

Smart Machine Health Prediction Based on Machine Learning in Industry Environment

 ,
,  and
and
Abstract
1. Introduction
1.1. Challenges of Conventional Machine Monitoring
1.2. Advantages of Prognostics and Systems Health Management (PHM)
2. Related Work
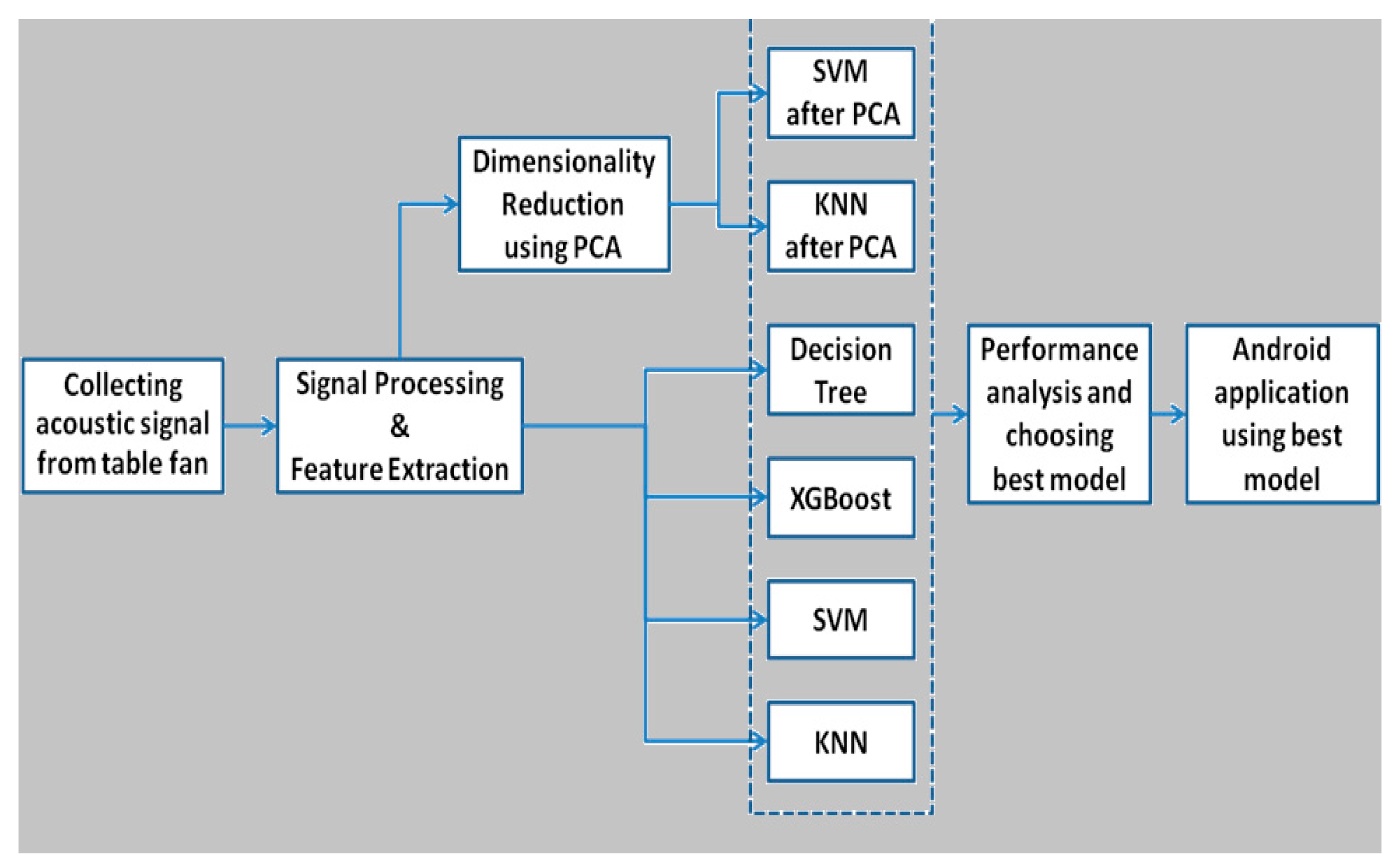
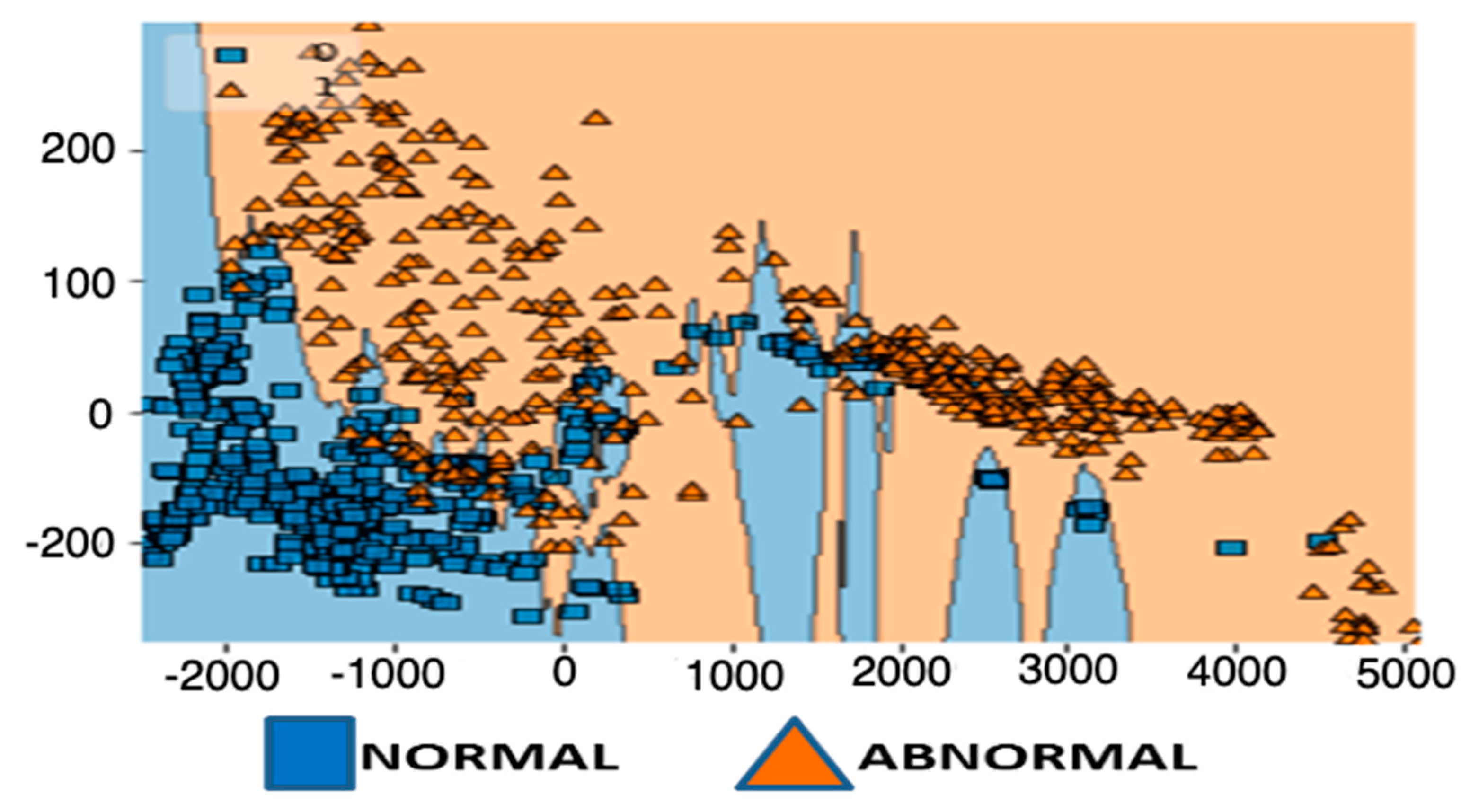
3. Proposed Solution
3.1. Usage of Algorithms
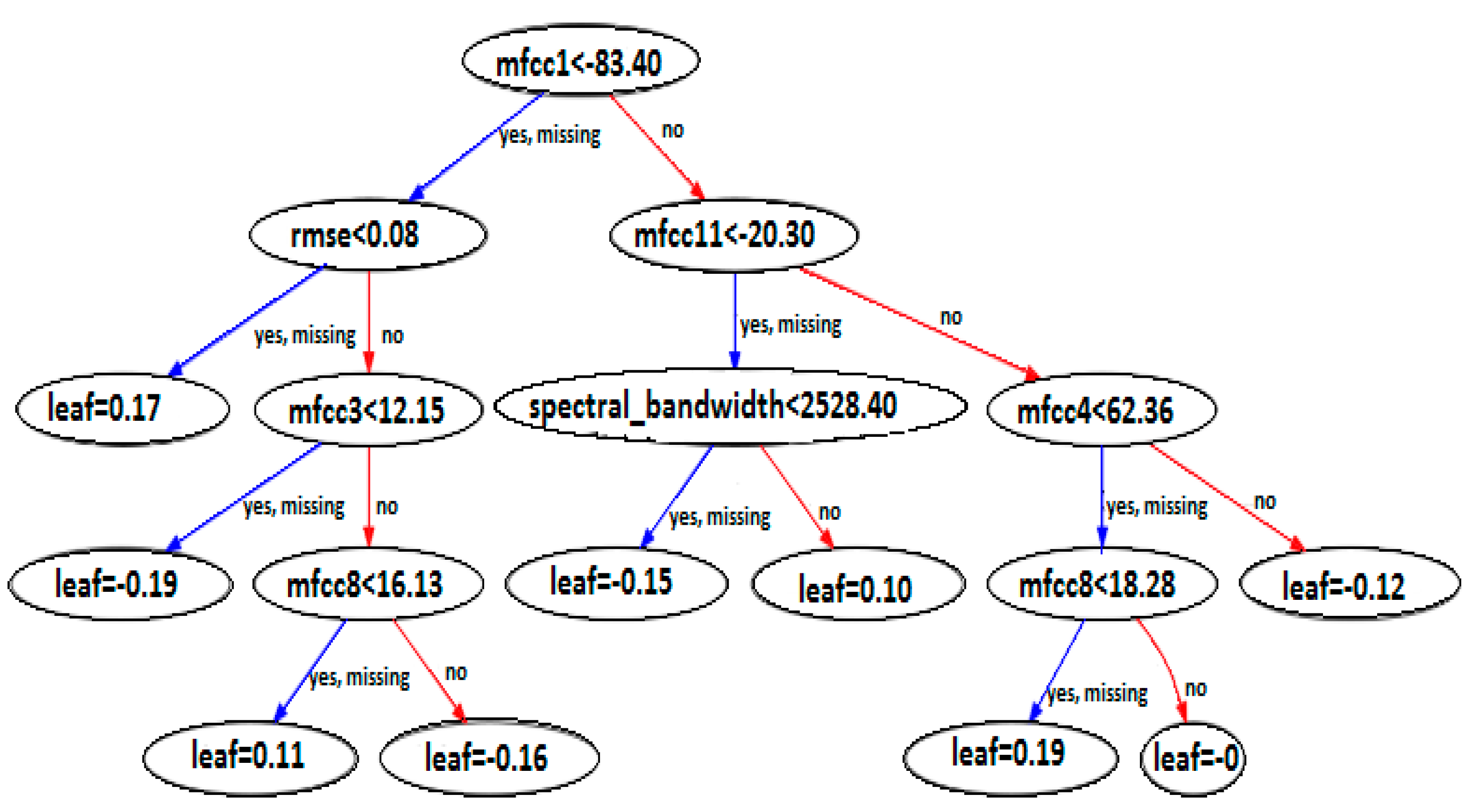
3.1.1. XGBoost Algorithm
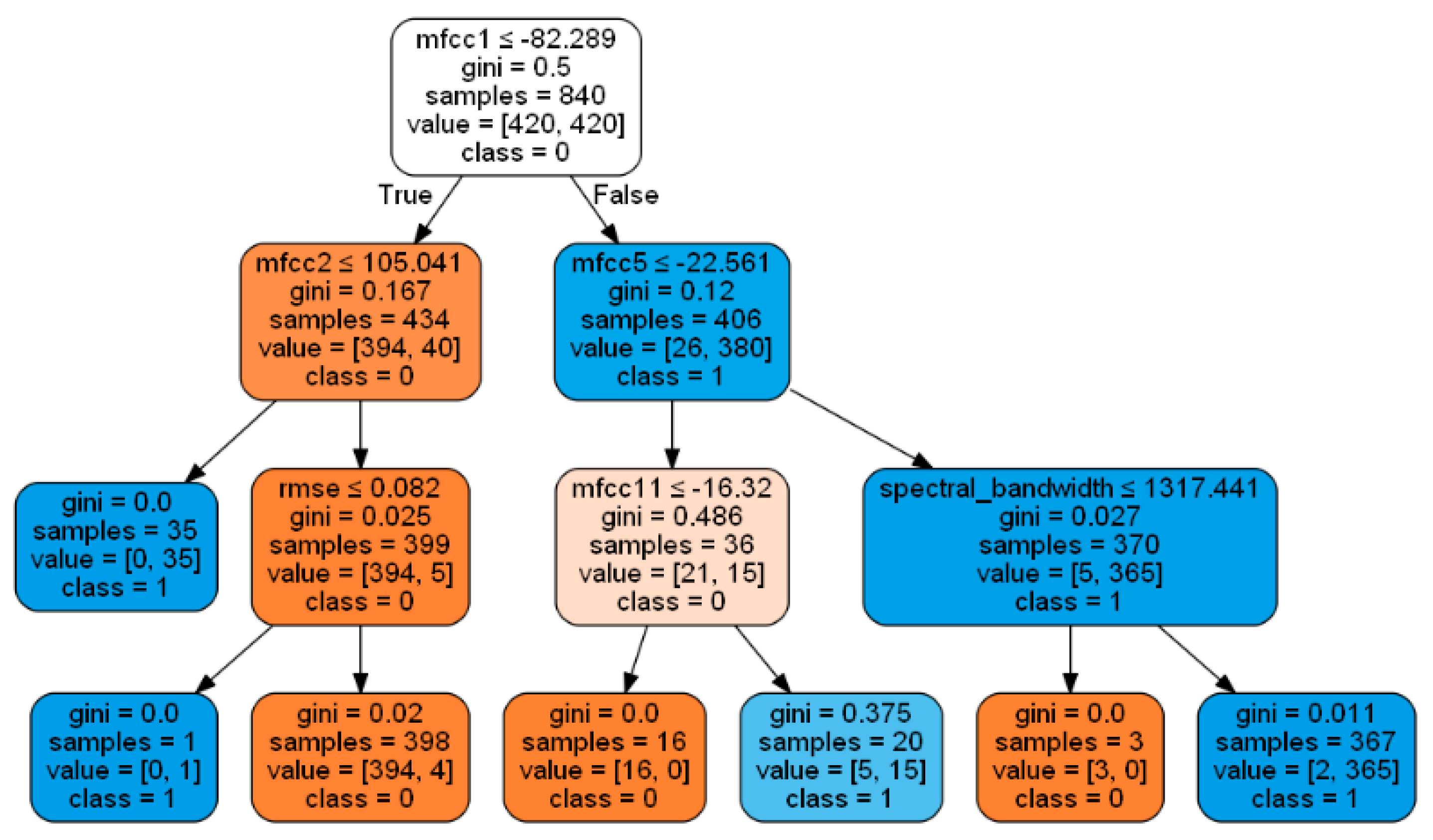
3.1.2. Decision Tree
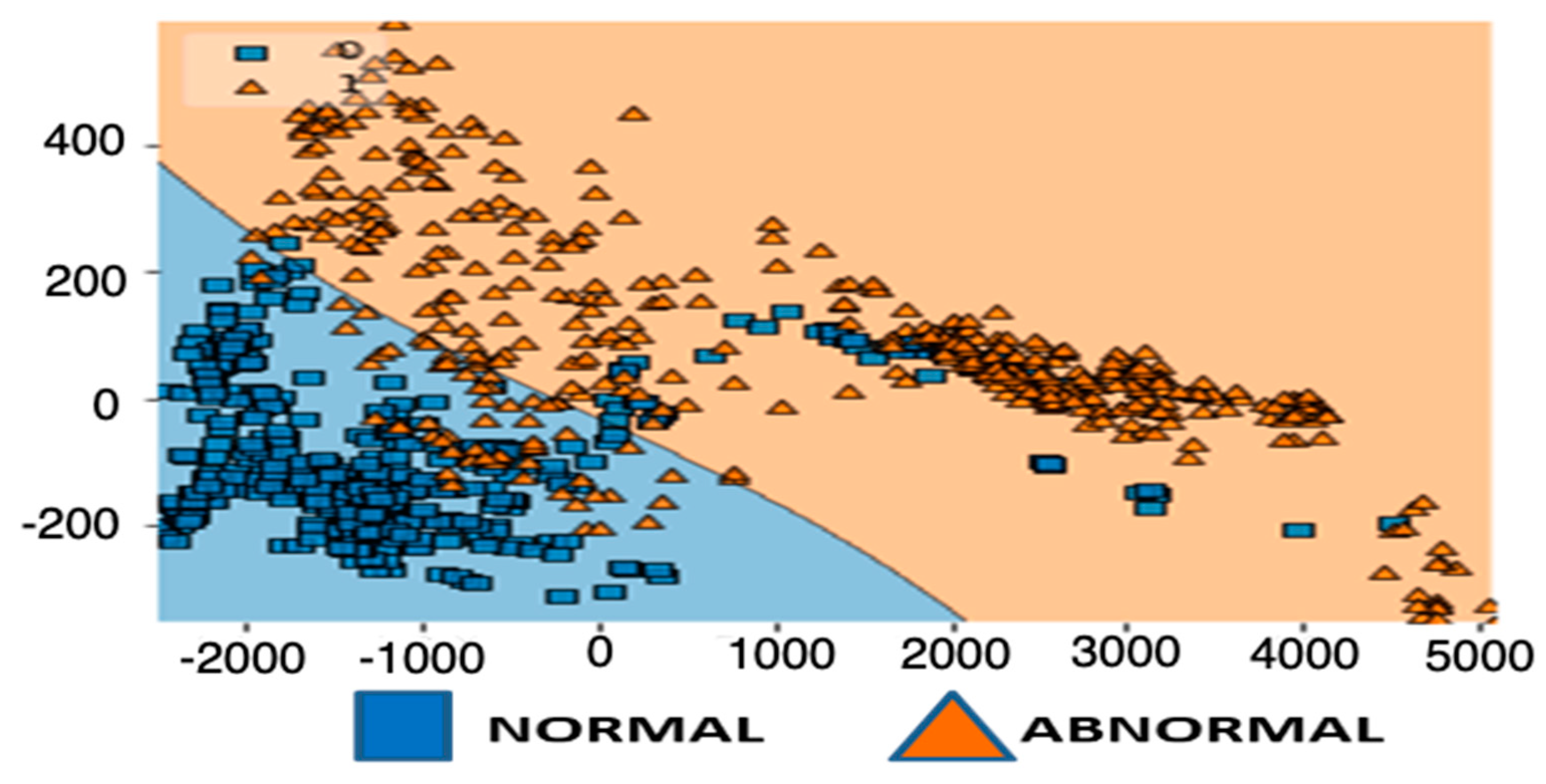
3.1.3. SVM Algorithm
3.1.4. KNN Model
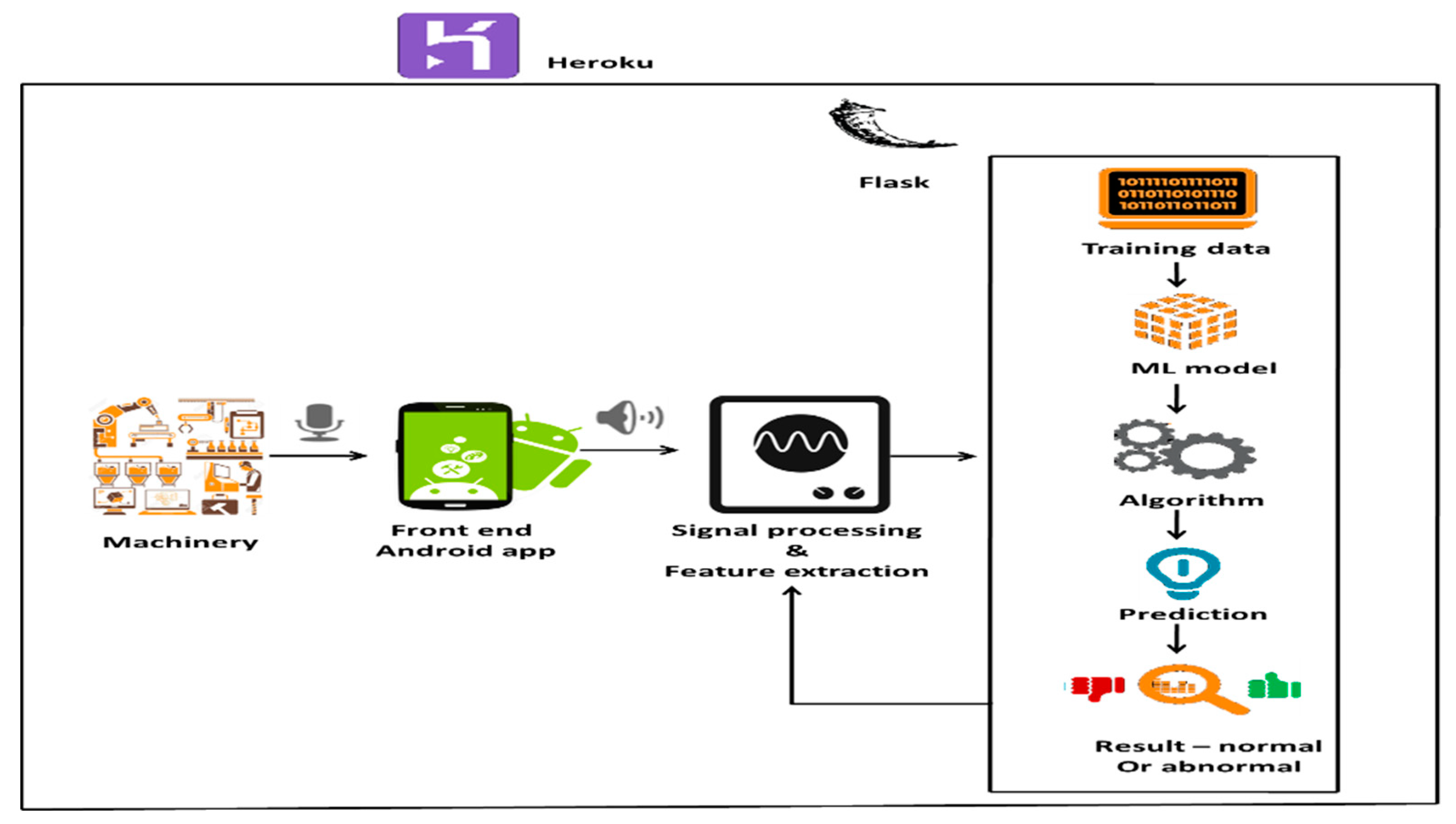
3.2. System Architecture
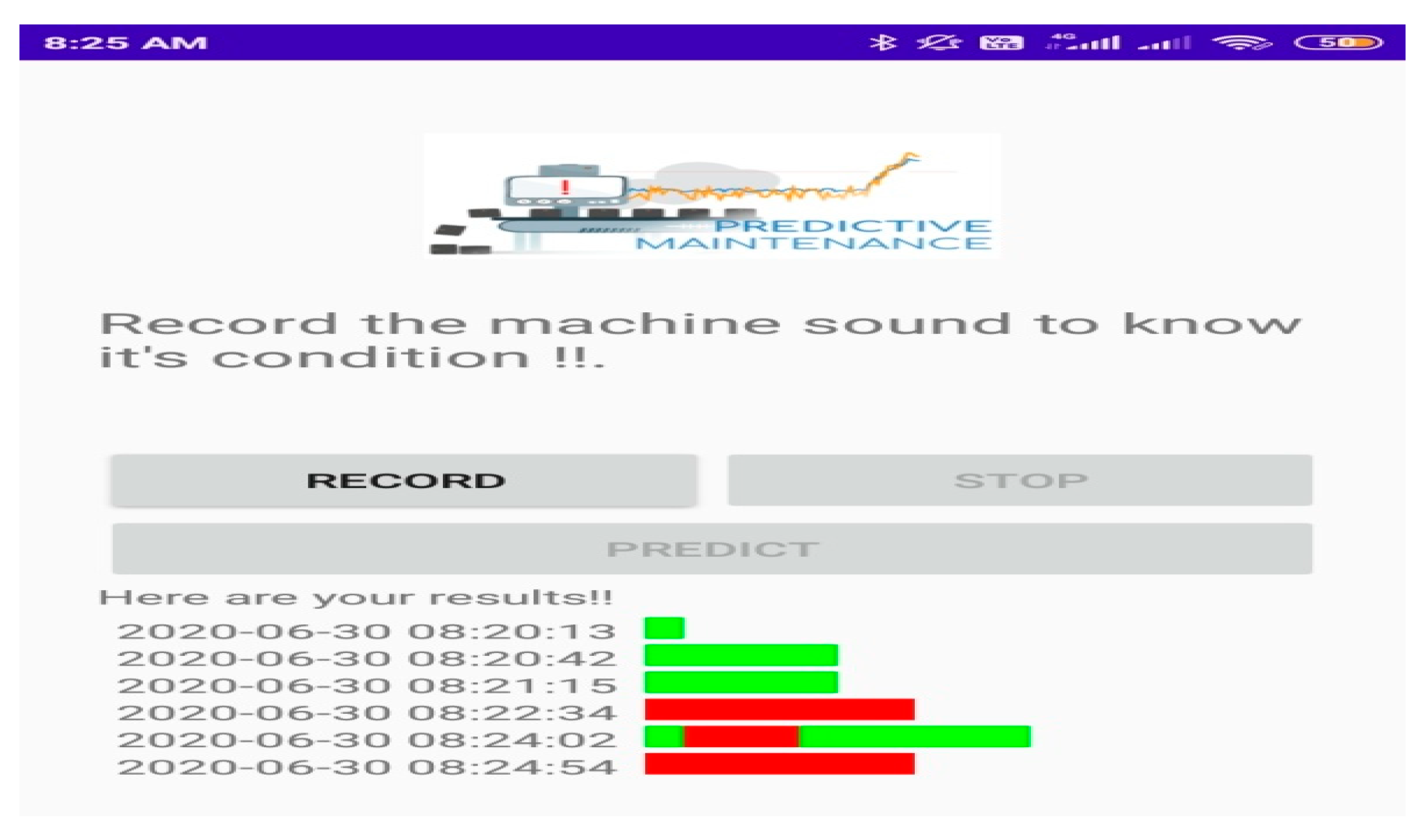
3.3. Development of User Interface
Features of User Interface
- Record Button—Starts the recording.
- Stop Button—Stops the recording and the file is saved in local machine.
- Predict Button—Sends the stored file to the Flask API (application programming interface), which carries out the prediction and returns the results to the android app (front end).
- Visualization—Process time is displayed alongside the received answer from the flask API, with red indicating abnormal and green indicating normal.
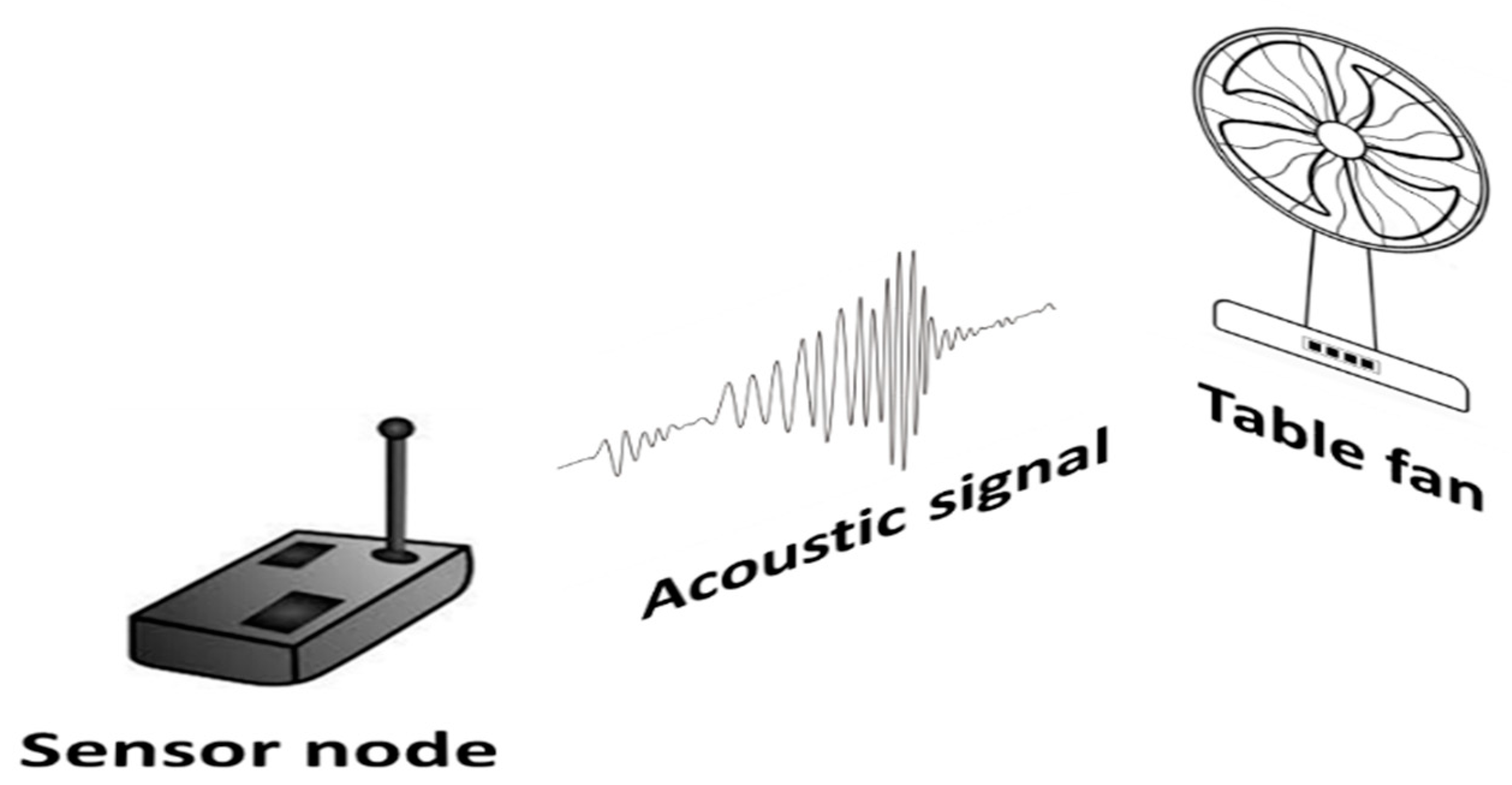
3.4. Experimental Setup
3.5. Dataset Description
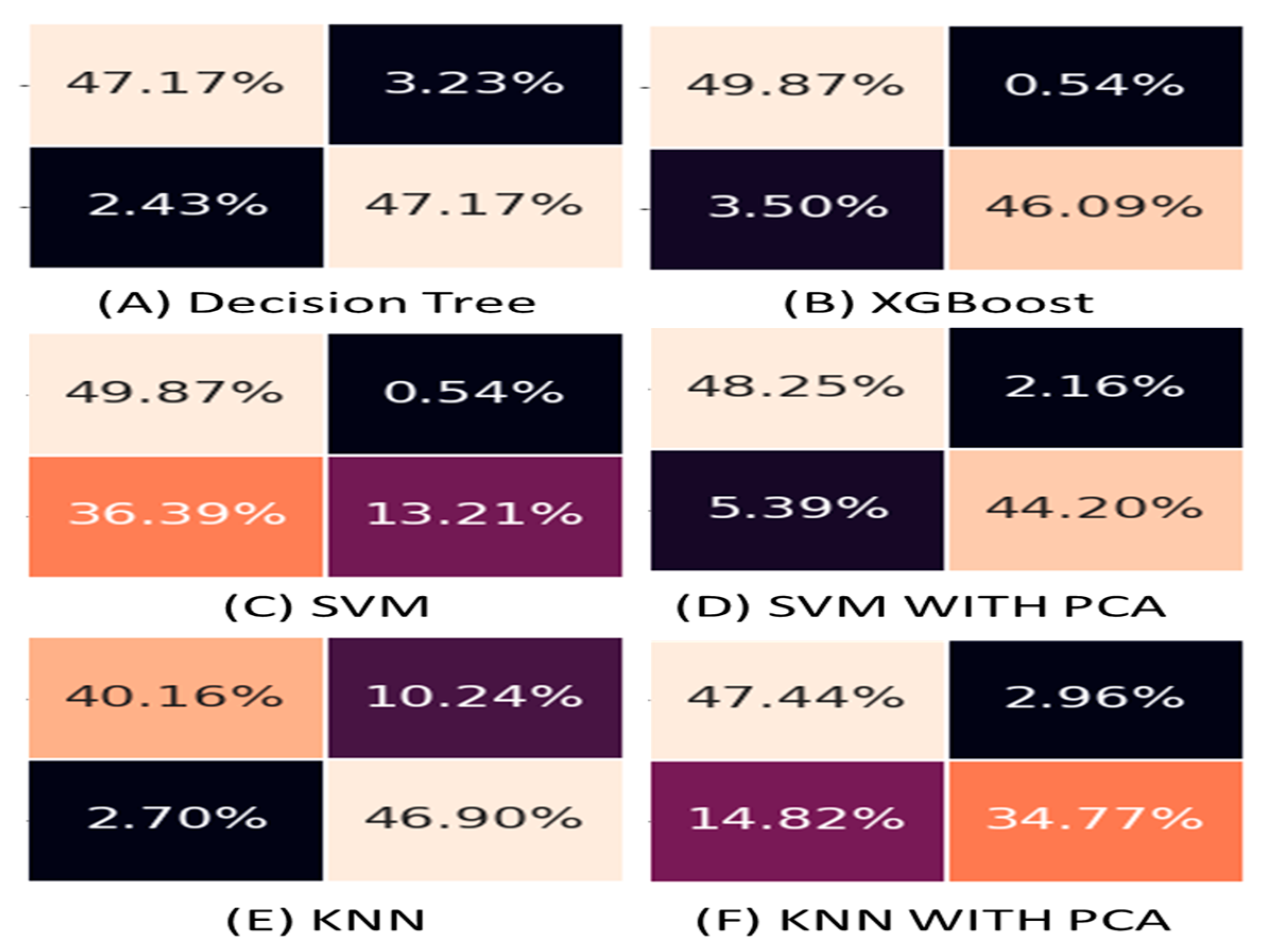
4. Results and Discussion
- Decision Tree: Classifier parameters such as criterion, max_depth, split, etc.;
- XGBoost: General parameters, booster parameters, and learning parameters;
- SVM: Regularization parameters; and
- KNN: value-n, weights(uniform) and type of algorithm.
Built of User Interface Using Android Environment and Flask
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kothamasu, R.; Huang, S.H.; Verduin, W.H. System health monitoring and prognostics—A review of current paradigms and practices. Int. J. Adv. Manuf. Technol. 2006, 28, 1012–1024. [Google Scholar] [CrossRef]
- 5 Causes of Equipment Faulure. Available online: https://www.fiixsoftware.com/blog/5-causes-of-equipment-failure-and-what-you-can-do-to-prevent-it/ (accessed on 9 November 2022).
- What Is Reactive Maintenance? Types, Benefits, Cost, and Examples. Available online: https://coastapp.com/blog/reactive-maintenance/ (accessed on 9 November 2022).
- Preventive Maintenance: The Ultimate Guide [2023]. Available online: https://blog.infraspeak.com/preventive-maintenance/ (accessed on 9 November 2022).
- Predicictive Maintenance Explained. Available online: https://www.reliableplant.com/Read/12495/preventive-predictive-maintenance (accessed on 9 November 2022).
- Kwon, D.; Hodkiewicz, M.R.; Fan, J.; Shibutani, T.; Pecht, M.G. IoT-Based Prognostics and Systems Health Management for Industrial Applications. IEEE Access 2016, 4, 3659–3670. [Google Scholar] [CrossRef]
- Kazemi, M.A.A.; Hajian, S.; Kiani, N. Quality Control and Classification of Steel Plates Faults Using Data Mining. Appl. Math. Inf. Sci. Lett. 2018, 6, 59–67. [Google Scholar] [CrossRef] [PubMed]
- Tran, V.T.; Yang, B.-S.; Oh, M.-S.; Tan, A.C.C. Machine condition prognosis based on regression trees and one-step-ahead prediction. Mech. Syst. Signal Process. 2008, 22, 1179–1193. [Google Scholar] [CrossRef]
- Paolanti, M.; Romeo, L.; Felicetti, A.; Mancini, A.; Frontoni, E.; Loncarski, J. Machine Learning approach for Predictive Maintenance in Industry 4.0. In Proceedings of the 14th IEEE/ASME International Conference on Mechatronic and Embedded Systems and Applications, MESA, Oulu, Finland, 2–4 July 2018. [Google Scholar]
- Jimenez-Cortadi, A.; Irigoien, I.; Boto, F.; Sierra, B.; Rodriguez, G. Predictive Maintenance on the Machining Process and Machine Tool. Appl. Sci. 2019, 10, 224. [Google Scholar] [CrossRef]
- Mahantesh, N.; Aditya, P.; Kumar, U. Integrated machine health monitoring: A knowledge based approach. Int. J. Syst. Assur. Eng. Manag. 2013, 5, 371–382. [Google Scholar] [CrossRef]
- Yan, R.; Gao, R.X. Approximate Entropy as a diagnostic tool for machine health monitoring. Mech. Syst. Signal Process. 2007, 21, 824–839. [Google Scholar] [CrossRef]
- Siafara, L.C.; Kholerdi, H.A.; Bratukhin, A.; TaheriNejad, N.; Wendt, A.; Jantsch, A.; Treytl, A.; Sauter, T. SAMBA: A self-aware health monitoring architecture for distributed industrial systems. In Proceedings of the IECON 2017-43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017. [Google Scholar]
- Lee, G.-Y.; Kim, M.; Quan, Y.-J.; Kim, M.-S.; Kim, T.J.Y.; Yoon, H.-S.; Min, S.; Kim, D.-H.; Mun, J.-W.; Oh, J.W.; et al. Machine health management in smart factory: A review. J. Mech. Sci. Technol. 2018, 32, 987–1009. [Google Scholar] [CrossRef]
- Gondal, I.; Yaqub, M.F.; Hua, X. Smart Phone Based Machine Condition Monitoring System. Lect. Notes Comput. Sci. 2012, 7667, 488–497. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Vachtsevanos, G. Prediction of Machine Health Condition Using Neuro-Fuzzy and Bayesian Algorithms. IEEE Trans. Instrum. Meas. 2011, 61, 297–306. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.-S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/latest/ (accessed on 9 November 2022).
- XGBoost Algorithm. Available online: https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d (accessed on 9 November 2022).
- XGBoost: Enhancement over Gradient Boosting Machines. Available online: https://medium.com/@ODSC/xgboost-enhancement-over-gradient-boosting-machines-73abafa49b14 (accessed on 9 November 2022).
- Understanding the Gini Index and Information Gain in Decision Trees. Available online: https://medium.com/analytics-steps/understanding-the-gini-index-and-information-gain-in-decision-trees-ab4720518ba8 (accessed on 9 November 2022).
- Sampaio, G.S.; Filho, A.R.D.A.V.; da Silva, L.S.; da Silva, L.A. Prediction of Motor Failure Time Using an Artificial Neural Network. Sensors 2019, 19, 4342. [Google Scholar] [CrossRef] [PubMed]
- Biswal, S.; Sabareesh, G. Design and development of a wind turbine test rig for condition monitoring studies. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015. [Google Scholar] [CrossRef]
- Tangirala, S. Evaluating the Impact of GINI Index and Information Gain on Classification using Decision Tree Classifier Algorithm. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 612–619. [Google Scholar] [CrossRef]
- Zhang, Y. Support Vector Machine Classification Algorithm and Its Application. In Information Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 179–186. [Google Scholar] [CrossRef]
- Wang, L. Research and Implementation of Machine Learning Classifier Based on KNN. IOP Conf. Series Mater. Sci. Eng. 2019, 677, 052038. [Google Scholar] [CrossRef]
- Kulkarni, K.; Devi, U.; Sirighee, A.; Hazra, J.; Rao, P. Predictive Maintenance for Supermarket Refrigeration Systems Using Only Case Temperature Data. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018. [Google Scholar]
- Meyda. Available online: https://meyda.js.org/audio-features (accessed on 9 November 2022).
- Fernandes, S.; Antunes, M.; Santiago, A.R.; Barraca, J.P.; Gomes, D.; Aguiar, R.L. Forecasting Appliances Failures: A Machine-Learning Approach to Predictive Maintenance. Information 2020, 11, 208. [Google Scholar] [CrossRef]
- Durbhaka, G.; Selvaraj, P. Predictive Maintenance for Wind Turbine Diagnostics using Vibration Signal Analysis based on Collaborative Recommendation Approach. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016. [Google Scholar] [CrossRef]
- Zero-Crossing Rate. Available online: https://wiki.aalto.fi/display/ITSP/Zero-crossing+rate (accessed on 9 November 2022).
- Speech Recognition-Feature Extraction MFCC & PLP. Available online: https://medium.com/@jonathan_hui/speech-recognition-feature-extraction-mfcc-plp-5455f5a69dd9 (accessed on 9 November 2022).
- Understanding Confusion Matrix. Available online: https://towardsdatascience.com/decoding-the-confusion-matrix-bb4801decbb (accessed on 9 November 2022).
- Hajian-Tilaki, K. Receiver Operator Characteristic Analysis of Biomarkers Evaluation in Diagnostic Research. J. Clin. Diagn. Res. 2018, 12, LE01–LE08. [Google Scholar] [CrossRef]
- Arias, P.A. Planning Models for Distribution Grid. U. Porto J. Eng. 2018, 4, 42–55. [Google Scholar] [CrossRef]
- Binding, A.; Dykeman, N.; Pang, S. Machine Learning Predictive Maintenance on Data in the Wild. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019. [Google Scholar] [CrossRef]
- Anshari, M.; Syafrudin, M.; Fitriyani, N.L. Fourth Industrial Revolution between Knowledge Management and Digital Humanities. Information 2022, 13, 292. [Google Scholar] [CrossRef]
- Saiz, F.A.; Alfaro, G.; Barandiaran, I. An Inspection and Classification System for Automotive Component Remanufacturing Industry Based on Ensemble Learning. Information 2021, 12, 489. [Google Scholar] [CrossRef]
- Vaccaro, L.; Sansonetti, G.; Micarelli, A. An Empirical Review of Automated Machine Learning. Computers 2021, 10, 11. [Google Scholar] [CrossRef]
- Mukhtar, H.; Rubaiee, S.; Krichen, M.; Alroobaea, R. An IoT Framework for Screening of COVID-19 using Real-Time Data from Wearable Sensors. Int. J. Environ. Res. Public Health 2021, 18, 4022. [Google Scholar] [CrossRef] [PubMed]
- Krichen, M.; Mechti, S.; Alroobaea, R.; Said, E.; Singh, P.; Khalaf, O.I.; Masud, M. A formal testing model for operating room control system using internet of things. Comput. Mater. Contin. 2021, 66, 2997–3011. [Google Scholar] [CrossRef]
- Yeruva, S.; Ding, J.; Gaddam, A.; Brahmananda Reddy, A. CoviCare: An Integrated System for COVID-19, Emerging Computational Approaches in Telehealth and Telemedicine: A Look at The Post-COVID-19 Landscape. In Advances in Data Science-Driven Technologies; Bentham Science Publishers: Sharjah, United Arab Emirates, 2022; Volume 1, pp. 88–115. [Google Scholar] [CrossRef]
- Lin, T.-K. PCA/SVM-Based Method for Pattern Detection in a Multisensor System. Math. Probl. Eng. 2018, 2018, 6486345. [Google Scholar] [CrossRef]
- Gasmi, K.; Ben Ltaifa, I.; Lejeune, G.; Alshammari, H.; Ben Ammar, L.; Mahmood, M.A. Optimal Deep Neural Network-Based Model for Answering Visual Medical Question. Cybern. Syst. 2021, 53, 403–424. [Google Scholar] [CrossRef]
- Zhou, Y.; Kumar, A.; Parkash, C.; Vashishtha, G.; Tang, H.; Glowacz, A.; Dong, A.; Xiang, J. Development of entropy measure for selecting highly sensitive WPT band to identify defective components of an axial piston pump. Appl. Acoust. 2023, 203, 109225. [Google Scholar] [CrossRef]
- Zhen, D.; Li, D.; Feng, G.; Zhang, H.; Gu, F. Rolling bearing fault diagnosis based on VMD reconstruction and DCS demodulation. Int. J. Hydromechatron. 2022, 5, 205–225. [Google Scholar] [CrossRef]
- Uppal, M.; Gupta, D.; Mahmoud, A.; Elmagzoub, M.A.; Sulaiman, A.; Al Reshan, M.S.; Shaikh, A.; Juneja, S. Fault Prediction Recommender Model for IoT Enabled Sensors Based Workplace. Sustainability 2023, 15, 1060. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNO | Attribute | Attribute Type | Description |
|---|---|---|---|
| 1. | Chroma stft | Float | Chromogram based feature |
| 2. | RMSE | Float | Root-Mean-Square (RMS) energy for each frame of the audio signal |
| 3. | Spectral Centroid | Float | Indicates the frequency where the energy of the spectrum is centered. |
| 4. | Spectral bandwidth | Float | Indicates the bandwidth of the spectrum for each frame of the audio signal |
| 5. | Spectral roll-off | Float | Indicates the volume of the right skewedness of the power spectrum |
| 6. | Zero crossing rate | Float | Indicates the number of times the amplitude of the audio signal pas through zero |
| 7. | MFCC | Float | Coefficients that build up the mel frequency cepstrum |
| Algorithm | Performance Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1 Score | Area under ROC Curve | |
| Decision Tree | 94.33 | 93.58 | 95.10 | 94.33 | 0.94 |
| XGBoost | 95.95 | 98.84 | 92.93 | 95.79 | 0.99 |
| SVM | 63.07 | 96.07 | 26.63 | 41.70 | 0.92 |
| SVM WITH PCA | 92.45 | 95.34 | 89.13 | 92.13 | 0.95 |
| KNN | 87.06 | 82.07 | 94.56 | 87.87 | 0.89 |
| KNN WITH PCA | 82.21 | 92.14 | 70.10 | 79.62 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeruva, S.; Gunuganti, J.; Kalva, S.; Salkuti, S.R.; Kim, S.-C. Smart Machine Health Prediction Based on Machine Learning in Industry Environment. Information 2023, 14, 181. https://doi.org/10.3390/info14030181
Yeruva S, Gunuganti J, Kalva S, Salkuti SR, Kim S-C. Smart Machine Health Prediction Based on Machine Learning in Industry Environment. Information. 2023; 14(3):181. https://doi.org/10.3390/info14030181
Chicago/Turabian StyleYeruva, Sagar, Jeshmitha Gunuganti, Sravani Kalva, Surender Reddy Salkuti, and Seong-Cheol Kim. 2023. "Smart Machine Health Prediction Based on Machine Learning in Industry Environment" Information 14, no. 3: 181. https://doi.org/10.3390/info14030181
APA StyleYeruva, S., Gunuganti, J., Kalva, S., Salkuti, S. R., & Kim, S.-C. (2023). Smart Machine Health Prediction Based on Machine Learning in Industry Environment. Information, 14(3), 181. https://doi.org/10.3390/info14030181