1. Introduction
Computer vision tasks can be divided into four categories, namely image classification, object location, object detection, and semantic segmentation. Among them, semantic segmentation is more advanced than the others. To improve the accuracy of segmentation, it must maximize the efficiency of an encoder to obtain relevant features and understand the context contained in an image. In semantic segmentation, the ultimate goal is to classify all the marked pixels in the image.
In the past, to improve the performance of Convolutional Neural Networks (CNNs) for semantic segmentation, pre-trained classification networks were usually used as backbones, such as VGG [
1], ResNet [
2], and DenseNet [
3] trained on ImageNet. Later, to enable the network to have a larger receptive field and also to restore small objects in an image, dilated convolution was proposed by Yu and Koltun [
4], and then was used in the subsequent research [
5,
6,
7]. To segment larger objects and solve existing multi-scale objects in an image, some techniques such as Pyramid Pooling Module in PSPNet [
8], Atrous Spatial Pyramid Pooling Module in DeepLabv2 [
9], and Hierarchical Feature Fusion Module in ESPNet [
10], were proposed. Later, feature fusions between encoders and decoders were proposed in the recent literature [
11,
12]. Finally, to enable computers to learn human viewing behaviors, an attention mechanism was derived, such as Squeeze-and-Excitation Block in SENet [
13] and Convolutional Block Attention Module [
14].
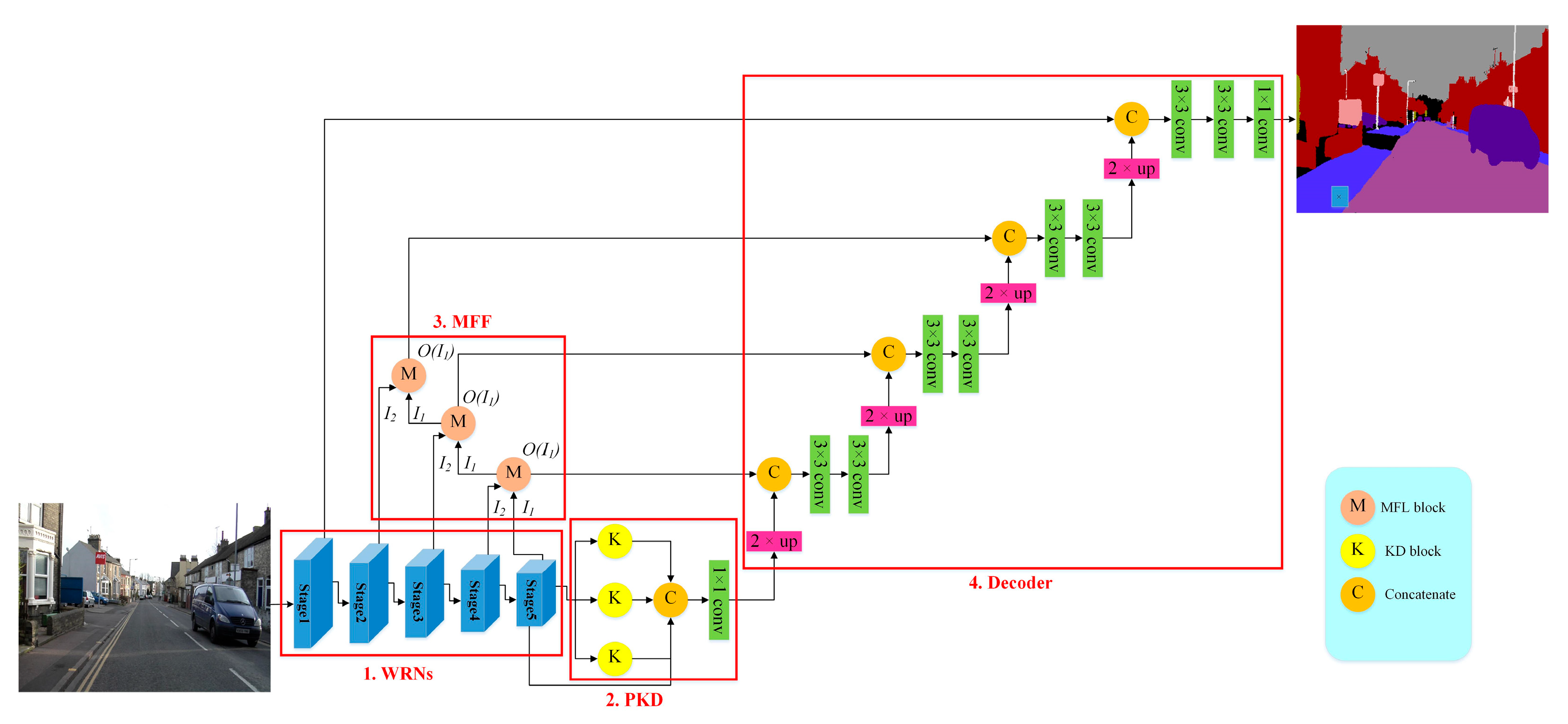
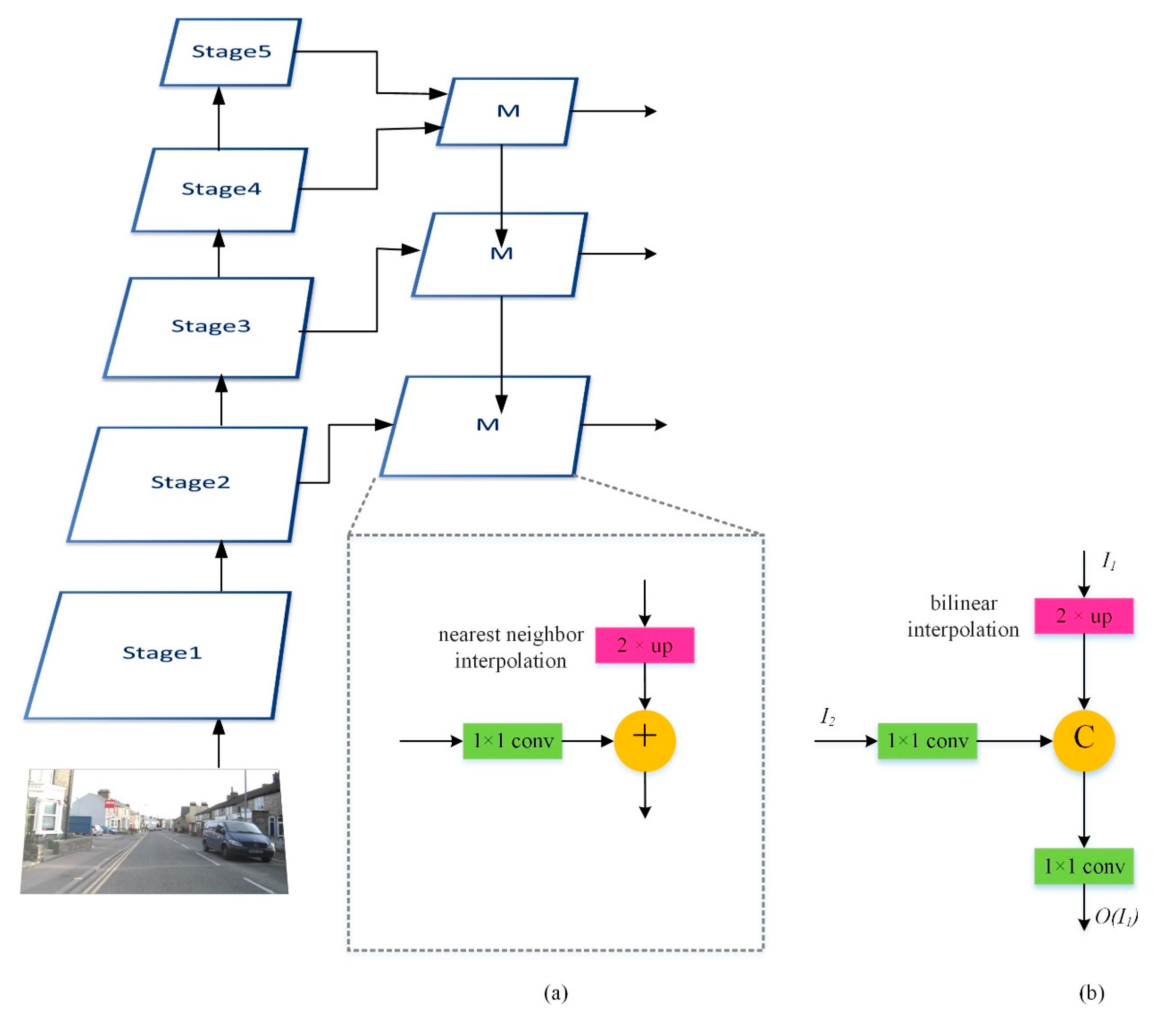
In this paper, we propose an image semantic segmentation model called the Dual-Pyramid Wide Residual Network (DPWRN) to solve the segmentation for cross-style datasets, which is suitable for diverse segmentation applications. In general, U-Net was the most frequently used as encoders and decoders in semantic segmentation. Here, in addition to an encoder and decoder, the model also consists of two extra modules to improve the accuracy of segmentation, i.e., Pyramid of Kernel paralleled with Dilation (PKD) and Multi-Feature Fusion (MFF), so-called Dual-Pyramid. In addition, in the previous work, most semantic segmentation models conducted experiments on datasets with only one style. In this paper, to evaluate the generalization of the DPWRN and its superiority over most state-of-the-art models, three datasets with completely different styles are tested in the experiments, i.e., Cambridge-driving Labeled Video Database (CamVid) [
15], Digital Retinal Images for Vessel Extraction (DRIVE) [
16], and eBDtheque [
17]. As a result, the DPWRN verified its generalization and also showed its superiority over most state-of-the-art models. In summary, we identify the novelty and contributions of this paper as follows:
A model called the DPWRN was proposed to solve image semantic segmentation, which integrated PKD and MFF to improve the accuracy of segmentation.
Three cross-style datasets were used to evaluate the generalization of the DPWRN, in contrast to only one-style dataset tested in existing semantic segmentation models.
The DPWRN achieved very good results, as compared with the state-of-the-art models, i.e., ranking third (mIoU 75.95%) on CamVid, ranking first (F1-score 83.6%) on DRIVE, and ranking the first (F1-score 86.87%) on eBDtheque.
The remainder of this paper is organized as follows. In
Section 2, the previous research related to image semantic segmentation is described. In
Section 3, an image semantic segmentation model is proposed to solve the segmentation for cross-style datasets, which is suitable for diverse segmentation applications. In
Section 4, to evaluate the generalization of the proposed model and its superiority over most state-of-the-art models, three datasets with completely different styles are tested in the experiments. Finally, we make conclusions and give future work in
Section 5.
2. Related Work
The earliest deep-learning network for image semantic segmentation was the Fully Convolutional Networks (FCNs) proposed by Long et al. [
11], which is an end-to-end network structure for the image classification on each pixel. To improve the network performance for image semantic segmentation, pre-trained image classification networks were usually used as backbones, such as VGG [
1], ResNet [
2], and DenseNet [
3] trained on ImageNet. In the down-sampling process, using multiple pooling layers or stride convolutions, the dimensionality of an input image can be reduced, the number of parameters is also reduced, and then a larger receptive field is obtained at the same time. Finally, the output stride of the feature map is 32. Next, in the up-sampling process, the image is restored for classification prediction.
However, output stride 32 is not beneficial to image semantic segmentation when an object size in an image is less than 32 × 32 since the object cannot be restored. To enable the network to have a larger receptive field and also to restore small objects in the image, dilated convolution was proposed by Yu and Koltun [
4]. In the down-sampling process, the original convolution layers in the later stages are replaced with dilated convolution layers to obtain the final high-resolution feature map. Later, Chen et al. [
5], Yamashita et al. [
6], and Liu et al. [
7] began to use dilated convolution to increase the receptive field.
In order to segment larger objects, it is important to increase the receptive field, but multi-scale objects could exist in an image. In PSPNet [
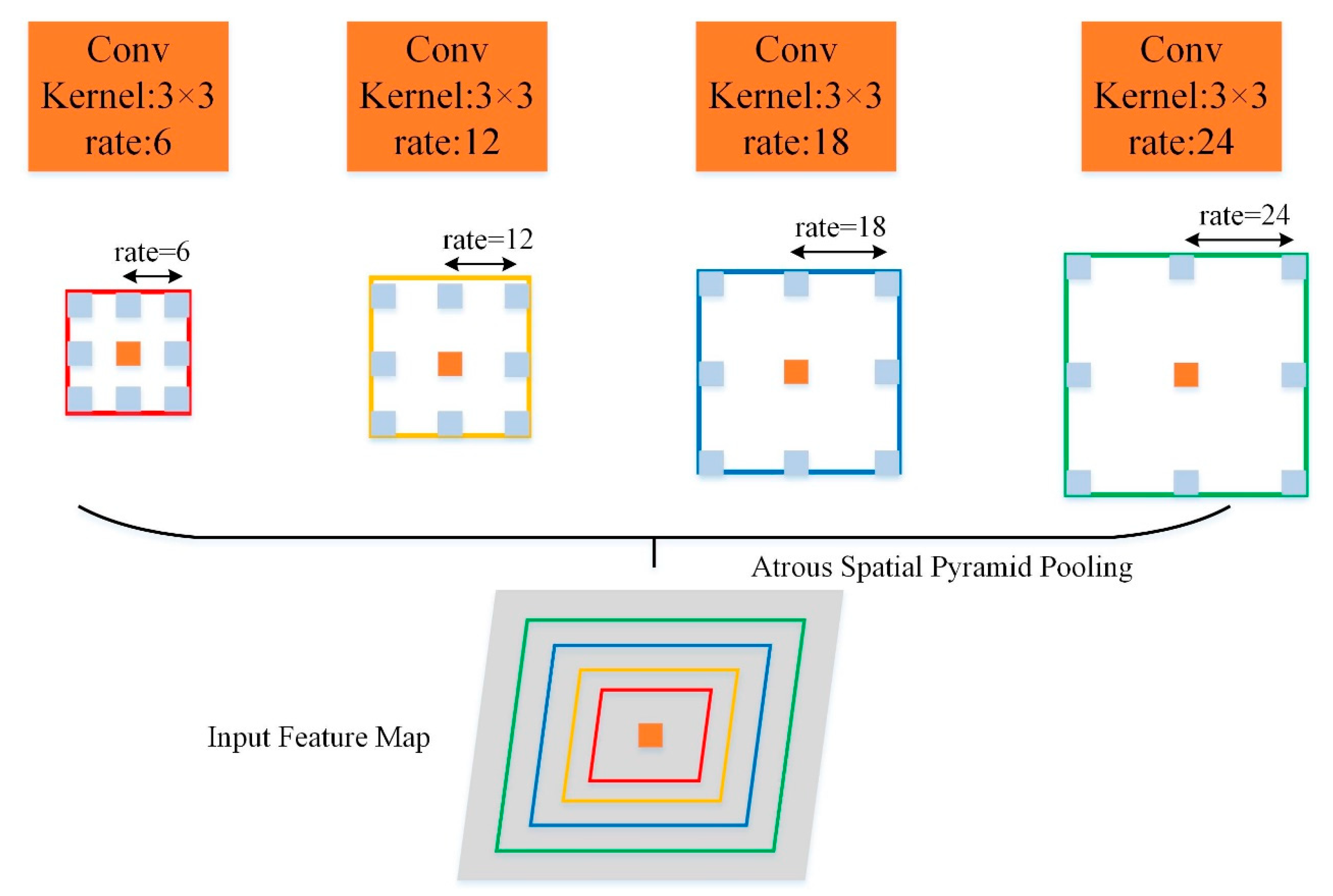
8], PPM (i.e., Pyramid Pooling Module) was proposed by Zhao et al., which uses multiple varying-size pooling kernels in parallel to obtain the features of different-scale objects. In DeepLabv2 [
9], the ASPP (i.e., Atrous Spatial Pyramid Pooling) module was proposed by Chen et al., which uses multiple varying-dilated-rate convolutions in parallel to obtain the features of different-scale objects. However, dilated convolution incurs gridding artifacts where adjacent pixels lack dependence on each other. This results in local information loss, especially when too large dilated rates cause the features to be obtained from a long distance with little correlation. To solve this problem, Mehta et al. proposed the HFF (i.e., Hierarchical Feature Fusion) module in ESPNet [
10]. The HFF module applies parallel dilated convolution and serial residuals to effectively eliminate gridding artifacts.
The receptive field can be divided into low, medium, and high, determined by the depth of an encoder. A deeper-layer encoder produces higher-order features, whereas a shallower-layer encoder produces lower-order features. If only high-order features are used to restore an image in a decoder, segmentation results could be inaccurate. Thus, feature fusions between encoders and decoders were proposed. Long et al. [
11] defined a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. In addition, Ronneberger et al. [
12] proposed U-Net, where the feature map of the decoder is concatenated with the correspondingly cropped feature map from the encoder to produce more accurate segmentations.
When humans watch a scene, they observe each block in the scene carefully by means of local attention and find the most significant part so as to understand the content of all objects in the scene. For the so-called contexts in an image, if only adjacent pixels are considered for semantic segmentation, the results will be inaccurate, especially at the boundary between two different object types. To enable computers to learn human viewing behaviors, an attention mechanism was derived. Hu et al. proposed the SE (i.e., Squeeze-and-Excitation) block in SENet [
13], which uses the channel attention mechanism to let the neural network learn what to look at, but the contexts of an image are not fully utilized. To solve this problem, Woo et al. [
14] proposed CBAM (i.e., Convolutional Block Attention Module), which uses not only a channel attention mechanism but also a spatial attention mechanism, enabling the neural network to learn what to look at and which parts of an object to look at.
Recently, the methods of Transformer combined with CNN have been employed in segmentation tasks. Zhang et al. [
18] proposed a hybrid semantic network (HSNet) combining both the advantages of Transformer and CNN and improving polyp segmentation. HSNet contains a cross-semantic attention module (CSA), a hybrid semantic complementary module (HSC), and a multi-scale prediction module (MSP). Dong et al. [
19] adopted a Transformer encoder in the proposed model Polyp-PVT, which learns more powerful and robust representations. In addition, Polyp-PVT also consists of three standard modules, i.e., a cascaded fusion module (CFM), a camouflage identification module (CIM), and a similarity aggregation module (SAM). Wang et al. [
20] proposed a multi-level fusion network, HIGF-Net, which uses a hierarchical guidance strategy to aggregate rich information to produce reliable segmentation results. HIGF-Net extracts deep global semantic information and shallow local spatial features of images together using Transformer and CNN encoders. Nanni et al. [
21] explored the potential of using the SAM (Segment-Anything Model) segmentator to enhance the segmentation capability of known methods. This work combines the logit segmentation masks produced by SAM with the ones provided by specialized segmentation models such as DeepLabv3+ and PVTv2.
Author Contributions
Conceptualization, Y.-F.H.; methodology, Y.-F.H.; software, G.-T.S.; validation, G.-T.S.; writing—original draft preparation, G.-T.S.; writing—review and editing, Y.-F.H.; supervision, Y.-F.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2016, arXiv:1511.07122v3. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587v3. [Google Scholar]
- Yamashita, T.; Furukawa, H.; Fujiyoshi, H. Multiple skip connections of dilated convolution network for semantic segmentation. In Proceedings of the 25th IEEE International Conference on Image Processing, Athens, Greece, 7–10 October 2018. [Google Scholar]
- Liu, L.; Pang, Y.; Zamir, S.W.; Khan, S.; Khan, F.S.; Shao, L. Filling the gaps in atrous convolution: Semantic segmentation with a better context. IEEE Access 2020, 8, 34019–34028. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Staal, J.; Abramoff, M.D.; Niemeijer, M.; Viergever, M.A.; van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Guérin, C.; Rigaud, C.; Mercier, A.; Ammar-Boudjelal, F.; Bertet, K.; Bouju, A.; Burie, J.C.; Louis, G.; Ogier, J.M.; Revel, A. eBDtheque: A representative database of comics. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Zhang, W.; Fu, C.; Zheng, Y.; Zhang, F.; Zhao, Y.; Sham, C.W. HSNet: A hybrid semantic network for polyp segmentation. Comput. Biol. Med. 2022, 150, 106173. [Google Scholar] [CrossRef]
- Dong, B.; Wang, W.; Fan, D.P.; Li, J.; Fu, H.; Shao, L. Polyp-PVT: Polyp segmentation with pyramid vision transformers. arXiv 2023, arXiv:2108.06932v7. [Google Scholar] [CrossRef]
- Wang, J.; Tian, S.; Yu, L.; Zhou, Z.; Wang, F.; Wang, Y. HIGF-Net: Hierarchical information-guided fusion network for polyp segmentation based on transformer and convolution feature learning. Comput. Biol. Med. 2023, 161, 107038. [Google Scholar] [CrossRef]
- Nanni, L.; Fusaro, D.; Fantozzi, C.; Pretto, A. Improving existing segmentators performance with zero-shot segmentators. Entropy 2023, 25, 1502. [Google Scholar] [CrossRef]
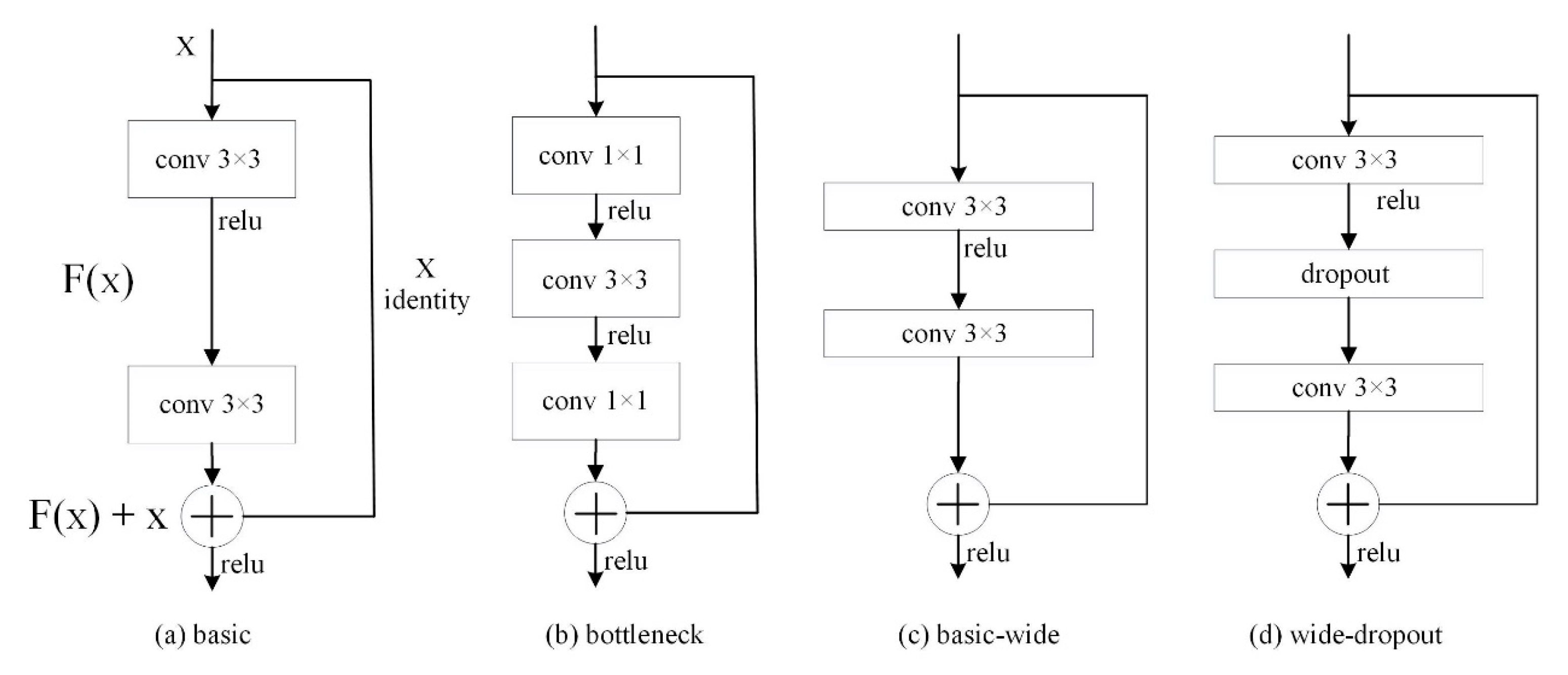
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2017, arXiv:1605.07146v4. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980v9. [Google Scholar]
- CIFAR-100. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 1 October 2023).
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. SA-UNet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021. [Google Scholar]
- Zhu, Y.; Sapra, K.; Reda, F.A.; Shih, K.J.; Newsam, S.; Tao, A.; Catanzaro, B. Improving semantic segmentation via video propagation and label relaxation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Huang, P.Y.; Hsu, W.T.; Chiu, C.Y.; Wu, T.F.; Sun, M. Efficient uncertainty estimation for semantic segmentation in videos. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bilinski, P.; Prisacariu, V. Dense decoder shortcut connections for single-pass semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chandra, S.; Couprie, C.; Kokkinos, I. Deep spatio-temporal random fields for efficient video segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, K.C.; Chiu, C.T.; Hsiao, S.C. Semantic segmentation via enhancing Context Information by fusing multiple high-level features. In Proceedings of the IEEE Workshop on Signal Processing Systems, Coimbra, Portugal, 20–22 October 2020. [Google Scholar]
- Nakayama, Y.; Lu, H.; Li, Y.; Kamiya, T. WideSegNeXt: Semantic image segmentation using wide residual network and next dilated unit. IEEE Sens. J. 2021, 21, 11427–11434. [Google Scholar] [CrossRef]
- Li, F.; Long, Z.; He, P.; Feng, P.; Guo, X.; Ren, X.; Wei, B.; Zhao, M.; Tang, B. Fully convolutional pyramidal networks for semantic segmentation. IEEE Access 2020, 8, 229132–229140. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. arXiv 2023, arXiv:2206.02066v3. [Google Scholar]
- Liskowski, P.; Krawiec, K. Segmenting retinal blood vessels with deep neural networks. IEEE Trans. Med. Imaging 2016, 35, 2369–2380. [Google Scholar] [CrossRef]
- Orlando, J.I.; Prokofyeva, E.; Blaschko, M.B. A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images. IEEE Trans. Biomed. Eng. 2017, 64, 16–27. [Google Scholar] [CrossRef]
- Yan, Z.; Yang, X.; Cheng, K.T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Trans. Biomed. Eng. 2018, 65, 1912–1923. [Google Scholar] [CrossRef]
- Wu, Y.; Xia, Y.; Song, Y.; Zhang, Y.; Cai, W. Multiscale network followed network model for retinal vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018. [Google Scholar]
- Wang, B.; Qiu, S.; He, H. Dual encoding U-Net for retinal vessel segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Wu, Y.; Xia, Y.; Song, Y.; Zhang, D.; Liu, D.; Zhang, C.; Cai, W. Vessel-Net: Retinal vessel segmentation under multi-path supervision. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Zhang, S.; Fu, H.; Yan, Y.; Zhang, Y.; Wu, Q.; Yang, M.; Tang, M.; Xu, Y. Attention guided network for retinal image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. IterNet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Zhou, Y.; Yu, H.; Shi, H. Study group learning: Improving retinal vessel segmentation trained with noisy labels. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021. [Google Scholar]
- Liu, W.; Yang, H.; Tian, T.; Cao, Z.; Pan, X.; Xu, W.; Jin, Y.; Gao, F. Full-resolution network and dual-threshold iteration for retinal vessel and coronary angiograph segmentation. IEEE J. Biomed. Health Inform. 2022, 26, 4623–4634. [Google Scholar] [CrossRef]
- Dubray, D.; Laubrock, J. Deep CNN-based speech balloon detection and segmentation for comic books. In Proceedings of the International Conference on Document Analysis and Recognition, Sydney, Australia, 20–25 September 2019. [Google Scholar]
- Arai, K.; Tolle, H. Method for real time text extraction of digital manga comic. Int. J. Image Process. 2011, 4, 669–676. [Google Scholar]
- Ho, A.K.N.; Burie, J.; Ogier, J. Panel and speech balloon extraction from comic books. In Proceedings of the 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, Queensland, Australia, 27–29 March 2012. [Google Scholar]
- Rigaud, C.; Burie, J.; Ogier, J.; Karatzas, D.; van de Weijer, J. An active contour model for speech balloon detection in comics. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013. [Google Scholar]
- Rigaud, C.; Burie, J.; Ogier, J. Text-independent speech balloon segmentation for comics and manga. In Proceedings of the IAPR International Workshop on Graphics Recognition, Sousse, Tunisia, 20–21 August 2015. [Google Scholar]
- Nguyen, N.V.; Rigaud, C.; Burie, J.C. Multi-task model for comic book image analysis. In Proceedings of the International Conference on Multimedia Modeling, Thessaloniki, Greece, 8–11 January 2019. [Google Scholar]
- Wang, C.M.; Huang, Y.F. Self-adaptive harmony search algorithm for optimization. Expert Syst. Appl. 2010, 37, 2826–2837. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}