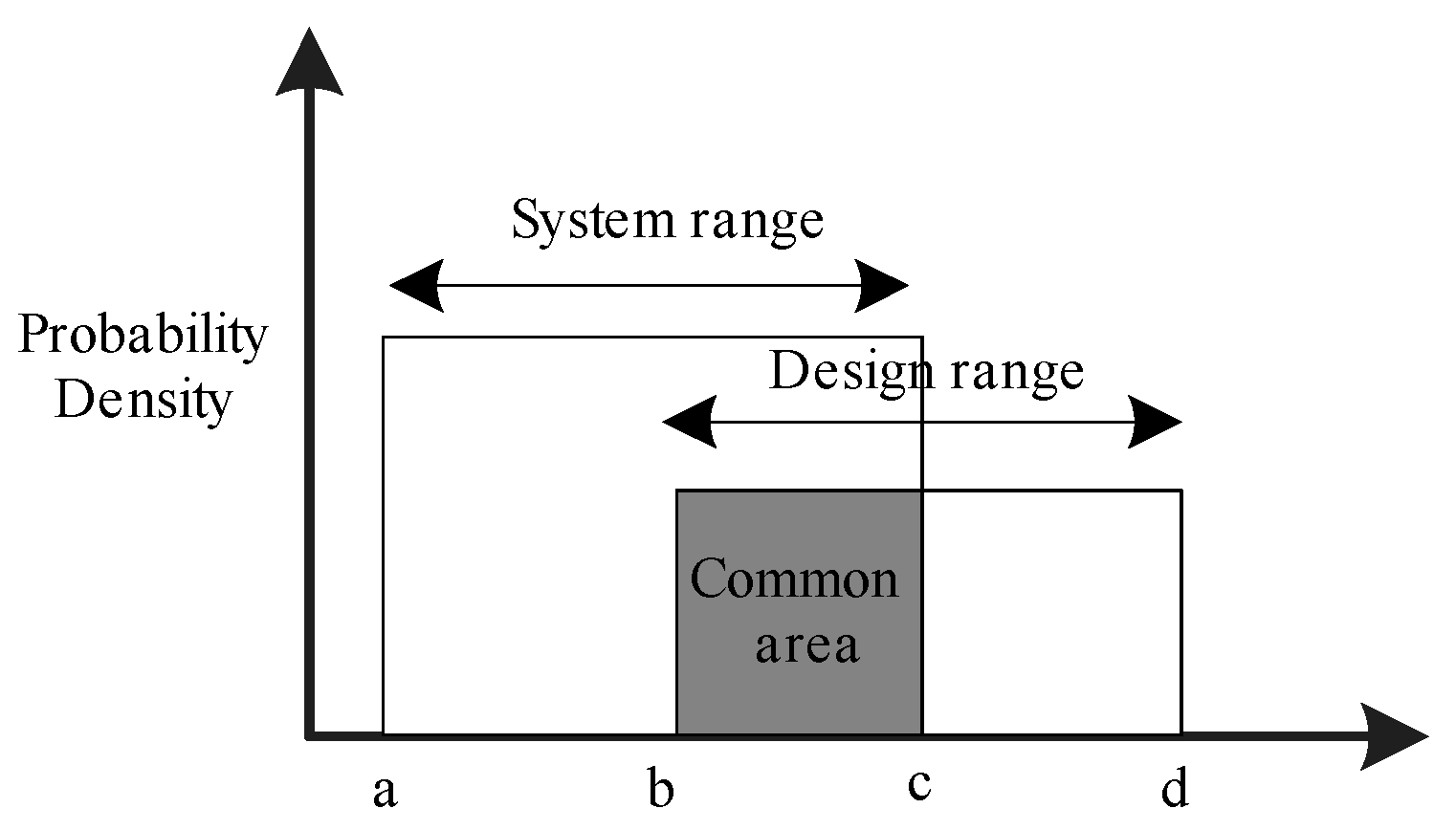
3.1.5. Knowledge Distance
3.2. Constructing the Matching Approach
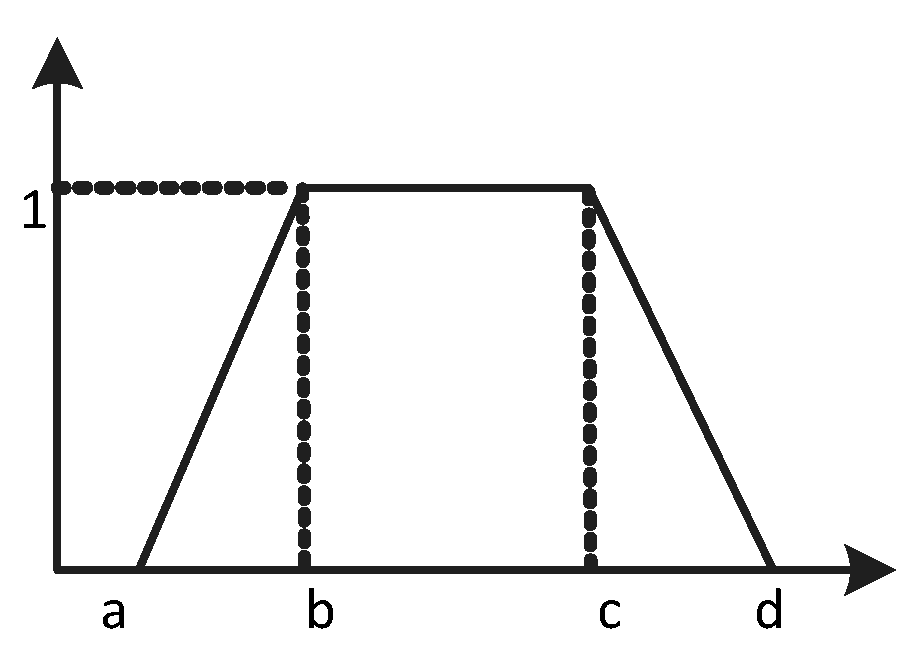
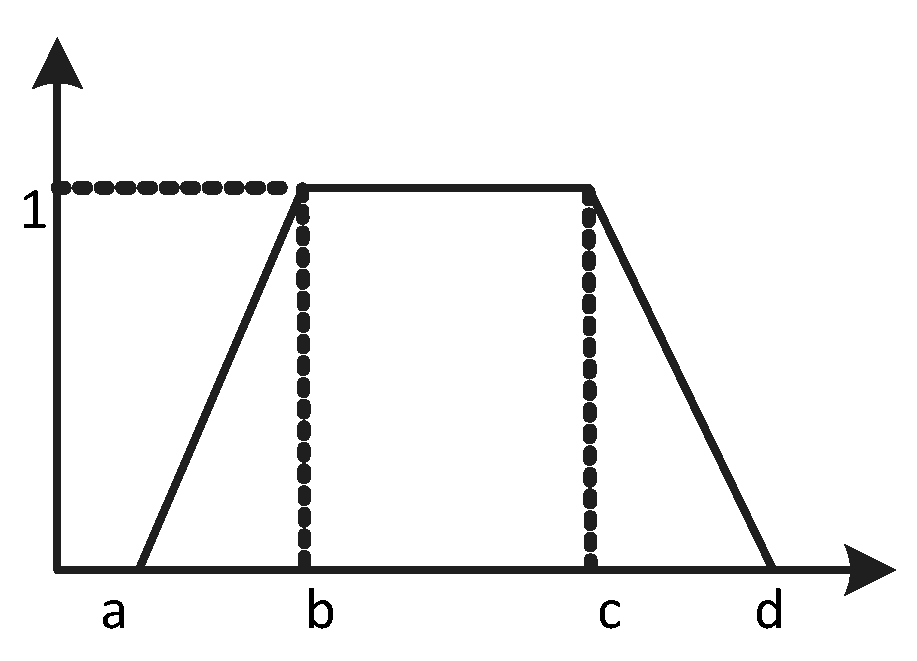
3.2.1. Expressing Opinions and Processing Rating Values
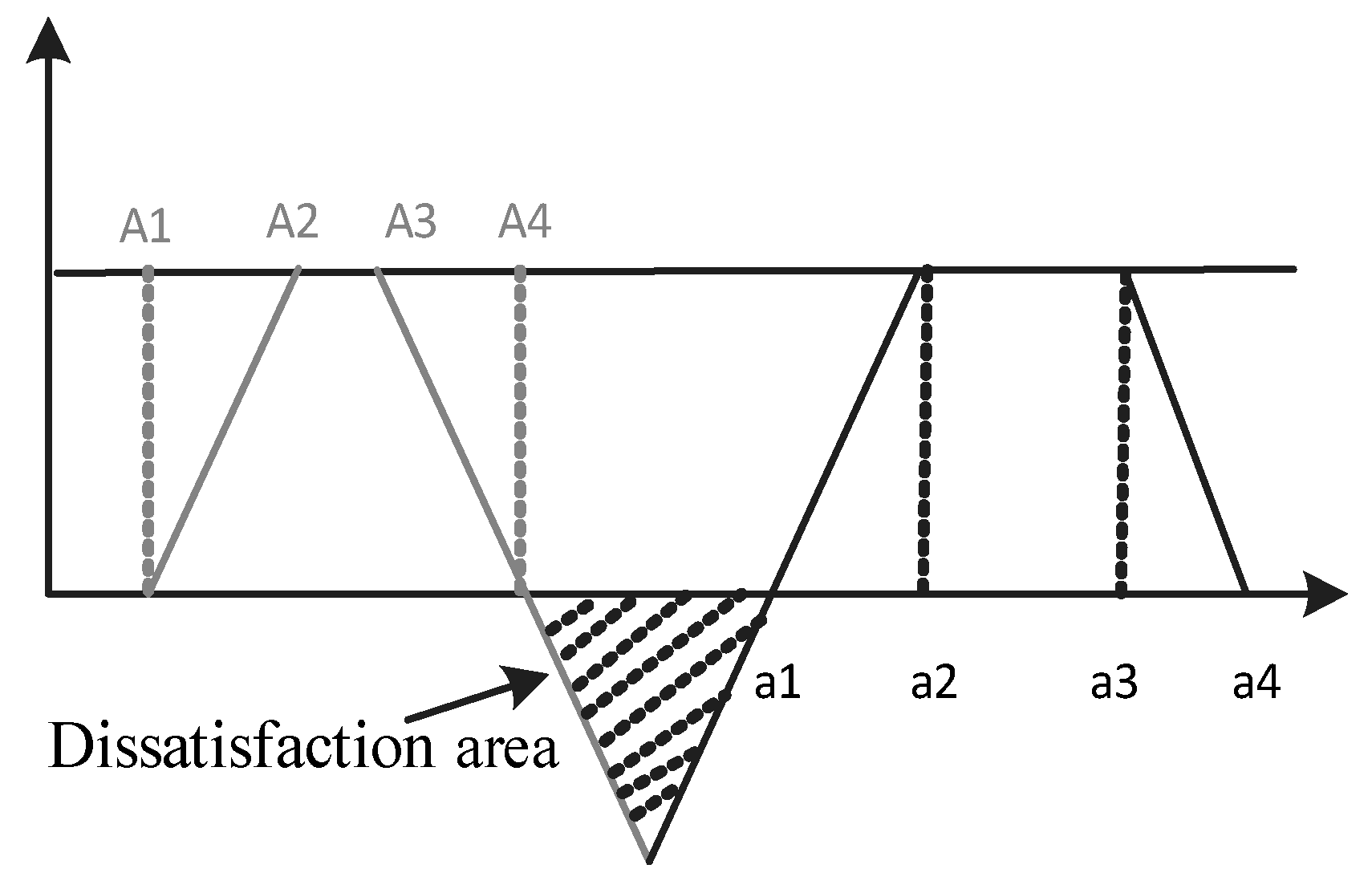
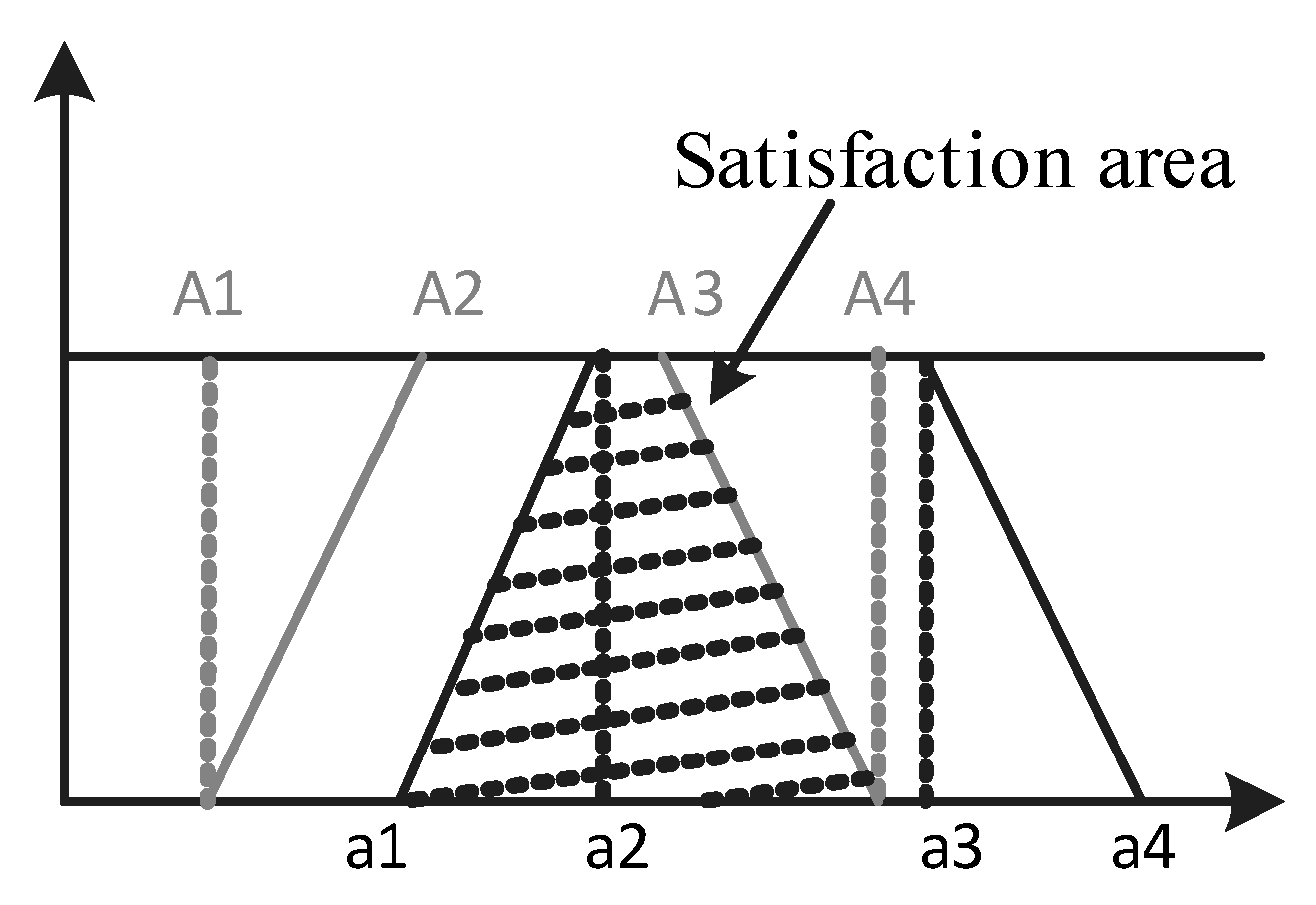
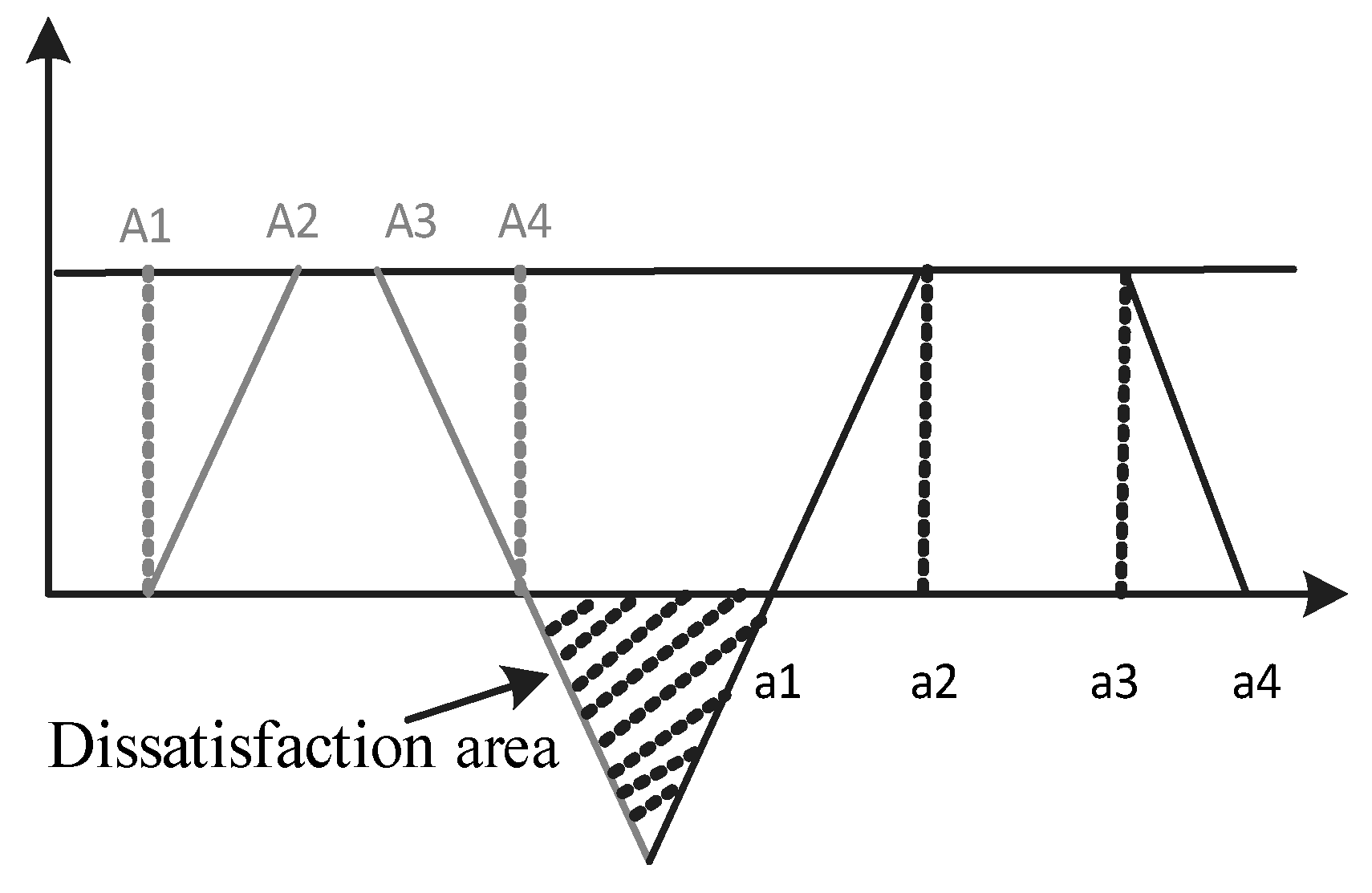
3.2.2. Measuring the Satisfaction
3.2.3. Constructing the Optimization Model
4. Evaluations
- (1)
- With the proposed approach, the needs of both users and experts are identified more comprehensively because of the expression of preferences from multiple aspects. The burden of finding experts is reduced. The only requirements of users are to express their preferences instead of strenuously searching each category and browsing the descriptions of experts. Since the match is made based not only on users’ preferences but also on experts’ preferences, the experts’ satisfaction with users is improved. As a result, experts are more willing to help the users and users can get more fitting help with higher quality. Moreover, searching and contacting experts repeatedly when the one-sided chosen expert is reluctant to help the user due to disagreement with their preferences or limited interest is avoided.
- (2)
- For experts, especially those whose expertise level is higher, the amount of users that ask them for help is reduced and the matched users are better fits for the experts’ preferences. It eases the burden of experts and makes the matched users more acceptable. As the match is based on the rating with respect to the criteria but not rating the people directly, users can be matched with suitable but unfamiliar experts. These unfamiliar experts will be consulted and will not be excluded from the tacit knowledge-sharing. The valuable tacit knowledge resources are utilized fully and efficiently.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Nonaka, I.; Hirotaka, T. The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Alavi, M.; Leidner, D.E. Knowledge management systems: Issues, challenges, and benefits. Commun. AIS 1999, 1, 1. [Google Scholar]
- Liao, S.H. Knowledge Management Technologies and Applications—Literature Review from 1995 to 2002. Exper. Syst. Appl. 2003, 25, 155–164. [Google Scholar] [CrossRef]
- Cavusgil, S.T.; Calantone, R.J.; Zhao, Y. Tacit knowledge transfer and firm innovation capability. J. Bus. Ind. Mark. 2003, 18, 6–21. [Google Scholar] [CrossRef]
- Hansen, M.T.; Nohria, N.; Tierney, T. What’s your strategy for managing knowledge? Harv. Bus. Rev. 1999, 77, 106–116. [Google Scholar] [PubMed]
- Polanyi, M. The Tacit Dimension. In Knowledge in Organizations; Prusak, L., Ed.; Butterworth-Heinemann: Boston, MA, USA, 1997; pp. 135–146. [Google Scholar]
- Arnett, D.B.; Wittmann, C.M. Improving marketing success: The role of tacit knowledge exchange between sales and marketing. J. Bus. Res. 2014, 67, 324–331. [Google Scholar] [CrossRef]
- Haldin-Herrgard, T. Difficulties in diffusion of tacit knowledge in organizations. J. Intellect. Cap. 2000, 1, 357–365. [Google Scholar] [CrossRef]
- Nash, C.; Collins, D. Tacit knowledge in expert coaching: Science or art? Quest 2006, 58, 465–477. [Google Scholar] [CrossRef]
- Alavi, M.; Leidner, D.E. Review: Knowledge management and knowledge management systems: Conceptual foundations and research issues. MIS Q. 2001, 25, 107–136. [Google Scholar] [CrossRef]
- Irma, B.F. Expert Seeker: A People-Finder Knowledge Management System; Florida International University: Miami, FL, USA, 2000. [Google Scholar]
- Microsoft SharePoint products and technologies. Available online: http://www.microsoft.com/sharepoint/ (accessed on 8 April 2016).
- Yang, K.-W.; Huh, S.-Y. Automatic expert identification using a text categorization technique in knowledge management systems. Exper. Syst. Appl. 2008, 34, 1445–1455. [Google Scholar] [CrossRef]
- Chen, Y.J.; Chen, Y.M.; Wu, M.S. An expert recommendation system for product empirical knowledge consultation. In Proceedings of the IEEE International Conference on Computer Science and Information Technology, Chengdu, China, 9–11 July 2010; pp. 23–27.
- Yukawa, T.; Kasahara, K.; Kato, T.; Kita, T. An expert recommendation system using concept-based relevance discernment. In Proceedings of the 13th International Conference on Tools with Artificial Intelligence, Dallas, TX, USA, 7–9 November 2001; pp. 257–264.
- Zhu, H.; Cao, H.; Xiong, H.; Chen, E.; Tian, J. Towards expert finding by leveraging relevant categories in authority ranking. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 2221–2224.
- Ehrlich, K.; Lin, C.Y.; Griffiths-Fisher, V. Searching for experts in the enterprise: Combining text and social network analysis. In Proceedings of the 2007 International ACM Conference on Supporting Group Work, Sanibel Island, FL, USA, 4–7 November 2007; pp. 117–126.
- Duan, Y.; Nie, W.; Coakes, E. Identifying key factors affecting transnational knowledge transfer. Inf. Manag. 2010, 47, 356–363. [Google Scholar] [CrossRef]
- Gupta, B.; Iyer, L.S.; Aronson, J.E. Knowledge management: Practices and challenges. Ind. Manag. Data Syst. 2000, 100, 17–21. [Google Scholar] [CrossRef]
- Robertson, M.; O’Malley Hammersley, G. Knowledge management practices within a knowledge-intensive firm: The significance of the people management dimension. J. Eur. Ind. Train. 2000, 24, 241–253. [Google Scholar] [CrossRef]
- Riege, A. Three-dozen knowledge-sharing barriers managers must consider. J. Knowl. Manag. 2005, 9, 18–35. [Google Scholar] [CrossRef]
- Soheil, S.N.; Kaveh, K.D. Application of a fuzzy TOPSIS method base on modified preference ratio and fuzzy distance measurement in assessment of traffic police centers performance. Appl. Soft Comput. 2010, 10, 1028–1039. [Google Scholar]
- Dong, M.; Li, S.; Zhang, H. Approaches to group decision making with incomplete information based on power geometric operators and triangular fuzzy AHP. Exper. Syst. Appl. 2015, 42, 7846–7857. [Google Scholar] [CrossRef]
- Zheng, G.; Zhu, N.; Tian, Z.; Chen, Y.; Sun, B. Application of a trapezoidal fuzzy AHP method for work safety evaluation and early warning rating of hot and humid environments. Saf. Sci. 2012, 50, 228–239. [Google Scholar] [CrossRef]
- Deng, Y.; Chan, F.T.; Wu, Y.; Wang, D. A new linguistic MCDM method based on multiple-criterion data fusion. Exper. Syst. Appl. 2011, 38, 6985–6993. [Google Scholar] [CrossRef]
- Zimmermann, H.-J. Fuzzy Set Theory—And Its Applications; Kluwer Academic Publishers: Boston, MA, USA, 1991. [Google Scholar]
- Sanayei, A.; Mousavi, S.F.; Yazdankhah, A. Group decision making process for supplier selection with VIKOR under fuzzy environment. Exper. Syst. Appl. 2010, 37, 24–30. [Google Scholar] [CrossRef]
- Kulak, O.; Cebi, S.; Kahraman, C. Applications of axiomatic design principles: A literature review. Expert Syst. Appl. 2010, 37, 6705–6717. [Google Scholar] [CrossRef]
- Suh, N.P. Design of thinking design machine. CIRP Ann. 1990, 39, 145–148. [Google Scholar] [CrossRef]
- Chen, X.; Fan, Z. Problem of Two-sided Matching between Venture Capitalists and Venture Enterprises Based on Axiomatic Design. Syst. Eng. 2010, 28, 9–16. [Google Scholar]
- Li, M.; Liu, L.; Li, C.B. Method for Knowledge Management System Selection Based on Improved Fuzzy Information Axiom. Ind. Eng. J. 2010, 13, 15–18. [Google Scholar]
- Kim, Y.A.; Song, H.S. Strategies for predicting local trust based on trust propagation in social networks. Knowledge- Based Syst. 2011, 24, 1360–1371. [Google Scholar] [CrossRef]
- Zhang, J.; Ackerman, M.S.; Adamic, L. Expertise networks in online communities: Structure and algorithms. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 221–230.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linguistic Variables | Fuzzy Numbers |
|---|---|
| Very low (VL) | (0,1,2,3) |
| Low (L) | (1,2,3,4) |
| Medium (M) | (3,4,5,6) |
| High (H) | (4,5,6,7) |
| Very low (VH) | (5,6,7,8) |
| User | ||||||||||||
| 0.14 | 1.00 | 1.00 | 0.41 | 3.00 | 1.00 | 0.37 | 0.00 | 1.00 | −6.65 | 3.00 | 3.00 | |
| 0.14 | 1.00 | 0.00 | 0.36 | 1.00 | 0.00 | 0.22 | 0.00 | 0.00 | −5.06 | 1.00 | 0.00 | |
| 0.15 | 1.00 | 1.00 | 0.37 | 4.99 | 3.00 | 0.28 | 0.00 | 0.00 | −4.96 | 1.00 | 3.00 | |
| 0.11 | 0.00 | 0.00 | 0.39 | 1.00 | 3.00 | 0.31 | 0.00 | 0.00 | −6.04 | 1.00 | 3.00 | |
| 0.18 | 1.00 | 1.00 | 0.38 | 0.00 | 1.00 | 0.28 | 0.00 | 0.00 | −5.35 | 3.00 | 3.00 | |
| 0.22 | 1.00 | 3.00 | 0.33 | 3.00 | 3.00 | 0.20 | 0.00 | 3.00 | −3.94 | 0.00 | 0.00 | |
| 0.21 | 0.00 | 3.00 | 0.38 | 0.00 | 0.00 | 0.23 | 0.00 | 1.00 | −5.03 | 3.00 | 3.00 | |
| 0.05 | 3.00 | 1.00 | 0.43 | 3.00 | 1.00 | 0.50 | 0.00 | 1.00 | −14.09 | 3.00 | 1.00 | |
| 0.19 | 1.00 | 0.00 | 0.39 | 3.00 | 3.00 | 0.30 | 1.00 | 0.00 | −5.44 | 1.00 | 3.00 | |
| 0.19 | 3.00 | 1.00 | 0.38 | 3.00 | 0.00 | 0.21 | 0.00 | 0.00 | −4.99 | 1.00 | 3.00 | |
| 0.21 | 0.00 | 1.00 | 0.40 | 1.00 | 3.00 | 0.24 | 0.00 | 1.00 | −5.23 | 1.00 | 1.00 | |
| 0.14 | 0.00 | 0.00 | 0.40 | 0.00 | 1.00 | 0.36 | 0.00 | 0.00 | −6.39 | 3.00 | 1.00 | |
| User | ||||||||||||
| 0.88 | 3.00 | 3.00 | 0.30 | 1.00 | 3.00 | 0.00 | 0.00 | 3.00 | 1.95 | 3.00 | 3.00 | |
| 0.68 | 1.00 | 0.00 | 0.28 | 1.00 | 3.00 | 0.00 | 1.00 | 3.00 | 1.64 | 1.00 | 0.00 | |
| 0.58 | 1.00 | 3.00 | 0.25 | 0.00 | 3.00 | 0.00 | 0.00 | 1.00 | 1.56 | 4.99 | −3.00 | |
| 0.83 | 1.00 | 3.00 | 0.26 | 0.00 | 3.00 | 0.00 | 0.00 | 1.00 | 1.80 | 1.00 | −3.00 | |
| 0.69 | 1.00 | 3.00 | 0.29 | −3.00 | 3.00 | 0.00 | 0.00 | 3.00 | 1.81 | −3.00 | 3.00 | |
| 0.38 | 3.00 | 3.00 | 0.12 | 3.00 | 3.00 | 0.00 | 1.00 | 3.00 | 1.50 | 1.00 | 3.00 | |
| 0.56 | −3.00 | 3.00 | 0.24 | −3.00 | 3.00 | 0.00 | 1.00 | 3.00 | 1.74 | 1.00 | 3.00 | |
| 1.16 | 1.00 | 1.00 | 0.51 | 0.00 | 3.00 | 0.05 | 0.00 | 3.00 | 2.10 | −3.00 | 1.00 | |
| 0.69 | 3.00 | 3.00 | 0.29 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.85 | 0.00 | 3.00 | |
| 0.54 | 3.00 | −3.00 | 0.23 | 1.00 | 3.00 | 0.00 | 1.00 | 1.00 | 1.64 | 3.00 | −3.00 | |
| 0.53 | 0.00 | 3.00 | 0.24 | 4.99 | 1.00 | 0.00 | 0.00 | 1.00 | 1.73 | 4.99 | 0.00 | |
| 0.88 | 1.00 | 3.00 | 0.29 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.94 | −3.00 | 3.00 | |
| Expert | ||||||||||||
| 0.00 | 2.00 | 2.23 | 1.00 | 2.00 | 0.64 | 1.00 | 2.00 | 1.74 | 1.00 | 2.00 | 2.37 | |
| 4.99 | −0.25 | 0.59 | 1.00 | −0.25 | 2.29 | 1.00 | −0.25 | 0.93 | 1.00 | −0.25 | 0.67 | |
| 0.00 | 1.00 | 1.80 | 0.00 | 1.00 | 1.86 | 0.00 | 1.00 | 1.98 | 0.00 | 1.00 | 0.22 | |
| 0.00 | −0.25 | 2.87 | 1.00 | −0.25 | 0.59 | 1.00 | −0.25 | 1.51 | 1.00 | −0.25 | 3.00 | |
| 0.00 | 2.00 | 2.43 | 1.00 | 2.00 | 0.17 | 0.00 | 2.00 | 2.52 | 0.00 | 2.00 | 1.17 | |
| 0.00 | 1.00 | 0.44 | 3.00 | 1.00 | 3.54 | 1.00 | 1.00 | 0.71 | 3.00 | 1.00 | 2.13 | |
| 0.00 | −0.25 | 2.31 | 1.00 | −0.25 | 0.18 | 1.00 | −0.25 | 1.74 | 1.00 | −0.25 | 1.81 | |
| 0.00 | 2.00 | 3.00 | 1.00 | 2.00 | 0.26 | 0.00 | 2.00 | 2.00 | 0.00 | 2.00 | 1.11 | |
| Expert | ||||||||||||
| 1.00 | 2.00 | 1.65 | 1.00 | 1.00 | 1.84 | 4.99 | 1.00 | 0.68 | 0.00 | 1.00 | 0.50 | |
| 0.00 | −0.25 | 1.95 | 1.00 | 2.00 | 1.37 | 4.99 | 2.00 | 1.71 | 0.00 | 2.00 | 0.23 | |
| 3.00 | 1.00 | 0.76 | 3.00 | 2.00 | 2.46 | 3.00 | 2.00 | 0.50 | 0.00 | 2.00 | −0.69 | |
| 1.00 | −0.25 | 0.12 | 0.00 | 2.00 | −0.59 | 1.00 | 2.00 | 1.63 | 1.00 | 2.00 | 0.50 | |
| 1.00 | 2.00 | 2.59 | 1.00 | 1.00 | 3.79 | 1.00 | 1.00 | 2.79 | 0.00 | 1.00 | −0.19 | |
| 1.00 | 1.00 | −0.72 | −3.00 | 2.00 | 0.81 | 0.00 | 2.00 | −1.01 | 1.00 | 2.00 | 0.68 | |
| 1.00 | −0.25 | −1.41 | 1.00 | 2.00 | −0.97 | 1.00 | 2.00 | −0.93 | 0.00 | 2.00 | 1.27 | |
| 1.00 | 2.00 | 2.20 | 1.00 | 1.00 | 2.52 | 1.00 | 1.00 | 1.40 | 0.00 | 1.00 | 0.50 | |
| Expert | ||||||||||||
| 1.00 | 1.00 | 2.03 | 0.00 | 1.00 | 2.71 | 1.00 | 1.00 | 2.03 | 0.00 | 2.00 | 2.52 | |
| 1.00 | 2.00 | 0.93 | 0.00 | 2.00 | −1.07 | 0.00 | 2.00 | 1.77 | 0.00 | −0.25 | 1.21 | |
| 0.00 | 2.00 | −0.05 | 0.00 | 2.00 | −1.98 | 3.00 | 2.00 | 0.78 | 3.00 | 1.00 | 0.26 | |
| 1.00 | 2.00 | −0.10 | 1.00 | 2.00 | −0.50 | 1.00 | 2.00 | 4.02 | 1.00 | −0.25 | 3.52 | |
| 1.00 | 1.00 | 1.62 | 1.00 | 1.00 | 2.22 | 1.00 | 1.00 | 2.87 | 0.00 | 2.00 | 3.31 | |
| 0.00 | 2.00 | 1.44 | 0.00 | 2.00 | −0.47 | 3.00 | 2.00 | 0.51 | −3.00 | 1.00 | 0.00 | |
| 0.00 | 2.00 | 0.85 | 0.00 | 2.00 | 0.33 | 1.00 | 2.00 | 1.98 | 0.00 | −0.25 | 1.68 | |
| 0.00 | 1.00 | 1.67 | 1.00 | 1.00 | 2.33 | 1.00 | 1.00 | 2.58 | 0.00 | 2.00 | 3.09 | |
| VH | H | VH | H | VH | VH | H | VH | H | VH | M | VH | |
| VH | VH | VH | H | H | VH | M | M | VH | M | M | H | |
| H | VH | H | H | VH | H | L | M | VH | VH | M | VH |
| VH | H | H | H | H | M | L | M | |
| M | H | VL | M | M | VL | VH | M | |
| M | M | M | H | M | VH | H | H |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Yuan, M. An Approach to the Match between Experts and Users in a Fuzzy Linguistic Environment. Information 2016, 7, 22. https://doi.org/10.3390/info7020022
Li M, Yuan M. An Approach to the Match between Experts and Users in a Fuzzy Linguistic Environment. Information. 2016; 7(2):22. https://doi.org/10.3390/info7020022
Chicago/Turabian StyleLi, Ming, and Mengyue Yuan. 2016. "An Approach to the Match between Experts and Users in a Fuzzy Linguistic Environment" Information 7, no. 2: 22. https://doi.org/10.3390/info7020022
APA StyleLi, M., & Yuan, M. (2016). An Approach to the Match between Experts and Users in a Fuzzy Linguistic Environment. Information, 7(2), 22. https://doi.org/10.3390/info7020022