
A Comprehensive Survey of Facet Ranking Approaches Used in Faceted Search Systems


Abstract
1. Introduction
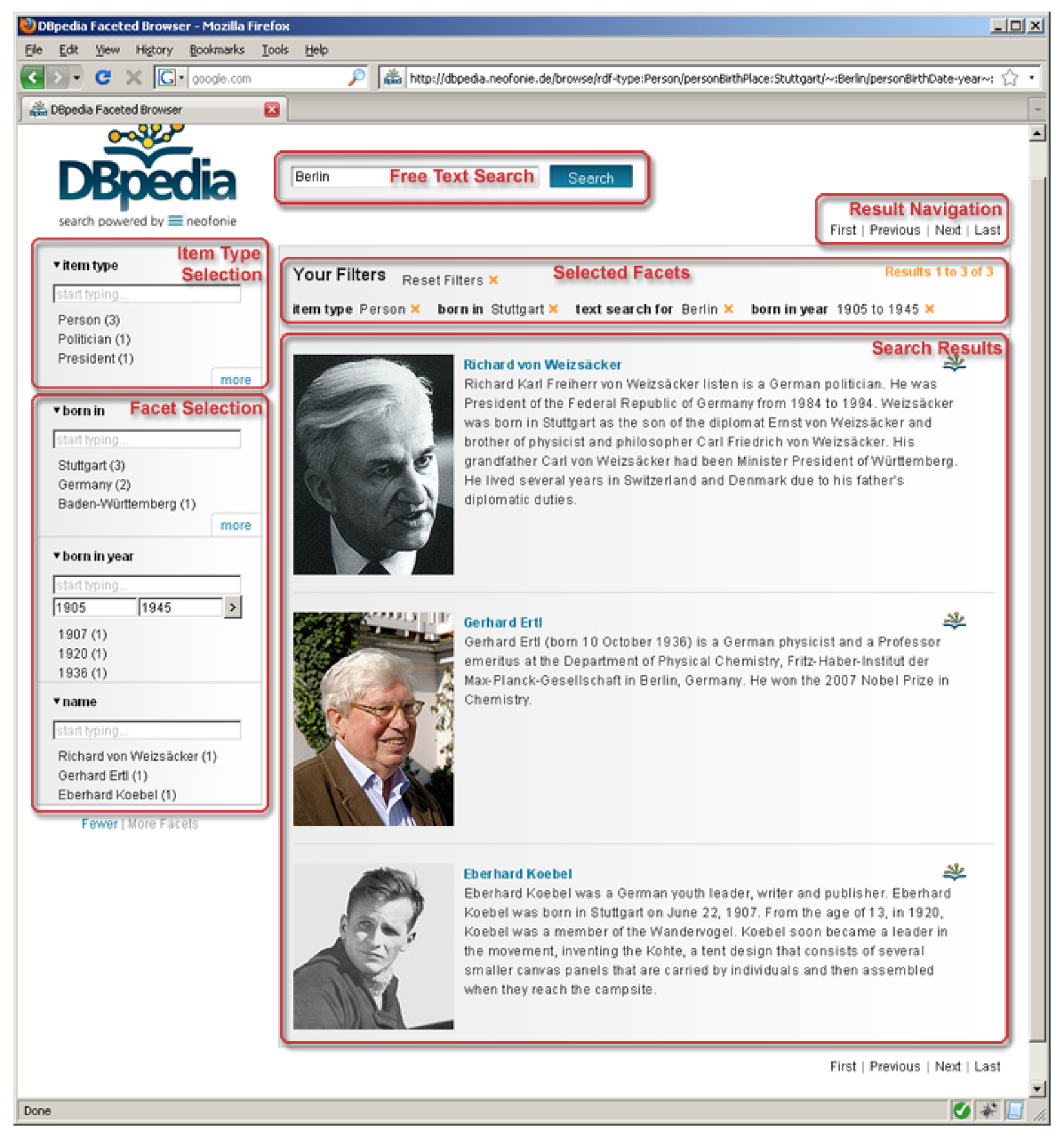
2. Faceted Search
“Asession-based interactive method for query formulation (commonly over a multi-dimensional information space) through simple clicks that offers an overview of the result set (groups and count information), never leading to empty results sets.”
“Asession-based interactive method for query formulation (commonly over a multi-dimensional information space) through simple clicks that offers an overview of the result set (groups and count information), never leading to empty results sets.”
2.1. The Search Process
- Type or refine a search query, or
- Navigate through multiple, independent facet hierarchies that describe the data by drill-down (refinement) or roll-up (generalization) operations.
2.2. User Interaction Model
2.3. Information Needs
2.3.1. Precision-Oriented Systems
2.3.2. Recall-Oriented Systems
2.4. Underlying Data Structure
- Structured data: The underlying dataset is derived from well-structured knowledge graphs or linked data. Resources in this case are entities, with facets and their values collected from the entities’ types, ontologies, attributes, or properties. Faceted browsing is the de facto standard for navigating structured datasets [7].However, faceted browsers based on knowledge bases still struggle when dealing with large volumes of triples. These methods require extensive querying of the triple stores to collect data about the facets and their values in order to support dynamic and interactive interfaces. Therefore, most of the systems adopting this approach are evaluated on small, domain-specific ontologies [1,7,16,20].Several software engineering and architectural considerations are involved in deciding how the data should be stored and retrieved in RDF stores in an interactive and responsive manner. In some cases, tools such as Facetize have been developed to prepare and transform structured data for faceted search [29]. Examples of an FSS operating on this kind of dataset can be found in [1,8,9,16,20].
- Unstructured data: These datasets contain unstructured data, e.g., for example, audio, images, or text such as web pages or user tweets. This data often shares some common characteristics with structured data which can be deemed as facets. Special techniques to process this data, according to the data type and search task, to extract facet values from the data are deployed. The design of these extraction methods often needs to take into account aspects such as processing time and algorithm complexity for extracting features from this kind of data. Example systems include [14,30,31,32].
- Semi-structured data: Semi-structured resources are objects that have some structured attributes or metadata but are also associated with unstructured data, e.g., long textual research papers, images, or audio files. The majority of facets in these datasets are obtained from the structured part of the data (i.e., attributes and their values). However, in some cases, they can also be extracted or generated from the unstructured part, e.g., top keywords in a research paper for an academic search engine. Example systems include [3,19,33,34,35,36].
3. Facets
3.1. What Is a Facet?
3.2. Different Facet Types

{kind=link}
{kind=link}
{kind=link}
| Method Name | Year | Information Need | Data Structure | Domain | Evaluation | Facets | |||
|---|---|---|---|---|---|---|---|---|---|
| Types | Ranking | Handling | Generation | ||||||
| Flamenco [5] | 2003 | R | Semi | Images | T | F | A | Same | - |
| OntoViews [11] | 2004 | R | Yes | Museums | - | F | M | Diff | M |
| Dakka et al. [43] | 2005 | - | Semi | Images + TV + Web | O | TF | IS | - | NLP |
| Faceted Categories [39] | 2006 | R | No | Food | T | TF | A | - | - |
| MSpace [13,45] | 2006 | R | Yes | Music | S | F | M + U | Same | Attr. |
| BrowseRDF [1] | 2006 | P | Yes | Digital Libraries+Criminal Records | T | F | IS | Same | Attr. |
| Koren et al. [3] | 2008 | P | Semi | Movies | S | F | CF + U | Same | Attr. |
| AFGF [40] | 2010 | P | No | Medical+Digital Libraries | O | TF | IS + C + Q | - | NLP |
| Facetedpedia [10] | 2010 | R | Yes | Wikipedia | T | F | IS + Q | Diff. | Attr. |
| Zowl et al. [46] | 2010 | P | No | Images | S | F | L | Same | NLP + EL |
| Faceted Wikipedia [8] | 2010 | R | Yes | Wikipedia | - | F | IS | Same | Attr. |
| Factic [15,47] | 2010 | P | Yes | Digital Libraries + Jobs + Images | T | F | U + L | Same | Attr. |
| FACeTOR [48] | 2010 | P | Semi | Cars + Movies | T | F | IS | Same | Attr. |
| AdaptiveTwitter [30] | 2011 | P | No | Social Media | S | F | U | Same | NLP |
| Let et al. [18] | 2012 | R | Yes | General Web | - | F | U | Same | Attr. |
| IOS [49] | 2012 | R | No | Digital Libraries + Fishery | T | TF | IS | - | EL |
| Faccy [22] | 2013 | P | Semi | E-commerce | S | F | IS + Q | Same | Attr. |
| Sah and Wade [25] | 2013 | R | Yes | Tourism | - | TF | U + C | - | Attr. |
| Liberman and Lempel [50] | 2014 | P | Semi | General Web | S | TF | L | - | M |
| FWS [14] | 2014 | - | No | General Web | S | TF | C + Q | - | NLP |
| FacetTree [51] | 2014 | R | Semi | Digital Libraries | T | F | - | Same | M + NLP |
| FeRoSA [26] | 2016 | R | Semi | Digital Libraries | T | F | M | Same | - |
| Hippalus [16] | 2016 | R | Yes | Politics + Sports + Marine | T | TF | M + U | Same | M |
| Vandic et al. [21] | 2017 | P | Semi | E-commerce | S | F | Q + IS | Same | Attr. |
| Facet Embeddings [27] | 2017 | R | No | Digital Libraries | O | TF | C | - | NLP |
| SemFacet [20,52] | 2017 | R | Yes | E-commerce | O | F | IS | Same | Attr. |
| SemanticScholar [19,28] | 2018 | R | Yes | Digital Libraries | - | F | IS | Same | Attr. |
| Bivens et al. [23] | 2019 | P | No | Technical Support | - | F | Q + U | Same | - |
| Feddoul et al. [53] | 2019 | R | Yes | Wikidata | T | F | IS | Same | Attr. |
| NaLa-Searc [44] | 2020 | P | Yes | Medical | T | F | - | Same | Attr. |
| Chantamunee et al. [36] | 2020 | P | Semi | Movies | S | F | CF | Same | Attr. |
| DFS [24,38] | 2020 | P | No | Technical Support | S | F | Q | Diff. | NLP + EL |
| FacetX [42] | 2020 | P | No | Jobs + Food + Movies | - | TF | - | - | NLP |
| Ali et al. [37,54,55] | 2021 | P | Semi | Tourism | S | T | U | - | Attr. |
| He et al. [56] | 2021 | R | No | Email Search | T | F | U + IS | Diff. | NLP |
| HSEarch [32] | 2021 | P | No | Medical | T | F | IS | Same | NLP + EL |
| PreFace [41,57] | 2021 | R | No | Digital Libraries | T | TF | Q + IS | NLP + EL | |
| Glass et al. [58] | 2021 | P | No | Technical Quality Assurance | S | F | Q | Same | NLP |
| RelFacet [59] | 2021 | R | Yes | DBpedia | T | PF | IS | - | Attr. |
| Knowledge Explorer [60] | 2022 | R | Yes | Geospatial | - | F | M + A | Diff. | Attr. |
| Schoegje et al. [61] | 2022 | R | No | Government | T | F | A | Same | M |
| Gollub et al. [62] | 2023 | R | Yes | DL | T | F | IS | Same | Attr. |
| Relatedly [63] | 2023 | R | No | DL | T | F | M + Q | Diff. | M + NLP |
| Sampo UI [64,65] | 2023 | R | Yes | DL + Art + Law + War | T | F | A + IS | Same | Attr. |
|
|
|
|
3.3. Facet Generation Methods
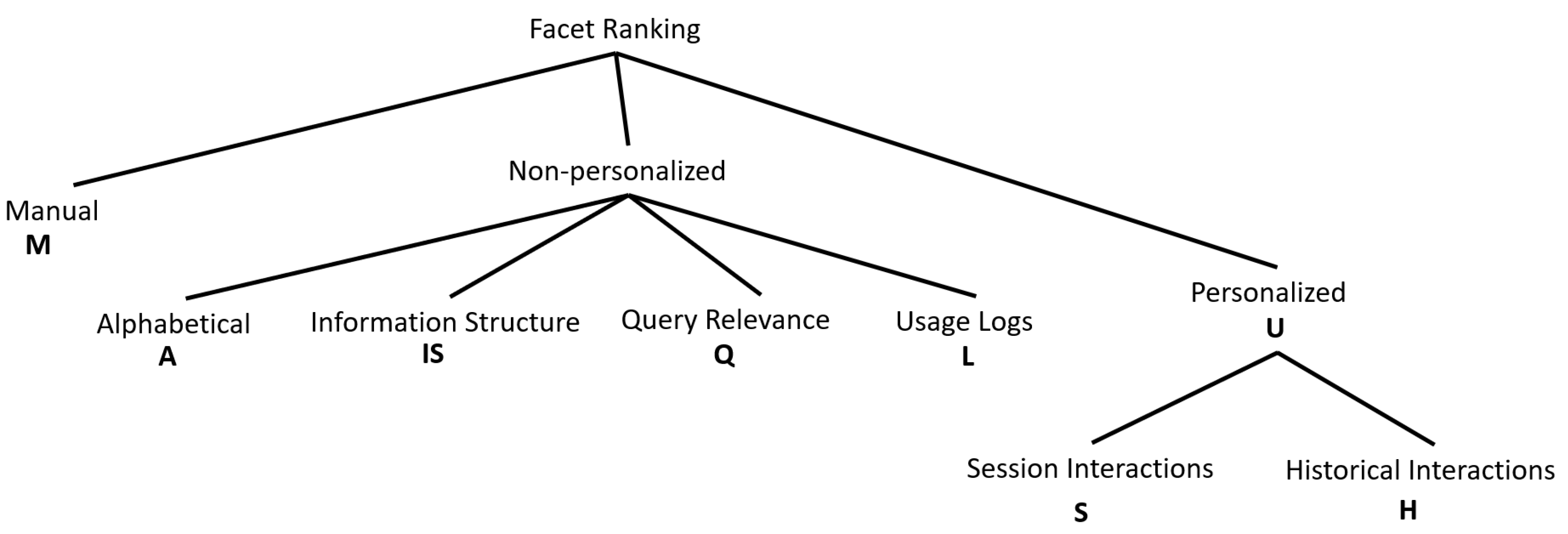
4. Facet Ranking
4.1. Manual Systems
4.2. Non-Personalized Methods
4.2.1. Information Structure-Based Ranking
4.2.2. Query Relevance Based
4.2.3. Usage Logs Based Ranking
4.3. Personalized Methods
4.3.1. Session Based Ranking
4.3.2. History Based Ranking
5. Evaluating Facet Ranking and Faceted Search Systems
5.1. Task-Based Evaluation
5.2. Simulation-Based Evaluation
5.3. Other Methods
5.4. Evaluation Domains and Collections
6. Summary of FSS Classification
6.1. Key Research Challenges
6.1.1. Establishing Facet Relevance
6.1.2. Maintaining the Multilevel Taxonomy Structure
6.1.3. Avoid Adding Complexity to the FSS
6.1.4. Deciding on a Search Task and Its Objectives
6.1.5. Evaluating Facet Ranking
7. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FSS | Facet Search Systems |
| CL | Collaborative Filtering |
| MF | Matrix Factorization |
| NLP | Natural Language Processing |
| IR | Information Retrieval |
| UI | User Interface |
References
- Oren, E.; Delbru, R.; Decker, S. Extending faceted navigation for RDF data. In International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 559–572. [Google Scholar]
- Niu, X.; Fan, X.; Zhang, T. Understanding Faceted Search from Data Science and Human Factor Perspectives. ACM Trans. Inf. Syst. 2019, 37. [Google Scholar] [CrossRef]
- Koren, J.; Zhang, Y.; Liu, X. Personalized interactive faceted search. In Proceedings of the 17th international conference on World Wide Web, Beijing China, 21–25 April 2008; pp. 477–486. [Google Scholar]
- Ben-Yitzhak, O.; Golbandi, N.; Har’El, N.; Lempel, R.; Neumann, A.; Ofek-Koifman, S.; Sheinwald, D.; Shekita, E.; Sznajder, B.; Yogev, S. Beyond Basic Faceted Search. In Proceedings of the 2008 International Conference on Web Search and Data Mining, Palo Alto, CA, USA, 11–12 February 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 33–44. [Google Scholar] [CrossRef]
- Yee, K.P.; Swearingen, K.; Li, K.; Hearst, M. Faceted metadata for image search and browsing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Ft. Lauderdale, FL, USA, 5–10 April 2003; pp. 401–408. [Google Scholar]
- Dumais, S. Faceted Search. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 1103–1109. [Google Scholar] [CrossRef]
- Tzitzikas, Y.; Manolis, N.; Papadakos, P. Faceted exploration of RDF/S datasets: A survey. J. Intell. Inf. Syst. 2017, 48, 329–364. [Google Scholar] [CrossRef]
- Hahn, R.; Bizer, C.; Sahnwaldt, C.; Herta, C.; Robinson, S.; Bürgle, M.; Düwiger, H.; Scheel, U. Faceted Wikipedia Search. In Proceedings of the Business Information Systems: 13th International Conference, BIS 2010, Berlin, Germany, 3–5 May 2010; Abramowicz, W., Tolksdorf, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–11. [Google Scholar] [CrossRef]
- Papadaki, M.E.; Spyratos, N.; Tzitzikas, Y. Towards Interactive Analytics over RDF Graphs. Algorithms 2021, 14, 34. [Google Scholar] [CrossRef]
- Li, C.; Yan, N.; Roy, S.B.; Lisham, L.; Das, G. Facetedpedia: Dynamic Generation of Query-dependent Faceted Interfaces for Wikipedia. In Proceedings of the 19th International Conference on World Wide Web, Raleigh North, CA, USA, 26–30 April 2010; ACM: New York, NY, USA, 2010; pp. 651–660. [Google Scholar] [CrossRef]
- Mäkelä, E.; Hyvönen, E.; Saarela, S.; Viljanen, K. OntoViews—A Tool for Creating Semantic Web Portals. In Proceedings of the Semantic Web—ISWC 2004: Third International Semantic Web Conference, Hiroshima, Japan, 7–11 November 2004; McIlraith, S.A., Plexousakis, D., van Harmelen, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 797–811. [Google Scholar] [CrossRef]
- Harth, A. VisiNav: A system for visual search and navigation on web data. Web Semant. Sci. Serv. Agents World Wide Web 2010, 8, 348–354. [Google Scholar] [CrossRef]
- Wilson, M.L.; White, R.W.; White, R.W. Evaluating advanced search interfaces using established information-seeking models. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1407–1422. [Google Scholar] [CrossRef]
- Kong, W.; Allan, J. Extending faceted search to the general web. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 839–848. [Google Scholar]
- Tvarozek, M.; Bieliková, M. Personalized faceted navigation in semantically enriched information spaces. Adv. Semant. Media Adapt. Pers. 2009, 2, 181–201. [Google Scholar]
- Tzitzikas, Y.; Dimitrakis, E. Preference-enriched Faceted Search for Voting Aid Applications. IEEE Trans. Emerg. Top. Comput. 2016, 7, 218–229. [Google Scholar] [CrossRef]
- Arenas, M.; Grau, B.C.; Kharlamov, E.; Marciuška, Š.; Zheleznyakov, D. Faceted search over RDF-based knowledge graphs. Web Semant. Sci. Serv. Agents World Wide Web 2016, 37, 55–74. [Google Scholar] [CrossRef]
- Le, T.; Vo, B.; Duong, T.H. Personalized Facets for Semantic Search Using Linked Open Data with Social Networks. In Proceedings of the 2012 Third International Conference on Innovations in Bio-Inspired Computing and Applications, Kaohsiung, Taiwan, 26–28 September 2012; pp. 312–317. [Google Scholar] [CrossRef]
- Xiong, C.; Power, R.; Callan, J. Explicit Semantic Ranking for Academic Search via Knowledge Graph Embedding. In Proceedings of the International World Wide Web Conference Committee (IW3C2), Perth, Australia, 3–7 April 2017. [Google Scholar]
- Kharlamov, E.; Giacomelli, L.; Sherkhonov, E.; Grau, B.C.; Kostylev, E.V.; Horrocks, I. Semfacet: Making hard faceted search easier. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2475–2478. [Google Scholar]
- Vandic, D.; Aanen, S.; Frasincar, F.; Kaymak, U. Dynamic Facet Ordering for Faceted Product Search Engines. IEEE Trans. Knowl. Data Eng. 2017, 29, 1004–1016. [Google Scholar] [CrossRef]
- Vandic, D.; Frasincar, F.; Kaymak, U. Facet selection algorithms for web product search. In Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2327–2332. [Google Scholar]
- Bivens, J.A.; Deng, Y.; El Maghraoui, K.; Mahindru, R.; Ramasamy, H.V.; Sarkar, S.; Wang, L. Dynamic Faceted Search. U.S. Patent 10,242,103, 26 March 2019. [Google Scholar]
- Mihindukulasooriya, N.; Mahindru, R.; Chowdhury, M.F.M.; Deng, Y.; Fauceglia, N.R.; Rossiello, G.; Dash, S.; Gliozzo, A.; Tao, S. Dynamic Faceted Search for Technical Support Exploiting Induced Knowledge. In Proceedings of the Semantic Web—ISWC 2020; Pan, J.Z., Tamma, V., d’Amato, C., Janowicz, K., Fu, B., Polleres, A., Seneviratne, O., Kagal, L., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 683–699. [Google Scholar]
- Sah, M.; Wade, V. Personalized Concept-Based Search and Exploration on the Web of Data Using Results Categorization. In Proceedings of the Semantic Web: Semantics and Big Data; Cimiano, P., Corcho, O., Presutti, V., Hollink, L., Rudolph, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 532–547. [Google Scholar]
- Chakraborty, T.; Krishna, A.; Singh, M.; Ganguly, N.; Goyal, P.; Mukherjee, A. FeRoSA: A Faceted Recommendation System for Scientific Articles. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 20th Pacific-Asia Conference, PAKDD 2016, Auckland, New Zealand, 19–22 April 2016; pp. 528–541. [Google Scholar]
- Houben, G.J. Facet Embeddings for Explorative Analytics in Digital Libraries. In Proceedings of the Research and Advanced Technology for Digital Libraries: 21st International Conference on Theory and Practice of Digital Libraries, TPDL 2017, Thessaloniki, Greece, 18–21 September 2017; p. 86. [Google Scholar]
- Ammar, W.; Groeneveld, D.; Bhagavatula, C.; Beltagy, I.; Crawford, M.; Downey, D.; Dunkelberger, J.; Elgohary, A.; Feldman, S.; Ha, V.; et al. Construction of the Literature Graph in Semantic Scholar. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 84–91. [Google Scholar] [CrossRef]
- Kokolaki, A.; Tzitzikas, Y. Facetize: An Interactive Tool for Cleaning and Transforming Datasets for Facilitating Exploratory Search. arXiv 2018, arXiv:1812.10734. [Google Scholar]
- Abel, F.; Celik, I.; Houben, G.J.; Siehndel, P. Leveraging the semantics of tweets for adaptive faceted search on twitter. In The Semantic Web–ISWC 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–17. [Google Scholar]
- Nguyen, H.S.; Pham, H.P.; Duong, T.H.; Nguyen, T.P.T.; Le, H.M.T. Personalized Facets for Faceted Search Using Wikipedia Disambiguation and Social Network. In Advanced Computational Methods for Knowledge Engineering; Springer: Berlin/Heidelberg, Germany, 2016; pp. 229–241. [Google Scholar]
- Inan, E.; Thompson, P.; Yates, T.; Ananiadou, S. HSEarch: Semantic Search System for Workplace Accident Reports. In Proceedings of the ECIR 2021: Advances in Information Retrieval; Hiemstra, D., Moens, M.F., Mothe, J., Perego, R., Potthast, M., Sebastiani, F., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 514–519. [Google Scholar]
- Mahdi, M.N.; Ahmad, A.R.; Ismail, R. Improving Faceted Search Results for Web-based Information Exploration. Int. J. Adv. Sci. Eng. Inf. Technol. 2020, 10, 1143–1152. [Google Scholar] [CrossRef]
- Chantamunee, S.; Wong, K.W.; Fung, C.C. Collaborative Filtering for Personalised Facet Selection. In Proceedings of the 10th International Conference on Advances in Information Technology; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Chantamunee, S.; Wong, K.W.; Fung, C.C. Deep Autoencoder on Personalized Facet Selection. In Proceedings of the Neural Information Processing; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 314–322. [Google Scholar]
- Chantamunee, S.; Wong, K.W.; Fung, C.C. An exploration of user–facet interaction in collaborative-based personalized multiple facet selection. Knowl.-Based Syst. 2020, 209, 106444. [Google Scholar] [CrossRef]
- Ali, E.; Caputo, A.; Lawless, S.; Conlan, O. Where should I go? A deep learning approach to personalize type-based facet ranking for POI suggestion. In Proceedings of the Web Information Systems Engineering–WISE 2021: 22nd International Conference on Web Information Systems Engineering, WISE 2021, Melbourne, VIC, Australia, 26–29 October 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 207–215. [Google Scholar]
- Kong, B.; Rajshree, N.; Gliozzo, A.M.; Fauceglia, N.R.; Farrell, R.G.; Chowdhury, M.F.M.; Mathur, A. Dynamic Faceted Search on a Document Corpus. US Patent App. 16/399,180, 5 November 2020. [Google Scholar]
- Hearst, M.A. Clustering versus Faceted Categories for Information Exploration. Commun. ACM 2006, 49, 59–61. [Google Scholar] [CrossRef]
- Latha, K.; Veni, K.R.; Rajaram, R. Afgf: An automatic facet generation framework for document retrieval. In Proceedings of the International Conference on Advances in Computer Engineering (ACE), Bangalore, India, 20–21 June 2010; pp. 110–114. [Google Scholar]
- Upadhyay, P.; Ramanath, M. PreFace++: Faceted Retrieval of Prerequisites and Technical Data. In Proceedings of the Advances in Information Retrieval; Hiemstra, D., Moens, M.F., Mothe, J., Perego, R., Potthast, M., Sebastiani, F., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 554–558. [Google Scholar]
- Affolter, R.; Weiler, A. FacetX: Dynamic Facet Generation for Advanced Information Filtering of Search Results. In Proceedings of the EDBT/ICDT Workshops, Copenhagen, Denmark, 30 March 2020. [Google Scholar]
- Dakka, W.; Ipeirotis, P.G.; Wood, K.R. Automatic Construction of Multifaceted Browsing Interfaces. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management; Association for Computing Machinery: New York, NY, USA, 2005; pp. 768–775. [Google Scholar] [CrossRef]
- Sánchez-Cervantes, J.L.; Alor-Hernández, G.; Paredes-Valverde, M.A.; Rodríguez-Mazahua, L.; Valencia-García, R. NaLa-Search: A multimodal, interaction-based architecture for faceted search on linked open data. J. Inf. Sci. 2020, 47, 0165551520930918. [Google Scholar] [CrossRef]
- schraefel, m.; Wilson, M.; Russell, A.; Smith, D.A. MSpace: Improving Information Access to Multimedia Domains with Multimodal Exploratory Search. Commun. ACM 2006, 49, 47–49. [Google Scholar] [CrossRef]
- van Zwol, R.; Pueyo, L.G.; Muralidharan, M.; Sigurbjornsson, B. Ranking entity facets based on user click feedback. In Proceedings of the 2010 IEEE Fourth International Conference on Semantic Computing, Pittsburgh, PA, USA, 22–24 September 2010; pp. 192–199. [Google Scholar]
- Tvarožek, M.; Bieliková, M. Factic: Personalized exploratory search in the semantic web. In Proceedings of the International Conference on Web Engineering; Springer: Berlin/Heidelberg, Germany, 2010; pp. 527–530. [Google Scholar]
- Kashyap, A.; Hristidis, V.; Petropoulos, M. FACeTOR: Cost-Driven Exploration of Faceted Query Results. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management; Association for Computing Machinery: New York, NY, USA, 2010; pp. 719–728. [Google Scholar] [CrossRef]
- Fafalios, P.; Kitsos, I.; Marketakis, Y.; Baldassarre, C.; Salampasis, M.; Tzitzikas, Y. Web searching with entity mining at query time. In Proceedings of the Information Retrieval Facility Conference; Springer: Berlin/Heidelberg, Germany, 2012; pp. 73–88. [Google Scholar]
- Liberman, S.; Lempel, R. Approximately optimal facet value selection. Sci. Comput. Program. 2014, 94, 18–31. [Google Scholar] [CrossRef]
- Móro, R.; Bieliková, M.; Burger, R.; Facet Tree for Personalized Web Documents Organization. Web Information Systems Engineering—WISE 2014: 15th International Conference, Thessaloniki, Greece, 12–14 October 2014; Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2014; pp. 372–387. [Google Scholar] [CrossRef]
- Kharlamov, E.; Giacomelli, L.; Sherkhonov, E.; Grau, B.C.; Kostylev, E.V.; Horrocks, I. Ranking, aggregation, and reachability in faceted search with semfacet. In Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, 23–25 October 2017. [Google Scholar]
- Feddoul, L.; Schindler, S.; Löffler, F. Automatic Facet Generation and Selection over Knowledge Graphs. In Proceedings of the Semantic Systems. The Power of AI and Knowledge Graphs; Acosta, M., Cudré-Mauroux, P., Maleshkova, M., Pellegrini, T., Sack, H., Sure-Vetter, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 310–325. [Google Scholar]
- Ali, E.; Caputo, A.; Lawless, S.; Conlan, O. A Probabilistic Approach to Personalize Type-based Facet Ranking for POI Suggestion. In Proceedings of the Web Engineering. ICWE 2021; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12706, pp. 175–182. [Google Scholar]
- Ali, E.; Caputo, A.; Lawless, S.; Conlan, O. Personalizing type-based facet ranking using BERT embeddings. In Further with Knowledge Graphs. Studies on the Semantic Web 53; IOS Press Ebooks: Amsterdam, The Netherlands, 2021. [Google Scholar]
- He, C.; Micallef, L.; Serim, B.; Vuong, T.; Ruotsalo, T.; Jacucci, G. Interactive Visual Facets to Support Fluid Exploratory Search. arXiv 2021, arXiv:2108.00920. [Google Scholar]
- Upadhyay, P.; Ramanath, M. PreFace: Faceted Retrieval of Prerequisites Using Domain-Specific Knowledge Bases. In Proceedings of the The Semantic Web—ISWC 2020; Pan, J.Z., Tamma, V., d’Amato, C., Janowicz, K., Fu, B., Polleres, A., Seneviratne, O., Kagal, L., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 601–618. [Google Scholar]
- Glass, M.; Chowdhury, M.F.M.; Deng, Y.; Mahindru, R.; Fauceglia, N.R.; Gliozzo, A.; Mihindukulasooriya, N. Dynamic Facet Selection by Maximizing Graded Relevance. In InterNLP 2021; Association for Computational Linguistics: Toronto, Canada, 2021; p. 32. [Google Scholar]
- Aso, T.; Amagasa, T.; Kitagawa, H. A system for relation-oriented faceted search over knowledge bases. Int. J. Web Inf. Syst. 2021, 17, 698–713. [Google Scholar] [CrossRef]
- Liu, Z.; Gu, Z.; Thelen, T.; Estrecha, S.G.; Zhu, R.; Fisher, C.K.; D’Onofrio, A.; Shimizu, C.; Janowicz, K.; Schildhauer, M.; et al. Knowledge explorer: Exploring the 12-billion-statement KnowWhereGraph using faceted search (demo paper). In Proceedings of the 30th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 1–4 November 2022; pp. 1–4. [Google Scholar]
- Schoegje, T.; de Vries, A.; Pieters, T. Adapting a Faceted Search Task Model for the Development of a Domain-Specific Council Information Search Engine. In Proceedings of the Electronic Government; Janssen, M., Csáki, C., Lindgren, I., Loukis, E., Melin, U., Viale Pereira, G., Rodríguez Bolívar, M.P., Tambouris, E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 402–418. [Google Scholar]
- Gollub, T.; Brockmeyer, J.; Stein, B.; Potthast, M. Dynamic Exploratory Search for the Information Retrieval Anthology. In Proceedings of the Advances in Information Retrieval: 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, 2–6 April 2023; pp. 242–247. [Google Scholar]
- Palani, S.; Naik, A.; Downey, D.; Zhang, A.X.; Bragg, J.; Chang, J.C. Relatedly: Scaffolding Literature Reviews with Existing Related Work Sections. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–20. [Google Scholar]
- Hyvönen, E. Digital Humanities on the Semantic Web: Sampo Model and Portal Series. Semant. Web 2023, 14, 729–744. [Google Scholar] [CrossRef]
- Ikkala, E.; Hyvönen, E.; Rantala, H.; Koho, M. Sampo-UI: A full stack JavaScript framework for developing semantic portal user interfaces. Semant. Web 2022, 13, 69–84. [Google Scholar] [CrossRef]
- Kitsos, I.; Magoutis, K.; Tzitzikas, Y. Scalable entity-based summarization of web search results using MapReduce. Distrib. Parallel Databases 2014, 32, 405–446. [Google Scholar] [CrossRef]
- Gollub, T.; Hutans, L.; Al Jami, T.; Stein, B. Exploratory Search Pipes with Scoped Facets. In Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, Santa Clara, CA, USA, 2–5 October 2019; pp. 245–248. [Google Scholar]
- Van Zwol, R.; Sigurbjornsson, B.; Adapala, R.; Garcia Pueyo, L.; Katiyar, A.; Kurapati, K.; Muralidharan, M.; Muthu, S.; Murdock, V.; Ng, P.; et al. Faceted exploration of image search results. In Proceedings of the 19th international conference on World Wide Web, Raleigh North, CA, USA, 26–30 April 2010; pp. 961–970. [Google Scholar]
- van Zwol, R.; Garcia Pueyo, L.; Muralidharan, M.; Sigurbjörnsson, B. Machine Learned Ranking of Entity Facets. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval; Association for Computing Machinery: New York, NY, USA, 2010; pp. 879–880. [Google Scholar] [CrossRef]
- Wang, Q.; Ramírez, G.; Marx, M.; Theobald, M.; Kamps, J. Overview of the INEX 2011 Data-Centric Track. In Proceedings of the Focused Retrieval of Content and Structure; Geva, S., Kamps, J., Schenkel, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 118–137. [Google Scholar]
- Ali, E.; Caputo, A.; Lawless, S.; Conlan, O. Dataset creation framework for personalized type-based facet ranking tasks evaluation. In Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction: 12th International Conference of the CLEF Association, CLEF 2021, Virtual Event, 21–24 September 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 27–39. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, E.; Caputo, A.; Jones, G.J.F. A Comprehensive Survey of Facet Ranking Approaches Used in Faceted Search Systems. Information 2023, 14, 387. https://doi.org/10.3390/info14070387
Ali E, Caputo A, Jones GJF. A Comprehensive Survey of Facet Ranking Approaches Used in Faceted Search Systems. Information. 2023; 14(7):387. https://doi.org/10.3390/info14070387
Chicago/Turabian StyleAli, Esraa, Annalina Caputo, and Gareth J. F. Jones. 2023. "A Comprehensive Survey of Facet Ranking Approaches Used in Faceted Search Systems" Information 14, no. 7: 387. https://doi.org/10.3390/info14070387
APA StyleAli, E., Caputo, A., & Jones, G. J. F. (2023). A Comprehensive Survey of Facet Ranking Approaches Used in Faceted Search Systems. Information, 14(7), 387. https://doi.org/10.3390/info14070387