
Ensemble System of Deep Neural Networks for Single-Channel Audio Separation
_Al-Kaltakchi.jpg)



Abstract
1. Introduction
2. Related Work
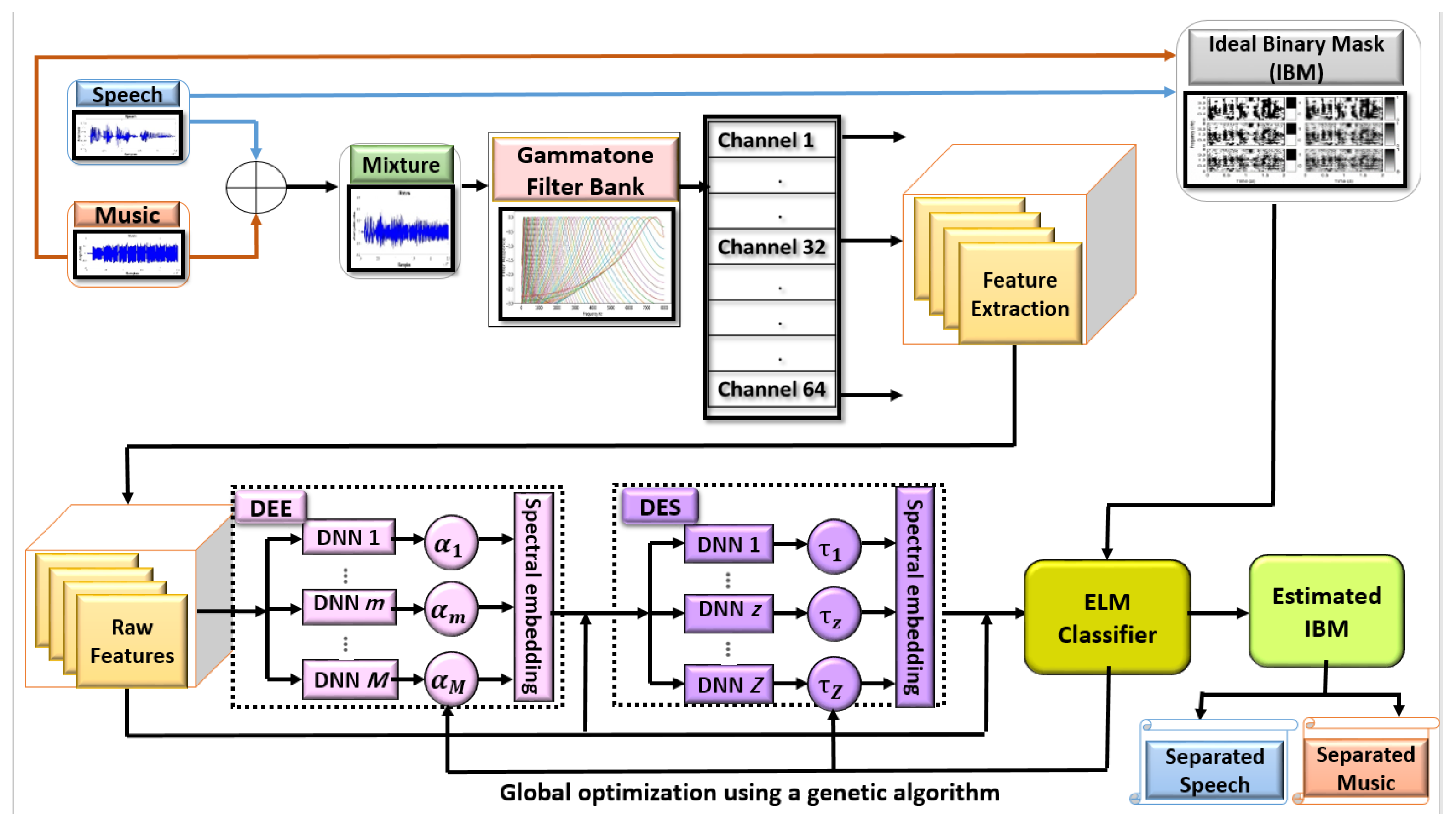
3. Overview of the System
4. The Proposed Ensemble System Using DNN
4.1. DNN Ensemble Embedding (DEE)
4.1.1. DNN Training
4.1.2. Spectral Embedding in Multiple Views
4.1.3. DNN Ensemble Stacking (DES)
4.1.4. ELM-Based Classification
4.1.5. Global Optimization with a Genetic Algorithm
- (i)
- Defining the fitness functionThe developed genetic algorithm’s fitness function in this step was to reduce the mean square error between the real TF unit value T and the estimated value :
- (ii)
- Determining the initial population of chromosomesFor both steps, the initial population size was selected as 1000 chromosomes (individuals) for this genetic algorithm. These initial chromosomes represent the first generation.
- (iii)
- EncodingEach chromosome in the population was encoded by using binary strings of 0 s and 1 s. Every was represented as a 10-bit string of binary numbers (0 s and 1 s) in the DEE step. Similarly, each chromosome (individual) refers to Z weights in the DES step. As a consequence, each chromosome was represented by bit strings.
- (iv)
- Boundary conditionsThe boundary conditions were set in both stages such that every element had a positive value.
- (v)
- Reproduction of next generationsThe fitness function was used to test each chromosome in the first generation () to calculate how effectively it solved the optimization issue. The chromosomes that performed better or were more fit were passed on to the next generations. They were wiped out otherwise. Crossover occurred when two chromosomes swapped some bits of the same region to produce two offspring, whereas mutation occurred when the bits in the chromosome were turned over (0 to 1 and vice versa). The occurrence of mutation was determined by the algorithm’s mutation probability () as well as a random number generated by the computer (). We set the value to in this stage. The mutation operator can be defined as follows:
- (vi)
- Until the best chromosome was attained, the processes of selection, crossover, and mutation were repeated.
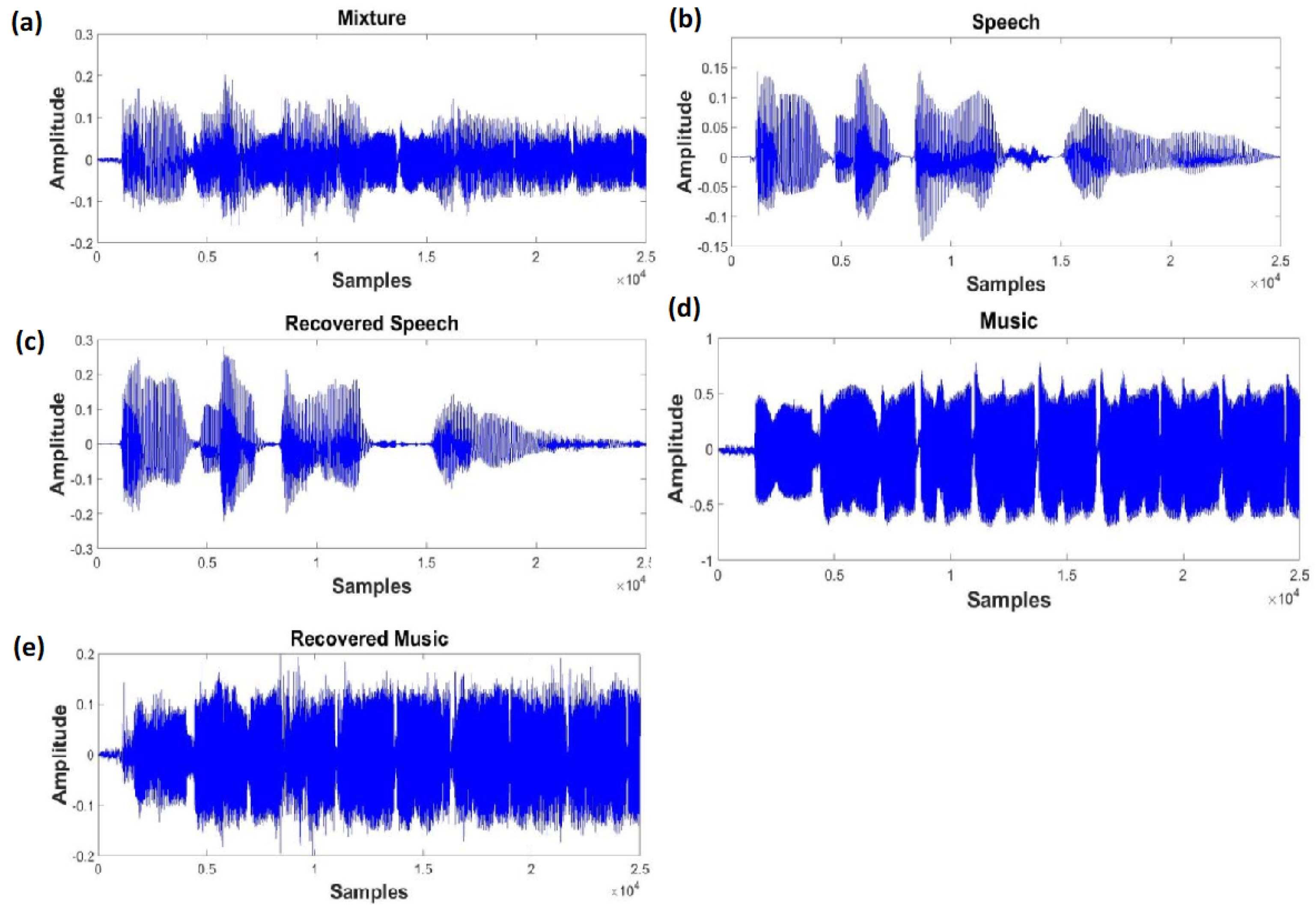
5. Experimental Results and Discussion
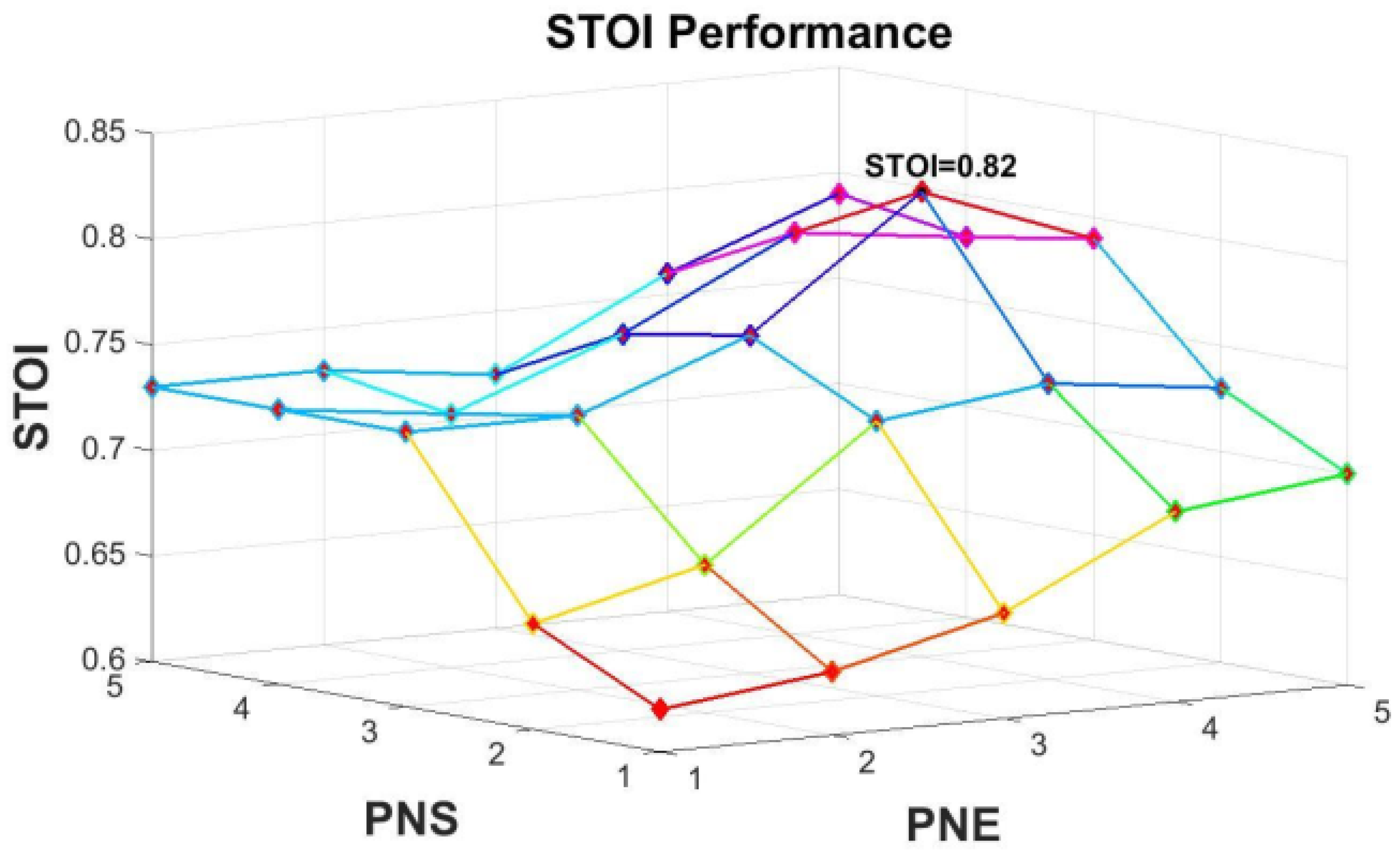
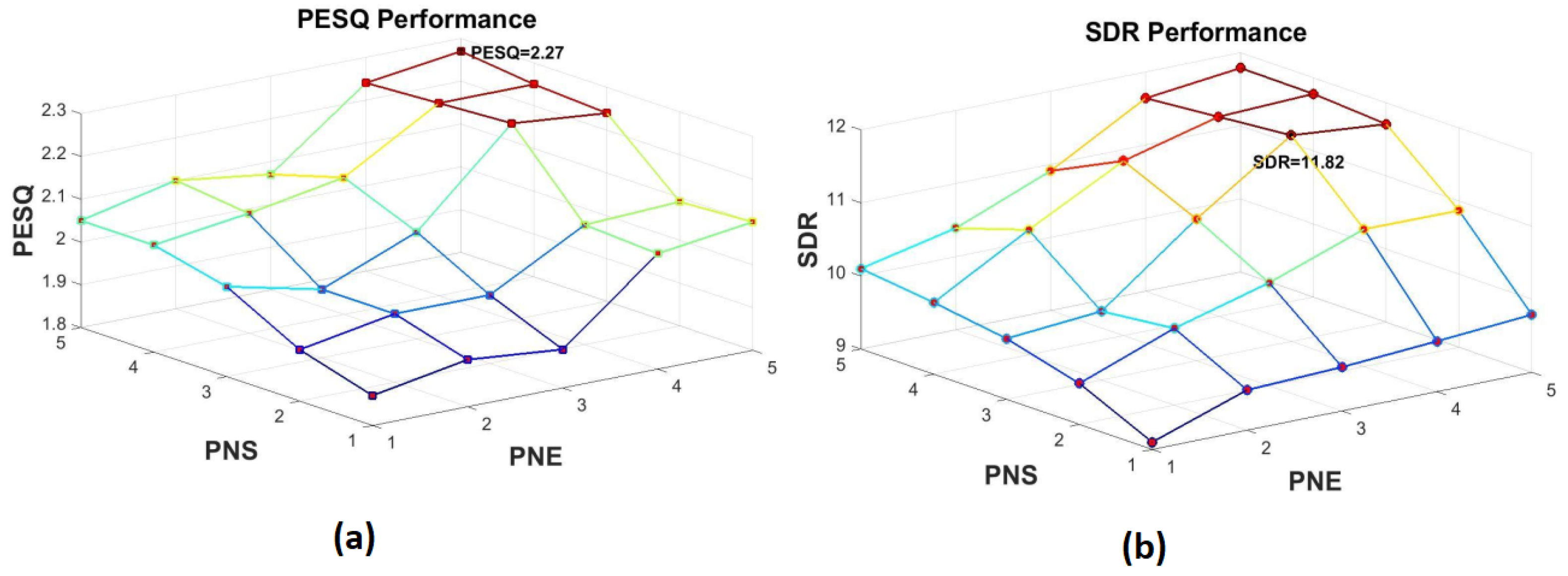
5.1. Optimizing the Number of DNNs
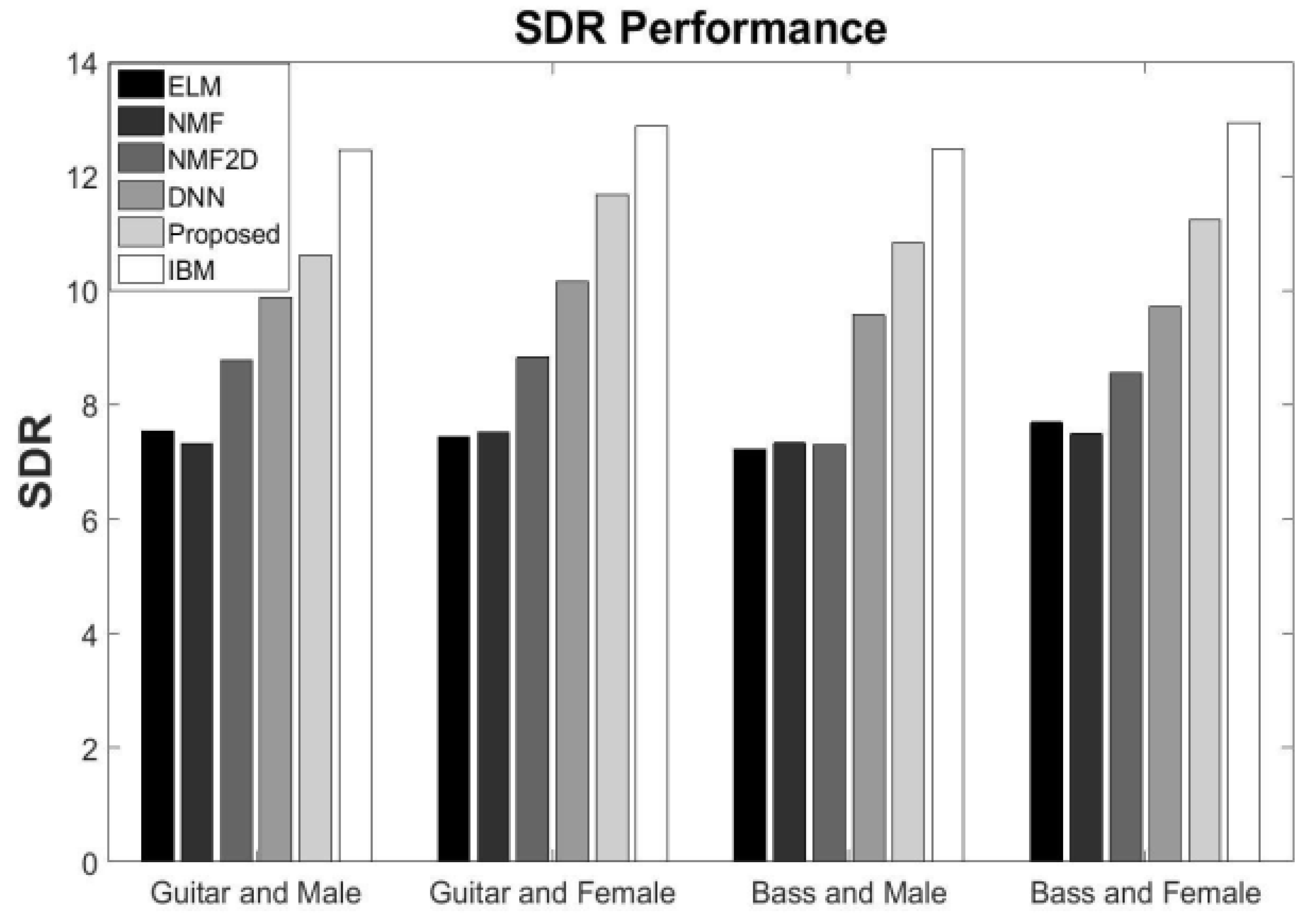
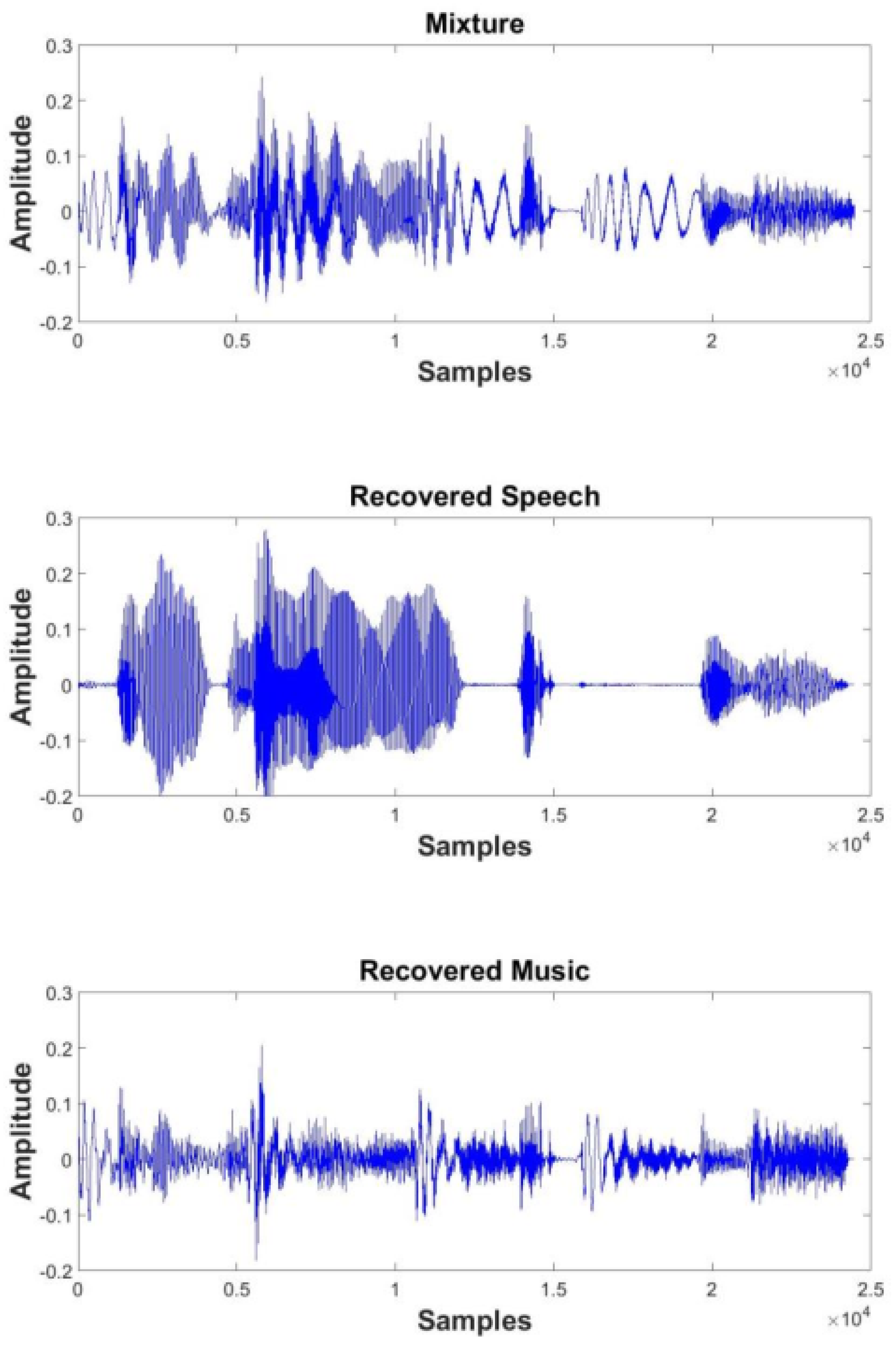
5.2. Speech Separation Performance
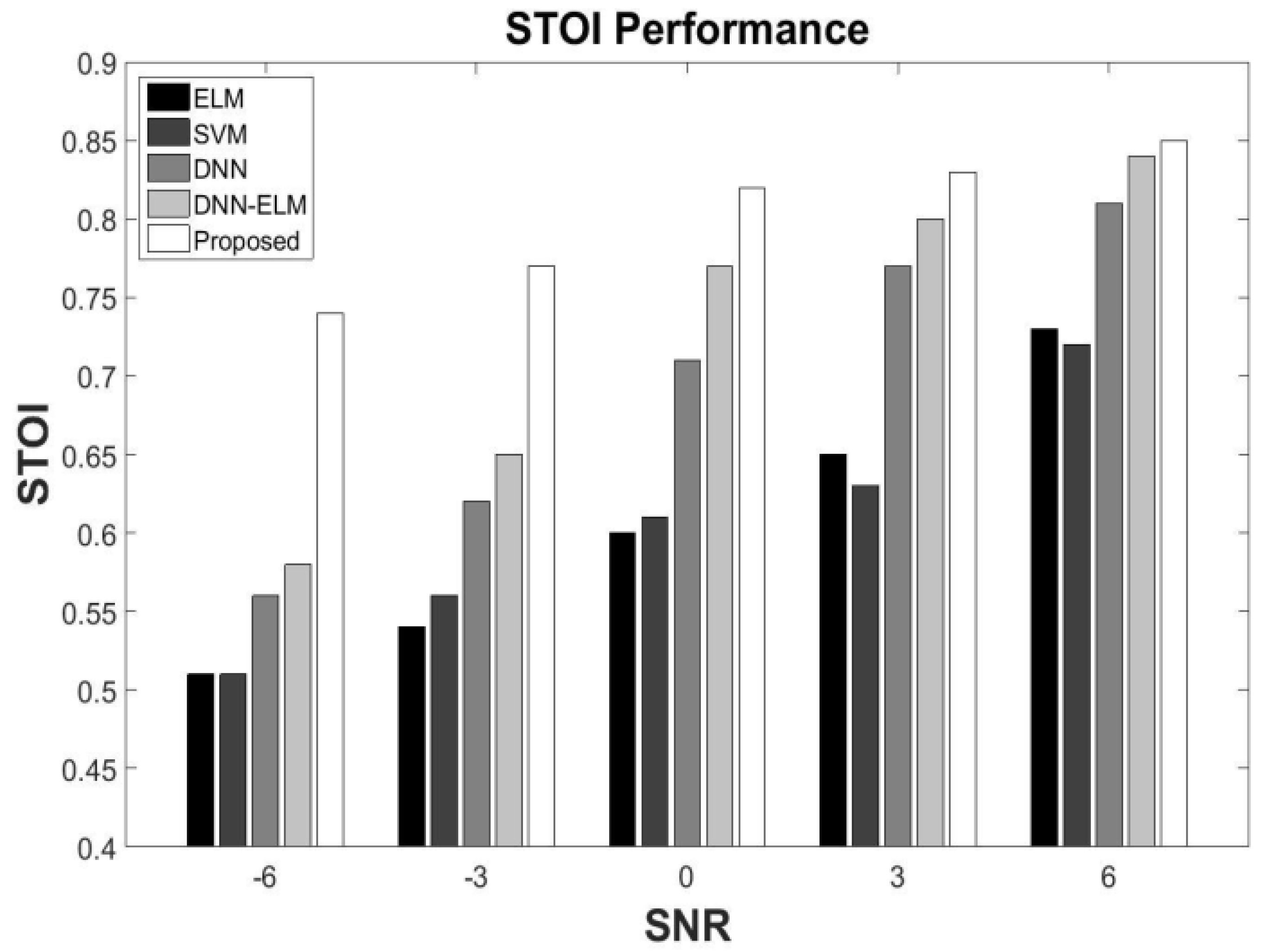
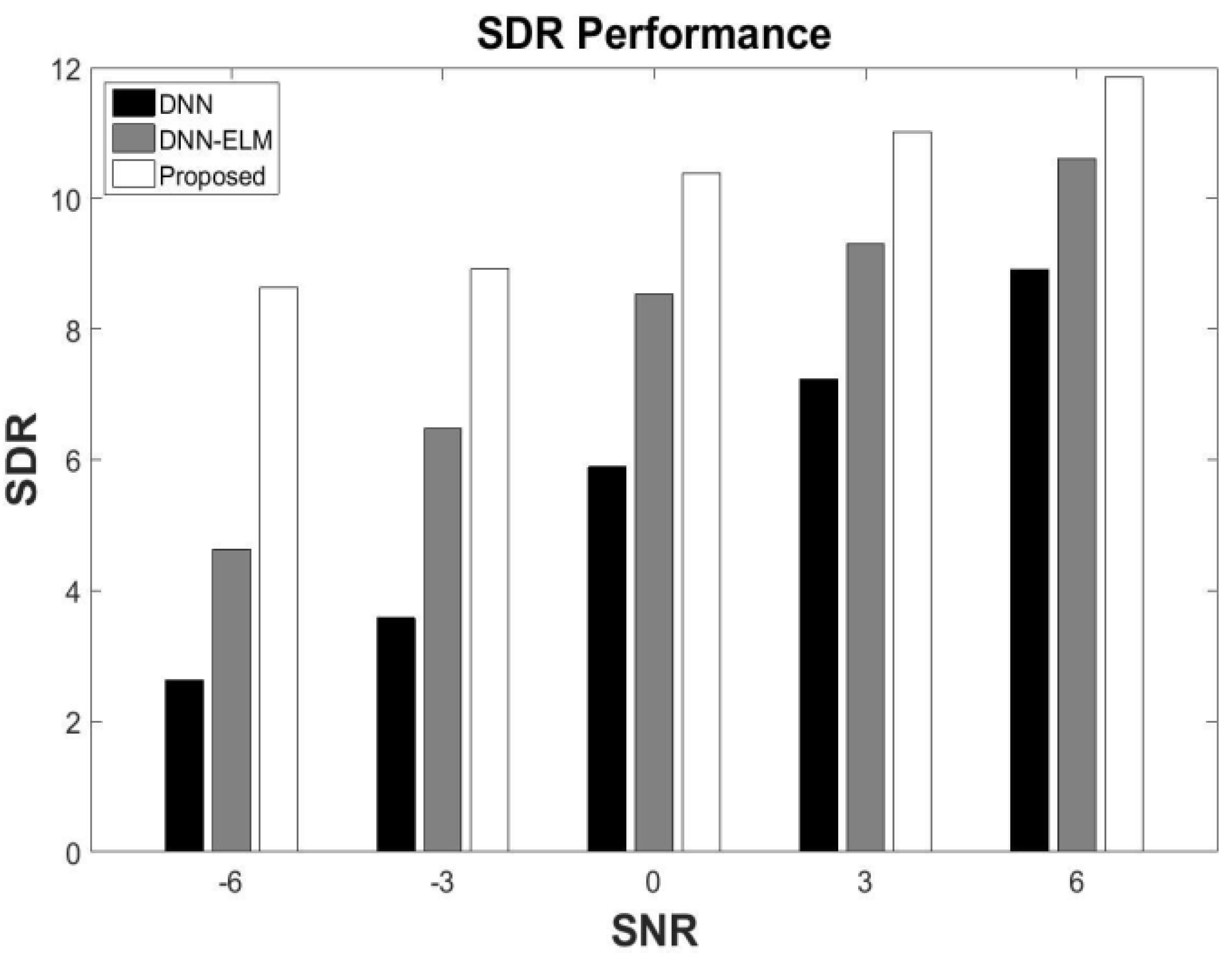
5.3. Generalization under Different SNR
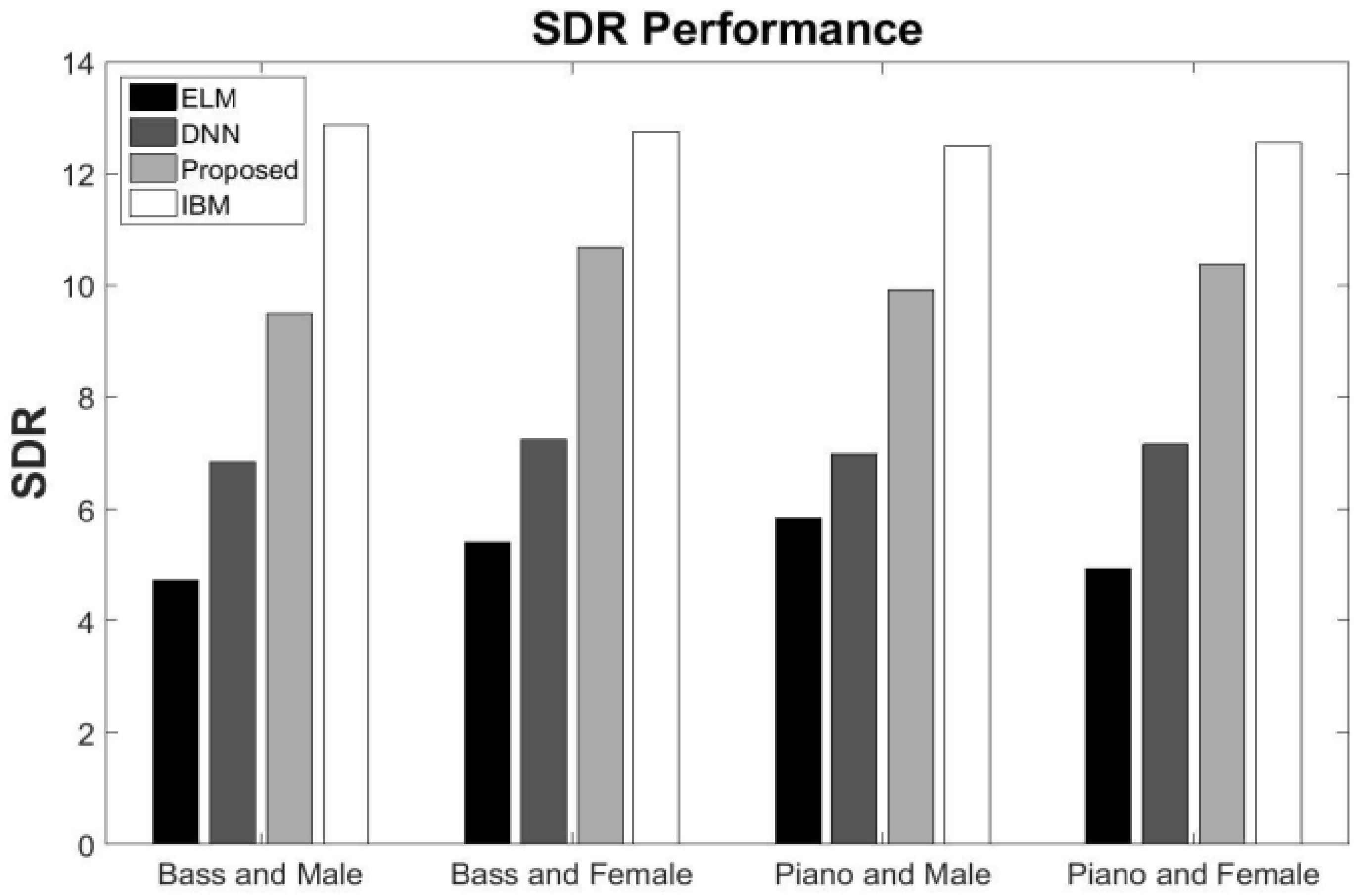
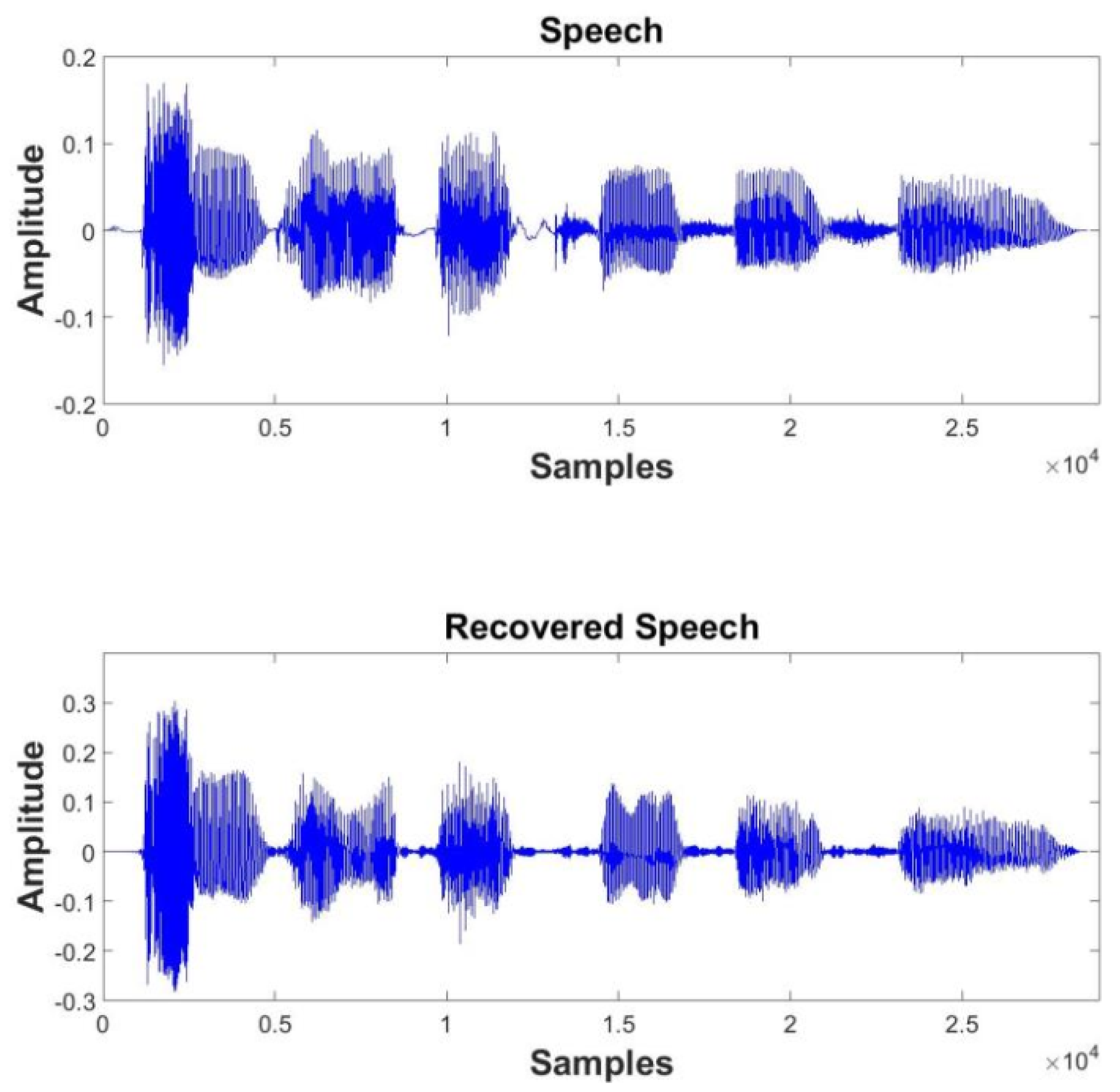
5.4. Generalization to Different Input Music
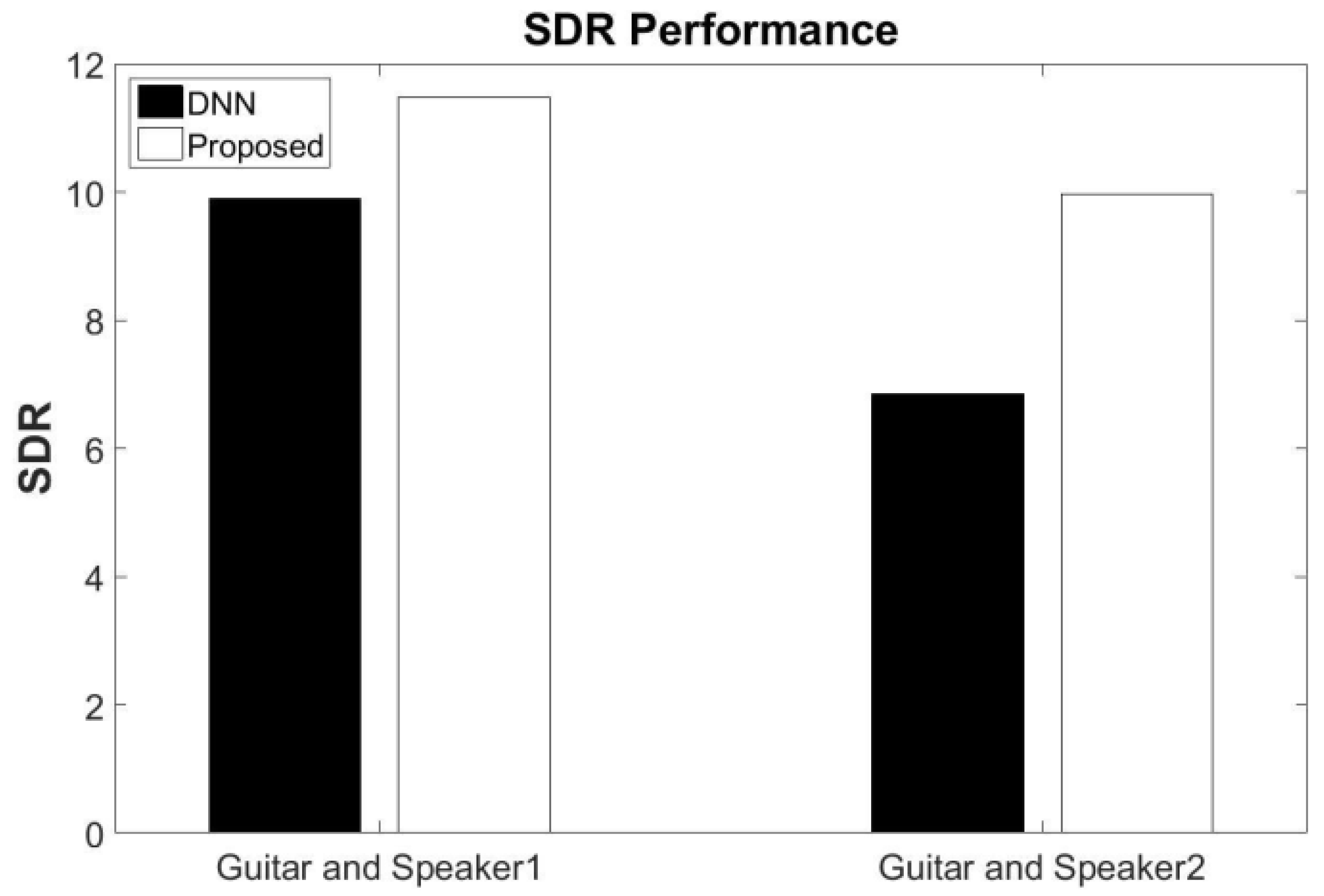
5.5. Generalization to Different Speaker
5.6. Comparisons with the Baseline Result
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| m | Number of DNN in DEE |
| n | Number of frames |
| Output of m-th DNN | |
| Activation function | |
| w | Weight parameter |
| Number of hidden layers | |
| E | Energy function |
| v | Visible layer |
| h | Hidden layer |
| Bias | |
| unit and vth unit | |
| m-th matrix contains features of n frames | |
| Variance | |
| Standard deviation | |
| m-th feature set j-th feature point | |
| k | Number of nearest features |
| Part mapping of patch | |
| Part embedding of patch | |
| v | Dimension of embedded features |
| k-dimensional column vector of jth patch on the mth feature set | |
| Width of the neighborhoods | |
| Weights of embedding | |
| Normalized graph Laplacian | |
| D | Degree matrix |
| Coefficient for controlling the interdependency | |
| Lagrange multiplier | |
| L | Lagrange function |
| Z | Number of DNN in DES |
| Output of z-th DNN | |
| -th output of ELM | |
| k | Number of hidden nodes |
| S | Activation function of ELM |
| -th input vector | |
| Parameters of activation function | |
| Output weight of ELM |
References
- Brown, G.J.; Cooke, M. Computational auditory scene analysis. Comput. Speech Lang. 1994, 8, 297–336. [Google Scholar] [CrossRef]
- Wang, D. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: New York, NY, USA, 2005; pp. 181–197. [Google Scholar]
- Xia, T.; Tao, D.; Mei, T.; Zhang, Y. Multiview spectral embedding. IEEE Trans. Syst. Man, Cybern. Part B Cybern. 2010, 40, 1438–1446. [Google Scholar]
- Shao, L.; Wu, D.; Li, X. Learning deep and wide: A spectral method for learning deep networks. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 2303–2308. [Google Scholar] [CrossRef]
- Garau, G.; Renals, S. Combining spectral representations for large-vocabulary continuous speech recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 508–518. [Google Scholar] [CrossRef]
- Grais, E.M.; Roma, G.; Simpson, A.J.; Plumbley, M.D. Two-stage single-channel audio source separation using deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1773–1783. [Google Scholar] [CrossRef]
- Wang, Y.; Du, J.; Dai, L.R.; Lee, C.H. A gender mixture detection approach to unsupervised single-channel speech separation based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1535–1546. [Google Scholar] [CrossRef]
- Zhao, M.; Yao, X.; Wang, J.; Yan, Y.; Gao, X.; Fan, Y. Single-channel blind source separation of spatial aliasing signal based on stacked-LSTM. Sensors 2021, 21, 4844. [Google Scholar] [CrossRef] [PubMed]
- Hwang, W.L.; Ho, J. Null space component analysis of one-shot single-channel source separation problem. IEEE Trans. Signal Process. 2021, 69, 2233–2251. [Google Scholar] [CrossRef]
- Duong, T.T.H.; Duong, N.Q.; Nguyen, P.C.; Nguyen, C.Q. Gaussian modeling-based multichannel audio source separation exploiting generic source spectral model. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 32–43. [Google Scholar] [CrossRef]
- Pezzoli, M.; Carabias-Orti, J.J.; Cobos, M.; Antonacci, F.; Sarti, A. Ray-space-based multichannel nonnegative matrix factorization for audio source separation. IEEE Signal Process. Lett. 2021, 28, 369–373. [Google Scholar] [CrossRef]
- Jin, Y.; Tang, C.; Liu, Q.; Wang, Y. Multi-head self-attention-based deep clustering for single-channel speech separation. IEEE Access 2020, 8, 100013–100021. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.T.; Lou, S.T. Generative adversarial networks for single channel separation of convolutive mixed speech signals. Neurocomputing 2021, 438, 63–71. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef]
- Gu, R.; Zhang, S.X.; Xu, Y.; Chen, L.; Zou, Y.; Yu, D. Multi-modal multi-channel target speech separation. IEEE J. Sel. Top. Signal Process. 2020, 14, 530–541. [Google Scholar] [CrossRef]
- Encinas, F.G.; Silva, L.A.; Mendes, A.S.; González, G.V.; Leithardt, V.R.Q.; Santana, J.F.D.P. Singular spectrum analysis for source separation in drone-based audio recording. IEEE Access 2021, 9, 43444–43457. [Google Scholar] [CrossRef]
- Zeghidour, N.; Grangier, D. Wavesplit: End-to-end speech separation by speaker clustering. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2840–2849. [Google Scholar] [CrossRef]
- Mika, D.; Budzik, G.; Jozwik, J. Single channel source separation with ICA-based time-frequency decomposition. Sensors 2020, 20, 2019. [Google Scholar] [CrossRef]
- Jiang, D.; He, Z.; Lin, Y.; Chen, Y.; Xu, L. An improved unsupervised single-channel speech separation algorithm for processing speech sensor signals. Wirel. Commun. Mob. Comput. 2021, 2021, 6655125. [Google Scholar] [CrossRef]
- Slizovskaia, O.; Haro, G.; Gómez, E. Conditioned source separation for musical instrument performances. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2083–2095. [Google Scholar] [CrossRef]
- Li, L.; Kameoka, H.; Makino, S. Majorization-minimization algorithm for discriminative non-negative matrix factorization. IEEE Access 2020, 8, 227399–227408. [Google Scholar] [CrossRef]
- Smith, S.; Pischella, M.; Terré, M. A moment-based estimation strategy for underdetermined single-sensor blind source separation. IEEE Signal Process. Lett. 2019, 26, 788–792. [Google Scholar] [CrossRef]
- Du, J.; Tu, Y.; Dai, L.R.; Lee, C.H. A regression approach to single-channel speech separation via high-resolution deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1424–1437. [Google Scholar] [CrossRef]
- Nugraha, A.A.; Liutkus, A.; Vincent, E. Multichannel audio source separation with deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1652–1664. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, H.; Nie, S.; Gao, G.; Liu, W. A pairwise algorithm using the deep stacking network for speech separation and pitch estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1066–1078. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D. Towards scaling up classification-based speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar] [CrossRef]
- Wang, Q.; Woo, W.L.; Dlay, S.S. Informed single-channel speech separation using HMM–GMM user-generated exemplar source. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 2087–2100. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Gao, B.; Woo, W.L.; Dlay, S.S. Single-channel blind separation using pseudo-stereo mixture and complex 2-D histogram. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1722–1735. [Google Scholar] [CrossRef] [PubMed]
- Ming, J.; Srinivasan, R.; Crookes, D.; Jafari, A. CLOSE—A data-driven approach to speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1355–1368. [Google Scholar] [CrossRef]
- Kim, W.; Stern, R.M. Mask classification for missing-feature reconstruction for robust speech recognition in unknown background noise. Speech Commun. 2011, 53, 1–11. [Google Scholar] [CrossRef]
- Hu, G.; Wang, D. Monaural speech segregation based on pitch tracking and amplitude modulation. IEEE Trans. Neural Netw. 2004, 15, 1135–1150. [Google Scholar] [CrossRef] [PubMed]
- Gao, B.; Woo, W.L.; Dlay, S.S. Unsupervised single-channel separation of nonstationary signals using Gammatone filterbank and itakura–saito nonnegative matrix two-dimensional factorizations. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 60, 662–675. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.J. Extreme learning machine with subnetwork hidden nodes for regression and classification. IEEE Trans. Cybern. 2015, 46, 2885–2898. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Deng, C.; Huang, G.B. Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 809–821. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man, Cybern. Part B Cybern. 2011, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.; Lu, Y.; Hu, Y.; Loizou, P.C. An algorithm that improves speech intelligibility in noise for normal-hearing listeners. J. Acoust. Soc. Am. 2009, 126, 1486–1494. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Han, K.; Wang, D. Exploring monaural features for classification-based speech segregation. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 270–279. [Google Scholar] [CrossRef]
- Hermansky, H.; Morgan, N. RASTA processing of speech. IEEE Trans. Speech Audio Process. 1994, 2, 578–589. [Google Scholar] [CrossRef]
- Al-Kaltakchi, M.; Woo, W.L.; Dlay, S.; Chambers, J.A. Evaluation of a speaker identification system with and without fusion using three databases in the presence of noise and handset effects. EURASIP J. Adv. Signal Process. 2017, 2017, 80. [Google Scholar] [CrossRef]
- Al-Kaltakchi, M.; Al-Nima, R.R.O.; Abdullah, M.A.; Abdullah, H.N. Thorough evaluation of TIMIT database speaker identification performance under noise with and without the G. 712 type handset. Int. J. Speech Technol. 2019, 22, 851–863. [Google Scholar] [CrossRef]
- Al-Kaltakchi, M.; Al-Nima, R.R.O.; Abdullah, M.A. Comparisons of extreme learning machine and backpropagation-based i-vectorapproach for speaker identification. Turk. J. Electr. Eng. Comput. Sci. 2020, 28, 1236–1245. [Google Scholar] [CrossRef]
- Al-Kaltakchi, M.; Abdullah, M.A.; Woo, W.L.; Dlay, S.S. Combined i-vector and extreme learning machine approach for robust speaker identification and evaluation with SITW 2016, NIST 2008, TIMIT databases. Circuits Syst. Signal Process. 2021, 40, 4903–4923. [Google Scholar] [CrossRef]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why does unsupervised pre-training help deep learning? In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 201–208. [Google Scholar]
- Mohammad, A.S.; Nguyen, D.H.H.; Rattani, A.; Puttagunta, R.S.; Li, Z.; Derakhshani, R.R. Authentication Verification Using Soft Biometric Traits. U.S. Patent 10,922,399, 16 February 2021. [Google Scholar]
- Mohammad, A.S. Multi-Modal Ocular Recognition in Presence of Occlusion in Mobile Devices; University of Missouri-Kansas City: Kansas City, MO, USA, 2018. [Google Scholar]
- Mohammad, A.S.; Rattani, A.; Derakhshani, R. Comparison of squeezed convolutional neural network models for eyeglasses detection in mobile environment. J. Comput. Sci. Coll. 2018, 33, 136–144. [Google Scholar]
- Mohammad, A.S.; Reddy, N.; James, F.; Beard, C. Demodulation of faded wireless signals using deep convolutional neural networks. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 969–975. [Google Scholar]
- Bezdek, J.; Hathaway, R. Some notes on alternating optimization. In Advances in Soft Computing—AFSS 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 187–195. [Google Scholar]
- Bhatia, R. Matrix Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 169. [Google Scholar]
- Barker, J.; Vincent, E.; Ma, N.; Christensen, H.; Green, P. The PASCAL CHiME speech separation and recognition challenge. Comput. Speech Lang. 2013, 27, 621–633. [Google Scholar] [CrossRef]
- Goto, M.; Hashiguchi, H.; Nishimura, T.; Oka, R. RWC Music Database: Music Genre Database and Musical Instrument Sound Database. 2003. Available online: http://jhir.library.jhu.edu/handle/1774.2/36 (accessed on 23 April 2023).
- Ellis, D. PLP, RASTA, and MFCC, Inversion in Matlab. 2005. Available online: http://www.ee.columbia.edu/~dpwe/resources/matlab/rastamat/ (accessed on 23 April 2023).
- Févotte, C.; Bertin, N.; Durrieu, J.L. Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Comput. 2009, 21, 793–830. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Time (s) | Testing Accuracy (%) | |
|---|---|---|---|
| Guitar and Male | MLP | 3335 | 93.8 ± 0.4 |
| DNN | 5667 | 97.4 ± 0.2 | |
| DSELM | 8.84 | 98.7 ± 0.3 | |
| Guitar and Female | MLP | 3146 | 94.1 ± 0.5 |
| DNN | 5326 | 97.2 ± 0.2 | |
| DSELM | 8.39 | 99.2 ± 0.2 | |
| Bass and Male | MLP | 3261 | 92.5 ± 0.4 |
| DNN | 5438 | 96.4 ± 0.3 | |
| DSELM | 8.21 | 98.3 ± 0.3 | |
| Bass and Female | MLP | 3094 | 93.9 ± 0.4 |
| DNN | 5296 | 97.1 ± 0.2 | |
| DSELM | 8.36 | 98.9 ± 0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Kaltakchi, M.T.S.; Mohammad, A.S.; Woo, W.L. Ensemble System of Deep Neural Networks for Single-Channel Audio Separation. Information 2023, 14, 352. https://doi.org/10.3390/info14070352
Al-Kaltakchi MTS, Mohammad AS, Woo WL. Ensemble System of Deep Neural Networks for Single-Channel Audio Separation. Information. 2023; 14(7):352. https://doi.org/10.3390/info14070352
Chicago/Turabian StyleAl-Kaltakchi, Musab T. S., Ahmad Saeed Mohammad, and Wai Lok Woo. 2023. "Ensemble System of Deep Neural Networks for Single-Channel Audio Separation" Information 14, no. 7: 352. https://doi.org/10.3390/info14070352
APA StyleAl-Kaltakchi, M. T. S., Mohammad, A. S., & Woo, W. L. (2023). Ensemble System of Deep Neural Networks for Single-Channel Audio Separation. Information, 14(7), 352. https://doi.org/10.3390/info14070352