
Adapting Off-the-Shelf Speech Recognition Systems for Novel Words

Abstract
1. Introduction
2. Related Works on Improving Speech Recognition Accuracy
2.1. Statistical Approaches
2.2. Deep Learning Approaches
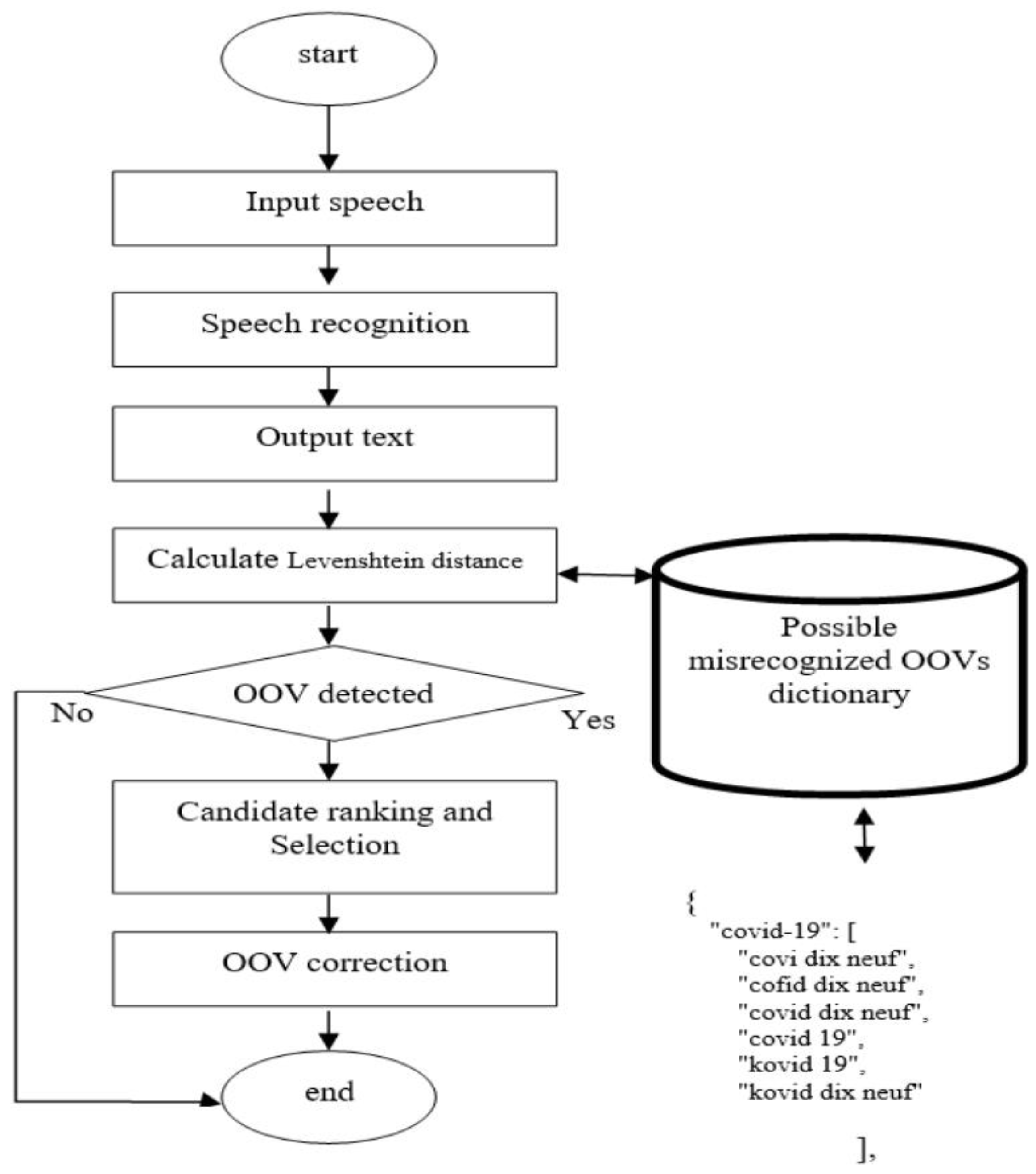
3. Methodology
3.1. Data Set
3.2. Speech Recognition System
3.3. Speech Recognition System Post-Processing
3.3.1. Levenshtein Algorithm
3.3.2. Damerau–Levenshtein Algorithm
- Dictionary Creation: The first step is to create a dictionary that includes both the misspelled words and their corresponding correct words, with the correct word being stored as a keyword in the dictionary.
- Searching for a Match: In this step, the word of interest (the output from the ASR) is searched within the dictionary values. If the word is found, then it is considered a misspelling. If not, then it is considered to be spelled correctly.
- Calculation of Levenshtein Distance: If a misspelling is identified in the previous step, then the word of interest is then subjected to the Levenshtein distance measure. This measure calculates the distance between the misspelled word and all words in the dictionary. The correct word is chosen as the keyword with the smallest Levenshtein distance, as this indicates the highest similarity between the two words.
4. Results and Discussion
- ♦
- Mascir relève de l’unsiversité Mohammed VI polytechnique.
- ♦
- Ma sœur relève de l’université Mohammed VI polytechnique.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| ASR System | Recognized Text with Different Accents: « COVID-19 a Impact Important Sur la Production D’aliments » |
|---|---|
| Speech-to-text API | mercredi 19 a un impact sur la protection d’allah |
| la copine de 19 a un impact important sur la production d’aliments | |
| ma COVID-19 a un impact important sur la production d’aliments | |
| VOSK API | la mauvaise dix-neuf a un impact important sur jim protection d’allure |
| la convives dix-neuf a un impact important sur la production d’aliments | |
| la coville dix-neuf un impact important sur la production d’aliments | |
| Wav2vec2.0 | lacovdnua un inpacinpton sur la protection d’al |
| la covitisnetea un impacte important sur la production d’alément | |
| la copitisneur e l’ipote dmportant sur leu production d’alim | |
| QuartzNet | l’alcrovie dix neuf a un impact important sur la production d’alian |
| la courbide est emportant sur la production d’als | |
| la couvite a un impact important sur la production d’animaux | |
| SpeechBrain | la crevée dix neuf a à un bac important sur la protection d’allemagne |
| la covie dix neuf a un impact important sur la production d’aligny | |
| la courbie dix neuf a un impact important sur la production d’alléments |
References
- Pollmann, K.; Ruff, C.; Vetter, K.; Zimmermann, G. Robot vs. Voice Assistant: Is playing with pepper more fun than playing with alexa? In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, New York, NY, USA, 23–26 March 2020; pp. 395–397. [Google Scholar] [CrossRef]
- How to Build Domain Specific Automatic Speech Recognition Models on GPUs|NVIDIA Developer Blog. Available online: https://developer.nvidia.com/blog/how-to-build-domain-specific-automatic-speech-recognition-models-on-gpus/ (accessed on 29 November 2021).
- Desot, T.; Portet, F.; Vacher, M. End-to-End Spoken Language Understanding: Performance analyses of a voice command task in a low resource setting. Comput. Speech Lang. 2022, 75, 101369. [Google Scholar] [CrossRef]
- Kim, J.; Kang, P. K-Wav2vec 2.0: Automatic Speech Recognition based on Joint Decoding of Graphemes and Syllables. arXiv 2021, arXiv:2110.05172v1. [Google Scholar]
- Laptev, A.; Andrusenko, A.; Podluzhny, I.; Mitrofanov, A.; Medennikov, I.; Matveev, Y. Dynamic Acoustic Unit Augmentation with BPE-Dropout for Low-Resource End-to-End Speech Recognition. Sensors 2021, 21, 3063. [Google Scholar] [CrossRef] [PubMed]
- Andrusenko, R.A.N.A.Y.; Romanenko, A. Improving out of vocabulary words recognition accuracy for an end-to-end Russian speech recognition system. Sci. Tech. J. Inf. Technol. Mech. Opt. 2022, 22, 1143–1149. [Google Scholar] [CrossRef]
- Lochter, J.V.; Silva, R.M.; Almeida, T.A. Multi-level out-of-vocabulary words handling approach. Knowl. Based Syst. 2022, 251, 108911. [Google Scholar] [CrossRef]
- Putri, F.Y.; Hoesen, D.; Lestari, D.P. Rule-Based Pronunciation Models to Handle OOV Words for Indonesian Automatic Speech Recognition System. In Proceedings of the 2019 5th International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, 23–24 October 2019; pp. 246–251. [Google Scholar] [CrossRef]
- Errattahi, R.; El Hannani, A.; Ouahmane, H. Automatic Speech Recognition Errors Detection and Correction: A Review. Procedia Comput. Sci. 2018, 128, 32–37. [Google Scholar] [CrossRef]
- Fadel, W.; Araf, I.; Bouchentouf, T.; Buvet, P.-A.; Bourzeix, F.; Bourja, O. Which French speech recognition system for assistant robots? In Proceedings of the 2022 2nd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 3–4 March 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Subramanyam, K. (n.d.). Improving Speech Recognition Accuracy Using Levenshtein Distance Algorithm. Academia.Edu. Retrieved 1 February 2023. Available online: https://www.academia.edu/download/62149839/Levenshtein_Distance_algorithm.pdf (accessed on 1 December 2022).
- Salimbajevs, A. Using sub-word n-gram models for dealing with OOV in large vocabulary speech recognition for Latvian. In Proceedings of the 20th Nordic Conference of Computational Linguistics (NODALIDA 2015), Vilnius, Lithuania, 15–18 May 2015. [Google Scholar]
- Réveil, B.; Demuynck, K.; Martens, J.-P. An improved two-stage mixed language model approach for handling out-of-vocabulary words in large vocabulary continuous speech recognition. Comput. Speech Lang. 2014, 28, 141–162. [Google Scholar] [CrossRef]
- Pellegrini, T.; Trancoso, I. Error detection in broadcast news ASR using Markov chains. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); LNAI; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6562, pp. 59–69. [Google Scholar] [CrossRef]
- Sarma, A.; Palmer, D.D. Context-based Speech Recognition Error Detection and Correction. In Proceedings of HLT-NAACL 2004: Short Papers; Association for Computational Linguistics: Boston, MA, USA, 2004; pp. 85–88. [Google Scholar] [CrossRef]
- Bassil, Y.; Semaan, P. ASR Context-Sensitive Error Correction Based on Microsoft N-Gram Dataset. arXiv 2012, arXiv:1203.5262. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Wang, J.; Tang, Z. Post Text Processing of Chinese Speech Recognition Based on Bidirectional LSTM Networks and CRF. Electronics 2019, 8, 1248. [Google Scholar] [CrossRef]
- Post-Editing and Rescoring of ASR Results with Edit Operations Tagging. Available online: https://www.researchgate.net/publication/351687519_Post-editing_and_Rescoring_of_ASR_Results_with_Edit_Operations_Tagging (accessed on 25 July 2022).
- Zhang, S.; Lei, M.; Yan, Z. Automatic Spelling Correction with Transformer for CTC-based End-to-End Speech Recognition. arXiv 2019, arXiv:1904.10045. [Google Scholar] [CrossRef]
- Emiru, E.D.; Xiong, S.; Li, Y.; Fesseha, A.; Diallo, M. Improving Amharic Speech Recognition System Using Connectionist Temporal Classification with Attention Model and Phoneme-Based Byte-Pair-Encodings. Information 2021, 12, 62. [Google Scholar] [CrossRef]
- Silva, R.M.; Lochter, J.V.; Almeida, T.A.; Yamakami, A. FastContext: Handling Out-of-Vocabulary Words Using the Word Structure and Context. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Cham, Switzerland, 2022; pp. 539–557. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, H.; Li, J.; Chai, S.; Wang, G.; Chen, G.; Zhang, W.-Q. The THUEE System Description for the IARPA OpenASR21 Challenge. arXiv 2022, arXiv:2206.14660. [Google Scholar] [CrossRef]
- Aouragh, S.L.; Yousfi, A.; Sidi, U.; Abdellah, M.B.; Hicham, G. Adapting the Levenshtein Distance to Contextual Spelling Correction. Int. J. Comput. Sci. Appl. Ótechnomathematics Res. Found. 2015, 12, 127–133. [Google Scholar]
- Twiefel, J.; Baumann, T.; Heinrich, S.; Wermter, S. Improving Domain-independent Cloud-Based Speech Recognition with Domain-Dependent Phonetic Post-Processing. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28, pp. 1529–1535. [Google Scholar]
- Traum, D.; Georgila, K.; Artstein, R.; Leuski, A. Evaluating Spoken Dialogue Processing for Time-Offset Interaction. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 199–208. [Google Scholar] [CrossRef]
- Byambakhishig, E.; Tanaka, K.; Aihara, R.; Nakashika, T.; Takiguchi, T.; Ariki, Y. Error correction of automatic speech recognition based on normalized web distance. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 2852–2856. [Google Scholar] [CrossRef]
- Leng, Y.; Tan, X.; Liu, W.; Song, K.; Wang, R.; Li, X.Y.; Tao, Q.; Lin, E.; Liu, T.Y. SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition. arxiv 2022, arXiv:2212.01039. [Google Scholar] [CrossRef]
- Ali, N.H.; Abdulmunim, M.E.; Ali, A.E. Auto-Correction Model for Lip Reading System. IRAQI J. Comput. Commun. Control Syst. Eng. 2022, 22, 63–71. [Google Scholar] [CrossRef]

| Audio_Path | Text |
|---|---|
| /audios/1.wav | quelles sont les communautés touchées par la pandémie de COVID-19 ? |
| /audios/2.wav /audios/3.wav | chefchaoun n’est pas très loin de tanger les marocains seront vaccinés avec sinopharm |
| ASR | Google API | Vosk API | QuartzNet | Wav2vec2.0 | CRDNN |
|---|---|---|---|---|---|
| WER | 0.38 | 0.57 | 0.48 | 0.55 | 0.47 |
| OOV Word | Misrecognized Words | Type of Mistake |
|---|---|---|
| COVID-19 | Couvi | Word reduction |
| covite dix-neuv | Missing/misspelled symbols | |
| lacovitedineuf | Multiple words separation | |
| mascir | Massir | misspelled symbols |
| Massyr | misspelled symbols | |
| Macir | misspelled symbols |
| ASR Systems | WER % before Post-Processing | WER % after Processing | |||
|---|---|---|---|---|---|
| Levenshtein | Damerau Levenshtein | ||||
| min = 0.2 | max = 0.8 | max = 0.85 | max = 0.9 | ||
| Speech-to-text | 38.27 | 37 | 38.37 | 38.36 | 37.72 |
| Wav2vec 2.0 | 55.96 | 51.71 | 51.26 | 53.08 | 51.71 |
| Quartznet | 48.35 | 48.04 | 47.08 | 47.44 | 47.81 |
| SpeechBrain | 47.03 | 45.98 | 45.63 | 45.81 | 45.93 |
| VOSK | 57.96 | 57.52 | 57.82 | 57.85 | 57.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fadel, W.; Bouchentouf, T.; Buvet, P.-A.; Bourja, O. Adapting Off-the-Shelf Speech Recognition Systems for Novel Words. Information 2023, 14, 179. https://doi.org/10.3390/info14030179
Fadel W, Bouchentouf T, Buvet P-A, Bourja O. Adapting Off-the-Shelf Speech Recognition Systems for Novel Words. Information. 2023; 14(3):179. https://doi.org/10.3390/info14030179
Chicago/Turabian StyleFadel, Wiam, Toumi Bouchentouf, Pierre-André Buvet, and Omar Bourja. 2023. "Adapting Off-the-Shelf Speech Recognition Systems for Novel Words" Information 14, no. 3: 179. https://doi.org/10.3390/info14030179
APA StyleFadel, W., Bouchentouf, T., Buvet, P.-A., & Bourja, O. (2023). Adapting Off-the-Shelf Speech Recognition Systems for Novel Words. Information, 14(3), 179. https://doi.org/10.3390/info14030179