The SP Theory of Intelligence: Benefits and Applications

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- Conceptual simplicity combined with descriptive and explanatory power.
- Simplification of computing systems, including software.
- Deeper insights and better solutions in several areas of application.
- Seamless integration of structures and functions within and between different areas of application.
2. A Little Philosophy
3. The SP Theory and the SP Machine: A Summary
- All kinds of knowledge are represented with patterns: arrays of atomic symbols in one or two dimensions.
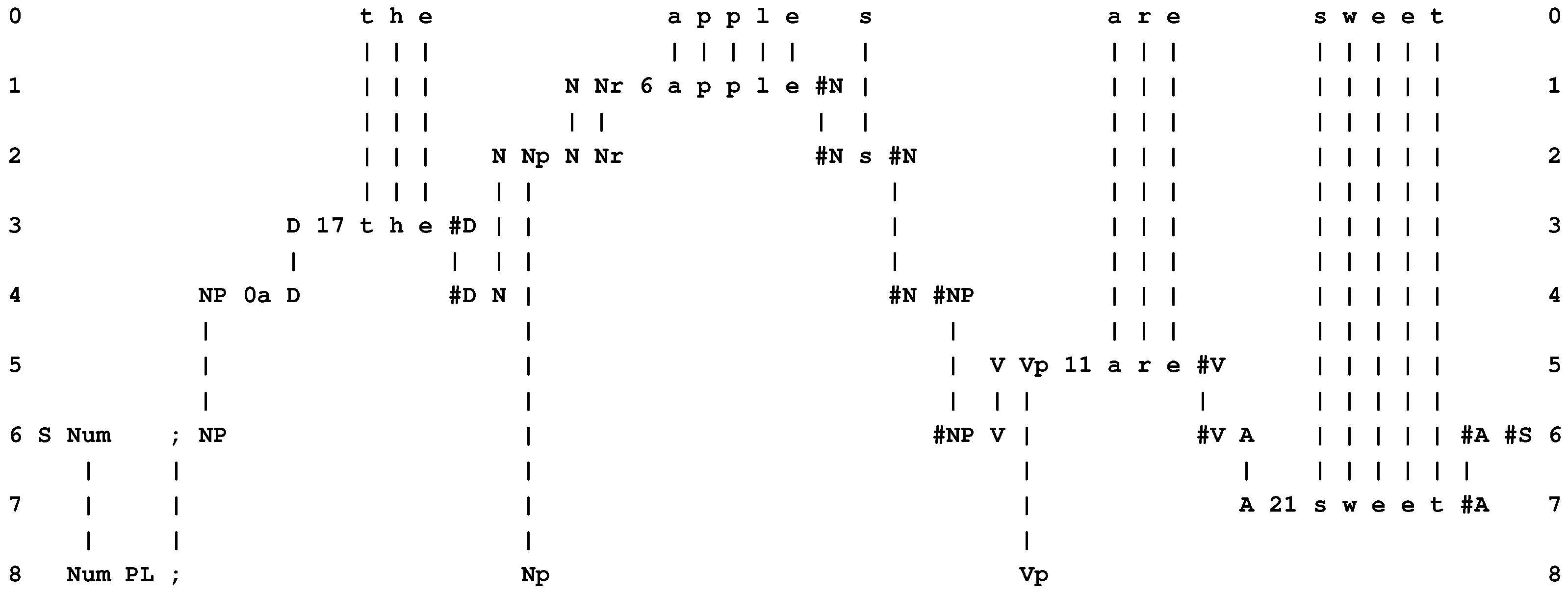
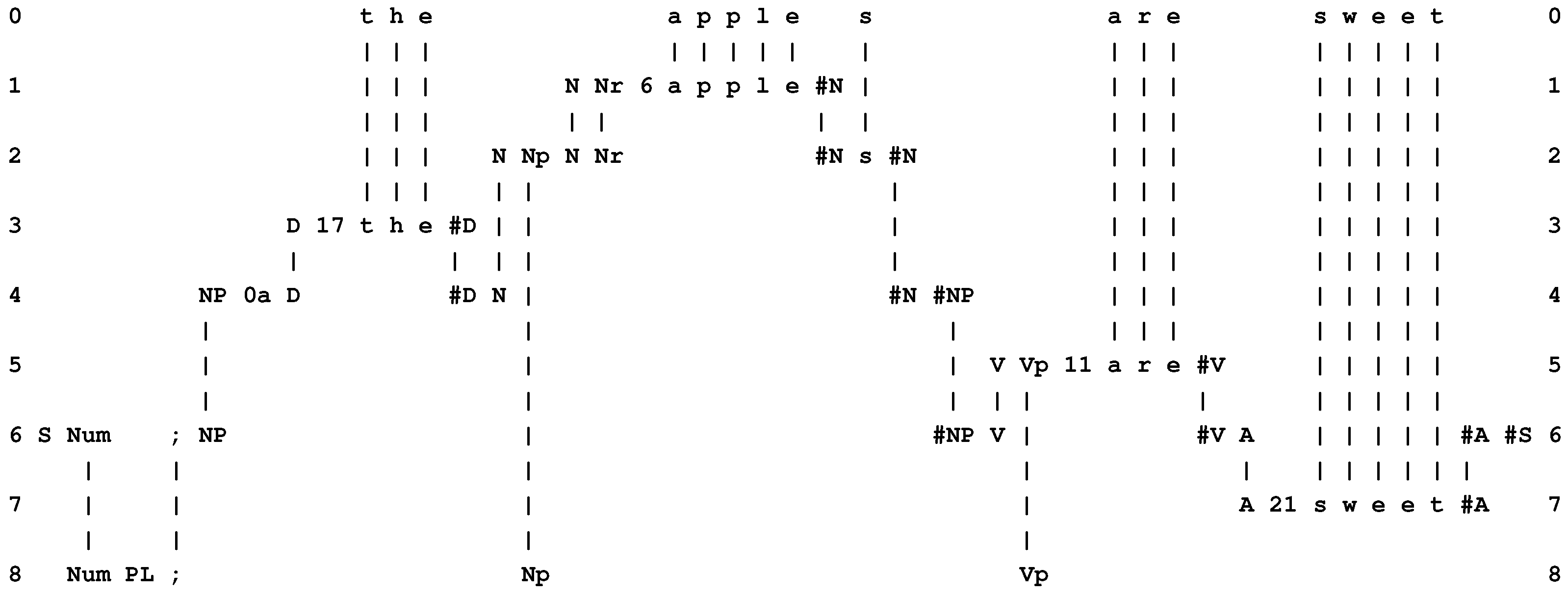
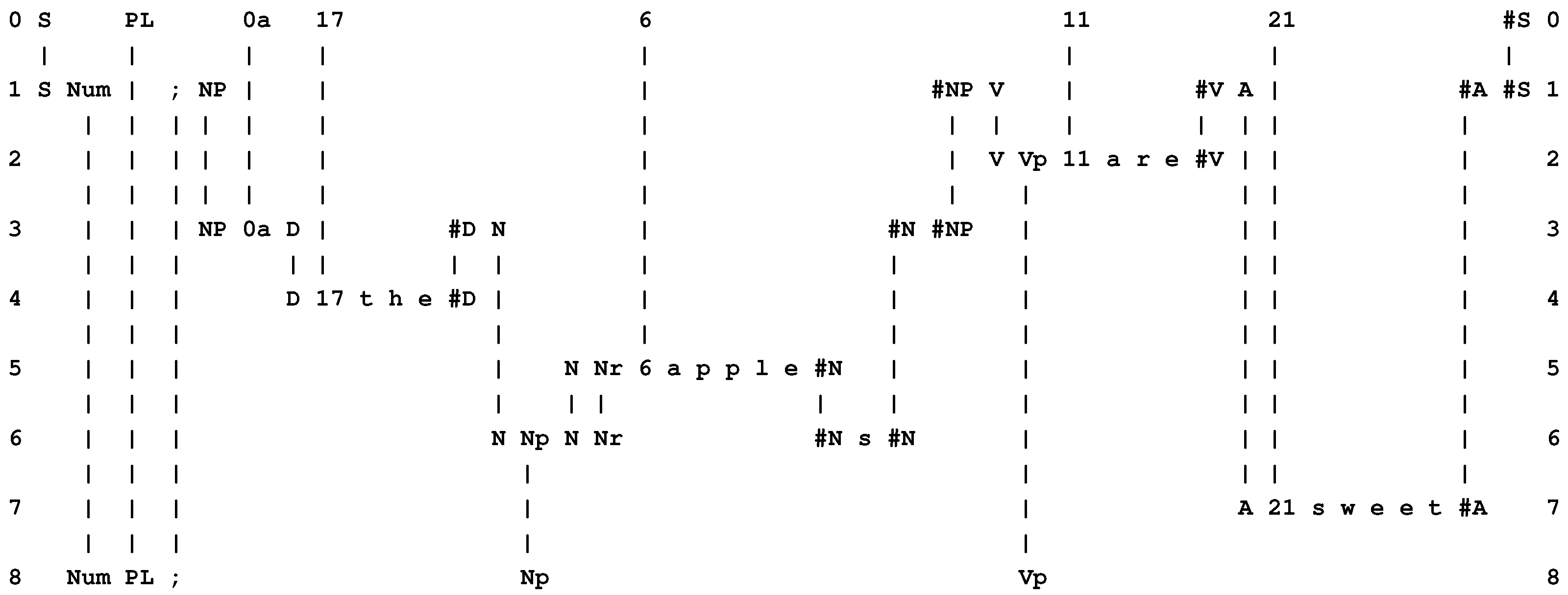
- At the heart of the system is compression of information via the matching and unification (merging) of patterns, and the building of multiple alignments like the one shown in Figure 1.
- The system learns by compressing “New” patterns to create “Old” patterns like those shown in rows 1 to 8 in Figure 1.
4. Combining Conceptual Simplicity with Descriptive and Explanatory Power
- The SP theory, including the multiple alignment concept, is not trivially simple but it is not unduly complicated either. The SP computer model (Sections 3.9, 3.10 and 9.2 in [1]; Section 3.1 in [2]), which is, apart from some associated thinking, the most comprehensive expression of the theory as it stands now, is embodied in an “exec” file requiring less than 500 KB of storage space.
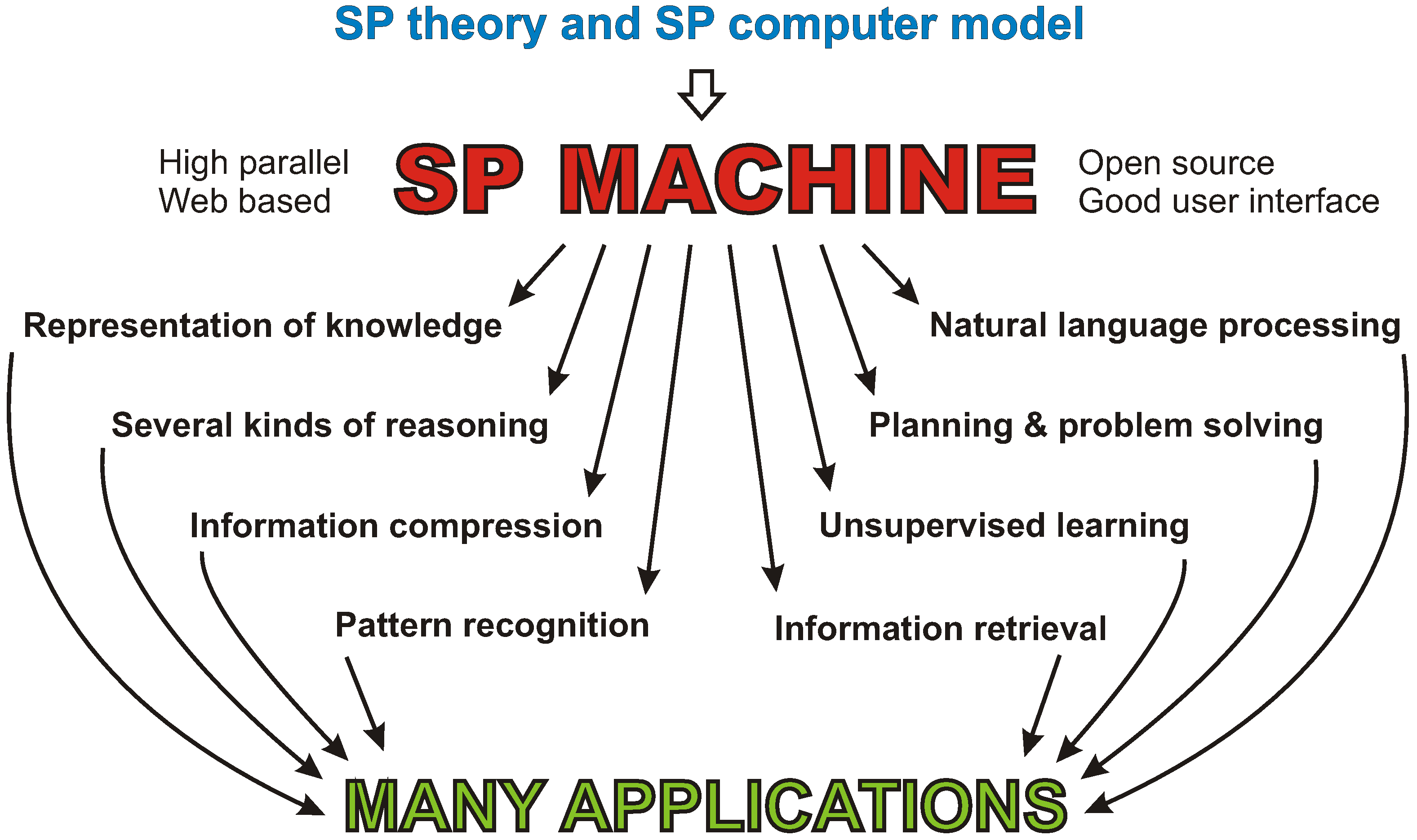
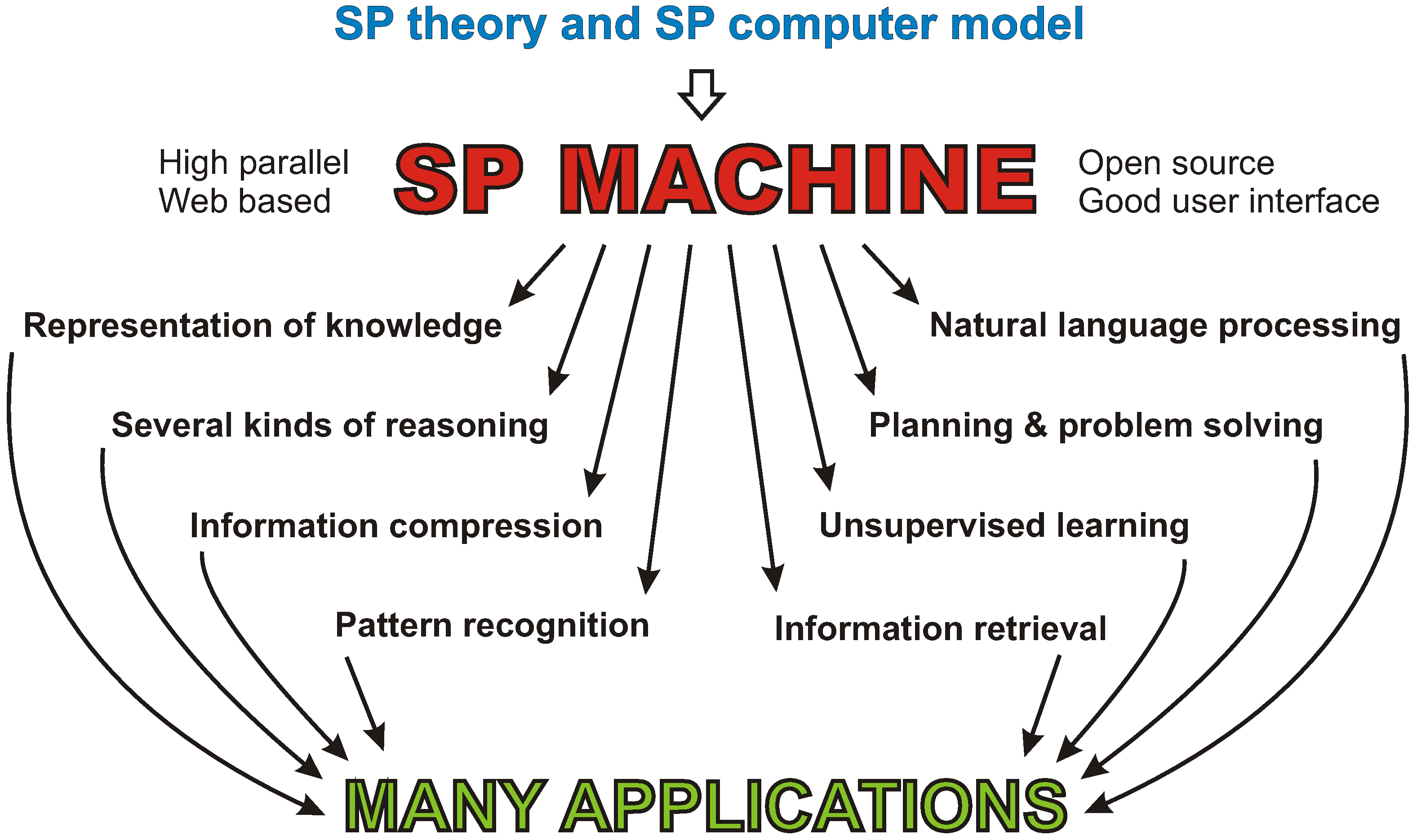
- Largely because of the versatility of the multiple alignment concept, the SP theory can model a range of concepts and phenomena in: unsupervised learning, concepts of “computing”, mathematics and logic, the representation of knowledge, natural language processing, pattern recognition, several kinds of probabilistic reasoning, information storage and retrieval, planning and problem solving, and information compression; and it has things to say about concepts in neuroscience and in human perception and cognition. (Chapters 4–13 in [1]; Sections 5–13 in [2]).
5. Simplification of Computing Systems, Including Software
- Domain-specific knowledge such as knowledge of accountancy, geography, the organization and procedures of a business, and so on [13].
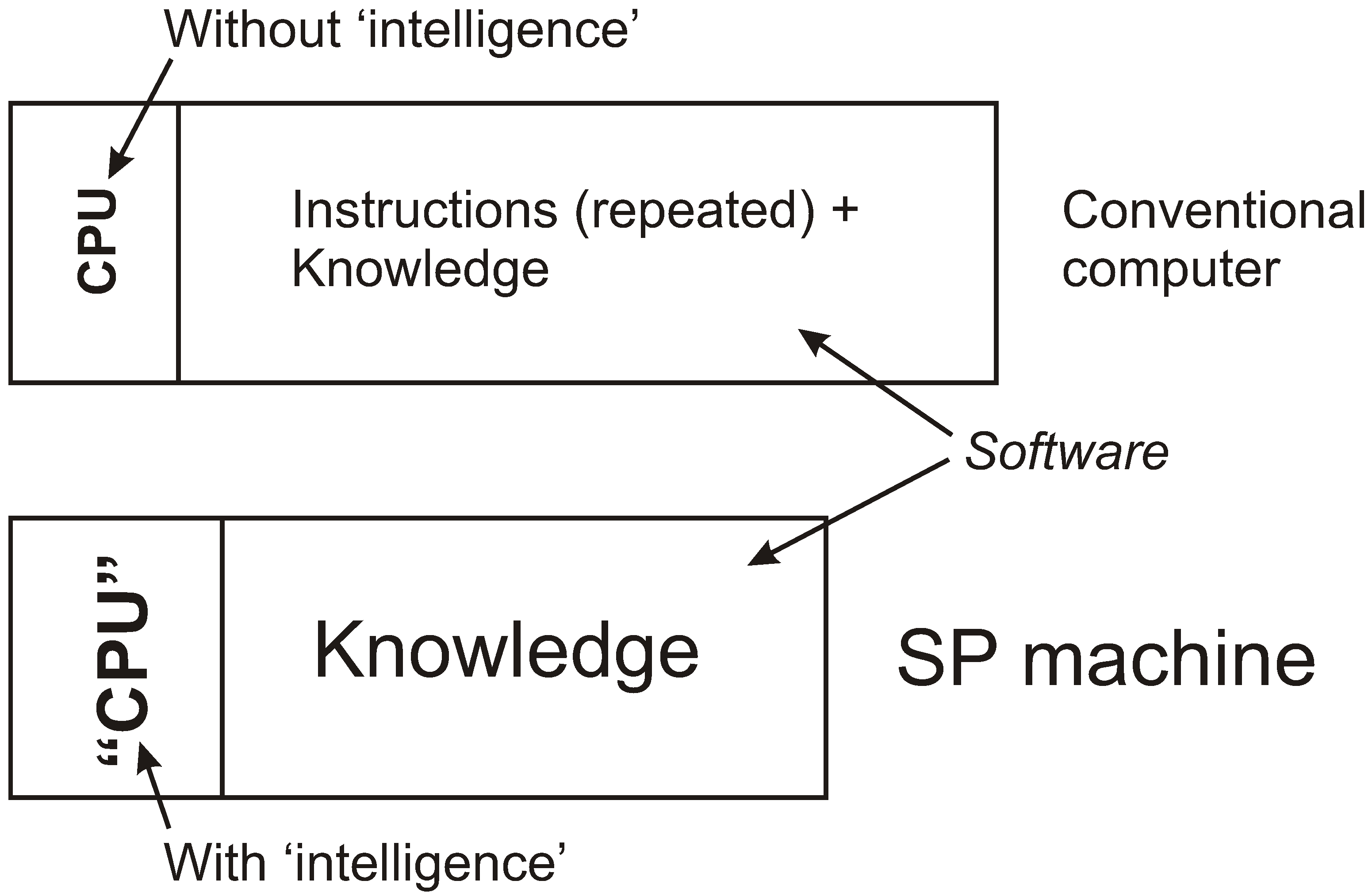
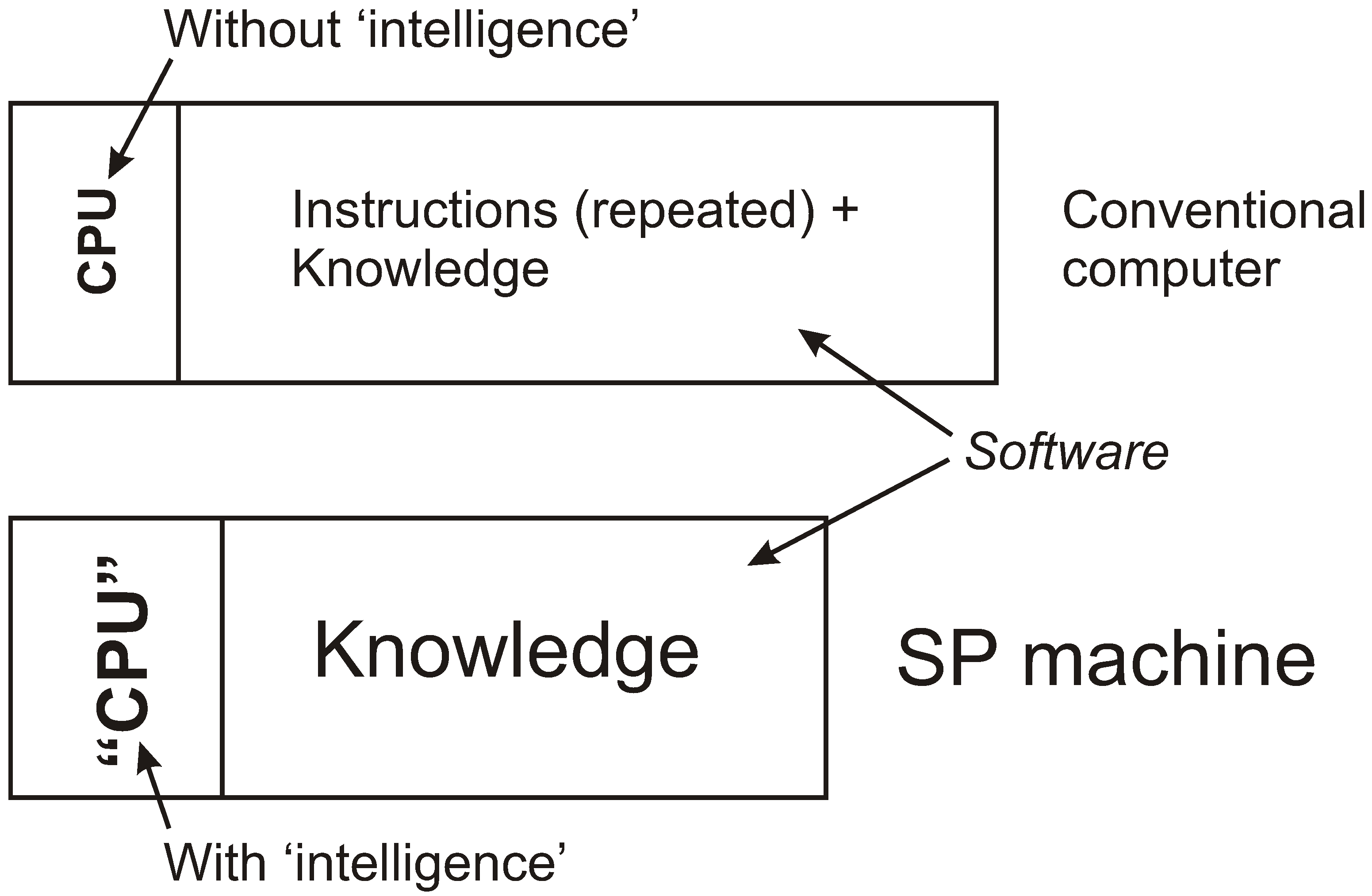
- Processing instructions to provide the intelligence that is missing in the CPU, chiefly processes for the matching and unification of patterns, and for searching amongst alternative matches to find one or more that are “good”. These kinds of processing instructions—let us call them MUP instructions—are used in many different kinds of application, meaning that there is a considerable amount of redundancy in conventional computing systems—where the term “system” includes both the variety of programs that may be run, as well as the hardware on which they run.
- Savings in development effort and associated costs. With more intelligence in the CPU there should be less need for it to be encoded in applications.
- Savings in development time. With a reduced need for hand crafting, applications may be developed more quickly.
- Savings in storage costs. There may be useful economies in the storage space required for application code.
- Related benefits noted in Section 6.7.
6. Deeper Insights and Better Solutions in Several Areas of Application
- The multiple alignment framework, with the use of one simple format for all kinds of knowledge, is likely to facilitate the seamless integration of the syntax and semantics of natural languages, with the kinds of subtle interaction described in Section 6.2, below.
- The multiple alignment framework provides for the integration of the relational, object-oriented, and network models for databases, with improvements in the relational model [15].
- The multiple alignment framework, with the use of one simple format for all kinds of knowledge, is likely to facilitate the learning of concepts that include diverse kinds of knowledge.
6.1. Unsupervised Learning
6.2. Applications in the Processing of Natural Language
- Compare “Fafnir, who plays third base on the Little League team, is a fine boy.” with “They called their son Fafnir, which is a ridiculous name.” [18] (p. 139). The choice of “who” or “which” in these two sentences—a syntactic issue—depends on the meaning of “Fafnir”. In the first sentence, it means a person, while in the second sentence it means a name.
- As a contrasting example, compare “John gave me the scissors; I am using them now.” with “John gave me the two-bladed cutting instrument; I am using it now.” [18] (p. 141). In this case, the choice of “them” or “it”—also a syntactic issue—depends on the syntactic form of what is referred to: “the scissors” has a plural form while “the two-bladed cutting instrument” has a singular form, although the two expressions have the same meaning.
6.2.1. Towards the Understanding and Translation of Natural Languages
- When translations are required amongst several different languages, it is only necessary to create n mappings, one between each of the n languages and the interlingua. This contrasts with syntax-to-syntax systems, where, in the most comprehensive application of this approach, pairs of languages are needed [20].
- It seems likely that the use of an interlingua will be essential if machine translation is ever to reach or exceed the standard that can be achieved by a good human translator.
6.2.2. Natural Language and Information Retrieval
- Since a usefully-large range of natural-language questions may be asked with fairly simple language, it would only be necessary—for any given language—to create a relatively simple set of syntactic rules and lexicon, with corresponding semantic structures, all of them expressed with SP patterns.
- It should be possible to create an online tool that would make it easy for the owner or manager of a business to create an ontology for that business that describes what it is, what it does, and the kinds of products or services that it sells. It would of course be necessary for many businesses to provide that kind of information.
- With those two things in place, it should be possible, via the SP system, to create a semantic analysis for a given query (as outlined in [1] (Section 5.7)) and to use that analysis to identify businesses or services that satisfy the query.
6.2.3. Going Beyond FAQs
6.2.4. Interactive Services
6.3. Towards a Versatile Intelligence for Autonomous Robots
- Potential for the kind of visual analysis needed to assimilate the many configurations of balls, pockets, and cue (Section 6.4, next).
- The versatility of the SP framework in the representation and processing of diverse kinds of knowledge (Section 7) should facilitate the seamless integration of visual information about the table, balls, and so on, with information about actions by the player and feedback from muscles and from touch.
- Via its processes for unsupervised learning [2] (Section 5), the SP system should be able to learn associations between visual, motor and feedback patterns, as described above. It appears that similar principles have potential in the kinds of everyday learning mentioned above.
6.4. Computer Vision
- It has potential to simplify and integrate several areas in computer vision, including feature detection and alignment, segmentation, deriving structure from motion, stitching of images together, stereo correspondence, scene analysis, and object recognition (see, for example, [24]). With regard to the last two topics:
- –
- Since scene analysis is, in some respects, similar to the parsing of natural language, and since the SP system performs well in parsing, it has potential in scene analysis as well. In the same way that a sentence may be parsed successfully without the need for explicit markers of the boundaries between successive words or between successive phrases or clauses, a scene may be analyzed into its component parts without the need for explicit boundaries between objects or other elements in a scene.
- –
- The SP system has potential for unsupervised learning of the knowledge required for recognition. For example, discrete objects may be identified by the matching and merging of patterns within stereo images (cf. [25,26]) or within successive frames in a video, in much the same way that the word structure of natural language may be discovered via the matching and unification of patterns [2] (Section 5.2). The system may also learn such things as classes of entity, and associations between entities, such as the association between black clouds and rain.
- The system is likely to facilitate the seamless integration of vision with other aspects of intelligence: reasoning, planning, problem solving, natural language processing, and so on.
- As noted in [2] (Sections 8 and 9), the system is robust in the face of errors of omission, commission or substitution—an essential feature of any system that is to achieve human-like capabilities in vision.
- With regard to those problems outlined in [2] (Section 3.3), that relate to vision, there are potential solutions:
- –
- It is likely that the framework can be generalized to accommodate patterns in two dimensions.
- –
- As noted in [2] (Section 3.3), 3D structures may be modeled using 2D patterns, somewhat in the manner of architects’ drawings. Knowledge of such structures may be built via the matching and unification of partially-overlapping 2D views [23] (Sections 6.1 and 6.2). Although such knowledge, as with people, may be partial and not geometrically accurate [27], it can, nevertheless, be quite serviceable for such purposes as getting around in one’s environment.
- –
- The framework has potential to support both the discovery and recognition of low-level perceptual features.
6.5. A Versatile Model for Intelligent Databases
- The system would provide a means of storing and managing the data that are gathered in such investigations, often in large amounts.
- It may help in the recognition of features or combinations of features that link a given crime to other crimes, either current or past—and likewise for suspects.
- The system’s capabilities in pattern recognition may also serve in the scanning of data to recognize indicators of criminal activity.
- It may prove useful in piecing together coherent patterns from partially-overlapping fragments of information, in much the same way that partially-overlapping digital photographs may be stitched together to create a larger picture.
- Given the capabilities of the SP system for different kinds of reasoning (Chapter 7 in [1] and Section 10 in [2]), including reasoning with information that is not complete, the system may prove useful in suggesting avenues to be explored, perhaps highlighting aspects of an investigation that might otherwise be overlooked.
- Transparency in the representation of knowledge [2] (Section 2.4) and in reasoning via the multiple alignment framework (Chapters 7 and 10 in [1] and Section 10 in [2]) are likely to prove useful where evidence needs to be examined in a court of law, an advantage over “sub-symbolic” systems that yield results without insight.
6.6. Software Engineering
6.6.1. Procedural Programming
- Procedure. A sequence of actions may be modeled with aone-dimensional SP pattern such as “do_A do_B do_C ...”.
- Variables, values and types. In the SP framework, any pair of neighboring symbols may function as a slot or variable into which other information may be inserted via the alignment of patterns. For example, the pair of symbols “Num ;” in row 6 of Figure 1 is, in effect, a variable containing the value “PL” from row 8. The “type” of the variable is defined by the range of values it may take, which itself derives from the set of Old patterns provided for the SP model when the multiple alignment was created. In this case, the variable “Num ;” may take the values “PL” (meaning “plural”) or “SNG” (meaning “singular”).
- Function or subroutine. In the SP framework, the effect of a function or subroutine may be achieved in much the same way as with variables and values. For example, the pattern “A 21 s w e e t #A” in row 7 of Figure 1 may be seen as a function or subroutine that has been “called” from the higher-level procedure “S Num ; NP #NP V #V A #A #S” in row 6 of the figure.
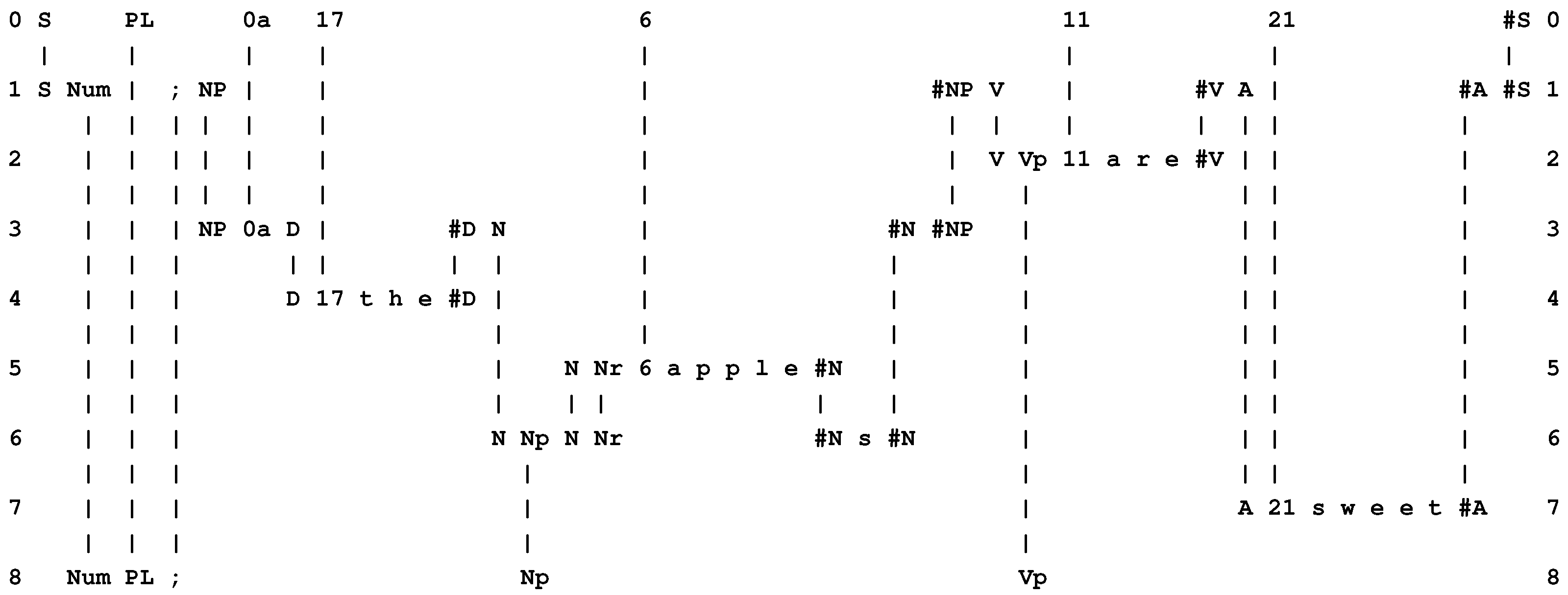
- Function with parameters. As can be seen in Figure 4, the SP system may be run “backwards”, much as can be done with an appropriately-designed Prolog program, generating “data” from “results” (Section 3.8 in [1] and Section 4.5 in [2]). In this example, the pattern “S Num ; NP #NP V #V A #A #S” may be seen as a “function”, and symbols like “PL 0a 17 ...” in row 0 may be seen as “values” for the “parameters” of the function.
- Conditional statements. The effect of the values just described is to select elements of the multiple alignment: “PL” selects the pattern “Num PL ; Np Vp”, “0a” selects “NP 0a D #D N #N #NP”, and so on. Each of these selections achieves the effect of a conditional statement in a conventional program: “If ‘PL’ then choose ‘Num PL ; Np Vp’ ”; “If ‘0a’ then choose ‘NP 0a D #D N #N #NP’ ”; and so on.
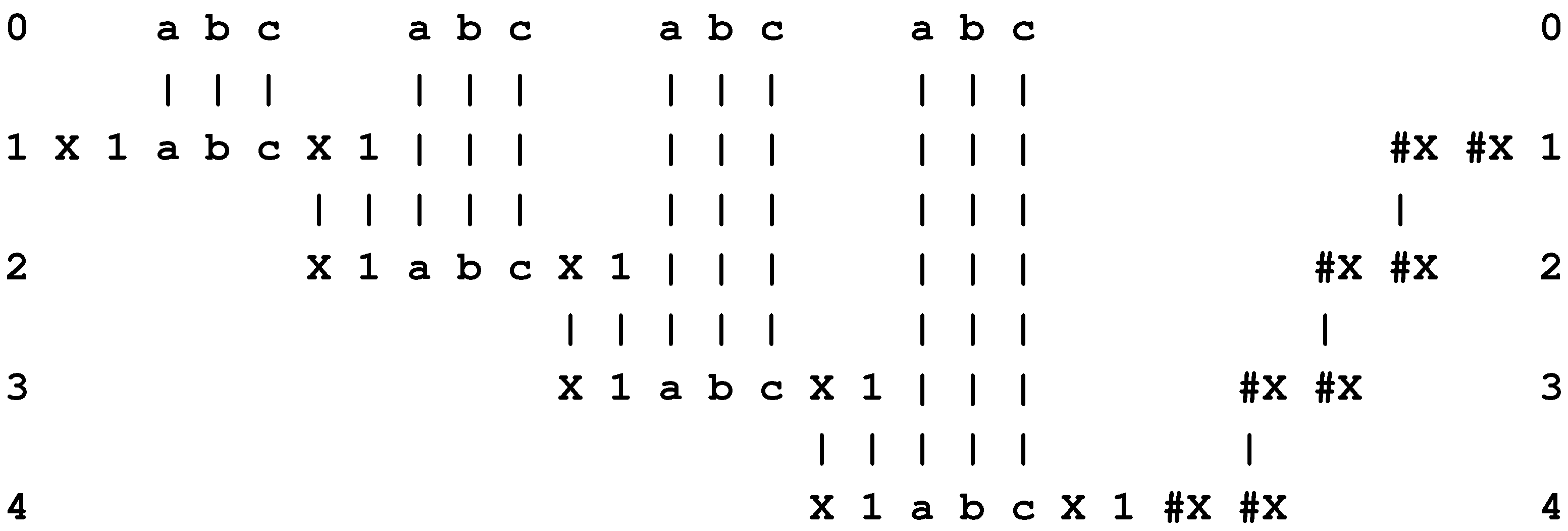
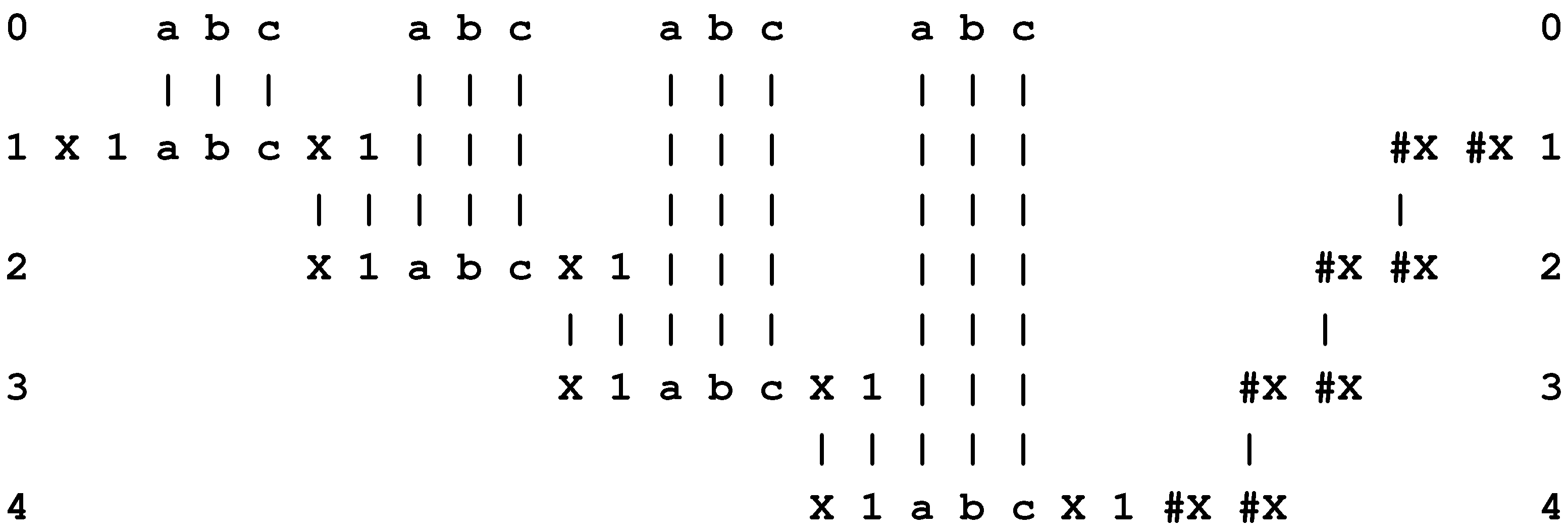
- Repetition of procedures. Conventional programs provide for the repetition of procedures with recursive functions and with statements like repeat ... until and do ... while. In the SP system, repetition may be encoded with recursive (self-referential) patterns like “X 1 a b c X 1 #X #X” which may be applied as shown in Figure 5.
- Integration of “programs” and “data”. Databases provide the mainstay of many software engineering projects and, as described in Chapter 6 in [1], Section 11 in [2] and [15], the SP system promises benefits in that area. In view of the versatility of SP patterns in the multiple alignment framework to represent varied kinds of knowledge [2] (Section 7), there is potential in software engineering projects for the seamless integration of “programs” with “data”.
- Object-oriented design. The SP system provides for object-oriented design with class hierarchies (including cross-classification), part-whole hierarchies, and inheritance of attributes (Section 6.4 in [1]; Section 9.1 in [2]). In view of the importance of object-oriented design in software engineering, this capability in the SP system is likely to prove useful for applications in that area.
6.6.2. No Compiling or Interpretation
6.6.3. Sequential and Parallel Processing
- The workings of the SP machine. In the projected SP machine [2] (Section 3.2), it is envisaged that, while the ordering of symbols would be respected when one pattern is matched with another, the process of matching two patterns may be done left-to-right, right-to-left, or with many symbols matched in parallel. Likewise, many pairs of patterns may be matched in parallel.
- Sequencing and parallelism in real-world processes. Although the SP machine may be flexible in the way parallelism is applied to the matching of patterns, the system needs to respect sequencing and parallelism in the real-world processes to which the system may be applied. In broad terms, this may be achieved via the SP patterns themselves:
- –
- A sequence of operations may be modeled via the left-to-right sequence of symbols in a one-dimensional SP pattern, with “subroutines” if required, as outlined in Section 6.6.1.
- –
- Since SP patterns at the “top” level are independent of each other, they may serve to model processes that may run in parallel.
Naturally, a realistic model of any real-world project is likely to need additional information about such things as timings, dependencies between processes, and resources required.
6.6.4. Automatic Programming
- Learning of ontologies. Knowledge of significant categories—people, buildings, vehicles, and so on—may be built up incrementally from information that users supply to the system. There is potential for the automatic structuring of such information in terms of class hierarchies and part-whole hierarchies.
6.6.5. Verification and Validation
6.6.6. Technical Debt
6.7. Information Compression
- It is intended that, normally, the SP machine will perform a relatively thorough search of the space of alternative unifications of patterns and achieve correspondingly high levels of compression.
- If, as anticipated with some further development, the system will be able to learn discontinuous dependencies in data (see [2] (Section 3.3)), it will tap into sources of redundancy that appear to be outside the scope of traditional methods for compression of information.
6.7.1. Economies in the Transmission of Information
- A “grammar” for I (which we may call G) containing patterns, at one or more levels of abstraction, that occur repeatedly in I.
- An “encoding” of I in terms of the grammar (which we may call E), including non-repeating information in I.
- A receiver (such as a TV set or a computer receiving web pages over the Internet) may be equipped with a grammar for the kind of information it is designed to receive, and some version of the SP system.
- Instead of transmitting “raw” data, or data that has been compressed in the traditional manner (containing both G and E), the encoding by itself would be sufficient.
- Using the SP system, the original data may be reconstructed fully, without any loss of information, by decoding the transmitted information (E) in terms of the stored copy of G.
- The growing popularity of video, TV and films on mobile services is putting pressure on mobile bandwidth [33], and increases in resolution will mean increasing demands for bandwidth via all transmission routes.
- It is likely that some of the bandwidth for terrestrial TV will be transferred to mobile services [34], creating an incentive to use the remaining bandwidth efficiently.
- There would be benefits in, for example, the transmission of information from a robot on Mars, or any other situation where a relatively large amount of information needs to be transmitted as quickly as possible over a relatively low-bandwidth channel.
6.7.2. Potential for Gains in Efficiency in Processing and in the Use of Energy
- I is compressed by finding recurrent patterns in I, like “Treaty on the Functioning of the European Union”, and replacing each instance of a given pattern by a relatively short code such as “TFEU”, or, more generally, compressing I via grammar discovery and encoding as described in [1] (Chapter 9 and Section 3.5) and [2] (Sections 4 and 5).
- Searching is done with “TFEU” instead of “Treaty on the Functioning of the European Union”, or, more generally, searching is done with a compressed representation of the search pattern via the encoding processes in the SP system.
6.8. Medical Diagnosis
- A format for representing diseases that is simple and intuitive.
- An ability to cope with errors and uncertainties in diagnostic information.
- The simplicity of storing statistical information as frequencies of occurrence of diseases.
- The system provides a method for evaluating alternative diagnostic hypotheses that yields true probabilities.
- It is a framework that should facilitate the unsupervised learning of medical knowledge and the integration of medical diagnosis with other AI applications.
6.9. Managing “Big Data” and Gaining Value from It
6.10. Other Areas of Application
6.10.1. Knowledge, Reasoning, and the Semantic Web
- Simplicity, versatility and integration in the representation of knowledge. The SP system combines simplicity in the underlying format for knowledge with the versatility to represent several different kinds of knowledge—and it facilitates the seamless integration of those different kinds of knowledge [2] (Section 7).
- Natural language understanding. As suggested in Section 6.2, the SP system has potential for the understanding of natural language. If that proves possible, semantic structures may be derived from textual information in web pages, without the need, in those web pages, for the separate provision of ontologies or the like.
- Automatic learning of ontologies. As suggested in [2] (Section 5.2), the SP system has potential, via the DONSVIC principle, for the extraction of interesting or useful structures from data. These may include the kinds of ontologies which have been a focus of interest in the development of the semantic web.
- Uncertainty and vagueness. The SP system is inherently probabilistic and it is robust in the face of incomplete information and errors of commission or substitution. These capabilities appear promising as a means of coping with uncertainty and vagueness in the semantic web [40].
6.10.2. Bioinformatics
- The formation of alignments amongst two or more sequences, much as in multiple alignment as currently understood in bioinformatics.
- The discovery or recognition of recurrent patterns in DNA or amino-acid sequences, including discontinuous patterns.
- The discovery of correlations between genes, or combinations of genes, and any or all of: diseases; signs or symptoms of diseases; or any other feature or combination of features of people, other animals, or plants.
6.10.3. Maintaining Multiple Versions and Parts of a Document or Web Page
6.10.4. Detection of Computer Viruses
- Recognition in the SP system is probabilistic, it does not depend on the presence or absence of any particular feature or combination of features, and it can cope with errors.
- By compressing known viruses into a set of SP patterns, the system can reduce the amount of information needed to specify viruses and, as a consequence, it can reduce the amount of processing needed for the detection of viruses.
6.10.5. Data Fusion
6.10.6. New Kinds of Computer
6.10.7. Development of Scientific Theories
- An “up market” emphasis in the SP program on finding structures that are good in terms of information compression.
- The DONSVIC principle, mentioned above—the discovery of natural structures via information compression [2] (Section 5.2). Structures that are good in terms of information compression seem generally to be structures that people regard as natural and meaningful.
- The versatility of the multiple alignment concept in the representation and processing of structures that are meaningful to people.
7. Seamless Integration of Structures and Functions within and between Different Areas of Application
8. Conclusions
Acknowledgments
Conflicts of Interest
References and Notes
- Wolff, J.G. Unifying Computing and Cognition: The SP Theory and Its Applications; CognitionResearch.org: Menai Bridge, UK, 2006. [Google Scholar]
- Wolff, J.G. The SP theory of intelligence: An overview. Information 2013, 4, 283–341. [Google Scholar] [CrossRef]
- According to this criterion, a good theory in a given area lies somewhere between things which are simple but very general—Such as the laws of arithmetic—And over-specific “theories” that simply repeat what it is they are meant to explain.
- Hence the name “SP”.
- Barrow, J.D. Pi in the Sky; Penguin Books: Harmondsworth, UK, 1992. [Google Scholar]
- Similar things were said by Allen Newell about research in human perception and cognition, in his well-known essay on why “You can’t play 20 questions with nature and win” ([47]. See also [48,49]). And writing about machine technologies to augment our senses, John Kelly and Steve Hamm say “... there’s a strong tendence [for scientists] to view each sensory field in isolation as specialists focus only on a single sensory capability. Experts in each sense don’t read journals devoted to the others, and they don’t attend one another’s conferences. ...” [45] (p. 74).
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1936, 42, 230–265. [Google Scholar]
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. A correction. Proc. Lond. Math. Soc. 1936, 42, 544–546. [Google Scholar]
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Dreyfus, H.L. What Computers Can’t Do: A Critique of Artificial Reason; Harper and Row: New York, NY, USA, 1972; Revised in 1979. [Google Scholar]
- Dreyfus, H.L. What Computers Still Can’t Do; MIT Press: New York, NY, USA, 1992. [Google Scholar]
- The latest version is SP70.
- Even in systems such as DBMSs or expert-system shells, mentioned above, the domain-specific knowledge which is loaded into the system may be regarded as part of the software.
- The reason for putting “CPU” in quote marks in the lower part of Figure 3 is that an SP machine may not have a discrete central processing unit like a conventional computer. The SP system is probably better suited to a “data-centric” style [45] (pp. 87–93), with a closer integration of data and processing than in conventional computers.
- Wolff, J.G. Towards an intelligent database system founded on the SP theory of computing and cognition. Data Knowl. Eng. 2007, 60, 596–624. [Google Scholar] [CrossRef]
- Wolff, J.G. Learning syntax and meanings through optimization and distributional analysis. In Categories and Processes in Language Acquisition; Levy, Y., Schlesinger, I.M., Braine, M.D.S., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 1988; pp. 179–215. [Google Scholar]
- Available online: www.cognitionresearch.org/lang learn.html (accessed on 19 December 2013).
- McCawley, J.D. The Role of Semantics in a Grammar. In Universals in Linguistic Theory; Lecture Notes in Artificial Intelligence; Bach, E., Harms, R.T., Eds.; Holt, Rinehart and Winston, Inc.: New York, NY, USA, 1968; pp. 125–169. [Google Scholar]
- See, for example, “Interlingual machine translation”, Wikipedia, available online: http://bit.ly/RlTcHU. retrieved 31 May 2013.
- That number may be reduced if one or more languages are used as stepping stones to the translation of others.
- This reference to autonomous robots does not in any way endorse or defend the unethical or illegal use of airborne drones or other autonomous robots to cause death, injury, or damage to property.
- Archibald, C.; Altman, A.; Greenspan, M.; Shoham, Y. Computational pool: A new challenge for game theory pragmatics. AI Mag. 2010, 31, 33–41. [Google Scholar]
- Wolff, J.G. Application of the SP theory of intelligence to the understanding of natural vision and the development of computer vision 2013. CognitionResearch.org: Menai Bridge, UK, unpublished work. 2013. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer: London, UK, 2011. [Google Scholar]
- As with information compression, a focus on the isolation of discrete objects in binocular vision is distinct from the more usual interest in the way that slight differences between the two images enables us to see the scene in depth.
- Marr, D.; Poggio, T. A computational theory of human stereo vision. Proc. R. Soc. Lond. B 1979, 204, 301–328. [Google Scholar] [CrossRef] [PubMed]
- The Ames room illusion shows that human vision does not always yield an accurate knowledge of 3D structures (see, for example, Wikipedia, available online: http://en.wikipedia.org/wiki/Ames_room. retrieved 4 December 2013).
- Related work includes “process mining” as in, for example, the “ProM” system, available online: http://bit.ly/13iS2Ch.
- See, for example, “Programming by demonstration”, Wikipedia, available online: http://bit.ly/121GrKJ. retrieved 6 June 2013.
- Notice that the distinction, just referenced, between domain-specific knowledge and MUP instructions is different from the often-made distinction between declarative programming and imperative or procedural programming. It is envisaged that the SP machine would reduce or eliminate the MUP instructions in software but that it would be able to model both the declarative “what” and (Section 6.6.1) the procedural “how” of the real world.
- Giltner, M.; Mueller, J.C.; Fiest, R.R. Data Compression, Encryption, and in-Line Transmission System. U.S. Patent 4,386,416, 31 May 1983. [Google Scholar]
- Storer, J.A. Data Compression: Methods and Theory; Computer Science Press: Rockville, MD, USA, 1988. [Google Scholar]
- See, for example, Data jam threat to UK mobile networks. BBC News, 16 November 2012. available online: http://bbc.in/T5g14s.
- See, for example, TVs will need retuning again to make room for mobile services. The Guardian, 16 November 2012. available online: http://bit.ly/ZZ9N8C.
- Wolff, J.G. Medical diagnosis as pattern recognition in a framework of information compression by multiple alignment, unification and search. Decis. Support Syst. 2006, 42, 608–625. [Google Scholar] [CrossRef]
- Wolff, J.G. The management and analysis of big data, and the SP theory of intelligence 2013. CognitionResearch.org: Menai Bridge, UK, unpublished work. 2013. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Scientific American 2001, 35–43. [Google Scholar] [CrossRef]
- Shadbolt, N.; Hall, W.; Berners-Lee, T. The semantic web revisited. IEEE Intell. Systems 2006, 21, 96–101. [Google Scholar] [CrossRef]
- See also W3C information about the semantic web at http://bit.ly/1bX7Nv.
- Lukasiewicz, T.; Straccia, U. Managing uncertainty and vagueness in description logics for the Semantic Web. Web Semant. Sci. Serv. Agents World Wide Web 2008, 6, 291–308. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Parts I and II. Inf. Control 1964, 7, 1–22, 224–254. [Google Scholar] [CrossRef]
- Wallace, C.S.; Boulton, D.M. An information measure for classification. Comput. J. 1968, 11, 185–195. [Google Scholar] [CrossRef]
- Rissanen, J. Modelling by the shortest data description. Autom. J. IFAC 1978, 14, 465–471. [Google Scholar] [CrossRef]
- See, for example, “Not like us: Artificial minds we can’t understand”, New Scientist, 10 August 2013. available online: http://bit.ly/15m1cnm. As noted in Section 6.5 of this article, transparency in the SP system, in both the representation of knowledge and in reasoning, may prove useful where evidence needs to be examined in a court of law.
- Kelly, J.E.; Hamm, S. Smart Machines: IBM’s Watson and the Era of Cognitive Computing; Columbia University Press: New York, NY, USA, 2013. [Google Scholar]
- Expected to be $3.8 trillion by 2014 (Gartner: Big data will help drive IT spending to $3.8 trillion in 2014. InfoWorld, 3 January 2013. available online: http://bit.ly/Z00SBr.)
- Newell, A. You Can’t Play 20 Questions with Nature and Win: Projective Comments on the Papers in This Symposium. In Visual Information Processing; Chase, W.G., Ed.; Academic Press: New York, NY, USA, 1973; pp. 283–308. [Google Scholar]
- Newell, A. Précis of Unified Theories of Cognition. Behav. Brain Sci. 1992, 15, 425–437. [Google Scholar] [CrossRef] [PubMed]
- Newell, A. Unified Theories of Cognition; Harvard University Press: Cambridge, MA, USA, 1990. [Google Scholar]
© 2013 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Wolff, J.G. The SP Theory of Intelligence: Benefits and Applications. Information 2014, 5, 1-27. https://doi.org/10.3390/info5010001
Wolff JG. The SP Theory of Intelligence: Benefits and Applications. Information. 2014; 5(1):1-27. https://doi.org/10.3390/info5010001
Chicago/Turabian StyleWolff, J. Gerard. 2014. "The SP Theory of Intelligence: Benefits and Applications" Information 5, no. 1: 1-27. https://doi.org/10.3390/info5010001
APA StyleWolff, J. G. (2014). The SP Theory of Intelligence: Benefits and Applications. Information, 5(1), 1-27. https://doi.org/10.3390/info5010001