
Ontology Learning Applications of Knowledge Base Construction for Microelectronic Systems Information


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
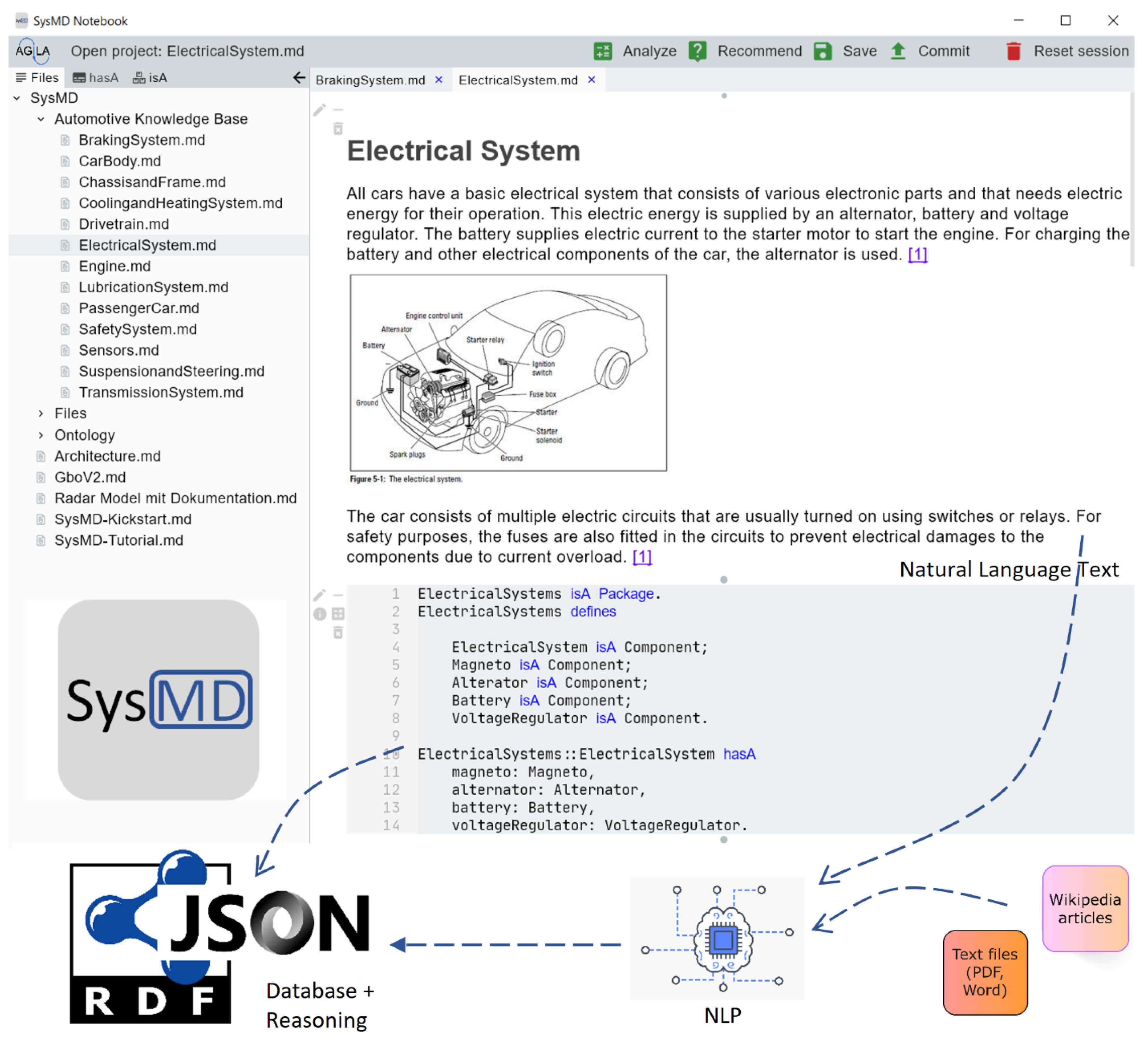
3.1. Knowledge Base Construction with the GENIAL! Basic Ontology
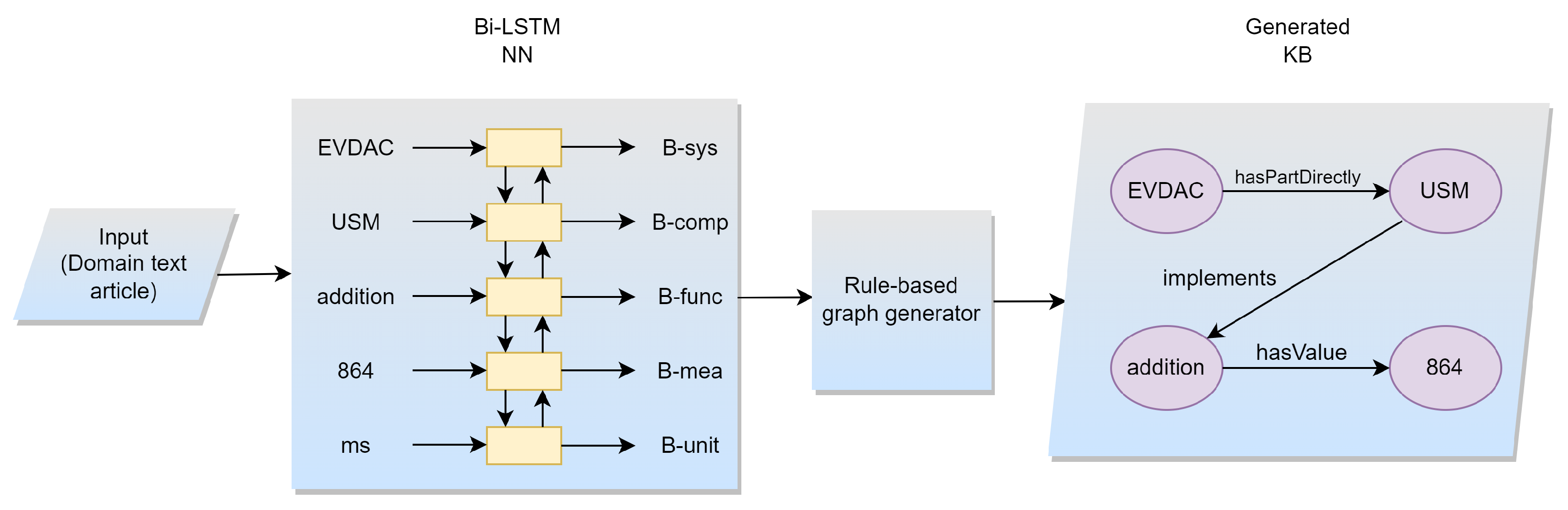
3.2. Approach
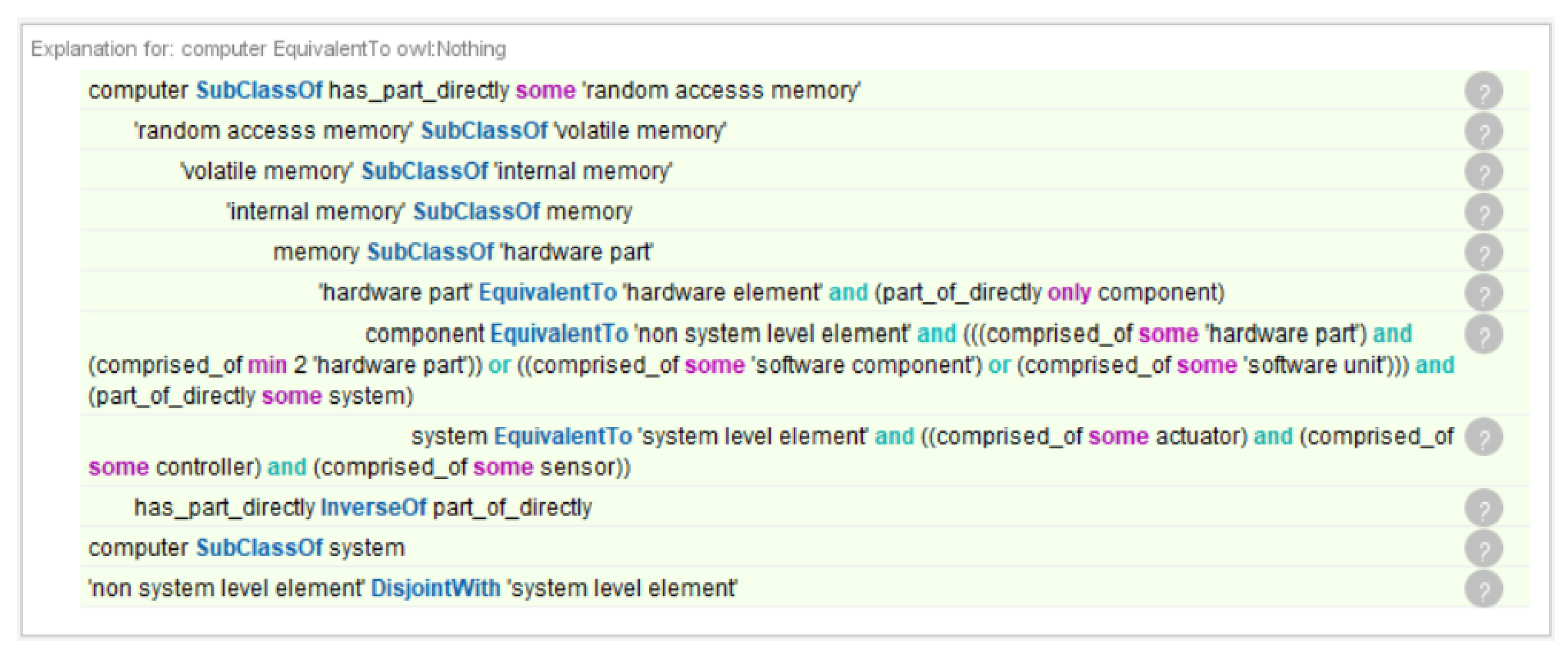
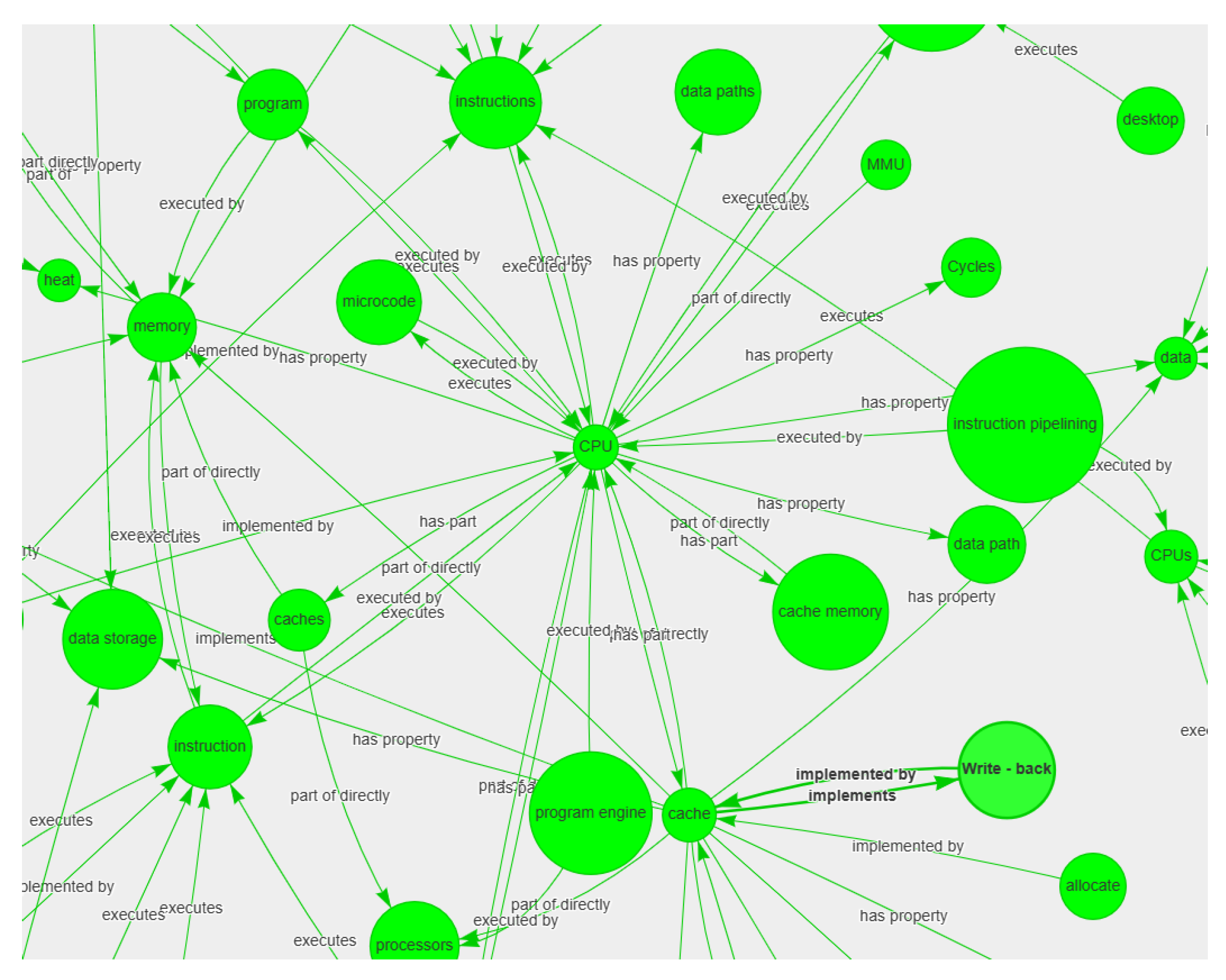
3.3. Reasoning Example
3.4. GBO
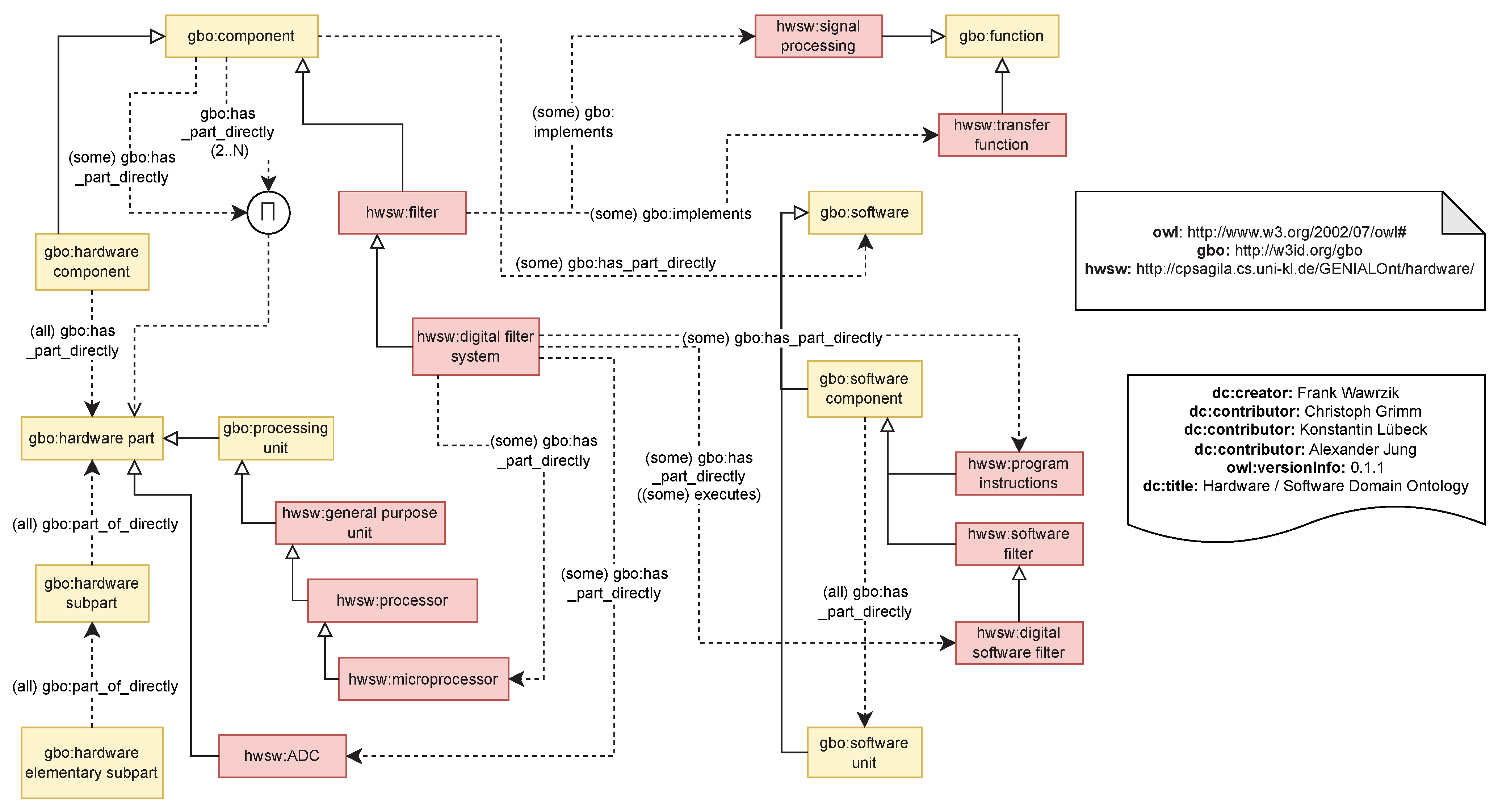
3.4.1. Overview
3.4.2. Selecting Classes and Reducing Scope

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Definition |
|---|---|
| system | System level element that is according to ISO 26262: set of components (3.21) or subsystems that relates at least a sensor, a controller, and an actuator with one another. “system level element” and ((comprised_of some actuator) and (comprised_of some controller) and (comprised_of some sensor)) |
| component | According to ISO26262: non-system level element (3.41) that is logically or technically separable and is comprised of more than one hardware part (3.71) or one or more software units (3.159). “non system level element” and (((comprised_of some “hardware part”) and (comprised_of min 2 “hardware part”)) or ((comprised_of some “software component”) or (comprised_of some “software unit”))) and (part_of_directly some system) |
| hardware component | According to ISO26262: non-system level element (3.41) that is logically or technically separable and is comprised of more than one hardware part (3.71). “hardware element” and (comprised_of only “hardware part”) and (comprised_of min 2 “hardware part”) |
| hardware part | A piece of hardware that is (according to ISO 26262) a portion of a hardware component (3.21) at the first level of hierarchical decomposition. “hardware element” and (part_of_directly only component) |
| hardware subpart | Portion of a hardware part (3.71) that can be logically divided and represents second or greater level of hierarchical decomposition. “hardware element” and (has_part_directly only (“hardware elementary subpart” or ”hardware subpart”)) and (part_of_directly only (“hardware part” or “hardware subpart”)) |
| function | A bfo:function that an element (e.g., system, component, hardware or software) implements. |
| software | From definition of element:
Note 1 to entry: When “software element” or “hardware element” is used, this phrase denotes an element of software only or an element of hardware only, respectively. “software element” is_executed_by some “processing unit” |
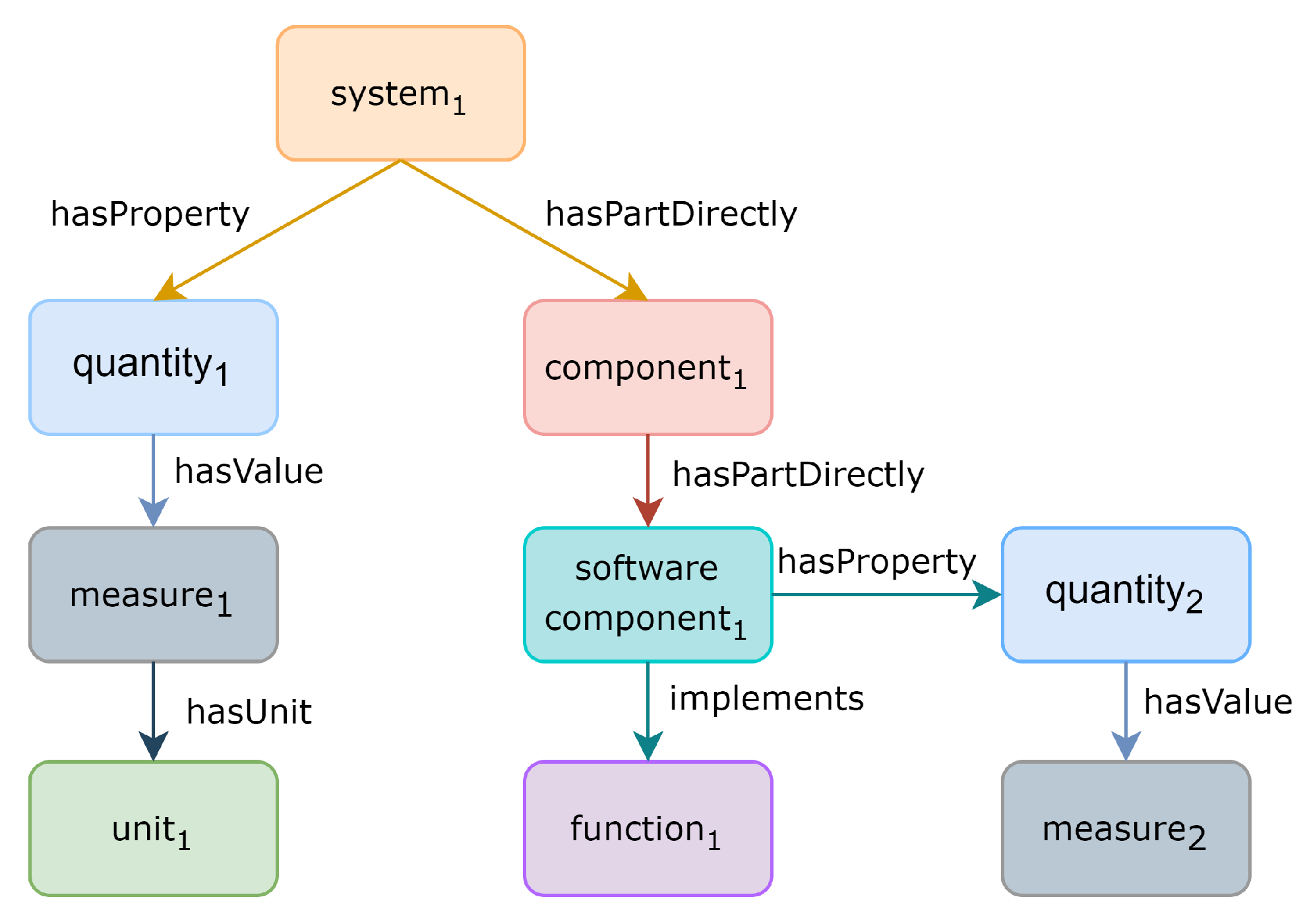
| quantity | A quantity is a (property that is quantifiable and a) representation of a quantifiable (standardized) aspect (such as length, mass, and time) of a phenomenon (e.g., a star, a molecule, or a food product). Quantities are classified according to similarity in their (implicit) metrological aspect, e.g., the length of my table and the length of my chair are both classified as length. |
| measure | A bfo:quality that are amounts of quantities. hasNumericalValue some rdfs:Literal |
| unit | A quality that is any standard used for comparison in measurements. |
3.5. Dataset
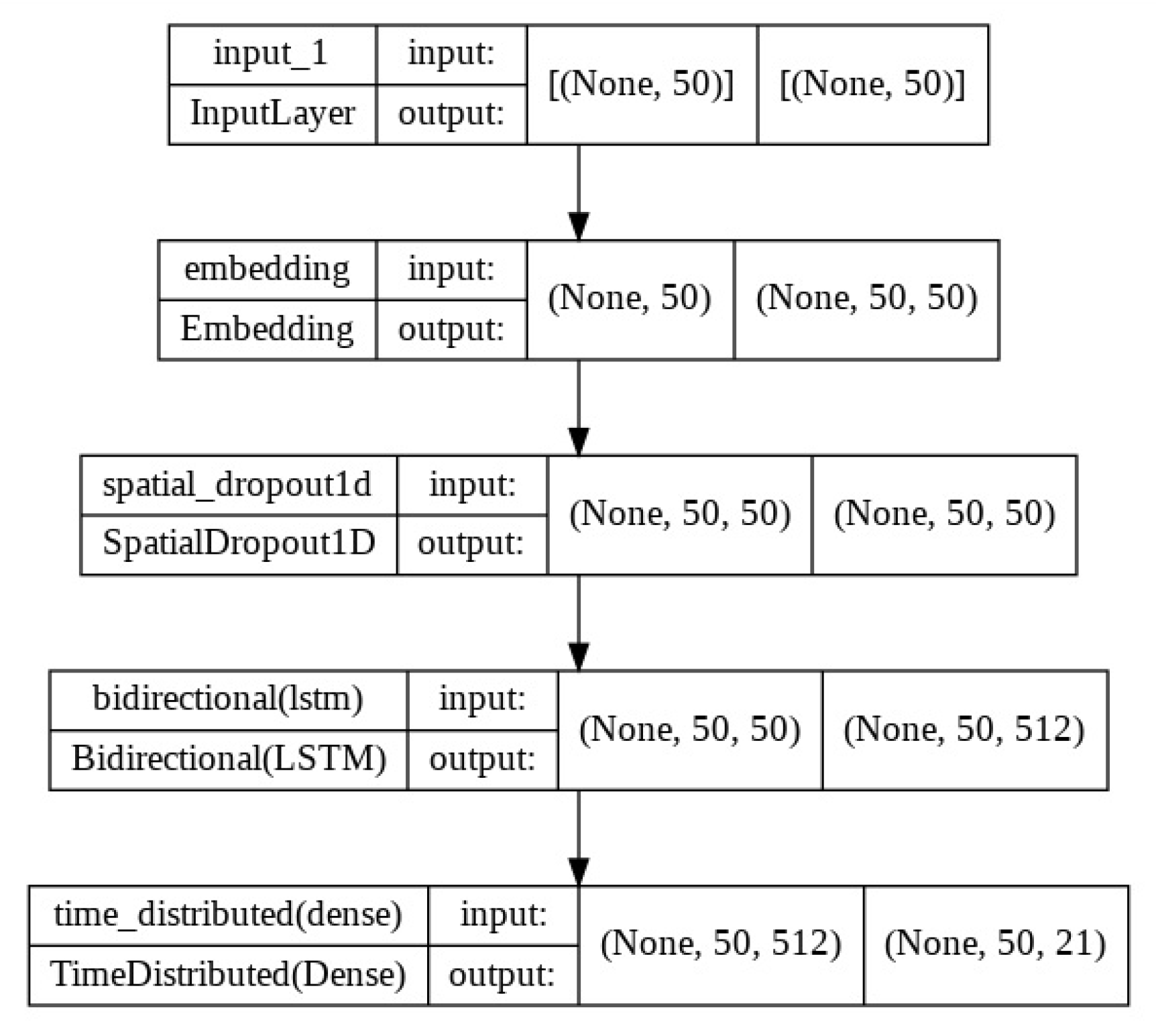
3.6. Application of Bi-LSTM
3.7. Data Preparation
3.8. Relationship Establishment
4. Results
4.1. Performance on Unseen Data
4.2. Validation
4.2.1. Manually
- The transformer uses a relationship “uses” between parts and functions, we classify it as subclass of “implements” in order to adhere to our schema and retain the other information as well (coherency);
- We recognize whether a property was falsely classified as a function, and readjust the dataset and graph (semantic accuracy).
4.2.2. Automatically
5. Discussion
5.1. Particular Examples and Their Considerations
- (1)
- A central processing unit (CPU), also called a central processor, main processor, or just processor, is the electronic circuitry that executes instructions comprised in a computer program.
- (2)
- The CPU performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program.
- (3)
- The principal components of a CPU include the arithmetic–logic unit (ALU) that performs arithmetic and logic operations, a processor that registers that supply operands to the ALU and stores the results of ALU operations, and a control unit that orchestrates the fetching (from memory), decoding, and execution (of instructions) by directing the coordinated operations of the ALU, registers, and other components.
5.2. General Challenges
5.2.1. Classification
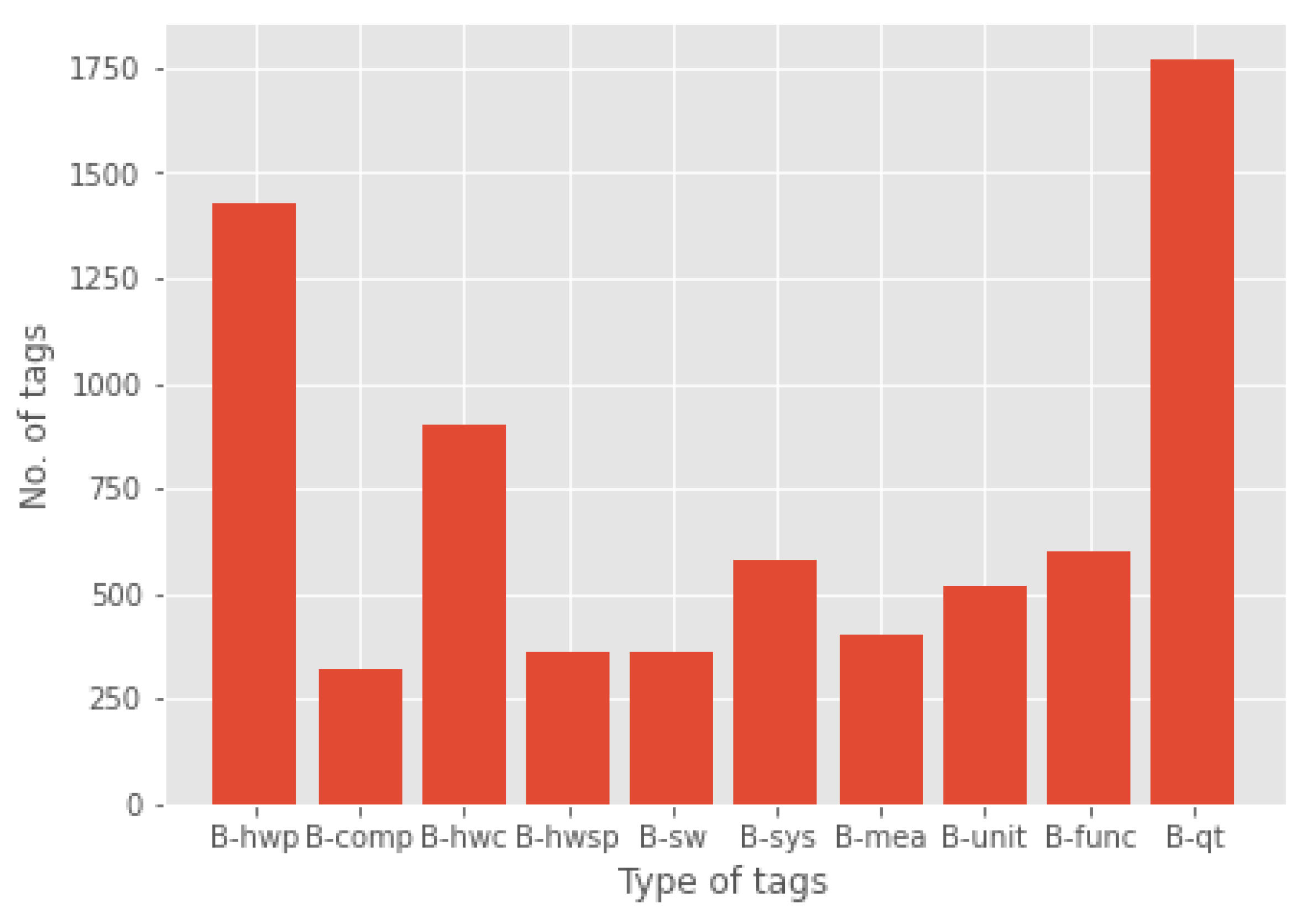
- Over and under-classification: While labeling data, we handpicked several microelectronics articles related to our ontology classes, and while labeling about 2307 sentences, we tagged a total of 1770 “quantities”, and this was a relatively high number compared to other classes, such as “component”, “hardware subpart”, and ”software”. The class "hardware part" similarly had a rather high count of 1426. These differences in class distribution led to dataset imbalances [47]. Moreover, we tagged examples of the “function” class from several different articles which were not similar to each other. Despite having a good count of “function” tags, our model initially struggled to predict the “function” class examples. It could only predict "function" examples that it had seen multiple times during training. Hence, the model achieved the lowest F1-score for the "function" class (Table 5). One of the most widely adopted techniques for overcoming imbalanced datasets is resampling data points. We used resampling to over-sample the minority classes by adding more examples. We applied the simplest implementation of over-sampling which is to duplicate random records from the minority class. However, we used oversampling sparingly to avoid the likelihood of overfitting. Figure 5, that we showed earlier, illustrates the class imbalance that we had to address. The oversampling technique alleviated the situation to an extent but the overall results could still be improved by adding more novel examples in new contexts.
- Adequacy of the current ontology model: We noticed that the ontological commitment was very tight and fitting to our ontology in general. For example, we defined a covering axiom to make the description of “hardware” complete with “hardware component”, “hardware part”, “hardware subpart”, and “hardware elementary subpart”, in accordance with the ISO26262 definition and terms we understood so that there was no other hardware. That axiom was fulfilled. We did not cover non-system level element and system level element, which was the right choice, because an acquired integrated circuit was found to be an element but neither a non-system level element nor a system level element. There are systems and other hardware that constitute integrated circuits, which would violate a covering axiom. Thus, classification is an intricate and precise task and loosening definitions and their use can support the building of the knowledge base from the ontology.
5.2.2. Other Challenges/Experiences
- Training: Although the definitions appeared rather simple to the expert, practice showed that even for trained personnel, conducting the classifications was challenging. Even after hours of training, usually, an ontologist is often still needed to resolve challenges and ambiguities, which is time-consuming and also costly. The accuracy of the trained personnel may be lower than the possible ideal and needs to be taken into account when calculating overall accuracy. On the other hand, the axioms can be tested if they still hold true for larger amounts of data and if the reasoning can be applied consistently, which also improves the ontology itself.
- Top-Level: The upper ontology proved useful. For example, distinguishing functions from processes, which are not only ontologically fundamentally different but also have important practical implications. The beginner may not notice that when they, for example, only use a domain ontology model without top level such as BFO for tagging.
- Natural Language: Ambiguities arise from building knowledge graphs from natural language documents. Often, when manually classified, careful revisions are possible and take place, examples are added, other additions such as source links are provided, metadata added, and so forth. In NL documents, sometimes terms are in plural, abbreviations slightly change, and repetitions occur. Furthermore, maybe most importantly, the structure has to be carefully thought about in terms of how to fit in some natural language constructs with the semantic triple or description logic constructs. Sometimes, there is more than one way with different theoretical or practical implications on how to build a knowledge graph.
- Ontology vs. Knowledge Graph: Ontologies constitute definitions, formal and informal, hierarchies of taxonomies, and other axioms as well as metadata. They contain few to moderate amounts of classes but they are well-considered. Our initial expectation as well as set up context was to establish the knowledge graph in a way that all necessary axioms would be present to perform reasoning. However, descriptions in, e.g., Wikipedia articles contain the definition only in the beginning and most of the other text only contains the words without explicit structures. Hence, relationships were (1) underrepresented and (2) often present without direct and explicit axioms. It is to be noted that this is not necessarily a limitation of the work and relationships or edges can be constructed using other means or based on referenced or related articles.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| OWL | Ontology Web Language |
| KG | Knowledge Graph |
| GENIAL | Common Electronics Roadmap for Innovations along the Automotive Value Chain |
| SysMD | System MarkDown |
| Bi-LSTM | Bi-directional Long Short Term Mermory |
| GBO | GENIAL! Basic Ontology |
| BFO | Basic Formal Ontology |
References
- Wątróbski, J. Ontology learning methods from text—An extensive knowledge-based approach. Procedia Comput. Sci. 2020, 176, 3356–3368. [Google Scholar] [CrossRef]
- Khadir, A.C.; Aliane, H.; Guessoum, A. Ontology learning: Grand tour and challenges. Comput. Sci. Rev. 2021, 39, 100339. [Google Scholar] [CrossRef]
- Wawrzik, F. Knowledge Representation in Engineering 4.0. Doctoral Thesis, Technische Universität Kaiserslautern, Kaiserslautern, Germany, 2022. [Google Scholar] [CrossRef]
- Dalecke, S.; Rafique, K.; Ratzke, A.; Grimm, C.; Koch, J. SysMD: Towards “Inclusive” Systems Engineering. In Proceedings of the 2022 IEEE 5th International Conference on Industrial Cyber-Physical Systems (ICPS), Coventry, UK, 24–26 May 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Wawrzik, F.; Lober, A. A Reasoner-Challenging Ontology from the Microelectronics Domain. In Proceedings of the Semantic Reasoning Evaluation Challenge (SemREC 2021) Co-Located with the 20th International Semantic Web Conference (ISWC 2021), Virtual Event, 27 October 2021; Volume 3123, pp. 1–12. [Google Scholar]
- Steigmiller, A.; Liebig, T.; Glimm, B. Konclude: System description. J. Web Semant. 2014, 27–28, 78–85. [Google Scholar] [CrossRef]
- Graves, H. Integrating SysML and OWL. In Proceedings of the 6th International Conference on OWL: Experiences and Directions—Volume 529, Chantilly, VA, USA, 23–24 October 2009; CEUR-WS.org: Aachen, Germany, 2009; pp. 117–124. [Google Scholar]
- Olszewska, J.I. 3D Spatial Reasoning Using the Clock Model. In Proceedings of the Research and Development in Intelligent Systems XXXII—Incorporating Applications and Innovations in Intelligent Systems XXIII. Proceedings of the AI-2015, The Thirty-Fifth SGAI International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, UK, 15–17 December 2015; Bramer, M., Petridis, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 147–154. [Google Scholar] [CrossRef]
- Belgueliel, Y.; Bourahla, M.; Mourad, B. Towards an Ontology for UML State Machines. Lect. Notes Softw. Eng. 2014, 2, 116–120. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy Ontology and LSTM-Based Text Mining: A Transportation Network Monitoring System for Assisting Travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H. Neural network-based tree translation for knowledge base construction. IEEE Access 2021, 9, 38706–38717. [Google Scholar] [CrossRef]
- Li, D.; Huang, L.; Ji, H.; Han, J. Biomedical event extraction based on knowledge-driven tree-LSTM. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 1421–1430. [Google Scholar]
- Shen, W.; Wang, J.; Luo, P.; Wang, M. Linden: Linking named entities with knowledge base via semantic knowledge. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 449–458. [Google Scholar]
- Drissi, A.; Khemiri, A.; Sassi, S.; Chbeir, R. A New Automatic Ontology Construction Method Based on Machine Learning Techniques: Application on Financial Corpus. In Proceedings of the 13th International Conference on Management of Digital EcoSystems, New York, NY, USA, 1–3 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 57–61. [Google Scholar] [CrossRef]
- Loster, M. Knowledge Base Construction with Machine Learning Methods. Ph.D. Thesis, Universität Potsdam, Potsdam, Germany, 2021. [Google Scholar] [CrossRef]
- Huguet Cabot, P.L.; Navigli, R. REBEL: Relation Extraction By End-to-end Language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 2370–2381. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for Knowledge Graph Completion. arXiv 2019, arXiv:1909.03193v2. [Google Scholar] [CrossRef]
- Elnagar, S.; Yoon, V.; Thomas, M. An Automatic Ontology Generation Framework with An Organizational Perspective. In Proceedings of the 53rd Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 2020. [Google Scholar] [CrossRef]
- Allemang, D.; Hendler, J. Chapter 12—Counting and sets in OWL. In Semantic Web for the Working Ontologist, 2nd ed.; Allemang, D., Hendler, J., Eds.; Morgan Kaufmann: Boston, MA, USA, 2011; pp. 249–278. [Google Scholar] [CrossRef]
- Wang, Q.; Yu, X. Reasoning over OWL/SWRL Ontologies under CWA and UNA for Industrial Applications. In Advances in Artificial Intelligence; Wang, D., Reynolds, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 789–798. [Google Scholar]
- Gusenkov, A.; Bukharaev, N.; Birialtsev, E. On ontology based data integration: Problems and solutions. J. Physics Conf. Ser. 2019, 1203, 012059. [Google Scholar] [CrossRef]
- Calvanese, D.; Giacomo, G.D.; Lembo, D.; Lenzerini, M.; Rosati, R. Ontology-Based Data Access and Integration. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer New York: New York, NY, USA, 2018; pp. 2590–2596. [Google Scholar] [CrossRef]
- Niu, F.; Zhang, C.; Ré, C.; Shavlik, J. Elementary: Large-Scale Knowledge-Base Construction via Machine Learning and Statistical Inference. Int. J. Semant. Web Inf. Syst. 2012, 8, 42–73. [Google Scholar] [CrossRef]
- Lamurias, A.; Sousa, D.; Clarke, L.; Couto, F. BO-LSTM: Classifying relations via long short-term memory networks along biomedical ontologies. BMC Bioinform. 2019, 20, 10. [Google Scholar] [CrossRef] [PubMed]
- Sanchez-Cisneros, D.; Galisteo, F. UEM-UC3M: An Ontology-Based Named Entity Recognition System for Biomedical Texts. In Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013); Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 622–627. Available online: https://aclanthology.org/S13-2104 (accessed on 26 February 2023).
- Agrawal, G.; Deng, Y.; Park, J.; Liu, H.; Chen, Y.C. Building Knowledge Graphs from Unstructured Texts: Applications and Impact Analyses in Cybersecurity Education. Information 2022, 13, 526. [Google Scholar] [CrossRef]
- Weichselbraun, A.; Waldvogel, R.; Fraefel, A.; van Schie, A.; Kuntschik, P. Building Knowledge Graphs and Recommender Systems for Suggesting Reskilling and Upskilling Options from the Web. Information 2022, 13, 510. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Z.; Rostami, M.; Ilievski, F.; Shbita, B. Demo: Knowledge Graph-Based Housing Market Analysis. In Proceedings of the Second International Workshop on Knowledge Graph Construction, Online, 6 June 2021. [Google Scholar]
- Jaworsky, M.; Tao, X.; Yong, J.; Pan, L.; Zhang, J.; Pokhrel, S. Automated Knowledge Graph Construction for Healthcare Domain. In Health Information Science; Traina, A., Wang, H., Zhang, Y., Siuly, S., Zhou, R., Chen, L., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 258–265. [Google Scholar]
- Mann, M.; Ilievski, F.; Rostami, M.; Aastha, A.; Shbita, B. Open Drug Knowledge Graph. In Proceedings of the Second International Workshop on Knowledge Graph Construction, Online, 6 June 2021. [Google Scholar]
- Arenas-Guerrero, J.; Scrocca, M.; Iglesias-Molina, A.; Toledo, J.; Gilo, L.P.; Doña, D.; Corcho, O.; Chaves-Fraga, D. Knowledge Graph Construction with R2RML and RML: An ETL System-based Overview. In Proceedings of the Second International Workshop on Knowledge Graph Construction, Online, 6 June 2021. [Google Scholar]
- Schröder, M.; Jilek, C.; Dengel, A. Mapping Spreadsheets to RDF: Supporting Excel in RML. In Proceedings of the Second International Workshop on Knowledge Graph Construction, Online, 6 June 2021. [Google Scholar]
- Masoud, M.; Pereira, B.; McCrae, J.; Buitelaar, P. Automatic Construction of Knowledge Graphs from Text and Structured Data: A Preliminary Literature Review. In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Zaragoza, Spain, 1–4 September 2021; Gromann, D., Sérasset, G., Declerck, T., McCrae, J.P., Gracia, J., Bosque-Gil, J., Bobillo, F., Heinisch, B., Eds.; Open Access Series in Informatics (OASIcs). Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2021; p. 19. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. In Neural Information Processing Systems; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 22419–22430. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. In Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The Efficient Transformer. arxiv 2020, arXiv:2001.04451. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting. arXiv 2022, arXiv:2201.12740. [Google Scholar] [CrossRef]
- Parsia, B.; Matentzoglu, N.; Gonçalves, R.; Glimm, B.; Steigmiller, A. The OWL Reasoner Evaluation (ORE) 2015 Competition Report. J. Autom. Reason. 2017, 59, 455–482. [Google Scholar] [CrossRef] [PubMed]
- Arp, R.; Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the Seventh Conference on Natural language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May 2003; pp. 172–175. [Google Scholar]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Marrero, M.; Urbano, J.; Sánchez-Cuadrado, S.; Morato, J.; Gómez-Berbís, J.M. Named Entity Recognition: Fallacies, challenges and opportunities. Comput. Stand. Interfaces 2013, 35, 482–489. [Google Scholar] [CrossRef]
- Ramshaw, L.A.; Marcus, M.P. Text chunking using transformation-based learning. In Natural Language Processing Using Very Large Corpora; Springer: Berlin/Heidelberg, Germany, 1999; pp. 157–176. [Google Scholar]
- Yacouby, R.; Axman, D. Probabilistic Extension of Precision, Recall, and F1 Score for More Thorough Evaluation of Classification Models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Association for Computational Linguistics, Online, 10 November 2020; pp. 79–91. [Google Scholar] [CrossRef]
- Pietrasik, M.; Reformat, M. A Simple Method for Inducing Class Taxonomies in Knowledge Graphs. In The Semantic Web; Harth, A., Kirrane, S., Ngonga Ngomo, A.C., Paulheim, H., Rula, A., Gentile, A.L., Haase, P., Cochez, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 53–68. [Google Scholar]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the Class Imbalance Problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 4, pp. 192–201. [Google Scholar] [CrossRef]
- Braşoveanu, A.M.P.; Andonie, R. Visualizing Transformers for NLP: A Brief Survey. In Proceedings of the 2020 24th International Conference Information Visualisation (IV), Melbourne, Australia, 7–11 September 2020; pp. 270–279. [Google Scholar] [CrossRef]









| Criteria | KG | Ontology |
|---|---|---|
| Assumption | OWA | CWA |
| Size | Massive | Relatively small |
| Scalability | Very scalable | Limited scalability |
| Scope | Problem-specific | Domain-specific |
| Real-time | Generated at runtime | Limited real-time capability |
| Timeliness | Fresh | Outdated |
| Generation | Automatic | Mostly by humans |
| Trustworthiness | Not very trustworthy | Trustworthy |
| Knowledge base type | More A-Box than T-Box | Usually more T-Box than A-Box |
| Markup language | RDF | RDF, OWL, OIL |
| Data Integration | Easily integrated | Hard to integrate |
| Quality (Correctness, Completeness) | Questionable | High Quality |
| Agility | Dynamic | Static |
| Redundancy | Very likely | Not likely |
| Reliability | Questionable | Reliable |
| Maintenance | Challenging | Burdensome |
| Evolution | Easy | Difficult |
| Security (licensing) | Questionable | Reasonable |
| Interoperability | Low | Moderate |
| Relevancy | Low | High |
| Computational Performance | Heavy | Light |
| Class I (Subject) | Relation (Predicate) | Class II (Object) |
|---|---|---|
| system | has part directly | component |
| hardware component | has part directly | hardware part |
| element | implements | function |
| processing unit | executes | software |
| hardware subpart | part of directly | hardware part |
| element | has property | quantity |
| quantity | has value | measure |
| measure | has unit | unit |
| No. | Article Name | Approximate Number of Tags |
|---|---|---|
| 1 | Adaptive cruise control | 270 |
| 2 | Arithmetic logic unit | 280 |
| 3 | Cache (computing) | 400 |
| 4 | Analog to digital converter | 592 |
| 5 | Charge Pump | 112 |
| 6 | Central Processing Unit | 900 |
| 7 | Digital image processing | 100 |
| 8 | Electronic filter | 200 |
| 9 | Floating-point unit | 170 |
| 10 | Hard disk drive | 1288 |
| 11 | Latency (engineering) | 180 |
| 12 | Motherboard | 390 |
| 13 | Network interface controller | 150 |
| 14 | Random-access memory | 500 |
| 15 | Software | 200 |
| 16 | Texture mapping unit | 120 |
| 17 | Voltage controlled oscillator | 231 |
| 18 | Power supply | 360 |
| 19 | Microcontroller | 800 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| comp | 0.65 | 0.63 | 0.64 | 51 |
| func | 0.35 | 0.38 | 0.36 | 98 |
| hwc | 0.66 | 0.59 | 0.62 | 193 |
| hwp | 0.65 | 0.64 | 0.64 | 307 |
| hwsp | 0.56 | 0.52 | 0.54 | 77 |
| mea | 0.68 | 0.88 | 0.77 | 72 |
| qt | 0.73 | 0.67 | 0.70 | 402 |
| sw | 0.51 | 0.58 | 0.54 | 57 |
| sys | 0.46 | 0.53 | 0.49 | 86 |
| unit | 0.75 | 0.81 | 0.78 | 116 |
| micro avg | 0.64 | 0.64 | 0.64 | 1459 |
| macro avg | 0.60 | 0.62 | 0.61 | 1459 |
| weighted avg | 0.64 | 0.64 | 0.64 | 1459 |
| Token | True Label | Predicted Label |
|---|---|---|
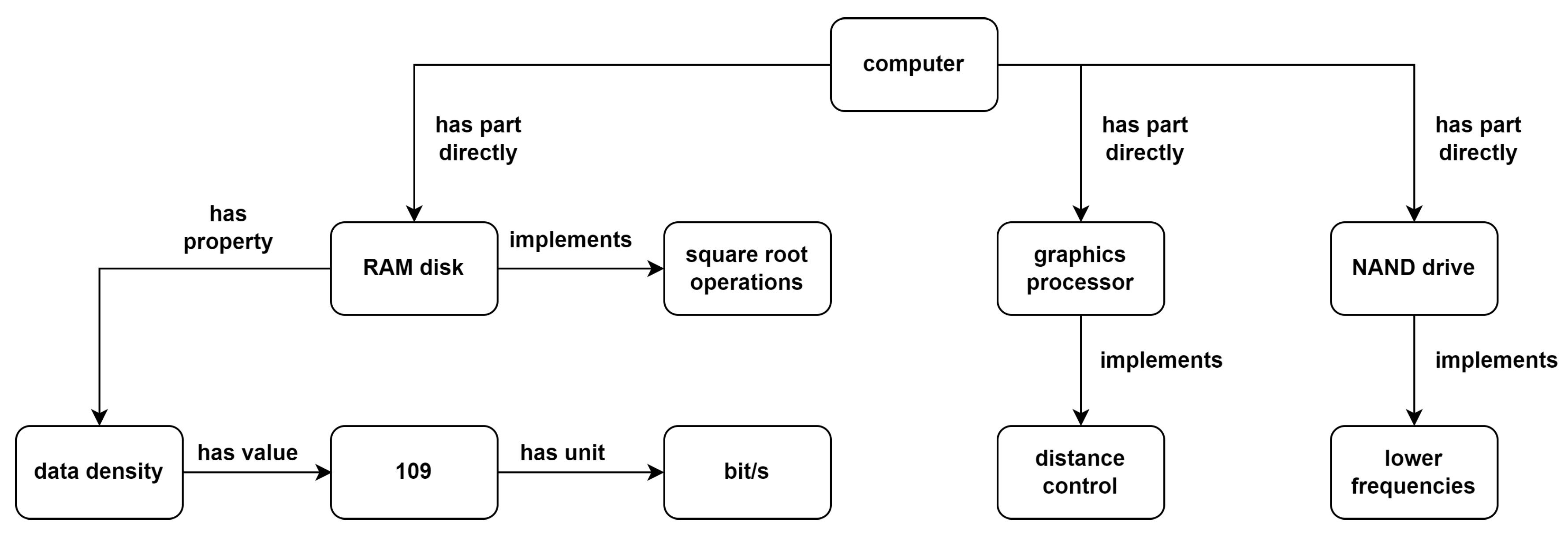
| computer | B-sys | B-sys |
| , | O | O |
| RAM | B-hwc | B-hwc |
| disk | I-hwc | I-hwc |
| , | O | O |
| data | B-qt | B-qt |
| density | I-qt | I-qt |
| , | O | O |
| 109 | B-mea | B-mea |
| bit | B-unit | B-unit |
| / | I-unit | I-unit |
| s | I-unit | I-unit |
| , | O | O |
| square | B-func | B-func |
| root | I-func | I-func |
| operations | I-func | I-func |
| , | O | O |
| graphics | B-hwp | B-hwp |
| processor | I-hwp | I-hwp |
| , | O | O |
| preview | B-sys | O |
| Distance | I-sys | B-func |
| control | I-sys | I-func |
| , | O | O |
| NAND | B-hwc | B-hwp |
| drive | I-hwc | I-hwp |
| , | O | O |
| lower | O | B-func |
| frequencies | B-qt | I-func |
| Token | Prediction |
|---|---|
| read | B-hwp |
| only | I-hwp |
| memory | I-hwp |
| , | O |
| addition | B-func |
| , | O |
| speed | B-qt |
| , | O |
| written | B-func |
| , | O |
| System/370 | B-sys |
| , | O |
| Apollo | B-sys |
| Guidance | I-sys |
| computer | I-sys |
| , | O |
| hard | B-hwc |
| disks | I-hwp |
| , | O |
| memory | B-hwp |
| cards | I-hwp |
| , | O |
| Keyboard | B-hwc |
| , | O |
| EPROM | B-unit |
| chips | I-unit |
| Token | True Label | Predicted Label |
|---|---|---|
| SRAM | B-hwsp | B-comp |
| caches | B-hwsp | I-comp |
| , | O | O |
| transmission | B-func | B-qt |
| , | O | O |
| lower | O | B-hwsp |
| unit | B-qt | I-hwsp |
| cost | I-qt | I-hwsp |
| , | O | O |
| Write | B-qt | I-qt |
| operation | I-qt | I-qt |
| , | O | O |
| SAS | B-comp | B-hwp |
| RAID | I-comp | B-hwp |
| Controller | I-comp | B-hwp |
| Token | POS | Label |
|---|---|---|
| A | DET | O |
| central | ADJ | B-hwp |
| processing | NOUN | I-hwp |
| unit | NOUN | I-hwp |
| ( | PUNCT | O |
| CPU | PROPN | B-hwp |
| ) | PUNCT | O |
| 0 | PUNCT | O |
| also | ADV | O |
| called | VERB | O |
| a | DET | O |
| central | ADV | B-hwp |
| processor | NOUN | I-hwp |
| 0 | PUNCT | O |
| main | ADJ | B-hwp |
| processor | NOUN | I-hwp |
| or | CCONJ | O |
| just | ADV | O |
| processor | NOUN | B-hwp |
| 0 | PUNCT | O |
| is | AUX | O |
| the | DET | O |
| electronic | ADJ | O |
| circuitry | NOUN | O |
| that | PRON | O |
| executes | VERB | O |
| instructions | NOUN | B-sw |
| comprising | VERB | O |
| a | DET | O |
| computer | NOUN | B-sw |
| program | NOUN | I-sw |
| . | PUNCT | O |
| The | DET | O |
| CPU | NOUN | B-hwp |
| performs | VERB | O |
| basic | ADJ | O |
| arithmetic | ADJ | B-func |
| 0 | PUNCT | O |
| logic | NOUN | B-func |
| 0 | PUNCT | O |
| controlling | VERB | B-func |
| 0 | PUNCT | O |
| and | CCONJ | O |
| input | NOUN | B-func |
| / | SYM | I-func |
| output | NOUN | I-func |
| operations | NOUN | I-func |
| specified | VERB | O |
| by | ADP | O |
| the | DET | O |
| instructions | NOUN | B-sw |
| in | ADP | O |
| the | DET | O |
| program | NOUN | B-sw |
| . | PUNCT | O |
| This | PRON | O |
| contrasts | VERB | O |
| with | ADP | O |
| external | ADJ | O |
| components | NOUN | O |
| such | ADJ | O |
| as | ADV | O |
| main | ADJ | B-hwp |
| memory | NOUN | I-hwp |
| and | CCONJ | O |
| I | NOUN | B-hwp |
| / | SYM | I-hwp |
| O | NOUN | I-hwp |
| circuitry | NOUN | I-hwp |
| 0 | PUNCT | O |
| and | CCONJ | O |
| specialized | ADJ | B-hwp |
| processors | NOUN | I-hwp |
| such | ADJ | O |
| as | ADP | O |
| graphics | NOUN | B-hwp |
| processing | NOUN | I-hwp |
| units | NOUN | I-hwp |
| ( | PUNCT | O |
| GPUs | NOUN | B-hwp |
| ) | PUNCT | O |
| . | PUNCT | O |
| The | PUNCT | O |
| form | PRON | O |
| 0 | VERB | O |
| design | NOUN | O |
| … | … | .. |
| Principal | ADJ | O |
| components | NOUN | O |
| of | ADP | O |
| a | DET | O |
| CPU | NOUN | B-hwp |
| include | VERB | O |
| the | DET | O |
| arithmetic | ADJ | B-hwsp |
| - | PUNCT | I-hwsp |
| logic | NOUN | I-hwsp |
| unit | NOUN | I-hwsp |
| ( | PUNCT | O |
| ALU | NOUN | B-hwsp |
| ) | PUNCT | O |
| that | PRON | O |
| performs | VERB | O |
| arithmetic | ADJ | B-func |
| and | CCONJ | O |
| logic | NOUN | B-func |
| operations | NOUN | I-func |
| 0 | PUNCT | O |
| processor | NOUN | O |
| registers | NOUN | O |
| that | NOUN | O |
| supply | NOUN | O |
| operands | VERB | B-qt |
| to | ADP | O |
| the | DET | O |
| ALU | NOUN | B-hwsp |
| and | CCONJ | O |
| store | VERB | O |
| the | DET | O |
| results | NOUN | O |
| of | ADP | O |
| ALU | ADJ | B-func |
| operations | NOUN | I-func |
| 0 | PUNCT | O |
| and | CCONJ | O |
| a | DET | O |
| control | NOUN | B-hwsp |
| unit | NOUN | I-hwsp |
| that | PRON | O |
| orchestrates | VERB | O |
| the | DET | O |
| fetching | NOUN | B-func |
| ( | PUNCT | O |
| from | ADP | O |
| memory | NOUN | B-hwp |
| ) | PUNCT | O |
| 0 | PUNCT | O |
| decoding | VERB | B-func |
| and | CCONJ | O |
| execution | VERB | B-func |
| of | ADP | O |
| instructions | NOUN | B-sw |
| by | ADP | O |
| directing | VERB | O |
| the | DET | O |
| coordinated | VERB | O |
| operations | NOUN | O |
| of | ADP | O |
| the | DET | O |
| ALU | PROPN | B-hwsp |
| 0 | PUNCT | O |
| registers | NOUN | O |
| and | CCONJ | O |
| other | ADJ | O |
| components | NOUN | O |
| . | PUNCT | O |
| Challenges | Descriptions | Proposed/Used Solutions |
|---|---|---|
| Over and under-classification. | Class imbalance. | Resampled to over-sample the minority classes by adding more examples. |
| The adequacy of the current ontology model. | Ontological commitment was very tight and fitting of our ontology in general. | Revise and evaluate your ontological model after applying ML methods and gathering your knowledge base content. |
| Training. | Labeling data required expert intervention. The accuracy of trained personnel may be lower than the expert. | Axioms could still be tested and reasoning could be applied. |
| Top-level. | Trained personnel may not have understood the subtle differences between closely related classes. | Continuously integrate knowledge and advantages of top level ontologies. |
| Natural language. | Ambiguities arise from building knowledge graphs from natural language documents. | Expert guidance and evaluation used. |
| Ontology vs. Knowledge graph. | Ontologies are small, very thoughtful, and highly accurate human build reference models, whereas knowledge graphs contain a significant amount of data and are most often machine-generated. | Combining both realities, building high-quality knowledge graphs based on ontology as reference and scientific approach. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wawrzik, F.; Rafique, K.A.; Rahman, F.; Grimm, C. Ontology Learning Applications of Knowledge Base Construction for Microelectronic Systems Information. Information 2023, 14, 176. https://doi.org/10.3390/info14030176
Wawrzik F, Rafique KA, Rahman F, Grimm C. Ontology Learning Applications of Knowledge Base Construction for Microelectronic Systems Information. Information. 2023; 14(3):176. https://doi.org/10.3390/info14030176
Chicago/Turabian StyleWawrzik, Frank, Khushnood Adil Rafique, Farin Rahman, and Christoph Grimm. 2023. "Ontology Learning Applications of Knowledge Base Construction for Microelectronic Systems Information" Information 14, no. 3: 176. https://doi.org/10.3390/info14030176
APA StyleWawrzik, F., Rafique, K. A., Rahman, F., & Grimm, C. (2023). Ontology Learning Applications of Knowledge Base Construction for Microelectronic Systems Information. Information, 14(3), 176. https://doi.org/10.3390/info14030176