
An Analytical Review of the Source Code Models for Exploit Analysis


Abstract
:1. Introduction
- Develop a reference semantic model of the exploit’s source code;
- Define features of the different attack actions considering the related classes of vulnerabilities and weaknesses;
- Develop methods for detection of the attack actions by using vulnerabilities in the real-time, mapping of the features as outlined in the previous step and the characteristics of the analyzed information system;
- Develop methods for assessing the severity of the vulnerabilities and attack actions.
- Detecting the objective features of vulnerabilities and attack actions as determined based on semantic analysis of the source codes of exploits and construction of patterns of their behavior, i.e., of the effects of maliciously intended algorithms on vulnerable software;
- Detecting the cyber attacks at early stages;
- Defining the metrics for the vulnerability assessment and dynamic assessment of a cyber attack’s severity based on the selected features.
- A comparative analysis and systematization of the proposed source code models and methods of source code analysis, including the exploit’s source code;
- The introduction of an initial semantic model of the exploit’s source code that is used for further definition of features of vulnerabilities and cyber attacks.
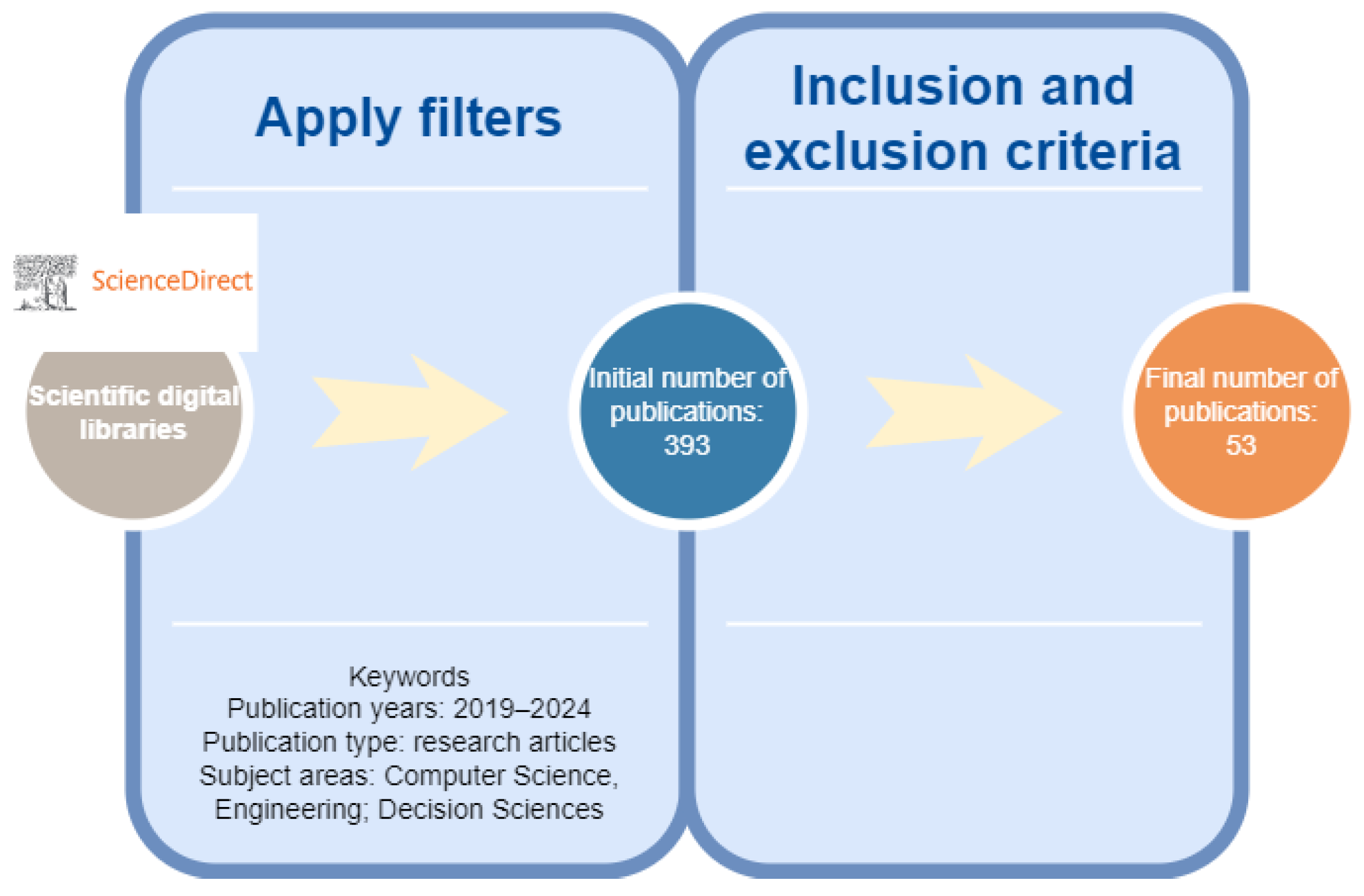
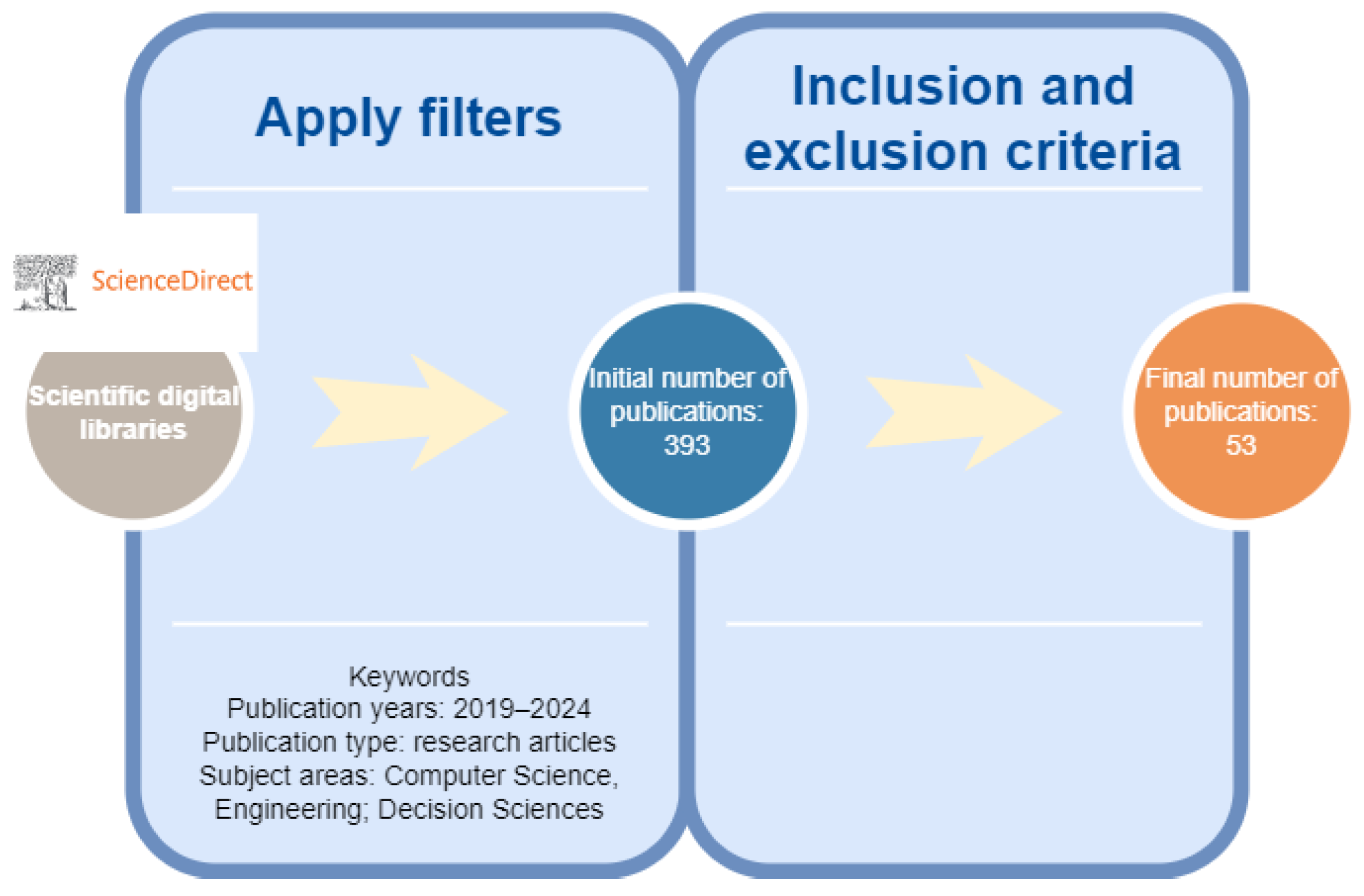
2. Methodology for the Literature Review and Analysis
3. Comparison with Other Literature Reviews
4. Models and Methods for the Exploit’s Source Code Analysis for the Vulnerability Detection and Assessment
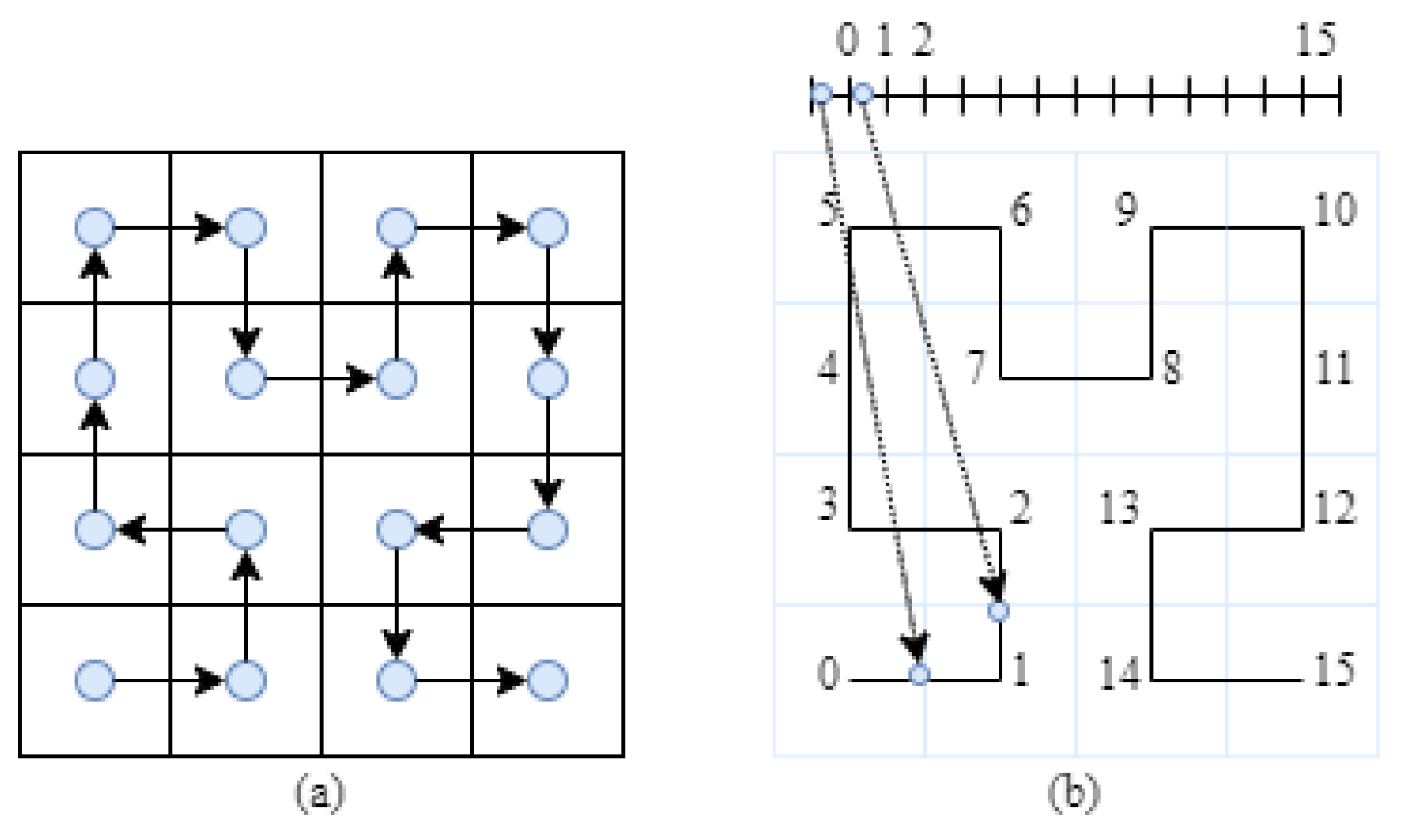
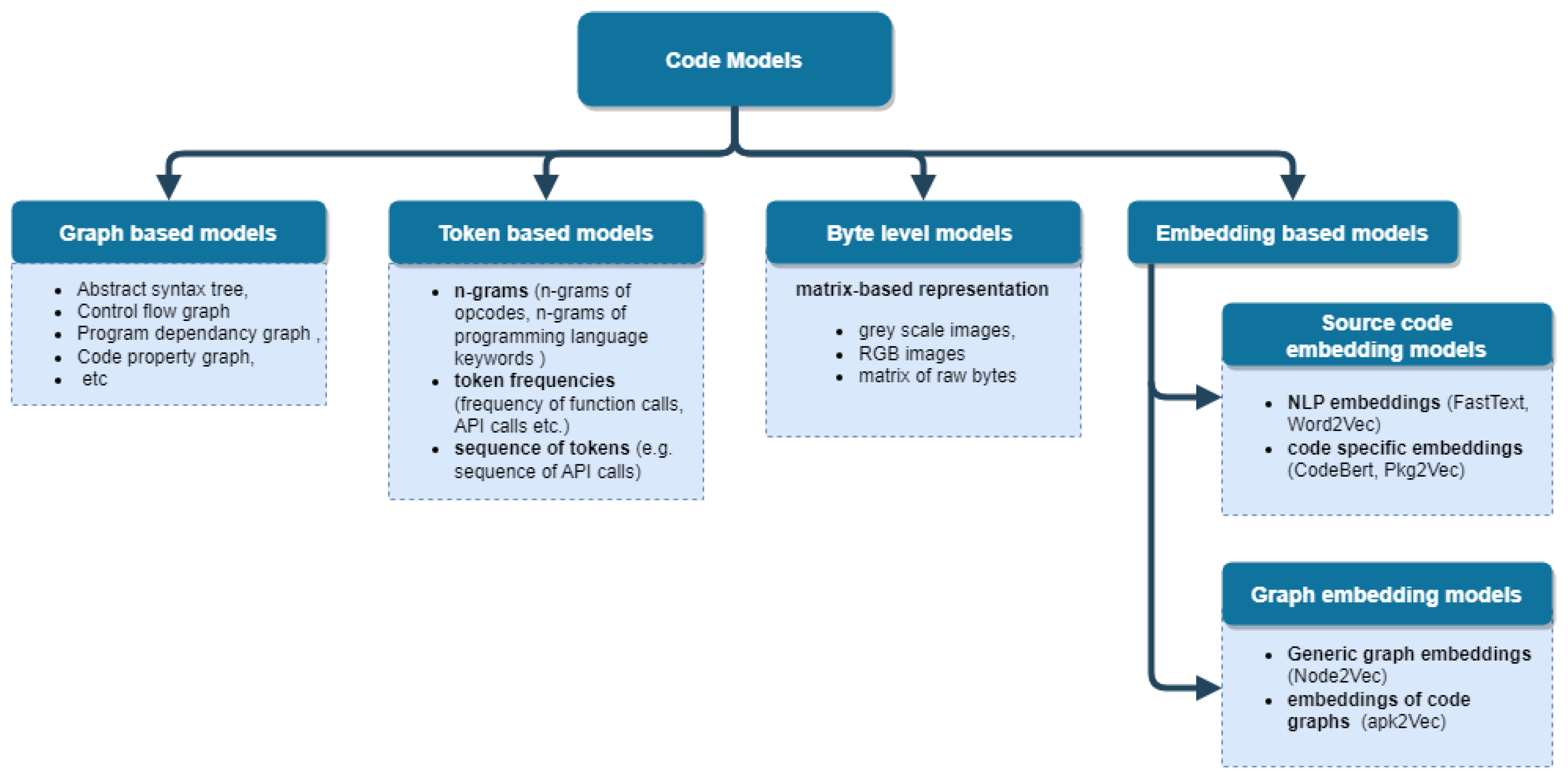
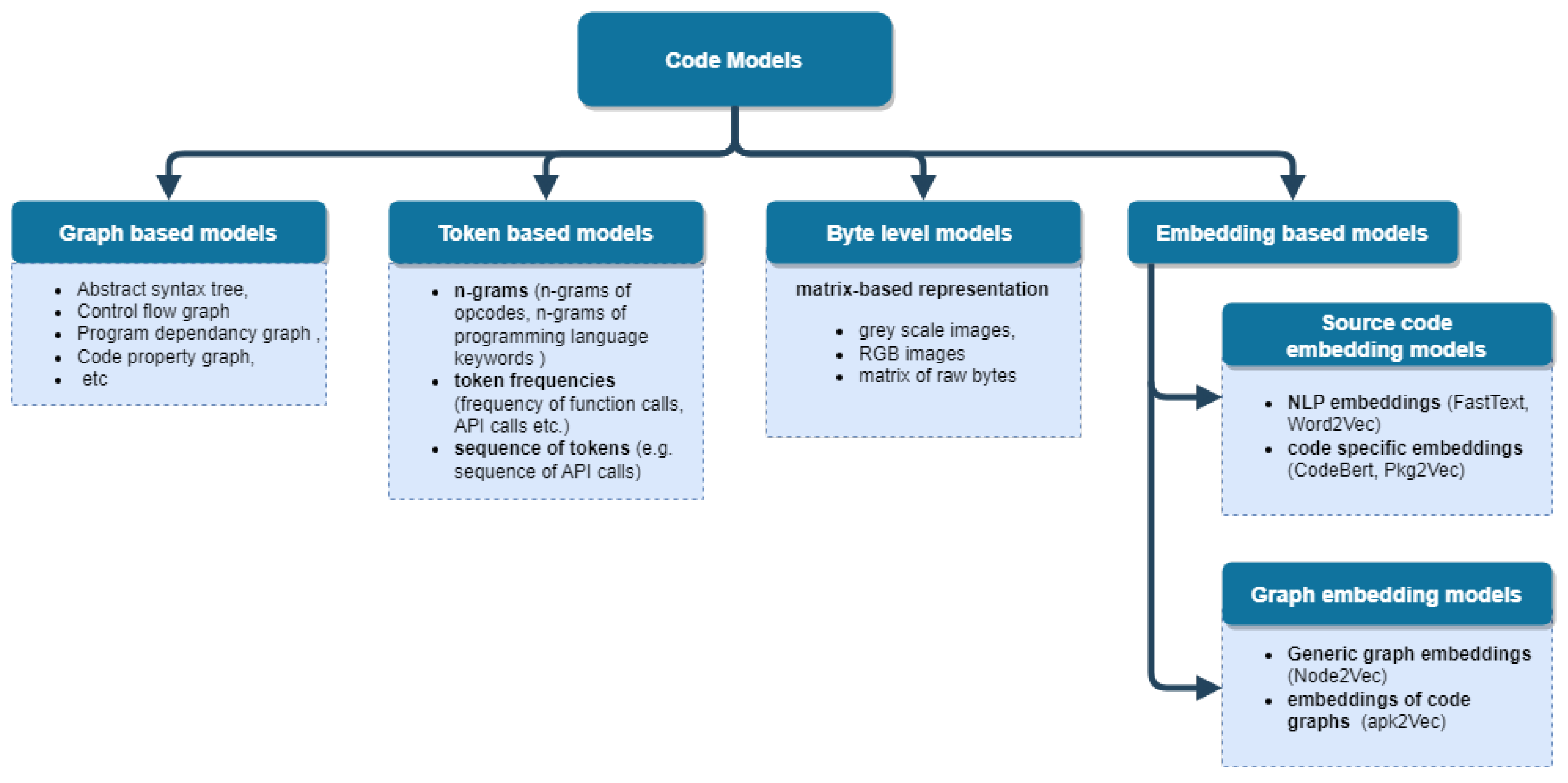
4.1. Source Code Models
- —the set of nodes;
- —the set of directed edges, ;
- —edge labels of one type: parent_of;
- —property assignments of nodes.
- —the set of statements of the programming language, , i.e., the CFG nodes are based on the AST nodes;
- —the set of edges, where edges define the possible control flow from one statement to another;
- —the edge labels flows_to;
- ⌀—means that there are no properties for the CFG.
- —the set of nodes;
- —the set of edges, where edges define function calls or variable usage, i.e., they link the variable definition and the statements where the variable is used;
- —the edge labels that include the edge label calls for the function calls and the edge label reaches for the variable usage;
- —the variable name of the variable definition for the variable usage edges.
- V—the set of nodes;
- E—the set of directed edges, ;
- —the labels for the edges E: , where ∑—the alphabet of the edge names;
- —the properties for edges and nodes: , where K—the set of property keys and S—the set of property values.
- —the set of nodes, , i.e., the ACID nodes are based on the AST nodes;
- —the set of the directed edges: ;
- —the labels for the edges : , where —the alphabet of the edge names;
- —the properties for nodes: , where —the set of property keys, —the set of property values.
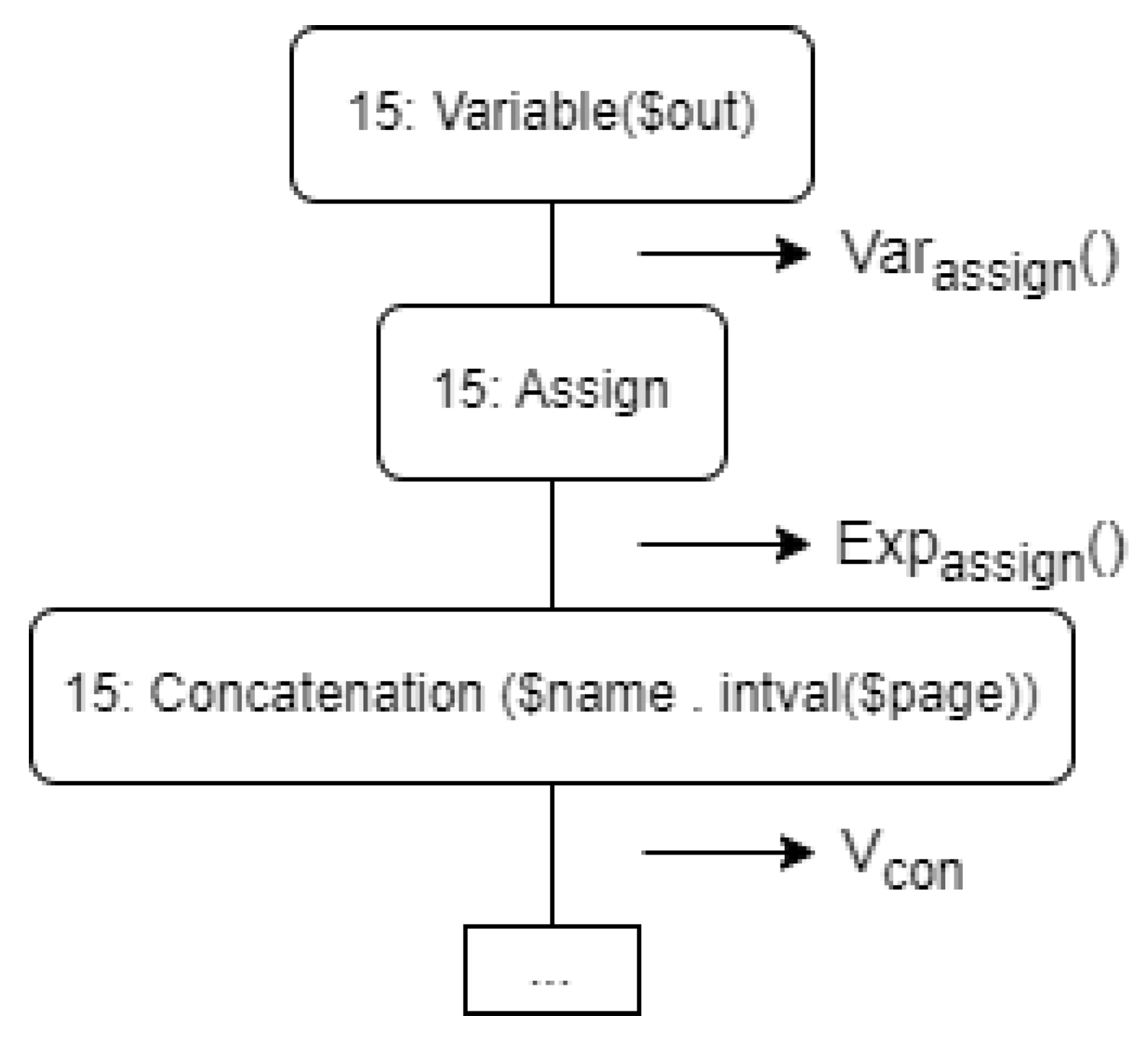
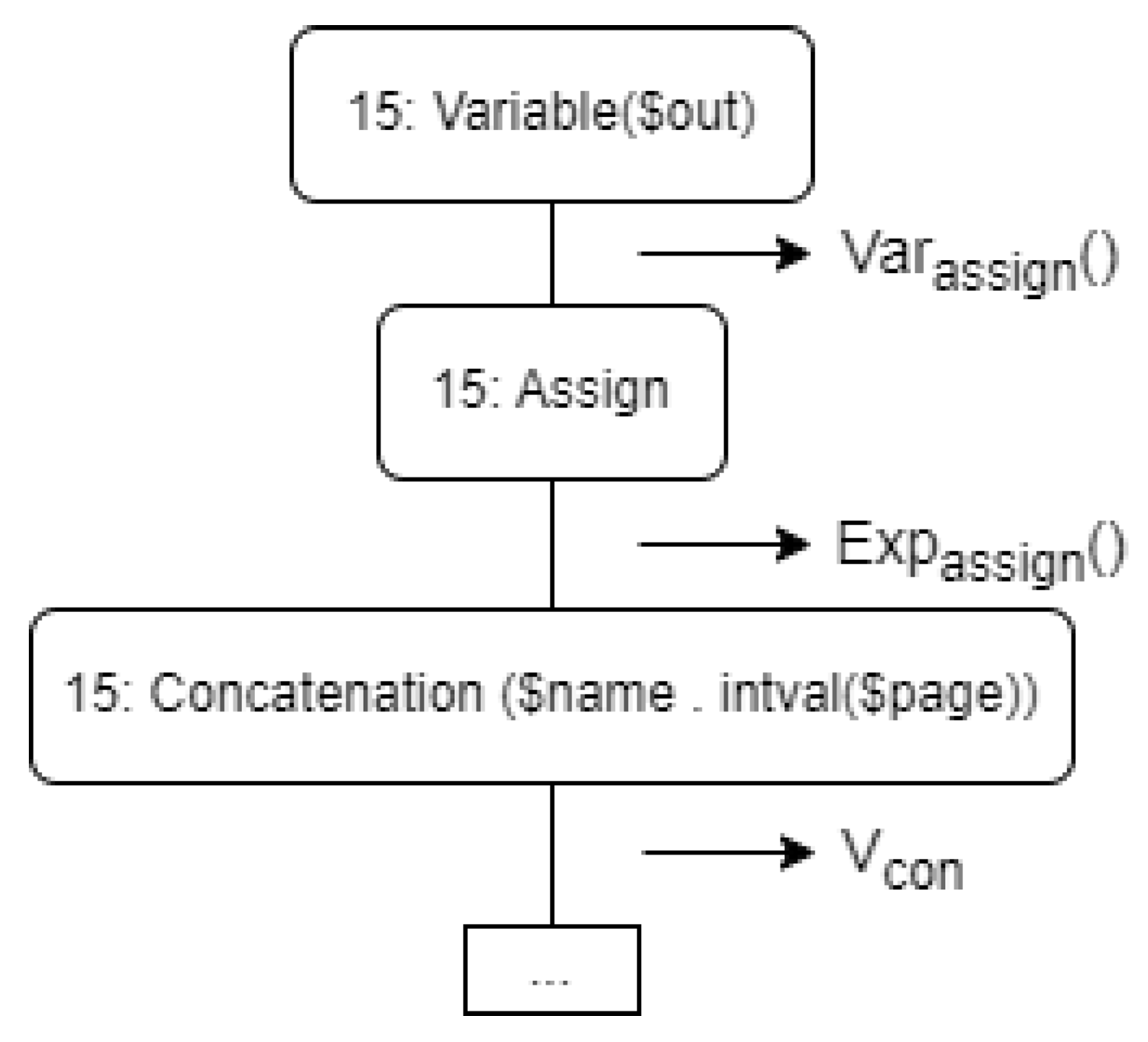
| Listing 1. Source code. |
| 15: \out = $name . intval($page); |
| Variable : Assignment : Expression |
4.2. Source Code Analysis Methods
4.3. Application of the Source Code Analysis Methods in Information Security
5. Tools for Code Analysis
6. Results and Discussion
7. Conclusions and Future Work
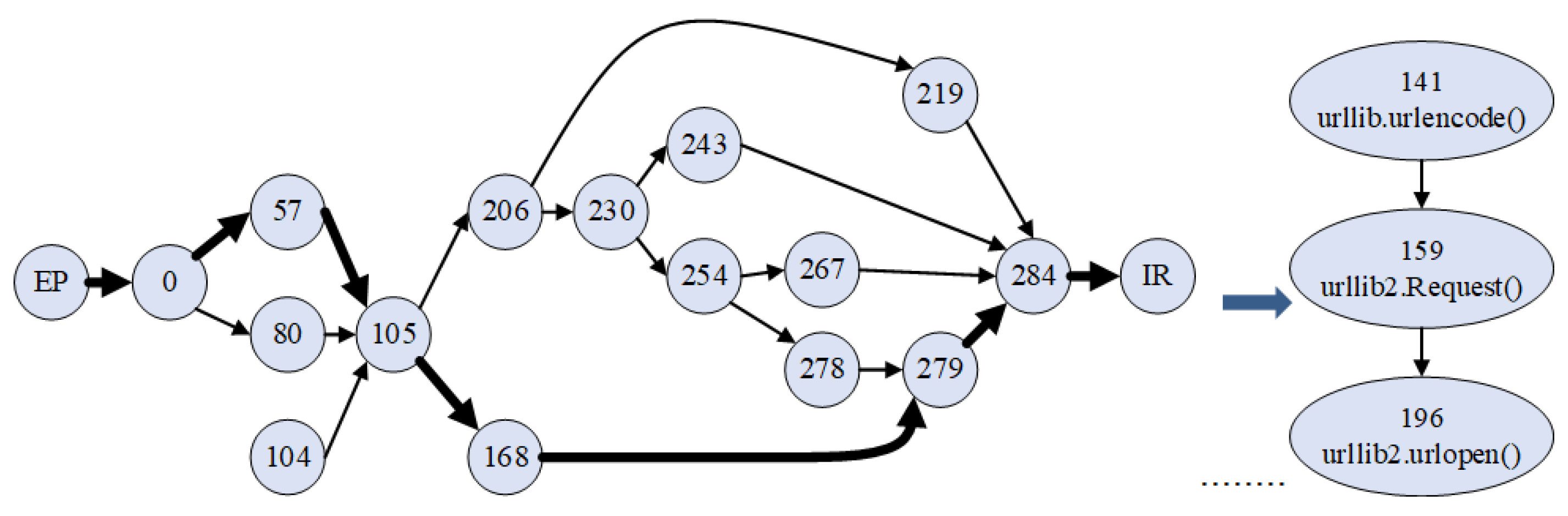
- —the nodes of the graph that correspond to “names” extracted from the executable code;
- E—the edges representing the “names” usage dependencies from the importing modules.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACID | Adversary-Controlled Input Dataflow |
| ASG | Abstract Semantic Graph |
| AST | Abstract Syntax Tree |
| CFG | Control Flow Graph |
| CPG | Code Property Graph |
| EC | Exclusion Criteria |
| FDR | False Discovery Rate |
| HOG | Histogram of Oriented Gradients |
| IC | Inclusion Criteria |
| KNN | K-Nearest Neighbors |
| LBP | Local Binary Patterns |
| PDG | Program Dependence Graph |
| PE | Portable Executable |
| PIPs | Possible Injection Paths |
| RF | Random Forest |
| RGSD | Reflection-Guided Static Slicing Diagram |
| RGSS | Reflection-Guided Static Slicing |
| RQs | Research Questions |
| SCDG | System Call Dependency Graph |
| SGD | Sink Dependency Graph |
| SVM | Support Vector Machine |
References
- Kitchenham, B.A. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004. [Google Scholar]
- Cui, L.; Cui, J.; Hao, Z.; Li, L.; Ding, Z.; Liu, Y. An empirical study of vulnerability discovery methods over the past ten years. Comput. Secur. 2022, 120, 102817. [Google Scholar] [CrossRef]
- Maniriho, P.; Mahmood, A.N.; Chowdhury, M.J.M. A study on malicious software behaviour analysis and detection techniques: Taxonomy, current trends and challenges. Future Gener. Comput. Syst. 2022, 130, 1–18. [Google Scholar] [CrossRef]
- Madan, S.; Sofat, S.; Bansal, D. Tools and Techniques for Collection and Analysis of Internet-of-Things malware: A systematic state-of-art review. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 9867–9888. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Guerra-Manzanares, A.; Bahsi, H. On the relativity of time: Implications and challenges of data drift on long-term effective android malware detection. Comput. Secur. 2022, 122, 102835. [Google Scholar] [CrossRef]
- Abaimov, S.; Bianchi, G. A survey on the application of deep learning for code injection detection. Array 2021, 11, 100077. [Google Scholar] [CrossRef]
- Kaur, A.; Nayyar, R. A Comparative Study of Static Code Analysis tools for Vulnerability Detection in C/C++ and JAVA Source Code. Procedia Comput. Sci. 2020, 171, 2023–2029. [Google Scholar] [CrossRef]
- Li, Z.; Huang, X.; Li, Y.; Chen, G. A comparative study of adversarial training methods for neural models of source code. Future Gener. Comput. Syst. 2023, 142, 165–181. [Google Scholar] [CrossRef]
- Caprile, B.; Potrich, A.; Ricca, F.; Tonella, P. Model centered interoperability for source code analysis. In Proceedings of the STEP 2003, Workshop on Software Analysis and Maintenance: Practices, Tools, Interoperability, Amsterdam, The Netherlands, 22–26 September 2003. [Google Scholar]
- Duffy, E. The Design & Implementation of an Abstract Semantic Graph for Statement-Level Dynamic Analysis of C++ Applications. 2011. Available online: https://tigerprints.clemson.edu/cgi/viewcontent.cgi?article=1832&context=all_dissertations (accessed on 26 June 2023).
- Schuckert, F.; Katt, B.; Langweg, H. Insecurity Refactoring: Automated Injection of Vulnerabilities in Source Code. Comput. Secur. 2023, 128, 103121. [Google Scholar] [CrossRef]
- Astdump 4.3. Available online: https://pypi.org/project/astdump/ (accessed on 26 June 2023).
- Batchelder, N. The Structure of .pyc Files. Available online: https://nedbatchelder.com/blog/200804/the_structure_of_pyc_files.html (accessed on 26 June 2023).
- Patterson, E.; Baldini, I.; Mojsilović, A.; Varshney, K.R. Semantic Representation of Data Science Programs. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, International Joint Conferences on Artificial Intelligence Organization, Stockholm, Sweden, 13–18 July 2018; pp. 5847–5849. [Google Scholar] [CrossRef]
- Coet, A. StatiCFG. Available online: https://github.com/coetaur0/staticfg (accessed on 26 June 2023).
- D’Onghia, M.; Salvadore, M.; Nespoli, B.M.; Carminati, M.; Polino, M.; Zanero, S. Apícula: Static detection of API calls in generic streams of bytes. Comput. Secur. 2022, 119, 102775. [Google Scholar] [CrossRef]
- Blais, M. Snakefood: Python Dependency Graphs. Available online: https://github.com/blais/snakefood (accessed on 26 June 2023).
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and Discovering Vulnerabilities with Code Property Graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 590–604. [Google Scholar] [CrossRef]
- Gharibi, G.; Tripathi, R.; Lee, Y. Code2graph: Automatic Generation of Static Call Graphs for Python Source Code. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 880–883. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Learning to detect Android malware via opcode sequences. Neurocomputing 2020, 396, 599–608. [Google Scholar] [CrossRef]
- Sebastio, S.; Baranov, E.; Biondi, F.; Decourbe, O.; Given-Wilson, T.; Legay, A.; Puodzius, C.; Quilbeuf, J. Optimizing symbolic execution for malware behavior classification. Comput. Secur. 2020, 93, 101775. [Google Scholar] [CrossRef]
- Gajrani, J.; Agarwal, U.; Laxmi, V.; Bezawada, B.; Gaur, M.S.; Tripathi, M.; Zemmari, A. EspyDroid+: Precise reflection analysis of android apps. Comput. Secur. 2020, 90, 101688. [Google Scholar] [CrossRef]
- Narayanan, A.; Soh, C.; Chen, L.; Liu, Y.; Wang, L. Apk2vec: Semi-Supervised Multi-view Representation Learning for Profiling Android Applications. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 357–366. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, S.; Mu, D. DouBiGRU-A: Software defect detection algorithm based on attention mechanism and double BiGRU. Comput. Secur. 2021, 111, 102459. [Google Scholar] [CrossRef]
- Kalgutkar, V.; Stakhanova, N.; Cook, P.; Matyukhina, A. Android Authorship Attribution through String Analysis. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018; ARES: Chicago Ridge, IL, USA, 2018. [Google Scholar] [CrossRef]
- Alazab, M.; Alazab, M.; Shalaginov, A.; Mesleh, A.; Awajan, A. Intelligent Mobile Malware Detection using Permission Requests and API calls. Future Gener. Comput. Syst. 2020, 107, 509–521. [Google Scholar] [CrossRef]
- Han, W.; Xue, J.; Wang, Y.; Huang, L.; Kong, Z.; Mao, L. MalDAE: Detecting and explaining malware based on correlation and fusion of static and dynamic characteristics. Comput. Secur. 2019, 83, 208–233. [Google Scholar] [CrossRef]
- Li, C.; Lv, Q.; Li, N.; Wang, Y.; Sun, D.; Qiao, Y. A novel deep framework for dynamic malware detection based on API sequence intrinsic features. Comput. Secur. 2022, 116, 102686. [Google Scholar] [CrossRef]
- Naeem, H.; Ullah, F.; Naeem, M.R.; Khalid, S.; Vasan, D.; Jabbar, S.; Saeed, S. Malware detection in industrial internet of things based on hybrid image visualization and deep learning model. Ad Hoc Netw. 2020, 105, 102154. [Google Scholar] [CrossRef]
- Naeem, H.; Guo, B.; Naeem, M.R.; Ullah, F.; Aldabbas, H.; Javed, M.S. Identification of malicious code variants based on image visualization. Comput. Electr. Eng. 2019, 76, 225–237. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Sudhakar; Kumar, S. MCFT-CNN: Malware classification with fine-tune convolution neural networks using traditional and transfer learning in Internet of Things. Future Gener. Comput. Syst. 2021, 125, 334–351. [Google Scholar] [CrossRef]
- O’Shaughnessy, S.; Sheridan, S. Image-based malware classification hybrid framework based on space-filling curves. Comput. Secur. 2022, 116, 102660. [Google Scholar] [CrossRef]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware Images: Visualization and Automatic Classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011. [Google Scholar] [CrossRef]
- Moses, T.; Barzanti, M. Static Analysis: A Dynamic Syntax Tree Implementation; BitBrainery University: London, UK, 2001. [Google Scholar]
- Neamtiu, I.; Foster, J.S.; Hicks, M. Understanding Source Code Evolution Using Abstract Syntax Tree Matching. In Proceedings of the 2005 International Workshop on Mining Software Repositories, New York, NY, USA, 15–16 May 2005; pp. 1–5. [Google Scholar] [CrossRef]
- Dániel, S.; Gábor, S.; Ádám, L.; Honfi, D. Graph-Based Source Code Analysis of Dynamically Typed Languages; Scientific Students’ Association Report; Budapest University of Technology and Economics: Budapest, Hungary, 2016. [Google Scholar]
- Gold, R. Control flow graphs and code coverage. Int. J. Appl. Math. Comput. Sci. 2010, 20, 739–749. [Google Scholar] [CrossRef]
- Agrawal, H.; Horgan, J.R. Dynamic program slicing. ACM SIGPLAN Not. 1990, 25, 246–256. [Google Scholar] [CrossRef]
- Hsieh, C.; Unger, E.A.; Mata-Toledo, R.A. Using program dependence graphs for information flow control. J. Syst. Softw. 1992, 17, 227–232. [Google Scholar] [CrossRef]
- Sun, H.; Cui, L.; Li, L.; Ding, Z.; Hao, Z.; Cui, J.; Liu, P. VDSimilar: Vulnerability detection based on code similarity of vulnerabilities and patches. Comput. Secur. 2021, 110, 102417. [Google Scholar] [CrossRef]
- Mateless, R.; Tsur, O.; Moskovitch, R. Pkg2Vec: Hierarchical package embedding for code authorship attribution. Future Gener. Comput. Syst. 2021, 116, 49–60. [Google Scholar] [CrossRef]
- Moti, Z.; Hashemi, S.; Karimipour, H.; Dehghantanha, A.; Jahromi, A.N.; Abdi, L.; Alavi, F. Generative adversarial network to detect unseen Internet of Things malware. Ad Hoc Netw. 2021, 122, 102591. [Google Scholar] [CrossRef]
- Frenklach, T.; Cohen, D.; Shabtai, A.; Puzis, R. Android malware detection via an app similarity graph. Comput. Secur. 2021, 109, 102386. [Google Scholar] [CrossRef]
- Pasqua, M.; Benini, A.; Contro, F.; Crosara, M.; Dalla Preda, M.; Ceccato, M. Enhancing Ethereum smart-contracts static analysis by computing a precise Control-Flow Graph of Ethereum bytecode. J. Syst. Softw. 2023, 200, 111653. [Google Scholar] [CrossRef]
- Gao, X.; Hu, C.; Shan, C.; Han, W. MaliCage: A packed malware family classification framework based on DNN and GAN. J. Inf. Secur. Appl. 2022, 68, 103267. [Google Scholar] [CrossRef]
- Mei, H.; Lin, G.; Fang, D.; Zhang, J. Detecting vulnerabilities in IoT software: New hybrid model and comprehensive data analysis. J. Inf. Secur. Appl. 2023, 74, 103467. [Google Scholar] [CrossRef]
- Liu, Z.; Fang, Y.; Huang, C.; Xu, Y. MFXSS: An effective XSS vulnerability detection method in JavaScript based on multi-feature model. Comput. Secur. 2023, 124, 103015. [Google Scholar] [CrossRef]
- Tian, J.; Xing, W.; Li, Z. BVDetector: A program slice-based binary code vulnerability intelligent detection system. Inf. Softw. Technol. 2020, 123, 106289. [Google Scholar] [CrossRef]
- Russo, E.R.; Di Sorbo, A.; Visaggio, C.A.; Canfora, G. Summarizing vulnerabilities’ descriptions to support experts during vulnerability assessment activities. J. Syst. Softw. 2019, 156, 84–99. [Google Scholar] [CrossRef]
- Kühn, P.; Relke, D.N.; Reuter, C. Common vulnerability scoring system prediction based on open source intelligence information sources. Comput. Secur. 2023, 131, 103286. [Google Scholar] [CrossRef]
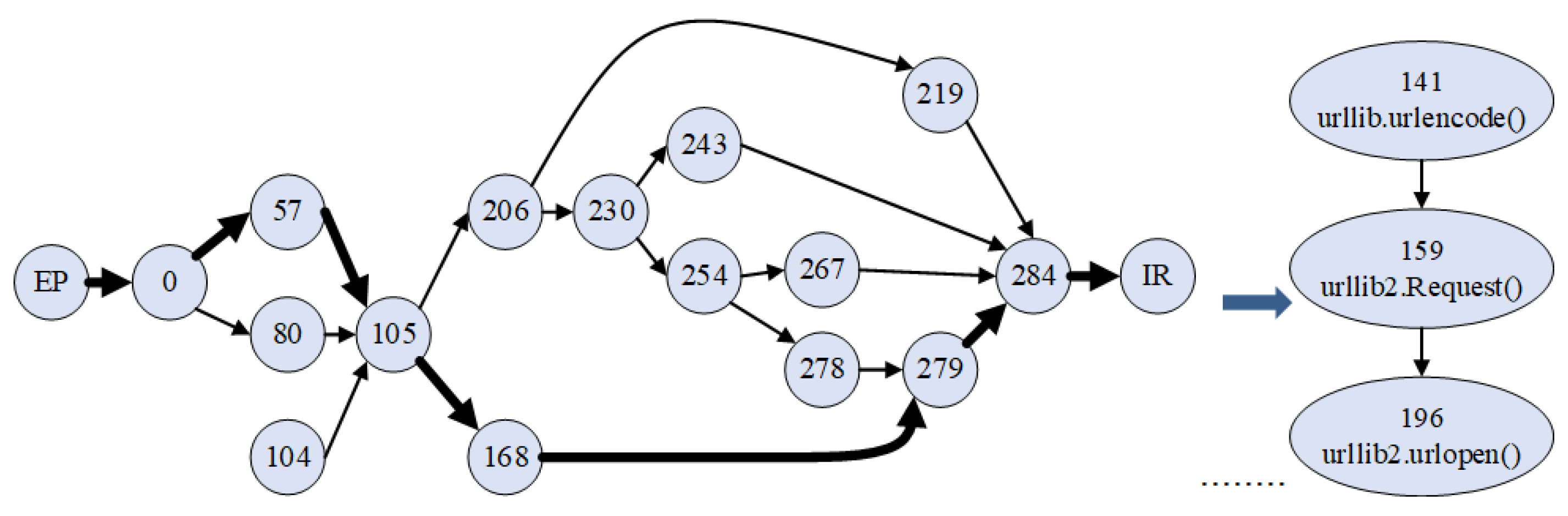

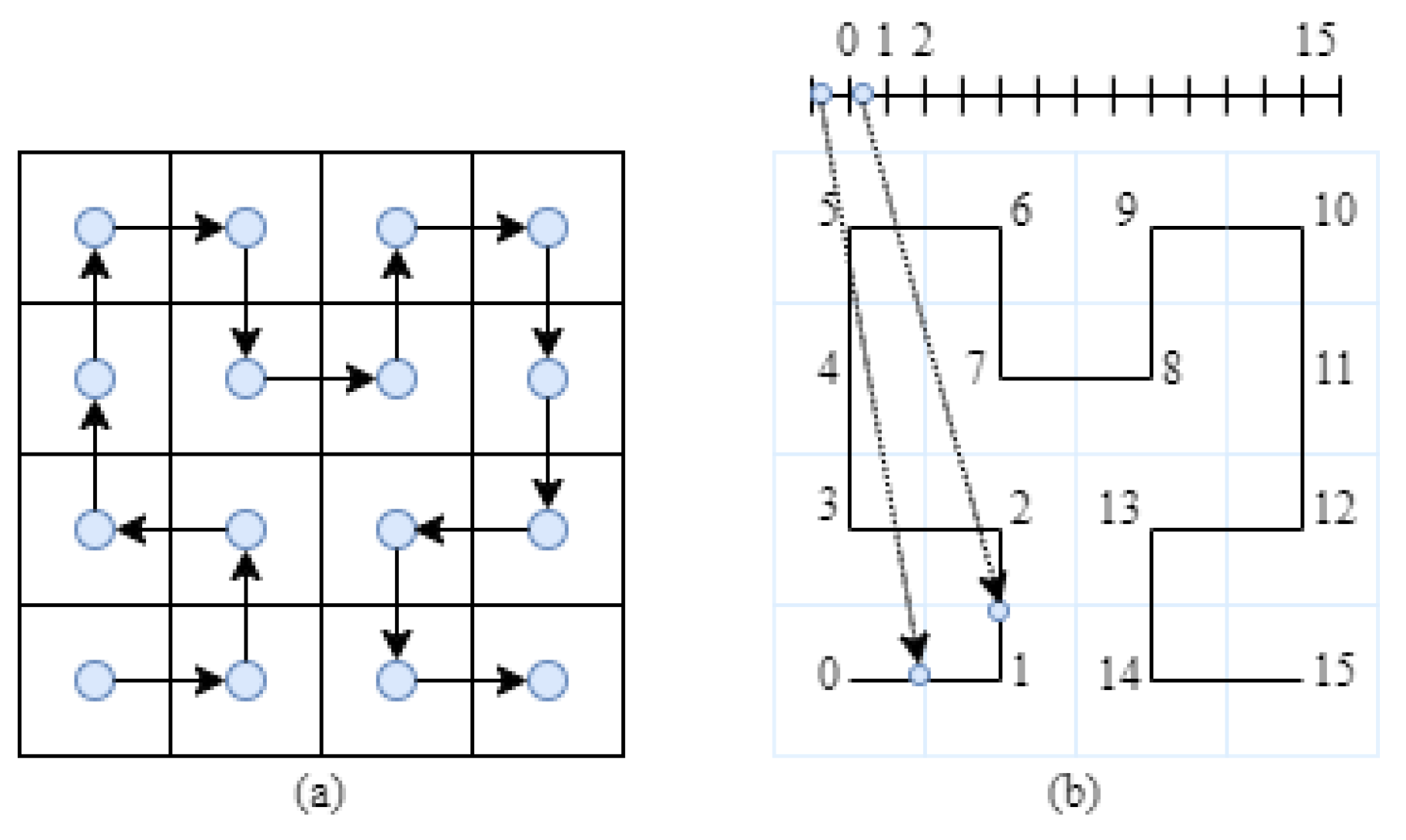
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Analysis Model and Method | Programming Languages (Input Data) | Evaluation Metrics | Application |
|---|---|---|---|---|
| Graph-based models | ||||
| [46] | CFG | Compiled Ethereum Virtual Machine bytecode | Success rate of constructing the CFG | Construction of the precise CFG graphs based on the analysis |
| [17] | CFG; the set of fingerprints; similarity measure | Binaries (PE) | Jaccard index; Recall; False Discovery Rate (FDR) | Malware detection |
| [12] | ACID tree. Tree traversal and rules to find place and insert vulnerability patterns. | PHP | TP and FP of the founded places to inject vulnerabilities | Code refactoring |
| [22] | SCDG; dynamic analysis based on a supervised ML (the methods are not specified) | Binaries | Execution time | Optimizing symbolic execution for malware behavior classification |
| [23] | Reflection Guided Static Diagram; Reflection Guided Static Analysis (RGSS) to limit number of paths for dynamic analysis based on ML (the methods are not specified) | Android Apps | Number of reflection calls logged and time | Reflection API calls detection |
| Token-based models | ||||
| [43] | Vectorized presentation of the code using Pkg2Vec | Source code decompiled from Dalvik bytecode (Android APK) | Accuracy and loss function | Source code authorship attribution task |
| [28] | A fusion model of dynamic and static API call sequences based on semantics mapping; TF–IDF method to construct feature vector, Mahalanobis distance to measure the similarity of feature vectors, Decision Tree, Random Forest, K-Nearest Neighbor, and Extreme Gradient Boosting for detection and classification | PE file | TP, TN, FP, FN, precision, recall, f1 score, accuracy | Malware detection and explanation |
| [47] | Binary header as a sequence of byte code, the CNN neural networks to extract features, GAN to generate adversarial samples of the packed malware. The classification of packed malware is performed using LSTM with attention mechanism | Binaries (PE files and ELF files) | TP, TN, FP, FN, precision, recall, f1 score, accuracy | Packed malware detection |
| Byte level models | ||||
| [30] | RGB image; convolutional neural network | Source code decompiled form Dalvik bytecode (Android APK) | Precision, recall, f1 measure, accuracy, time for image generation | Malware detection and classification |
| [31] | RGB image; analysis of the image textures’ features using KNN, SVM, NB | Binaries | Precision, recall, f1 measure, accuracy, time for image generation | Identification of the malware variants |
| [32] | RGB image; analysis of the images using pretrained CNN networks with different architectures: VGG16, VGG19, ResNet50, InceptionV3, MobileNetV2, DenseNet121, DenseNet169 | Android bytecode | – | Detection of malicious Android applications |
| [33] | Grayscale image; ResNet50 model and MCFT-CNN model trained with the knowledge from already trained ImageNet | Grayscale image generated from binaries | Confusion matrix, accuracy, precision, recall, and f measure | Malware classification and uncover |
| [34] | Space-filling curves to generate an image; LBP, Gabor filters, and HOG to extract features; RF, SVM and KNN for classification | 32-bit executable PE samples | Precision, recall, accuracy | Malware classification |
| Embedding-based models | ||||
| [48] | Code embedding representation based on CodeBERT | – | – | Detecting vulnerabilities in IoT applications |
| [42] | Code embedding representation based on analysis of word sequence in function; analysis is performed using a Siamese network consisting of BiLSTM and Attention mechanism | C/C++ | FNR, FPR, Accuracy, Precision, f measure | Detecting vulnerabilities in IoT applications |
| [45] | App similarity graph (ASG), which is constructed based on the similarity score calculated for a pair of applications. The similarity score is defined according to the set of functions used by APK. The ASG is used to obtain vector representation of the APK in order to apply classifiers (using node2vec transformation) | APK | Accuracy, f1 measure, AUC | Detection of the malware |
| [44] | vectorized representation of the Data Flow Graph paths, vectorized representation is constructed using Word2Vec | C/C++ source files | TP, TN, FP, FN, accuracy | Location of vulnerabilities in source code (buffer error (CWE-119) and resource management error (CWE-399)) |
| [49] | Combination of the AST and CFG. Graph convolution neural network and the bidirectional recurrent neural network to extract source code features. | JavaScript | TP and FP of the founded places to inject vulnerabilities | Detecting XSS vulnerabilities |
| [50] | CFG and PDG and program slice, which is a set of Assembler code lines extracted from a binary program, program slice is vectorized and analyzed using LSTM and GRU neural networks | C/C++ | FPR, FNR, precision, recall, f1 measure, accuracy | Vulnerability detection |
| [21] | Instruction call graph based on the opcodes; DNN | Android malware | TP, TN, FP, FN, Precision, Recall, f measure, Accuracy | Malware detection |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fedorchenko, E.; Novikova, E.; Fedorchenko, A.; Verevkin, S. An Analytical Review of the Source Code Models for Exploit Analysis. Information 2023, 14, 497. https://doi.org/10.3390/info14090497
Fedorchenko E, Novikova E, Fedorchenko A, Verevkin S. An Analytical Review of the Source Code Models for Exploit Analysis. Information. 2023; 14(9):497. https://doi.org/10.3390/info14090497
Chicago/Turabian StyleFedorchenko, Elena, Evgenia Novikova, Andrey Fedorchenko, and Sergei Verevkin. 2023. "An Analytical Review of the Source Code Models for Exploit Analysis" Information 14, no. 9: 497. https://doi.org/10.3390/info14090497
APA StyleFedorchenko, E., Novikova, E., Fedorchenko, A., & Verevkin, S. (2023). An Analytical Review of the Source Code Models for Exploit Analysis. Information, 14(9), 497. https://doi.org/10.3390/info14090497