
Multi-Class Visual Cyberbullying Detection Using Deep Neural Networks and the CVID Dataset

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- We have compiled a dataset from real-world environments, ensuring enhanced relevance and authenticity.
- We have considered data augmentation techniques to increase the dataset’s sample size and improve the model’s performance.
- We have implemented patch-based deep learning models and convolutional neural network (CNN)-based pretrained models to enhance the categorization accuracy.
- To enhance the model generalization, we have employed transfer learning techniques and fine-tuning strategies.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Dataset Description | Dataset Type | Model | Results |
|---|---|---|---|---|
| Zhong et al., 2016 [13] | A dataset of more than 3000 photos from Instagram was created, including uploaded photos and descriptions. | Text + Images | Word2Vec, OFF, BoW, and captions, DL-FS (stacked) | Overall accuracy of 68.55% with DL-FS (stacked) |
| Kumari et al., 2020 [23] | A dataset of 2100 images was manually collected from various sources, including Google, Instagram, Twitter, and Facebook. | Images | Multilayered CNN model | Weighted F1-score of 0.68 |
| Kumari et al., 2021 [26] | Manually generated dataset consisting of 3600 pictures with three levels of aggression categories: low, medium, and extreme. | Text + Images | VGG16 with a 3-layer CNN and BPSO | F1-score = 0.74 |
| Gomez et al., 2020 [24] | A multimodal dataset consisting of 150,000 tweets with both text and photo data. | Text + Images | InceptionV3 with OCR, LSTM for tweets processing | Accuracy = 0.73.2 AUC = 0.683 |
| Al-Ajlan et al., 2018 [20] | A 39,000-tweet Twitter dataset, with 9000 bullying tweets and 21,000 non-bullying tweets considered. | Text | CNN-CB | Accuracy = 0.95 |
| Pericherla et al., 2025 [27] | The dataset was originally collected from public sources, including Facebook, Twitter, and Instagram, and consists of 19,300 images. | Images | CB-2DCNN, CB-YOLO | CB-2DCNN: Acc = 0.9432, F1-score = 0.9592 CB-YOLO: Acc = 0.9785 F1-score = 0.9720 |
| Roy et al., 2022 [28] | A total of 3000 images were collected from Google searches, and some were taken from the dataset MMHS150K. | Images | VGG16, Inception V3 | Acc = 0.86 Acc = 0.89 |
| Pericherla et al., 2024 [29] | 19,300 images were manually annotated as either cyberbullying or not cyberbullying, which were originally collected from Facebook, Twitter, and Instagram by Vishwamitra et al. [30] | Images | CNBD combining Binary Encoder Image Transformer (BEiT) and Multi-layer perceptron (MLP) | Acc = 0.9630, Precision = 0.9616, Recall = 0.9630 |
2. Methodology
2.1. Dataset
2.2. Dataset Preprocessing
2.3. Dataset Augmentation
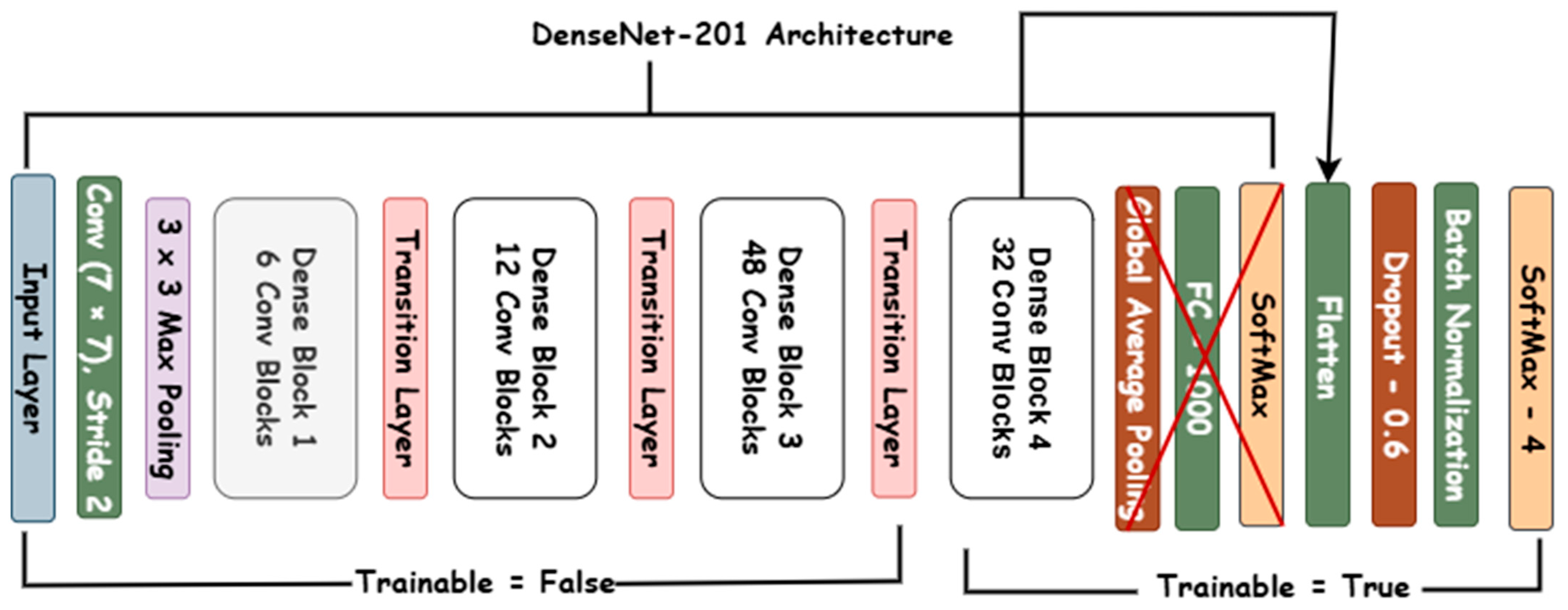
2.4. Proposed Fine-Tuned Model (D-Net)
3. Results and Discussion
3.1. Evaluation Measures
3.2. Experimental Setup
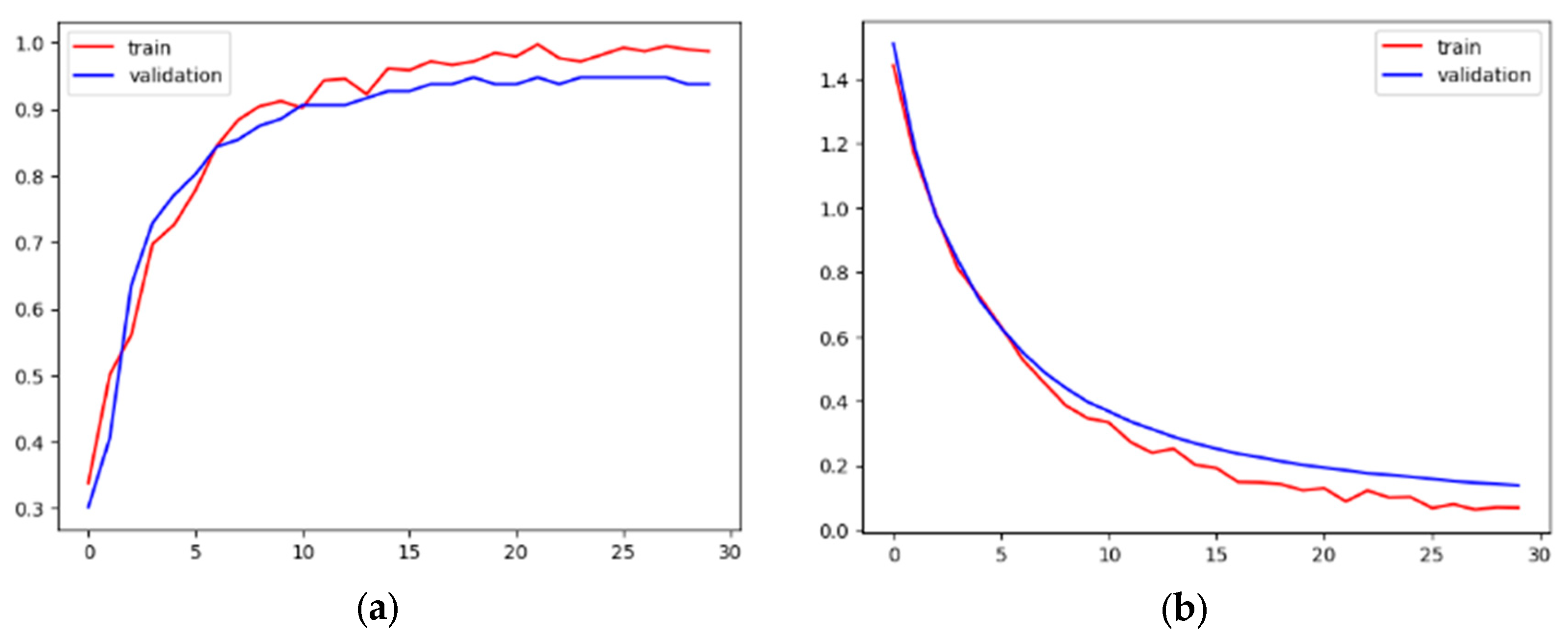
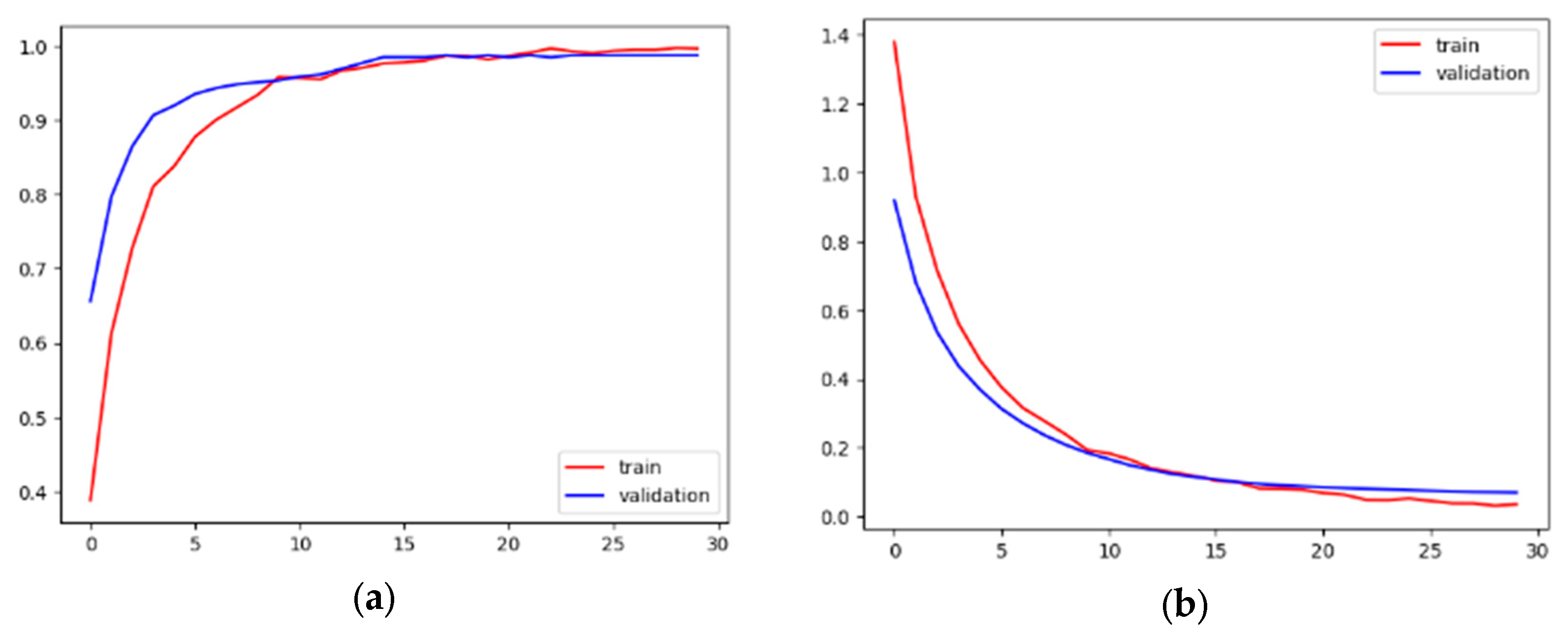
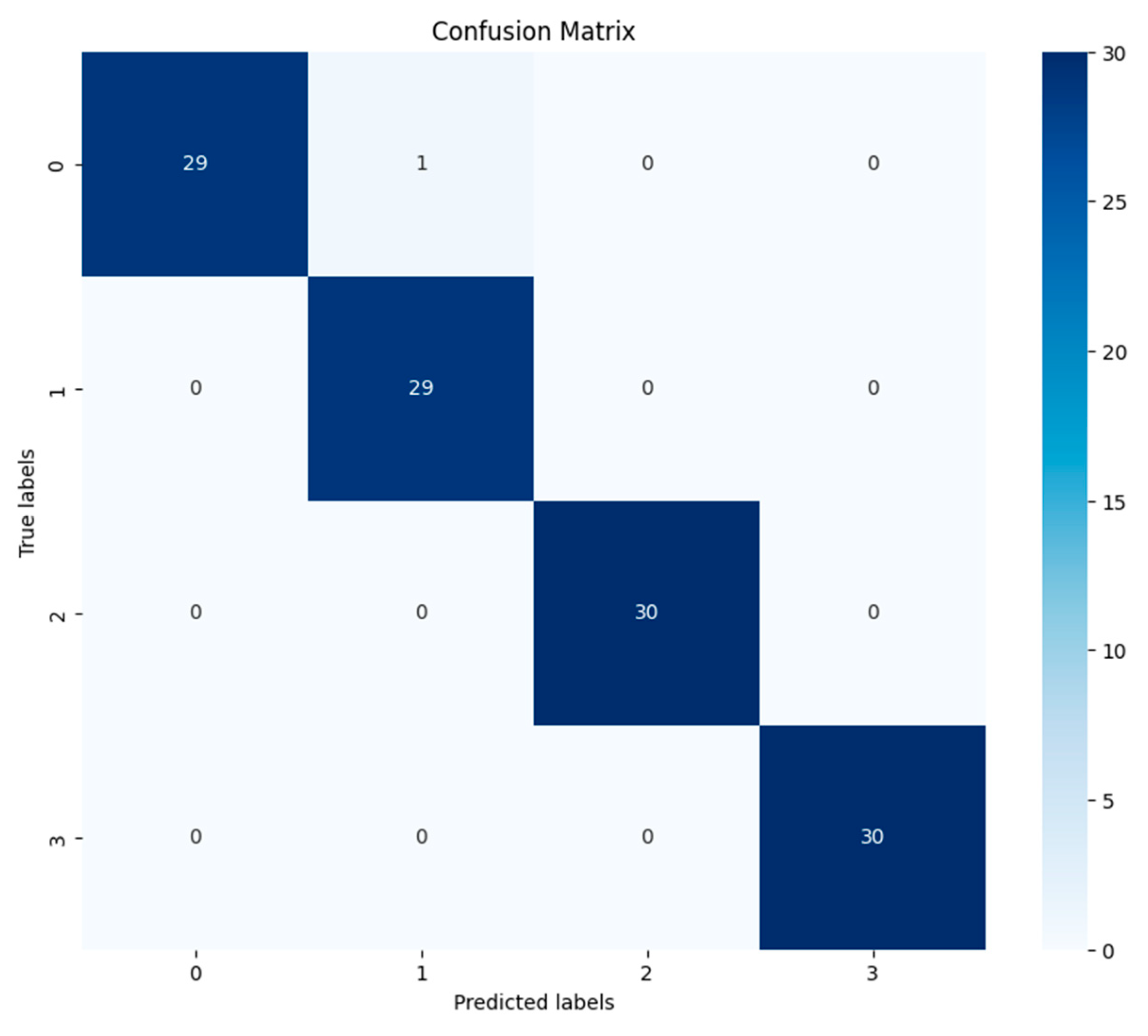
3.3. Proposed D-Net Model Results
3.4. Robustness of the Proposed Model
3.5. Practical Implications
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ozcan, S.; Homayounfard, A.; Simms, C.; Wasim, J. Technology Roadmapping Using Text Mining: A Foresight Study for the Retail Industry. IEEE Trans. Eng. Manag. 2022, 69, 228–244. [Google Scholar] [CrossRef]
- Smith, P.K.; Mahdavi, J.; Carvalho, M.; Fisher, S.; Russell, S.; Tippett, N. Cyberbullying: Its nature and impact in secondary school pupils. J. Child Psychol. Psychiatry 2008, 49, 376–385. [Google Scholar] [CrossRef]
- López-Vizcaíno, M.F.; Nóvoa, F.J.; Carneiro, V.; Cacheda, F. Early detection of cyberbullying on social media networks. Future Gener. Comput. Syst. 2021, 118, 219–229. [Google Scholar] [CrossRef]
- Cénat, J.M.; Hébert, M.; Blais, M.; Lavoie, F.; Guerrier, M.; Derivois, D. Cyberbullying, Psychological Distress and Self-Esteem among Youth in Quebec Schools. J. Affect. Disord. 2014, 169, 7–9. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.K.; Huang, Q.; Atrey, P.K. Cyberbullying detection using probabilistic socio-textual information fusion. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM, San Francisco, CA, USA, 18–21 August 2016; pp. 884–887. [Google Scholar] [CrossRef]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.M.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Khan, S.; Arabnia, H.R. Improving cyberbullying detection using Twitter users’ psychological features and machine learning. Comput. Secur. 2020, 90, 101710. [Google Scholar] [CrossRef]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 10th International Conference on Machine Learning and Applications, ICMLA, Honolulu, HI, USA, 18–21 December 2011; Volume 2, pp. 241–244. [Google Scholar] [CrossRef]
- Almomani, A.; Nahar, K.; Alauthman, M.; Al-Betar, M.A.; Yaseen, Q.; Gupta, B.B. Image Cyberbullying Detection and Recognition Using Transfer Deep Machine Learning. Int. J. Cogn. Comput. Eng. 2024, 5, 14–26. [Google Scholar] [CrossRef]
- Yu, X.; Yang, T.; Lu, J.; Shen, Y.; Lu, W.; Zhu, W.; Bao, Y.; Li, H.; Zhou, J. Deep transfer learning: A novel glucose prediction framework for new subjects with type 2 diabetes. Complex Intell. Syst. 2022, 8, 1875–1887. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Parwekar, P.; Damaševičius, R.; Mehmood, A.; Khan, J.A.; Naqvi, S.R. Human gait analysis for osteoarthritis prediction: A framework of deep learning and kernel extreme learning machine. Complex Intell. Syst. 2023, 9, 2665–2683. [Google Scholar] [CrossRef]
- Roy, P.K.; Singh, J.P.; Banerjee, S. Deep learning to filter SMS Spam. Future Gener. Comput. Syst. 2020, 102, 524–533. [Google Scholar] [CrossRef]
- Zhong, H.; Li, H.; Squicciarini, A.C.; Rajtmajer, S.M.; Griffin, C.; Miller, D.J.; Caragea, C. Content-Driven Detection of Cyberbullying on the Instagram Social Network. 2016. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; Available online: https://www.researchgate.net/publication/313796198 (accessed on 25 April 2024).
- Ali, W.N.H.W.; Mohd, M.; Fauzi, F. Cyberbullying Detection: An Overview. In Proceedings of the 2018 Cyber Resilience Conference, CRC, Putrajaya, Malaysia, 13–15 November 2018. [Google Scholar] [CrossRef]
- Hitkul, H.; Shah, R.R.; Kumaraguru, P.; Satoh, S. Maybe look closer? Detecting trolling prone images on Instagram. In Proceedings of the 2019 IEEE 5th International Conference on Multimedia Big Data, BigMM, Singapore, 11–13 September 2019; pp. 448–456. [Google Scholar] [CrossRef]
- Talpur, B.A.; O’Sullivan, D. Cyberbullying severity detection: A machine learning approach. PLoS ONE 2020, 15, e0240924. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Anand, M.; Eswari, R. Classification of abusive comments in social media using deep learning. In Proceedings of the 3rd International Conference on Computing Methodologies and Communication, ICCMC, Erode, India, 27–29 March 2019; pp. 974–977. [Google Scholar] [CrossRef]
- Li, Y.; Algarni, A.; Albathan, M.; Shen, Y.; Bijaksana, M.A. Relevance feature discovery for text mining. IEEE Trans. Knowl. Data Eng. 2015, 27, 1656–1669. [Google Scholar] [CrossRef]
- Al-Ajlan, M.A.; Ykhlef, M. Deep Learning Algorithm for Cyberbullying Detection. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 199–205. [Google Scholar] [CrossRef]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of Cyberbullying Using Deep Neural Network. In Proceedings of the 2019 5th International Conference on Advanced Computing and Communication Systems, ICACCS, Coimbatore, India, 15–16 March 2019; pp. 604–607. [Google Scholar] [CrossRef]
- Acı, Ç.İ.; Çürük, E.; Eşsiz, E.S. Automatic Detection of Cyberbullying in Formspring. Me, Myspace and Youtube Social Networks. Turk. J. Eng. 2019, 3, 168–178. [Google Scholar] [CrossRef]
- Kumari, K.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. Towards Cyberbullying-free social media in smart cities: A unified multi-modal approach. Soft Comput. 2020, 24, 11059–11070. [Google Scholar] [CrossRef]
- Gomez, R.; Gibert, J.; Gomez, L.; Karatzas, D. Exploring Hate Speech Detection in Multimodal Publications. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1470–1478. Available online: https://www.hatebase.org/ (accessed on 26 April 2024).
- Chen, J.; Yan, S.; Wong, K.C. Verbal aggression detection on Twitter comments: Convolutional neural network for short-text sentiment analysis. Neural. Comput. Appl. 2020, 32, 10809–10818. [Google Scholar] [CrossRef]
- Kumari, K.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. Multi-modal aggression identification using Convolutional Neural Network and Binary Particle Swarm Optimization. Future Gener. Comput. Syst. 2021, 118, 187–197. [Google Scholar] [CrossRef]
- Pericherla, S.; Ilavarasan, E. Cyberbullying detection and classification on social media images using Convolution Neural Networks and CB-YOLO model. Evol. Syst. 2025, 16, 43. [Google Scholar] [CrossRef]
- Roy, P.K.; Mali, F.U. Cyberbullying detection using deep transfer learning. Complex Intell. Syst. 2022, 8, 5449–5467. [Google Scholar] [CrossRef]
- Pericherla, S.; Ilavarasan, E. Overcoming the challenge of cyberbullying detection in images: A deep learning approach with image captioning and OCR integration. Int. J. Comput. Digit. Syst. 2024, 15, 393–401. [Google Scholar] [CrossRef]
- Vishwamitra, N.; Hu, H.; Luo, F.; Cheng, L. Towards understanding and detecting cyberbullying in real-world images. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Online, 14–17 December 2020. [Google Scholar]
- Nakkawita, N.; Pushpakumara, B. Development of a rating model for assessing the condition of steel railway bridges. J. Saf. Sustain. 2024, 1, 151–160. [Google Scholar] [CrossRef]
- Abellanosa, A.D.; Pereira, E.; Lefsrud, L.; Mohamed, Y. Integrating Knowledge Management and Large Language Models to Advance Construction Job Hazard Analysis: A Systematic Review and Conceptual Framework. J. Saf. Sustain. 2025; In Press. [Google Scholar] [CrossRef]



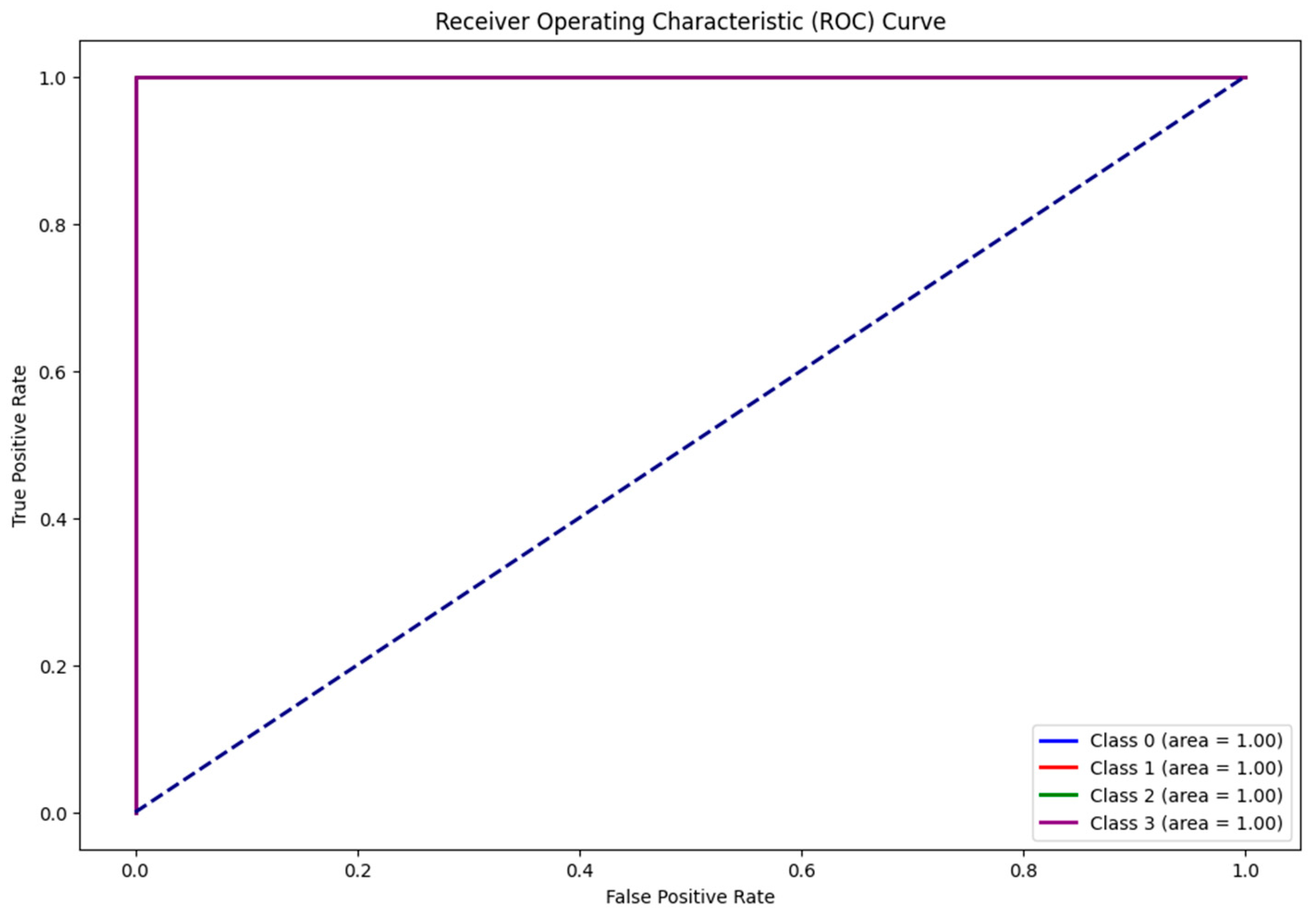
| Before Augmentation | Augment Only for Train | After Augmentation | |||
|---|---|---|---|---|---|
| Class | Train | Test | -- | Train | Test |
| Abuse | 181 | 30 | 300 | 481 | 30 |
| Curse | 176 | 29 | 305 | 481 | 29 |
| Discourage | 181 | 30 | 300 | 481 | 30 |
| Threat | 126 | 30 | 358 | 481 | 30 |
| Total | 664 | 119 | 1263 | 1924 | 119 |
| Hyperparameter | Value |
|---|---|
| Batch Size | 32 |
| Optimizer | RMSprop |
| Learning Rate | 1 × 10−5 |
| Epochs | 30 |
| Early Stopping Patience | 3 |
| Restore Best Weights | True |
| Image Size | 224 × 224 |
| Loss Function | Sparse Categorical Cross-Entropy |
| Activation Function | ReLU |
| Final Output Activation Function | SoftMax |
| Classification Report—D-Net (Before Augmentation) | ||||
| Class | Precision | Recall | F1-Score | Support |
| Abusing | 67% | 87% | 75% | 30 |
| Curse | 62% | 100% | 77% | 29 |
| Discourage | 9% | 10% | 10% | 30 |
| Threat | 0% | 0% | 0% | 30 |
| Accuracy | 49% | 119 | ||
| Macro Average | 35% | 49% | 40% | 119 |
| Weighted Average | 35% | 49% | 40% | 119 |
| Classification Report—D-Net (After Augmentation) | ||||
| Class | Precision | Recall | F1-Score | Support |
| Abusing | 100% | 97% | 98% | 30 |
| Curse | 97% | 100% | 98% | 29 |
| Discourage | 100% | 100% | 100% | 30 |
| Threat | 100% | 100% | 100% | 30 |
| Accuracy | 99% | 119 | ||
| Macro Average | 99% | 99% | 99% | 119 |
| Weighted Average | 99% | 99% | 99% | 119 |
| Model | Scores | ||
|---|---|---|---|
| Without Augmentation | |||
| Train | Val | Test | |
| VGG-16 | 100% | 93% | 92% |
| VGG-19 | 100% | 94% | 92% |
| Inception V3 | 100% | 93% | 93% |
| MobileNetV2 | 100% | 95% | 47% |
| ViT | 99% | 97% | 87% |
| D-Net | 100% | 94% | 49% |
| With Augmentation | |||
| VGG-16 | 99% | 97% | 95% |
| VGG-19 | 99% | 98% | 97% |
| Inception V3 | 98% | 94% | 94% |
| MobileNetV2 | 99% | 96% | 95% |
| ViT | 99% | 98% | 87% |
| D-Net | 100% | 99% | 99% |
| Rounded Evaluation Scores of the Proposed Model (Augmentation + Stratified K-Fold) | ||||||
|---|---|---|---|---|---|---|
| Class | Train Accuracy | Val Accuracy | Test Accuracy | Weighted Precision | Weighted Recall | Weighted F1-Score |
| Fold-1 | 100% | 99% | 100% | 100% | 100% | 100% |
| Fold-2 | 100% | 98% | 98% | 98% | 98% | 98% |
| Fold-3 | 100% | 99% | 100% | 100% | 100% | 100% |
| Fold-4 | 100% | 99% | 99% | 99% | 99% | 99% |
| Fold-5 | 100% | 97% | 99% | 99% | 99% | 99% |
| Average | 100% | 98% | 99% | 99% | 99% | 99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Samreen, Z.; Ahmad, A.; Amjad, L.; Muavia, H.; Dewi, C.; Kabir, M. Multi-Class Visual Cyberbullying Detection Using Deep Neural Networks and the CVID Dataset. Information 2025, 16, 630. https://doi.org/10.3390/info16080630
Arshed MA, Samreen Z, Ahmad A, Amjad L, Muavia H, Dewi C, Kabir M. Multi-Class Visual Cyberbullying Detection Using Deep Neural Networks and the CVID Dataset. Information. 2025; 16(8):630. https://doi.org/10.3390/info16080630
Chicago/Turabian StyleArshed, Muhammad Asad, Zunera Samreen, Arslan Ahmad, Laiba Amjad, Hasnain Muavia, Christine Dewi, and Muhammad Kabir. 2025. "Multi-Class Visual Cyberbullying Detection Using Deep Neural Networks and the CVID Dataset" Information 16, no. 8: 630. https://doi.org/10.3390/info16080630
APA StyleArshed, M. A., Samreen, Z., Ahmad, A., Amjad, L., Muavia, H., Dewi, C., & Kabir, M. (2025). Multi-Class Visual Cyberbullying Detection Using Deep Neural Networks and the CVID Dataset. Information, 16(8), 630. https://doi.org/10.3390/info16080630