
A Hybrid Semantic Representation Method Based on Fusion Conceptual Knowledge and Weighted Word Embeddings for English Texts

Abstract

1. Introduction
- It proposed a novel topic model that integrates conceptual knowledge by combining the Probase concept knowledge base with the LDA model, thereby enhancing the semantic information of topic vectors;
- It constructed a deep semantic representation model based on weighted word embeddings, leveraging the TF-IWF [14] value of each word to assess the significance of word embeddings and enhance the precision of text representation;
- It designed a hybrid semantic representation model that combines a topic model integrating conceptual knowledge with a weighted word embedding model and employs a feature information fusion strategy to enhance the accuracy and comprehensiveness of text representation;
- The hybrid semantic representation method, which combines a topic model integrating conceptual knowledge with a weighted word embedding model, was comprehensively evaluated on the English composition dataset to assess its performance.
2. Related Work
3. Methodology
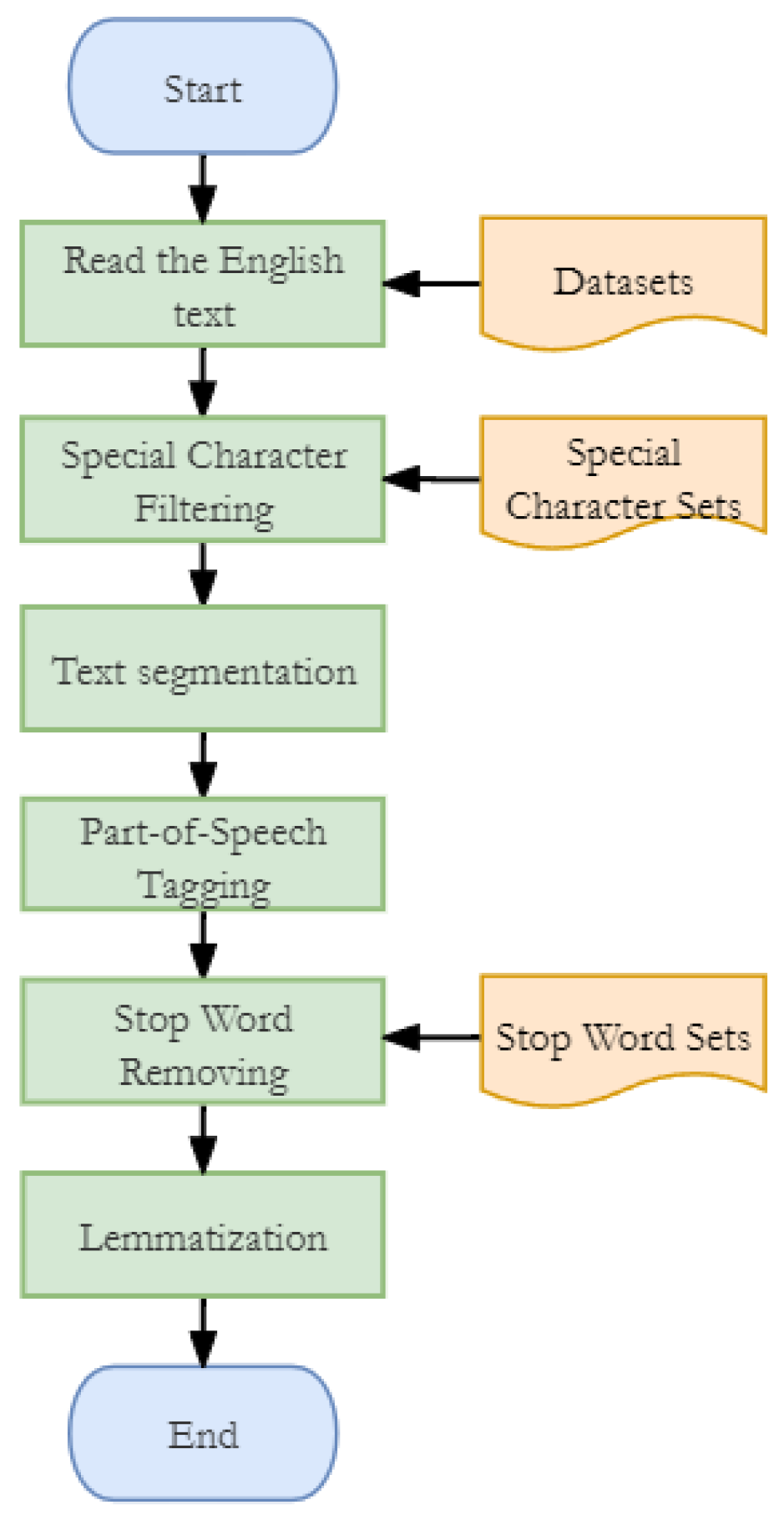
3.1. Model Preprocessing
3.1.1. Special Character Filtering
3.1.2. Text Segmentation
3.1.3. Part-of-Speech Tagging
3.1.4. Stop Word Removing
3.1.5. Lemmatization
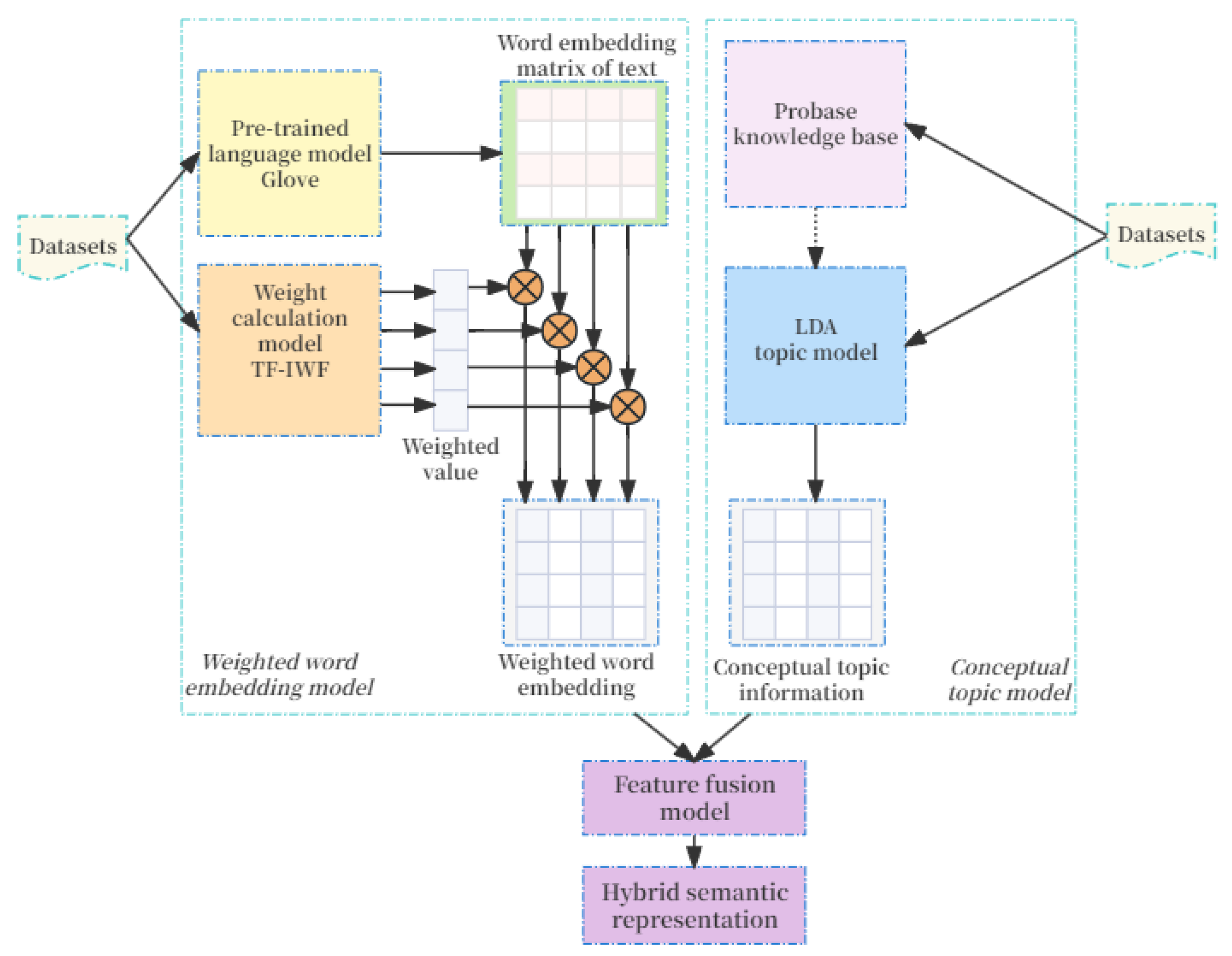
3.2. Model Structure
3.2.1. LDA Topic Model Integrated Conceptual Knowledge
3.2.2. Weighted Word Embedding Model
3.2.3. Feature Fusion Model
4. Results and Discussion
4.1. Dataset
4.2. Measure of Performance
4.3. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Babić, K.; Martinčić-Ipšić, S.; Meštrović, A. Survey of Neural Text Representation Models. Information 2020, 11, 511. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning—Based Text Classification. ACM Comput. Surv. 2021, 54, 40. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Patil, R.; Boit, S.; Gudivada, V.; Nandigam, J. A Survey of Text Representation and Embedding Techniques in NLP. IEEE Access 2023, 11, 36120–36146. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2018, 26, 794–804. [Google Scholar] [CrossRef]
- Jiang, Z.; Gao, S.; Chen, L. Study on Text Representation Method Based on Deep Learning and Topic Information. Computing 2019, 102, 623–642. [Google Scholar] [CrossRef]
- Cheng, X.; Yan, X.; Lan, Y.; Guo, J. BTM: Topic Modeling over Short Texts. IEEE Trans. Knowl. Data Eng. 2014, 26, 2928–2941. [Google Scholar] [CrossRef]
- Blei, D.M.; Griffiths, T.L.; Jordan, M.I. The Nested Chinese Restaurant Process and Bayesian Nonparametric Inference of Topic Hierarchies. J. ACM 2010, 57, 1–30. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Wu, W.; Li, H.; Wang, H.; Zhu, K.Q. Probase: A Probabilistic Taxonomy for Text Understanding. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 481–492. [Google Scholar]
- Xu, J.; Cai, Y. Incorporating Context-Relevant Concepts into Convolutional Neural Networks for Short Text Classification. Neurocomputing 2020, 386, 42–53. [Google Scholar] [CrossRef]
- Chauhan, U.; Shah, A. Topic Modeling Using Latent Dirichlet Allocation: A Survey. ACM Comput. Surv. 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Tian, H.; Wu, L. Microblog Emotional Analysis Based on TF-IWF Weighted Word2vec Model. In Proceedings of the IEEE 9th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 November 2018; pp. 893–896. [Google Scholar]
- Xun, G.; Li, Y.; Gao, J.; Zhang, A. Collaboratively Improving Topic Discovery and Word Embeddings by Coordinating Global and Local Contexts. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 535–543. [Google Scholar]
- Joshi, A.; Fidalgo, E.; Alegre, E.; Fernández-Robles, L. DeepSumm: Exploiting Topic Models and Sequence to Sequence Networks for Extractive Text Summarization. Expert Syst. Appl. 2023, 211, 118442. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Karras, C.; Karras, A.; Tsolis, D.; Giotopoulos, K.; Sioutas, S. Distributed Gibbs Sampling and LDA Modelling for Large Scale Big Data Management on PySpark. In Proceedings of the South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference, Ioannina, Greece, 23–25 September 2022; pp. 1–8. [Google Scholar]
- Huang, J.; Li, P.; Peng, M.; Xie, Q.; Xu, C. Research on Subject Pattern Based on Deep Learning. J. Comput. Sci. 2020, 43, 827–855. [Google Scholar]
- Wang, D.; Xu, Y.; Li, M.; Duan, Z.; Wang, C.; Chen, B.; Zhou, M. Knowledge-Aware Bayesian Deep Topic Model. Adv. Neural Inf. Process. Syst. 2022, 35, 14331–14344. [Google Scholar]
- Andrzejewski, D.; Zhu, X.; Craven, M. Incorporating Domain Knowledge into Topic Modeling via Dirichlet Forest Priors. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 25–32. [Google Scholar]
- Chen, J.; Zhang, K.; Zhou, Y.; Chen, Z.; Liu, Y.; Tang, Z.; Yin, L. A Novel Topic Model for Documents by Incorporating Semantic Relations between Words. Soft Comput. 2019, 24, 11407–11423. [Google Scholar] [CrossRef]
- Zhu, B.; Cai, Y.; Ren, H. Graph Neural Topic Model with Commonsense Knowledge. Inf. Process. Manag. 2023, 60, 103215. [Google Scholar] [CrossRef]
- Liang, Y.; Zhang, Y.; Wei, B.; Jin, Z.; Zhang, R.; Zhang, Y.; Chen, Q. Incorporating Knowledge Graph Embeddings into Topic Modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3119–3126. [Google Scholar]
- Shi, T.; Kang, K.; Choo, J.; Reddy, C.K. Short-Text Topic Modeling via Non-Negative Matrix Factorization Enriched with Local Word-Context Correlations. In Proceedings of the World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1105–1114. [Google Scholar]
- Ozyurt, B.; Ali Akcayol, M. A New Topic Modeling Based Approach for Aspect Extraction in Aspect Based Sentiment Analysis: SS-LDA. Expert Syst. Appl. 2021, 168, 114231. [Google Scholar] [CrossRef]
- Panichella, A. A Systematic Comparison of Search-Based Approaches for LDA Hyperparameter Tuning. Inf. Softw. Technol. 2021, 130, 106411. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Liu, R.; Ye, Z.; Lin, J. Experimental Explorations on Short Text Topic Mining between LDA and NMF Based Schemes. Knowl. Based Syst. 2019, 163, 1–13. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Peinelt, N.; Nguyen, D.; Liakata, M. TBERT: Topic Models and BERT Joining Forces for Semantic Similarity Detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7047–7055. [Google Scholar]
- Du, Q.; Li, N.; Liu, W.; Sun, D.; Yang, S.; Yue, F. A Topic Recognition Method of News Text Based on Word Embedding Enhancement. Comput. Intell. Neurosci. 2022, 2022, 4582480. [Google Scholar] [CrossRef]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
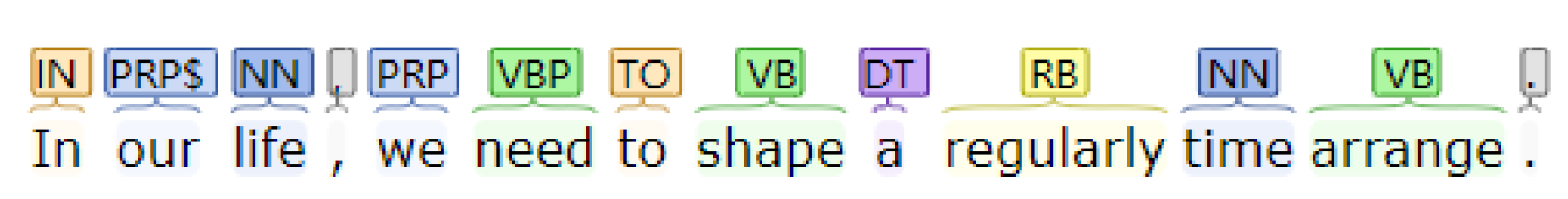


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Topic of Composition | Sources | On-Topic | Off-Topic |
|---|---|---|---|
| Practice Makes Perfect | CLEC | 1483 | 517 |
| Getting to Know the World Outside the Campus | CLEC | 1315 | 685 |
| How to make good use of college life | CLEC | 1267 | 733 |
| Chinese Traditional Festival | CLEC | 1036 | 964 |
| Whether it is important for college students to have a part-time job | ICCNALE | 1013 | 987 |
| Whether smoking should be completely banned at all the restaurants in the country | ICCNALE | 1124 | 876 |
| Write a response that explains how the features of the setting affect the cyclist. In your response, include examples from the essay that support your conclusion. | Kaggle | 1528 | 472 |
| Describe the mood created by the author in the memoir. Support your answer with relevant information from the memoir. | Kaggle | 1609 | 391 |
| True Class | Positive Sample | Negative Sample |
|---|---|---|
| Predicted Class | ||
| Positive sample | TP | FP |
| Negative sample | FN | TN |
| Precision | Recall | F1 | |
|---|---|---|---|
| = 0 | 90.63% | 89.51% | 90.07% |
| = 0.1 | 91.40% | 89.95% | 90.67% |
| = 0.3 | 92.76% | 90.43% | 91.58% |
| = 0.5 | 93.64% | 91.07% | 92.34% |
| = 0.7 | 94.17% | 91.93% | 93.03% |
| = 0.9 | 93.73% | 91.28% | 92.49% |
| = 1 | 93.22% | 90.89% | 92.04% |
| The Topic of Composition | Precision | Recall | F1 |
|---|---|---|---|
| Practice Makes Perfect | 94.73% | 87.12% | 90.77% |
| Getting to Know the World Outside the Campus | 93.65% | 88.39% | 90.94% |
| How to make good use of college life | 94.88% | 89.23% | 91.97% |
| Chinese Traditional Festival | 94.97% | 89.68% | 92.25% |
| Whether it is important for college students to have a part-time job | 92.49% | 87.61% | 89.98% |
| Whether smoking should be completely banned at all the restaurants in the country | 94.98% | 86.95% | 90.79% |
| Write a response that explains how the features of the setting affect the cyclist. In your response, include examples from the essay that support your conclusion. | 90.64% | 87.15% | 88.86% |
| Describe the mood created by the author in the memoir. Support your answer with relevant information from the memoir. | 91.12% | 86.78% | 88.90% |
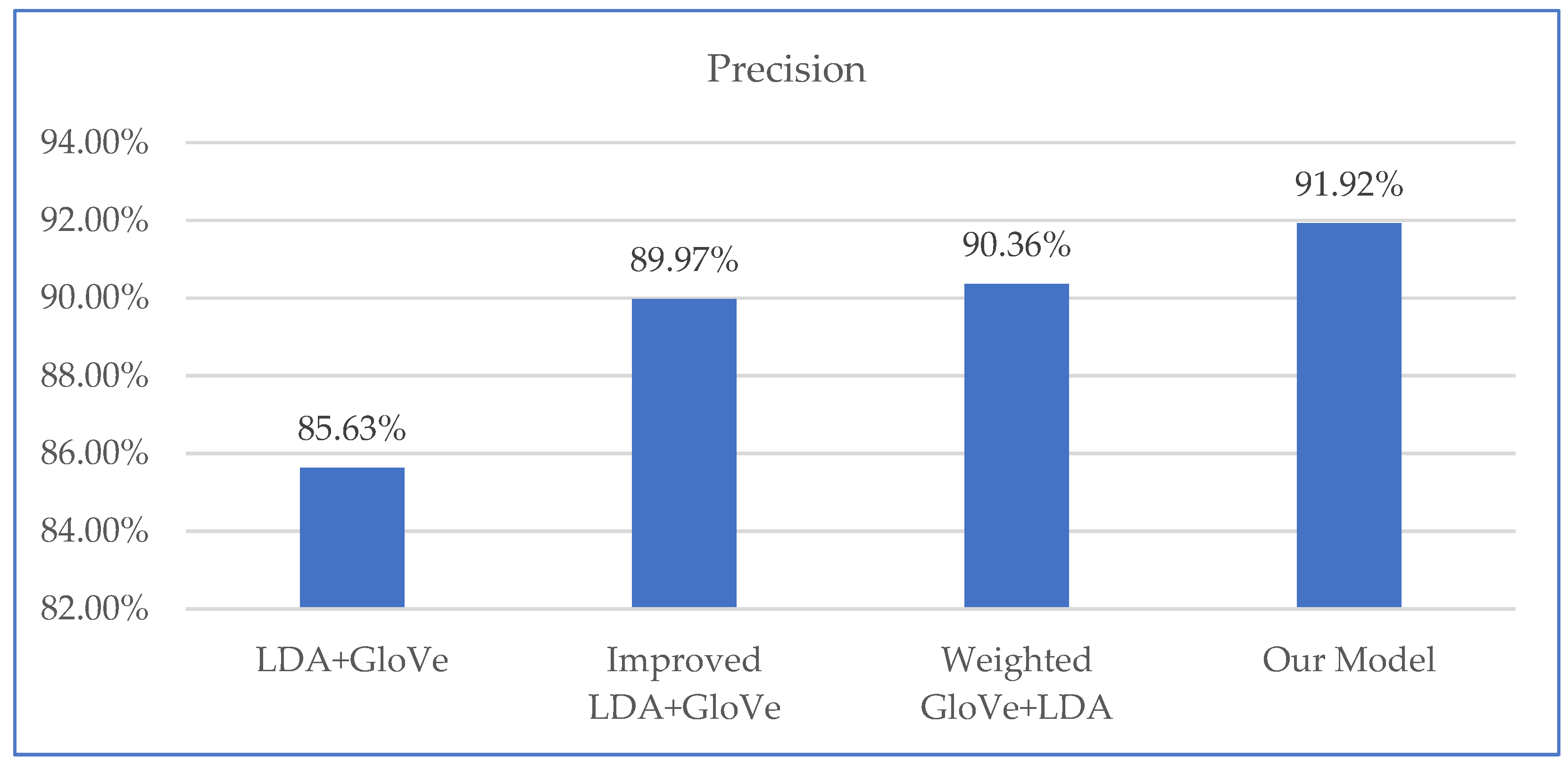
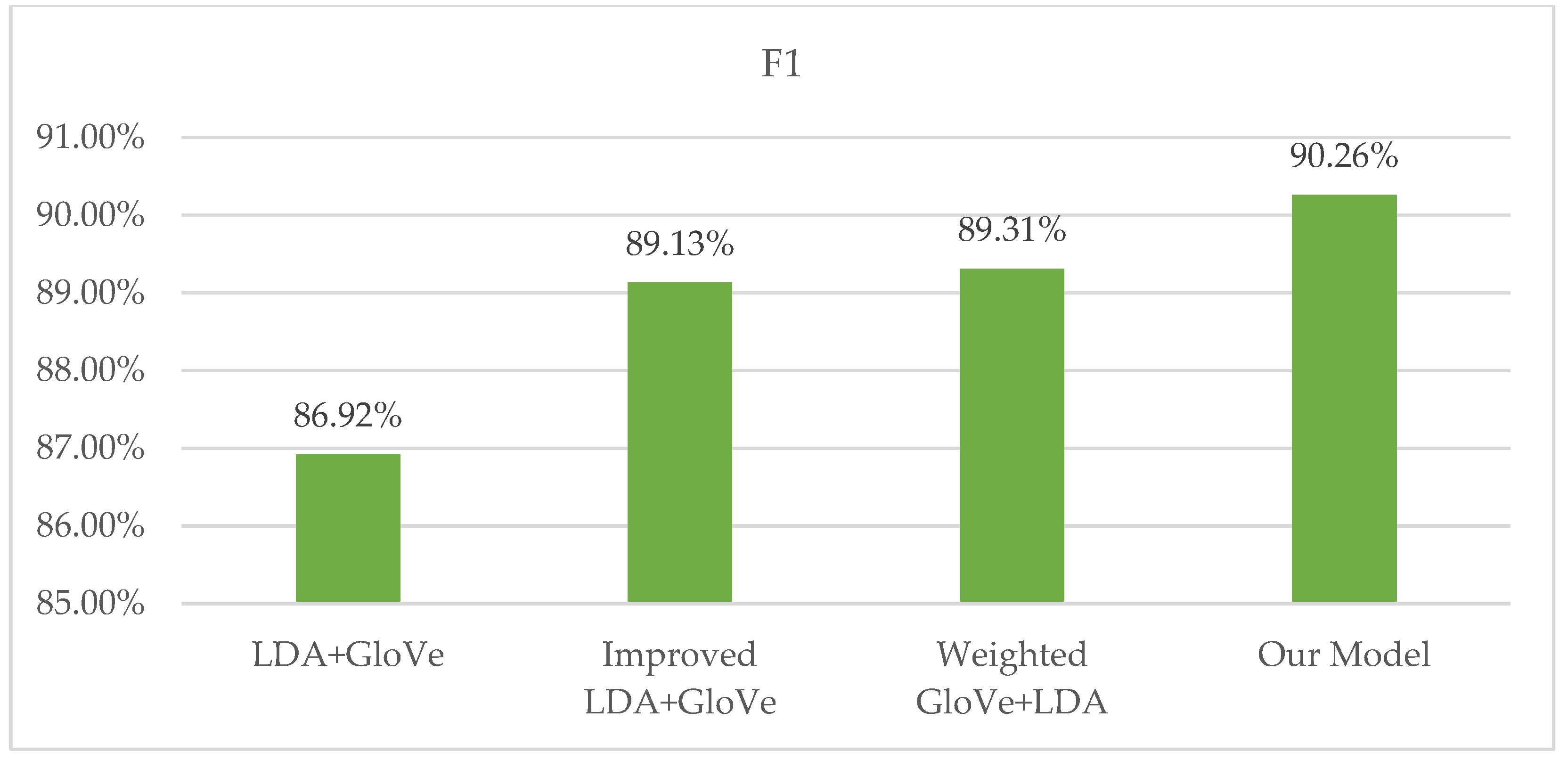
| Method | Precision | Recall | F1 |
|---|---|---|---|
| Word Embedding Model | 90.13% | 88.56% | 89.34% |
| LDA+Word Embedding Model | 90.74% | 88.27% | 89.49% |
| Our Model | 91.92% | 88.65% | 90.26% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Huang, G.; Qin, X.; Wang, Y.; Wang, J.; Zhou, Y. A Hybrid Semantic Representation Method Based on Fusion Conceptual Knowledge and Weighted Word Embeddings for English Texts. Information 2024, 15, 708. https://doi.org/10.3390/info15110708
Qiu Z, Huang G, Qin X, Wang Y, Wang J, Zhou Y. A Hybrid Semantic Representation Method Based on Fusion Conceptual Knowledge and Weighted Word Embeddings for English Texts. Information. 2024; 15(11):708. https://doi.org/10.3390/info15110708
Chicago/Turabian StyleQiu, Zan, Guimin Huang, Xingguo Qin, Yabing Wang, Jiahao Wang, and Ya Zhou. 2024. "A Hybrid Semantic Representation Method Based on Fusion Conceptual Knowledge and Weighted Word Embeddings for English Texts" Information 15, no. 11: 708. https://doi.org/10.3390/info15110708
APA StyleQiu, Z., Huang, G., Qin, X., Wang, Y., Wang, J., & Zhou, Y. (2024). A Hybrid Semantic Representation Method Based on Fusion Conceptual Knowledge and Weighted Word Embeddings for English Texts. Information, 15(11), 708. https://doi.org/10.3390/info15110708