


Towards a Conceptual Framework for Data Management in Business Intelligence

Abstract
:1. Introduction
1.1. Research Questions (RQs) and Objective
- What are some of the prominent BI (sub)frameworks? (RQ1)
- What are the advantages and disadvantages of the said BI frameworks? (RQ2)
2. Materials and Methods
The Use of Qualitative Propositions
- Content propositions are labeled as pC1, pC2, …, pCi for i ϵ {1, 2, 3, … n}. For a preliminary version of a proposition, we may add an alphabetic character after the number represented by “i” above. The use of these is illustrated throughout this article.
3. Literature Review
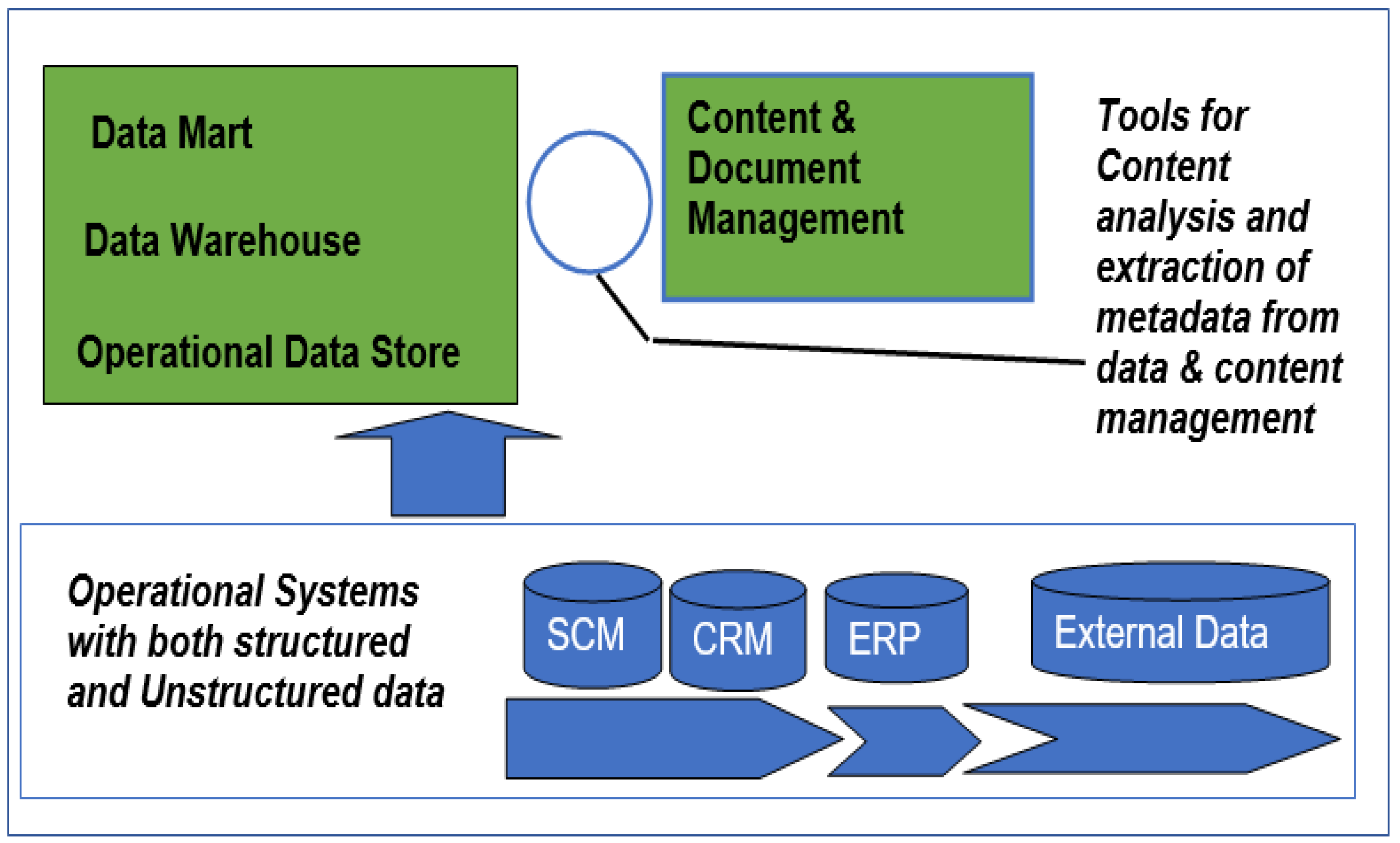
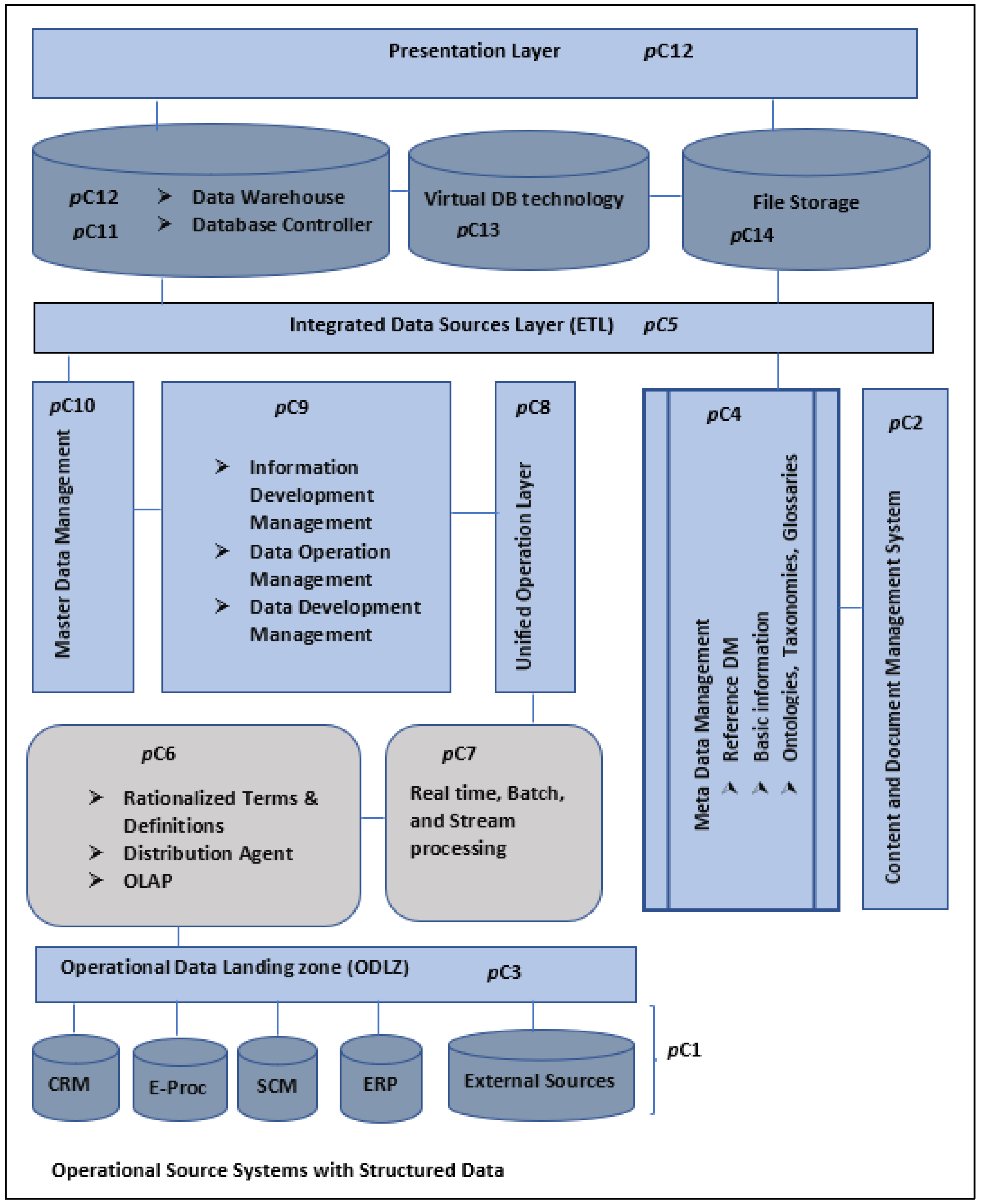
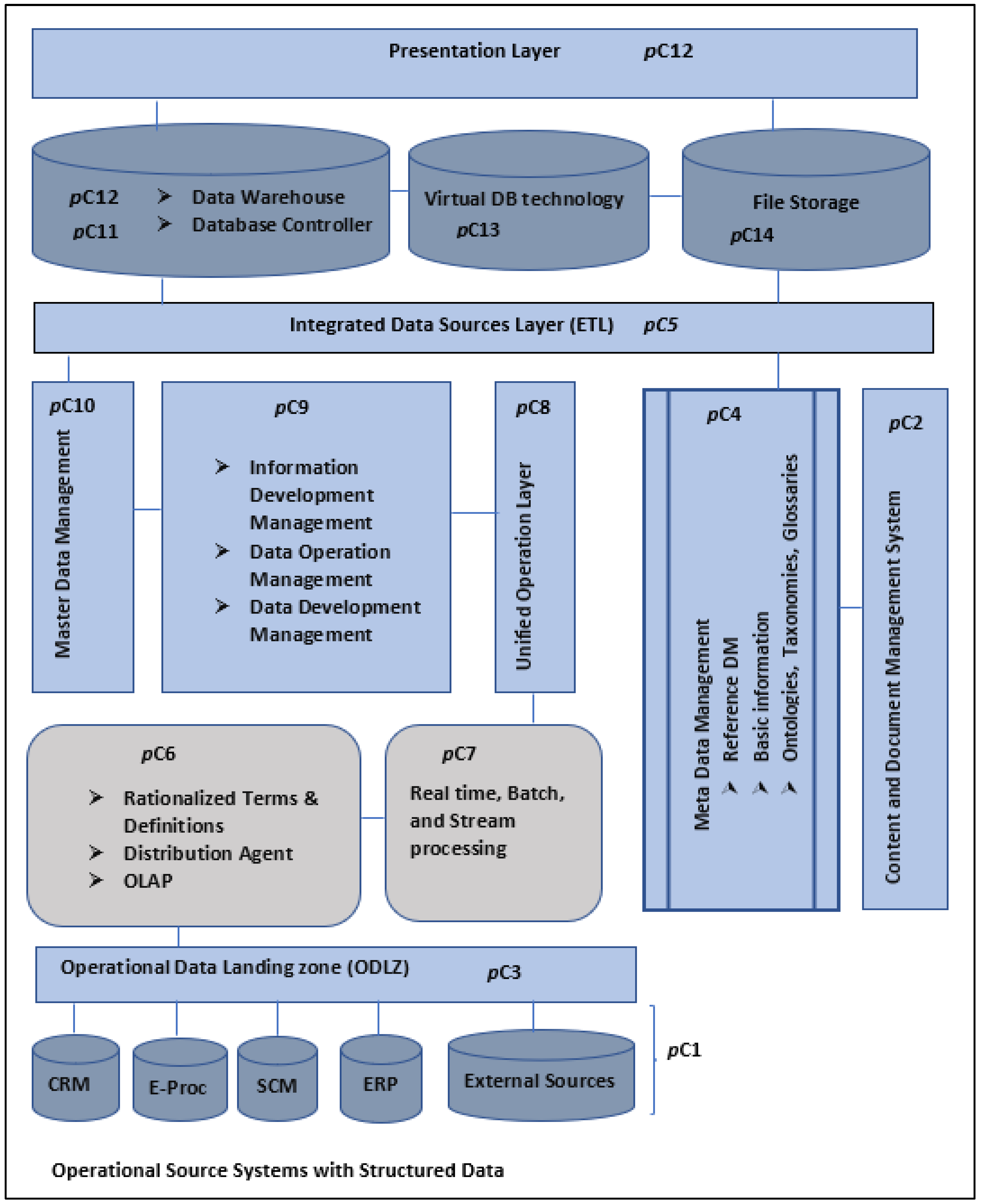
3.1. Data Layer Framework of Business Intelligence
- Proposition pC1a: An operational sources system made up of CRM, SCM, ERP, and external sources subsystems is a vital component of a BI framework as it facilitates data management through the transformation and loading of the data.
- Proposition pC1b: A BI framework should include the following components, as these facilitate data management through the transformation and loading of the data:
- ⮚
- An operational sources system made up of CRM, SCM, ERP, and external sources subsystems.
- ⮚
- A data warehouse is based on one or more data marts.
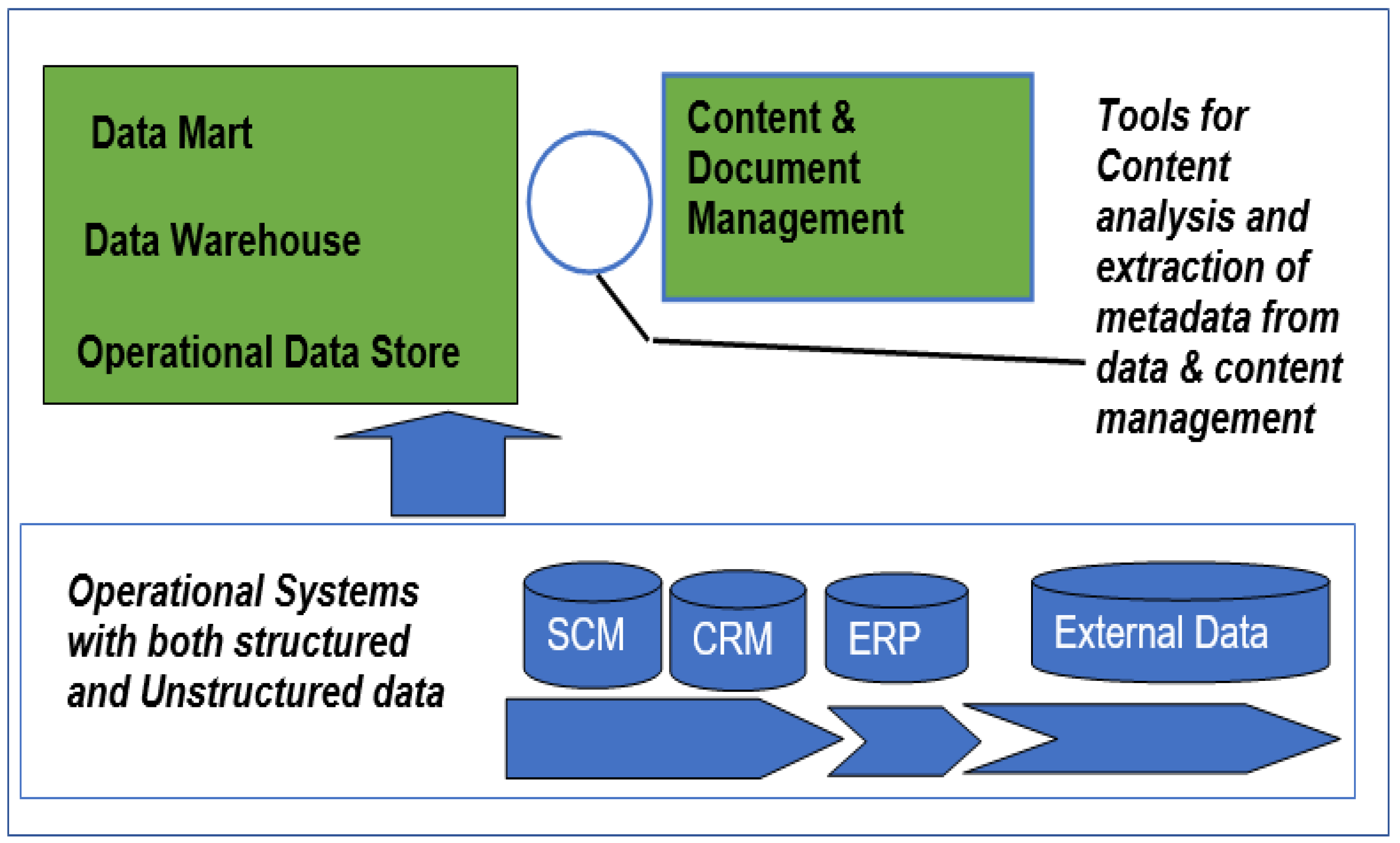
- Proposition pC2: Owing to the said advantages, a BI framework should include a content and document management (CDM) component to address the capturing, tracking, and storing of electronic documents.
- Proposition pC3: A BI framework should include an operational data landing zone (ODLZ) where all combined data are stored after it has been combined from different sources.
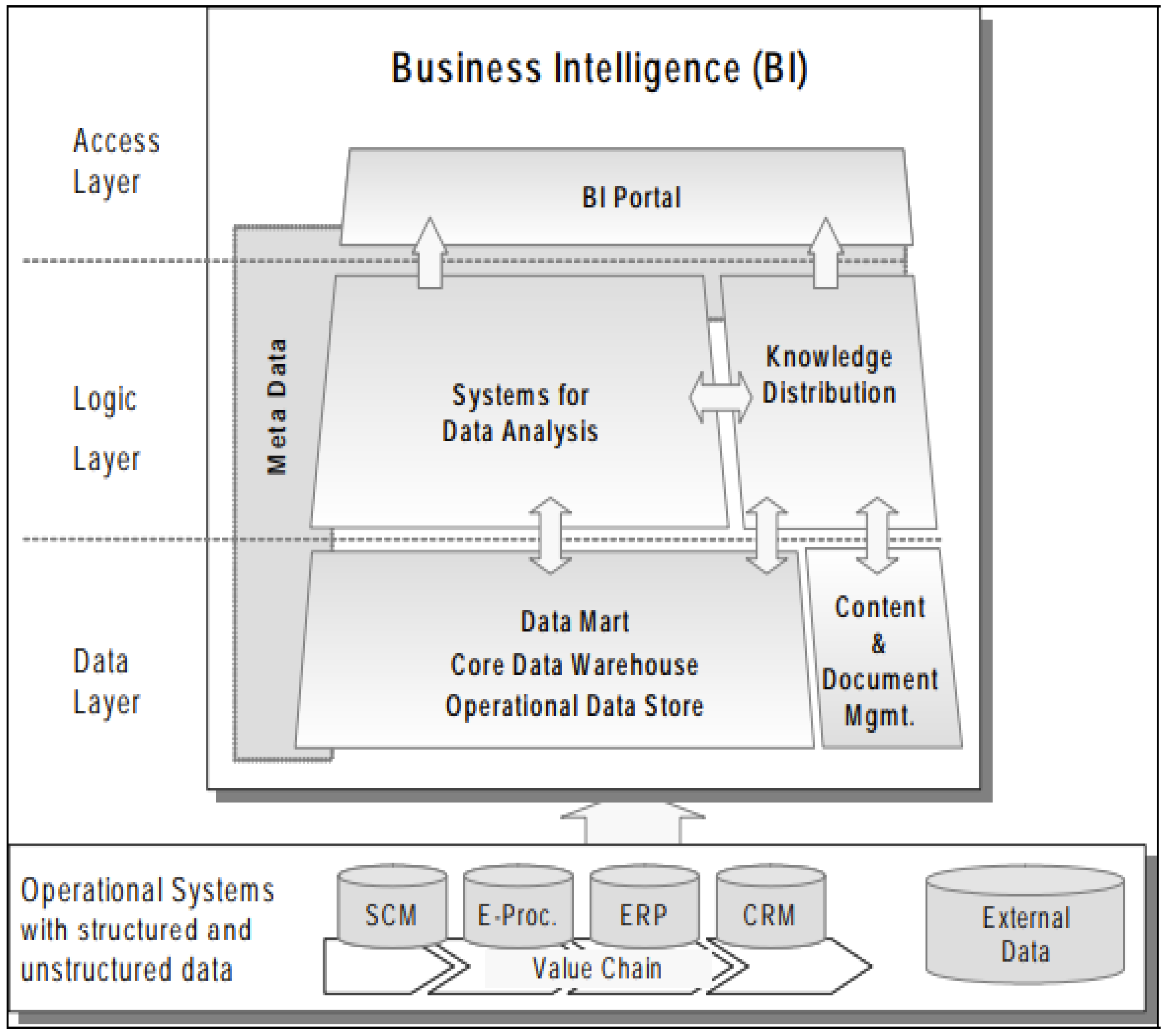
3.2. Conceptual Three-Layer Business Intelligence Architecture
- Proposition pC1: A BI framework should include the following components, as these facilitate data management through the transformation and loading of data:
- ⮚
- An operational sources system is made up of CRM, SCM, ERP, subsystems for external sources, and e-procurement (E-Proc).
- ⮚
- A data warehouse is based on one or more data marts.
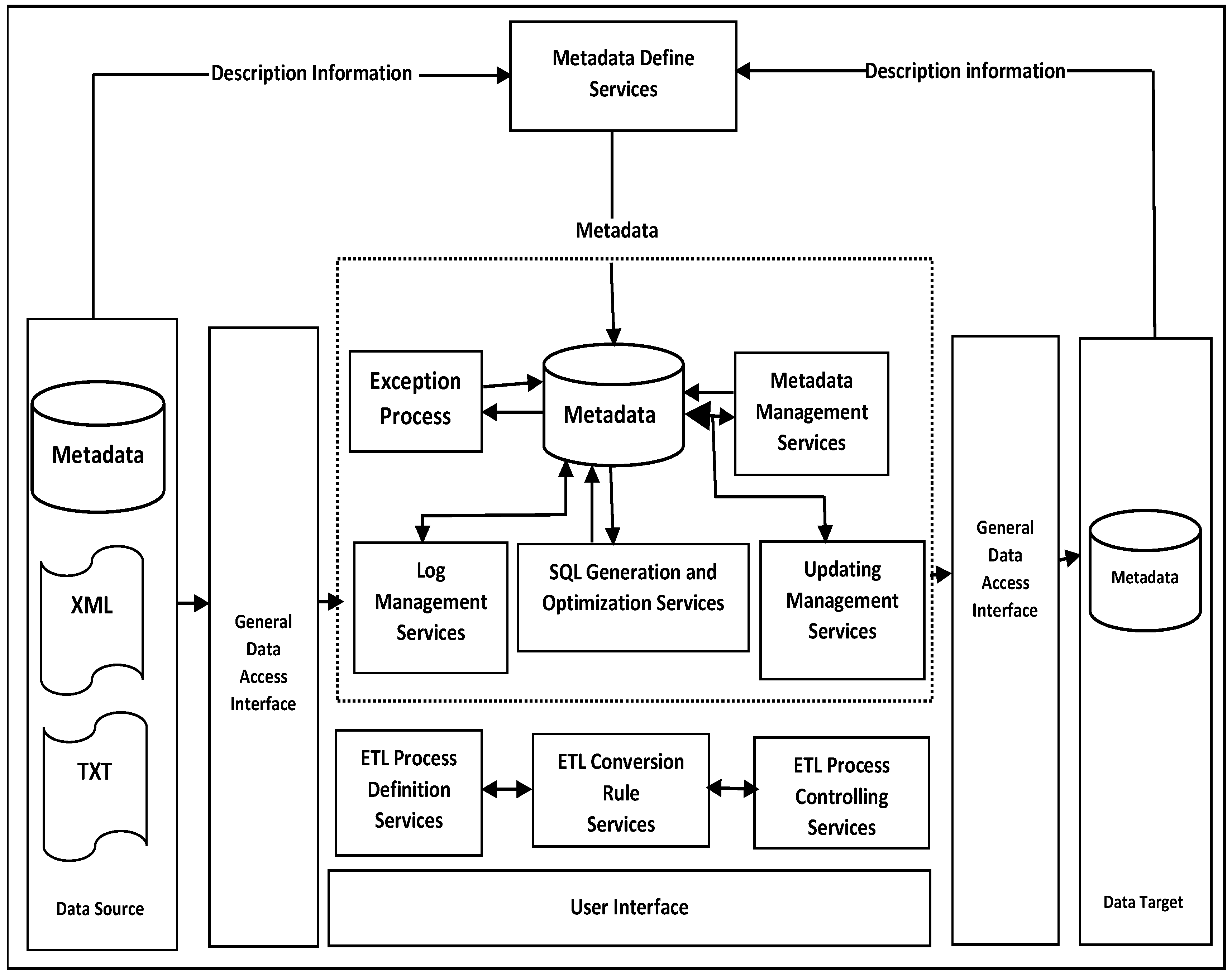
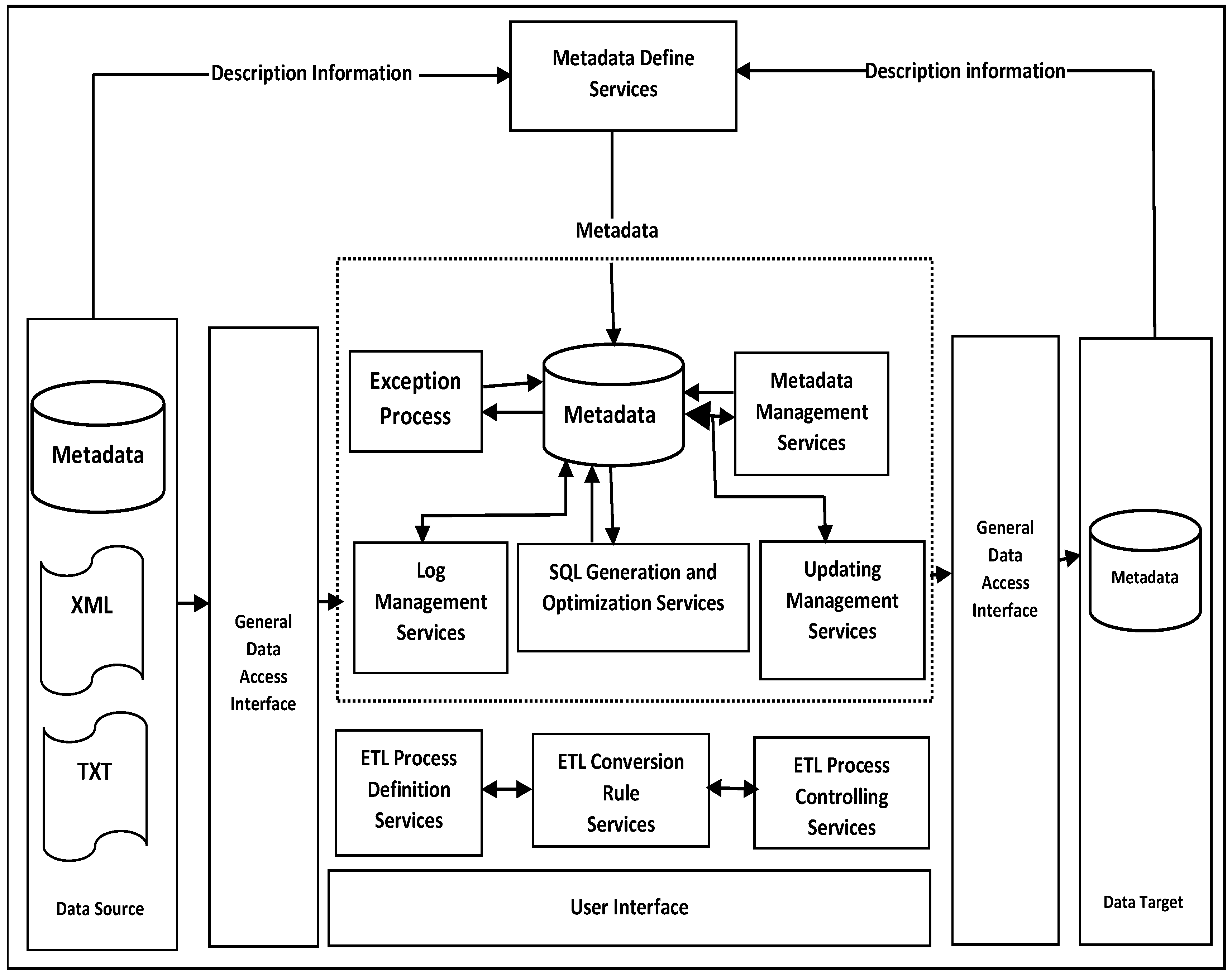
3.3. ETL Service Framework Based on Metadata
- Proposition pC4a: A BI framework should include a metadata management component as part of general data management.
- ⮚
- Metadata in the form of reference data management, whereby the structure used in the organization (internal department codes, internal product codes, employee organization codes, internal location codes, and so forth) is described, should be included [6].
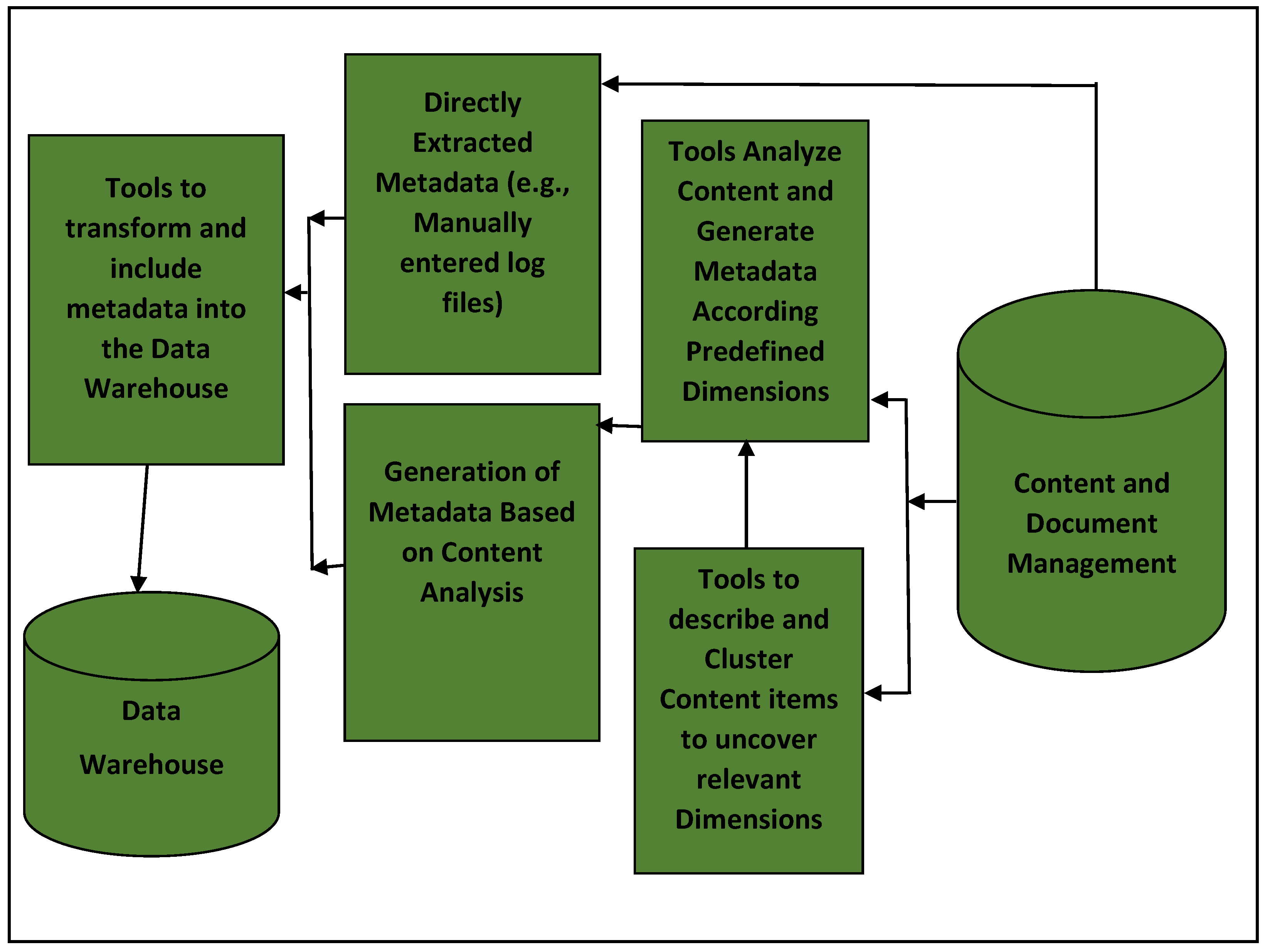
3.4. Framework of a Metadata Extract from Content and Document Management
- Proposition pC5a: A BI framework should include an integrated data source (IDS) layer because it is the part where all source data, including metadata extracted from content and document management systems, are combined.
- Proposition pC5: A BI Framework should include an integrated data source (IDS) layer:
- ⮚
- In the IDS, all source data, including metadata extracted from content and document management systems, are combined.
- ⮚
- The underlying ETL pipelines should adhere to the said ETL quality metrics (QoX).
- Assists with managing documents.
- Supports content-driven collaboration.
- Facilitates information creation, retention, and retrieval and embeds controlled and improved document distribution. These actions are often described by three simple verbs: scan, store, and retrieve.
- Bring together data sources of different origins and formats (e.g., structured and unstructured data). Consequently, it can apply single or multiple taxonomies or categorizations to a document or folder that allow documents to be classified and stored in more than one way from a “single instance”. Naturally, this may not be possible with paper formats.
- Provides high-level information security and centralized storage of data.
- Offers automated workflows.
- Proposition pC4: A BI framework should include a metadata management component, catering for metadata management as part of general data management to:
- ⮚
- Allow for reference data management whereby the structure used in the organization (internal department codes, internal product codes, employee organization codes, internal location codes, and so forth) is described [8].
- ⮚
- Summarize basic information about data, work with instances of data, and make findings.
- ⮚
- Assembling metadata from content and document management systems presents a challenge with respect to the efficiency of its extraction process(es).
- Server resources may be constrained since some content management systems (CMSs) can put a load on server resources.
3.5. BI Framework for Structured Data
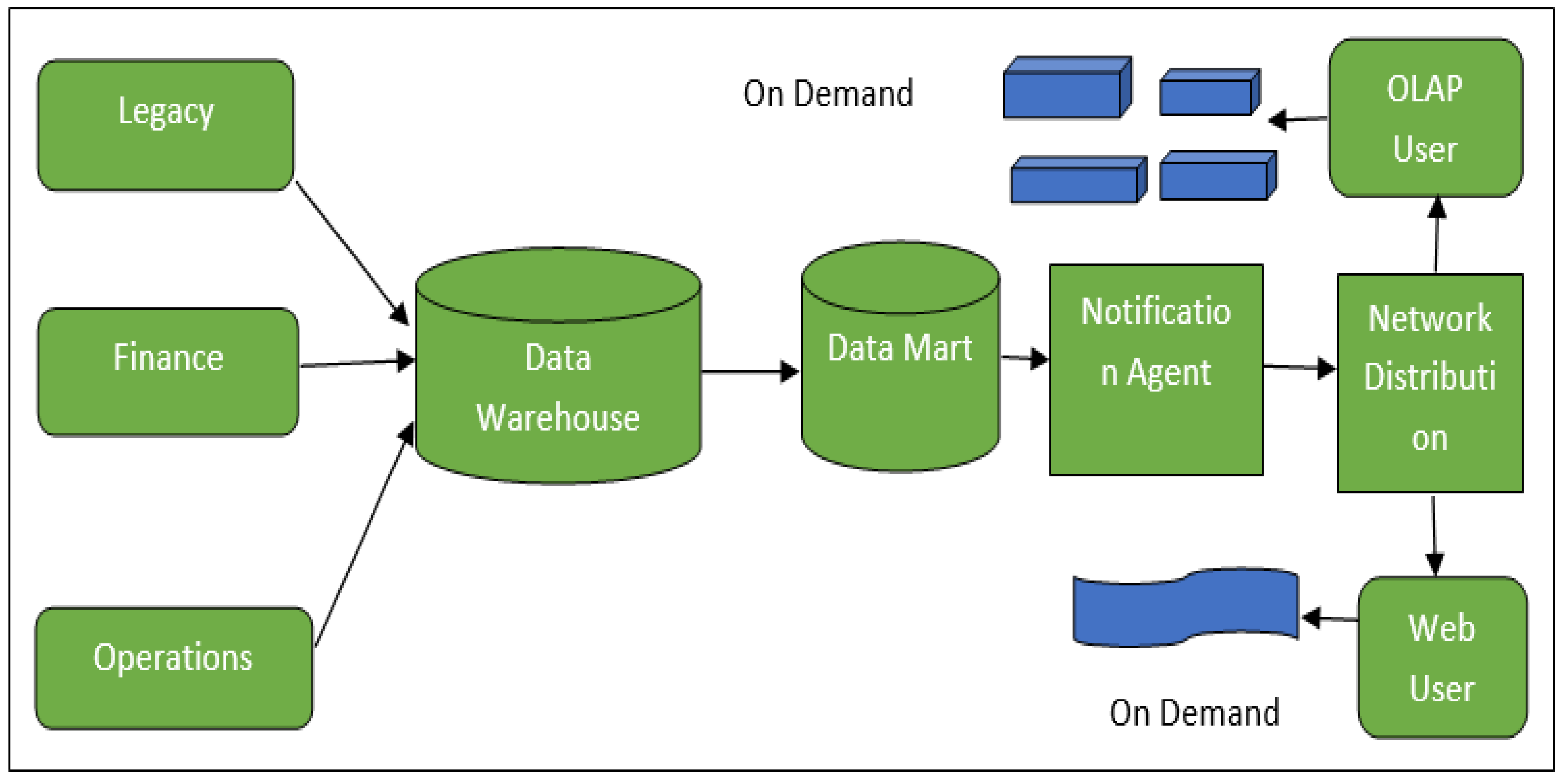
- Proposition pC6a: A BI framework dealing with both structured and unstructured data ought to include a notification agent, a distribution agent, and an OLAP component to assist the finance and operations sections that may be running legacy systems.
- Proposition pC6: A BI framework dealing with both structured and unstructured data ought to include:
- ⮚
- A notification agent, a distribution agent, and an OLAP component to assist the finance and operations sections that may be running legacy systems.
- ⮚
- Rationalized terms and definitions components, as well as an information development management component [15,20]. as follows:
- ❖
- Rationalized terms and definitions aim to reduce overlapping tools and data duplication and also promote BI standards.
- ❖
- With respect to information development management, structured and unstructured data should be transformed into useful information, which in turn may be transformed into knowledge.
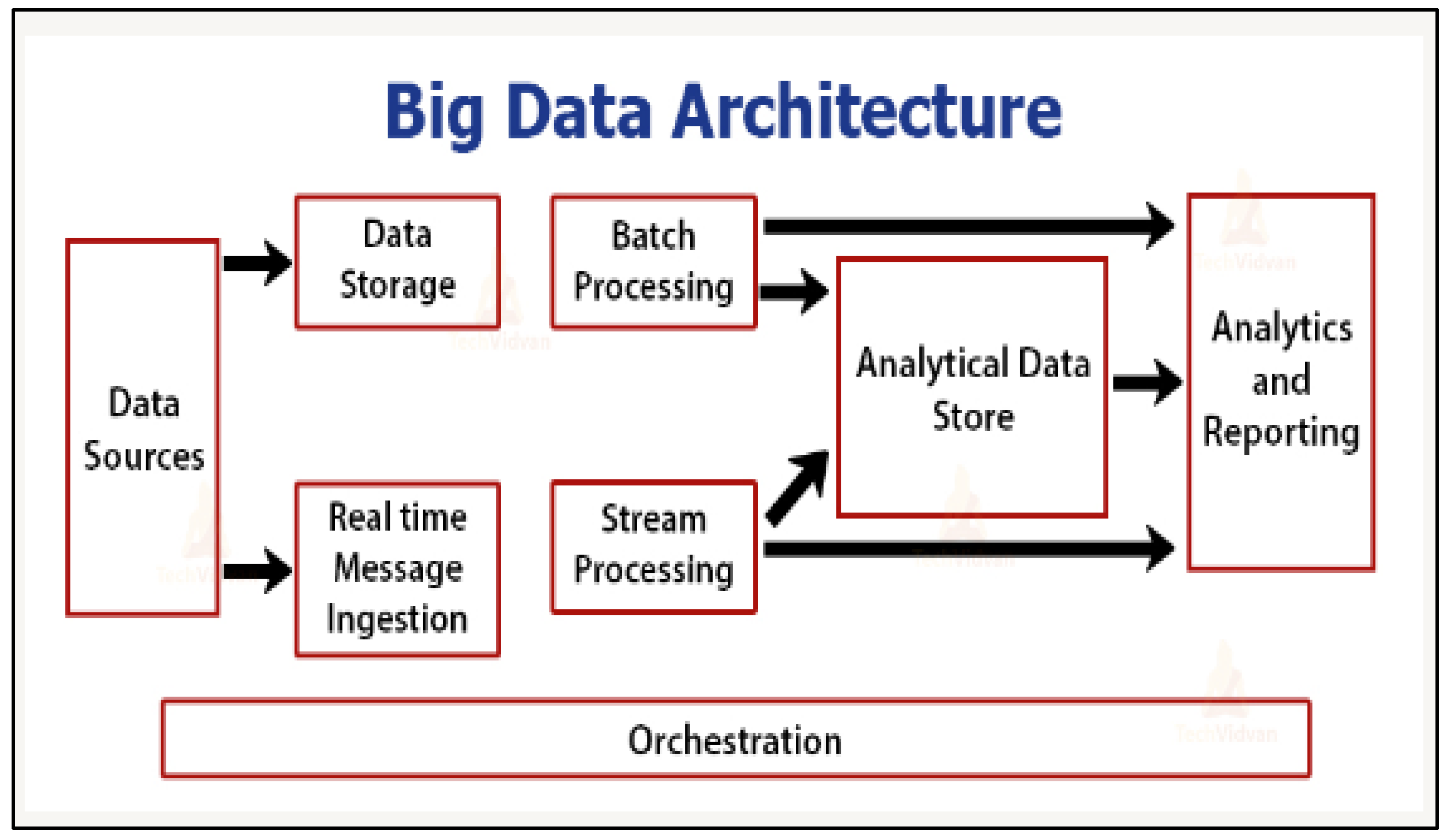
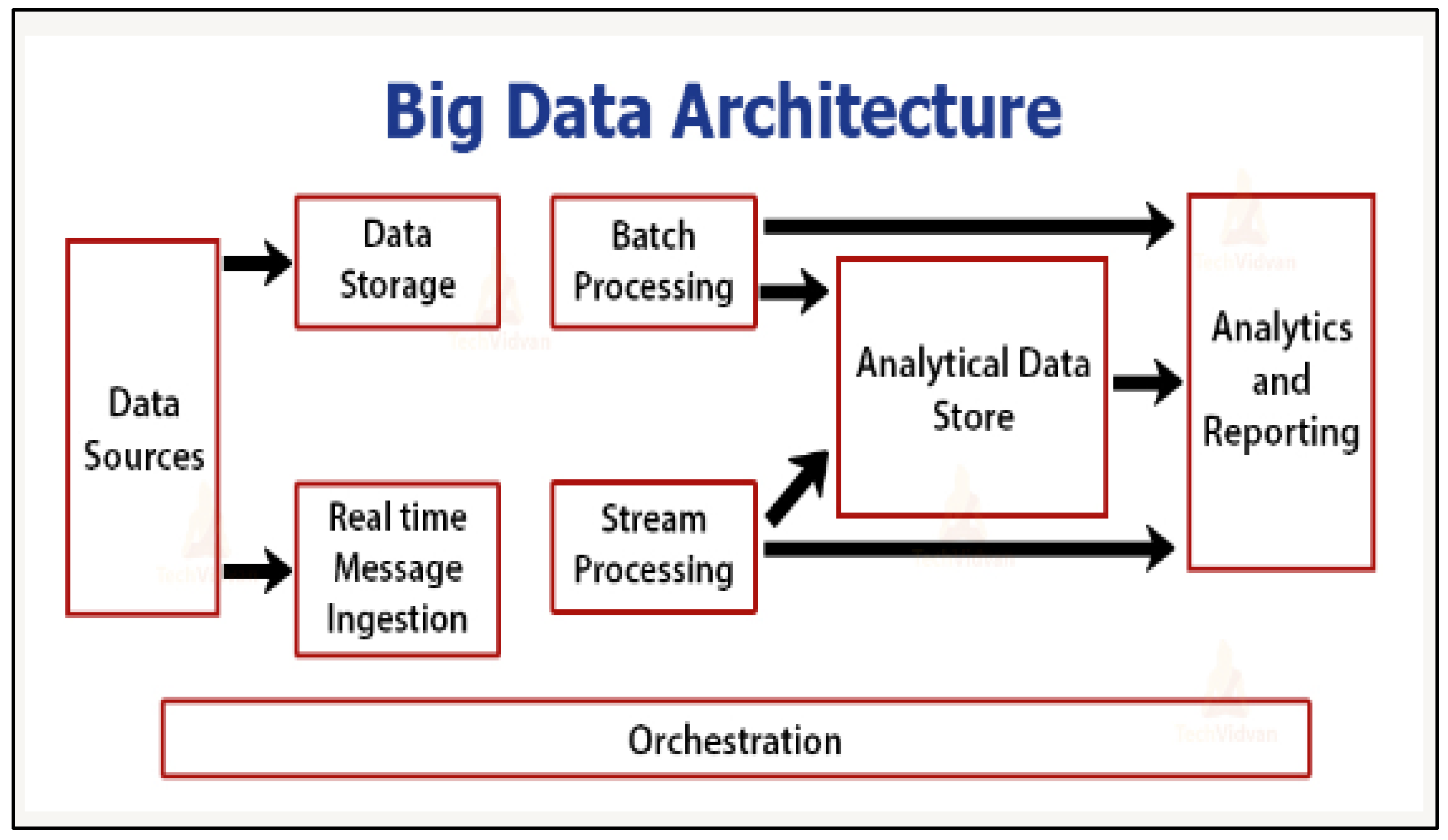
3.6. Big Data Architecture and Patterns Framework
- Maintains a data source component for source data.
- Offers a data-storage component for maintaining data.
- Embeds the functionality of ingesting data streams continuously for quick analysis via the stream processing component.
- Filters, transforms, and enhances data before passing it to the applications data stores and other processing engines.
- Proposition pC7: A BI framework dealing with data processing ought to include real-time, batch, and stream processing to assist with the processing of data either in batches or continuously as transactions happen on the operational side of the business.
- As a disadvantage, it makes data extraction hard as, most of the time, the data are not partitioned per business unit.
- As an ambiguity, neither the data storage nor the real-time message ingestion seem to feed into further components. Therefore, while the Figure 7 framework may appear to be an operational (dynamic) framework in which there is a left-to-right flow, it may indeed be a static framework.
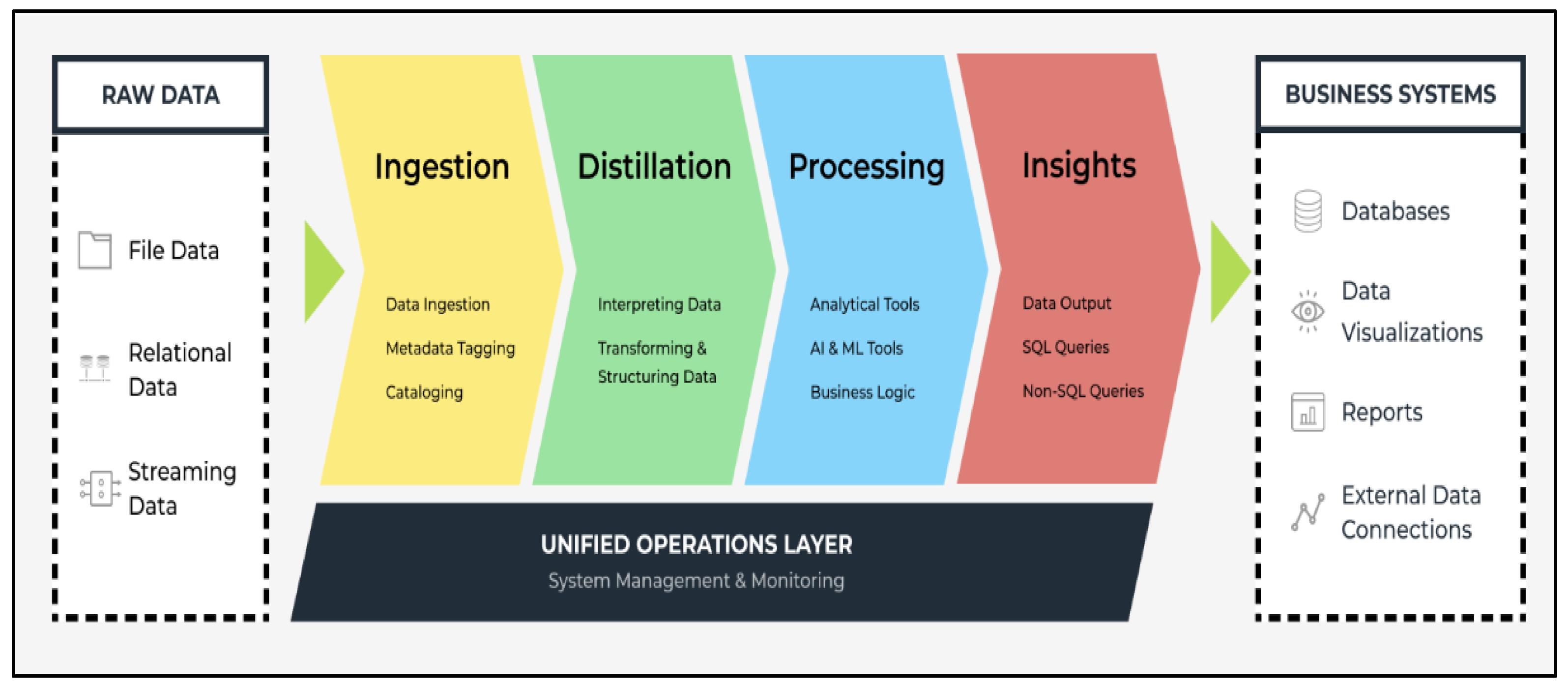
3.7. BI Data Lake Architecture Framework
- A variety of data, with respect to format, semantics, and so forth, are processed.
- The framework interfaces with external databases.
- The relational database model is supported.
- Backup and restore capabilities are provided.
- Data ingestion, data distillation, data processing, and data insight are supported.
- The framework is an operational (dynamic) framework since there is a left-to-right flow of data.
- Proposition pC8: A BI framework dealing with processing operational data ought to embed a unified operation layer that includes steps of ingestion, distillation, processing, which in turn utilizes various tools and business logic, and insights, all aimed at moving from raw data to business systems for reporting.
- Proposition pC9: A BI framework dealing with raw data should include:
- ⮚
- Data definition Management involves embedding all the formal processes for defining data.
- ⮚
- Data development management to:
- ❖
- Develop, collect, process, and interpret data.
- ❖
- Perform backup, restore, archive, and recall functions.
- ❖
- Cater for business restrictions and rules catered for by business logic (cf. proposition pC8).
- ⮚
- Data operations management to integrate people, processes, and products to enable consistent, automated, and secured data in large databases (or a warehouse—refer to proposition pC1).
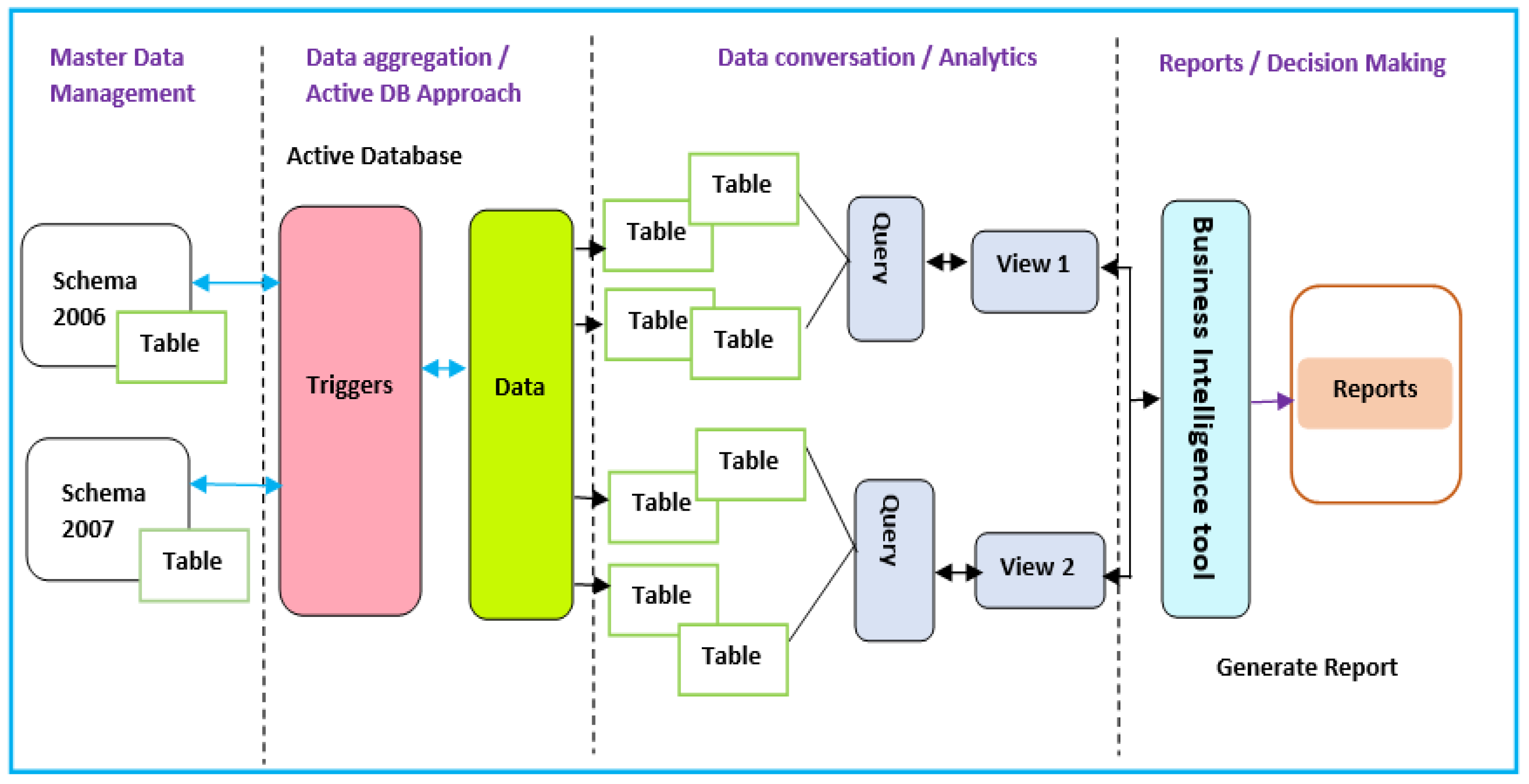
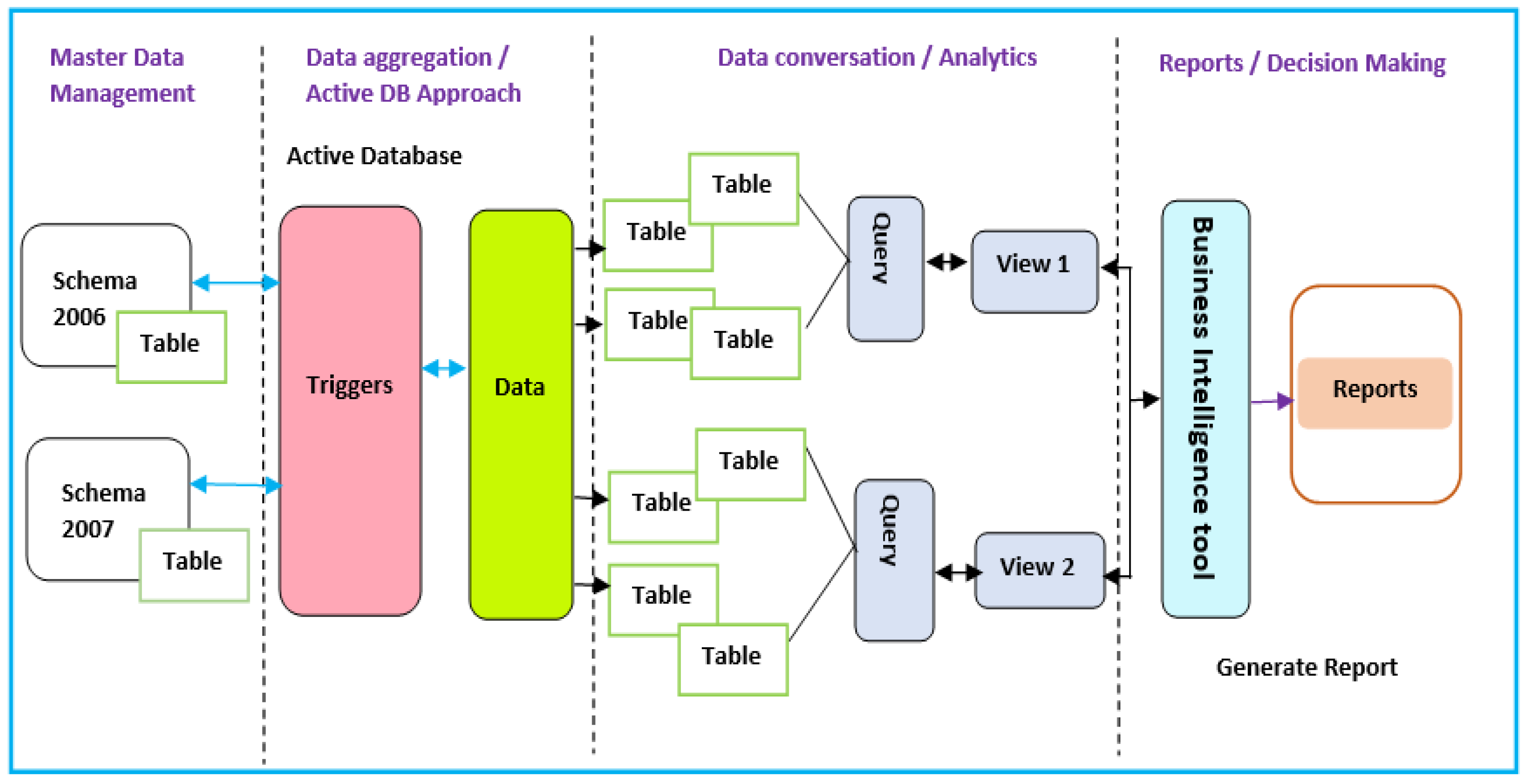
3.8. Business Intelligence Framework Using an Active Database Approach
- Master data management assists businesses in sourcing facts from a central source.
- Data analytics assist businesses in improving their performance.
- Data aggregation facilitates data analysis, providing leaders with improved insight.
- BI tools enable a business to visualize data and generate reports.
- Traditional database functionalities are enhanced through powerful rules for processing capabilities.
- A uniform and centralized description of the business rules relevant to the information system is enabled (cf. proposition pC8).
- Redundancy with respect to checking and repair operations is reduced.
- Proposition pC10: A BI framework dealing with processing in the context of an active database ought to:
- ⮚
- Include a master data management (MDM) component that facilitates data reconciliation, offering the benefit of maintaining data external to the organization as well as other data sources, for example, historical data (cf. Schema 2006, Schema 2007 in Figure 9).
- ⮚
- Embed data aggregation, whereby data are gathered from multiple sources and expressed in a summary form, i.e., reporting.
3.9. Traditional Business Intelligence (TBI) Architecture Framework
- Real-time data extraction.
- Multidimensional analysis at high speed on large volumes of data.
- Data storage via a staging area.
- Online transactional processing (OLTP).
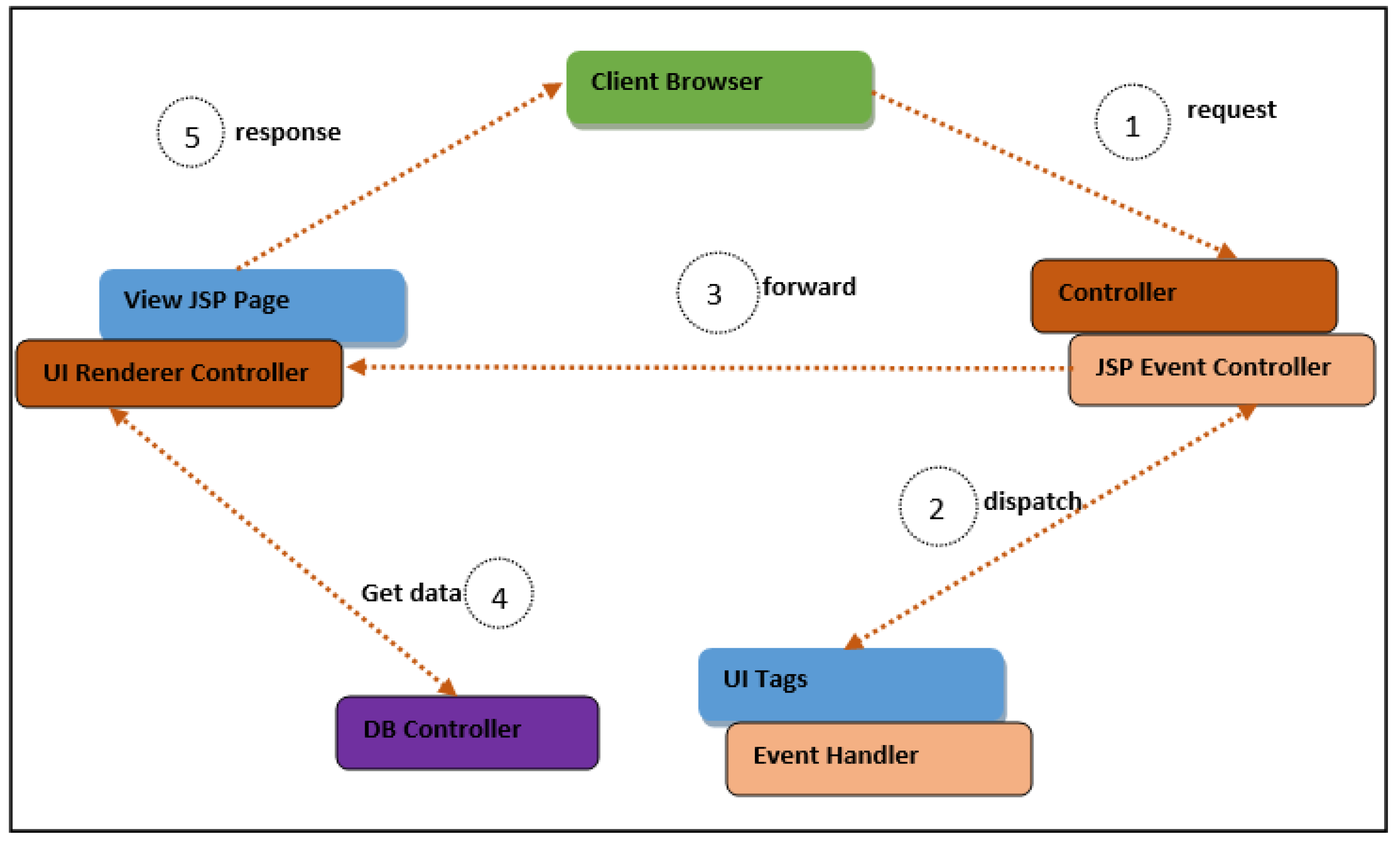
3.10. Logic Layer BI Framework
- Facilitating the creation of components containing non-Java code.
- Acting as an intermediate between the access layer and the data layer.
- Providing database control functionality that determines which data are to be processed and how such data are processed.
- Proposition pC11: If not part of the standard ICT infrastructure, a BI framework ought to embed a DB controller to determine the purpose for which and how such data are processed.
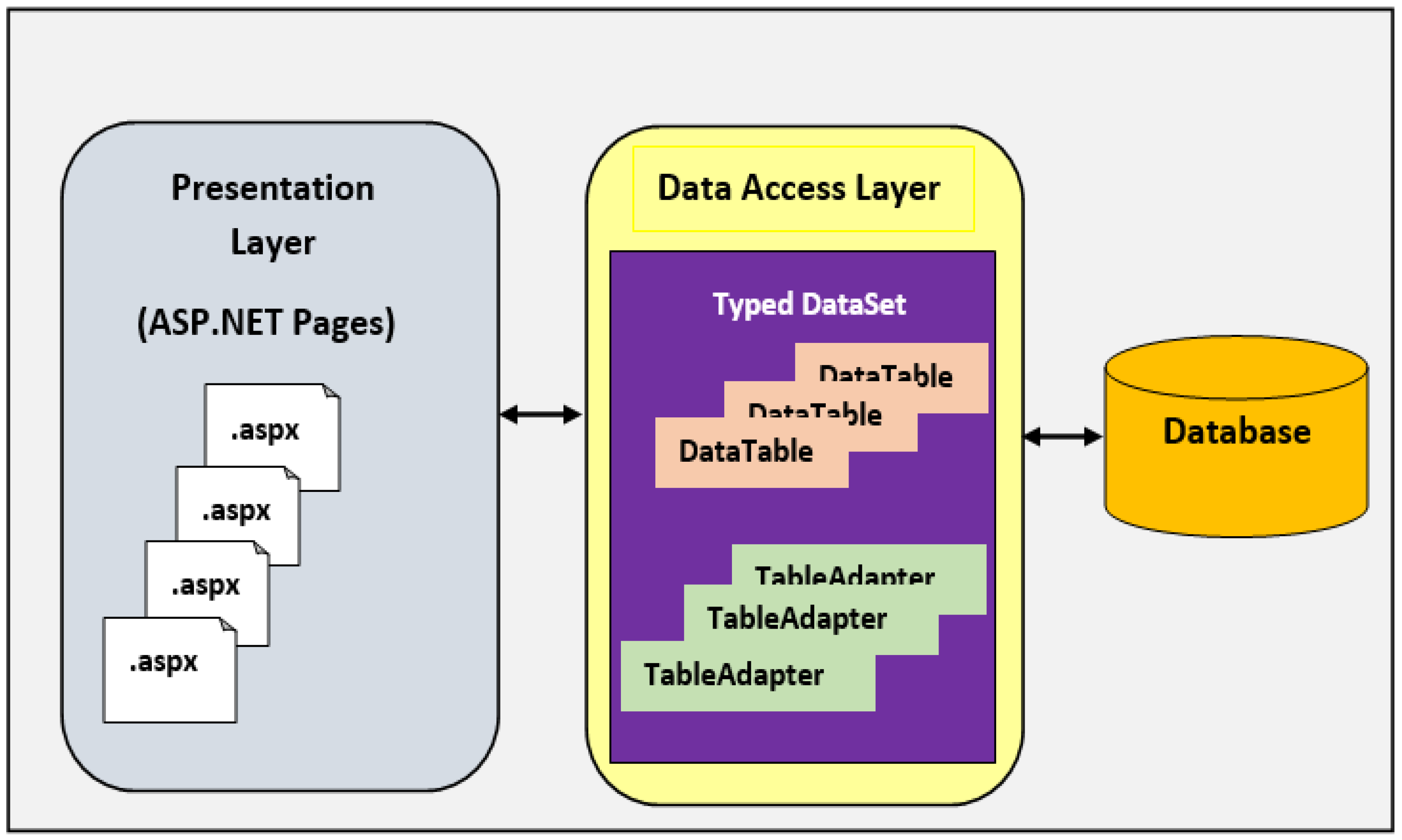
3.11. Access Layer Framework in a BI Environment
- Improved self-service data access.
- Lower ownership costs.
- Advanced querying leads to faster reporting and model building.
- Improved access to open-source capabilities.
- Proposition pC12: A BI framework ought to embed a presentation layer that is used to surface data cleanly from a data warehouse or data mart to the user.
3.12. Data Federation Framework
- Proposition pC13: A BI framework should embed virtual database technology to act as a container, allowing the view and query of multiple databases through a single API drawing from numerous sources.
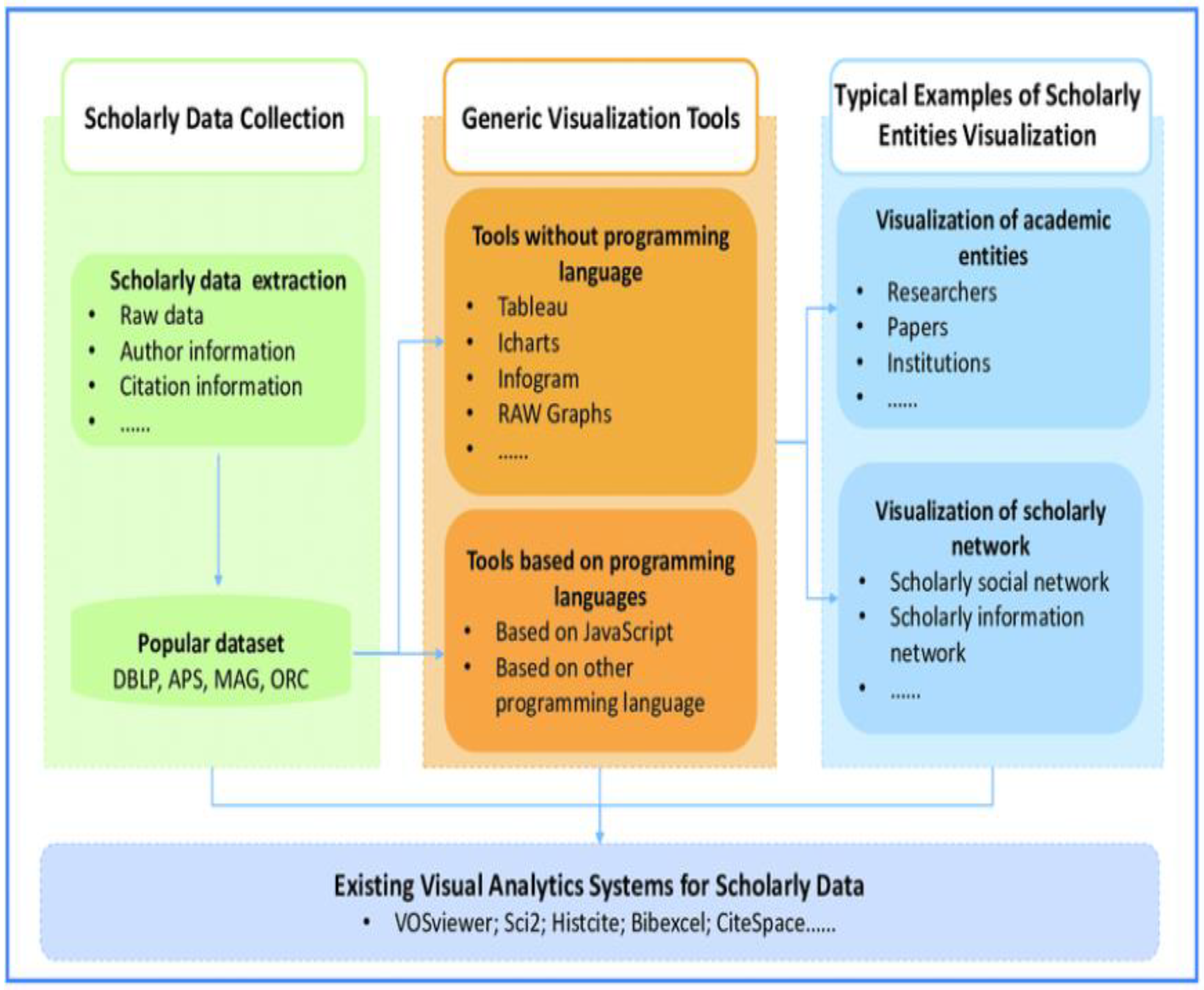
3.13. Data Visualization Conceptual Framework
- Data sets define attributes such as abstract, year, and authors.
- Data sets are described by metadata.
- Big data storage systems, for example, Hadoop.
- Proposition pC14: A BI framework ought to cater to file storage aspects, specifically for Hadoop-like big data aspects through visualization.
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kemper, H.G.; Baars, H. Management Support with Structured and Unstructured Data—An Integrated Business Intelligence Framework. Inf. Syst. Manag. 2008, 25, 132–148. [Google Scholar]
- Martins, A.; Martins, P.; Caldeira, F.; Sá, F. An evaluation of how big-data and data warehouses improve business intelligence decision making. Trends Innov. Inf. Syst. Technol. 2020, 1, 609–619. [Google Scholar]
- Alsmadi, I. Using Formal method for GUI model verification. In Design Solutions for User-Centric Information Systems; IGI Global: Hershey, PA, USA, 2017; pp. 175–183. [Google Scholar]
- Ackermann, J.G.; van der Poll, J.A. Reasoning Heuristics for the Theorem-Proving Platform Rodin/Event-B. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI’20), Las Vegas, NV, USA, 16–18 December 2020. [Google Scholar]
- Saunders, M.N.K.; Lewis, P.; Thornhill, A. Research Methods for Business Students, 8th ed.; Pearson: London, UK, 2022. [Google Scholar]
- van der Poll, J.A.; van der Poll, H.M. Assisting Postgraduate Students to Synthesis Qualitative Propositions to Develop a Conceptual Framework. J. New Gener. Sci. (JNGS) 2023, 21, 1061. [Google Scholar]
- Mbala, I.N.; van der Poll, J.A. Towards a Formal Modelling of Data Warehouse Systems Design. In Proceedings of the 18th JOHANNES-BURG Int’l Conference on Science, Engineering, Technology & Waste Management (SETWM-20), Johannesburg, South Africa, 16–17 November 2020. [Google Scholar]
- Shubham, J.; Sharma, S. Application of Data Warehouse in Decision Support and Business Intelligence System. In Proceedings of the 2018 Second International Conference on Green Computing and Internet of Things (ICGCIoT 2018), Bangalore, India, 19–18 August 2018. [Google Scholar]
- Inmon, W.H.; Nesavich, A. Tapping into Unstructured Data: Integrating Unstructured Data and Textual Analytics into Business Intelligence; Pearson Education: London, UK, 2007. [Google Scholar]
- Zafary, F. Implemetation of business intelligence considering the role of information systems integration and enterprise resource planning. J. Intell. Stud. Bus. 2020, 1, 59–74. [Google Scholar] [CrossRef]
- El Ghalbzouri, H.; El Bouhdidi, J. Integrating business intelligence with cloud computing: State of the art and fundamental concepts. Netw. Intell. Syst. Secur. Proc. NISS 2021 2022, 237, 197–213. [Google Scholar]
- Wang, H.; Ye, Z. An ETL Services Framework Based on Metadata. In Proceedings of the 2nd International Workshop on Intelligent Systems and Applications, Wuhan, China, 22–23 May 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Sachin, S.; Goyal, S.K.; Avinash, S.; Kamal, K. Nuts and Bolts of ETL in Data Warehouse. In Emerging Trends in Expert Applications and Security, Proceedings of ICETEAS; Springer: Singapore, 2018; pp. 1–9. [Google Scholar]
- Sreemathy, J.; Nisha, S.; Gokula Priya, R.M. Data Integration in ETL Using Talend. In Proceedings of the 6th International Conference on Advanced Computing and Communications Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 1444–1448. [Google Scholar]
- Ariyachandra, T.; Watson, H.J. Which Data Warehouse Architecture Is Most Successful? Bus. Intell. J. 2006, 11, 4–6. [Google Scholar]
- Cody, W.F.; Kreulen, J.T.; Krishna, V.; Spangler, W.S. The integration of business intelligence and knowledge management. IBM Syst. J. 2002, 41, 697–713. [Google Scholar] [CrossRef]
- Habermann, T. Metadata Life Cycles, Use Cases and Hierarchies. Geosciences 2018, 8, 179. [Google Scholar] [CrossRef]
- Ahmad, H.S.; Bazlamit, I.M.; Ayoush, M.D. Investigation of Document Management Systems in Small Size Construction Companies in Jordan. Procedia Eng. 2017, 182, 3–9. [Google Scholar] [CrossRef]
- Lemordant, P.; Bouzillé, G.; Mathieu, R.; Thenault, R.; Gibaud, B.; Garde, C.; Campillo-Gimenez, B.; Goudet, D.; Delarche, S.; Roland, Y.; et al. How to Optimize Connection Between PACS and Clinical Data Warehouse: A Web Service Approach Based on Full Metadata Integration. In MEDINFO 2021: One World, One Health–Global Partnership for Digital Innovation; IOS Press: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Negash, S. Business Intelligence. Commun. Assoc. Inf. Syst. 2004, 13, 177–195. [Google Scholar] [CrossRef]
- Baker, O.; Thien, C.N. A new Approach to Use Big Data Tools to Substitute Unstructured Data Warehouse. In Proceedings of the 2020 IEEE Conference on Big Data and Analytics (ICBDA), Kota Kinabalu, Malaysia, 17–19 November 2020; pp. 26–31. [Google Scholar]
- TechVidvan. Available online: https://Techvidvan.com/tutorials/big-data-architecture/. (accessed on 23 September 2023).
- Alnoukari, M. From business intelligence to big data: The power of analytics. In Research Anthology on Big Data Analytics, Architecture, and Applications; IGI Global: Hershey, PA, USA, 2022; pp. 823–841. [Google Scholar]
- Corallo, A.; Crespino, A.M.; Lazoi, M.; Lezzi, M. Model-based Big Data Analytics-as-a-Service framework in smart manufacturing, A case study. Robot. Comput.-Integr. Manuf. 2022, 76, 102331. [Google Scholar] [CrossRef]
- Harjdarbegovic, M. Data Lake Architecture: A Comprehensive Guide. Available online: https://www.virtasant.com/blog/data-lake-architecture (accessed on 23 September 2022).
- Kuppusamy, P.; Suresh Joseph, K. Building an Enterprise Data Lake for Educational Organizations for Prediction Analytics Using Deep Learning. In Proceedings of the International Conference on Deep Learning, Computing and Intelligence: ICDCI 2021, Chennai, India, 7–8 January 2021; Springer: Singapore, 2022; Volume 1396, pp. 65–81. [Google Scholar]
- Alwashahi, M. Business Intelligence Framework in Higher Education Admission Center (HEAC). Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2015, 5, 86–89. [Google Scholar]
- Dayal, U.; Castellanos, M.; Simitsis, A.; Wilkinson, K. Data Integration Flows for Business Intelligence. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology, Saint Petersburg, Russia, 24–26 March 2009. [Google Scholar]
- Zhao, J.; Feng, H.; Chen, Q.; de Soto, B.G. Developing a conceptual framework for the application of digital twin technologies to revamp building operation and maintenance processes. J. Build. Eng. 2022, 49, 104028. [Google Scholar] [CrossRef]
- Basile, L.J.; Carbonara, N.; Pellegrino, R.; Panniello, U. Business intelligence in the healthcare industry: The utilization of a data-driven approach to support clinical decision making. Technovation 2022, 120, 102482. [Google Scholar] [CrossRef]
- Sudarshan, T.S.; Jeandin, M.; Stiglich, J.J. Surface Modification Technologies XVIII: Proceedings of the Eighteenth International Conference on Surface Modification Technologies Held in Dijon, France, 15–17 November 2004; CRC Press: Boca Raton, FL, USA, 2023; Volume 18. [Google Scholar]
- Hussain, A.; Tahir, H.M.; Nuruzzaman, M. Industrial Web Application Customization Mechanism to Develop Quality Software and Improve Productivity through Object-oriented Application Toolkit Implementation. In Proceedings of the 14th International Conference on Software Engineering, Parallel and Distributed Systems, Dubai, United Arab Emirates, 22–24 February 2015. [Google Scholar]
- Mitchell, S. Microsoft. Available online: https://learn.microsoft.com/en-us/aspnet/web-forms/overview/data-access/introduction/creating-a-data-access-layer-vb (accessed on 23 September 2023).
- Eichler, C.M.; Bi, C.; Wang, C.; Little, J.C. A modular mechanistic framework for estimating exposure to SVOCs: Next Steps for modelling emission and partitioning of plasticizers and PFAS. J. Expo. Sci. Environ. Epidemiol. 2022, 32, 356–365. [Google Scholar] [CrossRef] [PubMed]
- TIBCO Data Federation. TIBCO. Available online: https://www.tibco.com/reference-center/what-is-a-data-federation (accessed on 23 September 2022).
- Choi, J.S.; Chun, S.J.; Lee, S. Hierarchical Distributed Overarching Architecture of Decoupled Federation and Orchestration Frameworks for Multidomain NFV MANOs. IEEE Commun. Mag. 2022, 60, 68–74. [Google Scholar] [CrossRef]
- Liu, T.; Tang, T.; Wang, W.; Xu, B.; Kong, X.; Xia, F. A Survey of Scholarly Data Visualization. IEEE Access 2016, 4, 2–15. [Google Scholar] [CrossRef]
- Börner, K.; Bueckle, A.; Ginda, M. Data visualization literacy: Definitions, conceptual frameworks, exercises, and assessments. Proc. Natl. Acad. Sci. USA 2019, 116, 1857–1864. [Google Scholar] [CrossRef] [PubMed]
- Ukhalkar, P.K.; Phursule, D.R.N.; Gadekar, D.D.P.; Sable, D.N.P. Business intelligence and Analytics: Challenges and Opportunities. Int. J. Adv. Sci. Technol. 2020, 29, 2669–2676. [Google Scholar]
- van der Poll, J.A. A Research Agenda for Embedding 4IR Technologies in the Leadership Management of Formal Methods. In Proceedings of the International Conference on Computational Science and Computational Intelligence (CSCI ’22), Las Vegas, NV, USA, 14–16 December 2022. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technicality | Focus Derivation | Administration | Functionality |
|---|---|---|---|
| Technical (Mostly structured) | Format | Filters | Capacity planning |
| Length | Aggregates Calculations | Space allocation | |
| Domain database | Expressions | Indexing Disk utilization |
| Proposition # | Description |
|---|---|
| Proposition pC1 | A BI framework should include the following components, as these facilitate data management through the transforming and loading of data:
|
| Proposition pC2 | Owing to the said advantages, a BI framework should include a content and document management (CDM) component to address the capture, tracking, and storage of electronic documents. |
| Proposition pC3 | A BI framework should include an operational data landing zone (ODLZ) where all combined data are stored after these have been combined from different sources. |
| Proposition pC4 | A BI framework should include a metadata management component to deal with metadata management as part of general data management to:
|
| Proposition pC5 | A BI framework should include an integrated data source (IDS) layer:
|
| Proposition pC6 | A BI framework dealing with both structured and unstructured data ought to include:
|
| Proposition pC7 | A BI framework dealing with data processing ought to include real-time, batch, and stream processing, to assist with the processing of data either in batches or continuously as transactions happen on the operational side of the business. |
| Proposition pC8 | A BI framework dealing with processing operational data ought to embed a unified operation layer that includes steps of ingestion, distillation, processing, which in turn utilizes various tools and business logic, and insights, all aimed at moving from raw data to business systems for reporting. |
| Proposition pC9 | A BI framework dealing with raw data should include:
|
| Proposition pC10 | A BI framework dealing with processing in the context of an active database ought to:
|
| Proposition pC11 | If not part of the standard ICT infrastructure, a BI framework ought to embed a DB controller to determine the purpose for which and how such data are processed. |
| Proposition pC12 | A BI framework ought to embed a presentation layer that is used to surface data cleanly from a data warehouse or data mart to the user. |
| Proposition pC13 | A BI framework should embed virtual database technology to act as a container, allowing the view and query of multiple databases through a single API drawing from numerous sources. |
| Proposition pC14 | A BI framework ought to cater to file storage aspects, specifically Hadoop-like big data aspects, through visualization. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mositsa, R.J.; Van der Poll, J.A.; Dongmo, C. Towards a Conceptual Framework for Data Management in Business Intelligence. Information 2023, 14, 547. https://doi.org/10.3390/info14100547
Mositsa RJ, Van der Poll JA, Dongmo C. Towards a Conceptual Framework for Data Management in Business Intelligence. Information. 2023; 14(10):547. https://doi.org/10.3390/info14100547
Chicago/Turabian StyleMositsa, Ramakolote Judas, John Andrew Van der Poll, and Cyrille Dongmo. 2023. "Towards a Conceptual Framework for Data Management in Business Intelligence" Information 14, no. 10: 547. https://doi.org/10.3390/info14100547
APA StyleMositsa, R. J., Van der Poll, J. A., & Dongmo, C. (2023). Towards a Conceptual Framework for Data Management in Business Intelligence. Information, 14(10), 547. https://doi.org/10.3390/info14100547