1. Introduction
The exponential growth in scholarly publications poses a significant challenge for researchers seeking to efficiently explore and navigate the vast landscape of the scientific literature [
1]. This proliferation of publications necessitates the development of strategies that go beyond traditional keyword-based search methods to facilitate effective and strategic reading practices. In response to this challenge, the structured representation of scientific papers has emerged as a valuable approach to enhancing FAIR research discovery and comprehension. By describing research contributions in a structured, machine-actionable format with respect to the salient properties of research, also regarded as research dimensions, similarly structured papers can be easily compared, offering researchers a systematic and quick snapshot of research progress within specific domains, thus providing them with efficient ways to stay updated with research progress.
One notable initiative aimed at publishing structured representations of scientific papers is the Open Research Knowledge Graph (ORKG,
https://orkg.org/ accessed on 23 April 2024) [
2]. The ORKG endeavors to describe papers in terms of various research dimensions or properties. Furthermore, a distinguishing characteristic of the properties is that they are also generically applicable across various contributions on the same problem, thus making the structured paper descriptions comparable. We illustrate this with two examples. For instance, the properties “model family”, “pretraining architecture”, “number of parameters”, “hardware used”, etc., can be effectively applied to offer structured, machine-actionable summaries of research contributions on the research problem “transformer model” in the domain of Computer Science (
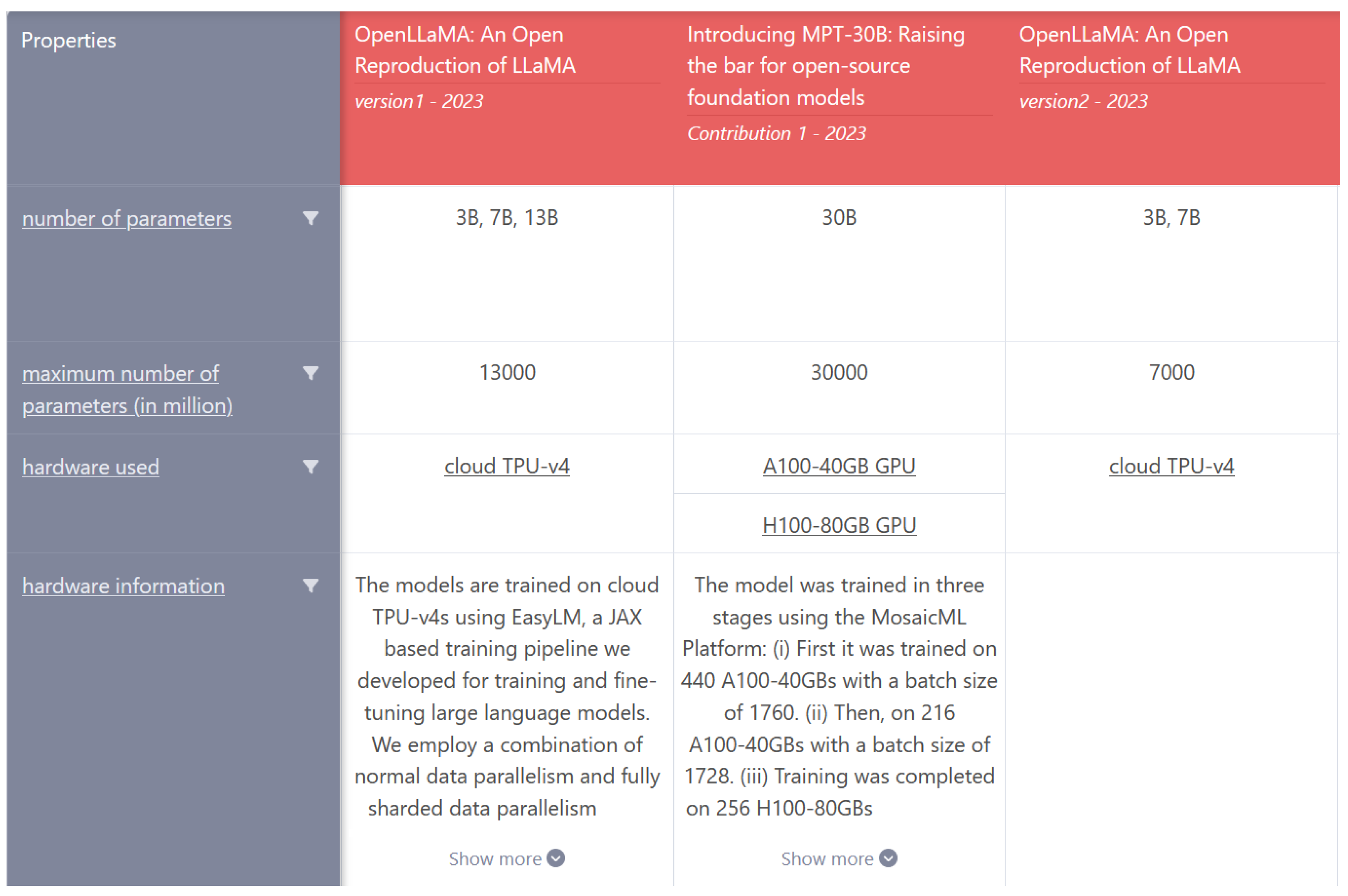
Figure 1). Thus, these properties can be explicitly stated as research comparison properties. As another example, papers with the research problem “DNA sequencing techniques” in the domain of Biology can be described as structured summaries based on the following properties: “sequencing platform”, “read length in base pairs”, “reagents cost”, and “runtime in days” (
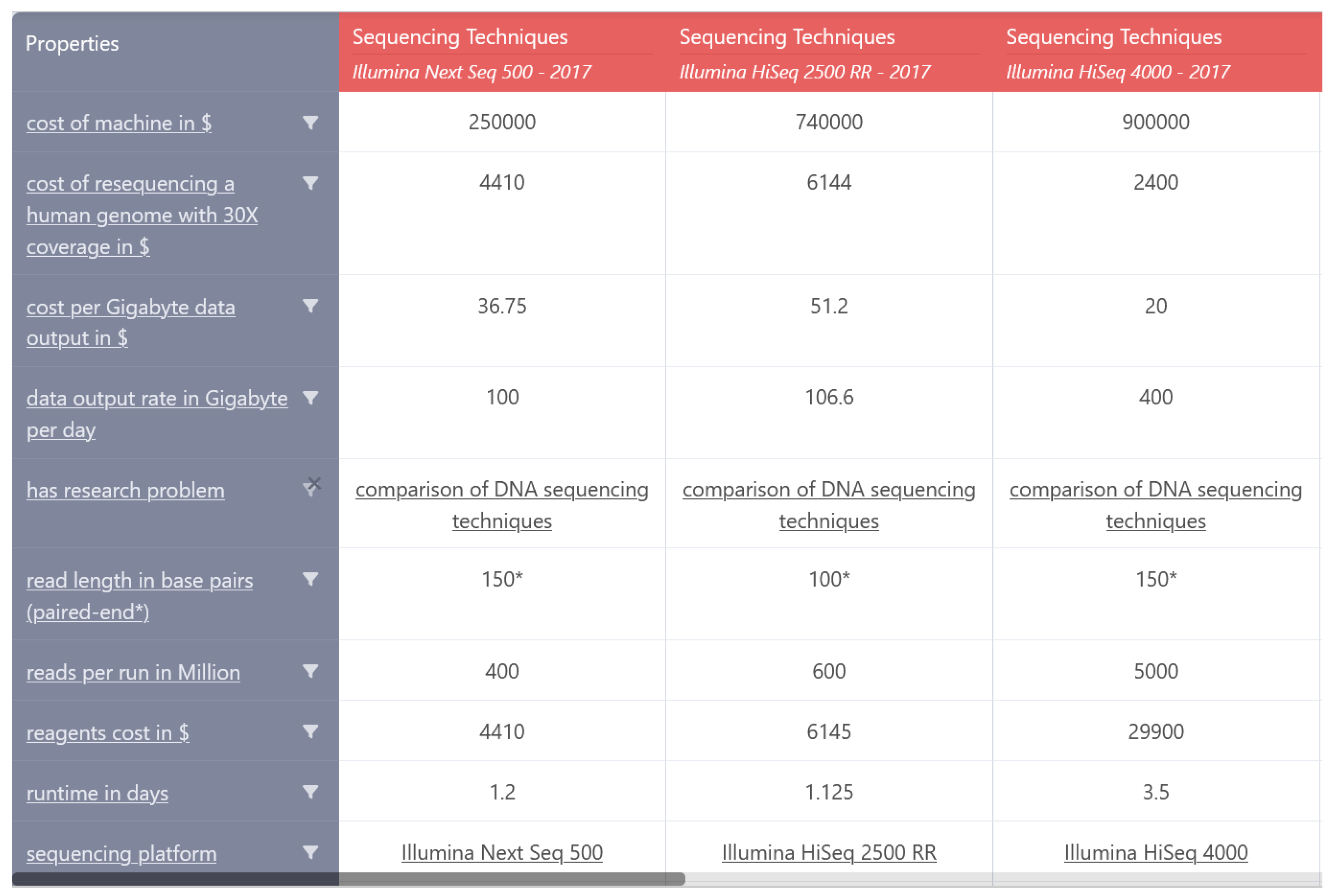
Figure 2). This type of paper description provides a structured framework for understanding and contextualizing research findings.
Notably, however, the predominant method in the ORKG for creating structured paper descriptions or research comparisons is manually performed by domain experts. This means that domain experts, based on their prior knowledge and experience on a research problem, select and describe the research comparison properties. While this ensures the high quality of the resulting structured papers in the ORKG, the manual annotation cycles cannot effectively scale the ORKG in practice. Specifically, the manual extraction of these salient properties of research or research comparison properties presents two significant challenges: (1) manual annotation is a time-consuming process, and (2) it introduces inconsistencies among human annotators, potentially leading to variations in interpretation and annotation.
To address the challenges associated with the manual annotation of research comparison properties,
this study tests the feasibility of using pretrained Large Language Models (LLMs) to automatically suggest or recommend research dimensions as candidate properties as a viable alternative solution. Specifically, three different LLM variants, viz., GPT-3.5-turbo [
3], Llama 2 [
4], and Mistral [
5], are tested and empirically compared for their advanced natural language processing (NLP) capabilities when applied to the task of recommending research dimensions as candidate properties. Our choice to apply LLMs is based on the following experimental consideration. The multidisciplinary nature of scientific research poses unique challenges to the identification and extraction of salient properties across domains. In this context, we hypothesize that LLMs, with their ability to contextualize and understand natural language at scale [
6,
7], are particularly well suited to navigate the complexities of interdisciplinary research and recommend relevant dimensions that capture the essence of diverse scholarly works. By automating the extraction process, LLMs aim to alleviate the time constraints associated with manual annotation and ensure a higher level of consistency in the specification of research dimensions by using the same system prompt or fine-tuning on gold-standard ORKG data to better align them with the task. The role of LLMs in this context is to assist human domain-expert annotators rather than replace them entirely. By leveraging the capabilities of LLMs, researchers can streamline the process of dimension extraction and enhance the efficiency and reliability of comparative analysis across diverse research fields.
In this context, the central
research question (RQ) is aimed at examining the performance of state-of-the-art LLMs in recommending research dimensions: specifically, “how good are LLMs in performing this task?” Can they replace humans? To address this RQ, we compiled a
multidisciplinary, gold-standard dataset of human-annotated scientific papers from the Open Research Knowledge Graph (ORKG), detailed in the Materials and Methods Section (see
Section 3.1). This dataset includes structured summary property annotations made by domain experts. We conducted a detailed comparative evaluation of domain-expert-annotated properties from the ORKG against the dimensions generated by LLMs for the same papers. This dataset is the first main contribution of this work. Furthermore, our central
RQ is examined with regard to the following four unique perspectives:
Semantic alignment and deviation assessment by GPT-3.5 between ORKG properties and LLM-generated dimensions;
The fine-grained property mapping accuracy of GPT-3.5;
SciNCL [
8] embedding-based cosine similarity between ORKG properties and LLM-generated dimensions;
A survey with human experts comparing their annotations of ORKG properties with the LLM-generated dimensions.
These evaluations as well as the resulting perspectives then constitute the second main contribution of this work.
Overall, the contribution of this work is a comprehensive set of insights into the readiness of LLMs to support human annotators in the task of structuring their research contributions. Our findings reveal a moderate alignment between LLM-generated dimensions and manually annotated ORKG properties, indicating the potential for LLMs to learn from human-annotated data. However, there is a noticeable gap in the mapping of dimensions generated by LLMs versus those annotated by domain experts, highlighting the need for fine-tuning LLMs on domain-specific datasets to reduce this disparity. Despite this gap, LLMs demonstrate the ability to capture the semantic relationships between LLM-generated dimensions and ORKG properties, particularly in a zero-shot setting, as evidenced by the strong correlation results of embedding similarity. In the survey, the human experts noted that while they were not ready to change their existing property annotations based on the LLM-generated dimensions, they highlighted the utility of the auto-LLM recommendation service at the time of creating the structured summary descriptions. This directly informs a future research direction for making LLMs fit for structured science summarization.
The structure of the rest of this paper is as follows:
Section 2 provides a brief summary of related work. In
Section 3—the Materials and Methods Section—we start by detailing our materials, including the creation of an evaluation dataset. We then describe our methodology, beginning with brief technical introductions to the three language models selected for this study. We also discuss the evaluation methods that we used, outlining three key types of similarity assessments performed between ORKG properties and LLM-generated research dimensions. Additionally, we introduce a human assessment survey that compares ORKG properties with LLM-generated dimensions. In
Section 4—the Results and Discussion Section—we provide an in-depth analysis of each evaluation’s outcomes. Finally,
Section 5 summarizes our findings, discusses their implications, and proposes future research avenues.
2. Related Work
LLMs in Scientific Literature Analysis. The utilization of LLMs for various NLP tasks has seen widespread adoption in recent years [
9,
10]. Within the realm of scientific literature analysis, researchers have explored the potential of LLMs for tasks such as generating summaries and abstracts of research papers [
11,
12], extracting insights and identifying patterns [
13], aiding in literature reviews [
14], enhancing knowledge integration [
15], etc. However, the specific application of LLMs for recommending research dimensions to obtain structured representations of research contributions is a relatively new area of investigation that we explore in this work. Furthermore, to offer insights into the readiness of LLMs for our novel task, we perform a comprehensive set of evaluations comparing the LLM-generated research dimensions and the human-expert-annotated properties. As a straightforward preliminary evaluation, we measure the semantic similarity between the LLM and human-annotated properties. To this end, we employ a specialized language model tuned for the scientific domain to create embeddings for the respective properties.
Various Scientific-Domain-Specific Language Models. The development of domain-specific language models has been a significant advancement in NLP. In the scientific domain, a series of specialized models have emerged. SciBERT, introduced by Beltagy et al. [
16], was the first language model tailored for scientific texts. This was followed by SPECTER, developed by Cohan et al. [
17]. More recently, Ostendorff et al. introduced SciNCL [
8], a language model designed to capture the semantic similarity between scientific concepts by leveraging pretrained BERT embeddings. In this study, to ensure comprehensiveness, we tested all the mentioned variants of language models. Our goal was to project ORKG properties and LLM-generated dimensions into a scientific embedding space, which served as a tool to evaluate their similarity.
Evaluating LLM-Generated Content. In the context of evaluating LLM-generated dimensions against manually curated properties, several studies have employed similarity measures to quantify the relatedness between the two sets of textual data. One widely used metric is cosine similarity, which measures the cosine of the angle between two vectors representing the dimensions [
18]. This measure has been employed in various studies, such as Yasunaga et al. [
19], who used cosine similarity to assess the similarity between summaries automatically generated by LLMs and human-written annotations. Similarly, Banerjee et al. [
20] employed cosine similarity as a metric to benchmark the accuracy of LLM-generated answers of autonomous conversational agents. In contrast to cosine similarity, other studies have explored alternative similarity measures for evaluating LLM-generated content. For instance, Jaccard similarity measures the intersection over the union of two sets, providing a measure of overlap between them [
21]. This measure has been employed in tasks such as document clustering and topic modeling [
22,
23]. Jaccard similarity offers a distinct perspective on the overlap between manually curated and LLM-generated properties, as it focuses on the shared elements between the two sets rather than their overall similarity. We considered both cosine and Jaccard similarity in our evaluation; however, based on our embedding representation, we ultimately chose to use cosine similarity as our distance measure.
Furthermore, aside from the straightforward similarity computations between the two sets of properties, we also leverage the capabilities of LLMs as evaluators. The utilization of LLMs as evaluators in various NLP tasks has been proven to be a successful approach in a number of recent publications. For instance, Kocmi and Federmann [
24] demonstrated the effectiveness of GPT-based metrics for assessing translation quality, achieving state-of-the-art accuracy in both reference-based and reference-free modes. Similarly, the Eval4NLP 2023 shared task, organized by Leiter et al. [
25], explored the use of LLMs as explainable metrics for machine translation and summary evaluation, showcasing the potential of prompting and score extraction techniques to achieve results on par with or even surpassing recent reference-free metrics. In our study, we employ the GPT-3.5 model as an evaluator, leveraging its capabilities to assess the quality, from its own judgment of semantic correspondence, of LLM-generated research dimensions with the human-curated properties in the ORKG.
In summary, previous research has laid the groundwork for evaluating LLMs’ performance in scientific literature analysis, and our study builds upon these efforts by exploring the application of LLMs for recommending research dimensions and evaluating their quality using specialized language models and similarity measures.
3. Materials and Methods
This section is organized into three subsections. In the first subsection, the creation of the gold-standard evaluation dataset from the ORKG with human-domain-expert-annotated research comparison properties used to assess their similarity to LLM-generated properties is described. The second subsection provides an overview of the three LLMs, viz., GPT-3.5, Llama 2, and Mistral, applied to automatically generate the research comparison properties, highlighting their respective technical characteristics. Lastly, the third subsection discusses the various evaluation methods used in this study, offering differing perspectives on the similarity comparison of ORKG properties for the instances in our gold-standard dataset versus those generated by the LLMs.
3.1. Material: Our Evaluation Dataset
As alluded to in the Introduction, answering the central
RQ of this work requires comparing the research dimensions generated by three different LLMs with the human-annotated research comparison properties in the ORKG. For this, we created an evaluation dataset of annotated research dimensions based on the ORKG. As a starting point, we curated a selection of ORKG Comparisons from
https://orkg.org/comparisons (accessed on 23 April 2024) that were created by experienced ORKG users. These users had varied research backgrounds. The selection criteria for comparisons from these users were as follows: the comparisons had to have at least 3 properties and contain at least 5 contributions, since we wanted to ensure that the properties were not too sparse a representation of a research problem but were those that generically reflected a research comparison over several works. Upon the application of these criteria, the resulting dataset comprised 103 ORKG Comparisons. These selected gold-standard comparisons contained 1317 papers from 35 different research fields addressing over 150 distinct research problems. The gold-standard dataset can be downloaded from the Leibniz University Data Repository at
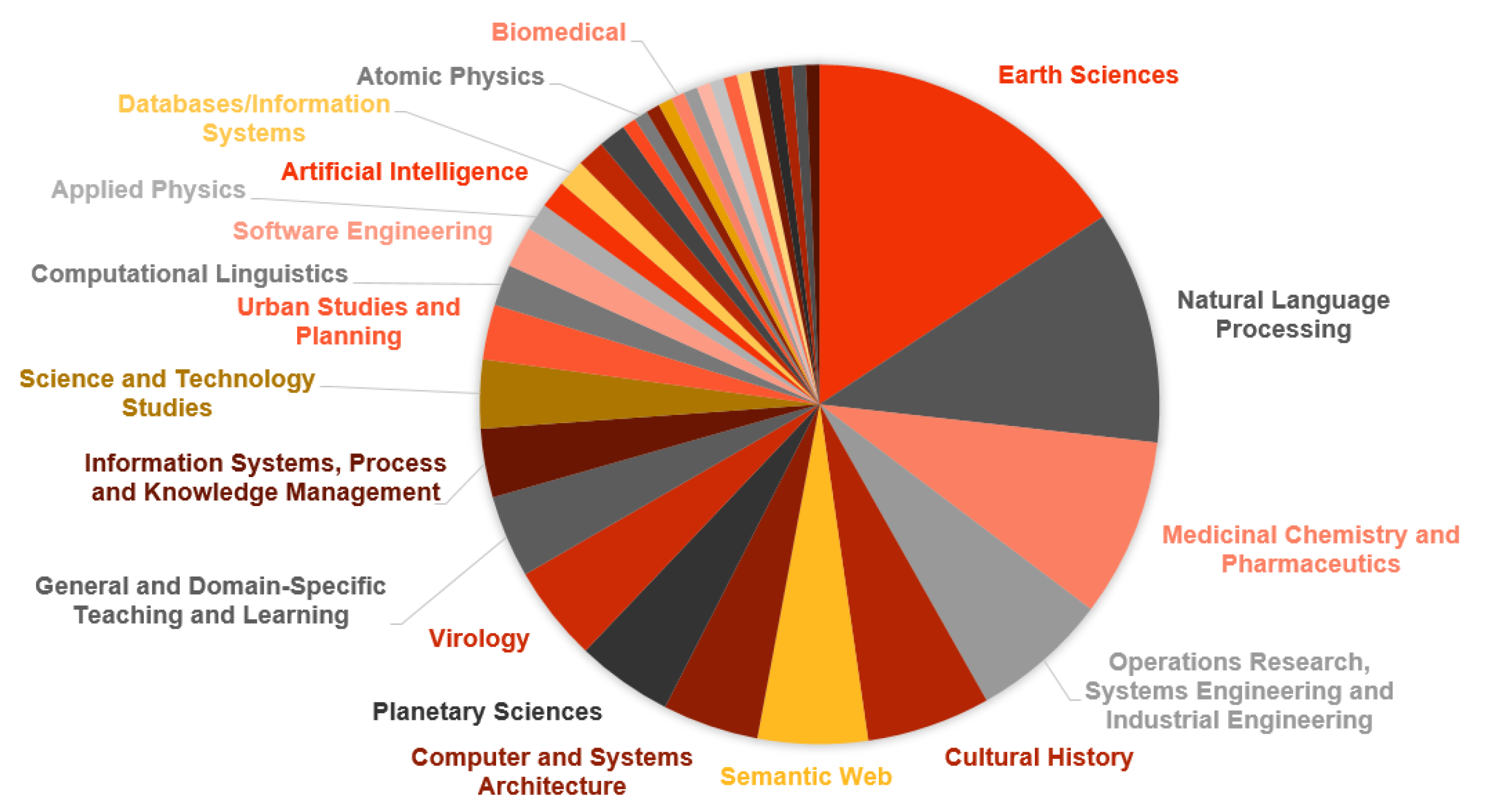
https://doi.org/10.25835/6oyn9d1n (accessed on 23 April 2024). The selection of comparisons ensured the diversity of the research fields’ distribution, comprising Earth Sciences, Natural Language Processing, Medicinal Chemistry and Pharmaceutics, Operations Research, Systems Engineering, Cultural History, Semantic Web, and others. See
Figure 3 for the full distribution of research fields in our dataset.
Once we had the comparisons, we then looked at the individual structured papers within each comparison and extracted their human-annotated properties. Thus, our resulting dataset is highly multidisciplinary, comprising structured paper instances from the ORKG with their corresponding domain-expert property annotations across different fields of research. For instance, the properties listed below were extracted from the comparison “A Catalog of Transformer Models” (
Figure 1):
["has model", "model family", "date created", "organization", "innovation",
"pretraining architecture", "pretraining task", "fine-tuning task",
"training corpus", "optimizer", "tokenization", "number of parameters",
"maximum number of parameters (in million)", "hardware used",
"hardware information", "extension", "has source code", "blog post",
"license", "research problem"]
Another example of structured papers’ properties in the comparison “Survey of sequencing techniques” (
Figure 2) is as follows:
["cost of machine in $", "cost of resequencing a human genome
with 30X coverage in $", "cost per Gigabyte data output in $",
"data output rate in Gigabyte per day", "has research problem",
"read length in base pairs (paired-end*) ", "reads per run in Million",
"reagents cost in $", "runtime in days", "sequencing platform",
"total data output yield in Gigabyte"]
The aforementioned dataset is now the gold standard that we use in the evaluations for the LLM-generated research dimensions. In this section, we provide a clear distinction between the terms ORKG properties and LLM-generated research dimensions. According to our hypothesis, ORKG properties are not necessarily identical to research dimensions. Contribution properties within the ORKG relate to specific attributes or characteristics associated with individual research papers in a comparison, outlining aspects such as authorship, publication year, methodology, and findings. Conversely, research dimensions encapsulate the multifaceted aspects of a given research problem, constituting the nuanced themes or axes along which scholarly investigations are conducted. ORKG contribution properties offer insights into the attributes of individual papers, whereas research dimensions operate at a broader level, revealing the finer-grained thematic fundamentals of research endeavors. While ORKG contribution properties focus on the specifics of research findings, research dimensions offer a more comprehensive context for analyzing a research question that can be used to find similar papers that share the same dimensions. In order to test the alignment of LLM-generated research dimensions with ORKG properties, several LLMs were selected for comparison, as described in the next section.
3.3. Method: Three Types of Similarity Evaluations between ORKG Properties and LLM-Generated Research Dimensions
This section outlines the methodology used to evaluate our dataset, namely, the automated evaluation of semantic alignment and deviation, as well as mapping between ORKG properties and LLM-generated research dimensions performed by GPT-3.5. Additionally, we present our approach to calculating the embedding similarity between properties and research dimensions.
3.3.1. Semantic Alignment and Deviation Evaluations Using GPT-3.5
To measure the semantic similarity between ORKG properties and LLM-generated research dimensions, we conducted semantic alignment and deviation assessments using an LLM-based evaluator. In this context, semantic alignment refers to the degree to which two sets of concepts share similar meanings, whereas semantic deviation assesses how far apart they are in terms of meaning. As the LLM evaluator, we leveraged GPT-3.5. As input, it was provided with both the lists of properties from ORKG and the dimensions extracted by the LLMs in a string format per research problem. Semantic alignment was rated on a scale from 1 to 5, using the following system prompt to perform this task:
You will be provided with two lists of strings, your task is to rate
the semantic alignment between the lists on the scale form 1 to 5.
Your response must only include an integer representing your assessment
of the semantic alignment, include no other text.
Additionally, the prompt included a detailed description of the scoring system shown in
Table 3.
To further validate the accuracy of our alignment scores, we leveraged GPT-3.5 as an evaluator again but this time to generate semantic deviation scores. By using this contrastive alignment versus deviation evaluation method, we can cross-reference where the LLM evaluator displays a strong agreement in its evaluation and assess the evaluations for reliability. Specifically, we evaluate the same set of manually curated properties and LLM-generated research dimensions using both agents, with the expectation that the ratings will exhibit an inverse relationship. In other words, high alignment scores should correspond to low deviation scores, and vice versa. The convergence of these opposing measures would provide strong evidence for the validity of our evaluation results. Similar to the task of alignment rating, the system prompt below was used to instruct GPT-3.5 to measure semantic deviation, and the ratings described in
Table 4 were also part of the prompt.
You will be provided with two lists of strings, your task is to rate
the semantic deviation between the lists on the scale form 1 to 5.
Your response must only include an integer representing your assessment
of the semantic deviation, include no other text.
By combining these two evaluations, we can gain a more nuanced understanding of the relationship between the ORKG properties and LLM-generated research dimensions.
5. Conclusions
In this study, we investigated the performance of state-of-the-art Large Language Models (LLMs) in recommending research dimensions, aiming to address the central research question: How effectively do LLMs perform in the task of recommending research dimensions? Through a series of evaluations, including semantic alignment and deviation assessments, property and research dimension mappings, embedding-based evaluations, and a human assessment survey, we sought to provide insights into the capabilities and limitations of LLMs in this domain.
The findings of our study elucidated several key aspects of LLM performance in recommending research dimensions. First, our semantic alignment and deviation assessments revealed a moderate level of alignment between manually curated ORKG properties and LLM-generated research dimensions, accompanied by a higher degree of deviation. While LLMs demonstrate some capacity to capture semantic similarities, there are notable differences between the concepts of structured paper properties and research dimensions. This suggests that LLMs may not fully emulate the nuanced inclinations of domain experts when structuring contributions.
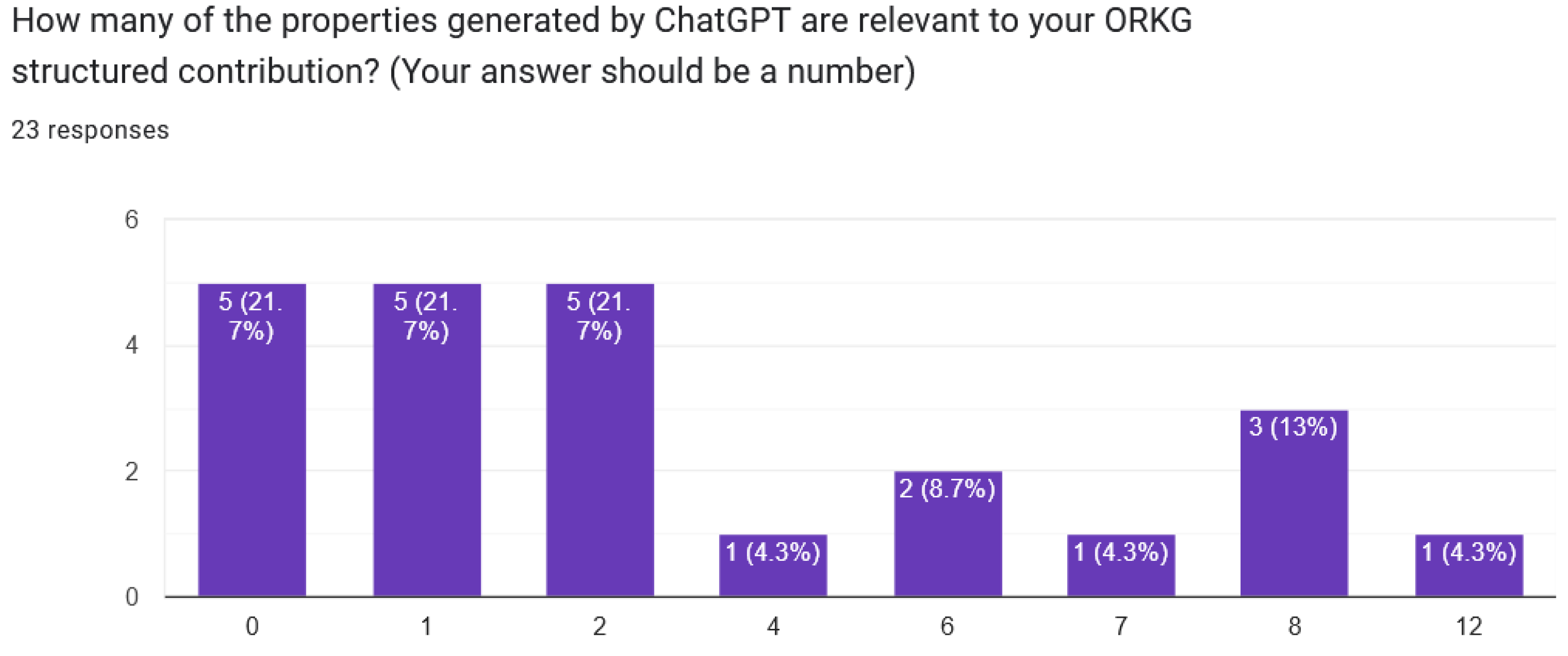
Second, our property and research dimension mapping analysis indicated a low number of mappings between paper properties and research dimensions. While LLMs can generate a more diverse set of research dimensions than ORKG properties, the degree of similarity is lower, highlighting the challenges in aligning LLM-generated dimensions with human-expert-curated properties.
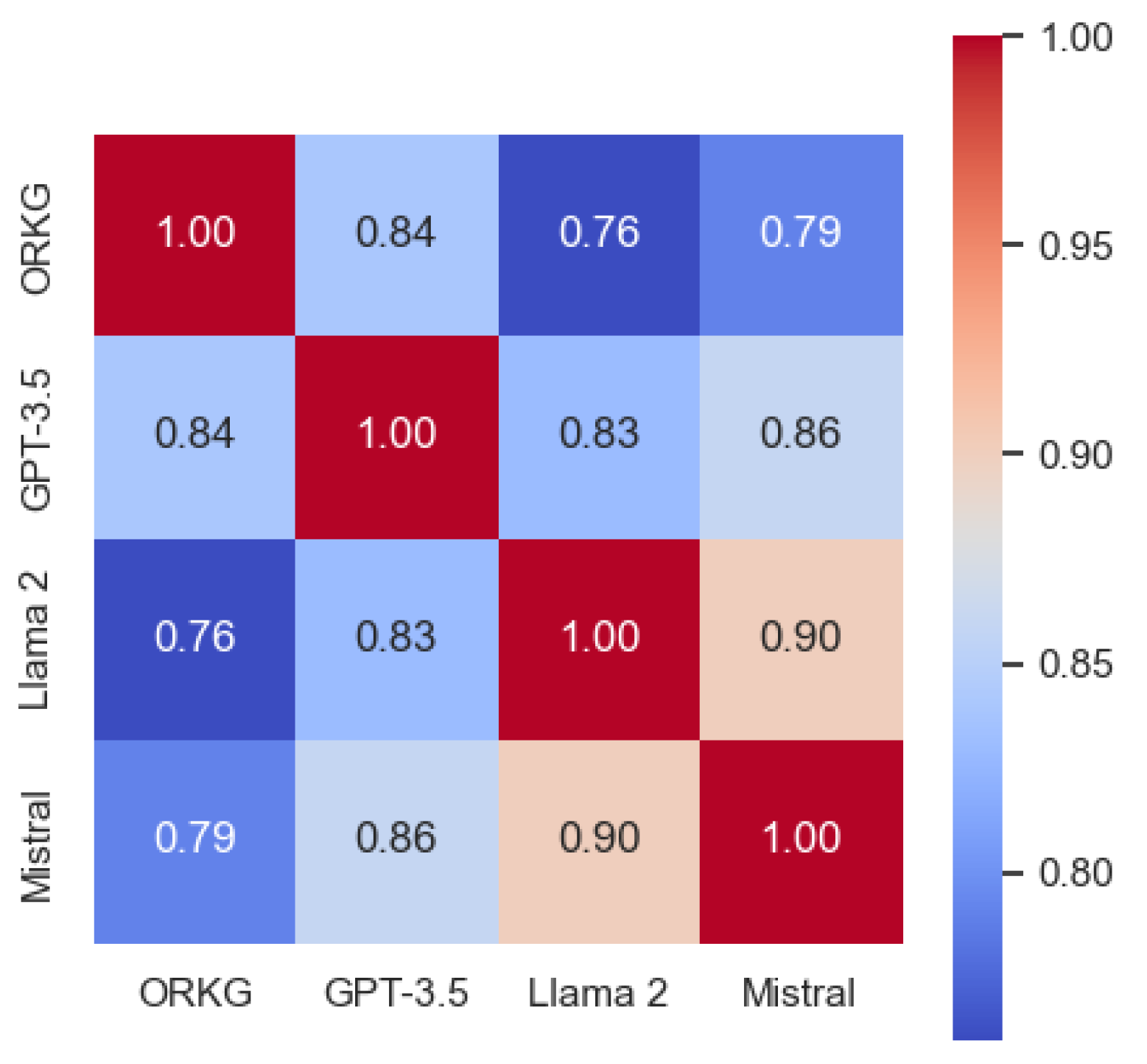
Third, our embedding-based evaluations showed that GPT-3.5 achieved the highest semantic similarity between ORKG properties and LLM-generated research dimensions, outperforming Mistral and Llama 2 in that order.
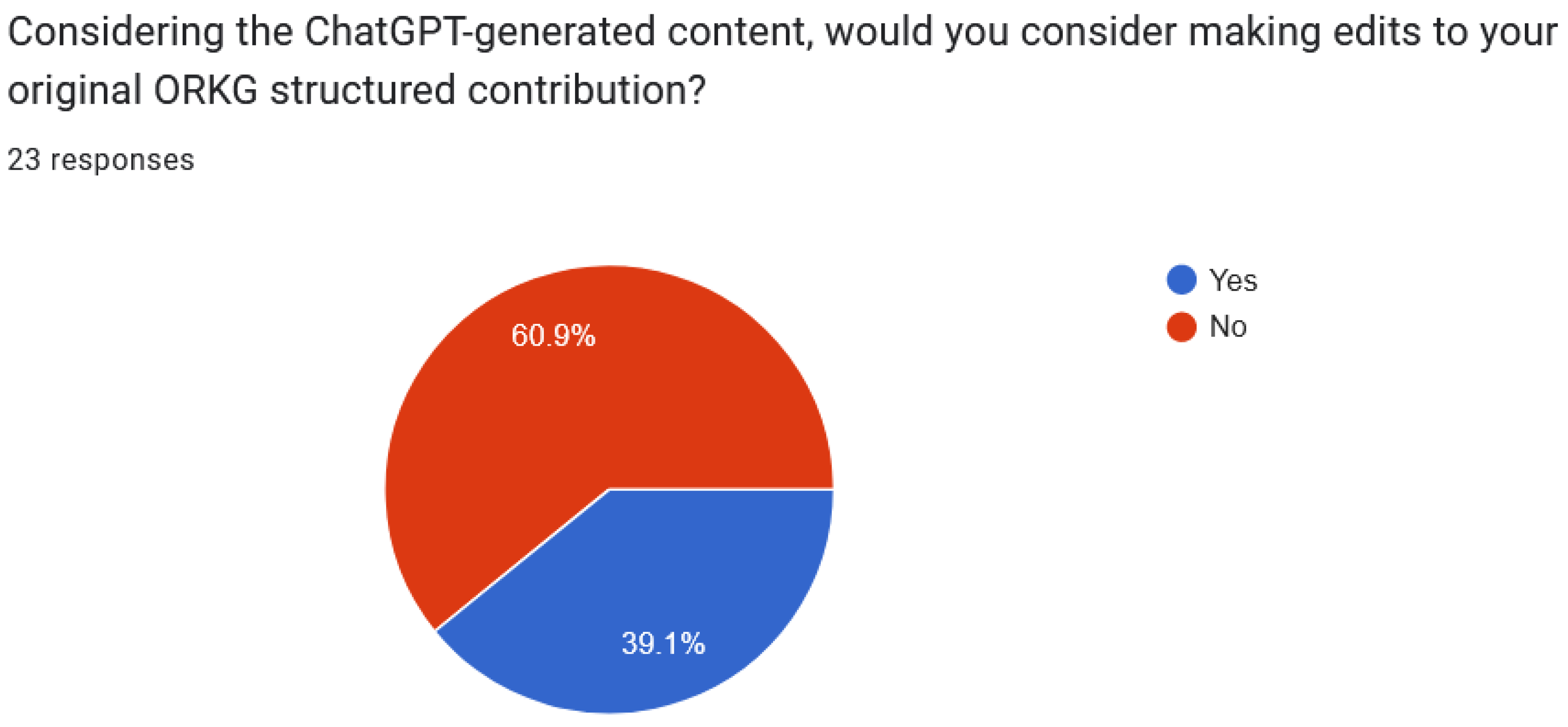
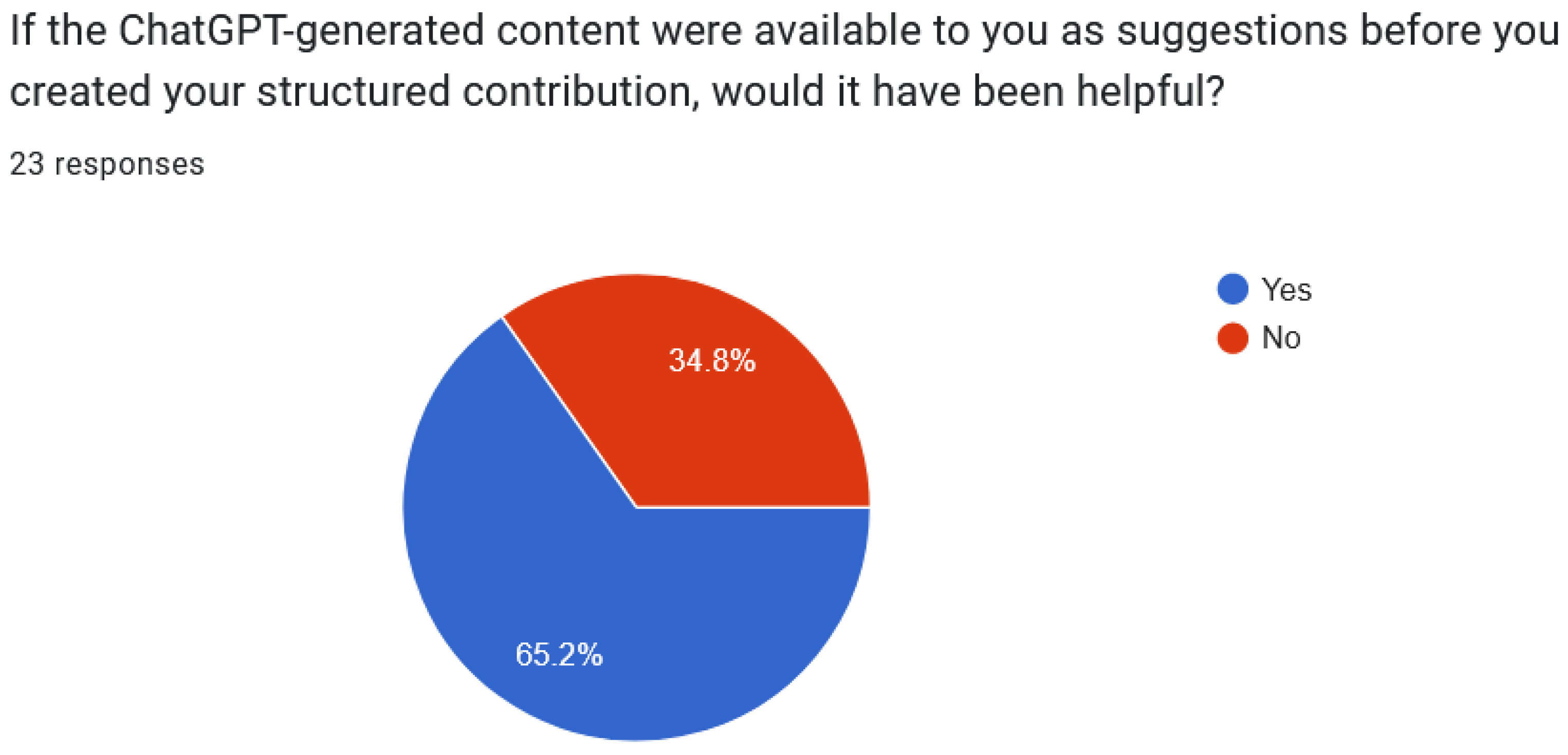
Fourth and finally, our human assessment survey provided valuable feedback from domain experts, indicating a moderate alignment between LLM-generated dimensions and manually annotated properties. While the suggestions provided by LLMs were deemed potentially helpful in various aspects of creating structured contributions, concerns regarding specificity and alignment with research goals were noted, suggesting areas for improvement.
While this study provides valuable insights into the performance of LLMs in generating research dimensions, there are several limitations that should be acknowledged. Firstly, the LLMs used in this research are trained on a wide range of text, not exclusively the scientific literature, which may affect their ability to accurately generate research dimensions. Secondly, due to hardware limitations, we were unable to test larger LLM models, restricting our evaluation to small and medium-sized models. Furthermore, this work represents the first empirical investigation into this novel research problem, defining a preliminary paradigm for future research in this area. As such, our evaluation focused on state-of-the-art LLMs, serving as a stepping stone for future studies to explore a broader range of LLM architectures and scales. Moving forward, researchers should consider testing a diverse array of LLMs, including larger models and those specifically fine-tuned for scientific domains, to gain a more comprehensive understanding of their capabilities and limitations in generating research dimensions.
In conclusion, our study contributes to a deeper understanding of LLM performance in recommending research dimensions to create structured science summary representations in the ORKG. While LLMs show promise as tools for automated research metadata creation and the retrieval of related work, further development is necessary to enhance their accuracy and relevance in this domain. Future research may explore the fine-tuning of LLMs on scientific domains to improve their performance in recommending research dimensions.
Author Contributions
Conceptualization, J.D. and S.E.; methodology, V.N.; validation, V.N.; investigation, V.N. and J.D.; resources, V.N. and J.D.; data curation, V.N.; writing—original draft preparation, V.N. and J.D.; writing—review and editing, J.D. and S.E.; visualization, V.N.; supervision, J.D. and S.E.; project administration, J.D.; funding acquisition, J.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the German BMBF project SCINEXT (ID 01lS22070), the European Research Council for ScienceGRAPH (GA ID: 819536), and German DFG for NFDI4DataScience (no. 460234259).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We thank all members of the ORKG Team for their dedication to creating and maintaining the ORKG platform. Furthermore, we thank all the participants of our survey for providing their insightful feedback and responses.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Arab Oghli, O.; D’Souza, J.; Auer, S. Clustering Semantic Predicates in the Open Research Knowledge Graph. In Proceedings of the International Conference on Asian Digital Libraries, Hanoi, Vietnam, 30 November–2 December 2022; Springer: Cham, Switzerland, 2022; pp. 477–484. [Google Scholar]
- Auer, S.; Oelen, A.; Haris, M.; Stocker, M.; D’Souza, J.; Farfar, K.E.; Vogt, L.; Prinz, M.; Wiens, V.; Jaradeh, M.Y. Improving access to scientific literature with knowledge graphs. Bibl. Forsch. Und Prax. 2020, 44, 516–529. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Harnad, S. Language Writ Large: LLMs, ChatGPT, Grounding, Meaning and Understanding. arXiv 2024, arXiv:2402.02243. [Google Scholar]
- Karanikolas, N.; Manga, E.; Samaridi, N.; Tousidou, E.; Vassilakopoulos, M. Large Language Models versus Natural Language Understanding and Generation. In Proceedings of the 27th Pan-Hellenic Conference on Progress in Computing and Informatics, Lamia, Greece, 24–26 November 2023; pp. 278–290. [Google Scholar]
- Ostendorff, M.; Rethmeier, N.; Augenstein, I.; Gipp, B.; Rehm, G. Neighborhood contrastive learning for scientific document representations with citation embeddings. arXiv 2022, arXiv:2202.06671. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Cai, H.; Cai, X.; Chang, J.; Li, S.; Yao, L.; Wang, C.; Gao, Z.; Li, Y.; Lin, M.; Yang, S.; et al. SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis. arXiv 2024, arXiv:2403.01976. [Google Scholar]
- Jin, H.; Zhang, Y.; Meng, D.; Wang, J.; Tan, J. A Comprehensive Survey on Process-Oriented Automatic Text Summarization with Exploration of LLM-Based Methods. arXiv 2024, arXiv:2403.02901. [Google Scholar]
- Liang, W.; Zhang, Y.; Cao, H.; Wang, B.; Ding, D.; Yang, X.; Vodrahalli, K.; He, S.; Smith, D.; Yin, Y.; et al. Can large language models provide useful feedback on research papers? A large-scale empirical analysis. arXiv 2023, arXiv:2310.01783. [Google Scholar]
- Antu, S.A.; Chen, H.; Richards, C.K. Using LLM (Large Language Model) to Improve Efficiency in Literature Review for Undergraduate Research. In Proceedings of the Workshop on Empowering Education with LLMs-the Next-Gen Interface and Content Generation, Tokyo, Japan, 7 July 2023; pp. 8–16. [Google Scholar]
- Latif, E.; Fang, L.; Ma, P.; Zhai, X. Knowledge distillation of llm for education. arXiv 2023, arXiv:2312.15842. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Cohan, A.; Feldman, S.; Beltagy, I.; Downey, D.; Weld, D.S. Specter: Document-level representation learning using citation-informed transformers. arXiv 2020, arXiv:2004.07180. [Google Scholar]
- Singhal, A. Modern information retrieval: A brief overview. IEEE Data Eng. Bull. 2001, 24, 35–43. [Google Scholar]
- Yasunaga, M.; Kasai, J.; Zhang, R.; Fabbri, A.R.; Li, I.; Friedman, D.; Radev, D.R. Scisummnet: A large annotated corpus and content-impact models for scientific paper summarization with citation networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Voulme 33, pp. 7386–7393. [Google Scholar]
- Banerjee, D.; Singh, P.; Avadhanam, A.; Srivastava, S. Benchmarking LLM powered chatbots: Methods and metrics. arXiv 2023, arXiv:2308.04624. [Google Scholar]
- Verma, V.; Aggarwal, R.K. A comparative analysis of similarity measures akin to the Jaccard index in collaborative recommendations: Empirical and theoretical perspective. Soc. Netw. Anal. Min. 2020, 10, 43. [Google Scholar] [CrossRef]
- Ferdous, R. An efficient k-means algorithm integrated with Jaccard distance measure for document clustering. In Proceedings of the 2009 First Asian Himalayas International Conference on Internet, Kathmundu, Nepa, 3–5 November 2009; IEEE: New York, NY, USA, 2009; pp. 1–6. [Google Scholar]
- O’callaghan, D.; Greene, D.; Carthy, J.; Cunningham, P. An analysis of the coherence of descriptors in topic modeling. Expert Syst. Appl. 2015, 42, 5645–5657. [Google Scholar] [CrossRef]
- Kocmi, T.; Federmann, C. Large language models are state-of-the-art evaluators of translation quality. arXiv 2023, arXiv:2302.14520. [Google Scholar]
- Leiter, C.; Opitz, J.; Deutsch, D.; Gao, Y.; Dror, R.; Eger, S. The eval4nlp 2023 shared task on prompting large language models as explainable metrics. arXiv 2023, arXiv:2310.19792. [Google Scholar]
- Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 23 April 2024).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Thakkar, H.; Manimaran, A. Comprehensive Examination of Instruction-Based Language Models: A Comparative Analysis of Mistral-7B and Llama-2-7B. In Proceedings of the 2023 International Conference on Emerging Research in Computational Science (ICERCS), Coimbatore, India, 1–8 December 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar]
- Open LLM Leaderboard. Available online: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard (accessed on 23 April 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}