

Generative AI and Its Implications for Definitions of Trust


Abstract
1. Introduction
2. Definitions of Trust and the OO Model of Trust
- Trust is a relation between A (the trustor) and B (the trustee). A and B can be human or artificial.
- Trust is a decision by A to delegate to B some aspect of importance to A in achieving a goal. We assume that an artificial agent A can make “decisions” (implemented by, for example, IF/THEN/ELSE statements) and that they involve some computation about the probability that B will behave as expected.
- Trust involves risk; the less information A has about B, the higher the risk, and the more trust is required. This is true for both artificial and human agents. In AAs, we expect that risk and trust are quantified or at least categorized explicitly; in humans, we do not expect that this proportionality is measured with mathematical precision.
- A has the expectation of gain by trusting B. In AAs, “expectation of gain” may refer to the expectation of the AA’s designer, or it may refer to an explicit expression in the source code that identifies this expected gain, or it may be something learned after the AA is deployed.
- B may or may not be aware that A trusts B. If B is human, circumstances may have prevented B from knowing that A trusts B. The same is true if B is an AA, but there is also some possibility that an AA trustee B may not even be capable of “knowing” in the traditional human sense.
- Positive outcomes when A trusts B encourage A to continue trusting B. If A is an AA, this cycle of trust—good outcome—more trust could be explicit in the design and implementation of the AA, or it could be implicit in data relationships, as in a neural net.
3. Examples of the Impact of GenAICs on Trust
3.1. Education
3.2. Business and Politics
3.3. Social Media
4. Re-Examining Trust and Its Underlying Assumptions
5. Modifying the OO Model: Do We Need to Create a New Class?
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wolf, M.J.; Miller, K.; Grodzinsky, F. Why we should have seen that coming: Comments on Microsoft’s Tay experiment, and wider implications. ACM SIGCAS Comput. Soc. 2017, 47, 54–64. [Google Scholar] [CrossRef]
- Orseau, L.; Ring, M. Self-modification and mortality in artificial agents. In Artificial General Intelligence. AGI 2011; Lecture Notes in Computer Science; Schmidhuber, J., Thórisson, K.R., Looks, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6830, pp. 1–10. [Google Scholar]
- Grodzinsky, F.; Miller, K.; Wolf, M.J. The ethics of designing artificial agents. Ethics Inf. Technol. 2008, 10, 115–121. [Google Scholar] [CrossRef]
- Grodzinsky, F.; Miller, K.; Wolf, M.J. Trust in artificial agents. In The Routledge Handbook on Trust and Philosophy; Simon, J., Ed.; Routledge: New York, NY, USA, 2020; pp. 298–312. [Google Scholar]
- Grodzinsky, F.; Miller, K.; Wolf, M.J. Developing artificial agents worthy of trust: “Would you buy a used car from this artificial agent?”. Ethics Inf. Technol. 2011, 13, 17–27. [Google Scholar] [CrossRef]
- Taddeo, M. Defining trust and e-trust: From old theories to new problems. Int. J. Technol. Hum. Interact. 2009, 5, 23–35. [Google Scholar] [CrossRef]
- Mittelstadt, B.D.; Allo, P.; Taddeo, M.; Wachter, S.; Floridi, L. The ethics of algorithms: Mapping the debate. Big Data Soc. 2016, 33, 2053951716679679. [Google Scholar] [CrossRef]
- Ferrario, A.; Loi, M.; Viganò, E. In AI we trust incrementally: A multi-layer model of trust to analyze human-artificial intelligence interactions. Philos. Technol. 2020, 33, 523–539. [Google Scholar] [CrossRef]
- Hou, F.; Jansen, S. A systematic literature review on trust in the software ecosystem. Empir. Softw. Eng. 2023, 28, 8. [Google Scholar] [CrossRef]
- Chen, Y.; Jensen, S.; Albert, L.J.; Gupta, S.; Lee, T. Artificial intelligence (AI) student assistants in the classroom: Designing chatbots to support student success. Inf. Syst. Front. 2023, 25, 161–182. [Google Scholar] [CrossRef]
- Essel, H.B.; Vlachopoulos, D.; Tachie-Menson, A.; Johnson, E.E.; Baah, P.K. The impact of a virtual teaching assistant (chatbot) on students’ learning in Ghanaian higher education. Int. J. Educ. Technol. High. Educ. 2022, 19, 57. [Google Scholar] [CrossRef]
- Labadze, L.; Grigolia, M.; Machaidze, L. Role of AI chatbots in education: Systematic literature review. Int. J. Educ. Technol. High. Educ. 2023, 20, 56. [Google Scholar] [CrossRef]
- Shalby, C. Fake Students Enrolled in Community Colleges. One Bot-Sleuthing Professor Fights Back. LA Times. Available online: https://www.latimes.com/california/story/2021-12-17/fake-student-bots-enrolled-in-community-colleges-one-professor-has-become-a-bot-sleuthing-continues-to-fight-them (accessed on 15 March 2024).
- Parry, M. Online professors pose as students to encourage real learning. Chron. High. Educ. 2009, 55, A10. [Google Scholar]
- Chen, H.; Magramo, K. Finance Worker Pays Out $25 Million after Video Call with Deepfake ‘Chief Financial Officer’. CNN. Available online: https://www.cnn.com/2024/02/04/asia/deepfake-cfo-scam-hong-kong-intl-hnk/index.html (accessed on 15 March 2024).
- Bohannon, M. Biden. Deepfake Robocall Urging Voters to Skip New Hampshire Primary Traced to Texas Company. Forbes. Available online: https://www.forbes.com/sites/mollybohannon/2024/02/06/biden-deepfake-robocall-urging-voters-to-skip-new-hampshire-primary-traced-to-texas-company/?sh=6c4b5f4b241b (accessed on 15 March 2024).
- Sodji, L. How We Made David Beckam Speak 9 Languages. Synthesia. Available online: https://www.synthesia.io/post/david-beckham (accessed on 15 June 2024).
- Tenbarge, K. Taylor Swift Deepfakes on X Falsely Depict Her Supporting Trump. NBC News. Available online: https://www.nbcnews.com/tech/internet/taylor-swift-deepfake-x-falsely-depict-supporting-trump-grammys-flag-rcna137620 (accessed on 15 March 2024).
- Coeckelbergh, M. Can We Trust Robots? Ethics Inf. Technol. 2012, 14, 53–60. [Google Scholar] [CrossRef]
- Bond, S. AI-Generated Deepfakes Are Moving Fast. Policymakers Can’t Keep Up. NPR. Available online: https://www.npr.org/2023/04/27/1172387911/how-can-people-spot-fake-images-created-by-artificial-intelligence (accessed on 5 April 2024).
- Cai, Z.G.; Haslett, D.A.; Duan, X.; Wang, S.; Pickering, M.J. Does ChatGPT Resemble Humans in Language Use? Available online: https://arxiv.org/abs/2303.08014 (accessed on 15 March 2024).
- Van Rooij, I.; Guest, O.; Adolfi, F.G.; de Haan, R.; Kolokolova, A.; Rich, P. Reclaiming AI as a theoretical tool for cognitive science. PsyArXiv 2023. [Google Scholar] [CrossRef]
- Weise, K.; Metz, C.; Grant, N.; Isaac, M. Inside the A.I. Arms Race that Changed Silicon Valley Forever. The New York Times. Available online: https://www.nytimes.com/2023/12/05/technology/ai-chatgpt-google-meta.html (accessed on 15 March 2024).
- Wu, X.; Duan, R.; Ni, J. Unveiling security, privacy, and ethical concerns of ChatGPT. J. Inf. Intell. 2024, 2, 102–115. [Google Scholar] [CrossRef]
- Lawson, G. 5 Examples of Ethical Issues in Software Development. TechTarget. Available online: https://www.techtarget.com/searchsoftwarequality/tip/5-examples-of-ethical-issues-in-software-development (accessed on 15 March 2024).
- Floridi, L. The Ethics of Artificial Intelligence: Principles, Challenges, and Opportunities; Oxford Academic: Oxford, UK, 2023. [Google Scholar]
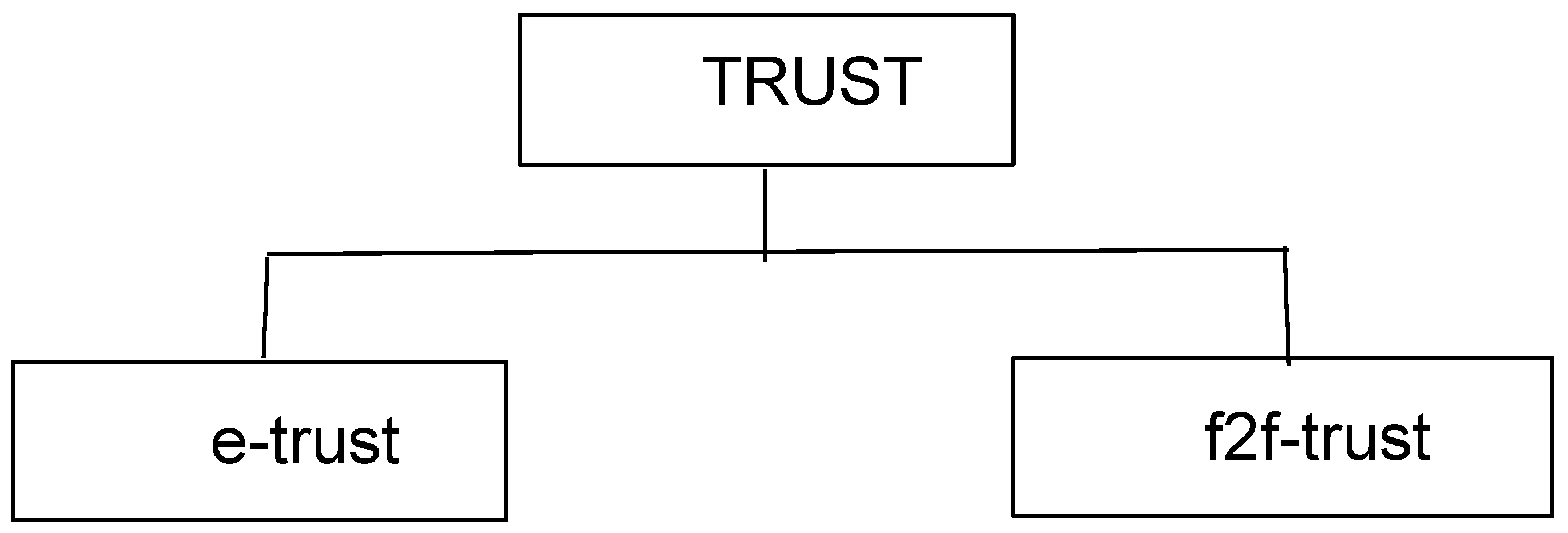


{kind=link}
{kind=link}
| H → H f2f-trust | H → H e-trust |
| H → AA f2f-trust | H → AA e-trust |
| AA → H f2f-trust | AA → H e-trust |
| AA → AA f2f-trust | AA → AA e-trust |
| H → H f2f-trust | H → H e-trust | H → ? e-trust |
| H → AA f2f-trust | H → AA e-trust | ? → AA e-trust |
| AA → H f2f-trust | AA → H e-trust | ? → H e-trust |
| AA → AA f2f-trust | AA → AA e-trust | AA → ? e-trust |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wolf, M.J.; Grodzinsky, F.; Miller, K.W. Generative AI and Its Implications for Definitions of Trust. Information 2024, 15, 542. https://doi.org/10.3390/info15090542
Wolf MJ, Grodzinsky F, Miller KW. Generative AI and Its Implications for Definitions of Trust. Information. 2024; 15(9):542. https://doi.org/10.3390/info15090542
Chicago/Turabian StyleWolf, Marty J., Frances Grodzinsky, and Keith W. Miller. 2024. "Generative AI and Its Implications for Definitions of Trust" Information 15, no. 9: 542. https://doi.org/10.3390/info15090542
APA StyleWolf, M. J., Grodzinsky, F., & Miller, K. W. (2024). Generative AI and Its Implications for Definitions of Trust. Information, 15(9), 542. https://doi.org/10.3390/info15090542