
Learned Text Representation for Amharic Information Retrieval and Natural Language Processing



Abstract
1. Introduction
2. Related Work
3. Construction of Learned Text Representations for Amharic
3.1. Amharic Language
3.2. Pre-Training Process
3.3. Construction of Amharic Pre-Training Models
3.3.1. Amharic Pre-Trained Word Embeddings
| Word-based: | <ለም, ለምስ, ምስክ, ስክር, ክርነ, ርነት, ነት>, and ለምስክርነት |
| Stem-based: | <ምስ, ምስክ, ስክር, ክር>, and ምስክር |
| Root-based: | <ም-, ም-ስ,-ስ-, ስ-ክ, -ክ-¸ ክ-ር, -ር>, and ም-ስ-ክ-ር |
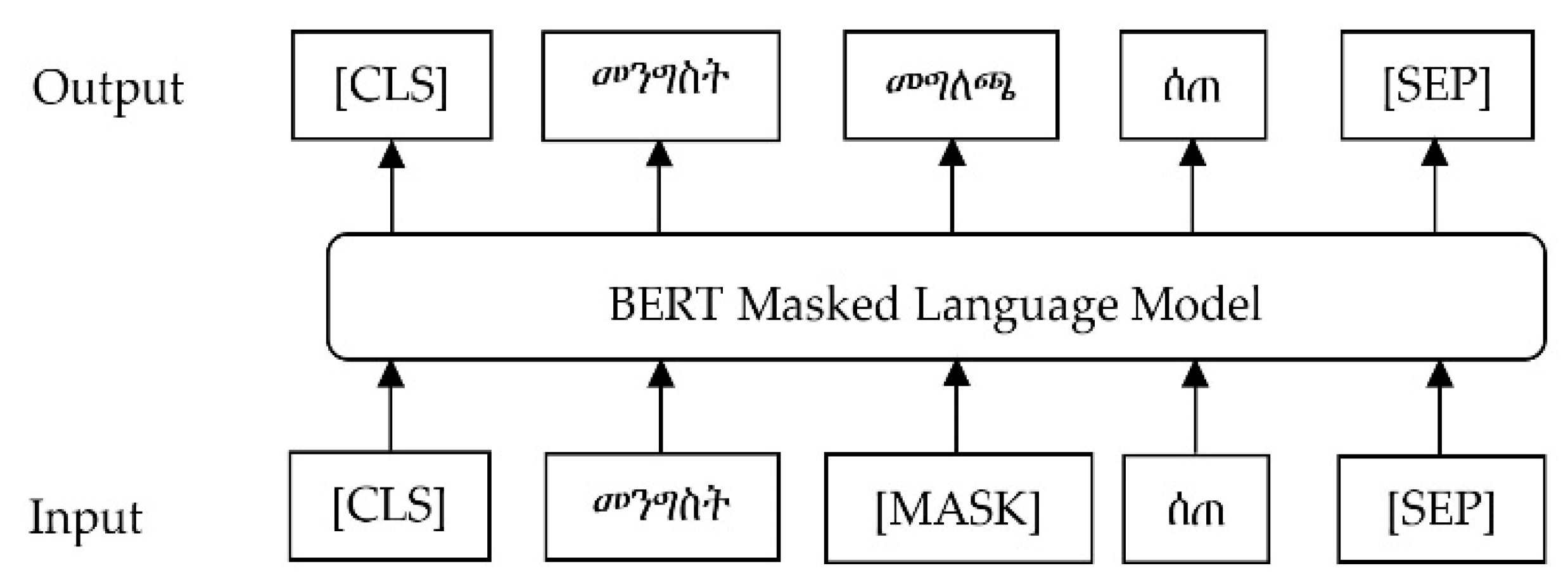
3.3.2. Amharic Pre-Trained BERT Language Models
3.4. Usability of Pre-Trained Amharic Word Embeddings and BERT Models
3.4.1. Pre-Trained Amharic Models for IR
3.4.2. Pre-Trained Amharic Models for Text Classification
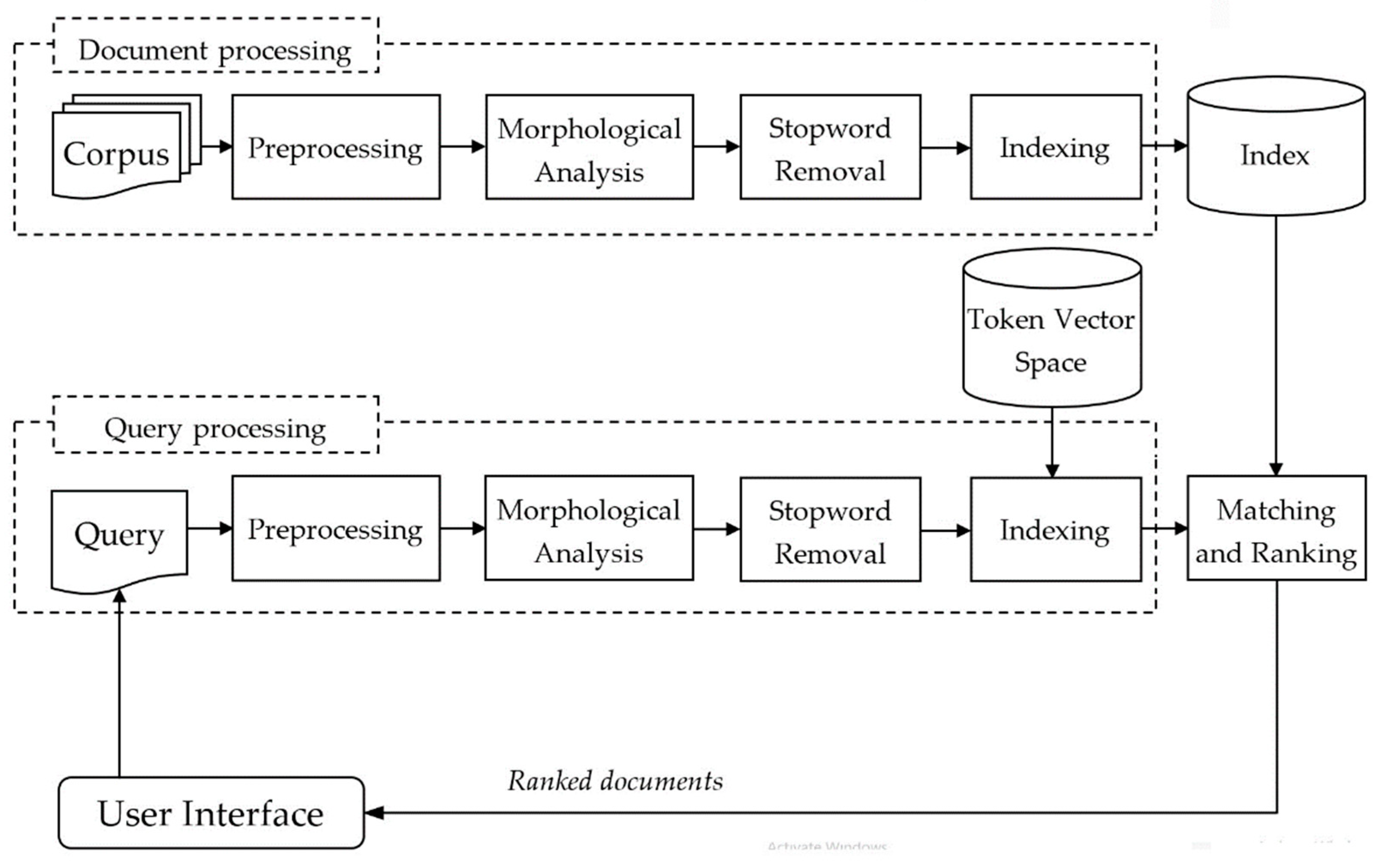
4. Experimental Framework
4.1. Implementation
4.2. Datasets
4.3. BERT Vocabulary
4.4. Pre-trained Models and Training Configurations
4.5. Evaluation Metrics
5. Results and Discussion
5.1. Result
5.1.1. Pre-Trained BERT Models
5.1.2. Fine Tuning
5.1.3. Query Expansion Using Word Embedding
5.2. Discussion
- i.
- Three BERT WordPiece tokenizers (word-based, stem-based, and root-based);
- ii.
- Three BERT byte-pair encoding (BPE) tokenizers (word-based, stem-based, and root-based);
- iii.
- Three BERT masked language models (word-based, stem-based, and root-based);
- iv.
- Three BERT next sentence prediction models (word-based, stem-based, and root-based);
- v.
- Nine word embedding models (word2vec, GloVe and fastText; each has word-based, stem-based and, root-based versions).
- i.
- Since our datasets are small relation to the requirement of BERT model, we tested only the effect of BERT at the base case. However, recently, BERT, at a large scale, has performed better than the base case on huge datasets. Therefore, the performance of the BERT model can be further enhanced with the use of a large corpus.
- ii.
- Recently, the use of the BERT model for ranking retrieval results has provided better performance. In our study, we evaluated the performance of the BERT model to identify relevant and non-relevant documents for a query rather than ranking. Thus, our IR system can be extended to include ranking of retrieval results using the BERT model.
5.3. Application of the Pre-Trained Word Embedding and BERT Models
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Lin, Y.; Sun, M. Representation Learning for Natural Language Processing; Open access e-book; Springer: Berlin/Heidelberg, Germany, 2020; ISBN 978-981-15-5572-5. Available online: https://link.springer.com/book/10.1007/978-981-15-5573-2 (accessed on 15 May 2022).
- Manning, C.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval; Draft e-book; Cambridge University Press: Cambridge, UK, 2010; Available online: https://nlp.stanford.edu/IR-book/pdf/irbookprint.pdf (accessed on 22 June 2022).
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Tellex, S.; Katz, B.; Lin, J.; Fernandes, A.; Marton, G. Quantitative evaluation of passage retrieval algorithms for question answering. In Proceedings of the 26th Annual international ACM SIGIR Conference on Research and Development in Information Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 41–47. [Google Scholar]
- Turian, J.; Ratinov, L.; Yoshua, B. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 384–394. [Google Scholar]
- Socher, R.; Bauer, J.; Manning, C.; Ng, A.Y. Parsing with compositional vector grammars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 455–465. [Google Scholar]
- Babic, K.; Martinčić-Ipšić, S.; Meštrovi’c, A. Survey of neural text representation models. Information 2020, 11, 511. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Logeswaran, L.; Lee, H. An efficient framework for learning sentence representations. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–16. [Google Scholar]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 957–966. [Google Scholar]
- Zhou, G.; He, T.; Zhao, J.; Hu, P. Learning continuous word embedding with metadata for question retrieval in community question answering. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 27–29 July 2015; pp. 250–259. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Athiwaratkun, B.; Gordon, A.; Anandkumar, A. Probabilistic fastText for multi-sense word embeddings. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1–11. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Antoun, W.; Bal, F.; Hajj, H. Arabert: Transformer-based model for Arabic language under-standing. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 9–15. [Google Scholar]
- Delobelle, P.; Winters, T.; Berendt, B. RobBERT: A Dutch RoBERTa-based language model. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–18 November 2020; pp. 3255–3265. [Google Scholar]
- Polignano, M.; Basile, P.; Gemmis, M.; Semeraro, G.; Basile, V. AlBERTo: Italian BERT language understanding model for NLP challenging tasks based on tweets. In Proceedings of the Sixth Italian Conference on Computational Linguistics (CLiC-It 2019), Bari, Italy, 13–15 November 2019; Volume 2481. [Google Scholar]
- Terumi, E.; Vitor, J.; Knafou, J.; Copara, J.; Oliveira, L.; Gumiel, Y.; Oliveira, L.; Teodoro, D.; Cabrera, E.; Moro, C. BioBERTpt-A Portuguese neural language model for clinical named entity recognition. In Proceedings of the 3rd Clinical Natural Language Processing Workshop, Online, 19 November 2020; pp. 65–72. [Google Scholar]
- Kuratov, Y.; Arkhipov, M. Adaptation of deep bidirectional multilingual transformers for Russian language. In Proceedings of the Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2019”, Newral Networks and Deep Learning Lab, Moscow, Russia, 29 May–1 June 2019; pp. 1–7. [Google Scholar]
- Martin, L.; Muller, B.; Javier, P.; Suárez, O.; Dupont, Y.; Romary, L.; Villemonte, É.; Clergerie, D.; Seddah, D.; Sagot, B. CamemBERT: A Tasty French language model. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7203–7219. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2022, 2, 225–250. [Google Scholar] [CrossRef]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Evaluation of corpora, resources and tools for Amharic information retrieval. In Proceedings of the ICAST2020, Bahir Dar, Ethiopia, 2–4 October 2020; pp. 470–483. [Google Scholar]
- Diaz, F.; Mitra, B.; Craswell, N. Query expansion with locally-trained word embeddings. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 367–377. [Google Scholar]
- Aklouche, B.; Bounhas, I.; Slimani, Y. Query expansion based on NLP and word embeddings. In Proceedings of the 27th Text REtrieval Conference (TREC 2018), Gaithersburg, ML, USA, 14–16 November 2018; pp. 1–7. [Google Scholar]
- Getnet, B.; Assabie, Y. Amharic information retrieval based on query expansion using semantic vocabulary. In Proceedings of the 8th EAI International Conference on Advancements of Science and Technology, Bahir Dar, Ethiopia, 2–4 October 2021; pp. 407–416. [Google Scholar]
- Deho, O.; Agangiba, W.; Aryeh, F.; Ansah, J. Sentiment analysis with word embedding. In Proceedings of the 2018 IEEE 7th International Conference on Adaptive Science & Technology (ICAST), Accra, Ghana, 22–24 August 2018; pp. 1–4. [Google Scholar]
- Acosta, J.; Norissa, L.; Mingxiao, L.; Ezra, F.; Andreea, C. Sentiment analysis of twitter messages using word2Vec. In Proceedings of the Student Faculty Research Day, CSIS, New York, NY, USA, 5 May 2017; pp. 1–7. [Google Scholar]
- Medved, M.; Horák, A. Sentence and Word embedding employed in Open question-Answering. In Proceedings of the 10th International Conference on Agents and Artificial Intelligence (ICAART 2018), Funchal, Portugal, 16–18 January 2018; pp. 486–492. [Google Scholar]
- Sun, Y.; Zheng, Y.; Hao, C.; Qiu, H. NSP-BERT: A Prompt-based few-shot learner through an original pre-training task—Next sentence prediction. In Proceedings of the 29th International Conference on Computational Linguistics, Yeongju, Republic of Korea, 12–17 October 2022; pp. 3233–3250. [Google Scholar]
- Shi, W.; Demberg, V. Next sentence prediction helps implicit discourse relation classification within and across domains. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5790–5796. [Google Scholar]
- Bai, H.; Zhao, H. Deep enhanced representation for implicit discourse relation recognition. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 571–583. [Google Scholar]
- Prasad, R.; Dinesh, N.; Lee, A.; Miltsakaki, E.; Robaldo, L.; Joshi, A.; Webber, B. The Penn Discourse TreeBank 2.0. In Proceedings of the Sixth Conference on International Language Resources and Evaluation (LREC-2008), Marrakech, Morocco, 28–30 May 2008; pp. 2961–2968. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for Chinese BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Aggarwal, A.; Chauhan, A.; Kumar, D.; Mittal, M.; Verma, S. Classification of fake news by fine-tuning deep bidirectional transformers based language model. EAI Endorsed Trans. Scalable Inf. Syst. 2020, 27, e10. [Google Scholar] [CrossRef]
- Protasha, N.; Sam, A.; Kowsher, M.; Murad, S.; Bairagi, A.; Masud, M.; Baz, M. Transfer learning for sentiment analysis using BERT based supervised fine-tuning. Sensors 2022, 22, 4157. [Google Scholar] [CrossRef] [PubMed]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning word vectors for 157 languages. In Proceedings of the International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; pp. 3483–3487. [Google Scholar]
- Eshetu, A.; Teshome, G.; Abebe, T. Learning word and sub-word vectors for Amharic (Less Resourced Language). Int. J. Adv. Eng. Res. Sci. (IJAERS) 2020, 7, 358–366. [Google Scholar] [CrossRef]
- Muhie, S.; Ayele, A.; Venkatesh, G.; Gashaw, I.; Biemann, C. Introducing various semantic models for Amharic: Experimentation and evaluation with multiple tasks and datasets. Future Internet 2021, 13, 275. [Google Scholar] [CrossRef]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Amharic adhoc information retrieval system based on morphological features. Appl. Sci. 2021, 12, 1294. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Construction of morpheme-based Amharic stopword list for information retrieval system. In Proceedings of the 8th EAI International Conference on Advancements of Science and Technology, Bahir Dar, Ethiopia, 2–4 October 2020; pp. 484–498. [Google Scholar]
- Alemayehu, N.; Willett, P. The effectiveness of stemming for information retrieval in Amharic. Program Electron. Libr. Inf. Syst. 2003, 37, 254–259. [Google Scholar] [CrossRef]
- Yimam, B. Yamarigna Sewasiw (Amharic Grammar), 2nd ed.; CASE: Addis Ababa, Ethiopia, 2000. [Google Scholar]
- Wolf, L. Reference Grammar of Amharic, 1st ed.; Otto Harrassowitz: Wiesbaden, Germany, 1995. [Google Scholar]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Amharic document representation for adhoc retrieval. In Proceedings of the 12th International Conference on Knowledge Discovery and Information Retrieval, Online, 2–4 November 2020; pp. 124–134. [Google Scholar]
- Arora, P.; Foster, J.; Jones, G. Query expansion for sentence retrieval using pseudo relevance feedback and word embedding. In Proceedings of the CLEF 2017, Dubline, Ireland, 11–14 September 2017; pp. 97–103. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune BERT for text classification? In Proceedings of the 21st China National Conference on Chinese Computational Linguistics, Nanchang, China, 14–16 October 2020; pp. 194–206. [Google Scholar]
- Palotti, J.; Scells, H.; Zuccon, G. TrecTools: An Open-source Python Library for Information Retrieval Practitioners Involved in TREC-like Campaigns. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’19), Paris, France, 21–25 July 2019; pp. 1325–1328. [Google Scholar] [CrossRef]
- Yeshambel, T.; Mothe, J.; Assabie, Y. 2AIRTC: The Amharic Adhoc information retrieval test collection. In Proceedings of the CLEF 2020, LNCS 12260, Thessaloniki, Greece, 22–25 September 2020; pp. 55–66. [Google Scholar]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Morphologically annotated Amharic text corpora. In Proceedings of the 44th ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 2349–2355. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Lin, J.; Nogueira, R.; Yates, A. Pre-trained transformers for text ranking: BERT and Beyond. In Proceedings of the NAACL-HLT, Mexico City, Mexico, 6–11 June 2021; pp. 1–4. [Google Scholar]
- Limsopatham, N. Effectively leveraging BERT for legal document classification. In Proceedings of the Natural Legal Language Processing Workshop 2021, Punta Cana, Dominican Republic, 10 November 2021; pp. 210–216. [Google Scholar]
- Chen, X.; Cong, P.; Lv, S. A long-text classification method of Chinese news based on BERT and CNN. IEEE Access 2022, 10, 34046–34057. [Google Scholar] [CrossRef]
- Goyal, T.; Bhadola, S.; Bhatia, K. Automatic query expansion using word embedding based on fuzzy graph connectivity measures. Int. J. Trend Sci. Res. Dev. (IJTSRD) 2021, 5, 1429–1442. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | Training Sample | Type |
|---|---|---|
| ጽሁፍ | (ጽሁፍ, የተጻፈው), (ጽሁፍ, የህክምና), (ጽሁፍ, እርዳታ) | Word |
| (ጽሁፍ, ጻፍ), (ጽሁፍ, ህክም), (ጽሁፍ, ርድ) | Stem | |
| (ጽ-ህ-ፍ, ጽ-ህ-ፍ), (ጽ-ህ-ፍ, ህ-ክ-ም), (ጽ-ህ-ፍ, ር-ድ) | Root | |
| የተጻፈው | (የተጻፈው, ጽሁፍ), (የተጻፈው, የህክምና), (የተጻፈው, እርዳታ), (የተጻፈው, ለመስጠት) | Word |
| (ጻፍ, ጽሁፍ), (ጻፍ, ህክም), (ጻፍ, ርድ), (ጻፍ, ስጥ) | Stem | |
| (ጽ-ህ-ፍ, ጽ-ህ-ፍ), (ጽ-ህ-ፍ, ህ-ክ-ም), (ጽ-ህ-ፍ, ር-ድ), (ጽ-ህ-ፍ, ስ-ጥ) | Root | |
| የህክምና | (የህክምና, ጽሁፍ), (የህክምና, የተጻፈው), (የህክምና, እርዳታ), (የህክምና, ለመስጠት), (የህክምና, አይደለም) | Word |
| (ህክም, ጽሁፍ), (ህክም, ጻፍ), (ህክም, ርድ), (ህክም, ስጥ) | Stem | |
| (ህ-ክ-ም, ጽ-ህ-ፍ), (ህ-ክ-ም, ጽ-ህ-ፍ), (ህ-ክ-ም, ር-ድ), (ህ-ክ-ም, ስ-ጥ) | Root | |
| እርዳታ | (እርዳታ, ጽሁፍ), (እርዳታ, የተጻፈው), (እርዳታ,የህክምና), (እርዳታ,ለመስጠት), (እርዳታ, አይደለም) | Word |
| (ርድ, ጽሁፍ), (ርድ, ጻፍ), (ርድ, ህክም), (ርድ, ስጥ) | Stem | |
| (ር-ድ, ጽ-ህ-ፍ), (ር-ድ, ጽ-ህ-ፍ), (ር-ድ, ህ-ክ-ም), (ር-ድ, ስ-ጥ) | Root | |
| ለመስጠት | (ለመስጠት, የተጻፈው), (ለመስጠት, የህክምና), (ለመስጠት, እርዳታ), (ለመስጠት, አይደለም) | Word |
| (ስጥ, ጻፍ), (ስጥ, ህክም), (ስጥ, ርድ) | Stem | |
| (ስ-ጥ, ጽ-ህ-ፍ), (ስ-ጥ, ህ-ክ-ም), (ስ-ጥ, ር-ድ) | Root |
| Model | Vector Size | Window Size | Epoch | Min_Count | Learning Rate |
|---|---|---|---|---|---|
| word2vec | 300 | 5 | 20 | 3 | 0.05 |
| GloVe | 100 | 10 | 30 | 5 | 0.05 |
| fastText | 100 | 5 | 30 | 5 | 0.05 |
| Model | Case | Layer Size | Batch Size | Max Length | Hidden | Attention | Total Parameters | Learning Rate |
|---|---|---|---|---|---|---|---|---|
| NSP | base | 12 | 16 | 512 | 768 | 12 | 110 M | 10−5 |
| MLM | base | 12 | 16 | 512 | 768 | 12 | 110 M | 10−5 |
| Dataset | Training Loss | |
|---|---|---|
| Epoch 5 | Epoch 10 | |
| Word-based | 0.253 | 0.480 |
| Stem-based | 0.458 | 0.497 |
| Root-based | 0.507 | 0.614 |
| Dataset | Model | Training Loss | Testing Loss | Accuracy | |||
|---|---|---|---|---|---|---|---|
| Epoch 5 | Epoch 10 | Epoch 5 | Epoch 10 | Epoch 5 | Epoch 10 | ||
| Word | base | 0.211 | 2.84 × 10−5 | 0.307 | 1.443 | 0.68 | 0.52 |
| Stem | base | 0.343 | 0.051 | 0.652 | 1.74 | 0.66 | 0.64 |
| Root | base | 0.432 | 0.0057 | 0.654 | 1.663 | 0.64 | 0.60 |
| Task | Training Loss | Validation Loss | F1-Score | Accuracy |
|---|---|---|---|---|
| Document classification based on subject | 0.03 | 0.58 | 0.91 | 0.89 |
| Relevance classification | 0.02 | 0.38 | 0.97 | 0.95 |
| Dataset | Retrieval Effectiveness | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CBOW | Skip-gram | |||||||||
| P@5 | P@10 | ndcg | R-prec | bpref | P@5 | P@10 | ndcg | R-prec | bpref | |
| Word-based | 0.53 | 0.51 | 0.70 | 0.45 | 0.43 | 0.53 | 0.51 | 0.70 | 0.45 | 0.43 |
| Stem-based | 0.40 | 0.35 | 0.55 | 0.32 | 0.30 | 0.40 | 0.35 | 0.55 | 0.32 | 0.30 |
| Root-based | 0.45 | 0.40 | 0.66 | 0.38 | 0.36 | 0.44 | 0.38 | 0.66 | 0.36 | 0.35 |
| Datasets | Retrieval Effectiveness | ||||
|---|---|---|---|---|---|
| P@5 | P@10 | ndcg | R-prec | bpref | |
| Word-based | 0.54 | 0.50 | 0.70 | 0.45 | 0.43 |
| Stem-based | 0.36 | 0.34 | 0.55 | 0.32 | 0.29 |
| Root-based | 0.41 | 0.38 | 0.66 | 0.37 | 0.34 |
| Dataset | Retrieval Effectiveness | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CBOW | Skip-Gram | |||||||||
| P@5 | P@10 | ndcg | R-Prec | bpref | P@5 | P@10 | ndcg | R-Prec | bpref | |
| Word-based | 0.50 | 0.44 | 0.66 | 0.37 | 0.34 | 0.60 | 0.56 | 0.75 | 0.49 | 0.47 |
| Stem-based | 0.30 | 0.27 | 0.51 | 0.26 | 0.22 | 0.32 | 0.30 | 0.52 | 0.26 | 0.23 |
| Root-based | 0.34 | 0.30 | 0.62 | 0.32 | 0.29 | 0.37 | 0.33 | 0.62 | 0.32 | 0.29 |
| Model | Word | Top 10 Most Similar Words |
|---|---|---|
| Word | በሽታ | በበሽታ, በሽታው, በበሽታው, በሽታወች, በሽታን, በሽ, በቫይረሱ, ቲቢ, ቫይረሶቹ, በኤችአይቪ |
| የምርመራ | የምርመራው, የምርመራና, የምርመራውን, የሙከራ, የቅስቀሳ, የጨረራ, የምርቃት, የቆጠራ, ለምርመራ, የሰመራ | |
| አገልግሎት | አገልግሎ, አገልግሎት, አገልግሎትም, አገልግሎቱ, አገልግሎቱም, አገልግሎትና, አገልግሎቱንና, አገልገሎት, አግልግሎት, አገልግሎታቸው | |
| መቆጣጠሪያ | መቆጣጠሪያና, መከታተያ, መቁጠሪያ, መቆያ, መቋቋሚያ, መከራከሪያ, መደገፊያ, ማጥፊያ, ማቆምያ, መደርደሪያ | |
| አክራሪነት | አክራሪነት, አክራሪነትና, አክራሪነትንና, አክራሪ, አክራሪና, አሸባሪነት, አክራሪነትን, አሸባሪነትና, አርበኝነት, አሳቢነት | |
| Stem | በሽታ | ኤችፒቪ, ቫይረስ, ካንሰር, ሽታ, በሽ, በሽት, ህመም, ህከም, ክትብ, አይቪ |
| ምርመር | መርመር, አጣር, ቆጣር, ህክም, ጣር, ጥርጣር, ምረመር, ኦዲት, ቆጣጣር, ክምር | |
| ገልግል | ገልግል, ገል, ገልጥ, ገልል, ግልግል, ገልበጥ, ገለገል, ገልገል, ገላገል, ገልጋል | |
| ቆጣጠር | ቆጣር, ቆጣጥር, ነጠር, ቆጣጣር, ከሰር, ከላካል, ፈንጠር, ከላከል, ቆጣ, ቁጠር | |
| ክራር | ክራር, ክራክ, ክራሪ, ጽንፍ, አክራር, አክራ, ክፍ, ሽብር, ጸረሽብር, ሙስሊም | |
| Root | በሽታ | በሽታ, ሽታ,ቫይረስ, በሽ, ሽት, ካንሰር, ወባ, ቲቢ, ቫይርስ, ኤችፒቪ |
| ም-ር-ም-ር | ክ-ም-ር, ም-ር-ጥ, ም-ም-ር, ም-ር-ር, ድ-ም-ር, እ-ም-ር, ም-ር-ዝ, ም-ር-ክ-ዝ, ም-ር-ቅ, ት-ር-ም-ስ | |
| ግ-ል-ግ-ል | ግ-ግ-ል, ግ-ል, እ-ግ-ል, ግ-ል-ት, ድ-ግ-ል, ግ-ል-ል, ግ-ል-ብ, ግ-ው-ል-ም-ስ, ን-ግ-ል-ት, ግ-ል-ጥ | |
| ቅ-ጥ-ጥ-ር | ን-ጥ-ጥ-ር, ቅ-ጥ-ር, ብ-ጥ-ር, ን-ጥ-ር, ቅ-ጥ-ቅ-ጥ, ስ-ቅ-ጥ-ጥ, ጥ-ር-ጥ-ር, ስ-ብ-ጥ-ር, ው-ጥ-ር, ቅ-ጥ-ፍ | |
| ክ-ር-ር | ክ-ር-ር, ክ-ር-ክ-ር, ክ-ር, ክ-ር-ይ, ጽ-ር-ር, ክ-ር-ም, ክ-ር-ፍ, ክ-ር-ምት, ብ-ር-ር, ክ-ን-ን |
| Model | Conventional Text Representation | ||
|---|---|---|---|
| Word-Based | Stem-Based | Root-Based | |
| word2vec | አቅርቦት, የግብአት, የግብርና, በሲሚንቶ | ቅረብ, ቀርብ, ቀረብ, ኤሌክትሪክ | ድ-ር-ግ, አቃቢ, ፍ-ል-ግ, እ-ጥ-ር |
| GloVe | አቅርቦትን, የግብአት, አቅርቦት, ፍላጐትና | ዋል, ምስጋን, ጥር, ወልድም | ም-ስ-ግ-ን, ጥ-ር, ሪፖርት, ጥ-ይ-ቅ |
| fastText | የአቅርቦትና, በአቅርቦትና, አቅርቦት, የአቅርቦት | ምስግን, ዋል, ቀርብ, ምስጋናው | ጥ-ር, ቅርስ, ም-ል-ክ-ት, ክ-ር-ክ-ር |
| Technique | Precision | ndgc | R-Prec | ||||
|---|---|---|---|---|---|---|---|
| P@5 | P@10 | P@15 | P@20 | MAP | |||
| Conventional | 0.56 | 0.49 | 0.44 | 0.40 | 0.43 | 0.65 | 0.43 |
| With query expansion | 0.60 | 0.56 | 0.50 | 0.47 | 0.51 | 0.75 | 0.49 |
| Language | Down Streaming Task | Model | Performance |
|---|---|---|---|
| English [54] | Document classification | BERT | 0.96 (F1-score) |
| Chinese [55] | Document classification | BERT | 0.97 (accuracy) |
| English [25] | Ad hoc retrieval | word2vec | 0.48 (NDCG) |
| English [56] | Query expansion | word2vec GloVe fastText | 0.086 (precision) 0.087 (precision) 0.087 (precision) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeshambel, T.; Mothe, J.; Assabie, Y. Learned Text Representation for Amharic Information Retrieval and Natural Language Processing. Information 2023, 14, 195. https://doi.org/10.3390/info14030195
Yeshambel T, Mothe J, Assabie Y. Learned Text Representation for Amharic Information Retrieval and Natural Language Processing. Information. 2023; 14(3):195. https://doi.org/10.3390/info14030195
Chicago/Turabian StyleYeshambel, Tilahun, Josiane Mothe, and Yaregal Assabie. 2023. "Learned Text Representation for Amharic Information Retrieval and Natural Language Processing" Information 14, no. 3: 195. https://doi.org/10.3390/info14030195
APA StyleYeshambel, T., Mothe, J., & Assabie, Y. (2023). Learned Text Representation for Amharic Information Retrieval and Natural Language Processing. Information, 14(3), 195. https://doi.org/10.3390/info14030195