ILSTMA: Enhancing Accuracy and Speed of Long-Term and Short-Term Memory Architecture

Abstract

1. Introduction
- This study optimizes the spatial layout of short-term and long-term memory, and building on this, it enhances LLM answer accuracy through an optimized retrieval algorithm and high-dimensional information summarization.
- This study integrates human forgetting theory with OS caching prefetch mechanisms, enhancing execution efficiency without modifying retrieval algorithmsa and providing a valuable reference for related studies.
- This study outlines the principles of partitioning the dataset and comprehensively evaluates the ILSTMA from multiple perspectives, demonstrating its efficiency.
2. Related Work
2.1. Large Language Models
2.2. Short-Term Memory
2.3. Long-Term Memory
3. Methodology
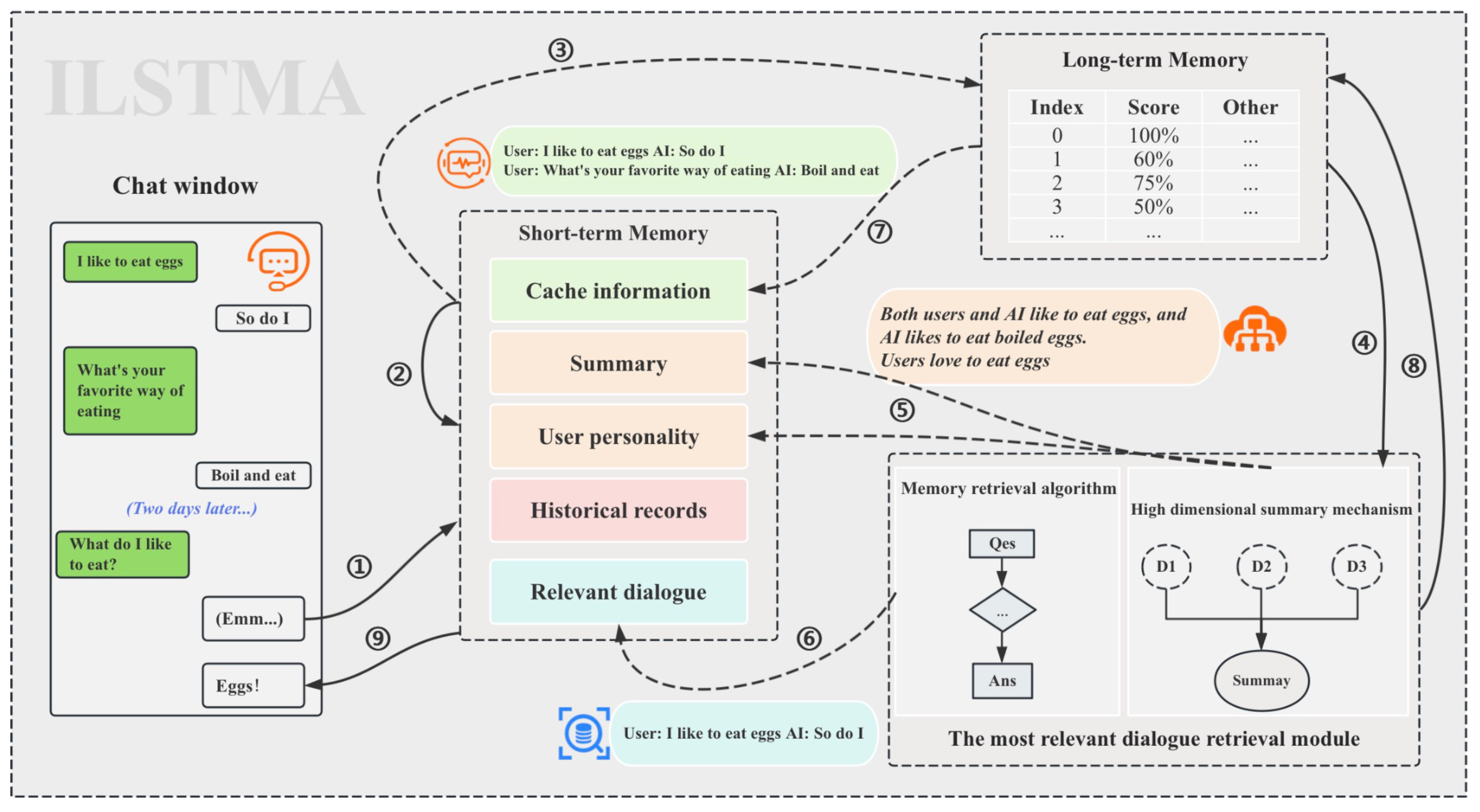
3.1. Architecture Overview
- Step-1: Collecting dialogues: The chat window collects user’s questions.
- Step-2: The hit judgment process: This step is the first part of the caching prefetch mechanism, wherein the ILSTMA checks whether the current short-term memory reference information (primarily cache information) and its own general knowledge are sufficient to answer the user’s question. This is a crucial assessment that directly determines the direction of the subsequent processes.
- Step-3: Cache hit: Selective step. If the decision in Step 2 is affirmative, the ILSTMA will notify the long-term memory to update the data while retaining the reference information in the short-term memory, excluding the historical records, in anticipation of future cache hits.
- Step-4: Providing information support from LTM: The most relevant dialogue retrieval module itself does not store data. The normal operation of both the indexing-based memory retrieval modification algorithm and the high-dimensional information summarization mechanism requires data retrieval from long-term memory.
- Step-5: Injecting high-dimensional information: Selective step. The high-dimension information summarization mechanism needs to summarize redundant dialogue content and extract user personality based on the dialogue. This high-dimensional information is then injected into the short-term memory as reference information. If the decision in Step 2 is affirmative, this step is unnecessary.
- Step-6: Injecting the most relevant dialogues: Selective step. This step requires the indexing-based memory retrieval modification algorithm to filter out the dialogues most relevant to the user’s question from a large set of dialogues, which will be injected into the short-term memory as reference information. Note that this step has a very high time complexity and is only triggered when the decision in Step 2 is not affirmative.
- Step-7: Cache missed: Selective step. If the decision in Step 2 is not affirmative, the ILSTMA will retrigger the caching prefetch mechanism and update the cache information in the short-term memory, aiming for a successful cache hit next time.
- Step-8: Updating LTM: The LTM needs to be updated in real-time. When a dialogue is recalled or high-dimensional summary information needs to be updated, this step is executed to overwrite the old information in the long-term memory.
- Step-9: Answer user’s question: The final step. When this step is executed, it indicates that the ILSTMA has gathered all the necessary conditions to answer the user’s question, allowing it to guide the LLM in generating a response.
3.2. Long-Term Memory Spatial Layout
3.3. Short-Term Memory Spatial Layout
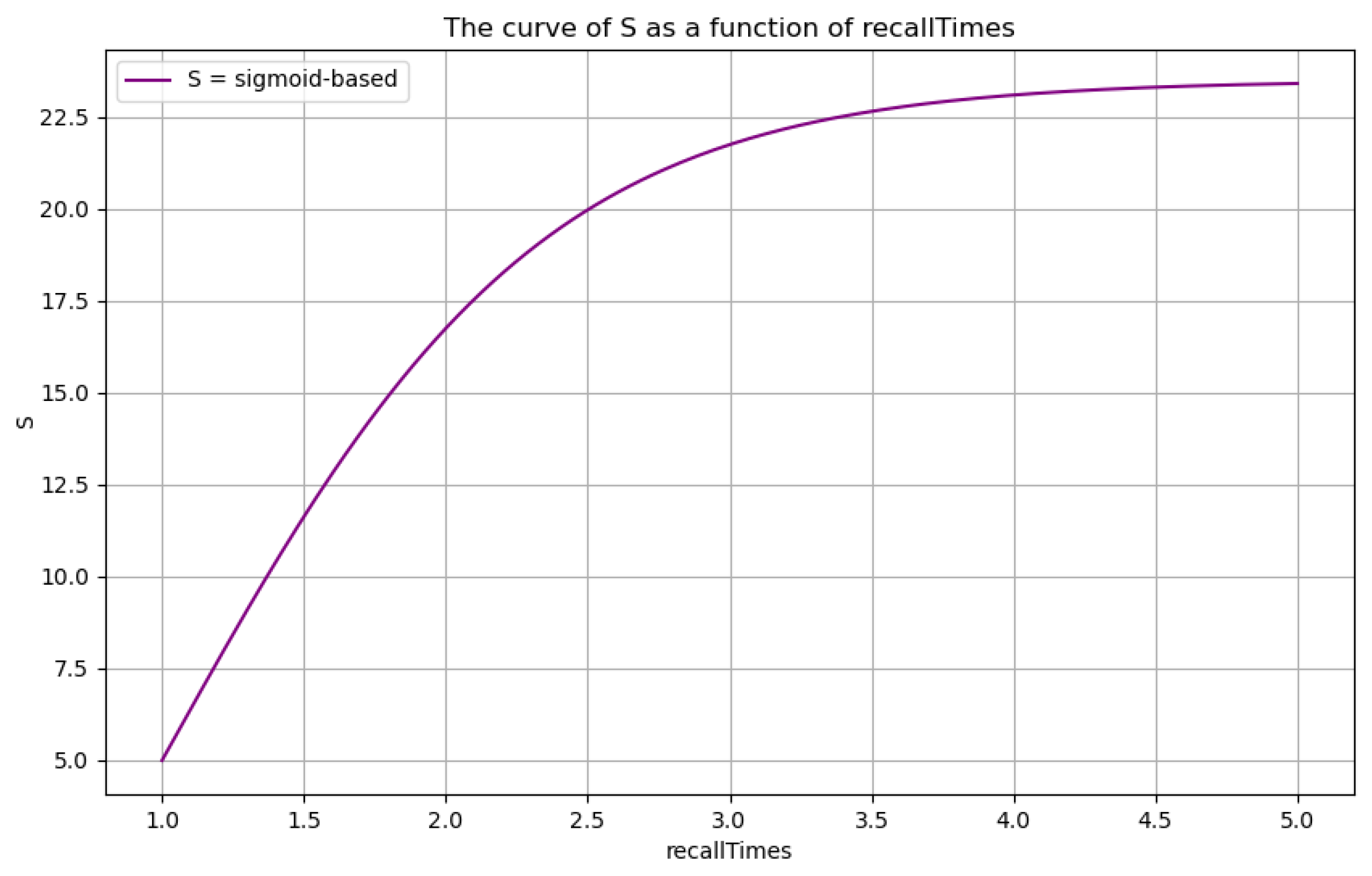
- Cache Information: This part of the information is one of the main characteristics of this study. When a user’s question arrives, the ILSTMA scans a part of the global memory table while simulating human thinking to calculate the caching prefetch score for each entry. Then, it injects the top-three dialogues with the highest scores into the short-term memory. If these three dialogues can answer the user’s upcoming questions, the system can bypass the process of searching for the most relevant information, significantly improving execution efficiency.
- Summary: Summary refers to the distilled insights obtained from historical dialogue records that are complex and highly redundant, and they are processed through the text summarization capabilities of the LLM. This type of information is typically characterized by its brevity and high level of abstraction, making it well suited to quickly conveying important content. In the ILSTMA, this high-dimensional summary information is regarded as auxiliary information because it allows the LLM to quickly grasp the general context of the user’s recall questions. This information not only provides relevant context but may also directly answer the user’s recall questions. Using high-dimensional summaries, the LLM can review previous conversational content more effectively, resulting in more precise and efficient responses.
- User Personality: Different users may exhibit varying personality traits when engaging in conversations on different topics. By analyzing historical dialogues to portray the user’s personality, it is possible to prompt the LLM to reflect the traits exhibited by the user in the current chat scenario. This can guide the LLM to generate responses that align more closely with the user’s personality preferences.
- Historical Records: This portion of space is essentially a queue, and the ILSTMA defaults to pushing the most recent seven turns of dialogue onto the queue. This information provides the LLM with recent context to inform its responses.
- Relevant dialogue: This segment stores the most relevant dialogues and is written only when a cache is missing. In this case, this reference information will become an important basis for answering the user’s recall questions.
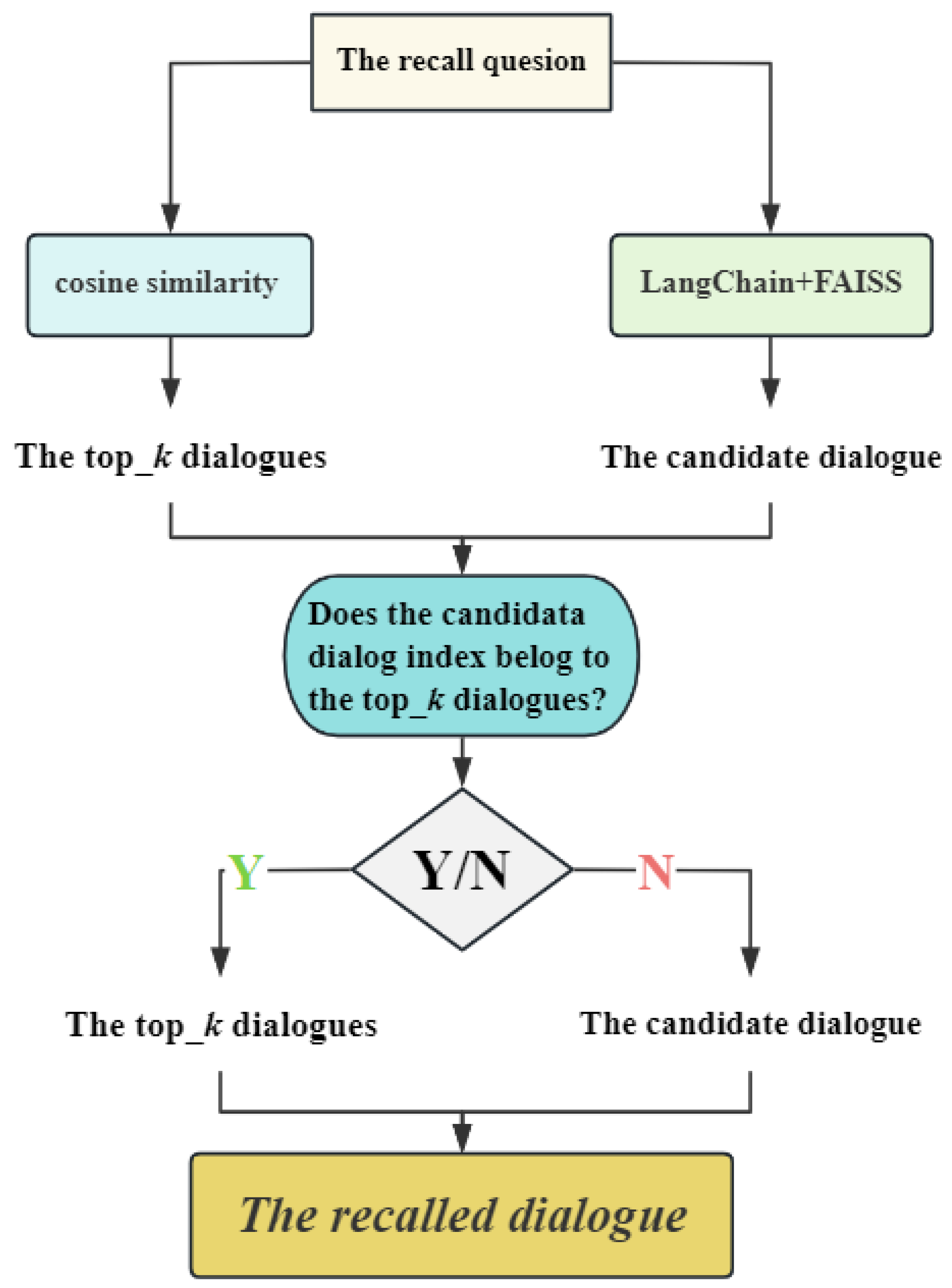
3.4. The Most Relevant Dialogue Retrieval Module
The Indexing-Based Memory Retrieval Modification Algorithm
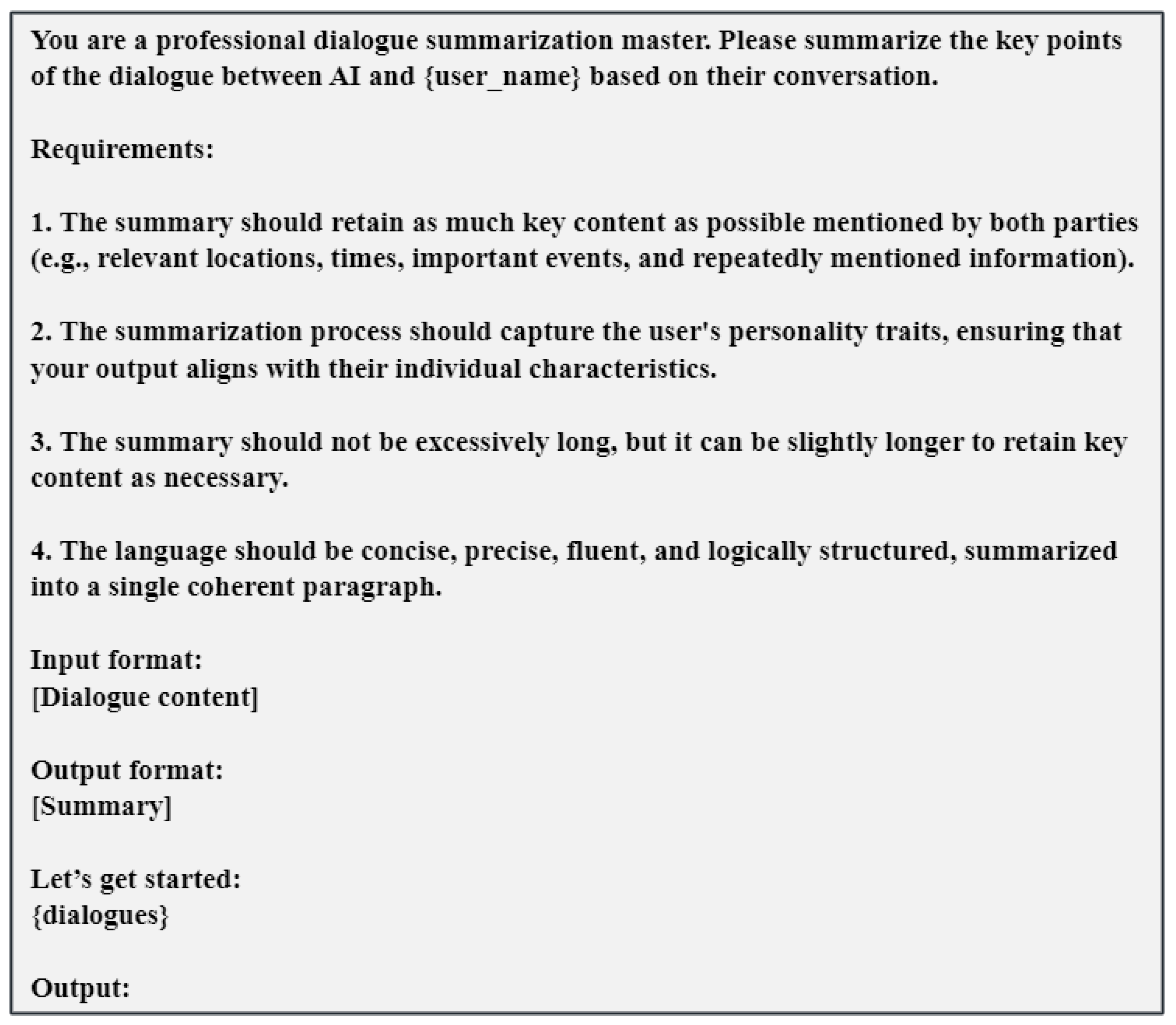
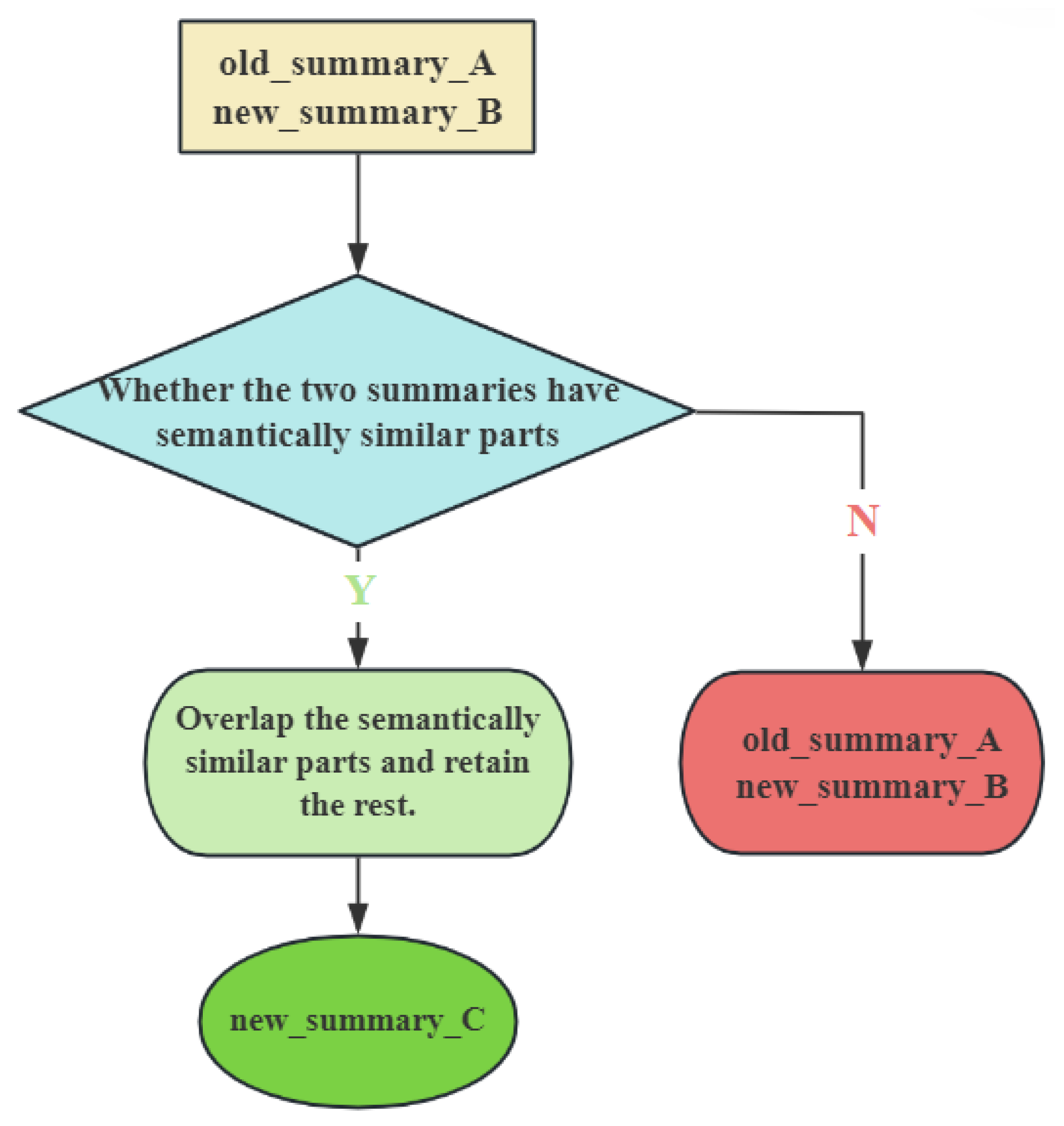
3.5. High-Dimensional Information Summarization Mechanism
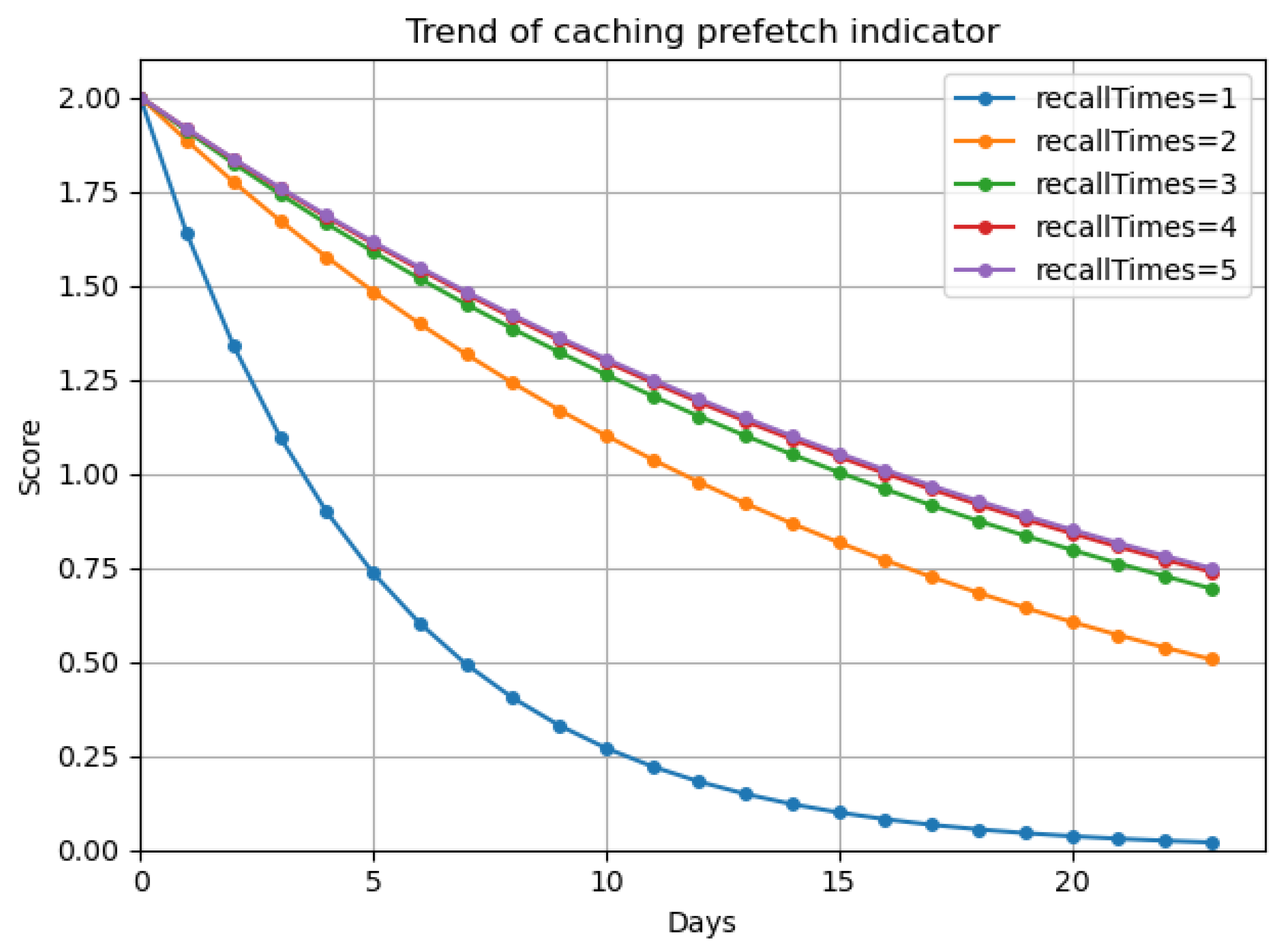
3.6. Caching Prefetch Mechanism
3.6.1. The Caching Prefetch Indicator
3.6.2. The Process of Caching Prefetch Mechanism
4. Experiments and Discussion
4.1. Dataset
4.1.1. Dataset Partitioning Principles
4.1.2. Dataset Introduction
4.2. Relevant Metrics
4.3. Main Results and Discussion
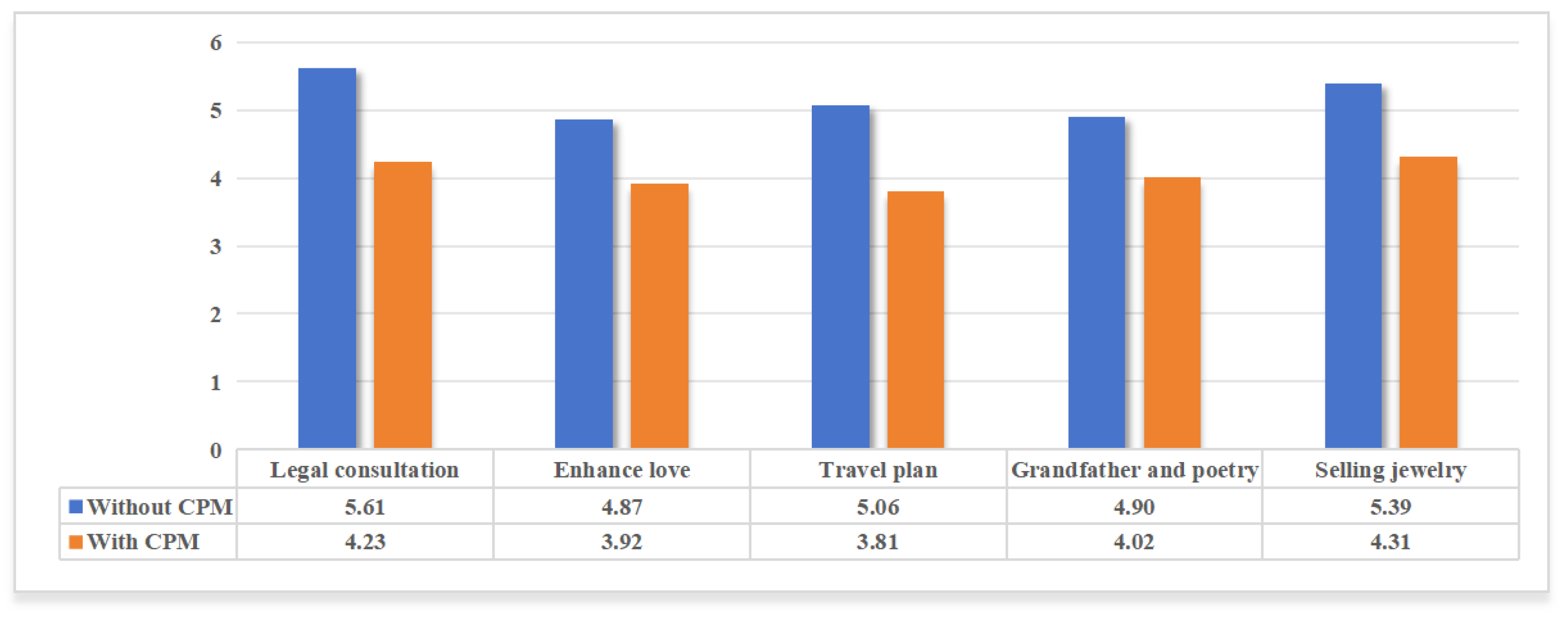
4.3.1. Hit Rate Analysis
4.3.2. Average Execution Time Analysis
4.3.3. Comprehensive Comparative Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
References
- OpenAI. ChatGPT. 2022. Available online: https://chat.openai.com/chat (accessed on 11 August 2024).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. Glm-130b: An open bilingual pre-trained model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Ratner, N.; Levine, Y.; Belinkov, Y.; Ram, O.; Magar, I.; Abend, O.; Karpas, E.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. Parallel context windows for large language models. arXiv 2022, arXiv:2212.10947. [Google Scholar]
- Wang, X.; Salmani, M.; Omidi, P.; Ren, X.; Rezagholizadeh, M.; Eshaghi, A. Beyond the limits: A survey of techniques to extend the context length in large language models. arXiv 2024, arXiv:2402.02244. [Google Scholar]
- Ng, Y.; Miyashita, D.; Hoshi, Y.; Morioka, Y.; Torii, O.; Kodama, T.; Deguchi, J. Simplyretrieve: A private and lightweight retrieval-centric generative ai tool. arXiv 2023, arXiv:2308.03983. [Google Scholar]
- Zhao, A.; Huang, D.; Xu, Q.; Lin, M.; Liu, Y.J.; Huang, G. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 19632–19642. [Google Scholar]
- Zhong, W.; Guo, L.; Gao, Q.; Ye, H.; Wang, Y. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 26–27 February 2024; Volume 38, pp. 19724–19731. [Google Scholar]
- Park, J.S.; O’Brien, J.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual Acm Symposium on User Interface Software and Technology, San Francisco, CA, USA, 29 October–1 November 2023; pp. 1–22. [Google Scholar]
- Liu, L.; Yang, X.; Shen, Y.; Hu, B.; Zhang, Z.; Gu, J.; Zhang, G. Think-in-memory: Recalling and post-thinking enable llms with long-term memory. arXiv 2023, arXiv:2311.08719. [Google Scholar]
- Ebbinghaus, H. Memory: A Contribution to Experimental. 1964. Available online: https://pmc.ncbi.nlm.nih.gov/articles/PMC4117135/ (accessed on 17 July 2024).
- Brown, G.D.; Lewandowsky, S. Forgetting in memory models: Arguments against trace decay and consolidation failure. In Forgetting; Psychology Press: East Sussex, UK, 2010; pp. 63–90. [Google Scholar]
- Cepeda, N.J.; Pashler, H.; Vul, E.; Wixted, J.T.; Rohrer, D. Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychol. Bull. 2006, 132, 354. [Google Scholar] [CrossRef]
- Lindsey, J.; Litwin-Kumar, A. Theory of systems memory consolidation via recall-gated plasticity. eLife 2023, 12. [Google Scholar] [CrossRef]
- Nadel, L.; Hardt, O. Update on memory systems and processes. Neuropsychopharmacology 2011, 36, 251–273. [Google Scholar] [CrossRef]
- Smith, A.M. Examining the Role of Retrieval Practice in Improving Memory Accessibility Under Stress. Ph.D. Thesis, Tufts University, Medford, MA, USA, 2018. [Google Scholar]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. J. Mach. Learn. Res. 2024, 25, 1–53. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Le Scao, T.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. Bloom: A 176b-Parameter Open-Access Multilingual Language Model. 2023. Available online: https://inria.hal.science/hal-03850124/ (accessed on 20 November 2023).
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar]
- Tay, Y.; Wei, J.; Chung, H.W.; Tran, V.Q.; So, D.R.; Shakeri, S.; Garcia, X.; Zheng, H.S.; Rao, J.; Chowdhery, A.; et al. Transcending scaling laws with 0.1% extra compute. arXiv, 2022; arXiv:2210.11399. [Google Scholar]
- Zeng, W.; Ren, X.; Su, T.; Wang, H.; Liao, Y.; Wang, Z.; Jiang, X.; Yang, Z.; Wang, K.; Zhang, X.; et al. Pangu-alpha: Large-scale autoregressive pretrained Chinese language models with auto-parallel computation. arXiv 2021, arXiv:2104.12369. [Google Scholar]
- Huawei Technologies Co., L. Huawei Technologies Co., L. Huawei mindspore ai development framework. In Artificial Intelligence Technology; Springer: Berlin/Heidelberg, Germany, 2022; pp. 137–162. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Iyer, S.; Lin, X.V.; Pasunuru, R.; Mihaylov, T.; Simig, D.; Yu, P.; Shuster, K.; Wang, T.; Liu, Q.; Koura, P.S.; et al. Opt-iml: Scaling language model instruction meta learning through the lens of generalization. arXiv 2022, arXiv:2212.12017. [Google Scholar]
- Muennighoff, N.; Wang, T.; Sutawika, L.; Roberts, A.; Biderman, S.; Scao, T.L.; Bari, M.S.; Shen, S.; Yong, Z.X.; Schoelkopf, H.; et al. Crosslingual generalization through multitask finetuning. arXiv 2022, arXiv:2211.01786. [Google Scholar]
- Li, R.; Allal, L.B.; Zi, Y.; Muennighoff, N.; Kocetkov, D.; Mou, C.; Marone, M.; Akiki, C.; Li, J.; Chim, J.; et al. Starcoder: May the source be with you! arXiv 2023, arXiv:2305.06161. [Google Scholar]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.; Tang, J.; Chen, X.; Lin, Y.; et al. A survey on large language model based autonomous agents. Front. Comput. Sci. 2024, 18, 186345. [Google Scholar]
- Rana, K.; Haviland, J.; Garg, S.; Abou-Chakra, J.; Reid, I.; Suenderhauf, N. Sayplan: Grounding large language models using 3d scene graphs for scalable task planning. arXiv 2023, arXiv:2307.06135. [Google Scholar]
- Zhu, A.; Martin, L.; Head, A.; Callison-Burch, C. CALYPSO: LLMs as Dungeon Master’s Assistants. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Salt Lake City, UT, USA, 8–12 October 2023; Volume 19, pp. 380–390. [Google Scholar]
- Fischer, K.A. Reflective linguistic programming (rlp): A stepping stone in socially-aware agi (socialagi). arXiv 2023, arXiv:2305.12647. [Google Scholar]
- Wang, Z.; Cai, S.; Chen, G.; Liu, A.; Ma, X.; Liang, Y. Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents. arXiv 2023, arXiv:2302.01560. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language agents with verbal reinforcement learning. Adv. Neural Inf. Process. Syst. 2024, 36, 8634–8652. [Google Scholar]
- Zhu, X.; Chen, Y.; Tian, H.; Tao, C.; Su, W.; Yang, C.; Huang, G.; Li, B.; Lu, L.; Wang, X.; et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv 2023, arXiv:2305.17144. [Google Scholar]
- Wang, G.; Xie, Y.; Jiang, Y.; Mandlekar, A.; Xiao, C.; Zhu, Y.; Fan, L.; Anandkumar, A. Voyager: An open-ended embodied agent with large language models. arXiv 2023, arXiv:2305.16291. [Google Scholar]
- Qian, C.; Cong, X.; Yang, C.; Chen, W.; Su, Y.; Xu, J.; Liu, Z.; Sun, M. Communicative agents for software development. arXiv 2023, arXiv:2307.07924. [Google Scholar]
- Lin, J.; Zhao, H.; Zhang, A.; Wu, Y.; Ping, H.; Chen, Q. Agentsims: An open-source sandbox for large language model evaluation. arXiv 2023, arXiv:2308.04026. [Google Scholar]
- Wang, B.; Liang, X.; Yang, J.; Huang, H.; Wu, S.; Wu, P.; Lu, L.; Ma, Z.; Li, Z. Enhancing large language model with self-controlled memory framework. arXiv 2023, arXiv:2304.13343. [Google Scholar]
- Huang, Z.; Gutierrez, S.; Kamana, H.; MacNeil, S. Memory sandbox: Transparent and interactive memory management for conversational agents. In Proceedings of the Adjunct Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology; San Francisco, CA, USA, 29 October–1 November 2023, pp. 1–3.
- Hu, C.; Fu, J.; Du, C.; Luo, S.; Zhao, J.; Zhao, H. Chatdb: Augmenting llms with databases as their symbolic memory. arXiv, 2023; arXiv:2306.03901. [Google Scholar]
- Zhou, X.; Li, G.; Liu, Z. Llm as dba. arXiv 2023, arXiv:2308.05481. [Google Scholar]
- Gutiérrez, B.J.; Shu, Y.; Gu, Y.; Yasunaga, M.; Su, Y. HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv 2024, arXiv:2405.14831. [Google Scholar]
- Zhou, W.; Jiang, Y.E.; Cui, P.; Wang, T.; Xiao, Z.; Hou, Y.; Cotterell, R.; Sachan, M. Recurrentgpt: Interactive generation of (arbitrarily) long text. arXiv 2023, arXiv:2305.13304. [Google Scholar]
- Wang, Q.; Ding, L.; Cao, Y.; Tian, Z.; Wang, S.; Tao, D.; Guo, L. Recursively summarizing enables long-term dialogue memory in large language models. arXiv 2023, arXiv:2308.15022. [Google Scholar]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019, 7, 535–547. [Google Scholar]
- LangChain Inc. LangChain. 2022. Available online: https://docs.langchain.com/docs/ (accessed on 13 August 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Time Interval | Recall Times | Text | Embedding Vector |
|---|---|---|---|---|
| 0 | 2 | 1 | xxx | xxx |
| 1 | 0 | 1 | xxx | xxx |
| 2 | 6 | 4 | xxx | xxx |
| 3 | 9 | 2 | xxx | xxx |
| 4 | 3 | 3 | xxx | xxx |
| … | … | … | … | … |
| Topic | Con_data | Rec_data | Ave_tokens |
|---|---|---|---|
| Legal consultation | 472 | 57 | 679.84 |
| Enhance love | 532 | 62 | 577.91 |
| Travel plan | 398 | 40 | 620.44 |
| Grandfather and poetry | 451 | 51 | 598.63 |
| Selling jewelry | 503 | 49 | 654.90 |
| Topic | Average Hit Rate |
|---|---|
| Legal consultation | 37.38% |
| Enhance love | 34.29% |
| Travel plan | 42.81% |
| Grandfather and poetry | 31.57% |
| Selling jewelry | 30.71% |
| Model | Average Execution Time |
|---|---|
| ILSTMA (Without CPM) | 5.17 |
| ILSTMA (With CPM) | 4.06 |
| MemoryBank | 4.87 |
| SCM | 4.10 |
| MemoChat | 4.31 |
| ChatRsum | 3.10 |
| Model | Answer Accuracy | Retrieve Accuracy | Recall Accuracy | Coherence |
|---|---|---|---|---|
| ILSTMA | 0.884 | 0.938 | 0.663 | 0.948 |
| MemoryBank | 0.624 | 0.640 | × | 0.927 |
| SCM | 0.849 | 0.934 | × | 0.943 |
| MemoChat | 0.609 | 0.512 | × | 0.932 |
| ChatRsum | 0.486 | × | × | 0.921 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ming, Z.; Wu, Z.; Chen, G. ILSTMA: Enhancing Accuracy and Speed of Long-Term and Short-Term Memory Architecture. Information 2025, 16, 251. https://doi.org/10.3390/info16040251
Ming Z, Wu Z, Chen G. ILSTMA: Enhancing Accuracy and Speed of Long-Term and Short-Term Memory Architecture. Information. 2025; 16(4):251. https://doi.org/10.3390/info16040251
Chicago/Turabian StyleMing, Zongyu, Zimu Wu, and Genlang Chen. 2025. "ILSTMA: Enhancing Accuracy and Speed of Long-Term and Short-Term Memory Architecture" Information 16, no. 4: 251. https://doi.org/10.3390/info16040251
APA StyleMing, Z., Wu, Z., & Chen, G. (2025). ILSTMA: Enhancing Accuracy and Speed of Long-Term and Short-Term Memory Architecture. Information, 16(4), 251. https://doi.org/10.3390/info16040251