



A New Social Media Analytics Method for Identifying Factors Contributing to COVID-19 Discussion Topics


Abstract
:1. Introduction
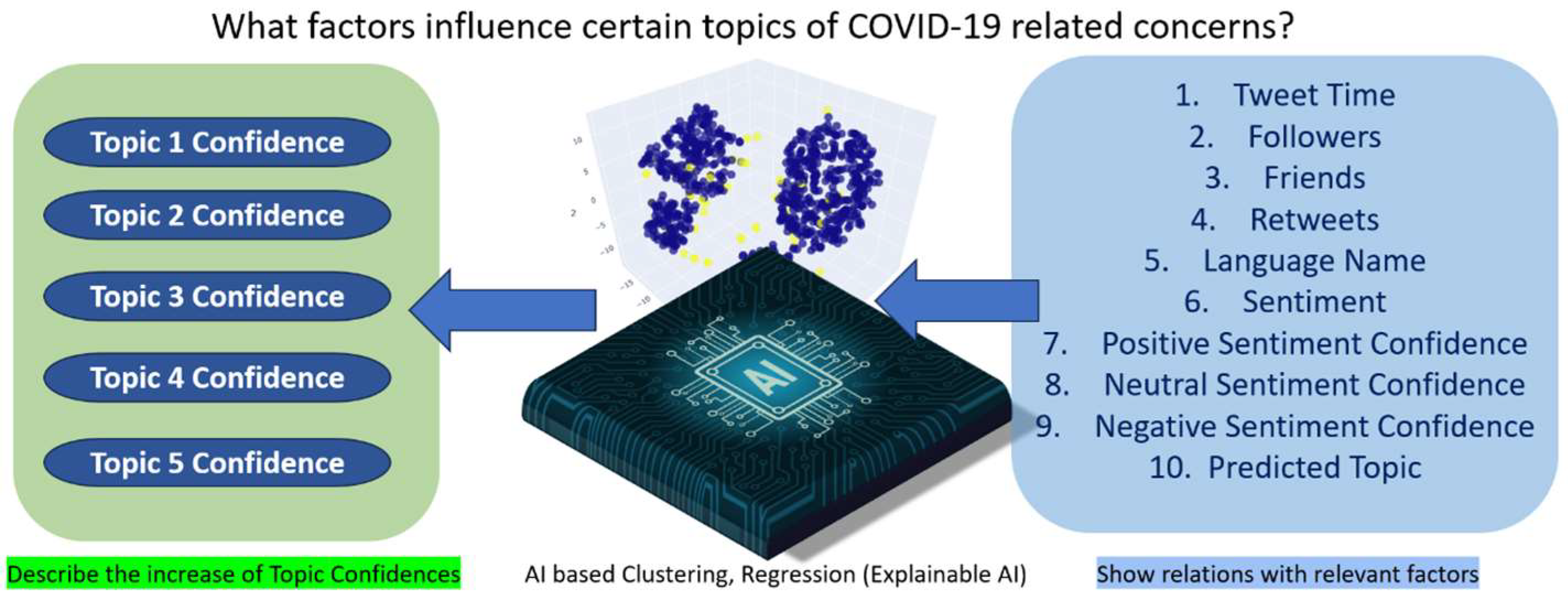
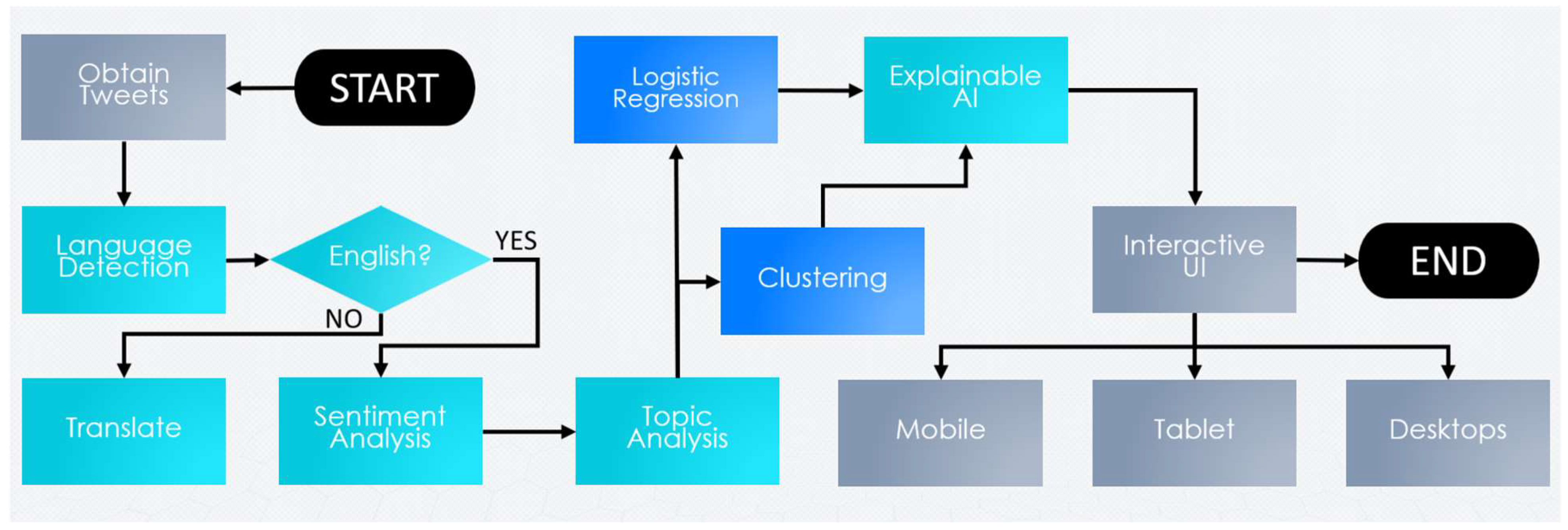
- An inventive framework, rooted in AI and NLP, is systematically employed. This framework integrates a spectrum of methodologies, including translation, sentiment analysis, topic analysis, regression, and clustering techniques, with the purpose of methodically discerning and expounding upon the factors that are pertinent to the diverse discourse topics encompassing COVID-19.
- This innovative approach underwent a rigorous examination and assessment, utilizing a dataset encompassing 152,070 tweets that were gathered within the temporal span from 15 July 2021 to 20 April 2023. Notably, this dataset encapsulates discourse in a wide array of 58 distinct languages.
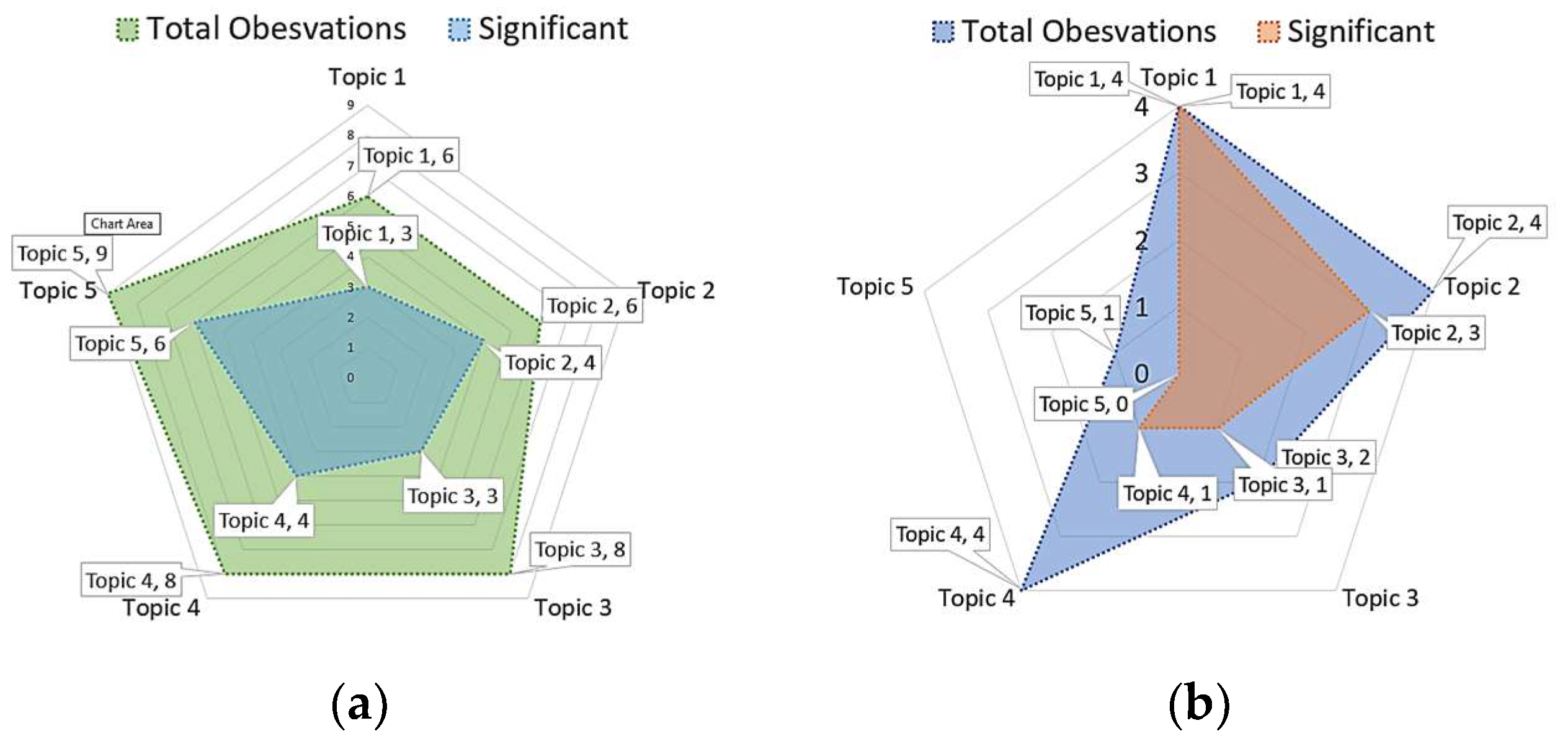
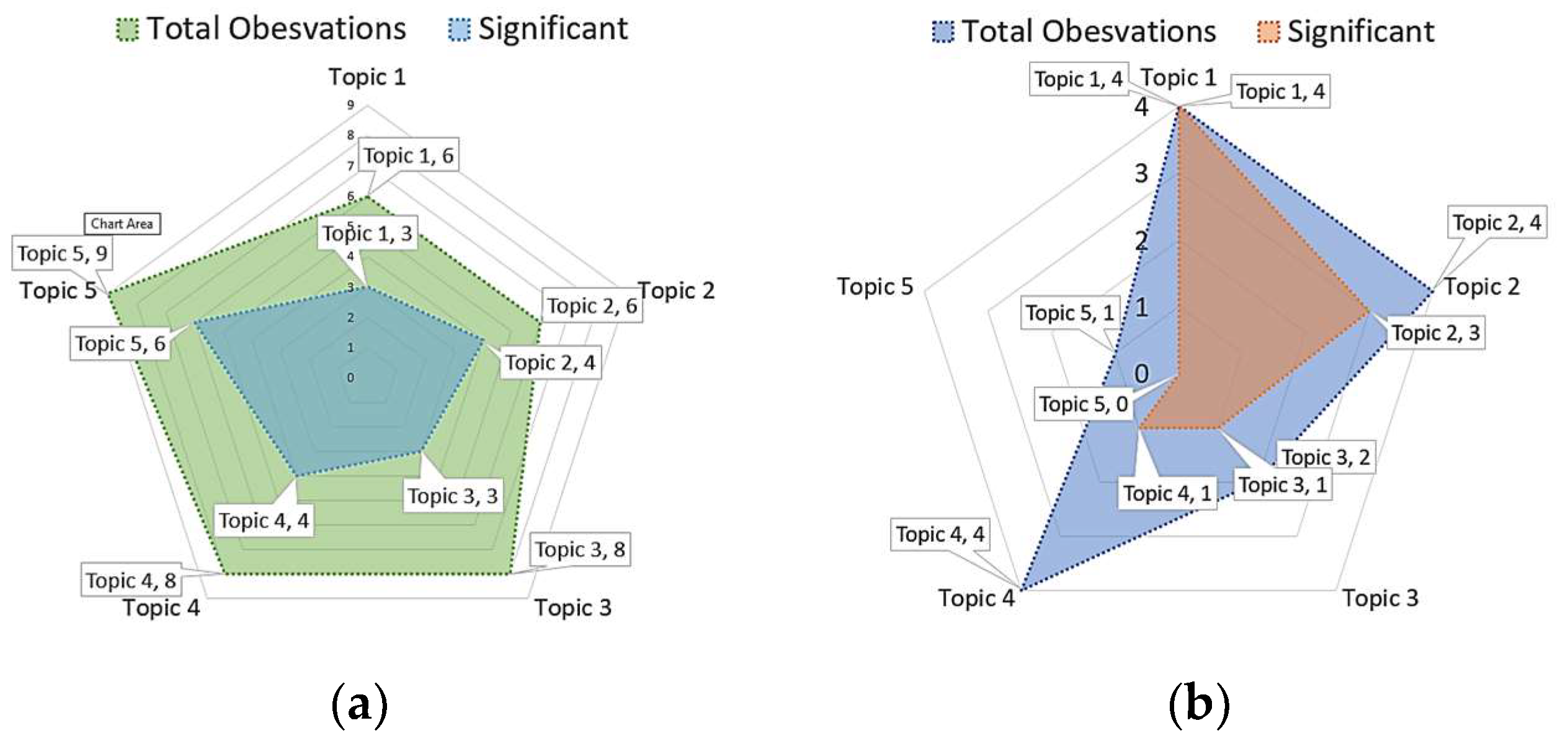
- AI- and NLP-based regression identified and described 37 observations, of which 20 were found to be significant. Moreover, clustering techniques identified 15 observations, containing nine of significance.
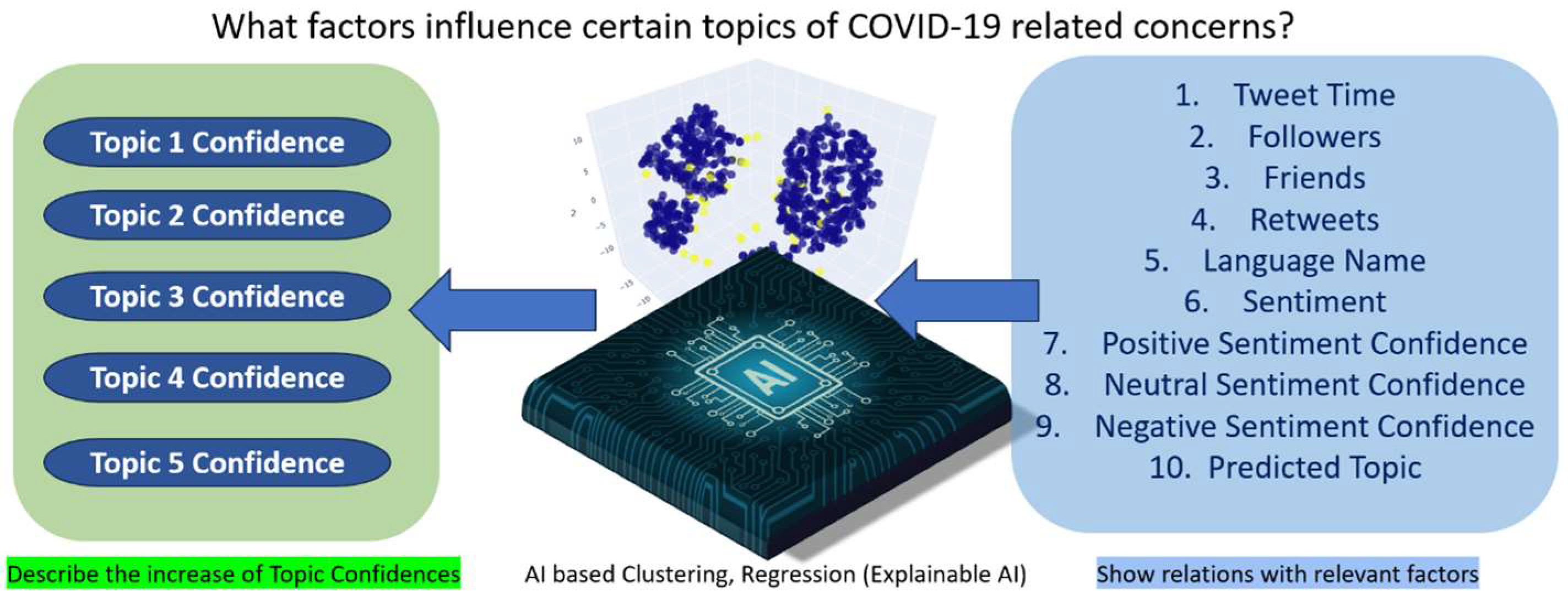
- These 52 observations, generated through AI-driven methods, elucidated the relationships existing between topic confidences, encompassing Topic 1 confidence, Topic 2 confidence, Topic 3 confidence, Topic 4 confidence, and Topic 5 confidence, and an extensive array of factors. These factors included variables such as tweet time, followers, friends, retweets, language name, sentiment, positive sentiment confidence, neutral sentiment confidence, negative sentiment confidence, and predicted Topic.
- This methodology could be applied to identify factors related to any discussion topics within any micro-blogging social media platforms.
2. Background Context and Literature
2.1. Global Perspective
2.2. Multilingual Analysis
2.3. Sentiment Analysis
2.4. Topic Analysis
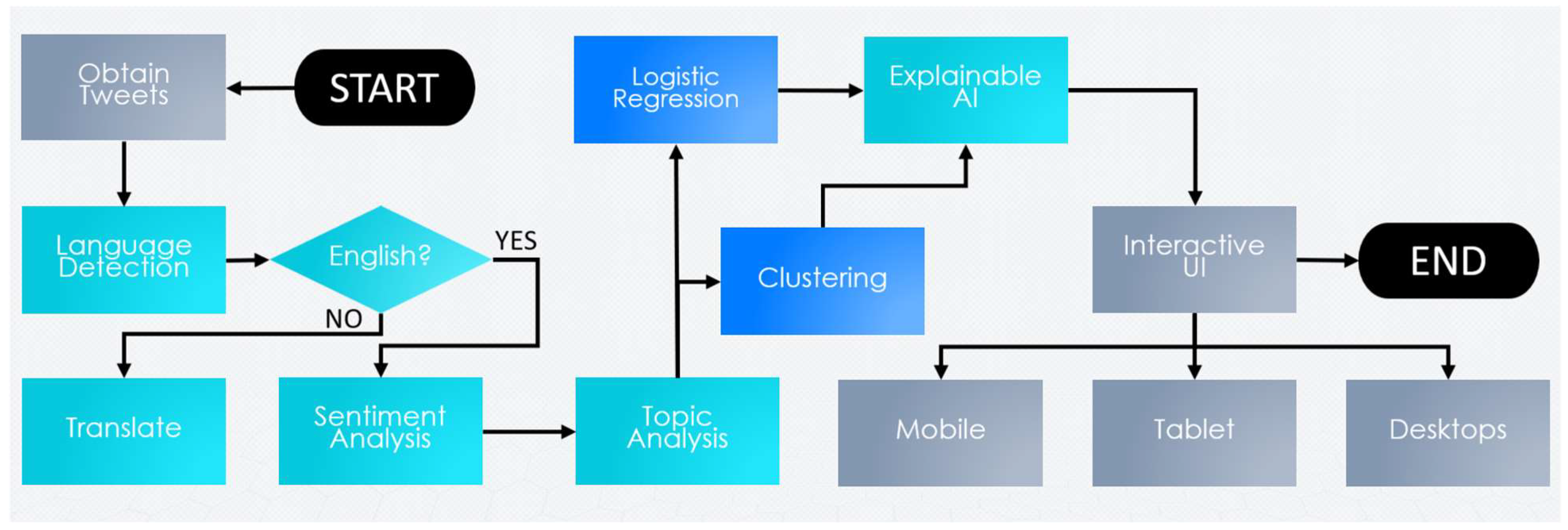
3. Materials and Methods
3.1. Tweet Acquisition
3.2. Language Detection
3.3. Translation (for Non-English Tweets)
3.4. Sentiment Analysis
3.5. Topic Analysis (LDA-Based)
3.6. Correlation Analysis
3.7. Explanatory Analysis (NLP-Based)
| Algorithm 1: Analysing the correlated factors of COVID-19-related Twitter topics. | |||
| 1. | # Step 1: Tweet acquisition T, m, f, d, r = ExtractTweetsContainingKeywords(“COVID”, “CORONA”) | ||
| 2. | # Step 2: Language detection for tweet in T: | ||
| 3. | l = DetectLanguage(tweet) | ||
| 4. | # Step 3: Translation (for non-English tweets) T_EN = [] | ||
| 5. | for tweet in T: | ||
| 6. | if l is not “English”: | ||
| 7. | t_EN = TranslateToEnglish(tweet) | ||
| 8. | T_EN.append(t_EN) | ||
| 9. | else: | ||
| 10. | T_EN.append(tweet) | ||
| 11. | # Step 4: Sentiment analysis for tweet in T_EN: | ||
| 12. | s, p, n, u = SentimentAnalysis(tweet) | ||
| 13. | # Step 5: Topic analysis (LDA-based) Topics, c1, c2, c3, c4, c5 = PerformLDATopicAnalysis(T_EN) | ||
| 14. | # Step 6: Correlation analysis Correlations = CorrelationAnalysis({c1, c2, c3, c4, c5}→{l, f, d, r, s, p, n, u}) | ||
| 15. | # Step 7: Explanatory analysis (NLP-based) Explanations = ExplainCorrelations(Correlations) | ||
| 16. | # Display results or save to file DisplayResults(Correlations, Explanations) | ||
4. Results and Discussion
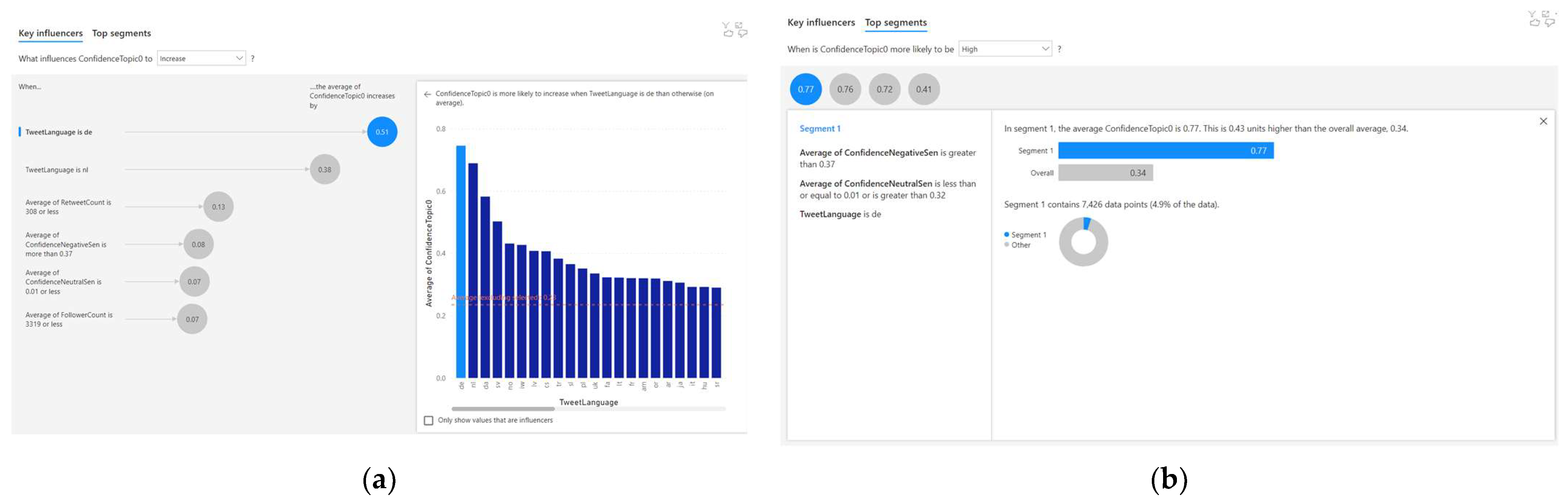
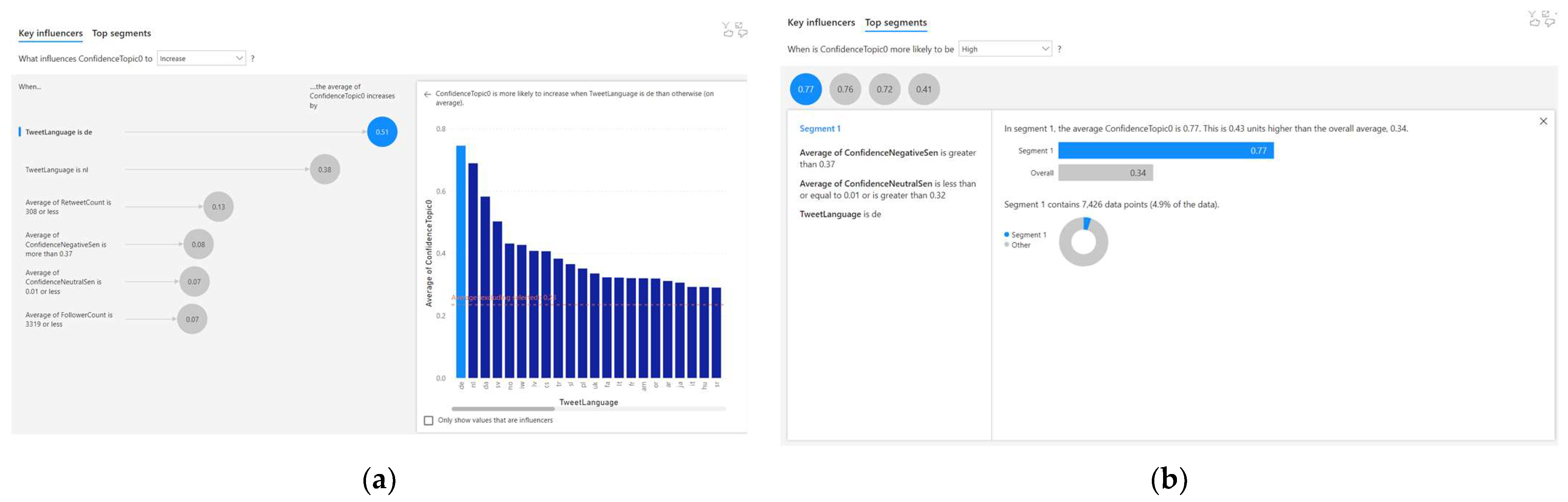
4.1. Analysing the Correlated Factors for Topic 1
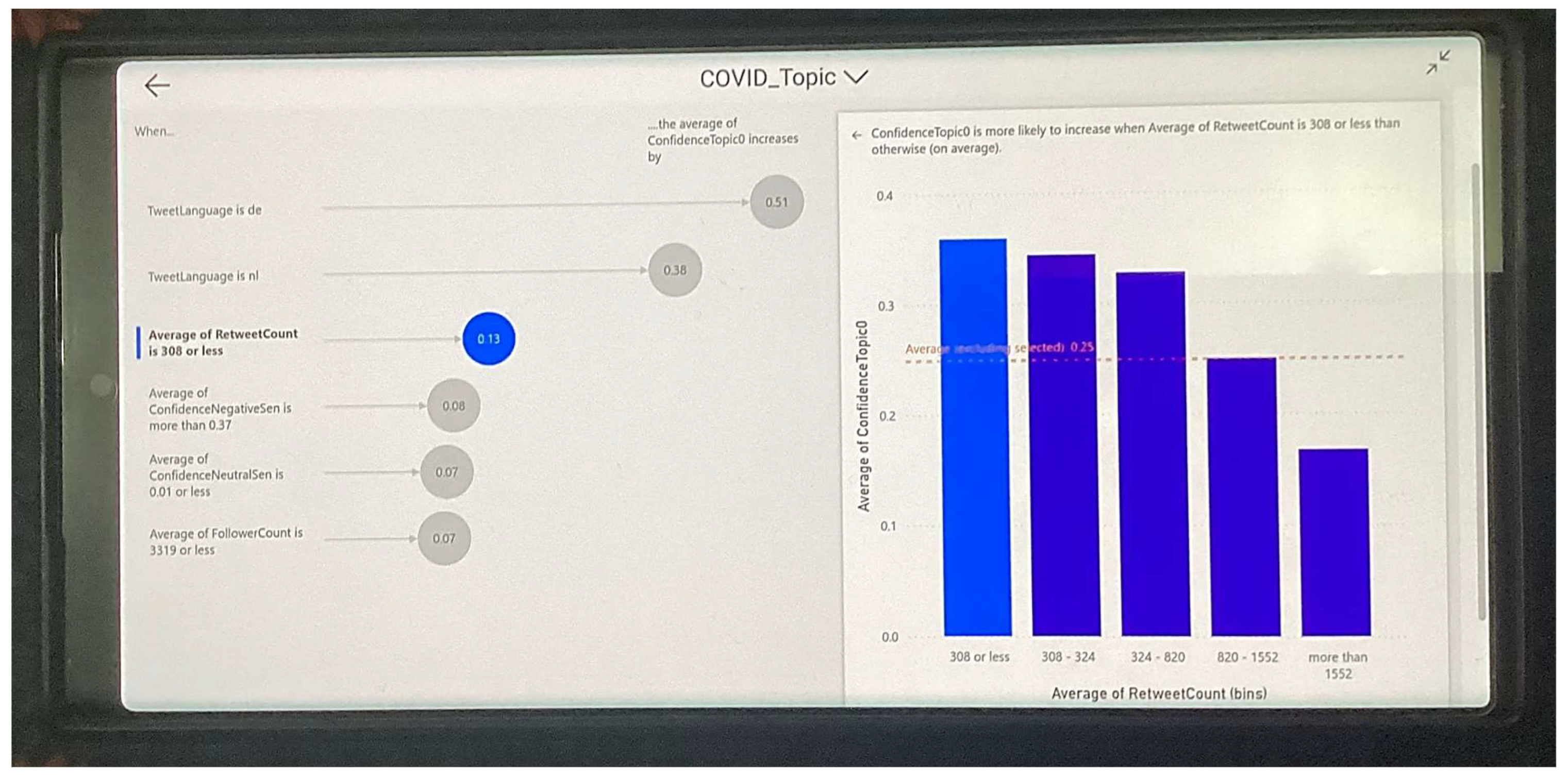
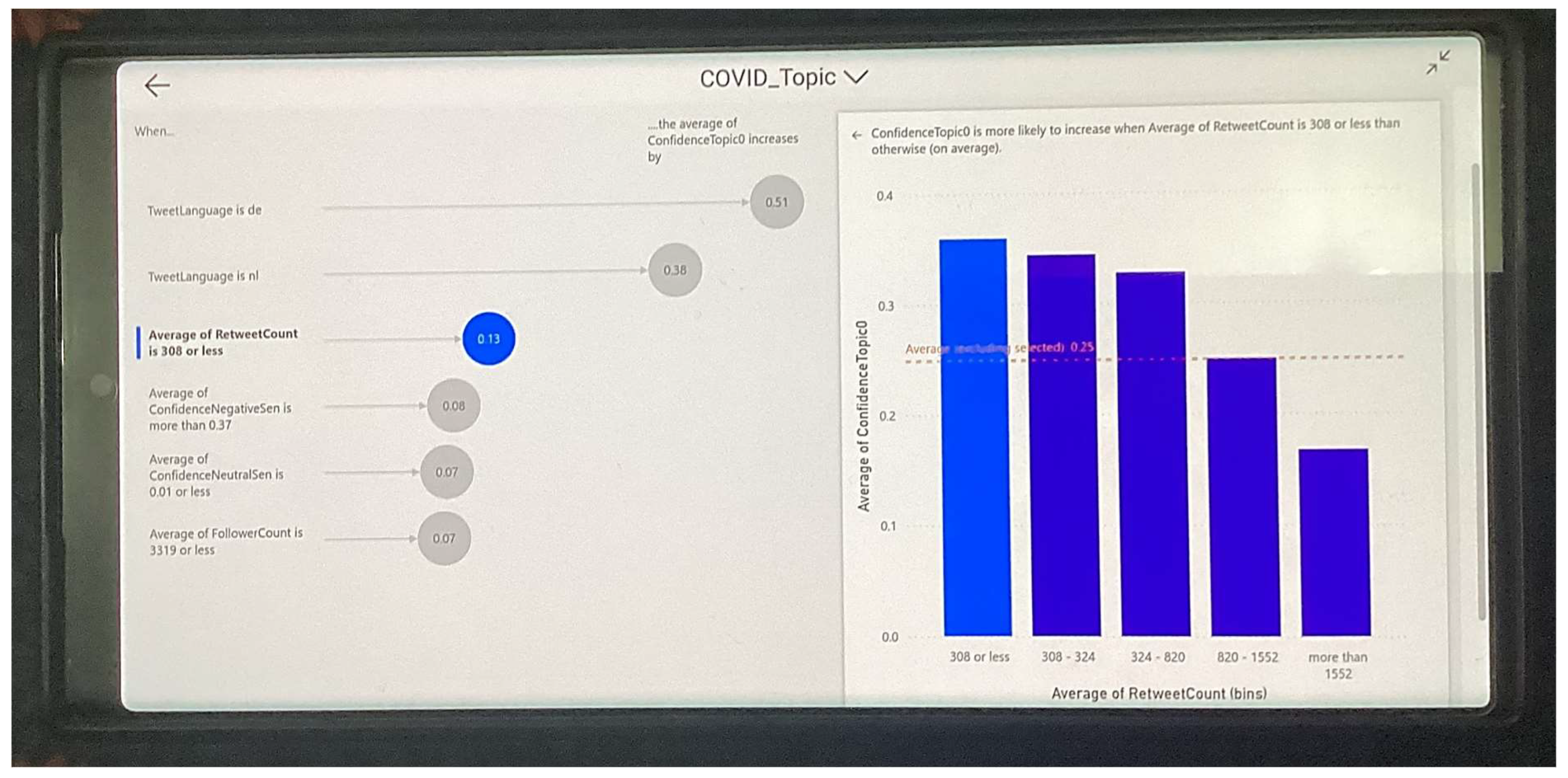
- When the tweet language is ‘de’, the average Topic 1 confidence increases by 0.51;
- When the tweet language is ‘nl’, the average Topic 1 confidence increases by 0.38;
- When the average retweet count is 308 or less, the average Topic 1 confidence increases by 0.13.
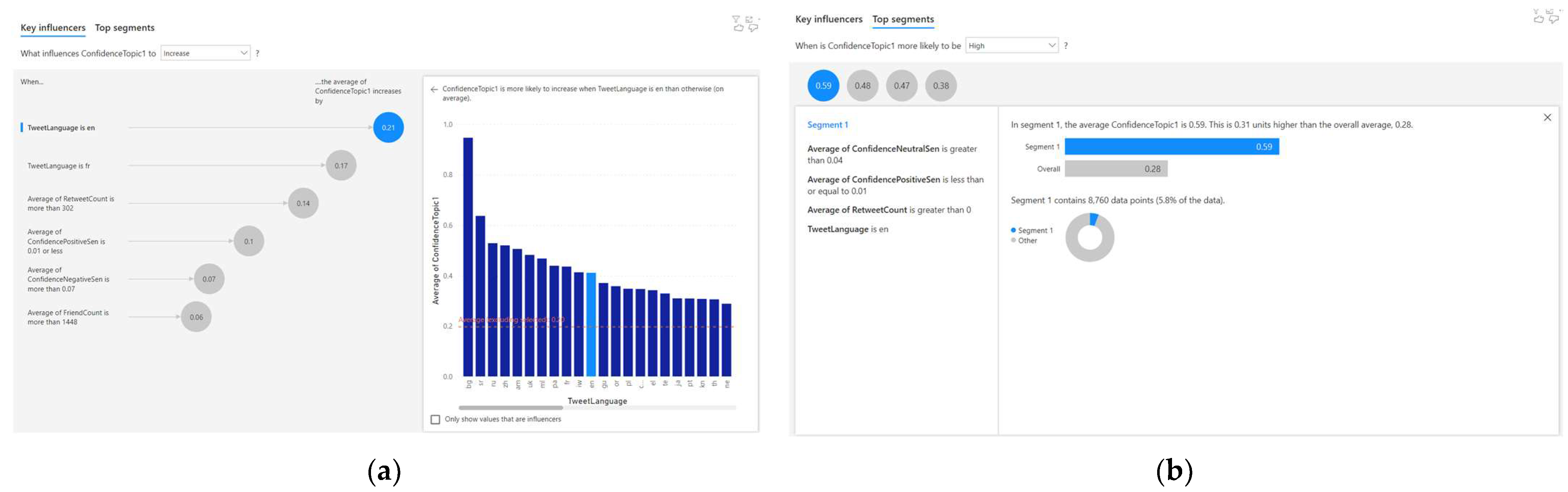
4.2. Analysing the Correlated Factors for Topic 2
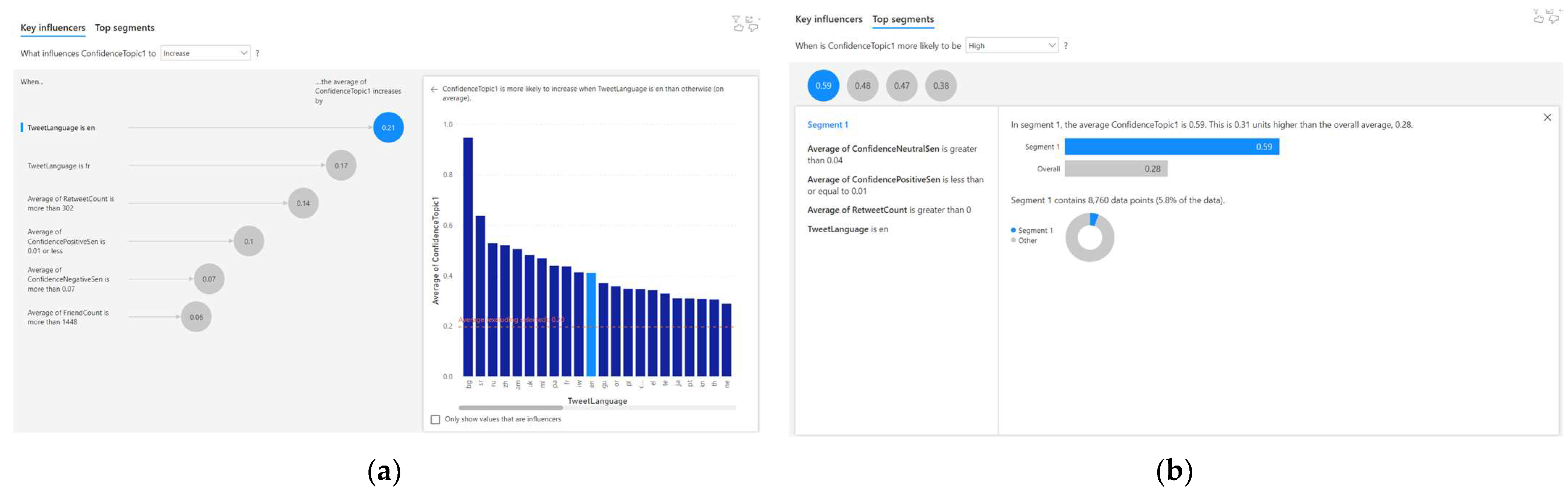
- When the tweet language is ‘en’, the average Topic 2 confidence increases by 0.21;
- When the tweet language is ‘fr’, the average Topic 2 confidence increases by 0.17;
- When the average retweet count is more than 302, the average Topic 2 confidence increases by 0.14;
- When the average confidence-positive sentiment is 0.01 or less, the average Topic 2 confidence increases by 0.1.
4.3. Analysing the Correlated Factors for Topic 3
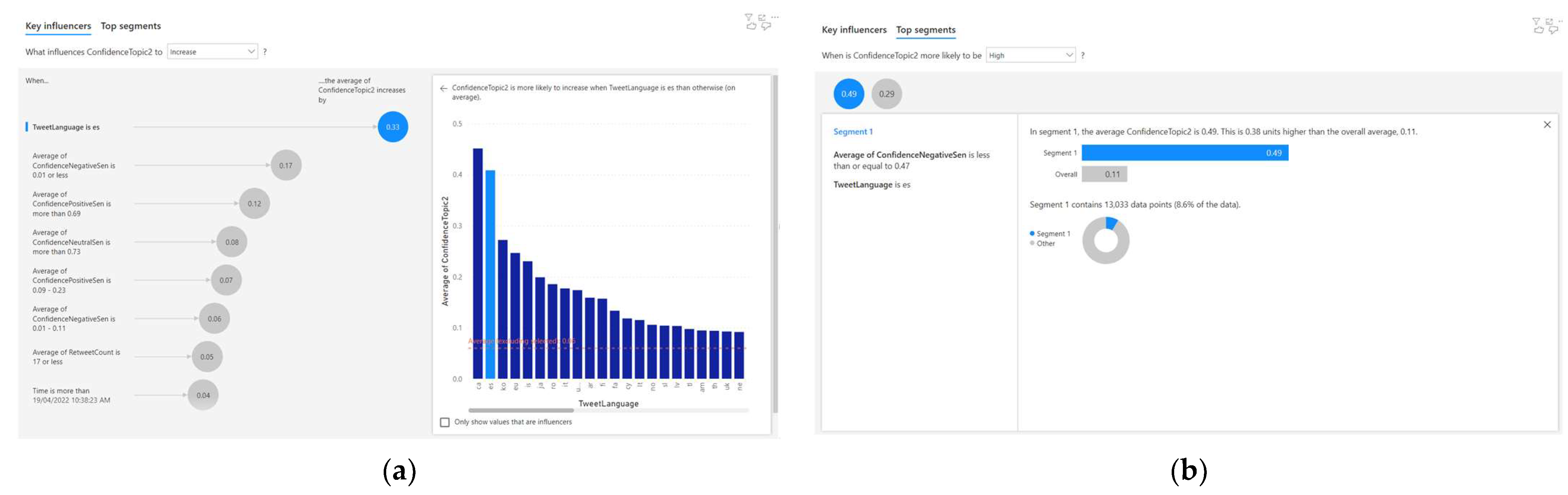
- When the tweet language is ‘es,’ the average Topic 3 confidence increases by 0.33;
- When the average confidence-negative sentiment is 0.01 or less, the average Topic 3 confidence increases by 0.17;
- When the average confidence-positive sentiment is more than 0.69, the average Topic 3 confidence increases by 0.12.
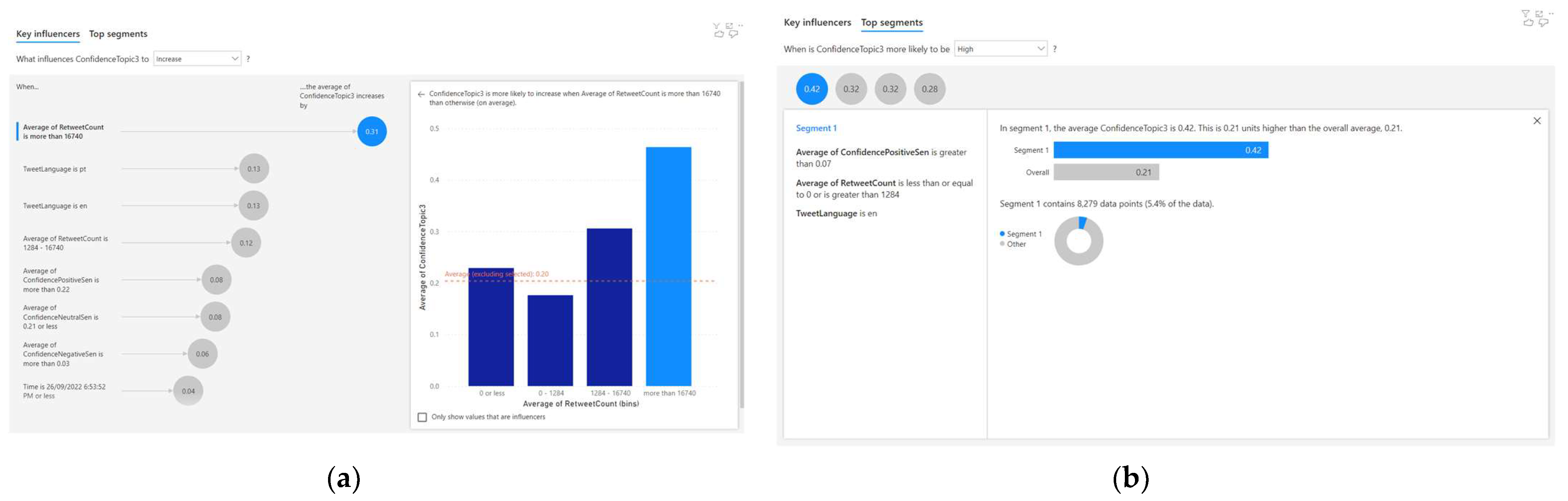
4.4. Analysing the Correlated Factors for Topic 4
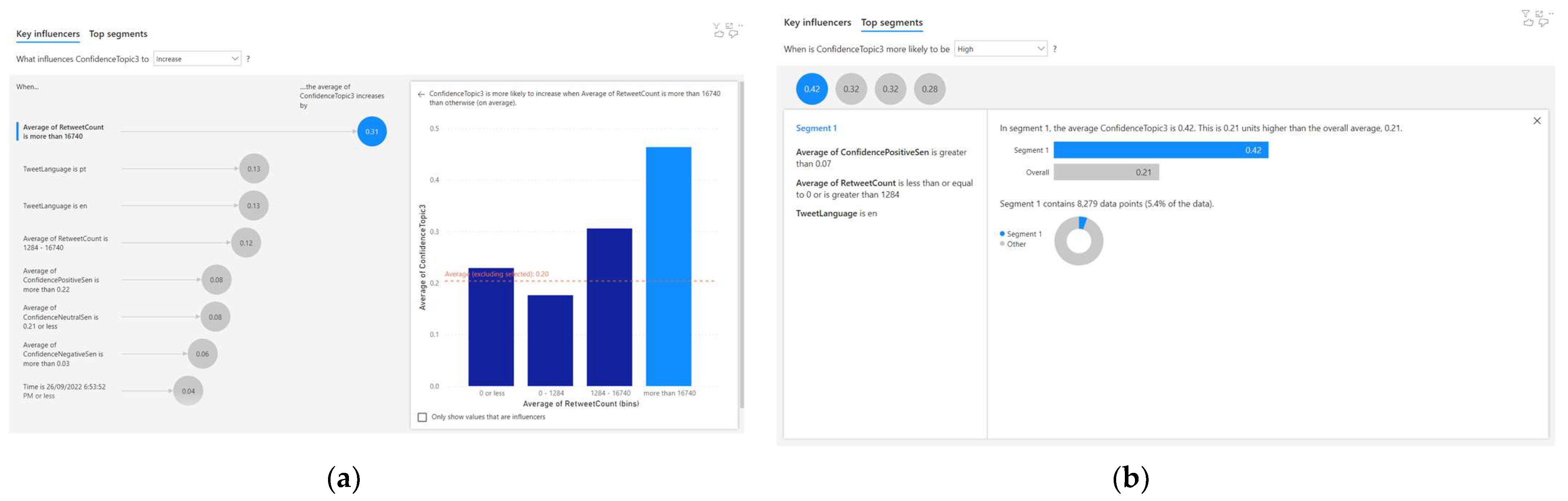
- When the average retweet count is more than 16,740, the average Topic 4 confidence increases by 0.31;
- When the tweet language is ‘pt’, the average Topic 4 confidence increases by 0.13;
- When the tweet language is ‘en’, the average Topic 4 confidence increases by 0.13;
- When the average retweet count is 1284–16740, the average Topic 4 confidence increases by 0.12.
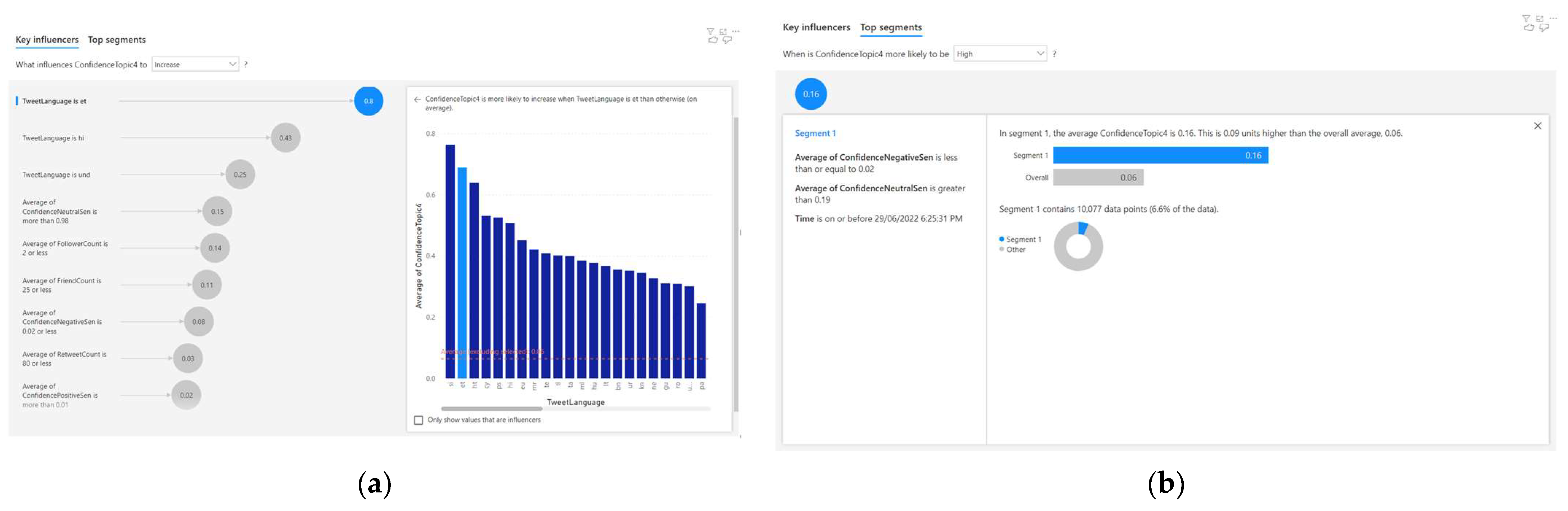
4.5. Analysing the Correlated Factors for Topic 5
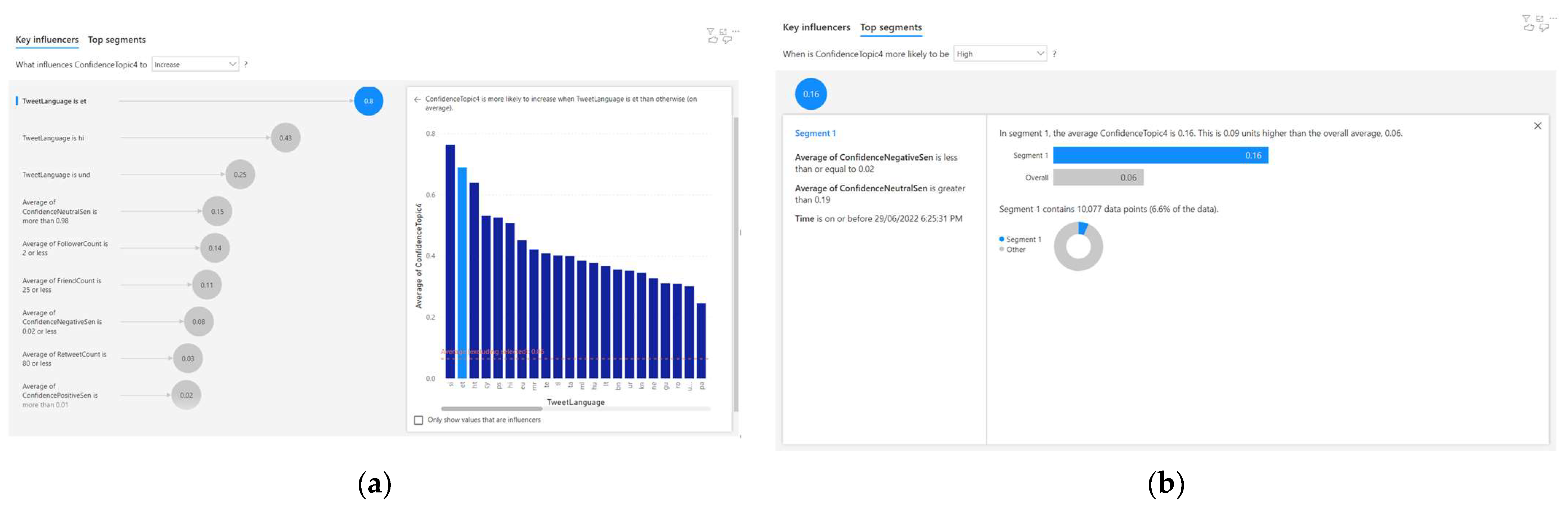
- When the language is ‘et’, the average Topic 5 confidence increases by 0.8;
- When the language is ‘hi’, the average Topic 5 confidence increases by 0.43;
- When the language is ‘und’, the average Topic 5 confidence increases by 0.25;
- When the average confidence-neutral sentiment is more than 0.98, the average Topic 5 confidence increases by 0.15;
- When the average follower count is 2 or less, the average Topic 5 confidence increases by 0.14;
- When average friend count is 25 or less, the average Topic 5 confidence increases by 0.11.
5. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Social Media & COVID-19: A Global Study of Digital Crisis Interaction among Gen Z and Millennials. 2021. Available online: https://www.who.int/news-room/feature-stories/detail/social-media-covid-19-a-global-study-of-digital-crisis-interaction-among-gen-z-and-millennials (accessed on 1 September 2023).
- Sufi, F. A New Social Media-Driven Cyber Threat Intelligence. Electronics 2023, 12, 1242. [Google Scholar] [CrossRef]
- Sufi, F. Algorithms in Low-Code-No-Code for Research Applications: A Practical Review. Algorithms 2023, 16, 108. [Google Scholar] [CrossRef]
- Sufi, F. A New AI-Based Semantic Cyber Intelligence Agent. Future Internet 2023, 15, 231. [Google Scholar] [CrossRef]
- Northwestern. Social Media Contributes to Misinformation about COVID-19. 2020. Available online: https://news.northwestern.edu/stories/2020/09/social-media-contributes-to-misinformation-about-covid-19/ (accessed on 1 September 2023).
- Hussain, A.; Ali, S.; Ahmed, M.; Hussain, S. The Anti-vaccination Movement: A Regression in Modern Medicine. Cureus 2018, 10, e2919. [Google Scholar] [CrossRef]
- Johnson, N.F.; Velásquez, N.; Restrepo, N.J.; Leahy, R.; Gabriel, N.; Oud, S.E.; Zheng, M.; Manrique, P.; Wuchty, S.; Lupu, Y. The online competition between pro- and anti-vaccination views. Nature 2020, 582, 230–233. [Google Scholar] [CrossRef]
- Benecke, O.; DeYoung, S.E. Anti-Vaccine Decision-Making and Measles Resurgence in the United States. Glob. Pediatr. Health 2019, 6, 2333794X19862949. [Google Scholar] [CrossRef]
- Li, C.-Y.; Renda, M.; Yusuf, F.; Geller, J.; Chun, S.A. Public Health Policy Monitoring through Public Perceptions: A Case of COVID-19 Tweet Analysis. Information 2022, 13, 543. [Google Scholar] [CrossRef]
- Gourisaria, M.K.; Chandra, S.; Das, H.; Patra, S.S.; Sahni, M.; Leon-Castro, E.; Singh, V.; Kumar, S. Semantic Analysis and Topic Modelling of Web-Scrapped COVID-19 Tweet Corpora through Data Mining Methodologies. Healthcare 2022, 10, 881. [Google Scholar] [CrossRef]
- Kwok, S.W.H.; Vadde, S.K.; Wang, G. Tweet Topics and Sentiments Relating to COVID-19 Vaccination Among Australian Twitter Users: Machine Learning Analysis. J. Med. Internet Res. 2021, 23, e26953. [Google Scholar] [CrossRef]
- Long, Z.; Alharthi, R.; Saddik, A.E. NeedFull—a Tweet Analysis Platform to Study Human Needs During the COVID-19 Pandemic in New York State. IEEE Access 2020, 8, 136046–136055. [Google Scholar] [CrossRef]
- Sufi, F.K. Automatic identification and explanation of root causes on COVID-19 index anomalies. MethodsX 2023, 10, 101960. [Google Scholar] [CrossRef]
- Sufi, F.K.; Razzak, I.; Khalil, I. Tracking Anti-Vax Social Movement Using AI-Based Social Media Monitoring. IEEE Trans. Technol. Soc. 2022, 3, 290–299. [Google Scholar] [CrossRef]
- Narasamma, V.L.; Sreedevi, M.; Kumar, G.V. Tweet Data Analysis on COVID-19 Outbreak. In Smart Technologies in Data Science and Communication; Lecture Notes in Networks and Systems Book Series (LNNS); Springer: Berlin/Heidelberg, Germany, 2021; Volume 210. [Google Scholar]
- Waheeb, S.A.; Khan, N.A.; Shang, X. Topic Modeling and Sentiment Analysis of Online Education in the COVID-19 Era Using Social Networks Based Datasets. Electronics 2022, 11, 715. [Google Scholar] [CrossRef]
- Storey, V.; O’Leary, D. Text Analysis of Evolving Emotions and Sentiments in COVID-19 Twitter Communication. Cognit. Comput. 2022. epub ahead of print. [Google Scholar] [CrossRef]
- Kabakus, T. A novel COVID-19 sentiment analysis in Turkish based on the combination of convolutional neural network and bidirectional long–short term memory on Twitter. Concurr. Comput. 2022, 34, e6883. Available online: https://api.semanticscholar.org/CorpusID:246851122 (accessed on 3 September 2023). [CrossRef] [PubMed]
- Joloudari, J.H.; Hussain, S.; Nematollahi, A.M.; Bagheri, R.; Fazl, F.; Alizadehsani, R.; Lashgari, R. BERT-deep CNN: State of the art for sentiment analysis of COVID-19 tweets. Soc. Netw. Anal. Min. 2022, 13, 99. [Google Scholar] [CrossRef]
- Mir, A.A.; Sevukan, R. Sentiment analysis of Indian Tweets about Covid-19 vaccines. J. Inf. Sci. 2022. epub ahead of print. [Google Scholar]
- Sufi, F.; Alsulami, M. Identifying drivers of COVID-19 vaccine sentiments for effective vaccination policy. Heliyon 2023, 9, e19195. [Google Scholar] [CrossRef]
- Lee, E.W.J.; Zheng, H.; Goh, D.H.-L.; Lee, C.S.; Theng, Y.L. Examining COVID-19 Tweet Diffusion Using an Integrated Social Amplification of Risk and Issue-Attention Cycle Framework. Health Commun. 2022. epub ahead of print. [Google Scholar] [CrossRef]
- Lanier, H.D.; Diaz, M.I.; Saleh, S.N.; Lehmann, C.U.; Medford, R.J. Analyzing COVID-19 disinformation on Twitter using the hashtags #scamdemic and #plandemic: Retrospective study. PLoS ONE 2022, 17, e0268409. [Google Scholar]
- Slavik, C.E.; Buttle, C.; Sturrock, S.L.; Darlington, J.C.; Yiannakoulias, N. Examining Tweet Content and Engagement of Canadian Public Health Agencies and Decision Makers During COVID-19: Mixed Methods Analysis. J. Med. Internet Res. 2021, 23, e24883. [Google Scholar] [CrossRef] [PubMed]
- Bijoy, B.S.; Saba, S.J.; Sarkar, S.; Islam, M.S.; Islam, S.R.; Amin, M.R.; Karmaker, S. COVID19α: Interactive Spatio-Temporal Visualization of COVID-19 Symptoms through Tweet Analysis. In Proceedings of the IUI ‘21 Companion: 26th International Conference on Intelligent User Interfaces—Companion, College Station, TX, USA, 14–17 April 2021. [Google Scholar]
- Shin, H.-S.; Kwon, H.-Y.; Seung-Jin, R. A New Text Classification Model Based on Contrastive Word Embedding for Detecting Cybersecurity Intelligence in Twitter. Electronics 2020, 9, 1527. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, Q.; Li, J.; Shao, M.; He, Z.; Li, B. TIMiner: Automatically extracting and analyzing categorized cyber threat intelligence from social data. Comput. Secur. 2020, 95, 101867–101874. [Google Scholar] [CrossRef]
- Schellekens, J. Release the bots of war: Social media and Artificial Intelligence as international cyber attack. Przegląd Eur. 2021, 4, 163–179. [Google Scholar] [CrossRef]
- Sun, N.; Zhang, J.; Gao, S.; Zhang, L.Y.; Camtepe, S.; Xiang, Y. Data Analytics of Crowdsourced Resources for Cybersecurity Intelligence. In Network and System Security, Proceedings of the 14th International Conference: NSS 2020, Melbourne, VIC, Australia, 25–27 November 2020; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; Volume 12570, pp. 3–21. [Google Scholar]
- Subroto, A.; Apriyana, A. Cyber risk prediction through social media big data analytics and statistical machine learning. J. Big Data 2019, 6, 1–19. [Google Scholar] [CrossRef]
- Hee, V.; Jacobs, G.; Emmery, C.; Desmet, B.; Lefever, E.; Verhoeven, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Automatic Detection of Cyberbullying in Social Media Text. PLoS ONE 2018, 13, e0203794. [Google Scholar]
- Shu, K.; Sliva, A.; Sampson, J.; Liu, H. Understanding Cyber Attack Behaviors with Sentiment Information on Social Media. In Social, Cultural, and Behavioral Modeling, Proceedings of the 11th International Conference: SBP-BRiMS 2018, Washington, DC, USA, 10–13 July 2018; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; Volume 10899, pp. 377–388. [Google Scholar]
- Alves, F.; Bettini, A.; Ferreira, P.M.; Bessani, A. Processing tweets for cybersecurity threat awareness. Inf. Syst. 2021, 95, 101586. [Google Scholar] [CrossRef]
- Microsoft Documentation. Text Analytics: A Collection of Features from AI Language that Extract, Classify, and Understand Text within Documents. 2023. Available online: https://azure.microsoft.com/en-us/products/ai-services/text-analytics (accessed on 6 August 2023).
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), Philadelphia, PA, USA, 6–7 July 2002. [Google Scholar]
- Turney, P.D. Thumbs up or thumbs down? Semantic orientation applied. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A Large-Scale Benchmark Twitter. IEEE Trans. Comput. Soc. Syst. 2020, 8, 1003–1015. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Q.; Wang, X.; Zhang, J. Characterizing the Propagation of Situational Information in Social Media During COVID-19 Epidemic: A Case Study on Weibo. IEEE Trans. Comput. Soc. Syst. 2020, 7, 556–562. [Google Scholar] [CrossRef]
- Cameron, D.; Smith, G.A.; Daniulaityte, R.; Sheth, A.P.; Dave, D.; Chen, L.; Anand, G.; Carlson, R.; Watkins, K.Z.; Falck, R. PREDOSE: A Semantic Web Platform for Drug Abuse Epidemiology using Social Media. J. Biomed. Inform. 2013, 46, 985–997. [Google Scholar] [CrossRef]
- Chen, X.; Faviez, C.; Schuck, S.; Lillo-Le-Louët, A.; Texier, N.; Dahamna, B.; Huot, C.; Foulquié, P.; Pereira, S.; Leroux, V.; et al. Mining Patients’ Narratives in Social Media for Pharmacovigilance: Adverse Effects and Misuse of Methylphenidate. Front. Pharmacol. 2018, 9, 541. [Google Scholar] [CrossRef] [PubMed]
- McNaughton, E.C.; Black, R.A.; Zulueta, M.G.; Budman, S.H.; Butler, S.F. Measuring online endorsement of prescription opioids abuse: An integrative methodology. Pharmacoepidemiol. Drug Saf. 2012, 21, 1081–1092. [Google Scholar] [CrossRef]
- Al-Twairesh, N.; Al-Negheimish, H. Surface and Deep Features Ensemble for Sentiment Analysis of Arabic Tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Vashisht, G.; Sinha, Y.N. Sentimental study of CAA by location-based tweets. Int. J. Inf. Technol. 2021, 13, 1555–1567. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi; Yazdavar, H.; Sheth, A. Challenges of Sentiment Analysis for Dynamic Events. IEEE Intell. Syst. 2017, 32, 70–75. [Google Scholar] [CrossRef]
- Yu, H.-F.; Hsieh, C.-J.; Chang, K.-W.; Lin, C.-J. Large Linear Classification When Data Cannot Fit in Memory. In Proceedings of the KDD ‘10: Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and Data Mining, Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Matthies, H.; Strang, G. The solution of non linear finite element equations. Int. J. Numer. Methods Eng. 1979, 14, 1613–1626. [Google Scholar] [CrossRef]
- Nocedal, J. Updating Quasi-Newton Matrices with Limited Storage. Math. Comput. 1980, 35, 773–782. [Google Scholar] [CrossRef]
- Microsoft Documentation. Choosing a Natural Language Processing Technology in Azure. 2020. Available online: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/natural-language-processing (accessed on 3 September 2023).
- Gurajala, S.; White, J.S.; Hudson, B.; Voter, B.R.; Matthews, J.N. Profile characteristics of fake Twitter accounts. Big Data Soc. 2016, 3, 2053951716674236. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018. [Google Scholar]
- Golder, S.; Ahmed, S.; Norman, G.; Booth, A. Attitudes Toward the Ethics of Research Using Social Media: A Systematic Review. J. Med. Internet Res. 2017, 19, e195. [Google Scholar] [CrossRef]
- Mikal, J.; Hurst, S.; Conway, M. Ethical issues in using Twitter for population-level depression monitoring: A qualitative study. BMC Med. Ethics 2016, 17, 22. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Multilingual | Global | Sentiment Analysis | Topic Analysis | Identifying Factors of Topic |
|---|---|---|---|---|---|
| [9] | No | No | Yes | No | No |
| [23] | No | No | Yes | Yes | No |
| [10] | No | No | Yes | Yes | No |
| [11] | No | No | Yes | Yes | No |
| [22] | No | Yes | No | Yes | No |
| [12] | No | No | Yes | No | No |
| [13] | Yes | Yes | Yes | No | No |
| [24] | No | No | No | No | No |
| [25] | No | No | No | No | No |
| [14] | Yes | Yes | Yes | No | No |
| [15] | No | Yes | Yes | No | No |
| [16] | No | Yes | Yes | Yes | No |
| [17] | No | Yes | Yes | No | No |
| [18] | No | No | Yes | No | No |
| [19] | No | Yes | Yes | No | No |
| [20] | No | No | Yes | Yes | No |
| [21] | Yes | Yes | Yes | No | No |
| This Study | Yes | Yes | Yes | Yes | Yes |
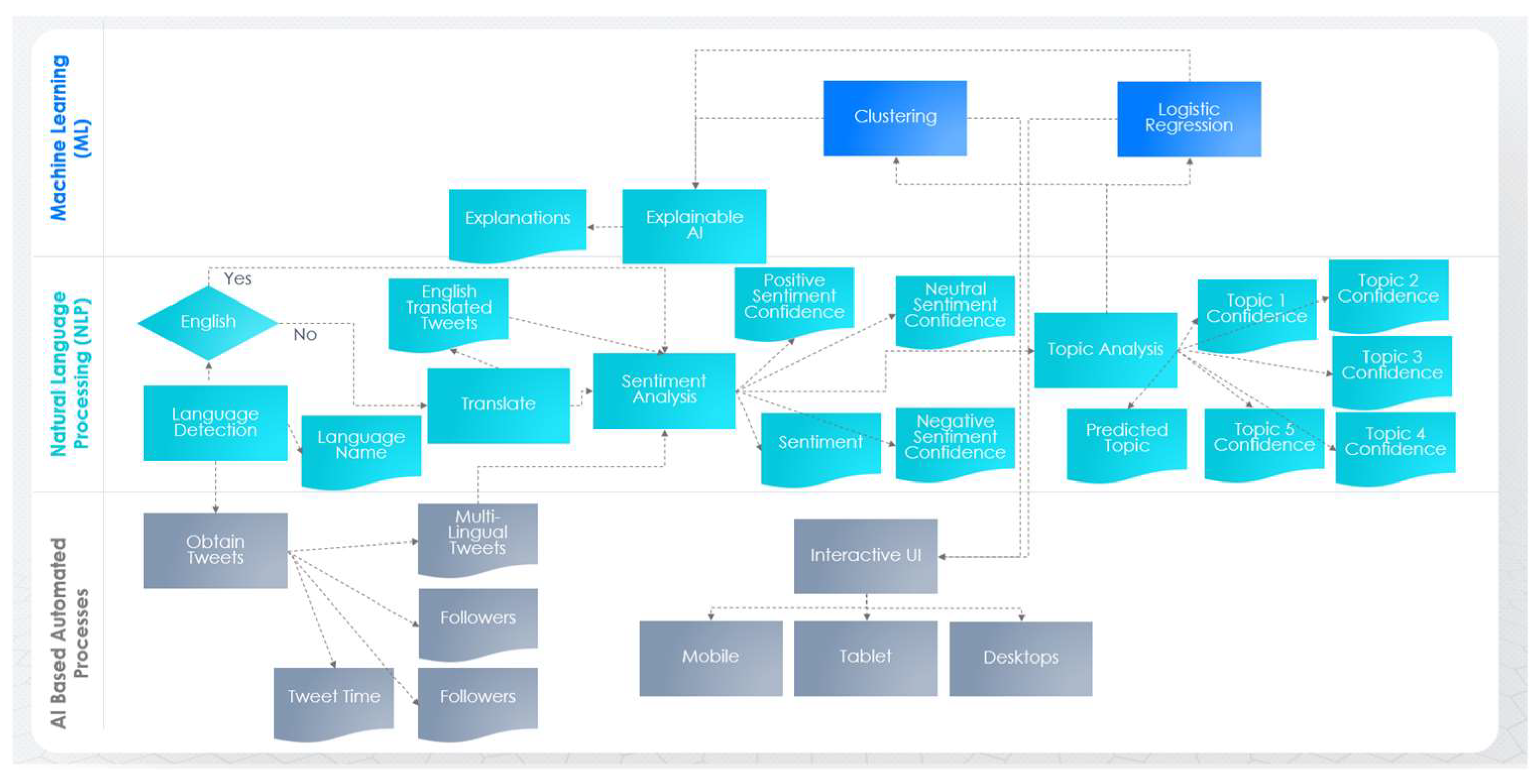
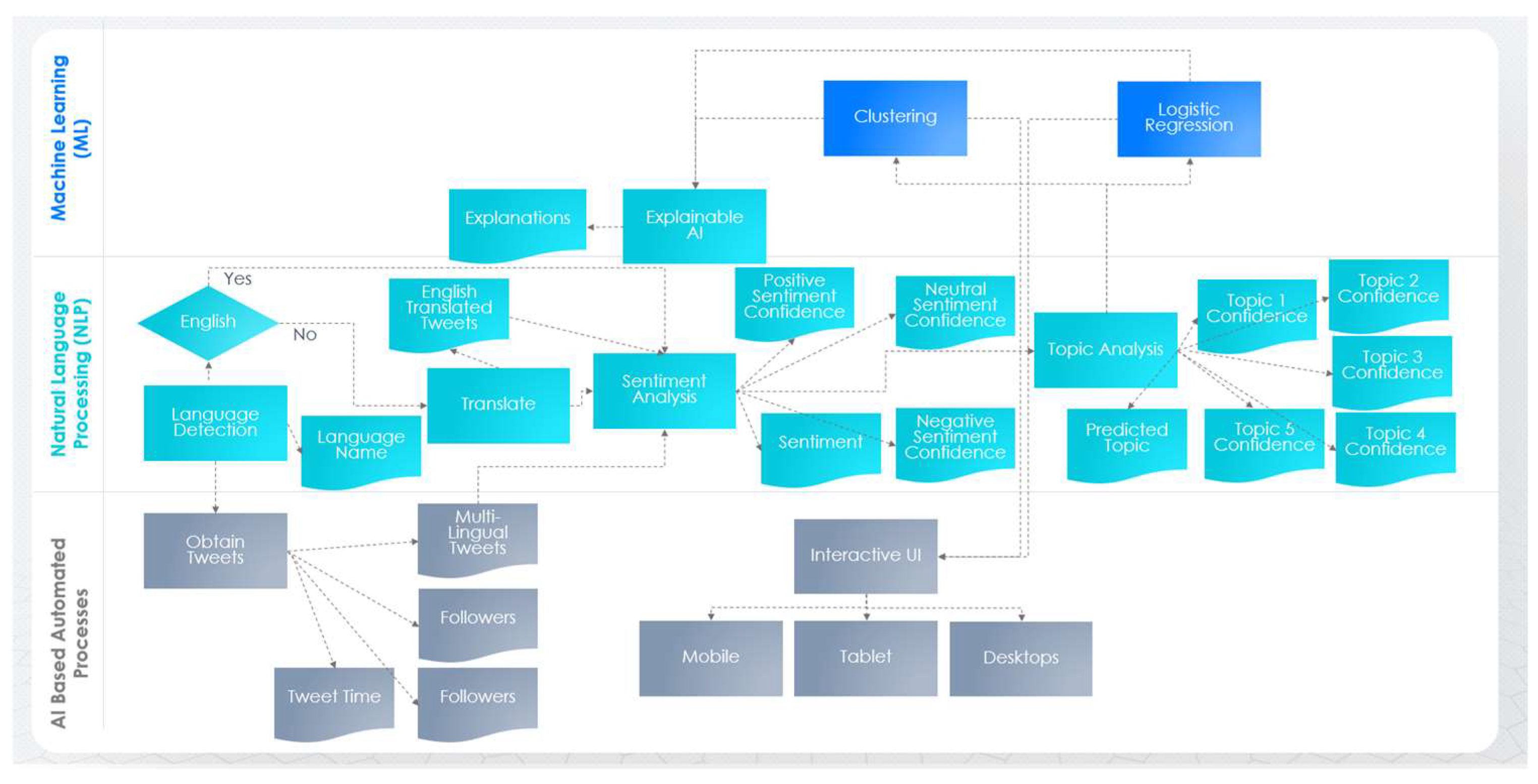
| Attribute Created by | Data Object/Attribute Name | Attribute Used by |
|---|---|---|
| Obtain Tweets | Multi-Lingual Tweets | Sentiment Analysis |
| Obtain Tweets | Tweet Time | Clustering, Logistic Regression, Explainable AI |
| Obtain Tweets | Followers | Clustering, Logistic Regression, Explainable AI |
| Obtain Tweets | Retweets | Clustering, Logistic Regression, Explainable AI |
| Translate | English Translated Tweets | Sentiment Analysis |
| Language Detection | Language Name | Clustering, Logistic Regression, Explainable AI |
| Sentiment Analysis | Sentiment | Clustering, Logistic Regression, Explainable AI |
| Sentiment Analysis | Positive Sentiment Confidence | Clustering, Logistic Regression, Explainable AI |
| Sentiment Analysis | Neutral Sentiment Confidence | Clustering, Logistic Regression, Explainable AI |
| Sentiment Analysis | Negative Sentiment Confidence | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Predicted Topic | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Topic 1 Confidence | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Topic 2 Confidence | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Topic 3 Confidence | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Topic 4 Confidence | Clustering, Logistic Regression, Explainable AI |
| Topic Analysis | Topic 5 Confidence | Clustering, Logistic Regression, Explainable AI |
| Explainable AI | Explanations | Interactive UI |
| Notation | Description |
|---|---|
| T | Extracted tweets as the output of ExtractTweetsContainingKeywords(“COVID”, “CORONA”) |
| m | Date and time of tweet as the output of ExtractTweetsContainingKeywords(“COVID”, “CORONA”) |
| f | Follower count as the output of ExtractTweetsContainingKeywords(“COVID”, “CORONA”) |
| d | Friend count as the output of ExtractTweetsContainingKeywords(“COVID”, “CORONA”) |
| r | Retweet count as the output of ExtractTweetsContainingKeywords(“COVID”, “CORONA”) |
| l | Tweet language as detected using DetectLanguage(Tweet) |
| s | Detected sentiment as the output of SentimentAnalysis(tweet) |
| p | Positive sentiment confidence as the output of SentimentAnalysis(tweet) |
| n | Negative sentiment confidence as the output of SentimentAnalysis(tweet) |
| u | Neutral sentiment confidence as the output of SentimentAnalysis(tweet) |
| Topic | Topic ID as the output of PerformLDATopicAnalysis(T_EN) |
| c1 | Topic 1 confidence as the output of PerformLDATopicAnalysis(T_EN) |
| c2 | Topic 2 confidence as the output of PerformLDATopicAnalysis(T_EN) |
| c3 | Topic 3 confidence as the output of PerformLDATopicAnalysis(T_EN) |
| c4 | Topic 4 confidence as the output of PerformLDATopicAnalysis(T_EN) |
| c5 | Topic 5 confidence as the output of PerformLDATopicAnalysis(T_EN) |
| Topic 1: Broad Discussion on Corona | Topic 2: COVID Statistics and Vaccination | Topic 3: Wordplay on ‘Corona’ | Topic 4: COVID Experiences/Updates | Topic 5: Likely Context of COVID in India | |||||
|---|---|---|---|---|---|---|---|---|---|
| Word | Weight | Word | Weight | Word | Weight | Word | Weight | Word | Weight |
| Corona | 19287 | COVID | 18257 | crown | 4871 | COVID | 9946 | Corona | 2560 |
| corona | 13595 | COVID | 15042 | Corona | 3743 | COVID | 6148 | corona | 2504 |
| people | 5770 | vaccine | 5295 | Crown | 1242 | COVID | 4899 | COVID | 932 |
| vaccination | 3255 | COVID | 4110 | https://t.co | 1161 | get | 3212 | CORONA | 710 |
| also | 3173 | cases | 3552 | Corona_Futbol | 582 | people | 3048 | https://t.co | 609 |
| measures | 2845 | people | 3413 | first | 517 | corona | 2811 | India | 589 |
| would | 2428 | deaths | 3404 | crowned | 495 | days | 2779 | hai | 533 |
| like | 2406 | new | 3379 | City | 490 | like | 2471 | amp | 446 |
| one | 2256 | vaccines | 2953 | today | 456 | got | 2250 | exam | 319 |
| many | 2241 | https://t.co | 2129 | going | 444 | died | 2134 | narendramodi | 290 |
| Top 5 Ranks | All | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Language | Tweets | Language | Tweets | Language | Tweets | Language | Tweets | Language | Tweets | Language | Tweets | |
| 1 | English | 60,855 | German | 25,477 | English | 27,050 | Spanish | 10,811 | English | 18,102 | English | 4717 |
| 2 | German | 30,212 | English | 8129 | Spanish | 3697 | English | 2857 | Spanish | 3863 | Hindi | 1212 |
| 3 | Spanish | 22,226 | Dutch | 5827 | French | 2713 | Japanese | 810 | Portuguese | 1806 | Spanish | 856 |
| 4 | Dutch | 7419 | Spanish | 2999 | German | 2147 | German | 523 | German | 1609 | In | 755 |
| 5 | French | 5748 | French | 1839 | Portuguese | 1613 | Portuguese | 418 | French | 860 | Unidentified | 647 |
| Prediction Topic | Count of TwitterID | Average Confidence-Negative Sentiment | Average Confidence-Neutral Sentiment | Average Confidence-Positive Sentiment | Average Follower Count | Average Friend Count | Average Retweet Count | Count of Tweet Language |
|---|---|---|---|---|---|---|---|---|
| Topic 1 | 50420 | 0.559371 | 0.293209 | 0.147265 | 5646.66 | 1154.27 | 350.71 | 51 |
| Topic 2 | 43060 | 0.539859 | 0.369295 | 0.090684 | 20447.33 | 1653.85 | 961.3 | 54 |
| Topic 3 | 17618 | 0.275259 | 0.485657 | 0.238882 | 17776.81 | 1265.74 | 314.4 | 43 |
| Topic 4 | 30470 | 0.54395 | 0.252615 | 0.203355 | 3606.61 | 1346.51 | 1323.62 | 49 |
| Topic 5 | 10502 | 0.318199 | 0.521049 | 0.160704 | 21259.78 | 1045.63 | 438.74 | 52 |
| Cluster Characteristics | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 |
|---|---|---|---|---|
| Avg. Topic 1 Confidence | 0.77 | 0.76 | 0.72 | 0.41 |
| Population Count | 7426 | 10,678 | 12,108 | 20,351 |
| Avg. Topic 2 Confidence | 0.59 | 0.48 | 0.47 | 0.38 |
| Population Count | 8760 | 11,574 | 12,573 | 10,995 |
| Avg. Topic 3 Confidence | 0.49 | 0.29 | - | - |
| Population Count | 13,033 | 9193 | - | - |
| Avg. Topic 4 Confidence | 0.42 | 0.32 | 0.32 | 0.28 |
| Population Count | 8279 | 10,395 | 10,443 | 13,471 |
| Avg. Topic 5 Confidence | 0.16 | - | - | - |
| Population Count | 10,077 | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sufi, F. A New Social Media Analytics Method for Identifying Factors Contributing to COVID-19 Discussion Topics. Information 2023, 14, 545. https://doi.org/10.3390/info14100545
Sufi F. A New Social Media Analytics Method for Identifying Factors Contributing to COVID-19 Discussion Topics. Information. 2023; 14(10):545. https://doi.org/10.3390/info14100545
Chicago/Turabian StyleSufi, Fahim. 2023. "A New Social Media Analytics Method for Identifying Factors Contributing to COVID-19 Discussion Topics" Information 14, no. 10: 545. https://doi.org/10.3390/info14100545
APA StyleSufi, F. (2023). A New Social Media Analytics Method for Identifying Factors Contributing to COVID-19 Discussion Topics. Information, 14(10), 545. https://doi.org/10.3390/info14100545