

Text Analytics on YouTube Comments for Food Products




Abstract
1. Introduction
- RQ1: What is the most appropriate sentiment analysis tool for our study when it comes to data labeling, among TextBlob, VADER, and GSA?
- RQ2: What is the most accurate ML algorithm to detect sentiment in YouTube food videos?
- RQ3: How are user engagement levels reflected on YouTube food videos, particularly concerning views, likes, comments, and engagement rate?
2. Theoretical Background
2.1. Plant-Based Products
2.2. Hedonic Products
2.3. YouTube Comments as User Generated Content
2.4. Sentiment Analysis
2.5. Related Work
3. Materials and Methods
3.1. Data Collection for Sentiment Analysis
3.2. Data Preprocessing
3.3. Feature Extraction Using Frequency-Inverse Document Frequency
3.4. Model Training and Testing
3.5. Evaluation of the Models
3.6. Engagement Metrics and User Interaction
3.6.1. Mann–Whitney Test
- H0: There is no significant difference in the distributions of engagement metrics between the two datasets.
- H1: There is a significant difference in the distributions of engagement metrics between the two datasets.
3.6.2. Descriptive Statistics
- Mean: Represents the average value, providing a central point around which data clusters.
- Median: Calculated as the middle value when data is sorted, offering a robust measure of central tendency, especially in the presence of outliers.
- Standard Deviation (Std): Quantifies variation or dispersion in the dataset, revealing insights into the spread of values around the mean [69].
- Variance (Var): Indicates how spread out values are, complementing standard deviation in assessing overall variability [70].
- Range: Calculated as the difference between maximum and minimum values, providing a straightforward measure of the overall dataset spread [71].
3.6.3. Statistical Analysis and Data Visualization
4. Results
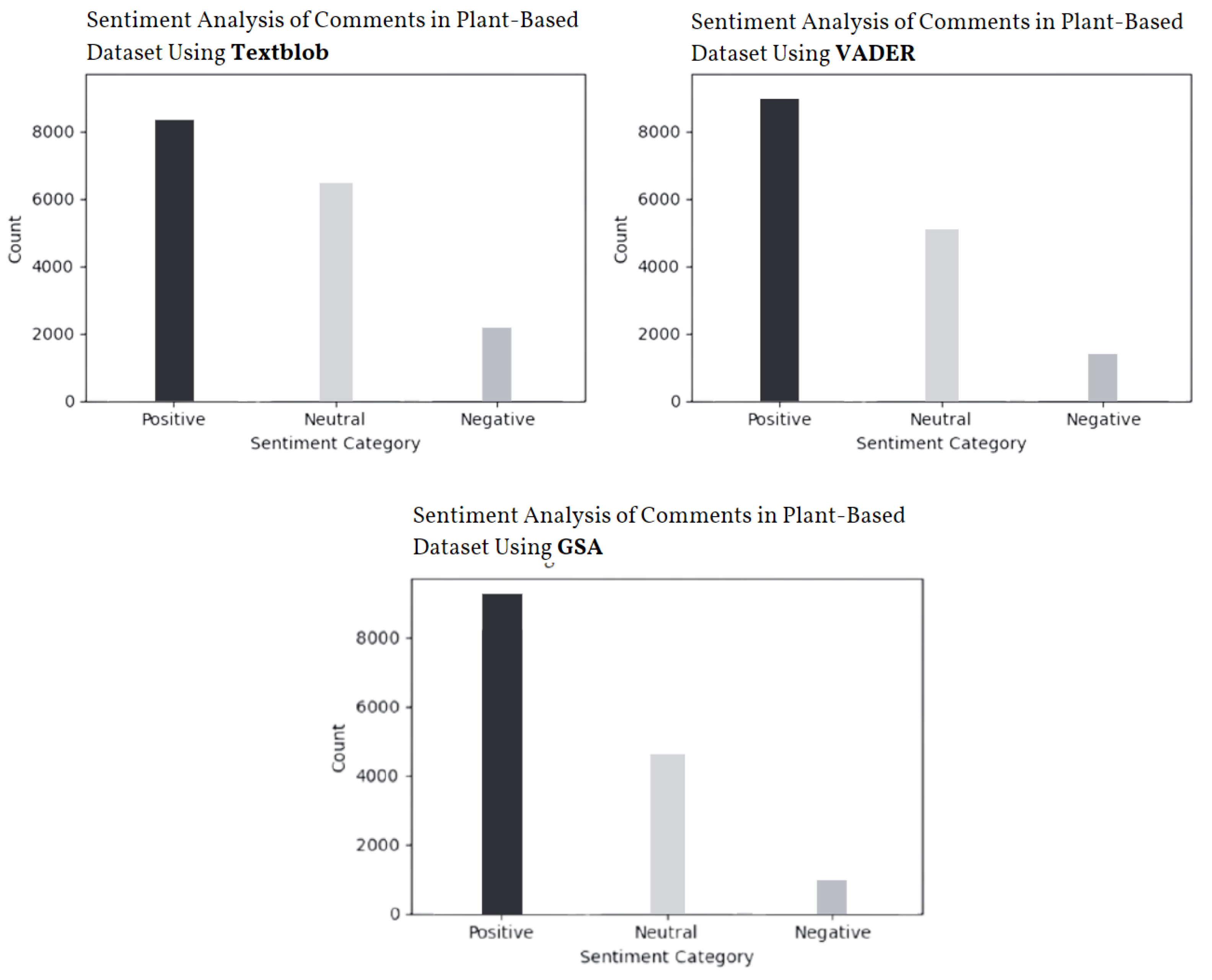
4.1. Comparison of Sentiment Analysis Tools: TextBlob, VADER, and GSA
4.2. Performance and Comparison of the ML Algorithms
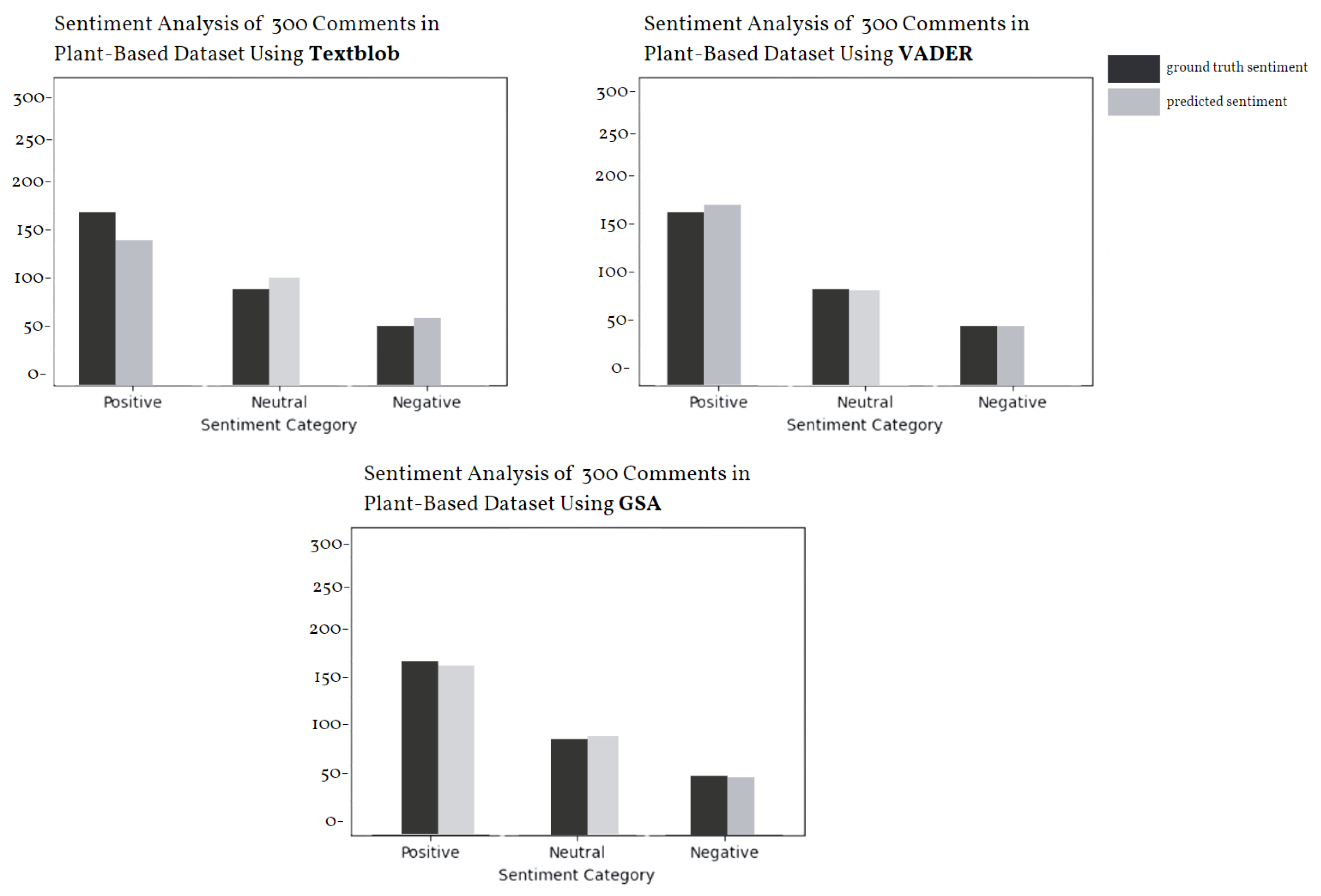
4.2.1. Performance and Comparison of the ML Algorithms in Plant-Based Dataset
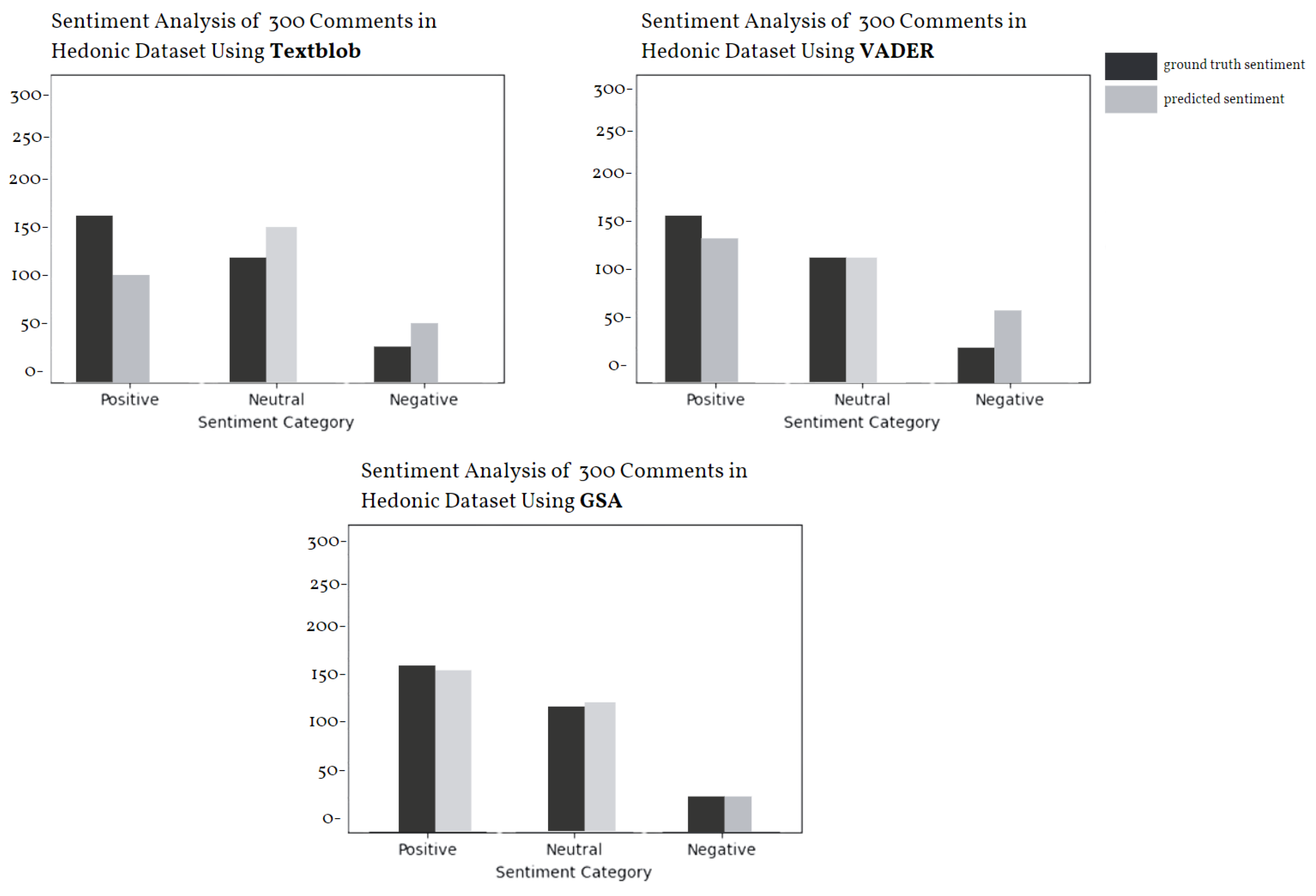
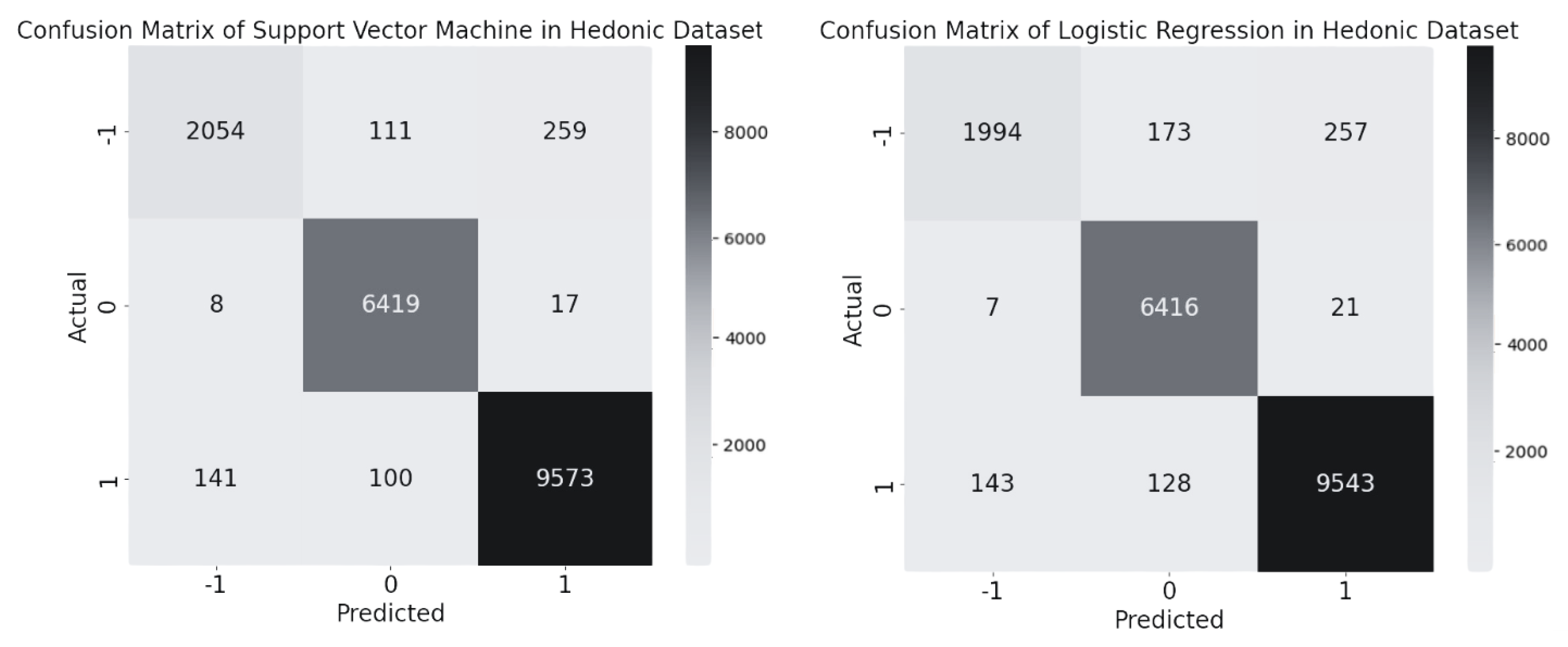
4.2.2. Performance and Comparison of the ML Algorithms in Hedonic Dataset
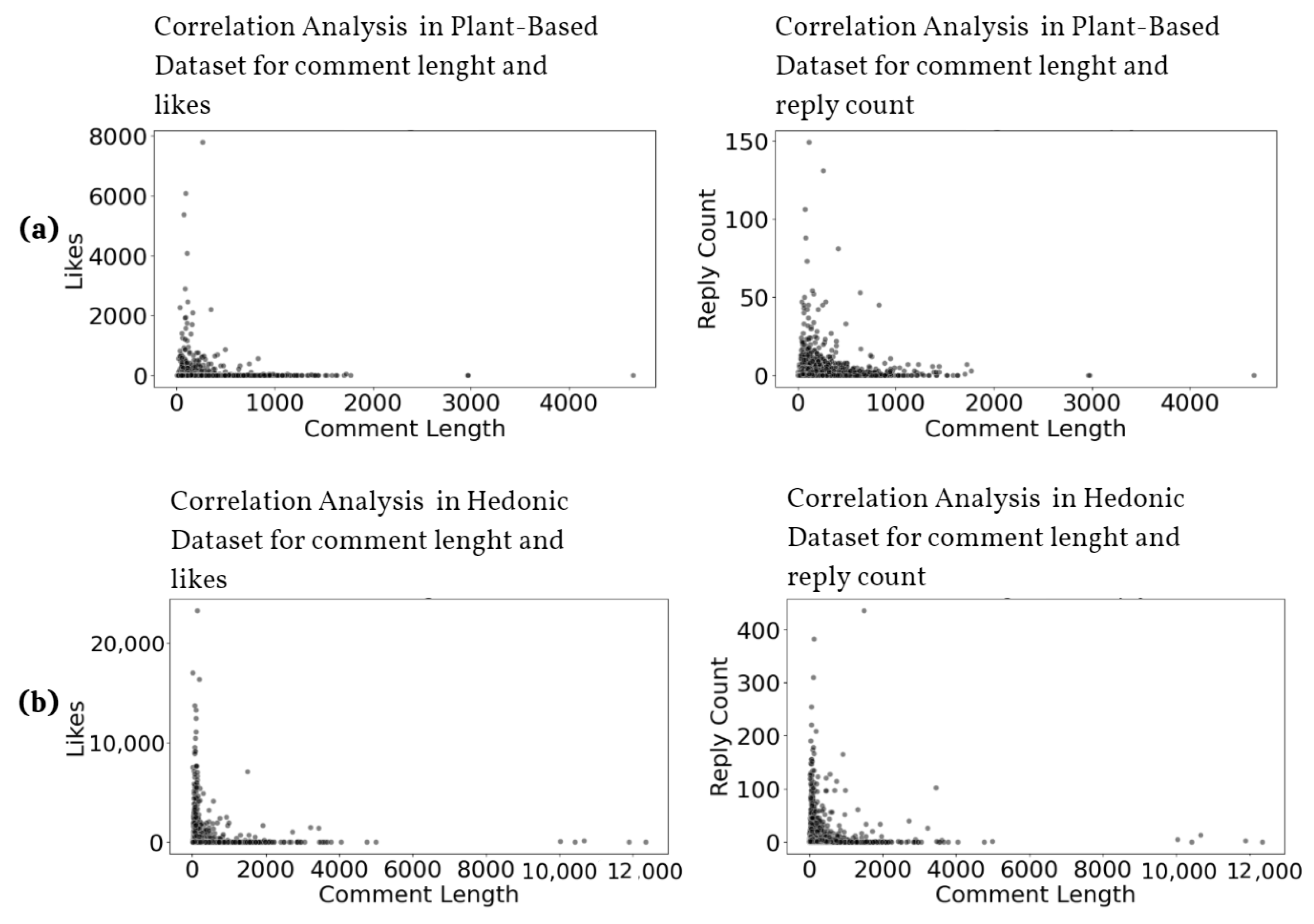
4.3. Engagement Metrics
5. Discussion
5.1. Future Work and Limitations
5.2. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, N.; Wu, S.; Liu, Y.; Feng, Z. Mapping social media engagement in the food supply chain. Technol. Forecast. Soc. Chang. 2023, 192, 122547. [Google Scholar] [CrossRef]
- Patra, T.; Rinnan, A.; Olsen, K. The physical stability of plant-based drinks and the analysis methods thereof. Food Hydrocoll. 2021, 118, 106770. [Google Scholar] [CrossRef]
- Kopplin, C.S.; Rausch, T.M. Above and beyond meat: The role of consumers’ dietary behavior for the purchase of plant-based food substitutes. Rev. Manag. Sci. 2021, 16, 1335–1364. [Google Scholar] [CrossRef]
- Onwezen, M.C. The application of systematic steps for interventions towards meat-reduced diets. Trends Food Sci. Technol. 2022, 19, 443–451. [Google Scholar] [CrossRef]
- Aschemann-Witzel, J.; Futtrup-Gantriisa, R.; Fraga, P.; Perez-Cueto, F.J.A. Plant-based food and protein trend from a business perspective: Markets, consumers, and the challenges and opportunities in the future. Crit. Rev. Food Sci. Nutr. 2020, 61, 3119–3128. [Google Scholar] [CrossRef]
- Martin, C.; Langé, C.; Marette, S. Importance of additional information, as a complement to information coming from packaging, to promote meat substitutes: A case study on a sausage based on vegetable proteins. Food Qual. Prefer. 2021, 87, 104058. [Google Scholar] [CrossRef]
- Kahleová, H.; Levin, S.; Barnard, N.D. Cardio-Metabolic benefits of Plant-Based diets. Nutrients 2017, 9, 848. [Google Scholar] [CrossRef]
- Alae-Carew, C.; Green, R.; Stewart, C.; Cook, B.; Dangour, A.D.; Scheelbeek, P.F.D. The role of plant-based alternative foods in sustainable and healthy food systems: Consumption trends in the UK. Sci. Total. Environ. 2022, 807, 151041. [Google Scholar] [CrossRef]
- Acquah, J.B.; Amissah, J.G.N.; Affrifah, N.S.; Wooster, T.J.; Danquah, A.O. Consumer perceptions of plant based beverages: The Ghanaian consumer’s perspective. Future Foods 2023, 7, 100229. [Google Scholar] [CrossRef]
- Yang, Q.; Eikelboom, E.; Linden, E.V.; de Vries, R.; Venema, P. A mild hybrid liquid separation to obtain functional mungbean protein. LWT 2022, 154, 112784. [Google Scholar] [CrossRef]
- Chmurzynska, A.; Mlodzik-Czyzewska, M.A.; Radziejewska, A.; Wiebe, D.J. Hedonic Hunger Is Associated with Intake of Certain High-Fat Food Types and BMI in 20- to 40-Year-Old Adults. J. Nutr. 2021, 151, 820–825. [Google Scholar] [CrossRef] [PubMed]
- Otterbring, T.; Folwarczny, M.; Gidlöf, K. Hunger effects on option quality for hedonic and utilitarian food products. Associated with Intake of Certain High-Fat Food Types and BMI in 20- to 40-Year-Old Adults. Food Qual. Prefer. 2023, 103, 104693. [Google Scholar] [CrossRef]
- Wakefield, K.L.; Inman, J.J. Situational price sensitivity: The role of consumption occasion, social context and income. J. Retail. 2003, 79, 199–212. [Google Scholar] [CrossRef]
- Dhar, R.; Wertenbroch, K. Consumer Choice between Hedonic and Utilitarian Goods. J. Mark. Res. 2000, 37, 60–71. [Google Scholar] [CrossRef]
- Cramer, L.; Antonides, G. Endowment effects for hedonic and utilitarian food products. Food Qual. Prefer. 2011, 22, 3–10. [Google Scholar] [CrossRef]
- Loebnitz, N.; Grunert, K.G. Impact of self-health awareness and perceived product benefits on purchase intentions for hedonic and utilitarian foods with nutrition claims. Food Qual. Prefer. 2018, 64, 221–231. [Google Scholar] [CrossRef]
- Fitriani, W.R.; Mulyono, A.B.; Hidayanto, A.N.; Munajat, Q. Reviewer’s communication style in YouTube product-review videos: Does it affect channel loyalty? Heliyon 2020, 6, e04880. [Google Scholar] [CrossRef]
- Castillo-Abdul, B.; Romero-Rodríguez, L.M.; Larrea-Ayala, A. Kid influencers in Spain: Understanding the themes they address and preteens’ engagement with their YouTube channels. Heliyon 2020, 6, e05056. [Google Scholar] [CrossRef]
- Oh, C.; Roumani, Y.; Nwankpa, J.K.; Hu, H.-F. Beyond likes and tweets: Consumer engagement behavior and movie box office in social media. Inf. Manag. 2017, 54, 25–37. [Google Scholar] [CrossRef]
- Kavitha, K.M.; Shetty, A.; Abreo, B.; D’Souza, A.; Kondana, A. Analysis and Classification of User Comments on YouTube Videos. Procedia Comput. Sci. 2020, 177, 593–598. [Google Scholar] [CrossRef]
- Manap, K.H.A.; Adzharudin, N.A. The Role of User Generated Content (UGC) in Social Media for Tourism Sector. The 2013 WEI International Academic Conference Proceedings 2013. Available online: https://www.westeastinstitute.com/wp-content/uploads/2013/07/Khairul-Hilmi-A-Manap.pdf (accessed on 10 October 2023).
- Bahtar, A.Z.; Muda, M. The Impact of User—Generated Content (UGC) on Product Reviews towards Online Purchasing—A Conceptual Framework. Procedia Econ. Financ. 2016, 37, 337–342. [Google Scholar] [CrossRef]
- Ganganwar, V.; Rajalakshmi, R. Implicit aspect extraction for sentiment Analysis: A survey of Recent approaches. Procedia Comput. Sci. 2019, 165, 485–491. [Google Scholar] [CrossRef]
- Dang, C.N.; García, M.N.M.; Prieta, F.D.L. Sentiment analysis Based on Deep Learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Xu, Q.; Chang, V.; Jayne, C. A systematic review of social media-based sentiment analysis: Emerging trends and challenges. Decis. Anal. J. 2022, 3, 100073. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Decis. Anal. J. 2021, 3, 100073. [Google Scholar] [CrossRef]
- Drus, Z.; Khalid, H. Sentiment Analysis in Social Media and its Application: Systematic Literature review. Procedia Comput. Sci. 2019, 161, 707–714. [Google Scholar] [CrossRef]
- Chalkias, I.; Tzafilkou, K.; Karapiperis, D.; Tjortjis, C. Learning Analytics on YouTube Educational Videos: Exploring Sentiment Analysis Methods and Topic Clustering. Electronics 2023, 12, 3949. [Google Scholar] [CrossRef]
- Rodríguez-Ibánez, M.; Casánez-Ventura, A.; Castejón-Mateos, F.; Cuenca-Jiménez, P.-M.M. A Review on Sentiment Analysis from Social Media Platforms. 2023. Available online: https://www.synopsys.com/glossary/what-is-dast.html (accessed on 5 October 2023).
- Anastasiou, P.; Tzafilkou, K.; Karapiperis, D.; Tjortjis, C. YouTube Sentiment Analysis on Healthcare Product Campaigns: Combining Lexicons and Machine Learning Models. Available online: https://doi.ieeecomputersociety.org/10.1109/IISA59645.2023.10345900 (accessed on 5 October 2023).
- Rajeswari, B.; Madhavan, S.; Venkatesakumar, R.; Riasudeen, S. Sentiment analysis of consumer reviews—A comparison of organic and regular food products usage. Rajagiri Manag. J. 2020, 14, 55–167. [Google Scholar] [CrossRef]
- Meza, X.V.; Yamanaka, T. Food Communication and its Related Sentiment in Local and Organic Food Videos on YouTube. J. Med. Internet Res. 2020, 22, 16761. [Google Scholar] [CrossRef]
- Lim, K.H.; Lim, T.M.; Tan, K.S.N.; Tan, L.P. Sentiment Analysis on Mixed Language Facebook Comments: A Food and Beverages Case Study. In Fundamental and Applied Sciences in Asia; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Tzafilkou, K.; Panavou, F.R.; Economides, A.A. Facially Expressed Emotions and Hedonic Liking on Social Media Food Marketing Campaigns:Comparing Different Types of Products and Media Posts. In Proceedings of the 2022 17th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP), Corfu, Greece, 3–4 November 2022. [Google Scholar] [CrossRef]
- Pastor, E.M.; Vizcaíno-Laorga, R.; Atauri-Mezquida, D. Health-related food advertising on kid YouTuber vlogger channels. Heliyon 2021, 7, e08178. [Google Scholar] [CrossRef]
- Tzafilkou, K.; Economides, A.A.; Panavou, F.R. You Look like You’ll Buy It! Purchase Intent Prediction Based on Facially Detected Emotions in Social Media Campaigns for Food Products. Computers 2023, 12, 88. [Google Scholar] [CrossRef]
- Shamoi, E.; Turdybay, A.; Shamoi, P.; Akhmetov, I.; Jaxylykova, A.; Pak, A. Sentiment analysis of vegan related tweets using mutual information for feature selection. PeerJ Comput. Sci. 2022, 8, e1149. [Google Scholar] [CrossRef]
- Thao, T.T.H. Exploring Consumer Opinions on Vegetarian Food by Sentiment Analysis Method. 2022. Available online: https://journalofscience.ou.edu.vn/index.php/econ-en/article/view/2256/1787 (accessed on 1 October 2023).
- Dalayya, S.; Elsaid, S.T.F.A.; Ng, K.H.; Song, T.L.; Lim, J.B.Y. Sentiment Analysis to Understand the Perception and Requirements of a Plant-Based Food App for Cancer Patients. Hum. Behav. Emerg. Technol. 2023, 2023, 8005764. [Google Scholar] [CrossRef]
- Bhuiyan, M.R.; Mahedi, M.H.; Hossain, N.; Tumpa, Z.N.; Hossain, S.A. An Attention Based Approach for Sentiment Analysis of Food Review Dataset. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020. [Google Scholar] [CrossRef]
- Gunawan, L.; Anggreainy, M.S.; Wihan, L.; Santy; Lesmana, G.Y.; Yusuf, S. Support vector machine based emotional analysis of restaurant reviews. Procedia Comput. Sci. 2023, 216, 479–484. [Google Scholar] [CrossRef]
- Thao, T.T.H. Lexicon development to measure emotions evoked by foods: A review. Meas. Food 2022, 7, 100054. [Google Scholar] [CrossRef]
- Liapakis, A. A Sentiment Lexicon-Based Analysis for Food and Beverage Industry reviews. The Greek Language Paradigm. 2020. Available online: https://aircconline.com/abstract/ijnlc/v9n2/9220ijnlc03.html (accessed on 8 October 2023).
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Xiao, L.; Xue, Y.; Wang, H.; Hu, X.; Gu, D.; Zhu, Y. Exploring fine-grained syntactic information for aspect-based sentiment classification with dual graph neural networks. Neurocomputing 2022, 471, 48–59. [Google Scholar] [CrossRef]
- Motz, A.; Ranta, E.; Sierra Calderon, A.; Adam, Q.; Alzhouri, F.; Ebrahimi, D. Live Sentiment Analysis Using Multiple Machine Learning and Text Processing Algorithms. Knowl.-Based Syst. 2022. Available online: https://www.sciencedirect.com/science/article/pii/S1877050922006287 (accessed on 5 October 2023). [CrossRef]
- Khan, R.; Rustam, F.; Kanwal, K.; Mehmood, A.; Sang Choi, G. US Based COVID-19 Tweets Sentiment Analysis Using TextBlob and Supervised Machine Learning Algorithms. 2021. Available online: https://ieeexplore.ieee.org/abstract/document/9445207/authors#authors (accessed on 5 October 2023).
- Aljedaani, W.; Rustam, F.; Wiem Mkaouer, M.; Ghallab, A.; Rupapara, V.; Bernard Washington, P.; Lee, E.; Ashraf, I. Sentiment Analysis on Twitter Data Integrating TextBlob and Deep Learning Models: The Case of US Airline Industry. 2022. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0950705122009017 (accessed on 5 October 2023).
- Edwin, F.; Joseph, O.; Godwin, O. Data Preprocessing Techniques for NLP in BI. 2024. Available online: https://www.researchgate.net/publication/379652291_Data_preprocessing_techniques_for_NLP_in_BI (accessed on 30 September 2023).
- Hemmatian, F.; Sohrabi, M.K. “D” A Survey on Classification Techniques for Opinion Mining and Sentiment Analysis. 2019. Available online: https://doi.org/10.1109/ICAIS50930.2021.9396049 (accessed on 30 September 2023).
- Textblob: Simplified Text Processing. Available online: https://textblob.readthedocs.io/en/dev/ (accessed on 30 September 2023).
- Hutto, C.J.; Gilbert, E.E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. In Proceedings of the Eighth International Conference on Weblogs and Social Media (ICWSM-14), Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Sentiment Analysis Natural Language API Google Cloud. Available online: https://cloud.google.com/natural-language/docs/analyzing-sentiment (accessed on 30 September 2023).
- Rosenberg, E.; Tarazona, C.; Mallor, F.; Eivazi, H.; Pastor-Escuredo, D.; Fuso-Nerini, F.; Vinuesa, R. Sentiment Analysis on Twitter Data Towards Climate Action. 2023. Available online: https://doi.org/10.21203/rs.3.rs-2434092/v1 (accessed on 5 November 2023).
- Lokanan, M. The tinder swindler: Analyzing public sentiments of romance fraud using machine learning and artificial intelligence. J. Econ. Criminol. 2023, 2, 100023. [Google Scholar] [CrossRef]
- Liang, M.; Niu, T. Research on Text Classification Techniques Based on Improved TF-IDF Algorithm and LSTM Inputs. Procedia Comput. Sci. 2022, 208, 460–470. [Google Scholar] [CrossRef]
- Cam, H.; Cam, A.V.; Demirel, U.; Ahmed, S. Sentiment analysis of financial Twitter posts on Twitter with the machine learning classifiers. Heliyon 2023, 10, 2405–8440. [Google Scholar] [CrossRef]
- Ghosal, S.; Jain, A. Depression and Suicide Risk Detection on Social Media using fastText Embedding and XGBoost Classifier. Procedia Comput. Sci. 2023, 218, 1631–1639. [Google Scholar] [CrossRef]
- Hidayat, T.H.J.; Ruldeviyani, Y.; Aditama, A.R.; Madya, G.R.; Nugraha, A.W.; Adisaputra, M.W. Sentiment analysis of twitter data related to Rinca Island development using Doc2Vec and SVM and logistic regression as classifier. Procedia Comput. Sci. 2022, 197, 660–667. [Google Scholar] [CrossRef]
- Fitri, V.A.; Andreswari, R.; Hasibuan, M.A. Sentiment Analysis of Social Media Twitter with Case of Anti-LGBT Campaign in Indonesia using Naïve Bayes, Decision Tree, and Random Forest Algorithm. Procedia Comput. Sci. 2019, 161, 765–772. [Google Scholar] [CrossRef]
- Halawani, H.T.; Mashraqi, A.M.; Badr, S.K.; Alkhalaf, S. Automated sentiment analysis in social media using Harris Hawks optimisation and deep learning techniques. Alex. Eng. J. 2023, 80, 433–443. [Google Scholar] [CrossRef]
- Zulfiker, M.S.; Kabir, N.; Biswas, A.A.; Zulfiker, S.; Uddin, M.S. Analyzing the public sentiment on COVID-19 vaccination in social media: Bangladesh context. Array 2022, 15, 100204. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 59–79. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. IJDKP 2015, 2, 1–11. [Google Scholar] [CrossRef]
- McClenaghan, E. Mann-Whitney U Test: Assumptions and Example. 2022. Available online: https://www.technologynetworks.com/informatics/articles/mann-whitney-u-test-assumptions-and-example-363425 (accessed on 20 October 2023).
- Kasuya, E. Mann—Whitney U test when variances are unequal. Anim. Behav. 2001, 61, 1247–1249. [Google Scholar] [CrossRef]
- Sethuraman, M. Measures of central tendency: Median and mode. J. Pharmacol. Pharmacother. 2011, 3, 214–215. [Google Scholar] [CrossRef]
- Sethuraman, M. Measures of central tendency: The mean. J. Pharmacol. Pharmacother. 2011, 2, 140–142. [Google Scholar] [CrossRef]
- Roberson, Q.M.; Sturman, M.C.; Simons, T. Does the Measure of Dispersion Matter in Multilevel Research? A Comparison of the Relative Performance of Dispersion Indexes. Organ. Res. Methods 2007, 10, 564–588. [Google Scholar] [CrossRef]
- Gawali, S. Dispersion of Data: Range, IQR, Variance, Standard Deviation. 2021. Available online: https://www.analyticsvidhya.com/blog/2021/04/dispersion-of-data-range-iqr-variance-standard-deviation/ (accessed on 20 October 2023).
- Sethuraman, M. Measures of dispersion. J. Pharmacol. Pharmacother. 2011, 2, 315–316. [Google Scholar] [CrossRef]
- Garay, J.; Yap, R.; Sabellano, M.J.G. An analysis on the insights of the anti-vaccine movement from social media posts using k-means clustering algorithm and VADER sentiment analyzer. IOP Conf. Ser. Mater. Sci. Eng. 2019, 482, 012043. [Google Scholar] [CrossRef]
- Elbagir, S.; Yang, J. Twitter Sentiment Analysis Using Natural Language Toolkit and VADER Sentiment. 2019. Available online: https://www.iaeng.org/publication/IMECS2019/IMECS2019_pp12-16.pdf (accessed on 5 October 2023).
- Diyasa, G.S.M.; Mandenni, N.M.I.M.; Fachrurrozi1, M.I.; Pradika, S.I.; Manab, K.R.N.; Sasmita, N.R. Twitter Sentiment Analysis as an Evaluation and Service Base on Python Textblob. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1125, 012034. [Google Scholar] [CrossRef]
- Hamid, M.H.A.; Yusoff, M.; Mohamed, A. Survey on highly imbalanced multi-class data. IJACSA 2022, 13. Available online: https://thesai.org/Publications/ViewPaper?Volume=13&Issue=6&Code=IJACSA&SerialNo=27 (accessed on 10 October 2023). [CrossRef]
- Optiz, J. From Bias and Prevalence to Macro F1, Kappa, and MCC: A Structured Overview of Metrics for Multi-Class Evaluation. 2022. Available online: https://api.semanticscholar.org/CorpusID:253270558 (accessed on 10 October 2023).
- Guo, X.; Yu, W.; Wang, X. An overview on fine-grained text Sentiment Analysis: Survey and challenges. J. Phys. Conf. Ser. 2022, 1757, 012038. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inclusion Criteria | Plant-Based Products |
|---|---|
| Video Content | The chosen videos focus on plant-based products, specifically on milk, butter, and yogurt. |
| Video Type | The selected videos are of the “how-to” or tutorial-style format, where the preparation of plant-based food products is demonstrated. |
| Comments | All the included videos have a minimum of 100 comments, ensuring that the dataset for sentiment analysis is substantial. |
| Language | The videos selected for analysis are exclusively in English, ensuring linguistic consistency. |
| Year | The chosen videos were uploaded within the last 5–6 years, aligning them with current trends in plant-based eating. |
| Duration of the video | All selected videos have a duration of less than 20 min, facilitating efficient analysis. |
| Inclusion Criteria | Hedonic Products |
|---|---|
| Video Content | The chosen videos focus on hedonic products, specifically on pizza, burgers, and cakes. |
| Video Type | The selected videos are of the “how-to” or tutorial-style format, where the preparation of hedonic food products is demonstrated. |
| Comments | All the included videos have a minimum of 100 comments, ensuring that the dataset for sentiment analysis is substantial. |
| Language | The videos selected for analysis are exclusively in English, ensuring linguistic consistency. |
| Year | The chosen videos were uploaded within the last 5–6 years, aligning them with current trends in hedonic eating. |
| Duration of the video | All selected videos have a duration of less than 16 min, facilitating efficient analysis. |
| TP (True Positive) | Instances correctly predicted as positive. |
| TN (True Negative) | Instances correctly predicted as negative. |
| FP (False Positive) | Instances incorrectly predicted as positive. |
| FN (False negative) | Instances incorrectly predicted as negative. |
| Metric | Formula |
|---|---|
| Accuracy | |
| Precision | |
| Recall | |
| F1 score |
| Comment | TextBlob | VADER | GSA |
|---|---|---|---|
| try thank easy peasy | positive | positive | positive |
| interested try shelf like milk | positive | positive | positive |
| thankuuuuuu want try | neutral | neutral | positive |
| many day store fridge | positive | neutral | positive |
| must costly | neutral | neutral | negative |
| use milk instead water | neutral | neutral | neutral |
| look fantastic go make simple clean | positive | positive | positive |
| add vanilla | neutral | neutral | neutral |
| thank much video love recipe almond milk best | positive | positive | positive |
| amaze | neutral | positive | positive |
| awesome video thank upload | positive | positive | positive |
| Comment | TextBlob | VADER | GSA |
|---|---|---|---|
| love work love pizza | positive | positive | positive |
| that’s heaven | neutral | neutral | positive |
| amazing burger easy inexpensive | positive | positive | positive |
| give heart attack | neutral | neutral | negative |
| cant get good nope | positive | neutral | negative |
| delicious love flavour vanilla nice recipe | positive | positive | positive |
| make cake home amaze thanks recipe best | positive | positive | positive |
| good cake recipe keep fridge minute pls reply thanks | positive | positive | positive |
| recreate ur recipe soooo perfect thanks much | positive | neutral | positive |
| become go cake deliciousness | neutral | positive | positive |
| wow look awesome thanks share | positive | positive | positive |
| Comment | TextBlob | VADER | GSA |
|---|---|---|---|
| like | neutral | neutral | positive |
| can pressure cancer | neutral | negative | negative |
| look amazing yum | positive | positive | positive |
| amaze | neutral | positive | positive |
| thank definitely try | neutral | neutral | positive |
| look yummy | neutral | positive | positive |
| look amaze long last fridge | negative | neutral | positive |
| great video cant wait try tonight | positive | positive | positive |
| look delicious | positive | positive | positive |
| look soo good omg | positive | positive | positive |
| Comment | TextBlob | Vader | GSA |
|---|---|---|---|
| yes pizza | neutral | neutral | positive |
| really love pizza | positive | positive | positive |
| amaze look delicious | positive | positive | positive |
| lose yeast | neutral | neutral | negative |
| fan pizza congratulation | neutral | positive | positive |
| yummy vanilla cake recipe | neutral | positive | positive |
| im person dont like pizza | neutral | neutral | negative |
| favourite pizza top mine chicken | negative | positive | positive |
| wow look tasty | negative | positive | positive |
| use plain self raise flour | negative | negative | neutral |
| Class | Precision | Recall | F1 Score | Support |
|---|---|---|---|---|
| Negative | 0.88 | 0.45 | 0.60 | 330 |
| Neutral | 0.86 | 0.97 | 0.91 | 1173 |
| Positive | 0.93 | 0.94 | 0.93 | 2070 |
| Accuracy | 0.90 | 3573 | ||
| Macro avg. | 0.89 | 0.79 | 0.81 | 3573 |
| Weighted avg. | 0.90 | 0.90 | 0.90 | 3573 |
| Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Support Vector Machine | 0.93 | 0.91 | 0.87 | 0.89 |
| Random Forest | 0.90 | 0.89 | 0.79 | 0.81 |
| Naïve Bayes | 0.81 | 0.75 | 0.67 | 0.70 |
| Logistic Regression | 0.93 | 0.90 | 0.85 | 0.87 |
| XGBoost | 0.91 | 0.89 | 0.83 | 0.85 |
| Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Support Vector Machine | 0.96 | 0.95 | 0.93 | 0.94 |
| Random Forest | 0.92 | 0.92 | 0.86 | 0.88 |
| Naïve Bayes | 0.79 | 0.78 | 0.72 | 0.74 |
| Logistic Regression | 0.96 | 0.95 | 0.93 | 0.94 |
| XGBoost | 0.92 | 0.91 | 0.86 | 0.88 |
| Class | −1 | 0 | 1 |
|---|---|---|---|
| TP | 2054 | 6419 | 9573 |
| TN | 16,109 | 12,207 | 8592 |
| FP | 149 | 211 | 276 |
| FN | 370 | 25 | 241 |
| Class | −1 | 0 | 1 |
|---|---|---|---|
| TP | 1994 | 6416 | 9543 |
| TN | 16,108 | 11,937 | 8590 |
| FP | 150 | 301 | 278 |
| FN | 430 | 28 | 271 |
| Variable | Statistic | p-Value | Result |
|---|---|---|---|
| Views | 1411.0 | Reject the null hypothesis.There is a significant difference. | |
| Comments | 1413.0 | Reject the null hypothesis.There is a significant difference. | |
| Likes | 1397.0 | Reject the null hypothesis.There is a significant difference. | |
| Engagement Rate | 241.0 | Reject the null hypothesis.There is a significant difference. |
| Plant Based: | Views | Comments | Likes | Engagement Rate |
|---|---|---|---|---|
| mean | 510.12 | 3.90 | ||
| median | 307.00 | 3.42 | ||
| std | 510.50 | 1.64 | ||
| min | 104.00 | 1.31 | ||
| max | 2174.00 | 9.08 | ||
| var | 260,611.14 | 2.69 | ||
| calculate_range | 2070.00 | 7.77 |
| Hedonic: | Views | Comments | Likes | Engagement Rate |
|---|---|---|---|---|
| mean | 6579.75 | 2.29 | ||
| median | 5544.00 | 2.10 | ||
| std | 4978.95 | 0.77 | ||
| min | 1798.00 | 0.70 | ||
| max | 25,168.00 | 4.06 | ||
| var | 24,789,956.63 | 0.59 | ||
| calculate_range | 23,370.00 | 3.36 |
| Dataset | Views | Comments | Likes | Engagement Rate |
|---|---|---|---|---|
| Plant-Based | 25.540.596 | 30.097 | 812.411 | 3.30% |
| Hedonic | 241.400.820 | 157.914 | 4.100.700 | 1.77% |
| Plant Based | |
|---|---|
| Year | Comment |
| 2018 | 1135 |
| 2019 | 3003 |
| 2020 | 4658 |
| 2021 | 4847 |
| 2022 | 1907 |
| 2023 | 1461 |
| Plant Based | |
|---|---|
| Year | Comment |
| 2018 | 8941 |
| 2019 | 15,011 |
| 2020 | 31,047 |
| 2021 | 28,186 |
| 2022 | 12,242 |
| 2023 | 11,876 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsiourlini, M.; Tzafilkou, K.; Karapiperis, D.; Tjortjis, C. Text Analytics on YouTube Comments for Food Products. Information 2024, 15, 599. https://doi.org/10.3390/info15100599
Tsiourlini M, Tzafilkou K, Karapiperis D, Tjortjis C. Text Analytics on YouTube Comments for Food Products. Information. 2024; 15(10):599. https://doi.org/10.3390/info15100599
Chicago/Turabian StyleTsiourlini, Maria, Katerina Tzafilkou, Dimitrios Karapiperis, and Christos Tjortjis. 2024. "Text Analytics on YouTube Comments for Food Products" Information 15, no. 10: 599. https://doi.org/10.3390/info15100599
APA StyleTsiourlini, M., Tzafilkou, K., Karapiperis, D., & Tjortjis, C. (2024). Text Analytics on YouTube Comments for Food Products. Information, 15(10), 599. https://doi.org/10.3390/info15100599