
An Effective Method for Detection and Recognition of Uyghur Texts in Images with Backgrounds


Abstract
:1. Introduction
- The Uyghur text is composed of a main part and an additional part at the image level. The characters in the main part always stick to each other, which belongs to a connected domain. The additional part is secondary but should not be ignored, which has one to three dots or other special structures.
- Words are the basic units of Uyghur text, and the length of each word is different.
- There are no uppercase or lowercase letters, but each letter has a different form, and use different forms in different locations.
- There is a “baseline” for every sentence in the middle of the text. Usually, each word on the baseline has the same height and the distance between them is similar.
- In view of the Uygur text characteristic, a new effective Uyghur text detection method based on channel enhanced MSERs and CNN is proposed.
- We improved the traditional CRNN network, and then carried on the text sequence recognition with the improved CRNN model to the Uygur texts in images with a simple background.
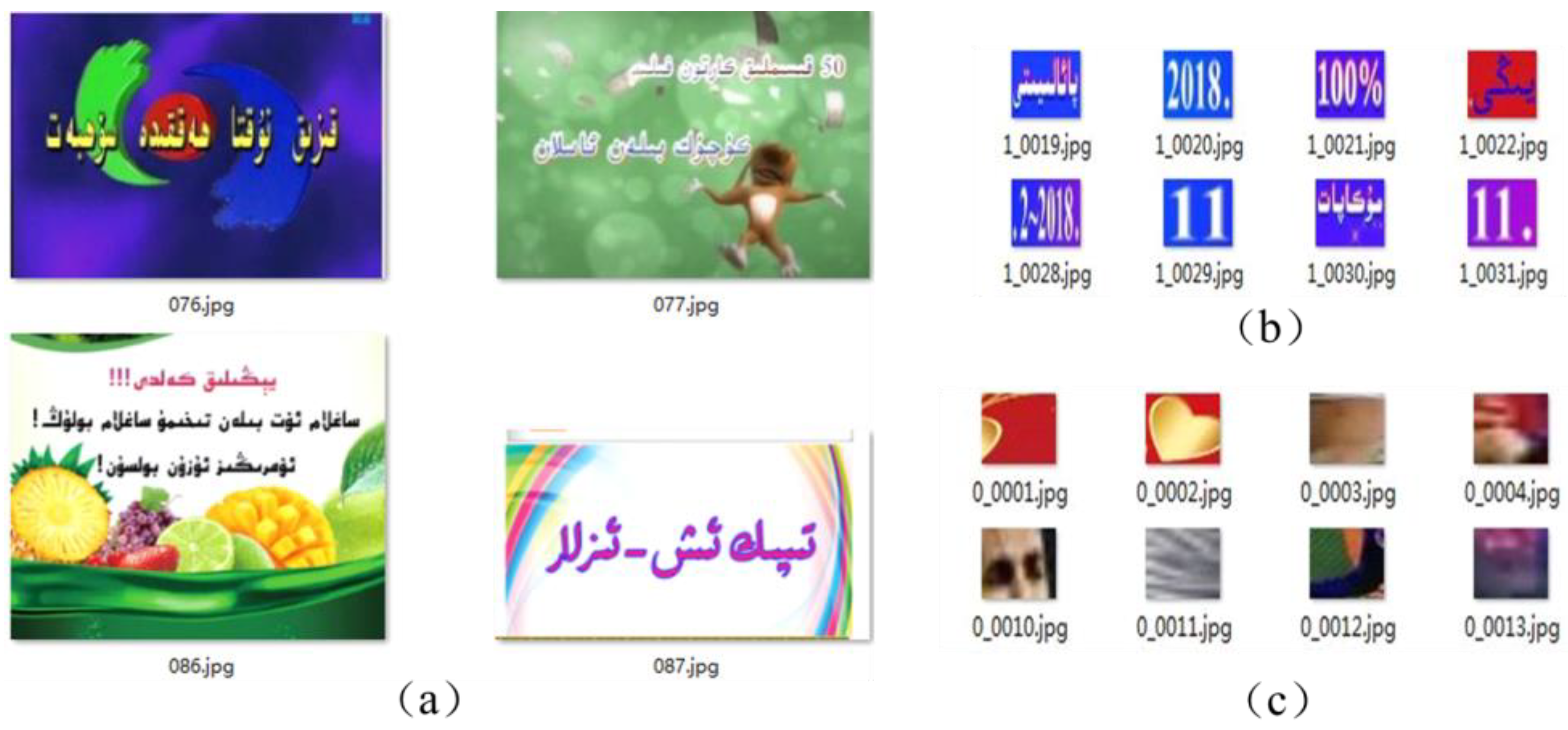
- In order to satisfy the image sample data needs for the text detection duty, the text detection data set was established. In order to meet the training and testing requirements of the improved CRNN network, a random text in the natural scene image production tool [9] was developed independently, and the text recognition dataset was established.
2. Related Work
3. Methods
3.1. Text Detection Method Based on Channel-Enhanced MSERs
- (1)
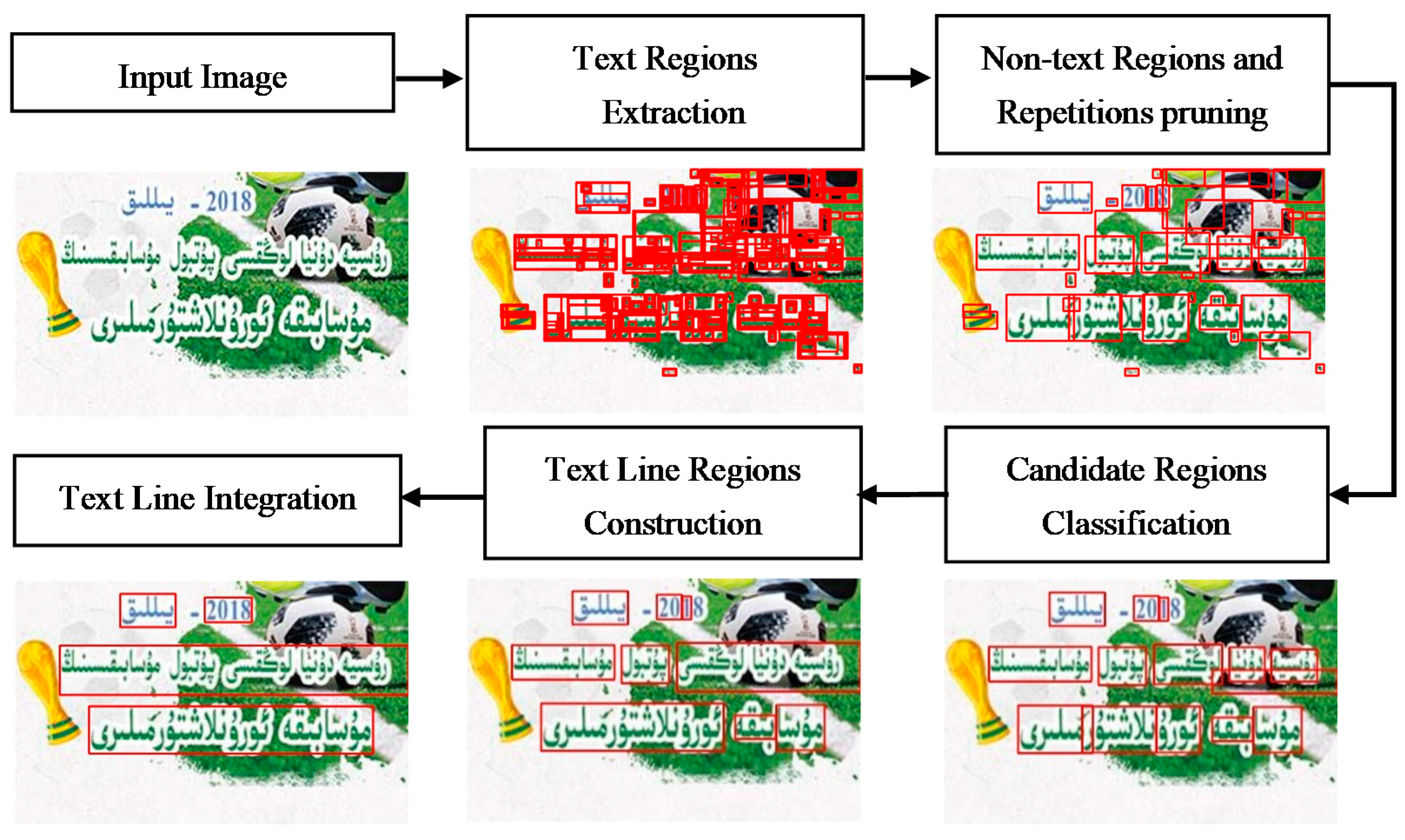
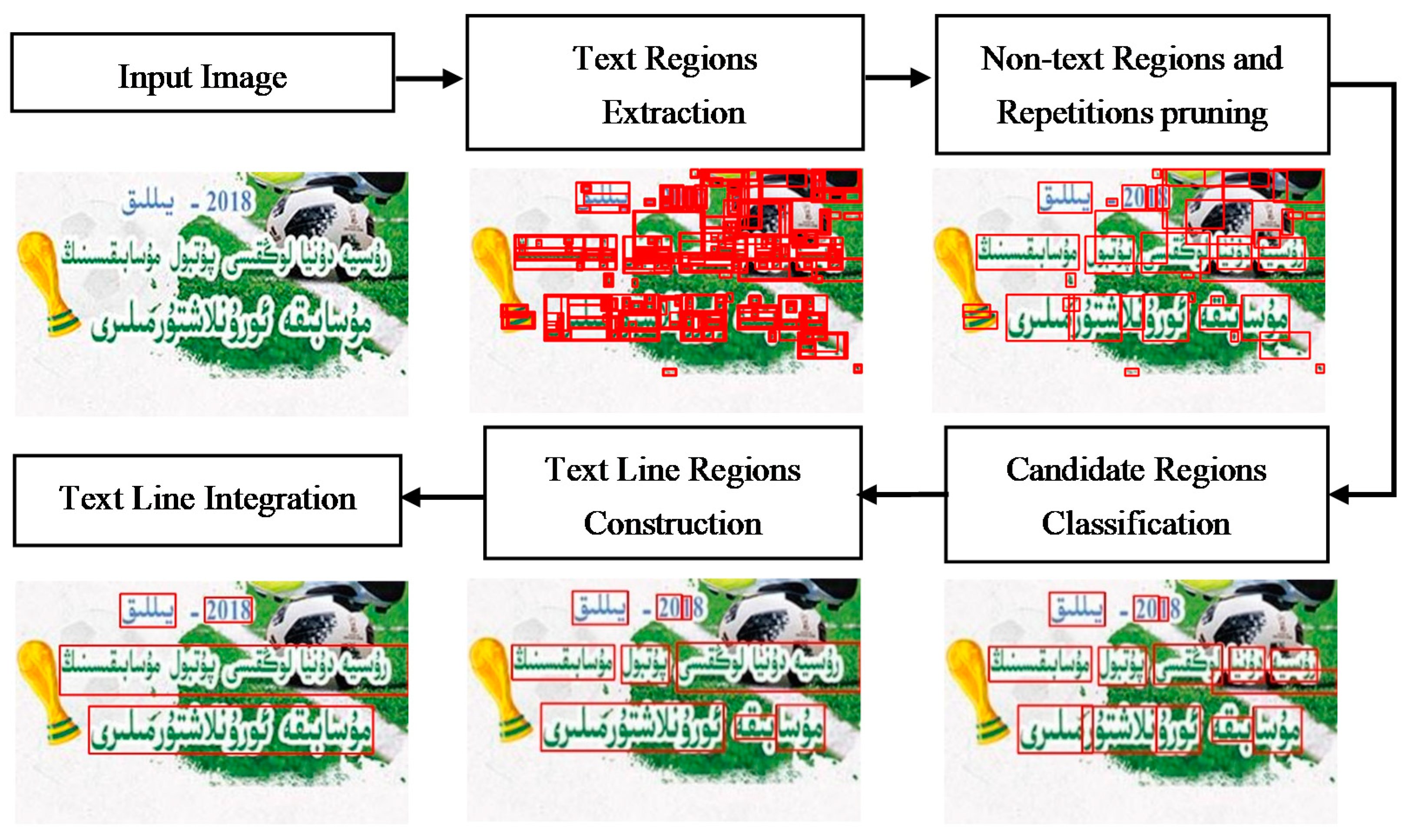
- Text Regions Extraction: at this stage, a new text candidate region extraction algorithm is put forward, which is based on the channel-enhanced MSERs according to the characteristics of text. Firstly, dynamically adjust the size of the input image, because it will cost more time if the input image is too large size and small text candidate regions missed if the input image is too small size. Then, the image is separated by channels and the B, G and R single-channel image is dilated respectively. In this way, the additional parts of the text in images are added to the main parts as much as possible to form a connected area. The MSERs [5] algorithm is executed in B, G and R single-channel respectively, then all candidate regions are marked up in the input image. We can see that almost all text candidate regions can be extracted using above method. But there are more overlapping regions and obvious non-text regions, so we have to remove them quickly.
- (2)
- Non-text Regions and Repetitions pruning: there are many regions returned in the Text Regions Extraction stage and most of them are overlapping regions and obvious non-text regions, which should be pruned. The obvious overlapping regions and non-text regions are pruned by setting some simple heuristic rules. Firstly, completely overlapping regions are pruned according to the position coordinates, and then the areas that are too large or small are pruned by calculating the area of the regions. If there are two not completely overlapping regions, if the intersection area is over 80 percent of the larger region, the smaller is pruned. In this way, most overlapping regions and obvious non-text regions are pruned.
- (3)
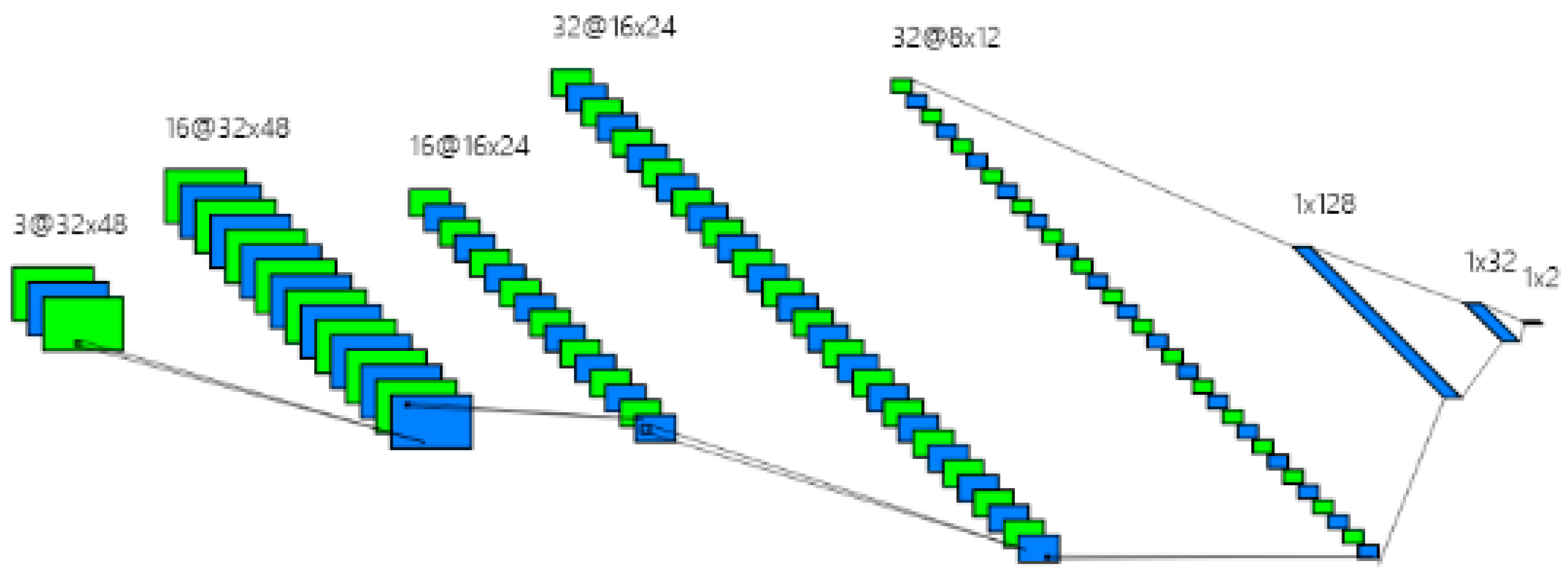
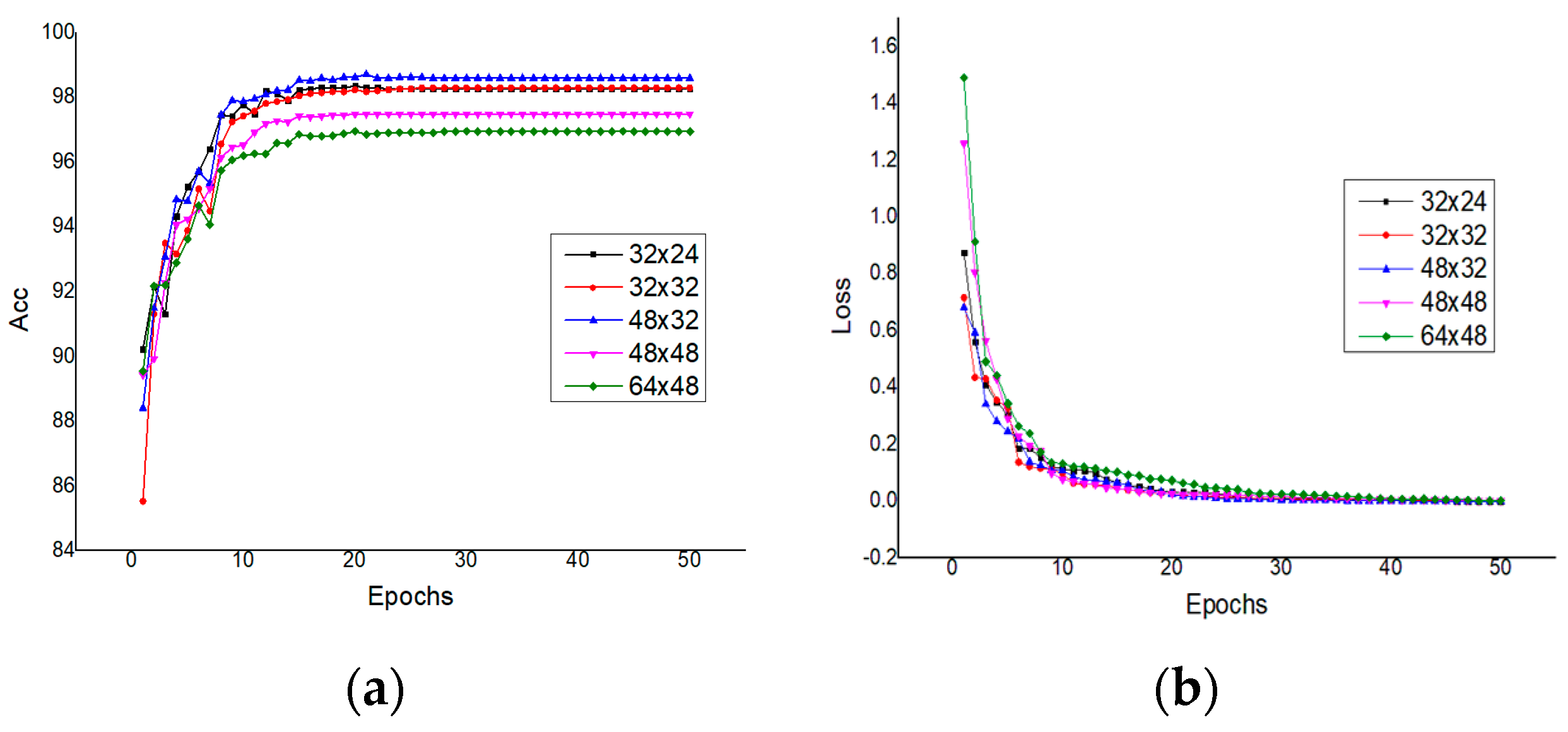
- Candidate Regions Classification: most of overlapping regions and obvious non-text regions are pruned by simple heuristic rules, but it is still necessary to determine the candidate regions are belong to text or not. In order to quickly and effectively remove the non-text regions which are hard to be pruned by heuristic rules, a simple CNN classification network is designed in reference to AlexNet [19]. The CNN classification model is trained with the crop image of the candidate regions. In terms of the characteristics of words and the phenomenon of many experimental comparisons, the crop image samples are all resized to () pixels (the results with different size will be discussed in the experiments). The most of the text regions are determined by the Candidate Regions Classification, and the non-text regions are removed from the candidate regions.
- (4)
- Text Line Regions Construction: after Candidate Regions Classification, only the text regions and a small number of non-text regions are left. We can see that some of the words are marked by multiple candidate areas, so that each candidate region is a part of the whole word and is unable to mark the complete vocabulary. For text detection, the candidate regions are connected into the word-level text candidate regions, which are built by the merge candidate regions algorithm. Firstly, the regions are connected together, which have intersection, and this process is taken from the left of the image to the right and from top to bottom. Then, if the spatial distance between the center positions of the two candidate regions is smaller than the distance between words, the regions are connected. A new rectangle is computed to contain the two regions when connecting two candidate regions.
- (5)
- Text Line Integration: one or more word-level text candidate regions appear on one horizontal line after Text Line Regions Construction, and a few text regions are omitted by the above stages, because the channel-enhanced MSERs algorithm is unable to detect all text regions, some of text regions are removed by the heuristic rules as non-text regions; the simple CNN classification model misclassifies the candidate regions and so on. In this stage, every word-level text candidate region sequentially searches forward and backward according to the color similarity and spatial relationship of the word-level text candidate regions. In this way, many regions are recalled as text regions, then they use the above CNN classification model to classify the recalling regions, and aggregate the omitted text regions into the word-level text candidate regions. Finally, connect the all regions together, and the text line is the final text detection result.
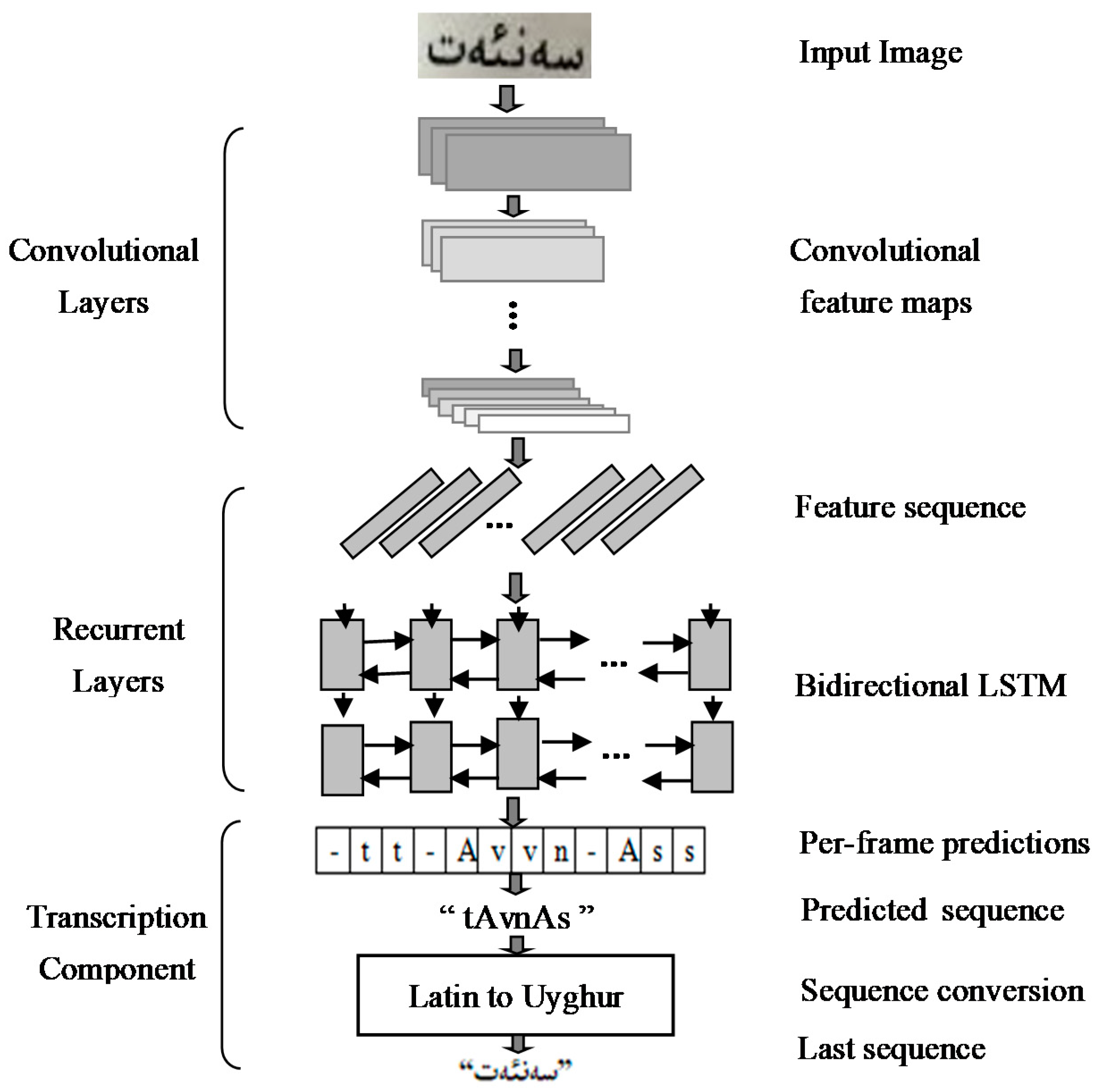
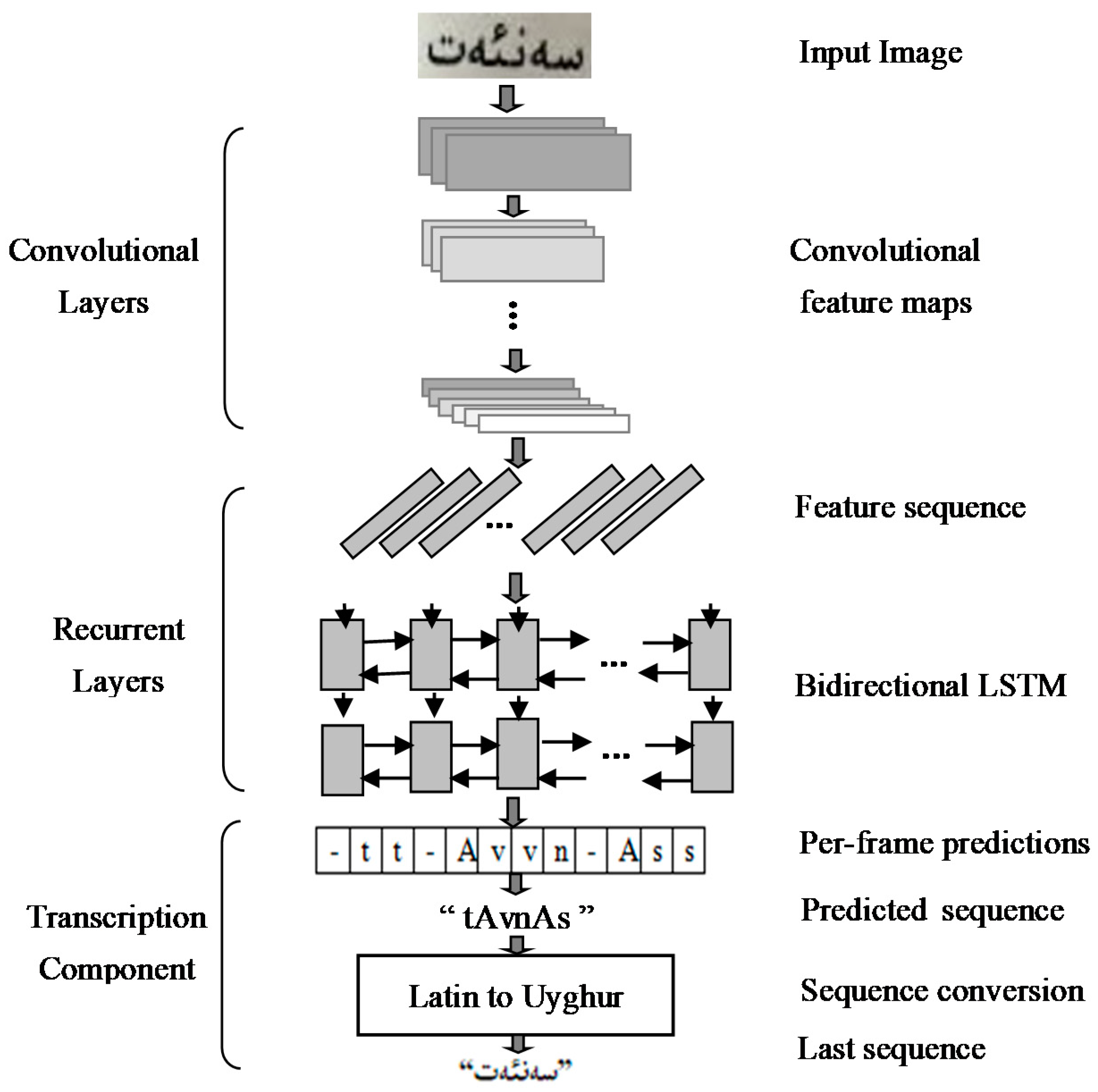
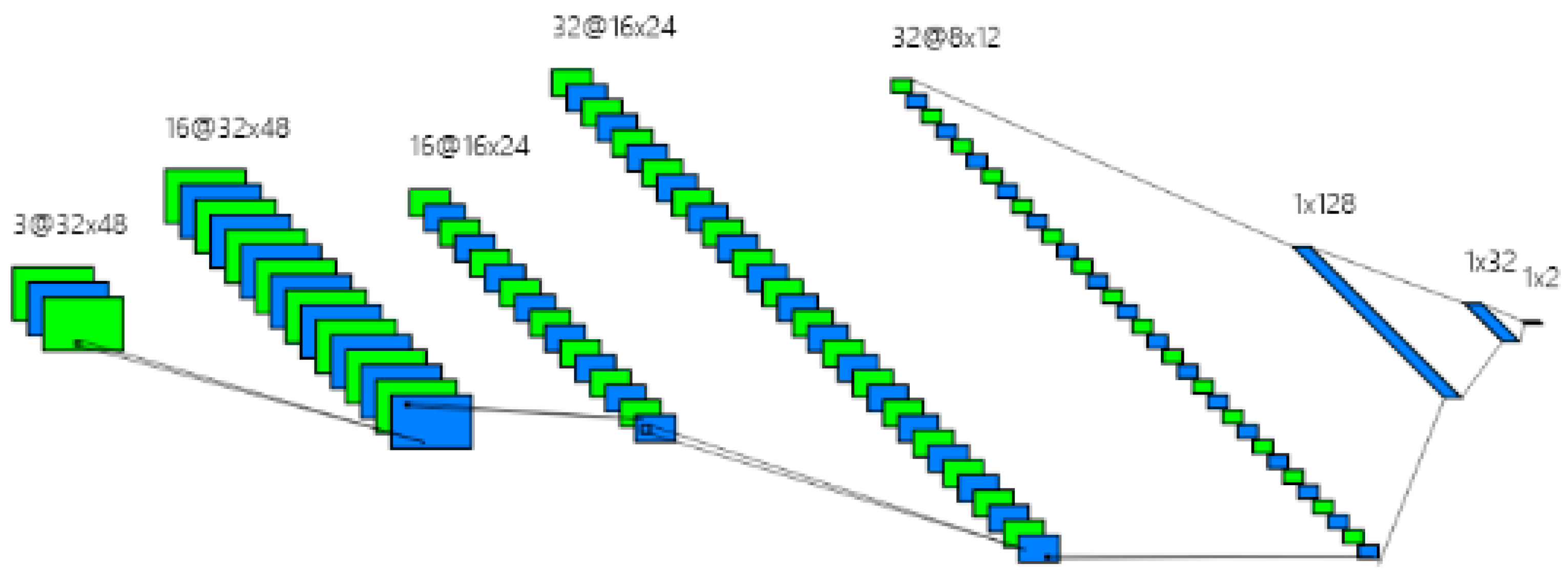
3.2. Uyghur Text Recognition Method Based on the Improved CRNN Network
4. Experiment
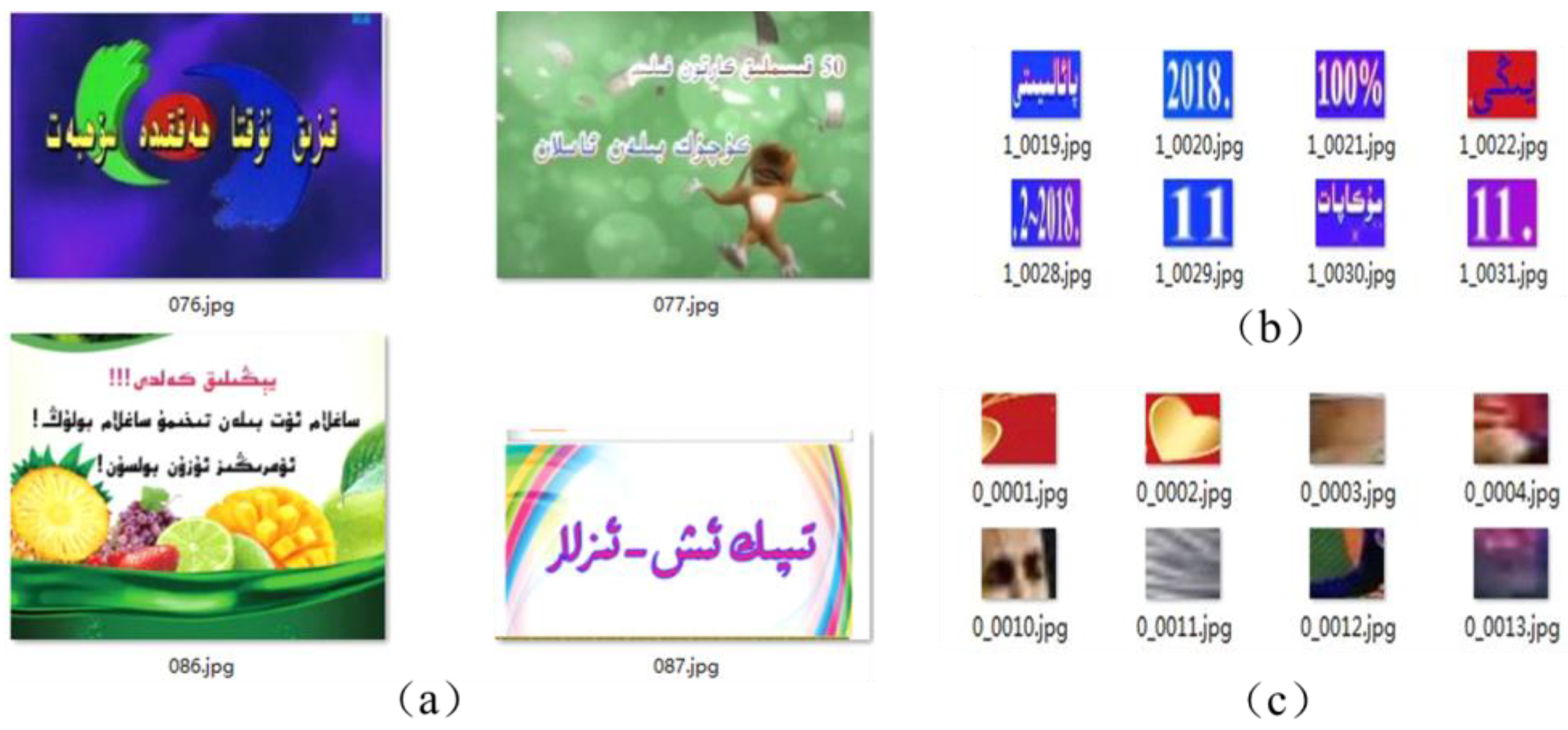
4.1. Datasets
4.2. Performance Evaluation Criteria
4.3. Experiments on Uyghur Text Detection
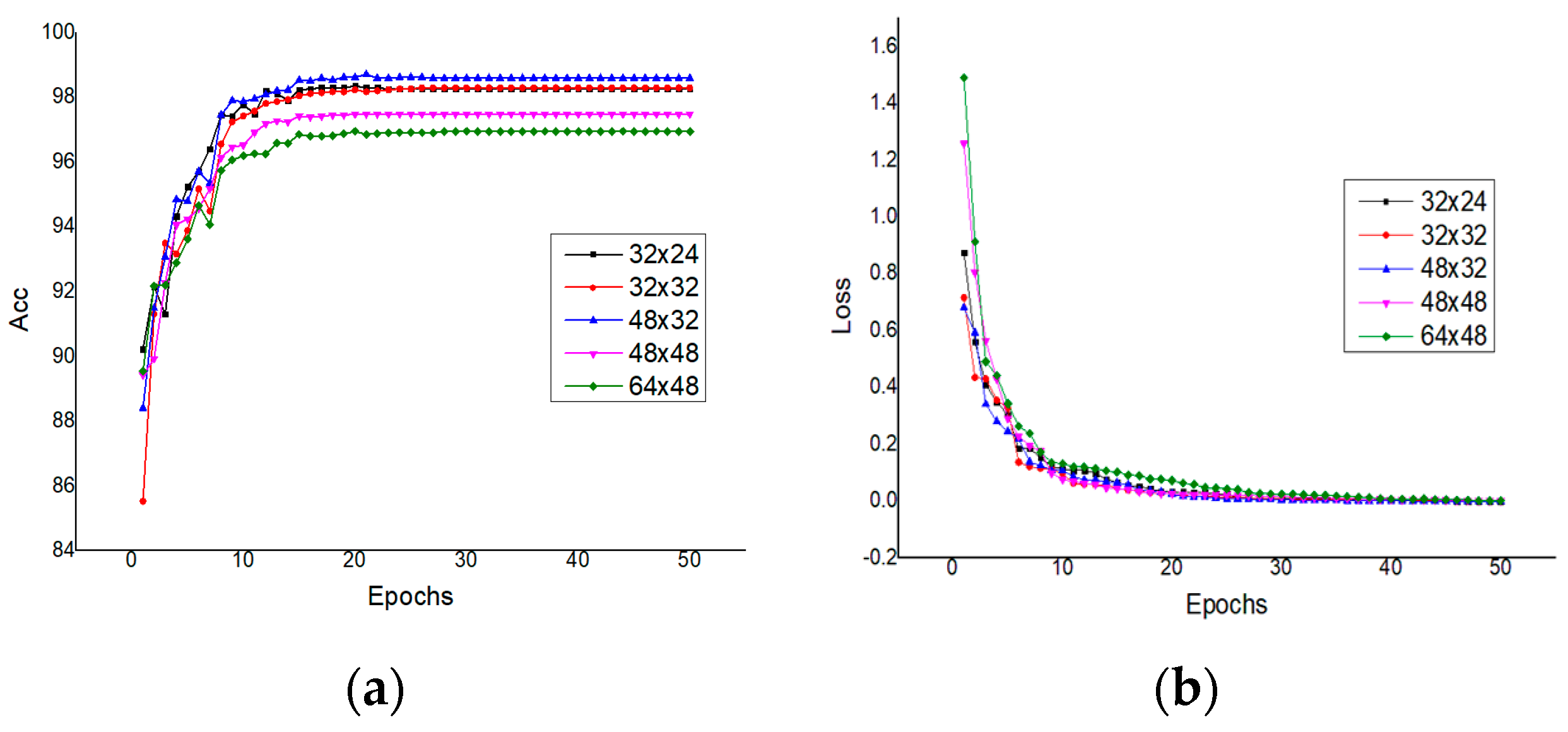
4.3.1. Implementation Details
4.3.2. Comparisons with Existing Methods
4.4. Experiments on Uyghur Text Recognition
4.4.1. Implementation Details
4.4.2. Comparisons with Original Method
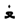 ” and “
” and “ 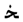 ” are similar, the original CRNN recognizes “
” are similar, the original CRNN recognizes “  ” as “
” as “ 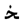 ”, but the improved CRNN recognize it correctly. The improved CRNN use a wider receptive field which is closer to the width of Uyghur characters, so it is more suitable for Uyghur text recognition, but false and repeated predictions still occur in the output text. For example, the receptive field of the feature extracted by CNN divides the character “
”, but the improved CRNN recognize it correctly. The improved CRNN use a wider receptive field which is closer to the width of Uyghur characters, so it is more suitable for Uyghur text recognition, but false and repeated predictions still occur in the output text. For example, the receptive field of the feature extracted by CNN divides the character “ 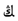 ” into “
” into “ 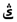 ” and “
” and “ 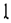 ”, and the two parts are recognized as “
”, and the two parts are recognized as “ 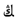 “ and “
“ and “  ”, in this case, the two networks recognize the additional chapter “
”, in this case, the two networks recognize the additional chapter “ 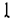 ”.
”.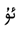 ” as “
” as “  “, but the original CRNN recognize it correctly. The improvement of CRNN network also has the problem of false and repeated predictions, but the recognition result is closer to the correct text sequence, and the editing distance and running time of testing are less than the original CRNN network. In general, the performance of the improved CRNN network in this paper is better than the original CRNN in the arbitrary length text in the natural scene image dataset, but its accuracy needs to be further improved.
“, but the original CRNN recognize it correctly. The improvement of CRNN network also has the problem of false and repeated predictions, but the recognition result is closer to the correct text sequence, and the editing distance and running time of testing are less than the original CRNN network. In general, the performance of the improved CRNN network in this paper is better than the original CRNN in the arbitrary length text in the natural scene image dataset, but its accuracy needs to be further improved.5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. arXiv 2018, arXiv:1811.04256. [Google Scholar] [CrossRef]
- Ye, Q.; Doermann, D. Text Detection and Recognition in Imagery: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text Recognition in the Wild: A Survey. ACM Comput. Surv. CSUR 2020, 54, 1–35. [Google Scholar] [CrossRef]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Song, Y.; Chen, J.; Xie, H.; Chen, Z.; Gao, X.; Chen, X. Robust and parallel Uyghur text localization in complex background images. Mach. Vis. Appl. 2017, 28, 755–769. [Google Scholar] [CrossRef]
- Bissacco, A.; Cummins, M.; Netzer, Y.; Neven, H. Photoocr: Reading text in uncontrolled conditions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Bai, J.; Chen, Z.; Feng, B.; Xu, B. Chinese Image Text Recognition on grayscale pixels. In Proceedings of the 2014 IEEE Inter-national Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1380–1384. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Deep features for text spotting. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 512–528. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Mou, Y.; Tan, L.; Yang, H.; Chen, J.; Liu, L.; Yan, R.; Huang, Y. PlugNet: Degradation Aware Scene Text Recognition Super-vised by a Pluggable Super-Resolution Unit. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Liu, X.; Liang, D.; Zhibo, Y.; Lu, T.; Shen, C. PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Xue, C.; Lu, S.; Bai, S.; Zhang, W.; Wang, C. I2C2W: Image-to-Character-to-Word Transformers for Accurate Scene Text Recognition. arXiv 2021, arXiv:2105.08383. [Google Scholar]
- Huang, M.; Liu, Y.; Peng, Z.; Liu, C.; Lin, D.; Zhu, S.; Yuan, N.; Ding, K.; Jin, L. SwinTextSpotter: Scene Text Spotting via Better Synergy between Text Detection and Text Recognition. arXiv 2022, arXiv:2203.10209. [Google Scholar]
- Fang, S.; Xie, H.; Chen, Z.; Zhu, S.; Gu, X.; Gao, X. Detecting Uyghur text in complex background images with convolutional neural network. Multimed. Tools Appl. 2017, 76, 15083–15103. [Google Scholar] [CrossRef]
- Alsharif, O.; Pineau, J. End-to-End Text Recognition with Hybrid HMM Maxout Models. arXiv 2013, arXiv:1310.1811. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Bai, J.; Chen, Z.; Feng, B.; Xu, B. Image character recognition using deep convolutional neural network learned from different languages. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 2560–2564. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Testing Set | Total | |
|---|---|---|---|---|
| Images | 823,680 | 102,960 | 102,960 | 1,029,600 |
| words | 68,640 | 8580 | 8580 | 85,800 |
| Methods | P | R | F |
|---|---|---|---|
| Our method | 0.881 | 0.872 | 0.876 |
| Channel-enhanced MSERs + CNN | 0.846 | 0.835 | 0.840 |
| Traditional MSER + CNN | 0.812 | 0.804 | 0.808 |
| Networks | Accuracy | AED |
|---|---|---|
| The Original CRNN | 0.782 | 0.458 |
| The Improved CRNN | 0.864 | 0.204 |
| Input Images | Networks | Results in Latin | Results in Uyghur | ED | Time |
|---|---|---|---|---|---|
 | The Original CRNN | vistatistikiliq | ئىستاتىستىكىلىق | 0 | 0.057 |
| The Improved CRNN | vistatistikiliq | ئىستاتىستىكىلىق | 0 | 0.039 | |
 | The Original CRNN | sUttcilikk | سۈتتچىلىكك | 2 | 0.062 |
| The Improved CRNN | sUtcilik | سۈتچىلىك | 0 | 0.047 | |
 | The Original CRNN | muNdixidiHinimizGa | مۇڭدىشىدىخىنىمىزغا | 1 | 0.094 |
| The Improved CRNN | muNdixidiGinimizGa | مۇڭدىشىدىغىنىمىزغا | 0 | 0.062 | |
 | The Original CRNN | cpeniqturuxinilN | چپېنىقتۇرۇشىنىلڭ | 3 | 0.062 |
| The Improved CRNN | ceniqturuxnilN | چېنىقتۇرۇشنىلڭ | 1 | 0.047 |
| Networks | Accuracy | AED |
|---|---|---|
| The Original CRNN | 0.728 | 0.716 |
| The Improved CRNN | 0.780 | 0.492 |
| Input Images | Networks | Results in Latin | Results in Uyghur | ED | Time |
|---|---|---|---|---|---|
 | The Original CRNN | kAtkAndin | كەتكەندىن | 0 | 0.0468 |
| The Improved CRNN | kAtkAndin | كەتكەندىن | 0 | 0.0311 | |
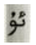 | The Original CRNN | vu | ئۇ | 0 | 0.0156 |
| The Improved CRNN | u | ۇ | 1 | 0.0156 | |
 | The Original CRNN | sistemissida | سىستېمىسسىدا | 1 | 0.0468 |
| The Improved CRNN | sistemisida | سىستېمىسىدا | 0 | 0.0312 | |
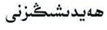 | The Original CRNN | Aydixiizni | ەيدىشىىزنى | 2 | 0.0468 |
| The Improved CRNN | hAydixiNizn | ھەيدىشىڭىزن | 1 | 0.0312 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrayim, M.; Mattohti, A.; Hamdulla, A. An Effective Method for Detection and Recognition of Uyghur Texts in Images with Backgrounds. Information 2022, 13, 332. https://doi.org/10.3390/info13070332
Ibrayim M, Mattohti A, Hamdulla A. An Effective Method for Detection and Recognition of Uyghur Texts in Images with Backgrounds. Information. 2022; 13(7):332. https://doi.org/10.3390/info13070332
Chicago/Turabian StyleIbrayim, Mayire, Ahmatjan Mattohti, and Askar Hamdulla. 2022. "An Effective Method for Detection and Recognition of Uyghur Texts in Images with Backgrounds" Information 13, no. 7: 332. https://doi.org/10.3390/info13070332
APA StyleIbrayim, M., Mattohti, A., & Hamdulla, A. (2022). An Effective Method for Detection and Recognition of Uyghur Texts in Images with Backgrounds. Information, 13(7), 332. https://doi.org/10.3390/info13070332