2. Related Research Work
Until now, academic research on movie box office prediction has mainly focused on the research of the movie box office prediction model and the influencing factors of the movie box office. In the early stages of the research on the movie box office prediction model, researchers mostly used the linear regression algorithm. Later, with the development of artificial intelligence, researchers gradually used various machine learning algorithms and neural networks to predict the movie box office. The research on the factors affecting the box office can be divided into two categories: static factors and dynamic factors. Static factors are the factors that have been determined before the film is released, such as the film name, director, actors, sequel, duration, production company, distribution company, schedule, film type, film language, film region, etc. Dynamic factors, such as a Weibo review, film review, the Baidu search index, film reputation, etc., are the factors that will affect the box office when the film is about to be released and has been released.
In terms of box office prediction model research, Wang Jinhui and Yan Siyu [
3] established a box office prediction model based on the Litman model [
4] and the Byeng-Hee Chang model [
5] by using multiple linear regression analysis. Wenbin Zhang and Steven Skiena [
6] used the Lydia news analysis system to predict the movie box office. After their analysis, it was found that the model using only news data achieved a similar performance to the model using IMDB data, and better performance could be achieved by combining them; a regression model is more suitable for low box office movies, while the KNN model is more suitable for high box office movies. Han Zhongming et al. [
7] proposed a GBRT model under the same data conditions, and the prediction effect was better than those of the random forest, decision tree, and nonlinear regression models. Li Jian Ping and Wang Shimin [
8] analyzed the influencing factors of the Chinese box office through grey correlation degree analysis, selected important factors, and made their prediction using a BP neural network, and this achieved a good prediction effect. Zheng Jian and Zhou Shangbo [
9] proposed a film box office prediction model based on a feedback neural network, which had a good effect in predicting box office classification. Ru Yunian et al. [
10] established a pre-screening box office prediction model based on deep learning, including a cross network and a dense network, which was superior to SVM and the random forest algorithm in the case of the same feature.
For the study of static factors, a relatively complete quantitative system of influencing factors has been formed at present. For example, Wang Zheng and Xu Min [
11] take the traditional OLS method and set the different critical values of the film; using the logit regression model, and considering the production quality, the types of films, and a variety of factors such as national income level, their research showed that the stars, director, score, prices, sequel, and schedule will have a positive impact on the box office. Based on the capital theory of sociologist Bourdieu, Zhao Xinxing and Gao Fuan [
12] made a comparative analysis of three regression results for the total box office, first week box office, and follow-up box office. The study showed that the director, leading actor, whether it was a sequel, and the IP adaptation with variables of economic capital and cultural capital played a positive role, while real events played a negative role. Among the variables of social capital, word-of-mouth and policy factors play a significant role in promoting the box office of theme films. Based on a two-dimensional analysis of static and dynamic perspective, Chen Haoshu [
13] divided the influencing factors into film release return, film release risk control, and film investment decision, and applied a structural equation and system dynamics model, respectively, to empirically analyze the impact of influencing factors on the world film box office in the short and long term. The analysis results showed that the film investment decision has the greatest impact on the world film box office. Awards and distribution companies have a significant positive correlation with the world film box office, while piracy has a significant negative correlation. In the long term, the impact of distribution risk control is relatively volatile. Bae and Kim [
14] studied the impact of movie titles on box office success, and the research results showed that informative movie titles had a positive impact on the box office income of films with insufficient publicity, but with the increase in promotional activities before release, such an impact would decrease. The dynamic factors affecting the box office mainly include the number of movie reviews, what the movie reviews say, the movie score, Weibo comments, Baidu search index, and so on.
With the development of the Internet, Weibo and Douban have gradually developed and become new platforms for people to discuss and spread movie information. More and more people pay attention to public opinion information on the Internet, which makes the impact of online word-of-mouth information on the box office more and more important. Many Chinese scholars have studied the impact of Douban reviews and Weibo reviews on the box office. For example, Hua Rui et al. [
15] used the C–D production function to measure the impact of various influencing factors on the box office. The study shows that word-of-mouth information will significantly promote box office growth, but with the box office growth, the positive impact of word-of-mouth information will also decline, and the promotional effect of modern propaganda methods on the box office is greater than that of traditional propaganda methods. Pei and Jiang Yinyan [
16] established a mathematical model of box office appeal using a questionnaire survey. Empirical results show that data related to film brands, such as word-of-mouth score have a greater impact on the box office, while the story adaptation, 3D technology, production company, and media publicity have less impact on the box office. Jiang Zhaojun et al. [
17] studied the relationship between online word-of-mouth information and the box office of animated films. Through the establishment of a multiple regression model, the test shows that the number of online word-of-mouth users, that is, the number of Douban-rated users, has obvious positive effects on the box office of animated films, and after the first week of release, it has a greater positive effect on the follow-up box office of animated films. Online word-of-mouth potency can only improve the box office of imported animated films, and the positive effect on the subsequent box office of imported animated films is stronger after the first week of release. Du et al. [
18] used microblog data to predict the box office, which is based on two sets of features: counting-based features and content-based features. For the former, they describe the characteristics from the user’s point of view, pay attention to the different values of different Weibo reviews, and eliminate the impact of junk users. Based on the features of content, they put forward a new semantic classification method for the box office, which makes features more relevant to the box office.
Basuroy et al. [
19] investigated how movie reviews affect box office performance, and how stars and budgets adjust this impact. The research shows that in the first week of the film release, the impact of bad reviews on the box office is greater than that of good reviews, and the impact of bad reviews on films will weaken with the passage of time. Popular stars and high budgets will boost the box office of films with bad reviews more than good reviews, but the effect on films with good reviews more than bad reviews is minimal, which provides insights for film companies on how to strategically manage film reviews to improve the box office. Gaenssle et al. [
20] conducted a study on the influencing factors of the box office success of Russian international films in 2012–2016, which provides a supplement to the research of the Russian film market. The box office success factors are divided into distribution-related factors, brand and star effects, and evaluation sources. Gaenssle et al. added regional variables, such as seasonality, the time span between the world and Russia, the attendance of international stars at the premiere of Russian films, and the adaptation of titles in line with Russian culture. The study found that the reviews of international film critics and the adaptation of film titles were most important. Lee and Choeh [
21] studied the impact of comment validity on the box office, and analyzed and verified the impact of comment quantity, comment grade, comment length, and comment usefulness on the Korean box office. Hyunmi Baek [
22] studied the impact of the word-of-mouth information of different types of social media on the box office at different stages of film release. In the early stages, Twitter has a greater impact on the box office revenue, while Yahoo has a greater impact on the box office in the later stages. The impact of blogs and YouTube varies little between the early and later stages. Lei Sun et al. [
23] investigated the impact of movie consumers’ willingness on movie marketing and the box office, and the willingness was measured by the number of people who wanted to see a film. This impact is tested by the step-by-step method and generalized least square method based on random effects, and it is found that consumer willingness and box office revenue have an inverted U-shaped distribution with event marketing intensity. From the second week before the release to the first week after the release, marketing activities have a significant positive impact on the box office. Ram Sharda and Dursun Delen [
24] transformed the box office prediction problem into a classification problem, not predicting the point estimate of box office revenue, but classifying according to the box office revenue of a film. According to the characteristics of the film’s score, competition, star, film type, technical effect, whether it is a sequel or not, and the number of screens, the neural network is used for modeling, and good results are achieved. Biramane et al. [
25] collected the data of movie features and social interaction from various social platforms (such as IMDb, YouTube, and Wikipedia), and established a prediction model by establishing the relationship between classic features, social media features, and movie box office success. The results showed that the prediction model established by combining classic and social factors has high accuracy.
At present, the research foundation of the influencing factors of film consumption and the box office prediction model is solid, and the evaluation framework of influencing factors, including the chief producer team, film characteristics, and word-of-mouth reviews, has been formed. Research methods are gradually extended to machine learning, neural networks, data-driven approaches in the context of big data, etc. In this paper, based on fully considering the complex and comprehensive influencing factors in the digital era, market information, gross national product, and other information will be introduced, and a multi-model ensemble method will be adopted for modeling in the research method to improve the effectiveness of the evaluation model.
3. Establishment of Prediction Model
3.1. Data Collection
The data used for modeling in this paper come from ENDATA, the Easy Professional Superior (EPS) data platform, the Chinese National Health and Health Commission, and the Baidu Index.
Movie information was downloaded and crawled from the movie box office information on the website of ENDATA, including the title of the movie, the number of people who want to watch the movie on MaoYan, the number of people who want to watch the movie on Taobao Film, the number of people who want to watch the movie on Douban, the movie’s score on MaoYan, the movie’s score on Taobao Film, the movie’s score on Douban, duration, actors, screenwriters, synopsis, release date, the annual number of movie screenings, the total number of movie screenings, the annual audience (10,000), the total audience (10,000), box office in the first week (10,000), the average ticket price, the number in the audience for an average screening, main genre, complete genre, director, production company, distribution company, movie format, country, investment scale, integrated marketing company, new media marketing company, producer, executive producer, publisher, movie attribute, service fee (10,000), and total box office (10,000).
Chinese micro-data on the EPS data platform was downloaded, including the consumption level of all residents (yuan), the consumption level of rural residents (yuan), the consumption level of urban residents (yuan), the consumption level index of all residents (1978 = 100), the consumption level of rural residents (1978 = 100), Gross Domestic Product (GDP) (100 million yuan), the proportion of the tertiary industry (GDP = 100), per capita disposable income of residents (yuan), cinema lines, screens in cinema lines (block), number of Internet users (10,000), Internet broadband access ports (10,000), Internet international export bandwidth (Mbps), proportion of administrative villages with Internet broadband services (%), Internet penetration rate (%), Internet broadband access users (10,000).
Since 1 January 2020, the National Health Commission (NHC) has started to report on the pneumonia cases of the novel coronavirus infection in China. In order to study whether the epidemic has had an impact on the box office, we searched the daily epidemic news on the NHC website since the outbreak. Currently, search engines have become an important way for consumers to know about movies. We used the Baidu search index every day from 30 days before the release to 30 days after the release according to the movie name for box office prediction.
3.2. Data Feature Processing and Analysis
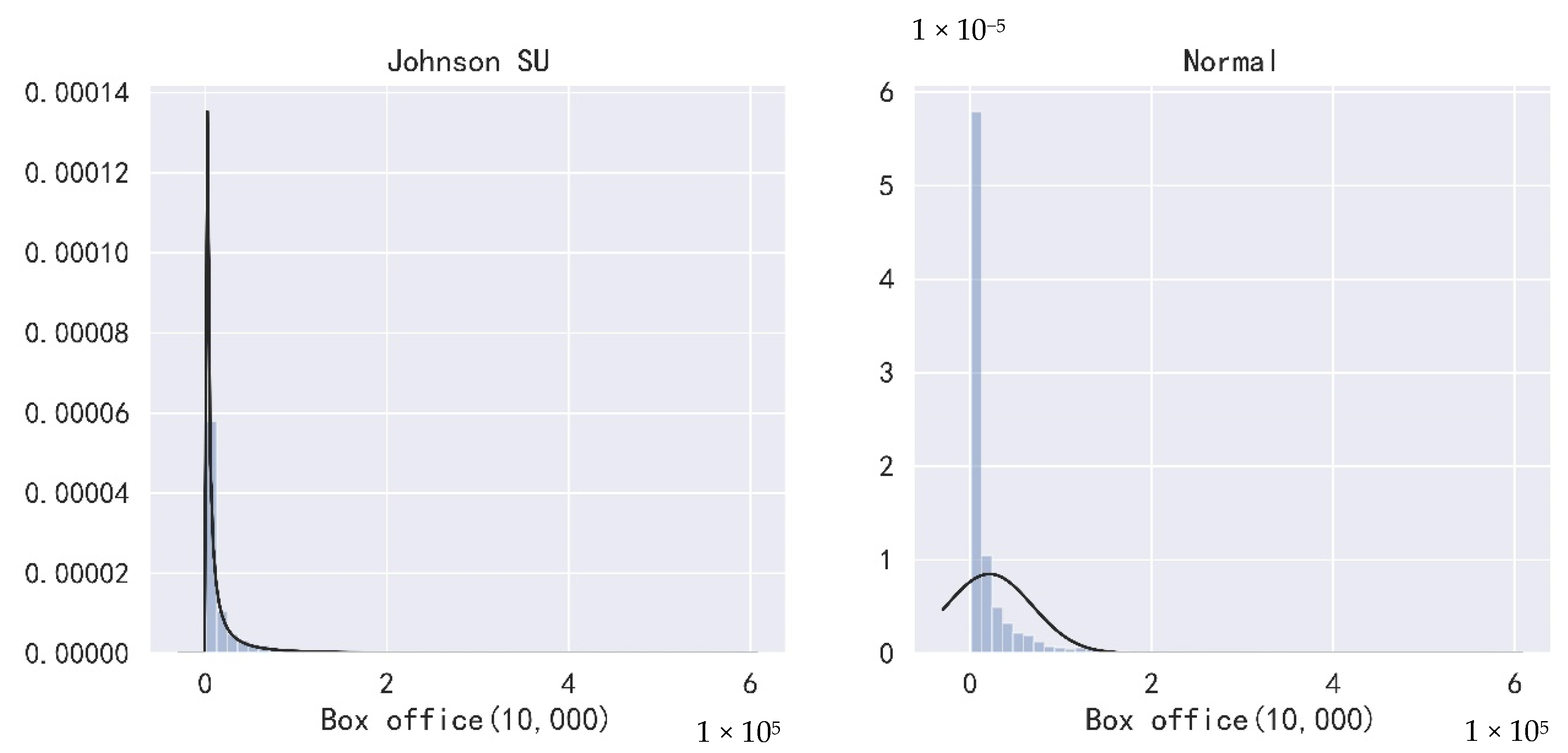
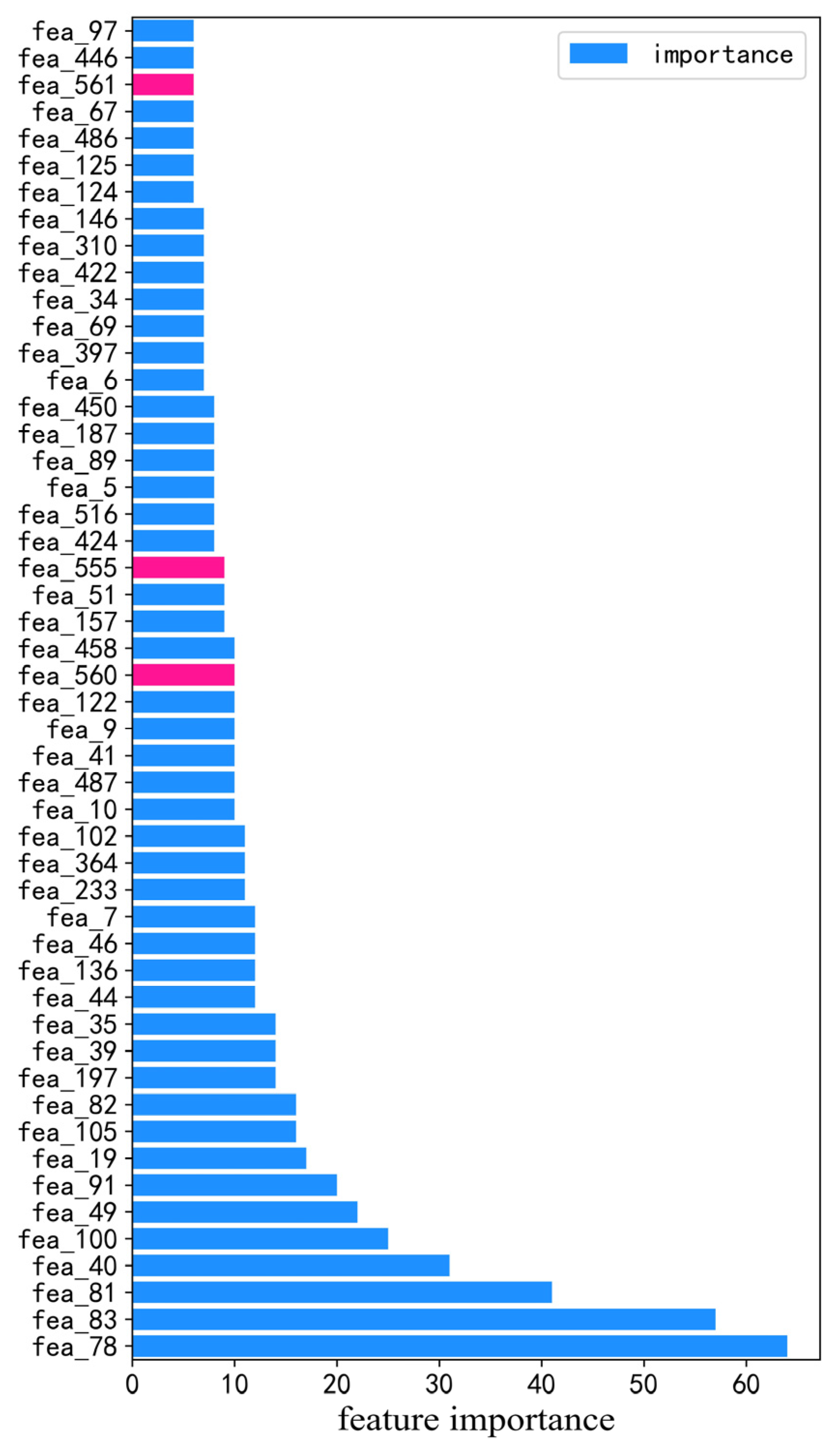
By deleting duplicate data and missing box office data in ENDATA, 5683 film data were left after processing, and the top 2000 films were used for box office prediction modeling after integrating the missing situations of other features of films. By checking the distribution of the film box office, illustrated in
Figure 1, it can be found that compared with the normal distribution, the distribution of the film box office is more consistent with the unbounded Johnson distribution. Thus, the value of the box office must be converted before regression.
3.2.4. Director, Actor, and Other Characteristic Data Processing
In order to measure the box office impact of each movie’s director, actor, writer, producer, executive producer, producer, production company, manufacturing company, distribution company, integrated marketing company, and new media marketing company, the following characteristics were derived by collating all movie data.
We set the first three actors of each film as the leading actors, and sorted out all the film data according to the characteristics of the film itself, such as the leading actor, screenwriter, director, publisher, executive producer, producer, production company, production company, distribution company, integrated marketing company, and new media marketing company. We added the number of these subjects in a film, the total number of films historically involved, the total box office in the past, and the average box office in the past for each film.
For each film’s director, screenwriter, and each leading actor, we added the features of the total number of the audience, on MaoYan, who wanted to watch the movies that these people had worked on in the past, the highest number of the audience, on MaoYan, who wanted to watch the movies that these people had worked on in the past, the average number of the audience, on MaoYan, who wanted to watch the movies that these people had worked on in the past, the total number of the audience, on Taobao Film, who wanted to watch the movies that these people had worked on in the past, the highest number of the audience, on Taobao Film, who wanted to watch the movies that these people had worked on in the past, the average number of the audience, on Taobao Film, who wanted to watch the movies that these people had worked on in the past, the total number of the audience, on Douban, who wanted to watch the movies that these people had worked on in the past, the highest number of the audience, on Douban, who wanted to watch the movies that these people had worked on in the past, the average number of the audience, on Douban, who wanted to watch the movies that these people had worked on in the past, the total score of the movies, on MaoYan, that these people had worked on in the past, the highest score of the movies, on MaoYan, that these people had worked on in the past, the average score of the movies, on MaoYan, that these people had worked on in the past, the total score of the movies, on Taobao Film, that these people had worked on in the past, the highest score of the movies, on Taobao Film, that these people had worked on in the past, the average score of the movies, on Taobao Film, that these people had worked on in the past, the total score of the movies, on Douban, that these people had worked on in the past, the highest score of the movies, on Douban, that these people had worked on in the past, the average score of the movies, on Douban, that these people had worked on in the past.
We added the first director (i.e., ranking the first director) for each movie data, the first screenwriter, the first producer, the first production company, the first manufacturing company, the first distribution company, and calculated the number of movies that they had worked on in the past, the total box office of movies that they had worked on in the past, the average box office of movies that they had worked on in the past, the total box office of movies that they had worked on in the last year, the number of movies that they had worked on in the last year, the average box office of the movies that they had worked on in the last year, the total box office of the movies that they had worked on in the last 3 years, the number of movies that they had worked on in the last 3 years, the average box office of the movies that they had worked on in the last 3 years, the total box office of the movies that they had worked on in the last 5 years, the number of movies that they had worked on in the last 5 years, the average box office of the movies that they had worked on in the last 5 years.
Based on all the movie data, we calculated the involvements and number of times of all actors, screenwriters, directors, publishers, executive producers, production companies, manufacturing companies, distribution companies in movies, to participate in the movie number sorting before the one percent threshold, to confirm the list of model actors, model scriptwriter, model director, model producer, model supervisor, model producer, model production company, model production company, and model distribution company, and, according to the actual work of each movie, to determine the number of model actors, model scriptwriters, model directors, model publishers, model executive producers, model producers, model production companies, model manufacturing companies, and model distribution companies, and add these data to the movie box office data features.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}