
Deep Learning Approach for Human Action Recognition Using a Time Saliency Map Based on Motion Features Considering Camera Movement and Shot in Video Image Sequences

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. State of the Art
- The cancellation of the camera movement based on optical flow;
- The use of optical flow and image frame difference to determine motion regions and processing only the selected regions in the later steps, which reduces about 90% of the required computation;
- The use of active contour and colour-based image segmentation in the motion regions for more accurate human segmentation from the scene background;
- The use of previously computed optical flow vectors at selected key points as final features to save computation time.
3. Materials and Methods
3.1. Shot Detection
3.2. Camera Movement Cancellation
3.3. Optical Flow
3.4. Time Analysis Block
3.5. Silhouette Image Extraction
3.6. Active Contour Segmentation
3.7. Colour-Based Image Segmentation
3.8. Final Feature Extraction
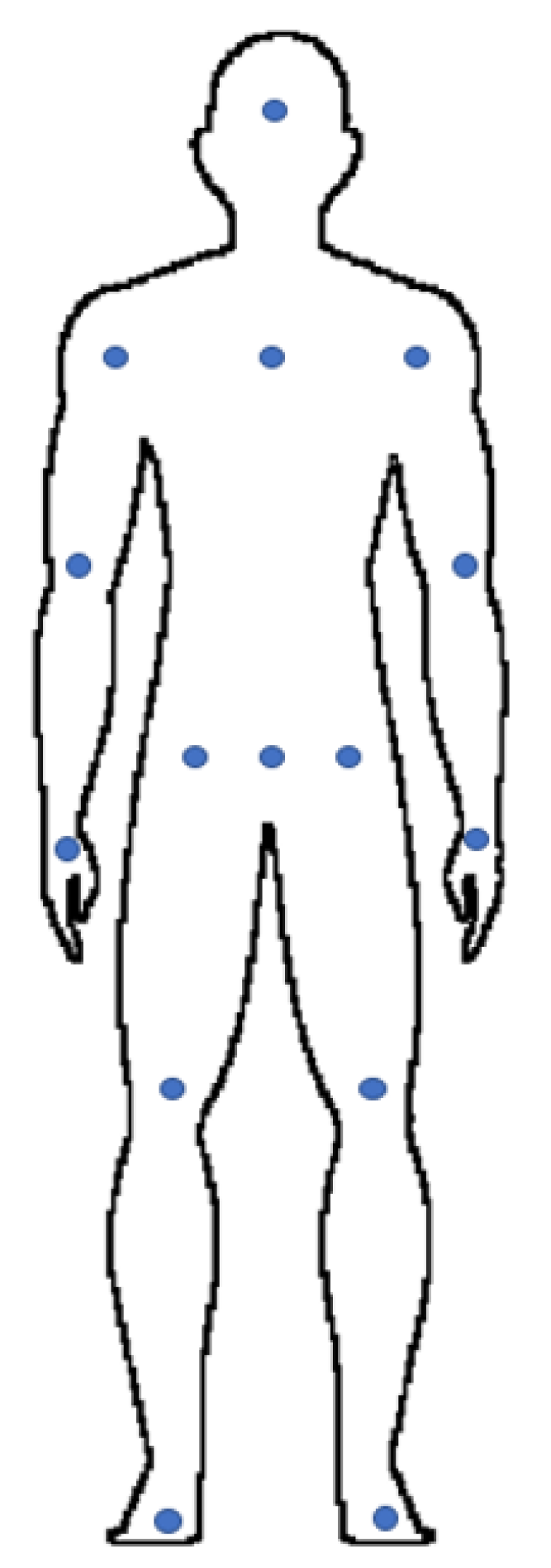
- A 15-point model was used in the dataset, including the whole body view. In cases where any of these 15 points are missing, the corresponding position is considered empty.
- In cases where a full body view is unavailable, the feature vector is created by selecting 65 points along the extracted contour, with equal distances between them, as key points.
- In the full-body model, the extracted feature includes the location of the points relative to point 9 as an approximation to the body centroid and the intensity and direction of the motion vector in the key points. If the 15-point model is not available, the point with the centre of the segments is considered the coordinate origin.
- In general, 65 points are selected, each with four features, including x and y locations and motion vector.
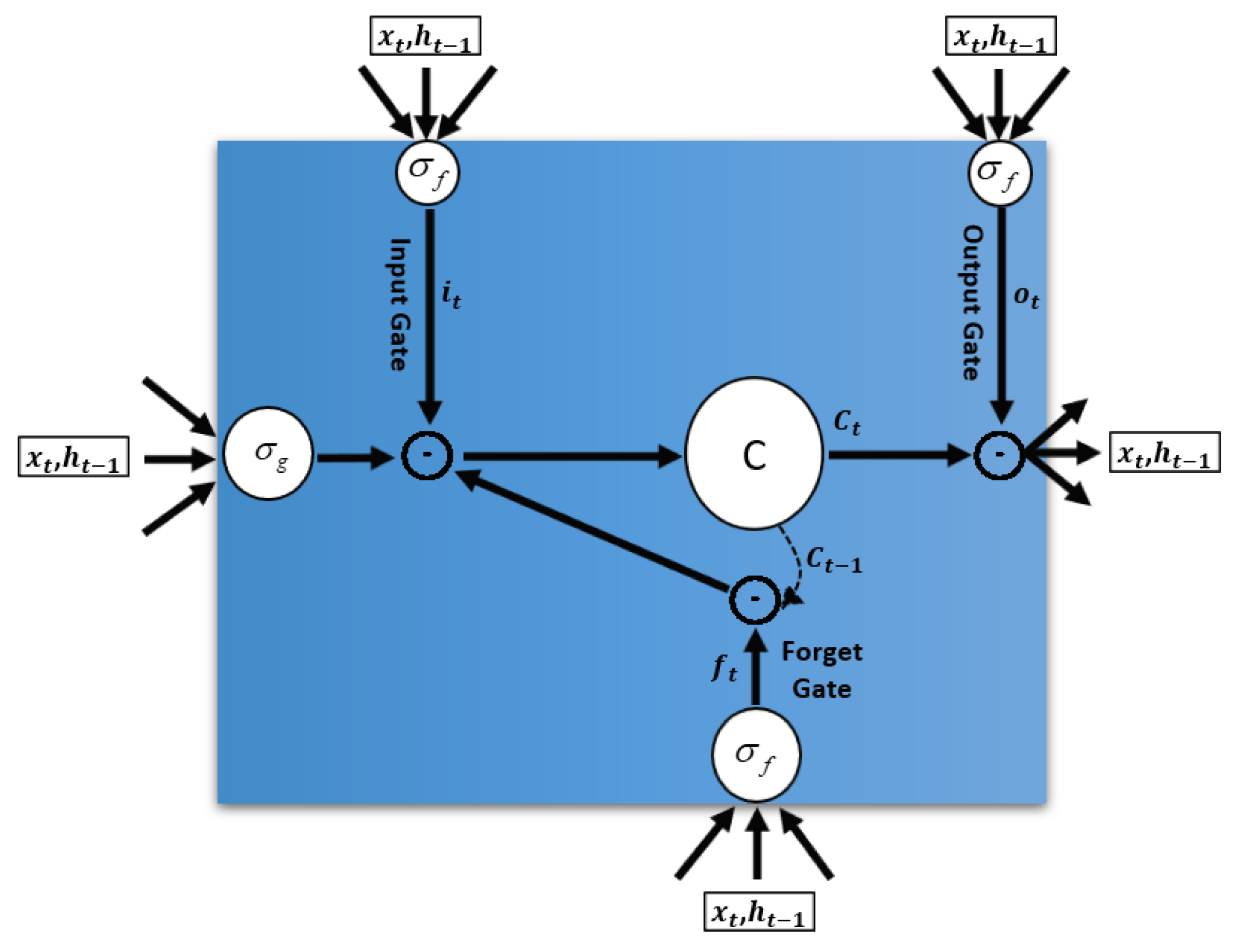
3.9. Long Short-Term Memory
4. Experimental Setting
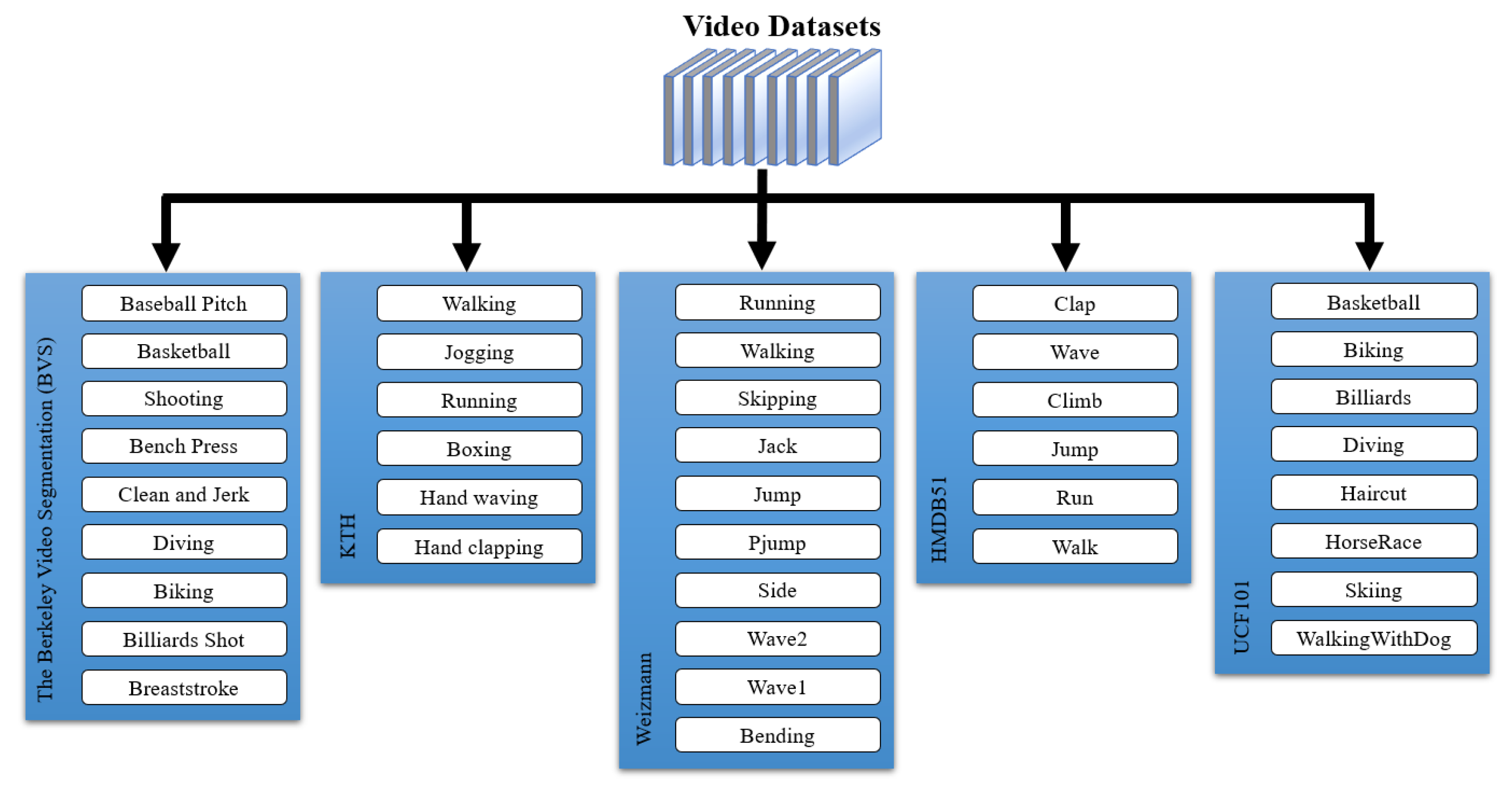
4.1. Datasets
4.1.1. Berkeley Video Segmentation Dataset
4.1.2. KTH Dataset
4.1.3. Weizmann Dataset
4.1.4. HMDB51 Dataset
- General facial actions;
- Facial actions with object manipulation;
- General body movements;
- Body movements with object interaction;
- Body movements with human interaction.
4.1.5. UCF101 Dataset
4.2. Evaluation Metrics
- True positive: Action exists and is correctly detected;
- True negative: Absence of action is correctly detected;
- False positive: Action does not exist, but the system mistakenly indicates its existence;
- False negative: Action is present but incorrectly detected as absent.
- If the element is interpreted based on the action associated with its row, it indicates the number of samples of row classes that were mistakenly assigned to other classes;
- If the element is interpreted based on the action associated with its column, it indicates the number of samples of other classes that were mistakenly assigned to the column class.
5. Experimental Results and Discussion
5.1. Time Features
5.2. Effect of the Different Steps of the Proposed Method
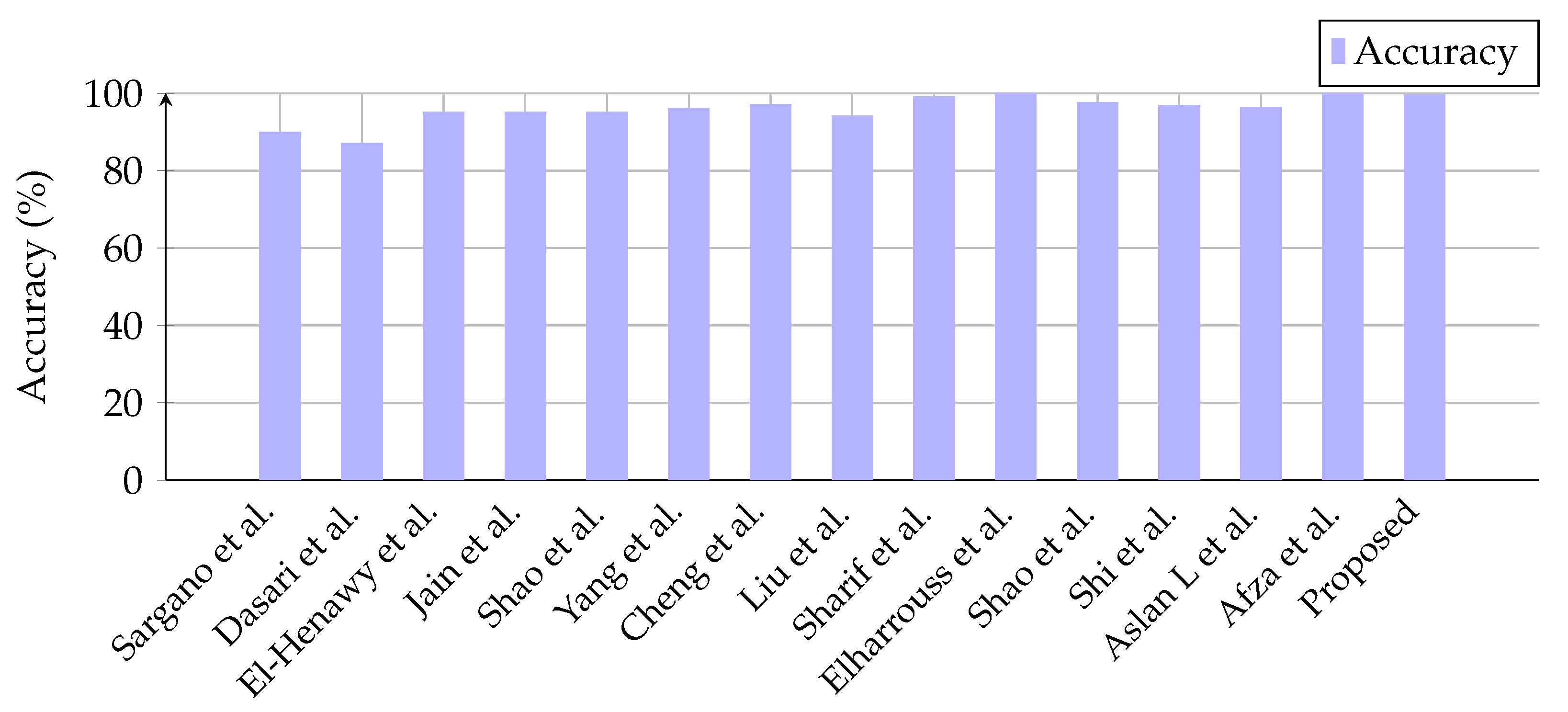
5.3. Comparison with Other Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caetano, C.; dos Santos, J.A.; Schwartz, W.R. Optical Flow Co-occurrence Matrices: A novel spatiotemporal feature descriptor. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1947–1952. [Google Scholar] [CrossRef]
- Gupta, A.; Balan, M.S. Action recognition from optical flow visualizations. In Proceedings of the 2nd International Conference on Computer Vision & Image Processing, Roorkee, India, 1 March 2018; pp. 397–408. [Google Scholar] [CrossRef]
- Kumar, S.S.; John, M. Human activity recognition using optical flow based feature set. In Proceedings of the 2016 IEEE International Carnahan Conference on Security Technology (ICCST), Orlando, FL, USA, 24–27 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Rashwan, H.A.; Garcia, M.A.; Abdulwahab, S.; Puig, D. Action representation and recognition through temporal co-occurrence of flow fields and convolutional neural networks. Multimed. Tools Appl. 2020, 79, 34141–34158. [Google Scholar] [CrossRef]
- Rashwan, H.A.; García, M.Á.; Chambon, S.; Puig, D. Gait representation and recognition from temporal co-occurrence of flow fields. Mach. Vis. Appl. 2019, 30, 139–152. [Google Scholar] [CrossRef]
- Xu, G.L.; Zhou, H.; Yuan, L.Y.; Huang, Y.Y. Using Improved Dense Trajectory Feature to Realize Action Recognition. J. Comput. 2021, 32, 94–108. [Google Scholar] [CrossRef]
- Liu, C.; Ying, J.; Yang, H.; Hu, X.; Liu, J. Improved human action recognition approach based on two-stream convolutional neural network model. Vis. Comput. 2021, 37, 1327–1341. [Google Scholar] [CrossRef]
- Kumar, B.S.; Raju, S.V.; Reddy, H.V. Human action recognition using a novel deep learning approach. Proc. Iop Conf. Ser. Mater. Sci. Eng. 2021, 1042, 012031. [Google Scholar] [CrossRef]
- Abdelbaky, A.; Aly, S. Two-stream spatiotemporal feature fusion for human action recognition. Vis. Comput. 2021, 37, 1821–1835. [Google Scholar] [CrossRef]
- Guha, R.; Khan, A.H.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. CGA: A new feature selection model for visual human action recognition. Neural Comput. Appl. 2021, 33, 5267–5286. [Google Scholar] [CrossRef]
- Dash, S.C.B.; Mishra, S.R.; Srujan Raju, K.; Narasimha Prasad, L. Human action recognition using a hybrid deep learning heuristic. Soft Comput. 2021, 25, 13079–13092. [Google Scholar] [CrossRef]
- Khan, M.A.; Zhang, Y.D.; Khan, S.A.; Attique, M.; Rehman, A.; Seo, S. A resource conscious human action recognition framework using 26-layered deep convolutional neural network. Multimed. Tools Appl. 2021, 80, 35827–35849. [Google Scholar] [CrossRef]
- Jaouedi, N.; Boujnah, N.; Bouhlel, M.S. A new hybrid deep learning model for human action recognition. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 447–453. [Google Scholar] [CrossRef]
- Zheng, Y.; Yao, H.; Sun, X.; Zhao, S.; Porikli, F. Distinctive action sketch for human action recognition. Signal Process. 2018, 144, 323–332. [Google Scholar] [CrossRef]
- Ramya, P.; Rajeswari, R. Human action recognition using distance transform and entropy based features. Multimed. Tools Appl. 2021, 80, 8147–8173. [Google Scholar] [CrossRef]
- Haddad, M.; Ghassab, V.K.; Najar, F.; Bouguila, N. A statistical framework for few-shot action recognition. Multimed. Tools Appl. 2021, 80, 24303–24318. [Google Scholar] [CrossRef]
- Snoun, A.; Jlidi, N.; Bouchrika, T.; Jemai, O.; Zaied, M. Towards a deep human activity recognition approach based on video to image transformation with skeleton data. Multimed. Tools Appl. 2021, 80, 29675–29698. [Google Scholar] [CrossRef]
- Abdelbaky, A.; Aly, S. Human action recognition using three orthogonal planes with unsupervised deep convolutional neural network. Multimed. Tools Appl. 2021, 80, 20019–20043. [Google Scholar] [CrossRef]
- Xia, L.; Ma, W. Human action recognition using high-order feature of optical flows. J. Supercomput. 2021, 77, 14230–14251. [Google Scholar] [CrossRef]
- Martínez Carrillo, F.; Gouiffès, M.; Garzón Villamizar, G.; Manzanera, A. A compact and recursive Riemannian motion descriptor for untrimmed activity recognition. J. Real-Time Image Process. 2021, 18, 1867–1880. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, X. Applying TS-DBN model into sports behavior recognition with deep learning approach. J. Supercomput. 2021, 77, 12192–12208. [Google Scholar] [CrossRef]
- Aghaei, A.; Nazari, A.; Moghaddam, M.E. Sparse deep LSTMs with convolutional attention for human action recognition. SN Comput. Sci. 2021, 2, 151. [Google Scholar] [CrossRef]
- Zebhi, S.; AlModarresi, S.M.T.; Abootalebi, V. Human activity recognition using pre-trained network with informative templates. Int. J. Mach. Learn. Cybern. 2021, 12, 3449–3461. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, X.; Chen, H.; Sun, J. Action Recognition in Videos with Spatio-Temporal Fusion 3D Convolutional Neural Networks. Pattern Recognit. Image Anal. 2021, 31, 580–587. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.S.; Armghan, A.; Alenezi, F. Human action recognition: A paradigm of best deep learning features selection and serial based extended fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Zheng, W.; Song, Y.; Zhang, C.; Yuan, X.; Li, Y. Scene image and human skeleton-based dual-stream human action recognition. Pattern Recognit. Lett. 2021, 148, 136–145. [Google Scholar] [CrossRef]
- Wu, C.; Li, Y.; Zhang, Y.; Liu, B. Double constrained bag of words for human action recognition. Signal Process. Image Commun. 2021, 98, 116399. [Google Scholar] [CrossRef]
- El-Assal, M.; Tirilly, P.; Bilasco, I.M. A Study On the Effects of Pre-processing On Spatio-temporal Action Recognition Using Spiking Neural Networks Trained with STDP. In Proceedings of the 2021 International Conference on Content-Based Multimedia Indexing (CBMI), Lille, France, 28–30 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Boualia, S.N.; Amara, N.E.B. 3D CNN for Human Action Recognition. In Proceedings of the 2021 18th International Multi-Conference on Systems, Signals & Devices (SSD), Monastir, Tunisia, 22–25 March 2021; pp. 276–282. [Google Scholar] [CrossRef]
- Mishra, O.; Kavimandan, P.; Kapoor, R. Modal Frequencies Based Human Action Recognition Using Silhouettes And Simplicial Elements. Int. J. Eng. 2022, 35, 45–52. [Google Scholar] [CrossRef]
- Ha, J.; Shin, J.; Park, H.; Paik, J. Action recognition network using stacked short-term deep features and bidirectional moving average. Appl. Sci. 2021, 11, 5563. [Google Scholar] [CrossRef]
- Gharahbagh, A.A.; Hajihashemi, V.; Ferreira, M.C.; Machado, J.J.; Tavares, J.M.R. Best Frame Selection to Enhance Training Step Efficiency in Video-Based Human Action Recognition. Appl. Sci. 2022, 12, 1830. [Google Scholar] [CrossRef]
- Hajihashemi, V.; Pakizeh, E. Human activity recognition in videos based on a Two Levels K-means and Hierarchical Codebooks. Int. J. Mechatron. Electr. Comput. Technol 2016, 6, 3152–3159. [Google Scholar]
- Deshpnande, A.; Warhade, K.K. An Improved Model for Human Activity Recognition by Integrated feature Approach and Optimized SVM. In Proceedings of the 2021 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 5–7 March 2021; pp. 571–576. [Google Scholar] [CrossRef]
- Ma, J.; Tao, X.; Ma, J.; Hong, X.; Gong, Y. Class incremental learning for video action classification. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 504–508. [Google Scholar] [CrossRef]
- Shekokar, R.; Kale, S. Deep Learning for Human Action Recognition. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Sawanglok, T.; Songmuang, P. Data Preparation for Reducing Computational Time with Transpose Stack Matrix for Action Recognition. In Proceedings of the 2021 13th International Conference on Knowledge and Smart Technology (KST), Bangsaen, Thailand, 21–24 January 2021; pp. 141–146. [Google Scholar] [CrossRef]
- Shi, S.; Jung, C. Deep Metric Learning for Human Action Recognition with SlowFast Networks. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Gao, Z.; Gu, Q.; Han, Z. Human Behavior Recognition Method based on Two-layer LSTM Network with Attention Mechanism. J. Phys. Conf. Ser. 2021, 2093, 012006. [Google Scholar] [CrossRef]
- Wang, J.; Xia, L.; Ma, W. Human action recognition based on motion feature and manifold learning. IEEE Access 2021, 9, 89287–89299. [Google Scholar] [CrossRef]
- Nasir, I.M.; Raza, M.; Shah, J.H.; Khan, M.A.; Rehman, A. Human action recognition using machine learning in uncontrolled environment. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 182–187. [Google Scholar] [CrossRef]
- Sowmyayani, S.; Rani, P. STHARNet: Spatio-temporal human action recognition network in content based video retrieval. Multimed. Tools Appl. 2022, 82, 38051–38066. [Google Scholar] [CrossRef]
- Singh, K.; Dhiman, C.; Vishwakarma, D.K.; Makhija, H.; Walia, G.S. A sparse coded composite descriptor for human activity recognition. Expert Syst. 2022, 39, e12805. [Google Scholar] [CrossRef]
- Mithsara, W. Comparative Analysis of AI-powered Approaches for Skeleton-based Child and Adult Action Recognition in Multi-person Environment. In Proceedings of the 2022 International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 15–17 March 2022; pp. 24–29. [Google Scholar] [CrossRef]
- Nair, S.A.L.; Megalingam, R.K. Fusion of Bag of Visual Words with Neural Network for Human Action Recognition. In Proceedings of the 2022 12th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 27–28 January 2022; pp. 14–19. [Google Scholar] [CrossRef]
- Megalingam, R.K.; Nair S., A.L. Human Action Recognition: A Review. In Proceedings of the 2021 10th International Conference on System Modeling & Advancement in Research Trends (SMART), Moradabad, India, 10–11 December 2021; pp. 249–252. [Google Scholar] [CrossRef]
- Bayoudh, K.; Hamdaoui, F.; Mtibaa, A. An Attention-based Hybrid 2D/3D CNN-LSTM for Human Action Recognition. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022; pp. 97–103. [Google Scholar] [CrossRef]
- Liang, Y.; Huang, H.; Li, J.; Dong, X.; Chen, M.; Yang, S.; Chen, H. Action recognition based on discrete cosine transform by optical pixel-wise encoding. APL Photonics 2022, 7, 116101. [Google Scholar] [CrossRef]
- Khater, S.; Hadhoud, M.; Fayek, M.B. A novel human activity recognition architecture: Using residual inception ConvLSTM layer. J. Eng. Appl. Sci. 2022, 69, 45. [Google Scholar] [CrossRef]
- Momin, M.S.; Sufian, A.; Barman, D.; Dutta, P.; Dong, M.; Leo, M. In-home older adults’ activity pattern monitoring using depth sensors: A review. Sensors 2022, 22, 9067. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Wu, Z.; Du, H. Research on Human Action Feature Detection and Recognition Algorithm Based on Deep Learning. Mob. Inf. Syst. 2022, 2022, 4652946. [Google Scholar] [CrossRef]
- Ahn, D.; Kim, S.; Hong, H.; Ko, B.C. STAR-Transformer: A spatio-temporal cross attention transformer for human action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 3330–3339. [Google Scholar]
- Vaitesswar, U.; Yeo, C.K. Multi-Range Mixed Graph Convolution Network for Skeleton-Based Action Recognition. In Proceedings of the 2023 5th Asia Pacific Information Technology Conference, Ho Chi Minh, Vietnam, 9–11 February 2023; pp. 49–54. [Google Scholar] [CrossRef]
- Lee, J.; Lee, M.; Lee, D.; Lee, S. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 10444–10453. [Google Scholar]
- Wu, J.; Wang, L.; Chong, G.; Feng, H. 2S-AGCN Human Behavior Recognition Based on New Partition Strategy. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 157–163. [Google Scholar] [CrossRef]
- Radulescu, B.A.; Radulescu, V. Modeling 3D convolution architecture for actions recognition. In Proceedings of the Information Storage and Processing Systems. American Society of Mechanical Engineers, Online, 2–3 June 2021; Volume 84799, p. V001T01A001. [Google Scholar] [CrossRef]
- Yan, Z.; Yongfeng, Q.; Xiaoxu, P. Dangerous Action Recognition for Spatial-Temporal Graph Convolutional Networks. In Proceedings of the 2022 IEEE 12th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 15–17 July 2022; pp. 216–219. [Google Scholar] [CrossRef]
- Liao, T.; Zhao, J.; Liu, Y.; Ivanov, K.; Xiong, J.; Yan, Y. Deep transfer learning with graph neural network for sensor-based human activity recognition. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 2445–2452. [Google Scholar] [CrossRef]
- Bi, C.; Yuan, Y.; Zhang, J.; Shi, Y.; Xiang, Y.; Wang, Y.; Zhang, R. Dynamic mode decomposition based video shot detection. IEEE Access 2018, 6, 21397–21407. [Google Scholar] [CrossRef]
- Lu, Z.M.; Shi, Y. Fast video shot boundary detection based on SVD and pattern matching. IEEE Trans. Image Process. 2013, 22, 5136–5145. [Google Scholar] [CrossRef]
- Mishra, R. Video shot boundary detection using hybrid dual tree complex wavelet transform with Walsh Hadamard transform. Multimed. Tools Appl. 2021, 80, 28109–28135. [Google Scholar] [CrossRef]
- Rashmi, B.; Nagendraswamy, H. Video shot boundary detection using block based cumulative approach. Multimed. Tools Appl. 2021, 80, 641–664. [Google Scholar] [CrossRef]
- Hu, W.C.; Chen, C.H.; Chen, T.Y.; Huang, D.Y.; Wu, Z.C. Moving object detection and tracking from video captured by moving camera. J. Vis. Commun. Image Represent. 2015, 30, 164–180. [Google Scholar] [CrossRef]
- Moore, B.E.; Gao, C.; Nadakuditi, R.R. Panoramic robust pca for foreground–background separation on noisy, free-motion camera video. IEEE Trans. Comput. Imaging 2019, 5, 195–211. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Yu, Q. Moving Object Detection under a Moving Camera via Background Orientation Reconstruction. Sensors 2020, 20, 3103. [Google Scholar] [CrossRef] [PubMed]
- Ahammed, M.J.; Venkata Rao, V.; Bajidvali, S. Human Gait Detection Using Silhouette Image Recognition. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 1320–1326. [Google Scholar]
- Lam, T.H.; Lee, R.S. A new representation for human gait recognition: Motion silhouettes image (MSI). In Advances in Biometrics; Springer: Berlin/Heidelberg, Germany, 2005; pp. 612–618. [Google Scholar] [CrossRef]
- Jawed, B.; Khalifa, O.O.; Bhuiyan, S.S.N. Human gait recognition system. In Proceedings of the 2018 7th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 19–20 September 2018; pp. 89–92. [Google Scholar] [CrossRef]
- Maity, S.; Chakrabarti, A.; Bhattacharjee, D. Robust human action recognition using AREI features and trajectory analysis from silhouette image sequence. IETE J. Res. 2019, 65, 236–249. [Google Scholar] [CrossRef]
- Vishwakarma, D.K.; Dhiman, C. A unified model for human activity recognition using spatial distribution of gradients and difference of Gaussian kernel. Vis. Comput. 2019, 35, 1595–1613. [Google Scholar] [CrossRef]
- Yang, D.; Peng, B.; Al-Huda, Z.; Malik, A.; Zhai, D. An overview of edge and object contour detection. Neurocomputing 2022, 488, 470–493. [Google Scholar] [CrossRef]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Cohen, L.D. On active contour models and balloons. CVGIP: Image Underst. 1991, 53, 211–218. [Google Scholar] [CrossRef]
- Xu, C.; Prince, J.L. Snakes, shapes, and gradient vector flow. IEEE Trans. Image Process. 1998, 7, 359–369. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Acton, S.T. Active contour external force using vector field convolution for image segmentation. IEEE Trans. Image Process. 2007, 16, 2096–2106. [Google Scholar] [CrossRef]
- Mumford, D.; Shah, J. Boundary detection by minimizing functionals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 9–13 June 1985; Volume 17, pp. 137–154. [Google Scholar]
- Caselles, V.; Kimmel, R.; Sapiro, G. Geodesic active contours. Int. J. Comput. Vis. 1997, 22, 61–79. [Google Scholar] [CrossRef]
- Chan, T.F.; Vese, L.A. Active contours without edges. IEEE Trans. Image Process. 2001, 10, 266–277. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Kao, C.Y.; Gore, J.C.; Ding, Z. Minimization of region-scalable fitting energy for image segmentation. IEEE Trans. Image Process. 2008, 17, 1940–1949. [Google Scholar] [CrossRef]
- Ghosh, A.; Bandyopadhyay, S. Image co-segmentation using dual active contours. Appl. Soft Comput. 2018, 66, 413–427. [Google Scholar] [CrossRef]
- Han, J.; Quan, R.; Zhang, D.; Nie, F. Robust object co-segmentation using background prior. IEEE Trans. Image Process. 2017, 27, 1639–1651. [Google Scholar] [CrossRef] [PubMed]
- Merdassi, H.; Barhoumi, W.; Zagrouba, E. A comprehensive overview of relevant methods of image cosegmentation. Expert Syst. Appl. 2020, 140, 112901. [Google Scholar] [CrossRef]
- Anitha, J.; Pandian, S.I.A.; Agnes, S.A. An efficient multilevel color image thresholding based on modified whale optimization algorithm. Expert Syst. Appl. 2021, 178, 115003. [Google Scholar] [CrossRef]
- Jing, Y.; Kong, T.; Wang, W.; Wang, L.; Li, L.; Tan, T. Locate then segment: A strong pipeline for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9858–9867. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In Proceedings of the European Conference on Computer Vision. Springer, Glasgow, UK, 23–28 August 2020; pp. 649–665. [Google Scholar] [CrossRef]
- Kabilan, R.; Devaraj, G.P.; Muthuraman, U.; Muthukumaran, N.; Gabriel, J.Z.; Swetha, R. Efficient color image segmentation using fastmap algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1134–1141. [Google Scholar] [CrossRef]
- Abualigah, L.; Almotairi, K.H.; Elaziz, M.A. Multilevel thresholding image segmentation using meta-heuristic optimization algorithms: Comparative analysis, open challenges and new trends. Appl. Intell. 2022, 53, 11654–11704. [Google Scholar] [CrossRef]
- Sathya, P.; Kalyani, R.; Sakthivel, V. Color image segmentation using Kapur, Otsu and minimum cross entropy functions based on exchange market algorithm. Expert Syst. Appl. 2021, 172, 114636. [Google Scholar] [CrossRef]
- Plyer, A.; Le Besnerais, G.; Champagnat, F. Massively parallel Lucas Kanade optical flow for real-time video processing applications. J. Real-Time Image Process. 2016, 11, 713–730. [Google Scholar] [CrossRef]
- Sundberg, P.; Brox, T.; Maire, M.; Arbeláez, P.; Malik, J. Occlusion boundary detection and figure/ground assignment from optical flow. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2233–2240. [Google Scholar] [CrossRef]
- Galasso, F.; Nagaraja, N.S.; Cardenas, T.J.; Brox, T.; Schiele, B. A unified video segmentation benchmark: Annotation, metrics and analysis. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3527–3534. [Google Scholar]
- Zhao, Q.; Yan, B.; Yang, J.; Shi, Y. Evolutionary Robust Clustering Over Time for Temporal Data. IEEE Trans. Cybern. 2022, 53, 4334–4346. [Google Scholar] [CrossRef]
- Han, D.; Xiao, Y.; Zhan, P.; Li, T.; Fan, M. A Semi-Supervised Video Object Segmentation Method Based on ConvNext and Unet. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022; pp. 7425–7431. [Google Scholar] [CrossRef]
- Hu, Y.T.; Huang, J.B.; Schwing, A.G. Unsupervised video object segmentation using motion saliency-guided spatio-temporal propagation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 2–14 September 2018; pp. 786–802. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar] [CrossRef]
- Laptev, I. Local Spatio-Temporal Image Features for Motion Interpretation. Ph.D. Thesis, KTH Numerisk Analys Och Datalogi, Stockholm, Sweden, 2004. [Google Scholar]
- Laptev, I.; Lindeberg, T. Local descriptors for spatio-temporal recognition. In Proceedings of the International Workshop on Spatial Coherence for Visual Motion Analysis, Prague, Czech Republic, 15 May 2004; pp. 91–103. [Google Scholar] [CrossRef]
- Laptev, I.; Lindeberg, T. Velocity adaptation of space-time interest points. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 1, pp. 52–56. [Google Scholar] [CrossRef]
- Laptev, I. On space-time interest points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1395–1402. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Human actions tracking and recognition based on body parts detection via Artificial neural network. In Proceedings of the 2020 3rd International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 17–19 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Nigam, S.; Khare, A. Integration of moment invariants and uniform local binary patterns for human activity recognition in video sequences. Multimed. Tools Appl. 2016, 75, 17303–17332. [Google Scholar] [CrossRef]
- Basavaiah, J.; Patil, C.; Patil, C. Robust feature extraction and classification based automated human action recognition system for multiple datasets. Int. J. Intell. Eng. Syst. 2020, 13, 13–24. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. A dataset of 101 human action classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Liu, H.; Ju, Z.; Ji, X.; Chan, C.S.; Khoury, M. Study of human action recognition based on improved spatio-temporal features. In Human Motion Sensing and Recognition; Springer: Berlin/Heidelberg, Germany, 2017; pp. 233–250. [Google Scholar] [CrossRef]
- Dasari, R.; Chen, C.W. Mpeg cdvs feature trajectories for action recognition in videos. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 301–304. [Google Scholar] [CrossRef]
- Sargano, A.B.; Wang, X.; Angelov, P.; Habib, Z. Human action recognition using transfer learning with deep representations. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AL, USA, 14–19 May 2017; pp. 463–469. [Google Scholar] [CrossRef]
- El-Henawy, I.; Ahmed, K.; Mahmoud, H. Action recognition using fast HOG3D of integral videos and Smith–Waterman partial matching. IET Image Process. 2018, 12, 896–908. [Google Scholar] [CrossRef]
- Jain, S.B.; Sreeraj, M. Multi-posture human detection based on hybrid HOG-BO feature. In Proceedings of the 2015 Fifth international conference on advances in computing and communications (ICACC), Kochi, India, 2–4 September 2015; pp. 37–40. [Google Scholar] [CrossRef]
- Shao, L.; Zhen, X.; Tao, D.; Li, X. Spatio-temporal Laplacian pyramid coding for action recognition. IEEE Trans. Cybern. 2013, 44, 817–827. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Ma, Z.; Xie, M. Action recognition based on multi-scale oriented neighborhood features. Int. J. Signal Process. Image Process. Pattern Recognit. 2015, 8, 241–254. [Google Scholar] [CrossRef]
- Cheng, S.; Yang, J.; Ma, Z.; Xie, M. Action recognition based on spatio-temporal log-Euclidean covariance matrix. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 95–106. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Akram, T.; Javed, M.Y.; Saba, T.; Rehman, A. A framework of human detection and action recognition based on uniform segmentation and combination of Euclidean distance and joint entropy-based features selection. EURASIP J. Image Video Process. 2017, 2017, 89. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A combined multiple action recognition and summarization for surveillance video sequences. Appl. Intell. 2021, 51, 690–712. [Google Scholar] [CrossRef]
- Shao, L.; Liu, L.; Yu, M. Kernelized multiview projection for robust action recognition. Int. J. Comput. Vis. 2016, 118, 115–129. [Google Scholar] [CrossRef]
- Shi, Y.; Tian, Y.; Wang, Y.; Huang, T. Sequential deep trajectory descriptor for action recognition with three-stream CNN. IEEE Trans. Multimed. 2017, 19, 1510–1520. [Google Scholar] [CrossRef]
- Aslan, M.F.; Durdu, A.; Sabanci, K. Human action recognition with bag of visual words using different machine learning methods and hyperparameter optimization. Neural Comput. Appl. 2020, 32, 8585–8597. [Google Scholar] [CrossRef]
- Afza, F.; Khan, M.A.; Sharif, M.; Kadry, S.; Manogaran, G.; Saba, T.; Ashraf, I.; Damaševičius, R. A framework of human action recognition using length control features fusion and weighted entropy-variances based feature selection. Image Vis. Comput. 2021, 106, 104090. [Google Scholar] [CrossRef]
- Jiang, J.; He, X.; Gao, M.; Wang, X.; Wu, X. Human action recognition via compressive-sensing-based dimensionality reduction. Optik 2015, 126, 882–887. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, W.; Li, Y. Human action recognition based on multifeature fusion. In Proceedings of the Chinese Intelligent Systems Conference, Xiamen, China, 22–23 October 2016; pp. 183–192. [Google Scholar] [CrossRef]
- Kamiński, Ł.; Maćkowiak, S.; Domański, M. Human activity recognition using standard descriptors of MPEG CDVS. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 121–126. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5552–5561. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 909–918. [Google Scholar]
- Zhang, X.Y.; Huang, Y.P.; Mi, Y.; Pei, Y.T.; Zou, Q.; Wang, S. Video sketch: A middle-level representation for action recognition. Appl. Intell. 2021, 51, 2589–2608. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar] [CrossRef]
- He, D.; Zhou, Z.; Gan, C.; Li, F.; Liu, X.; Li, Y.; Wang, L.; Wen, S. Stnet: Local and global spatial-temporal modeling for action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8401–8408. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, M.; Gan, W.; Wu, W.; Yan, J. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2000–2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actions | 101 |
| Clips | 13,320 |
| Groups per Action | 25 |
| Clips per Group | 4–7 |
| Mean Clip Length | 7.21 s |
| Total Duration | 1600 min |
| Min Clip Length | 1.06 s |
| Max Clip Length | 71.04 s |
| Image Frame Rate | 25 fps |
| Image Resolution | 320 × 240 |
| Audio | Yes (51 actions) |
| Walking | Jogging | Running | Boxing | Hand Waving | Hand Clapping | Accuracy (%) | |
|---|---|---|---|---|---|---|---|
| Walking | 27 | 3 | 0 | 0 | 0 | 0 | 90 |
| Jogging | 1 | 27 | 2 | 0 | 0 | 0 | 90 |
| Running | 0 | 3 | 27 | 0 | 0 | 0 | 90 |
| Boxing | 0 | 0 | 0 | 28 | 0 | 2 | 93 |
| Hand waving | 0 | 0 | 0 | 1 | 27 | 2 | 90 |
| Hand clapping | 0 | 0 | 0 | 0 | 0 | 29 | 100 |
| Accuracy (%) | 96 | 82 | 93 | 97 | 100 | 88 |
| Walking | Jogging | Running | Boxing | Hand Waving | Hand Clapping | Accuracy (%) | |
|---|---|---|---|---|---|---|---|
| Walking | 30 | 0 | 0 | 0 | 0 | 0 | 100 |
| Jogging | 0 | 30 | 0 | 0 | 0 | 0 | 100 |
| Running | 0 | 1 | 29 | 0 | 0 | 0 | 96.67 |
| Boxing | 0 | 0 | 0 | 30 | 0 | 0 | 100 |
| Hand waving | 0 | 0 | 0 | 0 | 30 | 0 | 100 |
| Hand clapping | 0 | 0 | 0 | 0 | 0 | 30 | 100 |
| Accuracy (%) | 100 | 96.77 | 100 | 100 | 100 | 100 |
| Activity | Running | Walking | Skipping | Jack | Jump | Pjump | Side | Wave2 | Wave1 | Bending | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Running | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Walking | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 66.67 |
| Skipping | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Jack | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 1 | 0 | 0 | 66.67 |
| Jump | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 100 |
| Pjump | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 | 66.67 |
| Side | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 66.67 |
| Wave2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 66.67 |
| Wave1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 100 |
| Bending | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 100 |
| Accuracy (%) | 75 | 66.67 | 100 | 100 | 100 | 100 | 66.67 | 66.67 | 75 | 100 |
| Activity | Running | Walking | Skipping | Jack | Jump | Pjump | Side | Wave2 | Wave1 | Bending | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Running | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Walking | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 66.67 |
| Skipping | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Jack | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Jump | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 100 |
| Pjump | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 100 |
| Side | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 100 |
| Wave2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 66.67 |
| Wave1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 100 |
| Bending | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 100 |
| Accuracy (%) | 75 | 66.67 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Total | Train | Test | |
|---|---|---|---|
| Clap | 130 | 91 | 39 |
| Wave | 68 | 76 | 32 |
| Climb | 151 | 66 | 45 |
| Jump | 232 | 162 | 70 |
| Run | 548 | 384 | 164 |
| Walk | 64 | 73 | 31 |
| Activity | Clap | Wave | Climb | Jump | Run | Walk | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| Clap | 22 | 10 | 3 | 2 | 1 | 1 | 56.41 |
| Wave | 7 | 20 | 1 | 3 | 1 | 0 | 62.50 |
| Climb | 0 | 6 | 22 | 10 | 5 | 2 | 48.89 |
| Jump | 8 | 10 | 12 | 32 | 3 | 5 | 45.71 |
| Run | 8 | 8 | 12 | 15 | 82 | 39 | 50.00 |
| Walk | 0 | 2 | 0 | 3 | 9 | 17 | 54.84 |
| Accuracy (%) | 48.89 | 35.71 | 44.00 | 49.23 | 81.19 | 26.56 |
| Activity | Clap | Wave | Climb | Jump | Run | Walk | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| Clap | 27 | 9 | 0 | 2 | 1 | 0 | 69.23 |
| Wave | 4 | 22 | 0 | 1 | 4 | 1 | 68.75 |
| Climb | 3 | 0 | 35 | 7 | 0 | 0 | 77.78 |
| Jump | 0 | 2 | 8 | 54 | 3 | 3 | 77.14 |
| Run | 3 | 6 | 4 | 9 | 108 | 34 | 65.85 |
| Walk | 0 | 0 | 4 | 0 | 2 | 25 | 80.65 |
| Accuracy (%) | 72.97 | 56.41 | 68.63 | 73.97 | 91.53 | 39.68 |
| Ref | Accuracy (%) |
|---|---|
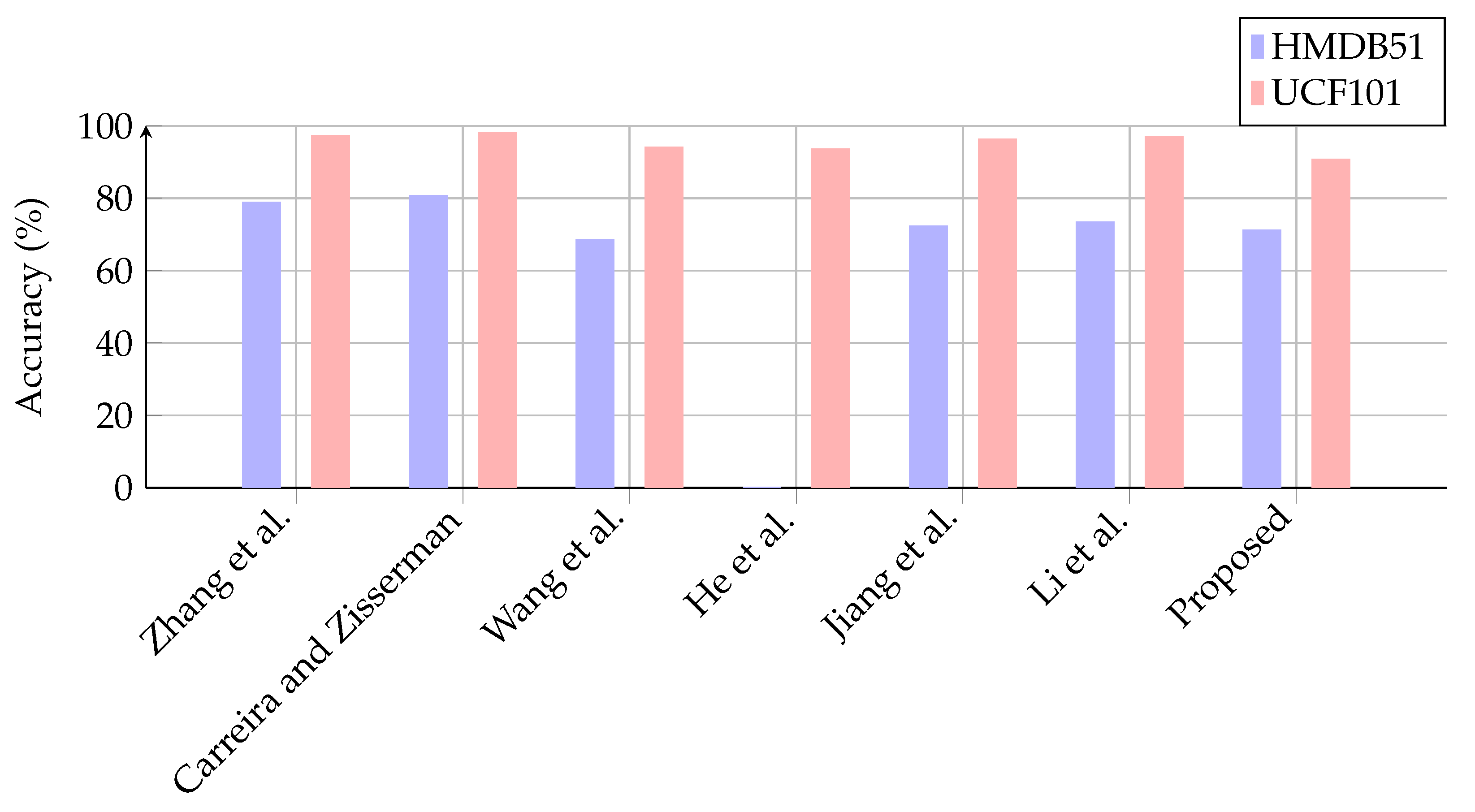
| Sargano et al. [113] | 89.86 |
| Dasari et al. [112] | 87 |
| El-Henawy et al. [114] | 95 |
| Jain et al. [115] | 95 |
| Shao et al. [116] | 95 |
| Yang et al. [117] | 96 |
| Cheng et al. [118] | 97 |
| Liu et al. [111] | 94 |
| Sharif et al. [119] | 99 |
| Elharrouss et al. [120] | 99.82 |
| Shao et al. [121] | 97.50 |
| Shi et al. [122] | 96.80 |
| Aslan L et al. [123] | 96.16 |
| Afza et al. [124] | 100 |
| Proposed | 99.44 |
| Ref | Accuracy (%) |
|---|---|
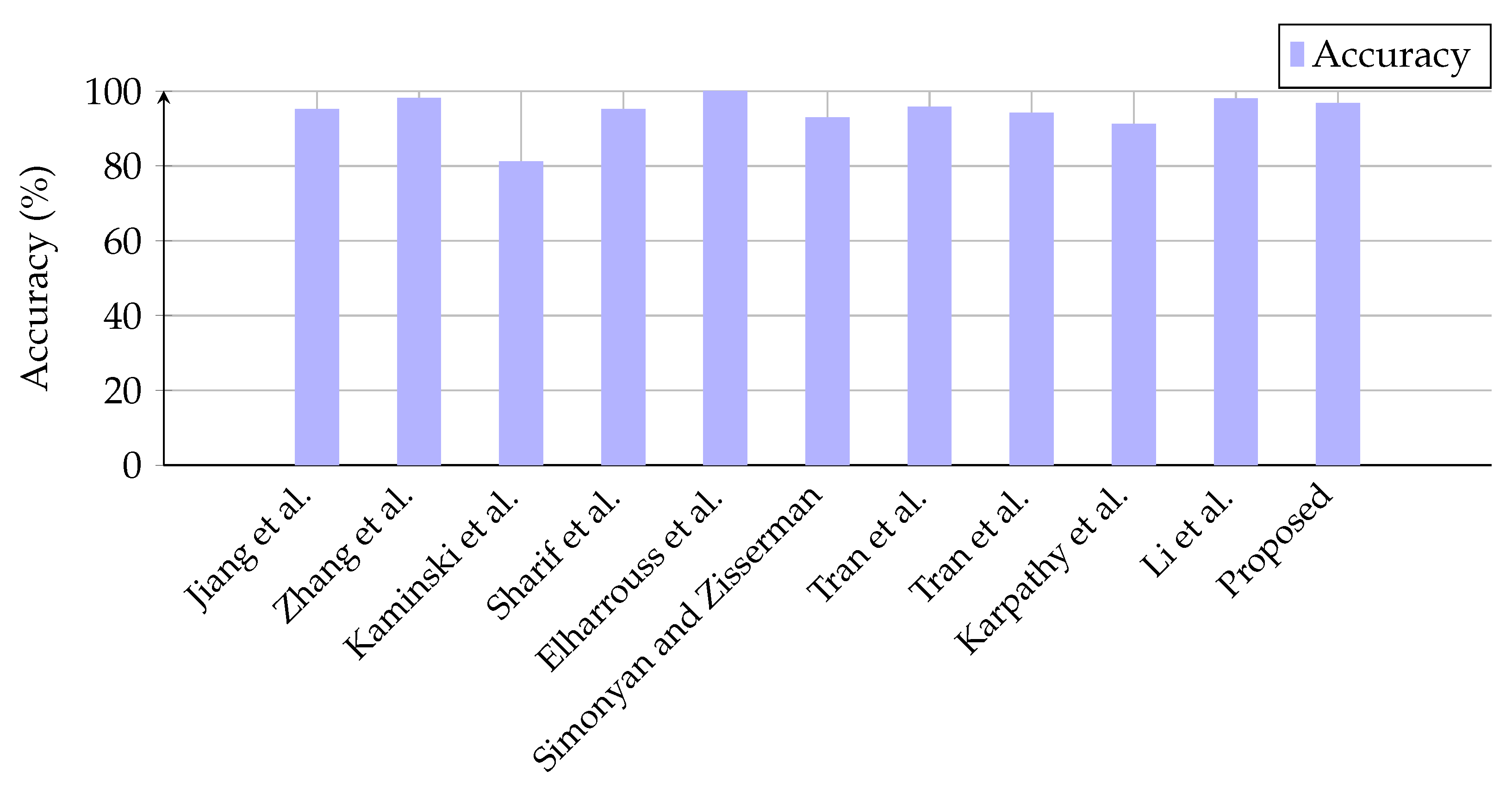
| Jiang et al. [125] | 95 |
| Zhang et al. [126] | 98 |
| Kaminski et al. [127] | 81 |
| Sharif et al. [119] | 95 |
| Elharrouss et al. [120] | 99.85 |
| Simonyan and Zisserman [128] | 92.80 |
| Tran et al. [129] | 95.69 |
| Tran et al. [130] | 94.03 |
| Karpathy et al. [131] | 91.11 |
| Li et al. [132] | 97.90 |
| Proposed | 96.67 |
| Activity | Basketball | Biking | Billiards | Diving | Haircut | HorseRace | Skiing | Walking with Dog | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|
| Basketball | 36 | 0 | 0 | 3 | 0 | 0 | 0 | 1 | 90 |
| Biking | 0 | 34 | 0 | 0 | 0 | 2 | 3 | 1 | 85 |
| Billiards | 1 | 0 | 41 | 0 | 0 | 0 | 0 | 3 | 91.11 |
| Diving | 3 | 0 | 0 | 40 | 0 | 2 | 0 | 0 | 88.89 |
| Haircut | 1 | 0 | 2 | 0 | 36 | 0 | 0 | 1 | 90 |
| HorseRace | 0 | 1 | 0 | 0 | 0 | 35 | 1 | 0 | 94.59 |
| Skiing | 0 | 3 | 0 | 0 | 0 | 0 | 37 | 0 | 92.5 |
| Walking with Dog | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 35 | 94.59 |
| Accuracy (%) | 85.71 | 89.47 | 93.18 | 93.02 | 100 | 89.74 | 90.24 | 85.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alavigharahbagh, A.; Hajihashemi, V.; Machado, J.J.M.; Tavares, J.M.R.S. Deep Learning Approach for Human Action Recognition Using a Time Saliency Map Based on Motion Features Considering Camera Movement and Shot in Video Image Sequences. Information 2023, 14, 616. https://doi.org/10.3390/info14110616
Alavigharahbagh A, Hajihashemi V, Machado JJM, Tavares JMRS. Deep Learning Approach for Human Action Recognition Using a Time Saliency Map Based on Motion Features Considering Camera Movement and Shot in Video Image Sequences. Information. 2023; 14(11):616. https://doi.org/10.3390/info14110616
Chicago/Turabian StyleAlavigharahbagh, Abdorreza, Vahid Hajihashemi, José J. M. Machado, and João Manuel R. S. Tavares. 2023. "Deep Learning Approach for Human Action Recognition Using a Time Saliency Map Based on Motion Features Considering Camera Movement and Shot in Video Image Sequences" Information 14, no. 11: 616. https://doi.org/10.3390/info14110616
APA StyleAlavigharahbagh, A., Hajihashemi, V., Machado, J. J. M., & Tavares, J. M. R. S. (2023). Deep Learning Approach for Human Action Recognition Using a Time Saliency Map Based on Motion Features Considering Camera Movement and Shot in Video Image Sequences. Information, 14(11), 616. https://doi.org/10.3390/info14110616